
1. 개요
에이전트는 AI 모델과 소통하면서 보유한 도구와 컨텍스트를 사용해 목표 기반 작업을 수행하는 자율 프로그램으로, 사실에 기반한 자율적인 의사 결정을 내릴 수 있습니다.
애플리케이션에 여러 에이전트가 필요에 따라 자율적으로 함께 작동하여 더 큰 목적을 달성하고 각 에이전트가 특정 중점 분야에 대해 독립적으로 알고 책임을 지는 경우 애플리케이션은 멀티 에이전트 시스템이 됩니다.
에이전트 개발 키트 (ADK)
에이전트 개발 키트 (ADK)는 AI 에이전트를 개발하고 배포하기 위한 유연한 모듈식 프레임워크입니다. ADK는 여러 개의 개별 에이전트 인스턴스를 멀티 에이전트 시스템 (MAS)으로 구성하여 정교한 애플리케이션을 빌드하는 것을 지원합니다.
ADK에서 멀티 에이전트 시스템은 다양한 에이전트가 계층 구조를 형성하여 더 큰 목표를 달성하기 위해 공동작업하거나 조정하는 애플리케이션입니다. 이러한 방식으로 애플리케이션을 구조화하면 향상된 모듈성, 전문성, 재사용성, 유지관리 용이성, 전용 워크플로 에이전트를 사용한 구조화된 제어 흐름 정의 기능 등 상당한 이점이 있습니다.
멀티 에이전트 시스템에서 유의해야 할 사항
첫째, 각 상담사의 전문 분야를 적절하게 이해하고 추론하는 것이 중요합니다. — '특정 작업에 특정 하위 상담사가 필요한 이유를 알고 있나요?' 먼저 이 문제를 해결하세요.
두 번째, 루트 에이전트와 함께 각 응답을 라우팅하고 이해하는 방법
세 번째, 이 문서에서 확인할 수 있는 여러 유형의 상담사 라우팅이 있습니다. 애플리케이션의 흐름에 적합한 것을 선택하세요. 또한 멀티 에이전트 시스템의 흐름 제어에 필요한 다양한 컨텍스트와 상태는 무엇인가요?
빌드할 항목
주방 리모델링을 처리하는 멀티 에이전트 시스템을 빌드해 보겠습니다. 3개의 에이전트로 시스템을 구축해 보겠습니다.
- Renovation Proposal Agent(리모델링 제안 에이전트)
- 허가 및 규정 준수 확인 에이전트
- 주문 상태 확인 에이전트
주방 리모델링 제안서 문서를 생성하는 리모델링 제안서 에이전트
허가 및 규정 준수 에이전트: 허가 및 규정 준수 관련 작업을 처리합니다.
주문 상태 확인 에이전트: AlloyDB에 설정된 주문 관리 데이터베이스에서 작업하여 자재의 주문 상태를 확인합니다.
요구사항에 따라 이러한 에이전트를 오케스트레이션하는 루트 에이전트가 있습니다.
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요 .
이 글을 읽고 Google Cloud를 시작하고 ADK를 사용하는 데 도움이 되는 크레딧을 받으려면 이 링크를 사용하여 크레딧을 사용하세요. 여기의 안내에 따라 사용할 수 있습니다. 이 링크는 5월 말까지만 사용할 수 있습니다.
- 이 링크를 클릭하여 Cloud Shell을 활성화합니다. Cloud Shell에서 해당 버튼을 클릭하여 Cloud Shell 터미널 (클라우드 명령어 실행)과 편집기 (프로젝트 빌드) 간에 전환할 수 있습니다.
- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
- Python 3.9 이상이 있어야 합니다.
- 다음 명령어를 실행하여 다음 API를 사용 설정합니다.
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- gcloud 명령어 및 사용법은 문서를 참조하세요.
3. 프로토타입
프로젝트에 'Gemini 2.5 Pro' 모델을 사용하기로 결정한 경우 이 단계를 건너뛸 수 있습니다.
Google AI Studio로 이동합니다. 프롬프트를 입력하기 시작합니다. 프롬프트는 다음과 같습니다.
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
오른쪽의 매개변수를 조정하고 구성하여 최적의 대답을 얻으세요.
이 간단한 설명을 바탕으로 Gemini가 리모델링을 시작할 수 있는 매우 상세한 프롬프트를 만들어 주었습니다. 결과적으로 Gemini를 사용하여 AI Studio와 모델에서 훨씬 더 나은 대답을 얻고 있습니다. 사용 사례에 따라 사용할 모델을 선택할 수도 있습니다.
Gemini 2.5 Pro를 선택했습니다. 이 모델은 Thinking 모델이므로 긴 형식의 분석과 자세한 문서에 대해 더 많은 출력 토큰(이 경우 최대 65,000개)을 얻을 수 있습니다. Gemini 사고 상자는 기본 추론 기능이 있고 긴 컨텍스트 요청을 처리할 수 있는 Gemini 2.5 Pro를 사용 설정하면 표시됩니다.
아래에서 응답 스니펫을 확인하세요.
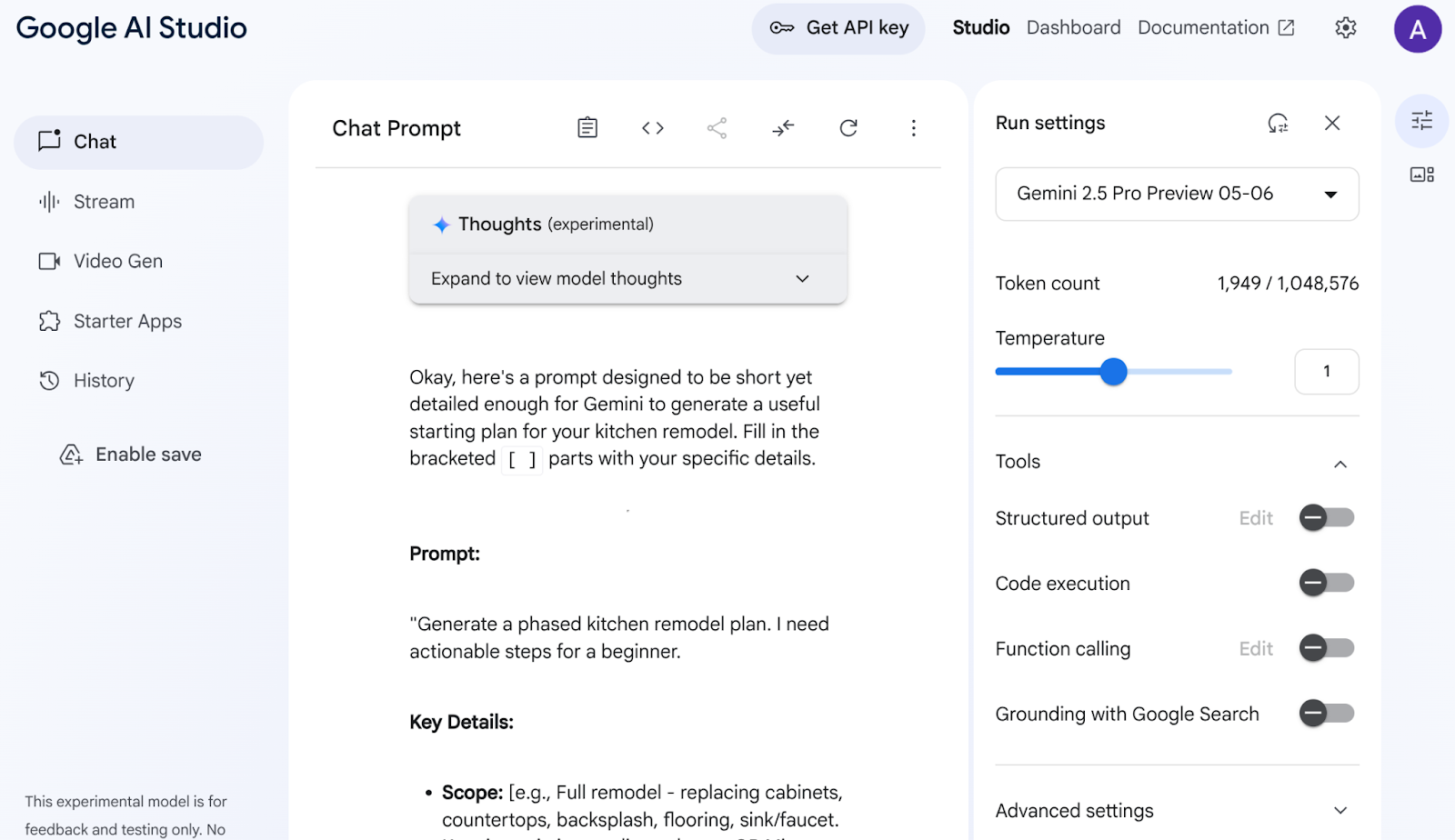
AI Studio가 내 데이터를 분석하여 캐비닛, 카운터탑, 백스플래시, 바닥재, 싱크, 응집력, 색상 팔레트, 소재 선택과 같은 모든 요소를 생성했습니다. Gemini가 출처를 인용하고 있습니다.
결과가 만족스러울 때까지 다른 모델을 선택하여 이 과정을 반복합니다. 하지만 Gemini 2.5가 있는데 왜 그렇게 해야 하나요? :)
이제 다른 프롬프트로 아이디어가 어떻게 구현되는지 확인해 보세요.
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
현재 주방 이미지 (또는 샘플 주방 이미지)로 연결되는 링크를 첨부합니다. 이미지를 생성할 수 있도록 모델을 'Gemini 2.0 Flash 프리뷰 이미지 생성'으로 변경합니다.
다음과 같은 출력이 표시됩니다.

이것이 바로 Gemini의 힘입니다.
동영상 이해부터 네이티브 이미지 생성, Google 검색으로 실제 정보에 그라운딩하는 작업까지 이 모든 건 Gemini로만 가능합니다.
AI Studio에서 이 프로토타입을 가져와 API 키를 잡고 Vertex AI ADK의 기능을 사용하여 완전한 에이전트 애플리케이션으로 확장할 수 있습니다.
4. ADK 설정
- 가상 환경 만들기 및 활성화 (권장)
Cloud Shell 터미널에서 가상 환경을 만듭니다.
python -m venv .venv
가상 환경을 활성화합니다.
source .venv/bin/activate
- ADK 설치
pip install google-adk
5. 프로젝트 구조
- Cloud Shell 터미널에서 원하는 프로젝트 위치에 디렉터리를 만듭니다.
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- Cloud Shell 편집기로 이동하여 파일을 만들어 다음 프로젝트 구조를 만듭니다 (처음에는 비어 있음).
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
6. 소스 코드
- 'init.py'로 이동하여 다음 콘텐츠로 업데이트합니다.
from . import agent
- agent.py로 이동하여 다음 경로의 다음 콘텐츠로 파일을 업데이트합니다.
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
agent.py에서 필요한 종속 항목을 가져오고, .env 파일에서 구성 매개변수를 검색하고, 이 애플리케이션에서 만들기로 한 3개의 하위 에이전트를 오케스트레이션하는 root_agent를 정의합니다. 이러한 하위 에이전트의 핵심 기능과 지원 기능을 지원하는 여러 도구가 있습니다.
- Cloud Storage 버킷이 있는지 확인
이는 에이전트가 생성하는 제안서 문서를 저장하기 위한 것입니다. Vertex AI로 만든 멀티 에이전트 시스템이 액세스할 수 있도록 이를 만들고 액세스 권한을 제공합니다. 방법은 다음과 같습니다.
https://cloud.google.com/storage/docs/creating-buckets#console
버킷 이름을 'next-demo-store'로 지정합니다. 다른 이름으로 지정하는 경우 .env 파일 (ENV Variables Setup 단계)에서 STORAGE_BUCKET 값을 업데이트해야 합니다.
- 버킷에 대한 액세스 권한을 설정하려면 Cloud Storage 콘솔로 이동하여 스토리지 버킷으로 이동합니다 (이 경우 버킷 이름은 'next-demo-storage'임). https://console.cloud.google.com/storage/browser/next-demo-storage
권한 -> 주 구성원 보기 -> 액세스 권한 부여로 이동합니다. 주 구성원을 'allUsers'로, 역할을 '스토리지 객체 사용자'로 선택합니다.
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- 종속 항목 목록 만들기
requirements.txt에 모든 종속 항목을 나열합니다. 저장소에서 이를 복사할 수 있습니다.
멀티 에이전트 시스템 소스 코드 설명
agent.py 파일은 에이전트 개발 키트 (ADK)를 사용하여 주방 리모델링 멀티 에이전트 시스템의 구조와 동작을 정의합니다. 주요 구성요소를 살펴보겠습니다.
에이전트 정의
RenovationProposalAgent
이 에이전트는 주방 리모델링 제안서 문서를 작성하는 역할을 합니다. 주방 크기, 원하는 스타일, 예산, 고객 선호도와 같은 입력 매개변수를 선택적으로 사용합니다. 이 정보를 기반으로 대규모 언어 모델 (LLM) Gemini 2.5를 사용하여 자세한 제안서를 생성합니다. 생성된 제안서는 Google Cloud Storage 버킷에 저장됩니다.
PermitsAndComplianceCheckAgent
이 에이전트는 리모델링 프로젝트가 현지 건축법 및 규정을 준수하는 데 중점을 둡니다. 제안된 리모델링 (예: 구조 변경, 전기 작업, 배관 수정)에 관한 정보를 수신하고 LLM을 사용하여 허가 요건 및 규정 준수 규칙을 확인합니다. 에이전트는 관련 규정을 수집하기 위해 외부 API에 액세스하도록 맞춤설정할 수 있는 지식 베이스의 정보를 사용합니다.
OrderingAgent
이 에이전트는 (지금 구현하지 않으려면 주석 처리해도 됨) 리모델링에 필요한 자재 및 장비의 주문 상태를 확인하는 작업을 처리합니다. 이 기능을 사용 설정하려면 설정 단계에 설명된 대로 Cloud Run 함수를 만들어야 합니다. 그러면 에이전트가 주문 정보가 포함된 AlloyDB 데이터베이스와 상호작용하는 이 Cloud Run 함수를 호출합니다. 실시간 데이터를 추적하기 위해 데이터베이스 시스템과 통합하는 방법을 보여줍니다.
루트 에이전트 (조정자)
root_agent는 멀티 에이전트 시스템의 중앙 조정자 역할을 합니다. 초기 리모델링 요청을 수신하고 요청의 필요에 따라 호출할 하위 에이전트를 결정합니다. 예를 들어 요청에 허가 요건 확인이 필요한 경우 PermitsAndComplianceCheckAgent를 호출합니다. 사용자가 주문 상태를 확인하려는 경우 OrderingAgent가 호출됩니다 (사용 설정된 경우).
그런 다음 root_agent가 하위 에이전트의 응답을 수집하고 이를 결합하여 사용자에게 포괄적인 응답을 제공합니다. 여기에는 제안서 요약, 필요한 허가증 목록, 주문 상태 업데이트 제공이 포함될 수 있습니다.
데이터 흐름 및 주요 개념
사용자가 ADK 인터페이스 (터미널 또는 웹 UI)를 통해 요청을 시작합니다.
- 요청이 root_agent에 의해 수신됩니다.
- root_agent는 요청을 분석하고 적절한 하위 에이전트로 라우팅합니다.
- 하위 에이전트는 LLM, 기술 자료, API, 데이터베이스를 사용하여 요청을 처리하고 응답을 생성합니다.
- 하위 에이전트가 root_agent에 응답을 반환합니다.
- root_agent가 응답을 결합하고 사용자에게 최종 출력을 제공합니다.
LLM (대규모 언어 모델)
에이전트는 LLM에 크게 의존하여 텍스트를 생성하고, 질문에 답변하고, 추론 작업을 실행합니다. LLM은 에이전트가 사용자 요청을 이해하고 응답할 수 있는 능력의 '두뇌'입니다. 이 애플리케이션에서는 Gemini 2.5를 사용합니다.
Google Cloud Storage
생성된 리모델링 제안서 문서를 저장하는 데 사용됩니다. 버킷을 만들고 에이전트가 버킷에 액세스할 수 있도록 필요한 권한을 부여해야 합니다.
Cloud Run (선택사항)
OrderingAgent는 Cloud Run 함수를 사용하여 AlloyDB와 인터페이스합니다. Cloud Run은 HTTP 요청에 대한 응답으로 코드를 실행하는 서버리스 환경을 제공합니다.
AlloyDB
OrderingAgent를 사용하는 경우 주문 정보를 저장할 AlloyDB 데이터베이스를 설정해야 합니다. 다음 섹션인 '데이터베이스 설정'에서 자세히 살펴보겠습니다.
.env 파일
.env 파일에는 API 키, 데이터베이스 사용자 인증 정보, 버킷 이름과 같은 민감한 정보가 저장됩니다. 이 파일을 안전하게 유지하고 저장소에 커밋하지 않는 것이 중요합니다. 또한 에이전트 및 Google Cloud 프로젝트의 구성 설정을 저장합니다. 일반적으로 root_agent 또는 지원 함수는 이 파일에서 값을 읽습니다. .env 파일에 필요한 모든 변수가 올바르게 설정되어 있는지 확인합니다. 여기에는 Cloud Storage 버킷 이름이 포함됩니다.
7. 데이터베이스 설정
ordering_agent가 사용하는 도구 중 하나인 'check_status'에서 AlloyDB 주문 데이터베이스에 액세스하여 주문 상태를 가져옵니다. 이 섹션에서는 AlloyDB 데이터베이스 클러스터와 인스턴스를 설정합니다.
클러스터 및 인스턴스 만들기
- Cloud 콘솔에서 AlloyDB 페이지로 이동합니다. Cloud 콘솔에서 대부분의 페이지를 쉽게 찾으려면 콘솔의 검색창을 사용하여 검색하면 됩니다.
- 해당 페이지에서 클러스터 만들기를 선택합니다.

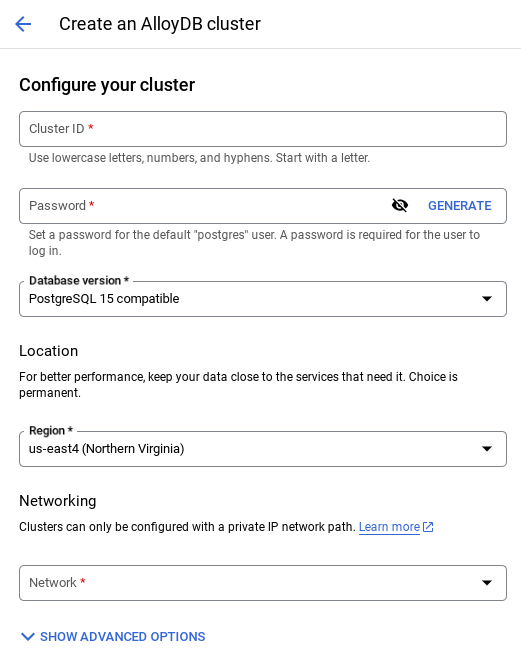
- 아래와 같은 화면이 표시됩니다. 다음 값으로 클러스터 및 인스턴스를 만듭니다 (저장소에서 애플리케이션 코드를 클론하는 경우 값이 일치하는지 확인).
- 클러스터 ID: '
vector-cluster' - password: "
alloydb" - PostgreSQL 15 / 최신 권장 버전
- 지역: "
us-central1" - 네트워킹: "
default"
- 기본 네트워크를 선택하면 아래와 같은 화면이 표시됩니다.
연결 설정을 선택합니다.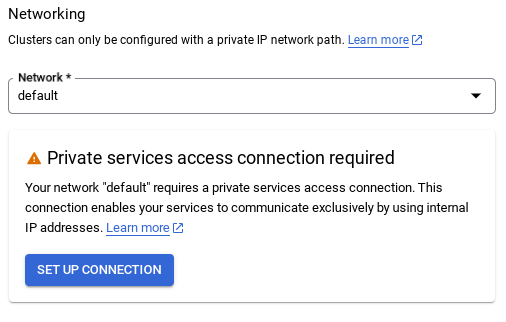
- 여기에서 '자동으로 할당된 IP 범위 사용'을 선택하고 계속을 클릭합니다. 정보를 검토한 후 연결 만들기를 선택합니다.

- 네트워크가 설정되면 클러스터를 계속 만들 수 있습니다. 클러스터 만들기를 클릭하여 아래와 같이 클러스터 설정을 완료합니다.

클러스터 / 인스턴스 구성 시 확인할 수 있는 인스턴스 ID를
vector-instance. 변경할 수 없는 경우 앞으로의 모든 참조에서 인스턴스 ID를 사용해야 합니다.
클러스터를 만드는 데 약 10분이 걸립니다. 성공하면 방금 만든 클러스터의 개요가 표시된 화면이 표시됩니다.
데이터 수집
이제 매장에 관한 데이터가 포함된 표를 추가할 차례입니다. AlloyDB로 이동하여 기본 클러스터와 AlloyDB Studio를 선택합니다.
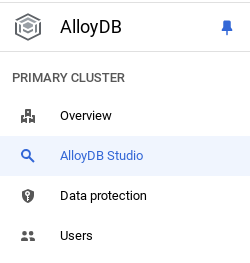
인스턴스 생성이 완료될 때까지 기다려야 할 수 있습니다. 완료되면 클러스터를 만들 때 만든 사용자 인증 정보를 사용하여 AlloyDB에 로그인합니다. PostgreSQL에 인증하려면 다음 데이터를 사용하세요.
- 사용자 이름 : '
postgres' - 데이터베이스 : '
postgres' - 비밀번호 : '
alloydb'
AlloyDB Studio에 인증되면 편집기에 SQL 명령어가 입력됩니다. 마지막 창 오른쪽에 있는 더하기 기호를 사용하여 여러 편집기 창을 추가할 수 있습니다.
필요에 따라 실행, 형식, 지우기 옵션을 사용하여 편집기 창에 AlloyDB 명령어를 입력합니다.
테이블 만들기
AlloyDB Studio에서 아래 DDL 문을 사용하여 테이블을 만들 수 있습니다.
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
레코드 삽입
위에서 언급한 database_script.sql 스크립트에서 insert 쿼리 문을 편집기에 복사합니다.
실행을 클릭합니다.
이제 데이터 세트가 준비되었으므로 상태를 추출하는 Java Cloud Run Functions 애플리케이션을 만들어 보겠습니다.
Java로 Cloud Run 함수를 만들어 주문 상태 정보 추출
- 여기에서 Cloud Run 함수를 만듭니다. https://console.cloud.google.com/run/create?deploymentType=function
- 함수 이름을 'check-status'로 설정하고 런타임으로 'Java 17'을 선택합니다.
- 데모 애플리케이션이므로 인증을 '인증되지 않은 호출 허용'으로 설정할 수 있습니다.
- 런타임으로 Java 17을 선택하고 소스 코드로 인라인 편집기를 선택합니다.
- 이때 자리표시자 코드가 편집기에 로드됩니다.
자리표시자 코드 바꾸기
- Java 파일 이름을 'ProposalOrdersTool.java'로, 클래스 이름을 'ProposalOrdersTool'로 변경합니다.
- ProposalOrdersTool.java 및 pom.xml의 자리표시자 코드를 이 저장소의 'Cloud Run Function' 폴더에 있는 해당 파일의 코드로 바꿉니다.
- ProposalOrdersTool.java에서 다음 코드 줄을 찾아 자리표시자 값을 구성의 값으로 바꿉니다.
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- '만들기'를 클릭합니다.
- Cloud Run 함수가 생성되고 배포됩니다.
중요한 단계:
배포가 완료되면 Cloud 함수가 AlloyDB 데이터베이스 인스턴스에 액세스할 수 있도록 VPC 커넥터를 만듭니다.
배포를 시작하면 Google Cloud Run Functions 콘솔에서 함수를 확인할 수 있습니다. 새로 만든 함수 (check-status)를 검색하고, 함수를 클릭한 다음 새 버전 수정 및 배포 (Cloud Run Functions 콘솔 상단의 수정 아이콘 (펜)으로 식별됨)를 클릭하고 다음을 변경합니다.
- 네트워킹 탭으로 이동합니다.
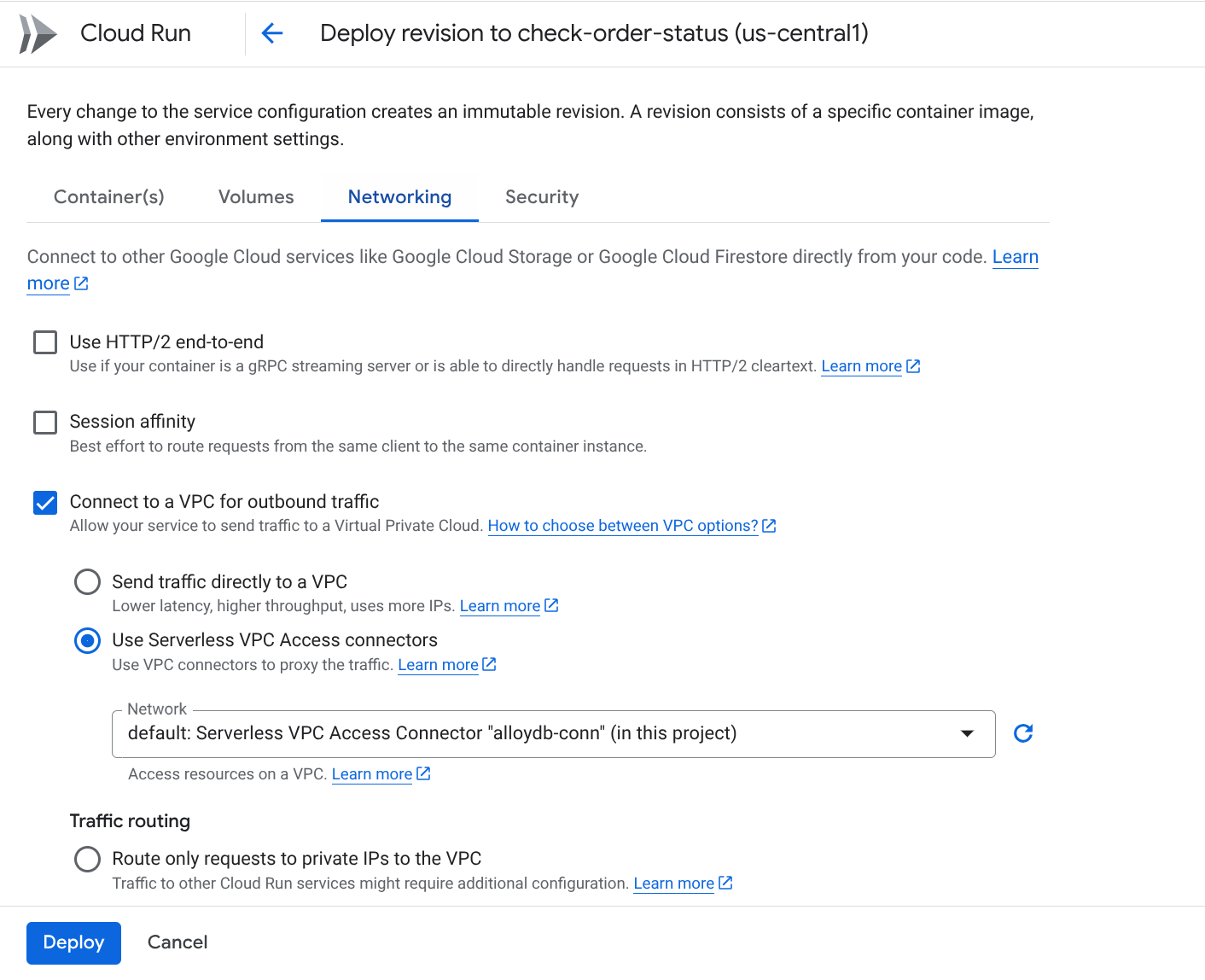
- '아웃바운드 트래픽을 위해 VPC에 연결'을 선택한 다음 '서버리스 VPC 액세스 커넥터 사용'을 선택합니다.
- 네트워크 드롭다운에서 설정을 클릭하고 네트워크 드롭다운을 클릭한 후 '새 VPC 커넥터 추가' 옵션을 선택합니다 (기본을 아직 구성하지 않은 경우). 표시되는 대화상자의 안내를 따릅니다.

- VPC 커넥터의 이름을 입력하고 리전이 인스턴스와 동일한지 확인합니다. 네트워크 값을 기본값으로 두고 서브넷을 사용 가능한 IP 범위(예: 10.8.0.0)가 있는 '커스텀 IP 범위'로 설정합니다.
- '확장 설정 표시'를 펼치고 구성이 정확히 다음과 같이 설정되어 있는지 확인합니다.

- 만들기를 클릭하면 이제 이 커넥터가 이그레스 설정에 표시됩니다.
- 새로 만든 커넥터를 선택합니다.
- 이 VPC 커넥터를 통해 모든 트래픽이 라우팅되도록 선택합니다.
- 다음을 클릭한 후 배포를 클릭합니다.
- 업데이트된 Cloud 함수가 배포되면 생성된 엔드포인트가 표시됩니다.
- Cloud Run Functions 콘솔 상단의 테스트 버튼을 클릭하고 Cloud Shell 터미널에서 결과 명령어를 실행하여 테스트할 수 있습니다.
- 배포된 엔드포인트는 .env 변수
CHECK_ORDER_STATUS_ENDPOINT에서 업데이트해야 하는 URL입니다.
8. 모델 설정
사용자 요청을 이해하고 응답을 생성하는 에이전트의 기능은 대규모 언어 모델 (LLM)에 의해 지원됩니다. 에이전트가 이 외부 LLM 서비스에 보안 호출을 해야 하며, 이를 위해서는 인증 사용자 인증 정보가 필요합니다. 유효한 인증이 없으면 LLM 서비스에서 에이전트의 요청을 거부하고 에이전트가 작동할 수 없습니다.
- Google AI Studio에서 API 키를 가져옵니다.
- .env 파일을 설정하는 다음 단계에서
<<your API KEY>>를 실제 API 키 값으로 바꿉니다.
9. 환경 변수 설정
- 이 저장소의 템플릿 .env 파일에서 매개변수 값을 설정합니다. 제 경우에는 .env에 다음과 같은 변수가 있습니다.
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
자리표시자를 값으로 바꿉니다.
10. 에이전트 실행
- 터미널을 사용하여 에이전트 프로젝트의 상위 디렉터리로 이동합니다.
cd renovation-agent
- 모든 종속 항목 설치
pip install -r requirements.txt
- Cloud Shell 터미널에서 다음 명령어를 실행하여 에이전트를 실행할 수 있습니다.
adk run .
- 다음 명령어를 실행하여 ADK 프로비저닝 웹 UI에서 실행할 수 있습니다.
adk web
- 다음 프롬프트로 테스트합니다.
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
11. 결과

12. Agent Engine에 배포
멀티 에이전트 시스템이 제대로 작동하는지 테스트했으므로 이제 서버리스로 만들어 누구나 / 모든 애플리케이션이 사용할 수 있도록 클라우드에서 제공해 보겠습니다. 저장소의 agent.py에서 아래 코드 스니펫의 주석 처리를 삭제하면 멀티 에이전트 시스템을 배포할 수 있습니다.
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
다음 명령어를 사용하여 프로젝트 폴더 내에서 agent.py를 다시 실행합니다.
>> cd adk-renovation-agent
>> python agent.py
이 코드는 완료하는 데 몇 분 정도 걸립니다. 완료되면 다음과 같은 엔드포인트가 표시됩니다.
'projects/123456789/locations/us-central1/reasoningEngines/123456'
새 파일 'test.py'를 추가하여 다음 코드로 배포된 에이전트를 테스트할 수 있습니다.
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
위 코드에서 자리표시자 '<<YOUR_DEPLOYED_ENGINE_ID>>'의 값을 바꾸고 'python test.py' 명령어를 실행하면 Agent Engine이 배포된 다중 에이전트 시스템과 상호작용하여 주방을 리모델링할 수 있습니다.
13. 한 줄 배포 옵션
배포된 멀티 에이전트 시스템을 테스트했으므로 이전 단계에서 실행한 배포 단계를 추상화하는 더 간단한 방법을 알아보겠습니다. 원라인 배포 옵션:
- Cloud Run:
구문:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
이 경우에는 다음과 같습니다.
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
배포된 엔드포인트를 다운스트림 통합에 사용할 수 있습니다.
- Agent Engine에:
구문:
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
이 경우에는 다음과 같습니다.
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
Google Cloud 콘솔의 Agent Engine UI에 새 에이전트가 표시됩니다. 자세한 내용은 이 블로그를 참고하세요.
14. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
15. 축하합니다
축하합니다. ADK를 사용하여 첫 번째 에이전트를 만들고 상호작용했습니다.