
1. Übersicht
In verschiedenen Branchen ist die kontextbezogene Suche eine wichtige Funktion, die das Herzstück ihrer Anwendungen bildet. Retrieval Augmented Generation ist mit seinen auf generativer KI basierenden Abrufmechanismen seit einiger Zeit ein wichtiger Faktor für diese entscheidende technologische Entwicklung. Generative Modelle mit ihren großen Kontextfenstern und der beeindruckenden Ausgabequalität verändern die KI. RAG bietet eine systematische Möglichkeit, Kontext in KI-Anwendungen und ‑Agents einzufügen und sie auf strukturierte Datenbanken oder Informationen aus verschiedenen Medien zu stützen. Diese Kontextdaten sind entscheidend für die Klarheit der Wahrheit und die Genauigkeit der Ausgabe. Aber wie genau sind diese Ergebnisse? Hängt Ihr Unternehmen größtenteils von der Genauigkeit dieser kontextbezogenen Übereinstimmungen und der Relevanz ab? Dann ist dieses Projekt genau das Richtige für dich!
Stellen Sie sich nun vor, wir könnten die Leistungsfähigkeit generativer Modelle nutzen und interaktive Agents entwickeln, die in der Lage sind, autonome Entscheidungen zu treffen, die auf solchen kontextkritischen Informationen basieren und auf Fakten beruhen. Das ist es, was wir heute entwickeln werden. Wir erstellen eine End-to-End-KI-Agent-App mit dem Agent Development Kit, das auf Advanced RAG in AlloyDB basiert, für eine Patentanalyseanwendung.
Der Patent Analysis Agent unterstützt den Nutzer dabei, kontextbezogene Patente für seinen Suchtext zu finden. Auf Anfrage liefert er eine klare und prägnante Erklärung sowie bei Bedarf zusätzliche Details zu einem ausgewählten Patent. Möchten Sie wissen, wie das geht? Legen wir los.
Ziel
Das Ziel ist einfach. Ein Nutzer kann anhand einer Textbeschreibung nach Patenten suchen und dann eine detaillierte Erklärung eines bestimmten Patents aus den Suchergebnissen erhalten. All das ist mit einem KI-Agenten möglich, der mit Java ADK, AlloyDB, Vector Search (mit erweiterten Indexen) und Gemini erstellt wurde. Die gesamte Anwendung wird serverlos in Cloud Run bereitgestellt.
Aufgaben
In diesem Lab werden Sie:
- AlloyDB-Instanz erstellen und Daten aus dem öffentlichen Patent-Dataset laden
- Erweiterte Vektorsuche in AlloyDB mit ScaNN- und Recall-Bewertungsfunktionen implementieren
- Agent mit dem Java ADK erstellen
- Implementieren Sie die serverseitige Logik der Datenbank in serverlosen Cloud Functions in Java.
- Agent in Cloud Run bereitstellen und testen
Das folgende Diagramm zeigt den Datenfluss und die Schritte, die für die Implementierung erforderlich sind.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Wenn Sie mit Cloud Shell verbunden sind, können Sie mit dem folgenden Befehl prüfen, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs. Sie können einen gcloud-Befehl im Cloud Shell-Terminal verwenden:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Alternativ zum gcloud-Befehl können Sie in der Konsole nach den einzelnen Produkten suchen oder diesen Link verwenden.
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
3. Datenbank einrichten
In diesem Lab verwenden wir AlloyDB als Datenbank für die Patentdaten. Darin werden Cluster verwendet, um alle Ressourcen wie Datenbanken und Logs zu speichern. Jeder Cluster hat eine primäre Instanz, die einen Zugriffspunkt auf die Daten bietet. Tabellen enthalten die tatsächlichen Daten.
Erstellen wir einen AlloyDB-Cluster, eine Instanz und eine Tabelle, in die das Patent-Dataset geladen wird.
Cluster und Instanz erstellen
- Rufen Sie in der Cloud Console die AlloyDB-Seite auf. Die meisten Seiten in der Cloud Console lassen sich ganz einfach über die Suchleiste der Console finden.
- Wählen Sie auf dieser Seite CLUSTER ERSTELLEN aus:

- Sie sehen einen Bildschirm wie den unten. Erstellen Sie einen Cluster und eine Instanz mit den folgenden Werten. Achten Sie darauf, dass die Werte übereinstimmen, wenn Sie den Anwendungscode aus dem Repository klonen:
- Cluster-ID: „
vector-cluster“ - password: "
alloydb" - PostgreSQL 15 / neueste empfohlene Version
- Region: "
us-central1" - Networking: „
default“

- Wenn Sie das Standardnetzwerk auswählen, wird ein Bildschirm wie der unten angezeigt.
Wählen Sie VERBINDUNG EINRICHTEN aus.
- Wählen Sie dort Automatisch zugewiesenen IP-Bereich verwenden aus und klicken Sie auf „Weiter“. Nachdem Sie die Informationen überprüft haben, wählen Sie „VERBINDUNG ERSTELLEN“ aus.

- Nachdem Sie Ihr Netzwerk eingerichtet haben, können Sie mit der Clustererstellung fortfahren. Klicken Sie auf CLUSTER ERSTELLEN, um die Einrichtung des Clusters abzuschließen (siehe unten):

Achten Sie darauf, die Instanz-ID zu ändern (die Sie bei der Konfiguration des Clusters / der Instanz finden), in
vector-instance: Wenn Sie sie nicht ändern können, denken Sie daran, Ihre Instanz-ID in allen anstehenden Verweisen zu verwenden.
Die Clustererstellung dauert etwa 10 Minuten. Nach erfolgreicher Ausführung sollte ein Bildschirm mit der Übersicht des gerade erstellten Clusters angezeigt werden.
4. Datenaufnahme
Jetzt ist es an der Zeit, eine Tabelle mit den Daten zum Geschäft hinzuzufügen. Rufen Sie AlloyDB auf, wählen Sie den primären Cluster und dann AlloyDB Studio aus:

Möglicherweise müssen Sie warten, bis die Instanz erstellt wurde. Melden Sie sich dann mit den Anmeldedaten in AlloyDB an, die Sie beim Erstellen des Clusters erstellt haben. Verwenden Sie die folgenden Daten für die Authentifizierung bei PostgreSQL:
- Nutzername: „
postgres“ - Datenbank: „
postgres“ - Passwort: „
alloydb“
Nachdem Sie sich erfolgreich in AlloyDB Studio authentifiziert haben, werden SQL-Befehle im Editor eingegeben. Sie können mehrere Editorfenster hinzufügen, indem Sie auf das Pluszeichen rechts neben dem letzten Fenster klicken.

Sie geben Befehle für AlloyDB in Editorfenstern ein und verwenden bei Bedarf die Optionen „Ausführen“, „Formatieren“ und „Löschen“.
Erweiterungen aktivieren
Für die Entwicklung dieser App verwenden wir die Erweiterungen pgvector und google_ml_integration. Mit der pgvector-Erweiterung können Sie Vektoreinbettungen speichern und durchsuchen. Die Erweiterung google_ml_integration bietet Funktionen, mit denen Sie auf Vertex AI-Vorhersageendpunkte zugreifen können, um Vorhersagen in SQL zu erhalten. Aktivieren Sie diese Erweiterungen, indem Sie die folgenden DDLs ausführen:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Wenn Sie prüfen möchten, welche Erweiterungen für Ihre Datenbank aktiviert wurden, führen Sie diesen SQL-Befehl aus:
select extname, extversion from pg_extension;
Tabelle erstellen
Sie können eine Tabelle mit der folgenden DDL-Anweisung in AlloyDB Studio erstellen:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
In der Spalte „abstract_embeddings“ können die Vektorwerte des Texts gespeichert werden.
Berechtigung gewähren
Führen Sie die folgende Anweisung aus, um die Ausführung der Funktion „embedding“ zu gewähren:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB-Dienstkonto die Rolle „Vertex AI User“ gewähren
Gewähren Sie in der Google Cloud IAM-Konsole dem AlloyDB-Dienstkonto (das so aussieht: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) Zugriff auf die Rolle „Vertex AI-Nutzer“. PROJECT_NUMBER enthält Ihre Projektnummer.
Alternativ können Sie den folgenden Befehl im Cloud Shell-Terminal ausführen:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Patentdaten in die Datenbank laden
Als Dataset verwenden wir die öffentlichen Google Patents-Datasets in BigQuery. Wir verwenden AlloyDB Studio, um unsere Abfragen auszuführen. Die Daten werden in dieser insert scripts sql-Datei in diesem repo gespeichert. Wir führen sie aus, um die Patentdaten zu laden.
- Öffnen Sie in der Google Cloud Console die Seite AlloyDB.
- Wählen Sie den neu erstellten Cluster aus und klicken Sie auf die Instanz.
- Klicken Sie im AlloyDB-Navigationsmenü auf AlloyDB Studio. Melden Sie sich mit Ihren Anmeldedaten an.
- Öffnen Sie einen neuen Tab, indem Sie rechts auf das Symbol Neuer Tab klicken.
- Kopieren Sie die
insert-Abfrageanweisungen aus den Dateieninsert_scripts1.sql,,insert_script2.sql,,insert_scripts3.sql,undinsert_scripts4.sqlund führen Sie sie einzeln aus. Sie können die 10 bis 50 INSERT-Anweisungen kopieren, um diesen Anwendungsfall schnell zu demonstrieren.
Klicken Sie zum Ausführen auf Ausführen. Die Ergebnisse Ihrer Abfrage werden in der Tabelle Ergebnisse angezeigt.
5. Einbettungen für Patentdaten erstellen
Testen wir zuerst die Einbettungsfunktion, indem wir die folgende Beispielabfrage ausführen:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dadurch sollte der Einbettungsvektor für den Beispieltext in der Anfrage zurückgegeben werden. Er sieht wie ein Array von Gleitkommazahlen aus. Das sieht so aus:
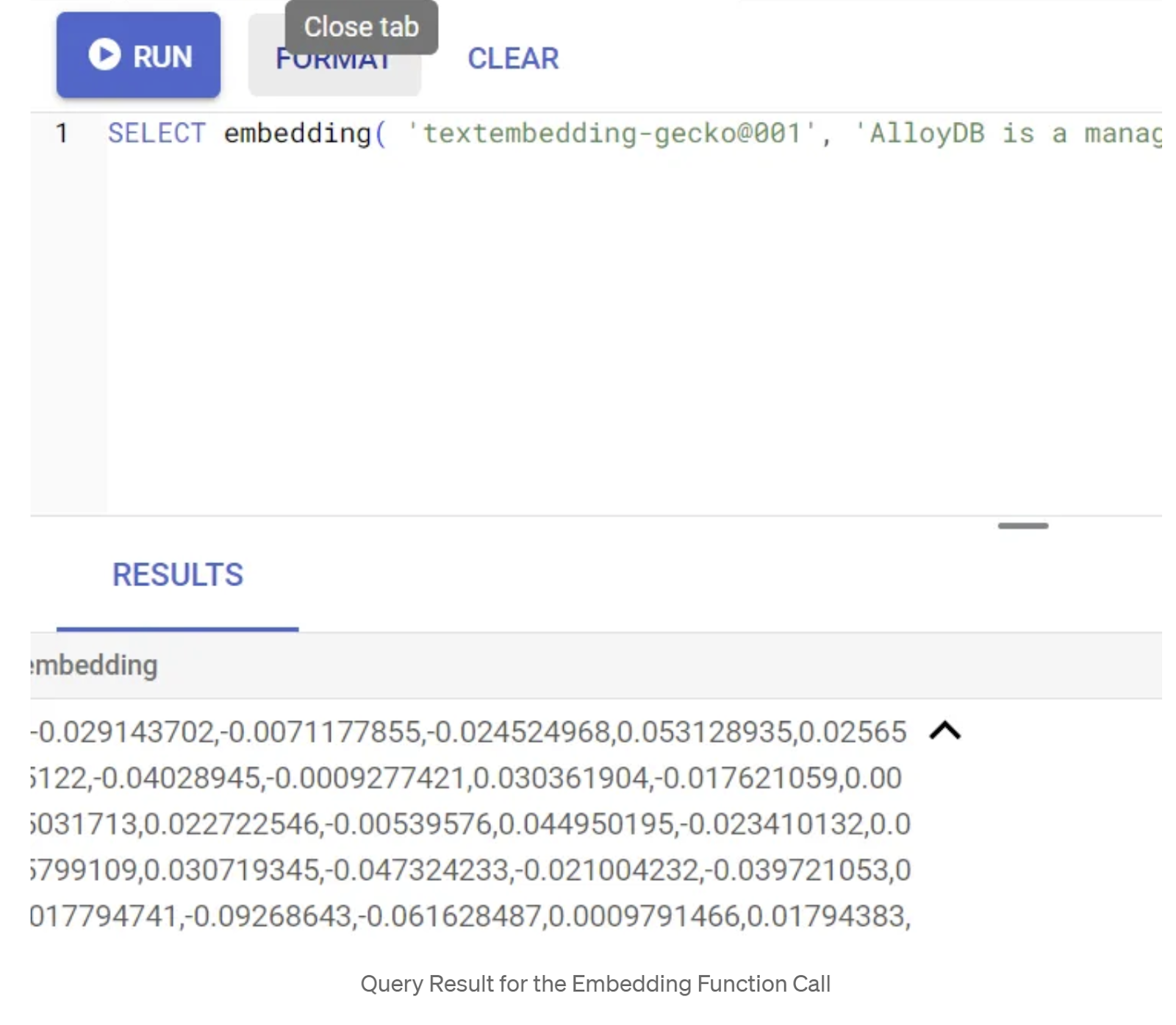
Vektorfeld „abstract_embeddings“ aktualisieren
Die folgende DML sollte verwendet werden, um die Patentzusammenfassungen in der Tabelle mit den entsprechenden Einbettungen zu aktualisieren, falls die Einbettungen für die Zusammenfassungen generiert werden müssen. In unserem Fall enthalten die Einfügeanweisungen jedoch bereits diese Einbettungen für jedes Abstract, sodass Sie die Methode „embeddings()“ nicht aufrufen müssen.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Vektorsuche durchführen
Nachdem die Tabelle, die Daten und die Einbettungen bereit sind, führen wir die Echtzeit-Vektorsuche für den Suchtext des Nutzers durch. Sie können dies testen, indem Sie die folgende Abfrage ausführen:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
In dieser Abfrage
- Der vom Nutzer gesuchte Text lautet: „Sentiment Analysis“.
- Wir wandeln sie mit dem Modell „text-embedding-005“ in der Methode „embedding()“ in Einbettungen um.
- „<=>“ steht für die Verwendung der Distanzmethode „COSINE SIMILARITY“.
- Wir konvertieren das Ergebnis der Einbettungsmethode in den Vektortyp, damit es mit den in der Datenbank gespeicherten Vektoren kompatibel ist.
- LIMIT 10 bedeutet, dass die zehn am besten passenden Ergebnisse für den Suchtext ausgewählt werden.
AlloyDB bietet folgende Vorteile für die Vektorsuche mit RAG:
Es gibt eine Reihe von Neuerungen. Zwei davon sind:
- Inline-Filterung
- Recall-Bewerter
Inline-Filterung
Bisher mussten Sie als Entwickler die Vector Search-Abfrage ausführen und sich um das Filtern und den Recall kümmern. Der AlloyDB-Abfrageoptimierer entscheidet, wie eine Abfrage mit Filtern ausgeführt wird. Das Inline-Filtern ist eine neue Technik zur Abfrageoptimierung, mit der der AlloyDB-Abfrageoptimierer sowohl die Metadatenfilterbedingungen als auch die Vektorsuche gleichzeitig auswerten kann. Dabei werden sowohl Vektorindexe als auch Indexe für die Metadatenspalten verwendet. Dadurch hat sich die Recall-Leistung erhöht, sodass Entwickler die Vorteile von AlloyDB sofort nutzen können.
Die Inline-Filterung eignet sich am besten für Fälle mit mittlerer Selektivität. Wenn AlloyDB den Vektorindex durchsucht, werden nur Distanzen für Vektoren berechnet, die den Metadatenfilterbedingungen entsprechen (Ihre funktionalen Filter in einer Abfrage, die normalerweise in der WHERE-Klausel verarbeitet werden). Dadurch wird die Leistung dieser Abfragen erheblich verbessert, was die Vorteile von Post-Filter oder Pre-Filter ergänzt.
- pgvector-Erweiterung installieren oder aktualisieren
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Wenn die pgvector-Erweiterung bereits installiert ist, führen Sie ein Upgrade der Vektorerweiterung auf Version 0.8.0.google-3 oder höher durch, um die Funktionen des Recall-Evaluators zu erhalten.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Dieser Schritt muss nur ausgeführt werden, wenn Ihre Vektorerweiterung <0.8.0.google-3 ist.
Wichtiger Hinweis:Wenn die Anzahl der Zeilen weniger als 100 beträgt, müssen Sie den ScaNN-Index nicht erstellen, da er für weniger Zeilen nicht gilt. Überspringen Sie in diesem Fall die folgenden Schritte.
- Wenn Sie ScaNN-Indizes erstellen möchten, installieren Sie die Erweiterung „alloydb_scann“.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Führen Sie zuerst die Vektorsuchanfrage ohne den Index und ohne aktivierten Inline-Filter aus:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Das Ergebnis sollte in etwa so aussehen:

- Führen Sie „Explain Analyze“ für die Anfrage aus (ohne Index und ohne Inline-Filterung):

Die Ausführungszeit beträgt 2,4 ms.
- Erstellen wir einen regulären Index für das Feld „num_claims“, damit wir danach filtern können:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Erstellen wir nun den ScaNN-Index für unsere Patent Search-Anwendung. Führen Sie Folgendes in AlloyDB Studio aus:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Wichtiger Hinweis : (num_leaves=32) gilt für unser gesamtes Dataset mit mehr als 1.000 Zeilen. Wenn die Anzahl der Zeilen weniger als 100 beträgt, müssen Sie keinen Index erstellen, da er für weniger Zeilen nicht gilt.
- Legen Sie das Inline-Filtern für den ScaNN-Index fest:
SET scann.enable_inline_filtering = on
- Führen Sie nun dieselbe Abfrage mit Filter und Vektorsuche aus:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
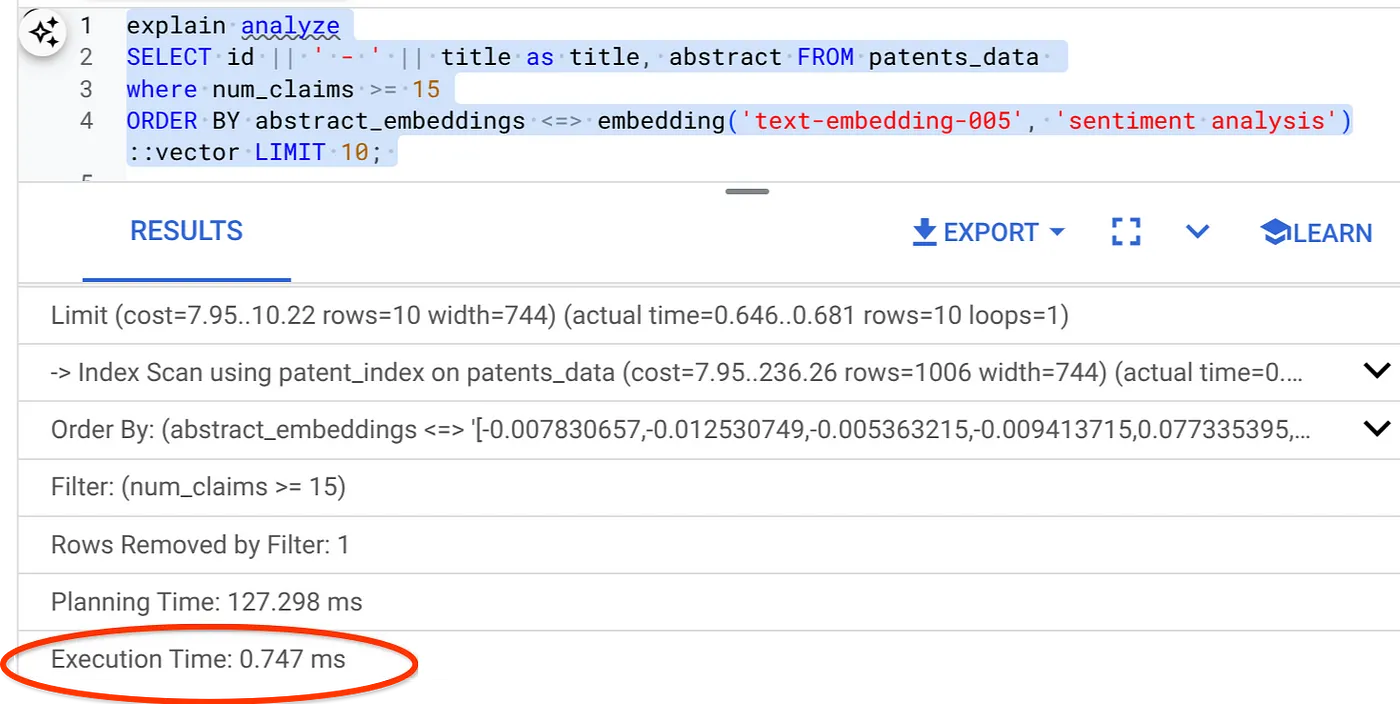
Wie Sie sehen, wird die Ausführungszeit für dieselbe Vektorsuche deutlich verkürzt. Der ScaNN-Index mit Inline-Filterung in der Vektorsuche hat dies ermöglicht.
Als Nächstes bewerten wir den Recall für diese ScaNN-basierte Vektorsuche.
Recall-Bewerter
Die Trefferquote bei der Ähnlichkeitssuche ist der Prozentsatz der relevanten Instanzen, die bei einer Suche abgerufen wurden, d.h. die Anzahl der richtig positiven Ergebnisse. Dies ist der gängigste Messwert zur Messung der Suchqualität. Eine Quelle für Recall-Verluste ist der Unterschied zwischen der Suche nach ungefähren nächsten Nachbarn (Approximate Nearest Neighbor, aNN) und der Suche nach k (exakten) nächsten Nachbarn (k-Nearest Neighbor, kNN). Vektorindexe wie ScaNN für AlloyDB implementieren aNN-Algorithmen. So können Sie die Vektorsuche in großen Datasets beschleunigen, wobei Sie einen geringen Recall-Verlust in Kauf nehmen. Mit AlloyDB können Sie diesen Kompromiss jetzt direkt in der Datenbank für einzelne Abfragen messen und dafür sorgen, dass er im Zeitverlauf stabil bleibt. Sie können Abfrage- und Indexparameter auf Grundlage dieser Informationen aktualisieren, um bessere Ergebnisse und eine bessere Leistung zu erzielen.
Mit der Funktion evaluate_query_recall können Sie die Trefferquote für eine Vektoranfrage für einen Vektorindex für eine bestimmte Konfiguration ermitteln. Mit dieser Funktion können Sie Ihre Parameter so anpassen, dass Sie die gewünschten Recall-Ergebnisse für Vektorabfragen erzielen. Der Recall ist der Messwert für die Suchqualität und wird als Prozentsatz der zurückgegebenen Ergebnisse definiert, die den Abfragevektoren objektiv am nächsten sind. Die Funktion evaluate_query_recall ist standardmäßig aktiviert.
Wichtiger Hinweis:
Wenn Sie bei den folgenden Schritten einen Fehler vom Typ „Permission denied“ für den HNSW-Index erhalten, überspringen Sie diesen gesamten Abschnitt zur Recall-Bewertung vorerst. Das kann mit Zugriffsbeschränkungen zusammenhängen, da die Funktion zum Zeitpunkt der Dokumentation dieses Codelabs gerade erst veröffentlicht wurde.
- Legen Sie das Flag „Enable Index Scan“ für den ScaNN-Index und den HNSW-Index fest:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Führen Sie die folgende Abfrage in AlloyDB Studio aus:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Die Funktion „evaluate_query_recall“ verwendet die Anfrage als Parameter und gibt den Recall zurück. Ich verwende dieselbe Abfrage, mit der ich die Leistung geprüft habe, als Funktionseingabeabfrage. Ich habe SCaNN als Indexmethode hinzugefügt. Weitere Parameteroptionen finden Sie in der Dokumentation.
Der Recall für diese Vektorsuchanfrage, die wir verwendet haben:

Der RECALL liegt bei 70%. Jetzt kann ich diese Informationen verwenden, um die Indexparameter, Methoden und Abfrageparameter zu ändern und die Erinnerung für diese Vektorsuche zu verbessern.
Ich habe die Anzahl der Zeilen im Ergebnis auf 7 (vorher 10) geändert und stelle eine leicht verbesserte RECALL von 86 % fest.

Das bedeutet, dass ich die Anzahl der Übereinstimmungen, die meine Nutzer sehen, in Echtzeit variieren kann, um die Relevanz der Übereinstimmungen entsprechend dem Suchkontext der Nutzer zu verbessern.
So ist es richtig! Es ist an der Zeit, die Datenbanklogik bereitzustellen und mit dem Agent fortzufahren.
7. Datenbanklogik serverlos auf den Webserver übertragen
Sind Sie bereit, diese App ins Web zu bringen? Gehen Sie dazu so vor:
- Rufen Sie Cloud Run-Funktionen in der Google Cloud Console auf, um eine neue Cloud Run-Funktion zu erstellen. Klicken Sie dazu auf „Funktion schreiben“ oder verwenden Sie den Link https://console.cloud.google.com/run/create?deploymentType=function.
- Wählen Sie die Option „Funktion mit einem Inline-Editor erstellen“ aus und beginnen Sie mit der Konfiguration. Geben Sie den Dienstnamen patent-search ein, wählen Sie die Region us-central1 und die Laufzeit Java 17 aus. Legen Sie die Authentifizierung auf Nicht authentifizierte Aufrufe zulassen fest.
- Führen Sie im Abschnitt „Container, Volumes, Netzwerk, Sicherheit“ die folgenden Schritte aus:
Rufen Sie den Tab „Netzwerk“ auf:

Wählen Sie Mit einer VPC für ausgehenden Traffic verbinden und dann Connectors für serverlosen VPC-Zugriff verwenden aus.
Klicken Sie im Drop-down-Menü „Netzwerk“ auf „Einstellungen“. Klicken Sie auf das Drop-down-Menü „Netzwerk“ und wählen Sie die Option Neuen VPC-Connector hinzufügen aus, sofern Sie den Standardconnector noch nicht konfiguriert haben. Folgen Sie der Anleitung im Pop-up-Dialogfeld:

Geben Sie einen Namen für den VPC-Connector an und achten Sie darauf, dass die Region mit der Ihrer Instanz übereinstimmt. Lassen Sie den Netzwerk-Wert auf dem Standardwert und legen Sie das Subnetz als benutzerdefinierten IP-Bereich mit dem IP-Bereich 10.8.0.0 oder einem ähnlichen verfügbaren Bereich fest.
Maximieren Sie die SKALIERUNGSEINSTELLUNGEN und prüfen Sie, ob die Konfiguration genau wie folgt eingestellt ist:

Klicken Sie auf ERSTELLEN. Der Connector sollte jetzt in den Einstellungen für ausgehenden Traffic aufgeführt sein.
Wählen Sie den neu erstellten Connector aus.
Wählen Sie aus, dass der gesamte Traffic über diesen VPC-Connector weitergeleitet werden soll.
Klicken Sie auf WEITER und dann auf BEREITSTELLEN.
- Standardmäßig wird der Einstiegspunkt auf „gcfv2.HelloHttpFunction“ festgelegt. Ersetzen Sie den Platzhaltercode in HelloHttpFunction.java und pom.xml Ihrer Cloud Run-Funktion durch den Code aus PatentSearch.java bzw. pom.xml. Ändern Sie den Namen der Klassendatei in „PatentSearch.java“.
- Denken Sie daran, den Platzhalter ************* und die AlloyDB-Verbindungsanmeldedaten in der Java-Datei durch Ihre Werte zu ersetzen. Die AlloyDB-Anmeldedaten sind die, die wir zu Beginn dieses Codelabs verwendet haben. Wenn Sie andere Werte verwendet haben, ändern Sie diese in der Java-Datei.
- Klicken Sie auf Bereitstellen.
- Nachdem die aktualisierte Cloud-Funktion bereitgestellt wurde, sollte der Endpunkt generiert werden. Kopieren Sie das und ersetzen Sie es im folgenden Befehl:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
Geschafft! So einfach lässt sich eine erweiterte Suche nach Vektorähnlichkeit im Kontext mit dem Embeddings-Modell für AlloyDB-Daten durchführen.
8. KI-Agenten mit dem Java ADK erstellen
Zuerst erstellen wir das Java-Projekt im Editor.
- Cloud Shell-Terminal aufrufen
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Bei Aufforderung autorisieren
- Wechseln Sie zum Cloud Shell-Editor, indem Sie oben in der Cloud Shell-Konsole auf das Editorsymbol klicken.

- Erstellen Sie in der Cloud Shell Editor-Konsole einen neuen Ordner mit dem Namen „adk-agents“.
Klicken Sie im Stammverzeichnis Ihrer Cloud Shell auf „Neuen Ordner erstellen“, wie unten dargestellt:

Geben Sie ihm den Namen „adk-agents“:
- Erstellen Sie die folgende Ordnerstruktur und die leeren Dateien mit den entsprechenden Dateinamen in der Struktur unten:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Öffnen Sie das GitHub-Repository in einem separaten Tab und kopieren Sie den Quellcode für die Dateien „App.java“ und „pom.xml“.
- Wenn Sie den Editor über das Symbol „In neuem Tab öffnen“ oben rechts in einem neuen Tab geöffnet haben, kann das Terminal unten auf der Seite geöffnet werden. Sie können sowohl den Editor als auch das Terminal parallel geöffnet haben und so frei arbeiten.
- Wechseln Sie nach dem Klonen zurück zur Cloud Shell Editor-Konsole.
- Da wir die Cloud Run-Funktion bereits erstellt haben, müssen Sie die Cloud Run-Funktionsdateien nicht aus dem Repo-Ordner kopieren.
Erste Schritte mit dem ADK Java SDK
Das ist ganz einfach. Im Klon-Schritt müssen Sie vor allem Folgendes sicherstellen:
- Abhängigkeiten hinzufügen:
Fügen Sie die Artefakte „google-adk“ und „google-adk-dev“ (für die Web-UI) in Ihre „pom.xml“-Datei ein. Wenn Sie die Quelle aus dem Repository kopiert haben, sind diese bereits in den Dateien enthalten. Sie müssen sie nicht angeben. Sie müssen lediglich eine Änderung am Cloud Run Function-Endpunkt vornehmen, damit er Ihrem bereitgestellten Endpunkt entspricht. Dies wird in den folgenden Schritten in diesem Abschnitt beschrieben.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Achten Sie darauf, dass Sie auf die pom.xml-Datei aus dem Quell-Repository verweisen, da für die Ausführung der Anwendung weitere Abhängigkeiten und Konfigurationen erforderlich sind.
- Projekt konfigurieren:
Achten Sie darauf, dass Ihre Java-Version (mindestens 17 empfohlen) und die Maven-Compilereinstellungen in Ihrer pom.xml-Datei korrekt konfiguriert sind. Sie können Ihr Projekt so konfigurieren, dass es der folgenden Struktur entspricht:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Agent und seine Tools definieren (App.java):
Hier kommt das ADK Java SDK ins Spiel. Wir definieren den Agent, seine Funktionen (Anweisungen) und die Tools, die er verwenden kann.
Hier finden Sie eine vereinfachte Version einiger Code-Snippets der Haupt-Agent-Klasse. Das vollständige Projekt finden Sie in diesem Projekt-Repository.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Wichtige ADK-Java-Codekomponenten:
- LlmAgent.builder():: Fluent API zum Konfigurieren Ihres Agents.
- .instruction(...): Enthält den Hauptprompt und die Richtlinien für das LLM, einschließlich der Angabe, wann welches Tool verwendet werden soll.
- FunctionTool.create(App.class, "methodName"): Registriert Ihre Java-Methoden ganz einfach als Tools, die der Agent aufrufen kann. Der String für den Methodennamen muss mit einer tatsächlichen öffentlichen statischen Methode übereinstimmen.
- @Schema(description = …): Hiermit werden Tool-Parameter annotiert, damit das LLM weiß, welche Eingaben für die einzelnen Tools erforderlich sind. Diese Beschreibung ist entscheidend für die richtige Auswahl des Tools und das Ausfüllen der Parameter.
- InvocationContext ctx:Wird automatisch an Tool-Methoden übergeben und bietet Zugriff auf den Sitzungsstatus (ctx.session().state()), Nutzerinformationen und mehr.
- .outputKey("patents"): Wenn ein Tool Daten zurückgibt, kann ADK diese automatisch im Sitzungsstatus unter diesem Schlüssel speichern. So kann explainPatent auf die Ergebnisse von getPatents zugreifen.
- VECTOR_SEARCH_ENDPOINT::Diese Variable enthält die funktionale Kernlogik für die kontextbezogene Frage-und-Antwort-Funktion für den Nutzer im Anwendungsfall der Patentsuche.
- Aktionspunkt: Sie müssen einen aktualisierten bereitgestellten Endpunktwert festlegen, sobald Sie den Schritt zur Java Cloud Run-Funktion aus dem vorherigen Abschnitt implementiert haben.
- searchTool: Dieses Tool interagiert mit dem Nutzer, um kontextuell relevante Patentübereinstimmungen aus der Patentdatenbank für den Suchtext des Nutzers zu finden.
- explainTool: Hier wird der Nutzer aufgefordert, ein bestimmtes Patent auszuwählen, das genauer untersucht werden soll. Anschließend wird die Patentzusammenfassung erstellt und auf Grundlage der Patentdetails können weitere Fragen des Nutzers beantwortet werden.
Wichtiger Hinweis: Ersetzen Sie die Variable VECTOR_SEARCH_ENDPOINT durch den bereitgestellten CRF-Endpunkt.
InvocationContext für zustandsorientierte Interaktionen nutzen
Eine der wichtigsten Funktionen für die Entwicklung nützlicher Agents ist die Verwaltung des Status über mehrere Unterhaltungsrunden hinweg. Der InvocationContext des ADK macht dies ganz einfach.
In unserer App.java:
- Wenn initAgent() definiert ist, verwenden wir .outputKey("patents"). Dadurch wird dem ADK mitgeteilt, dass Daten, die von einem Tool (z. B. getPatents) im Berichtsfeld zurückgegeben werden, im Sitzungsstatus unter dem Schlüssel „patents“ gespeichert werden sollen.
- In der Methode „explainPatent“ des Tools wird „InvocationContext ctx“ eingefügt:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
So kann das Tool „explainPatent“ auf die Patentliste zugreifen, die vom Tool „getPatents“ in einem vorherigen Turn abgerufen wurde. Dadurch wird die Unterhaltung zustandsbehaftet und kohärent.
9. Lokales CLI-Testen
Umgebungsvariablen definieren
Sie müssen zwei Umgebungsvariablen exportieren:
- Ein Gemini-Schlüssel, den Sie in AI Studio abrufen können:
Rufen Sie dazu https://aistudio.google.com/apikey auf und rufen Sie den API-Schlüssel für Ihr aktives Google Cloud-Projekt ab, in dem Sie diese Anwendung implementieren. Speichern Sie den Schlüssel an einem geeigneten Ort:

- Nachdem Sie den Schlüssel erhalten haben, öffnen Sie das Cloud Shell-Terminal und wechseln Sie mit dem folgenden Befehl in das neue Verzeichnis, das wir gerade erstellt haben (adk-agents):
cd adk-agents
- Eine Variable, um anzugeben, dass wir Vertex AI dieses Mal nicht verwenden.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Ersten Agent in der CLI ausführen
Verwenden Sie den folgenden Maven-Befehl in Ihrem Terminal, um diesen ersten Agent zu starten:
mvn compile exec:java -DmainClass="agents.App"
Die interaktive Antwort des Agents wird in Ihrem Terminal angezeigt.
10. In Cloud Run bereitstellen
Die Bereitstellung Ihres ADK-Java-Agents in Cloud Run ähnelt der Bereitstellung jeder anderen Java-Anwendung:
- Dockerfile: Erstellen Sie ein Dockerfile, um Ihre Java-Anwendung zu verpacken.
- Docker-Image erstellen und übertragen: Verwenden Sie Google Cloud Build und Artifact Registry.
- Sie können den oben genannten Schritt ausführen und in Cloud Run bereitstellen, indem Sie nur einen Befehl eingeben:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Ebenso würden Sie Ihre Java Cloud Run-Funktion (gcfv2.PatentSearch) bereitstellen. Alternativ können Sie die Java-Cloud Run-Funktion für die Datenbanklogik direkt über die Cloud Run-Funktionskonsole erstellen und bereitstellen.
11. Mit der Web-UI testen
Das ADK enthält eine praktische Web-UI zum lokalen Testen und Debuggen Ihres Agents. Wenn Sie „App.java“ lokal ausführen (z.B. mit „mvn exec:java -Dexec.mainClass=agents.App“, falls konfiguriert, oder einfach durch Ausführen der Hauptmethode), startet das ADK in der Regel einen lokalen Webserver.
In der ADK-Web-UI haben Sie folgende Möglichkeiten:
- Nachrichten an Ihren Kundenservicemitarbeiter senden
- Sehen Sie sich die Ereignisse an (Nutzernachricht, Tool-Aufruf, Tool-Antwort, LLM-Antwort).
- Sitzungsstatus prüfen
- Logs und Traces ansehen
Das ist während der Entwicklung von unschätzbarem Wert, um zu verstehen, wie Ihr Agent Anfragen verarbeitet und seine Tools verwendet. Dabei wird davon ausgegangen, dass Ihre mainClass in pom.xml auf com.google.adk.web.AdkWebServer festgelegt ist und Ihr Agent dort registriert ist oder Sie einen lokalen Test-Runner ausführen, der dies verfügbar macht.
Wenn Sie App.java mit dem InMemoryRunner und Scanner für die Konsoleneingabe ausführen, testen Sie die Kernlogik des Agents. Die Web-UI ist eine separate Komponente für eine visuellere Fehlersuche, die häufig verwendet wird, wenn das ADK Ihren Agent über HTTP bereitstellt.
Mit dem folgenden Maven-Befehl können Sie den lokalen SpringBoot-Server über Ihr Stammverzeichnis starten:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
Die Benutzeroberfläche ist oft über die URL zugänglich, die mit dem oben genannten Befehl ausgegeben wird. Wenn die Funktion in Cloud Run bereitgestellt wurde, sollten Sie über den Link „In Cloud Run bereitgestellt“ darauf zugreifen können.
Das Ergebnis sollte in einer interaktiven Benutzeroberfläche angezeigt werden.
Im folgenden Video sehen Sie unseren bereitgestellten Patent Agent:
Demo of a Quality Controlled Patent Agent with AlloyDB Inline Search & Recall Evaluation!

12. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Rufen Sie in der Google Cloud Console https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog auf.
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
13. Glückwunsch
Glückwunsch! Sie haben Ihren Patent Analysis Agent in Java erstellt, indem Sie die Funktionen von ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI und Vector Search kombiniert haben. Außerdem haben wir einen großen Schritt nach vorn gemacht, um kontextbezogene Ähnlichkeitssuchen so transformativ, effizient und wirklich aussagekräftig zu gestalten.
Jetzt loslegen
ADK-Dokumentation: [Link to Official ADK Java Docs]
Quellcode des Patent Analysis Agent: [Link zu Ihrem (jetzt öffentlichen) GitHub-Repository]
Java-Beispiel-KI-Agenten: [Link zum adk-samples-Repository]
ADK-Community beitreten: https://www.reddit.com/r/agentdevelopmentkit/
Viel Spaß beim Erstellen von Agents!