
1. Genel Bakış
Bağlamsal arama, farklı sektörlerde uygulamaların kalbini ve merkezini oluşturan kritik bir işlevdir. Retrieval Augmented Generation, üretken yapay zeka destekli alma mekanizmalarıyla bir süredir bu önemli teknoloji evriminin temel itici gücü olmuştur. Geniş bağlam pencereleri ve etkileyici çıkış kalitesiyle üretken modeller, yapay zekayı dönüştürüyor. RAG, bağlamı yapay zeka uygulamalarına ve aracılarına yerleştirmenin sistematik bir yolunu sunar. Bu sayede, yapılandırılmış veritabanlarında veya çeşitli medyaların bilgilerinde temel oluşturulur. Bu bağlamsal veriler, doğruluk ve çıktı doğruluğu açısından çok önemlidir. Ancak bu sonuçlar ne kadar doğrudur? İşletmeniz büyük ölçüde bu bağlamsal eşleşmelerin doğruluğuna ve alaka düzeyine mi bağlı? O zaman bu proje sizi çok eğlendirecek!
Şimdi de üretken modellerin gücünü kullanarak, bağlam açısından kritik bu tür bilgilerle desteklenen ve gerçekliğe dayalı özerk kararlar verebilen etkileşimli temsilciler oluşturabildiğimizi hayal edin. İşte bugün oluşturacağımız şey bu. Patent analizi uygulaması için AlloyDB'de gelişmiş RAG destekli Agent Development Kit'i kullanarak uçtan uca bir yapay zeka aracısı uygulaması oluşturacağız.
Patent Analizi Aracısı, kullanıcının arama metniyle bağlamsal olarak alakalı patentleri bulmasına yardımcı olur ve istendiğinde seçilen bir patentle ilgili net ve kısa bir açıklama ile gerekirse ek ayrıntılar sağlar. Nasıl yapıldığını görmeye hazır mısınız? Haydi başlayalım.
Hedef
Hedef basittir. Kullanıcının metin açıklamasına göre patent aramasını ve ardından arama sonuçlarından belirli bir patentin ayrıntılı açıklamasını almasını sağlayın. Tüm bunlar, Java ADK, AlloyDB, Vector Search (gelişmiş dizinlerle), Gemini ile oluşturulmuş bir yapay zeka aracısı kullanılarak ve uygulamanın tamamı Cloud Run'da sunucusuz olarak dağıtılarak yapılır.
Ne oluşturacaksınız?
Bu laboratuvar kapsamında şunları yapacaksınız:
- AlloyDB örneği oluşturma ve Patents Public Dataset verilerini yükleme
- ScaNN ve Recall değerlendirme özelliklerini kullanarak AlloyDB'de gelişmiş vektör araması uygulama
- Java ADK'yı kullanarak aracı oluşturma
- Veritabanı sunucu tarafı mantığını Java sunucusuz Cloud Functions'da uygulama
- Aracıyı Cloud Run'da dağıtma ve test etme
Aşağıdaki şemada, verilerin akışı ve uygulamayla ilgili adımlar gösterilmektedir.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Faturalandırmanın bir projede etkin olup olmadığını kontrol etmeyi öğrenin .
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulanıp doğrulanmadığını ve projenin proje kimliğinize ayarlanıp ayarlanmadığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu doğrulamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin. Cloud Shell terminalinde bir gcloud komutu kullanabilirsiniz:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Gcloud komutuna alternatif olarak, her ürünü arayarak veya bu bağlantıyı kullanarak konsolu kullanabilirsiniz.
gcloud komutları ve kullanımı için belgelere bakın.
3. Veritabanı kurulumu
Bu laboratuvarda patent verileri için veritabanı olarak AlloyDB'yi kullanacağız. Veritabanları ve günlükler gibi tüm kaynakları tutmak için kümeler kullanılır. Her kümede, verilere erişim noktası sağlayan bir birincil örnek bulunur. Tablolar gerçek verileri içerir.
Patent veri kümesinin yükleneceği bir AlloyDB kümesi, örneği ve tablosu oluşturalım.
Küme ve örnek oluşturma
- Cloud Console'da AlloyDB sayfasına gidin. Cloud Console'daki çoğu sayfayı bulmanın kolay bir yolu, konsolun arama çubuğunu kullanarak arama yapmaktır.
- Bu sayfada KÜME OLUŞTUR'u seçin:

- Aşağıdaki gibi bir ekran görürsünüz. Aşağıdaki değerlerle bir küme ve örnek oluşturun (Uygulama kodunu depodan klonluyorsanız değerlerin eşleştiğinden emin olun):
- küme kimliği: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / en son önerilen
- Bölge: "
us-central1" - Networking: "
default"

- Varsayılan ağı seçtiğinizde aşağıdaki gibi bir ekran görürsünüz.
BAĞLANTIYI AYARLA'yı seçin.
- Buradan "Otomatik olarak atanmış bir IP aralığı kullan"ı seçip Devam'ı tıklayın. Bilgileri inceledikten sonra BAĞLANTI OLUŞTUR'u seçin.

- Ağınız kurulduktan sonra kümenizi oluşturmaya devam edebilirsiniz. Aşağıda gösterildiği gibi küme kurulumunu tamamlamak için KÜME OLUŞTUR'u tıklayın:

Örnek kimliğini değiştirdiğinizden emin olun (küme / örnek yapılandırılırken bulabilirsiniz) ile
vector-instance. Değiştiremiyorsanız gelecekteki tüm referanslarda örnek kimliğinizi kullanmayı unutmayın.
Küme oluşturma işleminin yaklaşık 10 dakika süreceğini unutmayın. İşlem başarılı olduğunda, yeni oluşturduğunuz kümenizin genel görünümünü gösteren bir ekran görürsünüz.
4. Veri kullanımı
Şimdi de mağazayla ilgili verilerin bulunduğu bir tablo ekleme zamanı. AlloyDB'ye gidin, birincil kümeyi ve ardından AlloyDB Studio'yu seçin:

Örneğinizin oluşturulmasının tamamlanmasını beklemeniz gerekebilir. Bu işlem tamamlandıktan sonra, kümeyi oluştururken belirlediğiniz kimlik bilgilerini kullanarak AlloyDB'de oturum açın. PostgreSQL'de kimlik doğrulaması yapmak için aşağıdaki verileri kullanın:
- Kullanıcı adı : "
postgres" - Veritabanı : "
postgres" - Şifre : "
alloydb"
AlloyDB Studio'da kimlik doğrulama işlemini başarıyla tamamladıktan sonra SQL komutları Düzenleyici'ye girilir. Son pencerenin sağındaki artı işaretini kullanarak birden fazla Düzenleyici penceresi ekleyebilirsiniz.

Gerekli durumlarda Çalıştır, Biçimlendir ve Temizle seçeneklerini kullanarak AlloyDB ile ilgili komutları düzenleyici pencerelerine gireceksiniz.
Uzantıları etkinleştirme
Bu uygulamayı oluşturmak için pgvector ve google_ml_integration uzantılarını kullanacağız. pgvector uzantısı, vektör yerleştirmelerini depolamanıza ve aramanıza olanak tanır. google_ml_integration uzantısı, SQL'de tahmin almak için Vertex AI tahmin uç noktalarına erişmek üzere kullandığınız işlevleri sağlar. Aşağıdaki DDL'leri çalıştırarak bu uzantıları etkinleştirin:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Veritabanınızda etkinleştirilen uzantıları kontrol etmek istiyorsanız şu SQL komutunu çalıştırın:
select extname, extversion from pg_extension;
Tablo oluşturma
AlloyDB Studio'da aşağıdaki DDL ifadesini kullanarak bir tablo oluşturabilirsiniz:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings sütunu, metnin vektör değerlerinin depolanmasına olanak tanır.
İzin Ver
"embedding" işlevinde yürütme izni vermek için aşağıdaki ifadeyi çalıştırın:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB hizmet hesabına Vertex AI Kullanıcısı ROLÜ'nü verme
Google Cloud IAM Console'dan AlloyDB hizmet hesabına (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com şeklinde görünür) "Vertex AI Kullanıcısı" rolüne erişim izni verin. PROJECT_NUMBER, proje numaranızı içerir.
Alternatif olarak, aşağıdaki komutu Cloud Shell Terminali'nden çalıştırabilirsiniz:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Veritabanına patent verileri yükleme
Veri kümemiz olarak BigQuery'deki Google Patents Public Datasets (Google Patentleri Herkese Açık Veri Kümeleri) kullanılacaktır. Sorgularımızı çalıştırmak için AlloyDB Studio'yu kullanacağız. Veriler, bu repo'daki insert scripts sql dosyasına aktarılır ve patent verilerini yüklemek için bu dosya çalıştırılır.
- Google Cloud Console'da AlloyDB sayfasını açın.
- Yeni oluşturduğunuz kümeyi seçin ve örneği tıklayın.
- AlloyDB gezinme menüsünde AlloyDB Studio'yu tıklayın. Kimlik bilgilerinizle oturum açın.
- Sağdaki Yeni sekme simgesini tıklayarak yeni bir sekme açın.
insert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqldosyalarındakiinsertsorgu ifadelerini tek tek kopyalayıp çalıştırın. Bu kullanım alanının hızlı bir demosunu görmek için 10-50 ekleme ifadesini kopyalayıp çalıştırabilirsiniz.
Çalıştırmak için Çalıştır'ı tıklayın. Sorgunuzun sonuçları Sonuçlar tablosunda görünür.
5. Patent verileri için gömmeler oluşturma
Öncelikle aşağıdaki örnek sorguyu çalıştırarak yerleştirme işlevini test edelim:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Bu işlem, sorgudaki örnek metin için kayan nokta dizisi gibi görünen yerleştirme vektörünü döndürmelidir. Şöyle görünür:

abstract_embeddings adlı Vector alanını güncelleme
Özetler için yerleştirme oluşturulması gerekirse tablodaki patent özetlerini ilgili yerleştirmelerle güncellemek için aşağıdaki DML kullanılmalıdır. Ancak bizim durumumuzda, ekleme ifadeleri her özet için bu yerleştirmeleri zaten içerdiğinden embeddings() yöntemini çağırmanız gerekmez.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Vektör araması yapma
Tablo, veriler ve yerleştirmeler hazır olduğuna göre artık kullanıcı arama metni için gerçek zamanlı vektör araması yapabiliriz. Aşağıdaki sorguyu çalıştırarak bunu test edebilirsiniz:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Bu sorguda,
- Kullanıcının aradığı metin: "Sentiment Analysis" (Duygu Analizi).
- Bu metni, model: text-embedding-005 kullanarak embedding() yönteminde yerleştirmelere dönüştürüyoruz.
- "<=>", COSINE SIMILARITY uzaklık yönteminin kullanımını gösterir.
- Yerleştirme yönteminin sonucunu, veritabanında depolanan vektörlerle uyumlu hale getirmek için vektör türüne dönüştürüyoruz.
- LIMIT 10, arama metninin en yakın 10 eşleşmesinin seçildiğini gösterir.
AlloyDB, Vector Search RAG'yi bir üst seviyeye taşıyor:
Birçok yeni özellik kullanıma sunuldu. Geliştiricilere yönelik iki örnek:
- Satır İçi Filtreleme
- Geri Çağırma Değerlendiricisi
Satır İçi Filtreleme
Daha önce geliştirici olarak Vector Search sorgusunu çalıştırmanız, filtreleme ve geri çağırma işlemlerini yapmanız gerekiyordu. AlloyDB Query Optimizer, filtrelerle sorgunun nasıl yürütüleceği konusunda seçimler yapar. Satır içi filtreleme, AlloyDB sorgu optimizasyon aracının hem meta veri filtreleme koşullarını hem de vektör aramasını birlikte değerlendirmesine olanak tanıyan yeni bir sorgu optimizasyonu tekniğidir. Bu teknik, hem vektör dizinlerinden hem de meta veri sütunlarındaki dizinlerden yararlanır. Bu sayede hatırlama performansı arttı ve geliştiriciler, AlloyDB'nin kullanıma hazır sunduğu özelliklerden yararlanabildi.
Satır içi filtreleme, orta seçiciliğe sahip durumlar için en iyisidir. AlloyDB, vektör dizininde arama yaparken yalnızca meta veri filtreleme koşullarıyla eşleşen vektörlerin mesafelerini hesaplar (bir sorguda genellikle WHERE ifadesinde işlenen işlevsel filtreleriniz). Bu, filtre sonrası veya filtre öncesi avantajlarını tamamlayarak bu sorguların performansını büyük ölçüde artırır.
- pgvector uzantısını yükleme veya güncelleme
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
pgvector uzantısı zaten yüklüyse geri çağırma değerlendirici özelliklerini kullanmak için vektör uzantısını 0.8.0.google-3 veya sonraki bir sürüme yükseltin.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Bu adım yalnızca vektör uzantınız <0.8.0.google-3 ise uygulanmalıdır.
Önemli not: Satır sayınız 100'den azsa daha az satır için geçerli olmayacağından ScaNN dizini oluşturmanız gerekmez. Bu durumda lütfen aşağıdaki adımları atlayın.
- ScaNN dizinleri oluşturmak için alloydb_scann uzantısını yükleyin.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Öncelikle Vector Search sorgusunu dizin olmadan ve satır içi filtre etkinleştirilmeden çalıştırın:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Sonuç şuna benzer olmalıdır:

- Üzerinde Açıklama Analizi'ni çalıştırma (dizin veya satır içi filtreleme olmadan):

Yürütme süresi 2,4 ms
- num_claims alanında filtreleme yapabilmek için bu alanda normal bir dizin oluşturalım:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Patent Arama uygulamamız için ScaNN dizinini oluşturalım. AlloyDB Studio'nuzda aşağıdakileri çalıştırın:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Önemli not: (num_leaves=32), 1.000'den fazla satır içeren toplam veri kümemiz için geçerlidir. Satır sayınız 100'den azsa daha az satır için geçerli olmayacağından dizin oluşturmanız gerekmez.
- ScaNN dizininde satır içi filtrelemeyi etkinleştirin:
SET scann.enable_inline_filtering = on
- Şimdi aynı sorguyu filtre ve vektör aramasıyla birlikte çalıştıralım:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
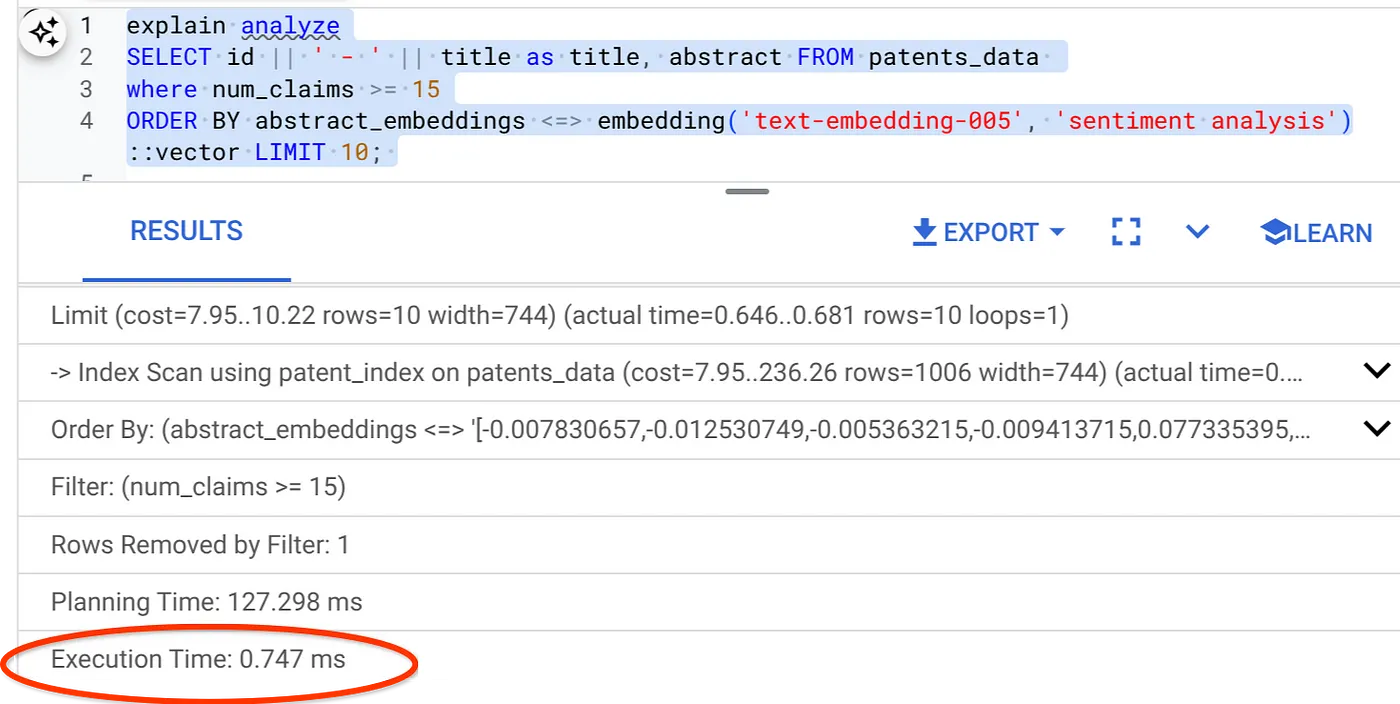
Aynı Vector Search için yürütme süresinin önemli ölçüde kısaldığını görebilirsiniz. Vector Search'teki satır içi filtreleme ile desteklenen ScaNN dizini bunu mümkün kıldı.
Şimdi de ScaNN'nin etkinleştirildiği bu vektör aramasının hatırlama oranını değerlendirelim.
Geri Çağırma Değerlendiricisi
Benzerlik aramasında geri çağırma, bir aramadan alınan alakalı örneklerin yüzdesidir. Diğer bir deyişle, doğru pozitiflerin sayısıdır. Bu metrik, arama kalitesini ölçmek için kullanılan en yaygın metriktir. Geri çağırma kaybının bir nedeni, yaklaşık en yakın komşu araması (aNN) ile k (tam) en yakın komşu araması (kNN) arasındaki farktır. AlloyDB'nin ScaNN'si gibi vektör dizinleri, aNN algoritmalarını uygular. Bu sayede, hatırlama konusunda küçük bir ödün vererek büyük veri kümelerinde vektör aramasını hızlandırabilirsiniz. AlloyDB artık bu dengeyi doğrudan veritabanında tek tek sorgular için ölçmenize ve zaman içinde istikrarlı olmasını sağlamanıza olanak tanır. Daha iyi sonuçlar ve performans elde etmek için bu bilgilere yanıt olarak sorgu ve dizin parametrelerini güncelleyebilirsiniz.
Belirli bir yapılandırma için vektör dizinindeki vektör sorgusunun geri çağırma değerini evaluate_query_recall işlevini kullanarak bulabilirsiniz. Bu işlev, istediğiniz vektör sorgusu hatırlama sonuçlarını elde etmek için parametrelerinizi ayarlamanıza olanak tanır. Geri çağırma, arama kalitesi için kullanılan metriktir ve sorgu vektörlerine en yakın olan döndürülen sonuçların yüzdesi olarak tanımlanır. evaluate_query_recall işlevi varsayılan olarak etkindir.
Önemli Not:
Aşağıdaki adımlarda HNSW dizininde "izin reddedildi" hatasıyla karşılaşırsanız bu hatırlama değerlendirmesi bölümünün tamamını şimdilik atlayın. Bu durum, bu codelab belgelendirilirken yeni yayınlandığı için erişim kısıtlamalarıyla ilgili olabilir.
- ScaNN dizininde ve HNSW dizininde Enable Index Scan işaretini ayarlayın:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio'da aşağıdaki sorguyu çalıştırın:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall işlevi, sorguyu parametre olarak alır ve geri çağırmasını döndürür. İşlev giriş sorgusu olarak performansı kontrol etmek için kullandığım sorguyu kullanıyorum. Dizin yöntemi olarak SCaNN'yi ekledim. Daha fazla parametre seçeneği için belgelere bakın.
Kullandığımız bu Vector Search sorgusunun hatırlama oranı:

Geri çağırmanın %70 olduğunu görüyorum. Artık bu bilgileri kullanarak dizin parametrelerini, yöntemlerini ve sorgu parametrelerini değiştirebilir ve bu Vector Search için hatırlama oranımı artırabilirim.
Sonuç kümesindeki satır sayısını 7 olarak değiştirdim (önceki değer 10) ve RECALL değerinin biraz iyileştiğini, yani %86 olduğunu görüyorum.

Bu sayede, kullanıcılarımın gördüğü eşleşme sayısını anlık olarak değiştirebiliyorum. Böylece, eşleşmelerin alaka düzeyini kullanıcıların arama bağlamına göre iyileştirebiliyorum.
Alright now! Veritabanı mantığını dağıtma ve aracıya geçme zamanı!!!
7. Veritabanı mantığını sunucusuz olarak web'e taşıma
Bu uygulamayı web'e taşımaya hazır mısınız? Aşağıdaki adımları uygulayın:
- "İşlev yaz"ı tıklayarak yeni bir Cloud Run işlevi oluşturmak için Google Cloud Console'da Cloud Run Functions'a gidin veya https://console.cloud.google.com/run/create?deploymentType=function bağlantısını kullanın.
- "İşlev oluşturmak için satır içi düzenleyici kullanın" seçeneğini belirleyin ve yapılandırmaya başlayın. Hizmet adı olarak "patent-search" ifadesini girin, bölge olarak "us-central1"i ve çalışma zamanı olarak "Java 17"'yi seçin. Kimlik doğrulama ayarını "Kimliği doğrulanmayan çağrılara izin ver" olarak belirleyin.
- "Kapsayıcılar, Birimler, Ağ İletişimi, Güvenlik" bölümünde aşağıdaki adımları hiçbir ayrıntıyı atlamadan uygulayın:
Ağ iletişimi sekmesine gidin:

"Giden trafik için bir VPC'ye bağlanın"ı ve ardından "Sunucusuz VPC Erişimi bağlayıcılarını kullanın"ı seçin.
Ağ açılır listesi ayarları bölümünde, Ağ açılır listesini tıklayın ve "Yeni VPC bağlayıcı ekle" seçeneğini belirleyin (varsayılan olanı henüz yapılandırmadıysanız) ve açılan iletişim kutusunda gördüğünüz talimatları uygulayın:

VPC bağlayıcısı için bir ad girin ve bölgenin örneğinizle aynı olduğundan emin olun. Ağ değerini varsayılan olarak bırakın ve alt ağı, 10.8.0.0 IP aralığına sahip özel IP aralığı olarak ayarlayın veya benzer bir aralık kullanın.
ÖLÇEKLENDİRME AYARLARINI GÖSTER'i genişletin ve yapılandırmanın tam olarak aşağıdaki gibi ayarlandığından emin olun:

OLUŞTUR'u tıkladığınızda bu bağlayıcı artık çıkış ayarlarında listelenir.
Yeni oluşturulan bağlayıcıyı seçin.
Tüm trafiğin bu VPC bağlayıcısı üzerinden yönlendirilmesini tercih edin.
SONRAKİ'yi ve ardından DAĞIT'ı tıklayın.
- Varsayılan olarak giriş noktası "gcfv2.HelloHttpFunction" olarak ayarlanır. Cloud Run işlevinizin HelloHttpFunction.java ve pom.xml dosyalarındaki yer tutucu kodu sırasıyla " PatentSearch.java" ve " pom.xml" dosyalarındaki kodla değiştirin. Sınıf dosyasının adını PatentSearch.java olarak değiştirin.
- Java dosyasında ************* yer tutucusunu ve AlloyDB bağlantı kimlik bilgilerini kendi değerlerinizle değiştirmeyi unutmayın. AlloyDB kimlik bilgileri, bu codelab'in başında kullandığımız kimlik bilgileridir. Farklı değerler kullandıysanız lütfen Java dosyasında bunları değiştirin.
- Dağıt'ı tıklayın.
- Güncellenen Cloud Functions işlevi dağıtıldıktan sonra oluşturulan uç noktayı görürsünüz. Bu değeri kopyalayıp aşağıdaki komutta değiştirin:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
İşte bu kadar. AlloyDB verilerinde Embeddings modelini kullanarak gelişmiş bir bağlamsal benzerlik vektör araması yapmak bu kadar basittir.
8. Java ADK ile aracı oluşturalım
Öncelikle düzenleyicideki Java projesiyle başlayalım.
- Cloud Shell Terminal'e gitme
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- İstendiğinde yetkilendirme
- Cloud Shell konsolunun üst kısmındaki düzenleyici simgesini tıklayarak Cloud Shell Düzenleyici'ye geçin.

- Açılış Cloud Shell Düzenleyici konsolunda yeni bir klasör oluşturun ve klasörü "adk-agents" olarak adlandırın.
Aşağıda gösterildiği gibi, Cloud Shell'inizin kök dizininde yeni klasör oluştur'u tıklayın:

"adk-agents" adını verin:

- Aşağıdaki klasör yapısını ve bu yapıdaki ilgili dosya adlarıyla boş dosyaları oluşturun:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- GitHub deposunu ayrı bir sekmede açın ve App.java ile pom.xml dosyalarının kaynak kodunu kopyalayın.
- Sağ üst köşedeki "Yeni sekmede aç" simgesini kullanarak düzenleyiciyi yeni bir sekmede açtıysanız terminali sayfanın alt kısmında açabilirsiniz. Hem düzenleyiciyi hem de terminali paralel olarak açabilir ve özgürce çalışabilirsiniz.
- Klonlama işlemi tamamlandıktan sonra Cloud Shell Düzenleyici konsoluna geri dönün.
- Cloud Run işlevini daha önce oluşturduğumuz için Cloud Run işlevi dosyalarını repo klasöründen kopyalamanıza gerek yoktur.
ADK Java SDK'sını kullanmaya başlama
Bu işlem oldukça basittir. Öncelikle klonlama adımında aşağıdakilerin ele alındığından emin olmanız gerekir:
- Bağımlılık Ekleme:
google-adk ve google-adk-dev (Web kullanıcı arayüzü için) yapılarını pom.xml dosyanıza ekleyin. Kaynağı depodan kopyaladıysanız bunlar zaten dosyalara dahil edilmiştir, eklemeniz gerekmez. Dağıtılan uç noktanızı yansıtmak için Cloud Run işlevi uç noktasında bir değişiklik yapmanız yeterlidir. Bu bölümdeki sonraki adımlarda bu konu ele alınmaktadır.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Uygulamanın çalışabilmesi için gerekli olan başka bağımlılıklar ve yapılandırmalar olduğundan kaynak deposundaki pom.xml dosyasına referans verdiğinizden emin olun.
- Projenizi Yapılandırma:
Java sürümünüzün (17 veya üzeri önerilir) ve Maven derleyici ayarlarınızın pom.xml dosyanızda doğru şekilde yapılandırıldığından emin olun. Projenizi aşağıdaki yapıyı takip edecek şekilde yapılandırabilirsiniz:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Temsilciyi ve Araçlarını Tanımlama (App.java):
ADK Java SDK'sının sihirli gücü burada ortaya çıkar. Aracımızı, özelliklerini (talimatlar) ve kullanabileceği araçları tanımlarız.
Ana aracı sınıfının birkaç kod snippet'inin basitleştirilmiş bir sürümünü burada bulabilirsiniz. Projenin tamamı için buradaki proje deposuna bakın.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Temel ADK Java Kodu Bileşenleri Vurgulanmıştır:
- LlmAgent.builder(): Aracınızı yapılandırmak için kullanılan akıcı API.
- .instruction(...): Hangi aracın ne zaman kullanılacağı da dahil olmak üzere LLM için temel istemi ve yönergeleri sağlar.
- FunctionTool.create(App.class, "methodName"): Java yöntemlerinizi, aracının çağırabileceği araçlar olarak kolayca kaydeder. Yöntem adı dizesi, gerçek bir herkese açık statik yöntemle eşleşmelidir.
- @Schema(description = ...): Araç parametrelerini açıklama ekleyerek LLM'nin her aracın hangi girişleri beklediğini anlamasına yardımcı olur. Bu açıklama, doğru araç seçimi ve parametre doldurma için çok önemlidir.
- InvocationContext ctx: Otomatik olarak araç yöntemlerine iletilir ve oturum durumuna (ctx.session().state()), kullanıcı bilgilerine ve daha fazlasına erişim sağlar.
- .outputKey("patents"): Bir araç veri döndürdüğünde ADK, bu verileri otomatik olarak oturum durumunda bu anahtarın altına kaydedebilir. explainPatent, getPatents'teki sonuçlara bu şekilde erişebilir.
- VECTOR_SEARCH_ENDPOINT: Bu, patent araması kullanım alanında kullanıcının bağlamsal soru-cevap işleviyle ilgili temel mantığı içeren bir değişkendir.
- Buradaki işlem öğesi: Önceki bölümdeki Java Cloud Run işlevi adımını uyguladıktan sonra güncellenmiş bir dağıtılmış uç nokta değeri ayarlamanız gerekir.
- searchTool: Bu araç, kullanıcının arama metni için patent veritabanında bağlamsal olarak alakalı patent eşleşmeleri bulmak üzere kullanıcıyla etkileşime girer.
- explainTool: Kullanıcıdan ayrıntılı inceleme için belirli bir patent ister. Ardından, patent özetini özetler ve sahip olduğu patent ayrıntılarına dayanarak kullanıcının diğer sorularını yanıtlayabilir.
Önemli Not: VECTOR_SEARCH_ENDPOINT değişkenini dağıtılan CRF uç noktanızla değiştirdiğinizden emin olun.
Durumlu etkileşimler için InvocationContext'ten yararlanma
Faydalı temsilciler oluşturmak için önemli özelliklerden biri, bir görüşmenin birden fazla adımında durumu yönetmektir. ADK'nın InvocationContext'i bu işlemi kolaylaştırır.
App.java dosyamızda:
- initAgent() tanımlandığında .outputKey("patents") kullanılır. Bu, ADK'ya bir araç (ör. getPatents) rapor alanında veri döndürdüğünde bu verilerin oturum durumunda "patents" anahtarı altında saklanması gerektiğini bildirir.
- explainPatent aracının yönteminde InvocationContext ctx'i iletiyoruz:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Bu sayede explainPatent aracı, önceki dönüşte getPatents aracı tarafından getirilen patent listesine erişebilir. Böylece görüşme durum bilgili ve tutarlı olur.
9. Yerel KSA Testi
Ortam değişkenlerini tanımlama
İki ortam değişkenini dışa aktarmanız gerekir:
- AI Studio'dan alabileceğiniz bir Gemini anahtarı:
Bunu yapmak için https://aistudio.google.com/apikey adresine gidin ve bu uygulamayı uyguladığınız etkin Google Cloud projenizin API anahtarını alıp bir yere kaydedin:
- Anahtarı aldıktan sonra Cloud Shell Terminal'i açın ve aşağıdaki komutu çalıştırarak yeni oluşturduğumuz adk-agents dizinine gidin:
cd adk-agents
- Bu sefer Vertex AI'ı kullanmadığımızı belirten bir değişken.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- İlk aracınızı KSA'da çalıştırma
Bu ilk aracıyı başlatmak için terminalinizde aşağıdaki Maven komutunu kullanın:
mvn compile exec:java -DmainClass="agents.App"
Temsilcinin etkileşimli yanıtını terminalinizde görürsünüz.
10. Cloud Run'a dağıtma
ADK Java aracınızı Cloud Run'a dağıtmak, diğer Java uygulamalarını dağıtmaya benzer:
- Dockerfile: Java uygulamanızı paketlemek için bir Dockerfile oluşturun.
- Docker görüntüsü oluşturma ve gönderme: Google Cloud Build ve Artifact Registry'yi kullanın.
- Yukarıdaki adımı gerçekleştirebilir ve Cloud Run'a dağıtımı tek bir komutla yapabilirsiniz:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Benzer şekilde, Java Cloud Run işlevinizi (gcfv2.PatentSearch) dağıtırsınız. Alternatif olarak, veritabanı mantığı için Java Cloud Run işlevini doğrudan Cloud Run işlevi konsolundan oluşturup dağıtabilirsiniz.
11. Web kullanıcı arayüzü ile test etme
ADK, temsilcinizin yerel olarak test edilmesi ve hatalarının ayıklanması için kullanışlı bir web kullanıcı arayüzüyle birlikte gelir. App.java dosyanızı yerel olarak çalıştırdığınızda (ör. yapılandırılmışsa mvn exec:java -Dexec.mainClass="agents.App" veya yalnızca ana yöntemi çalıştırarak) ADK genellikle yerel bir web sunucusu başlatır.
ADK Web kullanıcı arayüzü ile şunları yapabilirsiniz:
- Temsilcinize mesaj gönderme
- Etkinlikleri (kullanıcı mesajı, araç çağrısı, araç yanıtı, LLM yanıtı) görün.
- Oturum durumunu inceleyin.
- Günlükleri ve izleri görüntüleme
Bu, geliştirme sırasında aracınızın istekleri nasıl işlediğini ve araçlarını nasıl kullandığını anlamak için çok değerlidir. Bu işlem, pom.xml dosyasındaki mainClass'ınızın com.google.adk.web.AdkWebServer olarak ayarlandığını ve aracınızın bu sınıfa kaydedildiğini veya bunu kullanıma sunan yerel bir test çalıştırıcıyı çalıştırdığınızı varsayar.
App.java dosyanızı InMemoryRunner ve konsol girişi için Scanner ile çalıştırdığınızda temel aracı mantığını test edersiniz. Web kullanıcı arayüzü, daha görsel bir hata ayıklama deneyimi için ayrı bir bileşendir ve genellikle ADK, aracınıza HTTP üzerinden hizmet verdiğinde kullanılır.
SpringBoot yerel sunucusunu başlatmak için kök dizininizden aşağıdaki Maven komutunu kullanabilirsiniz:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
Arayüze genellikle yukarıdaki komutun çıktısı olan URL'den erişilebilir. Cloud Run'a dağıtılmışsa Cloud Run'a dağıtılmış bağlantısından erişebilirsiniz.
Sonucu etkileşimli bir arayüzde görebilirsiniz.
Patent Vekilimiz ile ilgili aşağıdaki videoya göz atın:
AlloyDB satır içi arama ve geri çağırma değerlendirmesi ile kalite kontrollü patent vekili demosu
12. Temizleme
Bu yayında kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog adresine gidin.
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog sayfasını ziyaret edin.
- Proje listesinde silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
13. Tebrikler
Tebrikler! ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI ve Vector Search'ün özelliklerini birleştirerek Java'da Patent Analizi Aracınızı başarıyla oluşturduk. Ayrıca, bağlamsal benzerlik aramalarını dönüştürücü, verimli ve gerçekten anlam odaklı hale getirme konusunda büyük bir adım attık.
Hemen Başlayın!
ADK Belgeleri: [Link to Official ADK Java Docs]
Patent Analizi Aracısı Kaynak Kodu: [Link to your (now public) GitHub Repo]
Java Örnek Aracıları: [link to the adk-samples repo]
ADK topluluğuna katılın: https://www.reddit.com/r/agentdevelopmentkit/
Keyifli temsilci oluşturma deneyimi dileriz.