
1. Panoramica
In diversi settori, la ricerca contestuale è una funzionalità fondamentale che costituisce il cuore e il centro delle applicazioni. La generazione aumentata dal recupero è da tempo un motore chiave di questa evoluzione tecnologica cruciale, grazie ai suoi meccanismi di recupero basati sull'AI generativa. I modelli generativi, con le loro ampie finestre contestuali e l'impressionante qualità dell'output, stanno trasformando l'AI. La RAG fornisce un modo sistematico per inserire il contesto nelle applicazioni e negli agenti di AI, basandoli su database strutturati o informazioni provenienti da vari media. Questi dati contestuali sono fondamentali per la chiarezza della verità e l'accuratezza dell'output, ma quanto sono accurati i risultati? La tua attività dipende in gran parte dall'accuratezza di queste corrispondenze contestuali e dalla pertinenza? Allora questo progetto ti farà ridere!
Ora immagina se potessimo sfruttare la potenza dei modelli generativi e creare agenti interattivi in grado di prendere decisioni autonome supportate da informazioni così importanti per il contesto e basate sulla verità. Questo è ciò che andremo a creare oggi. Creeremo un'app di agenti AI end-to-end utilizzando Agent Development Kit basato su RAG avanzato in AlloyDB per un'applicazione di analisi dei brevetti.
L'agente di analisi dei brevetti aiuta l'utente a trovare brevetti pertinenti al contesto del testo di ricerca e, su richiesta, fornisce una spiegazione chiara e concisa e ulteriori dettagli, se necessario, per un brevetto selezionato. Pronto a scoprire come si fa? Iniziamo.
Obiettivo
L'obiettivo è semplice: Consenti a un utente di cercare brevetti in base a una descrizione testuale e poi di ottenere una spiegazione dettagliata di un brevetto specifico dai risultati di ricerca. Tutto questo utilizzando un agente AI creato con Java ADK, AlloyDB, Vector Search (con indici avanzati), Gemini e l'intera applicazione di cui è stato eseguito il deployment serverless su Cloud Run.
Cosa creerai
Nell'ambito di questo lab, imparerai a:
- Crea un'istanza AlloyDB e carica i dati del set di dati pubblico sui brevetti
- Implementare la ricerca vettoriale avanzata in AlloyDB utilizzando le funzionalità di valutazione ScaNN e Recall
- Crea un agente utilizzando Java ADK
- Implementa la logica lato server del database in Cloud Functions serverless Java
- Esegui il deployment e testa l'agente in Cloud Run
Il seguente diagramma mostra il flusso di dati e i passaggi coinvolti nell'implementazione.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto .
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste. Puoi utilizzare un comando gcloud nel terminale Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
L'alternativa al comando gcloud è tramite la console, cercando ogni prodotto o utilizzando questo link.
Consulta la documentazione per i comandi e l'utilizzo di gcloud.
3. Configurazione del database
In questo lab utilizzeremo AlloyDB come database per i dati sui brevetti. Utilizza i cluster per contenere tutte le risorse, come database e log. Ogni cluster ha un'istanza primaria che fornisce un punto di accesso ai dati. Le tabelle conterranno i dati effettivi.
Creiamo un cluster, un'istanza e una tabella AlloyDB in cui verrà caricato il set di dati sui brevetti.
Crea un cluster e un'istanza
- Vai alla pagina AlloyDB nella console Cloud. Un modo semplice per trovare la maggior parte delle pagine in Cloud Console è cercarle utilizzando la barra di ricerca della console.
- Seleziona CREA CLUSTER da questa pagina:

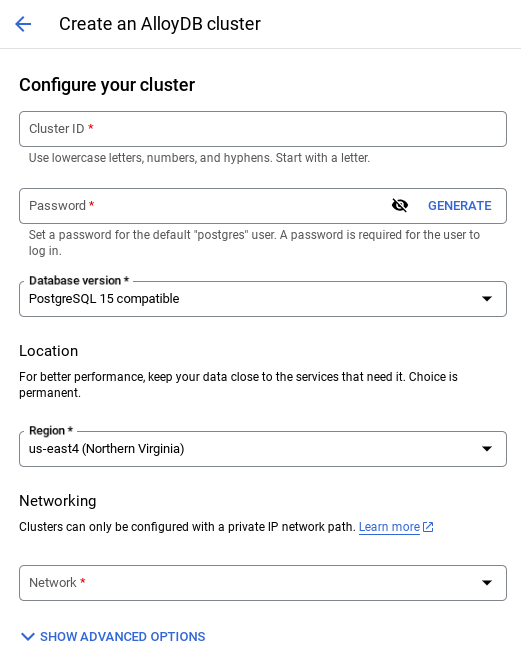
- Vedrai una schermata come quella riportata di seguito. Crea un cluster e un'istanza con i seguenti valori (assicurati che i valori corrispondano se cloni il codice dell'applicazione dal repository):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / ultima versione consigliata
- Regione: "
us-central1" - Networking: "
default"
- Quando selezioni la rete predefinita, viene visualizzata una schermata come quella riportata di seguito.
Seleziona CONFIGURA CONNESSIONE.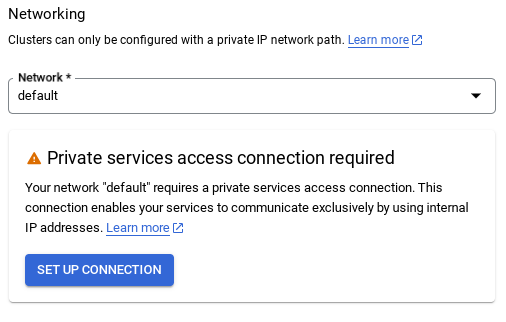
- Da qui, seleziona "Utilizza un intervallo IP allocato automaticamente" e fai clic su Continua. Dopo aver esaminato le informazioni, seleziona CREA CONNESSIONE.

- Una volta configurata la rete, puoi continuare a creare il cluster. Fai clic su CREA CLUSTER per completare la configurazione del cluster come mostrato di seguito:

Assicurati di modificare l'ID istanza (che puoi trovare al momento della configurazione del cluster / dell'istanza) in
vector-instance. Se non riesci a modificarlo, ricorda di utilizzare l'ID istanza in tutti i riferimenti futuri.
Tieni presente che la creazione del cluster richiederà circa 10 minuti. Una volta completata l'operazione, dovresti visualizzare una schermata che mostra la panoramica del cluster che hai appena creato.
4. Importazione dati
Ora è il momento di aggiungere una tabella con i dati del negozio. Vai ad AlloyDB, seleziona il cluster principale e poi AlloyDB Studio:

Potrebbe essere necessario attendere il completamento della creazione dell'istanza. Una volta creato, accedi ad AlloyDB utilizzando le credenziali che hai creato durante la creazione del cluster. Utilizza i seguenti dati per l'autenticazione a PostgreSQL:
- Nome utente : "
postgres" - Database : "
postgres" - Password : "
alloydb"
Una volta eseguita l'autenticazione in AlloyDB Studio, i comandi SQL vengono inseriti nell'editor. Puoi aggiungere più finestre dell'editor utilizzando il segno più a destra dell'ultima finestra.

Inserirai i comandi per AlloyDB nelle finestre dell'editor, utilizzando le opzioni Esegui, Formatta e Cancella in base alle esigenze.
Attivare le estensioni
Per creare questa app, utilizzeremo le estensioni pgvector e google_ml_integration. L'estensione pgvector ti consente di archiviare e cercare gli incorporamenti vettoriali. L'estensione google_ml_integration fornisce funzioni che utilizzi per accedere agli endpoint di previsione di Vertex AI per ottenere previsioni in SQL. Attiva queste estensioni eseguendo i seguenti DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Se vuoi controllare le estensioni abilitate nel tuo database, esegui questo comando SQL:
select extname, extversion from pg_extension;
Creare una tabella
Puoi creare una tabella utilizzando l'istruzione DDL riportata di seguito in AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
La colonna abstract_embeddings consentirà l'archiviazione dei valori vettoriali del testo.
Concedi autorizzazione
Esegui l'istruzione riportata di seguito per concedere l'esecuzione della funzione "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Concedi il ruolo Utente Vertex AI al service account AlloyDB
Dalla console Google Cloud IAM, concedi all'account di servizio AlloyDB (simile a service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) l'accesso al ruolo "Utente Vertex AI". PROJECT_NUMBER conterrà il numero del tuo progetto.
In alternativa, puoi eseguire il comando riportato di seguito dal terminale Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Caricare i dati dei brevetti nel database
Come set di dati utilizzeremo i set di dati pubblici di Google Patents su BigQuery. Utilizzeremo AlloyDB Studio per eseguire le query. I dati vengono inseriti in questo file insert scripts sql in questo repo e lo eseguiremo per caricare i dati dei brevetti.
- Nella console Google Cloud, apri la pagina AlloyDB.
- Seleziona il cluster appena creato e fai clic sull'istanza.
- Nel menu di navigazione di AlloyDB, fai clic su AlloyDB Studio. Accedi con le tue credenziali.
- Apri una nuova scheda facendo clic sull'icona Nuova scheda a destra.
- Copia ed esegui le istruzioni della query
insertdai fileinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqluno alla volta. Puoi eseguire le istruzioni di inserimento di 10-50 copie per una rapida demo di questo caso d'uso.
Per eseguire il test, fai clic su Esegui. I risultati della query vengono visualizzati nella tabella Risultati.
5. Crea incorporamenti per i dati dei brevetti
Innanzitutto, testiamo la funzione di incorporamento eseguendo la seguente query di esempio:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Dovrebbe restituire il vettore di incorporamento, che ha l'aspetto di un array di numeri in virgola mobile, per il testo di esempio nella query. Ecco come appare:
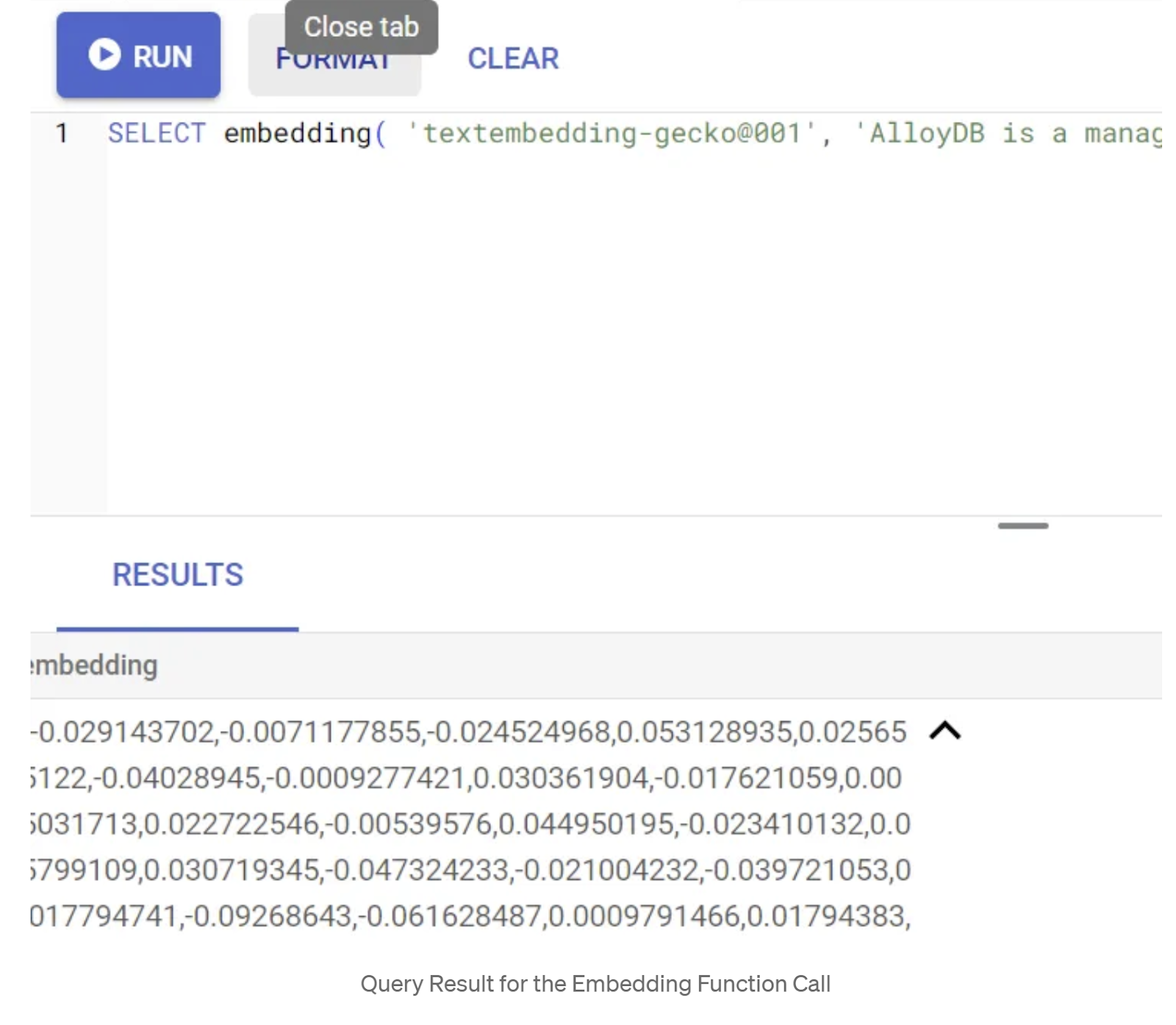
Aggiorna il campo Vettore abstract_embeddings
Il DML riportato di seguito deve essere utilizzato per aggiornare i riassunti dei brevetti nella tabella con gli incorporamenti corrispondenti nel caso in cui sia necessario generare gli incorporamenti per i riassunti. Nel nostro caso, però, le istruzioni di inserimento contengono già questi incorporamenti per ogni abstract, quindi non è necessario chiamare il metodo embeddings().
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Eseguire la ricerca vettoriale
Ora che la tabella, i dati e gli incorporamenti sono pronti, eseguiamo la ricerca vettoriale in tempo reale per il testo di ricerca dell'utente. Puoi testarlo eseguendo la query riportata di seguito:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
In questa query,
- Il testo cercato dall'utente è: "Analisi del sentiment".
- Lo convertiamo in embedding nel metodo embedding() utilizzando il modello text-embedding-005.
- "<=>" rappresenta l'utilizzo del metodo di distanza COSINE SIMILARITY.
- Stiamo convertendo il risultato del metodo di incorporamento in tipo di vettore per renderlo compatibile con i vettori archiviati nel database.
- LIMIT 10 indica che stiamo selezionando le 10 corrispondenze più vicine al testo di ricerca.
AlloyDB porta la RAG di Vector Search a un livello superiore:
Sono state introdotte diverse novità. Due di queste, incentrate sugli sviluppatori, sono:
- Filtro in linea
- Valutatore del richiamo
Filtro in linea
In precedenza, in qualità di sviluppatore, dovevi eseguire la query Vector Search e occuparti del filtraggio e del recupero. Lo strumento di ottimizzazione delle query di AlloyDB sceglie come eseguire una query con filtri. Il filtro in linea è una nuova tecnica di ottimizzazione delle query che consente all'ottimizzatore delle query AlloyDB di valutare contemporaneamente le condizioni di filtro dei metadati e la ricerca vettoriale, sfruttando sia gli indici vettoriali sia gli indici sulle colonne dei metadati. Ciò ha aumentato le prestazioni di richiamo, consentendo agli sviluppatori di sfruttare al meglio le funzionalità di AlloyDB pronte all'uso.
Il filtro in linea è ideale per i casi con selettività media. Quando AlloyDB esegue ricerche nell'indice vettoriale, calcola le distanze solo per i vettori che corrispondono alle condizioni di filtro dei metadati (i filtri funzionali in una query gestiti di solito nella clausola WHERE). In questo modo, le prestazioni di queste query migliorano notevolmente, integrando i vantaggi del pre-filtraggio o del post-filtraggio.
- Installare o aggiornare l'estensione pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Se l'estensione pgvector è già installata, esegui l'upgrade all'estensione vettoriale alla versione 0.8.0.google-3 o successive per ottenere le funzionalità di valutazione del richiamo.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Questo passaggio deve essere eseguito solo se l'estensione vettoriale è <0.8.0.google-3.
Nota importante:se il conteggio delle righe è inferiore a 100, non dovrai creare l'indice ScaNN, in quanto non verrà applicato a un numero inferiore di righe. In questo caso, ignora i passaggi che seguono.
- Per creare indici ScaNN, installa l'estensione alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- Per prima cosa, esegui la query di ricerca vettoriale senza l'indice e senza il filtro in linea attivato:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Il risultato dovrebbe essere simile a questo:
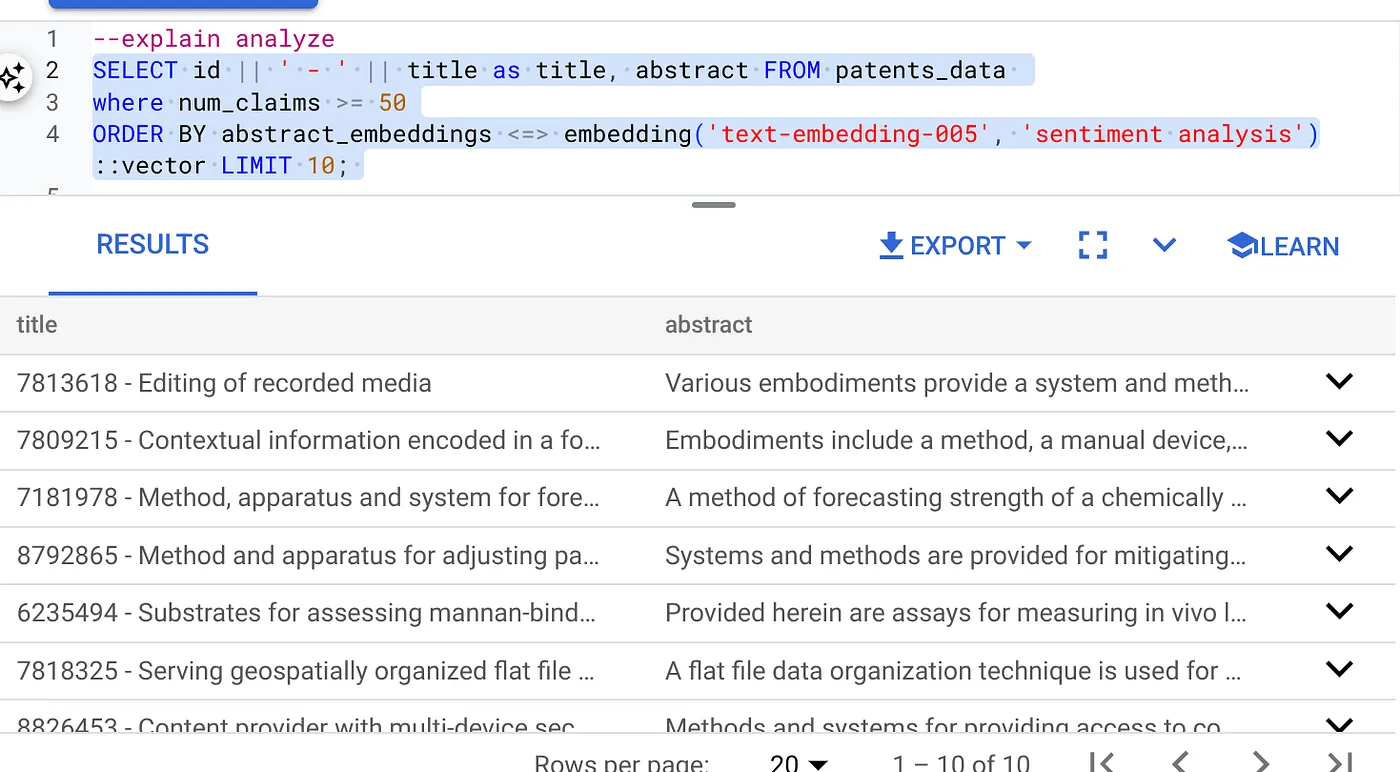
- Esegui Explain Analyze: (senza indice né filtro in linea)

Il tempo di esecuzione è di 2,4 ms
- Creiamo un indice normale sul campo num_claims in modo da poterlo filtrare:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Creiamo l'indice ScaNN per la nostra applicazione di ricerca di brevetti. Esegui il seguente comando da AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Nota importante: (num_leaves=32) si applica al nostro set di dati totale con più di 1000 righe. Se il conteggio delle righe è inferiore a 100, non è necessario creare un indice, in quanto non si applica a un numero inferiore di righe.
- Imposta il filtro in linea attivato nell'indice ScaNN:
SET scann.enable_inline_filtering = on
- Ora eseguiamo la stessa query con il filtro e la ricerca vettoriale:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
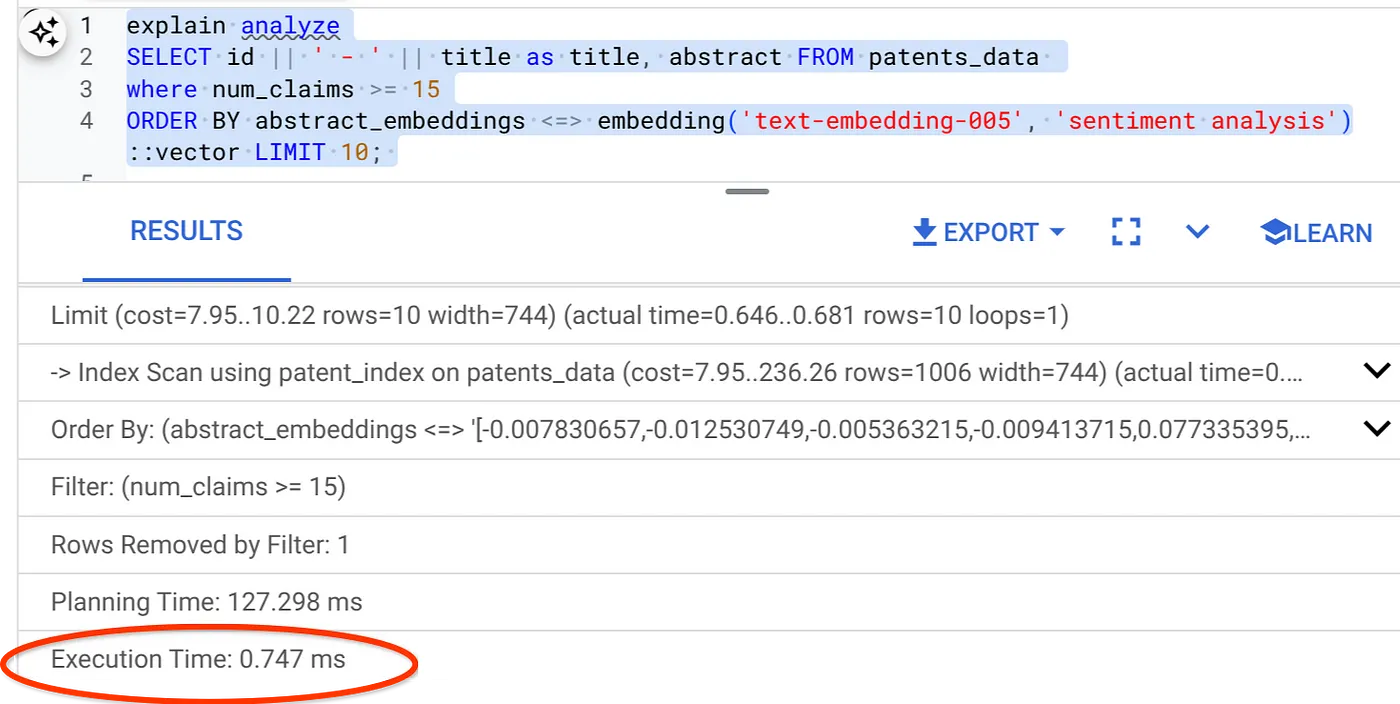
Come puoi vedere, il tempo di esecuzione è ridotto in modo significativo per la stessa ricerca vettoriale. L'indice ScaNN con filtro incorporato in Vector Search ha reso possibile tutto questo.
Successivamente, valutiamo il richiamo per questa ricerca vettoriale abilitata per ScaNN.
Valutatore del richiamo
Il richiamo nella ricerca per similarità è la percentuale di istanze pertinenti recuperate da una ricerca, ovvero il numero di veri positivi. Si tratta della metrica più comune utilizzata per misurare la qualità della ricerca. Una fonte di perdita di richiamo deriva dalla differenza tra la ricerca approssimativa del vicino più prossimo (ANN) e la ricerca esatta del vicino più prossimo (KNN). Gli indici vettoriali come ScaNN di AlloyDB implementano algoritmi ANN, consentendoti di velocizzare la ricerca vettoriale su set di dati di grandi dimensioni in cambio di un piccolo compromesso nel richiamo. Ora AlloyDB ti offre la possibilità di misurare questo compromesso direttamente nel database per le singole query e garantire che sia stabile nel tempo. Puoi aggiornare i parametri di query e indice in risposta a queste informazioni per ottenere risultati e prestazioni migliori.
Puoi trovare il richiamo per una query vettoriale su un indice vettoriale per una determinata configurazione utilizzando la funzione evaluate_query_recall. Questa funzione ti consente di ottimizzare i parametri per ottenere i risultati di richiamo della query vettoriale che desideri. Il richiamo è la metrica utilizzata per la qualità della ricerca ed è definito come la percentuale dei risultati restituiti che sono oggettivamente più vicini ai vettori di query. La funzione evaluate_query_recall è attiva per impostazione predefinita.
Nota importante:
Se nei passaggi successivi si verifica l'errore Autorizzazione negata nell'indice HNSW, per il momento salta l'intera sezione di valutazione del richiamo. A questo punto, potrebbe trattarsi di restrizioni di accesso, in quanto è stato rilasciato al momento della documentazione di questo codelab.
- Imposta il flag Enable Index Scan (Attiva scansione indice) sull'indice ScaNN e sull'indice HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Esegui la seguente query in AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
La funzione evaluate_query_recall accetta la query come parametro e ne restituisce il richiamo. Utilizzo la stessa query che ho utilizzato per controllare il rendimento come query di input della funzione. Ho aggiunto SCaNN come metodo di indice. Per ulteriori opzioni di parametri, consulta la documentazione.
Il richiamo per questa query di Vector Search che abbiamo utilizzato:
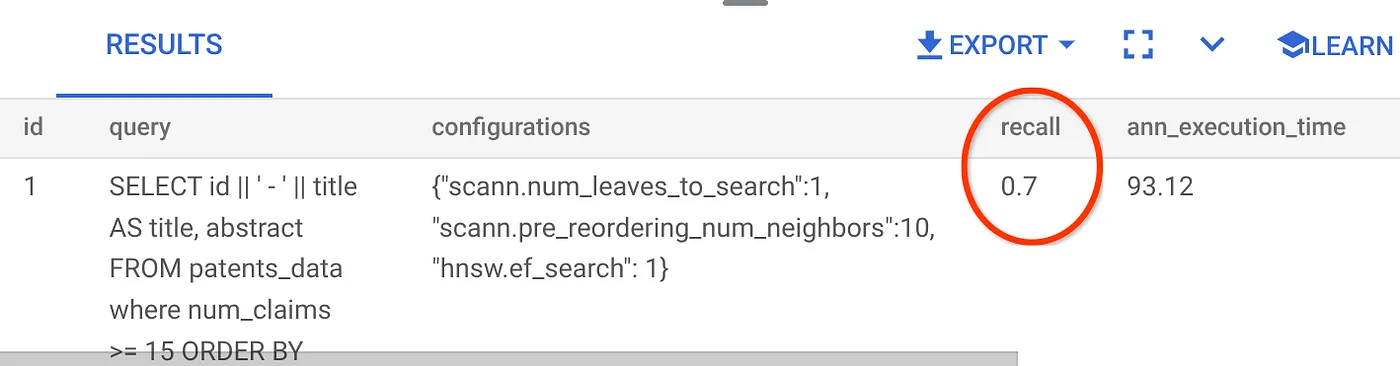
Vedo che il RECALL è del 70%. Ora posso utilizzare queste informazioni per modificare i parametri, i metodi e i parametri di query dell'indice e migliorare il recupero per questa ricerca vettoriale.
Ho modificato il numero di righe nel set di risultati portandolo a 7 (in precedenza erano 10) e ho notato un RECALL leggermente migliore, ovvero l'86%.
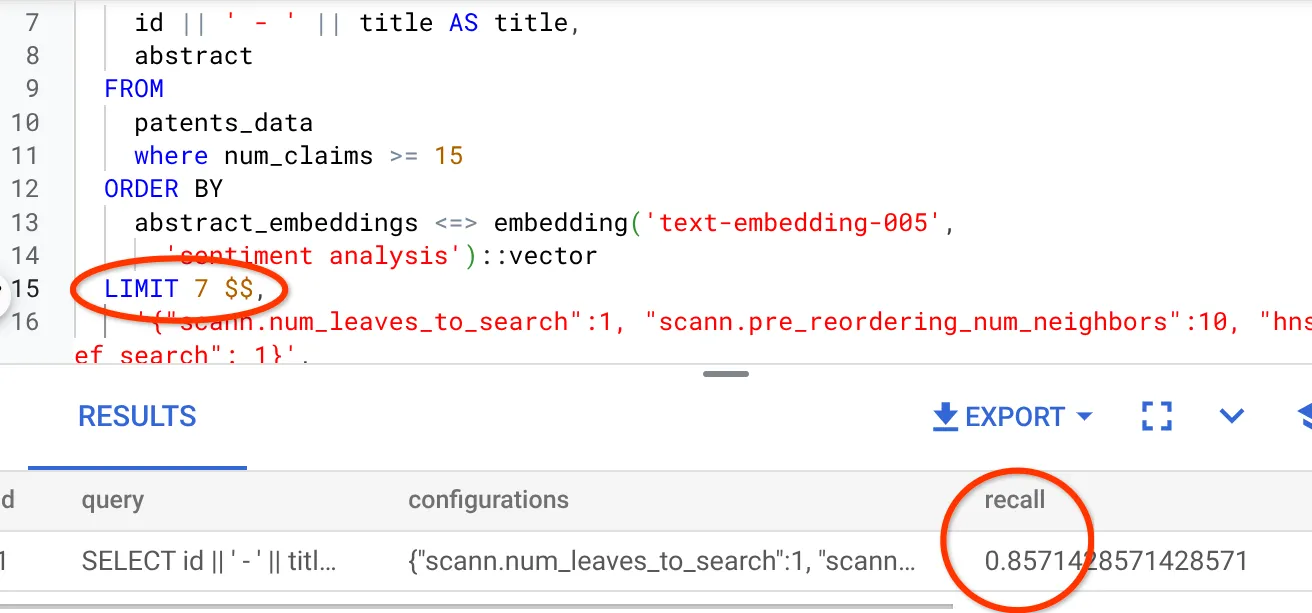
Ciò significa che in tempo reale posso variare il numero di corrispondenze che i miei utenti vedono per migliorare la pertinenza delle corrispondenze in base al contesto di ricerca degli utenti.
Bene. È il momento di eseguire il deployment della logica del database e passare all'agente.
7. Portare la logica del database sul web in modalità serverless
È tutto pronto per portare questa app sul web? Procedi nel seguente modo:
- Vai a Cloud Run Functions nella console Google Cloud per creare una nuova funzione Cloud Run facendo clic su "Scrivi una funzione" o utilizza il link: https://console.cloud.google.com/run/create?deploymentType=function.
- Scegli l'opzione "Usa un editor in linea per creare una funzione" e inizia la configurazione. Fornisci il nome del servizio "patent-search", scegli la regione "us-central1" e il runtime "Java 17". Imposta Autenticazione su "Consenti chiamate non autenticate".
- Nella sezione "Container, volumi, networking, sicurezza", segui i passaggi riportati di seguito senza tralasciare alcun dettaglio:
Vai alla scheda Networking:

Seleziona "Connettiti a un VPC per il traffico in uscita" e poi "Usa connettori di accesso VPC serverless".
Nel menu a discesa Rete, fai clic sul menu a discesa Rete e seleziona l'opzione "Aggiungi nuovo connettore VPC" (se non hai ancora configurato quello predefinito) e segui le istruzioni visualizzate nella finestra di dialogo visualizzata:

Fornisci un nome per il connettore VPC e assicurati che la regione sia la stessa dell'istanza. Lascia il valore Rete come predefinito e imposta Subnet come intervallo IP personalizzato con l'intervallo IP 10.8.0.0 o un valore simile disponibile.
Espandi MOSTRA IMPOSTAZIONI SCALATURA e assicurati che la configurazione sia impostata esattamente come segue:

Fai clic su CREA e il connettore dovrebbe essere elencato nelle impostazioni di uscita.
Seleziona il connettore appena creato.
Scegli di instradare tutto il traffico tramite questo connettore VPC.
Fai clic su AVANTI e poi su ESEGUI IL DEPLOYMENT.
- Per impostazione predefinita, il punto di ingresso è impostato su "gcfv2.HelloHttpFunction". Sostituisci il codice segnaposto in HelloHttpFunction.java e pom.xml della tua funzione Cloud Run con il codice di " PatentSearch.java" e " pom.xml" rispettivamente. Modifica il nome del file della classe in PatentSearch.java.
- Ricorda di modificare il segnaposto ************* e le credenziali di connessione AlloyDB con i tuoi valori nel file Java. Le credenziali di AlloyDB sono quelle che abbiamo utilizzato all'inizio di questo codelab. Se hai utilizzato valori diversi, modificali nel file Java.
- Fai clic su Esegui il deployment.
- Una volta eseguito il deployment della funzione Cloud Functions aggiornata, dovresti visualizzare l'endpoint generato. Copia questo valore e sostituiscilo nel seguente comando:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
È tutto. È così semplice eseguire una ricerca vettoriale avanzata di similarità contestuale utilizzando il modello di incorporamenti sui dati AlloyDB.
8. Creiamo l'agente con Java ADK
Per prima cosa, iniziamo con il progetto Java nell'editor.
- Vai al terminale Cloud Shell
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Autorizza quando richiesto
- Passa all'editor di Cloud Shell facendo clic sull'icona dell'editor nella parte superiore della console Cloud Shell.

- Nella console dell'editor di Cloud Shell di destinazione, crea una nuova cartella e chiamala "adk-agents".
Fai clic su Crea nuova cartella nella directory principale di Cloud Shell, come mostrato di seguito:

Assegna il nome "adk-agents":
- Crea la seguente struttura di cartelle e i file vuoti con i nomi file corrispondenti nella struttura riportata di seguito:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Apri il repository GitHub in una scheda separata e copia il codice sorgente dei file App.java e pom.xml.
- Se hai aperto l'editor in una nuova scheda utilizzando l'icona "Apri in una nuova scheda" nell'angolo in alto a destra, puoi aprire il terminale nella parte inferiore della pagina. Puoi tenere aperti sia l'editor che il terminale in parallelo, in modo da operare liberamente.
- Una volta clonato, torna alla console dell'editor di Cloud Shell.
- Poiché abbiamo già creato la funzione Cloud Run, non devi copiare i file della funzione Cloud Run dalla cartella del repository.
Inizia a utilizzare l'SDK Java ADK
È abbastanza semplice. Devi principalmente assicurarti che i seguenti elementi siano inclusi nel passaggio di clonazione:
- Aggiungi dipendenze:
Includi gli artefatti google-adk e google-adk-dev (per la UI web) nel file pom.xml. Se hai copiato l'origine dal repository, questi file sono già inclusi, quindi non devi aggiungerli. Devi solo apportare una modifica all'endpoint della funzione Cloud Run per riflettere l'endpoint di cui è stato eseguito il deployment. Questo aspetto è trattato nei passaggi successivi di questa sezione.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Assicurati di fare riferimento al file pom.xml dal repository di origine, poiché sono necessarie altre dipendenze e configurazioni per l'esecuzione dell'applicazione.
- Configurare il progetto:
Assicurati che la versione di Java (consigliata la 17 o versioni successive) e le impostazioni del compilatore Maven siano configurate correttamente nel file pom.xml. Puoi configurare il progetto in modo che segua la struttura riportata di seguito:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Definizione dell'agente e dei relativi strumenti (App.java):
È qui che si manifesta la magia dell'SDK ADK Java. Definiamo l'agente, le sue funzionalità (istruzioni) e gli strumenti che può utilizzare.
Qui puoi trovare una versione semplificata di alcuni snippet di codice della classe principale dell'agente. Per il progetto completo, consulta il repository del progetto qui.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Componenti chiave del codice Java dell'ADK evidenziati:
- LlmAgent.builder(): API fluida per configurare l'agente.
- .instruction(...): fornisce il prompt principale e le linee guida per l'LLM, incluso quando utilizzare quale strumento.
- FunctionTool.create(App.class, "methodName"): registra facilmente i tuoi metodi Java come strumenti che l'agente può richiamare. La stringa del nome del metodo deve corrispondere a un metodo statico pubblico effettivo.
- @Schema(description = …): annota i parametri dello strumento, aiutando l'LLM a capire quali input si aspetta ogni strumento. Questa descrizione è fondamentale per la selezione accurata dello strumento e il riempimento dei parametri.
- InvocationContext ctx: passato automaticamente ai metodi dello strumento, che consente di accedere allo stato della sessione (ctx.session().state()), alle informazioni dell'utente e altro ancora.
- .outputKey("patents"): quando uno strumento restituisce dati, ADK può memorizzarli automaticamente nello stato della sessione con questa chiave. In questo modo explainPatent può accedere ai risultati di getPatents.
- VECTOR_SEARCH_ENDPOINT: questa variabile contiene la logica funzionale principale per le domande e risposte contestuali per l'utente nello scenario di utilizzo della ricerca di brevetti.
- Elemento di azione qui: devi impostare un valore dell'endpoint di cui è stato eseguito il deployment aggiornato dopo aver implementato il passaggio della funzione Java Cloud Run della sezione precedente.
- searchTool: interagisce con l'utente per trovare corrispondenze di brevetti pertinenti dal punto di vista contestuale nel database dei brevetti per il testo di ricerca dell'utente.
- explainTool: chiede all'utente un brevetto specifico da analizzare in dettaglio. Poi riassume l'abstract del brevetto ed è in grado di rispondere ad altre domande dell'utente in base ai dettagli del brevetto in suo possesso.
Nota importante: assicurati di sostituire la variabile VECTOR_SEARCH_ENDPOINT con l'endpoint CRF di cui è stato eseguito il deployment.
Utilizzo di InvocationContext per interazioni stateful
Una delle funzionalità fondamentali per creare agenti utili è la gestione dello stato in più turni di una conversazione. InvocationContext di ADK semplifica questa operazione.
Nel nostro file App.java:
- Quando viene definito initAgent(), utilizziamo .outputKey("patents"). Indica ad ADK che quando uno strumento (come getPatents) restituisce dati nel campo del report, questi devono essere memorizzati nello stato della sessione con la chiave "patents".
- Nel metodo dello strumento explainPatent, inseriamo InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
Ciò consente allo strumento explainPatent di accedere all'elenco dei brevetti recuperato dallo strumento getPatents in un turno precedente, rendendo la conversazione stateful e coerente.
9. Test dell'interfaccia a riga di comando locale
Definisci le variabili di ambiente
Devi esportare due variabili di ambiente:
- Una chiave Gemini che puoi ottenere da AI Studio:
Per farlo, vai alla pagina https://aistudio.google.com/apikey, recupera la chiave API per il tuo progetto Google Cloud attivo in cui stai implementando questa applicazione e salvala da qualche parte:
- Una volta ottenuta la chiave, apri il terminale Cloud Shell e vai alla nuova directory appena creata adk-agents eseguendo questo comando:
cd adk-agents
- Una variabile per specificare che questa volta non utilizziamo Vertex AI.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Esegui il tuo primo agente nella CLI
Per avviare il primo agente, utilizza il seguente comando Maven nel terminale:
mvn compile exec:java -DmainClass="agents.App"
Vedrai la risposta interattiva dell'agente nel terminale.
10. Deployment in Cloud Run
Il deployment dell'agente Java ADK in Cloud Run è simile al deployment di qualsiasi altra applicazione Java:
- Dockerfile: crea un Dockerfile per creare il pacchetto della tua applicazione Java.
- Crea ed esegui il push dell'immagine Docker: utilizza Google Cloud Build e Artifact Registry.
- Puoi eseguire il passaggio precedente ed eseguire il deployment su Cloud Run con un solo comando:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Allo stesso modo, devi eseguire il deployment della tua funzione Cloud Run Java (gcfv2.PatentSearch). In alternativa, puoi creare ed eseguire il deployment della funzione Cloud Run Java per la logica del database direttamente dalla console Cloud Run Functions.
11. Test con l'interfaccia utente web
L'ADK include una pratica UI web per test e debug locali dell'agente. Quando esegui App.java localmente (ad es. mvn exec:java -Dexec.mainClass="agents.App" se configurato o semplicemente eseguendo il metodo principale), l'ADK in genere avvia un server web locale.
L'interfaccia utente web dell'ADK ti consente di:
- Inviare messaggi all'agente.
- Visualizza gli eventi (messaggio dell'utente, chiamata dello strumento, risposta dello strumento, risposta del modello linguistico di grandi dimensioni).
- Esamina lo stato della sessione.
- Visualizza log e tracce.
Questo è fondamentale durante lo sviluppo per capire come l'agente elabora le richieste e utilizza i suoi strumenti. Ciò presuppone che mainClass in pom.xml sia impostato su com.google.adk.web.AdkWebServer e che l'agente sia registrato, oppure che tu stia eseguendo un test runner locale che lo espone.
Quando esegui App.java con InMemoryRunner e Scanner per l'input della console, stai testando la logica principale dell'agente. L'interfaccia utente web è un componente separato per un'esperienza di debug più visiva, spesso utilizzata quando l'ADK pubblica l'agente tramite HTTP.
Puoi utilizzare il seguente comando Maven dalla directory principale per avviare il server locale SpringBoot:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
L'interfaccia è spesso accessibile all'URL restituito dal comando precedente. Se è Cloud Run deployed, dovresti essere in grado di accedervi dal link Cloud Run deployed.
Dovresti essere in grado di vedere il risultato in un'interfaccia interattiva.
Guarda il video qui sotto per vedere il nostro Patent Agent in azione:

12. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo post, segui questi passaggi:
- Nella console Google Cloud, vai a https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
13. Complimenti
Complimenti! Hai creato correttamente il tuo agente di analisi dei brevetti in Java combinando le funzionalità di ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI e Vector Search. Inoltre, abbiamo fatto un enorme passo avanti nel rendere le ricerche di similarità contestuale così trasformative, efficienti e realmente basate sul significato.
Inizia subito
Documentazione ADK: [Link alla documentazione Java ufficiale di ADK]
Codice sorgente dell'agente di analisi dei brevetti: [link al tuo repository GitHub (ora pubblico)]
Agenti di esempio Java: [link al repository adk-samples]
Unisciti alla community ADK: https://www.reddit.com/r/agentdevelopmentkit/
Buona creazione dell'agente.