
1. نظرة عامة
في هذا التمرين العملي، ستستخدم أداة "ماذا لو؟" لتحليل نموذج XGBoost تم تدريبه على بيانات مالية. بعد تحليل النموذج، سيتم نشره على Vertex AI الجديد من Cloud.
ما ستتعرّف عليه
ستتعرَّف على كيفية:
- تدريب نموذج XGBoost على مجموعة بيانات علنية خاصة بالرهن العقاري في دفتر ملاحظات مستضاف
- تحليل النموذج باستخدام أداة What-if
- تفعيل نموذج XGBoost على Vertex AI
يبلغ إجمالي تكلفة تشغيل هذا الدرس التطبيقي على Google Cloud حوالي 1 دولار أمريكي.
2. مقدّمة عن Vertex AI
يستخدم هذا المختبر أحدث منتج مستند إلى الذكاء الاصطناعي متاح على Google Cloud. تدمج Vertex AI عروض تعلُّم الآلة على Google Cloud في تجربة تطوير سلسة. في السابق، كان يمكن الوصول إلى النماذج المدرَّبة باستخدام AutoML والنماذج المخصَّصة من خلال خدمات منفصلة. يجمع العرض الجديد بين كليهما في واجهة برمجة تطبيقات واحدة، بالإضافة إلى منتجات جديدة أخرى. يمكنك أيضًا نقل المشاريع الحالية إلى Vertex AI. إذا كانت لديك أي ملاحظات، يُرجى الانتقال إلى صفحة الدعم.
تتضمّن Vertex AI العديد من المنتجات المختلفة لدعم مهام سير العمل الشاملة لتعلُّم الآلة. سيركّز هذا التمرين العملي على المنتجات الموضّحة أدناه: "التوقّع" و"دفاتر الملاحظات".

3- لمحة سريعة عن خوارزمية تعزيز التدرّج الشديد (XGBoost)
XGBoost هو إطار عمل لتعلُّم الآلة يستخدم أشجار القرارات وتحسين التدرّج لإنشاء نماذج تنبؤية. تعمل هذه الطريقة من خلال تجميع عدة أشجار قرارات معًا استنادًا إلى النتيجة المرتبطة بعُقد أوراق مختلفة في الشجرة.
المخطط البياني أدناه هو تمثيل مرئي لنموذج شجرة قرارات بسيط يقيّم ما إذا كان يجب لعب مباراة رياضية استنادًا إلى توقعات الطقس:

لماذا نستخدم XGBoost لهذا النموذج؟ في حين أنّ الشبكات العصبونية التقليدية أثبتت أنّها الأفضل في التعامل مع البيانات غير المنظَّمة، مثل الصور والنصوص، غالبًا ما تكون أشجار القرارات فعّالة للغاية في التعامل مع البيانات المنظَّمة، مثل مجموعة بيانات الرهن العقاري التي سنستخدمها في هذا الدرس التطبيقي حول الترميز.
4. إعداد البيئة
يجب أن يكون لديك مشروع على Google Cloud Platform مع تفعيل الفوترة لتتمكّن من تنفيذ هذا الدرس العملي. لإنشاء مشروع، اتّبِع التعليمات هنا.
الخطوة 1: تفعيل Compute Engine API
انتقِل إلى Compute Engine وانقر على تفعيل إذا لم يكن مفعّلاً بعد. يجب توفير هذه المعلومات لإنشاء مثيل دفتر الملاحظات.
الخطوة 2: تفعيل واجهة برمجة التطبيقات Vertex AI API
انتقِل إلى قسم Vertex في Cloud Console وانقر على تفعيل واجهة برمجة التطبيقات Vertex AI API.

الخطوة 3: إنشاء مثيل من Notebooks
من قسم Vertex في Cloud Console، انقر على Notebooks:

من هناك، انقر على مثيل جديد. بعد ذلك، اختَر نوع مثيل TensorFlow Enterprise 2.3 بدون وحدات معالجة الرسومات:
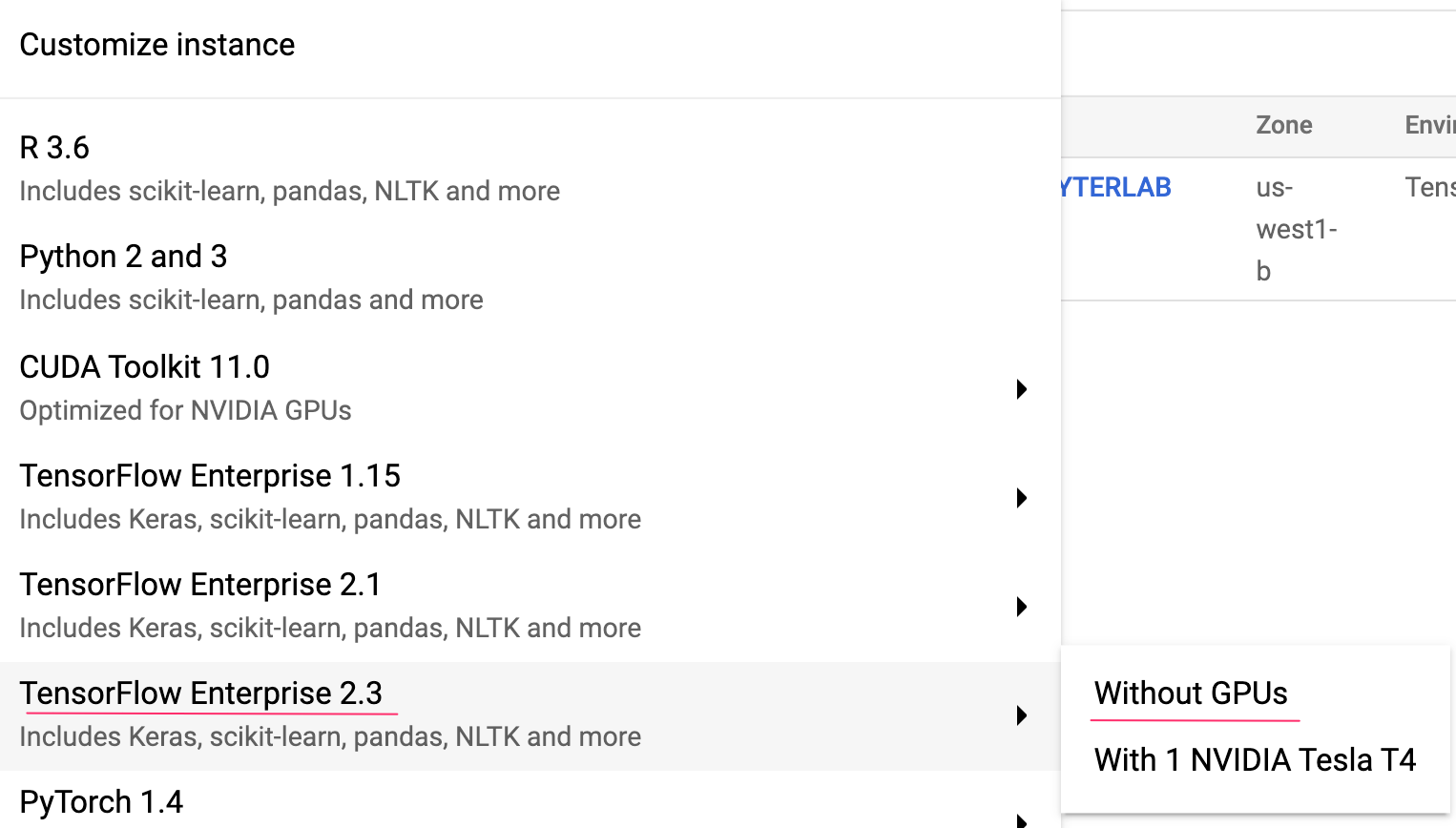
استخدِم الخيارات التلقائية، ثم انقر على إنشاء. بعد إنشاء المثيل، انقر على فتح JupyterLab.
الخطوة 4: تثبيت XGBoost
بعد فتح مثيل JupyterLab، عليك إضافة حزمة XGBoost.
لإجراء ذلك، اختَر "الوحدة الطرفية" من مشغّل التطبيقات:
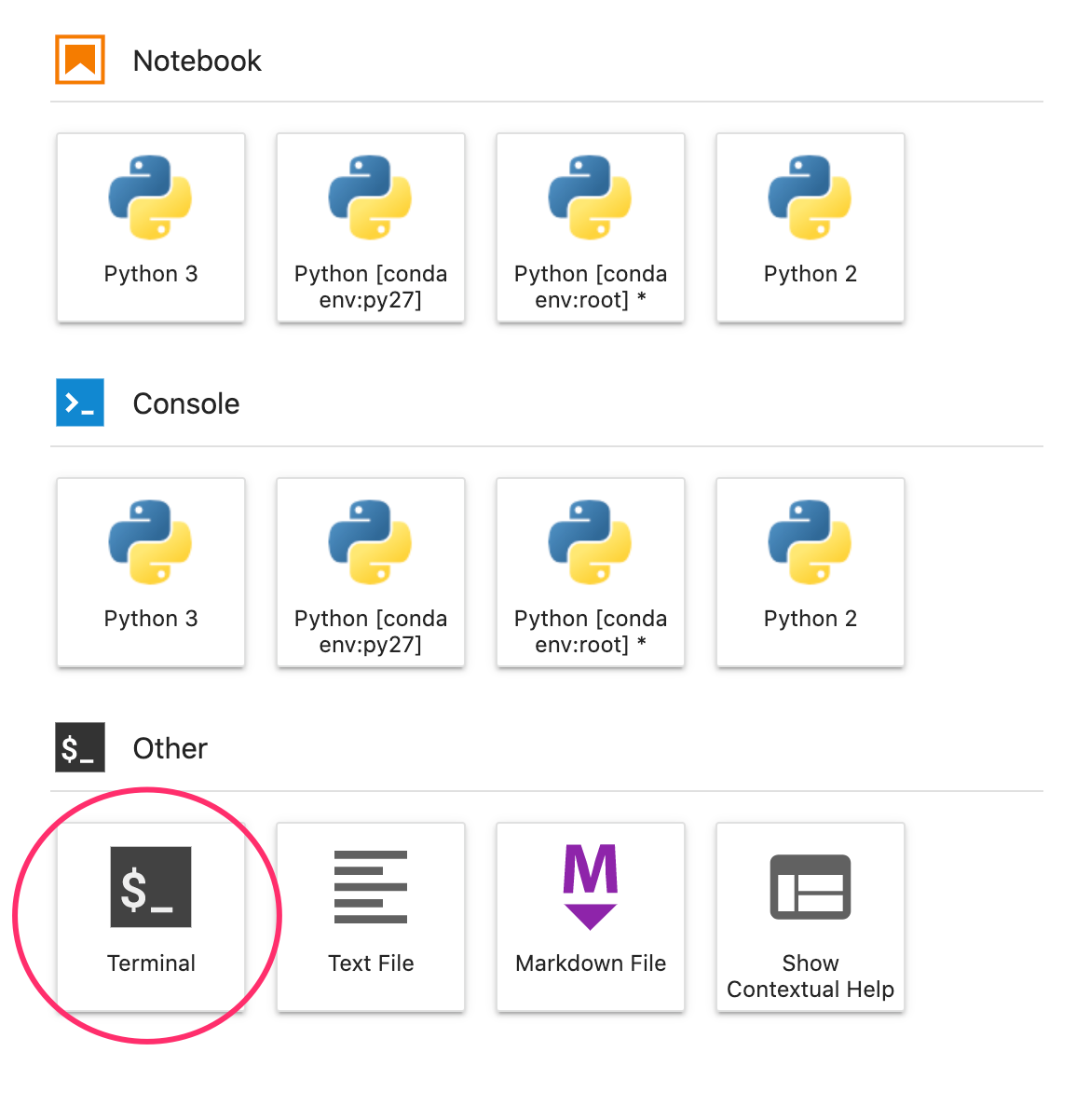
بعد ذلك، شغِّل ما يلي لتثبيت أحدث إصدار من XGBoost متوافق مع Vertex AI:
pip3 install xgboost==1.2
بعد اكتمال هذه العملية، افتح مثيلاً لدفتر ملاحظات Python 3 من مشغّل التطبيقات. أنت الآن جاهز للبدء في دفتر الملاحظات.
الخطوة 5: استيراد حِزم Python
في الخلية الأولى من دفتر الملاحظات، أضِف عمليات الاستيراد التالية وشغِّل الخلية. يمكنك تشغيله من خلال الضغط على زر السهم المتّجه لليسار في القائمة العلوية أو الضغط على command-enter:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
5- تنزيل البيانات ومعالجتها
سنستخدم مجموعة بيانات الرهن العقاري من ffiec.gov لتدريب نموذج XGBoost. لقد أجرينا بعض المعالجة المسبقة على مجموعة البيانات الأصلية وأنشأنا نسخة أصغر لتستخدمها في تدريب النموذج. سيتنبأ النموذج بما إذا كان سيتمّ قبول طلب رهن عقاري معيّن أم لا.
الخطوة 1: تنزيل مجموعة البيانات التي تمت معالجتها مسبقًا
لقد أتحنا لك نسخة من مجموعة البيانات في Google Cloud Storage. يمكنك تنزيلها من خلال تنفيذ الأمر gsutil التالي في دفتر ملاحظات Jupyter:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
الخطوة 2: قراءة مجموعة البيانات باستخدام Pandas
قبل إنشاء Pandas DataFrame، سننشئ dict لكل نوع بيانات في كل عمود حتى تتمكّن Pandas من قراءة مجموعة البيانات بشكل صحيح:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
بعد ذلك، سننشئ DataFrame، ونمرّر إليه أنواع البيانات التي حدّدناها أعلاه. من المهم ترتيب بياناتنا بشكل عشوائي في حال كانت مجموعة البيانات الأصلية مرتّبة بطريقة معيّنة. نستخدم أداة sklearn مساعدة باسم shuffle لإجراء ذلك، وقد استوردناها في الخلية الأولى:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
تتيح لنا data.head() معاينة الصفوف الخمسة الأولى من مجموعة البيانات في Pandas. من المفترض أن يظهر لك ما يلي بعد تشغيل الخلية أعلاه:

هذه هي الميزات التي سنستخدمها لتدريب نموذجنا. إذا انتقلت إلى نهاية الجدول، سيظهر لك العمود الأخير approved، وهو ما نتوقّعه. تشير القيمة 1 إلى أنّه تمت الموافقة على تطبيق معيّن، وتشير القيمة 0 إلى أنّه تم رفضه.
للاطّلاع على توزيع القيم المقبولة أو المرفوضة في مجموعة البيانات وإنشاء صفيفة numpy للتصنيفات، نفِّذ ما يلي:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
يحتوي% 66 تقريبًا من مجموعة البيانات على تطبيقات تمت الموافقة عليها.
الخطوة 3: إنشاء عمود وهمي للقيم الفئوية
تحتوي مجموعة البيانات هذه على مزيج من القيم الفئوية والرقمية، ولكن يتطلّب XGBoost أن تكون جميع الميزات رقمية. بدلاً من تمثيل القيم الفئوية باستخدام الترميز الأحادي، سنستفيد من الدالة get_dummies في Pandas لنموذج XGBoost.
تأخذ الدالة get_dummies عمودًا يتضمّن قيمًا محتمَلة متعددة وتحوّله إلى سلسلة من الأعمدة يتضمّن كلّ منها أصفارًا وآحادًا فقط. على سبيل المثال، إذا كان لدينا عمود "اللون" مع القيم المحتملة "أزرق" و "أحمر"، سيحوّل get_dummies ذلك إلى عمودَين باسم "اللون_أزرق" و "اللون_أحمر" مع جميع القيم المنطقية 0 و1.
لإنشاء أعمدة وهمية للميزات الفئوية، شغِّل الرمز التالي:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
عند معاينة البيانات هذه المرة، ستظهر لك ميزات فردية (مثل purchaser_type الموضّحة أدناه) مقسّمة إلى أعمدة متعددة:

الخطوة 4: تقسيم البيانات إلى مجموعات تدريب واختبار
من المفاهيم المهمة في تعلُّم الآلة تقسيم البيانات إلى مجموعتَي التدريب والاختبار. سنأخذ معظم بياناتنا ونستخدمها لتدريب نموذجنا، وسنحتفظ بالباقي لاختبار نموذجنا على بيانات لم يسبق له أن رآها.
أضِف الرمز التالي إلى دفتر ملاحظاتك، والذي يستخدم دالة train_test_split من Scikit-learn لتقسيم بياناتنا:
x,y = data.values,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
أنت الآن جاهز لإنشاء نموذجك وتدريبه.
6. إنشاء نموذج XGBoost وتدريبه وتقييمه
الخطوة 1: تحديد نموذج XGBoost وتدريبه
إنشاء نموذج في XGBoost هو أمر بسيط. سنستخدم الفئة XGBClassifier لإنشاء النموذج، وسنحتاج فقط إلى تمرير المَعلمة objective المناسبة لمهمة التصنيف المحدّدة. في هذه الحالة، نستخدم reg:logistic لأنّ لدينا مشكلة تصنيف ثنائي ونريد أن يعرض النموذج قيمة واحدة في النطاق (0,1): 0 لغير الموافق عليه و1 للموافق عليه.
ستنشئ التعليمة البرمجية التالية نموذج XGBoost:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
يمكنك تدريب النموذج باستخدام سطر واحد من الرمز البرمجي، وذلك من خلال استدعاء طريقة fit() وتمرير بيانات التدريب والتصنيفات إليها.
model.fit(x_train, y_train)
الخطوة 2: تقييم دقة النموذج
يمكننا الآن استخدام النموذج المدرَّب لإنشاء توقّعات بشأن بيانات الاختبار باستخدام الدالة predict().
بعد ذلك، سنستخدم الدالة accuracy_score() في Scikit-learn لحساب دقة النموذج استنادًا إلى أدائه في بيانات الاختبار. سنمرّر إليها قيم الحقيقة الأساسية مع القيم المتوقّعة للنموذج لكل مثال في مجموعة الاختبار:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
من المفترض أن تظهر لك دقة تبلغ حوالي 87%، ولكن قد تختلف هذه النسبة قليلاً لأنّ التعلّم الآلي يتضمّن دائمًا عنصرًا من العشوائية.
الخطوة 3: حفظ النموذج
لتوزيع النموذج، شغِّل الرمز التالي لحفظه في ملف محلي:
model.save_model('model.bst')
7. استخدام أداة "ماذا لو" لتفسير نموذجك
الخطوة 1: إنشاء تمثيل مرئي لـ "أداة ماذا لو"
لربط أداة "ماذا لو" بنموذجك المحلي، عليك تزويدها بمجموعة فرعية من أمثلة الاختبار بالإضافة إلى قيم الحقيقة الأساسية لهذه الأمثلة. لننشئ صفيفة Numpy تضم 500 من أمثلة الاختبار مع تصنيفاتها الصحيحة:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples],y_test[:num_wit_examples].reshape(-1,1)))
إنشاء أداة "ماذا لو" بسيط مثل إنشاء كائن WitConfigBuilder وتمرير النموذج الذي نريد تحليله إليه.
بما أنّ "أداة ماذا لو" تتوقّع قائمة بالنتائج لكل فئة في نموذجنا (في هذه الحالة 2)، سنستخدم طريقة predict_proba في XGBoost مع "أداة ماذا لو":
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_custom_predict_fn(model.predict_proba)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
يُرجى العِلم أنّ تحميل التمثيل المرئي سيستغرق دقيقة واحدة. عند تحميلها، من المفترض أن يظهر لك ما يلي:

يعرض المحور الصادي توقّعات النموذج، حيث يمثّل 1 توقّعًا approved بمستوى ثقة عالٍ، ويمثّل 0 توقّعًا denied بمستوى ثقة عالٍ. المحور س هو مجرد انتشار جميع نقاط البيانات التي تم تحميلها.
الخطوة 2: استكشاف نقاط البيانات الفردية
طريقة العرض التلقائية في "أداة ماذا لو" هي علامة التبويب محرّر نقاط البيانات. يمكنك هنا النقر على أي نقطة بيانات فردية للاطّلاع على ميزاتها وتغيير قيم الميزات ومعرفة كيف يؤثر هذا التغيير في توقّع النموذج لنقطة بيانات فردية.
في المثال أدناه، اخترنا نقطة بيانات قريبة من الحدّ 0 .5. تم الحصول على طلب الحصول على قرض عقاري المرتبط بنقطة البيانات المحدّدة هذه من "مكتب الحماية المالية للمستهلك". غيّرنا قيمة هذه الميزة إلى 0، وغيّرنا أيضًا قيمة agency_code_Department of Housing and Urban Development (HUD) إلى 1 لمعرفة تأثير ذلك في توقّعات النموذج إذا كان مصدر هذا القرض هو وزارة الإسكان والتنمية الحضرية:

كما نرى في القسم السفلي الأيسر من "أداة ماذا لو"، أدى تغيير هذه الميزة بشكل كبير إلى خفض توقّع النموذج approved بنسبة %32. قد يشير ذلك إلى أنّ الجهة التي تم الحصول منها على القرض لها تأثير كبير في نتائج النموذج، ولكننا بحاجة إلى إجراء المزيد من التحليلات للتأكّد من ذلك.
في الجزء السفلي الأيسر من واجهة المستخدم، يمكننا أيضًا الاطّلاع على قيمة الحقيقة الأساسية لكل نقطة بيانات ومقارنتها بتوقّع النموذج:

الخطوة 3: تحليل الوقائع الافتراضية
بعد ذلك، انقر على أي نقطة بيانات وحرِّك شريط التمرير عرض أقرب نقطة بيانات افتراضية إلى اليسار:

سيؤدي تحديد هذا الخيار إلى عرض نقطة البيانات التي تتضمّن قيم سمات مشابهة لتلك التي اخترتها في الأصل، ولكن مع توقّع معاكس. يمكنك بعد ذلك الانتقال سريعًا بين قيم السمة لمعرفة موضع اختلاف نقطتَي البيانات (يتم تمييز الاختلافات باللون الأخضر والخط العريض).
الخطوة 4: إلقاء نظرة على مخططات الاعتماد الجزئي
للاطّلاع على تأثير كل ميزة في توقّعات النموذج بشكل عام، ضَع علامة في المربّع رسومات التبعية الجزئية وتأكَّد من تحديد رسومات التبعية الجزئية العامة:

يمكننا هنا أن نرى أنّ القروض التي مصدرها وزارة الإسكان والتنمية الحضرية (HUD) لديها احتمال أعلى قليلاً للرفض. يكون الرسم البياني بهذا الشكل لأنّ رمز الوكالة هو ميزة منطقية، وبالتالي لا يمكن أن تكون القيم سوى 0 أو 1.
applicant_income_thousands هي ميزة رقمية، ويمكننا أن نرى في الرسم البياني للاعتماد الجزئي أنّ ارتفاع الدخل يزيد قليلاً من احتمال الموافقة على الطلب، ولكن فقط حتى حوالي 200 ألف دولار أمريكي. بعد بلوغ 200 ألف دولار أمريكي، لا تؤثر هذه الميزة في توقّعات النموذج.
الخطوة 5: استكشاف الأداء العام والإنصاف
بعد ذلك، انتقِل إلى علامة التبويب الأداء والإنصاف. تعرض هذه الصفحة إحصاءات الأداء العام لنتائج النموذج على مجموعة البيانات المقدَّمة، بما في ذلك مصفوفات الالتباس ومنحنيات الدقة والاستدعاء ومنحنيات ROC.
اختَر mortgage_status كعنصر Ground Truth Feature للاطّلاع على مصفوفة نجاح التوقعات:

تعرض مصفوفة نجاح التوقعات هذه التوقّعات الصحيحة والخاطئة التي قدّمها نموذجنا كنسبة مئوية من الإجمالي. إذا جمعت مربّعَي نعم الفعلية / نعم المتوقّعة ولا الفعلية / لا المتوقّعة، يجب أن يكون المجموع هو الدقة نفسها التي حقّقها النموذج (في هذه الحالة حوالي %87، مع أنّ نموذجك قد يختلف قليلاً لأنّ هناك عنصرًا عشوائيًا في تدريب نماذج تعلُّم الآلة).
يمكنك أيضًا تجربة شريط تمرير الحدّ الأدنى، ورفع وخفض نتيجة التصنيف الإيجابي التي يحتاج النموذج إلى عرضها قبل أن يقرّر التوقّع approved للقرض، ومعرفة كيف يؤدي ذلك إلى تغيير الدقة والإيجابيات الخاطئة والسلبيات الخاطئة. في هذه الحالة، تكون الدقة في أعلى مستوياتها عند عتبة 0.55.
بعد ذلك، في القائمة المنسدلة التقسيم حسب على يمين الصفحة، اختَر loan_purpose_Home_purchase:
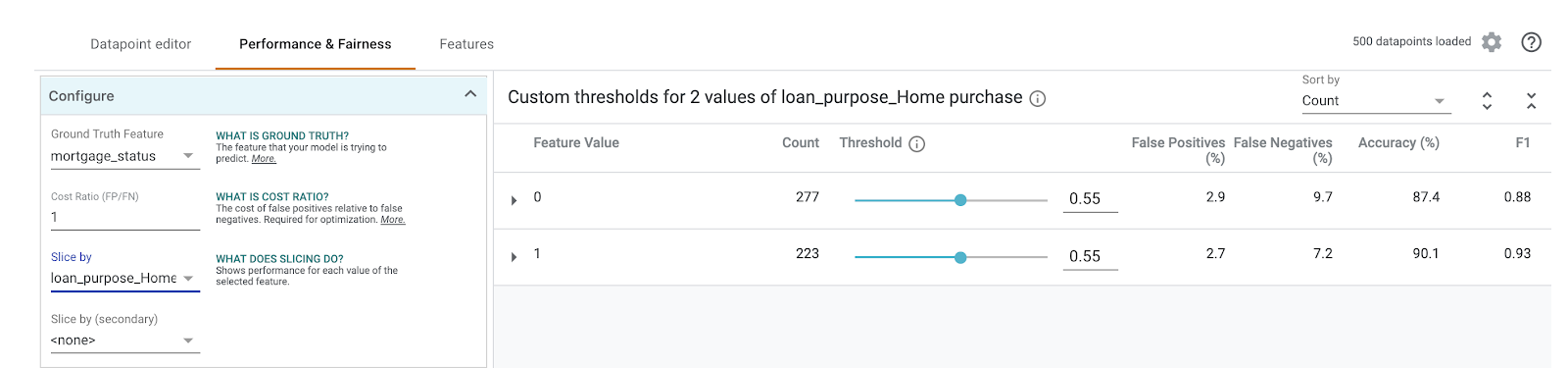
ستظهر لك الآن بيانات الأداء على المجموعتَين الفرعيتَين من بياناتك: يعرض القسم "0" الحالات التي لا يكون فيها القرض لشراء منزل، بينما يعرض القسم "1" الحالات التي يكون فيها القرض لشراء منزل. اطّلِع على معدّل الدقة ومعدّل النتائج الإيجابية الخاطئة ومعدّل النتائج السلبية الخاطئة بين الشريحتَين للبحث عن اختلافات في الأداء.
إذا وسّعت الصفوف للاطّلاع على مصفوفات الالتباس، يمكنك ملاحظة أنّ النموذج يتوقّع "موافقة" على% 70 تقريبًا من طلبات القروض لشراء المنازل، و% 46 فقط من القروض غير المخصّصة لشراء المنازل (ستختلف النسب المئوية الدقيقة حسب النموذج):

إذا اخترت تساوي الفئات الديمغرافية من أزرار الاختيار على اليمين، سيتم تعديل الحدّين ليتوقّع النموذج approved لنسبة مئوية مماثلة من مقدّمي الطلبات في كلتا الشريحتين. ما هو تأثير ذلك في الدقة والنتائج الإيجابية الخاطئة والنتائج السلبية الخاطئة لكل شريحة؟
الخطوة 6: استكشاف توزيع الميزات
أخيرًا، انتقِل إلى علامة التبويب الميزات في "أداة ماذا لو". تعرض هذه السمة توزيع القيم لكل ميزة في مجموعة البيانات:

يمكنك استخدام علامة التبويب هذه للتأكّد من أنّ مجموعة البيانات متوازنة. على سبيل المثال، يبدو أنّ عددًا قليلاً جدًا من القروض في مجموعة البيانات مصدره وكالة خدمات المزارع. لتحسين دقة النموذج، قد نفكّر في إضافة المزيد من القروض من تلك الوكالة إذا كانت البيانات متاحة.
لقد وصفنا هنا بعض الأفكار لاستكشاف "أداة ماذا لو؟". يمكنك مواصلة تجربة الأداة، فهناك العديد من المجالات الأخرى التي يمكنك استكشافها.
8. تفعيل النموذج في Vertex AI
لقد نجحنا في تشغيل النموذج محليًا، ولكن سيكون من الرائع أن نتمكّن من إجراء توقّعات عليه من أي مكان (وليس فقط من دفتر الملاحظات هذا). في هذه الخطوة، سننفّذها على السحابة الإلكترونية.
الخطوة 1: إنشاء حزمة Cloud Storage للنموذج
لنبدأ أولاً بتحديد بعض متغيرات البيئة التي سنستخدمها في بقية الدرس العملي. املأ القيم أدناه باسم مشروعك على Google Cloud واسم حزمة التخزين في السحابة الإلكترونية التي تريد إنشاءها (يجب أن يكون الاسم فريدًا على مستوى العالم) واسم الإصدار الأول من نموذجك:
# Update the variables below to your own Google Cloud project ID and GCS bucket name. You can leave the model name we've specified below:
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
MODEL_NAME = 'xgb_mortgage'
نحن الآن جاهزون لإنشاء حزمة تخزين لتخزين ملف نموذج XGBoost. سنشير إلى هذا الملف في Vertex AI عند التفعيل.
نفِّذ أمر gsutil التالي من داخل دفتر الملاحظات لإنشاء حزمة تخزين إقليمية:
!gsutil mb -l us-central1 $MODEL_BUCKET
الخطوة 2: نسخ ملف النموذج إلى Cloud Storage
بعد ذلك، سننسخ ملف النموذج المحفوظ XGBoost إلى Cloud Storage. نفِّذ أمر gsutil التالي:
!gsutil cp ./model.bst $MODEL_BUCKET
انتقِل إلى متصفِّح مساحة التخزين في Cloud Console للتأكّد من نسخ الملف:

الخطوة 3: إنشاء النموذج وتفعيله في نقطة نهاية
أوشكنا على الانتهاء من نشر النموذج على السحابة الإلكترونية. في Vertex AI، يمكن أن يحتوي النموذج على نقاط نهاية متعددة. سننشئ أولاً نموذجًا، ثم سننشئ نقطة نهاية ضمن هذا النموذج ونفعّلها.
أولاً، استخدِم واجهة سطر الأوامر gcloud لإنشاء النموذج:
!gcloud beta ai models upload \
--display-name=$MODEL_NAME \
--artifact-uri=$MODEL_BUCKET \
--container-image-uri=us-docker.pkg.dev/cloud-aiplatform/prediction/xgboost-cpu.1-2:latest \
--region=us-central1
ستشير المَعلمة artifact-uri إلى موقع "مساحة التخزين" الذي حفظت فيه نموذج XGBoost. تُعلم المَعلمة container-image-uri منصة Vertex AI بالحاوية المُعدّة مسبقًا التي يجب استخدامها للعرض. بعد اكتمال هذا الأمر، انتقِل إلى قسم النماذج في وحدة تحكّم Vertex للحصول على رقم تعريف النموذج الجديد. يمكنك العثور عليه هنا:
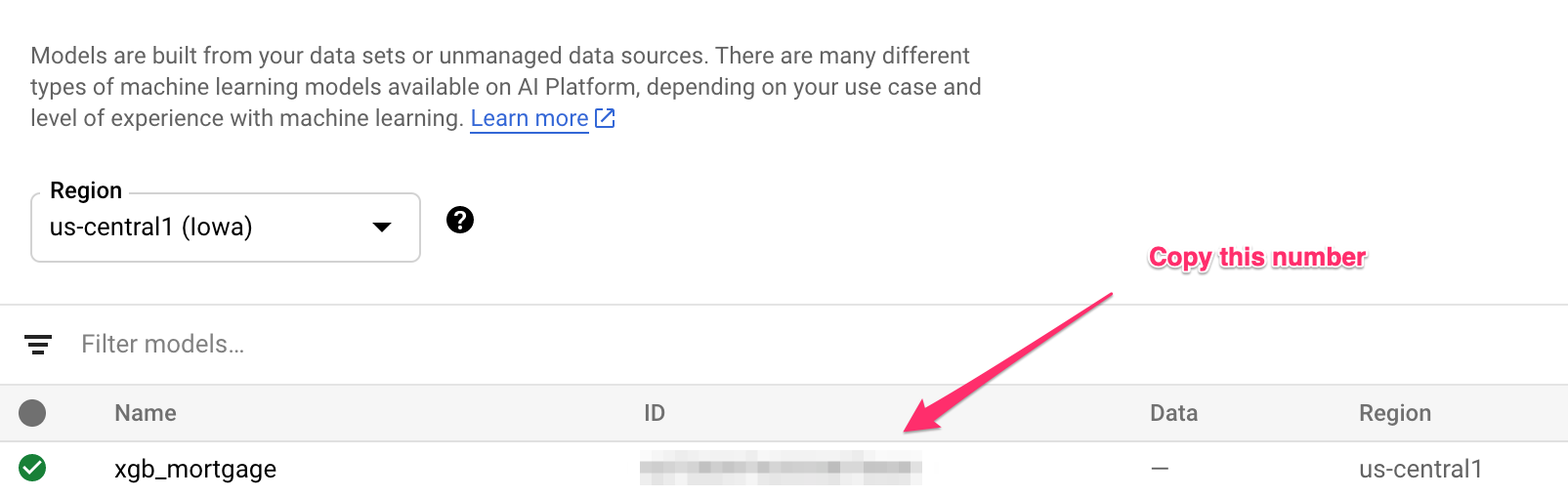
انسخ رقم التعريف هذا واحفظه في متغيّر:
MODEL_ID = "your_model_id"
حان الآن وقت إنشاء نقطة نهاية ضمن هذا النموذج. يمكننا إجراء ذلك باستخدام أمر gcloud التالي:
!gcloud beta ai endpoints create \
--display-name=xgb_mortgage_v1 \
--region=us-central1
عند اكتمال ذلك، من المفترض أن يظهر موقع نقطة النهاية مسجّلاً في ناتج دفتر الملاحظات. ابحث عن السطر الذي يشير إلى أنّه تم إنشاء نقطة النهاية باستخدام مسار يشبه ما يلي: projects/project_ID/locations/us-central1/endpoints/endpoint_ID. ثم استبدِل القيم أدناه بمعرّفات نقطة النهاية التي تم إنشاؤها أعلاه:
ENDPOINT_ID = "your_endpoint_id"
لنشر نقطة النهاية، نفِّذ أمر gcloud أدناه:
!gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=us-central1 \
--model=$MODEL_ID \
--display-name=xgb_mortgage_v1 \
--machine-type=n1-standard-2 \
--traffic-split=0=100
سيستغرق نشر نقطة النهاية من 5 إلى 10 دقائق تقريبًا. أثناء نشر نقطة النهاية، انتقِل إلى قسم النماذج في وحدة التحكّم. انقر على النموذج، وسيظهر لك نقطة النهاية التي يتم نشرها:

عند اكتمال عملية النشر بنجاح، ستظهر علامة اختيار خضراء في المكان الذي يظهر فيه مؤشر التحميل.
الخطوة 4: اختبار النموذج الذي تم نشره
للتأكّد من أنّ النموذج الذي تم نشره يعمل، اختبِره باستخدام gcloud لإجراء عملية توقّع. أولاً، احفظ ملف JSON يتضمّن مثالاً من مجموعة الاختبار:
%%writefile predictions.json
{
"instances": [
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
]
}
اختبِر النموذج من خلال تنفيذ أمر gcloud التالي:
!gcloud beta ai endpoints predict $ENDPOINT_ID \
--json-request=predictions.json \
--region=us-central1
من المفترض أن تظهر لك نتيجة توقّع النموذج في الناتج. تمت الموافقة على هذا المثال تحديدًا، لذا من المفترض أن تظهر قيمة قريبة من 1.
9- تنظيف
إذا أردت مواصلة استخدام دفتر الملاحظات هذا، ننصحك بإيقافه عندما لا يكون قيد الاستخدام. من واجهة مستخدم Notebooks في Cloud Console، اختَر دفتر الملاحظات، ثم انقر على إيقاف:

إذا أردت حذف جميع المراجع التي أنشأتها في هذا المختبر، ما عليك سوى حذف مثيل دفتر الملاحظات بدلاً من إيقافه.
لحذف نقطة النهاية التي نشرتها، انتقِل إلى قسم "نقاط النهاية" في وحدة تحكّم Vertex وانقر على رمز الحذف:

لحذف حزمة التخزين، استخدِم قائمة التنقّل في Cloud Console، وانتقِل إلى "مساحة التخزين"، واختَر الحزمة، ثم انقر على "حذف":
