
1. نظرة عامة
في مختلف الصناعات، يشكّل البحث السياقي وظيفة أساسية في صميم تطبيقاتها. لقد كان الجيل المعزّز للاسترجاع عاملاً رئيسيًا في هذا التطور التكنولوجي المهم منذ فترة طويلة، وذلك بفضل آليات الاسترجاع المستندة إلى الذكاء الاصطناعي التوليدي. تُحدث النماذج التوليدية تحوّلاً في الذكاء الاصطناعي بفضل قدرتها على استيعاب الكثير من المعلومات وجودة مخرجاتها العالية. توفّر ميزة "الاسترجاع والإنشاء" طريقة منهجية لإضافة السياق إلى تطبيقات الذكاء الاصطناعي وبرامجه، ما يتيح لها الاستناد إلى قواعد بيانات منظَّمة أو معلومات من وسائط مختلفة. تُعدّ هذه البيانات السياقية ضرورية لضمان وضوح المعلومات ودقة النتائج، ولكن ما مدى دقة هذه النتائج؟ هل يعتمد نشاطك التجاري بشكل كبير على دقة هذه المطابقات السياقية ومدى صلتها بالموضوع؟ إذًا هذا المشروع سيثير اهتمامك.
تخيّل الآن لو كان بإمكاننا الاستفادة من قوة النماذج التوليدية وإنشاء وكلاء تفاعليين قادرين على اتخاذ قرارات مستقلة استنادًا إلى هذه المعلومات المهمة للسياق والمستندة إلى الحقائق، هذا ما سنقوم بإنشائه اليوم. سننشئ تطبيقًا متكاملاً لوكيل يعمل بالذكاء الاصطناعي باستخدام "مجموعة أدوات تطوير الوكلاء" المستندة إلى تقنية RAG المتقدّمة في AlloyDB لتطبيق تحليل براءات الاختراع.
يساعد وكيل تحليل براءات الاختراع المستخدم في العثور على براءات اختراع ذات صلة بموضوع بحثه، ويقدّم عند الطلب شرحًا واضحًا وموجزًا وتفاصيل إضافية إذا لزم الأمر لبراءة اختراع محدّدة. هل أنت مستعد لمعرفة كيفية تنفيذ ذلك؟ لنطّلِع على التفاصيل.
الهدف
الهدف بسيط. السماح للمستخدم بالبحث عن براءات الاختراع استنادًا إلى وصف نصي، ثم الحصول على شرح مفصّل لبراءة اختراع معيّنة من نتائج البحث، وكل ذلك باستخدام وكيل يعمل بالذكاء الاصطناعي تم إنشاؤه باستخدام Java ADK وAlloyDB وVector Search (مع فهارس متقدّمة) وGemini، مع نشر التطبيق بأكمله بدون خادم على Cloud Run
ما ستنشئه
في هذا الدرس التطبيقي، ستنفّذ ما يلي:
- إنشاء مثيل AlloyDB وتحميل بيانات مجموعة البيانات العامة الخاصة ببراءات الاختراع
- تنفيذ ميزة "البحث المتّجه" المتقدّمة في AlloyDB باستخدام ميزتَي ScaNN وRecall eval
- إنشاء وكيل باستخدام Java ADK
- تنفيذ منطق من جهة خادم قاعدة البيانات في دوال Cloud بدون خادم بلغة Java
- نشر الوكيل واختباره في Cloud Run
يمثّل الرسم البياني التالي تدفّق البيانات والخطوات المتّبعة في عملية التنفيذ.
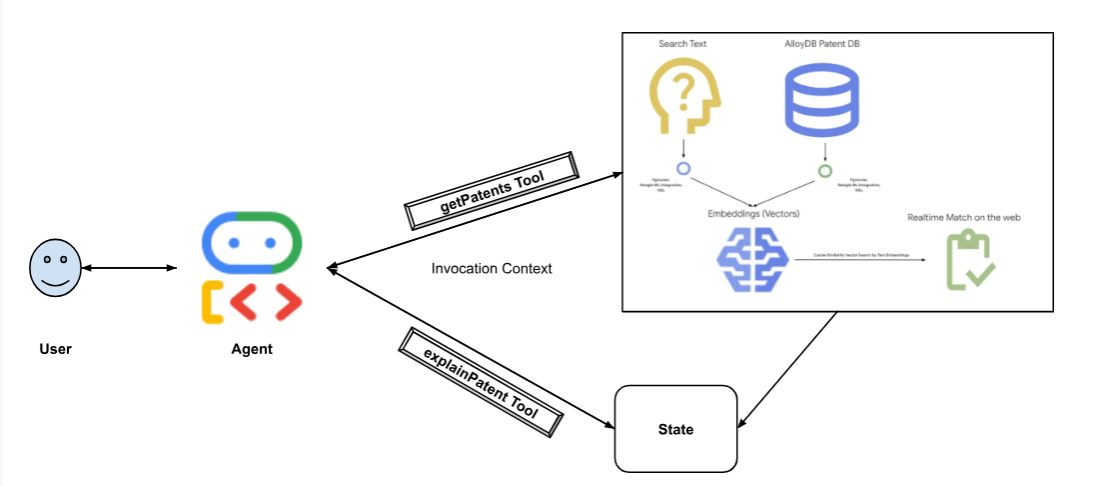
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
المتطلبات
2. قبل البدء
إنشاء مشروع
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر أو أنشِئ مشروعًا على Google Cloud.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud. تعرَّف على كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع .
- ستستخدم Cloud Shell، وهي بيئة سطر أوامر تعمل في Google Cloud. انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud".

- بعد الاتصال بـ Cloud Shell، يمكنك التأكّد من أنّك قد تم التحقّق من هويتك وأنّه تم ضبط المشروع على معرّف مشروعك باستخدام الأمر التالي:
gcloud auth list
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك.
gcloud config list project
- إذا لم يتم ضبط مشروعك، استخدِم الأمر التالي لضبطه:
gcloud config set project <YOUR_PROJECT_ID>
- فعِّل واجهات برمجة التطبيقات المطلوبة. يمكنك استخدام أمر gcloud في وحدة Cloud Shell الطرفية:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
يمكنك بدلاً من استخدام أمر gcloud، البحث عن كل منتج من خلال وحدة التحكّم أو استخدام هذا الرابط.
راجِع المستندات لمعرفة أوامر gcloud وطريقة استخدامها.
3- إعداد قاعدة البيانات
في هذا التمرين المعملي، سنستخدم AlloyDB كقاعدة بيانات لبيانات براءات الاختراع. يستخدم المجموعات للاحتفاظ بجميع الموارد، مثل قواعد البيانات والسجلات. تحتوي كل مجموعة على مثيل أساسي يوفّر نقطة وصول إلى البيانات. ستحتوي الجداول على البيانات الفعلية.
لننشئ مجموعة ومثيل وجدول AlloyDB سيتم تحميل مجموعة بيانات براءات الاختراع فيها.
إنشاء مجموعة ومثيل
- انتقِل إلى صفحة AlloyDB في Cloud Console. تتمثّل إحدى الطرق السهلة للعثور على معظم الصفحات في Cloud Console في البحث عنها باستخدام شريط البحث في وحدة التحكّم.
- اختَر إنشاء مجموعة من تلك الصفحة:

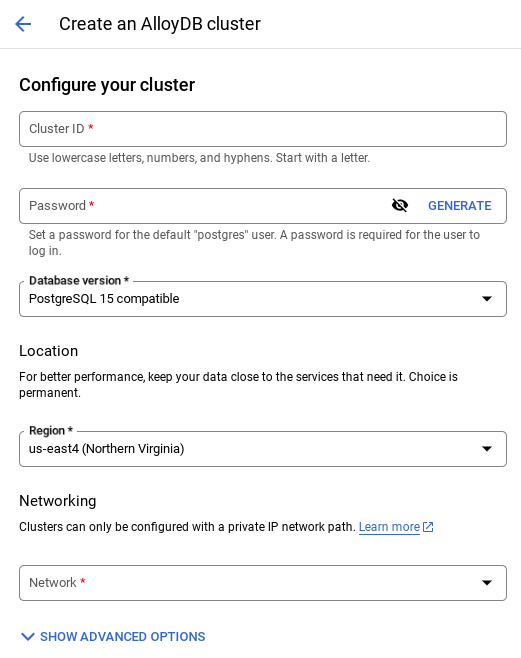
- ستظهر لك شاشة مشابهة للشاشة أدناه. أنشئ مجموعة ومثيل بالقيم التالية (تأكَّد من تطابق القيم في حال استنساخ رمز التطبيق من المستودع):
- معرّف المجموعة: "
vector-cluster" - كلمة المرور: "
alloydb" - PostgreSQL 15 / أحدث إصدار يُنصح به
- المنطقة: "
us-central1" - الشبكات: "
default"
- عند اختيار الشبكة التلقائية، ستظهر لك شاشة مثل الشاشة أدناه.
انقر على إعداد الاتصال.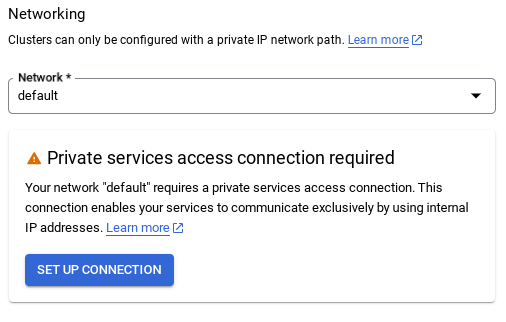
- بعد ذلك، اختَر استخدام نطاق عناوين IP مخصّص تلقائيًا وانقر على "متابعة". بعد مراجعة المعلومات، انقر على CREATE CONNECTION (إنشاء اتصال).

- بعد إعداد شبكتك، يمكنك مواصلة إنشاء مجموعتك. انقر على إنشاء مجموعة لإكمال إعداد المجموعة كما هو موضّح أدناه:

احرص على تغيير معرّف المثيل (الذي يمكنك العثور عليه عند إعداد المجموعة أو المثيل) إلى
vector-instance: إذا لم تتمكّن من تغييره، تذكَّر استخدام معرّف مثيلك في جميع المراجع القادمة.
يُرجى العِلم أنّ عملية إنشاء المجموعة ستستغرق حوالي 10 دقائق. بعد اكتمال العملية بنجاح، من المفترض أن تظهر لك شاشة تعرض نظرة عامة على المجموعة التي أنشأتها للتو.
4. نقل البيانات
حان الوقت الآن لإضافة جدول يتضمّن بيانات حول المتجر. انتقِل إلى AlloyDB، واختَر المجموعة الأساسية، ثم AlloyDB Studio:
قد تحتاج إلى الانتظار إلى أن يكتمل إنشاء الجهاز الظاهري. بعد ذلك، سجِّل الدخول إلى AlloyDB باستخدام بيانات الاعتماد التي أنشأتها عند إنشاء المجموعة. استخدِم البيانات التالية للمصادقة على PostgreSQL:
- اسم المستخدم : "
postgres" - قاعدة البيانات : "
postgres" - كلمة المرور : "
alloydb"
بعد إكمال عملية المصادقة بنجاح في AlloyDB Studio، يتم إدخال أوامر SQL في "المحرّر". يمكنك إضافة نوافذ "المحرّر" متعددة باستخدام علامة الجمع على يسار النافذة الأخيرة.
ستُدخل أوامر AlloyDB في نوافذ المحرّر، باستخدام الخيارات "تشغيل" و"تنسيق" و"محو" حسب الحاجة.
تفعيل الإضافات
لإنشاء هذا التطبيق، سنستخدم الإضافتين pgvector وgoogle_ml_integration. تتيح لك إضافة pgvector تخزين عمليات التضمين المتجهة والبحث عنها. توفّر إضافة google_ml_integration دوال يمكنك استخدامها للوصول إلى نقاط نهاية التوقّعات في Vertex AI من أجل الحصول على توقّعات في SQL. فعِّل هذه الإضافات من خلال تنفيذ تعريفات البيانات التالية:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
إذا أردت التحقّق من الإضافات التي تم تفعيلها في قاعدة البيانات، نفِّذ أمر SQL التالي:
select extname, extversion from pg_extension;
إنشاء جدول
يمكنك إنشاء جدول باستخدام عبارة DDL أدناه في AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
سيسمح عمود abstract_embeddings بتخزين قيم المتجهات للنص.
منح الإذن
نفِّذ العبارة أدناه لمنح إذن التنفيذ على الدالة "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
منح دور "مستخدم Vertex AI" لحساب خدمة AlloyDB
من وحدة تحكّم Google Cloud IAM، امنح حساب خدمة AlloyDB (الذي يبدو على النحو التالي: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) إذن الوصول إلى الدور "مستخدم Vertex AI". سيحتوي PROJECT_NUMBER على رقم مشروعك.
بدلاً من ذلك، يمكنك تنفيذ الأمر أدناه من "وحدة Cloud Shell الطرفية":
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
تحميل بيانات براءات الاختراع إلى قاعدة البيانات
سيتم استخدام مجموعات البيانات العامة لبراءات اختراع Google على BigQuery كمجموعة البيانات الخاصة بنا. سنستخدم AlloyDB Studio لتشغيل طلبات البحث. يتم استخراج البيانات إلى ملف insert scripts sql هذا في repo هذا، وسننّفذ هذا الملف لتحميل بيانات براءات الاختراع.
- في Google Cloud Console، افتح صفحة AlloyDB.
- اختَر المجموعة التي تم إنشاؤها حديثًا وانقر على الجهاز الظاهري.
- في قائمة التنقّل في AlloyDB، انقر على AlloyDB Studio. سجِّل الدخول باستخدام بيانات اعتمادك.
- افتح علامة تبويب جديدة من خلال النقر على رمز علامة تبويب جديدة على يسار الشاشة.
- انسخ عبارات طلب البحث
insertوشغِّلها من ملفاتinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlواحدًا تلو الآخر. يمكنك تشغيل عبارات الإدراج من 10 إلى 50 نسخة للحصول على عرض توضيحي سريع لحالة الاستخدام هذه.
لتشغيلها، انقر على تشغيل. تظهر نتائج طلب البحث في جدول النتائج.
5- إنشاء تضمينات لبيانات براءات الاختراع
لنختبر أولاً دالة التضمين من خلال تنفيذ نموذج الاستعلام التالي:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
من المفترض أن يعرض هذا الطلب متجه التضمينات، الذي يبدو كصفيف من الأرقام العشرية، للنص النموذجي في الطلب. يظهر على النحو التالي:
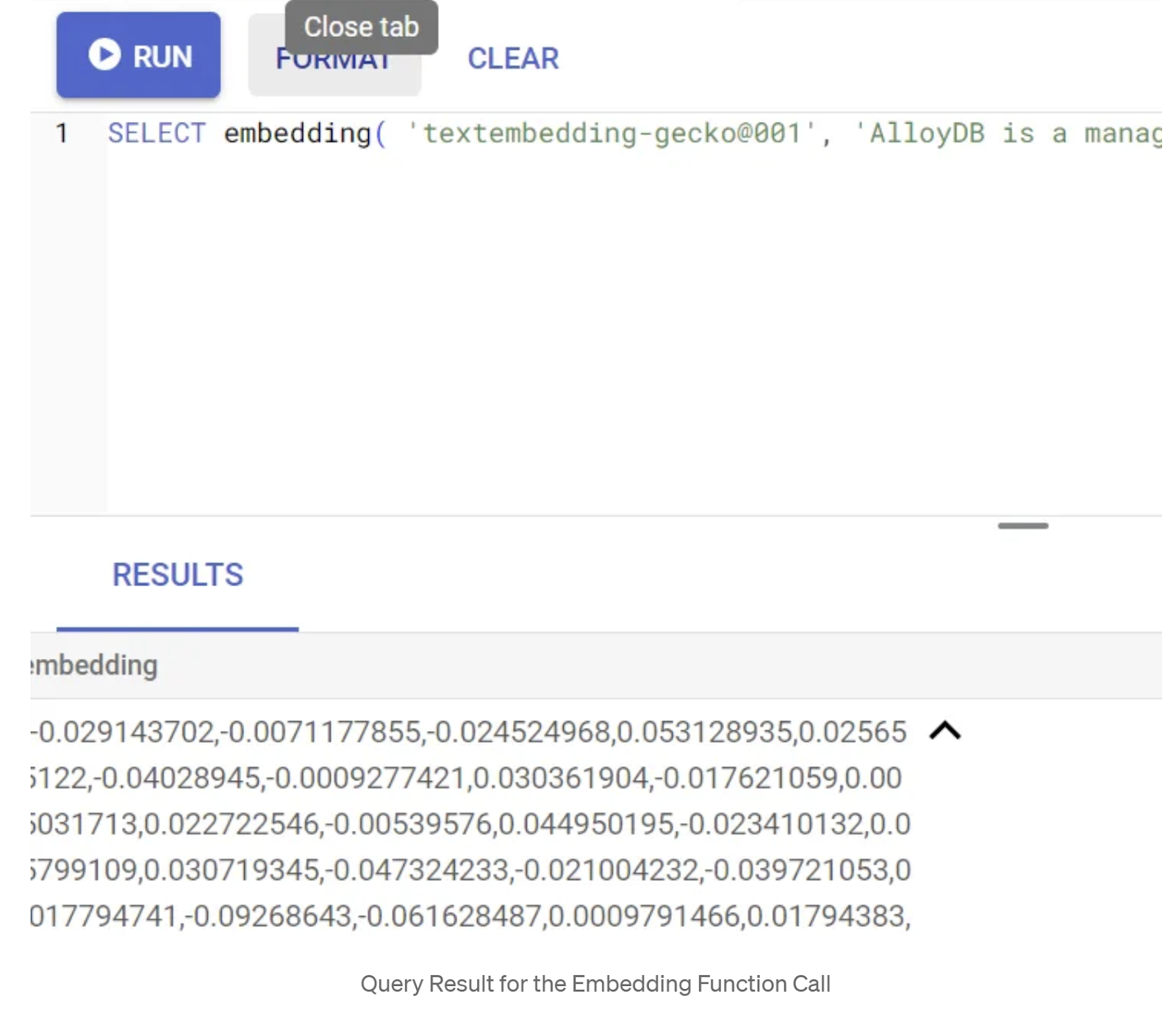
تعديل حقل "المتجهات" abstract_embeddings
يجب استخدام لغة معالجة البيانات (DML) أدناه لتعديل ملخّصات براءات الاختراع في الجدول باستخدام عمليات التضمين المقابلة في حال الحاجة إلى إنشاء عمليات التضمين للملخّصات. ولكن في حالتنا، تحتوي عبارات الإدراج على هذه التضمينات لكل ملخّص، لذا لا تحتاج إلى استدعاء طريقة embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. إجراء بحث عن المتّجهات
بعد أن أصبح الجدول والبيانات والتضمينات جاهزة، لننفّذ الآن عملية "البحث المتّجه" في الوقت الفعلي عن نص بحث المستخدم. يمكنك اختبار ذلك من خلال تنفيذ طلب البحث أدناه:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
في هذا الاستعلام،
- نص البحث الذي أدخله المستخدم هو: "تحليل المشاعر".
- نحوّل النص إلى تضمينات باستخدام الدالة embedding() وطراز text-embedding-005.
- يمثّل "<=>" استخدام طريقة قياس المسافة COSINE SIMILARITY.
- نحوّل نتيجة طريقة التضمين إلى نوع متّجه لجعلها متوافقة مع المتّجهات المخزّنة في قاعدة البيانات.
- يشير LIMIT 10 إلى أنّنا نختار 10 نتائج مطابقة لنص البحث.
ترتقي AlloyDB بميزة "البحث الدلالي" باستخدام تقنية RAG إلى مستوى جديد:
تم تقديم عدد كبير من الميزات. في ما يلي اثنان من هذه المؤشرات التي تركّز على المطوّرين:
- التصفية المضمّنة
- Recall Evaluator
التصفية المضمّنة
في السابق، كان على المطوّر إجراء طلب بحث عن تطابق جزئي، وكان عليه التعامل مع الفلترة والاسترجاع. يتّخذ "محسِّن طلبات البحث" في AlloyDB قرارات بشأن كيفية تنفيذ طلب بحث باستخدام الفلاتر. الفلترة المضمّنة هي أسلوب جديد لتحسين طلبات البحث يتيح لمحسِّن طلبات البحث في AlloyDB تقييم كلّ من شروط فلترة البيانات الوصفية والبحث المتّجه في الوقت نفسه، والاستفادة من كلّ من فهارس المتّجهات والفهارس في أعمدة البيانات الوصفية. وقد أدّى ذلك إلى تحسين أداء الاسترجاع، ما يتيح للمطوّرين الاستفادة من مزايا AlloyDB الجاهزة للاستخدام.
تكون الفلترة المضمّنة هي الأفضل في الحالات التي تتضمّن انتقائية متوسطة. أثناء بحث AlloyDB في فهرس المتجهات، لا يحتسب المسافات إلا للمتجهات التي تتطابق مع شروط فلترة البيانات الوصفية (الفلاتر الوظيفية في الاستعلام التي يتم التعامل معها عادةً في عبارة WHERE). يؤدي ذلك إلى تحسين الأداء بشكل كبير لهذه الطلبات، ما يكمّل مزايا الفلترة اللاحقة أو الفلترة المسبقة.
- تثبيت إضافة pgvector أو تحديثها
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
إذا كانت إضافة pgvector مثبَّتة من قبل، عليك ترقية إضافة المتّجه إلى الإصدار 0.8.0.google-3 أو إصدار أحدث للاستفادة من إمكانات أداة تقييم الاسترجاع.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
يجب تنفيذ هذه الخطوة فقط إذا كان إصدار إضافة المتّجه أقل من 0.8.0.google-3.
ملاحظة مهمة: إذا كان عدد الصفوف أقل من 100، لن تحتاج إلى إنشاء فهرس ScaNN في المقام الأول لأنّه لن ينطبق على عدد أقل من الصفوف. في هذه الحالة، يُرجى تخطّي الخطوات التالية.
- لإنشاء فهارس ScaNN، ثبِّت إضافة alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- أولاً، شغِّل استعلام "البحث المتّجه" بدون الفهرس وبدون تفعيل "الفلتر المضمّن":
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
يجب أن تكون النتيجة مشابهة لما يلي:

- تشغيل Explain Analyze عليه: (بدون فهرس ولا ميزة "التصفية المضمّنة")

يستغرق التنفيذ 2.4 ملي ثانية
- لننشئ فهرسًا عاديًا في الحقل num_claims حتى نتمكّن من الفلترة حسبه:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- لننشئ فهرس ScaNN لتطبيق "بحث براءات الاختراع". نفِّذ ما يلي من AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
ملاحظة مهمة: تنطبق (num_leaves=32) على مجموعة البيانات الكاملة التي تتضمّن أكثر من 1000 صف. إذا كان عدد الصفوف أقل من 100، لن تحتاج إلى إنشاء فهرس في المقام الأول لأنّه لن ينطبق على عدد الصفوف الأقل.
- اضبط ميزة "الفلترة المضمّنة" على "مفعّلة" في فهرس ScaNN:
SET scann.enable_inline_filtering = on
- الآن، لننفّذ طلب البحث نفسه مع تضمين فلتر و"البحث المتّجه":
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
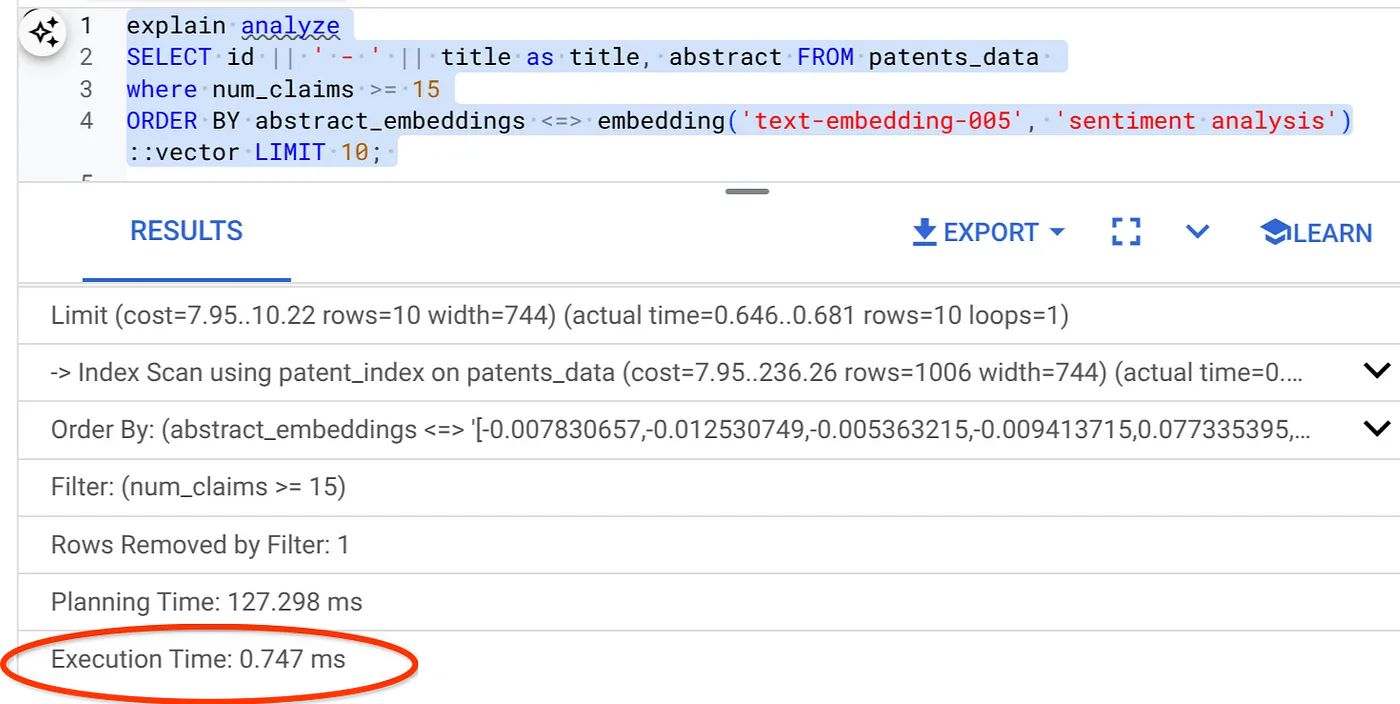
كما تلاحظ، تم تقليل وقت التنفيذ بشكلٍ كبير لعملية "البحث المتّجه" نفسها. أتاحت ميزة "الفلترة المضمّنة" المدمجة في فهرس ScaNN على "البحث المتّجه" إمكانية إجراء ذلك.
بعد ذلك، لنقيّم معدّل الاسترجاع لعملية البحث المتجهي المفعَّلة في ScaNN.
Recall Evaluator
في البحث المشابه، يشير التذكّر إلى النسبة المئوية للحالات ذات الصلة التي تم استرجاعها من عملية بحث، أي عدد النتائج الموجبة الصحيحة. هذا هو المقياس الأكثر شيوعًا المستخدَم لقياس جودة البحث. أحد أسباب فقدان الاسترجاع هو الفرق بين البحث عن الجيران الأقرب التقريبي، أو aNN، والبحث عن الجيران الأقرب k (التام)، أو kNN. تنفّذ فهارس المتجهات، مثل ScaNN في AlloyDB، خوارزميات aNN، ما يتيح لك تسريع البحث المتّجه في مجموعات البيانات الكبيرة مقابل تنازل بسيط في الاسترجاع. تتيح لك AlloyDB الآن إمكانية قياس هذا التوازن مباشرةً في قاعدة البيانات للاستعلامات الفردية والتأكّد من ثباته بمرور الوقت. يمكنك تعديل مَعلمات الطلب والفهرس استجابةً لهذه المعلومات لتحقيق نتائج وأداء أفضل.
يمكنك العثور على مقياس الاسترجاع لاستعلام متّجه في فهرس متّجه لإعدادات معيّنة باستخدام الدالة evaluate_query_recall. تتيح لك هذه الدالة ضبط المَعلمات لتحقيق نتائج استرجاع طلب البحث المتّجه التي تريدها. مقياس "الاسترجاع" هو المقياس المستخدَم لجودة البحث، ويتم تعريفه على أنّه النسبة المئوية للنتائج المعروضة التي تكون الأقرب موضوعيًا إلى متّجهات طلب البحث. تكون الدالة evaluate_query_recall مفعّلة تلقائيًا.
ملاحظة مهمة:
إذا واجهت خطأ "تم رفض الإذن" في فهرس HNSW في الخطوات التالية، تخطَّ قسم تقييم الاسترجاع بالكامل في الوقت الحالي. قد يكون ذلك مرتبطًا بقيود الوصول في هذه المرحلة، لأنّ هذه الميزة تم إطلاقها للتوّ عند إنشاء مستندات هذا الدرس التطبيقي العملي.
- اضبط علامة Enable Index Scan على فهرس ScaNN وفهرس HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- نفِّذ الاستعلام التالي في AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
تتلقّى الدالة evaluate_query_recall طلب البحث كمَعلمة وتعرض مدى استرجاعه. أستخدم طلب البحث نفسه الذي استخدمته للتحقّق من الأداء كطلب بحث إدخال للدالة. لقد أضفتُ SCaNN كطريقة فهرسة. لمزيد من خيارات المَعلمات، يُرجى الرجوع إلى المستندات.
معدّل الاسترجاع لطلب البحث هذا في Vector Search الذي كنا نستخدمه:
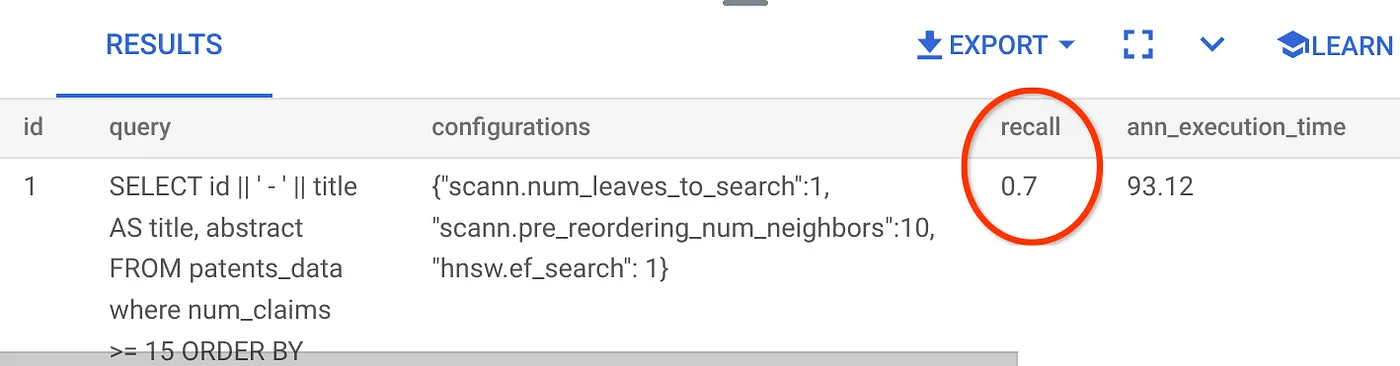
أرى أنّ معدّل الاستدعاء هو %70. يمكنني الآن استخدام هذه المعلومات لتغيير مَعلمات الفهرس والطرق ومَعلمات طلب البحث وتحسين استرجاع المعلومات في ميزة "البحث المتّجه".
لقد عدّلتُ عدد الصفوف في مجموعة النتائج إلى 7 (بدلاً من 10 سابقًا)، ولاحظتُ تحسّنًا طفيفًا في مقياس الاسترجاع، أي بنسبة %86.
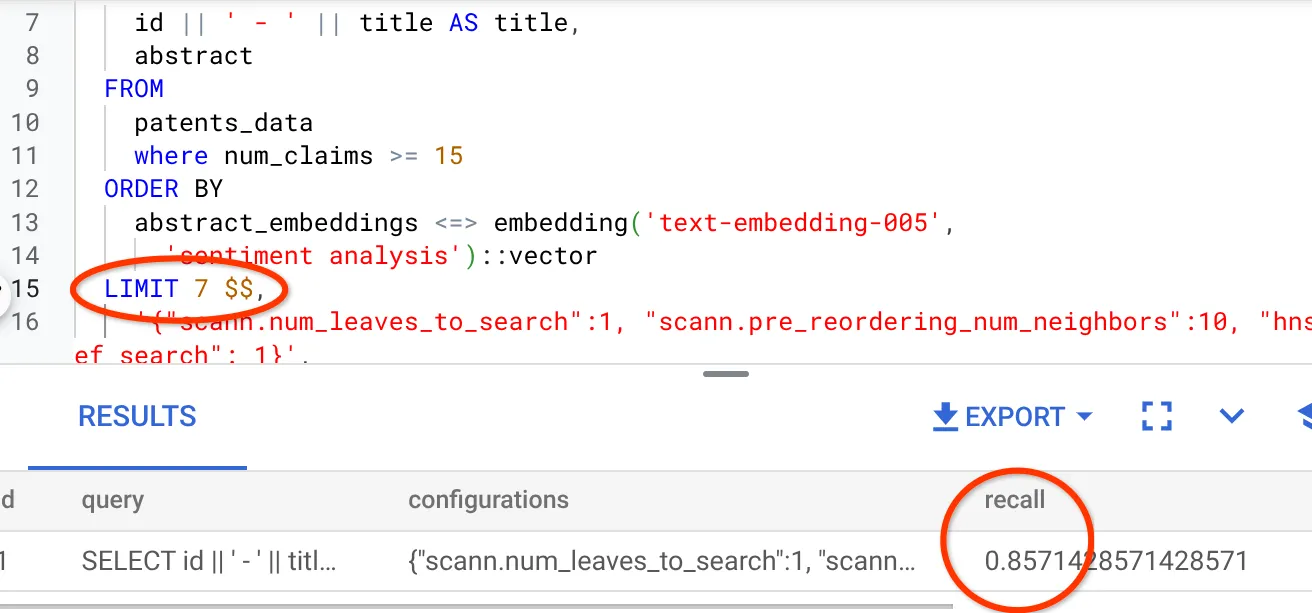
وهذا يعني أنّه يمكنني في الوقت الفعلي تغيير عدد النتائج التي يراها المستخدمون لتحسين مدى ملاءمتها وفقًا لسياق بحث المستخدمين.
حسناً الآن! حان الوقت لنشر منطق قاعدة البيانات والانتقال إلى الوكيل.
7. نقل منطق قاعدة البيانات إلى خادم الويب بدون خادم
هل أنت مستعد لنقل هذا التطبيق إلى الويب؟ يُرجى اتّباع الخطوات التالية:
- انتقِل إلى "وظائف Cloud Run" في Google Cloud Console لإنشاء وظيفة Cloud Run جديدة من خلال النقر على "كتابة وظيفة" أو استخدام الرابط: https://console.cloud.google.com/run/create?deploymentType=function.
- اختَر الخيار "استخدام محرِّر مضمّن لإنشاء دالة" وابدأ عملية الإعداد. قدِّم اسم الخدمة patent-search واختَر المنطقة us-central1 ووقت التشغيل Java 17. اضبط المصادقة على السماح باستدعاءات غير مصادَق عليها.
- في قسم "الحاويات ووحدات التخزين والشبكات والأمان"، اتّبِع الخطوات التالية بدون تفويت أي تفاصيل:
انتقِل إلى علامة التبويب "الاتصال بالشبكات" (Networking):
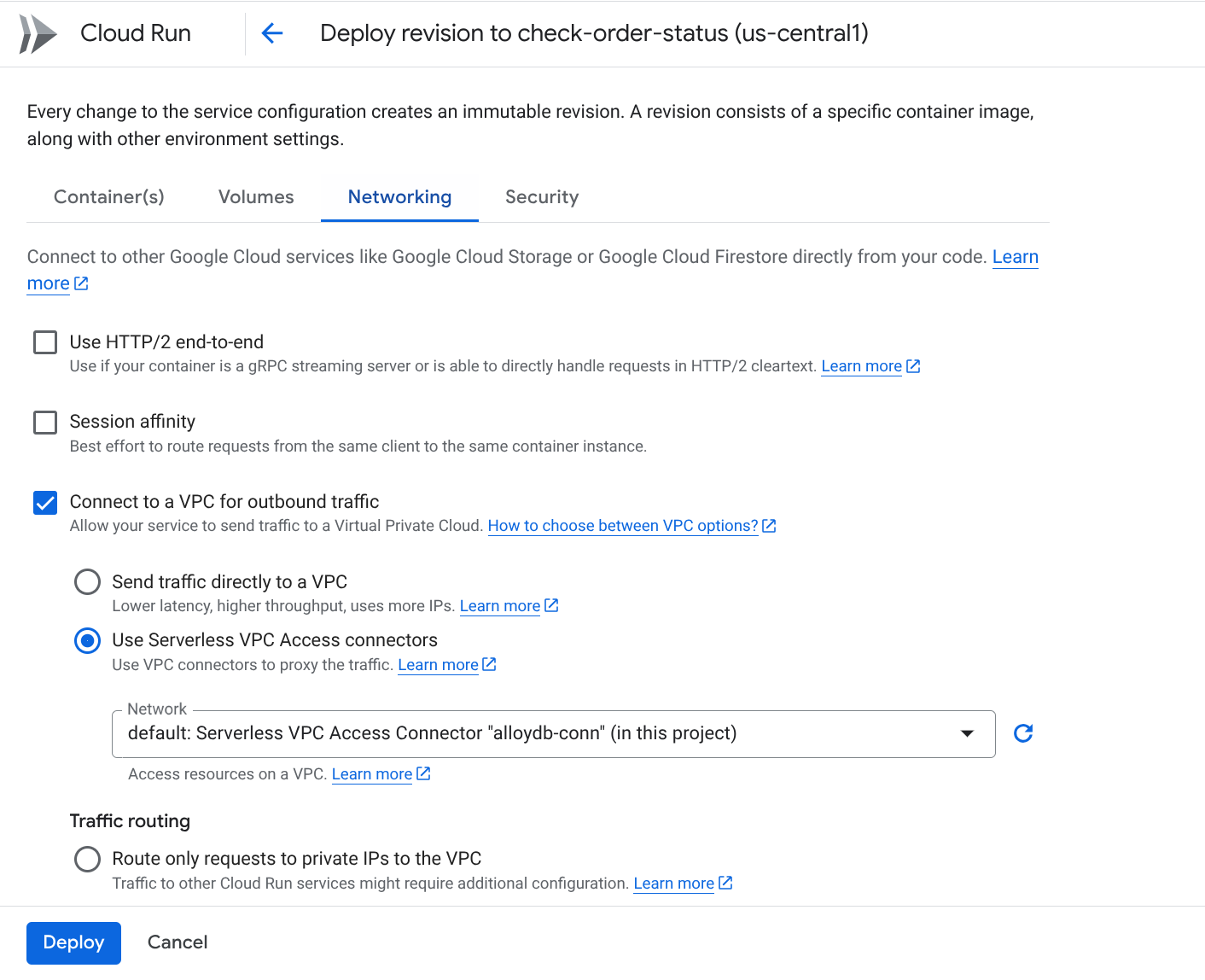
اختَر الاتصال بشبكة VPC لنقل البيانات الصادرة، ثم اختَر استخدام موصّلات إمكانية الوصول إلى VPC بدون خادم.
ضمن القائمة المنسدلة "الشبكة"، انقر على القائمة المنسدلة "الشبكة" واختَر الخيار إضافة رابط VPC جديد (إذا لم تكن قد أعددت الرابط التلقائي بعد)، واتّبِع التعليمات التي تظهر في مربّع الحوار المنبثق:

قدِّم اسمًا لموصّل VPC وتأكَّد من أنّ المنطقة هي نفسها منطقة المثيل. اترك قيمة "الشبكة" على الوضع التلقائي واضبط "الشبكة الفرعية" على "نطاق IP مخصّص" مع نطاق IP 10.8.0.0 أو نطاق مشابه متوفّر.
وسِّع SHOW SCALING SETTINGS وتأكَّد من ضبط الإعدادات على ما يلي بالضبط:
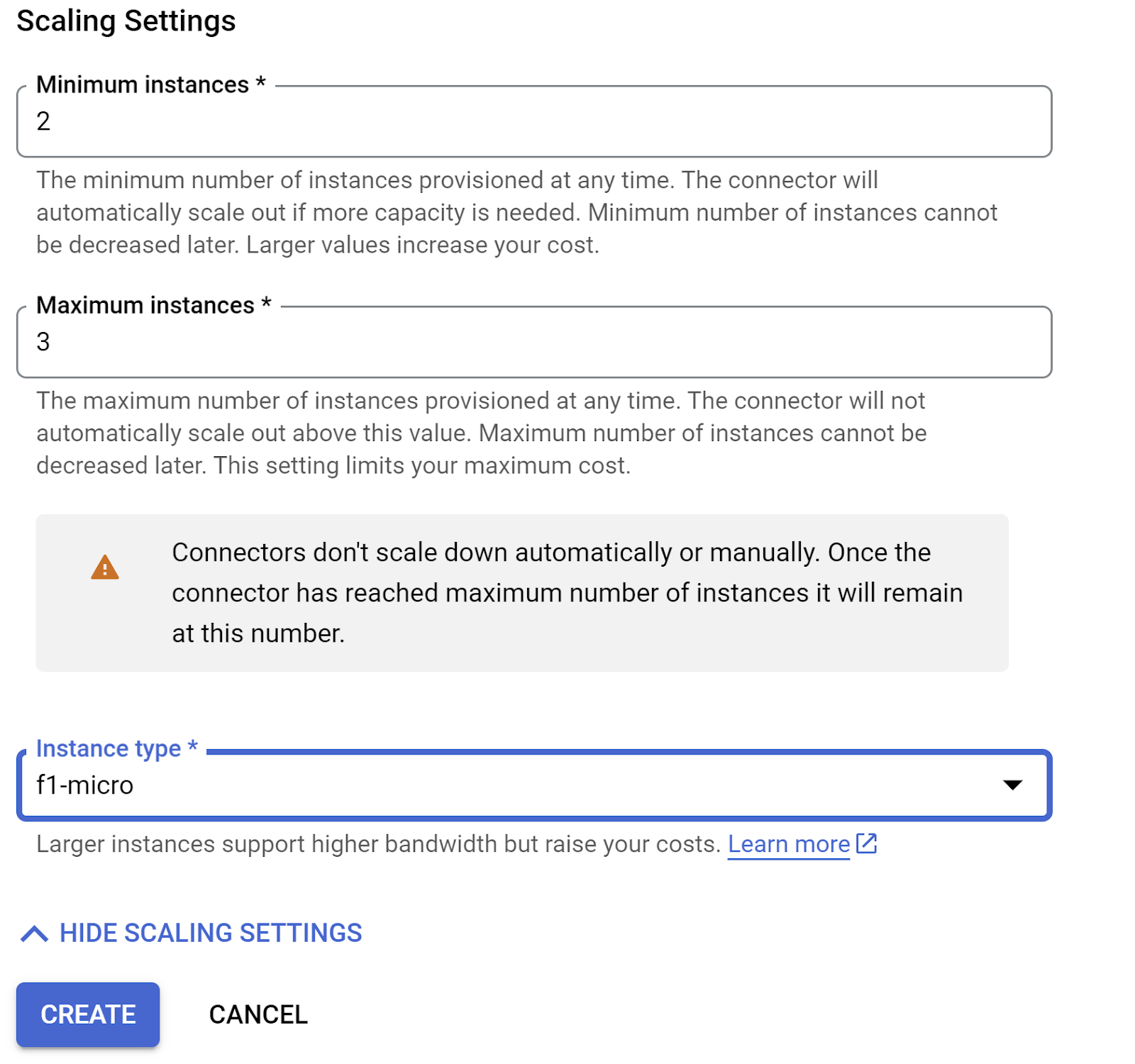
انقر على إنشاء، ومن المفترض أن يظهر هذا الرابط في إعدادات الخروج الآن.
اختَر الموصّل الذي تم إنشاؤه حديثًا.
اختَر توجيه كل حركة البيانات من خلال موصّل شبكة VPC هذا.
انقر على التالي ثم على نشر.
- سيتم ضبط نقطة الدخول تلقائيًا على "gcfv2.HelloHttpFunction". استبدِل رمز العنصر النائب في HelloHttpFunction.java وpom.xml الخاصَّين بـ "دالة Cloud Run" بالرمز من PatentSearch.java وpom.xml على التوالي. غيِّر اسم ملف الفئة إلى PatentSearch.java.
- تذكَّر تغيير العنصر النائب ************* وبيانات اعتماد الاتصال بـ AlloyDB بقيمك في ملف Java. بيانات اعتماد AlloyDB هي تلك التي استخدمناها في بداية هذا الدرس البرمجي. إذا كنت قد استخدمت قيمًا مختلفة، يُرجى تعديلها في ملف Java.
- انقر على نشر.
- بعد نشر Cloud Function المعدَّلة، من المفترض أن تظهر لك نقطة النهاية التي تم إنشاؤها. انسخ ذلك النص واستبدله في الأمر التالي:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
هذا كل شيء! بهذه البساطة، يمكنك إجراء عملية بحث متقدّمة عن المتّجهات المتشابهة سياقيًا باستخدام نموذج Embeddings على بيانات AlloyDB.
8. لننشئ الوكيل باستخدام Java ADK
لنبدأ أولاً بمشروع Java في المحرّر.
- الانتقال إلى "وحدة طرفية Cloud Shell"
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- السماح بالوصول عند الطلب
- يمكنك التبديل إلى "محرّر Cloud Shell" من خلال النقر على رمز المحرّر في أعلى وحدة تحكّم Cloud Shell.

- في وحدة تحكّم Cloud Shell Editor، أنشئ مجلدًا جديدًا وسمِّه "adk-agents".
انقر على "إنشاء مجلد جديد" في الدليل الجذر لـ Cloud Shell كما هو موضّح أدناه:

أطلِق عليها الاسم "adk-agents":
- أنشئ بنية المجلدات التالية والملفات الفارغة بأسماء الملفات المقابلة في البنية أدناه:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- افتح مستودع github في علامة تبويب منفصلة وانسخ الرمز المصدري للملفَين App.java وpom.xml.
- إذا كنت قد فتحت المحرّر في علامة تبويب جديدة باستخدام رمز "فتح في علامة تبويب جديدة" في أعلى يسار الصفحة، يمكنك فتح نافذة الوحدة الطرفية في أسفل الصفحة. يمكنك فتح كل من المحرِّر والوحدة الطرفية بالتوازي، ما يتيح لك العمل بحرية.
- بعد الاستنساخ، ارجع إلى وحدة تحكّم "محرّر Cloud Shell".
- بما أنّنا أنشأنا وظيفة Cloud Run، لست بحاجة إلى نسخ ملفات وظيفة Cloud Run من مجلد المستودع.
بدء استخدام حزمة تطوير البرامج (SDK) بلغة Java في "حزمة تطوير تطبيقات Android للسيارات"
الأمر بسيط جدًا. عليك في المقام الأول التأكّد من أنّ خطوة الاستنساخ تتضمّن ما يلي:
- إضافة التبعيات:
أدرِج العنصرين google-adk وgoogle-adk-dev (لواجهة مستخدم الويب) في ملف pom.xml. إذا نسخت المصدر من المستودع، تكون هذه المعلومات مضمّنة في الملفات، ولن تحتاج إلى تضمينها. ما عليك سوى إجراء تغيير في نقطة نهاية Cloud Run Function لعكس نقطة النهاية التي تم نشرها. سيتم تناولها في الخطوات القادمة في هذا القسم.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
احرص على الرجوع إلى ملف pom.xml من مستودع المصدر لأنّ هناك تبعيات وإعدادات أخرى مطلوبة لتشغيل التطبيق.
- ضبط إعدادات مشروعك:
تأكَّد من ضبط إصدار Java (يُنصح بالإصدار 17 أو أحدث) وإعدادات برنامج الترجمة البرمجية Maven بشكلٍ صحيح في ملف pom.xml. يمكنك ضبط مشروعك على النحو التالي:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- تحديد "الوكيل" وأدواته (App.java):
هنا يظهر سحر حزمة تطوير البرامج (SDK) بلغة Java في "حزمة تطوير تطبيقات Android" (ADK). نحدّد الوكيل وإمكاناته (التعليمات) والأدوات التي يمكنه استخدامها.
يمكنك العثور هنا على نسخة مبسّطة من بعض مقتطفات الرموز البرمجية لفئة الوكيل الرئيسية. للاطّلاع على المشروع الكامل، يُرجى الرجوع إلى مستودع المشروع هنا.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
أبرز مكوّنات رمز Java في حزمة تطوير التطبيقات:
- LlmAgent.builder(): واجهة برمجة تطبيقات سلسة لإعداد الوكيل.
- .instruction(...): يقدّم الطلب الأساسي والإرشادات للنموذج اللغوي الكبير، بما في ذلك الحالات التي يجب فيها استخدام أداة معيّنة.
- FunctionTool.create(App.class, "methodName"): تسجّل هذه الطريقة بسهولة طرق Java كأدوات يمكن للوكيل استدعاؤها. يجب أن تتطابق سلسلة اسم الطريقة مع طريقة ثابتة عامة فعلية.
- @Schema(description = ...): يضيف تعليقات توضيحية إلى مَعلمات الأدوات، ما يساعد النموذج اللغوي الكبير في فهم الإدخالات التي تتوقّعها كل أداة. هذا الوصف مهم لاختيار الأداة المناسبة وملء المَعلمات بدقة.
- InvocationContext ctx: يتم تمريرها تلقائيًا إلى طرق الأدوات، ما يتيح الوصول إلى حالة الجلسة (ctx.session().state()) ومعلومات المستخدم وغير ذلك.
- .outputKey("patents"): عندما تعرض أداة ما بيانات، يمكن لـ ADK تخزينها تلقائيًا في حالة الجلسة ضمن هذا المفتاح. إليك الطريقة التي يمكن من خلالها لأداة explainPatent الوصول إلى النتائج من getPatents.
- VECTOR_SEARCH_ENDPOINT: هذا متغير يحتوي على المنطق الوظيفي الأساسي لميزة "السؤال والأجوبة" السياقية للمستخدم في حالة استخدام البحث عن براءات الاختراع.
- عليك تنفيذ الإجراء التالي: عليك ضبط قيمة نقطة نهاية معدَّلة تم نشرها بعد تنفيذ خطوة "وظيفة Java Cloud Run" من القسم السابق.
- searchTool: تتفاعل هذه الأداة مع المستخدم للعثور على براءات اختراع ذات صلة سياقيًا من قاعدة بيانات براءات الاختراع لنص البحث الذي أدخله المستخدم.
- explainTool: يطلب هذا الإجراء من المستخدم تقديم براءة اختراع معيّنة للتعمّق فيها. بعد ذلك، تلخّص براءة الاختراع وتستطيع الإجابة عن المزيد من أسئلة المستخدم استنادًا إلى تفاصيل براءة الاختراع المتوفّرة لديها.
ملاحظة مهمة: احرص على استبدال المتغير VECTOR_SEARCH_ENDPOINT بنقطة نهاية CRF التي تم نشرها.
الاستفادة من InvocationContext للتفاعلات التي تحتفظ بحالتها
إحدى الميزات المهمة لإنشاء وكلاء مفيدين هي إدارة الحالة على مستوى عدة أدوار في المحادثة. تسهّل InvocationContext في حزمة تطوير التطبيقات (ADK) هذه العملية.
في ملف App.java:
- عند تحديد initAgent()، نستخدم .outputKey("patents"). يُعلم هذا الإعداد ADK أنّه عندما تعرض أداة (مثل getPatents) البيانات في حقل التقرير، يجب تخزين هذه البيانات في حالة الجلسة ضمن المفتاح "patents".
- في طريقة explainPatent الخاصة بالأداة، نضيف InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
يتيح ذلك لأداة explainPatent الوصول إلى قائمة براءات الاختراع التي تم استرجاعها بواسطة أداة getPatents في دورة سابقة، ما يجعل المحادثة ذات حالة ومتسقة.
9- اختبار واجهة سطر الأوامر المحلية
تحديد متغيرات البيئة
عليك تصدير متغيرَي بيئة:
- مفتاح Gemini يمكنك الحصول عليه من AI Studio:
لإجراء ذلك، انتقِل إلى https://aistudio.google.com/apikey واحصل على مفتاح واجهة برمجة التطبيقات لمشروعك النشط على Google Cloud الذي تنفّذ فيه هذا التطبيق، ثم احفظ المفتاح في مكان ما:
- بعد الحصول على المفتاح، افتح "وحدة طرفية Cloud Shell" وانتقِل إلى الدليل الجديد الذي أنشأناه للتو adk-agents من خلال تنفيذ الأمر التالي:
cd adk-agents
- متغيّر لتحديد أنّنا لن نستخدم Vertex AI هذه المرة.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- تشغيل الوكيل الأول على واجهة سطر الأوامر
لتشغيل هذا العامل الأول، استخدِم أمر Maven التالي في الوحدة الطرفية:
mvn compile exec:java -DmainClass="agents.App"
سيظهر لك الردّ التفاعلي من الوكيل في نافذة الجهاز.
10. النشر على Cloud Run
إنّ نشر وكيل Java الخاص بـ ADK على Cloud Run يشبه نشر أي تطبيق Java آخر:
- Dockerfile: أنشئ Dockerfile لتعبئة تطبيق Java.
- إنشاء صورة Docker ونشرها: استخدِم Google Cloud Build وArtifact Registry.
- يمكنك تنفيذ الخطوة أعلاه ونشرها على Cloud Run باستخدام أمر واحد فقط:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
وبالمثل، يمكنك نشر دالة Java Cloud Run (gcfv2.PatentSearch). بدلاً من ذلك، يمكنك إنشاء وظيفة Java Cloud Run Function ونشرها لمنطق قاعدة البيانات مباشرةً من وحدة تحكّم Cloud Run Function.
11. إجراء الاختبارات باستخدام واجهة مستخدم الويب
تتضمّن "حزمة تطوير التطبيقات" واجهة مستخدم سهلة الاستخدام على الويب لإجراء الاختبارات المحلية وتصحيح أخطاء الوكيل. عند تشغيل App.java محليًا (على سبيل المثال، mvn exec:java -Dexec.mainClass="agents.App" في حال ضبطه، أو مجرد تشغيل الطريقة الرئيسية)، يبدأ ADK عادةً خادم ويب محليًا.
تتيح لك واجهة مستخدم الويب الخاصة بـ ADK إجراء ما يلي:
- إرسال رسائل إلى موظف الدعم
- اطّلِع على الأحداث (رسالة المستخدم، واستدعاء الأداة، وردّ الأداة، وردّ النموذج اللغوي الكبير).
- فحص حالة الجلسة
- عرض السجلّات وعمليات التتبُّع
وهذا أمر قيّم للغاية أثناء عملية التطوير لفهم كيفية معالجة الوكيل للطلبات واستخدامه لأدواته. يفترض هذا أنّ mainClass في ملف pom.xml مضبوط على com.google.adk.web.AdkWebServer وأنّ وكيلك مسجّل فيه، أو أنّك تستخدم أداة تشغيل اختبار محلية تعرض هذا.
عند تشغيل App.java باستخدام InMemoryRunner وScanner لإدخال البيانات في وحدة التحكّم، فإنّك تختبر منطق الوكيل الأساسي. واجهة مستخدم الويب هي مكوّن منفصل لتجربة تصحيح أخطاء أكثر مرئية، ويتم استخدامها غالبًا عندما يقدّم ADK وكيلك عبر HTTP.
يمكنك استخدام أمر Maven التالي من الدليل الجذر لتشغيل خادم SpringBoot المحلي:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
يمكن غالبًا الوصول إلى الواجهة من خلال عنوان URL الذي يعرضه الأمر أعلاه. إذا كان تم نشره على Cloud Run، من المفترض أن تتمكّن من الوصول إليه من خلال الرابط الذي تم نشره عليه.
من المفترض أن تظهر لك النتيجة في واجهة تفاعلية.
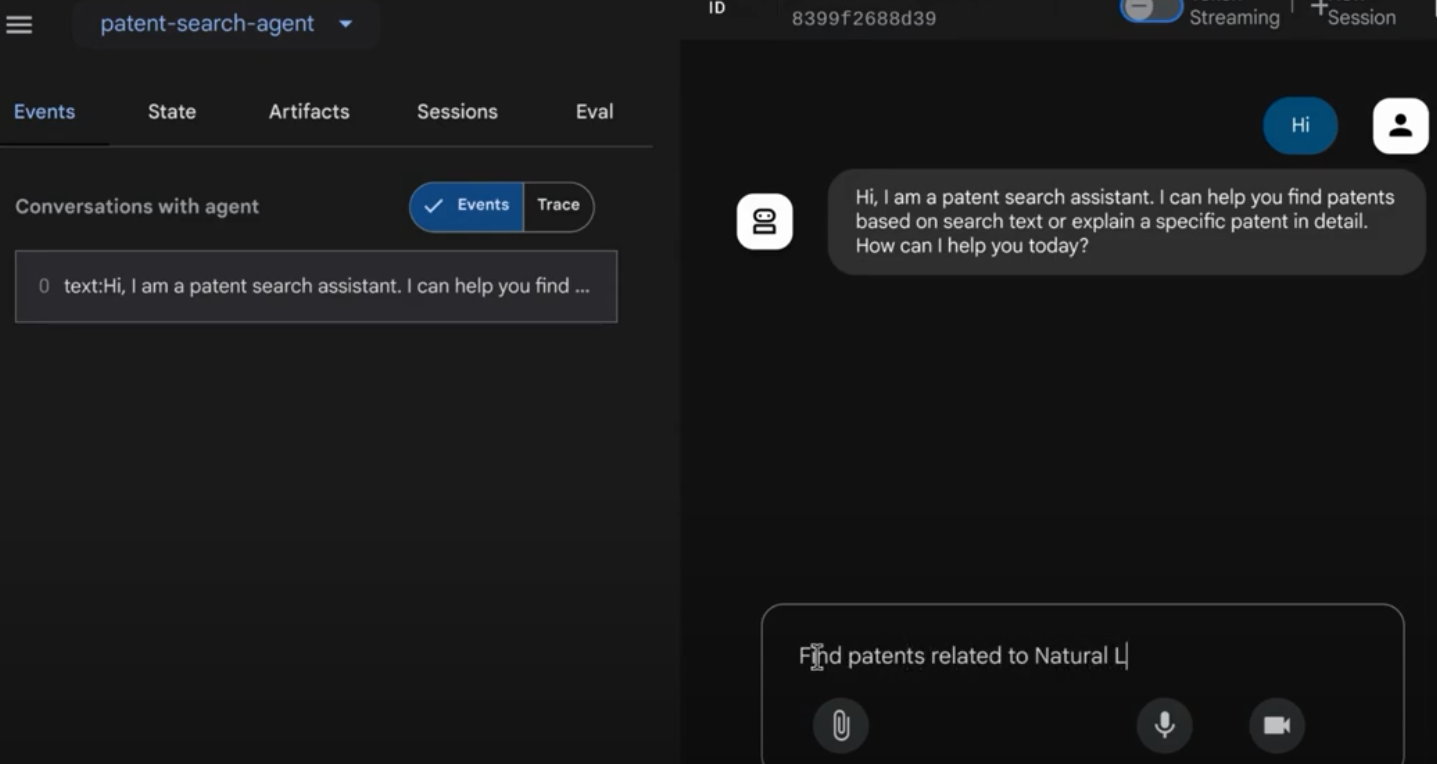
يمكنك مشاهدة الفيديو أدناه للتعرّف على "وكيل براءات الاختراع" الذي تم نشره:
12. تَنظيم
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذه المشاركة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- انتقِل إلى صفحة https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog.
- في قائمة المشاريع، اختَر المشروع الذي تريد حذفه، ثم انقر على حذف.
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على إيقاف لحذف المشروع.
13. تهانينا
تهانينا! لقد أنشأت بنجاح "وكيل تحليل براءات الاختراع" في Java من خلال الجمع بين إمكانات ADK وhttps://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog وVertex AI وVector Search، كما حقّقنا تقدّمًا كبيرًا في جعل عمليات البحث عن التشابه السياقي تحويلية وفعّالة ومستندة إلى المعنى.
ابدأ اليوم
مستندات ADK: [Link to Official ADK Java Docs]
رمز المصدر الخاص بـ "وكيل تحليل براءات الاختراع": [رابط إلى مستودع GitHub (العلني الآن)]
نماذج وكلاء Java: [link to the adk-samples repo]
الانضمام إلى منتدى ADK: https://www.reddit.com/r/agentdevelopmentkit/
نتمنّى لك تجربة ممتعة في إنشاء الوكلاء.