
1. Обзор
В различных отраслях контекстный поиск является критически важной функцией, которая составляет основу их приложений. Технология дополненной реальности (Retrieval Augmented Generation) уже довольно давно является ключевым фактором этой важной технологической эволюции благодаря своим механизмам поиска на основе генеративного ИИ. Генеративные модели с их широкими контекстными окнами и впечатляющим качеством вывода преобразуют ИИ. RAG предоставляет систематический способ внедрения контекста в приложения и агенты ИИ, поддерживая их в структурированных базах данных или информации из различных источников. Эти контекстные данные критически важны для ясности, достоверности и точности вывода, но насколько точны эти результаты? Ваш бизнес в значительной степени зависит от точности этих контекстных соответствий и релевантности? Тогда этот проект вам точно понравится!
А теперь представьте, что мы могли бы использовать мощь генеративных моделей и создать интерактивных агентов, способных принимать автономные решения, опираясь на такую контекстно-критическую информацию и основанную на истине. Именно это мы и собираемся создать сегодня. Мы создадим сквозное приложение ИИ-агента, используя Agent Development Kit на базе передовой RAG в AlloyDB, для приложения патентного анализа.
Patent Analysis Agent помогает пользователю находить патенты, соответствующие контексту поиска, и по запросу предоставляет чёткое и краткое объяснение выбранного патента, а также при необходимости дополнительные сведения. Готовы увидеть, как это работает? Давайте разберёмся!
Цель
Цель проста. Дать пользователю возможность искать патенты по текстовому описанию, а затем получать подробное объяснение конкретного патента из результатов поиска. Всё это с помощью ИИ-агента, созданного с использованием Java ADK, AlloyDB, Vector Search (с расширенными индексами), Gemini и всего приложения, развёрнутого бессерверно в Cloud Run.
Что вы построите
В рамках этой лабораторной работы вы:
- Создайте экземпляр AlloyDB и загрузите данные из общедоступного набора данных Patents.
- Реализуйте расширенный поиск векторов в AlloyDB с использованием функций ScaNN и Recall eval
- Создание агента с использованием Java ADK
- Реализуйте логику сервера базы данных в Java Serverless Cloud Functions
- Разверните и протестируйте агент в Cloud Run
На следующей диаграмме представлен поток данных и этапы реализации.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell вы проверяете, что вы уже прошли аутентификацию и что проекту присвоен ваш идентификатор проекта, с помощью следующей команды:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы подтвердить, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не настроен, используйте следующую команду для его настройки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API. Вы можете использовать команду gcloud в терминале Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Альтернативой команде gcloud является поиск каждого продукта через консоль или использование этой ссылки .
Информацию о командах и использовании gcloud см. в документации .
3. Настройка базы данных
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для патентных данных. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , обеспечивающий точку доступа к данным. Сами данные будут храниться в таблицах.
Давайте создадим кластер, экземпляр и таблицу AlloyDB, куда будет загружен набор данных о патентах.
Создать кластер и экземпляр
- Перейдите на страницу AlloyDB в Cloud Console. Большинство страниц в Cloud Console легко найти, используя строку поиска в консоли.
- Выберите СОЗДАТЬ КЛАСТЕР на этой странице:

- Вы увидите экран, подобный показанному ниже. Создайте кластер и экземпляр со следующими значениями (убедитесь, что значения совпадают, если вы клонируете код приложения из репозитория):
- идентификатор кластера : "
vector-cluster" - пароль : "
alloydb" - PostgreSQL 15 / последняя рекомендуемая версия
- Region : "
us-central1" - Сетевое подключение : "
default"

- При выборе сети по умолчанию вы увидите экран, подобный показанному ниже.
Выберите НАСТРОЙКА ПОДКЛЮЧЕНИЯ . 
- Далее выберите « Использовать автоматически назначенный диапазон IP-адресов » и нажмите «Продолжить». После ознакомления с информацией нажмите «СОЗДАТЬ ПОДКЛЮЧЕНИЕ».

- После настройки сети вы можете продолжить создание кластера. Нажмите «СОЗДАТЬ КЛАСТЕР» , чтобы завершить настройку кластера, как показано ниже:

Обязательно измените идентификатор экземпляра (который вы можете найти во время настройки кластера/экземпляра) на
vector-instance . Если вы не можете его изменить, не забудьте использовать идентификатор вашего экземпляра во всех последующих ссылках.
Обратите внимание, что создание кластера займёт около 10 минут. После успешного завершения вы увидите экран с обзором только что созданного кластера.
4. Прием данных
Теперь пора добавить таблицу с данными о магазине. Перейдите в AlloyDB, выберите основной кластер, а затем AlloyDB Studio:

Возможно, вам придётся дождаться завершения создания вашего экземпляра. После этого войдите в AlloyDB, используя учётные данные, которые вы создали при создании кластера. Для аутентификации в PostgreSQL используйте следующие данные:
- Имя пользователя: "
postgres" - База данных: "
postgres" - Пароль: "
alloydb"
После успешной аутентификации в AlloyDB Studio команды SQL вводятся в редакторе. Вы можете добавить несколько окон редактора, нажав на значок «плюс» справа от последнего окна.

Вы будете вводить команды для AlloyDB в окнах редактора, используя при необходимости параметры «Выполнить», «Форматировать» и «Очистить».
Включить расширения
Для создания этого приложения мы будем использовать расширения pgvector и google_ml_integration . Расширение pgvector позволяет хранить и искать векторные представления. Расширение google_ml_integration предоставляет функции для доступа к конечным точкам прогнозирования Vertex AI для получения прогнозов в SQL. Включите эти расширения, выполнив следующие DDL-файлы:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Если вы хотите проверить расширения, включенные в вашей базе данных, выполните следующую команду SQL:
select extname, extversion from pg_extension;
Создать таблицу
Вы можете создать таблицу, используя приведенный ниже оператор DDL в AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
Столбец abstract_embeddings позволит хранить векторные значения текста.
Предоставить разрешение
Выполните указанный ниже оператор, чтобы предоставить разрешение на выполнение функции «встраивания»:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте роль пользователя Vertex AI учетной записи службы AlloyDB.
В консоли Google Cloud IAM предоставьте учётной записи сервиса AlloyDB (которая выглядит так: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) доступ к роли «Пользователь Vertex AI». PROJECT_NUMBER будет содержать номер вашего проекта.
В качестве альтернативы вы можете выполнить следующую команду из терминала Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Загрузить патентные данные в базу данных
В качестве набора данных мы будем использовать общедоступные наборы данных Google Patents в BigQuery. Для выполнения запросов мы будем использовать AlloyDB Studio. Данные поступают в insert scripts sql в этом репозитории , который мы запустим для загрузки патентных данных.
- В консоли Google Cloud откройте страницу AlloyDB .
- Выберите только что созданный кластер и щелкните экземпляр.
- В меню навигации AlloyDB выберите AlloyDB Studio . Войдите, используя свои учётные данные.
- Откройте новую вкладку, нажав на значок «Новая вкладка» справа.
- Скопируйте и выполните операторы запроса
insertиз файловinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlпо одному. Вы можете выполнить копирование 10–50 операторов запроса на вставку для быстрой демонстрации этого варианта использования.
Чтобы выполнить запрос, нажмите кнопку «Выполнить» . Результаты запроса появятся в таблице «Результаты» .
5. Создание вложений для данных патентов
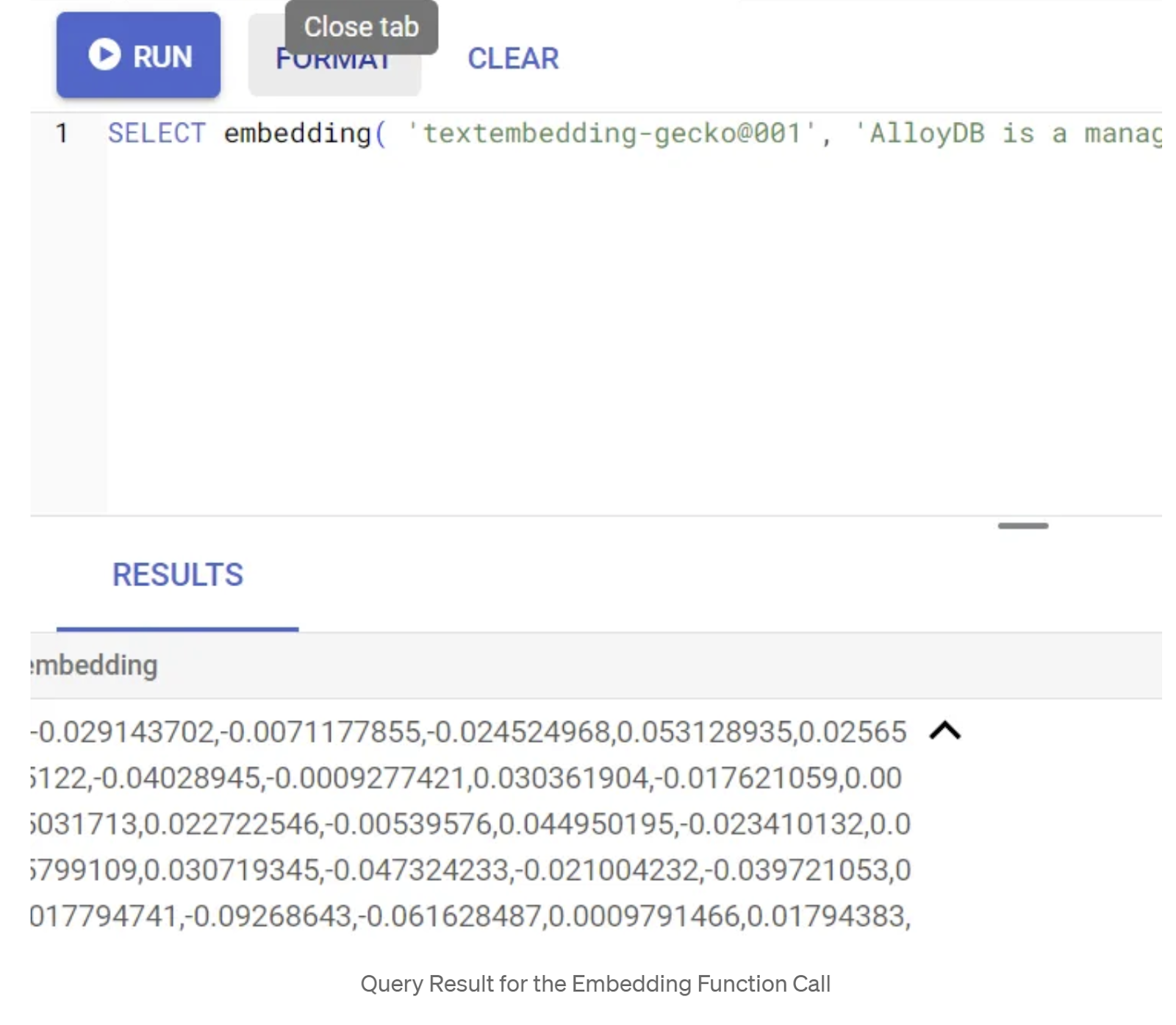
Сначала давайте протестируем функцию встраивания, выполнив следующий пример запроса:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Этот метод должен вернуть вектор вложений, который выглядит как массив чисел с плавающей точкой, для образца текста в запросе. Выглядит это примерно так:
Обновите векторное поле abstract_embeddings
Приведенный ниже DML-код следует использовать для обновления аннотаций патентов в таблице с соответствующими вложениями, если требуется сгенерировать вложения для аннотаций. Но в нашем случае операторы вставки уже содержат эти вложения для каждого аннотации, поэтому вызывать метод embeddings() не нужно.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Выполнить поиск вектора
Теперь, когда таблица, данные и встраивание готовы, давайте выполним векторный поиск в реальном времени по тексту поискового запроса пользователя. Вы можете проверить это, выполнив следующий запрос:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
В этом запросе,
- Пользователь искал текст: «Анализ настроений».
- Мы преобразуем его во встраивание в методе embedding(), используя модель: text-embedding-005.
- «<=>» представляет собой использование метода расстояния КОСИНУСНОГО ПОДОБИЯ.
- Мы преобразуем результат метода встраивания в векторный тип, чтобы сделать его совместимым с векторами, хранящимися в базе данных.
- LIMIT 10 означает, что мы выбираем 10 наиболее близких совпадений искомого текста.
AlloyDB выводит Vector Search RAG на новый уровень:
Введено немало нововведений. Два из них ориентированы на разработчиков:
- Встроенная фильтрация
- Оценщик отзывов
Встроенная фильтрация
Раньше разработчикам приходилось выполнять запросы векторного поиска, а также заниматься фильтрацией и повторным вызовом. Оптимизатор запросов AlloyDB выбирает способ выполнения запроса с фильтрами. Встроенная фильтрация — это новый метод оптимизации запросов, позволяющий оптимизатору запросов AlloyDB оценивать как условия фильтрации метаданных, так и векторный поиск, используя как векторные индексы, так и индексы по столбцам метаданных. Это повысило производительность повторного вызова, позволяя разработчикам использовать все преимущества AlloyDB прямо из коробки.
Встроенная фильтрация лучше всего подходит для случаев со средней селективностью. При поиске по индексу векторов AlloyDB вычисляет расстояния только для векторов, соответствующих условиям фильтрации метаданных (функциональным фильтрам в запросе, которые обычно обрабатываются в предложении WHERE). Это значительно повышает производительность таких запросов, дополняя преимущества пост- и предварительных фильтров .
- Установите или обновите расширение pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Если расширение pgvector уже установлено, обновите расширение вектора до версии 0.8.0.google-3 или более поздней, чтобы получить возможности оценщика повторных выборок.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Этот шаг необходимо выполнить только в том случае, если расширение вашего вектора <0.8.0.google-3.
Важно: если количество строк меньше 100, вам не нужно создавать индекс ScaNN изначально, так как он не будет применяться к меньшему количеству строк. В этом случае пропустите следующие шаги.
- Для создания индексов ScaNN установите расширение alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Сначала запустите запрос поиска векторов без индекса и без включенного встроенного фильтра:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Результат должен быть похож на:

- Запустить Explain Analyze для него: (без индекса и встроенной фильтрации)

Время выполнения 2,4 мс.
- Давайте создадим обычный индекс по полю num_claims, чтобы можно было фильтровать по нему:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Давайте создадим индекс ScaNN для нашего приложения поиска патентов. Выполните следующую команду в AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Важное примечание: (num_leaves=32) применимо к нашему общему набору данных, содержащему более 1000 строк. Если количество строк меньше 100, вам не нужно создавать индекс изначально, так как для меньшего количества строк он не применяется.
- Включите встроенную фильтрацию в индексе ScaNN:
SET scann.enable_inline_filtering = on
- Теперь давайте выполним тот же запрос с фильтром и поиском по вектору:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
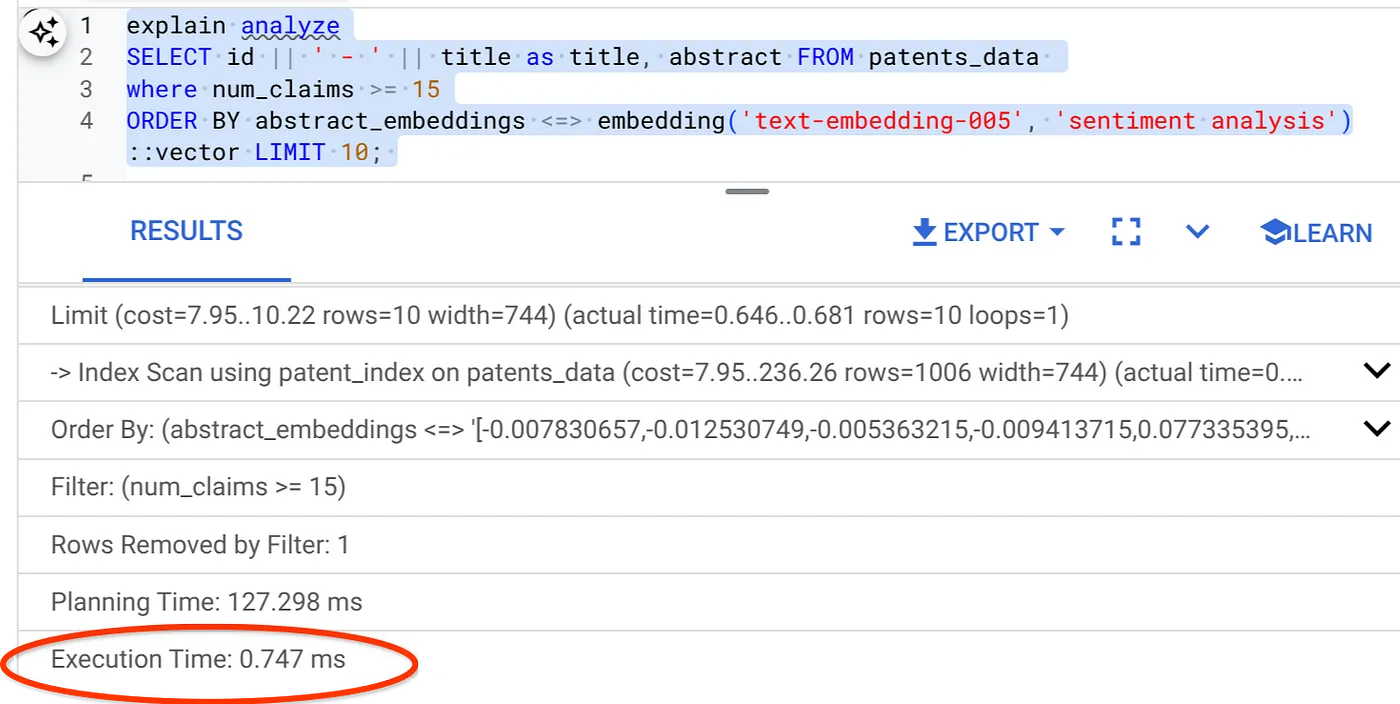
Как видите, время выполнения того же поиска векторов значительно сократилось. Индекс ScaNN с встроенной фильтрацией в поиске векторов сделал это возможным!
Далее давайте оценим полноту для этого векторного поиска с использованием ScaNN.
Оценщик отзывов
Полнота в поиске по сходству — это процент релевантных вхождений, полученных в результате поиска, то есть количество истинно положительных результатов. Это наиболее распространённая метрика, используемая для оценки качества поиска. Одним из источников потери полноты является разница между приближенным поиском ближайшего соседа (aNN) и точным поиском ближайшего соседа (kNN). Векторные индексы, такие как ScaNN от AlloyDB, реализуют алгоритмы aNN, позволяя ускорить векторный поиск в больших наборах данных за счёт небольшого снижения полноты. Теперь AlloyDB предоставляет возможность измерять этот компромисс непосредственно в базе данных для отдельных запросов и обеспечивать его стабильность с течением времени. Вы можете обновлять параметры запроса и индекса в соответствии с этой информацией для достижения лучших результатов и повышения производительности.
Вы можете определить полноту векторного запроса по векторному индексу для заданной конфигурации с помощью функции estimate_query_recall . Эта функция позволяет настроить параметры для достижения желаемых результатов полноты векторного запроса. Полнота — это метрика, используемая для оценки качества поиска, которая определяется как процент возвращённых результатов, объективно наиболее близких к векторам запроса. Функция estimate_query_recall включена по умолчанию.
Важное примечание:
Если на следующих этапах вы столкнётесь с ошибкой «Отказано в доступе» для индекса HNSW, пропустите пока весь раздел об оценке отзыва. На данном этапе это может быть связано с ограничениями доступа, поскольку они были опубликованы только на момент документирования этой практической работы.
- Установите флаг «Включить сканирование индекса» для индекса ScaNN и индекса HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Выполните следующий запрос в AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Функция estimate_query_recall принимает запрос в качестве параметра и возвращает его значение. В качестве входного запроса я использую тот же запрос, который использовался для проверки производительности. Я добавил SCaNN в качестве метода индексирования. Подробнее о параметрах см. в документации .
Для этого запроса поиска векторов мы использовали следующие данные:
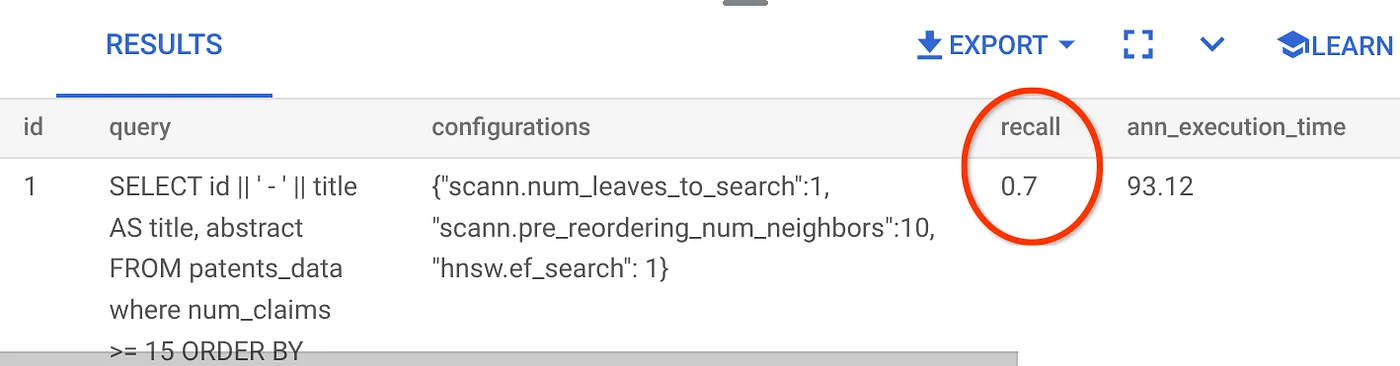
Я вижу, что полнота составляет 70%. Теперь я могу использовать эту информацию для изменения параметров индекса, методов и параметров запроса, чтобы улучшить полноту для этого векторного поиска!
Я изменил количество строк в результирующем наборе до 7 (ранее было 10) и вижу немного улучшенный показатель RECALL, а именно 86%.
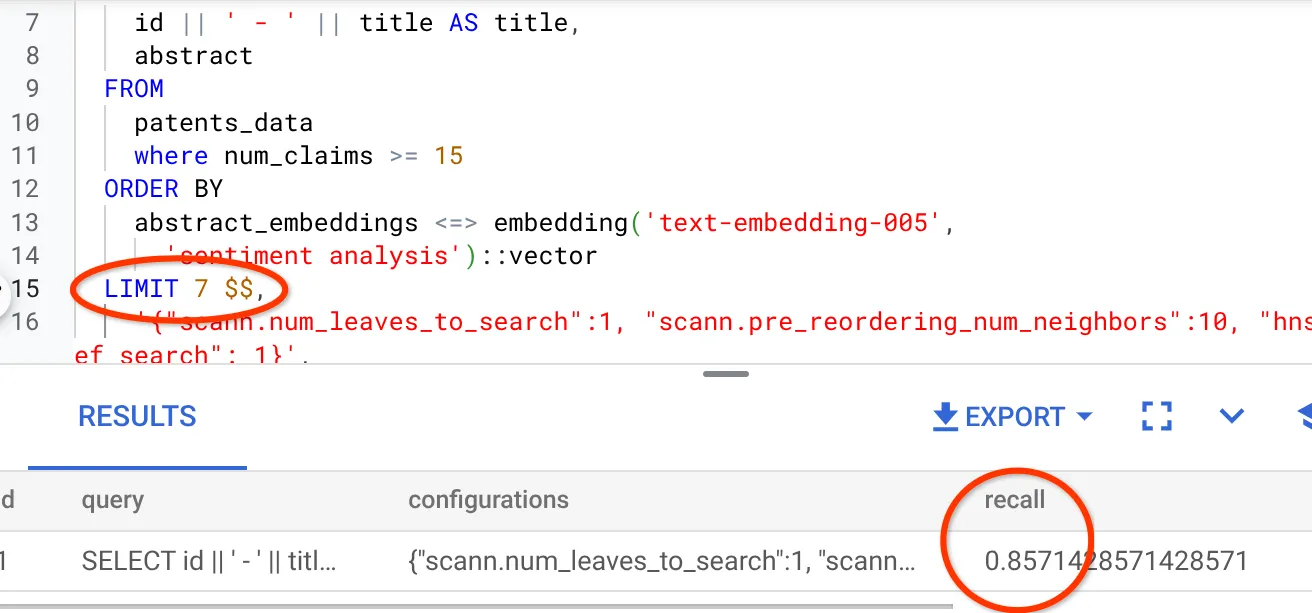
Это означает, что я могу в режиме реального времени изменять количество совпадений, которые видят мои пользователи, чтобы повысить релевантность совпадений в соответствии с контекстом поиска пользователя.
Отлично! Пора развернуть логику базы данных и перейти к агенту!!!
7. Перенесите логику базы данных на веб-сервер без использования
Готовы опубликовать это приложение в интернете? Выполните следующие шаги:
- Перейдите в раздел Cloud Run Functions в Google Cloud Console, чтобы создать новую функцию Cloud Run, нажав «Написать функцию» или воспользуйтесь ссылкой: https://console.cloud.google.com/run/create?deploymentType=function .
- Выберите опцию «Использовать встроенный редактор для создания функции» и начните настройку. Укажите имя службы « patent-search », выберите регион « us-central1 » и среду выполнения «Java 17» . Установите для параметра «Аутентификация» значение « Разрешить вызовы без аутентификации ».
- В разделе «Контейнеры, тома, сеть, безопасность» выполните следующие шаги, не упуская ни одной детали:
Перейдите на вкладку «Сеть»:

Выберите « Подключиться к VPC для исходящего трафика », а затем выберите « Использовать коннекторы Serverless VPC Access ».
В раскрывающемся списке «Сеть» выберите «Настройки», щелкните раскрывающийся список «Сеть» и выберите опцию « Добавить новый коннектор VPC » (если вы еще не настроили коннектор по умолчанию ), затем следуйте инструкциям, которые вы увидите во всплывающем диалоговом окне:

Укажите имя для VPC-коннектора и убедитесь, что регион совпадает с регионом вашего экземпляра. Оставьте значение «Сеть» по умолчанию и выберите для параметра «Подсеть» значение «Настраиваемый диапазон IP-адресов» (Custom IP Range) с диапазоном IP-адресов 10.8.0.0 или аналогичным доступным.
Разверните ПОКАЗАТЬ ПАРАМЕТРЫ МАСШТАБИРОВАНИЯ и убедитесь, что у вас установлена следующая конфигурация:

Нажмите кнопку СОЗДАТЬ , и этот соединитель теперь должен быть указан в настройках выхода.
Выберите только что созданный соединитель.
Выберите, чтобы весь трафик направлялся через этот VPC-коннектор.
Нажмите ДАЛЕЕ , а затем РАЗВЕРНУТЬ .
- По умолчанию точка входа будет установлена на gcfv2.HelloHttpFunction . Замените код-заполнитель в файлах HelloHttpFunction.java и pom.xml вашей функции Cloud Run кодом из PatentSearch.java и pom.xml соответственно. Измените имя файла класса на PatentSearch.java.
- Не забудьте заменить плейсхолдер ************* и учётные данные AlloyDB на свои значения из файла Java. Учётные данные AlloyDB — те же, что мы использовали в начале этой практической работы. Если вы использовали другие значения, пожалуйста, измените их в файле Java.
- Нажмите Развернуть .
- После развёртывания обновлённой облачной функции вы увидите сгенерированную конечную точку. Скопируйте её и замените в следующей команде:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
Вот и всё! Выполнить расширенный поиск векторов контекстного сходства с использованием модели Embeddings на основе данных AlloyDB очень просто.
8. Давайте создадим агента с помощью Java ADK
Для начала давайте начнем с проекта Java в редакторе.
- Перейдите в Cloud Shell Terminal.
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Авторизуйтесь при появлении соответствующего запроса
- Чтобы перейти в редактор Cloud Shell, щелкните значок редактора в верхней части консоли Cloud Shell.

- В консоли Cloud Shell Editor создайте новую папку и назовите ее «adk-agents»
Нажмите «Создать новую папку» в корневом каталоге вашей облачной оболочки, как показано ниже:

Назовите его «adk-agents»:
- Создайте следующую структуру папок и пустые файлы с соответствующими именами файлов в структуре ниже:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Откройте репозиторий github в отдельной вкладке и скопируйте исходный код файлов App.java и pom.xml.
- Если вы открыли редактор в новой вкладке с помощью значка «Открыть в новой вкладке» в правом верхнем углу, терминал можно открыть в нижней части страницы. Редактор и терминал можно открыть параллельно, что позволит вам работать с ними свободно.
- После клонирования вернитесь в консоль Cloud Shell Editor.
- Поскольку мы уже создали функцию Cloud Run, вам не нужно копировать файлы функции Cloud Run из папки репозитория .
Начало работы с ADK Java SDK
Это довольно просто. В первую очередь вам нужно убедиться, что на этапе клонирования учтены следующие моменты:
- Добавить зависимости:
Включите артефакты google-adk и google-adk-dev (для веб-интерфейса) в файл pom.xml. Если вы скопировали исходный код из репозитория, они уже включены в файлы, вам не нужно их добавлять. Вам просто нужно внести изменения в конечную точку функции Cloud Run, чтобы она соответствовала вашей развёрнутой конечной точке. Это будет рассмотрено в следующих шагах этого раздела.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Обязательно укажите ссылку на pom.xml из исходного репозитория, так как для запуска приложения необходимы другие зависимости и конфигурации.
- Настройте свой проект:
Убедитесь, что версия Java (рекомендуется 17+) и параметры компилятора Maven правильно настроены в файле pom.xml. Вы можете настроить свой проект, следуя следующей структуре:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Определение агента и его инструментов (App.java):
Именно здесь раскрывается магия Java SDK ADK. Мы определяем нашего агента, его возможности (инструкции) и инструменты, которые он может использовать.
Упрощённую версию нескольких фрагментов кода основного класса агента можно найти здесь. Полный проект можно найти в репозитории проекта здесь .
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Выделены основные компоненты кода Java ADK:
- LlmAgent.builder(): Fluent API для настройки вашего агента.
- .instruction(...): Содержит основные указания и рекомендации для LLM, включая информацию о том, когда какой инструмент использовать.
- FunctionTool.create(App.class, "methodName"): легко регистрирует ваши методы Java как инструменты, которые может вызывать агент. Строка имени метода должна соответствовать реальному открытому статическому методу.
- @Schema(description = ...): Аннотирует параметры инструмента, помогая LLM понять, какие входные данные ожидает каждый инструмент. Это описание критически важно для точного выбора инструмента и заполнения параметров.
- InvocationContext ctx: автоматически передается методам инструмента, предоставляя доступ к состоянию сеанса (ctx.session().state()), информации о пользователе и т. д.
- .outputKey("patents"): когда инструмент возвращает данные, ADK может автоматически сохранять их в состоянии сеанса по этому ключу. Именно так ExplainPatent может получить доступ к результатам из GetPatents.
- VECTOR_SEARCH_ENDPOINT: Это переменная, которая содержит основную функциональную логику для контекстных вопросов и ответов для пользователя в случае использования поиска патентов.
- Элемент действия здесь: вам необходимо задать обновленное значение развернутой конечной точки после реализации шага Java Cloud Run Function из предыдущего раздела.
- searchTool : взаимодействует с пользователем, помогая ему находить в базе данных патентов соответствующие контексту совпадения по тексту поиска пользователя.
- ExplainTool : запрашивает у пользователя конкретный патент для подробного изучения. Затем инструмент выводит краткое содержание патента и готов ответить на дополнительные вопросы пользователя, основываясь на имеющейся информации о патенте.
Важное примечание: обязательно замените переменную VECTOR_SEARCH_ENDPOINT развернутой конечной точкой CRF.
Использование InvocationContext для взаимодействия с сохранением состояния
Одна из важнейших функций для создания полезных агентов — управление состоянием на протяжении нескольких этапов диалога. InvocationContext в ADK упрощает эту задачу.
В нашем App.java:
- При определении initAgent() мы используем .outputKey("patents"). Это сообщает ADK, что когда инструмент (например, getPatents) возвращает данные в поле отчёта, эти данные должны быть сохранены в состоянии сеанса по ключу "patents".
- В методе инструмента ExplainPatent мы внедряем InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Это позволяет инструменту ExplainPatent получать доступ к списку патентов, полученному инструментом GetPatents на предыдущем этапе, что делает беседу последовательной и отслеживающей состояние.
9. Локальное тестирование CLI
Определить переменные среды
Вам необходимо экспортировать две переменные среды:
- Ключ Gemini, который вы можете получить в AI Studio:
Для этого перейдите по адресу https://aistudio.google.com/apikey и получите API-ключ для вашего активного проекта Google Cloud, в котором вы реализуете это приложение, и сохраните ключ где-нибудь:
- Получив ключ, откройте Cloud Shell Terminal и перейдите в новый каталог, который мы только что создали adk-agents, выполнив следующую команду:
cd adk-agents
- Переменная, указывающая, что на этот раз мы не используем Vertex AI.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Запустите свой первый агент в CLI
Чтобы запустить этот первый агент, используйте следующую команду Maven в терминале:
mvn compile exec:java -DmainClass="agents.App"
Вы увидите интерактивный ответ от агента на своем терминале.
10. Развертывание в Cloud Run
Развертывание агента Java ADK в Cloud Run аналогично развертыванию любого другого приложения Java:
- Dockerfile: создайте Dockerfile для упаковки вашего Java-приложения.
- Сборка и отправка образа Docker: используйте Google Cloud Build и Artifact Registry.
- Вы можете выполнить вышеуказанный шаг и выполнить развертывание в Cloud Run всего одной командой:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Аналогичным образом вы можете развернуть функцию Java Cloud Run Function (gcfv2.PatentSearch). В качестве альтернативы вы можете создать и развернуть функцию Java Cloud Run Function для логики базы данных непосредственно из консоли Cloud Run Function.
11. Тестирование с помощью веб-интерфейса
ADK поставляется с удобным веб-интерфейсом для локального тестирования и отладки агента. При локальном запуске App.java (например, mvn exec:java -Dexec.mainClass="agents.App", если это настроено, или просто при запуске метода main) ADK обычно запускает локальный веб-сервер.
Веб-интерфейс ADK позволяет:
- Отправляйте сообщения своему агенту.
- Просматривайте события (сообщение пользователя, вызов инструмента, ответ инструмента, ответ LLM).
- Проверьте состояние сеанса.
- Просмотр журналов и трассировок.
Это бесценно во время разработки для понимания того, как ваш агент обрабатывает запросы и использует свои инструменты. Предполагается, что ваш mainClass в pom.xml установлен на com.google.adk.web.AdkWebServer , и ваш агент зарегистрирован в нём, или вы используете локальный инструмент для запуска тестов, который предоставляет эту информацию.
При запуске App.java с InMemoryRunner и Scanner для ввода данных с консоли вы тестируете основную логику агента. Веб-интерфейс — это отдельный компонент для более визуальной отладки, часто используемый, когда ADK обслуживает агент по HTTP.
Для запуска локального сервера SpringBoot вы можете использовать следующую команду Maven из корневого каталога:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
Интерфейс часто доступен по URL-адресу, указанному в выводе команды выше. Если он развёрнут в Cloud Run , вы сможете получить к нему доступ по ссылке «Развёрнут в Cloud Run».
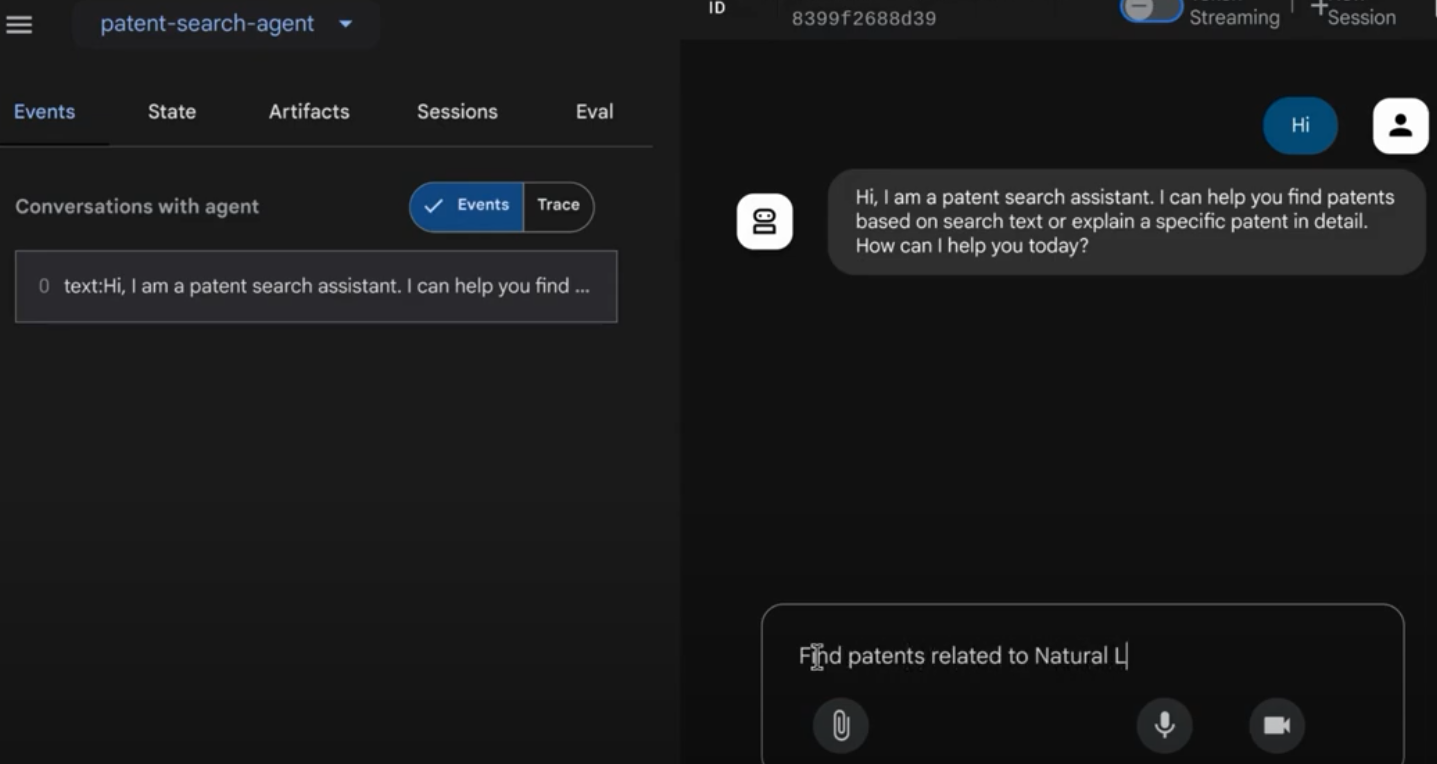
Результат вы сможете увидеть в интерактивном интерфейсе.
Посмотрите видео ниже о нашем патентном агенте:
Демонстрация патентного агента с контролем качества и встроенным поиском и оценкой отзыва AlloyDB!
12. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой публикации, выполните следующие действия:
- В консоли Google Cloud перейдите по адресу https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=страница блога.
- В списке проектов выберите проект, который вы хотите удалить, а затем нажмите Удалить .
- В диалоговом окне введите идентификатор проекта, а затем нажмите кнопку «Завершить» , чтобы удалить проект.
13. Поздравления
Поздравляем! Вы успешно создали свой агент патентного анализа на Java, объединив возможности ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog , Vertex AI и Vector Search. Кроме того, мы сделали огромный шаг вперёд, сделав поиск по контекстному сходству настолько преобразующим, эффективным и по-настоящему осмысленным.
Начните сегодня!
Документация ADK: [Ссылка на официальную документацию ADK Java]
Исходный код Patent Analysis Agent: [Ссылка на ваш (теперь общедоступный) репозиторий GitHub]
Примеры агентов Java: [ссылка на репозиторий adk-samples]
Присоединяйтесь к сообществу ADK: https://www.reddit.com/r/agentdevelopmentkit/
Удачного создания агента!