
1. Tổng quan
Trong nhiều ngành, tìm kiếm theo bối cảnh là một chức năng quan trọng, tạo nên cốt lõi và trung tâm của các ứng dụng. Cơ chế Tạo sinh tăng cường truy xuất là yếu tố chính thúc đẩy sự phát triển quan trọng của công nghệ này trong một thời gian khá dài nhờ cơ chế truy xuất dựa trên AI tạo sinh. Các mô hình tạo sinh, với cửa sổ ngữ cảnh lớn và chất lượng đầu ra ấn tượng, đang chuyển đổi AI. RAG cung cấp một cách có hệ thống để đưa ngữ cảnh vào các ứng dụng và tác nhân AI, dựa trên các cơ sở dữ liệu có cấu trúc hoặc thông tin từ nhiều phương tiện. Dữ liệu theo bối cảnh này rất quan trọng để đảm bảo tính rõ ràng và độ chính xác của kết quả. Tuy nhiên, những kết quả đó chính xác đến mức nào? Doanh nghiệp của bạn có phụ thuộc nhiều vào độ chính xác của các kết quả so khớp theo ngữ cảnh và mức độ liên quan này không? Vậy thì dự án này sẽ khiến bạn thích thú!
Giờ đây, hãy tưởng tượng nếu chúng ta có thể tận dụng sức mạnh của các mô hình tạo sinh và xây dựng các tác nhân tương tác có khả năng đưa ra quyết định tự chủ dựa trên thông tin quan trọng về bối cảnh như vậy và dựa trên sự thật; đó là những gì chúng ta sẽ xây dựng hôm nay. Chúng ta sẽ tạo một ứng dụng tác nhân AI toàn diện bằng cách sử dụng Agent Development Kit (Bộ công cụ phát triển tác nhân) dựa trên RAG nâng cao trong AlloyDB cho một ứng dụng phân tích bằng sáng chế.
Đặc vụ phân tích bằng sáng chế hỗ trợ người dùng tìm bằng sáng chế phù hợp theo ngữ cảnh với văn bản tìm kiếm của họ và khi được yêu cầu, đặc vụ này sẽ cung cấp thông tin giải thích rõ ràng, ngắn gọn và thông tin chi tiết bổ sung (nếu cần) cho một bằng sáng chế đã chọn. Bạn đã sẵn sàng xem cách thực hiện chưa? Hãy cùng tìm hiểu nhé!
Mục tiêu
Mục tiêu rất đơn giản. Cho phép người dùng tìm kiếm bằng sáng chế dựa trên nội dung mô tả bằng văn bản, sau đó nhận được lời giải thích chi tiết về một bằng sáng chế cụ thể trong kết quả tìm kiếm và tất cả những điều này đều được thực hiện bằng một tác nhân AI được xây dựng bằng Java ADK, AlloyDB, Vector Search (với các chỉ mục nâng cao), Gemini và toàn bộ ứng dụng được triển khai mà không cần máy chủ trên Cloud Run.
Sản phẩm bạn sẽ tạo ra
Trong phần này, bạn sẽ:
- Tạo một phiên bản AlloyDB và tải dữ liệu Patents Public Dataset
- Triển khai tính năng Tìm kiếm vectơ nâng cao trong AlloyDB bằng cách sử dụng các tính năng ScaNN và Recall eval
- Tạo một tác nhân bằng Java ADK
- Triển khai logic phía máy chủ cơ sở dữ liệu trong Cloud Functions không máy chủ của Java
- Triển khai và kiểm thử tác nhân trong Cloud Run
Sơ đồ sau đây minh hoạ luồng dữ liệu và các bước liên quan đến việc triển khai.
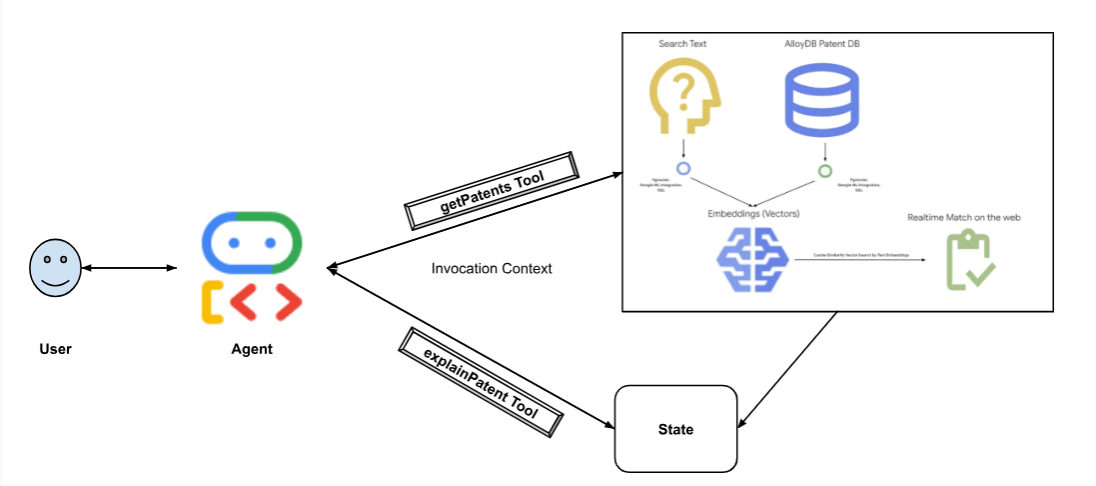
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Yêu cầu
2. Trước khi bắt đầu
Tạo một dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không .
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud. Nhấp vào biểu tượng Kích hoạt Cloud Shell ở đầu bảng điều khiển Google Cloud.

- Sau khi kết nối với Cloud Shell, bạn có thể kiểm tra để đảm bảo rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt:
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc. Bạn có thể dùng lệnh gcloud trong thiết bị đầu cuối Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Bạn có thể thay thế lệnh gcloud bằng cách tìm kiếm từng sản phẩm trên bảng điều khiển hoặc sử dụng đường liên kết này.
Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
3. Thiết lập cơ sở dữ liệu
Trong phòng thí nghiệm này, chúng ta sẽ sử dụng AlloyDB làm cơ sở dữ liệu cho dữ liệu bằng sáng chế. Nó sử dụng cụm để lưu giữ tất cả các tài nguyên, chẳng hạn như cơ sở dữ liệu và nhật ký. Mỗi cụm có một phiên bản chính cung cấp một điểm truy cập vào dữ liệu. Các bảng sẽ chứa dữ liệu thực tế.
Hãy tạo một cụm, phiên bản và bảng AlloyDB nơi tập dữ liệu bằng sáng chế sẽ được tải.
Tạo một cụm và phiên bản
- Chuyển đến trang AlloyDB trong Cloud Console. Một cách dễ dàng để tìm hầu hết các trang trong Cloud Console là tìm kiếm các trang đó bằng thanh tìm kiếm của bảng điều khiển.
- Chọn TẠO CỤM trên trang đó:

- Bạn sẽ thấy một màn hình như màn hình bên dưới. Tạo một cụm và phiên bản bằng các giá trị sau (Đảm bảo các giá trị khớp nhau trong trường hợp bạn đang sao chép mã ứng dụng từ kho lưu trữ):
- mã nhận dạng cụm: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / mới nhất được đề xuất
- Khu vực: "
us-central1" - Mạng: "
default"

- Khi chọn mạng mặc định, bạn sẽ thấy một màn hình như màn hình bên dưới.
Chọn THIẾT LẬP KẾT NỐI.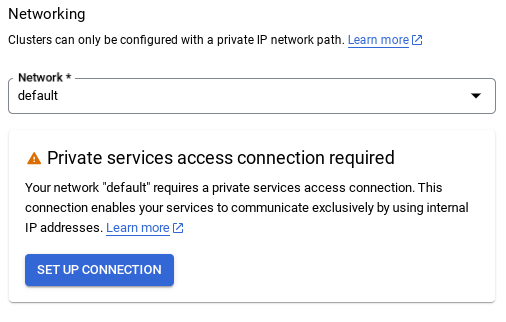
- Từ đó, hãy chọn "Sử dụng dải IP được phân bổ tự động" rồi chọn Tiếp tục. Sau khi xem xét thông tin, hãy chọn TẠO KẾT NỐI.

- Sau khi thiết lập mạng, bạn có thể tiếp tục tạo cụm. Nhấp vào TẠO CỤM để hoàn tất việc thiết lập cụm như minh hoạ bên dưới:

Đảm bảo bạn thay đổi mã nhận dạng phiên bản (bạn có thể tìm thấy mã này tại thời điểm định cấu hình cụm / phiên bản) thành
vector-instance. Nếu không thể thay đổi, hãy nhớ sử dụng mã nhận dạng phiên bản trong tất cả các thông tin tham chiếu sắp tới.
Xin lưu ý rằng quá trình tạo Cụm sẽ mất khoảng 10 phút. Sau khi tạo thành công, bạn sẽ thấy một màn hình cho biết thông tin tổng quan về cụm mà bạn vừa tạo.
4. Nhập dữ liệu
Bây giờ, đã đến lúc thêm một bảng có dữ liệu về cửa hàng. Chuyển đến AlloyDB, chọn cụm chính rồi chọn AlloyDB Studio:
Bạn có thể phải đợi phiên bản của mình được tạo xong. Sau khi tạo, hãy đăng nhập vào AlloyDB bằng thông tin đăng nhập mà bạn đã tạo khi tạo cụm. Sử dụng dữ liệu sau để xác thực với PostgreSQL:
- Tên người dùng : "
postgres" - Cơ sở dữ liệu : "
postgres" - Mật khẩu : "
alloydb"
Sau khi bạn xác thực thành công vào AlloyDB Studio, các lệnh SQL sẽ được nhập vào Trình chỉnh sửa. Bạn có thể thêm nhiều cửa sổ Trình chỉnh sửa bằng cách nhấp vào dấu cộng ở bên phải cửa sổ cuối cùng.
Bạn sẽ nhập các lệnh cho AlloyDB trong cửa sổ trình chỉnh sửa, sử dụng các lựa chọn Chạy, Định dạng và Xoá khi cần.
Bật tiện ích
Để tạo ứng dụng này, chúng ta sẽ sử dụng các tiện ích pgvector và google_ml_integration. Tiện ích pgvector cho phép bạn lưu trữ và tìm kiếm các vectơ nhúng. Tiện ích google_ml_integration cung cấp các hàm mà bạn dùng để truy cập vào các điểm cuối dự đoán của Vertex AI nhằm nhận thông tin dự đoán bằng SQL. Bật các tiện ích này bằng cách chạy các DDL sau:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Nếu bạn muốn kiểm tra các tiện ích đã được bật trên cơ sở dữ liệu, hãy chạy lệnh SQL sau:
select extname, extversion from pg_extension;
Tạo bảng
Bạn có thể tạo một bảng bằng câu lệnh DDL bên dưới trong AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
Cột abstract_embeddings sẽ cho phép lưu trữ các giá trị vectơ của văn bản.
Cấp quyền
Chạy câu lệnh bên dưới để cấp quyền thực thi cho hàm "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Cấp VAI TRÒ Người dùng Vertex AI cho tài khoản dịch vụ AlloyDB
Trên bảng điều khiển IAM của Google Cloud, hãy cấp cho tài khoản dịch vụ AlloyDB (có dạng như sau: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) quyền truy cập vào vai trò "Người dùng Vertex AI". PROJECT_NUMBER sẽ có số dự án của bạn.
Ngoài ra, bạn có thể chạy lệnh bên dưới trong Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Tải dữ liệu bằng sáng chế vào cơ sở dữ liệu
Chúng tôi sẽ sử dụng Tập dữ liệu công khai về bằng sáng chế của Google trên BigQuery làm tập dữ liệu. Chúng ta sẽ sử dụng AlloyDB Studio để chạy các truy vấn. Dữ liệu được lấy từ tệp insert scripts sql này trong repo này và chúng ta sẽ chạy tệp này để tải dữ liệu về bằng sáng chế.
- Trong Google Cloud Console, hãy mở trang AlloyDB.
- Chọn cụm bạn vừa tạo rồi nhấp vào phiên bản.
- Trong trình đơn điều hướng AlloyDB, hãy nhấp vào AlloyDB Studio. Đăng nhập bằng thông tin đăng nhập của bạn.
- Mở một thẻ mới bằng cách nhấp vào biểu tượng Thẻ mới ở bên phải.
- Sao chép và chạy từng câu lệnh truy vấn
inserttrong các tệpinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sql. Bạn có thể chạy 10-50 câu lệnh chèn bản sao để xem nhanh bản minh hoạ về trường hợp sử dụng này.
Để chạy, hãy nhấp vào Chạy. Kết quả của truy vấn sẽ xuất hiện trong bảng Results (Kết quả).
5. Tạo vectơ nhúng cho dữ liệu bằng sáng chế
Trước tiên, hãy kiểm thử hàm nhúng bằng cách chạy truy vấn mẫu sau:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Thao tác này sẽ trả về vectơ nhúng (có dạng như một mảng số thực) cho văn bản mẫu trong truy vấn. Có dạng như sau:
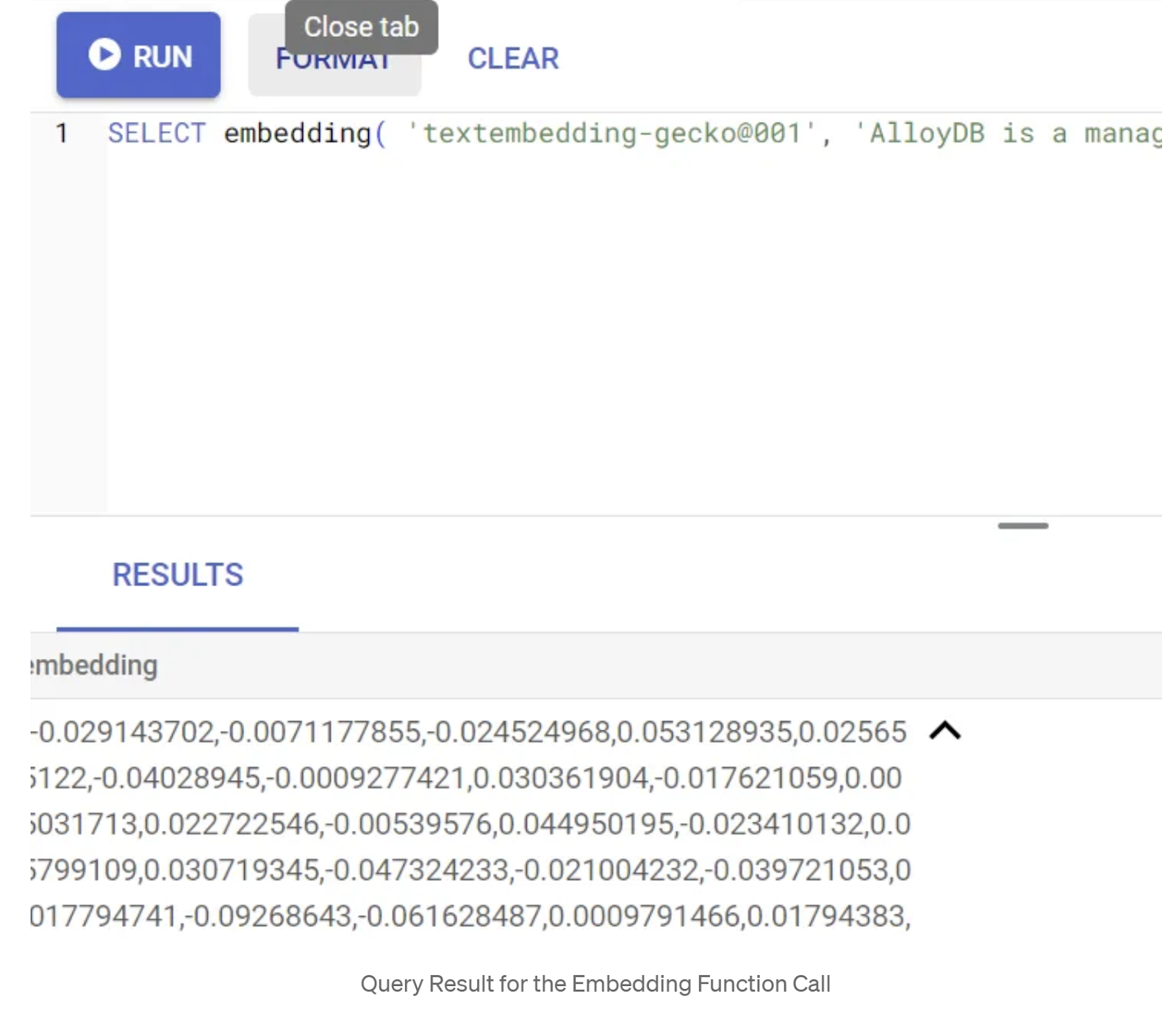
Cập nhật trường Vector abstract_embeddings
Bạn nên dùng DML dưới đây để cập nhật bản tóm tắt bằng sáng chế trong bảng bằng các vectơ nhúng tương ứng trong trường hợp cần tạo vectơ nhúng cho bản tóm tắt. Nhưng trong trường hợp của chúng ta, các câu lệnh chèn đã chứa những mục nhúng này cho từng bản tóm tắt, nên bạn không cần gọi phương thức embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Thực hiện tìm kiếm vectơ
Giờ đây, khi bảng, dữ liệu và các thành phần nhúng đều đã sẵn sàng, hãy thực hiện tính năng Tìm kiếm vectơ theo thời gian thực cho văn bản tìm kiếm của người dùng. Bạn có thể kiểm thử điều này bằng cách chạy truy vấn bên dưới:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Trong truy vấn này,
- Văn bản mà người dùng tìm kiếm là: "Phân tích tình cảm".
- Chúng ta sẽ chuyển đổi nó thành các mục nhúng trong phương thức embedding() bằng cách sử dụng mô hình: text-embedding-005.
- "<=>" biểu thị việc sử dụng phương thức khoảng cách COSINE SIMILARITY.
- Chúng tôi đang chuyển đổi kết quả của phương thức nhúng thành loại vectơ để tương thích với các vectơ được lưu trữ trong cơ sở dữ liệu.
- LIMIT 10 cho biết chúng ta đang chọn 10 kết quả phù hợp nhất với văn bản tìm kiếm.
AlloyDB nâng cao khả năng RAG của tính năng Tìm kiếm vectơ:
Có rất nhiều điều mới mẻ được giới thiệu. Hai trong số các chỉ số tập trung vào nhà phát triển là:
- Lọc cùng dòng
- Người đánh giá mức độ liên quan
Lọc cùng dòng
Trước đây, với tư cách là nhà phát triển, bạn sẽ phải thực hiện truy vấn Tìm kiếm vectơ và phải xử lý việc lọc và thu hồi. Trình tối ưu hoá truy vấn AlloyDB sẽ đưa ra lựa chọn về cách thực thi một truy vấn có bộ lọc. Lọc nội tuyến là một kỹ thuật tối ưu hoá truy vấn mới, cho phép trình tối ưu hoá truy vấn AlloyDB đánh giá cả điều kiện lọc siêu dữ liệu và tìm kiếm vectơ cùng lúc, tận dụng cả chỉ mục vectơ và chỉ mục trên các cột siêu dữ liệu. Điều này giúp tăng hiệu suất thu hồi, cho phép nhà phát triển tận dụng những gì mà AlloyDB cung cấp ngay từ đầu.
Lọc nội tuyến phù hợp nhất cho các trường hợp có tính chọn lọc trung bình. Khi tìm kiếm trong chỉ mục vectơ, AlloyDB chỉ tính toán khoảng cách cho những vectơ khớp với các điều kiện lọc siêu dữ liệu (các bộ lọc chức năng của bạn trong một truy vấn thường được xử lý trong mệnh đề WHERE). Điều này giúp cải thiện đáng kể hiệu suất cho các truy vấn này, bổ sung cho những lợi thế của bộ lọc sau hoặc bộ lọc trước.
- Cài đặt hoặc cập nhật tiện ích pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Nếu tiện ích pgvector đã được cài đặt, hãy nâng cấp tiện ích vectơ lên phiên bản 0.8.0.google-3 trở lên để có các chức năng của trình đánh giá khả năng thu hồi.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Bạn chỉ cần thực hiện bước này nếu tiện ích vectơ của bạn là <0.8.0.google-3.
Lưu ý quan trọng: Nếu số hàng của bạn ít hơn 100, thì bạn không cần tạo chỉ mục ScaNN ngay từ đầu vì chỉ mục này sẽ không áp dụng cho số hàng ít hơn. Trong trường hợp đó, vui lòng bỏ qua các bước sau.
- Để tạo chỉ mục ScaNN, hãy cài đặt tiện ích alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Trước tiên, hãy chạy Cụm từ tìm kiếm bằng vectơ mà không có chỉ mục và không bật Bộ lọc nội tuyến:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Kết quả sẽ có dạng tương tự như sau:

- Chạy tính năng Giải thích dữ liệu phân tích trên dữ liệu đó: (không có chỉ mục cũng như tính năng Lọc trực tiếp)
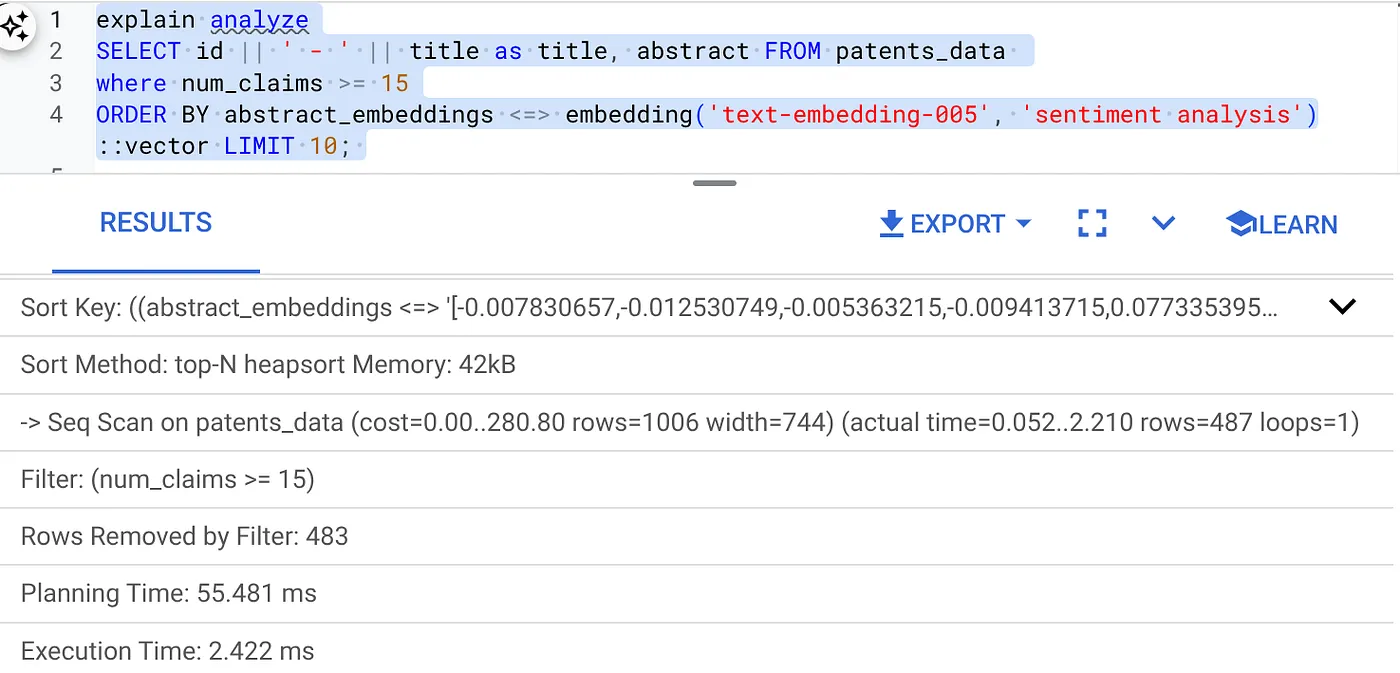
Thời gian thực thi là 2,4 mili giây
- Hãy tạo một chỉ mục thông thường trên trường num_claims để chúng ta có thể lọc theo chỉ mục đó:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Hãy tạo chỉ mục ScaNN cho ứng dụng Tìm kiếm bằng sáng chế. Chạy lệnh sau trong AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Lưu ý quan trọng: (num_leaves=32) áp dụng cho toàn bộ tập dữ liệu của chúng tôi với hơn 1.000 hàng. Nếu số hàng của bạn ít hơn 100, thì bạn không cần tạo chỉ mục ngay từ đầu vì chỉ mục sẽ không áp dụng cho số hàng ít hơn.
- Đặt tính năng Lọc cùng dòng được bật trên Chỉ mục ScaNN:
SET scann.enable_inline_filtering = on
- Bây giờ, hãy chạy cùng một truy vấn có bộ lọc và Tìm kiếm vectơ:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
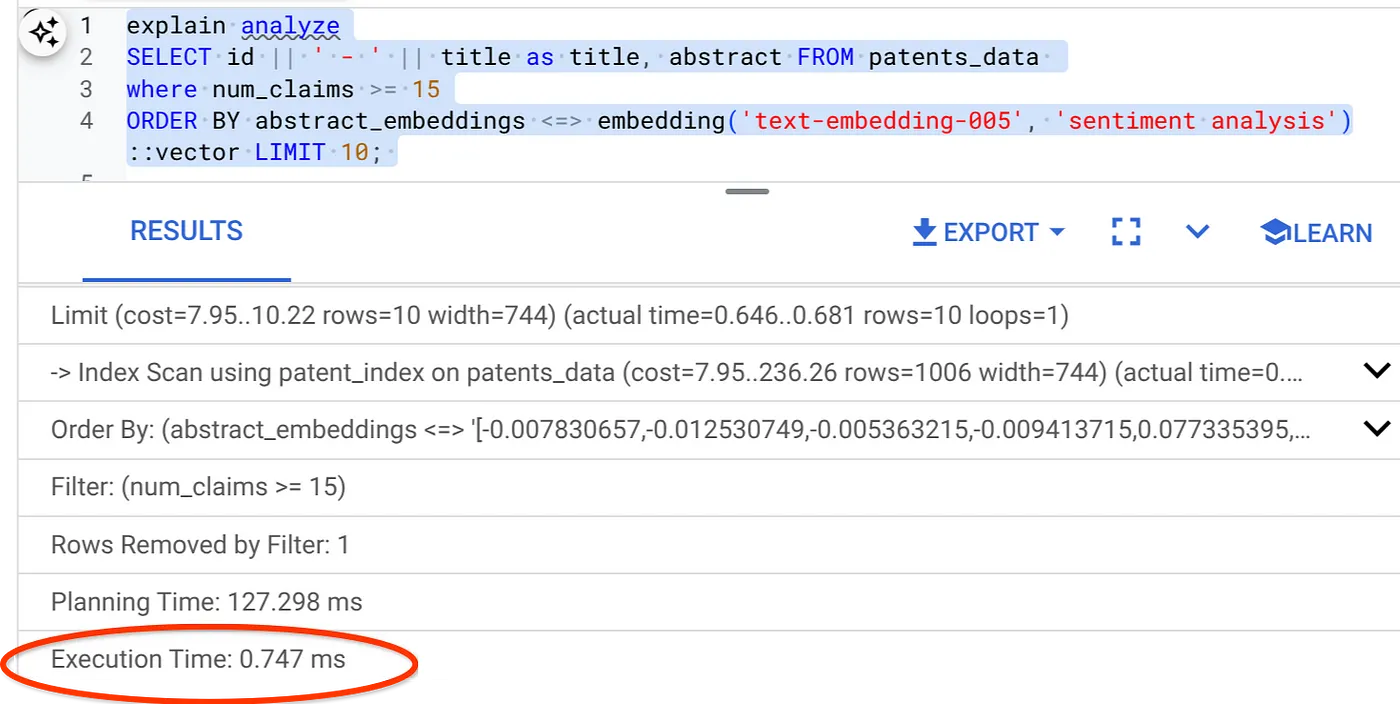
Như bạn có thể thấy, thời gian thực thi đã giảm đáng kể đối với cùng một tính năng Tìm kiếm vectơ. Chỉ mục ScaNN được tích hợp tính năng Lọc nội tuyến trên Vector Search đã giúp điều này trở thành hiện thực!!!
Tiếp theo, hãy đánh giá khả năng thu hồi cho tính năng Tìm kiếm vectơ được bật ScaNN này.
Người đánh giá mức độ liên quan
Độ thu hồi trong tìm kiếm tương tự là tỷ lệ phần trăm số trường hợp có liên quan được truy xuất từ một lượt tìm kiếm, tức là số lượng dương tính thật. Đây là chỉ số phổ biến nhất được dùng để đo lường chất lượng tìm kiếm. Một nguồn gây ra tình trạng mất thông tin thu hồi là sự khác biệt giữa tìm kiếm lân cận gần đúng (aNN) và tìm kiếm k lân cận (chính xác) (kNN). Các chỉ mục vectơ như ScaNN của AlloyDB triển khai các thuật toán aNN, cho phép bạn tăng tốc tìm kiếm vectơ trên các tập dữ liệu lớn để đổi lấy một sự đánh đổi nhỏ về khả năng thu hồi. Giờ đây, AlloyDB cho phép bạn đo lường trực tiếp sự đánh đổi này trong cơ sở dữ liệu cho từng truy vấn và đảm bảo rằng sự đánh đổi này ổn định theo thời gian. Bạn có thể cập nhật các tham số truy vấn và chỉ mục dựa trên thông tin này để đạt được kết quả và hiệu suất tốt hơn.
Bạn có thể tìm thấy độ thu hồi cho một truy vấn vectơ trên chỉ mục vectơ cho một cấu hình nhất định bằng cách sử dụng hàm evaluate_query_recall. Hàm này cho phép bạn điều chỉnh các tham số để đạt được kết quả truy vấn vectơ mà bạn muốn. Độ thu hồi là chỉ số được dùng cho chất lượng tìm kiếm và được xác định là tỷ lệ phần trăm kết quả được trả về gần nhất một cách khách quan với các vectơ truy vấn. Hàm evaluate_query_recall được bật theo mặc định.
Lưu ý quan trọng:
Nếu bạn gặp lỗi bị từ chối quyền trên chỉ mục HNSW trong các bước sau, hãy bỏ qua toàn bộ phần đánh giá khả năng thu hồi này. Nguyên nhân có thể là do các hạn chế về quyền truy cập tại thời điểm này vì tính năng này chỉ được phát hành vào thời điểm lớp học lập trình này được ghi lại.
- Đặt cờ Bật tính năng quét chỉ mục trên chỉ mục ScaNN và chỉ mục HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Chạy truy vấn sau trong AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Hàm evaluate_query_recall nhận truy vấn làm tham số và trả về độ thu hồi của truy vấn đó. Tôi đang sử dụng cùng một truy vấn mà tôi đã dùng để kiểm tra hiệu suất làm truy vấn đầu vào của hàm. Tôi đã thêm SCaNN làm phương thức lập chỉ mục. Để biết thêm các lựa chọn về tham số, hãy tham khảo tài liệu.
Độ chính xác của truy vấn Tìm kiếm vectơ mà chúng tôi đã sử dụng:

Tôi thấy TỶ LỆ NHỚ LẠI là 70%. Giờ đây, tôi có thể sử dụng thông tin này để thay đổi các tham số chỉ mục, phương thức và tham số truy vấn, đồng thời cải thiện khả năng truy xuất cho tính năng Tìm kiếm vectơ này!
Tôi đã sửa đổi số lượng hàng trong tập kết quả thành 7 (trước đây là 10) và tôi thấy RECALL (khả năng nhớ lại) đã tăng nhẹ, tức là 86%.
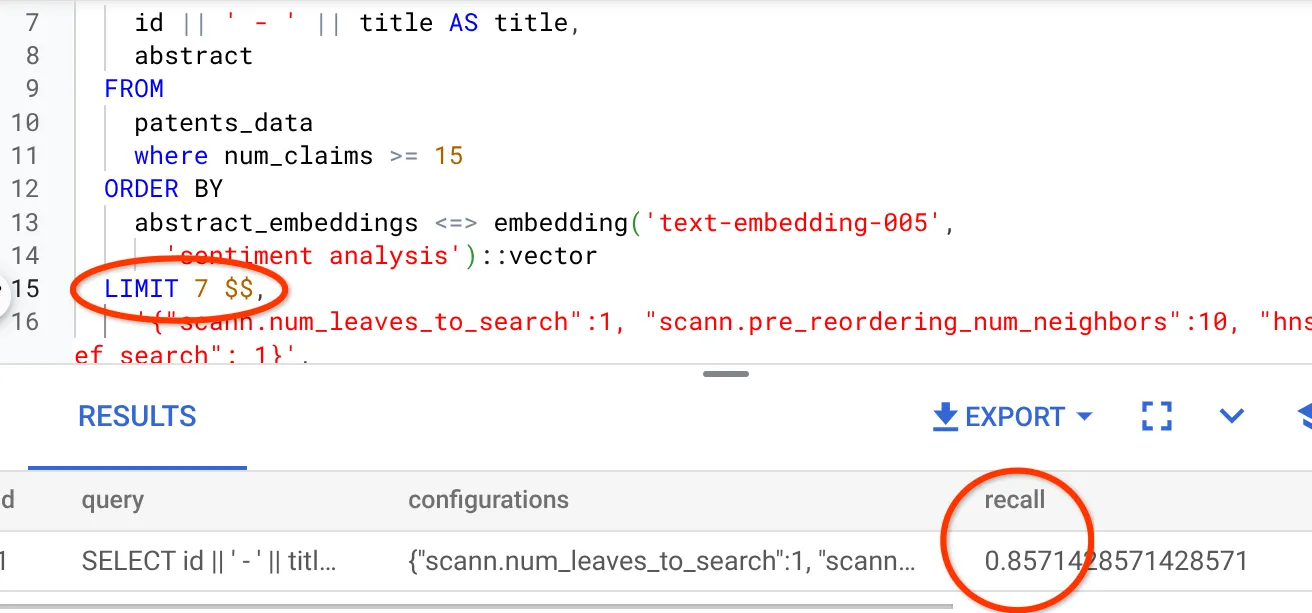
Điều này có nghĩa là tôi có thể thay đổi số lượng kết quả khớp mà người dùng thấy theo thời gian thực để cải thiện mức độ liên quan của kết quả khớp theo ngữ cảnh tìm kiếm của người dùng.
Được rồi! Đã đến lúc triển khai logic cơ sở dữ liệu và chuyển sang tác nhân!!!
7. Đưa logic cơ sở dữ liệu lên máy chủ web mà không cần máy chủ
Bạn đã sẵn sàng đưa ứng dụng này lên web chưa? Hãy làm theo các bước sau:
- Truy cập vào Cloud Run Functions trong Google Cloud Console để tạo một Cloud Run Function mới bằng cách nhấp vào "Viết một hàm" hoặc sử dụng đường liên kết: https://console.cloud.google.com/run/create?deploymentType=function.
- Chọn "Sử dụng trình chỉnh sửa nội tuyến để tạo một hàm" rồi bắt đầu định cấu hình. Cung cấp Tên dịch vụ "patent-search" và chọn Khu vực là "us-central1" và thời gian chạy là "Java 17". Đặt chế độ Xác thực thành "Cho phép lệnh gọi chưa được xác thực".
- Trong phần "Containers, Volumes, Networking, Security" (Vùng chứa, ổ đĩa, mạng, bảo mật), hãy làm theo các bước bên dưới mà không bỏ sót bất kỳ thông tin chi tiết nào:
Chuyển đến thẻ Kết nối mạng:
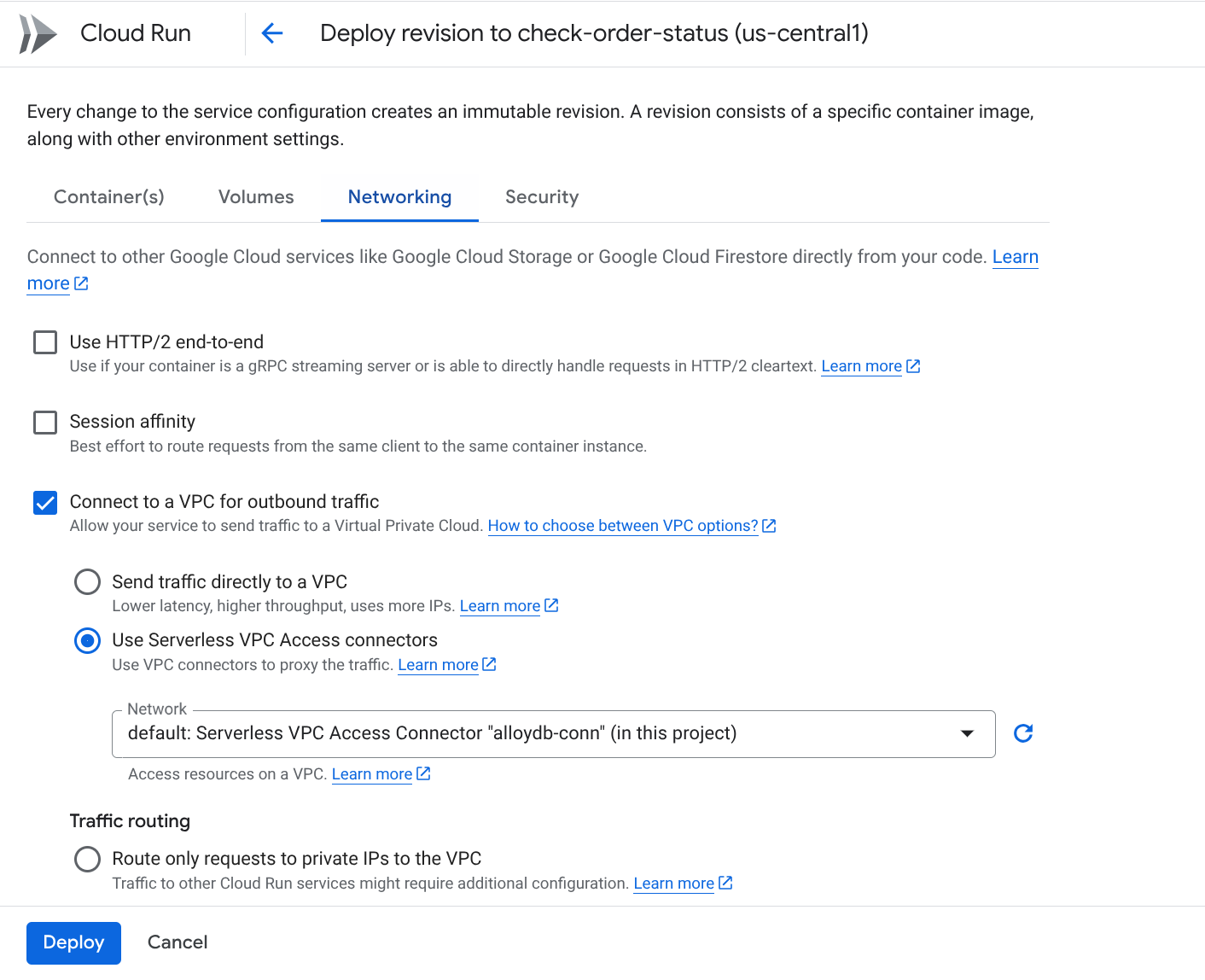
Chọn "Kết nối với một VPC cho lưu lượng truy cập đi", sau đó chọn "Sử dụng trình kết nối cho phép truy cập VPC không máy chủ"
Trong trình đơn thả xuống Mạng, hãy nhấp vào trình đơn thả xuống Mạng rồi chọn mục "Thêm Trình kết nối VPC mới" (nếu bạn chưa định cấu hình mặc định) và làm theo hướng dẫn mà bạn thấy trên hộp thoại bật lên:

Đặt tên cho Trình kết nối VPC và đảm bảo rằng khu vực này giống với khu vực của phiên bản. Để nguyên giá trị Mạng là mặc định và đặt Mạng con thành Dải IP tuỳ chỉnh với dải IP là 10.8.0.0 hoặc một dải IP tương tự có sẵn.
Mở rộng mục HIỂN THỊ CÁC CHẾ ĐỘ CÀI ĐẶT VỀ TỶ LỆ và đảm bảo bạn đã đặt cấu hình chính xác như sau:

Nhấp vào TẠO. Giờ đây, trình kết nối này sẽ xuất hiện trong phần cài đặt lưu lượng truy cập đi.
Chọn đầu nối vừa tạo.
Chọn định tuyến tất cả lưu lượng truy cập thông qua trình kết nối VPC này.
Nhấp vào TIẾP THEO rồi nhấp vào TRIỂN KHAI.
- Theo mặc định, chế độ này sẽ đặt Điểm truy cập thành "gcfv2.HelloHttpFunction". Thay thế mã phần giữ chỗ trong HelloHttpFunction.java và pom.xml của Hàm Cloud Run bằng mã tương ứng trong " PatentSearch.java" và " pom.xml". Thay đổi tên của tệp lớp thành PatentSearch.java.
- Hãy nhớ thay đổi phần giữ chỗ ************* và thông tin đăng nhập kết nối AlloyDB bằng các giá trị của bạn trong tệp Java. Thông tin đăng nhập AlloyDB là thông tin mà chúng ta đã dùng khi bắt đầu lớp học lập trình này. Nếu bạn đã sử dụng các giá trị khác nhau, vui lòng sửa đổi các giá trị đó trong tệp Java.
- Nhấp vào Triển khai.
- Sau khi triển khai Cloud Function đã cập nhật, bạn sẽ thấy điểm cuối được tạo. Sao chép khoá đó và thay thế trong lệnh sau:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
Vậy là xong! Bạn có thể dễ dàng thực hiện một thao tác Tìm kiếm vectơ tương tự theo ngữ cảnh nâng cao bằng cách sử dụng mô hình Nhúng trên dữ liệu AlloyDB.
8. Hãy tạo tác nhân bằng Java ADK
Trước tiên, hãy bắt đầu với dự án Java trong trình chỉnh sửa.
- Chuyển đến Cửa sổ dòng lệnh Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Cho phép khi có lời nhắc
- Chuyển sang Cloud Shell Editor bằng cách nhấp vào biểu tượng trình chỉnh sửa ở đầu bảng điều khiển Cloud Shell

- Trong bảng điều khiển Cloud Shell Editor, hãy tạo một thư mục mới và đặt tên là "adk-agents"
Nhấp vào biểu tượng tạo thư mục mới trong thư mục gốc của Cloud Shell như minh hoạ dưới đây:

Đặt tên là "adk-agents":

- Tạo cấu trúc thư mục sau và các tệp trống có tên tệp tương ứng trong cấu trúc bên dưới:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Mở github repo trong một thẻ riêng rồi sao chép mã nguồn cho các tệp App.java và pom.xml.
- Nếu đã mở trình chỉnh sửa trong một thẻ mới bằng biểu tượng "Mở trong thẻ mới" ở góc trên cùng bên phải, bạn có thể mở thiết bị đầu cuối ở cuối trang. Bạn có thể mở đồng thời cả trình chỉnh sửa và thiết bị đầu cuối để thoải mái thao tác.
- Sau khi sao chép, hãy chuyển lại về bảng điều khiển Cloud Shell Editor
- Vì chúng ta đã tạo Hàm Cloud Run, nên bạn không cần sao chép các tệp hàm Cloud Run từ thư mục kho lưu trữ.
Bắt đầu sử dụng ADK Java SDK
Việc này khá đơn giản. Bạn chủ yếu cần đảm bảo rằng bước sao chép của bạn bao gồm những nội dung sau:
- Thêm phần phụ thuộc:
Thêm các cấu phần phần mềm google-adk và google-adk-dev (cho Giao diện người dùng web) vào pom.xml. Nếu đã sao chép nguồn từ kho lưu trữ, thì các tệp này đã có trong các tệp, bạn không cần phải đưa chúng vào. Bạn chỉ cần thay đổi điểm cuối của Hàm Cloud Run để phản ánh điểm cuối đã triển khai. Nội dung này sẽ được đề cập trong các bước tiếp theo của phần này.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Hãy nhớ tham chiếu pom.xml từ kho lưu trữ nguồn vì có những phần phụ thuộc và cấu hình khác cần thiết để ứng dụng có thể chạy.
- Định cấu hình dự án của bạn:
Đảm bảo bạn đã định cấu hình chính xác phiên bản Java (nên dùng phiên bản 17 trở lên) và chế độ cài đặt trình biên dịch Maven trong pom.xml. Bạn có thể định cấu hình dự án của mình theo cấu trúc dưới đây:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Xác định tác nhân và các công cụ của tác nhân (App.java):
Đây là nơi thể hiện sức mạnh của ADK Java SDK. Chúng ta xác định tác nhân, các chức năng (hướng dẫn) và những công cụ mà tác nhân có thể sử dụng.
Bạn có thể tìm thấy phiên bản đơn giản của một số đoạn mã của lớp tác nhân chính tại đây. Để xem toàn bộ dự án, hãy tham khảo kho lưu trữ dự án tại đây.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Các thành phần mã Java ADK chính được làm nổi bật:
- LlmAgent.builder(): API linh hoạt để định cấu hình tác nhân của bạn.
- .instruction(...): Cung cấp lời nhắc và nguyên tắc cốt lõi cho LLM, bao gồm cả thời điểm sử dụng công cụ nào.
- FunctionTool.create(App.class, "methodName"): Dễ dàng đăng ký các phương thức Java của bạn làm công cụ mà tác nhân có thể gọi. Chuỗi tên phương thức phải khớp với một phương thức tĩnh công khai thực tế.
- @Schema(description = ...): Chú thích các tham số của công cụ, giúp LLM hiểu rõ mỗi công cụ cần những dữ liệu đầu vào nào. Thông tin mô tả này rất quan trọng để chọn công cụ và điền thông số một cách chính xác.
- InvocationContext ctx: Tự động truyền đến các phương thức công cụ, cho phép truy cập vào trạng thái phiên (ctx.session().state()), thông tin người dùng và nhiều thông tin khác.
- .outputKey("patents"): Khi một công cụ trả về dữ liệu, ADK có thể tự động lưu trữ dữ liệu đó trong trạng thái phiên theo khoá này. Đây là cách explainPatent có thể truy cập vào kết quả từ getPatents.
- VECTOR_SEARCH_ENDPOINT: Đây là một biến lưu giữ logic chức năng cốt lõi cho tính năng hỏi và đáp theo bối cảnh cho người dùng trong trường hợp sử dụng tìm kiếm bằng sáng chế.
- Việc cần làm: Bạn cần đặt một giá trị điểm cuối được triển khai mới sau khi triển khai bước Hàm Java Cloud Run trong phần trước.
- searchTool: Công cụ này tương tác với người dùng để tìm các kết quả trùng khớp về bằng sáng chế có liên quan theo ngữ cảnh trong cơ sở dữ liệu bằng sáng chế cho văn bản tìm kiếm của người dùng.
- explainTool: Công cụ này yêu cầu người dùng cung cấp một bằng sáng chế cụ thể để tìm hiểu sâu. Sau đó, AI sẽ tóm tắt nội dung trừu tượng của bằng sáng chế và có thể trả lời thêm các câu hỏi của người dùng dựa trên thông tin chi tiết về bằng sáng chế mà AI có.
Lưu ý quan trọng: Nhớ thay thế biến VECTOR_SEARCH_ENDPOINT bằng điểm cuối CRF đã triển khai của bạn.
Tận dụng InvocationContext cho các tương tác có trạng thái
Một trong những tính năng quan trọng để xây dựng các tác nhân hữu ích là quản lý trạng thái trong nhiều lượt của một cuộc trò chuyện. InvocationContext của ADK giúp việc này trở nên đơn giản.
Trong App.java:
- Khi initAgent() được xác định, chúng ta sẽ sử dụng .outputKey("patents"). Điều này cho ADK biết rằng khi một công cụ (chẳng hạn như getPatents) trả về dữ liệu trong trường báo cáo, dữ liệu đó sẽ được lưu trữ trong trạng thái phiên theo khoá "patents".
- Trong phương thức explainPatent của công cụ, chúng ta sẽ chèn InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Điều này cho phép công cụ explainPatent truy cập vào danh sách bằng sáng chế mà công cụ getPatents đã tìm nạp trong lượt trước, giúp cuộc trò chuyện có trạng thái và mạch lạc.
9. Kiểm thử CLI cục bộ
Xác định các biến môi trường
Bạn cần xuất 2 biến môi trường:
- Khoá Gemini mà bạn có thể lấy từ AI Studio:
Để làm việc đó, hãy truy cập vào https://aistudio.google.com/apikey rồi lấy Khoá API cho Dự án Google Cloud đang hoạt động mà bạn đang triển khai ứng dụng này, sau đó lưu khoá ở đâu đó:
- Sau khi bạn lấy được khoá, hãy mở Cloud Shell Terminal và chuyển đến thư mục mới mà bạn vừa tạo adk-agents bằng cách chạy lệnh sau:
cd adk-agents
- Một biến để chỉ định rằng chúng ta không sử dụng Vertex AI lần này.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Chạy tác nhân đầu tiên trên CLI
Để chạy tác nhân đầu tiên này, hãy dùng lệnh Maven sau trong cửa sổ dòng lệnh:
mvn compile exec:java -DmainClass="agents.App"
Bạn sẽ thấy phản hồi tương tác của tác nhân trong thiết bị đầu cuối.
10. Triển khai lên Cloud Run
Việc triển khai tác nhân Java ADK vào Cloud Run tương tự như việc triển khai bất kỳ ứng dụng Java nào khác:
- Dockerfile: Tạo một Dockerfile để đóng gói ứng dụng Java của bạn.
- Tạo và đẩy hình ảnh Docker: Sử dụng Google Cloud Build và Artifact Registry.
- Bạn có thể thực hiện bước trên và triển khai vào Cloud Run chỉ bằng một lệnh:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Tương tự, bạn sẽ triển khai Hàm Cloud Run Java (gcfv2.PatentSearch). Ngoài ra, bạn có thể tạo và triển khai Hàm Cloud Run Java cho logic cơ sở dữ liệu ngay từ bảng điều khiển Hàm Cloud Run.
11. Kiểm thử bằng giao diện người dùng trên web
ADK đi kèm với một giao diện người dùng web tiện dụng để kiểm thử và gỡ lỗi cục bộ cho tác nhân của bạn. Khi bạn chạy App.java cục bộ (ví dụ: mvn exec:java -Dexec.mainClass="agents.App" nếu được định cấu hình hoặc chỉ chạy phương thức chính), ADK thường sẽ khởi động một máy chủ web cục bộ.
Giao diện người dùng web ADK cho phép bạn:
- Gửi tin nhắn cho nhân viên hỗ trợ.
- Xem các sự kiện (tin nhắn của người dùng, lệnh gọi công cụ, phản hồi của công cụ, phản hồi của LLM).
- Kiểm tra trạng thái phiên.
- Xem nhật ký và dấu vết.
Điều này rất hữu ích trong quá trình phát triển để hiểu cách tác nhân xử lý các yêu cầu và sử dụng các công cụ của mình. Điều này giả định rằng mainClass của bạn trong pom.xml được đặt thành com.google.adk.web.AdkWebServer và tác nhân của bạn được đăng ký với lớp này, hoặc bạn đang chạy một trình chạy thử nghiệm cục bộ hiển thị lớp này.
Khi chạy App.java bằng InMemoryRunner và Scanner để nhập dữ liệu vào bảng điều khiển, bạn đang kiểm thử logic cốt lõi của tác nhân. Giao diện người dùng web là một thành phần riêng biệt để mang lại trải nghiệm gỡ lỗi trực quan hơn, thường được dùng khi ADK đang phân phát tác nhân của bạn qua HTTP.
Bạn có thể sử dụng lệnh Maven sau đây từ thư mục gốc để khởi chạy máy chủ cục bộ SpringBoot:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
Giao diện này thường có thể truy cập tại URL mà lệnh trên xuất ra. Nếu là Cloud Run được triển khai, bạn có thể truy cập vào ứng dụng đó thông qua đường liên kết Cloud Run được triển khai.
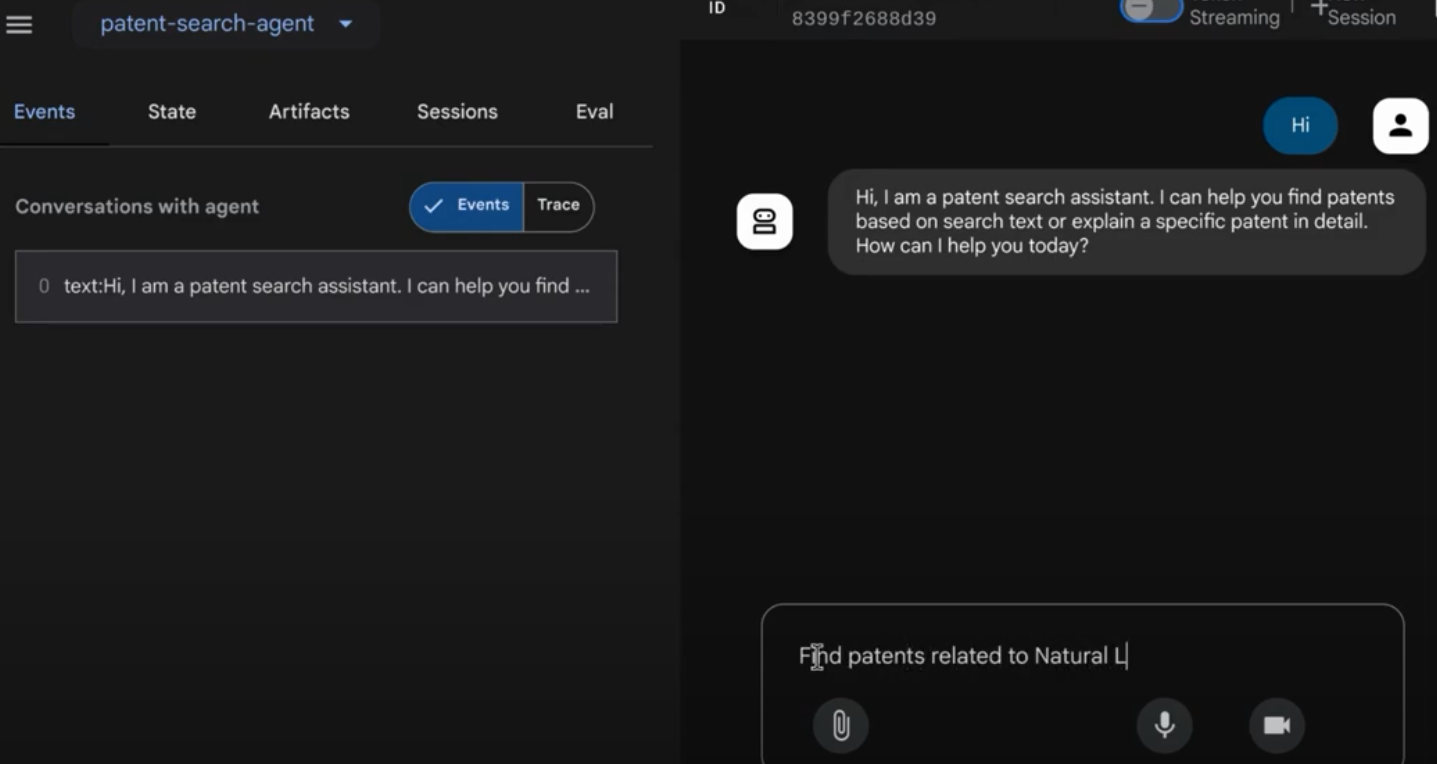
Bạn sẽ thấy kết quả trong một giao diện tương tác.
Hãy xem video dưới đây về Đại diện sáng chế mà chúng tôi đã triển khai:
12. Dọn dẹp
Để tránh bị tính phí cho tài khoản Google Cloud của bạn đối với các tài nguyên được dùng trong bài đăng này, hãy làm theo các bước sau:
- Trong Google Cloud Console, hãy chuyển đến trang https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog.
- Trong danh sách dự án, hãy chọn dự án mà bạn muốn xoá, rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.
13. Xin chúc mừng
Xin chúc mừng! Bạn đã tạo thành công Patent Analysis Agent (Tác nhân phân tích bằng sáng chế) bằng Java bằng cách kết hợp các chức năng của ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI và Vector Search. Ngoài ra, chúng tôi đã có một bước tiến lớn trong việc thực hiện các tìm kiếm tương tự theo ngữ cảnh, giúp các tìm kiếm này mang tính biến đổi, hiệu quả và thực sự hướng đến ý nghĩa.
Bắt đầu ngay hôm nay!
Tài liệu về ADK: [Link to Official ADK Java Docs]
Mã nguồn của Trợ lý phân tích bằng sáng chế: [Đường liên kết đến Kho lưu trữ GitHub (hiện ở chế độ công khai)]
Tác nhân mẫu Java: [link to the adk-samples repo]
Tham gia Cộng đồng ADK: https://www.reddit.com/r/agentdevelopmentkit/
Chúc bạn tạo được nhân viên hỗ trợ như ý!