
1. 개요
다양한 산업에서 컨텍스트 검색은 애플리케이션의 핵심을 이루는 중요한 기능입니다. 검색 증강 생성은 생성형 AI 기반 검색 메커니즘을 통해 오랫동안 이 중요한 기술 발전의 핵심 동인이었습니다. 생성형 모델은 큰 컨텍스트 윈도우와 인상적인 출력 품질로 AI를 혁신하고 있습니다. RAG는 AI 애플리케이션과 에이전트에 컨텍스트를 주입하여 구조화된 데이터베이스 또는 다양한 미디어의 정보를 기반으로 그라운딩하는 체계적인 방법을 제공합니다. 이러한 맥락 데이터는 사실의 명확성과 출력의 정확성에 매우 중요하지만, 결과의 정확성은 얼마나 될까요? 비즈니스가 이러한 맥락 일치 및 관련성의 정확성에 크게 의존하나요? 그렇다면 이 프로젝트가 마음에 드실 겁니다.
이제 생성형 모델의 힘을 활용하여 이러한 맥락에 중요한 정보를 기반으로 하고 사실에 근거하여 자율적으로 결정을 내릴 수 있는 대화형 에이전트를 구축할 수 있다고 상상해 보세요. 이것이 바로 오늘 우리가 구축할 것입니다. 특허 분석 애플리케이션을 위해 AlloyDB의 고급 RAG로 구동되는 에이전트 개발 키트를 사용하여 엔드 투 엔드 AI 에이전트 앱을 빌드합니다.
특허 분석 에이전트는 사용자가 검색 텍스트와 맥락상 관련성이 있는 특허를 찾도록 지원하며, 요청 시 선택한 특허에 대한 명확하고 간결한 설명과 필요한 경우 추가 세부정보를 제공합니다. 방법을 알아볼까요? 그럼 자세히 살펴보죠.
목표
목표는 간단합니다. 사용자가 텍스트 설명을 기반으로 특허를 검색한 다음 검색 결과에서 특정 특허에 대한 자세한 설명을 확인할 수 있습니다. 이 모든 작업은 Java ADK, AlloyDB, 벡터 검색 (고급 색인 포함), Gemini로 빌드된 AI 에이전트를 사용하여 이루어지며 전체 애플리케이션은 Cloud Run에 서버리스로 배포됩니다.
빌드할 항목
이 실습에서는 다음 작업을 수행합니다.
- AlloyDB 인스턴스를 만들고 특허 공개 데이터 세트 데이터 로드
- ScaNN 및 리콜 평가 기능을 사용하여 AlloyDB에서 고급 벡터 검색 구현
- Java ADK를 사용하여 에이전트 만들기
- Java 서버리스 Cloud Functions에서 데이터베이스 서버 측 로직 구현
- Cloud Run에서 에이전트 배포 및 테스트
다음 다이어그램은 구현과 관련된 데이터 흐름과 단계를 나타냅니다.
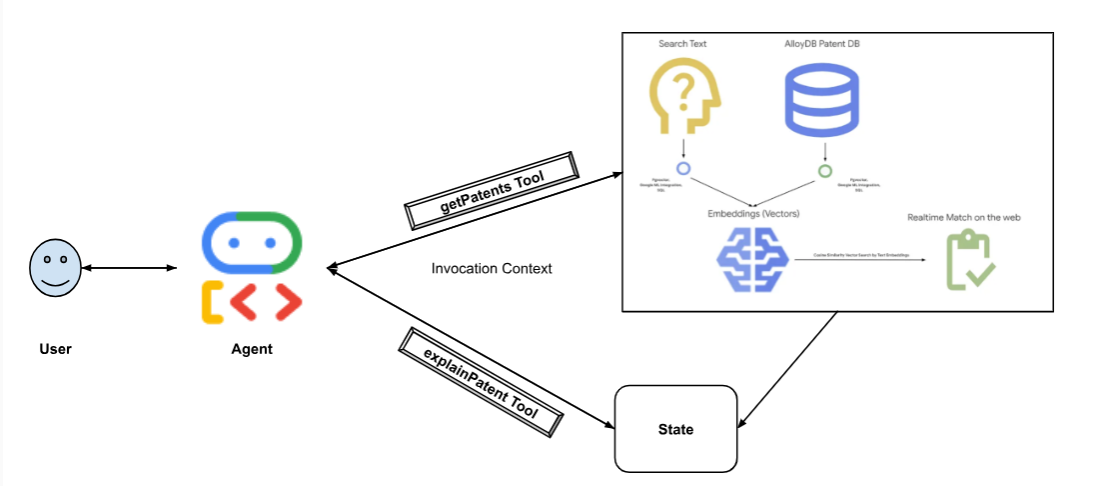
High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요 .
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 인증이 완료되었고 프로젝트가 해당 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API를 사용 설정합니다. Cloud Shell 터미널에서 gcloud 명령어를 사용할 수 있습니다.
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
gcloud 명령의 대안은 콘솔을 통해 각 제품을 검색하거나 이 링크를 사용하는 것입니다.
gcloud 명령어 및 사용법은 문서를 참조하세요.
3. 데이터베이스 설정
이 실습에서는 AlloyDB를 특허 데이터의 데이터베이스로 사용합니다. 클러스터를 사용하여 데이터베이스, 로그와 같은 모든 리소스를 보유합니다. 각 클러스터에는 데이터에 대한 액세스 포인트를 제공하는 기본 인스턴스가 있습니다. 테이블에는 실제 데이터가 저장됩니다.
특허 데이터 세트가 로드될 AlloyDB 클러스터, 인스턴스, 테이블을 만들어 보겠습니다.
클러스터 및 인스턴스 만들기
- Cloud 콘솔에서 AlloyDB 페이지로 이동합니다. Cloud 콘솔에서 대부분의 페이지를 쉽게 찾으려면 콘솔의 검색창을 사용하여 검색하면 됩니다.
- 해당 페이지에서 클러스터 만들기를 선택합니다.

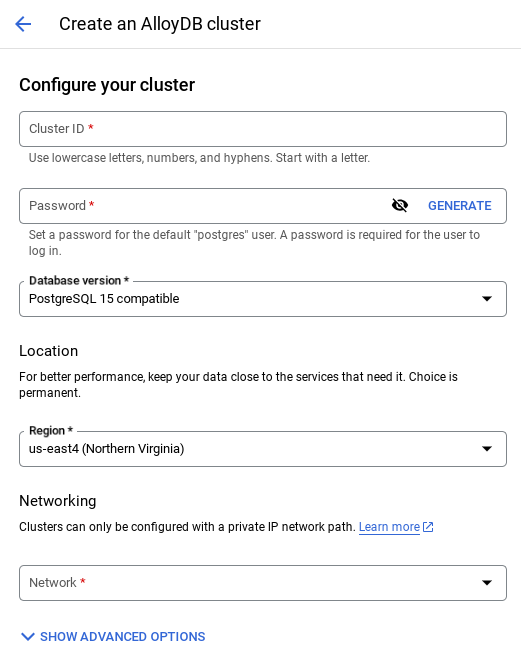
- 아래와 같은 화면이 표시됩니다. 다음 값으로 클러스터 및 인스턴스를 만듭니다. 저장소에서 애플리케이션 코드를 클론하는 경우 값이 일치하는지 확인하세요.
- 클러스터 ID: '
vector-cluster' - password: "
alloydb" - PostgreSQL 15 / 최신 권장 버전
- 지역: "
us-central1" - 네트워킹: "
default"
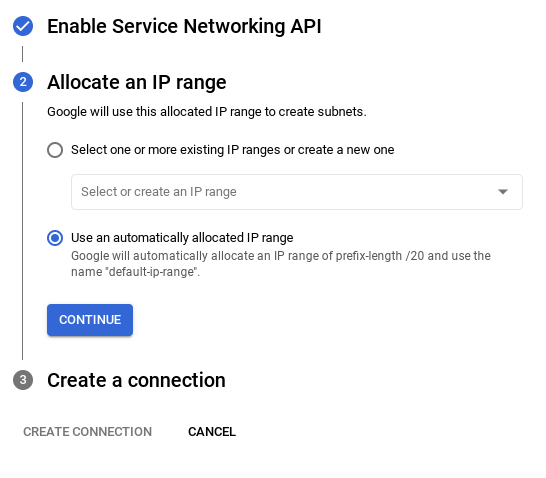
- 기본 네트워크를 선택하면 아래와 같은 화면이 표시됩니다.
연결 설정을 선택합니다.
- 여기에서 '자동으로 할당된 IP 범위 사용'을 선택하고 계속을 클릭합니다. 정보를 검토한 후 연결 만들기를 선택합니다.
- 네트워크가 설정되면 클러스터를 계속 만들 수 있습니다. 클러스터 만들기를 클릭하여 아래와 같이 클러스터 설정을 완료합니다.
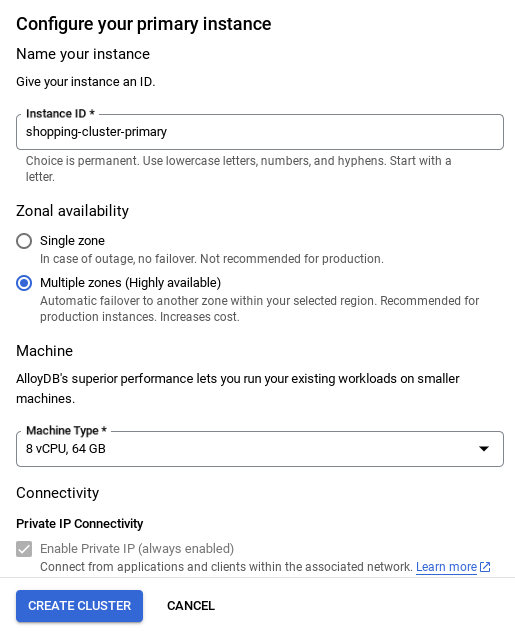
클러스터 / 인스턴스 구성 시 확인할 수 있는 인스턴스 ID를
vector-instance. 변경할 수 없는 경우 앞으로 나오는 모든 참조에서 인스턴스 ID를 사용해야 합니다.
클러스터를 만드는 데 약 10분이 걸립니다. 성공하면 방금 만든 클러스터의 개요가 표시된 화면이 표시됩니다.
4. 데이터 수집
이제 매장에 관한 데이터가 포함된 표를 추가할 차례입니다. AlloyDB로 이동하여 기본 클러스터와 AlloyDB Studio를 선택합니다.

인스턴스 생성이 완료될 때까지 기다려야 할 수 있습니다. 준비가 완료되면 클러스터를 만들 때 만든 사용자 인증 정보를 사용하여 AlloyDB에 로그인합니다. PostgreSQL에 인증하려면 다음 데이터를 사용하세요.
- 사용자 이름 : '
postgres' - 데이터베이스 : '
postgres' - 비밀번호 : '
alloydb'
AlloyDB Studio에서 인증이 완료되면 편집기에 SQL 명령어를 입력합니다. 마지막 창 오른쪽에 있는 더하기 기호를 사용하여 여러 편집기 창을 추가할 수 있습니다.
필요에 따라 실행, 형식 지정, 지우기 옵션을 사용하여 편집기 창에 AlloyDB 명령어를 입력합니다.
확장 프로그램 사용 설정
이 앱을 빌드하기 위해 확장 프로그램 pgvector 및 google_ml_integration를 사용합니다. pgvector 확장 프로그램을 사용하면 벡터 임베딩을 저장하고 검색할 수 있습니다. google_ml_integration 확장 프로그램은 Vertex AI 예측 엔드포인트에 액세스하여 SQL에서 예측을 가져오는 데 사용하는 함수를 제공합니다. 다음 DDL을 실행하여 이러한 확장 프로그램을 사용 설정합니다.
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
데이터베이스에서 사용 설정된 확장 프로그램을 확인하려면 다음 SQL 명령어를 실행합니다.
select extname, extversion from pg_extension;
테이블 만들기
AlloyDB Studio에서 아래 DDL 문을 사용하여 테이블을 만들 수 있습니다.
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
abstract_embeddings 열을 사용하면 텍스트의 벡터 값을 저장할 수 있습니다.
권한 부여
아래 문을 실행하여 'embedding' 함수에 대한 실행 권한을 부여합니다.
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB 서비스 계정에 Vertex AI 사용자 역할 부여
Google Cloud IAM 콘솔에서 AlloyDB 서비스 계정 (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)에 'Vertex AI 사용자' 역할에 대한 액세스 권한을 부여합니다. PROJECT_NUMBER에는 프로젝트 번호가 표시됩니다.
또는 Cloud Shell 터미널에서 아래 명령어를 실행할 수 있습니다.
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
데이터베이스에 특허 데이터 로드
BigQuery의 Google Patents 공개 데이터 세트가 데이터 세트로 사용됩니다. AlloyDB Studio를 사용하여 쿼리를 실행합니다. 데이터는 이 repo의 이 insert scripts sql 파일에 소싱되며, 이를 실행하여 특허 데이터를 로드합니다.
- Google Cloud 콘솔에서 AlloyDB 페이지를 엽니다.
- 새로 만든 클러스터를 선택하고 인스턴스를 클릭합니다.
- AlloyDB 탐색 메뉴에서 AlloyDB Studio를 클릭합니다. 사용자 인증 정보로 로그인합니다.
- 오른쪽에 있는 새 탭 아이콘을 클릭하여 새 탭을 엽니다.
insert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sql파일에서insert쿼리 문을 하나씩 복사하여 실행합니다. 이 사용 사례를 빠르게 데모하려면 10~50개의 삽입 문을 복사하여 실행하면 됩니다.
실행하려면 실행을 클릭합니다. 쿼리 결과가 결과 테이블에 표시됩니다.
5. 특허 데이터의 임베딩 생성
먼저 다음 샘플 쿼리를 실행하여 삽입 함수를 테스트해 보겠습니다.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
그러면 쿼리의 샘플 텍스트에 대한 임베딩 벡터가 반환됩니다. 이 벡터는 부동 소수점 배열과 같습니다. 다음과 같이 표시됩니다.
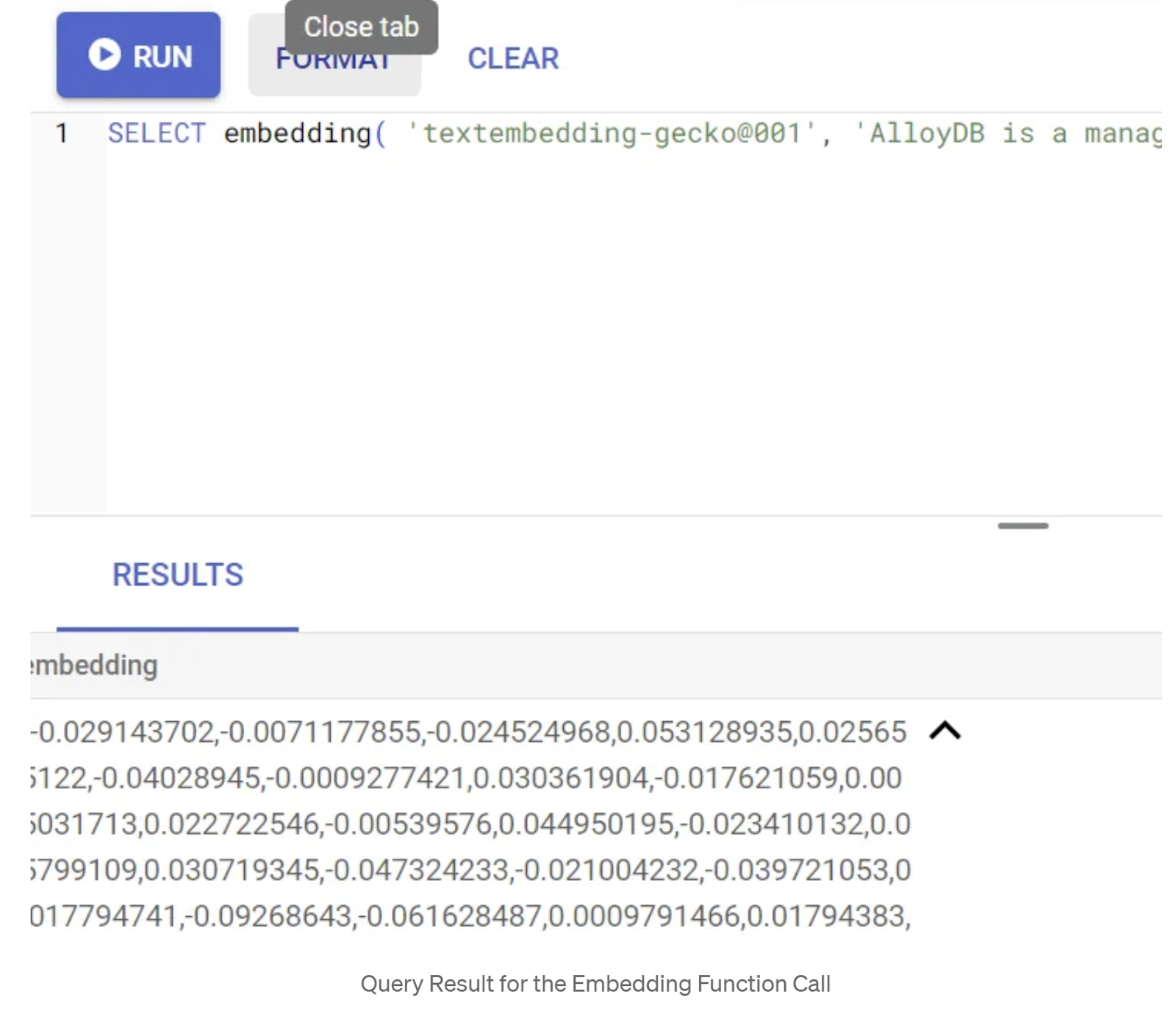
abstract_embeddings 벡터 필드 업데이트
초록에 대한 임베딩을 생성해야 하는 경우 아래 DML을 사용하여 테이블의 특허 초록을 해당 임베딩으로 업데이트해야 합니다. 하지만 이 경우에는 삽입 문에 각 초록에 대한 이러한 삽입이 이미 포함되어 있으므로 embeddings() 메서드를 호출하지 않아도 됩니다.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. 벡터 검색 실행
이제 테이블, 데이터, 임베딩이 모두 준비되었으므로 사용자 검색 텍스트에 대해 실시간 벡터 검색을 실행해 보겠습니다. 아래 쿼리를 실행하여 이를 테스트할 수 있습니다.
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
이 쿼리에서
- 사용자가 검색한 텍스트는 'Sentiment Analysis'입니다.
- 모델 text-embedding-005를 사용하여 embedding() 메서드에서 임베딩으로 변환합니다.
- '<=>'는 COSINE SIMILARITY 거리 메서드의 사용을 나타냅니다.
- 임베딩 메서드의 결과를 벡터 유형으로 변환하여 데이터베이스에 저장된 벡터와 호환되도록 합니다.
- LIMIT 10은 검색 텍스트와 가장 일치하는 10개를 선택한다는 것을 나타냅니다.
AlloyDB는 벡터 검색 RAG를 한 단계 더 발전시킵니다.
많은 기능이 도입되었습니다. 개발자 중심의 두 가지는 다음과 같습니다.
- 인라인 필터링
- 재현율 평가자
인라인 필터링
이전에는 개발자가 벡터 검색 쿼리를 실행하고 필터링 및 리콜을 처리해야 했습니다. AlloyDB 쿼리 최적화 도구는 필터가 있는 쿼리를 실행하는 방법을 선택합니다. 인라인 필터링은 AlloyDB 쿼리 최적화 프로그램이 메타데이터 필터링 조건과 벡터 검색을 동시에 평가하여 벡터 색인과 메타데이터 열의 색인을 모두 활용할 수 있도록 하는 새로운 쿼리 최적화 기법입니다. 이를 통해 회수 성능이 향상되어 개발자가 AlloyDB의 기본 기능을 활용할 수 있습니다.
인라인 필터링은 선택도가 중간인 경우에 가장 적합합니다. AlloyDB가 벡터 색인을 검색할 때 메타데이터 필터링 조건 (일반적으로 WHERE 절에서 처리되는 쿼리의 기능 필터)과 일치하는 벡터의 거리만 계산합니다. 이렇게 하면 사후 필터 또는 사전 필터의 장점을 보완하여 이러한 쿼리의 성능이 크게 향상됩니다.
- pgvector 확장 프로그램 설치 또는 업데이트
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
pgvector 확장 프로그램이 이미 설치되어 있는 경우 벡터 확장 프로그램을 버전 0.8.0.google-3 이상으로 업그레이드하여 리콜 평가기 기능을 사용하세요.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
이 단계는 벡터 확장 프로그램이 <0.8.0.google-3인 경우에만 실행해야 합니다.
중요: 행 수가 100개 미만인 경우 행 수가 적어 적용되지 않으므로 ScaNN 색인을 만들 필요가 없습니다. 이 경우 다음 단계를 건너뛰세요.
- ScaNN 색인을 만들려면 alloydb_scann 확장 프로그램을 설치하세요.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- 먼저 색인 없이, 인라인 필터가 사용 설정되지 않은 상태로 벡터 검색 쿼리를 실행합니다.
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
결과는 다음과 비슷하게 표시됩니다.

- 다음과 같이 Explain Analyze를 실행합니다(색인도 인라인 필터링도 없음).
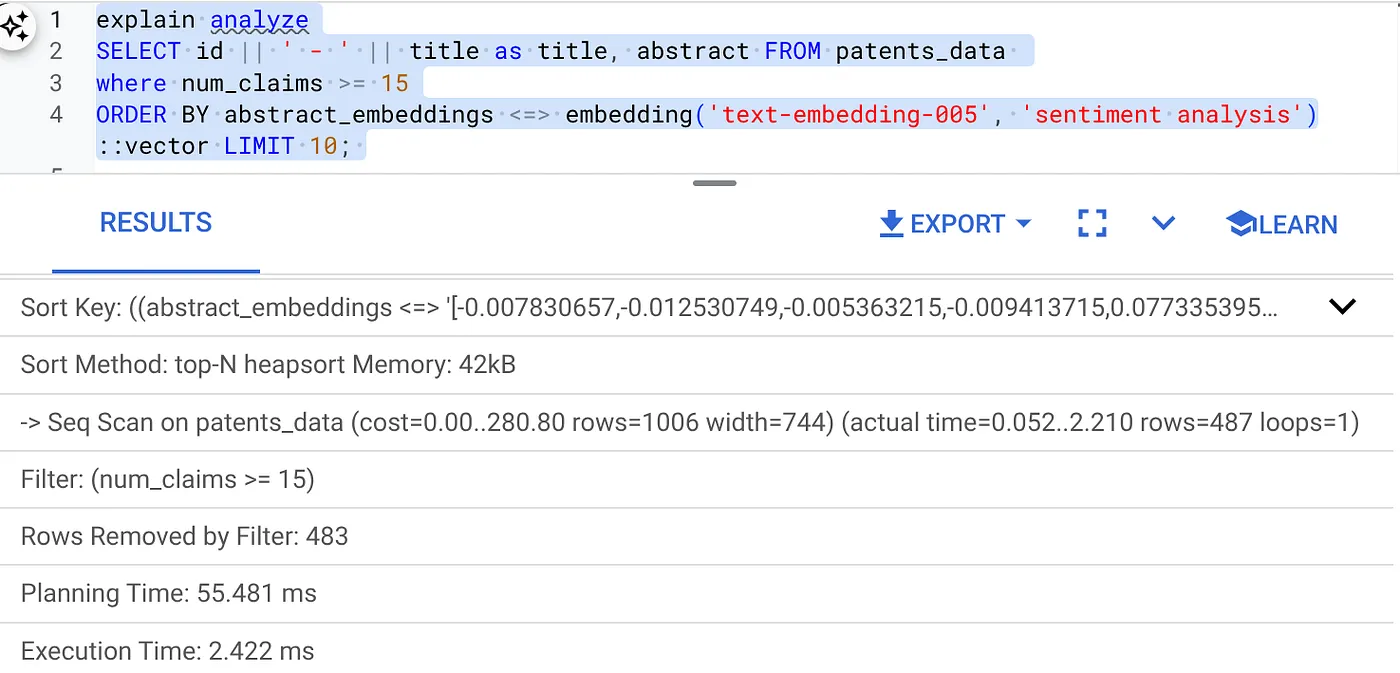
실행 시간은 2.4ms입니다.
- num_claims 필드에 일반 색인을 만들어 필터링할 수 있도록 하겠습니다.
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- 특허 검색 애플리케이션의 ScaNN 색인을 만들어 보겠습니다. AlloyDB Studio에서 다음을 실행합니다.
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
중요: (num_leaves=32)는 행이 1,000개 이상인 전체 데이터 세트에 적용됩니다. 행 수가 100개 미만인 경우 행 수가 적어 적용되지 않으므로 색인을 만들 필요가 없습니다.
- ScaNN 색인에서 인라인 필터링을 사용 설정합니다.
SET scann.enable_inline_filtering = on
- 이제 필터와 벡터 검색이 포함된 동일한 쿼리를 실행해 보겠습니다.
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
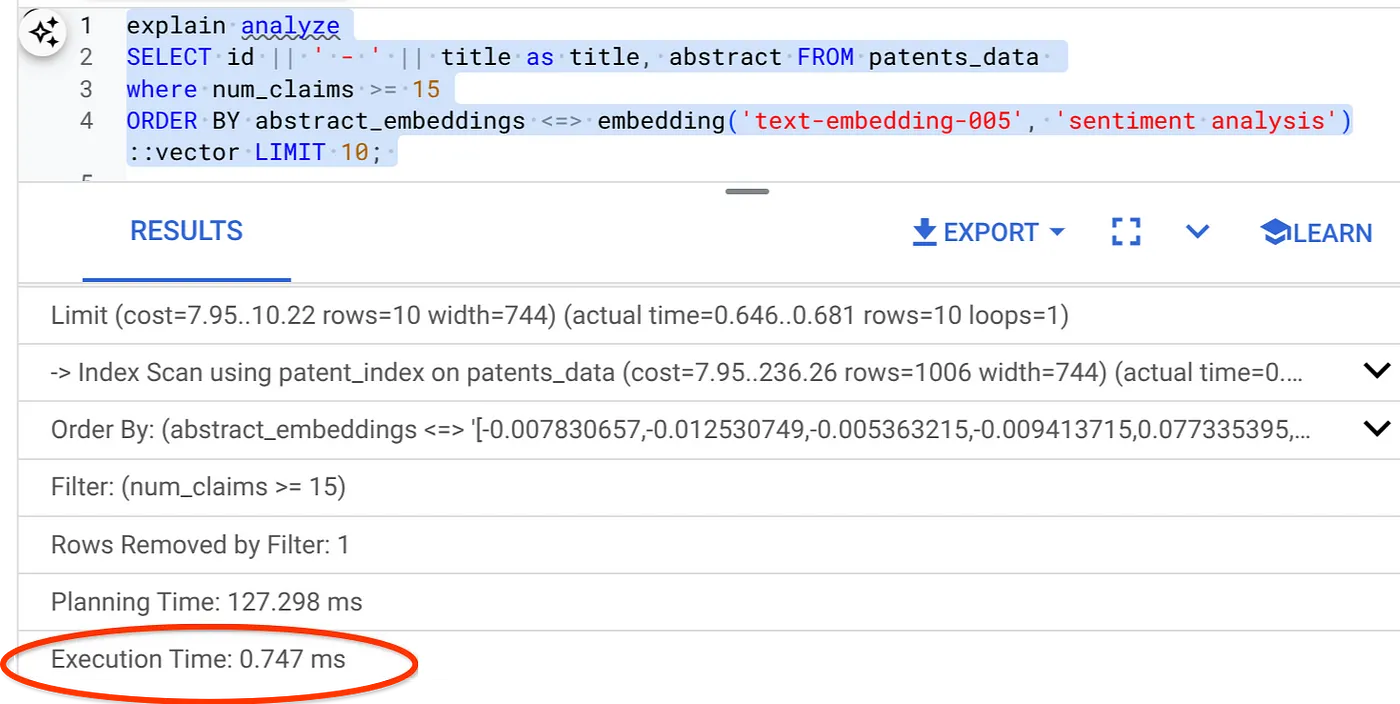
동일한 벡터 검색의 실행 시간이 크게 줄어든 것을 확인할 수 있습니다. 벡터 검색의 인라인 필터링이 적용된 ScaNN 색인 덕분에 가능해졌습니다.
다음으로 ScaNN 지원 벡터 검색의 재현율을 평가해 보겠습니다.
재현율 평가자
유사성 검색의 재현율은 검색에서 검색된 관련 인스턴스의 비율, 즉 참양성 수입니다. 검색 품질을 측정하는 데 가장 일반적으로 사용되는 측정항목입니다. 재현율 손실의 한 가지 원인은 근사 최근접 이웃 검색(aNN)과 k(정확한) 최근접 이웃 검색(kNN) 간의 차이입니다. AlloyDB의 ScaNN과 같은 벡터 색인은 aNN 알고리즘을 구현하므로, 재현율에서 약간의 절충을 하는 대신 대규모 데이터 세트에서 벡터 검색 속도를 높일 수 있습니다. 이제 AlloyDB를 사용하면 개별 쿼리에 대해 데이터베이스에서 직접 이 절충을 측정하고 시간이 지나도 안정적인지 확인할 수 있습니다. 이 정보를 바탕으로 쿼리 및 색인 매개변수를 업데이트하여 더 나은 결과와 성능을 얻을 수 있습니다.
evaluate_query_recall 함수를 사용하여 특정 구성의 벡터 색인에 대한 벡터 쿼리의 재현율을 확인할 수 있습니다. 이 함수를 사용하면 원하는 벡터 쿼리 리콜 결과를 얻을 수 있도록 매개변수를 조정할 수 있습니다. 재현율은 검색 품질에 사용되는 측정항목으로, 객관적으로 쿼리 벡터에 가장 가까운 반환된 결과의 비율로 정의됩니다. evaluate_query_recall 함수는 기본적으로 사용 설정되어 있습니다.
중요사항:
다음 단계에서 HNSW 색인에 대한 권한 거부 오류가 발생하면 지금은 이 전체 재현 평가 섹션을 건너뛰세요. 이 Codelab이 문서화될 때 막 출시되었으므로 액세스 제한과 관련이 있을 수 있습니다.
- ScaNN 색인 및 HNSW 색인에서 색인 스캔 사용 플래그를 설정합니다.
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- AlloyDB Studio에서 다음 쿼리를 실행합니다.
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
evaluate_query_recall 함수는 쿼리를 매개변수로 사용하고 리콜을 반환합니다. 성능을 확인하는 데 사용한 쿼리를 함수 입력 쿼리로 사용하고 있습니다. SCaNN을 색인 메서드로 추가했습니다. 매개변수 옵션에 대한 자세한 내용은 문서를 참고하세요.
지금까지 사용한 벡터 검색 쿼리의 리콜은 다음과 같습니다.
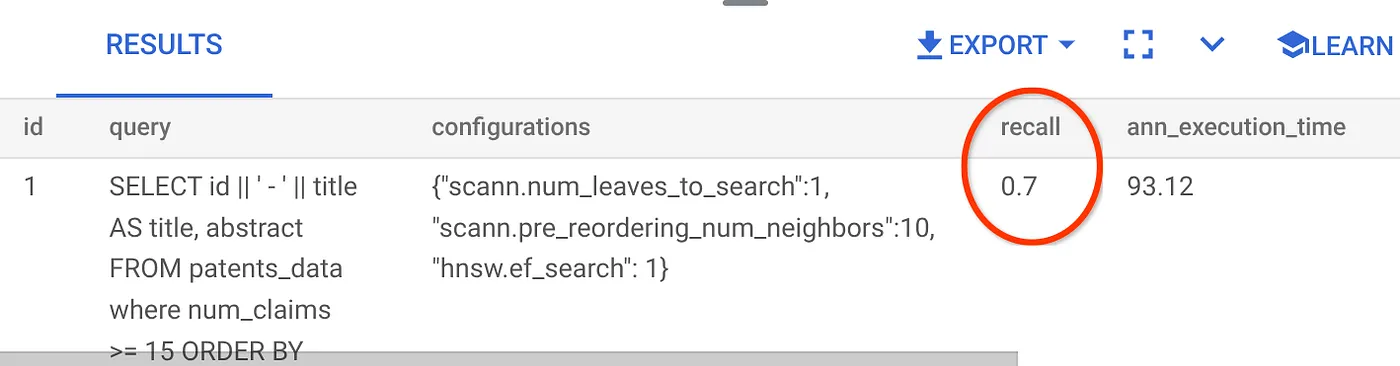
리콜이 70%인 것으로 확인됩니다. 이제 이 정보를 사용하여 색인 매개변수, 메서드, 쿼리 매개변수를 변경하고 이 벡터 검색의 재현율을 개선할 수 있습니다.
결과 집합의 행 수를 7 (이전에는 10)로 수정했더니 재현율이 약간 향상되어 86%가 되었습니다.
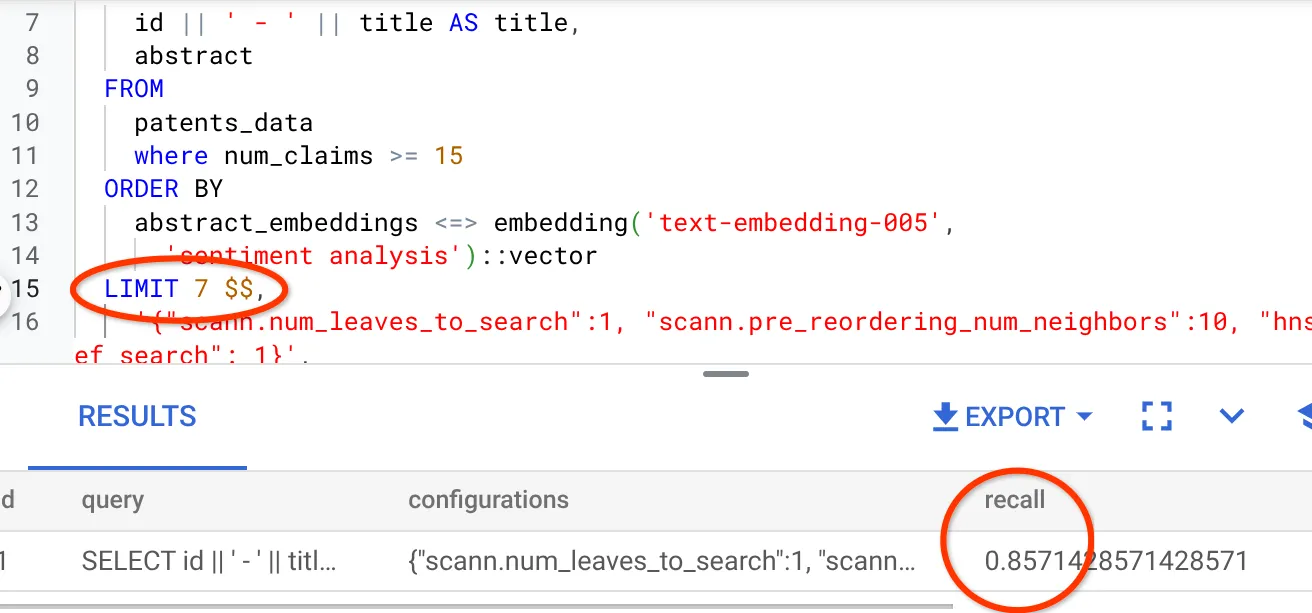
즉, 사용자의 검색 컨텍스트에 따라 일치 항목의 관련성을 개선하기 위해 사용자에게 표시되는 일치 항목의 수를 실시간으로 변경할 수 있습니다.
좋습니다. 이제 데이터베이스 로직을 배포하고 에이전트로 넘어갈 시간입니다.
7. 데이터베이스 로직을 서버리스로 웹에 가져오기
이 앱을 웹으로 가져올 준비가 되셨나요? 다음 단계를 따르세요.
- Google Cloud 콘솔의 Cloud Run Functions로 이동하여 '함수 작성'을 클릭하여 새 Cloud Run 함수를 만들거나 https://console.cloud.google.com/run/create?deploymentType=function 링크를 사용합니다.
- '인라인 편집기를 사용하여 함수 만들기' 옵션을 선택하고 구성을 시작합니다. 서비스 이름 'patent-search'를 입력하고 리전을 'us-central1', 런타임을 'Java 17'로 선택합니다. 인증을 '인증되지 않은 호출 허용'으로 설정합니다.
- '컨테이너, 볼륨, 네트워킹, 보안' 섹션에서 세부정보를 누락하지 않고 아래 단계를 따릅니다.
네트워킹 탭으로 이동합니다.
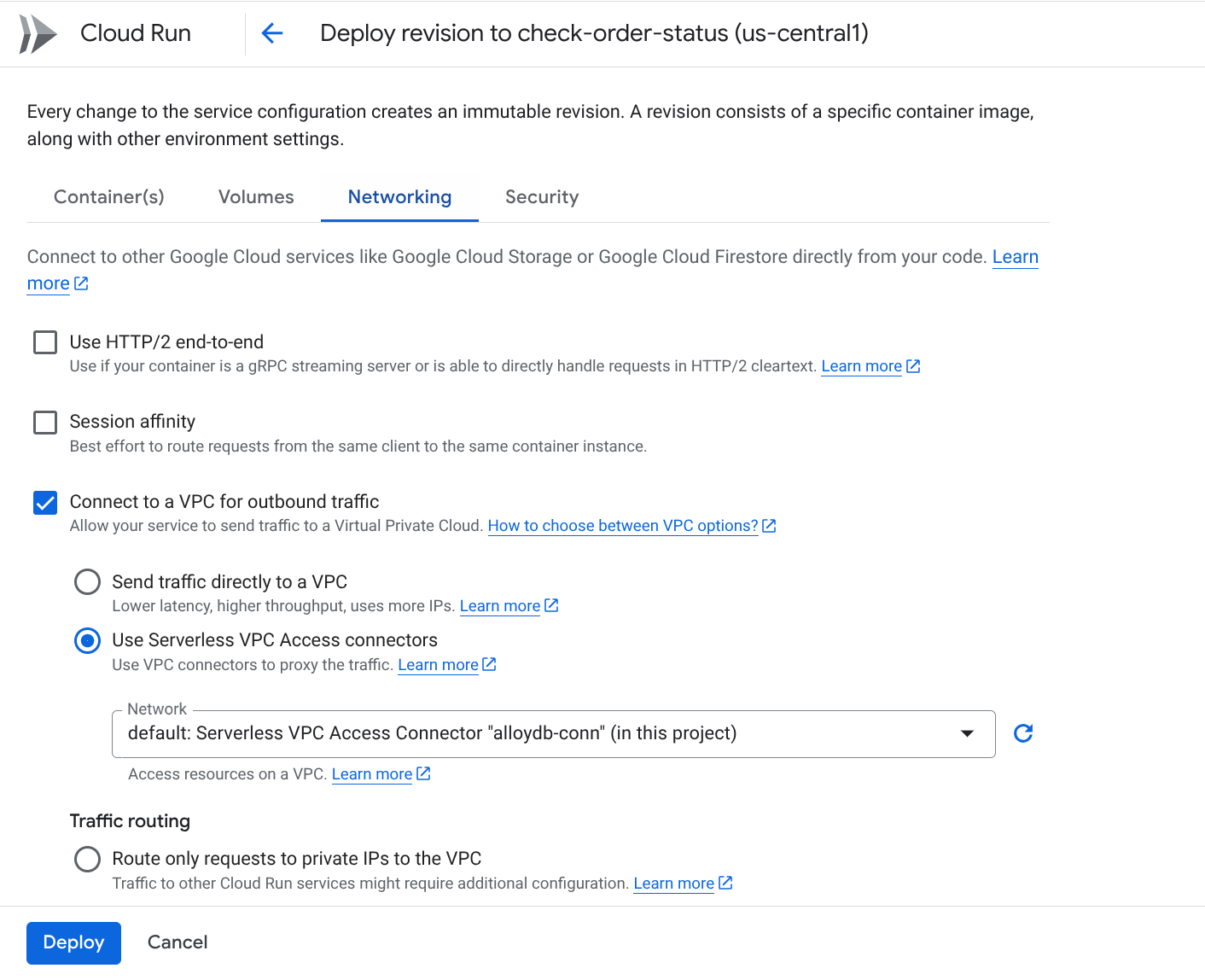
'아웃바운드 트래픽을 위해 VPC에 연결'을 선택한 다음 '서버리스 VPC 액세스 커넥터 사용'을 선택합니다.
네트워크 드롭다운에서 설정을 클릭하고 네트워크 드롭다운을 클릭한 후 '새 VPC 커넥터 추가' 옵션을 선택합니다 (기본을 아직 구성하지 않은 경우). 표시되는 대화상자의 안내를 따릅니다.

VPC 커넥터의 이름을 입력하고 리전이 인스턴스와 동일한지 확인합니다. 네트워크 값은 기본값으로 두고 서브넷을 사용 가능한 IP 범위(예: 10.8.0.0)가 있는 '커스텀 IP 범위'로 설정합니다.
'확장 설정 표시'를 펼치고 구성이 정확히 다음과 같이 설정되어 있는지 확인합니다.

만들기를 클릭하면 이제 이 커넥터가 이그레스 설정에 나열됩니다.
새로 만든 커넥터를 선택합니다.
이 VPC 커넥터를 통해 모든 트래픽이 라우팅되도록 선택합니다.
다음을 클릭한 후 배포를 클릭합니다.
- 기본적으로 진입점을 'gcfv2.HelloHttpFunction'으로 설정합니다. Cloud Run 함수의 HelloHttpFunction.java 및 pom.xml의 자리표시자 코드를 각각 'PatentSearch.java' 및 'pom.xml'의 코드로 바꿉니다. 클래스 파일의 이름을 PatentSearch.java로 변경합니다.
- Java 파일에서 ************* 자리표시자와 AlloyDB 연결 사용자 인증 정보를 실제 값으로 변경해야 합니다. AlloyDB 사용자 인증 정보는 이 Codelab을 시작할 때 사용한 사용자 인증 정보입니다. 다른 값을 사용한 경우 Java 파일에서 동일하게 수정하세요.
- 배포를 클릭합니다.
- 업데이트된 Cloud 함수가 배포되면 생성된 엔드포인트가 표시됩니다. 이를 복사하여 다음 명령어에서 바꿉니다.
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
작업이 끝났습니다. AlloyDB 데이터에서 임베딩 모델을 사용하여 고급 컨텍스트 유사성 벡터 검색을 수행하는 것은 이처럼 간단합니다.
8. Java ADK로 에이전트 빌드하기
먼저 편집기에서 Java 프로젝트를 시작해 보겠습니다.
- Cloud Shell 터미널로 이동
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- 메시지가 표시되면 승인
- Cloud Shell 콘솔 상단에서 편집기 아이콘을 클릭하여 Cloud Shell 편집기로 전환합니다.

- 랜딩 Cloud Shell 편집기 콘솔에서 새 폴더를 만들고 이름을 'adk-agents'로 지정합니다.
아래와 같이 Cloud Shell의 루트 디렉터리에서 새 폴더 만들기를 클릭합니다.
이름을 'adk-agents'로 지정합니다.
- 다음 폴더 구조와 아래 구조에 해당하는 파일 이름의 빈 파일을 만듭니다.
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- 별도의 탭에서 GitHub 저장소를 열고 App.java 및 pom.xml 파일의 소스 코드를 복사합니다.
- 오른쪽 상단의 '새 탭에서 열기' 아이콘을 사용하여 새 탭에서 편집기를 연 경우 페이지 하단에 터미널을 열 수 있습니다. 편집기와 터미널을 동시에 열어 자유롭게 작업할 수 있습니다.
- 클론이 완료되면 Cloud Shell 편집기 콘솔로 다시 전환합니다.
- Cloud Run 함수를 이미 만들었으므로 저장소 폴더에서 Cloud Run 함수 파일을 복사하지 않아도 됩니다.
ADK Java SDK 시작하기
꽤 간단합니다. 클론 단계에서 다음 사항이 포함되어야 합니다.
- 종속 항목 추가:
pom.xml에 google-adk 및 google-adk-dev (웹 UI용) 아티팩트를 포함합니다. 저장소에서 소스를 복사한 경우 이러한 항목이 이미 파일에 포함되어 있으므로 포함하지 않아도 됩니다. 배포된 엔드포인트를 반영하도록 Cloud Run 함수 엔드포인트를 변경하기만 하면 됩니다. 이 내용은 이 섹션의 다음 단계에서 다룹니다.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
애플리케이션이 실행되려면 다른 종속 항목과 구성이 필요하므로 소스 저장소의 pom.xml을 참조해야 합니다.
- 프로젝트 구성:
pom.xml에서 Java 버전 (17 이상 권장)과 Maven 컴파일러 설정이 올바르게 구성되어 있는지 확인합니다. 다음 구조를 따르도록 프로젝트를 구성할 수 있습니다.
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- 에이전트 및 도구 정의 (App.java):
여기서 ADK Java SDK의 마법이 빛을 발합니다. 에이전트, 에이전트의 기능 (지침), 에이전트가 사용할 수 있는 도구를 정의합니다.
여기에서 기본 에이전트 클래스의 몇 가지 코드 스니펫의 단순화된 버전을 확인할 수 있습니다. 전체 프로젝트는 여기의 프로젝트 저장소를 참고하세요.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
주요 ADK Java 코드 구성요소 강조 표시:
- LlmAgent.builder(): 에이전트를 구성하기 위한 플루언트 API입니다.
- .instruction(...): LLM의 핵심 프롬프트와 가이드라인을 제공합니다(예: 언제 어떤 도구를 사용할지).
- FunctionTool.create(App.class, 'methodName'): Java 메서드를 에이전트가 호출할 수 있는 도구로 쉽게 등록합니다. 메서드 이름 문자열은 실제 공개 정적 메서드와 일치해야 합니다.
- @Schema(description = ...): 도구 매개변수에 주석을 달아 LLM이 각 도구에 필요한 입력을 이해하도록 지원합니다. 이 설명은 정확한 도구 선택과 매개변수 입력에 매우 중요합니다.
- InvocationContext ctx: 도구 메서드에 자동으로 전달되어 세션 상태 (ctx.session().state()), 사용자 정보 등에 액세스할 수 있습니다.
- .outputKey("patents"): 도구가 데이터를 반환하면 ADK가 이 키 아래의 세션 상태에 데이터를 자동으로 저장할 수 있습니다. explainPatent가 getPatents의 결과에 액세스하는 방법입니다.
- VECTOR_SEARCH_ENDPOINT: 특허 검색 사용 사례에서 사용자의 컨텍스트 기반 Q&A의 핵심 기능 로직을 보유하는 변수입니다.
- 여기에서 취해야 할 조치: 이전 섹션의 Java Cloud Run 함수 단계를 구현한 후 업데이트된 배포된 엔드포인트 값을 설정해야 합니다.
- searchTool: 사용자 검색 텍스트에 대해 특허 데이터베이스에서 문맥상 관련성이 있는 특허를 찾기 위해 사용자와 상호작용합니다.
- explainTool: 사용자에게 자세히 살펴볼 특정 특허를 요청합니다. 그런 다음 특허 초록을 요약하고 보유한 특허 세부정보를 기반으로 사용자의 추가 질문에 답변할 수 있습니다.
중요: VECTOR_SEARCH_ENDPOINT 변수를 배포된 CRF 엔드포인트로 바꿔야 합니다.
스테이트풀 상호작용을 위해 InvocationContext 활용
유용한 에이전트를 빌드하는 데 중요한 기능 중 하나는 대화의 여러 턴에 걸쳐 상태를 관리하는 것입니다. ADK의 InvocationContext를 사용하면 간단하게 처리할 수 있습니다.
App.java에서 다음을 실행합니다.
- initAgent()가 정의된 경우 .outputKey("patents")를 사용합니다. 이는 도구 (예: getPatents)가 보고서 필드에 데이터를 반환할 때 해당 데이터가 'patents' 키 아래의 세션 상태에 저장되어야 함을 ADK에 알려줍니다.
- explainPatent 도구 메서드에서 InvocationContext ctx를 삽입합니다.
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
이를 통해 explainPatent 도구는 이전 턴에서 getPatents 도구로 가져온 특허 목록에 액세스할 수 있으므로 대화가 상태를 유지하고 일관성을 갖게 됩니다.
9. 로컬 CLI 테스트
환경 변수 정의
두 개의 환경 변수를 내보내야 합니다.
- AI Studio에서 가져올 수 있는 Gemini 키:
이렇게 하려면 https://aistudio.google.com/apikey로 이동하여 이 애플리케이션을 구현하는 활성 Google Cloud 프로젝트의 API 키를 가져와서 키를 어딘가에 저장하세요.
- 키를 획득한 후 Cloud Shell 터미널을 열고 다음 명령어를 실행하여 새로 만든 디렉터리 adk-agents로 이동합니다.
cd adk-agents
- 이번에는 Vertex AI를 사용하지 않음을 지정하는 변수입니다.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- CLI에서 첫 번째 에이전트 실행
이 첫 번째 에이전트를 실행하려면 터미널에서 다음 Maven 명령어를 사용하세요.
mvn compile exec:java -DmainClass="agents.App"
터미널에 에이전트의 대화형 응답이 표시됩니다.
10. Cloud Run에 배포
ADK Java 에이전트를 Cloud Run에 배포하는 것은 다른 Java 애플리케이션을 배포하는 것과 유사합니다.
- Dockerfile: Java 애플리케이션을 패키징하는 Dockerfile을 만듭니다.
- Docker 이미지 빌드 및 푸시: Google Cloud Build 및 Artifact Registry를 사용합니다.
- 위 단계를 수행하고 Cloud Run에 배포하는 데는 하나의 명령어만 있으면 됩니다.
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
마찬가지로 Java Cloud Run 함수 (gcfv2.PatentSearch)를 배포합니다. 또는 Cloud Run Functions 콘솔에서 직접 데이터베이스 로직용 Java Cloud Run 함수를 만들고 배포할 수 있습니다.
11. 웹 UI로 테스트
ADK에는 에이전트의 로컬 테스트 및 디버깅을 위한 편리한 웹 UI가 함께 제공됩니다. App.java를 로컬로 실행하면 (예: 구성된 경우 mvn exec:java -Dexec.mainClass="agents.App" 또는 main 메서드 실행) ADK가 일반적으로 로컬 웹 서버를 시작합니다.
ADK 웹 UI를 사용하면 다음 작업을 할 수 있습니다.
- 상담사에게 메시지를 보냅니다.
- 이벤트 (사용자 메시지, 도구 호출, 도구 응답, LLM 응답)를 확인합니다.
- 세션 상태를 검사합니다.
- 로그 및 트레이스 보기
이는 개발 중에 에이전트가 요청을 처리하고 도구를 사용하는 방식을 이해하는 데 매우 유용합니다. 이는 pom.xml의 mainClass가 com.google.adk.web.AdkWebServer로 설정되어 있고 에이전트가 여기에 등록되어 있거나 이를 노출하는 로컬 테스트 러너를 실행하고 있다고 가정합니다.
InMemoryRunner 및 콘솔 입력용 스캐너를 사용하여 App.java를 실행하면 핵심 에이전트 로직을 테스트하는 것입니다. 웹 UI는 더 시각적인 디버깅 환경을 위한 별도의 구성요소로, ADK가 HTTP를 통해 에이전트를 제공할 때 자주 사용됩니다.
루트 디렉터리에서 다음 Maven 명령어를 사용하여 SpringBoot 로컬 서버를 실행할 수 있습니다.
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
인터페이스는 위의 명령어가 출력하는 URL에서 액세스할 수 있는 경우가 많습니다. Cloud Run에 배포된 경우 Cloud Run에 배포된 링크에서 액세스할 수 있습니다.
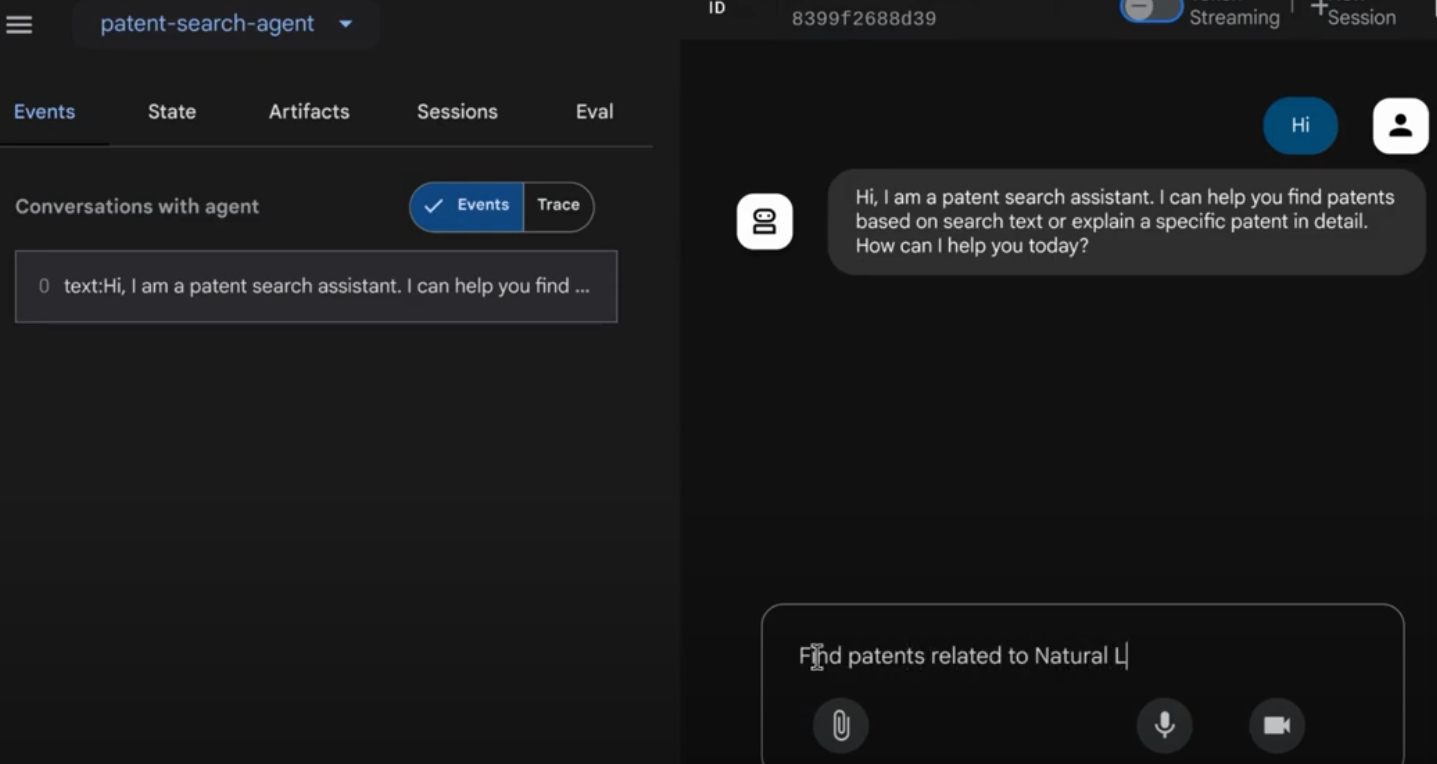
대화형 인터페이스에서 결과를 확인할 수 있습니다.
배포된 특허 대리인은 아래 동영상을 참고하세요.
AlloyDB 인라인 검색 및 리콜 평가를 사용한 품질 관리 특허 대리인 데모
12. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog으로 이동합니다.
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog 페이지를 참고하세요.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
13. 축하합니다
축하합니다. ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI, Vector Search의 기능을 결합하여 Java로 특허 분석 에이전트를 성공적으로 구축했습니다. 또한 맥락적 유사성 검색을 혁신적이고 효율적이며 진정으로 의미 기반으로 만드는 데 큰 진전을 이루었습니다.
지금 시작하기
ADK 문서: [공식 ADK Java 문서 링크]
특허 분석 에이전트 소스 코드: [현재 공개된 GitHub 저장소 링크]
Java 샘플 에이전트: [adk-samples 저장소 링크]
ADK 커뮤니티 가입: https://www.reddit.com/r/agentdevelopmentkit/
즐거운 에이전트 빌드 되세요.