
1. 概要
エージェントは、AI モデルと対話して、エージェントが持つツールとコンテキストを使用して目標ベースの操作を実行する自律型プログラムです。真実に基づいた自律的な意思決定を行うことができます。
アプリケーションに複数のエージェントがあり、それぞれが特定の重点分野について独立して知識を持ち、責任を負い、必要に応じて自律的に連携して、より大きな目的を達成する場合、そのアプリケーションはマルチエージェント システムになります。
Agent Development Kit(ADK)
Agent Development Kit(ADK)は、AI エージェントの開発とデプロイ用に設計された、柔軟性の高いモジュラー フレームワークです。ADK は、複数の個別のエージェント インスタンスをマルチエージェント システム(MAS)に構成して、高度なアプリケーションを構築することをサポートしています。
ADK では、マルチエージェント システムは、多くの場合階層を形成するさまざまなエージェントが連携または調整して、より大きな目標を達成するアプリケーションです。このようにアプリケーションを構造化すると、モジュール性、専門性、再利用性、保守性の向上や、専用のワークフロー エージェントを使用した構造化された制御フローの定義など、大きなメリットが得られます。
マルチエージェント システムの注意点
まず、各エージェントの専門分野を正しく理解し、その推論を把握することが重要です。- 「特定のサブエージェントが必要な理由を知っていますか?」、まずそれを解決します。
2 つ目は、ルート エージェントと統合して、各レスポンスをルーティングして理解する方法です。
3 つ目に、エージェントのルーティングには複数のタイプがあり、このドキュメントで確認できます。アプリケーションのフローに適した方を選択してください。また、マルチエージェント システムのフロー制御に必要なさまざまなコンテキストと状態も確認します。
作成するアプリの概要
キッチンのリフォームを処理するマルチエージェント システムを構築しましょう。そこで、3 つのエージェントでシステムを構築します。
- リフォーム提案エージェント
- Permits and Compliance Check Agent
- Order Status Check Agent(注文ステータス確認エージェント)
キッチン リフォームの提案書を生成するリフォーム提案エージェント。
Permits and Compliance Agent(許可とコンプライアンス エージェント): 許可とコンプライアンスに関連するタスクを処理します。
Order Status Check Agent: AlloyDB に設定した注文管理データベースで、マテリアルの注文ステータスを確認します。
要件に基づいてこれらのエージェントをオーケストレートするルート エージェントがあります。
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
また、Google Cloud の利用を開始して ADK を使用する際に役立つクレジットをご希望の場合は、こちらのリンクからクレジットをご利用ください。特典を利用するには、こちらの手順に沿って操作してください。このリンクは 5 月末まで有効です。
- このリンクをクリックして、Cloud Shell をアクティブにします。Cloud Shell の対応するボタンをクリックすると、Cloud Shell ターミナル(クラウド コマンドの実行用)とエディタ(プロジェクトのビルド用)を切り替えることができます。
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- Python 3.9 以降がインストールされていることを確認する
- 次のコマンドを実行して、次の API を有効にします。
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. プロトタイプ
プロジェクトに「Gemini 2.5 Pro」モデルを使用する場合は、この手順をスキップできます。
Google AI Studio に移動します。プロンプトの入力を開始します。次のプロンプトを入力してみます。
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
右側のパラメータを調整して構成し、最適なレスポンスを得ます。
この簡単な説明に基づいて、Gemini がリフォームを開始するための非常に詳細なプロンプトを作成してくれました。つまり、Gemini を使用して、AI Studio とモデルからさらに優れた回答を得ています。ユースケースに基づいて、使用するモデルを選択することもできます。
Gemini 2.5 Pro を選択しました。これは思考モデルであるため、長文の分析や詳細なドキュメントの場合、出力トークンがさらに多くなります(この場合は最大 65,000 トークン)。Gemini の思考ボックスは、ネイティブの推論機能を備え、長いコンテキスト リクエストを受け取ることができる Gemini 2.5 Pro を有効にすると表示されます。
レスポンスのスニペットを以下に示します。
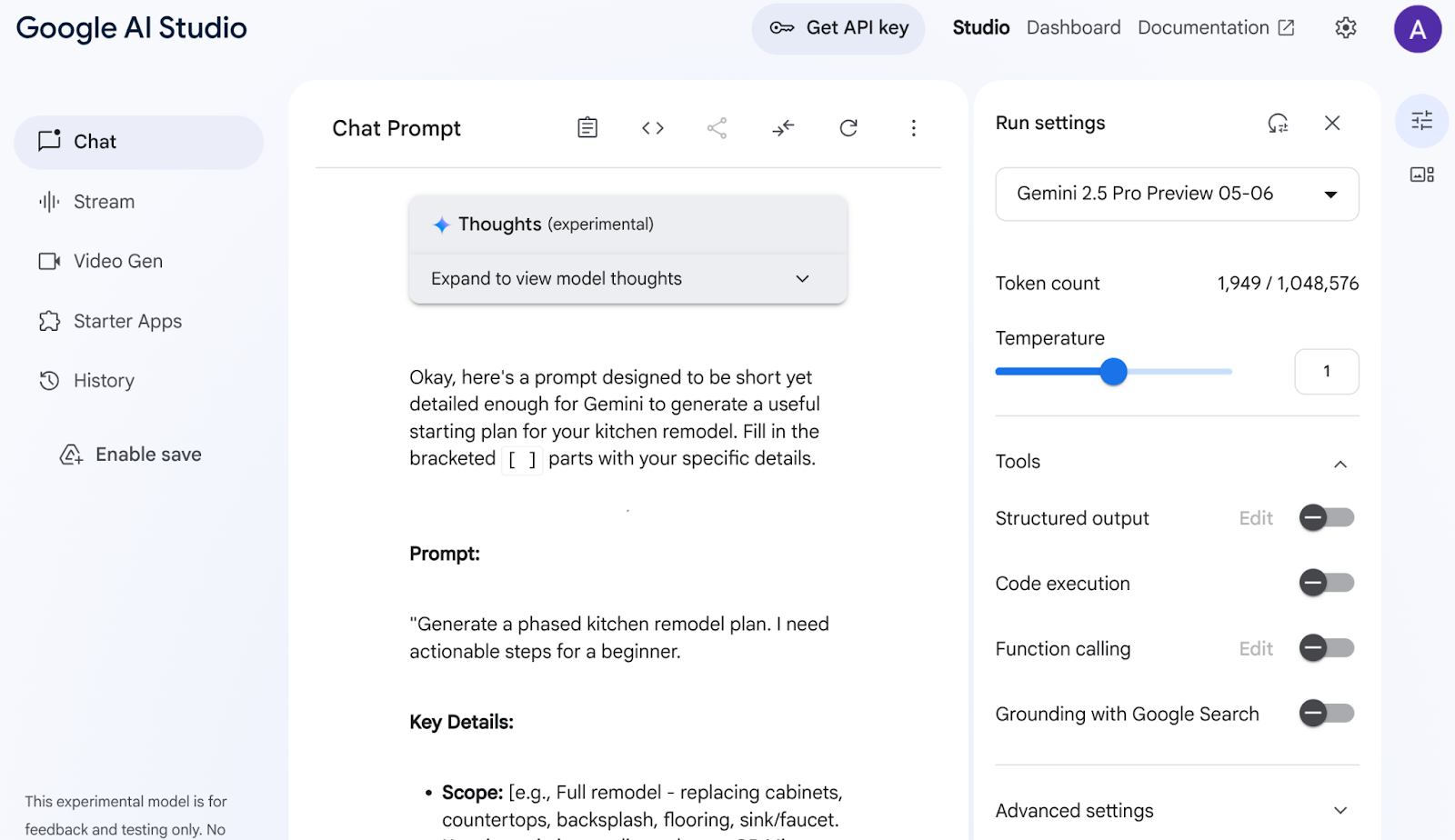
AI Studio はデータを分析し、キャビネット、カウンタートップ、バックスプラッシュ、床材、シンク、まとまり、カラーパレット、素材の選択など、さまざまなものを生成しました。Gemini は情報源も引用しています。
結果に満足するまで、さまざまなモデルを選択してこの手順を繰り返します。ただし、Gemini 2.5 があるのに、なぜそんなことをする必要があるのでしょうか。
それでは、別のプロンプトでアイデアが実現する様子を見てみましょう。
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
現在のキッチンの画像(またはキッチンのサンプル画像)へのリンクを添付します。モデルを「Gemini 2.0 Flash Preview Image Generation」に変更して、画像生成にアクセスできるようにします。
次のような出力が得られました。

これが Gemini の力です。
動画の理解、ネイティブな画像生成、Google 検索による実際の情報へのグラウンディングなどは Gemini でしか構築できないものです。
AI Studio でこのプロトタイプを作成し、API キーを取得して、Vertex AI ADK の機能を使用して完全なエージェント アプリケーションにスケーリングできます。
4. ADK のセットアップ
- 仮想環境を作成して有効にする(推奨)
Cloud Shell ターミナルで、仮想環境を作成します。
python -m venv .venv
仮想環境をアクティブにします。
source .venv/bin/activate
- ADK をインストールする
pip install google-adk
5. プロジェクト構造
- Cloud Shell のターミナルで、目的のプロジェクトの場所にディレクトリを作成します。
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- Cloud Shell エディタに移動し、ファイルを作成して次のプロジェクト構造を作成します(最初は空のファイルを作成します)。
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
6. ソースコード
- [init.py] に移動し、次の内容で更新します。
from . import agent
- agent.py に移動し、次のパスから次の内容でファイルを更新します。
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
agent.py では、必要な依存関係をインポートし、.env ファイルから構成パラメータを取得して、このアプリケーションで作成する 3 つのサブエージェントをオーケストレートする root_agent を定義します。これらのサブエージェントのコア機能とサポート機能を支援するツールがいくつかあります。
- Cloud Storage バケットがあることを確認する
これは、エージェントが生成する提案書を保存するためのものです。作成してアクセス権を付与し、Vertex AI で作成されたマルチエージェント システムがアクセスできるようにします。手順は次のとおりです。
https://cloud.google.com/storage/docs/creating-buckets#console
バケットに「next-demo-store」という名前を付けます。別の名前を付ける場合は、.env ファイル(環境変数の設定ステップ)で STORAGE_BUCKET の値を更新してください。
- バケットへのアクセスを設定するには、Cloud Storage のコンソールに移動し、ストレージ バケットに移動します(この例ではバケット名は「next-demo-storage」です。https://console.cloud.google.com/storage/browser/next-demo-storage)。
[権限] -> [プリンシパルを表示] -> [アクセスを許可] に移動します。プリンシパルに「allUsers」、ロールに「Storage オブジェクト ユーザー」を選択します。
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- 依存関係リストを作成する
requirements.txt にすべての依存関係をリストします。これは repo からコピーできます。
マルチエージェント システムのソースコードの説明
agent.py ファイルは、Agent Development Kit(ADK)を使用して、キッチン リフォームのマルチエージェント システムの構造と動作を定義します。主なコンポーネントを詳しく見ていきましょう。
エージェントの定義
RenovationProposalAgent
このエージェントは、キッチンのリフォーム提案書を作成する役割を担います。キッチン サイズ、希望するスタイル、予算、お客様の好みなどの入力パラメータをオプションで受け取ります。この情報に基づいて、大規模言語モデル(LLM)Gemini 2.5 を使用して詳細な提案を生成します。生成されたプロポーザルは、Google Cloud Storage バケットに保存されます。
PermitsAndComplianceCheckAgent
このエージェントは、改修プロジェクトが地域の建築基準法と規制に準拠していることを確認します。提案された改修(構造変更、電気工事、配管の変更など)に関する情報を受け取り、LLM を使用して許可要件とコンプライアンス ルールを確認します。エージェントは、ナレッジベースの情報を使用します(関連する規制を収集するために外部 API にアクセスするようにカスタマイズできます)。
OrderingAgent
このエージェントは、リフォームに必要な材料や設備の注文ステータスの確認を処理します(今すぐ実装しない場合はコメントアウトできます)。有効にするには、設定手順で説明されているように、Cloud Run 関数を作成する必要があります。エージェントは、この Cloud Run 関数を呼び出します。この関数は、注文情報を含む AlloyDB データベースとやり取りします。これは、リアルタイム データを追跡するためのデータベース システムとの統合を示しています。
ルート エージェント(オーケストレーター)
root_agent は、マルチエージェント システムの中心的なオーケストレーターとして機能します。最初のリフォーム リクエストを受け取り、リクエストのニーズに基づいて呼び出すサブエージェントを決定します。たとえば、リクエストで許可要件の確認が必要な場合は、PermitsAndComplianceCheckAgent が呼び出されます。お客様が注文ステータスの確認を希望すると、OrderingAgent が呼び出されます(有効になっている場合)。
ルートエージェントはサブエージェントからの回答を収集し、それらを組み合わせてユーザーに包括的な回答を提供します。これには、プロポーザルの要約、必要な許可証のリスティング、注文ステータスの更新などが含まれます。
データフローと主なコンセプト
ユーザーが ADK インターフェース(端末またはウェブ UI)からリクエストを開始します。
- リクエストは root_agent によって受信されます。
- root_agent はリクエストを分析し、適切なサブエージェントにルーティングします。
- サブエージェントは、LLM、ナレッジベース、API、データベースを使用してリクエストを処理し、レスポンスを生成します。
- サブエージェントは root_agent にレスポンスを返します。
- root_agent はレスポンスを組み合わせて、ユーザーに最終的な出力を提供します。
LLM(大規模言語モデル)
エージェントは、テキストの生成、質問への回答、推論タスクの実行を LLM に大きく依存しています。LLM は、エージェントがユーザーのリクエストを理解して応答する能力の背後にある「頭脳」です。このアプリケーションでは Gemini 2.5 を使用しています。
Google Cloud Storage
生成されたリフォーム提案書を保存するために使用されます。バケットを作成し、エージェントがアクセスするために必要な権限を付与する必要があります。
Cloud Run(省略可)
OrderingAgent は、Cloud Run 関数を使用して AlloyDB とのインターフェースをとります。Cloud Run は、HTTP リクエストに応答してコードを実行するサーバーレス環境を提供します。
AlloyDB
OrderingAgent を使用している場合は、注文情報を保存するように AlloyDB データベースを設定する必要があります。詳細については、次のセクション「データベースの設定」で説明します。
.env ファイル
.env ファイルには、API キー、データベース認証情報、バケット名などの機密情報が保存されます。このファイルは安全に保管し、リポジトリに commit しないことが重要です。また、エージェントと Google Cloud プロジェクトの構成設定も保存します。通常、root_agent またはサポート関数はこのファイルから値を読み取ります。.env ファイルで必要な変数がすべて正しく設定されていることを確認します。これには、Cloud Storage バケット名が含まれます。
7. データベースの設定
ordering_agent で使用されるツールの 1 つである「check_status」では、AlloyDB 注文データベースにアクセスして注文のステータスを取得します。このセクションでは、AlloyDB データベース クラスタとインスタンスを設定します。
クラスタとインスタンスを作成する
- Cloud コンソールの AlloyDB ページに移動します。Cloud コンソールでほとんどのページを簡単に見つけるには、コンソールの検索バーを使用して検索します。
- このページで [クラスタを作成] を選択します。

- 次のような画面が表示されます。次の値を使用してクラスタとインスタンスを作成します(リポジトリからアプリケーション コードを複製する場合は、値が一致していることを確認してください)。
- クラスタ ID: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / 最新の推奨バージョン
- Region: "
us-central1" - Networking: "
default"
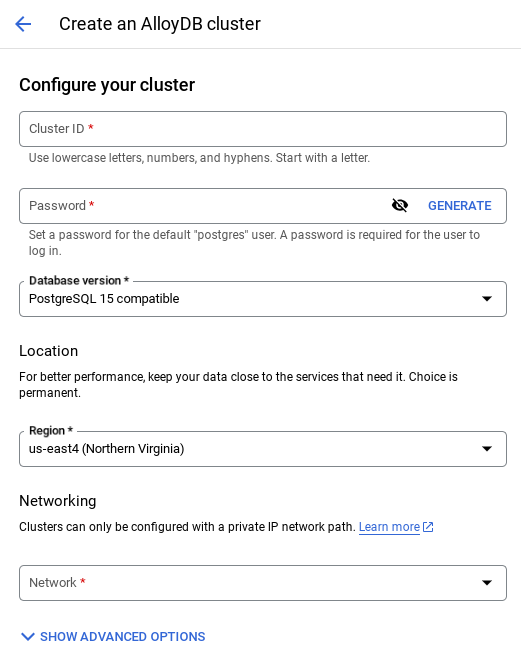
- デフォルト ネットワークを選択すると、次のような画面が表示されます。
[接続の設定] を選択します。
- [自動的に割り当てられた IP 範囲を使用する] を選択して、[続行] をクリックします。情報を確認したら、[接続を作成] を選択します。

- ネットワークを設定したら、クラスタの作成を続行できます。[CREATE CLUSTER] をクリックして、次のようにクラスタの設定を完了します。

インスタンス ID を必ず変更してください(クラスタ / インスタンスの構成時に確認できます)。
vector-instance。変更できない場合は、以降のすべての参照でインスタンス ID を使用してください。
クラスタの作成には 10 分ほどかかります。成功すると、作成したクラスタの概要を示す画面が表示されます。
データの取り込み
次に、店舗に関するデータを含むテーブルを追加します。AlloyDB に移動し、プライマリ クラスタと AlloyDB Studio を選択します。

インスタンスの作成が完了するまで待つ必要がある場合があります。完了したら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。PostgreSQL の認証には次のデータを使用します。
- ユーザー名: 「
postgres」 - データベース: 「
postgres」 - パスワード: 「
alloydb」
AlloyDB Studio への認証が成功すると、エディタに SQL コマンドが入力されます。最後のウィンドウの右にあるプラス記号を使用して、複数のエディタ ウィンドウを追加できます。

必要に応じて [実行]、[形式]、[クリア] オプションを使用して、エディタ ウィンドウに AlloyDB のコマンドを入力します。
テーブルを作成する
AlloyDB Studio で次の DDL ステートメントを使用してテーブルを作成できます。
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
レコードを挿入する
上記の database_script.sql スクリプトから insert クエリ ステートメントをエディタにコピーします。
[実行] をクリックします。
データセットの準備ができたので、ステータスを抽出する Java Cloud Run Functions アプリケーションを作成しましょう。
Java で Cloud Run functions の関数を作成して注文ステータス情報を抽出する
- Cloud Run 関数は、https://console.cloud.google.com/run/create?deploymentType=function から作成します。
- 関数名を「check-status」に設定し、ランタイムとして「Java 17」を選択します。
- これはデモ アプリケーションであるため、認証を [未認証の呼び出しを許可] に設定できます。
- ランタイムとして [Java 17] を選択し、ソースコードとして [インライン エディタ] を選択します。
- この時点で、プレースホルダ コードがエディタに読み込まれます。
プレースホルダ コードを置き換える
- Java ファイルの名前を「ProposalOrdersTool.java」に、クラス名を「ProposalOrdersTool」に変更します。
- ProposalOrdersTool.java と pom.xml のプレースホルダ コードを、この リポジトリの「Cloud Run Function」フォルダにあるそれぞれのファイルのコードに置き換えます。
- ProposalOrdersTool.java で次のコード行を見つけ、プレースホルダ値を構成の値に置き換えます。
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- [作成] をクリックします。
- Cloud Run 関数が作成され、デプロイされます。
重要な手順:
デプロイが完了したら、Cloud Functions が AlloyDB データベース インスタンスにアクセスできるように、VPC コネクタを作成します。
デプロイを開始すると、Google Cloud Run Functions コンソールに関数が表示されます。新しく作成した関数(check-status)を検索してクリックし、[新しいリビジョンの編集とデプロイ](Cloud Run Functions コンソールの最上部にある編集アイコン(ペン)で識別)をクリックして、次のように変更します。
- [ネットワーキング] タブに移動します。

- [アウトバウンド トラフィック用の VPC に接続する] を選択し、[サーバーレス VPC アクセス コネクタを使用する] を選択します。
- [ネットワーク] プルダウンで、[ネットワーク] プルダウンをクリックして [新しい VPC コネクタを追加] オプションを選択し(デフォルトのコネクタをまだ構成していない場合)、表示されるダイアログ ボックスの手順に沿って操作します。

- VPC コネクタの名前を指定し、リージョンがインスタンスと同じであることを確認します。[ネットワーク] の値はデフォルトのままにし、[サブネット] を [カスタム IP 範囲] に設定して、使用可能な IP 範囲(10.8.0.0 など)を指定します。
- [SHOW SCALING SETTINGS] を展開し、構成が次のとおりに設定されていることを確認します。

- [作成] をクリックすると、このコネクタが下り(外向き)設定に表示されます。
- 新しく作成したコネクタを選択します。
- すべてのトラフィックがこの VPC コネクタ経由でルーティングされるようにします。
- [次へ]、[デプロイ] の順にクリックします。
- 更新された Cloud Functions の関数がデプロイされると、エンドポイントが生成されます。
- Cloud Run Functions コンソールの上部にある [テスト] ボタンをクリックし、Cloud Shell ターミナルで結果のコマンドを実行してテストできます。
- デプロイされたエンドポイントは、.env 変数
CHECK_ORDER_STATUS_ENDPOINTで更新する必要がある URL です。
8. モデルの設定
エージェントがユーザー リクエストを理解してレスポンスを生成する機能は、大規模言語モデル(LLM)によって実現されています。エージェントは、この外部 LLM サービスに安全な呼び出しを行う必要があります。これには認証情報が必要です。有効な認証がないと、LLM サービスはエージェントのリクエストを拒否し、エージェントは機能できません。
- Google AI Studio から API キーを取得します。
- 次の手順で .env ファイルを設定するときに、
<<your API KEY>>を実際の API キーの値に置き換えます。
9. 環境変数の設定
- この リポジトリのテンプレート .env ファイルで、パラメータの値を設定します。私の場合は、.env に次の変数があります。
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
プレースホルダを実際の値に置き換えます。
10. エージェントを実行する
- ターミナルを使用して、エージェント プロジェクトの親ディレクトリに移動します。
cd renovation-agent
- すべての依存関係をインストールする
pip install -r requirements.txt
- Cloud Shell ターミナルで次のコマンドを実行して、エージェントを実行できます。
adk run .
- ADK プロビジョニング済みウェブ UI で実行するには、次のコマンドを実行します。
adk web
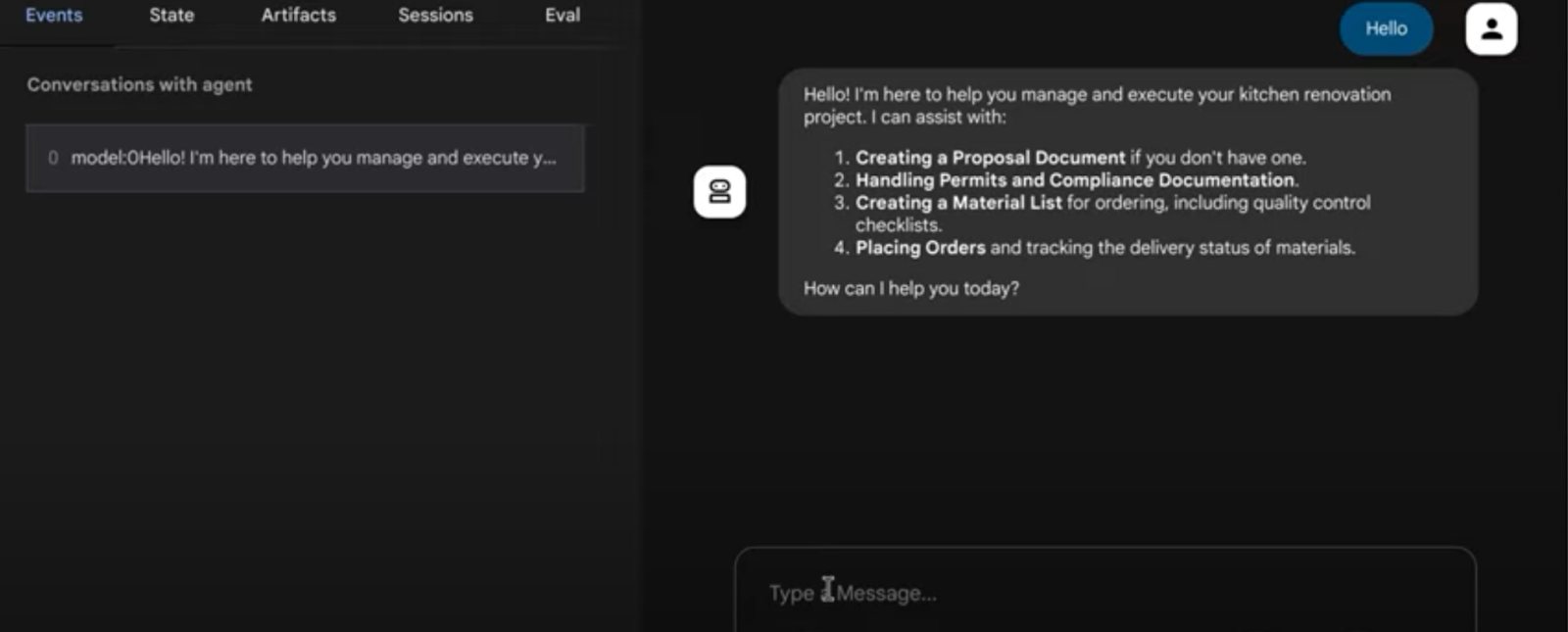
- 次のプロンプトでテストします。
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
11. 結果
@ キッチン リノベーション タスク用のマルチエージェント システム
12. Agent Engine へのデプロイ
マルチエージェント システムが正常に動作することを確認したので、サーバーレスにして、クラウドで誰でも / どのアプリケーションでも利用できるようにしましょう。リポジトリの agent.py で次のコード スニペットのコメントを解除すると、マルチエージェント システムをデプロイできます。
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
次のコマンドを使用して、プロジェクト フォルダ内から agent.py を再度実行します。
>> cd adk-renovation-agent
>> python agent.py
このコードの完了には数分かかります。完了すると、次のようなエンドポイントが返されます。
'projects/123456789/locations/us-central1/reasoningEngines/123456'
次のコードを使用して、新しいファイル「test.py」を追加することで、デプロイされたエージェントをテストできます。
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
上記のコードで、プレースホルダ「<<YOUR_DEPLOYED_ENGINE_ID>>」の値を置き換え、「python test.py」コマンドを実行すると、Agent Engine をデプロイしたマルチエージェント システムとやり取りしてキッチンをリフォームする準備が整います。
13. 1 行のデプロイ オプション
デプロイされたマルチエージェント システムをテストしたので、前のステップで行ったデプロイ ステップを抽象化するより簡単な方法を学びましょう。1 行のデプロイ オプション:
- Cloud Run の場合:
構文:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
この例の場合は、次のようになります。
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
デプロイされたエンドポイントは、ダウンストリーム統合に使用できます。
- Agent Engine に移動:
構文:
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
この例の場合は、次のようになります。
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
Google Cloud コンソールの Agent Engine UI に新しいエージェントが表示されます。詳細については、こちらのブログをご覧ください。
14. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順を行います。
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
15. 完了
おめでとうございます!ADK を使用して最初のエージェントを作成し、操作することができました。