
1. Ringkasan
Di berbagai industri, penelusuran kontekstual adalah fungsi penting yang menjadi inti dan pusat aplikasi mereka. Retrieval Augmented Generation telah menjadi pendorong utama evolusi teknologi penting ini selama beberapa waktu dengan mekanisme pengambilan yang didukung AI Generatif. Model generatif, dengan jendela konteks yang besar dan kualitas output yang mengesankan, mengubah AI. RAG menyediakan cara sistematis untuk memasukkan konteks ke dalam aplikasi dan agen AI, yang mendasarkannya pada database terstruktur atau informasi dari berbagai media. Data kontekstual ini sangat penting untuk kejelasan kebenaran dan akurasi output, tetapi seberapa akurat hasil tersebut? Apakah bisnis Anda sangat bergantung pada akurasi dan relevansi kecocokan kontekstual ini? Kalau begitu, project ini akan membuat Anda penasaran.
Sekarang bayangkan jika kita dapat memanfaatkan kecanggihan model generatif dan membangun agen interaktif yang mampu membuat keputusan secara mandiri yang didukung oleh informasi penting yang relevan dengan konteks dan didasarkan pada kebenaran; itulah yang akan kita bangun hari ini. Kita akan membuat aplikasi agen AI end-to-end menggunakan Agent Development Kit yang didukung oleh RAG canggih di AlloyDB untuk aplikasi analisis paten.
Patent Analysis Agent membantu pengguna menemukan paten yang relevan secara kontekstual dengan teks penelusuran mereka dan setelah diminta, memberikan penjelasan yang jelas dan ringkas serta detail tambahan jika diperlukan, untuk paten yang dipilih. Siap melihat cara melakukannya? Ayo kita mulai!
Tujuan
Tujuannya sederhana. Memungkinkan pengguna menelusuri paten berdasarkan deskripsi tekstual, lalu mendapatkan penjelasan mendetail tentang paten tertentu dari hasil penelusuran, dan semua ini menggunakan agen AI yang dibangun dengan Java ADK, AlloyDB, Vector Search (dengan indeks lanjutan), Gemini, dan seluruh aplikasi yang di-deploy tanpa server di Cloud Run.
Yang akan Anda build
Sebagai bagian dari lab ini, Anda akan:
- Membuat instance AlloyDB dan memuat data Set Data Publik Paten
- Menerapkan Penelusuran Vektor lanjutan di AlloyDB menggunakan fitur evaluasi ScaNN & Recall
- Membuat agen menggunakan Java ADK
- Menerapkan logika sisi server database di Cloud Functions serverless Java
- Men-deploy & menguji agen di Cloud Run
Diagram berikut menunjukkan alur data dan langkah-langkah yang terlibat dalam penerapan.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project .
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Mengaktifkan API yang diperlukan. Anda dapat menggunakan perintah gcloud di terminal Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Alternatif untuk perintah gcloud adalah melalui konsol dengan menelusuri setiap produk atau menggunakan link ini.
Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
3. Penyiapan database
Di lab ini, kita akan menggunakan AlloyDB sebagai database untuk data paten. Cloud SQL menggunakan cluster untuk menyimpan semua resource, seperti database dan log. Setiap cluster memiliki instance utama yang menyediakan titik akses ke data. Tabel akan menyimpan data sebenarnya.
Mari kita buat cluster, instance, dan tabel AlloyDB tempat set data paten akan dimuat.
Membuat cluster dan instance
- Buka halaman AlloyDB di Konsol Cloud. Cara mudah untuk menemukan sebagian besar halaman di Konsol Cloud adalah dengan menelusurinya menggunakan kotak penelusuran konsol.
- Pilih CREATE CLUSTER dari halaman tersebut:

- Anda akan melihat layar seperti di bawah. Buat cluster dan instance dengan nilai berikut (Pastikan nilai cocok jika Anda meng-clone kode aplikasi dari repo):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / versi terbaru yang direkomendasikan
- Region: "
us-central1" - Jaringan: "
default"

- Saat Anda memilih jaringan default, Anda akan melihat layar seperti di bawah.
Pilih SIAPKAN KONEKSI.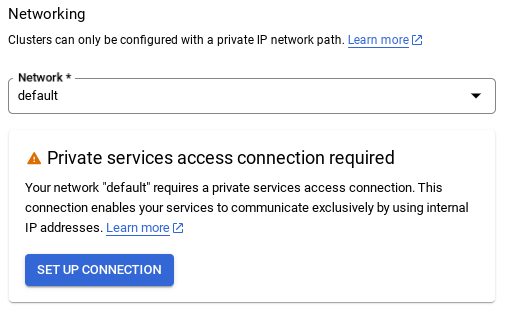
- Dari sana, pilih "Gunakan rentang IP yang dialokasikan secara otomatis" dan Lanjutkan. Setelah meninjau informasi, pilih BUAT KONEKSI.

- Setelah jaringan disiapkan, Anda dapat melanjutkan pembuatan cluster. Klik CREATE CLUSTER untuk menyelesaikan penyiapan cluster seperti yang ditunjukkan di bawah:

Pastikan untuk mengubah ID instance (yang dapat Anda temukan pada saat konfigurasi cluster / instance) menjadi
vector-instance. Jika Anda tidak dapat mengubahnya, ingatlah untuk menggunakan ID instance Anda dalam semua referensi mendatang.
Perhatikan bahwa pembuatan Cluster akan memerlukan waktu sekitar 10 menit. Setelah berhasil, Anda akan melihat layar yang menampilkan ringkasan cluster yang baru saja Anda buat.
4. Penyerapan data
Sekarang saatnya menambahkan tabel dengan data tentang toko. Buka AlloyDB, pilih cluster utama, lalu AlloyDB Studio:

Anda mungkin perlu menunggu hingga instance selesai dibuat. Setelah itu, login ke AlloyDB menggunakan kredensial yang Anda buat saat membuat cluster. Gunakan data berikut untuk melakukan autentikasi ke PostgreSQL:
- Nama pengguna : "
postgres" - Database : "
postgres" - Sandi : "
alloydb"
Setelah Anda berhasil melakukan autentikasi ke AlloyDB Studio, perintah SQL dimasukkan di Editor. Anda dapat menambahkan beberapa jendela Editor menggunakan tanda plus di sebelah kanan jendela terakhir.

Anda akan memasukkan perintah untuk AlloyDB di jendela editor, menggunakan opsi Jalankan, Format, dan Hapus sesuai kebutuhan.
Mengaktifkan Ekstensi
Untuk membangun aplikasi ini, kita akan menggunakan ekstensi pgvector dan google_ml_integration. Ekstensi pgvector memungkinkan Anda menyimpan dan menelusuri embedding vektor. Ekstensi google_ml_integration menyediakan fungsi yang Anda gunakan untuk mengakses endpoint prediksi Vertex AI guna mendapatkan prediksi di SQL. Aktifkan ekstensi ini dengan menjalankan DDL berikut:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jika Anda ingin memeriksa ekstensi yang telah diaktifkan di database Anda, jalankan perintah SQL ini:
select extname, extversion from pg_extension;
Membuat tabel
Anda dapat membuat tabel menggunakan pernyataan DDL di bawah di AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
Kolom abstract_embeddings akan memungkinkan penyimpanan untuk nilai vektor teks.
Berikan Izin
Jalankan pernyataan di bawah untuk memberikan izin eksekusi pada fungsi "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Memberikan PERAN Vertex AI User ke akun layanan AlloyDB
Dari konsol IAM Google Cloud, berikan akses ke peran "Pengguna Vertex AI" untuk akun layanan AlloyDB (yang terlihat seperti ini: service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com). PROJECT_NUMBER akan memiliki nomor project Anda.
Atau, Anda dapat menjalankan perintah di bawah dari Terminal Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Memuat data paten ke dalam database
Set Data Publik Google Paten di BigQuery akan digunakan sebagai set data kami. Kita akan menggunakan AlloyDB Studio untuk menjalankan kueri. Data ini berasal dari file insert scripts sql di repo ini dan kita akan menjalankannya untuk memuat data paten.
- Di konsol Google Cloud, buka halaman AlloyDB.
- Pilih cluster yang baru dibuat, lalu klik instance.
- Di menu Navigasi AlloyDB, klik AlloyDB Studio. Login dengan kredensial Anda.
- Buka tab baru dengan mengklik ikon Tab baru di sebelah kanan.
- Salin dan jalankan pernyataan kueri
insertdari fileinsert_scripts1.sql,,insert_script2.sql,,insert_scripts3.sql,, daninsert_scripts4.sqlsatu per satu. Anda dapat menjalankan pernyataan penyisipan salin 10-50 untuk demo cepat kasus penggunaan ini.
Untuk menjalankan, klik Run. Hasil kueri Anda akan muncul di tabel Results.
5. Membuat Embedding untuk data paten
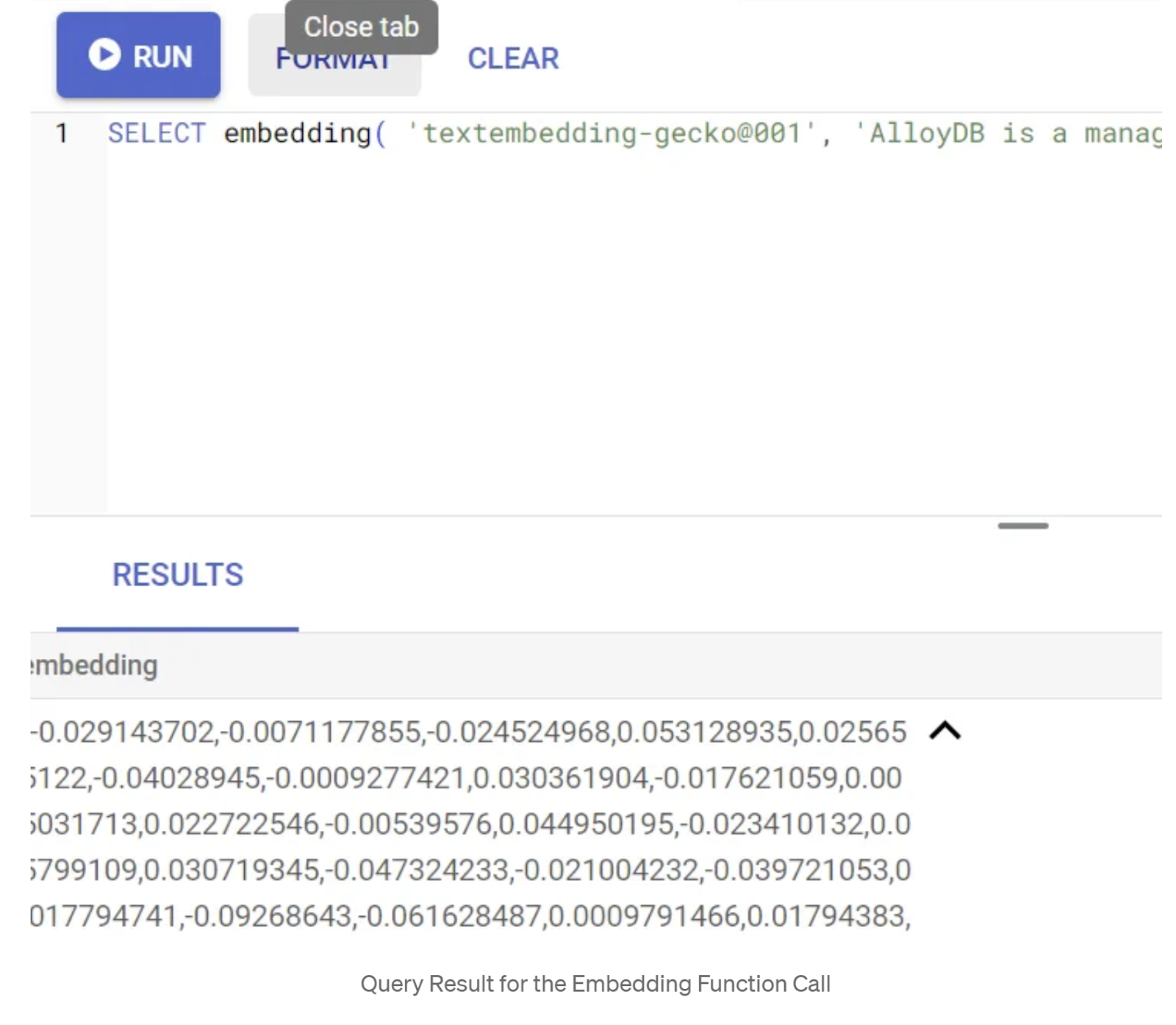
Pertama, mari kita uji fungsi penyematan dengan menjalankan contoh kueri berikut:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Ini akan menampilkan vektor embedding, yang terlihat seperti array float, untuk teks contoh dalam kueri. Tampilannya seperti ini:
Perbarui kolom Vektor abstract_embeddings
DML di bawah ini harus digunakan untuk memperbarui abstrak paten dalam tabel dengan sematan yang sesuai jika sematan perlu dibuat untuk abstrak. Namun, dalam kasus kami, pernyataan penyisipan sudah berisi sematan ini untuk setiap abstrak sehingga Anda tidak perlu memanggil metode embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Melakukan penelusuran Vektor
Setelah tabel, data, dan embedding siap, mari lakukan Penelusuran Vektor real time untuk teks penelusuran pengguna. Anda dapat mengujinya dengan menjalankan kueri di bawah:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Dalam kueri ini,
- Teks yang ditelusuri pengguna adalah: "Analisis Sentimen".
- Kita mengonversinya menjadi embedding dalam metode embedding() menggunakan model: text-embedding-005.
- "<=>" mewakili penggunaan metode jarak COSINE SIMILARITY.
- Kita mengonversi hasil metode embedding ke jenis vektor agar kompatibel dengan vektor yang disimpan dalam database.
- LIMIT 10 menunjukkan bahwa kita memilih 10 kecocokan terdekat dari teks penelusuran.
AlloyDB meningkatkan kualitas RAG Penelusuran Vektor:
Ada sejumlah hal baru yang diperkenalkan. Dua di antaranya yang berfokus pada developer adalah:
- Pemfilteran Inline
- Evaluator Perolehan
Pemfilteran Inline
Sebelumnya, sebagai developer, Anda harus melakukan kueri Vector Search dan menangani pemfilteran serta perolehan. Pengoptimal Kueri AlloyDB membuat pilihan tentang cara menjalankan kueri dengan filter. Pemfilteran inline adalah teknik pengoptimalan kueri baru yang memungkinkan pengoptimal kueri AlloyDB mengevaluasi kondisi pemfilteran metadata dan penelusuran vektor secara bersamaan, dengan memanfaatkan indeks vektor dan indeks pada kolom metadata. Hal ini telah meningkatkan performa recall, sehingga developer dapat memanfaatkan apa yang ditawarkan AlloyDB secara langsung.
Pemfilteran inline paling cocok untuk kasus dengan selektivitas sedang. Saat menelusuri indeks vektor, AlloyDB hanya menghitung jarak untuk vektor yang cocok dengan kondisi pemfilteran metadata (filter fungsional Anda dalam kueri yang biasanya ditangani dalam klausa WHERE). Hal ini sangat meningkatkan performa untuk kueri ini, yang melengkapi keunggulan pasca-filter atau pra-filter.
- Menginstal atau mengupdate ekstensi pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Jika ekstensi pgvector sudah diinstal, upgrade ekstensi vektor ke versi 0.8.0.google-3 atau yang lebih baru untuk mendapatkan kemampuan evaluator ingatan.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Langkah ini hanya perlu dijalankan jika ekstensi vektor Anda adalah <0.8.0.google-3.
Catatan penting: Jika jumlah baris Anda kurang dari 100, Anda tidak perlu membuat indeks ScaNN karena tidak akan berlaku untuk baris yang lebih sedikit. Dalam hal ini, lewati langkah-langkah berikut.
- Untuk membuat indeks ScaNN, instal ekstensi alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Pertama, jalankan Kueri Penelusuran Vektor tanpa indeks dan tanpa Filter Inline diaktifkan:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Hasilnya akan terlihat seperti:

- Jalankan Explain Analyze di dalamnya: (tanpa indeks maupun Pemfilteran Inline)

Waktu eksekusi adalah 2,4 md
- Mari kita buat indeks reguler pada kolom num_claims sehingga kita dapat memfilter berdasarkan kolom tersebut:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Mari kita buat indeks ScaNN untuk aplikasi Penelusuran Paten kita. Jalankan perintah berikut dari AlloyDB Studio Anda:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Catatan penting: (num_leaves=32) berlaku untuk total set data kami dengan lebih dari 1.000 baris. Jika jumlah baris Anda kurang dari 100, Anda tidak perlu membuat indeks karena tidak akan berlaku untuk baris yang lebih sedikit.
- Menetapkan Pemfilteran Inline yang diaktifkan pada Indeks ScaNN:
SET scann.enable_inline_filtering = on
- Sekarang, jalankan kueri yang sama dengan filter dan Penelusuran Vektor di dalamnya:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
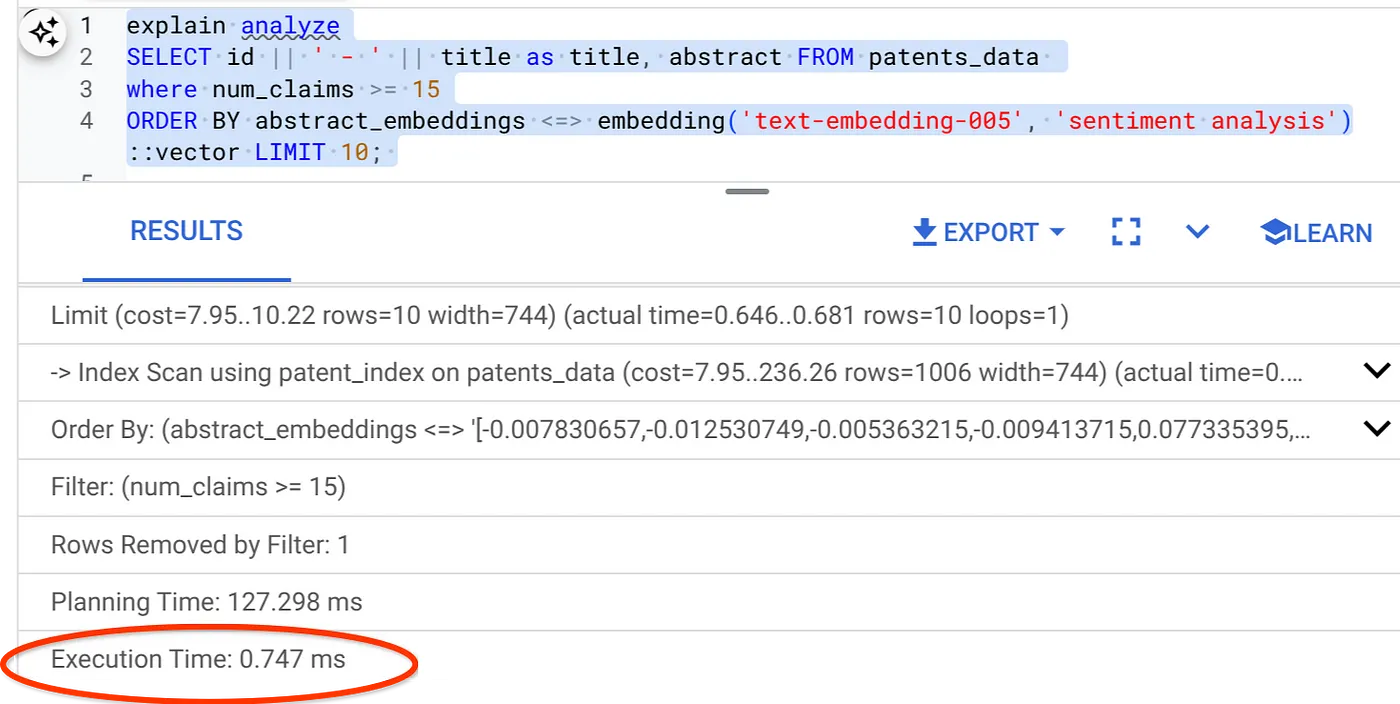
Seperti yang dapat Anda lihat, waktu eksekusi berkurang secara signifikan untuk Penelusuran Vektor yang sama. Indeks ScaNN dengan Pemfilteran Inline di Vector Search telah memungkinkan hal ini!!!
Selanjutnya, mari kita evaluasi recall untuk Vector Search yang diaktifkan ScaNN ini.
Evaluator Perolehan
Perolehan dalam penelusuran kemiripan adalah persentase instance relevan yang diambil dari penelusuran, yaitu jumlah positif benar. Ini adalah metrik paling umum yang digunakan untuk mengukur kualitas penelusuran. Salah satu sumber hilangnya recall berasal dari perbedaan antara penelusuran perkiraan tetangga terdekat, atau aNN, dan penelusuran k (exact) tetangga terdekat, atau kNN. Indeks vektor seperti ScaNN AlloyDB menerapkan algoritma aNN, sehingga Anda dapat mempercepat penelusuran vektor pada set data besar dengan sedikit kompromi dalam perolehan. Sekarang, AlloyDB memberi Anda kemampuan untuk mengukur kompromi ini secara langsung di database untuk setiap kueri dan memastikan bahwa kompromi tersebut stabil dari waktu ke waktu. Anda dapat memperbarui parameter kueri dan indeks sebagai respons terhadap informasi ini untuk mendapatkan hasil dan performa yang lebih baik.
Anda dapat menemukan recall untuk kueri vektor pada indeks vektor untuk konfigurasi tertentu menggunakan fungsi evaluate_query_recall. Fungsi ini memungkinkan Anda menyesuaikan parameter untuk mendapatkan hasil perolehan kueri vektor yang Anda inginkan. Recall adalah metrik yang digunakan untuk kualitas penelusuran, dan ditentukan sebagai persentase hasil yang ditampilkan yang secara objektif paling dekat dengan vektor kueri. Fungsi evaluate_query_recall diaktifkan secara default.
Catatan Penting:
Jika Anda mengalami error izin ditolak pada indeks HNSW dalam langkah-langkah berikut, lewati seluruh bagian evaluasi perolehan ini untuk saat ini. Hal ini mungkin terkait dengan batasan akses karena baru dirilis pada saat codelab ini didokumentasikan.
- Tetapkan tanda Enable Index Scan pada indeks ScaNN & indeks HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Jalankan kueri berikut di AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Fungsi evaluate_query_recall menggunakan kueri sebagai parameter dan menampilkan perolehan kueri tersebut. Saya menggunakan kueri yang sama dengan yang saya gunakan untuk memeriksa performa sebagai kueri input fungsi. Saya telah menambahkan SCaNN sebagai metode indeks. Untuk opsi parameter lainnya, lihat dokumentasi.
Recall untuk kueri Penelusuran Vektor yang telah kita gunakan:
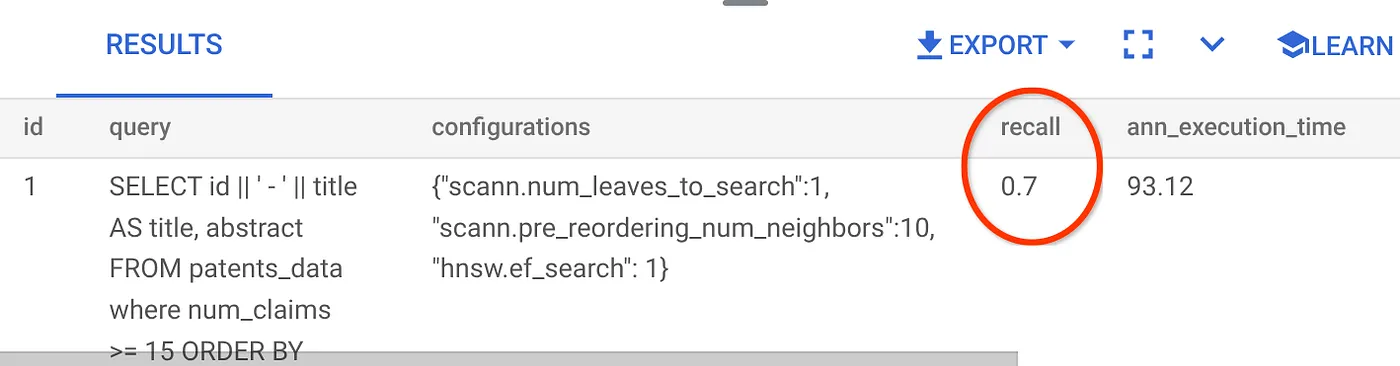
Saya melihat bahwa RECALL adalah 70%. Sekarang saya dapat menggunakan informasi ini untuk mengubah parameter indeks, metode, dan parameter kueri serta meningkatkan kemampuan mengingat saya untuk Penelusuran Vektor ini.
Saya telah mengubah jumlah baris dalam set hasil menjadi 7 (dari 10 sebelumnya) dan saya melihat RECALL yang sedikit lebih baik, yaitu 86%.

Artinya, secara real time, saya dapat memvariasikan jumlah kecocokan yang dilihat pengguna untuk meningkatkan relevansi kecocokan sesuai dengan konteks penelusuran pengguna.
Oke! Saatnya men-deploy logika database dan beralih ke agen.
7. Menerapkan logika database ke web tanpa server
Siap membawa aplikasi ini ke web? Ikuti langkah-langkah di bawah ini:
- Buka Cloud Run Functions di Konsol Google Cloud untuk membuat Cloud Run Function baru dengan mengklik "Write a function" atau menggunakan link: https://console.cloud.google.com/run/create?deploymentType=function.
- Pilih opsi "Gunakan editor inline untuk membuat fungsi" dan mulai konfigurasi. Berikan Nama Layanan "patent-search", pilih Region sebagai "us-central1", dan pilih runtime sebagai "Java 17". Tetapkan Autentikasi ke "Izinkan pemanggilan tanpa autentikasi".
- Di bagian "Containers, Volumes, Networking, Security", ikuti langkah-langkah di bawah tanpa melewatkan detail apa pun:
Buka tab Jaringan:

Pilih "Hubungkan ke VPC untuk traffic keluar", lalu pilih "Gunakan konektor Akses VPC Serverless".
Di bagian setelan dropdown Jaringan, Klik dropdown Jaringan dan pilih opsi "Tambahkan Konektor VPC Baru" (jika Anda belum mengonfigurasi yang default) dan ikuti petunjuk yang Anda lihat di kotak dialog yang muncul:

Berikan nama untuk VPC Connector dan pastikan regionnya sama dengan instance Anda. Biarkan nilai Jaringan sebagai default dan tetapkan Subnet sebagai Rentang IP Kustom dengan rentang IP 10.8.0.0 atau yang serupa yang tersedia.
Perluas SHOW SCALING SETTINGS dan pastikan Anda telah menyetel konfigurasi persis seperti berikut:

Klik CREATE dan konektor ini akan tercantum di setelan egress sekarang.
Pilih konektor yang baru dibuat.
Pilih agar semua traffic dirutekan melalui konektor VPC ini.
Klik BERIKUTNYA, lalu DEPLOY.
- Secara default, Entry Point akan ditetapkan ke "gcfv2.HelloHttpFunction". Ganti kode placeholder di HelloHttpFunction.java dan pom.xml Cloud Run Function Anda dengan kode dari " PatentSearch.java" dan " pom.xml". Ubah nama file class menjadi PatentSearch.java.
- Jangan lupa untuk mengganti placeholder ************* dan kredensial koneksi AlloyDB dengan nilai Anda di file Java. Kredensial AlloyDB adalah kredensial yang kita gunakan di awal codelab ini. Jika Anda telah menggunakan nilai yang berbeda, ubah nilai tersebut dalam file Java.
- Klik Deploy.
- Setelah Cloud Function yang diupdate di-deploy, Anda akan melihat endpoint yang dihasilkan. Salin dan ganti di perintah berikut:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
Selesai. Semudah itu melakukan Penelusuran Vektor Kesamaan Kontekstual tingkat lanjut menggunakan model Embeddings pada data AlloyDB.
8. Mari kita bangun agen dengan Java ADK
Pertama, mari kita mulai dengan project Java di editor.
- Buka Terminal Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Memberikan otorisasi saat diminta
- Beralih ke Cloud Shell Editor dengan mengklik ikon editor dari bagian atas konsol Cloud Shell

- Di konsol Cloud Shell Editor yang terbuka, buat folder baru dan beri nama "adk-agents"
Klik buat folder baru di direktori root Cloud Shell Anda seperti yang ditunjukkan di bawah:

Beri nama "adk-agents":

- Buat struktur folder berikut dan file kosong dengan nama file yang sesuai dalam struktur di bawah:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Buka repositori github di tab terpisah dan salin kode sumber untuk file App.java dan pom.xml.
- Jika Anda telah membuka editor di tab baru menggunakan ikon "Buka di tab baru" di pojok kanan atas, Anda dapat membuka terminal di bagian bawah halaman. Anda dapat membuka editor dan terminal secara paralel sehingga Anda dapat beroperasi dengan bebas.
- Setelah dikloning, beralihlah kembali ke konsol Cloud Shell Editor
- Karena kita telah membuat Fungsi Cloud Run, Anda tidak perlu menyalin file fungsi Cloud Run dari folder repo.
Mulai menggunakan ADK Java SDK
Prosesnya cukup mudah. Anda terutama harus memastikan hal berikut tercakup dalam langkah cloning:
- Menambahkan Dependensi:
Sertakan artefak google-adk dan google-adk-dev (untuk UI Web) di pom.xml Anda. Jika Anda menyalin sumber dari repo, dependensi ini sudah disertakan dalam file, Anda tidak perlu menyertakannya. Anda hanya perlu membuat perubahan di endpoint Cloud Run Function untuk mencerminkan endpoint yang di-deploy. Hal ini dibahas dalam langkah-langkah berikutnya di bagian ini.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Pastikan untuk mereferensikan pom.xml dari repositori sumber karena ada dependensi dan konfigurasi lain yang diperlukan agar aplikasi dapat berjalan.
- Mengonfigurasi Project Anda:
Pastikan setelan compiler Java (direkomendasikan 17+) dan Maven dikonfigurasi dengan benar di pom.xml Anda. Anda dapat mengonfigurasi project untuk mengikuti struktur di bawah:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Menentukan Agen dan Alatnya (App.java):
Di sinilah keajaiban ADK Java SDK terlihat. Kita menentukan agen, kemampuannya (petunjuk), dan alat yang dapat digunakannya.
Temukan versi sederhana dari beberapa cuplikan kode class agen utama di sini. Untuk melihat project lengkapnya, lihat repo project di sini.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Komponen Kode Java ADK Utama yang Disoroti:
- LlmAgent.builder(): Fluent API untuk mengonfigurasi agen Anda.
- .instruction(...): Memberikan perintah dan panduan inti untuk LLM, termasuk kapan harus menggunakan alat yang mana.
- FunctionTool.create(App.class, "methodName"): Mendaftarkan metode Java Anda dengan mudah sebagai alat yang dapat dipanggil oleh agen. String nama metode harus cocok dengan metode statis publik yang sebenarnya.
- @Schema(description = ...): Memberi anotasi pada parameter alat, sehingga membantu LLM memahami input yang diharapkan oleh setiap alat. Deskripsi ini sangat penting untuk pemilihan alat dan pengisian parameter yang akurat.
- InvocationContext ctx: Diteruskan secara otomatis ke metode alat, sehingga memberikan akses ke status sesi (ctx.session().state()), informasi pengguna, dan lainnya.
- .outputKey("patents"): Saat alat menampilkan data, ADK dapat menyimpannya secara otomatis di status sesi dengan kunci ini. Berikut cara explainPatent dapat mengakses hasil dari getPatents.
- VECTOR_SEARCH_ENDPOINT: Ini adalah variabel yang menyimpan logika fungsional inti untuk Tanya Jawab kontekstual bagi pengguna dalam kasus penggunaan penelusuran paten.
- Item Tindakan di sini: Anda perlu menetapkan nilai endpoint yang di-deploy yang diperbarui setelah menerapkan langkah Java Cloud Run Function dari bagian sebelumnya.
- searchTool: Alat ini berinteraksi dengan pengguna untuk menemukan kecocokan paten yang relevan secara kontekstual dari database paten untuk teks penelusuran pengguna.
- explainTool: Alat ini meminta pengguna untuk memilih paten tertentu yang akan dipelajari secara mendalam. Kemudian, model ini meringkas abstrak paten dan dapat menjawab lebih banyak pertanyaan dari pengguna berdasarkan detail paten yang dimilikinya.
Catatan Penting: Pastikan untuk mengganti variabel VECTOR_SEARCH_ENDPOINT dengan endpoint CRF yang di-deploy.
Memanfaatkan InvocationContext untuk Interaksi Stateful
Salah satu fitur penting untuk membangun agen yang berguna adalah mengelola status di beberapa giliran percakapan. InvocationContext ADK mempermudah hal ini.
Di App.java:
- Jika initAgent() ditentukan, kita menggunakan .outputKey("patents"). Hal ini memberi tahu ADK bahwa saat alat (seperti getPatents) menampilkan data di kolom laporannya, data tersebut harus disimpan dalam status sesi dengan kunci "patents".
- Dalam metode alat explainPatent, kita menyuntikkan InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Hal ini memungkinkan alat explainPatent mengakses daftar paten yang diambil oleh alat getPatents pada giliran sebelumnya, sehingga percakapan menjadi stateful dan koheren.
9. Pengujian CLI Lokal
Menentukan variabel lingkungan
Anda harus mengekspor dua variabel lingkungan:
- Kunci Gemini yang bisa Anda dapatkan dari AI Studio:
Untuk melakukannya, buka https://aistudio.google.com/apikey dan dapatkan Kunci API untuk Project Google Cloud aktif tempat Anda menerapkan aplikasi ini, lalu simpan kunci tersebut di suatu tempat:
- Setelah Anda mendapatkan kunci, buka Terminal Cloud Shell dan pindah ke direktori baru yang baru saja kita buat, yaitu adk-agents, dengan menjalankan perintah berikut:
cd adk-agents
- Variabel untuk menentukan bahwa kita tidak menggunakan Vertex AI kali ini.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Menjalankan agen pertama Anda di CLI
Untuk meluncurkan agen pertama ini, gunakan perintah Maven berikut di terminal Anda:
mvn compile exec:java -DmainClass="agents.App"
Anda akan melihat respons interaktif dari agen di terminal Anda.
10. Men-deploy ke Cloud Run
Men-deploy agen Java ADK ke Cloud Run mirip dengan men-deploy aplikasi Java lainnya:
- Dockerfile: Buat Dockerfile untuk memaketkan aplikasi Java Anda.
- Membangun & Mengirim Image Docker: Gunakan Google Cloud Build dan Artifact Registry.
- Anda dapat melakukan langkah di atas & men-deploy ke Cloud Run hanya dalam satu perintah:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Demikian pula, Anda akan men-deploy Java Cloud Run Function (gcfv2.PatentSearch). Atau, Anda dapat membuat dan men-deploy Java Cloud Run Function untuk logika database langsung dari konsol Cloud Run Function.
11. Pengujian dengan UI Web
ADK dilengkapi dengan UI Web praktis untuk pengujian dan proses debug agen Anda secara lokal. Saat Anda menjalankan App.java secara lokal (misalnya, mvn exec:java -Dexec.mainClass="agents.App" jika dikonfigurasi, atau hanya menjalankan metode utama), ADK biasanya memulai server web lokal.
UI Web ADK memungkinkan Anda:
- Mengirim pesan ke agen Anda.
- Lihat peristiwa (pesan pengguna, panggilan alat, respons alat, respons LLM).
- Periksa status sesi.
- Melihat log dan rekaman aktivitas.
Hal ini sangat berharga selama pengembangan untuk memahami cara agen Anda memproses permintaan dan menggunakan alatnya. Hal ini mengasumsikan bahwa mainClass Anda di pom.xml disetel ke com.google.adk.web.AdkWebServer dan agen Anda terdaftar di dalamnya, atau Anda menjalankan peluncur pengujian lokal yang mengeksposnya.
Saat menjalankan App.java dengan InMemoryRunner dan Scanner untuk input konsol, Anda sedang menguji logika agen inti. UI Web adalah komponen terpisah untuk pengalaman penelusuran bug yang lebih visual, yang sering digunakan saat ADK menayangkan agen Anda melalui HTTP.
Anda dapat menggunakan perintah Maven berikut dari direktori root untuk meluncurkan server lokal SpringBoot:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
Antarmuka ini sering kali dapat diakses di URL yang dihasilkan oleh perintah di atas. Jika di-deploy di Cloud Run, Anda akan dapat mengaksesnya dari link yang di-deploy di Cloud Run.
Anda akan dapat melihat hasilnya di antarmuka interaktif.
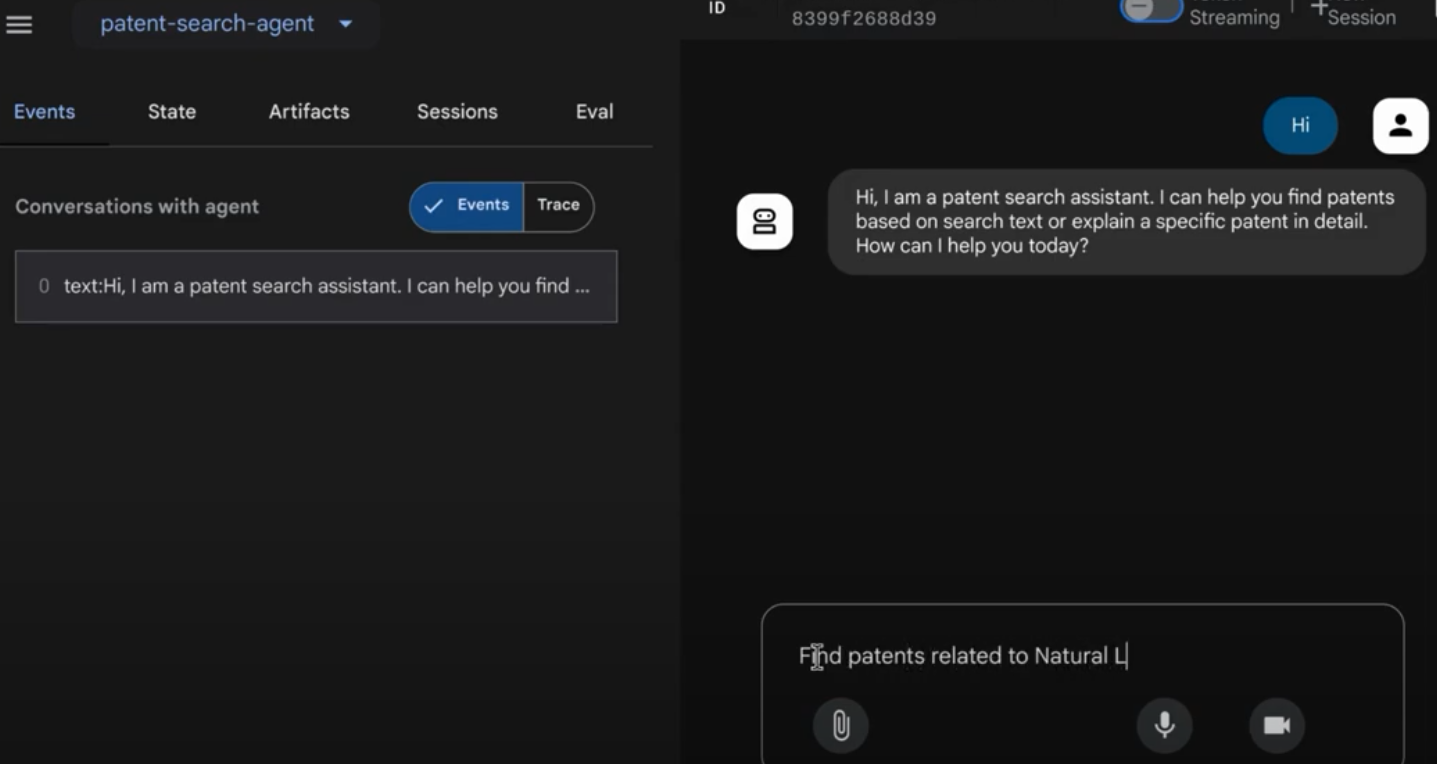
Tonton video di bawah untuk melihat Agen Paten kami yang telah di-deploy:
Demo Agen Paten yang Dikontrol Kualitasnya dengan Evaluasi Pencarian Inline & Recall AlloyDB!
12. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam posting ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
13. Selamat
Selamat! Anda telah berhasil membuat Agen Analisis Paten di Java dengan menggabungkan kemampuan ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI, dan Vector Search. Selain itu, kami telah membuat lompatan besar dalam menjadikan penelusuran kesamaan kontekstual sangat transformatif, efisien, dan benar-benar berbasis makna.
Mulai Sekarang!
Dokumentasi ADK: [Link to Official ADK Java Docs]
Kode Sumber Agen Analisis Paten: [Link ke Repo GitHub Anda (yang kini bersifat publik)]
Agen Contoh Java: [link to the adk-samples repo]
Bergabung dengan Komunitas ADK: https://www.reddit.com/r/agentdevelopmentkit/
Selamat membuat agen!