
۱. مرور کلی
یک عامل ، یک برنامهی خودکار است که با یک مدل هوش مصنوعی صحبت میکند تا با استفاده از ابزارها و زمینهای که در اختیار دارد، عملیاتی مبتنی بر هدف را انجام دهد و قادر به تصمیمگیری خودکار مبتنی بر حقیقت است!
وقتی برنامه شما چندین عامل دارد که به صورت مستقل و با هم کار میکنند تا به هدف بزرگتر خود برسند و هر یک از عوامل آن به طور مستقل در یک حوزه تمرکز خاص آگاه و مسئول باشند، برنامه شما به یک سیستم چندعامله تبدیل میشود.
کیت توسعه عامل (ADK)
کیت توسعه عامل (ADK) یک چارچوب انعطافپذیر و ماژولار برای توسعه و استقرار عاملهای هوش مصنوعی است. ADK با ترکیب چندین نمونه عامل مجزا در یک سیستم چندعاملی (MAS) از ساخت برنامههای پیچیده پشتیبانی میکند.
در ADK، یک سیستم چندعاملی، برنامهای است که در آن عاملهای مختلف، که اغلب یک سلسله مراتب را تشکیل میدهند، برای دستیابی به یک هدف بزرگتر با هم همکاری یا هماهنگی میکنند. ساختاردهی برنامه شما به این روش، مزایای قابل توجهی از جمله ماژولاریتی پیشرفته، تخصصگرایی، قابلیت استفاده مجدد، قابلیت نگهداری و امکان تعریف جریانهای کنترل ساختاریافته با استفاده از عاملهای گردش کار اختصاصی را ارائه میدهد.
نکاتی که باید در مورد سیستم چندعاملی در نظر داشته باشید
اول ، مهم است که درک و استدلال درستی از تخصص هر عامل داشته باشید. - "آیا میدانید چرا برای چیزی به یک عامل فرعی خاص نیاز دارید؟"، ابتدا آن را بفهمید.
دوم ، چگونه آنها را با یک عامل ریشه گرد هم آوریم تا هر یک از پاسخها را مسیریابی و تفسیر کنیم.
سوم ، انواع مختلفی از مسیریابی عامل وجود دارد که میتوانید در این مستندات پیدا کنید. مطمئن شوید که کدام یک با جریان برنامه شما مطابقت دارد. همچنین زمینهها و حالتهای مختلفی که برای کنترل جریان سیستم چندعاملی خود نیاز دارید چیست.
آنچه خواهید ساخت
بیایید یک سیستم چندعاملی برای مدیریت بازسازی آشپزخانه بسازیم. این کاری است که ما انجام خواهیم داد. ما سیستمی با ۳ عامل خواهیم ساخت.
- نماینده پیشنهاد نوسازی
- نماینده بررسی مجوزها و انطباق
- نماینده بررسی وضعیت سفارش
نماینده طرح نوسازی، برای تهیه سند طرح نوسازی آشپزخانه.
نماینده مجوزها و انطباق، برای رسیدگی به مجوزها و وظایف مرتبط با انطباق.
نماینده بررسی وضعیت سفارش، برای بررسی وضعیت سفارش مواد با کار بر روی پایگاه داده مدیریت سفارش که در AlloyDB راهاندازی کردهایم.
ما یک عامل ریشه خواهیم داشت که این عوامل را بر اساس نیاز هماهنگ میکند.
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
همچنین اگر در حال خواندن این مطلب هستید و مایلید برای شروع کار با Google Cloud و استفاده از ADK اعتبار دریافت کنید، از این لینک برای استفاده از اعتبار استفاده کنید. میتوانید دستورالعملهای اینجا را برای استفاده از آن دنبال کنید. لطفاً توجه داشته باشید که این لینک فقط تا پایان ماه مه برای استفاده معتبر است.
- با کلیک روی این لینک، Cloud Shell را فعال کنید. میتوانید با کلیک روی دکمه مربوطه از Cloud Shell، بین Cloud Shell Terminal (برای اجرای دستورات ابری) و Editor (برای ساخت پروژهها) جابجا شوید.
- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- حتماً پایتون ۳.۹+ داشته باشید
- با اجرای دستورات زیر، API های زیر را فعال کنید:
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- برای دستورات و نحوهی استفاده از gcloud به مستندات مراجعه کنید.
۳. نمونه اولیه
اگر تصمیم دارید از مدل « Gemini 2.5 Pro » برای این پروژه استفاده کنید، میتوانید از این مرحله صرف نظر کنید.
به Google AI Studio بروید. شروع به تایپ کردن دستور مورد نظر خود کنید. دستور من این است:
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
پارامترهای سمت راست را تنظیم و پیکربندی کنید تا به پاسخ بهینه برسید.
بر اساس این توضیح ساده، Gemini یک دستورالعمل فوقالعاده دقیق برای شروع بازسازی به من داد! در واقع، ما از Gemini استفاده میکنیم تا پاسخهای بهتری از AI Studio و مدلهایمان دریافت کنیم. شما همچنین میتوانید بر اساس مورد استفاده خود، مدلهای مختلفی را برای استفاده انتخاب کنید.
ما Gemini 2.5 Pro را انتخاب کردهایم. این یک مدل Thinking است، به این معنی که ما توکنهای خروجی بیشتری، در این مورد تا 65 هزار توکن، برای تحلیلهای طولانی و اسناد دقیق دریافت میکنیم. جعبه تفکر Gemini زمانی فعال میشود که Gemini 2.5 Pro را فعال کنید که دارای قابلیتهای استدلال بومی است و میتواند درخواستهای متنی طولانی را بپذیرد.
گزیدهای از پاسخ را در زیر ببینید:

استودیو هوش مصنوعی دادههای من را تجزیه و تحلیل کرد و همه این موارد مانند کابینت، کانترها، دیوارپوش، کفپوش، سینک، انسجام، پالت رنگ و انتخاب مواد را تولید کرد. Gemini حتی منابع را ذکر میکند!
این کار را با مدلهای مختلف تکرار کنید تا از نتیجه راضی شوید. اما به نظر من وقتی Gemini 2.5 را دارید، چرا باید همه این کارها را انجام دهید :)
به هر حال، حالا سعی کنید با یک مثال متفاوت، این ایده را به واقعیت تبدیل کنید:
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
لینکی به تصویر آشپزخانه فعلی خود (یا هر تصویر نمونه آشپزخانه ) ضمیمه کنید. مدل را به "Gemini 2.0 Flash Preview Image Generation" تغییر دهید تا بتوانید به تصاویر تولید شده دسترسی داشته باشید.
من این خروجی را گرفتم:

این قدرت جوزا است!
از درک ویدیوها گرفته تا تولید تصویر بومی و استخراج اطلاعات واقعی با جستجوی گوگل - چیزهایی وجود دارد که فقط با Gemini میتوان ساخت.
از استودیوی هوش مصنوعی، میتوانید این نمونه اولیه را بردارید، کلید API را دریافت کنید و با استفاده از قدرت Vertex AI ADK، آن را به یک برنامه عامل کامل تبدیل کنید.
۴. تنظیمات ADK
- ایجاد و فعالسازی محیط مجازی (توصیه شده)
از ترمینال Cloud Shell خود، یک محیط مجازی ایجاد کنید:
python -m venv .venv
فعال کردن محیط مجازی:
source .venv/bin/activate
- نصب ADK
pip install google-adk
۵. ساختار پروژه
- از ترمینال Cloud Shell، یک دایرکتوری در محل پروژه مورد نظر خود ایجاد کنید
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- به ویرایشگر Cloud Shell بروید و با ایجاد فایلها (ابتدا خالی) ساختار پروژه زیر را ایجاد کنید:
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
۶. کد منبع
- به " init .py" بروید و با محتوای زیر بهروزرسانی کنید:
from . import agent
- به فایل agent.py بروید و فایل را با محتوای زیر از مسیر زیر بهروزرسانی کنید:
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
در agent.py، وابستگیهای لازم را وارد میکنیم، پارامترهای پیکربندی را از فایل .env بازیابی میکنیم و root_agent را تعریف میکنیم که 3 زیرعاملی را که قرار است در این برنامه ایجاد کنیم، هماهنگ میکند. ابزارهای متعددی وجود دارند که به هسته و عملکردهای پشتیبانی این زیرعاملها کمک میکنند.
- مطمئن شوید که Cloud Storage Bucket را دارید
این برای ذخیره سند پیشنهادی است که عامل تولید میکند. آن را ایجاد کنید و دسترسی را فراهم کنید تا سیستم چندعاملی ایجاد شده با Vertex AI بتواند به آن دسترسی داشته باشد. در اینجا نحوه انجام این کار آمده است:
https://cloud.google.com/storage/docs/creating-buckets#console
نام سطل خود را « next-demo-store » بگذارید. اگر نام دیگری برای آن انتخاب میکنید، فراموش نکنید که مقدار STORAGE_BUCKET را در فایل .env (در مرحله تنظیم متغیرهای ENV) بهروزرسانی کنید.
- برای تنظیم دسترسی به سطل، به کنسول ذخیرهسازی ابری و به سطل ذخیرهسازی خود بروید (در مورد ما نام سطل "next-demo-storage" است: https://console.cloud.google.com/storage/browser/next-demo-storage .
به مسیر Permissions -> View Principals -> Grant Access بروید. Principals را به عنوان "allUsers" و Role را به عنوان "Storage Object User" انتخاب کنید.
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- ایجاد لیست وابستگیها
تمام وابستگیها را در requirements.txt فهرست کنید. میتوانید این را از مخزن کپی کنید.
توضیح کد منبع سیستم چندعاملی
فایل agent.py ساختار و رفتار سیستم چندعاملی نوسازی آشپزخانه ما را با استفاده از کیت توسعه عامل (ADK) تعریف میکند. بیایید اجزای کلیدی را تجزیه کنیم:
تعاریف عامل
نماینده طرح نوسازی
این عامل مسئول ایجاد سند پیشنهاد نوسازی آشپزخانه است. این عامل به صورت اختیاری پارامترهای ورودی مانند اندازه آشپزخانه، سبک مورد نظر، بودجه و ترجیحات مشتری را دریافت میکند. بر اساس این اطلاعات، از یک مدل زبان بزرگ (LLM) Gemini 2.5 برای تولید یک پیشنهاد دقیق استفاده میکند. سپس پیشنهاد تولید شده در یک مخزن ذخیرهسازی ابری گوگل ذخیره میشود.
مجوزها و انطباق بررسی کننده
این نماینده بر اطمینان از پایبندی پروژه نوسازی به قوانین و مقررات ساختمان محلی تمرکز دارد. این نماینده اطلاعات مربوط به نوسازی پیشنهادی (مثلاً تغییرات سازهای، کارهای برقی، اصلاحات لولهکشی) را دریافت میکند و از LLM برای بررسی الزامات مجوز و قوانین انطباق استفاده میکند. نماینده از اطلاعات یک پایگاه دانش (که میتوانید آن را برای دسترسی به APIهای خارجی جهت جمعآوری مقررات مربوطه سفارشی کنید) استفاده میکند.
نماینده سفارش
این عامل (اگر نمیخواهید اکنون آن را پیادهسازی کنید، میتوانید آن را به صورت کامنت بنویسید)، بررسی وضعیت سفارش مصالح و تجهیزات مورد نیاز برای بازسازی را انجام میدهد. برای فعال کردن آن، باید یک تابع Cloud Run همانطور که در مراحل راهاندازی توضیح داده شده است، ایجاد کنید. سپس عامل این تابع Cloud Run را فراخوانی میکند که با یک پایگاه داده AlloyDB حاوی اطلاعات سفارش تعامل دارد. این نشان دهنده ادغام با یک سیستم پایگاه داده برای ردیابی دادههای بلادرنگ است.
عامل ریشه (هماهنگکننده)
root_agent به عنوان هماهنگکننده مرکزی سیستم چندعاملی عمل میکند. این عامل درخواست نوسازی اولیه را دریافت میکند و بر اساس نیازهای درخواست، تعیین میکند که کدام زیرعاملها را فراخوانی کند. به عنوان مثال، اگر درخواست نیاز به بررسی الزامات مجوز داشته باشد، عامل PermitsAndComplianceCheckAgent را فراخوانی میکند. اگر کاربر بخواهد وضعیت سفارش را بررسی کند، عامل OrderingAgent را (در صورت فعال بودن) فراخوانی میکند.
سپس root_agent پاسخها را از زیر-عاملها جمعآوری کرده و آنها را ترکیب میکند تا یک پاسخ جامع به کاربر ارائه دهد. این میتواند شامل خلاصه کردن پیشنهاد، فهرست مجوزهای مورد نیاز و ارائه بهروزرسانیهای وضعیت سفارش باشد.
جریان داده و مفاهیم کلیدی
کاربر از طریق رابط ADK (ترمینال یا رابط کاربری وب) درخواستی را آغاز میکند.
- درخواست توسط root_agent دریافت میشود.
- root_agent درخواست را تجزیه و تحلیل کرده و آن را به sub-agent های مناسب هدایت میکند.
- زیر-عاملها از LLMها، پایگاههای دانش، APIها و پایگاههای داده برای پردازش درخواست و تولید پاسخها استفاده میکنند.
- زیر-عاملها پاسخهای خود را به root_agent برمیگردانند.
- تابع root_agent پاسخها را ترکیب کرده و خروجی نهایی را به کاربر ارائه میدهد.
LLM (مدلهای زبان بزرگ)
عاملها برای تولید متن، پاسخ به سوالات و انجام وظایف استدلالی به شدت به LLMها متکی هستند. LLMها "مغز" پشت توانایی عاملها برای درک و پاسخ به درخواستهای کاربر هستند. ما در این برنامه از Gemini 2.5 استفاده میکنیم.
فضای ذخیرهسازی ابری گوگل
برای ذخیره اسناد پیشنهاد نوسازی تولید شده استفاده میشود. شما باید یک سطل ایجاد کنید و مجوزهای لازم را برای دسترسی به آن به نمایندگان اعطا کنید.
اجرای ابری (اختیاری)
OrderingAgent از یک تابع Cloud Run برای ارتباط با AlloyDB استفاده میکند. Cloud Run یک محیط بدون سرور برای اجرای کد در پاسخ به درخواستهای HTTP فراهم میکند.
آلیاژ دیبی
اگر از OrderingAgent استفاده میکنید، باید یک پایگاه داده AlloyDB برای ذخیره اطلاعات سفارش راهاندازی کنید. جزئیات آن را در بخش بعدی که «تنظیمات پایگاه داده» است، بررسی خواهیم کرد.
فایل .env
فایل .env اطلاعات حساسی مانند کلیدهای API، اعتبارنامههای پایگاه داده و نامهای باکت را ذخیره میکند. بسیار مهم است که این فایل را ایمن نگه دارید و آن را در مخزن خود ذخیره نکنید. همچنین تنظیمات پیکربندی برای عاملها و پروژه Google Cloud شما را ذخیره میکند. root_agent یا توابع پشتیبانی معمولاً مقادیر را از این فایل میخوانند. مطمئن شوید که همه متغیرهای مورد نیاز به درستی در فایل .env تنظیم شدهاند. این شامل نام باکت Cloud Storage نیز میشود.
۷. راهاندازی پایگاه داده
در یکی از ابزارهای مورد استفاده توسط ordering_agent، به نام "check_status"، ما به پایگاه داده سفارشات AlloyDB دسترسی پیدا میکنیم تا وضعیت سفارشات را دریافت کنیم. در این بخش، خوشه و نمونه پایگاه داده AlloyDB را راهاندازی خواهیم کرد.
ایجاد یک کلاستر و نمونه
- در کنسول ابری، صفحه AlloyDB را پیمایش کنید. یک راه آسان برای یافتن اکثر صفحات در کنسول ابری، جستجوی آنها با استفاده از نوار جستجوی کنسول است.
- از آن صفحه، گزینه CREATE CLUSTER را انتخاب کنید:

- صفحهای مانند تصویر زیر خواهید دید. یک کلاستر و نمونه با مقادیر زیر ایجاد کنید (مطمئن شوید که مقادیر مطابقت دارند، در صورتی که کد برنامه را از مخزن کپی میکنید):
- شناسه خوشه : "
vector-cluster" - رمز عبور : "
alloydb" - PostgreSQL 15 / آخرین نسخه توصیه شده
- منطقه : "
us-central1" - شبکه : "
default"

- وقتی شبکه پیشفرض را انتخاب میکنید، صفحهای مانند تصویر زیر مشاهده خواهید کرد.
تنظیم اتصال را انتخاب کنید. 
- از آنجا، « استفاده از یک محدوده IP اختصاص داده شده خودکار » را انتخاب کرده و ادامه دهید. پس از بررسی اطلاعات، «ایجاد اتصال» را انتخاب کنید.

- پس از راهاندازی شبکه، میتوانید به ایجاد خوشه خود ادامه دهید. برای تکمیل راهاندازی خوشه، مطابق شکل زیر، روی CREATE CLUSTER کلیک کنید:
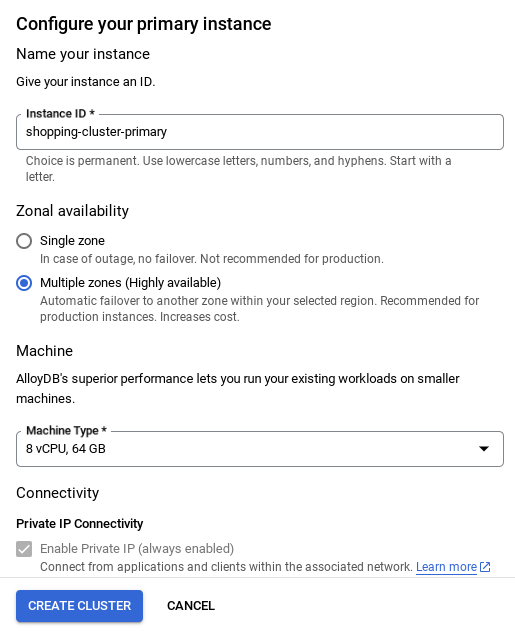
مطمئن شوید که شناسه نمونه (که میتوانید در زمان پیکربندی خوشه/نمونه پیدا کنید) را به ... تغییر دهید.
اگر نمیتوانید آن را تغییر دهید، به یاد داشته باشید که در تمام ارجاعات بعدی از vector-instance نمونه خود استفاده کنید .
توجه داشته باشید که ایجاد خوشه حدود ۱۰ دقیقه طول خواهد کشید. پس از موفقیتآمیز بودن، باید صفحهای را مشاهده کنید که نمای کلی خوشه ایجاد شده شما را نشان میدهد.
مصرف داده
حالا وقت آن رسیده که یک جدول با دادههای مربوط به فروشگاه اضافه کنیم. به AlloyDB بروید، خوشه اصلی و سپس AlloyDB Studio را انتخاب کنید:

ممکن است لازم باشد منتظر بمانید تا نمونه شما به طور کامل ایجاد شود. پس از اتمام این کار، با استفاده از اعتبارنامههایی که هنگام ایجاد خوشه ایجاد کردهاید، وارد AlloyDB شوید. از دادههای زیر برای تأیید اعتبار در PostgreSQL استفاده کنید:
- نام کاربری: "
postgres" - پایگاه داده: "
postgres" - رمز عبور: "
alloydb"
پس از اینکه با موفقیت در AlloyDB Studio احراز هویت شدید، دستورات SQL در ویرایشگر وارد میشوند. میتوانید با استفاده از علامت + در سمت راست آخرین پنجره، چندین پنجره ویرایشگر اضافه کنید.

شما میتوانید دستورات AlloyDB را در پنجرههای ویرایشگر وارد کنید و در صورت لزوم از گزینههای Run، Format و Clear استفاده کنید.
ایجاد یک جدول
شما میتوانید با استفاده از دستور DDL زیر در AlloyDB Studio یک جدول ایجاد کنید:
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
درج رکوردها
عبارت insert query را از اسکریپت database_script.sql که در بالا ذکر شد، در ویرایشگر کپی کنید.
روی اجرا کلیک کنید.
حالا که مجموعه داده آماده است، بیایید یک برنامه Java Cloud Run Functions برای استخراج وضعیت ایجاد کنیم.
یک تابع Cloud Run در جاوا ایجاد کنید تا اطلاعات وضعیت سفارش را استخراج کند.
- تابع Cloud Run را از اینجا ایجاد کنید: https://console.cloud.google.com/run/create?deploymentType=function
- نام تابع را « check-status » قرار دهید و « Java 17 » را به عنوان زمان اجرا انتخاب کنید.
- از آنجایی که این یک برنامه آزمایشی است، میتوانید احراز هویت را روی « مجاز کردن فراخوانیهای احراز هویت نشده » تنظیم کنید.
- جاوا ۱۷ را به عنوان زمان اجرا و ویرایشگر درونخطی را برای کد منبع انتخاب کنید.
- در این مرحله، کد placeholder در ویرایشگر بارگذاری میشود.
کد جایگزین را جایگزین کنید
- نام فایل جاوا را به " ProposalOrdersTool.java " و نام کلاس را به " ProposalOrdersTool " تغییر دهید.
- کد جایگزین موجود در ProposalOrdersTool.java و pom.xml را با کدی از فایلهای مربوطه در پوشه "Cloud Run Function" در این مخزن جایگزین کنید.
- در فایل ProposalOrdersTool.java خط کد زیر را پیدا کنید، مقادیر placeholder را با مقادیر پیکربندی خود جایگزین کنید:
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- روی ایجاد کلیک کنید.
- تابع Cloud Run ایجاد و مستقر خواهد شد.
مرحله مهم:
پس از استقرار، برای اینکه تابع ابری بتواند به نمونه پایگاه داده AlloyDB ما دسترسی پیدا کند، رابط VPC را ایجاد خواهیم کرد.
پس از آماده شدن برای استقرار، باید بتوانید توابع را در کنسول Google Cloud Run Functions مشاهده کنید. تابع تازه ایجاد شده ( check-status ) را جستجو کنید، روی آن کلیک کنید، سپس روی ویرایش و استقرار نسخههای جدید (که با نماد ویرایش (قلم) در بالای کنسول Cloud Run Functions مشخص شده است) کلیک کنید و موارد زیر را تغییر دهید:
- به برگه شبکه بروید:
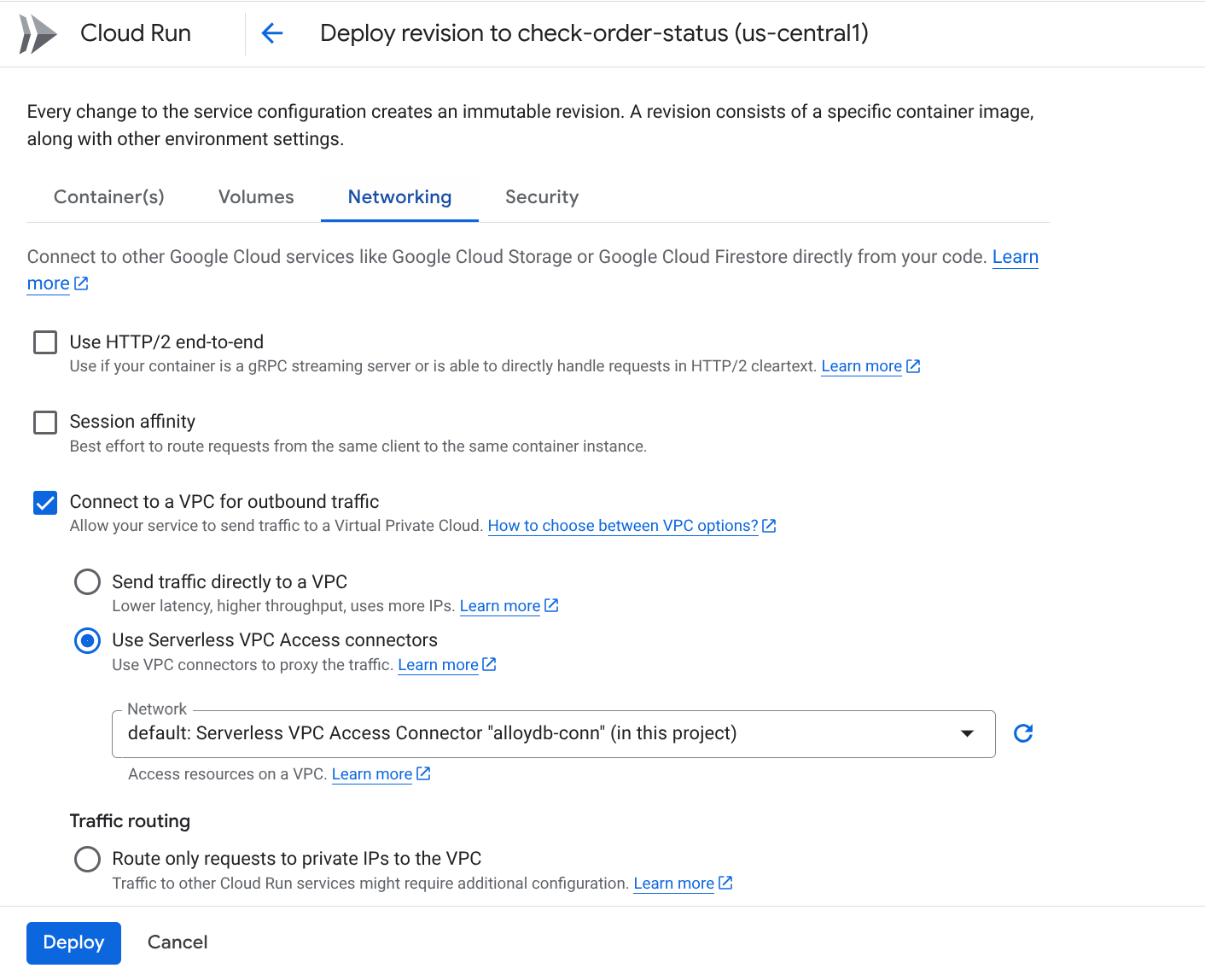
- گزینه « اتصال به یک VPC برای ترافیک خروجی » و سپس « استفاده از کانکتورهای دسترسی VPC بدون سرور » را انتخاب کنید.
- در منوی کشویی Network، تنظیمات، روی منوی کشویی Network کلیک کنید و گزینه " Add New VPC Connector " را انتخاب کنید (اگر قبلاً گزینه پیشفرض را پیکربندی نکردهاید) و دستورالعملهای نمایش داده شده در کادر محاورهای را دنبال کنید:

- یک نام برای رابط VPC انتخاب کنید و مطمئن شوید که منطقه آن با منطقه شما یکسان است. مقدار Network را به صورت پیشفرض رها کنید و Subnet را روی Custom IP Range با محدوده IP 10.8.0.0 یا چیزی مشابه آن که در دسترس است، تنظیم کنید.
- SHOW SCALINING SETTINGS را باز کنید و مطمئن شوید که پیکربندی دقیقاً روی موارد زیر تنظیم شده است:

- روی CREATE کلیک کنید و این کانکتور اکنون باید در تنظیمات خروجی فهرست شده باشد.
- کانکتور تازه ایجاد شده را انتخاب کنید.
- انتخاب کنید که تمام ترافیک از طریق این کانکتور VPC هدایت شود.
- روی NEXT و سپس DEPLOY کلیک کنید.
- پس از استقرار تابع ابری بهروزرسانیشده، باید نقطه پایانی ایجاد شده را مشاهده کنید.
- شما باید بتوانید با کلیک بر روی دکمه TEST در بالای کنسول Cloud Run Functions و اجرای دستور حاصل در ترمینال Cloud Shell، آن را آزمایش کنید.
- نقطه پایانی مستقر شده، URL ای است که باید در متغیر .env به نام
CHECK_ORDER_STATUS_ENDPOINTبهروزرسانی کنید.
۸. تنظیمات مدل
توانایی عامل شما در درک درخواستهای کاربر و تولید پاسخها توسط یک مدل زبان بزرگ (LLM) پشتیبانی میشود. عامل شما باید تماسهای امنی را با این سرویس LLM خارجی برقرار کند که مستلزم اعتبارنامههای احراز هویت است. بدون احراز هویت معتبر، سرویس LLM درخواستهای عامل را رد میکند و عامل قادر به عملکرد نخواهد بود.
- یک کلید API از Google AI Studio دریافت کنید.
- در مرحله بعدی که فایل .env را تنظیم میکنید،
<<your API KEY>>را با مقدار واقعی API KEY خود جایگزین کنید.
۹. تنظیمات متغیرهای ENV
- مقادیر پارامترهای خود را در فایل .env قالب موجود در این مخزن تنظیم کنید. در مورد من، فایل .env این متغیرها را دارد:
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
مقادیر خود را جایگزین متغیرهایی کنید.
۱۰. عامل خود را اجرا کنید
- با استفاده از ترمینال، به دایرکتوری والد پروژه عامل خود بروید:
cd renovation-agent
- نصب تمام وابستگیها
pip install -r requirements.txt
- برای اجرای عامل میتوانید دستور زیر را در ترمینال Cloud Shell خود اجرا کنید:
adk run .
- برای اجرای آن در یک رابط کاربری وبِ ارائه شده توسط ADK، میتوانید دستور زیر را اجرا کنید:
adk web
- با دستور زیر تست کنید:
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
۱۱. نتیجه
@ سیستم چند عاملی برای وظایف نوسازی آشپزخانه

۱۲. استقرار در موتور عامل
حالا که سیستم چندعاملی را به خوبی آزمایش کردهاید، بیایید آن را بدون سرور کنیم و روی فضای ابری در دسترس قرار دهیم تا هر کسی/هر برنامهای بتواند از آن استفاده کند. قطعه کد زیر را در agent.py از مخزن آنها از حالت کامنت خارج کنید و آماده استقرار سیستم چندعاملی خود هستید:
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
دوباره فایل agent.py را از داخل پوشه پروژه با دستور زیر اجرا کنید:
>> cd adk-renovation-agent
>> python agent.py
تکمیل این کد چند دقیقه طول میکشد. پس از اتمام، نقطه پایانی مانند این دریافت خواهید کرد:
'projects/123456789/locations/us-central1/reasoningEngines/123456'
شما میتوانید با اضافه کردن یک فایل جدید به نام " test.py " با استفاده از کد زیر، عامل مستقر شده خود را آزمایش کنید.
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
در کد بالا، مقدار مربوط به عبارت " <<YOUR_DEPLOYED_ENGINE_ID>> " را جایگزین کنید و دستور " python test.py " را اجرا کنید. حال، شما آماده اجرای این دستور برای تعامل با یک سیستم چندعامله که توسط Agent Engine مستقر شده است، هستید و آماده بازسازی آشپزخانه خود هستید!!!
۱۳. گزینههای استقرار تکخطی
حالا که سیستم چندعاملی مستقر شده را آزمایش کردهاید، بیایید روشهای سادهتری را یاد بگیریم که مرحله استقرار را که در مرحله قبل انجام دادیم، خلاصه میکنند: گزینههای استقرار تکخطی:
- برای اجرای ابری:
نحو:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
در این مورد:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
شما میتوانید از نقطه پایانی مستقر شده برای یکپارچهسازیهای پاییندستی استفاده کنید.
- به موتور عامل:
نحو:
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
در این مورد:
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
شما باید یک عامل جدید را در رابط کاربری Agent Engine در کنسول Google Cloud مشاهده کنید. برای جزئیات بیشتر به این وبلاگ مراجعه کنید.
۱۴. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
۱۵. تبریک
تبریک! شما با موفقیت اولین عامل خود را با استفاده از ADK ایجاد و با آن تعامل داشتید!