
1. 概要
さまざまな業界で、コンテキスト検索はアプリケーションの中核をなす重要な機能です。検索拡張生成は、生成 AI を活用した検索メカニズムにより、この重要な技術進化を長らく推進してきました。大規模なコンテキスト ウィンドウと優れた出力品質を備えた生成モデルは、AI を変革しています。RAG は、AI アプリケーションとエージェントにコンテキストを注入し、構造化データベースやさまざまなメディアからの情報に基づいてグラウンディングするための体系的な方法を提供します。このコンテキスト データは、真実の明確さと出力の精度にとって重要ですが、その結果はどの程度正確ですか?ビジネスは、これらのコンテキスト マッチの精度と関連性に大きく依存していますか?このプロジェクトはあなたをくすぐるでしょう。
生成モデルの力を借りて、コンテキストに不可欠な情報に裏付けられ、真実に基づいた自律的な意思決定を行うことができるインタラクティブ エージェントを構築できると想像してみてください。これが、本日構築するものです。AlloyDB の高度な RAG を基盤とする Agent Development Kit を使用して、特許分析アプリケーション用のエンドツーエンドの AI エージェント アプリを構築します。
特許分析エージェントは、検索テキストに関連する特許を見つけるのを支援し、選択した特許について、要求に応じて明確かつ簡潔な説明と、必要に応じて追加の詳細情報を提供します。手順を確認してみましょう。それでは始めましょう。
目標
目標はシンプルです。ユーザーがテキストの説明に基づいて特許を検索し、検索結果から特定の特許の詳細な説明を取得できるようにします。これらはすべて、Java ADK、AlloyDB、ベクトル検索(高度なインデックス付き)、Gemini を使用して構築された AI エージェントを使用し、アプリケーション全体が Cloud Run にサーバーレスでデプロイされます。
作成するアプリの概要
このラボでは、次の作業を行います。
- AlloyDB インスタンスを作成して Patents Public Dataset のデータを読み込む
- ScaNN と再現率評価機能を使用して AlloyDB に高度なベクトル検索を実装する
- Java ADK を使用してエージェントを作成する
- Java サーバーレス Cloud Functions でデータベースのサーバーサイド ロジックを実装する
- Cloud Run でエージェントをデプロイしてテストする
次の図は、実装に関わるデータの流れと手順を表しています。

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.cn/static/patent-search-java-adk/img/7875ca05ca6f7cab.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証が完了しており、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にします。Cloud Shell ターミナルで gcloud コマンドを使用できます。
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud コマンドの代わりに、コンソールで各プロダクトを検索するか、こちらのリンクを使用します。
gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. データベースの設定
このラボでは、特許データのデータベースとして AlloyDB を使用します。クラスタを使用して、データベースやログなどのすべてのリソースを保持します。各クラスタには、データへのアクセス ポイントを提供するプライマリ インスタンスがあります。テーブルには実際のデータが格納されます。
特許データセットが読み込まれる AlloyDB クラスタ、インスタンス、テーブルを作成しましょう。
クラスタとインスタンスを作成する
- Cloud コンソールの AlloyDB ページに移動します。Cloud コンソールでほとんどのページを簡単に見つけるには、コンソールの検索バーを使用して検索します。
- このページで [クラスタを作成] を選択します。

- 次のような画面が表示されます。次の値を使用してクラスタとインスタンスを作成します(リポジトリからアプリケーション コードを複製する場合は、値が一致していることを確認してください)。
- クラスタ ID: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / 最新の推奨バージョン
- Region: "
us-central1" - Networking: "
default"

- デフォルトのネットワークを選択すると、次のような画面が表示されます。
[接続の設定] を選択します。
- [自動的に割り振られた IP 範囲を使用する] を選択して、[続行] をクリックします。情報を確認したら、[接続を作成] を選択します。

- ネットワークを設定したら、クラスタの作成を続行できます。[CREATE CLUSTER] をクリックして、次のようにクラスタの設定を完了します。

インスタンス ID を必ず変更してください(クラスタ / インスタンスの構成時に確認できます)。
vector-instance。変更できない場合は、以降のすべての参照でインスタンス ID を使用してください。
クラスタの作成には 10 分ほどかかります。成功すると、作成したクラスタの概要を示す画面が表示されます。
4. データの取り込み
次に、店舗に関するデータを含むテーブルを追加します。AlloyDB に移動し、プライマリ クラスタと AlloyDB Studio を選択します。
インスタンスの作成が完了するまで待つ必要がある場合があります。準備ができたら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。PostgreSQL への認証には、次のデータを使用します。
- ユーザー名: 「
postgres」 - データベース: 「
postgres」 - パスワード: 「
alloydb」
AlloyDB Studio への認証が成功すると、エディタに SQL コマンドが入力されます。最後のウィンドウの右にあるプラス記号を使用して、複数のエディタ ウィンドウを追加できます。

必要に応じて [実行]、[形式]、[クリア] オプションを使用して、エディタ ウィンドウに AlloyDB のコマンドを入力します。
拡張機能を有効にする
このアプリのビルドには、拡張機能 pgvector と google_ml_integration を使用します。pgvector 拡張機能を使用すると、ベクトル エンベディングを保存して検索できます。google_ml_integration 拡張機能は、Vertex AI 予測エンドポイントにアクセスして SQL で予測を取得するために使用する関数を提供します。次の DDL を実行して、これらの拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
データベースで有効になっている拡張機能を確認するには、次の SQL コマンドを実行します。
select extname, extversion from pg_extension;
テーブルを作成する
AlloyDB Studio で次の DDL ステートメントを使用してテーブルを作成できます。
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings 列には、テキストのベクトル値を格納できます。
権限を付与
次のステートメントを実行して、「embedding」関数に対する実行権限を付与します。
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB サービス アカウントに Vertex AI ユーザーロールを付与する
Google Cloud IAM コンソールで、AlloyDB サービス アカウント(service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com のような形式)に「Vertex AI ユーザー」ロールへのアクセス権を付与します。PROJECT_NUMBER にはプロジェクト番号が設定されます。
または、Cloud Shell ターミナルから次のコマンドを実行することもできます。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
特許データをデータベースに読み込む
BigQuery の Google Patents 一般公開データセットをデータセットとして使用します。AlloyDB Studio を使用してクエリを実行します。データは、この repoのこの insert scripts sql ファイルにソースが設定されています。このファイルを実行して、特許データを読み込みます。
- Google Cloud コンソールで、[AlloyDB] ページを開きます。
- 新しく作成したクラスタを選択し、インスタンスをクリックします。
- AlloyDB のナビゲーション メニューで、[AlloyDB Studio] をクリックします。自分の認証情報でログインします。
- 右側の [新しいタブ] アイコンをクリックして、新しいタブを開きます。
insert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlファイルからinsertクエリ ステートメントを 1 つずつコピーして実行します。このユースケースの簡単なデモとして、10 ~ 50 個の挿入ステートメントを実行できます。
実行するには、[実行] をクリックします。クエリの結果が [結果] テーブルに表示されます。
5. 特許データのエンベディングを作成する
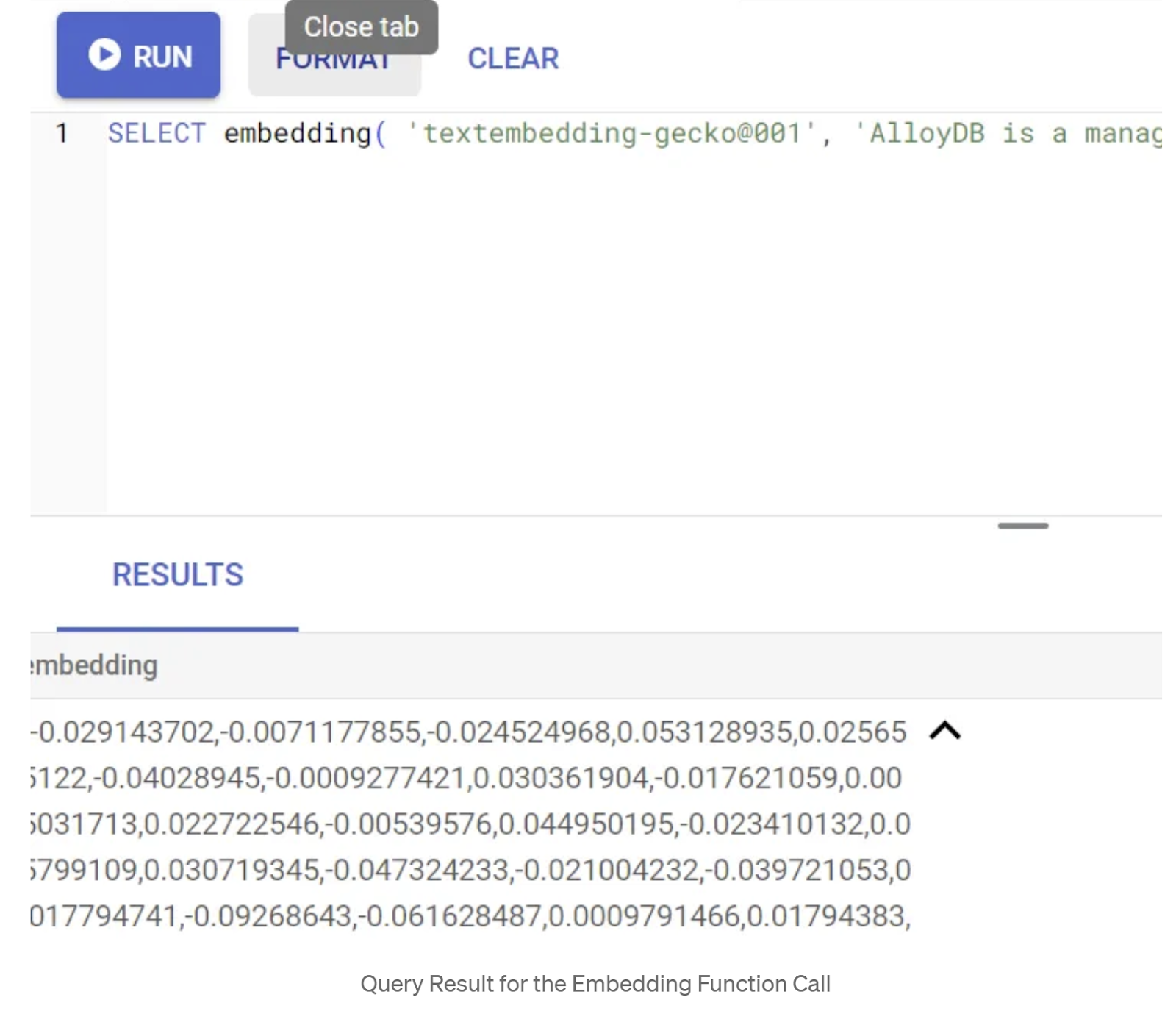
まず、次のサンプルクエリを実行して、エンベディング関数をテストします。
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
これにより、クエリ内のサンプル テキストのエンベディング ベクトル(浮動小数点数の配列のようなもの)が返されます。次のように表示されます。
abstract_embeddings ベクトル フィールドを更新する
要約のエンベディングを生成する必要がある場合は、次の DML を使用して、テーブル内の特許要約を対応するエンベディングで更新する必要があります。ただし、この例では、挿入ステートメントに各要約のエンベディングがすでに含まれているため、embeddings() メソッドを呼び出す必要はありません。
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. ベクトル検索を実行する
テーブル、データ、エンベディングの準備が整ったので、ユーザーの検索テキストに対してリアルタイムのベクトル検索を実行しましょう。これをテストするには、次のクエリを実行します。
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
このクエリでは、
- ユーザーが検索したテキストは「Sentiment Analysis」です。
- モデル text-embedding-005 を使用して、embedding() メソッドでエンベディングに変換しています。
- "<=>" は、COSINE SIMILARITY 距離メソッドの使用を表します。
- エンベディング メソッドの結果をベクトル型に変換して、データベースに保存されているベクトルと互換性を持たせています。
- LIMIT 10 は、検索テキストの最も近い一致を 10 個選択することを表します。
AlloyDB は、ベクトル検索 RAG を次のレベルに引き上げます。
多くのことが導入されています。デベロッパー向けの 2 つの機能は次のとおりです。
- インライン フィルタリング
- 再現率の評価ツール
インライン フィルタリング
以前は、デベロッパーがベクトル検索クエリを実行し、フィルタリングと再現率を処理する必要がありました。AlloyDB クエリ オプティマイザーは、フィルタ付きクエリの実行方法を最適化します。インライン フィルタリングは新しいクエリ最適化手法であり、これにより AlloyDB クエリ オプティマイザーは、ベクトル インデックスとメタデータ列のインデックスの両方を活用して、メタデータのフィルタ条件とベクトル検索の両方を同時に評価できます。これにより、再現率のパフォーマンスが向上し、デベロッパーは AlloyDB が提供する機能をすぐに利用できるようになりました。
インライン フィルタリングは、選択性が中程度の場合に最適です。AlloyDB はベクトル インデックスを検索する際に、メタデータのフィルタ条件(通常はクエリの WHERE 句で処理される関数フィルタ)に一致するベクトルの距離のみを計算します。これにより、ポストフィルタやプレフィルタの利点を補完し、クエリのパフォーマンスを大幅に向上させます。
- pgvector 拡張機能をインストールまたは更新する
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
pgvector 拡張機能がすでにインストールされている場合は、ベクトル拡張機能をバージョン 0.8.0.google-3 以降にアップグレードして、再現率評価ツールを利用できるようにします。
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
この手順は、ベクトル拡張機能が 0.8.0.google-3 より前のバージョンである場合にのみ実行する必要があります。
重要な注意事項: 行数が 100 未満の場合は、行数が少ないため ScaNN インデックスを作成する必要はありません。その場合は、以下の手順をスキップしてください。
- ScaNN インデックスを作成するには、alloydb_scann 拡張機能をインストールします。
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- まず、インデックスとインライン フィルタを有効にせずにベクトル検索クエリを実行します。
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
結果は次のようになります。

- (インデックスもインライン フィルタリングもない状態で)Explain Analyze を実行します。

実行時間は 2.4 ミリ秒です
- num_claims フィールドに通常のインデックスを作成して、このフィールドでフィルタできるようにします。
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- 特許検索アプリケーションの ScaNN インデックスを作成しましょう。AlloyDB Studio から次のコマンドを実行します。
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
重要な注意事項: (num_leaves=32) は、1,000 行以上のデータセット全体に適用されます。行数が 100 未満の場合は、インデックスを作成する必要はありません。行数が少ない場合は適用されないためです。
- ScaNN インデックスでインライン フィルタリングを有効にします。
SET scann.enable_inline_filtering = on
- 次に、フィルタとベクトル検索を含む同じクエリを実行します。
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
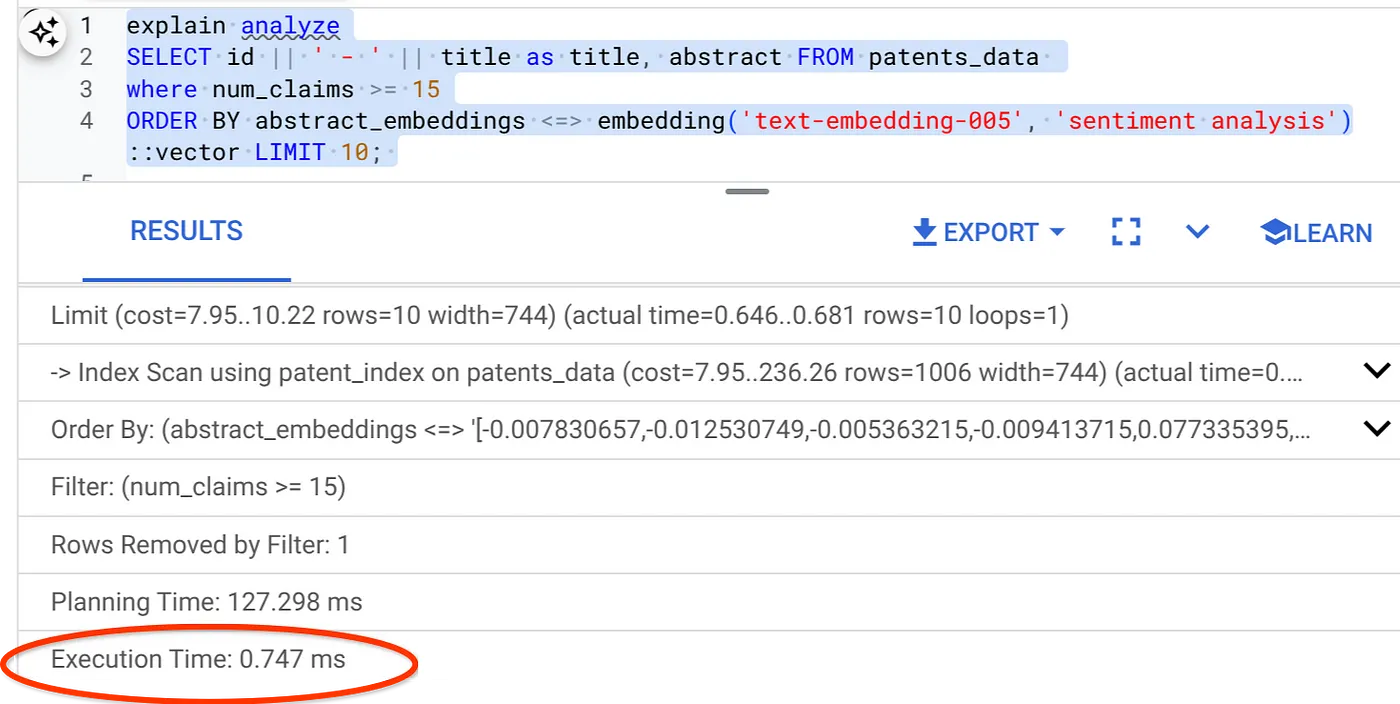
ご覧のとおり、同じベクトル検索の実行時間が大幅に短縮されています。ベクトル検索のインライン フィルタリングが組み込まれた ScaNN インデックスにより、これが可能になりました。
次に、この ScaNN 対応のベクトル検索の再現率を評価します。
再現率の評価ツール
類似検索における再現率とは、検索から取得された該当インスタンスの割合、つまり真陽性の数です。これは、検索品質の測定に使用される最も一般的な指標です。再現率低下の一因は、近似最近傍検索(aNN)と K 最近傍検索(kNN)の違いにあります。AlloyDB の ScaNN などのベクトル インデックスは aNN アルゴリズムを実装しており、再現率のわずかなトレードオフと引き換えに、大規模データセットでのベクトル検索を高速化できます。AlloyDB では、個々のクエリのトレードオフをデータベース内で直接測定し、経時的な安定性を確認できるようになりました。この情報に応じてクエリやインデックスのパラメータを更新すれば、より良い検索結果とパフォーマンスを実現できます。
特定の構成のベクトル インデックスに対するベクトルクエリの再現率は、evaluate_query_recall 関数で確認できます。この関数を使用すると、目的のベクトルクエリの再現率を達成するようにパラメータをチューニングできます。再現率は検索品質に使用される指標で、クエリベクトルに客観的に最も近い結果が返された割合として定義されます。evaluate_query_recall 関数はデフォルトでオンになっています。
注意事項:
次の手順で HNSW インデックスに対する権限拒否エラーが発生した場合は、このリコール評価セクション全体をスキップしてください。この Codelab のドキュメント作成時点ではリリースされたばかりであるため、この時点でアクセス制限が適用されている可能性があります。
- ScaNN インデックスと HNSW インデックスで Enable Index Scan フラグを設定します。
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio で次のクエリを実行します。
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 関数はクエリをパラメータとして受け取り、その再現率を返します。パフォーマンスの確認に使用したクエリを、関数入力クエリとして使用しています。インデックス メソッドとして SCaNN を追加しました。その他のパラメータ オプションについては、ドキュメントをご覧ください。
これまで使用してきたこのベクトル検索クエリの再現率は次のとおりです。

リコール率は 70% です。この情報を使用して、インデックス パラメータ、メソッド、クエリ パラメータを変更し、このベクトル検索の再現率を改善できます。
結果セットの行数を 7(以前は 10)に変更したところ、再現率がわずかに向上し、86% になりました。

つまり、ユーザーの検索コンテキストに応じて、ユーザーに表示される一致の数をリアルタイムで調整し、一致の関連性を高めることができます。
これで大丈夫です。データベース ロジックをデプロイして、エージェントに進みましょう。
7. データベース ロジックをサーバーレスでウェブに移行する
このアプリをウェブに移行する準備はできていますか?手順は次のとおりです。
- Google Cloud コンソールの Cloud Run Functions に移動し、[関数を作成] をクリックして新しい Cloud Run 関数を作成するか、リンク(https://console.cloud.google.com/run/create?deploymentType=function)を使用します。
- [インライン エディタで関数を作成する] オプションを選択して、構成を開始します。サービス名として「patent-search」を指定し、リージョンとして「us-central1」、ランタイムとして「Java 17」を選択します。[認証] を [未認証の呼び出しを許可] に設定します。
- [コンテナ、ボリューム、ネットワーキング、セキュリティ] セクションで、次の手順に沿って詳細を漏らさずに入力します。
[ネットワーキング] タブに移動します。

[アウトバウンド トラフィック用の VPC に接続する] を選択し、[サーバーレス VPC アクセス コネクタを使用する] を選択します。
[ネットワーク] プルダウンで、[ネットワーク] プルダウンをクリックして [新しい VPC コネクタを追加] オプションを選択し(まだデフォルトのコネクタを構成していない場合)、表示されるダイアログ ボックスの手順に沿って操作します。

VPC コネクタの名前を指定し、リージョンがインスタンスと同じであることを確認します。[ネットワーク] の値はデフォルトのままにして、[サブネット] を [カスタム IP 範囲] に設定し、使用可能な IP 範囲(10.8.0.0 など)を指定します。
[SHOW SCALING SETTINGS] を展開し、構成が次のとおりに設定されていることを確認します。

[作成] をクリックすると、このコネクタが下り(外向き)設定に表示されます。
新しく作成したコネクタを選択します。
すべてのトラフィックがこの VPC コネクタ経由でルーティングされるようにします。
[次へ]、[デプロイ] の順にクリックします。
- デフォルトでは、エントリ ポイントは「gcfv2.HelloHttpFunction」に設定されます。Cloud Run functions の HelloHttpFunction.java と pom.xml のプレースホルダ コードを、それぞれ「PatentSearch.java」と「pom.xml」のコードに置き換えます。クラスファイルの名前を PatentSearch.java に変更します。
- Java ファイルで、************ プレースホルダと AlloyDB 接続認証情報を自分の値に変更してください。AlloyDB の認証情報は、この Codelab の開始時に使用したものです。異なる値を使用している場合は、Java ファイルで同じ値を指定してください。
- [デプロイ] をクリックします。
- 更新された Cloud Functions の関数がデプロイされると、エンドポイントが生成されます。コピーして、次のコマンドで置き換えます。
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
これで、AlloyDB データでエンベディング モデルを使用して高度なコンテキスト類似性ベクトル検索を実行するのは、これほど簡単です。
8. Java ADK を使用してエージェントを構築しましょう。
まず、エディタで Java プロジェクトを開始しましょう。
- Cloud Shell ターミナルに移動する
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- プロンプトが表示されたら承認する
- Cloud Shell コンソールの上部にあるエディタ アイコンをクリックして、Cloud Shell エディタに切り替えます。

- Cloud Shell エディタ コンソールのランディング ページで、新しいフォルダを作成して「adk-agents」という名前を付けます。
次の図に示すように、Cloud Shell のルート ディレクトリで [新しいフォルダを作成] をクリックします。

「adk-agents」という名前を付けます。
- 次のフォルダ構造と、対応するファイル名を持つ空のファイルを作成します。
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- 別のタブで GitHub リポジトリを開き、App.java ファイルと pom.xml ファイルのソースコードをコピーします。
- 右上の [新しいタブで開く] アイコンを使用してエディタを新しいタブで開いた場合は、ページの下部にターミナルを開くことができます。エディタとターミナルを並行して開くことができるため、自由に操作できます。
- クローンが完了したら、Cloud Shell エディタ コンソールに戻ります。
- Cloud Run 関数はすでに作成されているため、repo フォルダから Cloud Run 関数ファイルをコピーする必要はありません。
ADK Java SDK スタートガイド
これはかなり簡単です。主に、クローン作成の手順で次の項目がカバーされていることを確認する必要があります。
- 依存関係を追加する:
pom.xml に google-adk と google-adk-dev(ウェブ UI 用)のアーティファクトを含めます。リポジトリからソースをコピーした場合、これらはすでにファイルに含まれているため、含める必要はありません。デプロイされたエンドポイントを反映するように、Cloud Run functions のエンドポイントを変更するだけです。このセクションの次の手順で説明します。
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
アプリケーションを実行するために必要な他の依存関係と構成があるため、移行元リポジトリの pom.xml を参照してください。
- プロジェクトを構成する:
pom.xml で Java バージョン(17 以降を推奨)と Maven コンパイラ設定が正しく構成されていることを確認します。プロジェクトを次の構造になるように構成できます。
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- エージェントとそのツールを定義する(App.java):
ここで ADK Java SDK の真価が発揮されます。エージェント、その機能(指示)、使用できるツールを定義します。
メイン エージェント クラスのコード スニペットの簡略版を以下に示します。プロジェクト全体については、こちらのプロジェクト リポジトリをご覧ください。
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
ADK Java コードの主なコンポーネント:
- LlmAgent.builder(): エージェントを構成するための Fluent API。
- .instruction(...): どのツールをいつ使用するかなど、LLM のコア プロンプトとガイドラインを提供します。
- FunctionTool.create(App.class, "methodName"): エージェントが呼び出すことができるツールとして、Java メソッドを簡単に登録できます。メソッド名文字列は、実際のパブリック静的メソッドと一致している必要があります。
- @Schema(description = ...): ツール パラメータにアノテーションを付け、LLM が各ツールで想定される入力を理解できるようにします。この説明は、ツールを正確に選択し、パラメータを入力するうえで重要です。
- InvocationContext ctx: ツールメソッドに自動的に渡され、セッション状態(ctx.session().state())、ユーザー情報などにアクセスできます。
- .outputKey("patents"): ツールがデータを返すと、ADK はこのキーの下のセッション状態にデータを自動的に保存できます。explainPatent が getPatents の結果にアクセスする方法は次のとおりです。
- VECTOR_SEARCH_ENDPOINT: 特許検索のユースケースで、ユーザーのコンテキスト Q&A のコア機能ロジックを保持する変数です。
- ここでのアクション アイテム: 前のセクションの Java Cloud Run 関数ステップを実装したら、更新されたデプロイ済みエンドポイント値を設定する必要があります。
- searchTool: ユーザーの検索テキストについて、特許データベースからコンテキストに関連する特許を検索するためにユーザーとやり取りします。
- explainTool: ユーザーに、詳しく調べる特定の特許を尋ねます。次に、特許の要約を作成し、特許の詳細に基づいてユーザーからの質問に回答します。
重要な注意事項: VECTOR_SEARCH_ENDPOINT 変数は、デプロイした CRF エンドポイントに置き換えてください。
ステートフル インタラクションに InvocationContext を活用する
有用なエージェントを構築するための重要な機能の 1 つは、会話の複数のターンにわたる状態の管理です。ADK の InvocationContext を使用すると、この処理が簡単になります。
App.java の場合:
- initAgent() が定義されている場合は、.outputKey("patents") を使用します。これは、ツール(getPatents など)がレポート フィールドでデータを返すときに、そのデータをキー「patents」でセッション状態に保存するように ADK に指示します。
- explainPatent ツールメソッドでは、InvocationContext ctx を挿入します。
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
これにより、explainPatent ツールは前のターンで getPatents ツールによって取得された特許リストにアクセスできるようになり、会話がステートフルで一貫性のあるものになります。
9. ローカル CLI テスト
環境変数を定義する
次の 2 つの環境変数をエクスポートする必要があります。
- AI Studio から取得できる Gemini キー:
これを行うには、https://aistudio.google.com/apikey にアクセスし、このアプリケーションを実装するアクティブな Google Cloud プロジェクトの API キーを取得して、キーをどこかに保存します。

- キーを取得したら、Cloud Shell ターミナルを開き、次のコマンドを実行して、作成したばかりの新しいディレクトリ adk-agents に移動します。
cd adk-agents
- 今回は Vertex AI を使用しないことを指定する変数。
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- CLI で初めてのエージェントを実行する
この最初のエージェントを起動するには、ターミナルで次の Maven コマンドを使用します。
mvn compile exec:java -DmainClass="agents.App"
ターミナルにエージェントからのインタラクティブなレスポンスが表示されます。
10. Cloud Run へのデプロイ
ADK Java エージェントを Cloud Run にデプロイする方法は、他の Java アプリケーションをデプロイする方法と似ています。
- Dockerfile: Java アプリケーションをパッケージ化する Dockerfile を作成します。
- Docker イメージのビルドと push: Google Cloud Build と Artifact Registry を使用します。
- 上記のステップを実行して Cloud Run にデプロイするには、次の 1 つのコマンドを実行します。
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
同様に、Java Cloud Run 関数(gcfv2.PatentSearch)をデプロイします。または、Cloud Run functions コンソールからデータベース ロジック用の Java Cloud Run functions を直接作成してデプロイすることもできます。
11. ウェブ UI でテストする
ADK には、エージェントのローカル テストとデバッグに便利なウェブ UI が付属しています。App.java をローカルで実行すると(構成されている場合は mvn exec:java -Dexec.mainClass="agents.App"、または単に main メソッドを実行)、通常、ADK はローカル ウェブサーバーを起動します。
ADK ウェブ UI では、次のことができます。
- エージェントにメッセージを送信します。
- イベント(ユーザー メッセージ、ツール呼び出し、ツール レスポンス、LLM レスポンス)を確認します。
- セッションの状態を検査します。
- ログとトレースを表示します。
これは、エージェントがリクエストを処理してツールを使用する方法を把握するうえで、開発中に非常に役立ちます。これは、pom.xml の mainClass が com.google.adk.web.AdkWebServer に設定され、エージェントがそれに登録されているか、これを公開するローカル テスト ランナーを実行していることを前提としています。
InMemoryRunner とコンソール入力用の Scanner を使用して App.java を実行すると、コア エージェントのロジックをテストすることになります。ウェブ UI は、より視覚的なデバッグ エクスペリエンスを実現するための独立したコンポーネントです。ADK が HTTP 経由でエージェントを提供している場合によく使用されます。
ルート ディレクトリから次の Maven コマンドを使用して、SpringBoot ローカル サーバーを起動できます。
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
このインターフェースには、上記のコマンドが出力する URL でアクセスできることがよくあります。Cloud Run deployed の場合は、Cloud Run deployed リンクからアクセスできます。
インタラクティブ インターフェースで結果を確認できます。
以下に、デプロイされた特許弁理士の動画をご紹介します。
AlloyDB インライン検索と再現率評価による品質管理された特許弁理士のデモ

12. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。
- Google Cloud コンソールで、https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog に移動します。
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog ページ。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
13. 完了
これで、ADK、https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog、Vertex AI、ベクトル検索の機能を組み合わせて、Java で特許分析エージェントを構築しました。また、コンテキスト類似性検索を革新的なものにし、効率を高め、真に意味のあるものにするという大きな進歩を遂げました。
ぜひご登録ください
ADK ドキュメント: [公式 ADK Java ドキュメントへのリンク]
特許分析エージェントのソースコード: [(公開された)GitHub リポジトリへのリンク]
Java サンプル エージェント: [adk-samples リポジトリへのリンク]
ADK コミュニティに参加する: https://www.reddit.com/r/agentdevelopmentkit/
エージェントの構築をお楽しみください。