
1. نظرة عامة
ستتعلم في هذا التمرين المعملي كيفية إنشاء شبكات عصبية التفافية وتدريبها وضبطها من البداية باستخدام Keras وTensorflow 2. ويمكن تنفيذ ذلك في دقائق باستخدام طاقة وحدات معالجة الموتّرات. ستستكشف أيضًا مناهج متعددة بدءًا من التعلم البسيط للغاية وصولاً إلى البُنى الالتفافية الحديثة مثل Squeezenet. يشتمل هذا التمرين المعملي على تفسيرات نظرية عن الشبكات العصبية، كما يعد نقطة انطلاق جيدة للمطورين الذين يتعلمون عن التعلم المتعمق.
قد تكون قراءة مقالات التعلّم المعمّق صعبة ومربكة. دعنا نلقي نظرة عملية على بُنى الشبكة العصبونية الالتفافية الحديثة.

ما ستتعرَّف عليه
- يمكنك استخدام وحدات معالجة Keras وTensor (TPU) لإنشاء نماذج مخصَّصة بشكل أسرع.
- استخدام واجهة برمجة التطبيقات tf.data.Dataset وتنسيق TFRecord لتحميل بيانات التدريب بكفاءة.
- للغش 😈، باستخدام التعلم الآلي بدلاً من إنشاء نماذجك الخاصة.
- لاستخدام أنماط نموذج Keras المتسلسلة والوظيفية.
- لإنشاء مُصنِّف Keras الخاص بك باستخدام طبقة softmax وفقدان الطاقة عبر الإنتروبيا.
- لضبط نموذجك باستخدام مجموعة جيدة من الطبقات الالتفافية.
- لاستكشاف الأفكار الحديثة لهندسة الإحالات الناجحة مثل الوحدات ومتوسط التجميع العالمي، وما إلى ذلك
- بناء حوار حديث وبسيط باستخدام بنية Squeezenet.
الملاحظات
إذا لاحظت أي أخطاء في التمرين المعملي الخاص بالرموز، يُرجى إخبارنا بذلك. يمكن تقديم الملاحظات من خلال مشاكل GitHub [ رابط الملاحظات].
2. دليل البدء السريع لخدمة Google Colaboratory
يستخدم هذا التمرين المعملي متعاون Google ولا يتطلب أي إعداد من جانبك. ويمكنك تشغيلها من جهاز Chromebook. يُرجى فتح الملف أدناه وتنفيذ الخلايا للتعرّف على أوراق ملاحظات Colab.
اختيار إحدى خلفيات وحدة معالجة الموتّرات
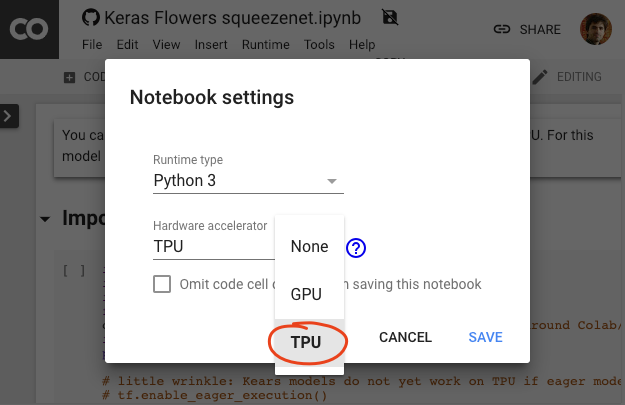
في قائمة Colab، اختَر وقت التشغيل >. غيِّر نوع بيئة التشغيل ثم اختَر "وحدة معالجة الموتّرات". سوف تستخدم في هذا التمرين المعملي وحدة معالجة بيانات (TPU) قوية للتدريب الذي يتم تسريعه باستخدام الأجهزة. سيتم الاتصال ببيئة التشغيل تلقائيًا عند التنفيذ الأول، أو يمكنك استخدام الزر "اتصال" في أعلى الجانب الأيسر.
تنفيذ ورقة الملاحظات
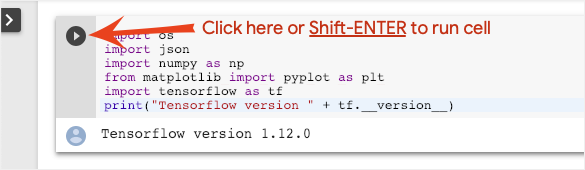
نفِّذ الخلايا واحدة تلو الأخرى عن طريق النقر على خلية واستخدام Shift-ENTER. يمكنك أيضًا تشغيل ورقة الملاحظات بالكامل باستخدام "بيئة التشغيل" > تنفيذ الكل
جدول المحتويات

تحتوي جميع أوراق الملاحظات على جدول محتويات. يمكنك فتحه باستخدام السهم الأسود على اليمين.
الخلايا المخفية

لن تعرض بعض الخلايا إلا عناوينها. هذه ميزة خاصة بأوراق الملاحظات في Colab. يمكنك النقر مرّتين عليها لرؤية الرمز بداخلها، ولكن عادةً لا يكون ذلك مثيرًا للاهتمام. عادةً ما تكون دوال الدعم أو التصورات. لا تزال بحاجة إلى تشغيل هذه الخلايا حتى يتم تحديد الدوال داخلها.
المصادقة
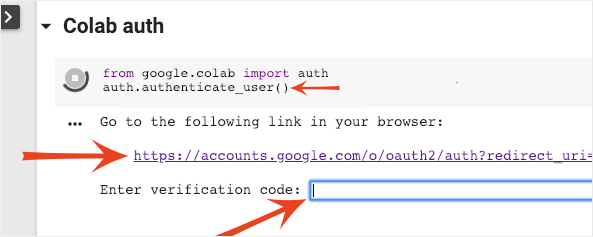
يمكن لخدمة Colab الوصول إلى حِزم Google Cloud Storage الخاصة بك بشرط المصادقة باستخدام حساب معتمَد. سيؤدي مقتطف الرمز أعلاه إلى بدء عملية مصادقة.
3- [INFO] ما هي وحدات معالجة Tensor (TPU)؟
باختصار

رمز تدريب نموذج على وحدة معالجة الموتّرات في Keras (واستخدام وحدة معالجة الرسومات أو وحدة المعالجة المركزية (CPU) في حال عدم توفّر وحدة معالجة الموتّرات):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
سنستخدم اليوم وحدات معالجة الموتّرات لإنشاء مصنِّف زهور وتحسينه بالسرعات التفاعلية (دقائق لكل تمرين تدريبي).

ما هي أسباب استخدام وحدات معالجة الموتّرات؟
يتم تنظيم وحدات معالجة الرسومات الحديثة استنادًا إلى "النواة" القابلة للبرمجة، وهي بنية مرنة للغاية تتيح لها معالجة مجموعة من المهام، مثل العرض الثلاثي الأبعاد والتعلّم المعمّق والمحاكاة المادية وما إلى ذلك. من ناحية أخرى، تقوم وحدات معالجة الموتّرات بإقران معالج متجه كلاسيكي بوحدة ضرب مصفوفة مخصصة وتتفوّق في أي مهمة تهيمن عليها عمليات ضرب المصفوفة الكبيرة، مثل الشبكات العصبونية.

صورة توضيحية: طبقة شبكة عصبية كثيفة كضرب مصفوفة، مع معالجة مجموعة من ثماني صور من خلال الشبكة العصبونية في وقت واحد يُرجى تنفيذ عملية ضرب العمود في سطر واحد للتأكد من أنها تُخرِج مجموع ترجيح لجميع قيم وحدات البكسل في الصورة. ويمكن تمثيل الطبقات الالتفافية في صورة عمليات ضرب المصفوفات أيضًا على الرغم من تعقيدها بعض الشيء ( الشرح هنا في القسم 1).
الأجهزة
MXU وVPU
يتكوّن الإصدار الثاني من وحدة معالجة الموتّرات من وحدة مصفوفة مصفوفة (MXU) تعمل على تنفيذ عمليات ضرب المصفوفة ووحدة معالجة المتّجهات (VPU) لجميع المهام الأخرى مثل عمليات التفعيل وsoftmax وغير ذلك. ويعالج VPU العمليات الحسابية float32 وint32. من ناحية أخرى، تعمل وحدة قياس الأداء (MXU) بتنسيق نقطة عائمة بدقة مختلطة 16-32 بت.
نقطة عائمة بدقة مختلطة وbfloat16
تحسب MXU عمليات ضرب المصفوفة باستخدام مدخلات bfloat16 ومخرجات float32. ويتم تنفيذ التراكمات المتوسطة بدقة float32.
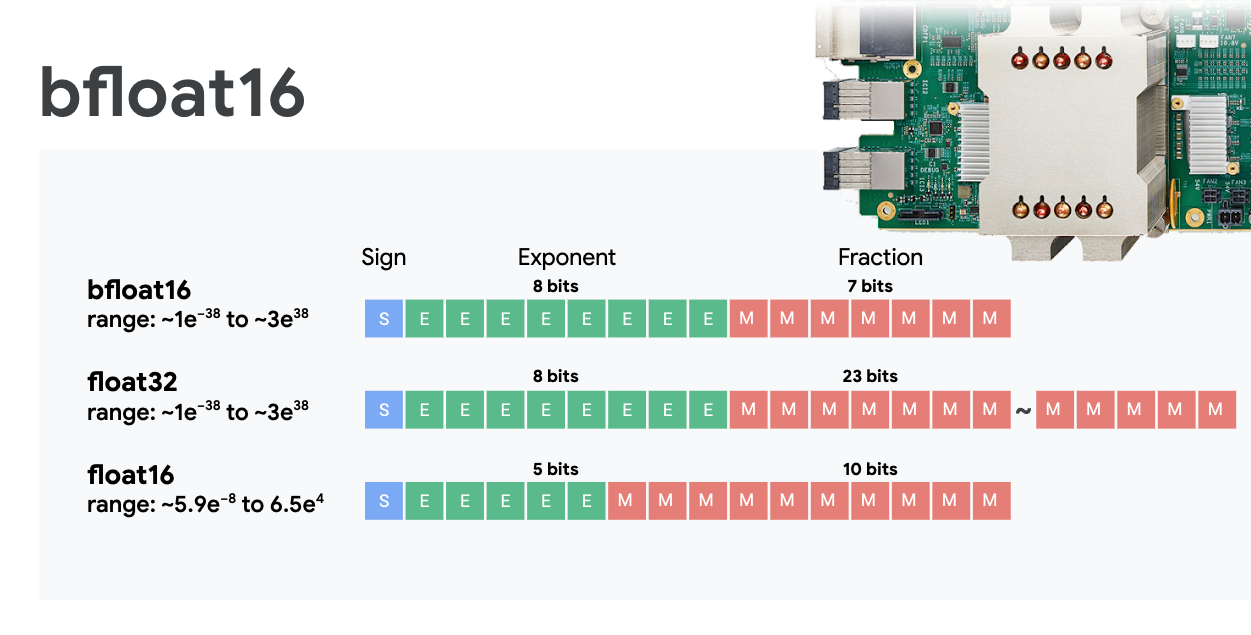
عادةً ما يكون التدريب على الشبكة العصبية مقاومًا للضوضاء الناتجة عن تقليل دقة النقاط العائمة. هناك حالات يساعد فيها الضجيج في التقارب أيضًا. عادةً ما يتم استخدام دقة النقطة العائمة بتنسيق 16 بت لتسريع العمليات الحسابية، غير أنّ النطاقَين float16 وfloat32 يحتويان على نطاقات مختلفة جدًا. عادةً ما يؤدي خفض الدقة من العدد العشري 32 إلى العدد العشري 16 إلى حدوث تدفقات أعلى وتدفق منخفض. توجد حلول ولكن يلزم عمل إضافي عادةً لعمل float16.
ولهذا السبب قدّمت Google تنسيق bfloat16 في وحدات معالجة الموتّرات. bfloat16 هو عدد عائم 32 تم اقتطاعه بنفس وحدات بت الأس ونطاقه مثل float32. هذا بالإضافة إلى حقيقة أنّ وحدات معالجة الموتّرات تحتسب عمليات ضرب المصفوفات بدقة مختلطة مع مخرجات bfloat16 والمخرجات float32، وهو ما يعني أنّه لا يلزم عادةً إجراء أي تغييرات في الرموز للاستفادة من نتائج الدقة المنخفضة في الأداء.
المصفوفة الانسيابية
تنفذ MXU عمليات ضرب المصفوفة في الأجهزة باستخدام ما يُعرف باسم "الصفيفة الانقباضية" البنية التي تتدفق فيها عناصر البيانات من خلال صفيف من وحدات الحوسبة للأجهزة. (في المجال الطبي، تشير كلمة "انقباضي" إلى انقباضات القلب وتدفق الدم، هنا لتدفق البيانات).
العنصر الأساسي لعملية ضرب المصفوفة هو ناتج الضرب النقطي بين خط من مصفوفة واحدة وعمود من المصفوفة الأخرى (راجع الرسم التوضيحي أعلى هذا القسم). بالنسبة لعملية ضرب المصفوفة Y=X*W، سيكون أحد عناصر النتيجة هو:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
على وحدة معالجة الرسومات، يمكن للمرء برمجة هذا الناتج النقطي إلى "نواة" في وحدة معالجة الرسومات ثم تنفيذها على أكبر عدد ممكن من "النواة" كما هي بالتوازي لمحاولة حساب كل قيمة للمصفوفة الناتجة دفعة واحدة. إذا كانت المصفوفة الناتجة كبيرة بحجم 128×128، فسيتطلب ذلك 128x128=16K "نواة" متاحة وهو ما لا يكون ممكنًا عادةً. تحتوي أكبر وحدات معالجة الرسومات على 4,000 نواة تقريبًا. من ناحية أخرى، تستخدم وحدة معالجة الموتّرات الحدّ الأدنى من الأجهزة لوحدات الحوسبة في وحدة معالجة الموتّرات (MXU)، وهي تشمل فقط bfloat16 x bfloat16 => float32 مراكمات مضاعفة، ولا ينطبق أي إجراء آخر. وهي صغيرة للغاية لدرجة أنّ وحدة معالجة الموتّرات يمكنها تنفيذ 16 كيلوبايت في وحدة MXU128 × 128 بكسل ومعالجة عملية ضرب المصفوفة هذه دفعة واحدة.
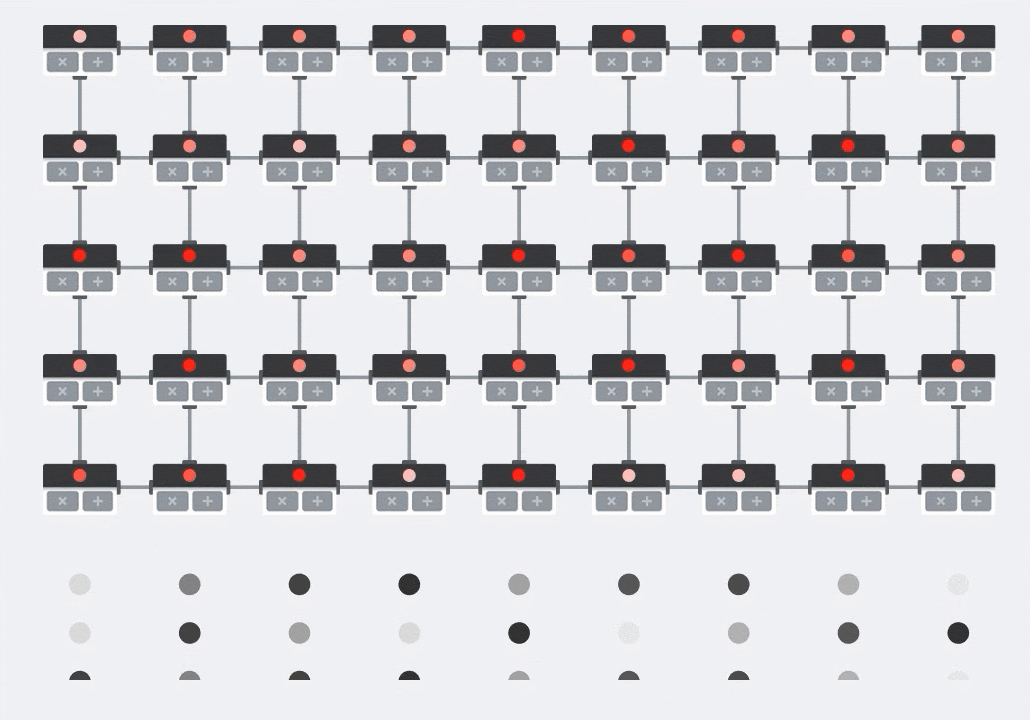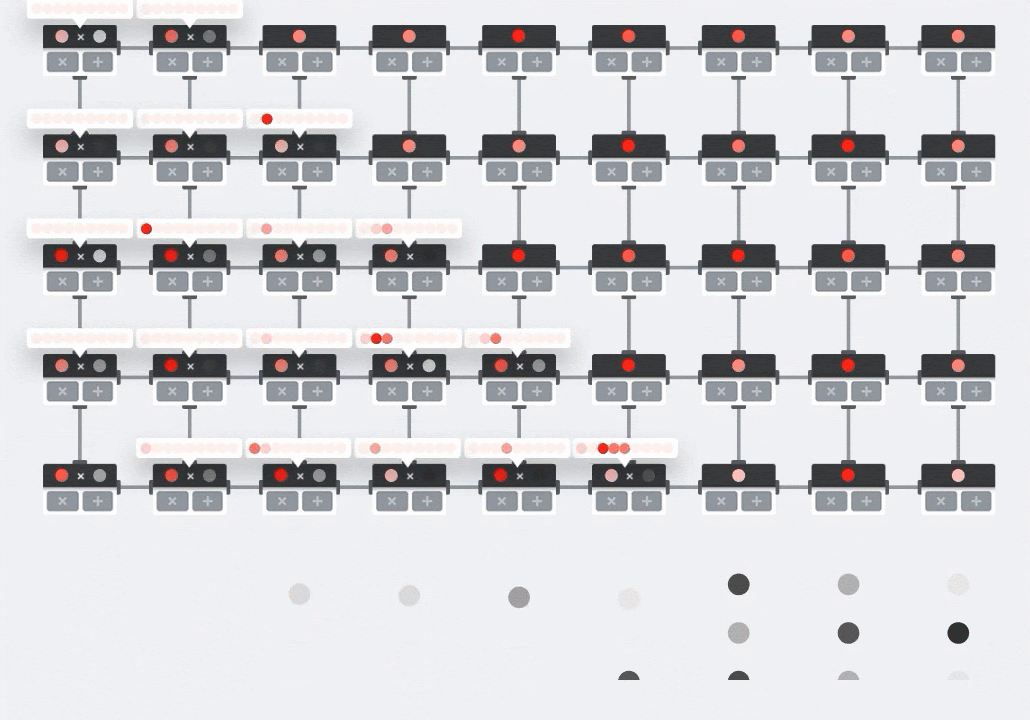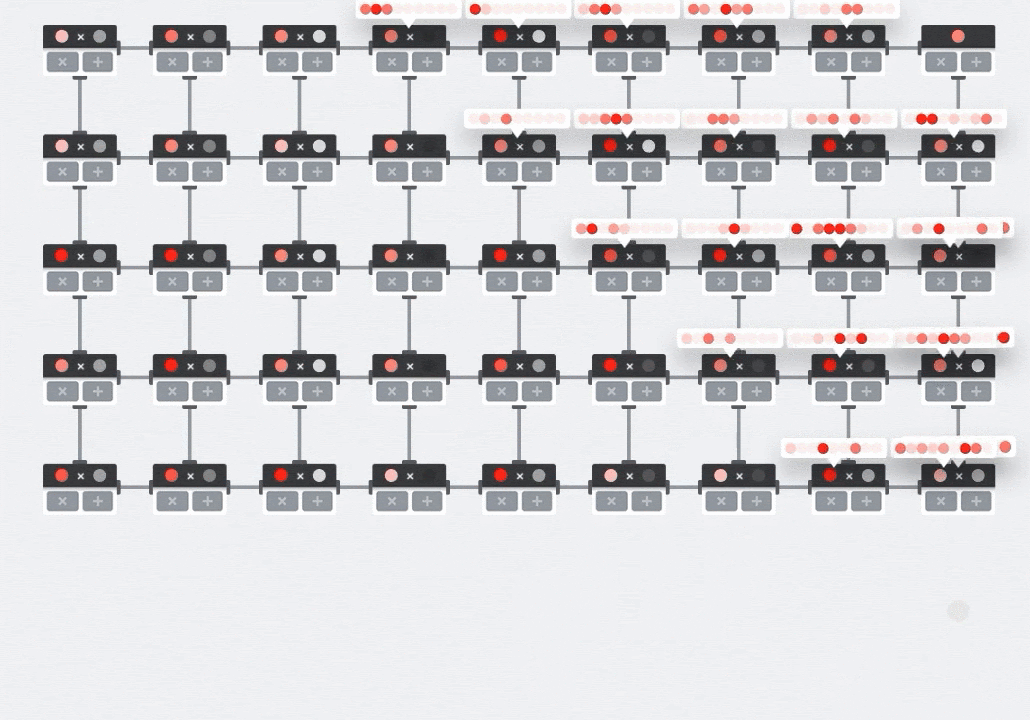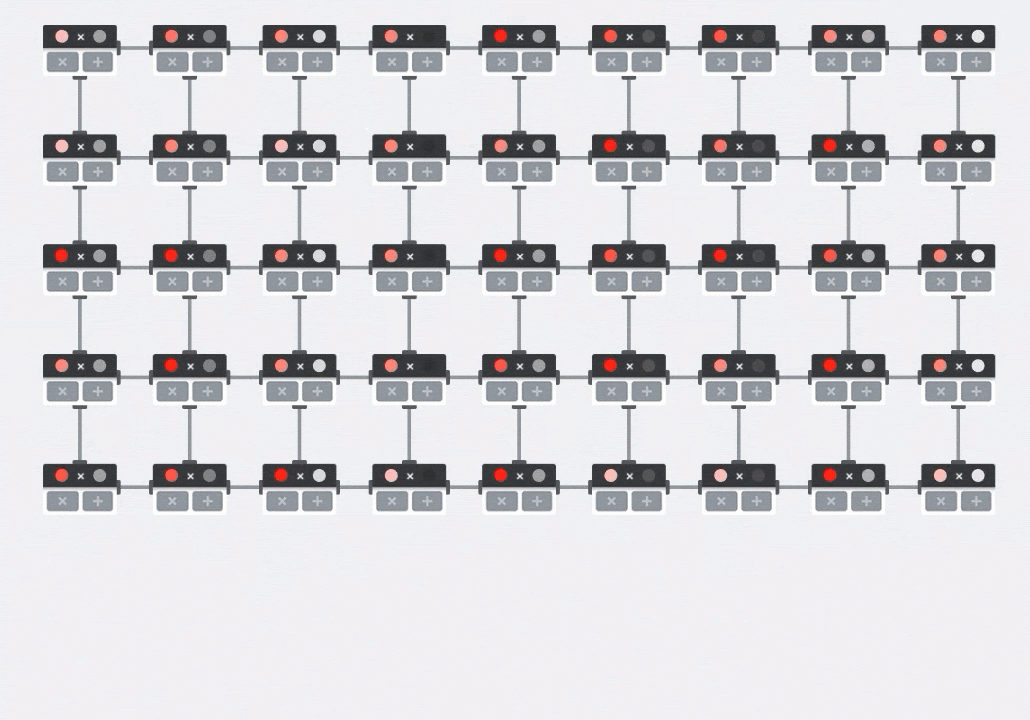
صورة توضيحية: صفيفة MXU الانقباضية. عناصر الحوسبة هي مراكمات الضربات. يتم تحميل قيم مصفوفة واحدة في الصفيف (النقاط الحمراء). تتدفق قيم المصفوفة الأخرى من خلال الصفيف (نقاط رمادية). تنشر الخطوط العمودية القيم لأعلى. تنشر الخطوط الأفقية المجاميع الجزئية. ويُترك تمرينًا للمستخدم للتحقّق من أنّه عند تدفق البيانات من خلال الصفيف، ستحصل على نتيجة ضرب المصفوفة الناتجة من الجانب الأيمن.
علاوة على ذلك، أثناء احتساب حاصل الضرب النقطي (MXU)، تتدفق المجاميع المتوسطة ببساطة بين وحدات الحوسبة المتجاورة. لا حاجة إلى تخزينها واستردادها إلى/من الذاكرة أو حتى ملف تسجيل. والنتيجة النهائية هي أن بنية المصفوفة الانقباضية (TPU) لها كثافة ملحوظة وفائدة كبيرة، فضلاً عن مزايا سرعة غير تُذكر على وحدة معالجة الرسومات، عند حساب ضربات المصفوفة.
وحدة معالجة الموتّرات في السحابة الإلكترونية
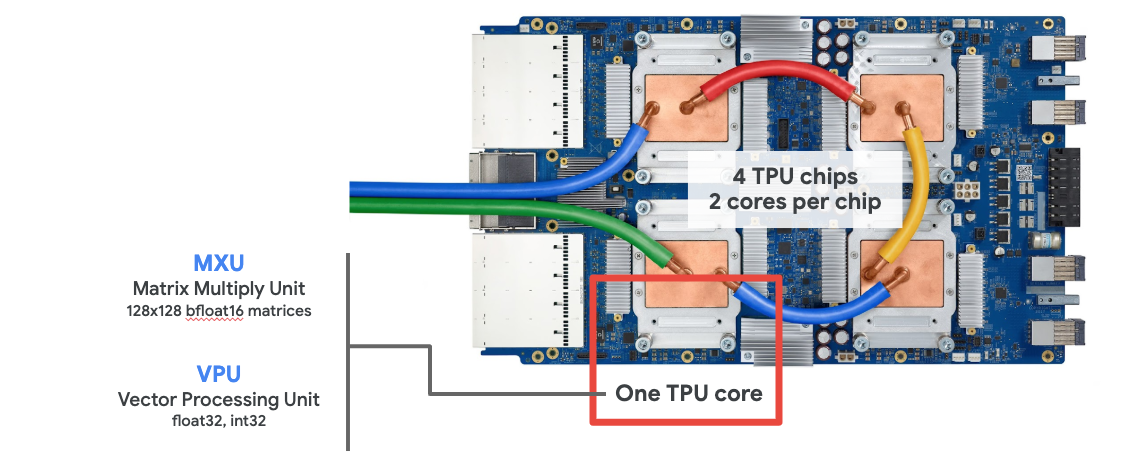
عند طلب " Cloud TPU الإصدار 2" في Google Cloud Platform، ستحصل على جهاز افتراضي (VM) يحتوي على لوحة TPU مرفقة بمنفذ PCI. تحتوي لوحة TPU على أربع شرائح TPU ثنائية النواة. يتميز كل نواة من وحدات معالجة الموتّرات بوحدة معالجة المتجهات (VPU) وبحجم 128×128 MXU (وحدة ضرب MatriX). إنّ "وحدة معالجة الموتّرات" (Cloud TPU) هذه عادةً ما يتم توصيله من خلال الشبكة بالجهاز الافتراضي الذي يطلبه. لكي تبدو الصورة الكاملة على النحو التالي:
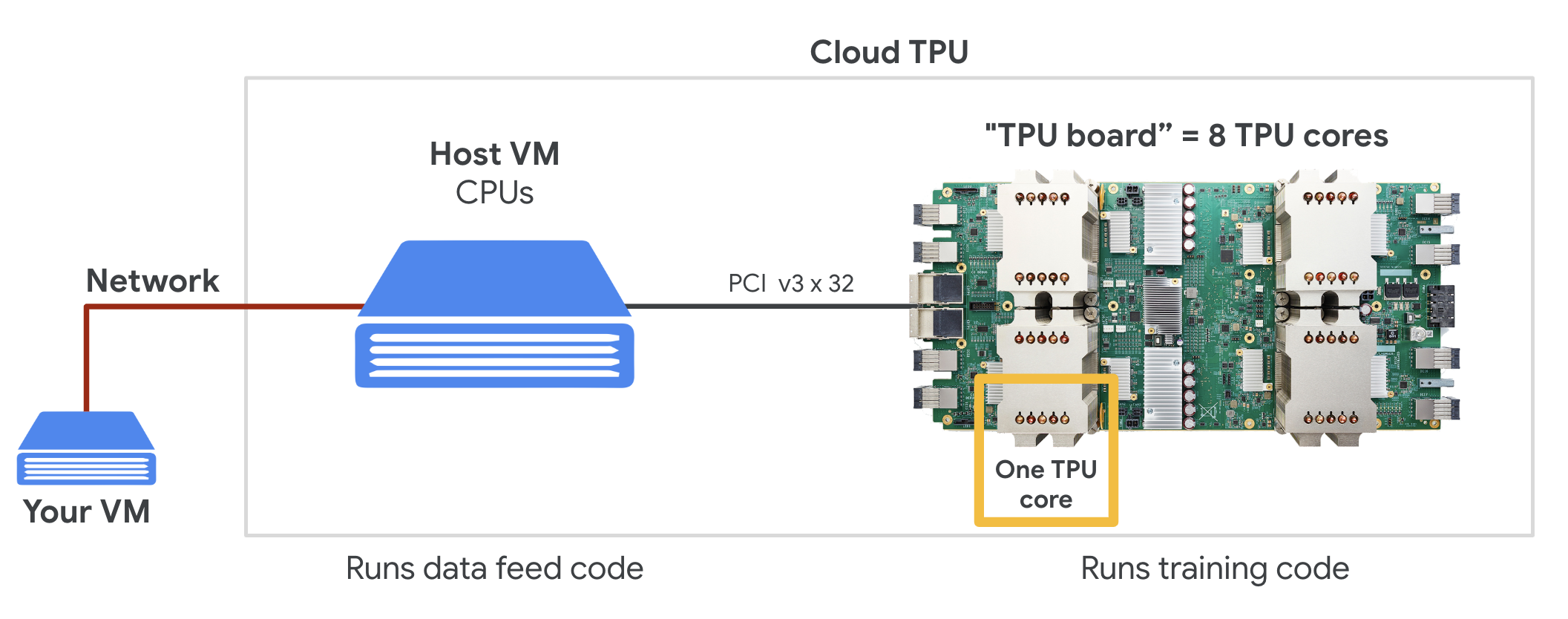
صورة توضيحية: جهاز افتراضي (VM) مزوّد بـ "وحدة معالجة الموتّرات" (Cloud TPU) المرتبطة بالشبكة مسرِّعة أعمال. "وحدة معالجة الموتّرات في السحابة الإلكترونية" الجهاز نفسه مكوَّن من جهاز افتراضي (VM) مزوّد بلوحة TPU متصلة بمنفذ PCI ومزوَّدة بأربع شرائح TPU ثنائية النواة.
لوحات TPU
يتم ربط وحدات معالجة الموتّرات في مراكز بيانات Google بشبكة حوسبة عالية الأداء (HPC) يمكن أن تجعلها تظهر كمُسرّع كبير جدًا. تطلق عليها Google أجهزة pod pods التي يمكن أن تضم ما يصل إلى 512 وحدة معالجة مركزية من TPU الإصدار 2 أو 2048 TPU v3.

صورة توضيحية: لوحة TPU v3 يتم توصيل لوحات ورفوف وحدة معالجة الموتّرات من خلال وصلة HPC.
أثناء التدريب، يتم تبادل التدرجات بين نوى وحدة معالجة الموتّرات باستخدام الخوارزمية الخالية الكل ( شرح جيد لاستنتاج الكل هنا). يمكن للنموذج الذي يتم تدريبه الاستفادة من الأجهزة عن طريق التدريب على أحجام الدفعات الكبيرة.

صورة توضيحية: مزامنة التدرجات أثناء التدريب باستخدام خوارزمية التقليل على مستوى شبكة HPC ثنائية الأبعاد (TPU) الخاصة بالطاقة الحلقية المتشابكة (TPU) من Google.
البرامج
تدريب كبير الحجم
إنّ حجم الدُفعة المثالي لوحدات معالجة الموتّرات هو 128 عنصر بيانات لكل وحدة معالجة مركزية (TPU) أساسية، ولكن يمكن أن تُظهر الأجهزة استخدامًا جيدًا من 8 عناصر بيانات لكل وحدة معالجة معالجة مركزية (TPU). تذكَّر أنّ وحدة معالجة الموتّرات في السحابة الإلكترونية تضمّ 8 أنوية.
في هذا التمرين المعملي عن الترميز، سنستخدم واجهة برمجة تطبيقات Keras. في Keras، تكون الدُفعة التي تحدِّدها هي الحجم العمومي لوحدة معالجة الموتّرات بالكامل. وسيتم تقسيم دُفعاتك تلقائيًا إلى 8 نوى وتشغيلها على 8 نوى لوحدة معالجة الموتّرات.

للحصول على نصائح إضافية بشأن الأداء، يمكنك الاطّلاع على دليل أداء TPU. بالنسبة إلى أحجام الدُفعات الكبيرة جدًا، قد يلزم توخي الحذر في بعض الطُرز، ويمكنك الاطّلاع على LARSOptimizer للحصول على مزيد من التفاصيل.
مزيد من المعلومات: XLA
تحدد برامج Tensorflow الرسوم البيانية الحسابية. لا تُشغِّل وحدة معالجة الموتّرات رمز Python مباشرةً، بل تشغِّل الرسم البياني الحسابي المحدّد في برنامج Tensorflow. في الخيارات المتقدمة، يعمل المحول البرمجي المسمى XLA (محول الجبر الخطي المسرّع) على تحويل الرسم البياني TensorFlow لعقد العملية الحاسوبية إلى رمز وحدة معالجة الموتّرات. ينفذ هذا المحول البرمجي أيضًا العديد من التحسينات المتقدمة على الرمز البرمجي وتنسيق الذاكرة. وتتم عملية التجميع تلقائيًا أثناء إرسال العمل إلى وحدة معالجة الموتّرات. ليس عليك تضمين XLA في سلسلة الإصدار بشكل صريح.
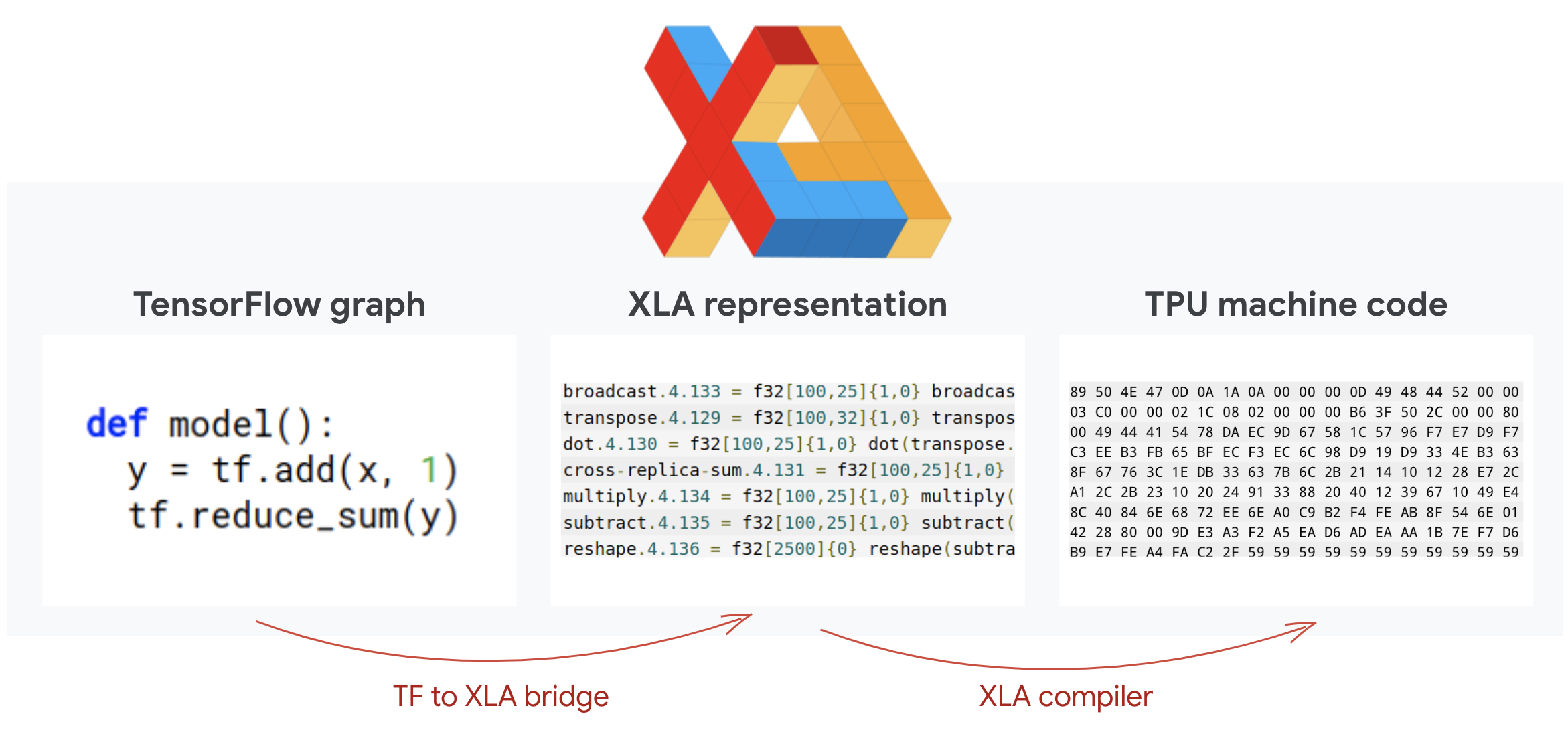
صورة توضيحية: للتشغيل على وحدة معالجة الموتّرات، تتم أولاً ترجمة الرسم البياني للاحتساب الذي حدّده برنامج Tensorflow إلى تمثيل مجمِّع الجبر الخطي المسرّع XLA، ثم تجميعه في رمز XLA إلى رمز جهاز TPU.
استخدام وحدات معالجة الموتّرات في Keras
تتوفّر وحدات معالجة الموتّرات من خلال واجهة برمجة التطبيقات Keras اعتبارًا من الإصدار 2.1 من Tensorflow. تتوافق تقنية Keras مع وحدات معالجة الموتّرات ووحدات معالجة الموتّرات. في ما يلي مثال يعمل مع وحدات معالجة الموتّرات ووحدات معالجة الرسومات ووحدة المعالجة المركزية(CPU):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
في مقتطف الرمز هذا:
- يعثر محرّك البحث
TPUClusterResolver().connect()على وحدة معالجة الموتّرات على الشبكة. وتعمل بدون معلَمات على معظم أنظمة Google Cloud (وظائف AI Platform وColloratory وKubeflow والأجهزة الافتراضية للتعلُّم المحسَّن التي تم إنشاؤها باستخدام أداة "ctpu up"). تعرف هذه الأنظمة مكان وحدة معالجة الموتّرات الخاصة بها بفضل متغيّر بيئة TPU_NAME. إذا أنشأت وحدة معالجة الموتّرات يدويًا، يمكنك ضبط بيئة TPU_NAME. var. أو على الجهاز الافتراضي الذي تستخدمه منه، أو يمكنك طلب الرقمTPUClusterResolverباستخدام المَعلمات الصريحة:TPUClusterResolver(tp_uname, zone, project). TPUStrategyهو الجزء الذي ينفّذ التوزيع و"all-reduce" خوارزمية مزامنة التدرج.- يتم تطبيق الإستراتيجية من خلال نطاق. يجب تحديد النموذج ضمن نطاق الإستراتيجية().
- تتوقع الدالة
tpu_model.fitوجود عنصر tf.data.Dataset لإدخال تدريب وحدة معالجة الموتّرات.
المهام الشائعة لنقل بيانات وحدة معالجة الموتّرات
- في حين أنّ هناك العديد من الطرق لتحميل البيانات في نموذج Tensorflow، إلا أنّه يجب استخدام واجهة برمجة التطبيقات
tf.data.DatasetAPI بالنسبة إلى وحدات معالجة الموتّرات. - فوحدات معالجة الموتّرات سريعة جدًا وغالبًا ما يصبح نقل البيانات العائق عند تشغيلها. تتوفّر أدوات يمكنك استخدامها لرصد المؤثِّرات السلبية على البيانات ونصائح الأداء الأخرى في دليل أداء TPU.
- يتم التعامل مع أرقام int8 أو int16 على أنها int32. لا تشتمل وحدة معالجة الموتّرات على أجهزة صحيحة تعمل على أقل من 32 بت.
- بعض عمليات Tensorflow غير متاحة. القائمة هنا. الخبر السار هو أن هذا القيد لا ينطبق إلا على التعليمات البرمجية للتدريب، أي الانتقال للأمام والخلف من خلال نموذجك. لا يزال بإمكانك استخدام جميع عمليات Tensorflow في مسار إدخال البيانات لأنّه سيتم تنفيذها على وحدة المعالجة المركزية (CPU).
- لا يمكن استخدام
tf.py_funcمع وحدة معالجة الموتّرات.
4. جارٍ تحميل البيانات






سوف نعمل على مجموعة بيانات لصور الزهور. والهدف هو معرفة تصنيفها إلى 5 أنواع من الزهور. يتم تحميل البيانات باستخدام واجهة برمجة تطبيقات tf.data.Dataset. أولاً، نعرّفك على واجهة برمجة التطبيقات
التدريب العملي
يُرجى فتح ورقة الملاحظات التالية وتنفيذ الخلايا (Shift-ENTER) واتّباع التعليمات أينما تظهر لك رسالة "مطلوب العمل" التصنيف.

Fun with tf.data.Dataset (playground).ipynb
معلومات إضافية
لمحة عن "الزهور" مجموعة البيانات
يتم تنظيم مجموعة البيانات في 5 مجلدات. يحتوي كل مجلد على زهور من نوع واحد. وهذه المجلدات تُسمى زهور دوار الشمس، وأقحوانه، والهندباء البرية، والتوليب، والورود. تتم استضافة البيانات في حزمة عامة على Google Cloud Storage. مقتطف:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
ما سبب أهمية tf.data.Dataset؟
يقبل كل من Keras وTensorflow مجموعات البيانات في جميع وظائف التدريب والتقييم التابعة لهما. بمجرد تحميل البيانات في مجموعة بيانات، توفر واجهة برمجة التطبيقات جميع الوظائف الشائعة المفيدة لبيانات تدريب الشبكة العصبية:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
يمكنك العثور على نصائح بشأن الأداء وأفضل ممارسات مجموعات البيانات في هذه المقالة. يمكنك العثور على المستندات المرجعية هنا.
أساسيات tf.data.Dataset
عادة ما تأتي البيانات في ملفات متعددة، هنا الصور. يمكنك إنشاء مجموعة بيانات لأسماء الملفات عن طريق استدعاء:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
يمكنك بعد ذلك "تعيين" دالة لكل اسم ملف تعمل عادةً على تحميل الملف وفك ترميزه إلى بيانات فعلية في الذاكرة:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
للتكرار التحسيني في مجموعة بيانات:
for data in my_dataset:
print(data)
مجموعات بيانات الصفوف
في التعلّم الخاضع للإشراف، تتكون مجموعة بيانات التدريب عادةً من أزواج من بيانات التدريب والإجابات الصحيحة. وللسماح بذلك، يمكن لدالة فك الترميز عرض الصفوف. سيكون لديك بعد ذلك مجموعة بيانات من الصفوف وسيتم إرجاع الصفوف عند التكرار التحسيني. القيم التي يتم عرضها هي موتّرات Tensorflow جاهزة لاستهلاكها في النموذج. يمكنك طلب .numpy() عليها للاطّلاع على القيم الأولية:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
الخاتمة:عملية تحميل الصور واحدة تلو الأخرى بطيئة.
أثناء التكرار التحسيني لمجموعة البيانات هذه، سترى أنه يمكنك تحميل شيء مثل صورة واحدة أو اثنتين في الثانية. هذا بطيء جدًا! ويمكن لمسرِّعات الأجهزة التي سنستخدمها للتدريب أن تظل مضاعفة بهذا المعدّل. انتقِل إلى القسم التالي لمعرفة كيف سنحقّق ذلك.
الحلّ
ها هو دفتر الحل. يمكنك استخدامه إذا واجهتك مشكلة.
Fun with tf.data.Dataset (solution).ipynb
النقاط التي تناولناها
- 👀 tf.data.Dataset.list_files
- 🎉 tf.data.Dataset.map
- 🎉 مجموعات بيانات الصفوف
- 😀 التكرار من خلال مجموعات البيانات
يرجى تخصيص بعض الوقت لاستعراض قائمة التحقق هذه في ذهنك.
5- تحميل البيانات بسرعة
تتميز مسرِّعات الأجهزة لوحدة معالجة Tensor (TPU) التي سنستخدمها في هذا التمرين بالسرعة الكبيرة جدًا. غالبًا ما يتمثل التحدي في إطعامهم البيانات بسرعة كافية لإبقائهم مشغولين. يمكن لخدمة Google Cloud Storage الحفاظ على سرعة معالجة بيانات عالية جدًا، ولكن كما هو الحال مع جميع أنظمة التخزين في السحابة الإلكترونية، فإنّ بدء الاتصال يكلف بعض الشبكة ذهابًا وإيابًا. ولذلك، ليس من المثالي تخزين بياناتنا كآلاف من الملفات الفردية. سنقوم بتجميعها في عدد أقل من الملفات واستخدام قوة tf.data.Dataset للقراءة من ملفات متعددة بالتوازي.
القراءة السلسة
يتوفّر في ورقة الملاحظات التالية الرمز الذي يحمّل ملفات الصور ويغيّر حجمها إلى حجم شائع ثم يخزّنها في 16 ملف TFRecord. يرجى قراءته بسرعة. ليس من الضروري تنفيذ هذا الإجراء لأنّه سيتم توفير بيانات بتنسيق TFRecord بشكل صحيح لبقية الدرس التطبيقي حول الترميز.
Flower pictures to TFRecords.ipynb
تنسيق مثالي للبيانات لضمان سرعة معالجة البيانات في GCS
تنسيق ملف TFRecord
إنّ تنسيق الملف المفضّل لمنصة Tensorflow لتخزين البيانات هو تنسيق TFRecord المستند إلى protobuf. يمكنك أيضًا استخدام تنسيقات التسلسل الأخرى، ولكن يمكنك تحميل مجموعة بيانات من ملفات TFRecord مباشرةً عن طريق كتابة:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
للحصول على الأداء الأمثل، ننصحك باستخدام الرمز البرمجي الأكثر تعقيدًا للقراءة من ملفات TFRecord متعددة في الوقت نفسه. ستتم قراءة هذا الرمز من ملفات N بالتوازي مع تجاهل ترتيب البيانات لصالح سرعة القراءة.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
ورقة الملاحظات الموجزة عن TFRecord
يمكن تخزين ثلاثة أنواع من البيانات في TFRecords: سلاسل بايت (قائمة بالبايت)، وأعداد صحيحة بحجم 64 بت، وعدد عائم 32 بت. يتم تخزينها دائمًا كقوائم، وسيكون عنصر البيانات المفرد قائمة بحجم 1. يمكنك استخدام الدوال المساعدة التالية لتخزين البيانات في TFRecords.
كتابة سلاسل البايت
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
كتابة الأعداد الصحيحة
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
كتابة الأعداد العشرية
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
كتابة TFRecord باستخدام وسائل المساعدة المذكورة أعلاه
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
لقراءة البيانات من TFRecords، يجب أولاً الإفصاح عن تنسيق السجلّات التي خزّنتها. في البيان، يمكنك الوصول إلى أي حقل مُسمّى كقائمة طول ثابتة أو قائمة طول متغيرة:
القراءة من TFRecords
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
مقتطفات الرموز المفيدة:
قراءة عناصر البيانات الفردية
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
قراءة قوائم العناصر الثابتة الحجم
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
قراءة عدد متغيّر لعناصر البيانات
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
تعرض VarLenFeature متجهًا متفرقًا ويجب تنفيذ خطوة إضافية بعد فك ترميز TFRecord:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
من الممكن أيضًا أن تكون هناك حقول اختيارية في TFRecords. في حال تحديد قيمة تلقائية عند قراءة حقل، سيتم عرض القيمة التلقائية بدلاً من خطأ في حال عدم توفّر الحقل.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
النقاط التي تناولناها
- 🎉 تقسيم ملفات البيانات للوصول السريع من GCS
- ذات كيفية كتابة سجلّات TFRecords. (هل نسيت بناء الجملة بالفعل؟ لا بأس، يُرجى وضع إشارة مرجعية على هذه الصفحة كورقة ملاحظات مرجعية)
- 🎉 جارٍ تحميل مجموعة بيانات من TFRecords باستخدام TFRecordDataset
يرجى تخصيص بعض الوقت لاستعراض قائمة التحقق هذه في ذهنك.
6- [معلومات] مصنِّف الشبكة العصبونية 101
باختصار
إذا كانت جميع المصطلحات الغامقة في الفقرة التالية معروفة لك بالفعل، يمكنك الانتقال إلى التمرين التالي. إذا كنت في بداية مسيرتك في التعلم المتعمق، فمرحبًا بك، ونرجو مواصلة القراءة.
بالنسبة للنماذج المبنية كسلسلة من الطبقات، يوفر Keras واجهة برمجة التطبيقات التسلسلية. على سبيل المثال، يمكن كتابة مصنف صور يستخدم ثلاث طبقات كثيفة باللغة Keras على النحو التالي:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
الشبكة العصبونية الكثيفة
وهذه هي أبسط شبكة عصبية لتصنيف الصور. وهو يتكون من "الخلايا العصبية" مرتبة في طبقات. الطبقة الأولى تعالج البيانات وتدخل مخرجاتها في طبقات أخرى. يُطلق عليه "كثيف" لأنه يتم ربط كل خلية عصبية بجميع الخلايا العصبية في الطبقة السابقة.
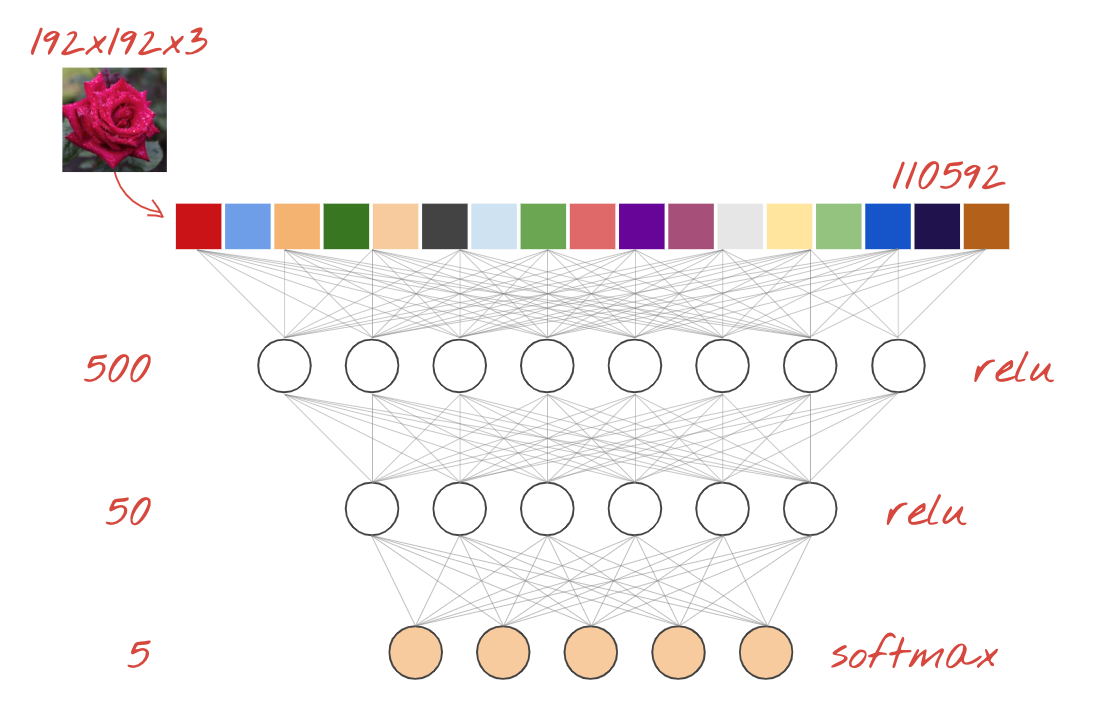
يمكنك إدخال صورة إلى مثل هذه الشبكة عن طريق تسوية قيم النموذج اللوني أحمر أخضر أزرق (RGB) لكل وحدات البكسل في خط متجه طويل واستخدامها كمدخلات. وهذا ليس أفضل أسلوب للتعرف على الصور ولكننا سنعمل على تحسينه لاحقًا.
الخلايا العصبية وعمليات التفعيل وخوارزمية RELU
"الخلية العصبية" تحسب المجموع المرجّح لجميع إدخالاته، وتضيف قيمة تسمى "تحيز" وتغذي النتيجة من خلال ما يسمى "دالة التفعيل". القيم التقديرية والتحيز غير معروفة في البداية. سيتم إعدادها بشكل عشوائي و"تعلمها" من خلال تدريب الشبكة العصبية على الكثير من البيانات المعروفة.
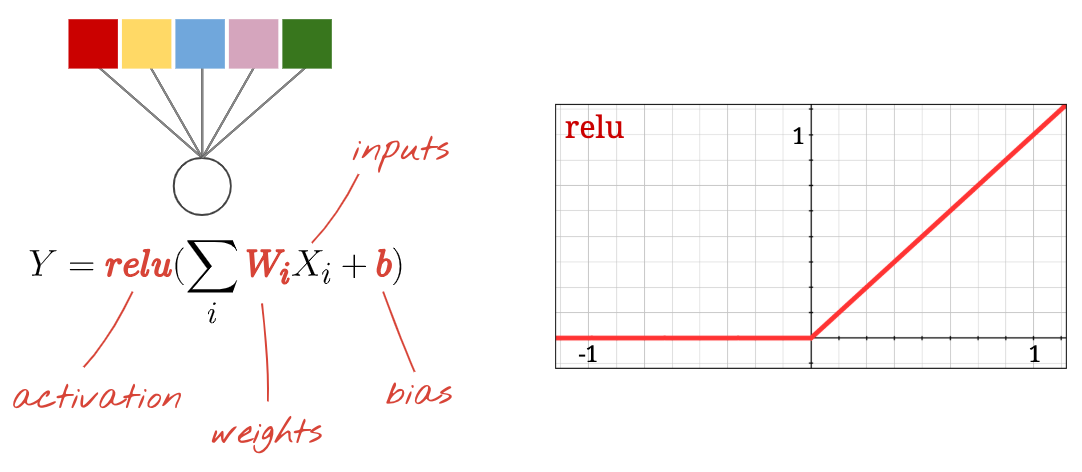
تسمى دالة التفعيل الأكثر شيوعًا RELU للوحدة الخطية المصححة. إنها دالة بسيطة للغاية كما ترون في الرسم البياني أعلاه.
تفعيل Softmax
تنتهي الشبكة أعلاه بطبقة مكونة من 5 خلايا عصبية لأننا نصنف الزهور إلى 5 فئات (وردة، توليب، الهندباء، أقحوان، دوار الشمس). يتم تنشيط الخلايا العصبية في الطبقات المتوسطة باستخدام وظيفة تفعيل RELU الكلاسيكية. على الرغم من ذلك، في الطبقة الأخيرة، نريد حساب الأعداد بين 0 و1 التي تمثّل احتمالية أن تكون هذه الزهرة وردة وزهرة توليب وما إلى ذلك. لذلك، سنستخدم دالة تفعيل تُسمّى "softmax".
يتم تطبيق softmax على متجه من خلال أخذ الأس لكل عنصر ثم تسوية الخط المتجه، عادةً باستخدام المعيار L1 (مجموع القيم المطلقة) بحيث تضيف القيم ما يصل إلى 1 ويمكن تفسيرها على أنها احتمالات.
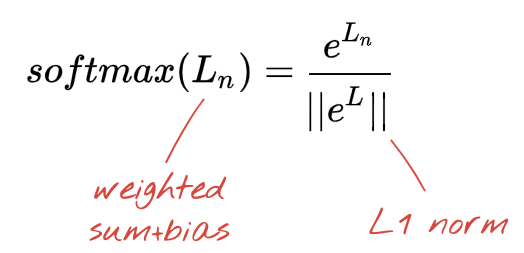
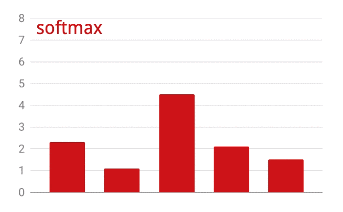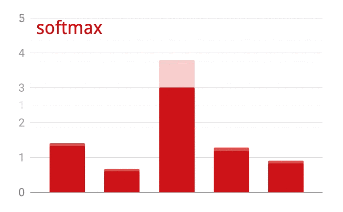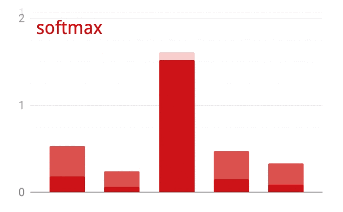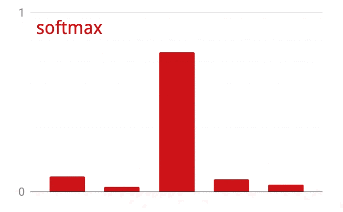
الخسارة العابرة للإنتروبيا
والآن بعد أن تُنتج شبكتنا العصبية تنبؤات من الصور المدخلة، نحتاج إلى قياس مدى جودتها، أي المسافة بين ما تخبرنا به الشبكة والإجابات الصحيحة، والتي تُعرف غالبًا باسم "التصنيفات". تذكر أن لدينا التسميات الصحيحة لجميع الصور في مجموعة البيانات.
قد تصلح أي مسافة، ولكن بالنسبة لمشكلات التصنيف، يتم استخدام ما يسمى "المسافة بين الإنتروبيا" هي الأكثر فعالية. سنسمي هذا الخطأ أو "خسارة" الدالة:
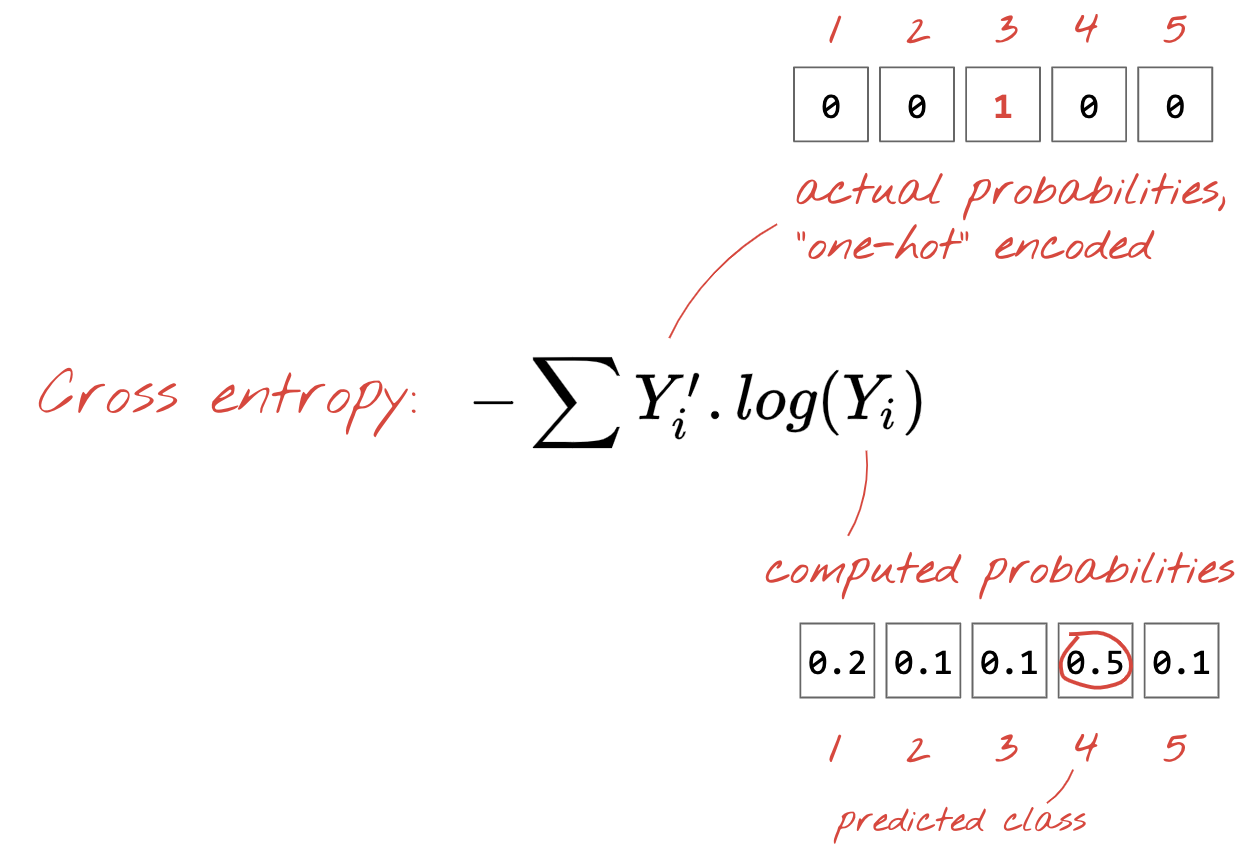
انحدار التدرج
"تدريب" الشبكة العصبية تعني في الواقع استخدام صور وتسميات التدريب لضبط الأوزان والتحيزات وذلك لتقليل وظيفة فقدان بين القصور. إليك طريقة عملها.
القصور عبري هو دالة الأوزان والتحيزات ووحدات البكسل للصورة التطبيقية وفئتها المعروفة.
إذا احتسبنا المشتقات الجزئية للإنتروبيا المتداخلة نسبيًا مع جميع معاملات الترجيح وجميع الانحيازات التي حصلنا عليها على "تدرج"، محسوبًا لصورة معينة وتصنيفها والقيمة الحالية للأوزان والانحرافات. تذكر أنه يمكن أن يكون لدينا ملايين الأوزان والتحيزات، وبالتالي فإن حساب التدرج يشبه الكثير من العمل. لحسن الحظ، تُجري Tensorflow ذلك نيابةً عنا. الخاصية الرياضية للتدرج هي أنه يشير إلى "لأعلى". وبما أننا نريد أن نتجه إلى حيث يكون القصور المشترك منخفضًا، فإننا نسير في الاتجاه المعاكس. ونقوم بتحديث الأوزان والتحيزات بجزء من التدرج. ثم نكرر الأمر نفسه مرارًا وتكرارًا باستخدام المجموعات التالية من صور التدريب والتصنيفات في حلقة تدريب. ونأمل أن يتلاءم هذا مع مكان يكون فيه القصور عبر الحد الأدنى هو الحد الأدنى، على الرغم من أنه لا يوجد شيء يضمن أن هذا الحد الأدنى فريد من نوعه.
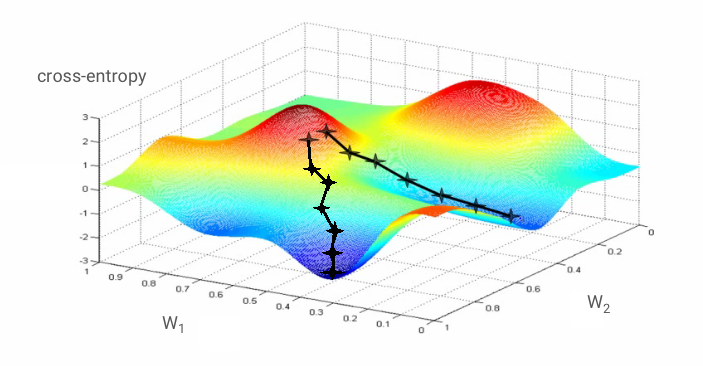
التجميع السريع والزخم
يمكنك حساب التدرج على مثال صورة واحدة فقط وتحديث الأوزان والانحيازات على الفور، ولكن عند إجراء ذلك على مجموعة من 128 صورة مثلاً، ستمنح 128 صورة تدرّجًا يمثل بشكل أفضل القيود التي تفرضها نماذج الصور المختلفة ومن ثم يتقارب مع الحلّ بشكل أسرع. حجم الدفعة الصغيرة هو معلمة قابلة للتعديل.
وهذه التقنية، تُسمّى أحيانًا "الانحدار العشوائي المتدرج" وهناك فائدة أخرى أكثر واقعية: فالعمل مع الدُفعات يعني أيضًا العمل على مصفوفات أكبر حجمًا، وعادةً ما يكون تحسين هذه المصفوفات أسهل في ما يتعلّق بوحدات معالجة الرسومات ووحدات معالجة الموتّرات.
بالرغم من ذلك، يمكن أن يكون التقارب فوضويًا بعض الشيء، ويمكن أن يتوقف حتى إذا كان خط متجه التدرج بأكملها بأصفار. هل هذا يعني أننا وجدنا الحد الأدنى؟ ليس دائمًا. قد يكون عنصر التدرج صفرًا في قيمة الحد الأدنى أو الحد الأقصى. في حال كان الخط المتجه للتدرج الذي يحتوي على ملايين العناصر، إذا كانت جميعها أصفارًا، فإن احتمالية تطابق كل صفر مع الحد الأدنى وعدم وجود أي منها حتى نقطة قصوى صغيرة جدًا. في عالم متعدد الأبعاد، تعتبر نقاط السرج شائعة جدًا ولا نريد التوقف عندها.
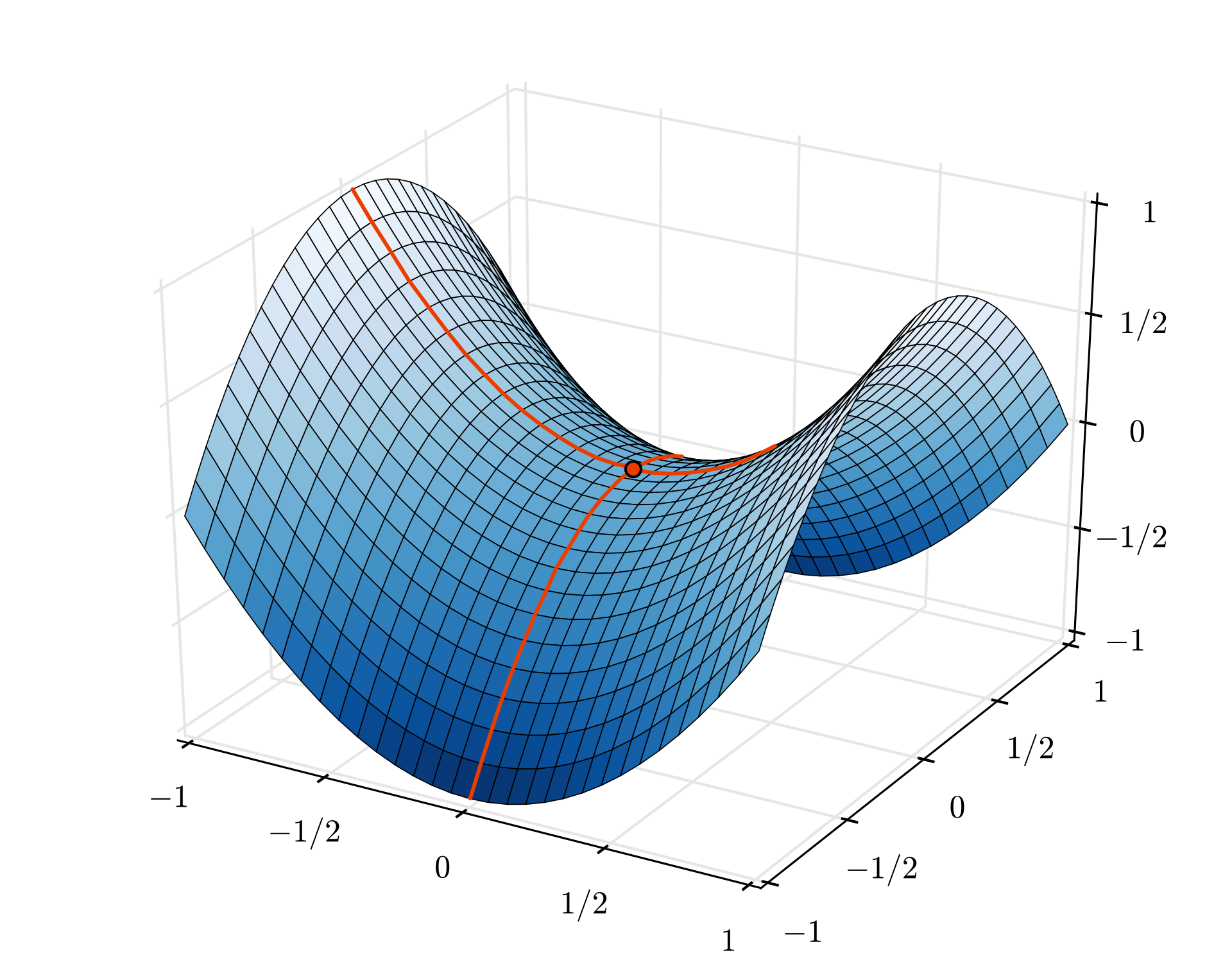
صورة توضيحية: نقطة سرج. التدرج هو 0 ولكنه ليس حدًا أدنى في جميع الاتجاهات. (إسناد الصور Wikimedia: من Nicoguaro - عملك الخاص، CC BY 3.0)
الحل هو إضافة بعض الزخم إلى خوارزمية التحسين بحيث يمكنها تجاوز نقاط السرج بدون توقف.
مسرد المصطلحات
دفعة أو دفعة صغيرة: يتم دائمًا إجراء التدريب على دُفعات من بيانات التدريب والتصنيفات. ويساعد ذلك في تقارب الخوارزمية. "الدُفعة" هو البعد الأول لمعرضات البيانات. على سبيل المثال، يحتوي متفرع الشكل [100، 192، 192، 3] على 100 صورة بحجم 192×192 بكسل مع ثلاث قيم لكل بكسل (RGB).
خسارة الإنتروبيا: دالة خسارة خاصة غالبًا ما تُستخدم في المصنِّفات.
الطبقة الكثيفة: طبقة من الخلايا العصبية التي تتصل فيها كل خلية عصبية بجميع الخلايا العصبية في الطبقة السابقة.
الميزات: يُطلق على مدخلات الشبكة العصبية أحيانًا اسم "الميزات". يسمى فن معرفة أي أجزاء من مجموعة البيانات (أو مجموعات من الأجزاء) للتغذية في الشبكة العصبية للحصول على تنبؤات جيدة باسم "هندسة الخصائص".
labels: اسم آخر لـ "classes" الإجابات الصحيحة أو الإجابات الصحيحة في مشكلة تصنيف خاضعة للإشراف
معدّل التعلّم: جزء من التدرج يتم من خلاله تعديل الأوزان والانحيازات في كل تكرار في حلقة التدريب.
logits: تسمى مخرجات طبقة الخلايا العصبية قبل تطبيق دالة التفعيل باسم "logits". يأتي المصطلح من "الدالة اللوجستية" يُعرف أيضًا باسم "الدالة السينية" التي كانت أكثر وظائف التفعيل شيوعًا. "المخرجات العصبية قبل الدالة اللوجستية" تم اختصارها إلى "logits".
الخسارة: دالة الخطأ التي تقارن مخرجات الشبكة العصبونية بالإجابات الصحيحة
الخلية العصبونية: تحسب المجموع المرجّح لمدخلاتها وتضيف انحيازًا وتغذي النتيجة من خلال إحدى وظائف التفعيل.
ترميز واحد فعال: يتم ترميز الفئة 3 من 5 كمتجه مكون من 5 عناصر، جميع الأصفار باستثناء الصف الثالث وهو 1.
relu: وحدة خطية مُصحَّحة وظيفة تفعيل شائعة للخلايا العصبية.
sigmoid: دالة تفعيل أخرى كانت شائعة ولا تزال مفيدة في حالات خاصة.
softmax: دالة تفعيل خاصة تعمل على متجه وتزيد من الفرق بين المكوِّن الأكبر وجميع العناصر الأخرى، كما تعمل على ضبط الخط المتجه ليصبح مجموعه 1 بحيث يمكن تفسيره على أنه متجه للاحتمالات. تُستخدم كخطوة أخيرة في المصنِّفات.
tenor: "تينسور" يشبه المصفوفة ولكن بعدد عشوائي من الأبعاد. المتسلل أحادي البعد هو متجه. والمتسلل الثنائي الأبعاد هو مصفوفة. ومن ثم يمكنك الحصول على متسابقات ذات أبعاد 3 أو 4 أو 5 أو أكثر.
7. نقل التعلّم
بالنسبة إلى مشكلة تصنيف الصور، قد لا تكون الطبقات الكثيفة كافية على الأرجح. علينا التعرف على الطبقات الالتفافية والطرق العديدة التي يمكنك من خلالها ترتيبها.
ولكن يمكننا أيضًا أخذ اختصار! هناك شبكات عصبية التفافية مدربة بالكامل متاحة للتنزيل. من الممكن قطع الطبقة الأخيرة، وهي رأس تصنيف softmax، واستبدالها بطبقةك الخاصة. تظل جميع الأوزان والتحيزات المدربة كما هي، وما عليك سوى إعادة تدريب طبقة softmax التي تضيفها. تُسمّى هذه التقنية التعلّم الانتقالي، وهي تعمل بشكل مدهش طالما أن مجموعة البيانات التي تم تدريب الشبكة العصبية عليها مسبقًا "قريبة بما يكفي". لك.
التدريب العملي
يُرجى فتح ورقة الملاحظات التالية وتنفيذ الخلايا (Shift-ENTER) واتّباع التعليمات أينما تظهر لك رسالة "مطلوب العمل" التصنيف.
Keras Flowers transfer learning (playground).ipynb
معلومات إضافية
من خلال التعلم المنقولة، يمكنك الاستفادة من بُنى الشبكة العصبونية الالتفافية المتقدمة التي طوّرها كبار الباحثين ومن التدريب المسبق على مجموعة بيانات ضخمة من الصور. في حالتنا هذه، سننقل التعلم من شبكة مدرَّبة على ImageNet، وهي قاعدة بيانات للصور تحتوي على العديد من النباتات والمشاهد الخارجية، وهي قريبة بما يكفي من الزهور.
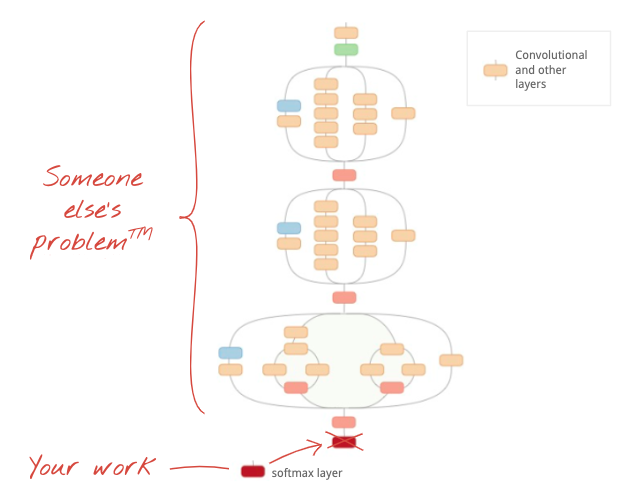
صورة توضيحية: إعادة تدريب رأس التصنيف فقط باستخدام شبكة عصبية التفافية معقّدة، وقد سبق أن تم تدريبها كصندوق أسود هذا هو التعلم الناتج. وسنرى كيف تعمل هذه الترتيبات المعقدة من الطبقات الالتفافية لاحقًا. في الوقت الحالي، هذه مشكلة شخص آخر.
نقل التعلّم في Keras
في Keras، يمكنك إنشاء مثيل لنموذج مدرَّب مسبقًا من مجموعة tf.keras.applications.*. على سبيل المثال، يعد MobileNet V2 بنية التفافية جيدة للغاية تظل في الحجم معقولاً. عند اختيار include_top=False، ستحصل على النموذج المدرَّب مسبقًا بدون طبقة softmax النهائية بحيث يمكنك إضافة نموذجك الخاص:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
ويجب أيضًا الحرص على ضبط الإعدادات pretrained_model.trainable = False. وستعمل هذه الميزة على تجميد القيم التقديرية والانحيازات للنموذج المدرَّب مسبقًا بحيث يتم تدريب طبقة softmax فقط. عادة ما يتضمن هذا ترجيحات قليلة نسبيًا ويمكن القيام به بسرعة ودون الحاجة إلى مجموعة بيانات كبيرة جدًا. ومع ذلك، إذا كان لديك الكثير من البيانات، يمكن أن تعمل نماذج التعلُّم في نقل البيانات بشكل أفضل باستخدام "pretrained_model.trainable = True". ثم توفر الأوزان المدرّبة مسبقًا قيمًا أولية ممتازة ولا يزال من الممكن تعديلها بالتدريب لتناسب مشكلتك بشكل أفضل.
وأخيرًا، لاحِظ الطبقة Flatten() التي تم إدراجها قبل طبقة softmax الكثيفة. تعمل الطبقات الكثيفة على المتجهات المسطحة للبيانات، ولكننا لا نعرف ما إذا كان هذا ما يعرضه النموذج المدرّب مسبقًا. هذا هو السبب في أننا بحاجة إلى التسوية. في الفصل التالي، بينما نتعمق في البنى الالتفافية، سنشرح تنسيق البيانات الذي تعرضه الطبقات الالتفافية.
يُفترض أن تصل الدقة إلى نسبة تقترب من 75% بهذه الطريقة.
الحلّ
ها هو دفتر الحل. يمكنك استخدامه إذا واجهتك مشكلة.
Keras Flowers transfer learning (solution).ipynb
النقاط التي تناولناها
- 👀 طريقة كتابة مصنِّف باللغة Keras
- 🤓 تكتمل باستخدام الطبقة الأخيرة softmax، وفقدان الطاقة بين الإنتروبيا.
- 😈 نقل بيانات التعلُّم
- 🎉 تدريب نموذجك الأول
- 🧐 بعد فقدانها ودقتها أثناء التدريب
يرجى تخصيص بعض الوقت لاستعراض قائمة التحقق هذه في ذهنك.
8. [INFO] الشبكات العصبية الالتفافية
باختصار
إذا كانت جميع المصطلحات الغامقة في الفقرة التالية معروفة لك بالفعل، يمكنك الانتقال إلى التمرين التالي. إذا كنت من المبتدئين في استخدام الشبكات العصبية الالتفافية، فيُرجى مواصلة القراءة.
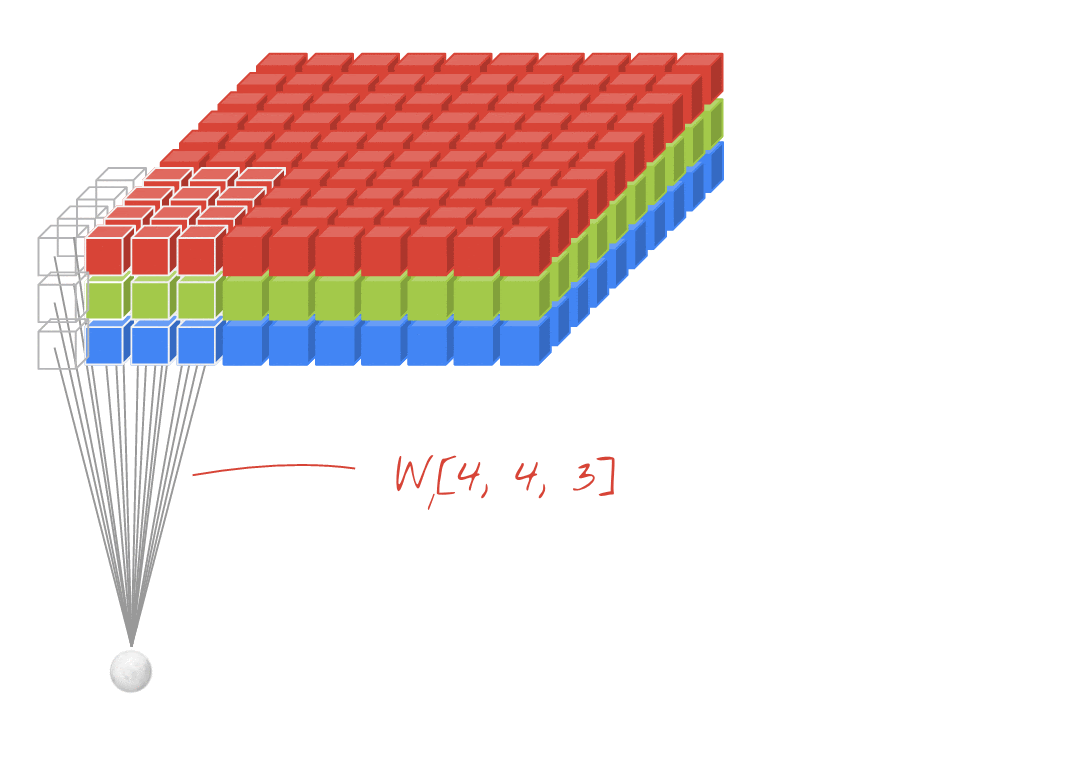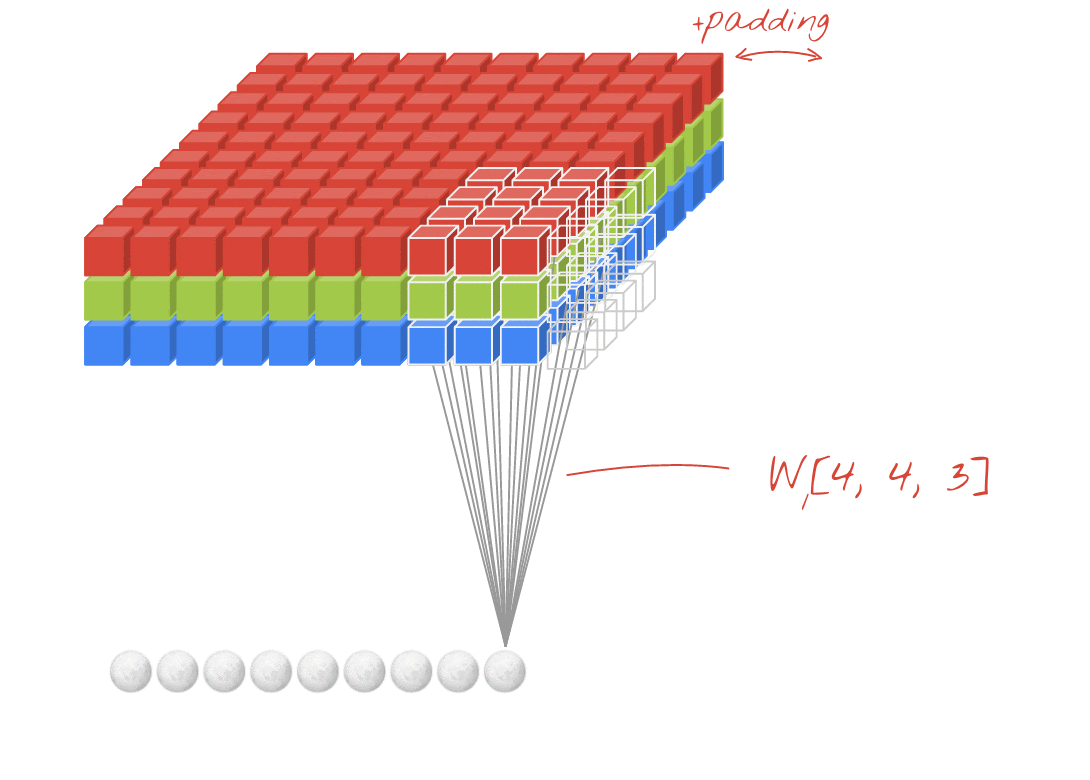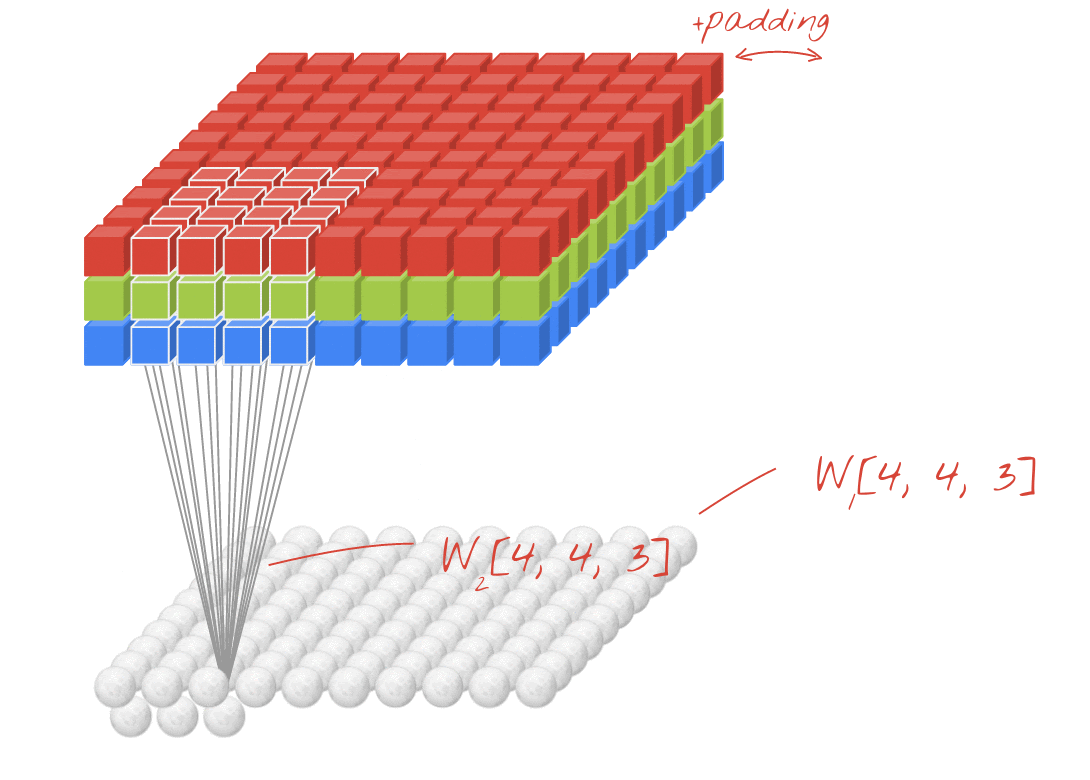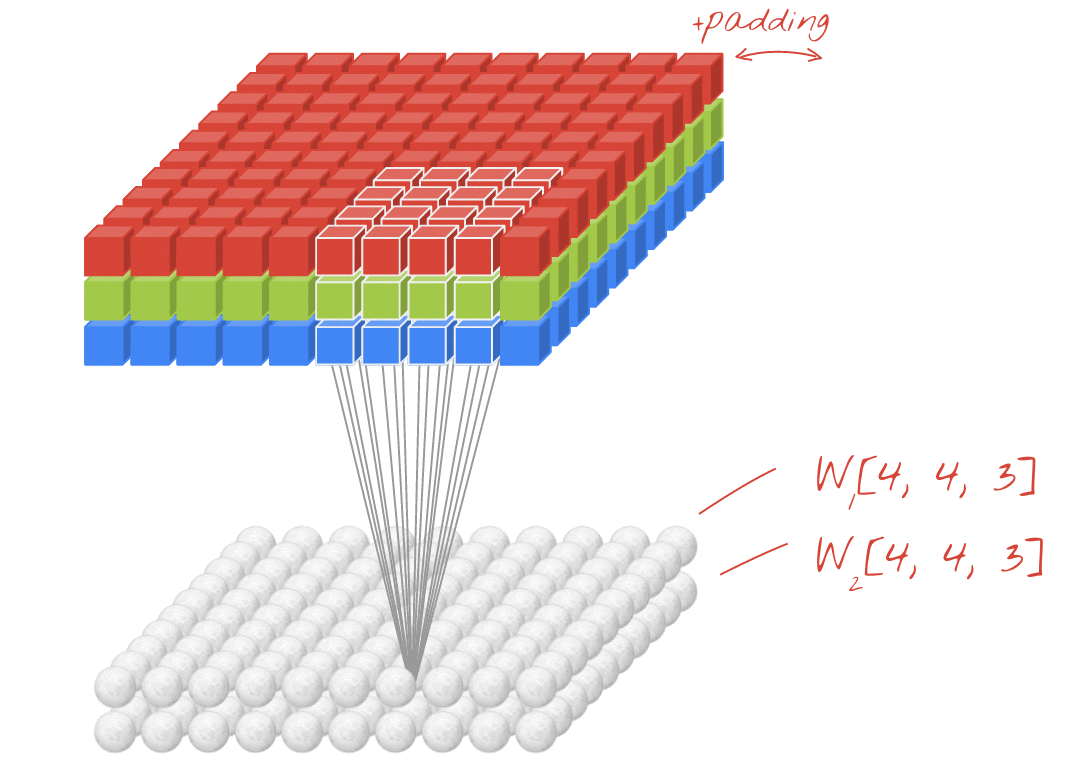
صورة توضيحية: فلترة صورة باستخدام فلترَين متتاليَين يتألف كلٌّ منهما من 4x4x3=48 ترجيحات قابلة للتعلُّم
هذه هي الطريقة التي تبدو بها الشبكة العصبية الالتفافية البسيطة في Keras:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
الشبكات العصبية الالتفافية 101
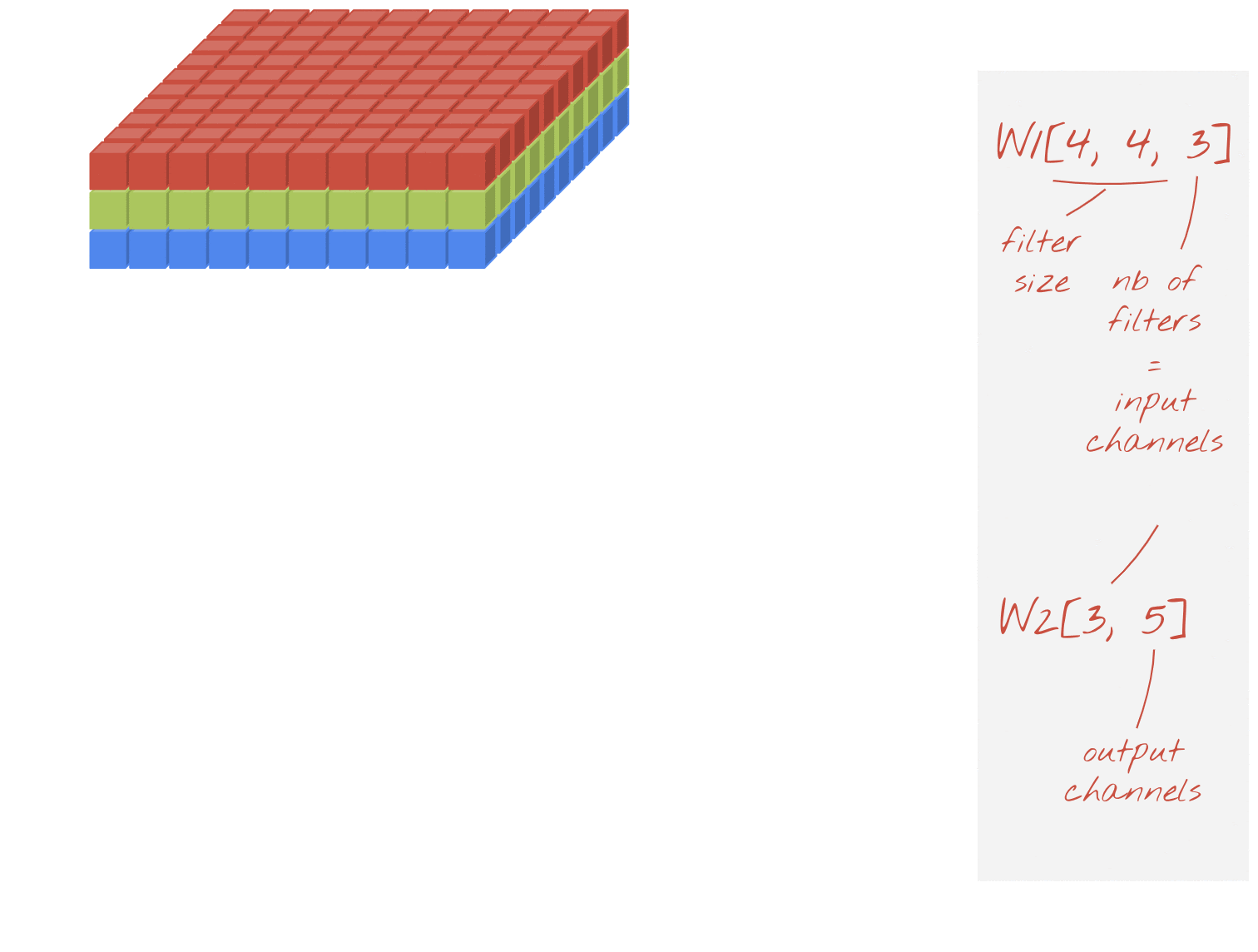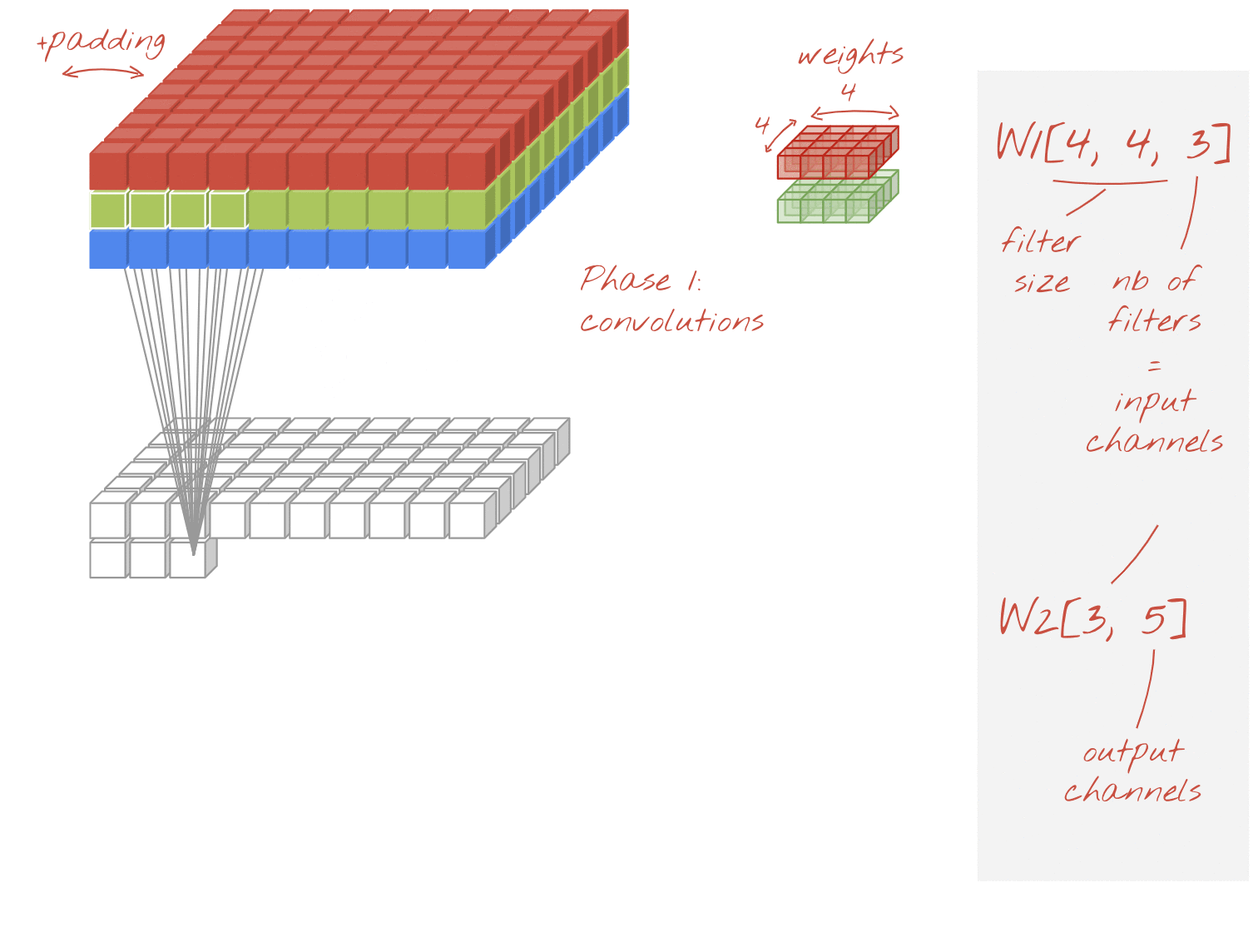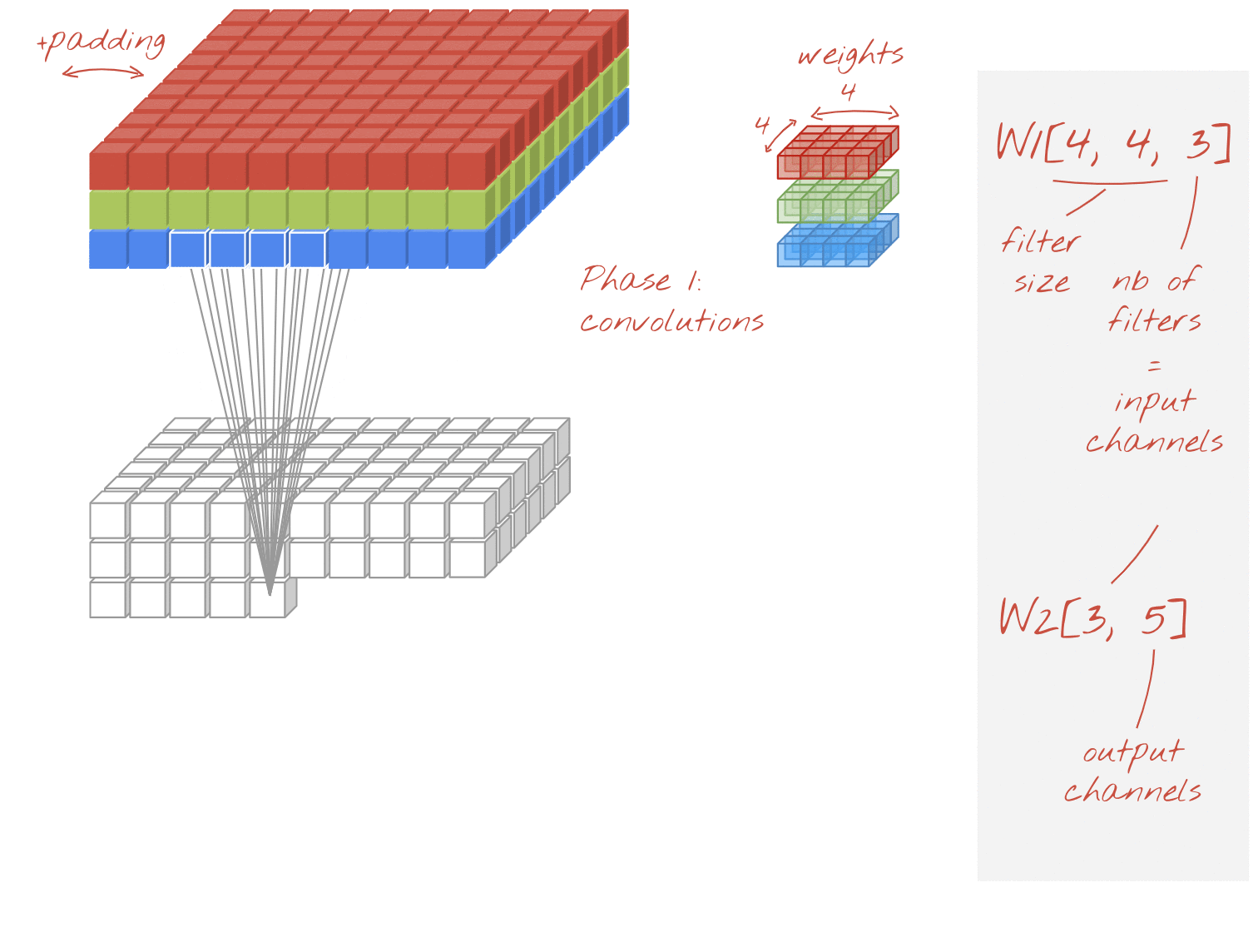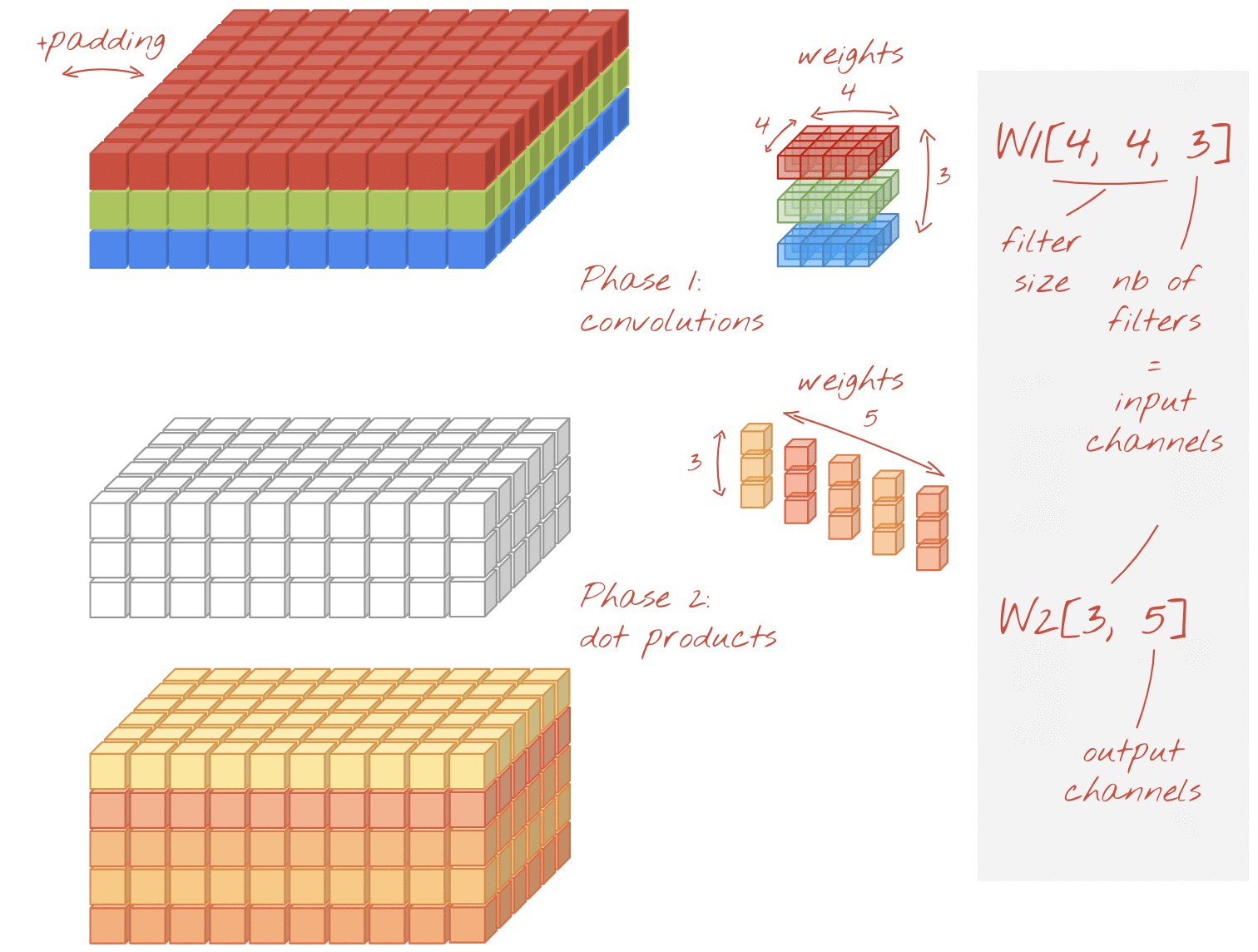
في إحدى طبقات الشبكة الالتفافية، "خلية عصبية" واحدة مجموع مرجّح للبكسل فوقها مباشرةً، عبر منطقة صغيرة من الصورة فقط. فهي تضيف تحيزًا وتغذي المجموع من خلال دالة تنشيط، تمامًا كما تفعل الخلية العصبية في طبقة كثيفة منتظمة. ثم تتكرر هذه العملية على مستوى الصورة بأكملها باستخدام الأوزان نفسها. تذكر أنه في الطبقات الكثيفة، لكل خلية عصبية أوزانها الخاصة. هنا، "تصحيح" واحد تنزلق من الأوزان عبر الصورة في كلا الاتجاهين ("التفاف"). يحتوي الناتج على عدد قيم مماثل لعدد وحدات البكسل في الصورة (مع ذلك، يلزم وجود بعض المساحة المتروكة عند الحواف). إنها عملية تصفية، باستخدام عامل تصفية 4×4×3=48 ترجيح.
ومع ذلك، لن يكون 48 ترجيحًا كافيًا. لإضافة المزيد من درجات الحرية، نكرر العملية نفسها مع مجموعة جديدة من الترجيح. وينتج عن ذلك مجموعة جديدة من مخرجات الفلاتر. لنسميها "قناة" للمخرجات عن طريق التشابه مع قنوات R وG وB في صورة الإدخال.
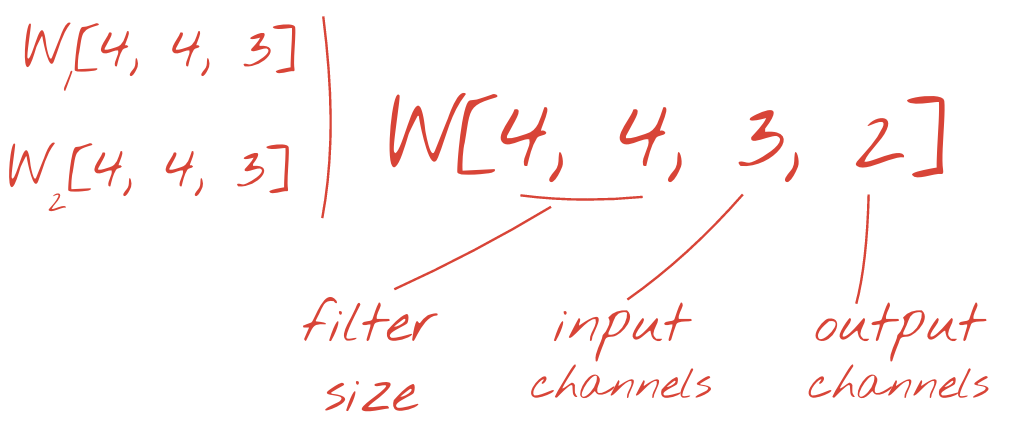
يمكن تلخيص مجموعتي الترجيح (أو أكثر) في صورة متوتر واحد بإضافة بُعد جديد. يعطينا هذا الشكل العام لموتر الأوزان لطبقة التفافية. بما أن عدد قنوات الإدخال والإخراج هو معامل، يمكننا البدء في تكديس وتسلسل الطبقات الالتفافية.
صورة توضيحية: شبكة عصبية التفافية تحوّل "مكعبات" البيانات إلى "مكعبات" أخرى من البيانات
عمليات التفاف ثابتة وأقصى حدّ للتجميع
ومن خلال إجراء عمليات الالتفاف بخطوة 2 أو 3، يمكننا أيضًا تقليص مكعب البيانات الناتج في أبعاده الأفقية. هناك طريقتان شائعتان للقيام بذلك:
- التفاف موسّع: فلتر يتم تمريره كما هو موضح أعلاه ولكن بخطوة >1
- الحد الأقصى لتجميع: نافذة منزلق تقوم بتطبيق عملية MAX (عادةً على التصحيحات 2×2، ويتكرر كل 2 بكسل)

صورة توضيحية: يؤدي تحريك نافذة الحوسبة بمقدار 3 بكسل إلى الحصول على قيم إخراج أقل. تُعدّ عمليات الالتفاف المتدرّجة أو الحدّ الأقصى لتجميع البيانات (الحد الأقصى للانزلاق بخطوة 2×2 في نافذة بحجم 2×2) من طرق تقليص مكعب البيانات في الأبعاد الأفقية.
مصنِّف ثوري
وأخيرًا، نرفق عنوان تصنيف بتسوية مكعب البيانات الأخير وإمداده بطبقة كثيفة منشَّطة بواسطة softmax. يمكن أن يظهر المصنِّف الالتفافي النموذجي على النحو التالي:
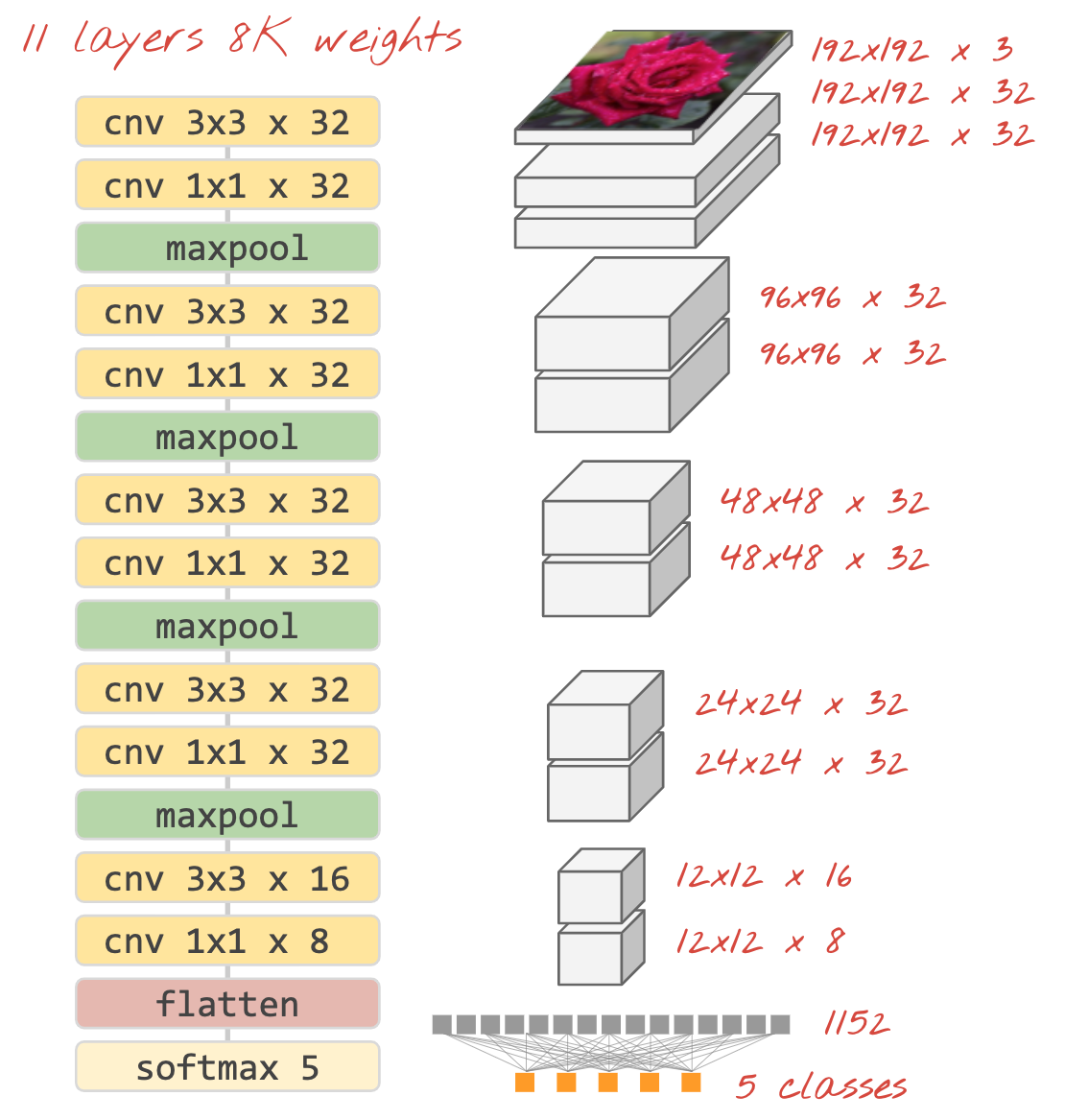
صورة توضيحية: مصنِّف صور يستخدم طبقات التفافية وطبقة softmax. يتم استخدام فلاتر 3×3 و1×1. تأخذ طبقات maxpool الحد الأقصى لمجموعات نقاط البيانات 2x2. يتم تنفيذ رأس التصنيف مع طبقة كثيفة مع تفعيل softmax.
In Keras
يمكن كتابة مكدس الالتفاف الموضح أعلاه بلغة Keras على النحو التالي:
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. إحالاتك الناجحة المخصّصة
التدريب العملي
دعونا نبني وندرب شبكة عصبية التفافية من البداية. يتيح لنا استخدام وحدة معالجة الموتّرات التكرار بسرعة كبيرة. يُرجى فتح ورقة الملاحظات التالية وتنفيذ الخلايا (Shift-ENTER) واتّباع التعليمات أينما تظهر لك رسالة "مطلوب العمل" التصنيف.
Keras_Flowers_TPU (playground).ipynb
والهدف من ذلك هو التغلب على الدقة البالغة 75% لنموذج تعلُّم النقل. وكانت هناك ميزة لهذا النموذج، إذ أنه قد تم تدريبه مسبقًا على مجموعة بيانات تضم ملايين الصور، في حين أن لدينا هنا 3670 صورة فقط. هل يمكنك مطابقته على الأقل؟
معلومات إضافية
كم عدد الطبقات، ما حجم الطبقات؟
يعد تحديد أحجام الطبقات فنًا أكثر من كونه علمًا. عليك أن تجد التوازن الصحيح بين وجود معلمات قليلة جدًا والكثير جدًا من المعلمات (القيم والتحيزات). لا تستطيع الشبكة العصبية أن تمثل مدى تعقيد أشكال الزهور، وذلك بسبب قلة الأوزان. مع وجود عدد كبير جدًا، يمكن أن يكون عرضة "للإفراط في التخصيص"، أي التخصص في صور التدريب وعدم القدرة على التعميم. مع وجود الكثير من المعاملات، سيكون تدريب النموذج بطيئًا أيضًا. في Keras، تعرض الدالة model.summary() بنية النموذج وعدد المَعلمات الخاصة به:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
بعض النصائح:
- وجود طبقات متعددة هو ما يجعل "عمق" فعالية الشبكات العصبية. بالنسبة لمشكلة التعرف على الزهور البسيطة هذه، تكون 5 إلى 10 طبقات منطقية.
- استخدِم فلاتر صغيرة. عادةً ما تكون فلاتر 3x3 جيدة في كل مكان.
- يمكن استخدام فلاتر 1×1 أيضًا ومنخفضة التكلفة. إنها ليست "تصفية" أي شيء سوى حساب المجموعات الخطية للقنوات. استبدِلها بفلاتر حقيقية. (يمكنك الاطلاع على مزيد من المعلومات حول "عمليات الالتفاف 1×1" في القسم التالي).
- بالنسبة لمشكلة تصنيف مثل هذه، يتم تقليل العينة بشكل متكرر باستخدام الحد الأقصى لطبقات التجميع (أو الالتفافات بخطوة >1). أنت لا تهتم بمكان الزهرة، بل فقط أنها وردة أو هندباء، لذا فإن فقدان المعلومات س وص ليس مهمًا وتصفية المناطق الأصغر حجمًا أرخص.
- يصبح عدد الفلاتر عادةً مشابهًا لعدد الفئات في نهاية الشبكة (لماذا؟ يمكنك الاطّلاع على خدعة "متوسط التجميع العالمي" أدناه). في حال التصنيف إلى مئات الفئات، يمكنك زيادة عدد الفلاتر تدريجيًا في الطبقات المتتالية. بالنسبة لمجموعة بيانات الزهور التي تحتوي على 5 فئات، لن تكون التصفية باستخدام 5 عوامل تصفية فقط كافية. يمكنك استخدام عدد الفلاتر نفسه في معظم الطبقات، على سبيل المثال 32 وخفضه في النهاية.
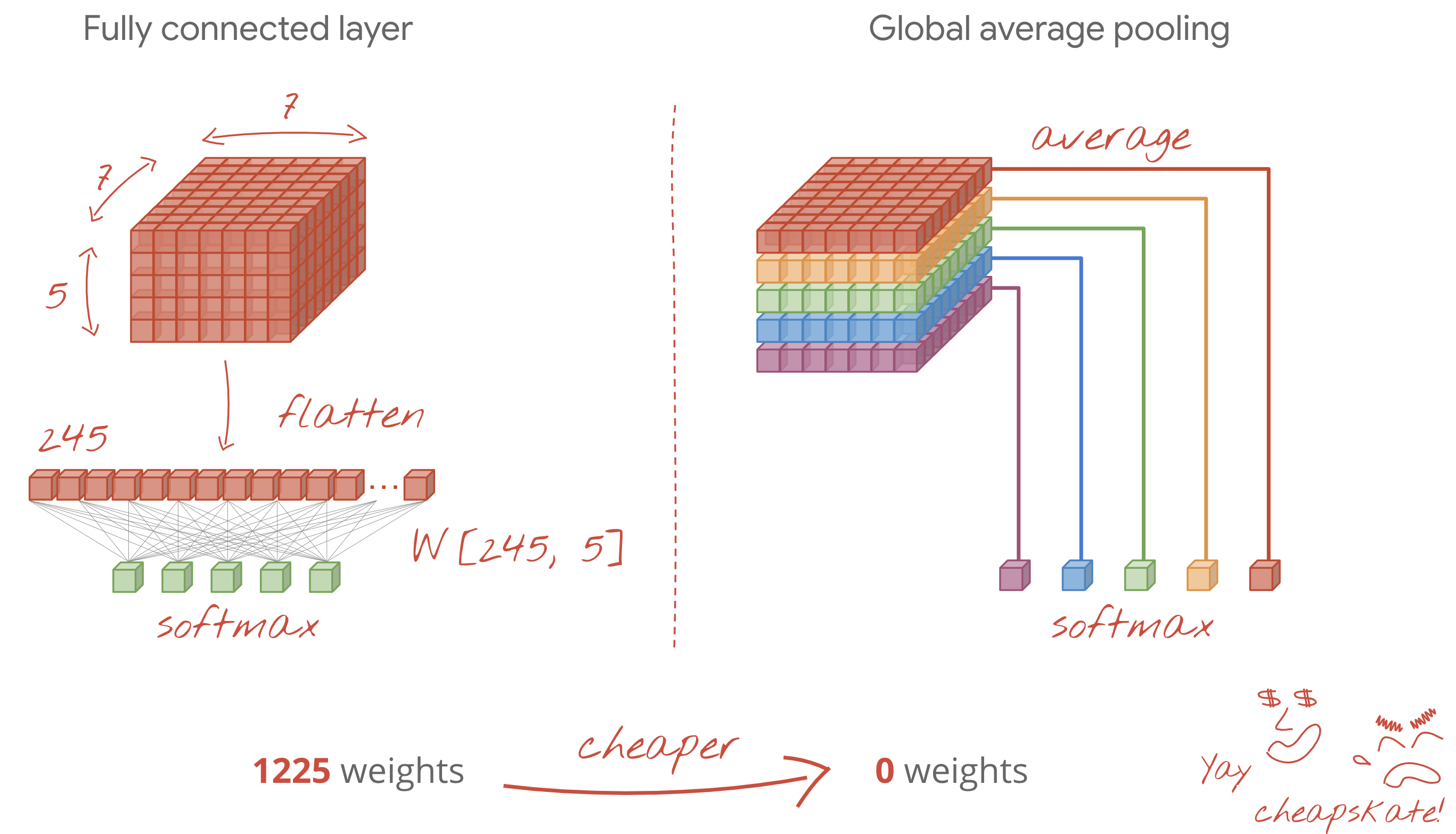
- الطبقات الكثيفة النهائية باهظة الثمن. يمكن أن يكون لها أوزان أكثر من جميع الطبقات الالتفافية مجتمعة. على سب حاوِل أن تكون مدروسًا أو جرِّب تجميع متوسط عالمي (انظر أدناه).
متوسط التجميع على مستوى العالم
بدلاً من استخدام طبقة كثيفة مكلفة في نهاية أي شبكة عصبية التفافية، يمكنك تقسيم البيانات الواردة "مكعب" في العديد من الأجزاء مثل الصفوف، ومتوسّط قيمها وقدِّمها من خلال دالة تفعيل softmax. وهذه الطريقة لإنشاء رأس التصنيف تكلف 0 أوزان. في Keras، الصيغة هي tf.keras.layers.GlobalAveragePooling2D().
الحلّ
ها هو دفتر الحل. يمكنك استخدامه إذا واجهتك مشكلة.
Keras_Flowers_TPU (solution).ipynb
النقاط التي تناولناها
- ✅ لعبة مع طبقات التفافية
- 🤓 اختبرتُ الحد الأقصى للتجميع وعدد الخطوات ومتوسط التجميع العالمي ...
- 👈 تم تكرارنا على نموذج حقيقي سريع على وحدة معالجة الموتّرات
يرجى تخصيص بعض الوقت لاستعراض قائمة التحقق هذه في ذهنك.
10. [INFO] البُنى الالتفافية الحديثة
باختصار
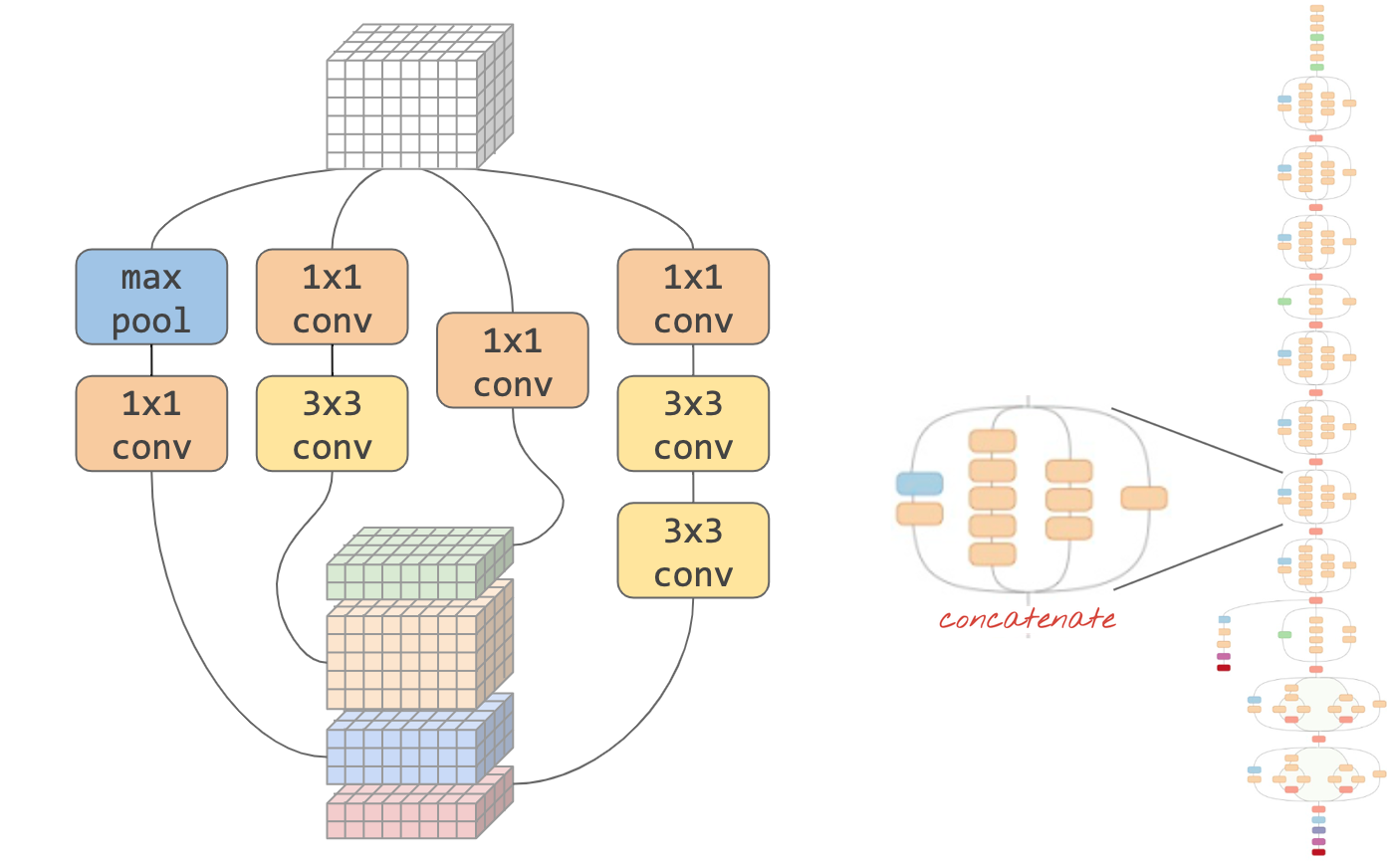
صورة توضيحية: "وحدة" التفافية ما هو أفضل خيار في هذه المرحلة؟ طبقة الحد الأقصى للتجميع المتبوع بطبقة التفافية 1×1 أم تركيبة مختلفة من الطبقات؟ جرِّب كل هذه الخيارات وتسلسل النتائج واترك الشبكة تقرر. على اليمين: " inception" هندسة التفافية باستخدام هذه الوحدات.
في Keras، لإنشاء نماذج حيث يمكن أن يتفرع تدفق البيانات داخل وخارج، عليك استخدام الدالة "الوظيفي" ونمط النموذج. يُرجى الاطّلاع على المثال أدناه:
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
حيل أخرى بتكلفة منخفضة
فلاتر صغيرة 3×3
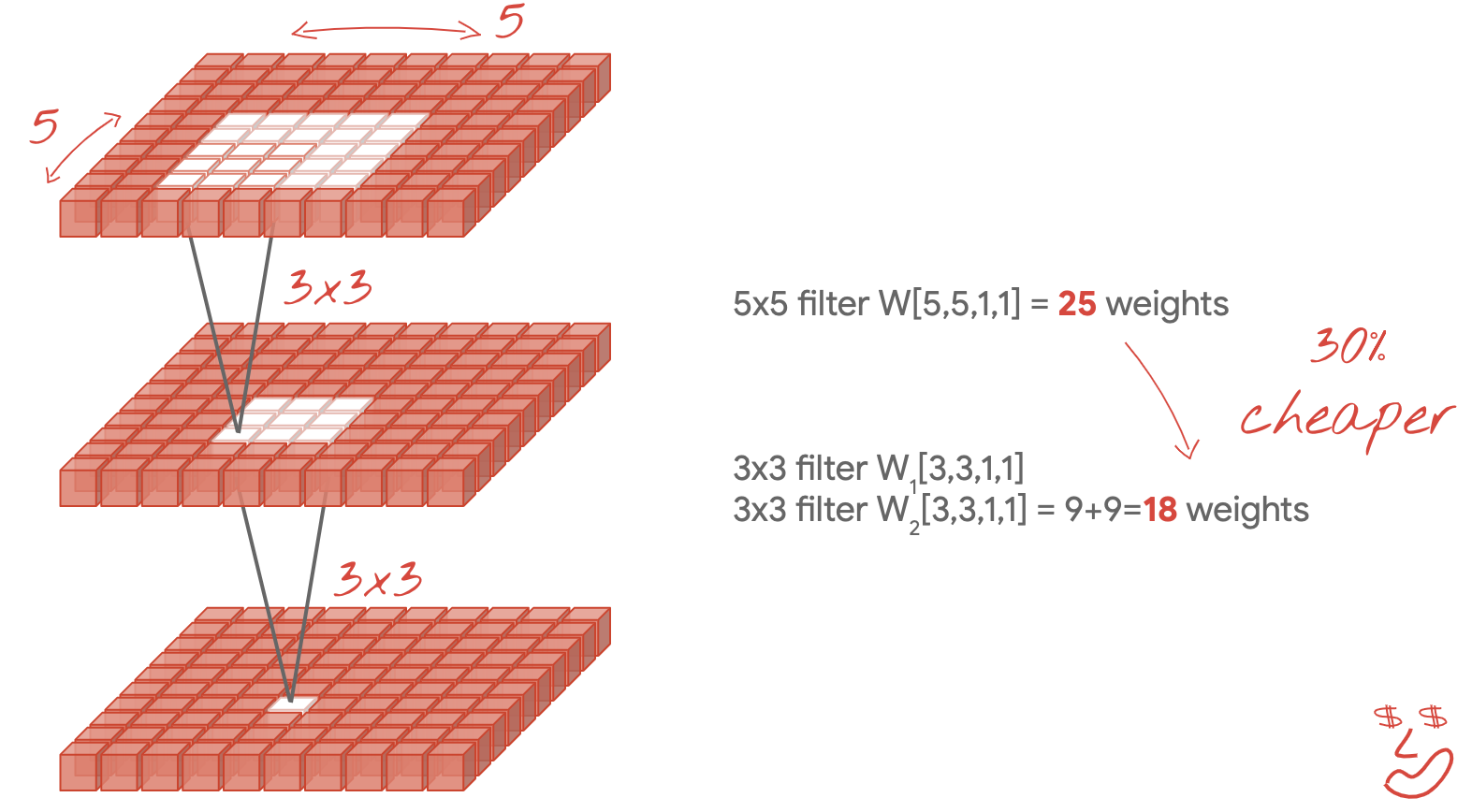
في هذا الرسم التوضيحي، تشاهد نتيجة فلترَين متتاليَين 3x3. حاول تتبع نقاط البيانات التي ساهمت في النتيجة: يحسب هذان الفلتران المتتاليان 3×3 جزء من منطقة 5×5. وهي ليست نفس التركيبة التي ستحسبها الفلتر 5×5، ولكن الأمر يستحق التجربة لأن فلترين متتاليين 3×3 أرخص من فلتر واحد مقاس 5×5.
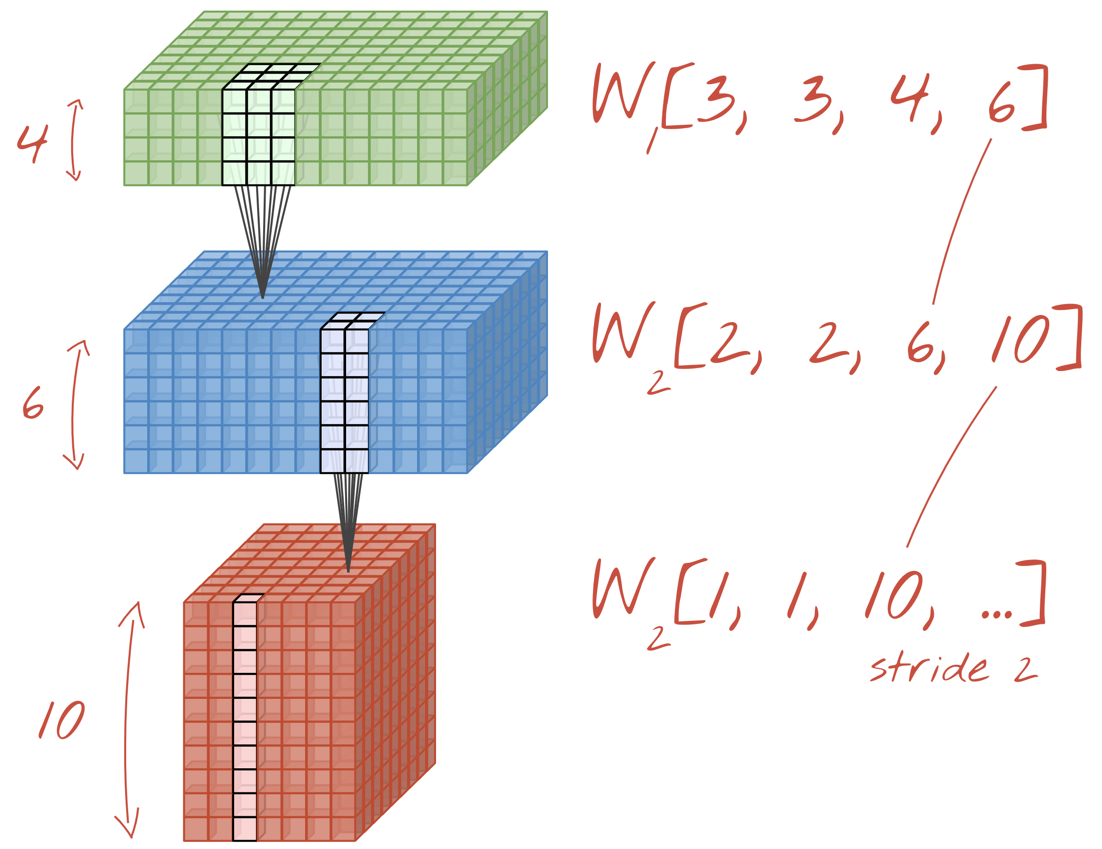
عمليات الالتفاف 1×1؟
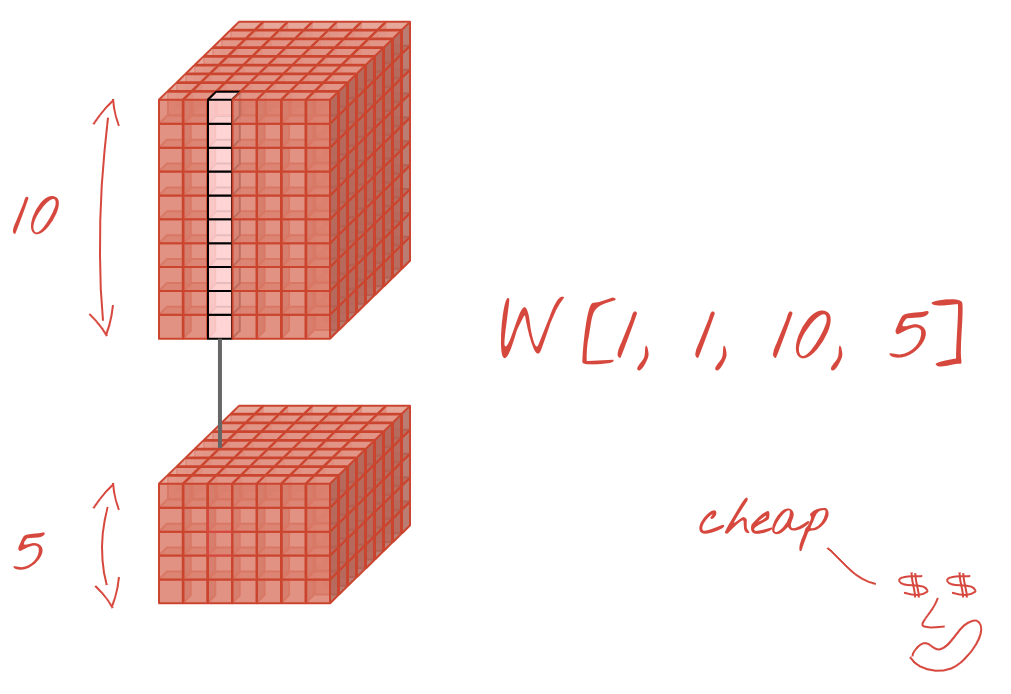
ومن الناحية الرياضية، تشير علامة "1×1" الالتفاف هو ضرب في ثابت، وليس مفهومًا مفيدًا للغاية. في الشبكات العصبية الالتفافية، تذكر أن عامل التصفية يطبق على مكعب بيانات، وليس فقط على صورة ثنائية الأبعاد. ومن ثم، فإن قيمة "1x1" تحسب عامل التصفية المجموع المرجح لعمود 1×1 من البيانات (راجع الرسم التوضيحي) وعند تمريره على مستوى البيانات، ستحصل على مجموعة خطية من قنوات الإدخال. هذا مفيد بالفعل. إذا كنت تعتقد أن القنوات هي نتائج عمليات فلترة فردية، على سبيل المثال، فلتر لـ "آذان مدببة"، وآخر لـ "شارات" وثالث لـ "عين الحشرة" ثم "1x1" ستحسب الطبقة الالتفافية العديد من المجموعات الخطية المحتملة لهذه الميزات، والتي قد تكون مفيدة عند البحث عن "قطة". علاوة على ذلك، تستخدم طبقات 1×1 أوزان أقل.
11. سكيزينت
تم عرض طريقة بسيطة لتجميع هذه الأفكار معًا في "Squeezenet" ورق. يقترح المؤلفون تصميم وحدة التفافية بسيطة للغاية، باستخدام طبقات التفافية 1×1 و3×3 فقط.
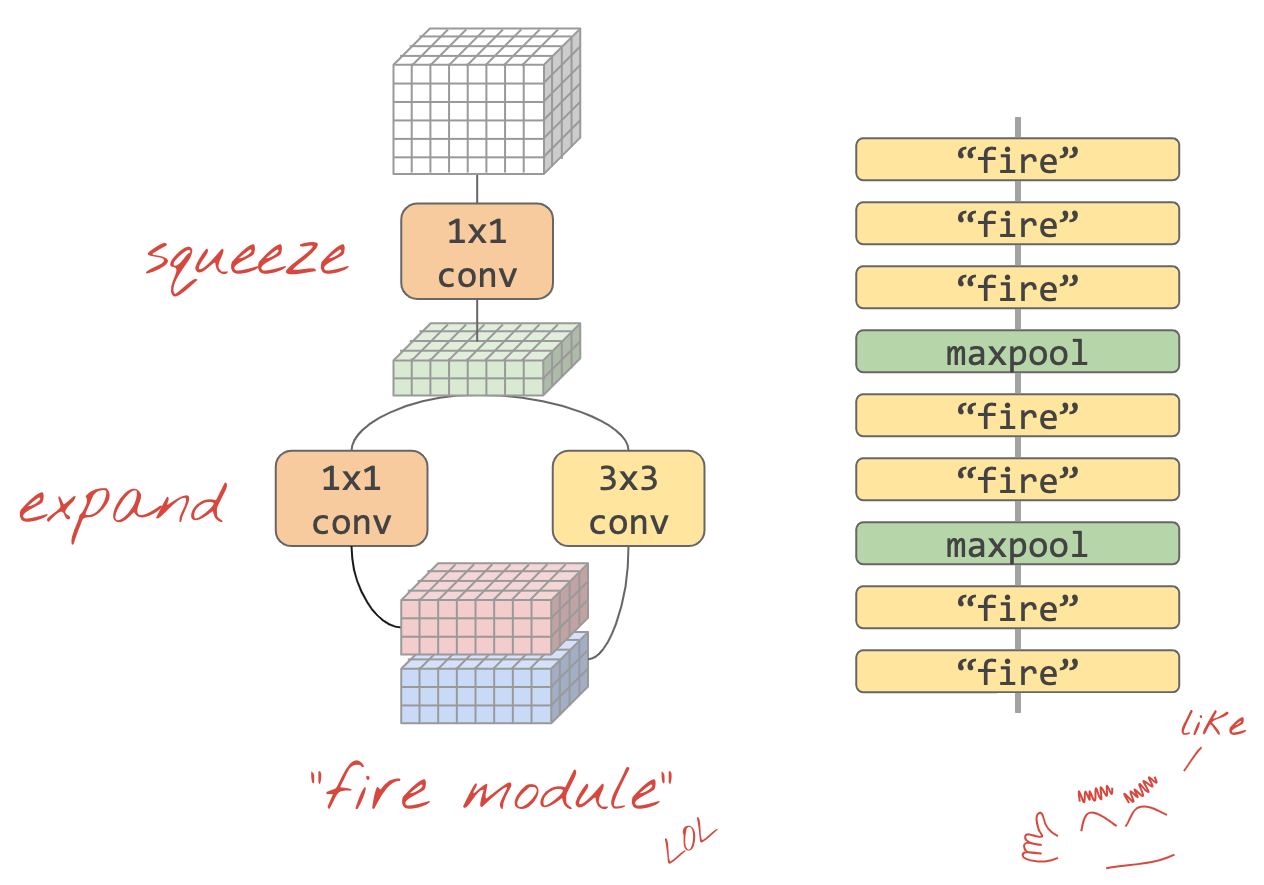
صورة توضيحية: بنية squeezenet المستندة إلى "الوحدات النارية" يتم تبديل طبقة 1×1 التي "تضغط" البيانات الواردة في البعد الرأسي متبوعًا بطبقتين التفافيتين متوازيتين 1×1 و3×3 "تتوسع" مدى عمق البيانات مجددًا
التدريب العملي
استمر في دفتر ملاحظاتك السابق وصمم شبكة عصبية التفافية مستوحاة من الضربة الضغطية. ستحتاج إلى تغيير رمز النموذج إلى "النمط الوظيفي" في Keras.
Keras_Flowers_TPU (playground).ipynb
معلومات إضافية
سيكون من المفيد في هذا التمرين تحديد دالة مساعدة لوحدة squeezenet:
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
الهدف هذه المرة هو الوصول إلى دقة 80٪.
الإجراءات المقترَحة
ابدأ بطبقة التفافية واحدة، ثم اتّبِع الخطوات بـ "fire_modules"، بالتناوب مع MaxPooling2D(pool_size=2) طبقات. يمكنك تجربة طبقتَين إلى 4 طبقات تجميع كحدّ أقصى في الشبكة، وكذلك مع وحدة أو اثنتين أو ثلاث وحدات من وحدات النار المتتالية بين طبقات التجميع القصوى.
في وحدات الإضاءة، يمكن استخدام طبقة "الضغط" يجب أن تكون المعلمة أصغر من "expand" . هذه المعاملات هي في الواقع أعداد من الفلاتر. تتراوح عادةً من 8 إلى 196. يمكنك تجربة البِنى التي يزداد فيها عدد الفلاتر تدريجيًا عبر الشبكة، أو البُنى الأساسية التي تحتوي جميع وحدات النار على عدد الفلاتر نفسه.
يُرجى الاطّلاع على المثال أدناه:
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
في هذه المرحلة، قد تلاحظ أن تجاربك لا تسير على ما يرام وأن هدف الدقة البالغة 80٪ يبدو بعيد المنال. حان الوقت للتعرّف على بعض الأفكار الجديدة بتكلفة منخفضة.
التسوية المجمّعة
ستساعد قاعدة المجموعة في حل مشاكل التقارب التي تواجهها. سيكون هناك شرح تفصيلي حول هذه التقنية في ورشة العمل القادمة، وفي الوقت الحالي، يرجى استخدامها باعتبارها "صندوق أسود" من خلال إضافة هذا الخط بعد كل طبقة التفافية في شبكتك، بما في ذلك الطبقات داخل دالة fire_module:
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
يجب خفض معلَمة الزخم من قيمتها التلقائية 0.99 إلى 0.9 لأنّ مجموعة البيانات صغيرة. لا عليك الاهتمام بهذه التفاصيل في الوقت الحالي.
زيادة البيانات
سوف تحصل على نقاط مئوية أخرى من خلال زيادة البيانات عن طريق عمليات تحويل سهلة مثل تقلب اليسار واليمين لتغييرات التشبع:


يمكنك تنفيذ ذلك بسهولة في Tensorflow باستخدام واجهة برمجة التطبيقات tf.data.Dataset. تحديد دالة تحويل جديدة لبياناتك:
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
بعد ذلك، استخدمها في تحويل البيانات النهائي (مجموعات بيانات التدريب والتحقق من صحة الخلية، الدالة "get_batched_dataset"):
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
لا تنسَ أن تجعل زيادة البيانات اختيارية وإضافة الرمز اللازم للتأكّد من زيادة مجموعة بيانات التدريب فقط. ليس من المنطقي زيادة مجموعة بيانات التحقق من الصحة.
يجب أن تكون الدقة بنسبة 80% في الـ 35 حقبة قريبة الآن.
الحلّ
ها هو دفتر الحل. يمكنك استخدامه إذا واجهتك مشكلة.
Keras_Flowers_TPU_squeezenet.ipynb
النقاط التي تناولناها
- 👈 "أسلوب وظيفي" في "كيراس" طرازات
- 🤓 بنية Squeezenet
- 🤓 زيادة البيانات باستخدام tf.data.datset
يرجى تخصيص بعض الوقت لاستعراض قائمة التحقق هذه في ذهنك.
12. تحسين Xception
عمليات التفاف يمكن فصلها
هناك طريقة مختلفة لتطبيق الطبقات الالتفافية ازدادت رواجها مؤخرًا: وهي تثبيت التفافات قابلة للفصل بين العمق. أعلم أنّه يمكن التحدّث بجرعة، ولكن مفهومه بسيط جدًا. ويتم تنفيذها في TensorFlow وKeras باسم tf.keras.layers.SeparableConv2D.
يعمل الالتفاف القابل للفصل أيضًا على تشغيل عامل تصفية على الصورة ولكنه يستخدم مجموعة مميزة من الأوزان لكل قناة من الصورة المدخلة. ويتبع ذلك "التفاف 1×1"، وهو سلسلة من نواتج النقاط التي ينتج عنها المجموع المرجح للقنوات التي تمت تصفيتها. مع ترجيحات جديدة في كل مرة، يتم حساب العديد من عمليات إعادة الدمج المرجحة للقنوات حسب الضرورة.
صورة توضيحية: بثبات قابلة للفصل المرحلة 1: عمليات الالتفاف باستخدام فلتر منفصل لكل قناة المرحلة 2: عمليات إعادة التركيب الخطي للقنوات. يتم تكرارها مع مجموعة جديدة من القيم التقديرية إلى أن يتم الوصول إلى العدد المطلوب من قنوات المخرجات. يمكن تكرار المرحلة 1 أيضًا، مع استخدام أوزان جديدة في كل مرة، ولكن من الناحية العملية، يمكن تكرارها في حالات نادرة.
يتم استخدام الالتفاف القابل للفصل في أحدث بُنى الشبكات الالتفافية: MobileNetV2، وXception، وEfficientNet. بالمناسبة، إنّ MobileNetV2 هو ما استخدمته سابقًا لنقل التعلُّم.
وهي أرخص من عمليات الالتفاف المنتظمة واكتشفت فعاليتها في الممارسة العملية. في ما يلي عدد الوزن للمثال الموضّح أعلاه:
الطبقة الالتفافية: 4 × 4 × 3 × 5 = 240
الطبقة الالتفافية القابلة للفصل: 4 × 4 × 3 + 3 × 5 = 48 + 15 = 63
ويتم تركه كتمرين للقارئ لحساب عدد عمليات الضرب المطلوبة لتطبيق كل نمط من مقاييس الطبقة الالتفافية بطريقة مماثلة. وتكون عمليات الالتفاف القابلة للفصل أصغر حجمًا وأكثر فاعلية من الناحية الحسابية.
التدريب العملي
إعادة التشغيل من صفحة "نقل التعلُّم" ، ولكن هذه المرة حدد Xception كنموذج مدرَّب مسبقًا. تستخدم Xception عمليات التفاف قابلة للفصل فقط. اترك جميع الأوزان قابلة للتدريب. وسنعمل على ضبط الأوزان المدرّبة مسبقًا على البيانات بدلاً من استخدام الطبقات المدرّبة مسبقًا على هذا النحو.
Keras Flowers transfer learning (playground).ipynb
الهدف: الدقة > 95% (لا، بالطبع يمكن تحقيق ذلك!)
هذا هو التمرين الأخير، فهو يتطلب المزيد من أعمال البرمجة وعلوم البيانات.
معلومات إضافية عن الضبط
تتوفّر منصة Xception ضمن النماذج العادية المدرّبة مسبقًا في tf.keras.application.* لا تنس ترك جميع الأوزان قابلة للتدريب هذه المرة.
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
للحصول على نتائج جيدة عند ضبط النموذج، ستحتاج إلى الانتباه إلى معدّل التعلّم واستخدام جدول لمعدّل التعلّم مع فترة تحسين. مثال:
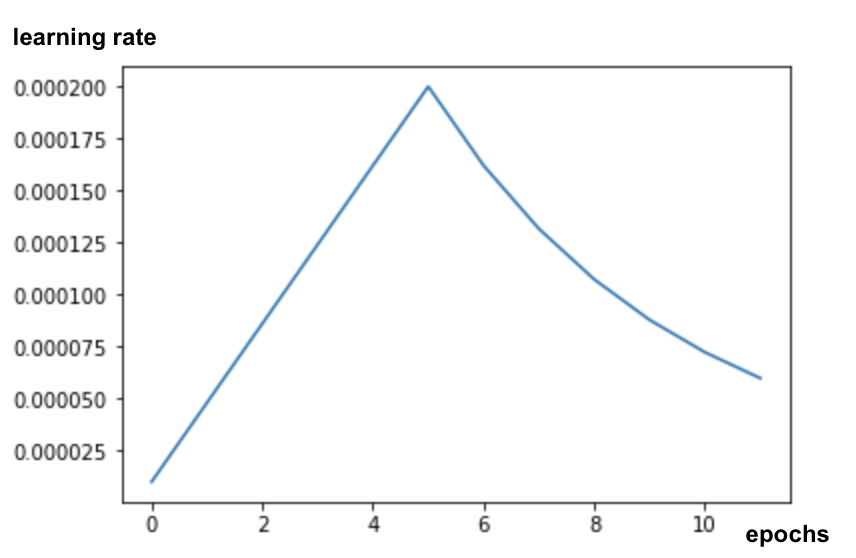
قد يؤدي البدء بمعدل تعلُّم قياسي إلى إيقاف الأوزان المدرّبة مسبقًا للنموذج. يؤدي البدء إلى الاحتفاظ بها بشكل تدريجي حتى يتمكن النموذج من الوصول إلى بياناتك من أجل تعديلها بطريقة معقولة. بعد المنحدر، يمكنك المتابعة بمعدل تعلم ثابت أو متناقص بشكل كبير.
في Keras، يتم تحديد معدل التعلم من خلال استدعاء يمكنك من خلاله حساب معدل التعلم المناسب لكل حقبة. سيُجري Keras معدّل التعلّم الصحيح إلى المحسِّن في كل حقبة.
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
الحلّ
ها هو دفتر الحل. يمكنك استخدامه إذا واجهتك مشكلة.
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
النقاط التي تناولناها
- ️ لقد تم اختيار الالتفاف القابل للفصل بين العمق.
- 🤓 جداول معدّل التعلُّم
- 😈 ضبط نموذج مدرَّب مسبقًا.
يرجى تخصيص بعض الوقت لاستعراض قائمة التحقق هذه في ذهنك.
13. تهانينا!
لقد أنشأت أول شبكة عصبية التفافية حديثة ودرّبتها على دقة تزيد عن 90%، وتكرارت التدريبات المتتالية في دقائق فقط بفضل وحدات معالجة الموتّرات.
استخدام وحدات معالجة الموتّرات عمليًا
تتوفّر وحدات معالجة الموتّرات ووحدات معالجة الرسومات (GPU) على Vertex AI في Google Cloud:
- على الأجهزة الافتراضية التي تستخدم ميزة Deep Learning VM
- في أجهزة كمبيوتر Vertex AI الدفترية
- في وظائف Vertex AI Training Jobs
وأخيرًا، نرحِّب بملاحظاتك. يُرجى إخبارنا بما إذا لاحظت أمرًا غير صحيح في هذا التمرين المعملي أو إذا كنت تعتقد أنه ينبغي تحسينه. يمكن تقديم الملاحظات من خلال مشاكل GitHub [ رابط الملاحظات].

|
|

