
1. Descripción general
En diferentes industrias, la búsqueda contextual es una funcionalidad fundamental que constituye el corazón y el centro de sus aplicaciones. La generación aumentada por recuperación ha sido un factor clave de esta crucial evolución tecnológica durante bastante tiempo con sus mecanismos de recuperación potenciados por IA generativa. Los modelos generativos, con sus grandes ventanas de contexto y su impresionante calidad de salida, están transformando la IA. La RAG proporciona una forma sistemática de incorporar contexto en las aplicaciones y los agentes de IA, fundamentándolos en bases de datos estructuradas o información de diversos medios. Estos datos contextuales son fundamentales para la claridad de la verdad y la precisión de los resultados, pero ¿qué tan precisos son esos resultados? ¿Tu empresa depende en gran medida de la precisión y la relevancia de estas coincidencias contextuales? Entonces, este proyecto te encantará.
Ahora imagina si pudiéramos aprovechar el poder de los modelos generativos y crear agentes interactivos capaces de tomar decisiones autónomas respaldadas por información tan crítica para el contexto y fundamentadas en la verdad. Eso es lo que vamos a crear hoy. Crearemos una app de agente de IA integral con el kit de desarrollo de agentes potenciado por RAG avanzado en AlloyDB para una aplicación de análisis de patentes.
El Agente de análisis de patentes ayuda al usuario a encontrar patentes contextualmente relevantes para su texto de búsqueda y, cuando se le solicita, proporciona una explicación clara y concisa, y detalles adicionales si es necesario, para una patente seleccionada. ¿Quieres ver cómo se hace? Comencemos.
Objetivo
El objetivo es simple. Permite que un usuario busque patentes según una descripción textual y, luego, obtenga una explicación detallada de una patente específica en los resultados de la búsqueda. Todo esto se realiza con un agente de IA creado con el ADK de Java, AlloyDB, la búsqueda de vectores (con índices avanzados), Gemini y toda la aplicación implementada de forma sin servidor en Cloud Run.
Qué compilarás
Como parte de este lab, realizarás las siguientes tareas:
- Crea una instancia de AlloyDB y carga datos del conjunto de datos públicos de patentes
- Implementa la búsqueda de vectores avanzada en AlloyDB con las funciones de ScaNN y de evaluación de recuperación
- Crea un agente con el ADK de Java
- Implementa la lógica del servidor de la base de datos en Cloud Functions sin servidores de Java
- Implementa y prueba el agente en Cloud Run
En el siguiente diagrama, se representa el flujo de datos y los pasos involucrados en la implementación.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto .
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con el ID de tu proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las API necesarias. Puedes usar un comando de gcloud en la terminal de Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
La alternativa al comando de gcloud es a través de la consola, buscando cada producto o usando este vínculo.
Consulta la documentación para ver los comandos y el uso de gcloud.
3. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para los datos de patentes. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Crearemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de patentes.
Crea un clúster y una instancia
- Navega por la página de AlloyDB en Cloud Console. Una forma sencilla de encontrar la mayoría de las páginas en la consola de Cloud es buscarlas con la barra de búsqueda de la consola.
- Selecciona CREATE CLUSTER en esa página:

- Verás una pantalla como la que se muestra a continuación. Crea un clúster y una instancia con los siguientes valores (asegúrate de que los valores coincidan si clonas el código de la aplicación desde el repo):
- ID del clúster: "
vector-cluster" - contraseña: "
alloydb" - PostgreSQL 15 o la versión recomendada más reciente
- Región: "
us-central1" - Networking: "
default"

- Cuando selecciones la red predeterminada, verás una pantalla como la que se muestra a continuación.
Selecciona CONFIGURAR CONEXIÓN.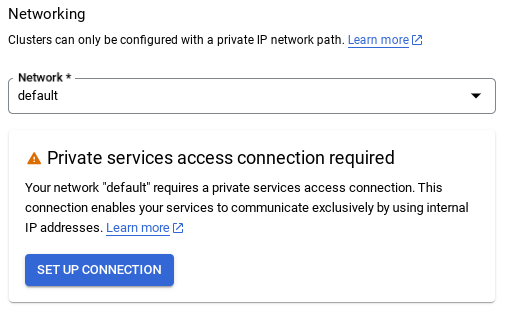
- Allí, selecciona "Usar un rango de IP asignado automáticamente" y haz clic en Continuar. Después de revisar la información, selecciona CREAR CONEXIÓN.

- Una vez que configures tu red, podrás continuar con la creación del clúster. Haz clic en CREATE CLUSTER para completar la configuración del clúster, como se muestra a continuación:

Asegúrate de cambiar el ID de la instancia (que puedes encontrar en el momento de configurar el clúster o la instancia) a
vector-instance. Si no puedes cambiarlo, recuerda usar el ID de tu instancia en todas las referencias futuras.
Ten en cuenta que la creación del clúster tardará alrededor de 10 minutos. Una vez que se complete correctamente, deberías ver una pantalla que muestre el resumen del clúster que acabas de crear.
4. Transferencia de datos
Ahora es el momento de agregar una tabla con los datos de la tienda. Navega a AlloyDB, selecciona el clúster principal y, luego, AlloyDB Studio:

Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo esté, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para la autenticación en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb"
Una vez que te hayas autenticado correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.

Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Si quieres verificar las extensiones que se habilitaron en tu base de datos, ejecuta este comando SQL:
select extname, extversion from pg_extension;
Crea una tabla
Puedes crear una tabla con la siguiente instrucción DDL en AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
La columna abstract_embeddings permitirá almacenar los valores de vector del texto.
Otorgar permiso
Ejecuta la siguiente instrucción para otorgar permiso de ejecución en la función "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
En la consola de IAM de Google Cloud, otorga a la cuenta de servicio de AlloyDB (que se ve así: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acceso al rol "Usuario de Vertex AI". PROJECT_NUMBER tendrá tu número de proyecto.
Como alternativa, puedes ejecutar el siguiente comando desde la terminal de Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carga datos de patentes en la base de datos
Usaremos los conjuntos de datos públicos de patentes de Google en BigQuery como nuestro conjunto de datos. Usaremos AlloyDB Studio para ejecutar nuestras consultas. Los datos se obtienen de este archivo insert scripts sql en este repo, y ejecutaremos esto para cargar los datos de patentes.
- En la consola de Google Cloud, abre la página AlloyDB.
- Selecciona el clúster que acabas de crear y haz clic en la instancia.
- En el menú de navegación de AlloyDB, haz clic en AlloyDB Studio. Accede con tus credenciales.
- Haz clic en el ícono Pestaña nueva a la derecha para abrir una pestaña nueva.
- Copia y ejecuta las instrucciones de consulta
insertde los archivosinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqluno por uno. Puedes ejecutar las instrucciones de inserción de copias de 10 a 50 para obtener una demostración rápida de este caso de uso.
Para ejecutarlo, haz clic en Ejecutar. Los resultados de tu consulta aparecen en la tabla Resultados.
5. Crea embeddings para los datos de patentes
Primero, probemos la función de incorporación ejecutando la siguiente consulta de muestra:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Esto debería devolver el vector de embeddings, que se ve como un array de números de punto flotante, para el texto de muestra en la búsqueda. Se verá de la siguiente manera:
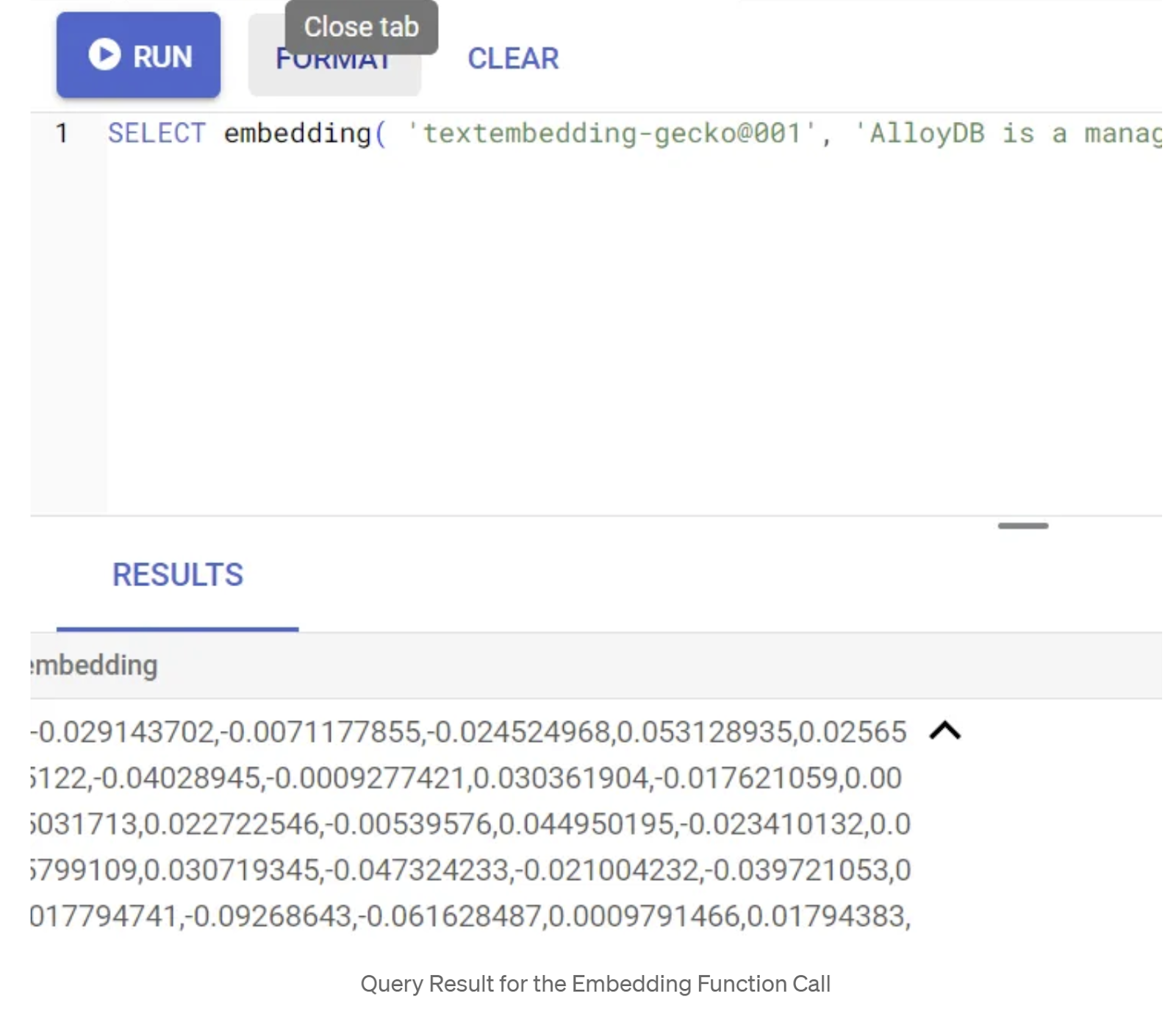
Actualiza el campo Vector de abstract_embeddings
El siguiente DML se debe usar para actualizar los resúmenes de patentes en la tabla con las incorporaciones correspondientes en caso de que sea necesario generarlas para los resúmenes. Pero, en nuestro caso, las instrucciones de inserción ya contienen estas incorporaciones para cada resumen, por lo que no es necesario que llames al método embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Realiza una búsqueda de vectores
Ahora que la tabla, los datos y los embeddings están listos, realicemos la búsqueda de vectores en tiempo real para el texto de búsqueda del usuario. Para probarlo, ejecuta la siguiente consulta:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
En esta búsqueda,
- El texto de búsqueda del usuario es "Análisis de opiniones".
- Lo convertimos en embeddings en el método embedding() con el modelo text-embedding-005.
- "<=>" representa el uso del método de distancia COSINE SIMILARITY.
- Convertimos el resultado del método de incorporación al tipo de vector para que sea compatible con los vectores almacenados en la base de datos.
- LIMIT 10 representa que seleccionamos las 10 coincidencias más cercanas del texto de búsqueda.
AlloyDB lleva la RAG de la búsqueda de vectores al siguiente nivel:
Se introdujeron varias cosas buenas. Dos de las que se enfocan en los desarrolladores son las siguientes:
- Filtrado intercalado
- Evaluador de recuperación
Filtrado intercalado
Anteriormente, como desarrollador, debías realizar la búsqueda de vectores y encargarte del filtrado y la recuperación. El optimizador de consultas de AlloyDB toma decisiones sobre cómo ejecutar una consulta con filtros. El filtrado intercalado es una nueva técnica de optimización de consultas que permite que el optimizador de consultas de AlloyDB evalúe las condiciones de filtrado de metadatos y la búsqueda de vectores de forma simultánea, aprovechando los índices de vectores y los índices en las columnas de metadatos. Esto hizo que aumentara el rendimiento de la recuperación, lo que permite a los desarrolladores aprovechar las ventajas que ofrece AlloyDB de inmediato.
El filtrado intercalado es mejor para los casos con selectividad media. A medida que AlloyDB busca en el índice de vectores, solo calcula las distancias para los vectores que coinciden con las condiciones de filtrado de metadatos (tus filtros funcionales en una consulta que, por lo general, se controlan en la cláusula WHERE). Esto mejora enormemente el rendimiento de estas consultas y complementa las ventajas del filtrado posterior o previo.
- Instala o actualiza la extensión pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Si la extensión pgvector ya está instalada, actualiza la extensión de vector a la versión 0.8.0.google-3 o posterior para obtener capacidades del evaluador de recuperación.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Este paso solo debe ejecutarse si tu extensión de vectores es anterior a la versión 0.8.0.google-3.
Nota importante: Si el recuento de filas es inferior a 100, no será necesario que crees el índice de ScaNN, ya que no se aplicará para menos filas. En ese caso, omite los siguientes pasos.
- Para crear índices de ScaNN, instala la extensión alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Primero, ejecuta la consulta de Vector Search sin el índice y sin el filtro intercalado habilitado:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
El resultado debería ser similar al siguiente:

- Ejecuta Explain Analyze en ella: (sin indexación ni filtrado intercalado)

El tiempo de ejecución es de 2.4 ms
- Creemos un índice normal en el campo num_claims para poder filtrarlo:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Creemos el índice de ScaNN para nuestra aplicación de búsqueda de patentes. Ejecuta lo siguiente desde AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Nota importante: (num_leaves=32) se aplica a nuestro conjunto de datos total con más de 1,000 filas. Si el recuento de filas es inferior a 100, no será necesario que crees un índice, ya que no se aplicará para menos filas.
- Establece el filtrado intercalado habilitado en el índice de ScaNN:
SET scann.enable_inline_filtering = on
- Ahora, ejecutemos la misma consulta con el filtro y Vector Search:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
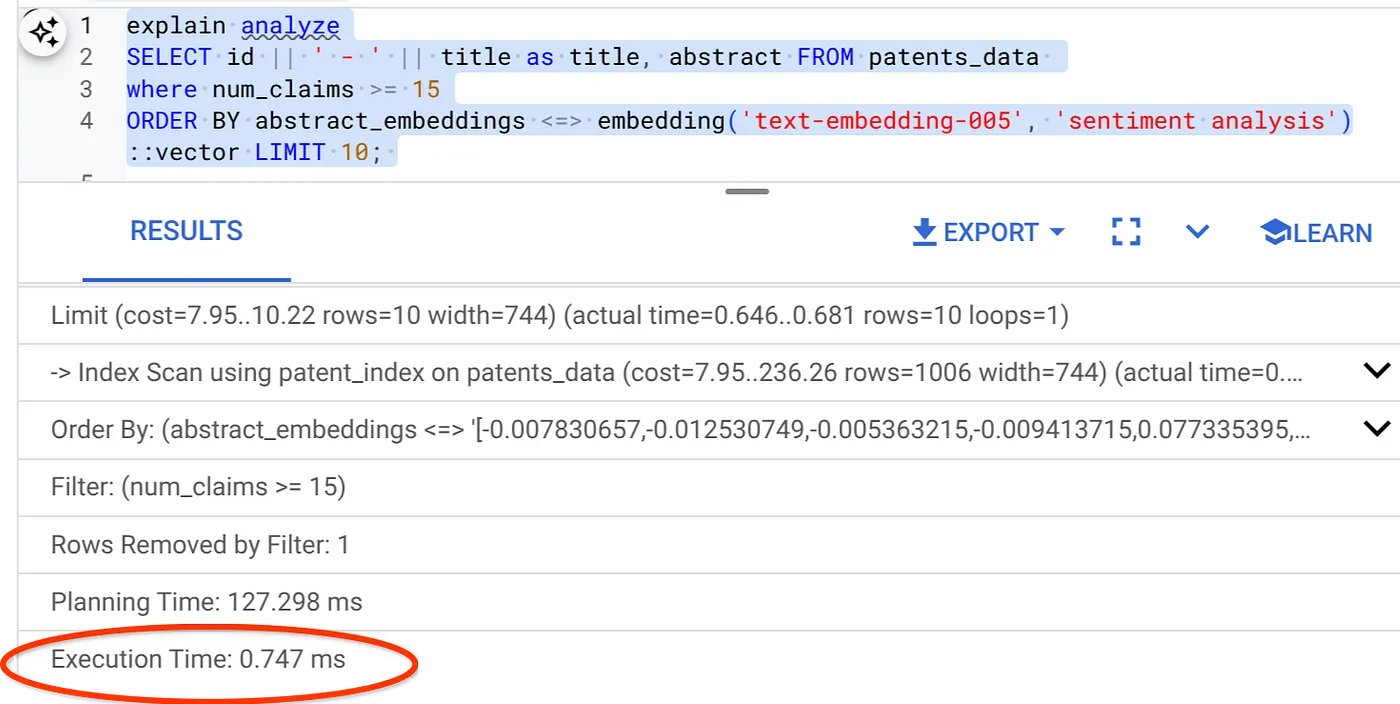
Como puedes ver, el tiempo de ejecución se reduce significativamente para la misma búsqueda de vectores. El índice de ScaNN con filtrado intercalado en Vector Search hizo posible esto.
A continuación, evaluemos la recuperación para esta búsqueda de vectores habilitada para ScaNN.
Evaluador de recuperación
La recuperación en la búsqueda por similitud es el porcentaje de instancias relevantes que se recuperaron de una búsqueda, es decir, la cantidad de verdaderos positivos. Esta es la métrica más común que se usa para medir la calidad de la búsqueda. Una fuente de pérdida de recuperación proviene de la diferencia entre la búsqueda de vecino más cercano aproximado, o aNN, y la búsqueda de k (exacto) vecinos más cercanos, o kNN. Los índices de vectores, como ScaNN de AlloyDB, implementan algoritmos de aNN, lo que te permite acelerar la búsqueda de vectores en grandes conjuntos de datos a cambio de una pequeña compensación en la recuperación. Ahora, AlloyDB te permite medir esta compensación directamente en la base de datos para consultas individuales y garantizar que sea estable con el tiempo. Puedes actualizar los parámetros de índice y consulta en respuesta a esta información para obtener mejores resultados y rendimiento.
Puedes encontrar la recuperación de una búsqueda vectorial en un índice de vectores para una configuración determinada con la función evaluate_query_recall. Esta función te permite ajustar tus parámetros para lograr los resultados de recuperación de la búsqueda vectorial que deseas. La recuperación es la métrica que se usa para la calidad de la búsqueda y se define como el porcentaje de los resultados devueltos que son objetivamente los más cercanos a los vectores de la búsqueda. La función evaluate_query_recall está activada de forma predeterminada.
Nota importante:
Si tienes problemas de permisos denegados en el índice de HNSW en los siguientes pasos, omite toda esta sección de evaluación de recuperación por el momento. Es posible que se deba a restricciones de acceso en este punto, ya que se acaba de lanzar en el momento en que se documenta este codelab.
- Establece la marca Enable Index Scan en el índice de ScaNN y el índice de HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Ejecuta la siguiente consulta en AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La función evaluate_query_recall toma la búsqueda como parámetro y devuelve su recuperación. Uso la misma consulta que usé para verificar el rendimiento como consulta de entrada de la función. Agregué SCaNN como método de indexación. Para obtener más opciones de parámetros, consulta la documentación.
La recuperación para esta búsqueda de vectores que hemos estado usando es la siguiente:

Veo que el RECALL es del 70%. Ahora puedo usar esta información para cambiar los parámetros de índice, los métodos y los parámetros de consulta, y mejorar la recuperación de esta búsqueda vectorial.
Modifiqué la cantidad de filas del conjunto de resultados a 7 (antes eran 10) y veo una RECALL ligeramente mejorada, es decir, un 86%.
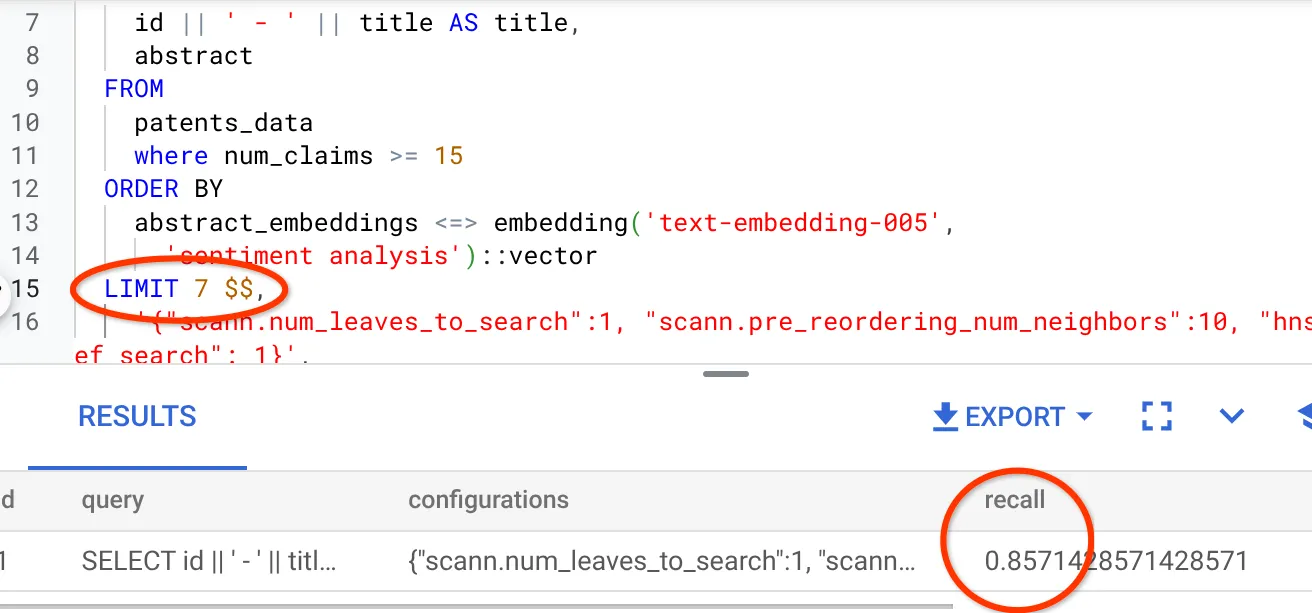
Esto significa que, en tiempo real, puedo variar la cantidad de coincidencias que ven mis usuarios para mejorar la relevancia de las coincidencias según el contexto de búsqueda de los usuarios.
¡Muy bien! Es hora de implementar la lógica de la base de datos y pasar al agente.
7. Lleva la lógica de la base de datos a la Web sin servidores
¿Todo listo para llevar esta app a la Web? Siga los pasos que se indican a continuación:
- Ve a Cloud Run Functions en la consola de Google Cloud para crear una nueva función de Cloud Run. Para ello, haz clic en "Escribir una función" o usa el siguiente vínculo: https://console.cloud.google.com/run/create?deploymentType=function.
- Elige la opción "Usar un editor intercalado para crear una función" y comienza la configuración. Proporciona el nombre del servicio "patent-search", elige la región "us-central1" y el tiempo de ejecución "Java 17". Establece la autenticación en "Permitir invocaciones sin autenticar".
- En la sección "Contenedores, volúmenes, Herramientas de redes y seguridad", sigue los pasos que se indican a continuación sin omitir ningún detalle:
Ve a la pestaña Networking:

Selecciona "Conéctate a una VPC para el tráfico saliente" y, luego, "Usa conectores de acceso a VPC sin servidores".
En el menú desplegable Red, haz clic en el menú desplegable Red y selecciona la opción "Agregar un conector de VPC nuevo" (si aún no configuraste el predeterminado) y sigue las instrucciones que aparecen en el cuadro de diálogo emergente:

Proporciona un nombre para el conector de VPC y asegúrate de que la región sea la misma que la de tu instancia. Deja el valor de la red como predeterminado y establece la subred como rango de IP personalizado con el rango de IP 10.8.0.0 o uno similar que esté disponible.
Expande SHOW SCALING SETTINGS y asegúrate de que la configuración sea exactamente la siguiente:

Haz clic en CREATE y este conector debería aparecer en la configuración de salida.
Selecciona el conector recién creado.
Opta por que todo el tráfico se enrute a través de este conector de VPC.
Haz clic en SIGUIENTE y, luego, en IMPLEMENTAR.
- De forma predeterminada, se establecería el punto de entrada en "gcfv2.HelloHttpFunction". Reemplaza el código del marcador de posición en HelloHttpFunction.java y pom.xml de tu Cloud Run Function por el código de " PatentSearch.java" y " pom.xml", respectivamente. Cambia el nombre del archivo de clase a PatentSearch.java.
- Recuerda cambiar el marcador de posición ************* y las credenciales de conexión de AlloyDB por tus valores en el archivo Java. Las credenciales de AlloyDB son las que usamos al comienzo de este codelab. Si usaste valores diferentes, modifícalos en el archivo Java.
- Haz clic en Implementar.
- Una vez que se implemente la Cloud Function actualizada, deberías ver el extremo generado. Copia ese valor y reemplázalo en el siguiente comando:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
Eso es todo. Así de simple es realizar una búsqueda avanzada de vectores de similitud contextual con el modelo de Embeddings en los datos de AlloyDB.
8. Compilaremos el agente con el ADK de Java
Primero, comencemos con el proyecto de Java en el editor.
- Navega a la terminal de Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Autoriza cuando se te solicite
- Haz clic en el ícono del editor en la parte superior de la consola de Cloud Shell para cambiar al editor de Cloud Shell.

- En la consola del editor de Cloud Shell de la página de destino, crea una carpeta nueva y asígnale el nombre "adk-agents".
Haz clic en Crear carpeta nueva en el directorio raíz de Cloud Shell, como se muestra a continuación:

Asigna el nombre "adk-agents":
- Crea la siguiente estructura de carpetas y los archivos vacíos con los nombres de archivo correspondientes en la siguiente estructura:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Abre el repositorio de GitHub en una pestaña separada y copia el código fuente de los archivos App.java y pom.xml.
- Si abriste el editor en una pestaña nueva con el ícono "Abrir en una pestaña nueva" en la esquina superior derecha, puedes abrir la terminal en la parte inferior de la página. Puedes tener el editor y la terminal abiertos en paralelo, lo que te permite operar con libertad.
- Una vez clonado, vuelve a la consola del editor de Cloud Shell.
- Como ya creamos la función de Cloud Run, no es necesario que copies los archivos de la función de Cloud Run desde la carpeta repo.
Primeros pasos con el SDK de Java del ADK
Es bastante sencillo. Principalmente, deberás asegurarte de que se incluyan los siguientes elementos en el paso de clonación:
- Agrega dependencias:
Incluye los artefactos google-adk y google-adk-dev (para la IU web) en tu pom.xml. Si copiaste el código fuente del repositorio, estos ya se incluyen en los archivos, por lo que no es necesario que los incluyas. Solo debes realizar un cambio en el extremo de la función de Cloud Run para que refleje el extremo implementado. Se explica en los próximos pasos de esta sección.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Asegúrate de hacer referencia al archivo pom.xml del repositorio de origen, ya que hay otras dependencias y configuraciones que se necesitan para que la aplicación pueda ejecutarse.
- Configura tu proyecto:
Asegúrate de que la versión de Java (se recomienda la 17 o una posterior) y la configuración del compilador de Maven estén configuradas correctamente en tu pom.xml. Puedes configurar tu proyecto para que siga la siguiente estructura:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Cómo definir el agente y sus herramientas (App.java):
Aquí es donde se destaca la magia del SDK de Java del ADK. Definimos nuestro agente, sus capacidades (instrucciones) y las herramientas que puede usar.
Aquí encontrarás una versión simplificada de algunos fragmentos de código de la clase del agente principal. Para ver el proyecto completo, consulta el repositorio del proyecto aquí.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Componentes clave del código Java del ADK destacados:
- LlmAgent.builder(): API fluida para configurar tu agente.
- .instruction(…): Proporciona la instrucción principal y los lineamientos para el LLM, incluido cuándo usar cada herramienta.
- FunctionTool.create(App.class, "methodName"): Registra fácilmente tus métodos de Java como herramientas que el agente puede invocar. La cadena del nombre del método debe coincidir con un método estático público real.
- @Schema(description = …): Anota los parámetros de la herramienta, lo que ayuda al LLM a comprender qué entradas espera cada herramienta. Esta descripción es fundamental para seleccionar la herramienta y completar los parámetros de forma precisa.
- InvocationContext ctx: Se pasa automáticamente a los métodos de herramientas, lo que brinda acceso al estado de la sesión (ctx.session().state()), la información del usuario y mucho más.
- .outputKey("patents"): Cuando una herramienta devuelve datos, el ADK puede almacenarlos automáticamente en el estado de la sesión con esta clave. Así es como explainPatent puede acceder a los resultados de getPatents.
- VECTOR_SEARCH_ENDPOINT: Esta es una variable que contiene la lógica funcional principal para las preguntas y respuestas contextuales para el usuario en el caso de uso de la búsqueda de patentes.
- Elemento de acción aquí: Debes establecer un valor de extremo implementado actualizado una vez que implementes el paso de la función de Cloud Run de Java de la sección anterior.
- searchTool: Interactúa con el usuario para encontrar coincidencias de patentes pertinentes según el contexto en la base de datos de patentes para el texto de búsqueda del usuario.
- explainTool: Le pide al usuario una patente específica para analizarla en detalle. Luego, resume el resumen de la patente y puede responder más preguntas del usuario en función de los detalles de la patente que tiene.
Nota importante: Asegúrate de reemplazar la variable VECTOR_SEARCH_ENDPOINT por el extremo de CRF implementado.
Cómo aprovechar InvocationContext para las interacciones con estado
Una de las funciones fundamentales para crear agentes útiles es la administración del estado en varios turnos de una conversación. InvocationContext del ADK facilita esta tarea.
En nuestro App.java:
- Cuando se define initAgent(), usamos .outputKey("patents"). Esto le indica al ADK que, cuando una herramienta (como getPatents) devuelva datos en su campo de informe, esos datos se deben almacenar en el estado de la sesión con la clave "patents".
- En el método de la herramienta explainPatent, insertamos InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Esto permite que la herramienta explainPatent acceda a la lista de patentes recuperada por la herramienta getPatents en un turno anterior, lo que hace que la conversación tenga estado y sea coherente.
9. Pruebas locales de la CLI
Define las variables de entorno.
Deberás exportar dos variables de entorno:
- Una clave de Gemini que puedes obtener en AI Studio:
Para ello, ve a https://aistudio.google.com/apikey, obtén la clave de API de tu proyecto de Google Cloud activo en el que implementarás esta aplicación y guárdala en algún lugar:

- Una vez que obtengas la clave, abre la terminal de Cloud Shell y muévete al nuevo directorio que acabamos de crear adk-agents ejecutando el siguiente comando:
cd adk-agents
- Es una variable para especificar que no usaremos Vertex AI esta vez.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Ejecuta tu primer agente en la CLI
Para iniciar este primer agente, usa el siguiente comando de Maven en tu terminal:
mvn compile exec:java -DmainClass="agents.App"
Verás la respuesta interactiva del agente en tu terminal.
10. Implementa en Cloud Run
Implementar tu agente de Java del ADK en Cloud Run es similar a implementar cualquier otra aplicación de Java:
- Dockerfile: Crea un Dockerfile para empaquetar tu aplicación en Java.
- Compila y envía la imagen de Docker: Usa Google Cloud Build y Artifact Registry.
- Puedes realizar el paso anterior y realizar la implementación en Cloud Run con un solo comando:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
De manera similar, implementarías tu Cloud Run Function de Java (gcfv2.PatentSearch). Como alternativa, puedes crear e implementar la función Java de Cloud Run para la lógica de la base de datos directamente desde la consola de Cloud Run Functions.
11. Pruebas con la IU web
El ADK incluye una IU web práctica para probar y depurar tu agente de forma local. Cuando ejecutas tu App.java de forma local (p.ej., mvn exec:java -Dexec.mainClass="agents.App" si está configurado, o simplemente ejecutas el método principal), el ADK suele iniciar un servidor web local.
La IU web del ADK te permite hacer lo siguiente:
- Enviar mensajes a tu agente
- Ver los eventos (mensaje del usuario, llamada a herramienta, respuesta de herramienta, respuesta del LLM)
- Inspecciona el estado de la sesión.
- Visualizar registros y seguimientos
Esto es muy valioso durante el desarrollo para comprender cómo tu agente procesa las solicitudes y usa sus herramientas. Esto supone que tu mainClass en pom.xml está configurada como com.google.adk.web.AdkWebServer y que tu agente está registrado en ella, o que estás ejecutando un ejecutor de pruebas local que expone esto.
Cuando ejecutas tu App.java con su InMemoryRunner y Scanner para la entrada de la consola, estás probando la lógica principal del agente. La IU web es un componente independiente para una experiencia de depuración más visual, que se suele usar cuando el ADK entrega tu agente a través de HTTP.
Puedes usar el siguiente comando de Maven desde tu directorio raíz para iniciar el servidor local de SpringBoot:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
A menudo, se puede acceder a la interfaz en la URL que genera el comando anterior. Si se implementó en Cloud Run, deberías poder acceder a él desde el vínculo de implementación de Cloud Run.
Deberías poder ver el resultado en una interfaz interactiva.
Mira el siguiente video para ver nuestro agente de patentes implementado:

12. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- Página https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
13. Felicitaciones
¡Felicitaciones! Combinaste con éxito las capacidades de ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI y Vector Search para crear tu agente de análisis de patentes en Java. Además, dimos un gran paso para que las búsquedas de similitud contextual sean transformadoras, eficientes y verdaderamente basadas en el significado.
¡Comienza hoy mismo!
Documentación del ADK: [Vínculo a la documentación oficial del ADK para Java]
Código fuente del agente de análisis de patentes: [Vínculo a tu repositorio de GitHub (ahora público)]
Agentes de muestra de Java: [vínculo al repo de adk-samples]
Únete a la comunidad del ADK: https://www.reddit.com/r/agentdevelopmentkit/
¡Feliz compilación de agentes!