
1. Przegląd
W różnych branżach wyszukiwanie kontekstowe jest kluczową funkcją, która stanowi podstawę aplikacji. Technologia Retrieval Augmented Generation od dłuższego czasu jest kluczowym czynnikiem tego ważnego rozwoju technologicznego dzięki mechanizmom wyszukiwania opartym na generatywnej AI. Modele generatywne, z ich dużymi oknami kontekstu i imponującą jakością danych wyjściowych, zmieniają AI. RAG to systematyczny sposób na wstrzykiwanie kontekstu do aplikacji i agentów AI, który opiera je na ustrukturyzowanych bazach danych lub informacjach z różnych mediów. Te dane kontekstowe są kluczowe dla jasności i dokładności wyników, ale jak dokładne są te wyniki? Czy Twoja firma w dużej mierze zależy od dokładności tych dopasowań kontekstowych i trafności? W takim razie ten projekt Cię rozbawi!
Wyobraź sobie, że możemy wykorzystać moc modeli generatywnych i stworzyć interaktywne agenty, które są w stanie podejmować autonomiczne decyzje na podstawie tak ważnych informacji kontekstowych i opartych na prawdzie. Właśnie to dziś zrobimy. Utworzymy kompleksową aplikację z agentem AI, korzystając z pakietu ADK opartego na zaawansowanej funkcji RAG w AlloyDB, która będzie służyć do analizy patentów.
Agent do analizy patentów pomaga użytkownikowi znaleźć patenty powiązane kontekstowo z tekstem wyszukiwania, a na prośbę użytkownika podaje jasne i zwięzłe wyjaśnienie oraz dodatkowe szczegóły dotyczące wybranego patentu. Chcesz zobaczyć, jak to się robi? Zaczynajmy!
Cel
Cel jest prosty. Umożliwia użytkownikowi wyszukiwanie patentów na podstawie opisu tekstowego, a następnie uzyskiwanie szczegółowych wyjaśnień dotyczących konkretnego patentu z wyników wyszukiwania. Wszystko to jest możliwe dzięki agentowi AI utworzonemu za pomocą Java ADK, AlloyDB, wyszukiwania wektorowego (z indeksami zaawansowanymi), Gemini i całej aplikacji wdrożonej bezserwerowo w Cloud Run.
Co utworzysz
W tym module:
- Tworzenie instancji AlloyDB i wczytywanie danych z publicznego zbioru danych Patents
- Wdrażanie zaawansowanego wyszukiwania wektorowego w AlloyDB za pomocą funkcji ScaNN i Recall eval
- Tworzenie agenta za pomocą pakietu ADK w Javie
- Implementowanie logiki po stronie serwera bazy danych w bezserwerowych funkcjach Cloud Functions w języku Java
- Wdrażanie i testowanie agenta w Cloud Run
Poniższy diagram przedstawia przepływ danych i etapy wdrażania.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy jesteś już uwierzytelniony i czy projekt jest ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API. Możesz użyć polecenia gcloud w terminalu Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Alternatywą dla polecenia gcloud jest wyszukanie poszczególnych usług w konsoli lub skorzystanie z tego linku.
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Konfiguracja bazy danych
W tym module użyjemy AlloyDB jako bazy danych do przechowywania danych patentowych. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję podstawową, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie załadowany zbiór danych patentów.
Tworzenie klastra i instancji
- Otwórz stronę AlloyDB w konsoli Cloud. Najprostszym sposobem na znalezienie większości stron w Cloud Console jest wyszukanie ich za pomocą paska wyszukiwania w konsoli.
- Na tej stronie kliknij UTWÓRZ KLASTER:

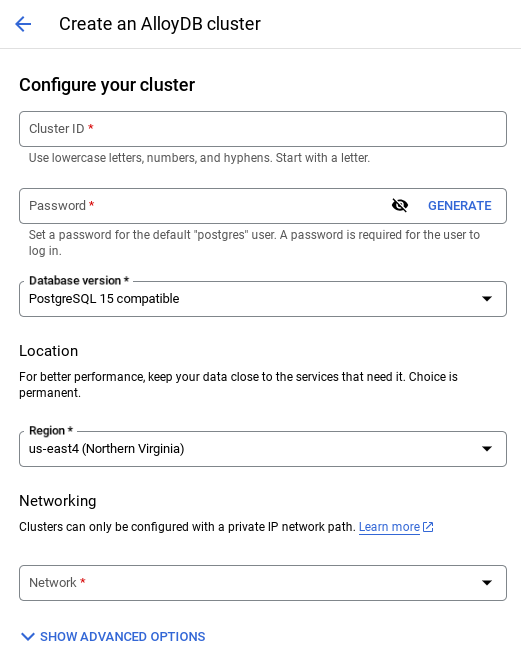
- Wyświetli się ekran podobny do tego poniżej. Utwórz klaster i instancję z tymi wartościami (upewnij się, że wartości są zgodne, jeśli klonujesz kod aplikacji z repozytorium):
- id klastra: „
vector-cluster” - password: "
alloydb" - PostgreSQL 15 / najnowsza zalecana
- Region: "
us-central1" - Sieć: „
default”
- Po wybraniu sieci domyślnej zobaczysz ekran podobny do tego poniżej.
Kliknij SKONFIGURUJ POŁĄCZENIE.
- Następnie wybierz „Użyj automatycznie przydzielonego zakresu adresów IP” i kliknij Dalej. Po sprawdzeniu informacji kliknij UTWÓRZ POŁĄCZENIE.

- Po skonfigurowaniu sieci możesz kontynuować tworzenie klastra. Kliknij UTWÓRZ KLASTER, aby dokończyć konfigurowanie klastra, jak pokazano poniżej:

Pamiętaj, aby zmienić identyfikator instancji (który możesz znaleźć podczas konfigurowania klastra lub instancji) na
vector-instance. Jeśli nie możesz go zmienić, pamiętaj, aby we wszystkich kolejnych odwołaniach używać identyfikatora instancji.
Pamiętaj, że utworzenie klastra zajmie około 10 minut. Po zakończeniu procesu powinien wyświetlić się ekran z omówieniem utworzonego klastra.
4. Pozyskiwanie danych
Teraz dodaj tabelę z danymi o sklepie. Otwórz AlloyDB, wybierz klaster główny, a następnie AlloyDB Studio:

Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb”
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wpisywane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.

Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, w razie potrzeby korzystając z opcji Uruchom, Formatuj i Wyczyść.
Włącz rozszerzenia
Do utworzenia tej aplikacji użyjemy rozszerzeń pgvector i google_ml_integration. Rozszerzenie pgvector umożliwia przechowywanie wektorów dystrybucyjnych i wyszukiwanie ich. Rozszerzenie google_ml_integration udostępnia funkcje, których możesz używać do uzyskiwania dostępu do punktów końcowych prognozowania Vertex AI w celu uzyskiwania prognoz w SQL. Włącz te rozszerzenia, uruchamiając te DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jeśli chcesz sprawdzić, które rozszerzenia są włączone w Twojej bazie danych, uruchom to polecenie SQL:
select extname, extversion from pg_extension;
Tworzenie tabeli
Tabelę możesz utworzyć za pomocą instrukcji DDL poniżej w AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
Kolumna abstract_embeddings będzie umożliwiać przechowywanie wartości wektorowych tekstu.
Przyznaj uprawnienia
Aby przyznać uprawnienia do wykonywania funkcji „embedding”, uruchom to polecenie:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Przyznawanie roli Użytkownik Vertex AI kontu usługi AlloyDB
W konsoli IAM Google Cloud przyznaj kontu usługi AlloyDB (które wygląda tak: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) dostęp do roli „Użytkownik Vertex AI”. Zmienna PROJECT_NUMBER będzie zawierać numer Twojego projektu.
Możesz też uruchomić to polecenie w terminalu Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Wczytywanie danych patentowych do bazy danych
Jako zbioru danych użyjemy publicznych zbiorów danych Google Patents w BigQuery. Do uruchamiania zapytań będziemy używać AlloyDB Studio. Dane są pobierane do tego pliku insert scripts sql w tym repo. Uruchomimy go, aby wczytać dane patentowe.
- W konsoli Google Cloud otwórz stronę AlloyDB.
- Wybierz nowo utworzony klaster i kliknij instancję.
- W menu nawigacyjnym AlloyDB kliknij AlloyDB Studio. Zaloguj się za pomocą swoich danych logowania.
- Otwórz nową kartę, klikając ikonę Nowa karta po prawej stronie.
- Skopiuj i uruchom kolejno instrukcje zapytania
insertz plikówinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sql. Aby szybko zapoznać się z tym przypadkiem użycia, możesz uruchomić 10–50 instrukcji wstawiania kopii.
Aby uruchomić, kliknij Uruchom. Wyniki zapytania pojawią się w tabeli Wyniki.
5. Tworzenie wektorów dystrybucyjnych na podstawie danych patentowych
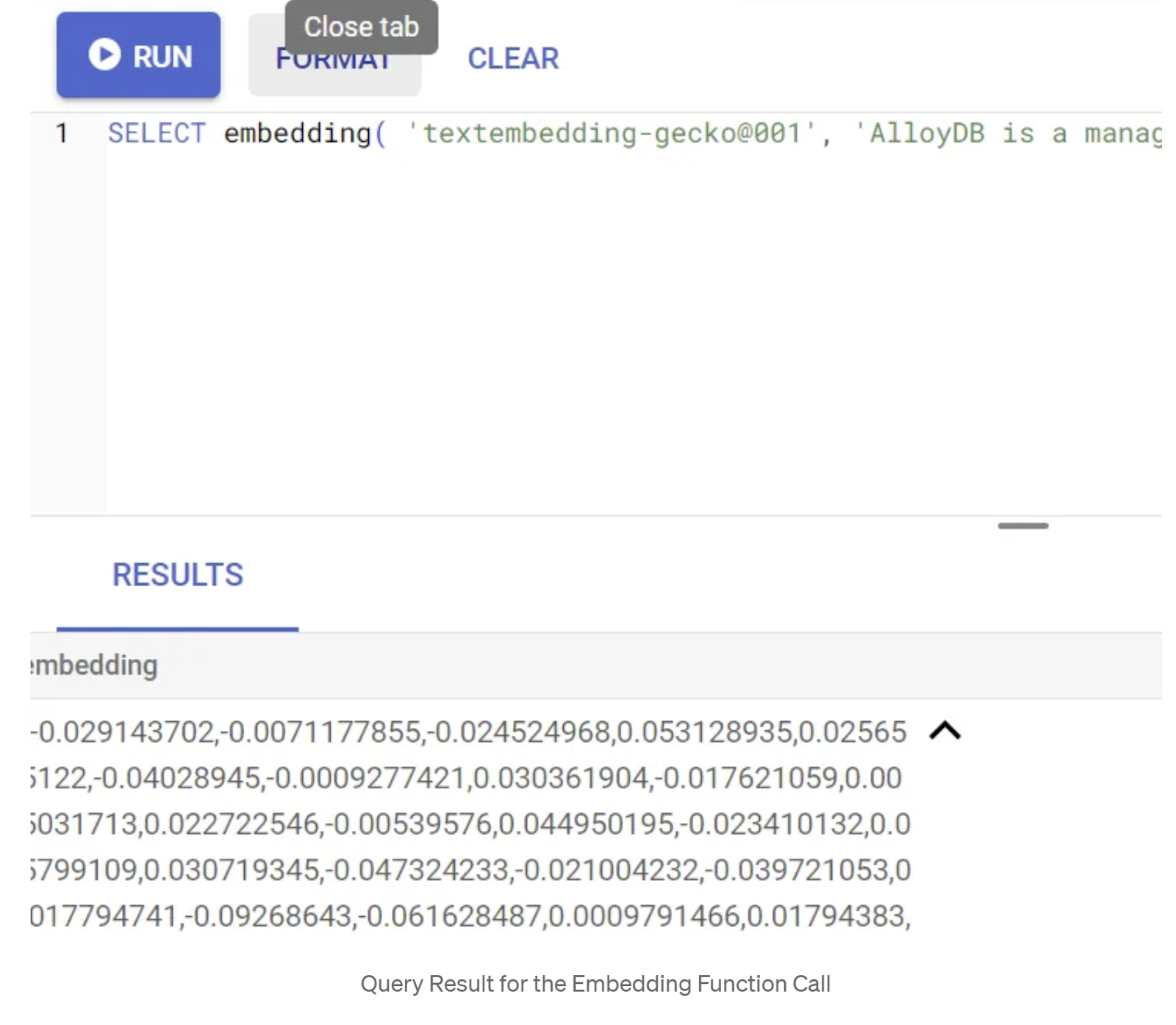
Najpierw przetestujmy funkcję osadzania, uruchamiając to przykładowe zapytanie:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Powinien on zwrócić wektor osadzania, który wygląda jak tablica liczb zmiennoprzecinkowych, dla przykładowego tekstu w zapytaniu. Wygląda to tak:
Zaktualizuj pole wektora abstract_embeddings
Poniższy język DML należy stosować do aktualizowania w tabeli streszczeń patentów o odpowiednie osadzenia w przypadku, gdy osadzenia muszą zostać wygenerowane dla streszczeń. W naszym przypadku instrukcje wstawiania zawierają już te osadzania dla każdego abstraktu, więc nie musisz wywoływać metody embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Wykonywanie wyszukiwania wektorowego
Gdy tabela, dane i wektory są gotowe, możemy przeprowadzić wyszukiwanie wektorowe w czasie rzeczywistym dla tekstu wyszukiwanego przez użytkownika. Możesz to sprawdzić, uruchamiając to zapytanie:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
W tym zapytaniu
- Tekst wyszukiwany przez użytkownika to „Sentiment Analysis”.
- Konwertujemy go na wektory dystrybucyjne w metodzie embedding() za pomocą modelu text-embedding-005.
- „<=>” oznacza użycie metody odległości COSINE SIMILARITY.
- Wynik metody osadzania przekształcamy w typ wektora, aby był zgodny z wektorami przechowywanymi w bazie danych.
- LIMIT 10 oznacza, że wybieramy 10 najbliższych dopasowań tekstu wyszukiwania.
AlloyDB przenosi wyszukiwanie wektorowe RAG na wyższy poziom:
Wprowadzono wiele nowości. Oto 2 z nich, które są przeznaczone dla programistów:
- Filtrowanie w tekście
- Oceniający czułość
Filtrowanie w tekście
Wcześniej deweloper musiał wykonywać zapytanie wyszukiwania wektorowego i zajmować się filtrowaniem oraz przywoływaniem. Optymalizator zapytań AlloyDB decyduje o sposobie wykonywania zapytania z filtrami. Filtrowanie wbudowane to nowa technika optymalizacji zapytań, która umożliwia optymalizatorowi zapytań AlloyDB ocenę zarówno warunków filtrowania metadanych, jak i wyszukiwania wektorowego, z wykorzystaniem indeksów wektorowych i indeksów w kolumnach metadanych. Dzięki temu zwiększyła się skuteczność przywoływania, co pozwala deweloperom korzystać z funkcji AlloyDB od razu po wyjęciu z pudełka.
Filtrowanie wbudowane najlepiej sprawdza się w przypadku średniej selektywności. Podczas przeszukiwania indeksu wektorowego AlloyDB oblicza odległości tylko w przypadku wektorów, które spełniają warunki filtrowania metadanych (filtry funkcjonalne w zapytaniu zwykle obsługiwane w klauzuli WHERE). Znacznie zwiększa to wydajność tych zapytań, uzupełniając zalety filtrowania po lub przed.
- Instalowanie i aktualizowanie rozszerzenia pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Jeśli rozszerzenie pgvector jest już zainstalowane, uaktualnij je do wersji 0.8.0.google-3 lub nowszej, aby uzyskać funkcje oceny przywoływania.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Ten krok musisz wykonać tylko wtedy, gdy Twoje rozszerzenie wektorowe ma wersję starszą niż 0.8.0.google-3.
Ważna uwaga: jeśli liczba wierszy jest mniejsza niż 100, nie musisz tworzyć indeksu ScaNN, ponieważ nie będzie on stosowany w przypadku mniejszej liczby wierszy. W takim przypadku pomiń kolejne kroki.
- Aby utworzyć indeksy ScaNN, zainstaluj rozszerzenie alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Najpierw uruchom zapytanie w ramach wyszukiwania wektorowego bez indeksu i bez włączonego filtra wbudowanego:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Wynik powinien być podobny do tego:

- Uruchom na nim funkcję Wyjaśnij analizę (bez indeksu ani filtrowania w tekście):

Czas wykonywania to 2,4 ms
- Utwórzmy zwykły indeks w polu num_claims, aby można było filtrować według niego:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Utwórzmy indeks ScaNN dla naszej aplikacji do wyszukiwania patentów. W AlloyDB Studio wykonaj te czynności:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Ważna uwaga: (num_leaves=32) dotyczy naszego pełnego zbioru danych zawierającego ponad 1000 wierszy. Jeśli liczba wierszy jest mniejsza niż 100, nie musisz tworzyć indeksu, ponieważ nie będzie on miał zastosowania w przypadku mniejszej liczby wierszy.
- Włącz filtrowanie wbudowane w indeksie ScaNN:
SET scann.enable_inline_filtering = on
- Teraz uruchommy to samo zapytanie z filtrem i wyszukiwaniem wektorowym:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
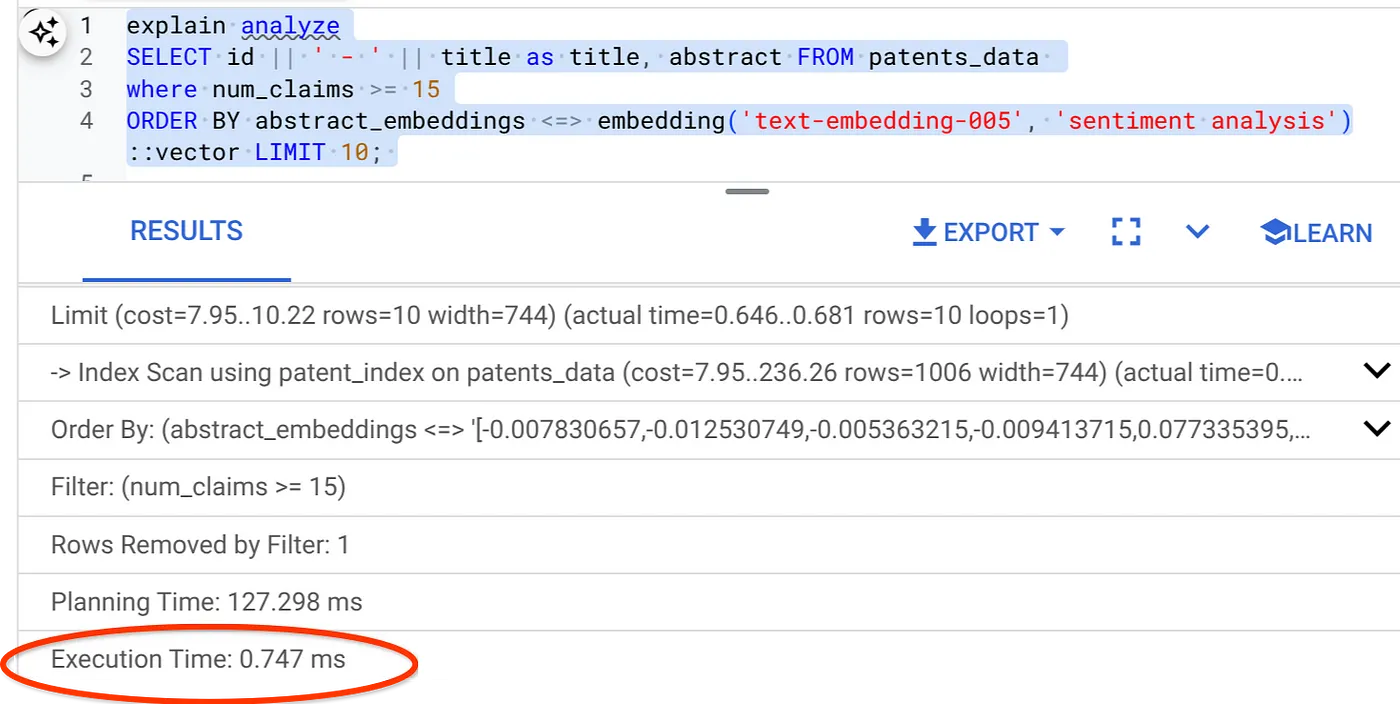
Jak widać, czas wykonania tego samego wyszukiwania wektorowego znacznie się skrócił. Umożliwia to indeks ScaNN z filtrowaniem wbudowanym w wyszukiwarce wektorowej.
Następnie sprawdźmy skuteczność tego wyszukiwania wektorowego z włączoną funkcją ScaNN.
Oceniający czułość
Wyszukiwanie podobieństw to odsetek trafnych instancji, które zostały pobrane z wyszukiwania, czyli liczba wyników prawdziwie pozytywnych. To najczęściej używane dane do pomiaru jakości wyszukiwania. Jednym ze źródeł utraty precyzji jest różnica między przybliżonym wyszukiwaniem najbliższych sąsiadów (aNN) a wyszukiwaniem k najbliższych sąsiadów (kNN). Indeksy wektorowe, takie jak ScaNN w AlloyDB, implementują algorytmy aNN, co pozwala przyspieszyć wyszukiwanie wektorowe w dużych zbiorach danych w zamian za niewielkie obniżenie czułości. AlloyDB umożliwia teraz bezpośrednie mierzenie tego kompromisu w bazie danych w przypadku poszczególnych zapytań i zapewnia jego stabilność w czasie. Na podstawie tych informacji możesz aktualizować parametry zapytań i indeksów, aby osiągać lepsze wyniki i wydajność.
Wartość przypomnienia dla zapytania wektorowego w indeksie wektorowym w przypadku danej konfiguracji możesz znaleźć za pomocą funkcji evaluate_query_recall. Ta funkcja umożliwia dostosowanie parametrów w celu uzyskania oczekiwanych wyników zapytania wektorowego. Jakość wyszukiwania mierzymy za pomocą wskaźnika precyzji, który określa procent zwróconych wyników, które są obiektywnie najbliższe wektorom zapytania. Funkcja evaluate_query_recall jest domyślnie włączona.
Ważna uwaga:
Jeśli podczas wykonywania poniższych czynności pojawi się błąd odmowy uprawnień w indeksie HNSW, na razie pomiń całą sekcję oceny przywoływania. Może to być związane z ograniczeniami dostępu, ponieważ w momencie tworzenia tego przewodnika usługa jest dopiero udostępniana.
- Ustaw flagę Enable Index Scan na indeksie ScaNN i indeksie HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Uruchom to zapytanie w AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Funkcja evaluate_query_recall przyjmuje zapytanie jako parametr i zwraca jego przypomnienie. Używam tego samego zapytania, którego użyłem do sprawdzenia wydajności, jako zapytania wejściowego funkcji. Jako metodę indeksowania dodano SCaNN. Więcej opcji parametrów znajdziesz w dokumentacji.
Wartość przypomnienia dla używanego przez nas zapytania do wyszukiwarki wektorowej:

Widzę, że wartość RECALL wynosi 70%. Teraz mogę użyć tych informacji, aby zmienić parametry indeksu, metody i parametry zapytań oraz poprawić skuteczność wyszukiwania wektorowego.
Zmieniłem liczbę wierszy w zbiorze wyników na 7 (wcześniej było to 10) i widzę nieco lepszy WYNIK, czyli 86%.
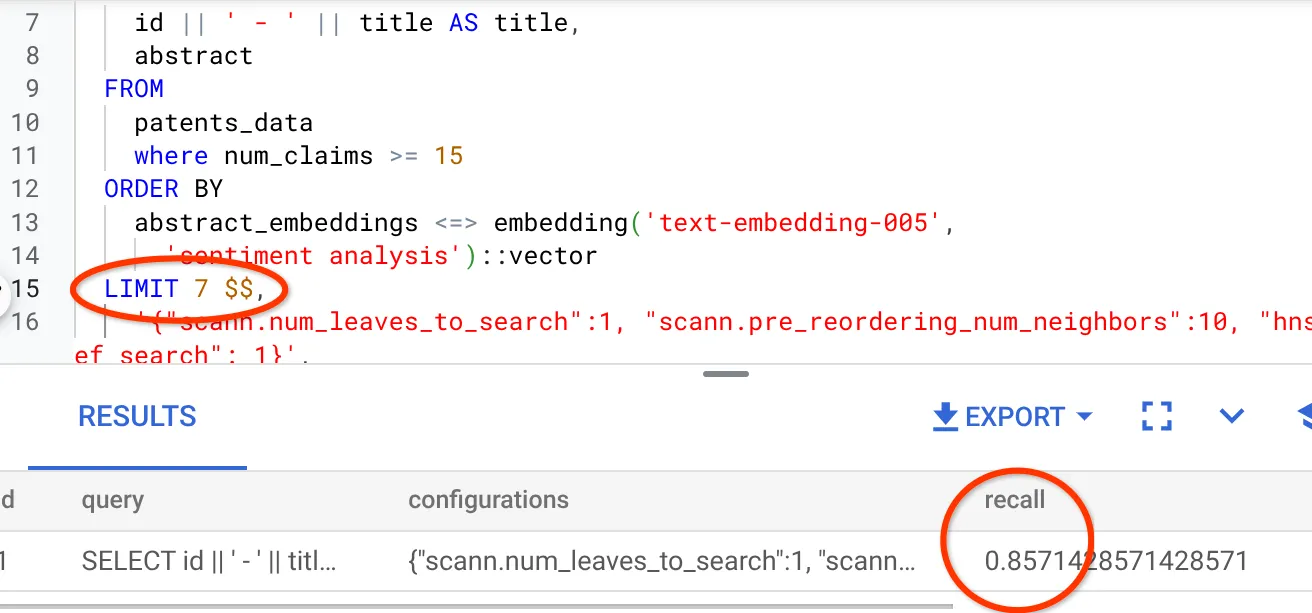
Oznacza to, że w czasie rzeczywistym mogę zmieniać liczbę dopasowań wyświetlanych użytkownikom, aby zwiększać ich trafność w zależności od kontekstu wyszukiwania.
No dobrze. Czas wdrożyć logikę bazy danych i przejść do agenta.
7. Przenoszenie logiki bazy danych na serwer internetowy bezserwerowo
Chcesz udostępnić tę aplikację w internecie? Wykonaj te czynności:
- Otwórz Cloud Run Functions w konsoli Google Cloud, aby utworzyć nową funkcję Cloud Run. W tym celu kliknij „Write a function” (Napisz funkcję) lub użyj linku: https://console.cloud.google.com/run/create?deploymentType=function.
- Wybierz opcję „Aby stworzyć funkcję, skorzystaj z edycji bezpośredniej” i rozpocznij konfigurację. Podaj nazwę usługi „patent-search”, wybierz region „us-central1” i środowisko wykonawcze „Java 17”. Ustaw uwierzytelnianie na „Zezwalaj na nieuwierzytelnione wywołania”.
- W sekcji „Kontenery, woluminy, sieć, zabezpieczenia” wykonaj te czynności, nie pomijając żadnych szczegółów:
Otwórz kartę Sieć:

Wybierz „Łącz się z siecią VPC w przypadku ruchu wychodzącego”, a następnie „Używaj oprogramowania sprzęgającego bezserwerowego dostępu do VPC”.
W menu Sieć kliknij menu Sieć i wybierz opcję „Dodaj nowe połączenie VPC” (jeśli nie masz jeszcze skonfigurowanego połączenia domyślnego) i postępuj zgodnie z instrukcjami wyświetlanymi w wyskakującym okienku:

Podaj nazwę oprogramowania sprzęgającego VPC i upewnij się, że region jest taki sam jak w przypadku instancji. Pozostaw domyślną wartość Sieć i ustaw Podsieć jako Niestandardowy zakres adresów IP z zakresem adresów IP 10.8.0.0 lub podobnym, który jest dostępny.
Rozwiń POKAŻ USTAWIENIA SKALOWANIA i upewnij się, że konfiguracja jest dokładnie taka:

Kliknij UTWÓRZ. Ten łącznik powinien być teraz widoczny w ustawieniach ruchu wychodzącego.
Wybierz nowo utworzone oprogramowanie sprzęgające.
Wybierz opcję kierowania całego ruchu przez to oprogramowanie sprzęgające z dostępem do VPC.
Kliknij DALEJ, a potem WDRÓŻ.
- Domyślnie punkt wejścia zostanie ustawiony na „gcfv2.HelloHttpFunction”. Zastąp kod zmiennej w plikach HelloHttpFunction.java i pom.xml funkcji Cloud Run kodem z plików „ PatentSearch.java” i „ pom.xml”. Zmień nazwę pliku klasy na PatentSearch.java.
- Pamiętaj, aby w pliku Java zastąpić obiekt zastępczy ************* i dane logowania do połączenia z AlloyDB odpowiednimi wartościami. Dane logowania do AlloyDB to te, których użyliśmy na początku tego samouczka. Jeśli używasz innych wartości, zmień je w pliku Java.
- Kliknij Wdróż.
- Po wdrożeniu zaktualizowanej funkcji w Cloud Functions powinien pojawić się wygenerowany punkt końcowy. Skopiuj ten ciąg znaków i zastąp nim ciąg w tym poleceniu:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
Znakomicie. Wykonywanie zaawansowanego wyszukiwania wektorowego podobieństwa kontekstowego za pomocą modelu Embeddings na danych AlloyDB jest tak proste.
8. Tworzenie agenta za pomocą ADK w Javie
Najpierw zacznijmy od projektu Java w edytorze.
- Otwieranie terminala Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Autoryzacja po wyświetleniu prośby
- Przełącz się na edytor Cloud Shell, klikając ikonę edytora u góry konsoli Cloud Shell.

- W konsoli edytora Cloud Shell utwórz nowy folder i nadaj mu nazwę „adk-agents”.
W katalogu głównym Cloud Shell kliknij „Utwórz nowy folder”, jak pokazano poniżej:

Nadaj mu nazwę „adk-agents”:
- Utwórz tę strukturę folderów i puste pliki o odpowiednich nazwach:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Otwórz repozytorium GitHub na osobnej karcie i skopiuj kod źródłowy plików App.java i pom.xml.
- Jeśli edytor został otwarty w nowej karcie za pomocą ikony „Otwórz w nowej karcie” w prawym górnym rogu, możesz otworzyć terminal u dołu strony. Możesz otworzyć edytor i terminal równolegle, co pozwoli Ci swobodnie pracować.
- Po sklonowaniu wróć do konsoli edytora Cloud Shell.
- Funkcja Cloud Run została już utworzona, więc nie musisz kopiować plików funkcji Cloud Run z folderu repozytorium.
Pierwsze kroki z pakietem ADK Java SDK
To dość proste. W kroku klonowania musisz przede wszystkim zadbać o to, aby:
- Dodawanie zależności:
Do pliku pom.xml dodaj artefakty google-adk i google-adk-dev (w przypadku interfejsu internetowego). Jeśli skopiujesz źródło z repozytorium, te informacje będą już zawarte w plikach, więc nie musisz ich dodawać. Wystarczy, że wprowadzisz zmianę w punkcie końcowym funkcji Cloud Run, aby odzwierciedlał wdrożony punkt końcowy. Opisujemy to w kolejnych krokach w tej sekcji.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Pamiętaj, aby odwoływać się do pliku pom.xml z repozytorium źródłowego, ponieważ aplikacja wymaga innych zależności i konfiguracji.
- Konfigurowanie projektu:
Sprawdź, czy wersja Javy (zalecana to 17 lub nowsza) i ustawienia kompilatora Maven są prawidłowo skonfigurowane w pliku pom.xml. Możesz skonfigurować projekt tak, aby miał poniższą strukturę:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Definiowanie agenta i jego narzędzi (App.java):
W tym miejscu ujawnia się magia pakietu ADK Java SDK. Określamy agenta, jego możliwości (instrukcje) i narzędzia, z których może korzystać.
Uproszczoną wersję kilku fragmentów kodu głównej klasy agenta znajdziesz tutaj. Pełny projekt znajdziesz w repozytorium projektu tutaj.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Wyróżnione kluczowe komponenty kodu ADK w Javie:
- LlmAgent.builder(): interfejs API do konfiguracji agenta.
- .instruction(...): zawiera podstawowy prompt i wytyczne dla modelu LLM, w tym informacje o tym, kiedy używać którego narzędzia.
- FunctionTool.create(App.class, "methodName"): łatwo rejestruje metody Java jako narzędzia, które agent może wywoływać. Ciąg znaków nazwy metody musi być zgodny z rzeczywistą publiczną metodą statyczną.
- @Schema(description = ...): dodaje adnotacje do parametrów narzędzia, pomagając LLM zrozumieć, jakich danych wejściowych oczekuje każde narzędzie. Ten opis jest kluczowy dla prawidłowego wyboru narzędzia i wypełnienia parametrów.
- InvocationContext ctx: przekazywany automatycznie do metod narzędzia, co daje dostęp do stanu sesji (ctx.session().state()), informacji o użytkowniku i innych danych.
- .outputKey("patents"): gdy narzędzie zwraca dane, ADK może automatycznie przechowywać je w stanie sesji pod tym kluczem. W ten sposób funkcja explainPatent może uzyskać dostęp do wyników funkcji getPatents.
- VECTOR_SEARCH_ENDPOINT: zmienna zawierająca podstawową logikę funkcjonalną kontekstowych pytań i odpowiedzi dla użytkownika w przypadku wyszukiwania patentów.
- Działanie: po wykonaniu kroku wdrażania funkcji Cloud Run w języku Java z poprzedniej sekcji musisz ustawić zaktualizowaną wartość wdrożonego punktu końcowego.
- searchTool: narzędzie to wchodzi w interakcję z użytkownikiem, aby znaleźć w bazie danych patentów kontekstowo dopasowane patenty do tekstu wyszukiwania użytkownika.
- explainTool: prosi użytkownika o szczegółowe informacje na temat konkretnego patentu. Następnie podsumowuje streszczenie patentu i może odpowiadać na kolejne pytania użytkownika na podstawie szczegółów patentu, które posiada.
Ważna uwaga: zastąp zmienną VECTOR_SEARCH_ENDPOINT wdrożonym punktem końcowym CRF.
Wykorzystywanie InvocationContext w interakcjach stanowych
Jedną z najważniejszych funkcji tworzenia przydatnych agentów jest zarządzanie stanem w wielu turach rozmowy. Ułatwia to interfejs InvocationContext pakietu ADK.
W pliku App.java:
- Gdy zdefiniowana jest funkcja initAgent(), używamy metody .outputKey("patents"). Informuje to ADK, że gdy narzędzie (np. getPatents) zwraca dane w swoim polu raportu, dane te powinny być przechowywane w stanie sesji pod kluczem „patents”.
- W metodzie narzędzia explainPatent wstrzykujemy InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Dzięki temu narzędzie explainPatent może uzyskać dostęp do listy patentów pobranej przez narzędzie getPatents w poprzedniej turze, co sprawia, że rozmowa jest stanowa i spójna.
9. Testowanie lokalnego interfejsu wiersza poleceń
Definiowanie zmiennych środowiskowych
Musisz wyeksportować 2 zmienne środowiskowe:
- Klucz Gemini, który możesz uzyskać w AI Studio:
Aby to zrobić, wejdź na stronę https://aistudio.google.com/apikey i uzyskaj klucz interfejsu API dla aktywnego projektu Google Cloud, w którym wdrażasz tę aplikację. Zapisz klucz w bezpiecznym miejscu:
- Po uzyskaniu klucza otwórz terminal Cloud Shell i przejdź do nowego katalogu adk-agents, który właśnie utworzyliśmy, uruchamiając to polecenie:
cd adk-agents
- Zmienna określająca, że tym razem nie używamy Vertex AI.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Uruchamianie pierwszego agenta w interfejsie wiersza poleceń
Aby uruchomić pierwszego agenta, użyj w terminalu tego polecenia Maven:
mvn compile exec:java -DmainClass="agents.App"
W terminalu zobaczysz interaktywną odpowiedź agenta.
10. Wdrażanie w Cloud Run
Wdrażanie agenta ADK w Javie w Cloud Run jest podobne do wdrażania dowolnej innej aplikacji w Javie:
- Dockerfile: utwórz plik Dockerfile, aby spakować aplikację w Javie.
- Tworzenie i przesyłanie obrazu Dockera: użyj Google Cloud Build i Artifact Registry.
- Powyższy krok i wdrożenie w Cloud Run możesz wykonać za pomocą jednego polecenia:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Podobnie wdrożysz funkcję Cloud Run w języku Java (gcfv2.PatentSearch). Możesz też utworzyć i wdrożyć funkcję Cloud Run w języku Java na potrzeby logiki bazy danych bezpośrednio z konsoli Cloud Run Function.
11. Testowanie za pomocą interfejsu internetowego
ADK zawiera przydatny interfejs internetowy do lokalnego testowania i debugowania agenta. Gdy uruchomisz plik App.java lokalnie (np. mvn exec:java -Dexec.mainClass="agents.App" w przypadku skonfigurowania lub po prostu uruchamiając metodę główną), ADK zwykle uruchamia lokalny serwer WWW.
Interfejs internetowy ADK umożliwia:
- Wysyłaj wiadomości do agenta.
- Wyświetl zdarzenia (wiadomość użytkownika, wywołanie narzędzia, odpowiedź narzędzia, odpowiedź LLM).
- Sprawdź stan sesji.
- Wyświetlanie logów i śladów.
Jest to nieocenione podczas tworzenia, ponieważ pozwala zrozumieć, jak agent przetwarza żądania i korzysta z narzędzi. Zakładamy, że w pliku pom.xml główna klasa (mainClass) jest ustawiona na com.google.adk.web.AdkWebServer, a agent jest w niej zarejestrowany lub uruchamiasz lokalny moduł uruchamiający testy, który udostępnia tę klasę.
Uruchamiając plik App.java za pomocą klasy InMemoryRunner i klasy Scanner do wprowadzania danych w konsoli, testujesz podstawową logikę agenta. Interfejs internetowy to osobny komponent, który zapewnia bardziej wizualne debugowanie. Jest on często używany, gdy ADK obsługuje agenta przez HTTP.
Aby uruchomić lokalny serwer SpringBoot, w katalogu głównym możesz użyć tego polecenia Maven:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
Interfejs jest często dostępny pod adresem URL, który wyświetla powyższe polecenie. Jeśli jest to wdrożona usługa Cloud Run, możesz uzyskać do niej dostęp za pomocą linku do wdrożonej usługi Cloud Run.
Wynik powinien być widoczny w interaktywnym interfejsie.
Obejrzyj poniższy film, aby zobaczyć wdrożonego agenta patentowego:

12. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog.
- Na liście projektów wybierz projekt, który chcesz usunąć, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
13. Gratulacje
Gratulacje! Udało Ci się utworzyć w Javie agenta do analizy patentów, łącząc możliwości ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI i Vector Search. Zrobiliśmy też ogromny krok naprzód w kierunku przekształcenia wyszukiwania podobieństw kontekstowych w naprawdę znaczące, wydajne i przynoszące przełomowe rezultaty.
Zacznij już dziś!
Dokumentacja pakietu ADK: [Link do oficjalnej dokumentacji pakietu ADK w języku Java]
Kod źródłowy agenta analizy patentów: [Link do Twojego (obecnie publicznego) repozytorium GitHub]
Przykładowe agenty w Javie: [link do repozytorium adk-samples]
Dołącz do społeczności ADK: https://www.reddit.com/r/agentdevelopmentkit/
Miłego tworzenia agentów!