
程式碼研究室簡介
1. 總覽
在各個產業中,內容比對搜尋都是應用程式的核心功能。檢索增強生成技術已在相當長的一段時間內,以生成式 AI 技術為基礎的檢索機制,成為這項重要技術演進的關鍵推手。生成式模型擁有廣泛的脈絡視窗和出色的輸出品質,正在改變 AI 的發展方向。RAG 提供系統化方式,可將情境資料注入 AI 應用程式和代理程式,並以結構化資料庫或各種媒體的資訊做為基礎。這些背景資料對於釐清真相和確保輸出結果的準確性至關重要,但這些結果的準確性如何?貴公司是否在很大程度上依賴這些內容比對和關聯度的準確度?那麼,這項專案一定會讓您愛不釋手!
想像一下,如果我們能運用生成式模型的力量,建立互動式代理程式,在這種關鍵情境資訊的支援下,做出以事實為依據的自主決策,那麼我們今天就會著手建構這類代理程式。我們將使用 Agent Development Kit (由 AlloyDB 中的進階 RAG 技術輔助),為專利分析應用程式建構端對端 AI 服務機器人應用程式。
專利分析服務代理人可協助使用者找到與搜尋字詞相關的專利,並在使用者要求時,針對所選專利提供清楚簡潔的說明,以及必要的其他詳細資料。準備好查看實際運作情形了嗎?讓我們一起來瞭解
目標
目標很簡單,允許使用者根據文字說明搜尋專利,然後從搜尋結果中取得特定專利的詳細說明,並使用採用 Java ADK 建構的 AI 代理程式、AlloyDB、向量搜尋 (含進階索引)、Gemini 和在 Cloud Run 上以無伺服器方式部署的整個應用程式,執行上述操作。
建構項目
在本實驗室中,您將:
- 建立 AlloyDB 執行個體並載入專利公開資料集資料
- 使用 ScaNN 和 Recall 評估功能,在 AlloyDB 中實作進階向量搜尋
- 使用 Java ADK 建立代理程式
- 在 Java 無伺服器 Cloud Functions 中實作資料庫伺服器端邏輯
- 在 Cloud Run 中部署及測試代理程式
下圖顯示實作過程中涉及的資料流程和步驟。
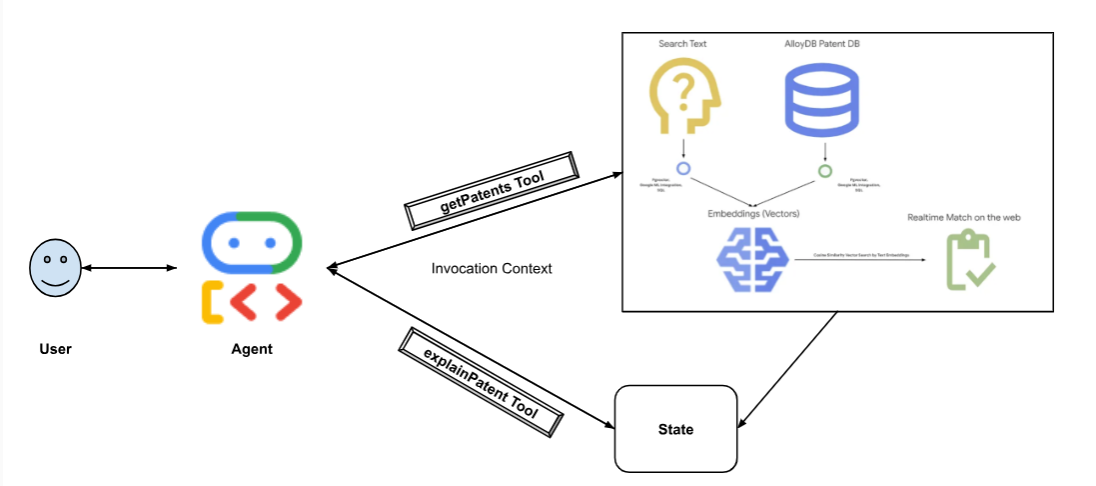
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
需求條件
2. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是在 Google Cloud 中執行的指令列環境。按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連線至 Cloud Shell 後,請使用下列指令確認您已通過驗證,且專案已設為您的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令知道您的專案。
gcloud config list project
- 如果未設定專案,請使用下列指令進行設定:
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API。您可以在 Cloud Shell 終端機中使用 gcloud 指令:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
您可以透過主控台搜尋每項產品,或使用這個連結,來代替 gcloud 指令。
如要瞭解 gcloud 指令和用法,請參閱說明文件。
3. 資料庫設定
在本實驗室中,我們會使用 AlloyDB 做為專利資料的資料庫。它會使用叢集來保存所有資源,例如資料庫和記錄。每個叢集都有一個主要例項,可提供資料的存取點。資料表會儲存實際資料。
讓我們建立 AlloyDB 叢集、執行個體和資料表,用於載入專利資料集。
建立叢集和執行個體
- 前往 Cloud 控制台的 AlloyDB 頁面。如要輕鬆在 Cloud Console 中找到大部分的頁面,請使用控制台的搜尋列進行搜尋。
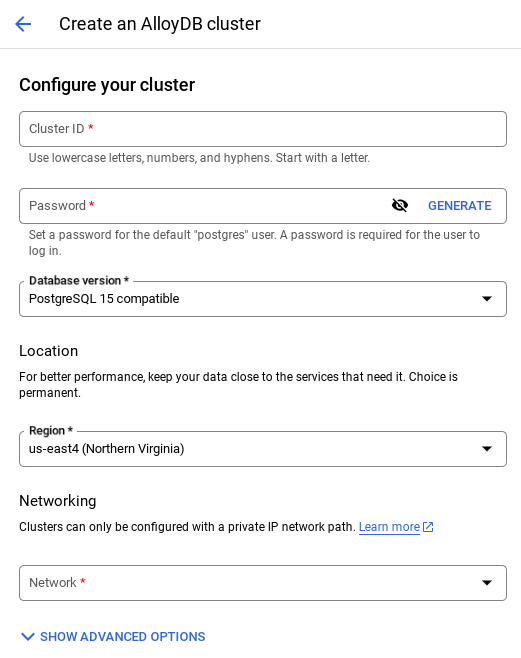
- 在該頁面中選取「建立叢集」:

- 您會看到類似下方的畫面。使用下列值建立叢集和執行個體 (如果您要從存放區複製應用程式程式碼,請務必確認這些值相符):
- 叢集 ID:"
vector-cluster" - 密碼:"
alloydb" - PostgreSQL 15 / 最新版本 (建議使用)
- Region:"
us-central1" - 網路:"
default"
- 選取預設網路後,畫面會顯示如下圖所示畫面。
選取「設定連線」。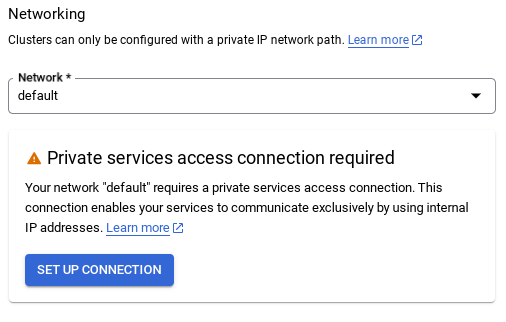
- 接著選取「使用系統自動分配的 IP 範圍」,然後按一下「繼續」。查看相關資訊後,請選取「建立連線」。
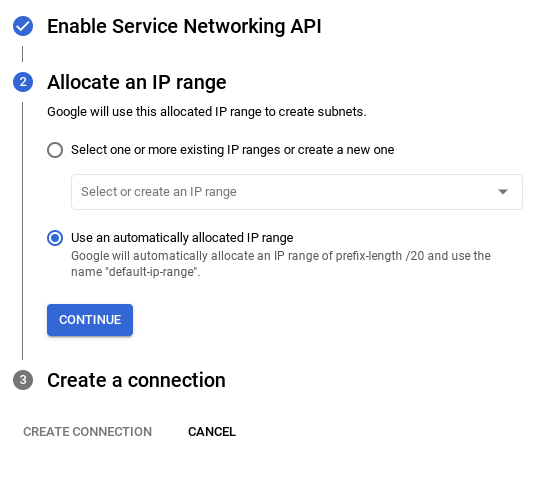
- 網路設定完成後,您可以繼續建立叢集。按一下「CREATE CLUSTER」,完成叢集設定,如下所示:

請務必變更執行個體 ID (您可以在設定叢集 / 執行個體時找到) 為
vector-instance。如果無法變更,請務必在所有後續參照中使用例項 ID。
請注意,叢集建立作業大約需要 10 分鐘。成功後,畫面上會顯示剛剛建立的叢集總覽。
4. 資料擷取
接下來,我們要新增一個包含商店資料的表格。前往 AlloyDB,選取主要叢集,然後選取 AlloyDB Studio:
您可能需要等待執行個體建立完成。完成後,請使用建立叢集時建立的憑證登入 AlloyDB。使用下列資料驗證 PostgreSQL:
- 使用者名稱:"
postgres" - 資料庫:
postgres - 密碼:
alloydb
成功驗證 AlloyDB Studio 後,您就可以在編輯器中輸入 SQL 指令。您可以使用最後一個視窗右側的加號新增多個編輯器視窗。

您會在編輯器視窗中輸入 AlloyDB 指令,並視需要使用「Run」、「Format」和「Clear」選項。
啟用擴充功能
我們將使用擴充功能 pgvector 和 google_ml_integration 來建構這個應用程式。pgvector 擴充功能可讓您儲存及搜尋向量嵌入資料。google_ml_integration 擴充功能提供的函式可用於存取 Vertex AI 預測端點,以便在 SQL 中取得預測結果。執行下列 DDL 啟用這些擴充功能:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
如要檢查資料庫已啟用的擴充功能,請執行下列 SQL 指令:
select extname, extversion from pg_extension;
建立表格
您可以在 AlloyDB Studio 中使用下列 DDL 陳述式建立資料表:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings 欄可儲存文字的向量值。
授予權限
執行下列陳述式,授權執行「嵌入」函式:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
將 Vertex AI 使用者角色授予 AlloyDB 服務帳戶
在 Google Cloud IAM 控制台中,將「Vertex AI 使用者」角色授予 AlloyDB 服務帳戶 (格式如下:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)。PROJECT_NUMBER 會顯示您的專案編號。
或者,您也可以在 Cloud Shell 終端機中執行下列指令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
將專利資料載入資料庫
我們會使用 BigQuery 中的 Google Patents 公開資料集做為資料集。我們將使用 AlloyDB Studio 執行查詢。資料會匯入這個 insert_scripts.sql 檔案,我們會執行這個檔案來載入專利資料。
- 在 Google Cloud 控制台中,開啟 AlloyDB 頁面。
- 選取新建立的叢集,然後按一下執行個體。
- 在 AlloyDB 導覽選單中,按一下「AlloyDB Studio」。使用憑證登入。
- 按一下右側的「新分頁」圖示,開啟新分頁。
- 請將上述
insert_scripts.sql指令碼中的insert查詢陳述式複製到編輯器中。您可以複製 10 到 50 個插入陳述式,快速示範這個用途。 - 按一下「執行」。查詢結果會顯示在「結果」表格中。
5. 為專利資料建立嵌入
首先,請執行以下查詢範例來測試嵌入函式:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
這應該會針對查詢中的範例文字,傳回看起來像浮點陣列的嵌入向量。如下所示:

更新 abstract_embeddings 向量欄位
執行下列 DML,使用對應的嵌入資料更新資料表中的專利摘要:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. 執行向量搜尋
表格、資料和嵌入內容都已準備就緒,現在讓我們針對使用者搜尋文字執行即時向量搜尋。您可以執行下列查詢來測試這項功能:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
在這個查詢中,
- 使用者搜尋的文字為:「Sentiment Analysis」。
- 我們會使用模型 text-embedding-005,在 embedding() 方法中將其轉換為嵌入。
- "<=>" 代表使用 COSINE SIMILARITY 距離方法。
- 我們將嵌入方法的結果轉換為向量類型,以便與資料庫中儲存的向量相容。
- LIMIT 10 代表我們會選取與搜尋文字最相符的 10 個項目。
AlloyDB 可將向量搜尋 RAG 提升至更高層級:
我們推出了許多新功能,其中兩個以開發人員為主的功能如下:
- 內嵌式篩選
- 喚回評估工具
內嵌式篩選
以往開發人員必須執行向量搜尋查詢,並處理篩選和回憶功能。AlloyDB 查詢最佳化工具會選擇如何執行含有篩選條件的查詢。內嵌篩選是一種新的查詢最佳化技術,可讓 AlloyDB 查詢最佳化工具同時評估中繼資料篩選條件和向量搜尋,並利用中繼資料欄的向量索引和索引。這項功能可提高喚回效能,讓開發人員充分利用 AlloyDB 提供的即用功能。
內嵌式篩選最適合中等選擇性。當 AlloyDB 搜尋向量索引時,只會為符合結構描述資料篩選條件的向量計算距離 (查詢中的函式篩選器通常會在 WHERE 子句中處理)。這項功能可大幅改善這些查詢的效能,並補足後置篩選或前置篩選的優點。
- 安裝或更新 pgvector 擴充功能
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
如果您已安裝 pgvector 擴充功能,請將向量擴充功能升級至 0.8.0.google-3 以上版本,以便使用回溯評估工具功能。
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
只有在向量擴充功能為 <0.8.0.google-3 時,才需要執行這個步驟。
重要注意事項:如果資料列數量少於 100,您就不必建立 ScaNN 索引,因為索引不適用於較少的資料列。請略過下列步驟。
- 如要建立 ScaNN 索引,請安裝 alloydb_scann 擴充功能。
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- 首先,請在未啟用索引和內嵌篩選器的情況下,執行向量搜尋查詢:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
結果應類似於以下內容:

- 對其執行 Explain Analyze:(沒有索引或內嵌篩選)

執行時間為 2.4 毫秒
- 我們將在 num_claims 欄位上建立一般索引,以便篩選:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- 讓我們為專利搜尋應用程式建立 ScaNN 索引。在 AlloyDB Studio 中執行下列指令:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
重要注意事項: (num_leaves=32) 適用於資料集的總列數超過 1000 列。如果資料列計數少於 100,則不需要建立索引,因為索引不適用於較少的資料列。
- 設定在 ScaNN 索引上啟用內嵌篩選功能:
SET scann.enable_inline_filtering = on
- 現在,請執行含有篩選器和向量搜尋的相同查詢:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
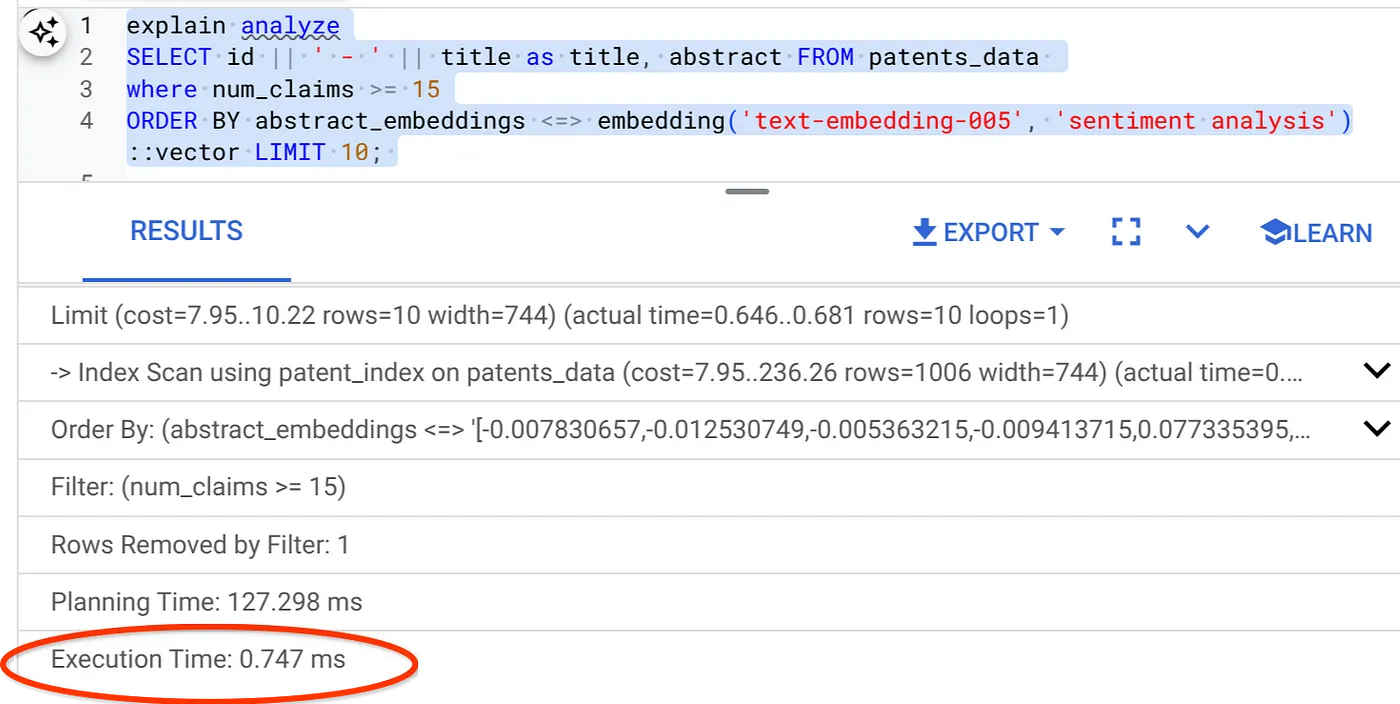
如您所見,執行相同向量搜尋的時間大幅縮短。在向量搜尋中加入內嵌篩選器並注入 ScaNN 索引,就能實現這項功能!
接下來,我們來評估啟用 ScaNN 的向量搜尋功能的回溯率。
喚回評估工具
相似搜尋中的回憶率,是指從搜尋中擷取的相關例項百分比,也就是真陽性個案的數量。這是評估搜尋品質最常用的指標。回溯損失的其中一個原因,是近似近鄰搜尋 (ANN) 與 k (精確) 近鄰搜尋 (KNN) 之間的差異。向量索引 (例如 AlloyDB 的 ScaNN) 會實作近似近鄰演算法,讓您在大型資料集上加快向量搜尋速度,但須犧牲一點召回率。如今,AlloyDB 可讓您直接在資料庫中評估個別查詢的權衡,並確保長期穩定性。您可以根據這項資訊更新查詢和索引參數,以便取得更優異的結果和效能。
您可以使用 evaluate_query_recall 函式,找出向量查詢在特定配置的向量索引中的回憶率。這個函式可讓您調整參數,以便取得所需的向量查詢回溯結果。召回率是用於評估搜尋品質的指標,定義為與查詢向量客觀上最接近的傳回結果百分比。系統預設會啟用 evaluate_query_recall 函式。
重要注意事項:
如果您在執行下列步驟時,遇到 HNSW 索引的權限遭拒錯誤,請先略過整個回憶評估部分。這可能與目前的存取限制有關,因為本程式碼研究室的說明文件是在該限制發布後才撰寫。
- 在 ScaNN 索引和 HNSW 索引上設定「啟用索引掃描」標記:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- 在 AlloyDB Studio 中執行以下查詢:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 函式會將查詢做為參數,並傳回其回憶率。我使用用於檢查效能的查詢做為函式輸入查詢。我已將 SCaNN 新增為索引方法。如需更多參數選項,請參閱說明文件。
我們使用這個向量搜尋查詢的回憶率:

我發現 RECALL 為 70%。我現在可以使用這項資訊變更索引參數、方法和查詢參數,並提高這個向量搜尋的回憶率!
我已將結果集中的列數修改為 7 列 (先前為 10 列),發現 RECALL 略有提升,即 86%。
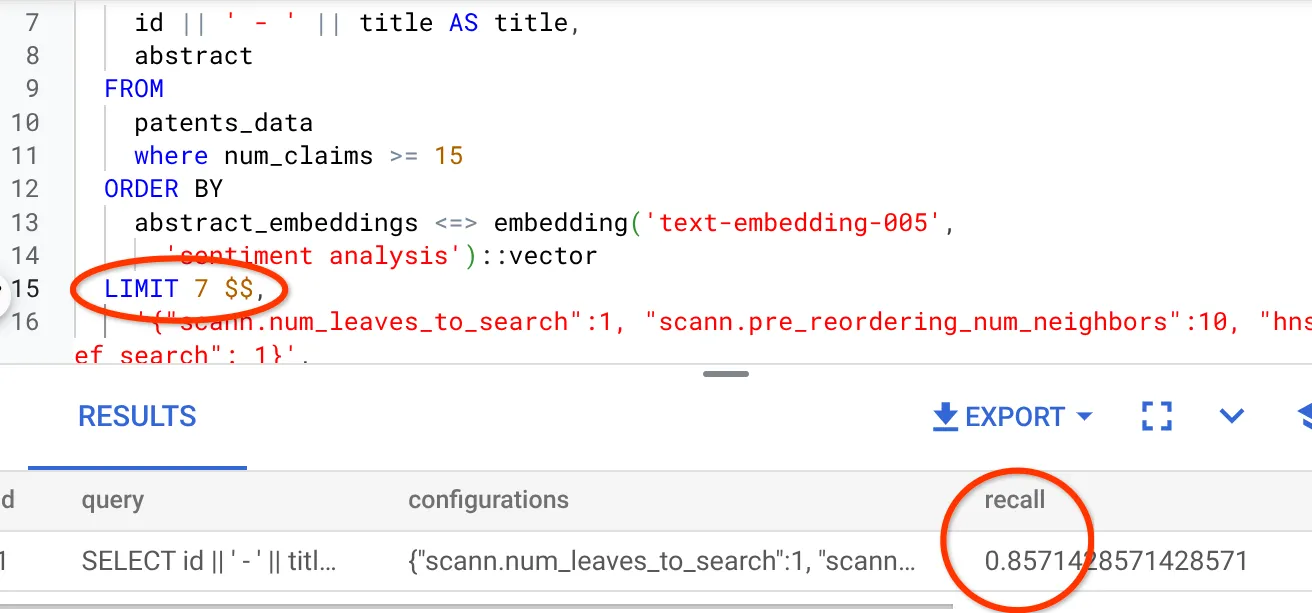
也就是說,我可以在即時情況下調整使用者看到的相符項目數量,根據使用者的搜尋情境改善相符項目的相關性。
沒問題了!是時候部署資料庫邏輯,並繼續處理代理程式了!
7. 將資料庫邏輯無伺服器化
準備好將這個應用程式移至網路了嗎?步驟如下:
- 前往 Google Cloud 控制台的 Cloud Run 函式,建立新的 Cloud Run 函式,或使用以下連結:https://console.cloud.google.com/functions/add。
- 選取「Cloud Run 函式」做為環境。提供「patent-search」做為函式名稱,並選擇「us-central1」做為區域。將「驗證」設為「允許未經驗證的叫用」,然後按一下「NEXT」。選擇 Java 17 做為執行階段,並為原始碼選擇內嵌編輯器。
- 根據預設,這個值會將進入點設為「gcfv2.HelloHttpFunction」。將 Cloud Run 函式的 HelloHttpFunction.java 和 pom.xml 中的預留位置程式碼,分別替換為「PatentSearch.java」和「pom.xml」中的程式碼。將類別檔案的名稱變更為 PatentSearch.java。
- 請記得將 Java 檔案中的 ************* 預留位置和 AlloyDB 連線憑證,改為您的值。AlloyDB 憑證是我們在本程式碼研究室一開始時使用的憑證。如果您使用其他值,請在 Java 檔案中修改相同的值。
- 按一下 [Deploy] (部署)。
重要步驟:
部署完成後,我們會建立 VPC 連接器,讓 Cloud 函式可以存取 AlloyDB 資料庫執行個體。
部署作業完成後,您應該會在 Google Cloud Run Functions 控制台中看到函式。搜尋新建立的函式 (patent-search),然後按一下該函式,接著點選「編輯並部署新修訂版本」(可透過 Cloud Run 函式控制台頂端的「編輯」圖示 (筆) 辨識),然後變更下列項目:
- 前往「Networking」(網路) 分頁:

- 依序選取「連線至虛擬私有雲,以傳出流量」和「使用無伺服器虛擬私有雲存取連接器」
- 在「Network」下拉式選單的「Settings」下方,點選「Network」下拉式選單,然後選取「Add New VPC Connector」選項 (如果您尚未設定「預設」),並按照彈出式對話方塊中的操作說明進行:

- 請為 VPC 連接器提供名稱,並確認區域與執行個體相同。將「Network」值保留為預設值,並將「Subnet」設為「Custom IP Range」,IP 範圍為 10.8.0.0 或可用的類似值。
- 展開「顯示縮放設定」,並確認設定已正確設為下列項目:
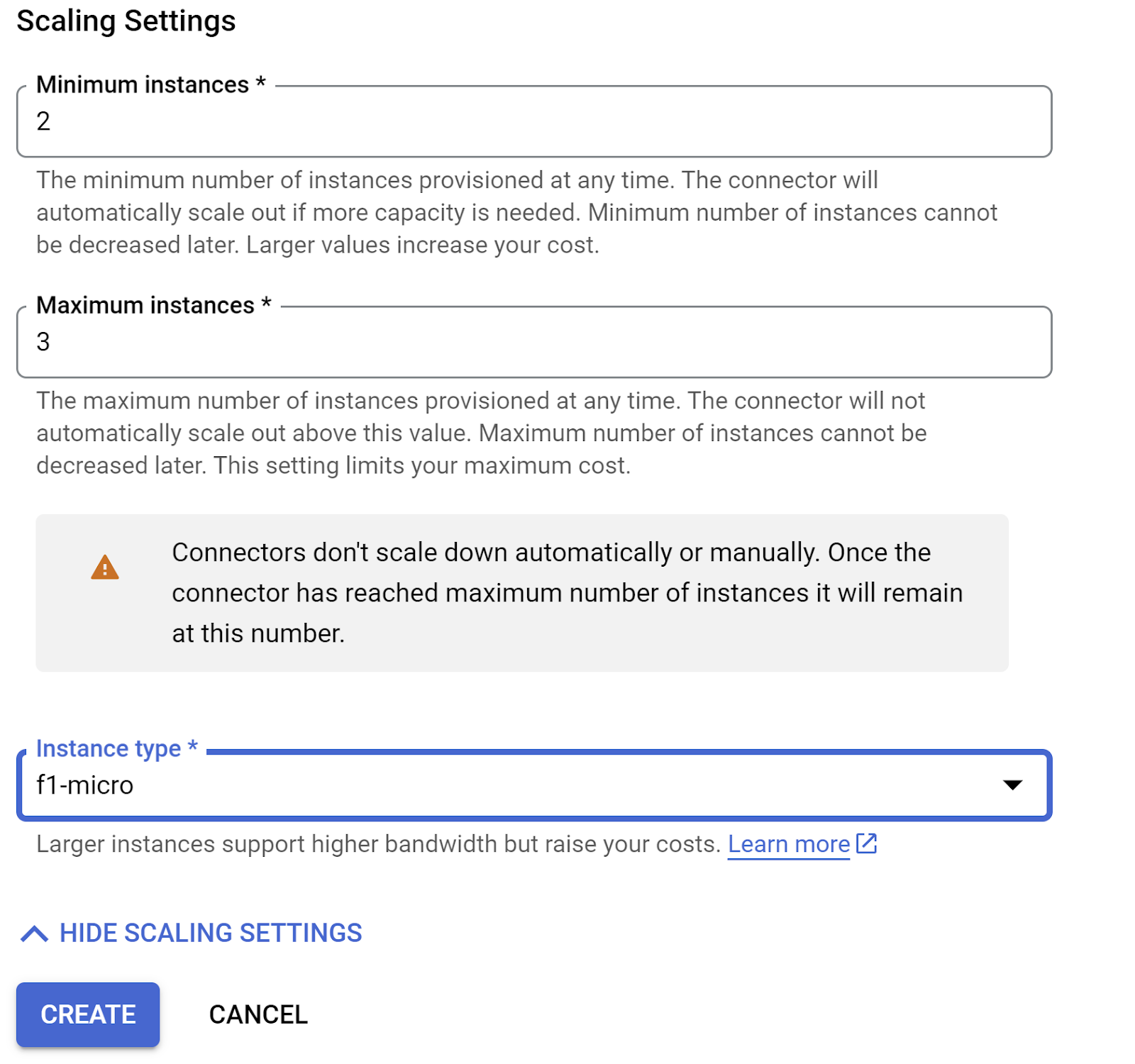
- 按一下「建立」,這個連接器現在應該會列在出口設定中。
- 選取新建的連接器。
- 選擇將所有流量轉送至這個虛擬私有雲連接器。
- 依序點選「NEXT」和「DEPLOY」。
- 更新後的 Cloud 函式部署完成後,您應該會看到產生的端點。複製該值,並取代下列指令中的值:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
大功告成!只要在 AlloyDB 資料上使用嵌入模型,就能輕鬆執行進階的內容相似度向量搜尋。
8. 讓我們使用 Java ADK 建構代理程式
首先,我們在編輯器中開始使用 Java 專案。
- 前往 Cloud Shell 終端機
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- 在系統顯示提示時授權
- 按一下 Cloud Shell 控制台頂端的編輯器圖示,切換至 Cloud Shell 編輯器

- 在 Cloud Shell 編輯器控制台中建立新資料夾,並將其命名為「adk-agents」
在 Cloud Shell 的根目錄中按一下「建立新資料夾」,如下所示:

將其命名為「adk-agents」:
- 請建立下列資料夾結構,並在下列結構中建立空白檔案,並使用對應的檔案名稱:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- 在另一個分頁中開啟 GitHub 存放區,然後複製 App.java 和 pom.xml 檔案的原始程式碼。
- 如果您已使用右上角的「在新分頁中開啟」圖示,在新分頁中開啟編輯器,則可以將終端機開啟在頁面底部。您可以同時開啟編輯器和終端機,讓您自由操作。
- 複製完成後,切換回 Cloud Shell 編輯器控制台
- 我們已建立 Cloud Run 函式,因此不需要複製 存放區資料夾中的 Cloud Run 函式檔案。
開始使用 ADK Java SDK
這項操作相當簡單。您主要需要確保複製步驟涵蓋以下項目:
- 新增依附元件:
在 pom.xml 中加入 google-adk 和 google-adk-dev (適用於 Web UI) 成果。
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
請務必從來源存放區參照 pom.xml,因為應用程式需要其他依附元件和設定才能執行。
- 設定專案:
請確認 Java 版本 (建議使用 17 以上版本) 和 Maven 編譯器設定已正確設定在 pom.xml 中。您可以將專案設定為遵循下列結構:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- 定義服務專員及其工具 (App.java):
這就是 ADK Java SDK 的魔力所在。我們會定義服務機器人、其功能 (指示) 和可使用的工具。
您可以在此處找到主要代理程式類別的幾個程式碼片段的簡化版本。如需完整專案,請參閱這裡的專案存放區。
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
醒目顯示的關鍵 ADK Java 程式碼元件:
- LlmAgent.builder(): 用於設定服務的流暢 API。
- .instruction(...):提供大型語言模型的核心提示和指南,包括何時使用哪個工具。
- FunctionTool.create(App.class, "methodName"):輕鬆將 Java 方法註冊為代理程式可叫用的工具。方法名稱字串必須與實際的公開靜態方法相符。
- @Schema(description = ...):為工具參數加上註解,協助 LLM 瞭解每個工具預期的輸入內容。這項說明對於正確選擇工具和填入參數至關重要。
- InvocationContext ctx:自動傳遞至工具方法,提供工作階段狀態 (ctx.session().state())、使用者資訊等存取權。
- .outputKey("patents"):當工具傳回資料時,ADT 可自動將資料儲存在此鍵下的會話狀態中。以下是 explainPatent 如何存取 getPatents 的結果。
- VECTOR_SEARCH_ENDPOINT:這個變數會在專利搜尋用途中,為使用者提供內容相關的問答功能,並保留相關核心功能邏輯。
- 這裡的行動項目:在實作上一節的 Java Cloud Run 函式步驟後,您需要設定更新的已部署端點值。
- searchTool:與使用者互動,根據使用者的搜尋文字,從專利資料庫中找出與內容相關的專利。
- explainTool:要求使用者提供特定專利,以便深入探討。接著,系統會摘要專利摘要,並根據所擁有的專利詳細資料回答使用者提出的更多問題。
重要注意事項:請務必將 VECTOR_SEARCH_ENDPOINT 變數替換為已部署的 CRF 端點。
運用 InvocationContext 進行有狀態互動
建構實用代理程式時,其中一個關鍵功能就是在多輪對話中管理狀態。ADK 的 InvocationContext 可讓這項作業變得簡單明瞭。
在 App.java 中:
- 定義 initAgent() 時,我們會使用 .outputKey("patents")。這會告訴 ADK,當工具 (例如 getPatents) 在其報表欄位中傳回資料時,應將該資料儲存在工作階段狀態的「patents」鍵下。
- 在 explainPatent 工具方法中,我們會插入 InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
這可讓 explainPatent 工具存取 getPatents 工具在先前回合中擷取的專利清單,讓對話具有狀態且連貫。
9. 本機 CLI 測試
定義環境變數
您需要匯出兩個環境變數:
- 可從 AI Studio 取得的 Gemini 金鑰:
如要這麼做,請前往 https://aistudio.google.com/apikey,為您要實作此應用程式的有效 Google Cloud 專案取得 API 金鑰,並將金鑰儲存在某處:
- 取得金鑰後,請開啟 Cloud Shell 終端機,然後執行下列指令,前往我們剛剛建立的 adk-agents 新目錄:
cd adk-agents
- 這個變數可指定我們這次未使用 Vertex AI。
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- 在 CLI 上執行第一個服務專員
如要啟動這個第一個代理程式,請在終端機中使用下列 Maven 指令:
mvn compile exec:java -DmainClass="agents.App"
您會在終端機中看到服務專員的互動式回應。
10. 部署至 Cloud Run
將 ADK Java 代理程式部署至 Cloud Run 的做法,與部署任何其他 Java 應用程式類似:
- Dockerfile:建立 Dockerfile 來封裝 Java 應用程式。
- 建構及推送 Docker 映像檔:使用 Google Cloud Build 和 Artifact Registry。
- 您可以執行上述步驟,並透過單一指令將應用程式部署至 Cloud Run:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
同樣地,您會部署 Java Cloud Run 函式 (gcfv2.PatentSearch)。或者,您也可以直接透過 Cloud Run 函式控制台,為資料庫邏輯建立及部署 Java Cloud Run 函式。
11. 使用網路 UI 進行測試
ADK 隨附方便的網頁 UI,可用於本機測試及偵錯代理程式。當您在本機執行 App.java (例如,如果已設定,請使用 mvn exec:java -Dexec.mainClass="agents.App",或只執行 main 方法) 時,ADT 通常會啟動本機網路伺服器。
您可以透過 ADK 網頁版 UI 執行下列操作:
- 傳送訊息給客服專員。
- 查看事件 (使用者訊息、工具呼叫、工具回應、大型語言模型回應)。
- 檢查工作階段狀態。
- 查看記錄和追蹤記錄。
這在開發期間非常實用,可協助您瞭解代理程式如何處理要求及使用工具。這會假設您在 pom.xml 中將 mainClass 設為 com.google.adk.web.AdkWebServer,且您的代理程式已註冊至此,或是您正在執行會公開此值的本機測試執行程式。
當您使用 InMemoryRunner 和主控台輸入的掃描器執行 App.java 時,就會測試核心代理程式邏輯。Web UI 是獨立的元件,可提供更直觀的偵錯體驗,通常用於 ADK 透過 HTTP 為代理程式提供服務時。
您可以在根目錄中使用下列 Maven 指令,啟動 SpringBoot 本機伺服器:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
您通常可以透過上述指令輸出的網址存取介面。如果是已部署至 Cloud Run,您應該可以透過 Cloud Run 部署連結存取。
您應該可以在互動式介面中看到結果。
請觀看以下影片,瞭解我們部署的專利代理人:
AlloyDB 內嵌搜尋和回憶評估功能,可用於展示品質控管專利代理人的功能!

12. 清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取這篇文章中所用資源的費用,請按照下列步驟操作:
- 在 Google Cloud 控制台中,前往 https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog 頁面。
- 在專案清單中選取要刪除的專案,然後點按「刪除」。
- 在對話方塊中輸入專案 ID,然後按一下「Shut down」(關閉) 即可刪除專案。
13. 恭喜
恭喜!您已成功在 Java 中建構專利分析代理程式,結合了 ADK、https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog Vertex AI 和 Vector Search 的功能,我們也已取得重大突破,讓內容相似搜尋功能變得更具轉型、更有效率,並真正以意義為導向。
立即開始使用!
ADK 說明文件:[官方 ADK Java 說明文件的連結]
專利分析代理程式原始碼:[連結至 (現已公開) GitHub 存放區]
Java 範例代理程式:[連結至 adk-samples 存放區]
加入 ADK 社群:https://www.reddit.com/r/agentdevelopmentkit/
祝您建構代理程式愉快!