
1. 개요
이 실습에서는 What-If 도구를 사용하여 금융 데이터로 학습된 XGBoost 모델을 분석합니다. 모델을 분석한 후에는 Cloud의 새로운 Vertex AI에 배포합니다.
학습 내용
다음 작업을 수행하는 방법을 배우게 됩니다.
- 호스팅된 노트북에서 공개 주택담보대출 데이터 세트로 XGBoost 모델 학습
- What-If 도구를 사용하여 모델 분석
- Vertex AI에 XGBoost 모델 배포
Google Cloud에서 이 실습을 진행하는 데 드는 총 비용은 약 $1 입니다.
2. Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 이전할 수도 있습니다. 의견이 있는 경우 지원 페이지를 참고하세요.
Vertex AI에는 엔드 투 엔드 ML 워크플로를 지원하는 다양한 제품이 포함되어 있습니다. 이 실습에서는 아래에 강조 표시된 예측 및 Notebooks 제품에 중점을 둡니다.

3. 간단한 XGBoost 기본사항
XGBoost는 예측 모델을 빌드하기 위해 결정 트리와 그래디언트 부스팅을 사용하는 머신러닝 프레임워크입니다. 트리의 여러 리프 노드와 연결된 점수를 기반으로 여러 결정 트리를 함께 앙상블하여 작동합니다.
아래 다이어그램은 일기예보를 기반으로 스포츠 경기를 진행해야 하는지 평가하는 간단한 결정 트리 모델의 시각화입니다.

이 모델에 XGBoost를 사용하는 이유는 무엇인가요? 기존 신경망은 이미지 및 텍스트와 같은 비정형 데이터에서 가장 우수한 성능을 보이는 것으로 나타났지만 결정 트리는 이 Codelab에서 사용할 주택담보대출 데이터 세트와 같은 정형 데이터에서 매우 우수한 성능을 보이는 경우가 많습니다.
4. 환경 설정
이 Codelab을 실행하려면 결제가 사용 설정된 Google Cloud Platform 프로젝트가 필요합니다. 프로젝트를 만들려면 여기의 안내를 따르세요.
1단계: Compute Engine API 사용 설정
아직 사용 설정되지 않은 경우 Compute Engine으로 이동하고 사용 설정을 선택합니다. 이것은 노트북 인스턴스를 생성하는 데 필요합니다.
2단계: Vertex AI API 사용 설정
Cloud 콘솔의 Vertex 섹션으로 이동하고 Vertex AI API 사용 설정을 클릭합니다.

3단계: Notebooks 인스턴스 만들기
Cloud 콘솔의 Vertex 섹션에서 Notebooks를 클릭합니다.
여기에서 새 인스턴스 를 선택합니다. 그런 다음 GPU가 없는 TensorFlow Enterprise 2.3 인스턴스 유형을 선택합니다.

기본 옵션을 사용한 다음 만들기 를 클릭합니다. 인스턴스가 생성되면 JupyterLab 열기 를 선택합니다.
4단계: XGBoost 설치
JupyterLab 인스턴스가 열리면 XGBoost 패키지를 추가해야 합니다.
이렇게 하려면 런처에서 터미널을 선택합니다.

그런 다음 다음을 실행하여 Vertex AI에서 지원하는 최신 버전의 XGBoost를 설치합니다.
pip3 install xgboost==1.2
이 작업이 완료되면 런처에서 Python 3 노트북 인스턴스를 엽니다. 이제 노트북에서 시작할 준비가 되었습니다.
5단계: Python 패키지 가져오기
노트북의 첫 번째 셀에서 다음 가져오기를 추가하고 셀을 실행합니다. 상단 메뉴에서 오른쪽 화살표 버튼을 누르거나 command-enter를 눌러 실행할 수 있습니다.
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
5. 데이터 다운로드 및 처리
ffiec.gov의 주택담보대출 데이터 세트를 사용하여 XGBoost 모델을 학습시킵니다. 원본 데이터 세트에 사전 처리를 수행하고 모델을 학습시키는 데 사용할 수 있는 더 작은 버전을 만들었습니다. 모델은 특정 주택담보대출 신청이 승인될지 여부 를 예측합니다.
1단계: 사전 처리된 데이터 세트 다운로드
Google Cloud Storage에서 데이터 세트 버전을 사용할 수 있도록 했습니다. Jupyter 노트북에서 다음 gsutil 명령어를 실행하여 다운로드할 수 있습니다.
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
2단계: Pandas로 데이터 세트 읽기
Pandas DataFrame을 만들기 전에 Pandas에서 데이터 세트를 올바르게 읽을 수 있도록 각 열의 데이터 유형 dict를 만듭니다.
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
다음으로 위에 지정한 데이터 유형을 전달하여 DataFrame을 만듭니다. 원본 데이터 세트가 특정 방식으로 정렬된 경우 데이터를 셔플하는 것이 중요합니다. 첫 번째 셀에서 가져온 shuffle이라는 sklearn 유틸리티를 사용하여 이 작업을 실행합니다.
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head()를 사용하면 Pandas에서 데이터 세트의 처음 5개 행을 미리 볼 수 있습니다. 위의 셀을 실행하면 다음과 같은 내용이 표시됩니다.
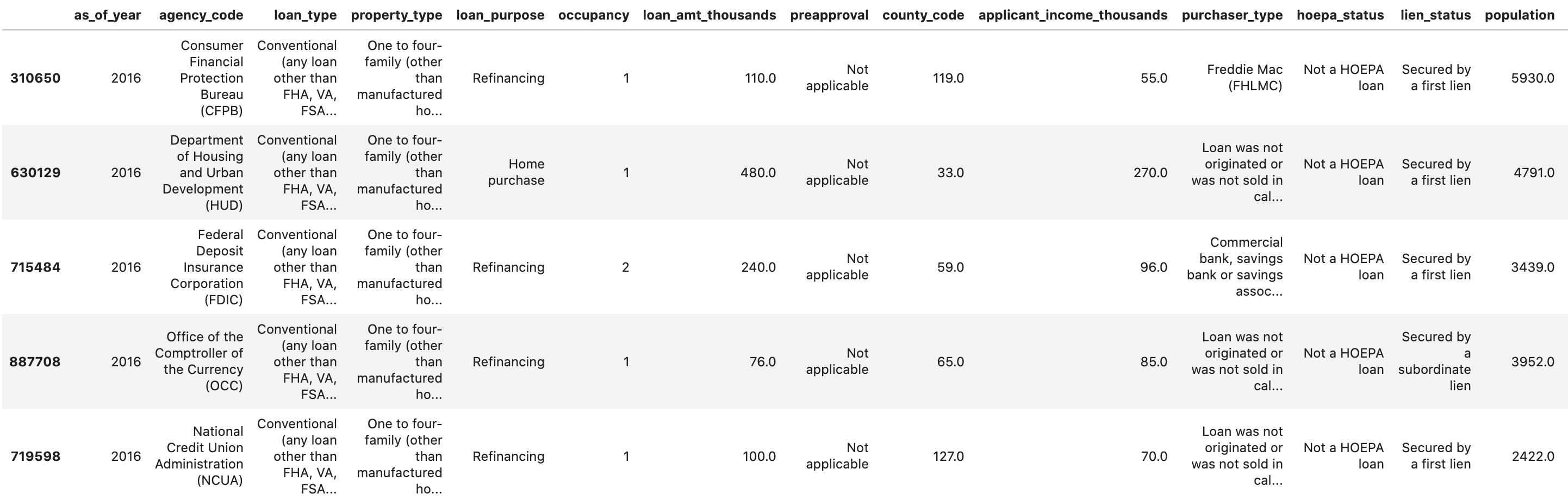
이러한 특성은 모델을 학습시키는 데 사용됩니다. 끝까지 스크롤하면 예측하는 항목인 마지막 열 approved가 표시됩니다. 1 값은 특정 애플리케이션이 승인되었음을 나타내고 0은 거부되었음을 나타냅니다.
데이터 세트에서 승인 / 거부 값의 분포를 확인하고 라벨의 numpy 배열을 만들려면 다음을 실행합니다.
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
데이터 세트의 약 66% 에 승인된 애플리케이션이 포함되어 있습니다.
3단계: 카테고리 값의 더미 열 만들기
이 데이터 세트에는 카테고리 값과 숫자 값이 혼합되어 있지만 XGBoost에서는 모든 특성이 숫자여야 합니다. 카테고리 값을 원-핫 인코딩을 사용하여 나타내는 대신 XGBoost 모델에서는 Pandas get_dummies 함수를 활용합니다.
get_dummies 는 가능한 값이 여러 개 있는 열을 가져와서 0과 1만 포함된 일련의 열로 변환합니다. 예를 들어 가능한 값이 'blue'와 'red'인 'color' 열이 있는 경우 get_dummies는 이를 모든 부울 0 및 1 값이 있는 'color_blue' 및 'color_red'라는 2개의 열로 변환합니다.
카테고리 특성의 더미 열을 만들려면 다음 코드를 실행합니다.
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
이번에 데이터를 미리 보면 단일 특성 (아래 그림의 purchaser_type과 같은)이 여러 열로 분할된 것을 확인할 수 있습니다.

4단계: 데이터를 학습 세트와 테스트 세트로 분할
머신러닝에서 중요한 개념은 학습 / 테스트 분할입니다. 대부분의 데이터를 가져와서 모델을 학습시키는 데 사용하고 나머지는 이전에 본 적이 없는 데이터로 모델을 테스트하기 위해 따로 보관합니다.
Scikit-learn 함수 train_test_split을 사용하여 데이터를 분할하는 다음 코드를 노트북에 추가합니다.
x,y = data.values,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
이제 모델을 빌드하고 학습시킬 준비가 되었습니다.
6. XGBoost 모델 빌드, 학습, 평가
1단계: XGBoost 모델 정의 및 학습
XGBoost에서 모델을 만드는 것은 간단합니다. XGBClassifier 클래스를 사용하여 모델을 만들고 특정 분류 작업에 적합한 objective 매개변수를 전달하기만 하면 됩니다. 이 경우 이진 분류 문제가 있고 모델이 (0,1) 범위의 단일 값을 출력하도록 하므로 reg:logistic을 사용합니다. 승인되지 않은 경우 0, 승인된 경우 1입니다.
다음 코드는 XGBoost 모델을 만듭니다.
model = xgb.XGBClassifier(
objective='reg:logistic'
)
한 줄의 코드로 모델을 학습시키고 fit() 메서드를 호출하여 학습 데이터와 라벨을 전달할 수 있습니다.
model.fit(x_train, y_train)
2단계: 모델의 정확도 평가
이제 학습된 모델을 사용하여 predict() 함수로 테스트 데이터에 대한 예측을 생성할 수 있습니다.
그런 다음 Scikit-learn의 accuracy_score() 함수를 사용하여 테스트 데이터에서 모델의 성능을 기반으로 모델의 정확도를 계산합니다. 테스트 세트의 각 예시에 대해 모델의 예측 값과 함께 정답 값을 전달합니다.
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
정확도는 87% 정도이지만 머신러닝에는 항상 무작위 요소가 있으므로 약간 다를 수 있습니다.
3단계: 모델 저장
모델을 배포하려면 다음 코드를 실행하여 로컬 파일에 저장합니다.
model.save_model('model.bst')
7. What-If 도구를 사용하여 모델 해석
1단계: What-If 도구 시각화 만들기
What-If 도구를 로컬 모델에 연결하려면 테스트 예시의 하위 집합과 해당 예시의 정답 값을 전달해야 합니다. 정답 라벨과 함께 테스트 예시 500개의 Numpy 배열을 만들어 보겠습니다.
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples],y_test[:num_wit_examples].reshape(-1,1)))
What-If 도구를 인스턴스화하는 것은 WitConfigBuilder 객체를 만들고 분석하려는 모델을 전달하는 것만큼 간단합니다.
What-If 도구에는 모델의 각 클래스 (이 경우 2개)의 점수 목록이 필요하므로 What-If 도구와 함께 XGBoost의 predict_proba 메서드를 사용합니다.
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_custom_predict_fn(model.predict_proba)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
시각화를 로드하는 데 1분 정도 걸립니다. 로드되면 다음이 표시됩니다.

y축은 모델의 예측을 보여주며 1은 신뢰도가 높은 approved 예측이고 0은 신뢰도가 높은 denied 예측입니다. x축은 로드된 모든 데이터 포인트의 분포입니다.
2단계: 개별 데이터 포인트 탐색
What-If 도구의 기본 뷰는 데이터 포인트 편집기 탭입니다. 여기에서 개별 데이터 포인트를 클릭하여 특성을 확인하고, 특성 값을 변경하고, 변경사항이 개별 데이터 포인트에 대한 모델의 예측에 미치는 영향을 확인할 수 있습니다.
아래 예시에서는 .5 임곗값에 가까운 데이터 포인트를 선택했습니다. 이 특정 데이터 포인트와 연결된 주택담보대출 신청은 CFPB에서 시작되었습니다. 이 특성을 0으로 변경하고 agency_code_Department of Housing and Urban Development (HUD)의 값을 1로 변경하여 이 대출이 HUD에서 시작된 경우 모델의 예측에 어떤 영향을 미치는지 확인했습니다.

What-If 도구의 왼쪽 하단 섹션에서 볼 수 있듯이 이 특성을 변경하면 모델의 approved 예측이 32% 감소했습니다. 이는 대출이 시작된 기관이 모델의 출력에 큰 영향을 미친다는 것을 나타낼 수 있지만 확실히 하려면 추가 분석을 수행해야 합니다.
UI의 왼쪽 하단 부분에서 각 데이터 포인트의 정답 값을 확인하고 모델의 예측과 비교할 수도 있습니다.

3단계: 반사실적 분석
다음으로 데이터 포인트를 클릭하고 가장 가까운 반사실적 데이터 포인트 표시 슬라이더를 오른쪽으로 이동합니다.

이 옵션을 선택하면 선택한 원본 데이터 포인트와 가장 유사한 특성 값 을 갖지만 예측은 반대인 데이터 포인트가 표시됩니다. 그런 다음 특성 값을 스크롤하여 두 데이터 포인트가 다른 위치를 확인할 수 있습니다 (차이점은 녹색으로 굵게 강조 표시됨).
4단계: 부분 종속성 플롯 살펴보기
각 특성이 모델의 전반적인 예측에 미치는 영향을 확인하려면 부분 종속성 플롯 체크박스를 선택하고 전역 부분 종속성 플롯 이 선택되어 있는지 확인합니다.

여기에서 HUD에서 시작된 대출은 거부될 가능성이 약간 더 높다는 것을 확인할 수 있습니다. 기관 코드는 부울 특성이므로 값은 정확히 0 또는 1일 수만 있기 때문에 그래프가 이 모양입니다.
applicant_income_thousands는 숫자 특성이며 부분 종속성 플롯에서 소득이 높을수록 신청이 승인될 가능성이 약간 높아지지만 약 20만 달러까지만 높아진다는 것을 확인할 수 있습니다. 20만 달러를 넘으면 이 특성은 모델의 예측에 영향을 미치지 않습니다.
5단계: 전반적인 성능 및 공정성 탐색
다음으로 성능 및 공정성 탭으로 이동합니다. 여기에는 혼동 행렬, PR 곡선, ROC 곡선을 비롯하여 제공된 데이터 세트에서 모델의 결과에 대한 전반적인 성능 통계가 표시됩니다.
정답 특성으로 mortgage_status를 선택하여 혼동 행렬을 확인합니다.

이 혼동 행렬은 모델의 올바른 예측과 잘못된 예측을 전체의 비율 로 보여줍니다. 실제 예 / 예측 예 및 실제 아니요 / 예측 아니요 사각형을 더하면 모델과 동일한 정확도 (이 경우 약 87%, ML 모델 학습에는 무작위 요소가 있으므로 모델이 약간 다를 수 있음)가 더해집니다.
또한 임곗값 슬라이더를 사용하여 모델이 대출에 대해 approved를 예측하기 전에 반환해야 하는 양성 분류 점수를 높이거나 낮추고 정확도, 거짓양성, 거짓음성이 어떻게 변하는지 실험할 수 있습니다. 이 경우 정확도는 임곗값 .55 정도에서 가장 높습니다.
다음으로 왼쪽 기준으로 분할 드롭다운에서 loan_purpose_Home_purchase를 선택합니다.

이제 데이터의 두 하위 집합에 대한 성능이 표시됩니다. '0' 슬라이스는 대출이 주택 구매를 위한 것이 아닌 경우를 보여주고 '1' 슬라이스는 대출이 주택 구매를 위한 경우를 보여줍니다. 두 슬라이스 간의 정확도, 거짓양성, 거짓음성 비율을 확인하여 성능의 차이를 찾습니다.
행을 펼쳐서 혼동 행렬을 살펴보면 모델이 주택 구매를 위한 대출 신청의 약 70% 에 대해 '승인됨'을 예측하고 주택 구매를 위한 것이 아닌 대출의 46% 에 대해서만 '승인됨'을 예측하는 것을 확인할 수 있습니다 (정확한 비율은 모델에 따라 다름).

왼쪽의 라디오 버튼에서 인구통계학적 패리티 를 선택하면 두 임곗값이 조정되어 모델이 두 슬라이스 모두에서 비슷한 비율의 신청자에 대해 approved를 예측합니다. 각 슬라이스의 정확도, 거짓양성, 거짓음성에 어떤 영향을 미치나요?
6단계: 특성 분포 탐색
마지막으로 What-If 도구의 특성 탭으로 이동합니다. 여기에는 데이터 세트의 각 특성 값 분포가 표시됩니다.
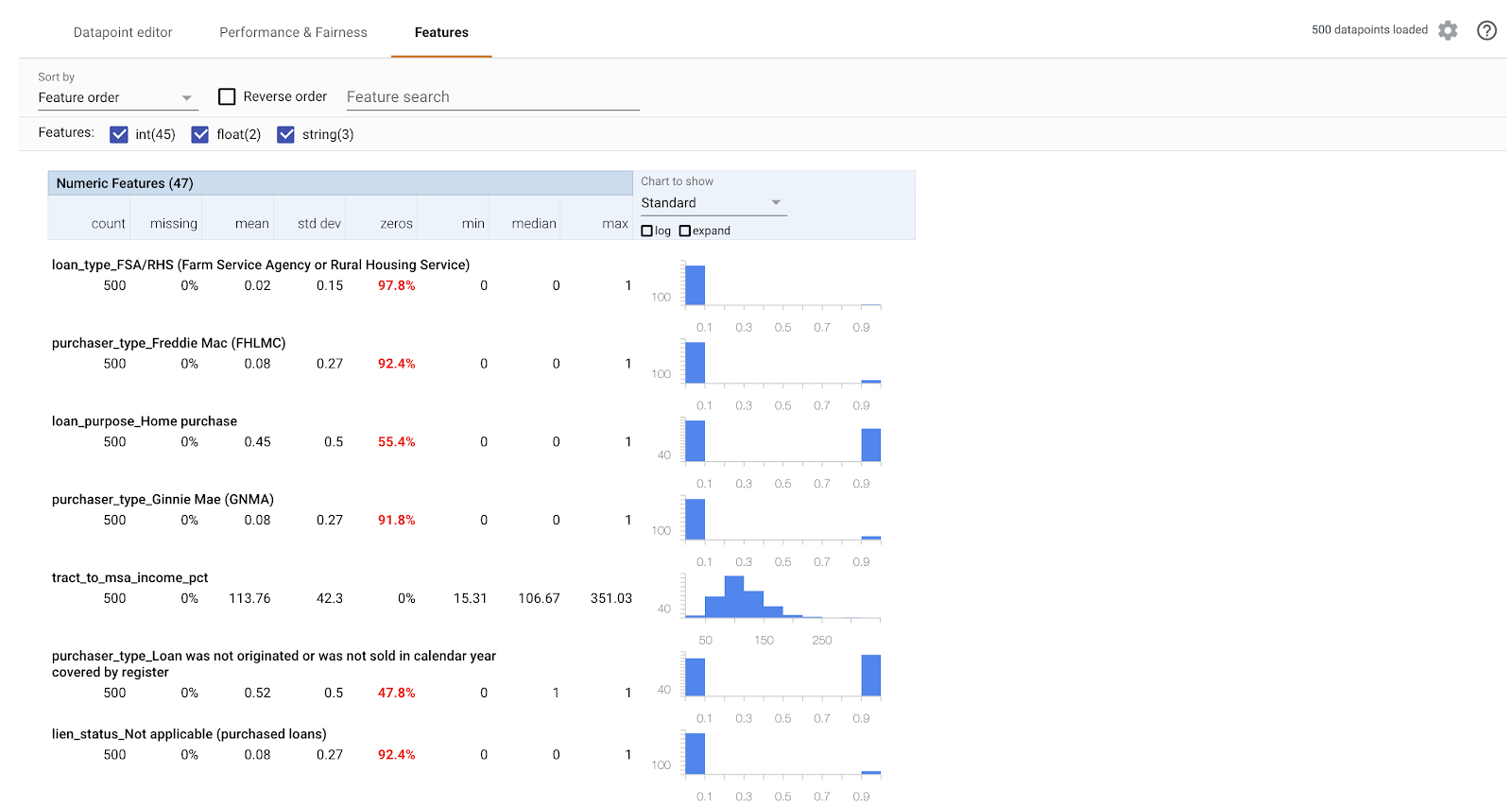
이 탭을 사용하여 데이터 세트의 균형을 맞출 수 있습니다. 예를 들어 데이터 세트에서 농업 서비스국에서 시작된 대출은 매우 적은 것으로 보입니다. 모델 정확도를 개선하기 위해 데이터가 있는 경우 해당 기관의 대출을 더 추가하는 것이 좋습니다.
여기에서는 몇 가지 What-If 도구 탐색 아이디어를 설명했습니다. 도구를 계속 사용해 보세요. 탐색할 영역이 훨씬 더 많습니다.
8. Vertex AI에 모델 배포
모델이 로컬에서 작동하지만 이 노트북뿐만 아니라 어디에서나 모델에 대한 예측을 할 수 있다면 좋을 것입니다. 이 단계에서는 클라우드에 배포합니다.
1단계: 모델의 Cloud Storage 버킷 만들기
먼저 Codelab의 나머지 부분에서 사용할 몇 가지 환경 변수를 정의해 보겠습니다. 아래 값을 Google Cloud 프로젝트 이름, 만들려는 Cloud Storage 버킷 이름 (전역적으로 고유해야 함), 모델의 첫 번째 버전의 버전 이름으로 채웁니다.
# Update the variables below to your own Google Cloud project ID and GCS bucket name. You can leave the model name we've specified below:
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
MODEL_NAME = 'xgb_mortgage'
이제 XGBoost 모델 파일을 저장할 스토리지 버킷을 만들 준비가 되었습니다. 배포할 때 Vertex AI가 이 파일을 가리키도록 합니다.
노트북 내에서 이 gsutil 명령어를 실행하여 리전 스토리지 버킷을 만듭니다.
!gsutil mb -l us-central1 $MODEL_BUCKET
2단계: 모델 파일을 Cloud Storage에 복사
다음으로 XGBoost 저장 모델 파일을 Cloud Storage에 복사합니다. 다음 gsutil 명령어를 실행합니다.
!gsutil cp ./model.bst $MODEL_BUCKET
Cloud 콘솔의 스토리지 브라우저로 이동하여 파일이 복사되었는지 확인합니다.

3단계: 모델을 만들고 엔드포인트에 배포
이제 모델을 클라우드에 배포할 준비가 거의 되었습니다. Vertex AI에서 모델은 여러 엔드포인트를 보유할 수 있습니다. 먼저 모델을 만든 다음 해당 모델 내에서 엔드포인트를 만들고 배포합니다.
먼저 gcloud CLI를 사용하여 모델을 만듭니다.
!gcloud beta ai models upload \
--display-name=$MODEL_NAME \
--artifact-uri=$MODEL_BUCKET \
--container-image-uri=us-docker.pkg.dev/cloud-aiplatform/prediction/xgboost-cpu.1-2:latest \
--region=us-central1
artifact-uri 매개변수는 XGBoost 모델을 저장한 스토리지 위치를 가리킵니다. container-image-uri 매개변수는 Vertex AI에 서빙에 사용할 사전 빌드된 컨테이너를 알려줍니다. 이 명령어가 완료되면 Vertex 콘솔의 모델 섹션으로 이동하여 새 모델의 ID를 가져옵니다. 여기에서 찾을 수 있습니다.

해당 ID를 복사하여 변수에 저장합니다.
MODEL_ID = "your_model_id"
이제 이 모델 내에서 엔드포인트를 만들 차례입니다. 이 gcloud 명령어를 사용하여 이 작업을 실행할 수 있습니다.
!gcloud beta ai endpoints create \
--display-name=xgb_mortgage_v1 \
--region=us-central1
이 작업이 완료되면 엔드포인트의 위치가 노트북 출력에 로깅됩니다. 엔드포인트가 다음과 같은 경로로 생성되었다는 줄을 찾습니다. projects/project_ID/locations/us-central1/endpoints/endpoint_ID. 그런 다음 아래 값을 위에서 만든 엔드포인트의 ID로 바꿉니다.
ENDPOINT_ID = "your_endpoint_id"
엔드포인트를 배포하려면 아래 gcloud 명령어를 실행합니다.
!gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=us-central1 \
--model=$MODEL_ID \
--display-name=xgb_mortgage_v1 \
--machine-type=n1-standard-2 \
--traffic-split=0=100
엔드포인트 배포가 완료되는 데 약 5~10분이 걸립니다. 엔드포인트가 배포되는 동안 콘솔의 모델 섹션으로 이동합니다. 모델을 클릭하면 엔드포인트가 배포되는 것을 확인할 수 있습니다.
배포가 완료되면 로드 스피너가 있는 위치에 녹색 체크 표시가 표시됩니다.
4단계: 배포된 모델 테스트
배포된 모델이 작동하는지 확인하려면 gcloud를 사용하여 예측을 실행하여 테스트합니다. 먼저 테스트 세트의 예시가 포함된 JSON 파일을 저장합니다.
%%writefile predictions.json
{
"instances": [
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
]
}
이 gcloud 명령어를 실행하여 모델을 테스트합니다.
!gcloud beta ai endpoints predict $ENDPOINT_ID \
--json-request=predictions.json \
--region=us-central1
출력에 모델의 예측이 표시됩니다. 이 특정 예시는 승인되었으므로 1에 가까운 값이 표시됩니다.
9. 삭제
이 노트북을 계속 사용하려면 사용하지 않을 때 노트북을 끄는 것이 좋습니다. Cloud 콘솔의 Notebooks UI에서 노트북을 선택한 다음 중지를 선택합니다.

이 실습에서 만든 모든 리소스를 삭제하려면 노트북 인스턴스를 중지하는 대신 삭제하면 됩니다.
배포한 엔드포인트를 삭제하려면 Vertex 콘솔의 엔드포인트 섹션으로 이동하고 삭제 아이콘을 클릭합니다.

스토리지 버킷을 삭제하려면 Cloud 콘솔의 탐색 메뉴를 사용하여 스토리지로 이동하고 버킷을 선택하고 '삭제'를 클릭합니다.
