
1. 概览
在不同行业中,情境搜索是一项关键功能,是其应用的核心和中心。检索增强生成 (RAG) 凭借其由生成式 AI 提供支持的检索机制,长期以来一直是推动这项关键技术演进的主要因素。生成式模型具有大上下文窗口和出色的输出质量,正在改变 AI 领域。RAG 提供了一种系统性的方法,可将上下文注入 AI 应用和代理中,从而使它们能够基于结构化数据库或各种媒体中的信息。这些上下文数据对于清晰地呈现事实和提高输出的准确性至关重要,但这些结果的准确性如何呢?您的业务是否在很大程度上依赖于这些情境匹配和相关性的准确性?那么这个项目一定会让您心动!
现在,不妨想象一下,如果我们能利用生成模型的强大功能,构建出能够根据此类至关重要的背景信息做出自主决策并以事实为依据的交互式智能体,会怎么样?这正是我们今天要构建的。我们将使用智能体开发套件构建一个端到端 AI 智能体应用,该应用由 AlloyDB 中的高级 RAG 提供支持,用于专利分析应用。
专利分析代理可帮助用户查找与其搜索文本在情境上相关的专利,并在用户提出要求时,针对所选专利提供清晰简洁的说明和所需的其他详细信息。准备好了解具体操作方法了吗?下面我们就来深入探讨一下。
目标
目标很简单。允许用户根据文本说明搜索专利,然后从搜索结果中获取特定专利的详细说明,所有这些操作都通过使用 Java ADK、AlloyDB、向量搜索(使用高级索引)、Gemini 构建的 AI 智能体完成,并且整个应用以无服务器方式部署在 Cloud Run 上。
构建内容
在本实验中,您将:
- 创建 AlloyDB 实例并加载“专利公开数据集”数据
- 使用 ScaNN 和召回率评估功能在 AlloyDB 中实现高级向量搜索
- 使用 Java ADK 创建代理
- 在 Java 无服务器 Cloud Functions 中实现数据库服务器端逻辑
- 在 Cloud Run 中部署和测试代理
下图展示了实现过程中涉及的数据流和步骤。
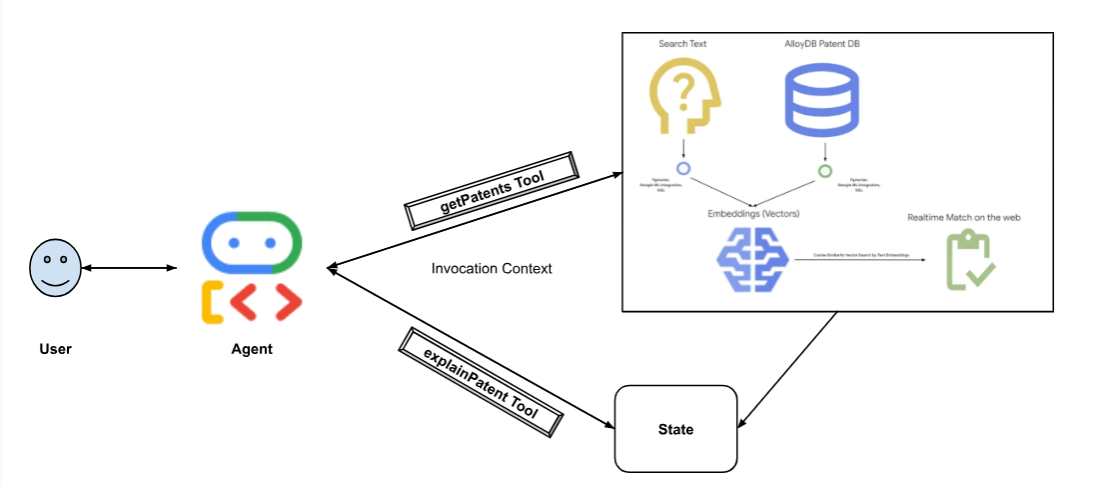
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
要求
2. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 启用所需的 API。 您可以在 Cloud Shell 终端中使用 gcloud 命令:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
除了使用 gcloud 命令,您还可以通过控制台搜索每个产品或使用此链接。
如需了解 gcloud 命令和用法,请参阅文档。
3. 数据库设置
在本实验中,我们将使用 AlloyDB 作为专利数据的数据库。它使用集群来保存所有资源,例如数据库和日志。每个集群都有一个主实例,可提供对数据的接入点。表将包含实际数据。
接下来,我们来创建 AlloyDB 集群、实例和表,以便加载专利数据集。
创建集群和实例
- 在 Cloud 控制台中浏览 AlloyDB 页面。在 Cloud 控制台中查找大多数页面的简单方法是使用控制台的搜索栏进行搜索。
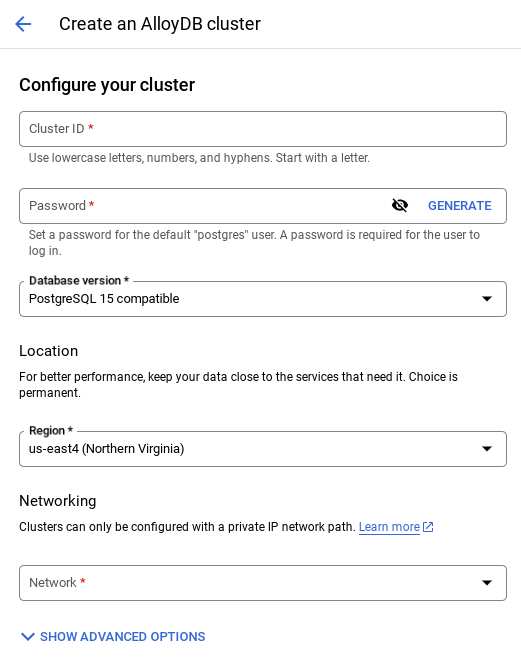
- 在该页面中选择创建集群:

- 您会看到如下所示的界面。使用以下值创建 集群和实例(如果您要从代码库克隆应用代码,请确保这些值匹配):
- 集群 ID:“
vector-cluster” - 密码:“
alloydb” - PostgreSQL 15 / 最新推荐版本
- 区域:“
us-central1” - 网络:“
default”
- 选择默认网络后,您会看到如下所示的界面。
选择设置连接。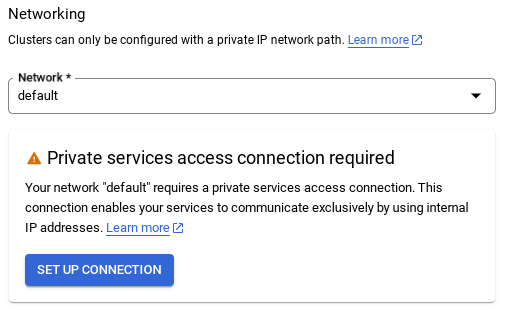
- 然后,选择“使用自动分配的 IP 范围”,然后点击“继续”。查看信息后,选择“创建连接”。
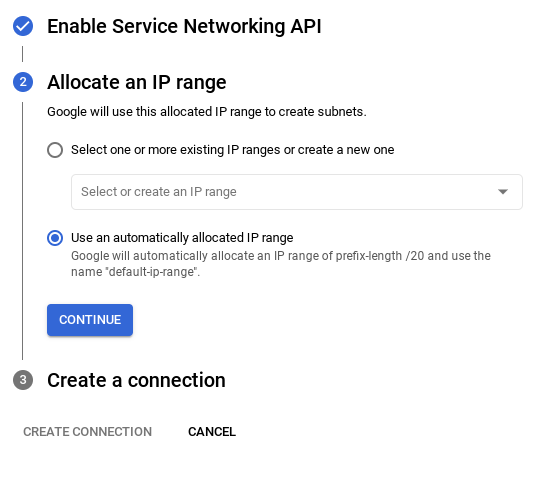
- 设置好网络后,您可以继续创建集群。点击创建集群以完成集群设置,如下所示:
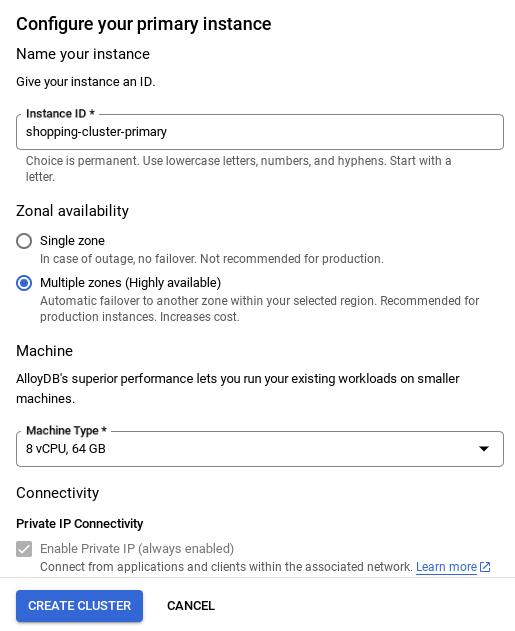
请务必将实例 ID(可在配置集群 / 实例时找到)更改为
vector-instance。如果您无法更改,请务必在所有后续引用中使用您的实例 ID。
请注意,创建集群大约需要 10 分钟。成功后,您应该会看到一个屏幕,其中显示了您刚刚创建的集群的概览。
4. 数据注入
现在,我们来添加一个包含商店相关数据的表格。前往 AlloyDB,选择主集群,然后选择 AlloyDB Studio:
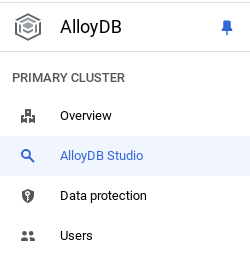
您可能需要等待实例完成创建。完成后,使用您在创建集群时创建的凭据登录 AlloyDB。使用以下数据向 PostgreSQL 进行身份验证:
- 用户名:“
postgres” - 数据库:“
postgres” - 密码:“
alloydb”
成功通过身份验证进入 AlloyDB Studio 后,您可以在编辑器中输入 SQL 命令。您可以使用最后一个窗口右侧的加号添加多个编辑器窗口。
您将在编辑器窗口中输入 AlloyDB 命令,并根据需要使用“运行”“格式”和“清除”选项。
启用扩展程序
在构建此应用时,我们将使用扩展程序 pgvector 和 google_ml_integration。借助 pgvector 扩展程序,您可以存储和搜索向量嵌入。google_ml_integration 扩展程序提供用于访问 Vertex AI 预测端点以在 SQL 中获取预测结果的函数。运行以下 DDL 以启用这些扩展程序:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
如果您想查看数据库上已启用的扩展程序,请运行以下 SQL 命令:
select extname, extversion from pg_extension;
创建表
您可以在 AlloyDB Studio 中使用以下 DDL 语句创建表:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings 列将用于存储文本的向量值。
授予权限
运行以下语句,以授予对“embedding”函数的执行权限:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
为 AlloyDB 服务账号授予 Vertex AI User 角色
在 Google Cloud IAM 控制台中,向 AlloyDB 服务账号(格式如下:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)授予“Vertex AI 用户”角色访问权限。PROJECT_NUMBER 将包含您的项目编号。
或者,您也可以从 Cloud Shell 终端运行以下命令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
将专利数据加载到数据库中
我们将使用 BigQuery 上的 Google 专利公共数据集作为我们的数据集。我们将使用 AlloyDB Studio 运行查询。数据源位于此 repo 中的 insert scripts sql 文件中,我们将运行此文件来加载专利数据。
- 在 Google Cloud 控制台中,打开 AlloyDB 页面。
- 选择新创建的集群,然后点击相应实例。
- 在 AlloyDB 导航菜单中,点击 AlloyDB Studio。使用凭据登录。
- 点击右侧的新标签页图标,打开新标签页。
- 复制并运行
insert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sql文件中的insert查询语句。您可以运行 10-50 个复制插入语句,快速演示此使用情形。
如需运行,请点击运行。查询结果会显示在结果表中。
5. 为专利数据创建嵌入
首先,我们运行以下示例查询来测试嵌入函数:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
这应该会返回查询中示例文本的嵌入向量(看起来像一个浮点数数组)。如下所示:
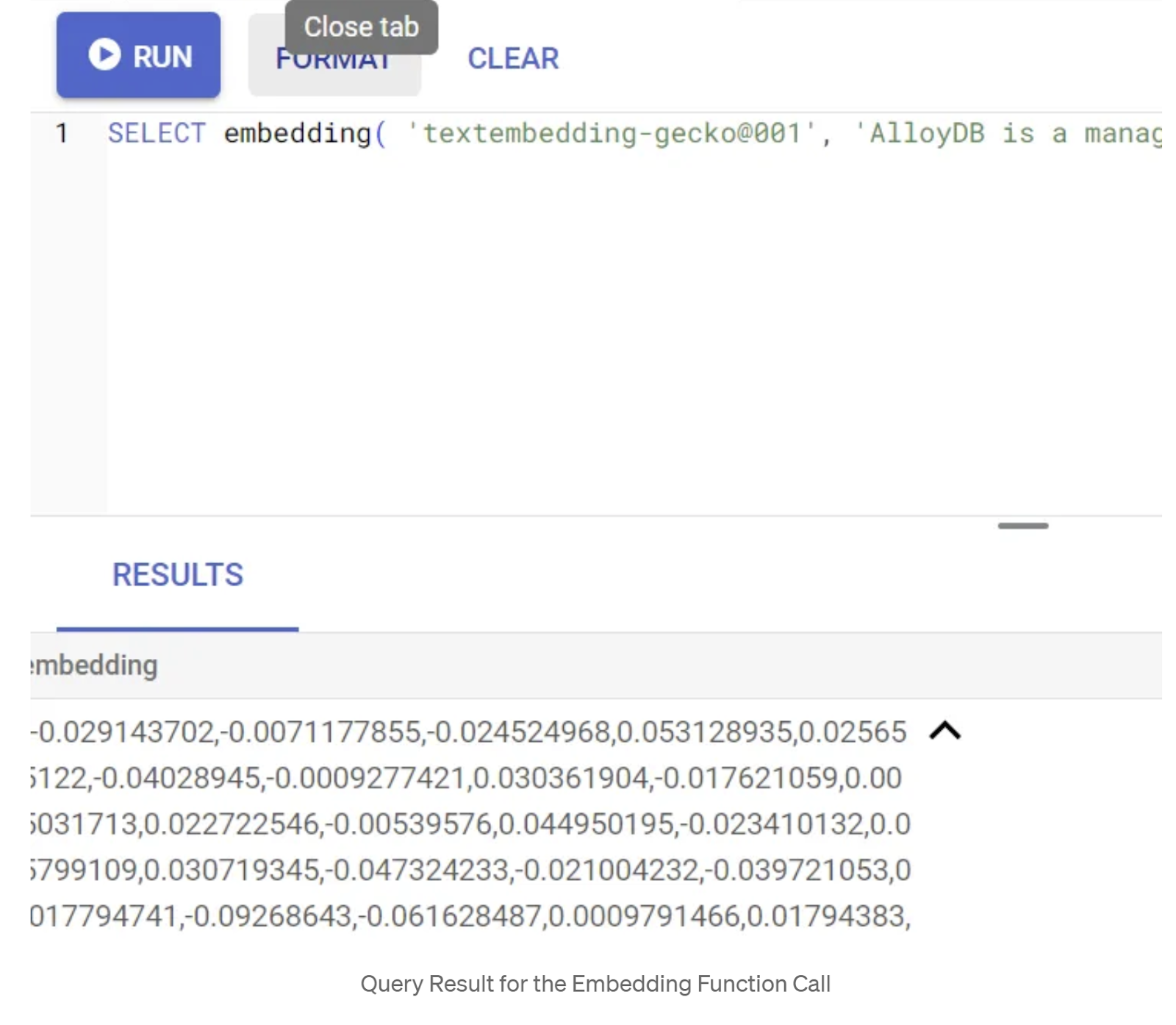
更新 abstract_embeddings 向量字段
如果需要为摘要生成嵌入内容,应使用以下 DML 更新表中的专利摘要,使其包含相应的嵌入内容。但在我们的示例中,插入语句已包含每个摘要的这些嵌入内容,因此您无需调用 embeddings() 方法。
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. 执行向量搜索
现在,表、数据和嵌入都已准备就绪,接下来我们来针对用户搜索文本执行实时向量搜索。您可以通过运行以下查询来测试这一点:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
在此查询中,
- 用户搜索的文本为:“情感分析”。
- 我们正在使用模型 text-embedding-005 在 embedding() 方法中将其转换为嵌入。
- “<=>”表示使用余弦相似度距离方法。
- 我们将嵌入方法的结果转换为向量类型,以使其与存储在数据库中的向量兼容。
- LIMIT 10 表示我们选择的是与搜索文本最接近的 10 个匹配项。
AlloyDB 将向量搜索 RAG 提升到了新的高度:
我们推出了许多新功能。其中两个以开发者为中心:
- 内嵌过滤
- 召回率评估器
内嵌过滤
以前,作为开发者,您必须执行 Vector Search 查询,并处理过滤和召回率问题。AlloyDB 查询优化器会选择如何执行带有过滤条件的查询。内嵌过滤是一种新的查询优化技术,可让 AlloyDB 查询优化器同时评估元数据过滤条件和向量搜索,并利用向量索引和元数据列上的索引。这提高了召回率性能,使开发者能够充分利用 AlloyDB 的开箱即用功能。
内嵌过滤最适合中等选择性的情况。当 AlloyDB 搜索向量索引时,只会计算符合元数据过滤条件(查询中通常在 WHERE 子句中处理的功能性过滤条件)的向量的距离。这可大幅提升这些查询的性能,从而弥补后过滤或预过滤的优势。
- 安装或更新 pgvector 扩展程序
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
如果 pgvector 扩展程序已安装,请将向量扩展程序升级到 0.8.0.google-3 或更高版本,以获取召回率评估器功能。
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
只有当您的矢量扩展程序低于 0.8.0.google-3 时,才需要执行此步骤。
重要提示:如果您的行数少于 100,则无需创建 ScaNN 索引,因为该索引不适用于行数较少的情况。在这种情况下,请跳过以下步骤。
- 如需创建 ScaNN 索引,请安装 alloydb_scann 扩展程序。
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- 首先,在不使用索引且未启用内嵌过滤器的前提下运行 Vector Search 查询:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
结果应如下所示:
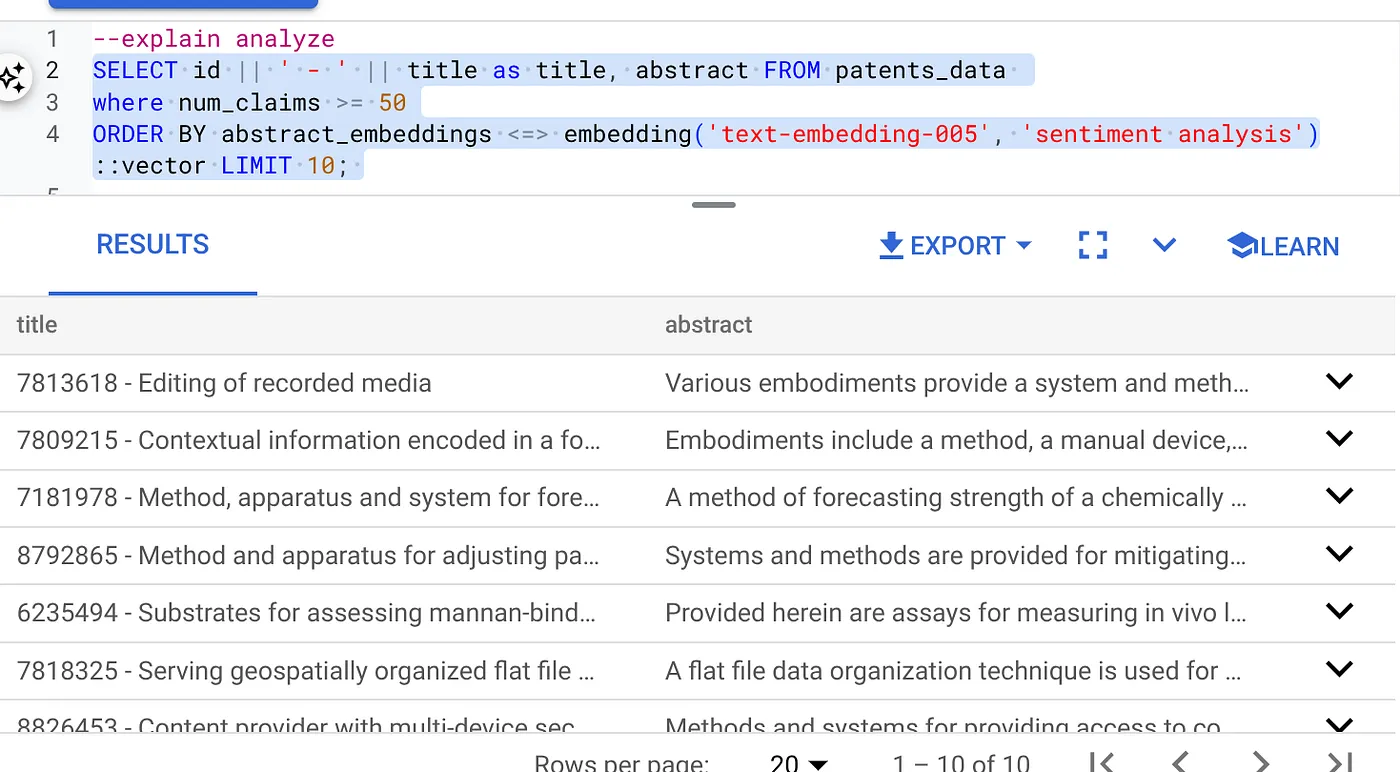
- 对其运行 Explain Analyze:(不使用索引和内嵌过滤)
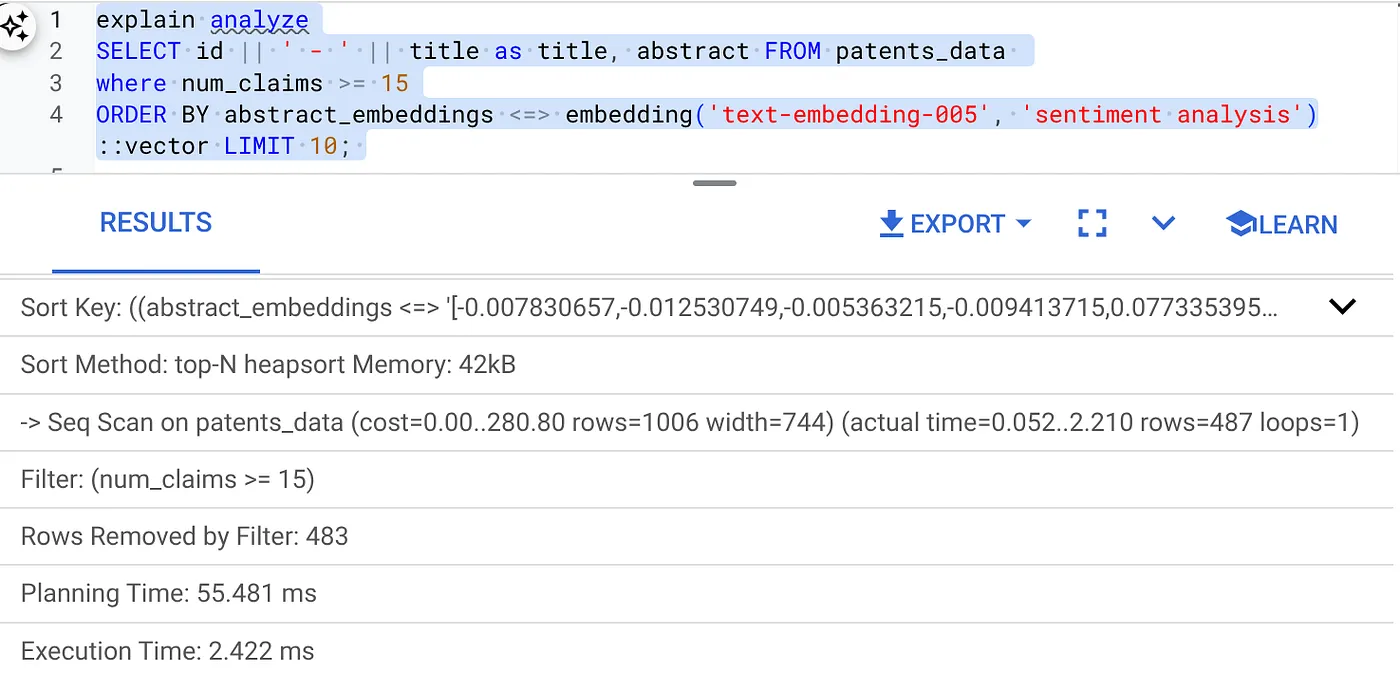
执行时间为 2.4 毫秒
- 让我们在 num_claims 字段上创建一个常规索引,以便按该字段进行过滤:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- 让我们为专利搜索应用创建 ScaNN 索引。在 AlloyDB Studio 中运行以下命令:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
重要提示: (num_leaves=32) 适用于包含 1000 行以上的完整数据集。如果您的行数少于 100,则无需创建索引,因为索引不适用于行数较少的情况。
- 设置在 ScaNN 索引上启用的内嵌过滤:
SET scann.enable_inline_filtering = on
- 现在,我们来运行同一查询,但其中包含过滤条件和 Vector Search:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
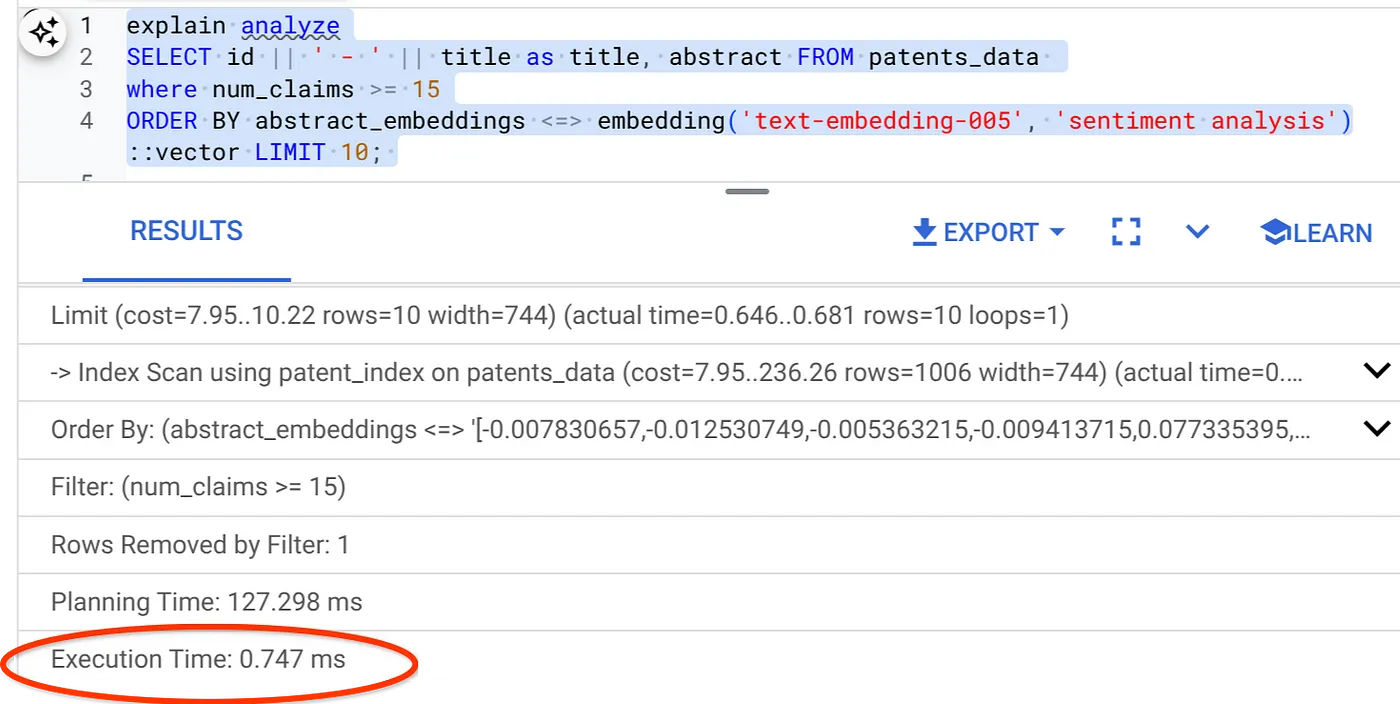
如您所见,对于相同的向量搜索,执行时间显著缩短。Vector Search 中融入了内嵌过滤功能的 ScaNN 索引实现了这一点!
接下来,我们来评估启用 ScaNN 的向量搜索的召回率。
召回率评估器
相似度搜索中的召回率是指从搜索中检索到的相关实例的百分比,即真正例数。这是衡量搜索质量最常用的指标。召回率损失的一个来源是近似最近邻搜索 (aNN) 与 k(精确)近邻搜索 (kNN) 之间的差异。AlloyDB 的 ScaNN 等向量索引实现了 aNN 算法,让您能够加快对大型数据集的向量搜索速度,但召回率会略有下降。现在,AlloyDB 可让您直接在数据库中针对各个查询衡量这种权衡,并确保其随时间推移保持稳定。您可以根据这些信息更新查询和索引参数,以获得更好的结果和性能。
您可以使用 evaluate_query_recall 函数获得采用给定配置时,对向量索引进行的向量查询的召回率。借助此函数,您可以对参数进行调优以实现所需的向量查询召回率结果。召回率是一种用于衡量搜索质量的指标,定义为返回结果中与查询向量客观上最接近的结果所占的百分比。默认情况下,evaluate_query_recall 函数处于开启状态。
重要提示:
如果您在以下步骤中遇到 HNSW 索引的权限被拒错误,请暂时跳过整个召回率评估部分。这可能与当前阶段的访问权限限制有关,因为此功能是在编写此 Codelab 文档时刚刚发布。
- 在 ScaNN 索引和 HNSW 索引上设置“启用索引扫描”标志:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- 在 AlloyDB Studio 中运行以下查询:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 函数会将查询作为参数并返回其召回率。我将用于检查性能的查询用作函数输入查询。我已添加 SCaNN 作为索引方法。如需了解更多参数选项,请参阅文档。
我们一直在使用的 Vector Search 查询的召回率:
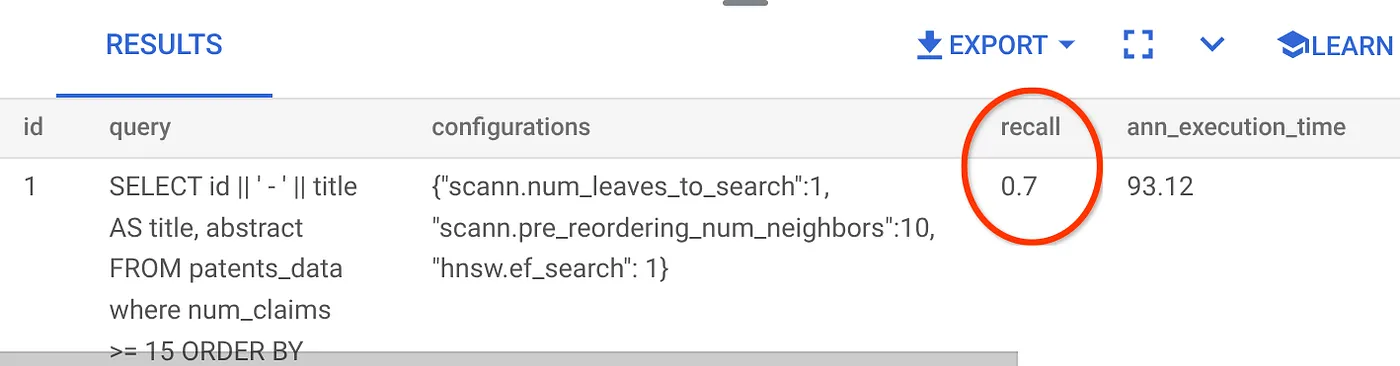
我看到召回率为 70%。现在,我可以利用这些信息来更改索引参数、方法和查询参数,从而提高向量搜索的召回率!
我已将结果集中的行数从之前的 10 行修改为 7 行,发现召回率略有提高,即 86%。
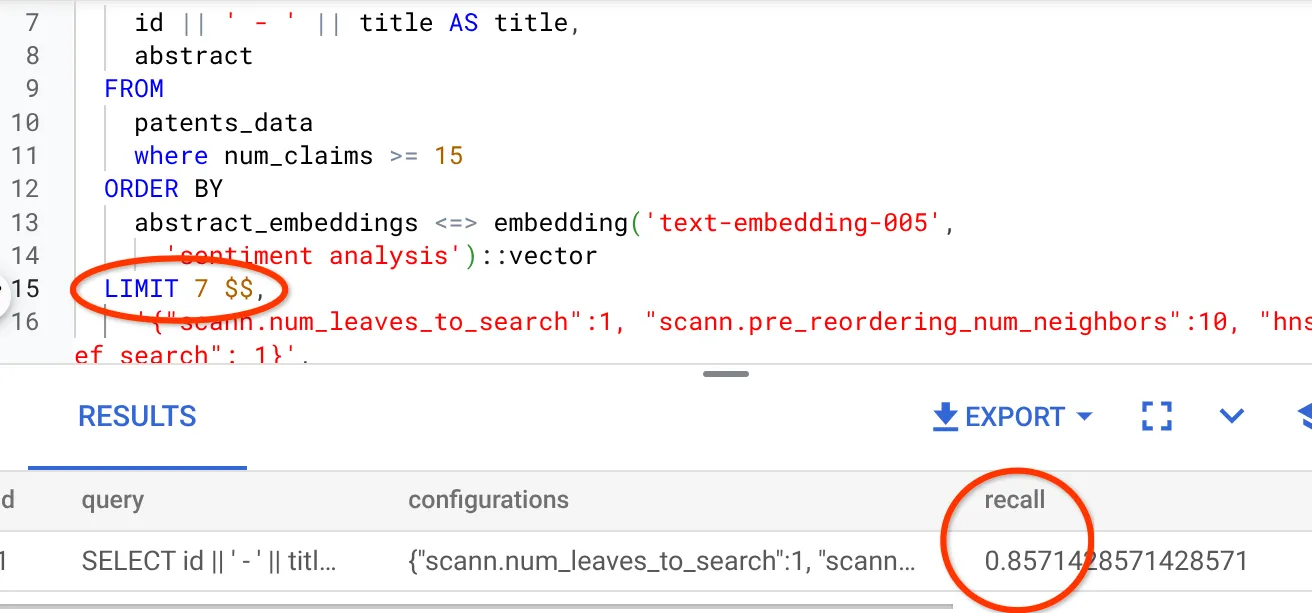
这意味着,我可以根据用户的搜索情境实时调整用户看到的匹配项数量,以提高匹配项的相关性。
现在可以了!现在,该部署数据库逻辑并继续开发代理了!
7. 以无服务器方式将数据库逻辑迁移到 Web 服务器
准备好将此应用迁移到 Web 上了吗?请按以下步骤操作:
- 前往 Google Cloud 控制台中的 Cloud Run Functions,然后点击“编写函数”以创建新的 Cloud Run 函数,或者使用以下链接:https://console.cloud.google.com/run/create?deploymentType=function。
- 选择“使用内嵌编辑器创建函数”选项,然后开始配置。提供服务名称“patent-search”,选择区域“us-central1”和运行时“Java 17”。将“身份验证”设置为“允许未经身份验证的调用”。
- 在“容器、卷、网络、安全性”部分中,按照以下步骤操作,不要遗漏任何细节:
前往“网络”标签页:
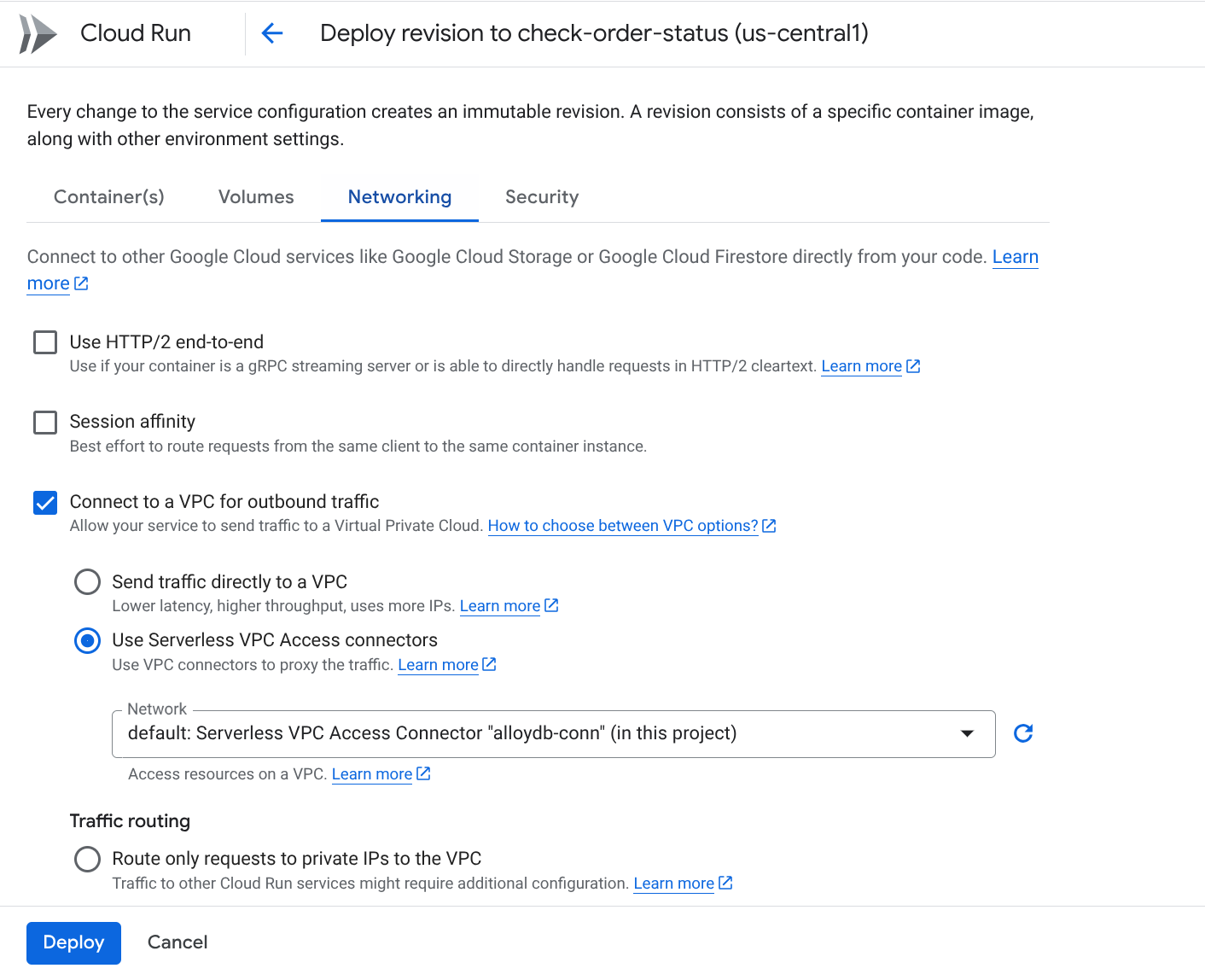
选择“连接到 VPC 以获取出站流量”,然后选择“使用无服务器 VPC 访问通道连接器”
在“网络”下拉菜单下,点击“网络”下拉菜单,然后选择“添加新的 VPC 连接器”选项(如果您尚未配置默认连接器),并按照随即显示的对话框中的说明操作:
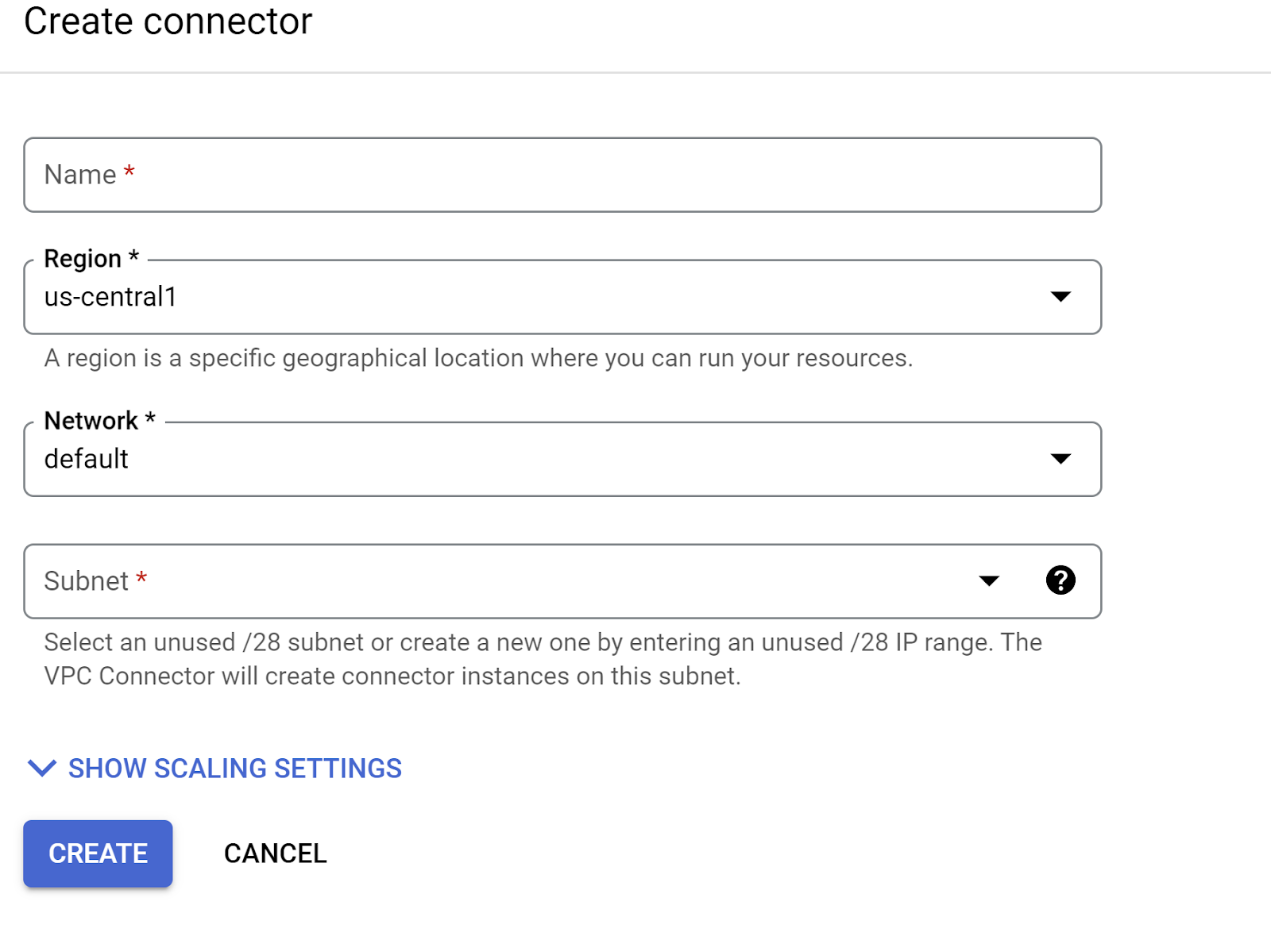
为 VPC 连接器提供一个名称,并确保该区域与您的实例相同。将“网络”值保留为默认值,并将“子网”设置为“自定义 IP 范围”,IP 范围为 10.8.0.0 或类似的可用范围。
展开“显示缩放设置”,并确保您的配置完全符合以下要求:
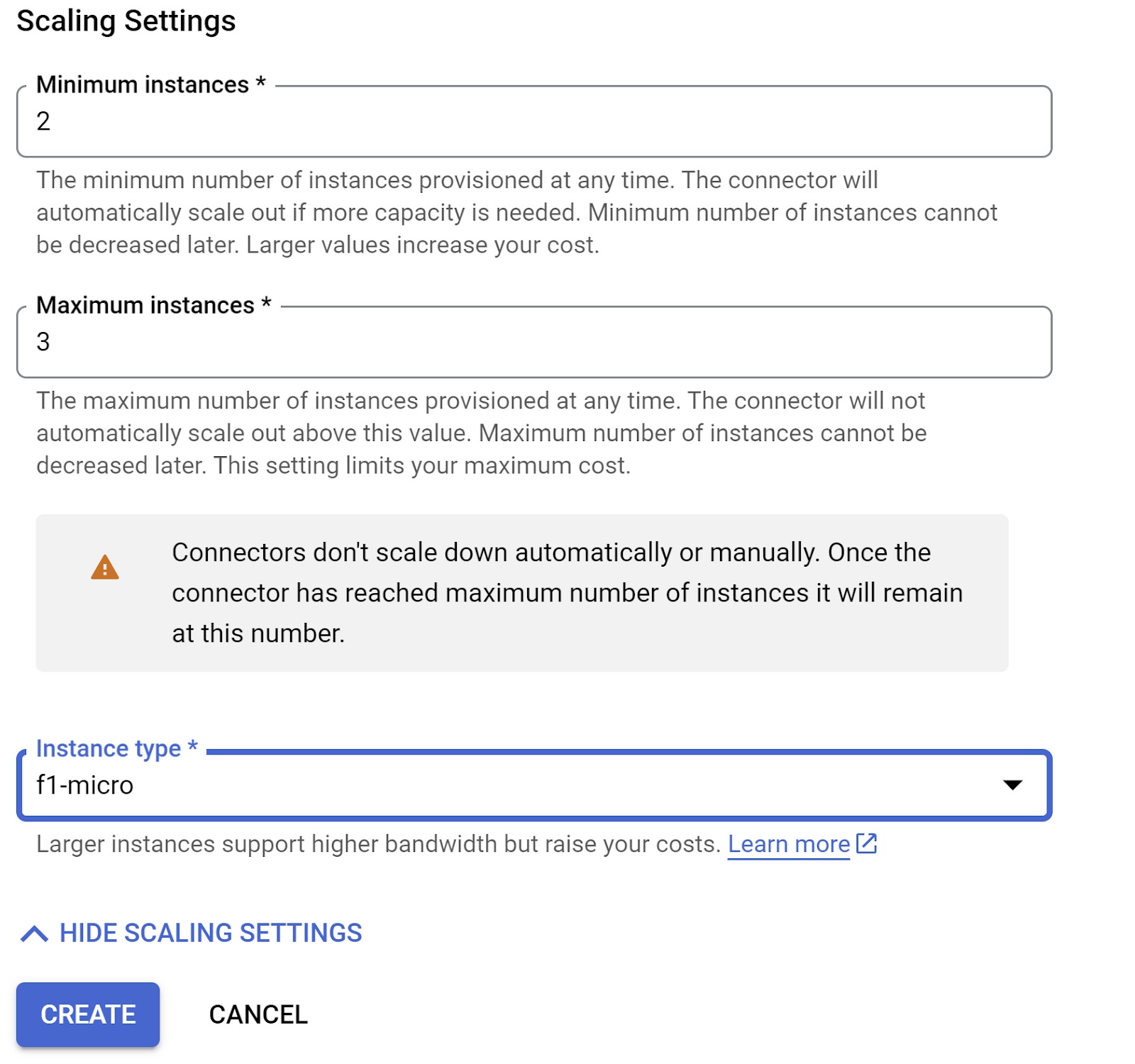
点击 CREATE,此连接器现在应会列在出站流量设置中。
选择新创建的连接器。
选择通过此 VPC 连接器路由所有流量。
点击下一步,然后点击部署。
- 默认情况下,它会将入口点设置为“gcfv2.HelloHttpFunction”。将 Cloud Run 函数的 HelloHttpFunction.java 和 pom.xml 中的占位符代码分别替换为“PatentSearch.java”和“pom.xml”中的代码。将类文件的名称更改为 PatentSearch.java。
- 请务必将 Java 文件中的 ************* 占位符和 AlloyDB 连接凭据替换为您的值。AlloyDB 凭据是我们在本 Codelab 开始时使用的凭据。如果您使用了不同的值,请在 Java 文件中进行修改。
- 点击部署。
- 部署更新后的 Cloud Functions 函数后,您应该会看到生成的端点。复制该内容并替换以下命令中的相应部分:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
大功告成!使用 AlloyDB 数据上的嵌入模型执行高级情境相似度向量搜索就是这么简单。
8. 让我们使用 Java ADK 构建智能体
首先,我们从编辑器中的 Java 项目开始。
- 前往 Cloud Shell 终端
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- 在系统提示时进行授权
- 点击 Cloud Shell 控制台顶部的编辑器图标,切换到 Cloud Shell 编辑器

- 在着陆 Cloud Shell 编辑器控制台中,创建一个名为“adk-agents”的新文件夹
点击 Cloud Shell 根目录中的“创建新文件夹”,如下所示:
将其命名为“adk-agents”:
- 创建以下文件夹结构,并在该结构中创建具有相应文件名的空文件:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- 在单独的标签页中打开 GitHub 代码库,然后复制文件 App.java 和 pom.xml 的源代码。
- 如果您之前使用右上角的“在新标签页中打开”图标在新标签页中打开了编辑器,则可以在页面底部打开终端。您可以同时打开编辑器和终端,以便自由操作。
- 克隆完成后,切换回 Cloud Shell 编辑器控制台
- 由于我们已创建 Cloud Run 函数,因此您无需复制 repo 文件夹中的 Cloud Run 函数文件。
ADK Java SDK 使用入门
这相当简单。您主要需要确保克隆步骤涵盖以下内容:
- 添加依赖项:
在 pom.xml 中添加 google-adk 和 google-adk-dev(适用于 Web 界面)制品。如果您从代码库复制了源代码,则这些依赖项已包含在文件中,您无需再添加它们。您只需更改 Cloud Run 函数端点,以反映已部署的端点。本部分接下来的步骤将介绍如何执行此操作。
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
请务必引用源代码库中的 pom.xml,因为应用需要其他依赖项和配置才能运行。
- 配置项目:
确保您的 Java 版本(建议使用 17 及更高版本)和 Maven 编译器设置已在 pom.xml 中正确配置。您可以将项目配置为遵循以下结构:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- 定义代理及其工具 (App.java):
ADK Java SDK 的神奇之处就在于此。我们定义了智能体、其功能(指令)以及它可以使用的工具。
点击此处可查看主要代理类的一些简化版代码段。如需查看完整项目,请点击此处参阅项目代码库。
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
突出显示了关键的 ADK Java 代码组件:
- LlmAgent.builder()::用于配置代理的流畅 API。
- .instruction(...): 为 LLM 提供核心提示和指南,包括何时使用哪种工具。
- FunctionTool.create(App.class, "methodName"):可轻松将 Java 方法注册为代理可调用的工具。方法名称字符串必须与实际的公开静态方法匹配。
- @Schema(description = ...): 注释工具参数,帮助 LLM 了解每个工具所需的输入内容。此说明对于准确选择工具和填充参数至关重要。
- InvocationContext ctx:自动传递给工具方法,用于访问会话状态 (ctx.session().state())、用户信息等。
- .outputKey("patents"): 当工具返回数据时,ADK 可以自动将其存储在此键下的会话状态中。这就是 explainPatent 如何访问 getPatents 的结果。
- VECTOR_SEARCH_ENDPOINT::此变量包含专利搜索用例中用户的内容相关问答的核心功能逻辑。
- 此处的操作项:在实现上一部分中的 Java Cloud Run 函数步骤后,您需要设置更新后的已部署端点值。
- searchTool:此工具会与用户互动,从专利数据库中查找与用户搜索文本相关的专利匹配项。
- explainTool:此工具会要求用户提供要深入分析的特定专利。然后,它会总结专利摘要,并能够根据其掌握的专利详细信息回答用户的更多问题。
重要提示:请务必将 VECTOR_SEARCH_ENDPOINT 变量替换为您部署的 CRF 端点。
利用 InvocationContext 实现有状态的互动
构建实用智能体的一项关键功能是管理对话的多个轮次之间的状态。ADK 的 InvocationContext 可让此过程变得简单明了。
在我们的 App.java 中:
- 定义 initAgent() 时,我们使用 .outputKey("patents")。这会告知 ADK,当某个工具(例如 getPatents)在其报告字段中返回数据时,该数据应存储在键为“patents”的会话状态下。
- 在 explainPatent 工具方法中,我们注入了 InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
这样一来,explainPatent 工具便可以访问 getPatents 工具在上一轮中提取的专利列表,从而使对话具有状态并保持连贯性。
9. 本地 CLI 测试
定义环境变量
您需要导出两个环境变量:
- 您可以从 AI Studio 获取的 Gemini 密钥:
为此,请前往 https://aistudio.google.com/apikey,获取您正在实现此应用的有效 Google Cloud 项目的 API 密钥,并将该密钥保存在某个位置:
- 获取密钥后,打开 Cloud Shell 终端,然后运行以下命令,移动到我们刚刚创建的新目录 adk-agents:
cd adk-agents
- 一个变量,用于指定我们这次不使用 Vertex AI。
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- 在 CLI 上运行您的首个代理
如需启动此第一个代理,请在终端中使用以下 Maven 命令:
mvn compile exec:java -DmainClass="agents.App"
您会在终端中看到智能体的互动式回答。
10. 部署到 Cloud Run
将 ADK Java 代理部署到 Cloud Run 与部署任何其他 Java 应用类似:
- Dockerfile:创建 Dockerfile 以打包 Java 应用。
- 构建并推送 Docker 映像:使用 Google Cloud Build 和 Artifact Registry。
- 您只需一条命令即可执行上述步骤并部署到 Cloud Run:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
同样,您需要部署 Java Cloud Run 函数 (gcfv2.PatentSearch)。或者,您也可以直接从 Cloud Run Function 控制台创建和部署用于数据库逻辑的 Java Cloud Run Function。
11. 使用 Web 界面进行测试
ADK 附带一个便捷的 Web 界面,可用于在本地测试和调试智能体。当您在本地运行 App.java 时(例如,如果已配置,则运行 mvn exec:java -Dexec.mainClass="agents.App",或者只是运行 main 方法),ADK 通常会启动本地 Web 服务器。
借助 ADK 网页界面,您可以:
- 向代理发送消息。
- 查看事件(用户消息、工具调用、工具响应、LLM 响应)。
- 检查会话状态。
- 查看日志和轨迹。
在开发过程中,这对于了解代理如何处理请求和使用工具非常有价值。这假设 pom.xml 中的 mainClass 设置为 com.google.adk.web.AdkWebServer,并且您的代理已向其注册,或者您正在运行公开此内容的本地测试运行程序。
使用 InMemoryRunner 和 Scanner 运行 App.java 以进行控制台输入时,您正在测试核心代理逻辑。Web 界面是一个单独的组件,可提供更直观的调试体验,通常在 ADK 通过 HTTP 为代理提供服务时使用。
您可以在根目录中使用以下 Maven 命令启动 SpringBoot 本地服务器:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
该界面通常可通过上述命令输出的网址访问。如果是已部署的 Cloud Run,您应该能够通过已部署的 Cloud Run 链接访问它。
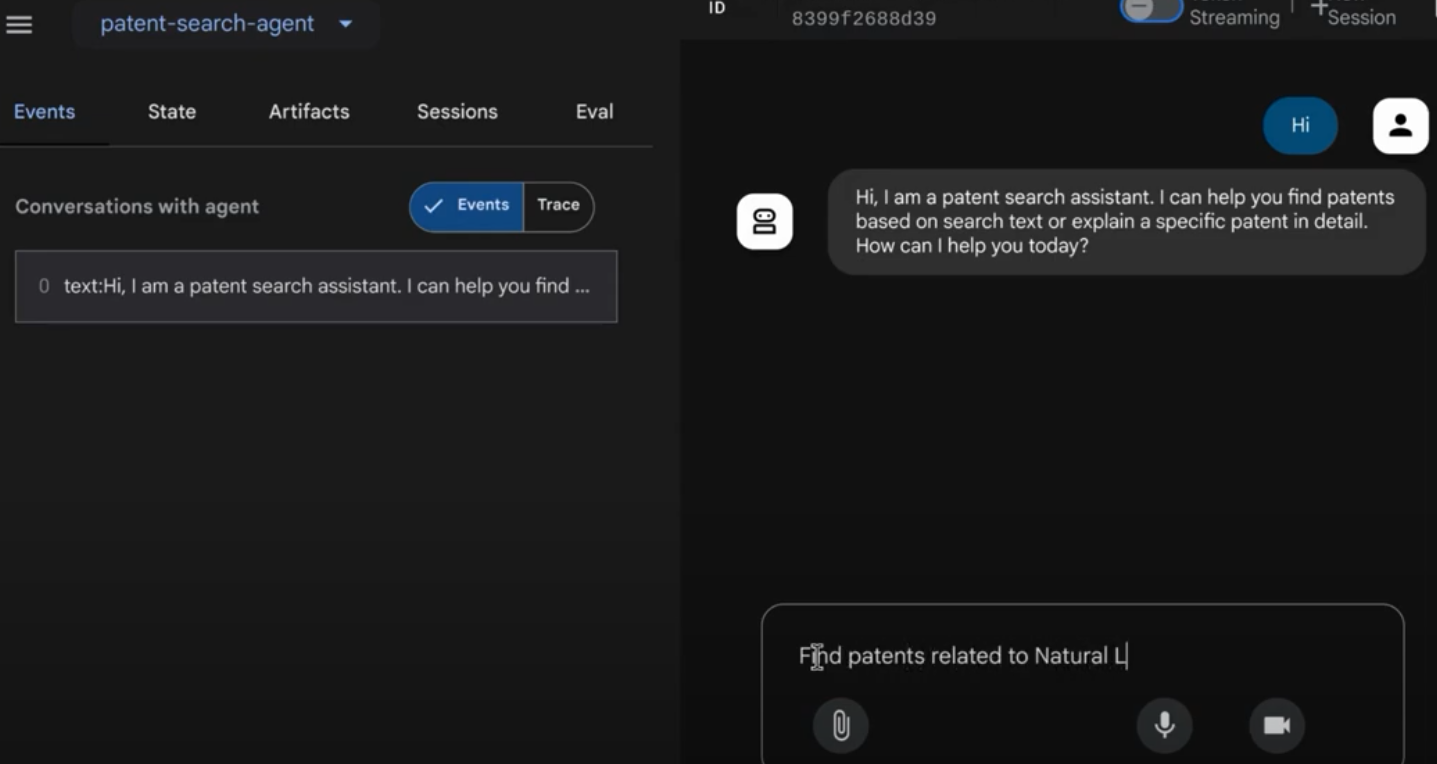
您应该能够在互动式界面中看到结果。
请观看以下视频,了解我们部署的专利代理:
演示了具有 AlloyDB 内嵌搜索和召回评估功能的质量受控专利代理!
12. 清理
为避免系统因本博文中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作:
- 在 Google Cloud 控制台中,前往 https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog 页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关停以删除项目。
13. 恭喜
恭喜!您已成功结合使用 ADK、https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog、Vertex AI 和 Vector Search 的能力,在打造变革性、高效且真正以语义为导向的上下文相似性搜索方面取得了巨大进步,从而在 Java 中构建了专利分析代理。
立即开始使用!
ADK 文档:[指向官方 ADK Java 文档的链接]
专利分析代理源代码:[指向您(现已公开)的 GitHub 代码库的链接]
Java 示例代理:[指向 adk-samples 代码库的链接]
加入 ADK 社区:https://www.reddit.com/r/agentdevelopmentkit/
祝您智能体构建顺利!