
1. 概览
智能体是一种自主程序,它会与 AI 模型对话,使用其拥有的工具和上下文执行基于目标的运算,并且能够根据事实做出自主决策!
如果您的应用有多个智能体,这些智能体可以自主协作,也可以根据需要共同协作,以实现更大的目标,并且每个智能体都具备独立的知识,负责特定的专注领域,那么您的应用就成为了多智能体系统。
智能体开发套件 (ADK)
智能体开发套件 (ADK) 是一个灵活的模块化框架,用于开发和部署 AI 智能体。ADK 支持通过将多个不同的智能体实例组合成多智能体系统 (MAS) 来构建复杂的应用。
在 ADK 中,多智能体系统是指一个应用,其中不同的智能体(通常形成层次结构)通过协作或协调来实现更大的目标。以这种方式构建应用具有显著优势,包括增强的模块化、专业化、可重用性、可维护性,以及使用专用工作流代理定义结构化控制流的能力。
多智能体系统的注意事项
首先,务必要正确理解和推理每个智能体的专业领域。- “do you know why you need a specific sub-agent for something”,先解决这个问题。
其次,如何将它们与根代理结合起来,以路由和理解每个回答。
第三,您可以在本文档中找到多种类型的客服人员转接。请确保选择适合您应用流程的方案。此外,还需要考虑多智能体系统的流控制所需的各种上下文和状态。
构建内容
我们来构建一个多智能体系统来处理厨房翻新事宜。这就是我们要做的。我们将构建一个包含 3 个代理的系统。
- 装修方案智能体
- 许可和合规性检查代理
- 订单状态检查代理
装修提案代理,用于生成厨房装修提案文档。
许可和合规性代理,负责处理许可和合规性相关任务。
订单状态检查代理,用于通过处理我们在 AlloyDB 中设置的订单管理数据库来检查物料的订单状态。
我们将有一个根代理,用于根据要求协调这些代理。
要求
2. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
如果您正在阅读本文,并且希望获得一些赠金来帮助您开始使用 Google Cloud 和 ADK,请点击此链接兑换赠金。您可以按照此处的说明兑换。请注意,此链接仅在 5 月底之前有效,可用于兑换。
- 点击此链接,激活 Cloud Shell。您可以在 Cloud Shell 中点击相应按钮,在 Cloud Shell 终端(用于运行云命令)和编辑器(用于构建项目)之间切换。
- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 请确保安装了 Python 3.9 或更高版本
- 运行以下命令以启用以下 API:
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- 如需了解 gcloud 命令和用法,请参阅文档。
3. 原型
如果您决定为项目选择“Gemini 2.5 Pro”模型,则可以跳过此步骤。
前往 Google AI Studio。开始输入提示。我的提示是:
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
调整和配置右侧的参数,以获得最佳回答。
根据这个简单的描述,Gemini 为我生成了一个非常详细的提示,让我可以开始装修了!实际上,我们是使用 Gemini 来让 AI Studio 和我们的模型提供更出色的回答。您还可以根据自己的使用场景选择不同的模型。
我们选择了 Gemini 2.5 Pro。这是一个思考模型,这意味着我们可以获得更多输出令牌,在本例中最多可获得 65,000 个令牌,用于生成长篇分析和详细文档。当您启用 Gemini 2.5 Pro 时,系统会显示 Gemini 思考框,该模型具有原生推理能力,可以处理长上下文请求。
请参阅下方的响应代码段:

AI Studio 分析了我的数据,并生成了橱柜、台面、防溅挡板、地板、水槽、凝聚力、调色板和材料选择等所有这些内容。Gemini 甚至还会注明信息来源!
冲洗并重复此过程,选择不同的模型,直到您对结果感到满意为止。不过,我想说,既然有 Gemini 2.5,何必费尽心思呢 :)
无论如何,现在尝试使用不同的提示,看看这个想法能否实现:
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
附上您当前厨房(或任何厨房示例图片)的图片链接。将模型更改为“Gemini 2.0 Flash 预览版图片生成”,以便您能够生成图片。
我获得了以下输出:

这就是 Gemini 的强大之处!
从理解视频、原生生成图片,到通过 Google 搜索获取真实信息,只有 Gemini 强力赋能才能实现这些功能。
在 AI Studio 中,您可以获取此原型、获取 API 密钥,并借助 Vertex AI ADK 的强大功能将其扩展为完整的代理应用。
4. ADK 设置
- 创建并激活虚拟环境(推荐)
在 Cloud Shell 终端中,创建虚拟环境:
python -m venv .venv
激活虚拟环境:
source .venv/bin/activate
- 安装 ADK
pip install google-adk
5. 项目结构
- 在 Cloud Shell 终端中,在所需项目位置创建一个目录
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- 前往 Cloud Shell 编辑器,然后创建以下项目结构(先创建空文件):
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
6. 源代码
- 前往“init.py”,并更新为以下内容:
from . import agent
- 前往 agent.py,然后使用以下路径中的以下内容更新该文件:
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
在 agent.py 中,我们导入必要的依赖项,从 .env 文件中检索配置参数,并定义 root_agent,该 root_agent 用于编排我们在此应用中创建的 3 个子代理。有多种工具可帮助实现这些子代理的核心功能和支持功能。
- 确保您拥有 Cloud Storage 存储分区
用于存储代理生成的提案文档。创建该服务账号并授予访问权限,以便使用 Vertex AI 创建的多智能体系统可以访问该服务账号。具体方法如下:
https://cloud.google.com/storage/docs/creating-buckets#console
将存储分区命名为“next-demo-store”。如果您将其命名为其他名称,请务必更新 .env 文件(在“设置环境变量”步骤中)中 STORAGE_BUCKET 的值。
- 如需设置对存储分区的访问权限,请前往 Cloud Storage 控制台,然后前往您的存储分区(在本例中,存储分区名称为“next-demo-storage”:https://console.cloud.google.com/storage/browser/next-demo-storage)。
依次前往“权限”>“查看正文”>“授予访问权限”。选择“allUsers”作为正文,“Storage Object User”作为角色。
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- 创建依赖项列表
在 requirements.txt 中列出所有依赖项。您可以从 repo 中复制此内容。
多智能体系统源代码说明
agent.py 文件使用智能体开发套件 (ADK) 定义了厨房改造多智能体系统的结构和行为。下面我们来详细了解一下关键组件:
代理定义
RenovationProposalAgent
此代理负责创建厨房改造方案文档。它还可以选择性地接受输入参数,例如厨房大小、所需风格、预算和客户偏好。根据这些信息,它会使用大语言模型 (LLM) Gemini 2.5 生成详细的提案。然后,生成的提案会存储在 Google Cloud Storage 存储分区中。
PermitsAndComplianceCheckAgent
此代理专注于确保装修项目符合当地的建筑规范和法规。它会接收有关拟建装修工程的信息(例如结构变更、电气工程、管道改造),并使用 LLM 检查许可要求和合规性规则。智能体使用知识库中的信息(您可以自定义该知识库以访问外部 API 来收集相关法规)。
OrderingAgent
此代理(如果您现在不想实现,可以将其注释掉)负责检查装修所需材料和设备的订单状态。如需启用此功能,您需要按照设置步骤中的说明创建 Cloud Run 函数。然后,代理会调用此 Cloud Run 函数,该函数会与包含订单信息的 AlloyDB 数据库进行交互。这展示了与数据库系统的集成,以跟踪实时数据。
根代理(编排系统)
root_agent 充当多智能体系统的中央编排程序。它接收初始装修请求,并根据请求的需求确定要调用哪些子代理。例如,如果请求需要检查许可要求,则会调用 PermitsAndComplianceCheckAgent。如果用户想查看订单状态,系统会调用 OrderingAgent(如果已启用)。
然后,根代理会收集子代理的回答,并将它们合并起来,为用户提供全面的回答。这可能包括总结提案、列出所需许可,以及提供订单状态更新。
数据流和关键概念
用户通过 ADK 界面(终端或 Web 界面)发起请求。
- 根代理收到请求。
- root_agent 会分析请求并将其路由到相应的子代理。
- 子代理使用 LLM、知识库、API 和数据库来处理请求并生成回答。
- 分代理将其响应返回给 root_agent。
- 根代理会合并响应,并向用户提供最终输出。
LLM(大语言模型)
智能体在生成文本、回答问题和执行推理任务时,很大程度上依赖于 LLM。LLM 是智能体能够理解和响应用户请求的“大脑”。我们在此应用中使用的是 Gemini 2.5。
Google Cloud Storage
用于存储生成的装修方案文档。您需要创建一个存储分区,并授予代理访问该存储分区所需的权限。
Cloud Run(可选)
OrderingAgent 使用 Cloud Run function 与 AlloyDB 进行交互。Cloud Run 提供了一个无服务器环境,用于执行代码以响应 HTTP 请求。
AlloyDB
如果您使用的是 OrderingAgent,则需要设置 AlloyDB 数据库来存储订单信息。我们将在下一部分“数据库设置”中详细介绍它。
.env 文件
.env 文件用于存储 API 密钥、数据库凭据和存储分区名称等敏感信息。请务必确保此文件的安全性,并且不要将其提交到代码库中。它还存储代理和 Google Cloud 云项目的配置设置。root_agent 或支持函数通常会从此文件中读取值。确保在 .env 文件中正确设置了所有必需的变量。包括 Cloud Storage 存储分区名称
7. 数据库设置
在 ordering_agent 使用的某个名为“check_status”的工具中,我们访问 AlloyDB 订单数据库以获取订单状态。在本部分中,我们将设置 AlloyDB 数据库集群和实例。
创建集群和实例
- 在 Cloud 控制台中浏览 AlloyDB 页面。在 Cloud 控制台中查找大多数页面的简单方法是使用控制台的搜索栏进行搜索。
- 在该页面中选择创建集群:

- 您会看到如下所示的界面。使用以下值创建 集群和实例(如果您要从代码库克隆应用代码,请确保这些值匹配):
- 集群 ID:“
vector-cluster” - 密码:“
alloydb” - PostgreSQL 15 / 最新推荐版本
- 区域:“
us-central1” - 网络:“
default”

- 选择默认网络后,您会看到如下所示的界面。
选择设置连接。
- 然后,选择“使用自动分配的 IP 范围”,然后点击“继续”。查看信息后,选择“创建连接”。

- 设置好网络后,您可以继续创建集群。点击创建集群以完成集群设置,如下所示:

请务必将实例 ID(可在配置集群 / 实例时找到)更改为
vector-instance。如果您无法更改,请务必在所有后续引用中使用您的实例 ID。
请注意,创建集群大约需要 10 分钟。成功后,您应该会看到一个屏幕,其中显示了您刚刚创建的集群的概览。
数据注入
现在,我们来添加一个包含商店相关数据的表格。前往 AlloyDB,选择主集群,然后选择 AlloyDB Studio:

您可能需要等待实例完成创建。完成后,使用您在创建集群时创建的凭据登录 AlloyDB。使用以下数据向 PostgreSQL 进行身份验证:
- 用户名:“
postgres” - 数据库:“
postgres” - 密码:“
alloydb”
成功通过身份验证进入 AlloyDB Studio 后,您可以在编辑器中输入 SQL 命令。您可以使用最后一个窗口右侧的加号添加多个编辑器窗口。

您将在编辑器窗口中输入 AlloyDB 命令,并根据需要使用“运行”“格式”和“清除”选项。
创建表
您可以在 AlloyDB Studio 中使用以下 DDL 语句创建表:
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
插入记录
将上述 database_script.sql 脚本中的 insert 查询语句复制到编辑器中。
点击运行。
现在,数据集已准备就绪,接下来我们创建一个 Java Cloud Run Functions 应用来提取状态。
创建 Java Cloud Run 函数以提取订单状态信息
- 点击以下链接创建 Cloud Run 函数:https://console.cloud.google.com/run/create?deploymentType=function
- 将函数名称设置为“check-status”,并选择“Java 17”作为运行时。
- 由于这是一个演示应用,您可以将身份验证设置为“Allow unauthenticated invocations”(允许未通过身份验证的调用)。
- 选择 Java 17 作为运行时,并选择“内嵌编辑器”作为源代码。
- 此时,占位代码将加载到编辑器中。
替换占位符代码
- 将 Java 文件的名称更改为“ProposalOrdersTool.java”,并将类名称更改为“ProposalOrdersTool”。
- 将 ProposalOrdersTool.java 和 pom.xml 中的占位代码替换为此代码库中“Cloud Run Function”文件夹内的相应文件中的代码。
- 在 ProposalOrdersTool.java 中找到以下代码行,将占位值替换为配置中的值:
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- 点击“创建”。
- 系统将创建并部署 Cloud Run 函数。
重要步骤:
部署完成后,为了允许 Cloud Function 访问 AlloyDB 数据库实例,我们将创建 VPC 连接器。
开始部署后,您应该可以在 Google Cloud Run Functions 控制台中看到这些函数。搜索新创建的函数 (check-status),点击该函数,然后点击 EDIT AND DEPLOY NEW REVISIONS(Cloud Run Functions 控制台顶部带有“修改”图标 [笔]),并更改以下内容:
- 前往“网络”标签页:
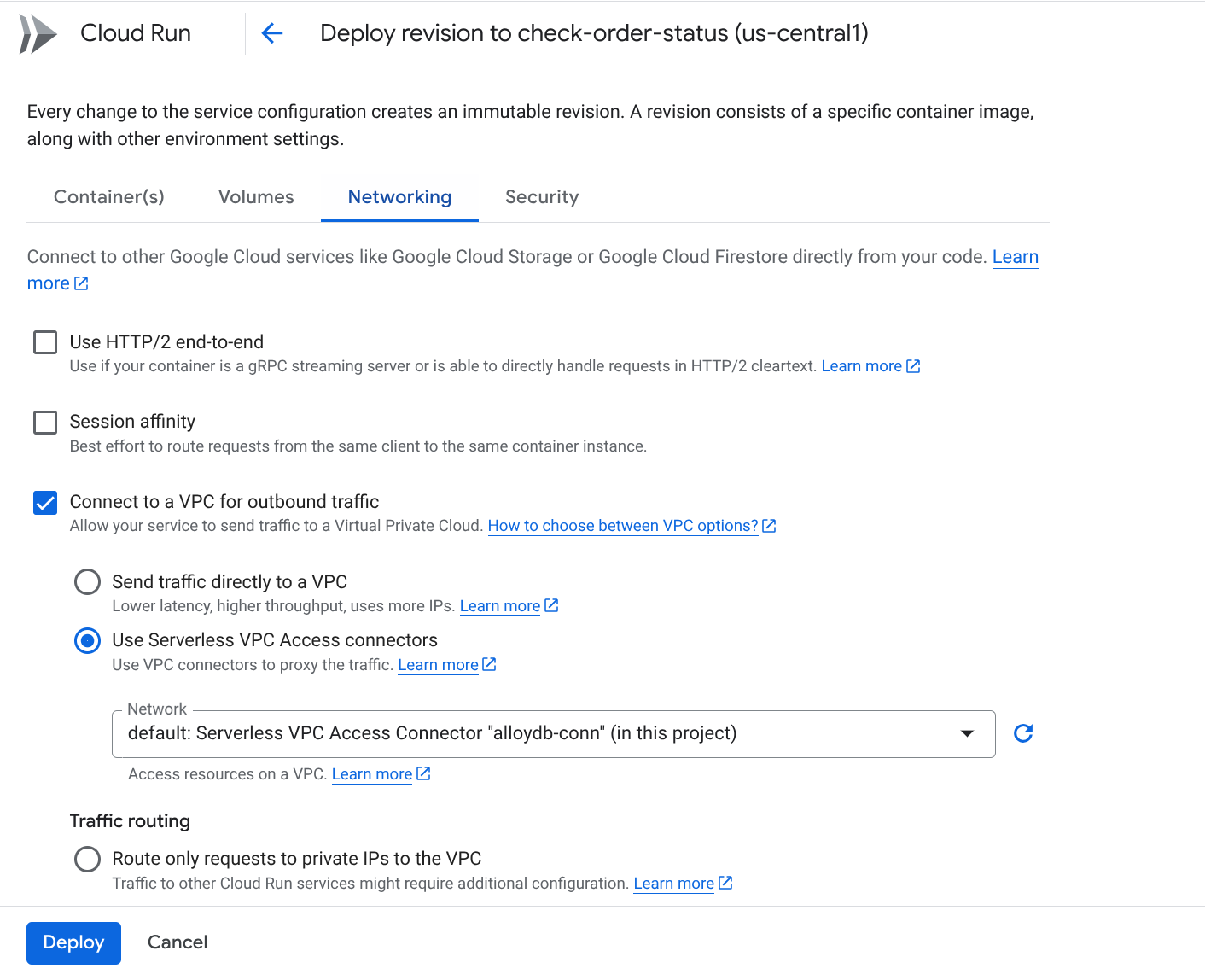
- 选择“连接到 VPC 以获取出站流量”,然后选择“使用无服务器 VPC 访问通道连接器”
- 在“网络”下拉菜单下,点击“网络”下拉菜单,然后选择“添加新的 VPC 连接器”选项(如果您尚未配置默认连接器),并按照随即显示的对话框中的说明操作:

- 为 VPC 连接器提供一个名称,并确保该区域与您的实例相同。将“网络”值保留为默认值,并将“子网”设置为“自定义 IP 范围”,IP 范围为 10.8.0.0 或类似的可用范围。
- 展开“显示缩放设置”,并确保您的配置完全符合以下要求:

- 点击 CREATE,此连接器现在应会列在出站流量设置中。
- 选择新创建的连接器。
- 选择通过此 VPC 连接器路由所有流量。
- 点击下一步,然后点击部署。
- 部署更新后的 Cloud Functions 函数后,您应该会看到生成的端点。
- 您应该可以通过以下方式测试该函数:点击 Cloud Run Functions 控制台顶部的“测试”按钮,然后在 Cloud Shell 终端中执行生成的命令。
- 部署的端点是您需要在 .env 变量
CHECK_ORDER_STATUS_ENDPOINT中更新的网址。
8. 模型设置
智能体理解用户请求和生成回答的能力由大语言模型 (LLM) 提供支持。您的代理需要安全地调用此外部 LLM 服务,这需要身份验证凭据。如果没有有效的身份验证,LLM 服务会拒绝代理的请求,并且代理将无法正常运行。
- 从 Google AI Studio 获取 API 密钥。
- 在下一步中,您将设置 .env 文件,请将
<<your API KEY>>替换为您的实际 API 密钥值。
9. 环境变量设置
- 在此代码库中,为模板 .env 文件中的参数设置值。在我的示例中,.env 包含以下变量:
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
将占位符替换为您的值。
10. 运行代理
- 使用终端,前往智能体项目的父级目录:
cd renovation-agent
- 安装所有依赖项
pip install -r requirements.txt
- 您可以在 Cloud Shell 终端中运行以下命令来执行代理:
adk run .
- 您可以运行以下命令,在 ADK 配置的 Web 界面中运行该应用:
adk web
- 使用以下提示进行测试:
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
11. 结果

12. 部署到 Agent Engine
既然您已测试过该多智能体系统,确认其运行正常,接下来我们将其设为无服务器,并使其可在云端使用,以便任何人 / 任何应用都能使用它。取消注释该代码库中 agent.py 中的以下代码段,然后即可部署多智能体系统:
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
使用以下命令再次从项目文件夹中执行 agent.py:
>> cd adk-renovation-agent
>> python agent.py
此代码需要几分钟才能完成。完成后,您将收到一个如下所示的端点:
'projects/123456789/locations/us-central1/reasoningEngines/123456'
您可以通过添加新文件“test.py”,使用以下代码测试已部署的代理
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
在上述代码中,替换占位符“<<YOUR_DEPLOYED_ENGINE_ID>>”的值,然后运行命令“python test.py”,这样您就可以执行此命令来与已部署 Agent Engine 的多代理系统进行交互,并开始装修厨房了!
13. 单行部署选项
现在,您已经测试了已部署的多智能体系统,接下来让我们学习更简单的方法,这些方法可以抽象化我们在上一步中执行的部署步骤:单行部署选项:
- 到 Cloud Run:
语法:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
在此示例中:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
您可以将已部署的端点用于下游集成。
- 对于 Agent Engine:
语法:
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
在此示例中:
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
您应该会在 Google Cloud 控制台内的 Agent Engine 界面中看到新代理。如需了解详情,请参阅这篇博文。
14. 清理
为避免系统因本博文中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作:
- 在 Google Cloud 控制台中,前往管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关停以删除项目。
15. 恭喜
恭喜!您已使用 ADK 成功创建并与您的第一个智能体进行了互动!