
1. Overview
Across different industries, contextual search is a critical functionality that forms the heart and center of their applications. Retrieval Augmented Generation has been a key driver of this crucial tech evolution for quite some time now with its Generative AI powered retrieval mechanisms. Generative models, with their large context windows and impressive output quality, are transforming AI. RAG provides a systematic way to inject context into AI applications and agents, grounding them in structured databases or information from various media. This contextual data is crucial for clarity of truth and accuracy of output, but how accurate are those results? Does your business depend largely on the accuracy of these contextual matches and relevance? Then this project is going to tickle you!
Now imagine if we could take the power of generative models and build interactive agents that are capable of making autonomous decisions backed by such context-critical information and grounded in truth; that's what we are going to build today. We are going to build an end to end AI agent app using Agent Development Kit powered by advanced RAG in AlloyDB for a patent analysis application.
Patent Analysis Agent assists the user in finding contextually relevant patents to their search text and upon asking, provides a clear and concise explanation and additional details if required, for a selected patent. Ready to see how it's done? Let's dive in!
Objective
The goal is simple. Allow a user to search for patents based on a textual description and then get a detailed explanation of a specific patent from the search results and all of this using an AI agent built with Java ADK, AlloyDB, Vector Search (with advanced indexes), Gemini and the entire application deployed serverlessly on Cloud Run.
What you'll build
As part of this lab, you will:
- Create an AlloyDB instance and load Patents Public Dataset data
- Implement advanced Vector Search in AlloyDB using ScaNN & Recall eval features
- Create an agent using Java ADK
- Implement the database server-side logic in Java serverless Cloud Functions
- Deploy & test the agent in Cloud Run
The following diagram represents the flow of data and steps involved in the implementation.

High level diagram representing the flow of the Patent Search Agent with AlloyDB & ADK
Requirements
2. Before you begin
Create a project
- In the Google Cloud Console, on the project selector page, select or create a Google Cloud project.
- Make sure that billing is enabled for your Cloud project. Learn how to check if billing is enabled on a project .
- You'll use Cloud Shell, a command-line environment running in Google Cloud. Click Activate Cloud Shell at the top of the Google Cloud console.

- Once connected to Cloud Shell, you check that you're already authenticated and that the project is set to your project ID using the following command:
gcloud auth list
- Run the following command in Cloud Shell to confirm that the gcloud command knows about your project.
gcloud config list project
- If your project is not set, use the following command to set it:
gcloud config set project <YOUR_PROJECT_ID>
- Enable the required APIs. You can use a gcloud command in the Cloud Shell terminal:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
The alternative to the gcloud command is through the console by searching for each product or using this link.
Refer documentation for gcloud commands and usage.
3. Database setup
In this lab we'll use AlloyDB as the database for the patent data. It uses clusters to hold all of the resources, such as databases and logs. Each cluster has a primary instance that provides an access point to the data. Tables will hold the actual data.
Let's create an AlloyDB cluster, instance and table where the patent dataset will be loaded.
Create a cluster and instance
- Navigate the AlloyDB page in the Cloud Console. An easy way to find most pages in Cloud Console is to search for them using the search bar of the console.
- Select CREATE CLUSTER from that page:

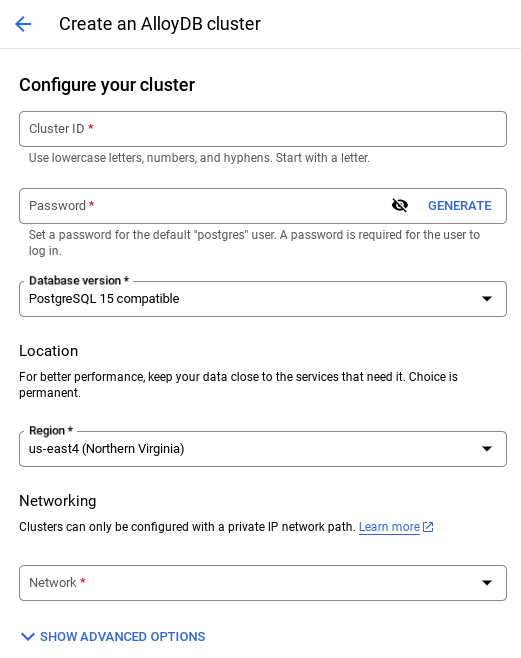
- You'll see a screen like the one below. Create a cluster and instance with the following values (Make sure the values match in case you are cloning the application code from the repo):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / latest recommended
- Region: "
us-central1" - Networking: "
default"
- When you select the default network, you'll see a screen like the one below.
Select SET UP CONNECTION.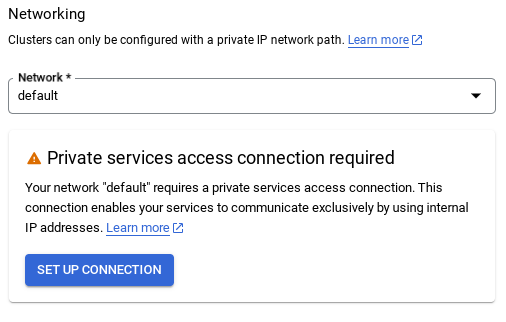
- From there, select "Use an automatically allocated IP range" and Continue. After reviewing the information, select CREATE CONNECTION.
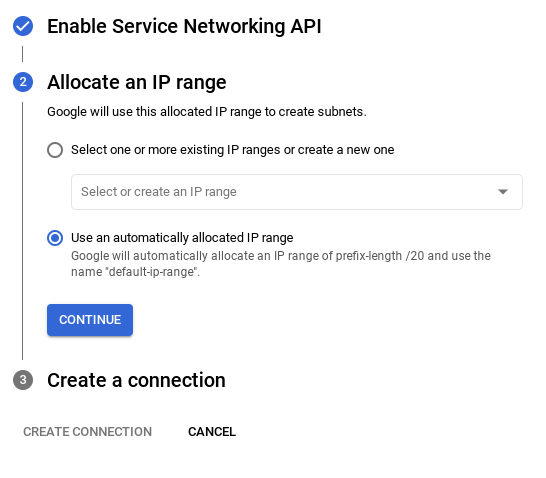
- Once your network is set up, you can continue to create your cluster. Click CREATE CLUSTER to complete setting up of the cluster as shown below:
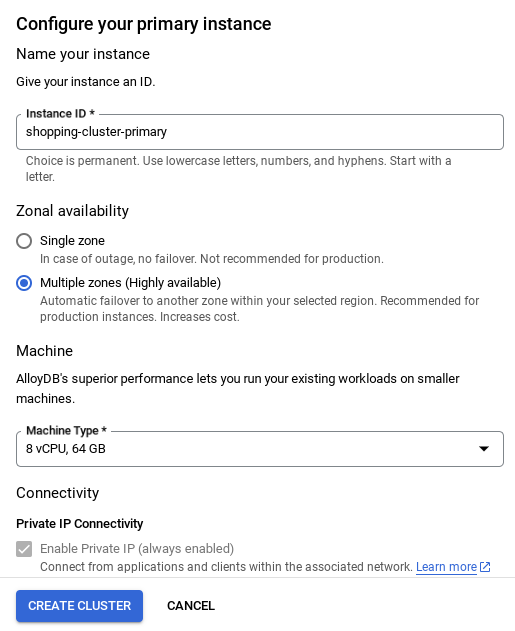
Make sure to change the instance id (which you can find at the time of configuration of the cluster / instance) to
vector-instance. If you cannot change it, remember to use your instance id in all the upcoming references.
Note that the Cluster creation will take around 10 minutes. Once it is successful, you should see a screen that shows the overview of your cluster you just created.
4. Data ingestion
Now it's time to add a table with the data about the store. Navigate to AlloyDB, select the primary cluster and then AlloyDB Studio:
You may need to wait for your instance to finish being created. Once it is, sign into AlloyDB using the credentials you created when you created the cluster. Use the following data for authenticating to PostgreSQL:
- Username : "
postgres" - Database : "
postgres" - Password : "
alloydb"
Once you have authenticated successfully into AlloyDB Studio, SQL commands are entered in the Editor. You can add multiple Editor windows using the plus to the right of the last window.
You'll enter commands for AlloyDB in editor windows, using the Run, Format, and Clear options as necessary.
Enable Extensions
For building this app, we will use the extensions pgvector and google_ml_integration. The pgvector extension allows you to store and search vector embeddings. The google_ml_integration extension provides functions you use to access Vertex AI prediction endpoints to get predictions in SQL. Enable these extensions by running the following DDLs:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
If you would like to check the extensions that have been enabled on your database, run this SQL command:
select extname, extversion from pg_extension;
Create a table
You can create a table using the DDL statement below in the AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
The abstract_embeddings column will allow storage for the vector values of the text.
Grant Permission
Run the below statement to grant execute on the "embedding" function:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Grant Vertex AI User ROLE to the AlloyDB service account
From Google Cloud IAM console, grant the AlloyDB service account (that looks like this: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) access to the role "Vertex AI User". PROJECT_NUMBER will have your project number.
Alternatively you can run the below command from the Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Load patent data into the database
The Google Patents Public Datasets on BigQuery will be used as our dataset. We will use the AlloyDB Studio to run our queries. The data is sourced into this insert scripts sql file in this repo and we will run this to load the patent data.
- In the Google Cloud console, open the AlloyDB page.
- Select your newly created cluster and click the instance.
- In the AlloyDB Navigation menu, click AlloyDB Studio. Sign in with your credentials.
- Open a new tab by clicking the New tab icon on the right.
- Copy and run the
insertquery statements from theinsert_scripts1.sql,insert_script2.sql,insert_scripts3.sql,insert_scripts4.sqlfiles one by one. You can run the copy 10-50 insert statements for a quick demo of this use case.
To run, click Run. The results of your query appear in the Results table.
5. Create Embeddings for patents data
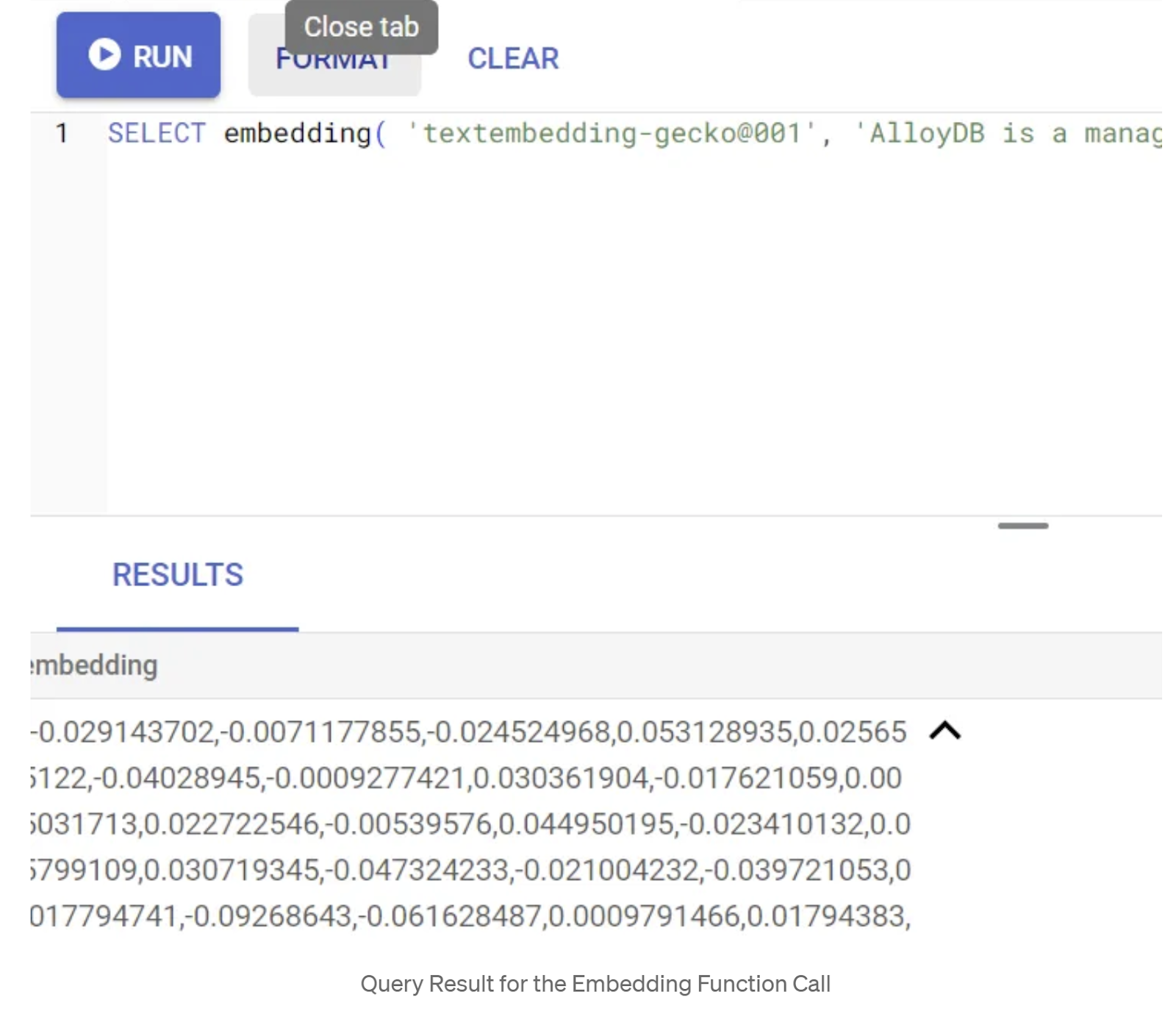
First let's test the embedding function, by running the following sample query:
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
This should return the embeddings vector, that looks like an array of floats, for the sample text in the query. Looks like this:
Update the abstract_embeddings Vector field
The below DML should be used to update the patent abstracts in the table with the corresponding embeddings in case the embeddings need to be generated for the abstracts. But in our case, the insert statements already contain these embeddings for each abstract so you need not call the embeddings() method.
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
6. Perform Vector search
Now that the table, data, embeddings are all ready, let's perform the real time Vector Search for the user search text. You can test this by running the query below:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
In this query,
- The user searched text is: "Sentiment Analysis".
- We are converting it to embeddings in the embedding() method using the model: text-embedding-005.
- "<=>" represents the use of the COSINE SIMILARITY distance method.
- We are converting the embedding method's result to vector type to make it compatible with the vectors stored in the database.
- LIMIT 10 represents that we are selecting the 10 closest matches of the search text.
AlloyDB takes Vector Search RAG to the next level:
There are a good number of things introduced. Two of the developer-focused ones are:
- Inline Filtering
- Recall Evaluator
Inline Filtering
Previously as a developer, you would have to perform the Vector Search query and have to go deal with the filtering and recall. AlloyDB Query Optimizer makes choices on how to execute a query with filters. Inline filtering, is a new query optimization technique that allows the AlloyDB query optimizer to evaluate both the metadata filtering conditions and the vector search alongside, leveraging both vector indexes and indexes on the metadata columns. This has made recall performance increase, allowing developers to take advantage of what AlloyDB has to offer out of the box.
Inline filtering is best for cases with medium selectivity. As AlloyDB searches through the vector index, it only computes distances for vectors that match the metadata filtering conditions (your functional filters in a query usually handled in the WHERE clause). This massively improves performance for these queries complementing the advantages of post-filter or pre-filter.
- Install or update the pgvector extension
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
If the pgvector extension is already installed, upgrade the vector extension to version 0.8.0.google-3 or later to get recall evaluator capabilities.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
This step needs to be executed only if your vector extension is <0.8.0.google-3.
Important note: If your row count is less than 100, you won't need to create the ScaNN index in the first place as it won't apply for less rows. Please skip the following steps in that case.
- To create ScaNN indexes, install the alloydb_scann extension.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
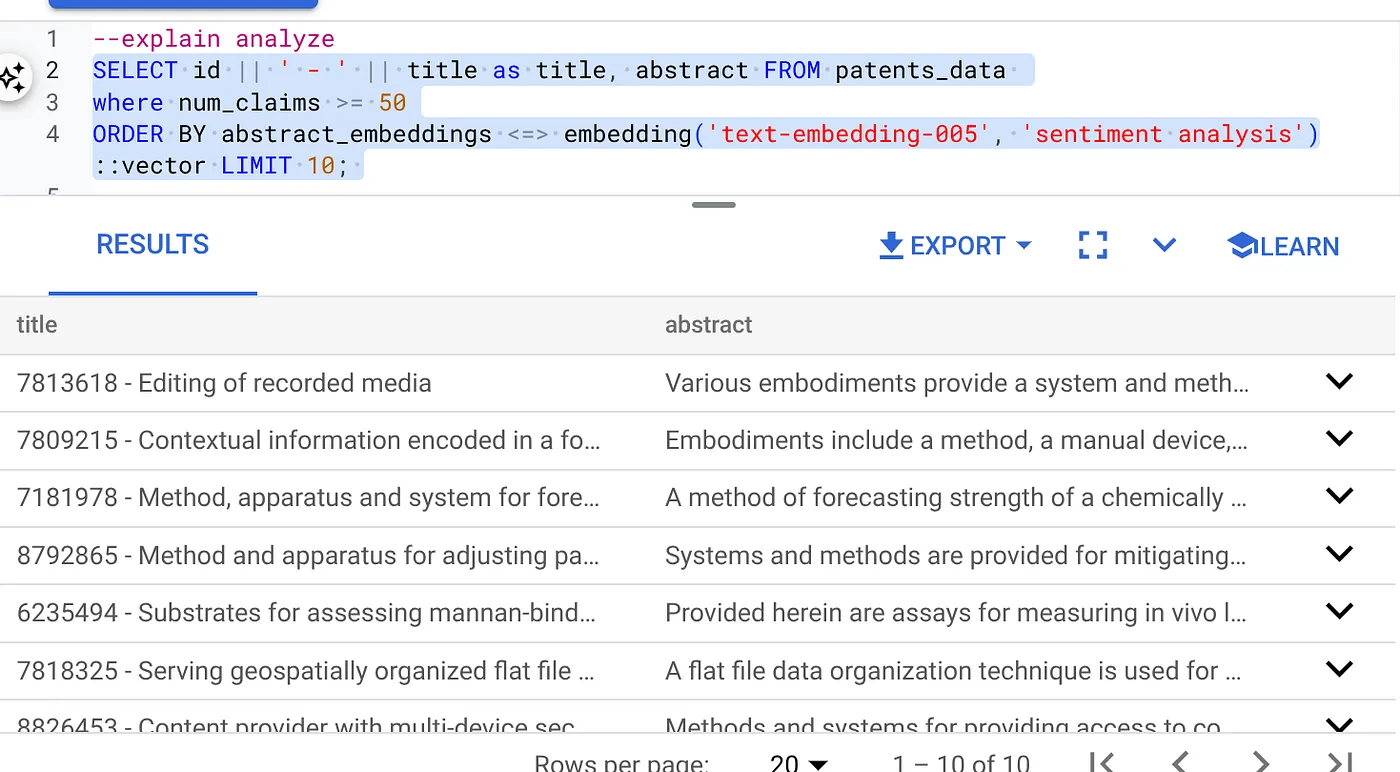
- First run the Vector Search Query without the index and without the Inline Filter enabled:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Result should be similar to:
- Run Explain Analyze on it: (with no index nor Inline Filtering)
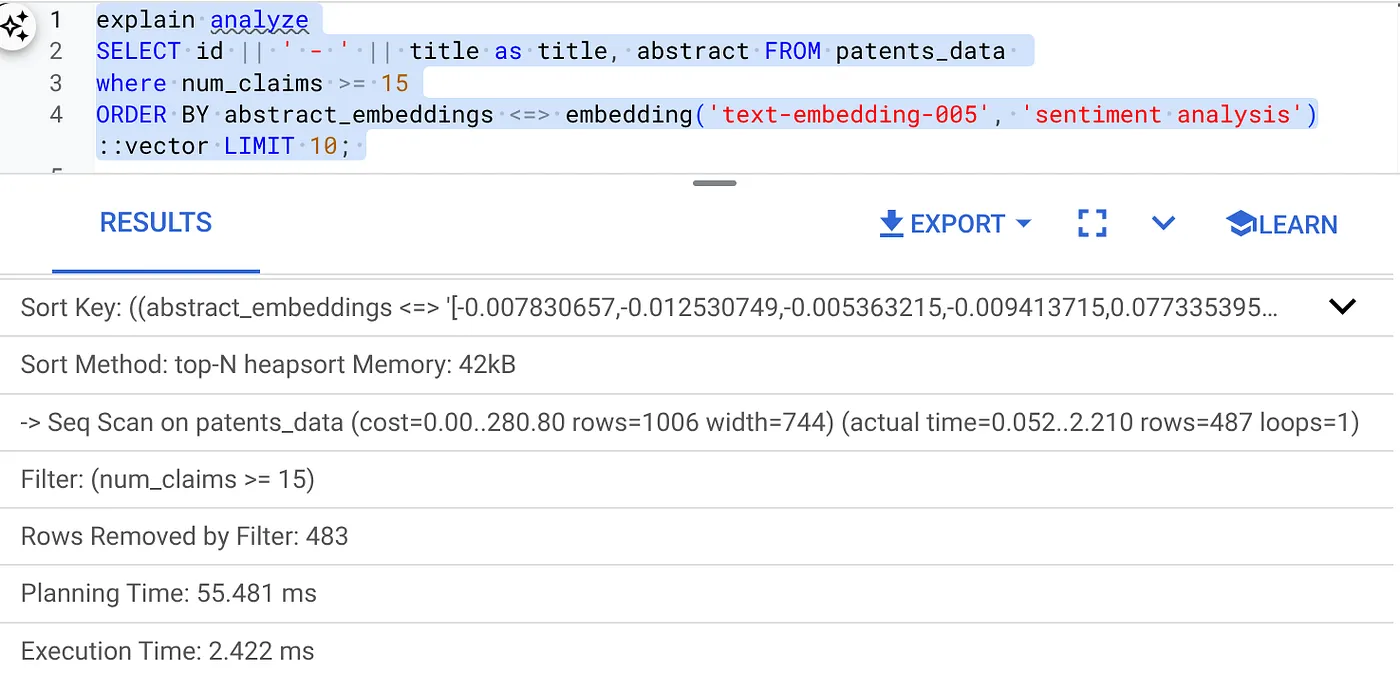
The execution time is 2.4 ms
- Let's create a regular index on the num_claims field so we can filter by it:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Let's create the ScaNN index for our Patent Search application. Run the following from your AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Important note: (num_leaves=32) applies for our total dataset with 1000+ rows. If your row count is less than 100, you won't need to create an index in the first place as it won't apply for less rows.
- Set the Inline Filtering enabled on the ScaNN Index:
SET scann.enable_inline_filtering = on
- Now, let's run the same query with filter and Vector Search in it:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
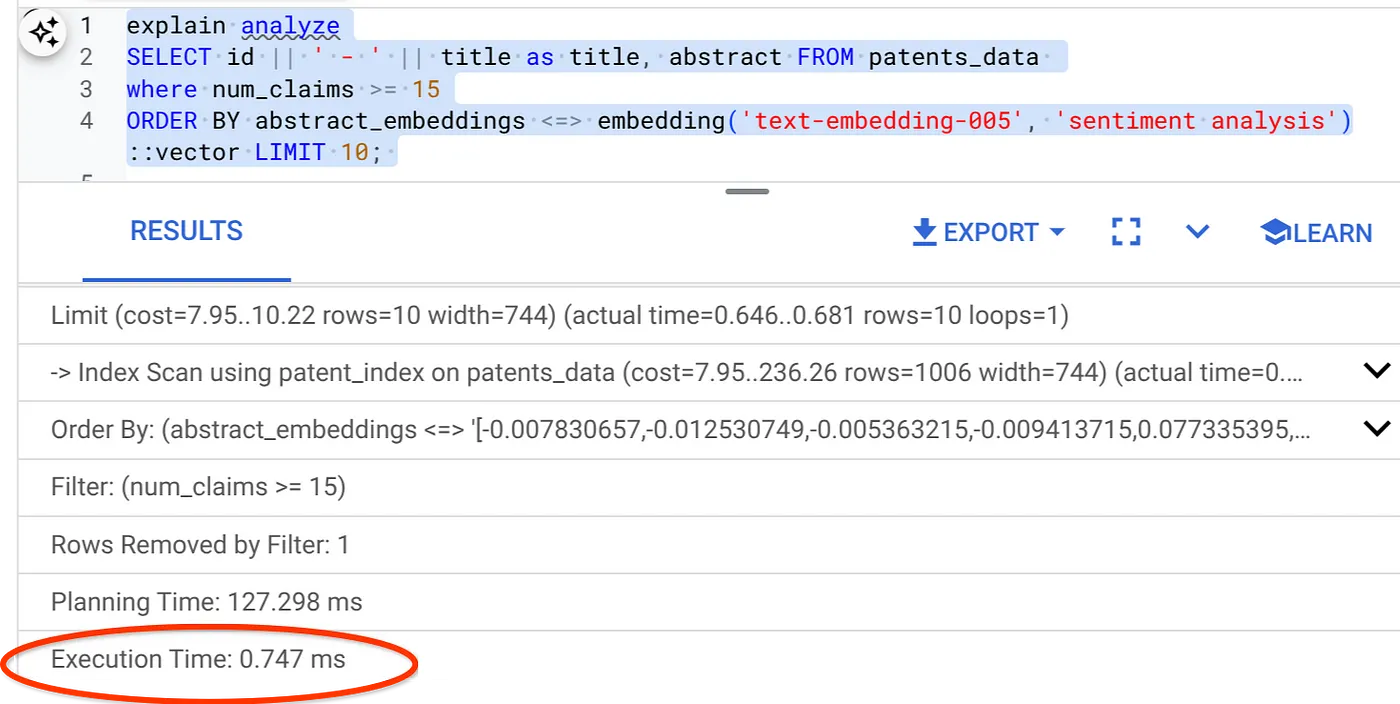
As you can see the execution time is reduced significantly for the same Vector Search. The Inline Filtering infused ScaNN index on the Vector Search has made this possible!!!
Next, let's evaluate recall for this ScaNN enabled Vector Search.
Recall Evaluator
Recall in similarity search is the percentage of relevant instances that were retrieved from a search, i.e. the number of true positives. This is the most common metric used for measuring search quality. One source of recall loss comes from the difference between approximate nearest neighbor search, or aNN, and k (exact) nearest neighbor search, or kNN. Vector indexes like AlloyDB's ScaNN implement aNN algorithms, allowing you to speed up vector search on large datasets in exchange for a small tradeoff in recall. Now, AlloyDB provides you with the ability to measure this tradeoff directly in the database for individual queries and ensure that it is stable over time. You can update query and index parameters in response to this information to achieve better results and performance.
You can find the recall for a vector query on a vector index for a given configuration using the evaluate_query_recall function. This function lets you tune your parameters to achieve the vector query recall results that you want. Recall is the metric used for search quality, and is defined as the percentage of the returned results that are objectively closest to the query vectors. The evaluate_query_recall function is turned on by default.
Important Note:
If you are facing permission denied error on HNSW index in the following steps, skip this entire recall evaluation section for now. It might have to do with access restrictions at this point as it is just released at the time this codelab is documented.
- Set the Enable Index Scan flag on the ScaNN Index & HNSW index:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Run the following query in AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
The evaluate_query_recall function takes in the query as a parameter and returns its recall. I'm using the same query that I used to check performance as the function input query. I have added SCaNN as the index method. For more parameter options refer the documentation.
The recall for this Vector Search query we have been using:
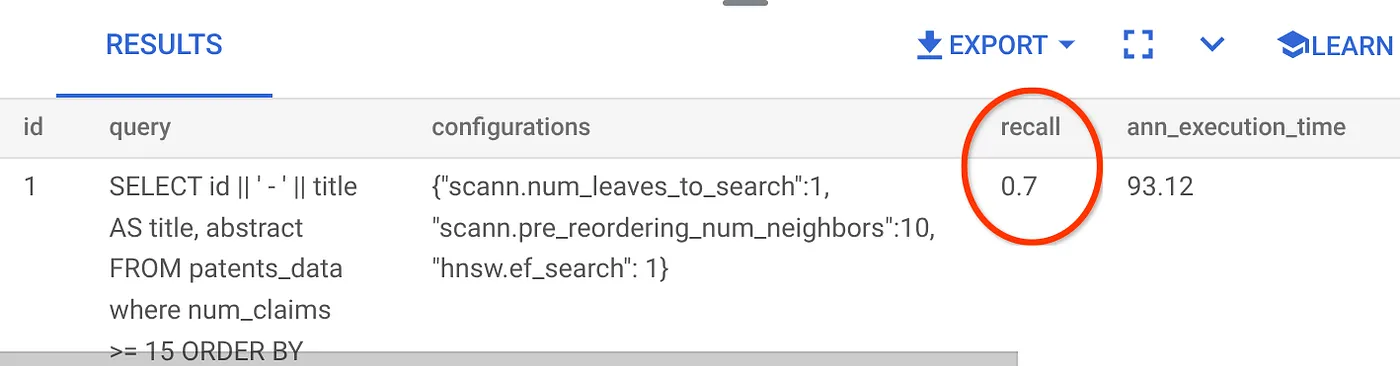
I see that the RECALL is 70%. Now I can use this information to change the index parameters, methods and query parameters and improve my recall for this Vector Search!
I have modified the number of rows in the result set to 7 (from 10 previously) and I see a slightly improved RECALL, i.e. 86%.
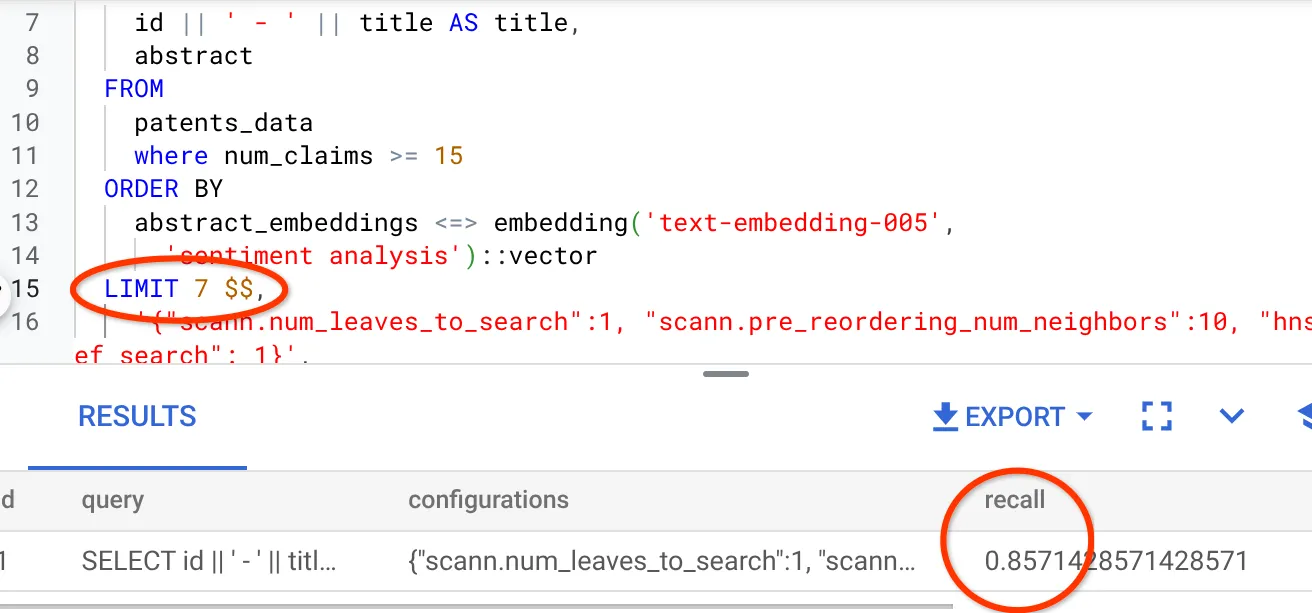
This means in real-time I can vary the number of matches that my users get to see to improve the relevance of the matches in accordance with the users' search context.
Alright now! Time to deploy the database logic and move on to the agent!!!
7. Take the database logic to the web serverlessly
Ready for taking this app to the web? Follow the steps below:
- Go to Cloud Run Functions in Google Cloud Console to create a new Cloud Run Function by clicking "Write a function" or use the link: https://console.cloud.google.com/run/create?deploymentType=function.
- Choose "Use an inline editor to create a function" option and start configuration. Provide Service Name "patent-search" and choose Region as "us-central1" and runtime as "Java 17". Set Authentication to "Allow unauthenticated invocations".
- In the section for "Containers, Volumes, Networking, Security" section, and follow the steps below without missing any detail:
Go to the Networking tab:
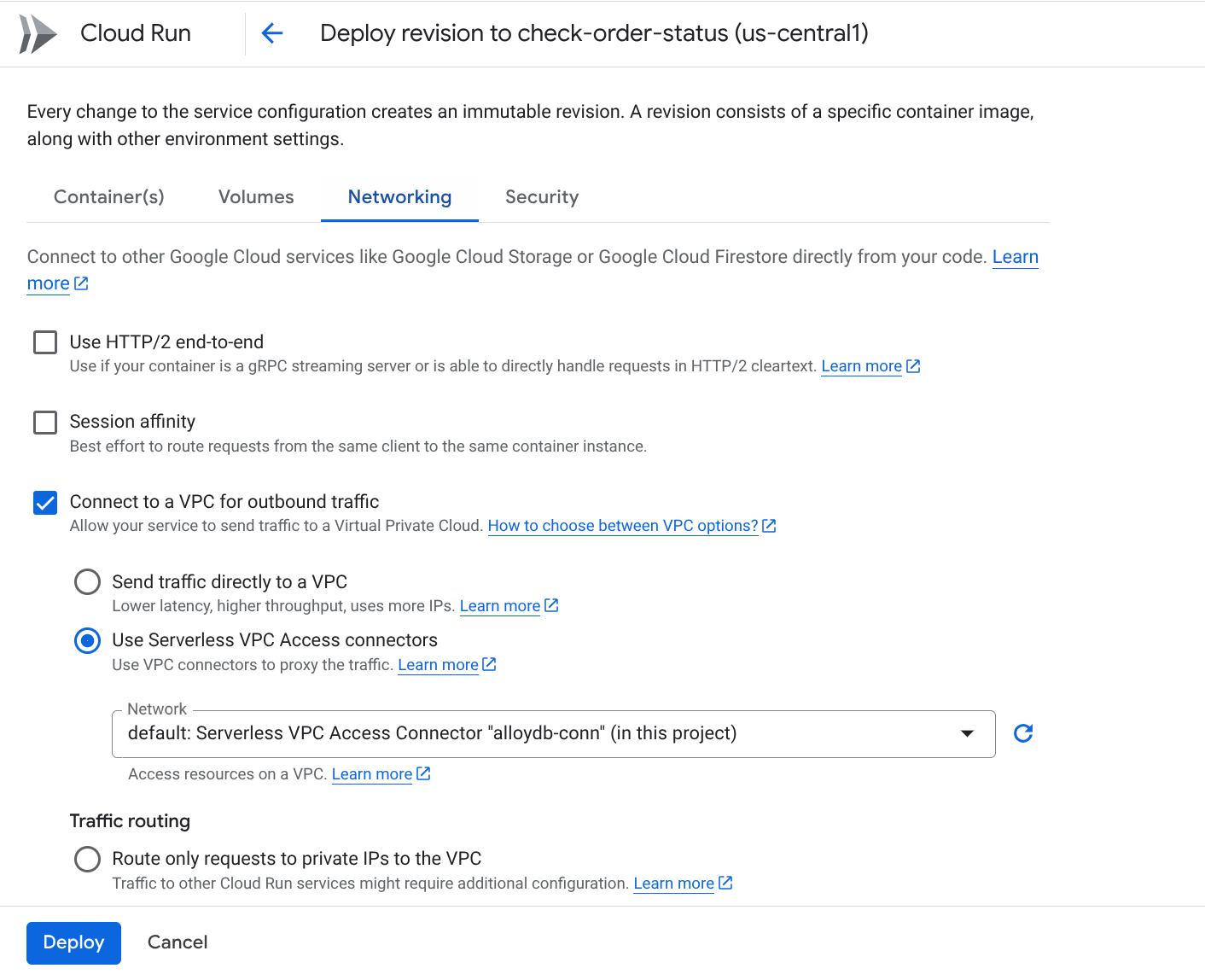
Select "Connect to a VPC for outbound traffic" and then select "Use Serverless VPC Access connectors"
Under the Network dropdown, settings, Click on the Network dropdown and select "Add New VPC Connector" option (if you have not already configured the default one) and follow the instructions you see on the dialog box that pops-up:
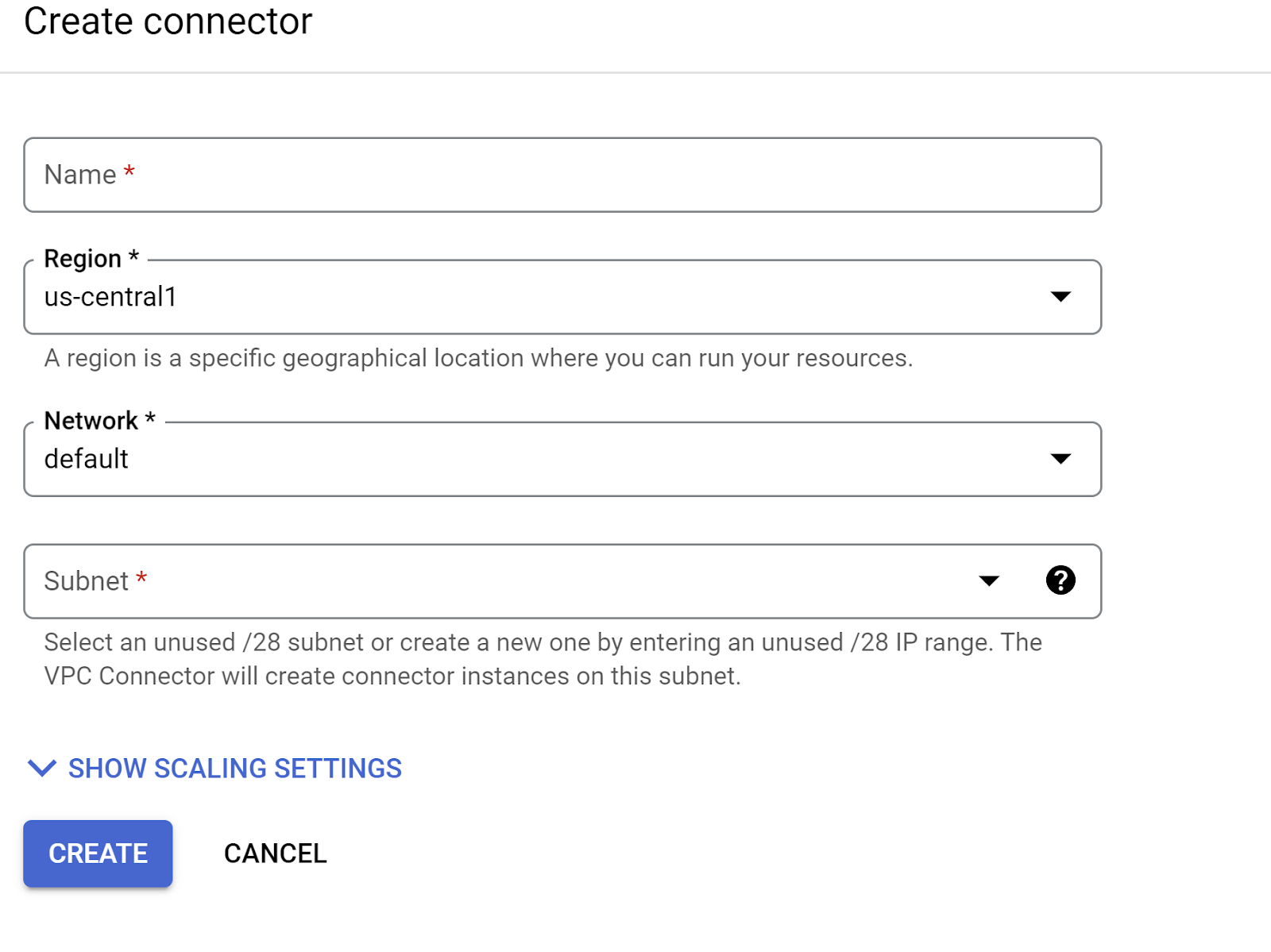
Provide a name for the VPC Connector and make sure the region is the same as your instance. Leave the Network value as default and set Subnet as Custom IP Range with the IP range of 10.8.0.0 or something similar that is available.
Expand SHOW SCALING SETTINGS and make sure you have the configuration set to exactly the following:
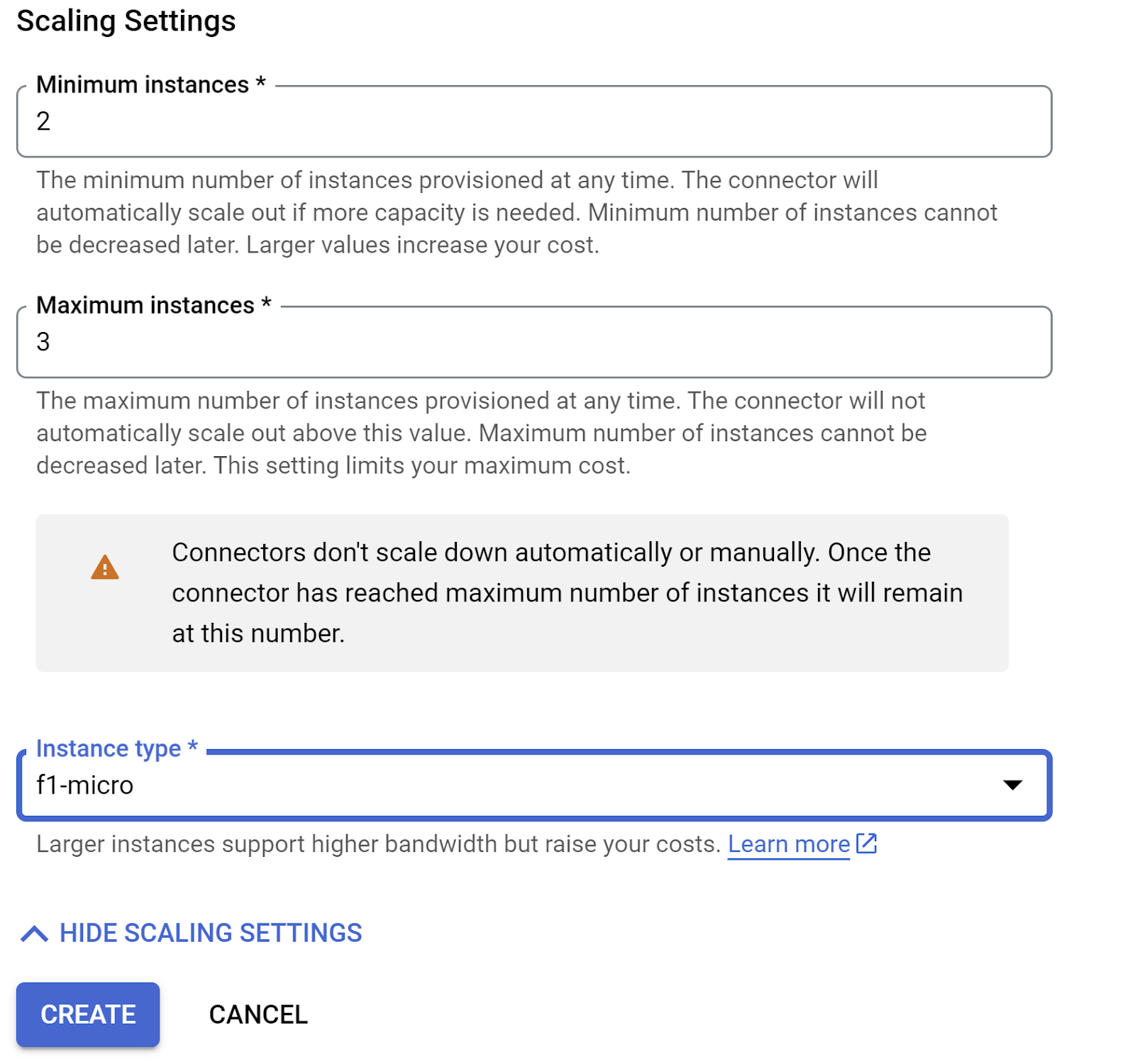
Click CREATE and this connector should be listed in the egress settings now.
Select the newly created connector.
Opt for all traffic to be routed through this VPC connector.
Click NEXT and then DEPLOY.
- By default it would set the Entry Point to "gcfv2.HelloHttpFunction". Replace the placeholder code in HelloHttpFunction.java and pom.xml of your Cloud Run Function with the code from " PatentSearch.java" and the " pom.xml" respectively. Change the name of the class file to PatentSearch.java.
- Remember to change the ************* placeholder and the AlloyDB connection credentials with your values in the Java file. The AlloyDB credentials are the ones that we had used at the start of this codelab. If you have used different values, please modify the same in the Java file.
- Click Deploy.
- Once the updated Cloud Function is deployed, you should see the endpoint generated. Copy that and replace in the following command:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST <<YOUR_ENDPOINT>> \
-H 'Content-Type: application/json' \
-d '{"search":"Sentiment Analysis"}'
That's it! It is that simple to perform an advanced Contextual Similarity Vector Search using the Embeddings model on AlloyDB data.
8. Let's build the agent with Java ADK
First, let's get started with the Java project in the editor.
- Navigate to Cloud Shell Terminal
https://shell.cloud.google.com/?fromcloudshell=true&show=ide%2Cterminal
- Authorize when prompted
- Toggle to Cloud Shell Editor by click the editor icon from the top of the Cloud Shell console

- In the landing Cloud Shell Editor console, create a new folder and name it "adk-agents"
Click create new folder in the root directory of your cloud shell as shown below:

Name it "adk-agents":
- Create the following folder structure and the empty files with the corresponding file names in the structure below:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Open the github repo in a separate tab and copy the source code for the files App.java and pom.xml.
- If you had opened up the editor in a new tab using the "Open in new tab" icon in the top right corner, you can have the terminal opened in the bottom of the page. You can have both the editor and terminal open in parallel allowing you to operate freely.
- Once cloned, toggle back to the Cloud Shell Editor console
- Since we have already created the Cloud Run Function, you don't need to copy the Cloud Run function files from the repo folder.
Getting started with the ADK Java SDK
It is fairly straightforward. You'll primarily need to ensure the following are covered in your clone step:
- Add Dependencies:
Include the google-adk and google-adk-dev (for the Web UI) artifacts in your pom.xml. If you copied the source from the repo, these are already included in the files, you don't have to include them. You just need to make a change in the Cloud Run Function endpoint to reflect your deployed endpoint. It is covered in the upcoming steps in this section.
<!-- The ADK core dependency -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk</artifactId>
<version>0.1.0</version>
</dependency>
<!-- The ADK dev web UI to debug your agent -->
<dependency>
<groupId>com.google.adk</groupId>
<artifactId>google-adk-dev</artifactId>
<version>0.1.0</version>
</dependency>
Make sure to reference the pom.xml from the source repository as there are other dependencies and configurations that are needed for the application to be able to run.
- Configure Your Project:
Ensure your Java version (17+ recommended) and Maven compiler settings are correctly configured in your pom.xml. You can configure your project to follow the below structure:
adk-agents/
└—— pom.xml
└—— src/
└—— main/
└—— java/
└—— agents/
└—— App.java
- Defining the Agent and Its Tools (App.java):
This is where the magic of the ADK Java SDK shines. We define our agent, its capabilities (instructions), and the tools it can use.
Find a simplified version of a few code snippets of the main agent class here. For the full project refer to the project repo here.
// App.java (Simplified Snippets)
package agents;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.BaseAgent;
import com.google.adk.agents.InvocationContext;
import com.google.adk.tools.Annotations.Schema;
import com.google.adk.tools.FunctionTool;
// ... other imports
public class App {
static FunctionTool searchTool = FunctionTool.create(App.class, "getPatents");
static FunctionTool explainTool = FunctionTool.create(App.class, "explainPatent");
public static BaseAgent ROOT_AGENT = initAgent();
public static BaseAgent initAgent() {
return LlmAgent.builder()
.name("patent-search-agent")
.description("Patent Search agent")
.model("gemini-2.0-flash-001") // Specify your desired Gemini model
.instruction(
"""
You are a helpful patent search assistant capable of 2 things:
// ... complete instructions ...
""")
.tools(searchTool, explainTool)
.outputKey("patents") // Key to store tool output in session state
.build();
}
// --- Tool: Get Patents ---
public static Map<String, String> getPatents(
@Schema(name="searchText",description = "The search text for which the user wants to find matching patents")
String searchText) {
try {
String patentsJson = vectorSearch(searchText); // Calls our Cloud Run Function
return Map.of("status", "success", "report", patentsJson);
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error fetching patents.");
}
}
// --- Tool: Explain Patent (Leveraging InvocationContext) ---
public static Map<String, String> explainPatent(
@Schema(name="patentId",description = "The patent id for which the user wants to get more explanation for, from the database")
String patentId,
@Schema(name="ctx",description = "The list of patent abstracts from the database from which the user can pick the one to get more explanation for")
InvocationContext ctx) { // Note the InvocationContext
try {
// Retrieve previous patent search results from session state
String previousResults = (String) ctx.session().state().get("patents");
if (previousResults != null && !previousResults.isEmpty()) {
// Logic to find the specific patent abstract from 'previousResults' by 'patentId'
String[] patentEntries = previousResults.split("\n\n\n\n");
for (String entry : patentEntries) {
if (entry.contains(patentId)) { // Simplified check
// The agent will then use its instructions to summarize this 'report'
return Map.of("status", "success", "report", entry);
}
}
}
return Map.of("status", "error", "report", "Patent ID not found in previous search.");
} catch (Exception e) {
// Log error
return Map.of("status", "error", "report", "Error explaining patent.");
}
}
public static void main(String[] args) throws Exception {
InMemoryRunner runner = new InMemoryRunner(ROOT_AGENT);
// ... (Session creation and main input loop - shown in your source)
}
}
Key ADK Java Code Components Highlighted:
- LlmAgent.builder(): Fluent API for configuring your agent.
- .instruction(...): Provides the core prompt and guidelines for the LLM, including when to use which tool.
- FunctionTool.create(App.class, "methodName"): Easily registers your Java methods as tools the agent can invoke. The method name string must match an actual public static method.
- @Schema(description = ...): Annotates tool parameters, helping the LLM understand what inputs each tool expects. This description is crucial for accurate tool selection and parameter filling.
- InvocationContext ctx: Passed automatically to tool methods, giving access to session state (ctx.session().state()), user information, and more.
- .outputKey("patents"): When a tool returns data, ADK can automatically store it in the session state under this key. This is how explainPatent can access the results from getPatents.
- VECTOR_SEARCH_ENDPOINT: This is a variable that holds the core functional logic for the contextual Q&A for the user in the patent search use case.
- Action Item here: You need to set an updated deployed endpoint value once you implement the Java Cloud Run Function step from the previous section.
- searchTool: This engages with the user to find contextually relevant patent matches from the patent database for the user's search text.
- explainTool: This asks the user for a specific patent to deep-dive. Then it summarizes the patent abstract and is ankle to answer more questions from the user based on the patent details it has.
Important Note: Make sure to replace the VECTOR_SEARCH_ENDPOINT variable with your deployed CRF endpoint.
Leveraging InvocationContext for Stateful Interactions
One of the critical features for building useful agents is managing state across multiple turns of a conversation. ADK's InvocationContext makes this straightforward.
In our App.java:
- When initAgent() is defined, we use .outputKey("patents"). This tells ADK that when a tool (like getPatents) returns data in its report field, that data should be stored in the session state under the key "patents".
- In the explainPatent tool method, we inject InvocationContext ctx:
public static Map<String, String> explainPatent(
@Schema(description = "...") String patentId, InvocationContext ctx) {
String previousResults = (String) ctx.session().state().get("patents");
// ... use previousResults ...
}
This allows the explainPatent tool to access the patent list fetched by the getPatents tool in a previous turn, making the conversation stateful and coherent.
9. Local CLI Testing
Define environment variables
You'll need to export two environment variables:
- A Gemini key that you can get from AI Studio:
To do that, go to https://aistudio.google.com/apikey and get you API Key for your active Google Cloud Project that you are implementing this application in and save the key somewhere:
- Once you have obtained the key, open Cloud Shell Terminal and move to the new directory that we just created adk-agents by running the following command:
cd adk-agents
- A variable to specify we're not using Vertex AI this time.
export GOOGLE_GENAI_USE_VERTEXAI=FALSE
export GOOGLE_API_KEY=AIzaSyDF...
- Run your first agent on the CLI
To launch this first agent, use the following Maven command in your terminal:
mvn compile exec:java -DmainClass="agents.App"
You would see the interactive response from the agent in your terminal.
10. Deploying to Cloud Run
Deploying your ADK Java agent to Cloud Run is similar to deploying any other Java application:
- Dockerfile: Create a Dockerfile to package your Java application.
- Build & Push Docker Image: Use Google Cloud Build and Artifact Registry.
- You can perform the above step & deploy to Cloud Run in just one command:
gcloud run deploy --source . --set-env-vars GOOGLE_API_KEY=<<Your_Gemini_Key>>
Similarly, you'd deploy your Java Cloud Run Function (gcfv2.PatentSearch). Alternatively, you can create and deploy the Java Cloud Run Function for the database logic directly from the Cloud Run Function console.
11. Testing with Web UI
The ADK comes with a handy Web UI for local testing and debugging of your agent. When you run your App.java locally (e.g., mvn exec:java -Dexec.mainClass="agents.App" if configured, or just running the main method), the ADK typically starts a local web server.
The ADK Web UI allows you to:
- Send messages to your agent.
- See the events (user message, tool call, tool response, LLM response).
- Inspect session state.
- View logs and traces.
This is invaluable during development for understanding how your agent processes requests and uses its tools. This assumes your mainClass in pom.xml is set to com.google.adk.web.AdkWebServer and your agent is registered with it, or you are running a local test runner that exposes this.
When running your App.java with its InMemoryRunner and Scanner for console input, you're testing the core agent logic. The Web UI is a separate component for a more visual debugging experience, often used when ADK is serving your agent over HTTP.
You can use the following Maven command from your root directory to launch the SpringBoot local server:
mvn compile exec:java -Dexec.args="--adk.agents.source-dir=src/main/java/ --logging.level.com.google.adk.dev=TRACE --logging.level.com.google.adk.demo.agents=TRACE"
The interface is often accessible at the URL the above command outputs with. If it is Cloud Run deployed, you should be able to access it from the Cloud Run deployed link.
You should be able to see the result in an interactive interface.
Check out the video below for our deployed Patent Agent:
Demo of a Quality Controlled Patent Agent with AlloyDB Inline Search & Recall Evaluation!

12. Clean up
To avoid incurring charges to your Google Cloud account for the resources used in this post, follow these steps:
- In the Google Cloud console, go to the https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog
- https://console.cloud.google.com/cloud-resource-manager?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
13. Congratulations
Congratulations! You have successfully built your Patent Analysis Agent in Java by combining the capabilities of ADK, https://cloud.google.com/alloydb/docs?utm_campaign=CDR_0x1d2a42f5_default_b419133749&utm_medium=external&utm_source=blog, Vertex AI, and Vector Search, also we've taken a giant leap forward in making contextual similarity searches so transformative, efficient, and truly meaning-driven.
Get Started Today!
ADK Documentation: [Link to Official ADK Java Docs]
Patent Analysis Agent Source Code: [Link to your (now public) GitHub Repo]
Java Sample Agents: [link to the adk-samples repo]
Join the ADK Community: https://www.reddit.com/r/agentdevelopmentkit/
Happy agent building!