۱. مرور کلی
در این آزمایش، شما از ابزار What-if برای تجزیه و تحلیل یک مدل XGBoost که بر روی دادههای مالی آموزش دیده است، استفاده خواهید کرد. پس از تجزیه و تحلیل مدل، آن را در هوش مصنوعی جدید Vertex شرکت Cloud مستقر خواهید کرد.
آنچه یاد میگیرید
شما یاد خواهید گرفت که چگونه:
- یک مدل XGBoost را روی مجموعه دادههای وام مسکن عمومی در یک نوتبوک میزبانیشده آموزش دهید
- مدل را با استفاده از ابزار What-if تجزیه و تحلیل کنید
- مدل XGBoost را روی Vertex AI مستقر کنید
هزینه کل اجرای این آزمایشگاه در گوگل کلود حدود ۱ دلار است.
۲. مقدمهای بر هوش مصنوعی ورتکس
این آزمایشگاه از جدیدترین محصول هوش مصنوعی موجود در Google Cloud استفاده میکند. Vertex AI، محصولات یادگیری ماشین را در Google Cloud ادغام میکند تا یک تجربه توسعه یکپارچه را فراهم کند. پیش از این، مدلهای آموزشدیده با AutoML و مدلهای سفارشی از طریق سرویسهای جداگانه قابل دسترسی بودند. این محصول جدید، هر دو را در یک API واحد، به همراه سایر محصولات جدید، ترکیب میکند. همچنین میتوانید پروژههای موجود را به Vertex AI منتقل کنید. در صورت داشتن هرگونه بازخورد، لطفاً به صفحه پشتیبانی مراجعه کنید.
هوش مصنوعی ورتکس شامل محصولات مختلفی برای پشتیبانی از گردشهای کاری یادگیری ماشینی سرتاسری است. این آزمایشگاه بر روی محصولات برجسته زیر تمرکز خواهد کرد: پیشبینی و دفترچه یادداشت.

۳. یک شروع سریع با XGBoost
XGBoost یک چارچوب یادگیری ماشینی است که از درختهای تصمیمگیری و تقویت گرادیان برای ساخت مدلهای پیشبینی استفاده میکند. این چارچوب با ادغام چندین درخت تصمیمگیری بر اساس امتیاز مرتبط با گرههای برگ مختلف در یک درخت، کار میکند.
نمودار زیر تجسمی از یک مدل درخت تصمیم ساده است که ارزیابی میکند آیا یک بازی ورزشی باید بر اساس پیشبینی آب و هوا انجام شود یا خیر:

چرا از XGBoost برای این مدل استفاده میکنیم؟ در حالی که شبکههای عصبی سنتی نشان دادهاند که در دادههای بدون ساختار مانند تصاویر و متن بهترین عملکرد را دارند، درختهای تصمیم اغلب در دادههای ساختاریافته مانند مجموعه داده وام مسکن که در این آزمایشگاه کد از آن استفاده خواهیم کرد، عملکرد بسیار خوبی دارند.
۴. محیط خود را راهاندازی کنید
برای اجرای این codelab به یک پروژه Google Cloud Platform با قابلیت پرداخت صورتحساب نیاز دارید. برای ایجاد یک پروژه، دستورالعملهای اینجا را دنبال کنید.
مرحله ۱: فعال کردن رابط برنامهنویسی کاربردی موتور محاسبات
به Compute Engine بروید و اگر از قبل فعال نشده است، آن را فعال کنید . برای ایجاد نمونه نوتبوک خود به این مورد نیاز خواهید داشت.
مرحله 2: فعال کردن API هوش مصنوعی Vertex
به بخش Vertex در کنسول ابری خود بروید و روی Enable Vertex AI API کلیک کنید.

مرحله ۳: ایجاد یک نمونه از Notebooks
از بخش Vertex کنسول ابری خود، روی Notebooks کلیک کنید:

از آنجا، New Instance را انتخاب کنید. سپس نوع نمونه TensorFlow Enterprise 2.3 را بدون GPU انتخاب کنید:

از گزینههای پیشفرض استفاده کنید و سپس روی «ایجاد» کلیک کنید. پس از ایجاد نمونه، «باز کردن JupyterLab» را انتخاب کنید.
مرحله ۴: نصب XGBoost
پس از باز شدن نمونه JupyterLab، باید بسته XGBoost را اضافه کنید.
برای انجام این کار، ترمینال را از لانچر انتخاب کنید:

سپس دستور زیر را برای نصب آخرین نسخه XGBoost که توسط Vertex AI پشتیبانی میشود، اجرا کنید:
pip3 install xgboost==1.2
پس از اتمام این کار، یک نمونه Python 3 Notebook را از لانچر باز کنید. شما آماده شروع کار در نوتبوک خود هستید!
مرحله ۵: وارد کردن بستههای پایتون
در سلول اول دفترچه یادداشت خود، موارد زیر را وارد کرده و سلول را اجرا کنید. میتوانید آن را با فشار دادن دکمه فلش سمت راست در منوی بالا یا فشار دادن کلید ترکیبی command-enter اجرا کنید:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
۵. دانلود و پردازش دادهها
ما از یک مجموعه داده وام مسکن از ffiec.gov برای آموزش مدل XGBoost استفاده خواهیم کرد. ما پیشپردازشهایی را روی مجموعه داده اصلی انجام دادهایم و یک نسخه کوچکتر برای آموزش مدل ایجاد کردهایم. این مدل پیشبینی میکند که آیا یک درخواست وام مسکن خاص تأیید خواهد شد یا خیر .
مرحله ۱: دانلود مجموعه دادههای پیشپردازششده
ما نسخهای از مجموعه دادهها را در فضای ابری گوگل (Google Cloud Storage) برای شما در دسترس قرار دادهایم. میتوانید با اجرای دستور gsutil زیر در نوتبوک ژوپیتر خود، آن را دانلود کنید:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
مرحله ۲: خواندن مجموعه دادهها با Pandas
قبل از ایجاد قاب داده Pandas، یک dict از نوع داده هر ستون ایجاد میکنیم تا Pandas مجموعه داده ما را به درستی بخواند:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
در مرحله بعد، یک DataFrame ایجاد میکنیم و انواع دادههایی را که در بالا مشخص کردیم، به آن منتقل میکنیم. در صورتی که مجموعه دادههای اصلی به شیوهای خاص مرتب شده باشند، مهم است که دادههای خود را به صورت درهمریخته (brush) مرتب کنیم. ما برای انجام این کار از یک ابزار sklearn به نام shuffle استفاده میکنیم که در سلول اول وارد کردیم:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() به ما اجازه میدهد پنج ردیف اول مجموعه داده خود را در Pandas پیشنمایش کنیم. پس از اجرای سلول بالا، باید چیزی شبیه به این را ببینید:

اینها ویژگیهایی هستند که ما برای آموزش مدل خود استفاده خواهیم کرد. اگر تا انتها اسکرول کنید، ستون آخر approved خواهید دید، که همان چیزی است که ما پیشبینی میکنیم. مقدار 1 نشان میدهد که یک برنامه خاص تأیید شده و 0 نشان میدهد که رد شده است.
برای مشاهده توزیع مقادیر تایید شده/رد شده در مجموعه داده و ایجاد یک آرایه نامپای از برچسبها، دستور زیر را اجرا کنید:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
حدود ۶۶٪ از مجموعه دادهها شامل برنامههای تأیید شده است.
مرحله ۳: ایجاد ستون ساختگی برای مقادیر دستهبندیشده
این مجموعه داده شامل ترکیبی از مقادیر دستهای و عددی است، اما XGBoost ایجاب میکند که همه ویژگیها عددی باشند. به جای نمایش مقادیر دستهای با استفاده از کدگذاری وان-هات ، برای مدل XGBoost خود از تابع get_dummies در Pandas بهره خواهیم برد.
get_dummies یک ستون با چندین مقدار ممکن را میگیرد و آن را به مجموعهای از ستونها تبدیل میکند که هر کدام فقط شامل ۰ و ۱ هستند. برای مثال، اگر ستونی به نام "color" با مقادیر ممکن "blue" و "red" داشته باشیم، تابع get_dummies این ستون را به ۲ ستون به نامهای "color_blue" و "color_red" با تمام مقادیر بولی ۰ و ۱ تبدیل میکند.
برای ایجاد ستونهای ساختگی برای ویژگیهای دستهبندیشده، کد زیر را اجرا کنید:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
وقتی این بار دادهها را پیشنمایش میکنید، خواهید دید که ویژگیهای تکی (مانند purchaser_type که در تصویر زیر نشان داده شده است) به چندین ستون تقسیم شدهاند:

مرحله ۴: تقسیم دادهها به مجموعههای آموزش و آزمایش
یک مفهوم مهم در یادگیری ماشین، تقسیم آموزش/آزمون است. ما بخش عمدهای از دادهها را برای آموزش مدل خود استفاده میکنیم و بقیه را برای آزمایش مدل خود روی دادههایی که قبلاً هرگز دیده نشده است، کنار میگذاریم.
کد زیر را به دفترچه یادداشت خود اضافه کنید، که از تابع train_test_split در Scikit-learn برای تقسیم دادهها استفاده میکند:
x,y = data.values,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
حالا شما آمادهاید تا مدل خود را بسازید و آموزش دهید!
۶. ساخت، آموزش و ارزیابی یک مدل XGBoost
مرحله ۱: تعریف و آموزش مدل XGBoost
ایجاد یک مدل در XGBoost ساده است. ما از کلاس XGBClassifier برای ایجاد مدل استفاده خواهیم کرد و فقط باید پارامتر objective مناسب را برای وظیفه طبقهبندی خاص خود ارسال کنیم. در این حالت reg:logistic استفاده میکنیم زیرا یک مسئله طبقهبندی دودویی داریم و میخواهیم مدل یک مقدار واحد در محدوده (0،1) را خروجی دهد: 0 برای عدم تأیید و 1 برای تأیید.
کد زیر یک مدل XGBoost ایجاد میکند:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
شما میتوانید مدل را با یک خط کد آموزش دهید، متد fit() را فراخوانی کنید و دادههای آموزشی و برچسبها را به آن ارسال کنید.
model.fit(x_train, y_train)
مرحله ۲: ارزیابی دقت مدل
اکنون میتوانیم از مدل آموزشدیده خود برای تولید پیشبینی روی دادههای آزمایشی با تابع predict() استفاده کنیم.
سپس از تابع accuracy_score() در Scikit-learn برای محاسبه دقت مدل خود بر اساس نحوه عملکرد آن بر روی دادههای تست استفاده خواهیم کرد. مقادیر واقعی را به همراه مقادیر پیشبینیشده مدل برای هر مثال در مجموعه تست خود به آن ارسال خواهیم کرد:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
شما باید دقتی حدود ۸۷٪ را ببینید، اما دقت شما کمی متفاوت خواهد بود زیرا همیشه عنصری از تصادفی بودن در یادگیری ماشین وجود دارد.
مرحله ۳: مدل خود را ذخیره کنید
برای استقرار مدل، کد زیر را اجرا کنید تا آن را در یک فایل محلی ذخیره کنید:
model.save_model('model.bst')
۷. از ابزار What-if برای تفسیر مدل خود استفاده کنید
مرحله ۱: ایجاد تجسم ابزار What-if
برای اتصال ابزار What-if به مدل محلی خود، باید زیرمجموعهای از نمونههای آزمایشی خود را به همراه مقادیر حقیقی برای آن نمونهها به آن ارسال کنید. بیایید یک آرایه Numpy از ۵۰۰ نمونه آزمایشی خود را به همراه برچسبهای حقیقی آنها ایجاد کنیم:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples],y_test[:num_wit_examples].reshape(-1,1)))
نمونهسازی ابزار What-if به سادگی ایجاد یک شیء WitConfigBuilder و ارسال مدلی که میخواهیم تحلیل کنیم به آن است.
از آنجایی که ابزار What-if انتظار دارد لیستی از نمرات برای هر کلاس در مدل ما (در این مورد ۲) نمایش داده شود، ما از متد predict_proba در XGBoost با ابزار What-If استفاده خواهیم کرد:
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_custom_predict_fn(model.predict_proba)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
توجه داشته باشید که بارگذاری تصویرسازی یک دقیقه طول میکشد. پس از بارگذاری، باید تصویر زیر را مشاهده کنید:

محور y پیشبینی مدل را به ما نشان میدهد، که 1 پیشبینی با اطمینان بالا approved و 0 پیشبینی با اطمینان بالا denied است. محور x فقط پراکندگی تمام نقاط داده بارگذاری شده است.
مرحله ۲: نقاط داده منفرد را کاوش کنید
نمای پیشفرض در ابزار What-if، تب ویرایشگر Datapoint است. در اینجا میتوانید روی هر نقطه داده کلیک کنید تا ویژگیهای آن را ببینید، مقادیر ویژگی را تغییر دهید و ببینید که چگونه این تغییر بر پیشبینی مدل روی یک نقطه داده تأثیر میگذارد.
در مثال زیر، ما یک نقطه داده نزدیک به آستانه ۰.۵ را انتخاب کردیم. درخواست وام مسکن مرتبط با این نقطه داده خاص از CFPB سرچشمه گرفته است. ما آن ویژگی را به ۰ تغییر دادیم و همچنین مقدار agency_code_Department of Housing and Urban Development (HUD) را به ۱ تغییر دادیم تا ببینیم اگر این وام از HUD سرچشمه گرفته باشد، چه اتفاقی برای پیشبینی مدل میافتد:

همانطور که در بخش پایین سمت چپ ابزار What-if میبینیم، تغییر این ویژگی پیشبینی approved مدل را به میزان قابل توجهی ۳۲٪ کاهش داده است. این میتواند نشان دهد که آژانسی که وام از آن گرفته شده است، تأثیر زیادی بر خروجی مدل دارد، اما برای اطمینان بیشتر باید تجزیه و تحلیل بیشتری انجام دهیم.
در قسمت پایین سمت چپ رابط کاربری، میتوانیم مقدار واقعی هر نقطه داده را نیز ببینیم و آن را با پیشبینی مدل مقایسه کنیم:

مرحله ۳: تحلیل خلاف واقع
سپس، روی هر نقطه داده کلیک کنید و اسلایدر نمایش نزدیکترین نقطه داده خلاف واقع را به سمت راست حرکت دهید:

با انتخاب این گزینه، نقطه دادهای که بیشترین شباهت را به مقدار ویژگی اولیه انتخاب شده شما دارد، اما پیشبینی آن برعکس است، به شما نشان داده میشود. سپس میتوانید مقادیر ویژگی را مرور کنید تا ببینید دو نقطه داده در کجا با هم تفاوت دارند (تفاوتها با رنگ سبز و پررنگ مشخص شدهاند).
مرحله ۴: به نمودارهای وابستگی جزئی نگاه کنید
برای مشاهدهی چگونگی تأثیر هر ویژگی بر پیشبینیهای کلی مدل، کادر « نمودارهای وابستگی جزئی» (Partial dependency plots) را علامت بزنید و مطمئن شوید که «نمودارهای وابستگی جزئی سراسری» (Global partial dependency plots) انتخاب شده است:

در اینجا میتوانیم ببینیم که وامهای صادر شده از HUD احتمال رد شدن کمی بیشتری دارند. نمودار به این شکل است زیرا کد آژانس یک ویژگی بولی است، بنابراین مقادیر فقط میتوانند دقیقاً 0 یا 1 باشند.
applicant_income_thousands یک ویژگی عددی است و در نمودار وابستگی جزئی میتوانیم ببینیم که درآمد بالاتر، احتمال تأیید درخواست را کمی افزایش میدهد، اما فقط تا حدود ۲۰۰ هزار دلار. پس از ۲۰۰ هزار دلار، این ویژگی تاثیری بر پیشبینی مدل ندارد.
مرحله ۵: عملکرد کلی و انصاف را بررسی کنید
سپس، به برگه «عملکرد و انصاف» (Performance & Fairness) بروید. این برگه، آمار کلی عملکرد نتایج مدل روی مجموعه دادههای ارائه شده، شامل ماتریسهای درهمریختگی، منحنیهای PR و منحنیهای ROC را نشان میدهد.
برای دیدن ماتریس درهمریختگی، mortgage_status به عنوان ویژگی حقیقت زمینی انتخاب کنید:

این ماتریس سردرگمی، پیشبینیهای درست و نادرست مدل ما را به صورت درصدی از کل نشان میدهد. اگر مربعهای «بله واقعی/بله پیشبینیشده» و « خیر واقعی/خیر پیشبینیشده» را با هم جمع کنید، باید به دقتی مشابه مدل شما برسد (در این مورد حدود ۸۷٪)، اگرچه مدل شما ممکن است کمی متفاوت باشد زیرا عنصری از تصادفی بودن در آموزش مدلهای یادگیری ماشین وجود دارد).
شما همچنین میتوانید با اسلایدر آستانه آزمایش کنید، امتیاز طبقهبندی مثبتی را که مدل باید قبل از تصمیمگیری برای پیشبینی وام approved برگرداند، افزایش و کاهش دهید و ببینید که چگونه این امر دقت، مثبتهای کاذب و منفیهای کاذب را تغییر میدهد. در این حالت، دقت در حدود آستانه 0.55 بالاترین است.
سپس، در منوی کشویی Slice by سمت چپ، گزینه loan_purpose_Home_purchase را انتخاب کنید:
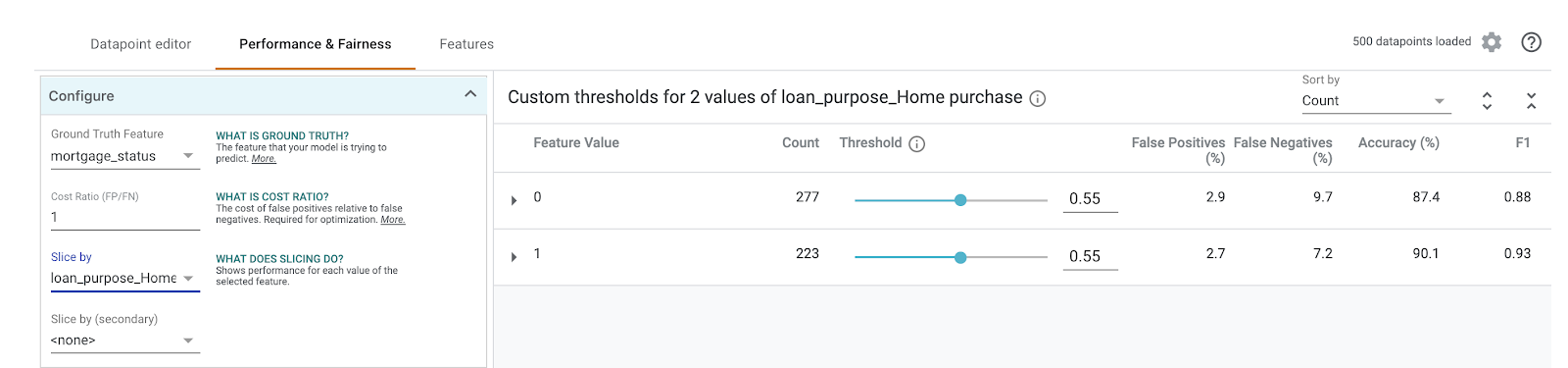
اکنون عملکرد را در دو زیرمجموعه از دادههای خود مشاهده خواهید کرد: برش "0" زمانی را نشان میدهد که وام برای خرید خانه نیست و برش "1" زمانی است که وام برای خرید خانه است. برای بررسی تفاوتها در عملکرد، دقت، مثبت کاذب و منفی کاذب را بین دو برش بررسی کنید.
اگر ردیفها را گسترش دهید تا ماتریسهای درهمریختگی را مشاهده کنید، میتوانید ببینید که مدل پیشبینی میکند حدود ۷۰٪ از درخواستهای وام برای خرید خانه و تنها ۴۶٪ از وامهایی که برای خرید خانه نیستند، «تایید شده» هستند (درصد دقیق در مدل شما متفاوت خواهد بود):

اگر از دکمههای رادیویی سمت چپ، گزینه «برابری جمعیتی» را انتخاب کنید، دو آستانه طوری تنظیم میشوند که مدل، درصد مشابهی از متقاضیان را در هر دو برش، approved پیشبینی کند. این چه تأثیری بر دقت، مثبتهای کاذب و منفیهای کاذب برای هر برش دارد؟
مرحله ۶: بررسی توزیع ویژگیها
در نهایت، به تب Features در ابزار What-if بروید. این تب توزیع مقادیر هر ویژگی در مجموعه داده شما را نشان میدهد:

میتوانید از این تب برای اطمینان از متعادل بودن مجموعه دادههای خود استفاده کنید. برای مثال، به نظر میرسد تعداد بسیار کمی از وامهای موجود در مجموعه دادهها از آژانس خدمات کشاورزی سرچشمه گرفتهاند. برای بهبود دقت مدل، در صورت موجود بودن دادهها، میتوانیم وامهای بیشتری از آن آژانس اضافه کنیم.
ما در اینجا فقط چند ایده برای کاوش در مورد ابزار What-if را شرح دادهایم. میتوانید به کار با این ابزار ادامه دهید، حوزههای بسیار بیشتری برای کاوش وجود دارد!
۸. مدل را در Vertex AI مستقر کنید
ما مدل خود را به صورت محلی کار میکنیم، اما خوب میشد اگر میتوانستیم از هر جایی (نه فقط این دفترچه یادداشت!) روی آن پیشبینی انجام دهیم. در این مرحله، آن را در فضای ابری مستقر خواهیم کرد.
مرحله ۱: ایجاد یک فضای ذخیرهسازی ابری برای مدل ما
بیایید ابتدا برخی از متغیرهای محیطی را که در ادامهی کد از آنها استفاده خواهیم کرد، تعریف کنیم. مقادیر زیر را با نام پروژهی گوگل کلود خود، نام باکت ذخیرهسازی ابری که میخواهید ایجاد کنید (باید به صورت سراسری منحصر به فرد باشد) و نام نسخهی اولین نسخهی مدل خود پر کنید:
# Update the variables below to your own Google Cloud project ID and GCS bucket name. You can leave the model name we've specified below:
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
MODEL_NAME = 'xgb_mortgage'
حالا آمادهایم تا یک مخزن ذخیرهسازی برای ذخیره فایل مدل XGBoost خود ایجاد کنیم. هنگام استقرار، Vertex AI را به این فایل ارجاع خواهیم داد.
برای ایجاد یک مخزن ذخیرهسازی منطقهای، دستور gsutil را از داخل نوتبوک خود اجرا کنید:
!gsutil mb -l us-central1 $MODEL_BUCKET
مرحله ۲: فایل مدل را در فضای ذخیرهسازی ابری کپی کنید
در مرحله بعد، فایل مدل ذخیره شده XGBoost خود را در فضای ابری کپی خواهیم کرد. دستور gsutil زیر را اجرا کنید:
!gsutil cp ./model.bst $MODEL_BUCKET
برای تأیید کپی شدن فایل، به مرورگر ذخیرهسازی در کنسول ابری خود بروید:

مرحله ۳: ایجاد مدل و استقرار در یک نقطه پایانی
تقریباً آمادهایم تا مدل را در فضای ابری مستقر کنیم! در Vertex AI، یک مدل میتواند چندین نقطه پایانی داشته باشد. ابتدا یک مدل ایجاد میکنیم، سپس یک نقطه پایانی درون آن مدل ایجاد کرده و آن را مستقر میکنیم.
ابتدا، از رابط خط فرمان gcloud برای ایجاد مدل خود استفاده کنید:
!gcloud beta ai models upload \
--display-name=$MODEL_NAME \
--artifact-uri=$MODEL_BUCKET \
--container-image-uri=us-docker.pkg.dev/cloud-aiplatform/prediction/xgboost-cpu.1-2:latest \
--region=us-central1
پارامتر artifact-uri به محل ذخیرهسازی که مدل XGBoost خود را در آن ذخیره کردهاید، اشاره میکند. پارامتر container-image-uri به Vertex AI میگوید که از کدام کانتینر از پیش ساخته شده برای ارائه استفاده کند. پس از اتمام این دستور، به بخش مدلهای کنسول Vertex خود بروید تا شناسه مدل جدید خود را دریافت کنید. میتوانید آن را در اینجا پیدا کنید:
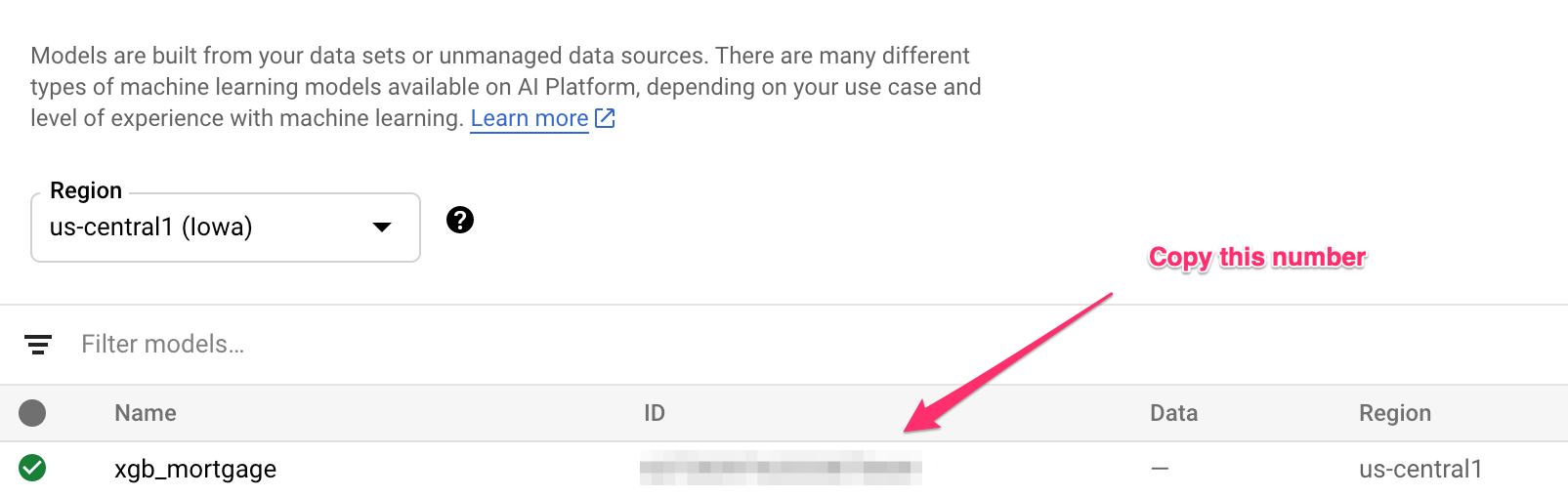
آن شناسه را کپی کرده و در یک متغیر ذخیره کنید:
MODEL_ID = "your_model_id"
حالا وقت آن رسیده که یک نقطه پایانی درون این مدل ایجاد کنیم. میتوانیم این کار را با دستور gcloud انجام دهیم:
!gcloud beta ai endpoints create \
--display-name=xgb_mortgage_v1 \
--region=us-central1
وقتی این کار تمام شد، باید موقعیت نقطه پایانی خود را در خروجی نوتبوک ما مشاهده کنید. به دنبال خطی باشید که میگوید نقطه پایانی با مسیری شبیه به زیر ایجاد شده است: projects/project_ID/locations/us-central1/endpoints/endpoint_ID. سپس مقادیر زیر را با شناسههای نقطه پایانی خود که در بالا ایجاد کردهاید جایگزین کنید:
ENDPOINT_ID = "your_endpoint_id"
برای استقرار نقطه پایانی خود، دستور gcloud زیر را اجرا کنید:
!gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=us-central1 \
--model=$MODEL_ID \
--display-name=xgb_mortgage_v1 \
--machine-type=n1-standard-2 \
--traffic-split=0=100
استقرار نقطه پایانی حدود ۵ تا ۱۰ دقیقه طول خواهد کشید. در حالی که نقطه پایانی شما در حال استقرار است، به بخش مدلهای کنسول خود بروید. روی مدل خود کلیک کنید تا ببینید که نقطه پایانی شما در حال استقرار است:

وقتی عملیات با موفقیت انجام شد، یک علامت تیک سبز رنگ در محل قرارگیری چرخندهی بارگذاری مشاهده خواهید کرد.
مرحله ۴: مدل پیادهسازی شده را آزمایش کنید
برای اطمینان از اینکه مدل پیادهسازیشده شما کار میکند، آن را با استفاده از gcloud برای پیشبینی آزمایش کنید. ابتدا، یک فایل JSON با مثالی از مجموعه آزمایشی ما ذخیره کنید:
%%writefile predictions.json
{
"instances": [
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
]
}
مدل خود را با اجرای این دستور gcloud آزمایش کنید:
!gcloud beta ai endpoints predict $ENDPOINT_ID \
--json-request=predictions.json \
--region=us-central1
شما باید پیشبینی مدل خود را در خروجی ببینید. این مثال خاص تأیید شد، بنابراین باید مقداری نزدیک به ۱ را ببینید.
۹. پاکسازی
اگر میخواهید به استفاده از این دفترچه یادداشت ادامه دهید، توصیه میشود وقتی از آن استفاده نمیکنید، آن را خاموش کنید. از رابط کاربری دفترچه یادداشتها در کنسول ابری خود، دفترچه یادداشت را انتخاب کرده و سپس توقف را انتخاب کنید:

اگر میخواهید تمام منابعی را که در این آزمایشگاه ایجاد کردهاید حذف کنید، به جای متوقف کردن آن، کافیست نمونه نوتبوک را حذف کنید.
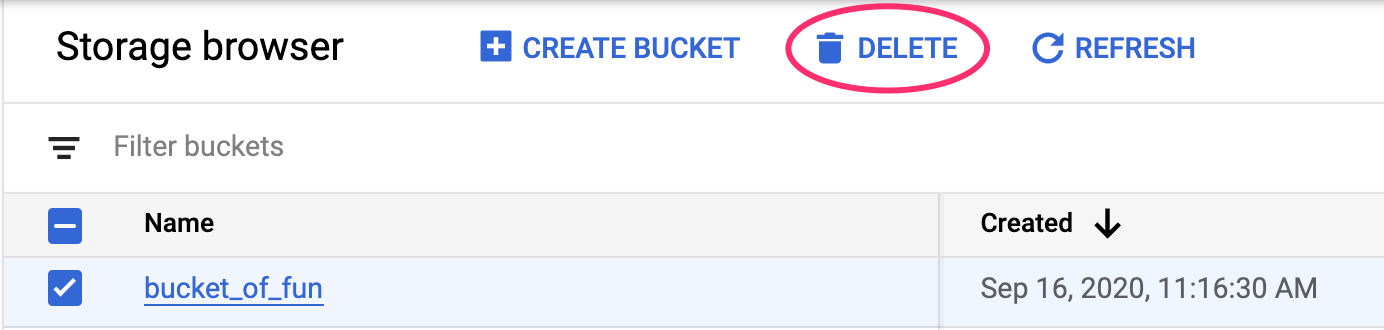
برای حذف نقطه پایانی که مستقر کردهاید، به بخش نقاط پایانی کنسول Vertex خود بروید و روی نماد حذف کلیک کنید:

برای حذف Storage Bucket، با استفاده از منوی ناوبری در Cloud Console خود، به Storage بروید، Bucket خود را انتخاب کنید و روی Delete کلیک کنید: