
1. ภาพรวม
ในห้องทดลองนี้ คุณจะได้เรียนรู้วิธีสร้าง ฝึก และปรับแต่งโครงข่ายประสาทเทียมแบบ Convolution ของคุณเองตั้งแต่ต้นด้วย Keras และ Tensorflow 2 ซึ่งตอนนี้ทำได้ภายในไม่กี่นาทีโดยใช้ประสิทธิภาพของ TPU นอกจากนี้ คุณยังจะได้ดูแนวทางต่างๆ ตั้งแต่การเรียนรู้แบบถ่ายโอนที่เรียบง่ายไปจนถึงสถาปัตยกรรมแบบ Convolutional ที่ทันสมัย เช่น Squeezenet ห้องทดลองนี้มีคำอธิบายเชิงทฤษฎีเกี่ยวกับโครงข่ายประสาทเทียมและเป็นจุดเริ่มต้นที่ดีสำหรับนักพัฒนาซอฟต์แวร์ที่กำลังเรียนรู้เกี่ยวกับการเรียนรู้เชิงลึก
การอ่านเอกสารเกี่ยวกับการเรียนรู้เชิงลึกอาจเป็นเรื่องยากและน่าสับสน มาดูสถาปัตยกรรมของโครงข่ายระบบประสาทเทียมแบบคอนโวลูชันสมัยใหม่กัน

สิ่งที่คุณจะได้เรียนรู้
- หากต้องการใช้ Keras และ Tensor Processing Unit (TPU) เพื่อสร้างโมเดลที่กำหนดเองได้เร็วขึ้น
- ใช้ tf.data.Dataset API และรูปแบบ TFRecord เพื่อโหลดข้อมูลฝึกฝนอย่างมีประสิทธิภาพ
- หากต้องการโกง 😈 ให้ใช้การเรียนรู้แบบถ่ายโอนแทนการสร้างโมเดลของคุณเอง
- หากต้องการใช้รูปแบบโมเดล Keras Sequential และ Functional
- หากต้องการสร้างตัวแยกประเภท Keras ของคุณเองด้วยเลเยอร์ Softmax และการสูญเสีย Cross-Entropy
- เพื่อปรับแต่งโมเดลด้วยการเลือกเลเยอร์ Convolutional ที่ดี
- เพื่อสำรวจแนวคิดสถาปัตยกรรม ConvNet สมัยใหม่ เช่น โมดูล การพูลโดยเฉลี่ยทั่วโลก เป็นต้น
- เพื่อสร้าง ConvNet ที่ทันสมัยแบบง่ายๆ โดยใช้สถาปัตยกรรม SqueezeNet
ความคิดเห็น
หากพบสิ่งผิดปกติใน Codelab นี้ โปรดแจ้งให้เราทราบ คุณแสดงความคิดเห็นได้ผ่านปัญหาใน GitHub [feedback link]
2. คู่มือเริ่มต้นฉบับย่อของ Google Colaboratory
แล็บนี้ใช้ Google Collaboratory และคุณไม่จำเป็นต้องตั้งค่าใดๆ คุณเรียกใช้ได้จาก Chromebook โปรดเปิดไฟล์ด้านล่างและเรียกใช้เซลล์เพื่อให้คุ้นเคยกับสมุดบันทึก Colab
เลือกแบ็กเอนด์ TPU
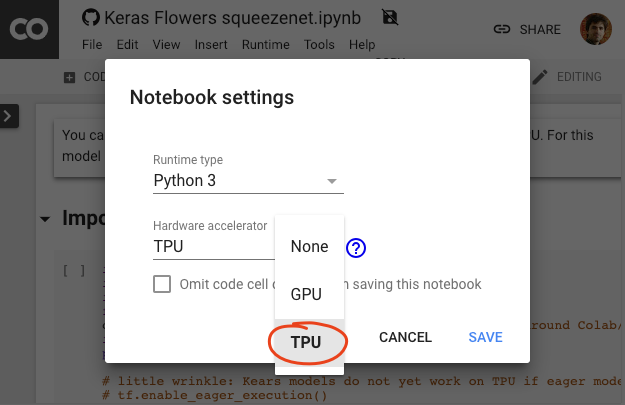
ในเมนู Colab ให้เลือกรันไทม์ > เปลี่ยนประเภทรันไทม์ แล้วเลือก TPU ในโค้ดแล็บนี้ คุณจะได้ใช้ TPU (Tensor Processing Unit) ที่มีประสิทธิภาพซึ่งได้รับการสนับสนุนสำหรับการฝึกที่เร่งด้วยฮาร์ดแวร์ การเชื่อมต่อกับรันไทม์จะเกิดขึ้นโดยอัตโนมัติเมื่อมีการดำเนินการครั้งแรก หรือคุณจะใช้ปุ่ม "เชื่อมต่อ" ที่มุมขวาบนก็ได้
การดำเนินการ Notebook
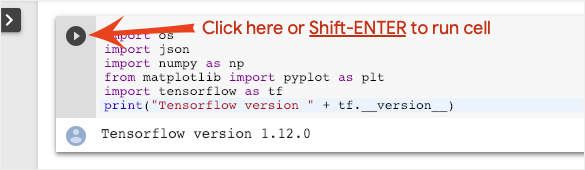
เรียกใช้เซลล์ทีละเซลล์โดยคลิกเซลล์และใช้ Shift-ENTER นอกจากนี้ คุณยังเรียกใช้ทั้งสมุดบันทึกได้ด้วยรันไทม์ > เรียกใช้ทั้งหมด
สารบัญ

Notebook ทุกรายการมีสารบัญ คุณเปิดได้โดยใช้ลูกศรสีดำทางด้านซ้าย
เซลล์ที่ซ่อนอยู่

บางเซลล์จะแสดงเฉพาะชื่อ ฟีเจอร์นี้เป็นฟีเจอร์สมุดบันทึกเฉพาะของ Colab คุณดับเบิลคลิกที่ไฟล์เพื่อดูโค้ดภายในได้ แต่โดยปกติแล้วโค้ดจะไม่น่าสนใจนัก โดยปกติจะเป็นฟังก์ชันการสนับสนุนหรือการแสดงภาพ คุณยังคงต้องเรียกใช้เซลล์เหล่านี้เพื่อให้ฟังก์ชันภายในได้รับการกำหนด
การตรวจสอบสิทธิ์
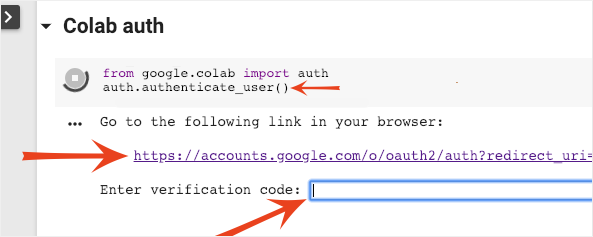
Colab สามารถเข้าถึง Bucket ของ Google Cloud Storage ส่วนตัวได้หากคุณตรวจสอบสิทธิ์ด้วยบัญชีที่ได้รับอนุญาต ข้อมูลโค้ดด้านบนจะทริกเกอร์กระบวนการตรวจสอบสิทธิ์
3. [INFO] Tensor Processing Unit (TPU) คืออะไร
โดยสรุป

โค้ดสำหรับการฝึกโมเดลบน TPU ใน Keras (และใช้ GPU หรือ CPU แทนหากไม่มี TPU)
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
วันนี้เราจะใช้ TPU เพื่อสร้างและเพิ่มประสิทธิภาพตัวแยกประเภทดอกไม้ด้วยความเร็วแบบอินเทอร์แอกทีฟ (นาทีต่อการเรียกใช้การฝึก)

ทำไมต้อง TPU
GPU สมัยใหม่ได้รับการจัดระเบียบโดยมี "คอร์" ที่ตั้งโปรแกรมได้ ซึ่งเป็นสถาปัตยกรรมที่มีความยืดหยุ่นสูงที่ช่วยให้ GPU สามารถจัดการงานต่างๆ ได้ เช่น การแสดงผล 3 มิติ การเรียนรู้เชิงลึก การจำลองทางกายภาพ ฯลฯ ในทางกลับกัน TPU จะจับคู่โปรเซสเซอร์เวกเตอร์แบบคลาสสิกกับหน่วยคูณเมทริกซ์เฉพาะ และทำงานได้ดีในทุกงานที่การคูณเมทริกซ์ขนาดใหญ่มีบทบาทสำคัญ เช่น โครงข่ายประสาทเทียม

ภาพประกอบ: เลเยอร์โครงข่ายระบบประสาทเทียมแบบหนาแน่นเป็นการคูณเมทริกซ์ โดยมีการประมวลผลรูปภาพ 8 รูปพร้อมกันผ่านโครงข่ายระบบประสาทเทียม โปรดทำการคูณ 1 แถว x คอลัมน์เพื่อยืนยันว่าฟีเจอร์นี้จะหาผลรวมแบบถ่วงน้ำหนักของค่าพิกเซลทั้งหมดของรูปภาพ เลเยอร์ Convolutional สามารถแสดงเป็นการคูณเมทริกซ์ได้เช่นกัน แม้ว่าจะซับซ้อนกว่าเล็กน้อย ( คำอธิบายที่นี่ในส่วนที่ 1)
ฮาร์ดแวร์
MXU และ VPU
แกน TPU v2 ประกอบด้วยหน่วยคูณเมทริกซ์ (MXU) ซึ่งทำการคูณเมทริกซ์ และหน่วยประมวลผลเวกเตอร์ (VPU) สำหรับงานอื่นๆ ทั้งหมด เช่น การเปิดใช้งาน, Softmax เป็นต้น โดย VPU จะจัดการการคำนวณ float32 และ int32 ในทางกลับกัน MXU จะทำงานในรูปแบบจุดลอยตัวแบบความแม่นยำผสม 16-32 บิต
จุดลอยแบบความแม่นยำผสมและ bfloat16
MXU จะคำนวณการคูณเมทริกซ์โดยใช้อินพุต bfloat16 และเอาต์พุต float32 การสะสมระดับกลางจะดำเนินการด้วยความแม่นยำของ float32
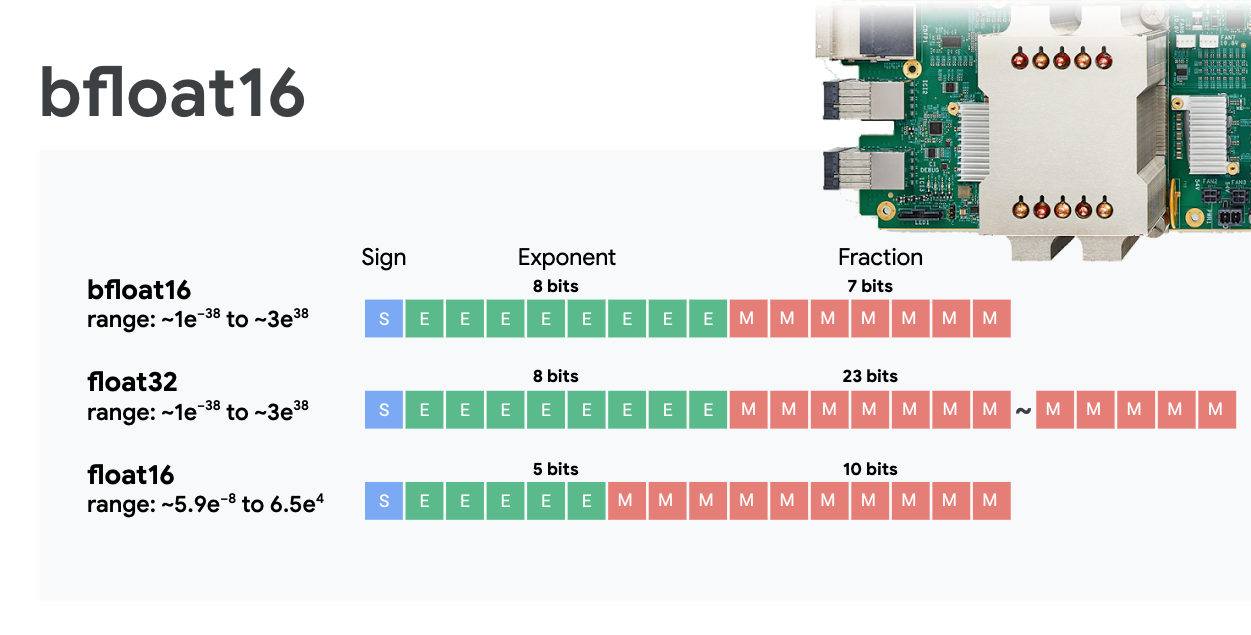
โดยปกติแล้วการฝึกโครงข่ายระบบประสาทเทียมจะทนทานต่อสัญญาณรบกวนที่เกิดจากความแม่นยำของจุดลอยตัวที่ลดลง ในบางกรณี สัญญาณรบกวนอาจช่วยให้เครื่องมือเพิ่มประสิทธิภาพบรรลุเป้าหมายได้ โดยปกติแล้ว ความแม่นยำแบบจุดลอยตัว 16 บิตจะใช้เพื่อเร่งการคำนวณ แต่รูปแบบ float16 และ float32 มีช่วงที่แตกต่างกันมาก การลดความแม่นยำจาก float32 เป็น float16 มักทำให้เกิดการล้นและอันเดอร์โฟลว์ แม้จะมีโซลูชันอยู่ แต่โดยปกติแล้วจะต้องมีการดำเนินการเพิ่มเติมเพื่อให้ float16 ทำงานได้
ด้วยเหตุนี้ Google จึงเปิดตัวรูปแบบ bfloat16 ใน TPU ซึ่งเป็น float32 ที่ตัดทอนแล้วโดยมีบิตเลขชี้กำลังและช่วงเหมือนกับ float32 ทุกประการ การที่ TPU คำนวณการคูณเมทริกซ์ในความแม่นยำแบบผสมโดยมีอินพุตเป็น bfloat16 แต่อินพุตเป็น float32 หมายความว่าโดยปกติแล้วไม่จำเป็นต้องเปลี่ยนแปลงโค้ดเพื่อให้ได้รับประโยชน์จากประสิทธิภาพที่เพิ่มขึ้นของความแม่นยำที่ลดลง
อาร์เรย์ซิสโตลิก
MXU จะใช้การคูณเมทริกซ์ในฮาร์ดแวร์โดยใช้สถาปัตยกรรมที่เรียกว่า "systolic array" ซึ่งองค์ประกอบข้อมูลจะไหลผ่านอาร์เรย์ของหน่วยการคำนวณฮาร์ดแวร์ (ในทางการแพทย์ "ซิสโทลิก" หมายถึงการบีบตัวของหัวใจและการไหลเวียนของเลือด แต่ในที่นี้หมายถึงการไหลเวียนของข้อมูล)
องค์ประกอบพื้นฐานของการคูณเมทริกซ์คือผลคูณจุดระหว่างแถวจากเมทริกซ์หนึ่งกับคอลัมน์จากเมทริกซ์อีกเมทริกซ์หนึ่ง (ดูภาพที่ด้านบนของส่วนนี้) สำหรับการคูณเมทริกซ์ Y=X*W องค์ประกอบหนึ่งของผลลัพธ์จะเป็นดังนี้
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
ใน GPU เราจะเขียนโปรแกรมผลคูณจุดนี้ลงใน "แกน" ของ GPU แล้วรันใน "แกน" ให้ได้มากที่สุดแบบขนานเพื่อพยายามคำนวณค่าทุกค่าของเมทริกซ์ผลลัพธ์พร้อมกัน หากเมทริกซ์ที่ได้มีขนาด 128x128 จะต้องมี "แกน" 128x128=16K ซึ่งโดยปกติแล้วจะเป็นไปไม่ได้ GPU ที่ใหญ่ที่สุดมีประมาณ 4,000 คอร์ ในทางกลับกัน TPU จะใช้ฮาร์ดแวร์ขั้นต่ำสำหรับหน่วยประมวลผลใน MXU ซึ่งมีเพียงbfloat16 x bfloat16 => float32ตัวคูณสะสมเท่านั้น ซึ่งมีขนาดเล็กมากจน TPU สามารถติดตั้งใช้งานได้ถึง 16,000 รายการใน MXU ขนาด 128x128 และประมวลผลการคูณเมทริกซ์นี้ได้ในครั้งเดียว
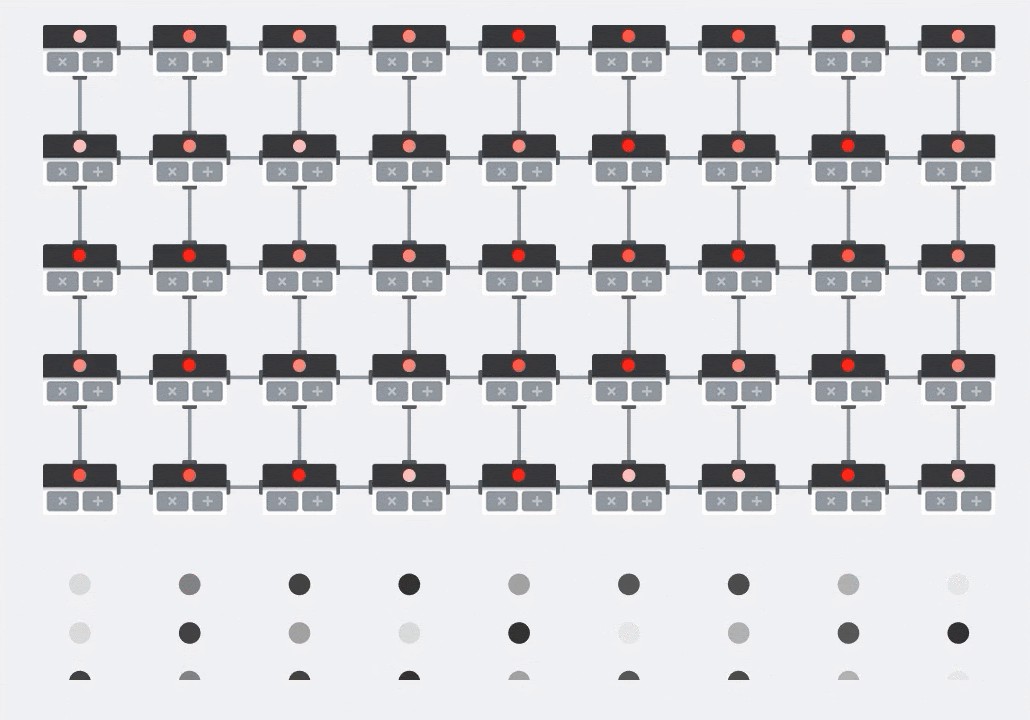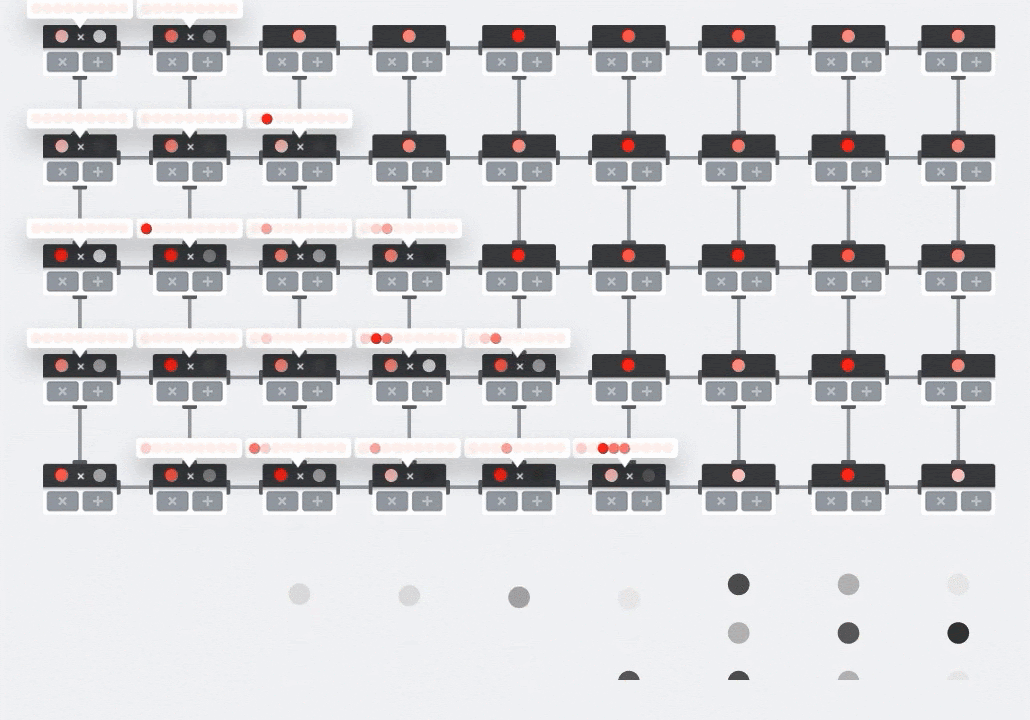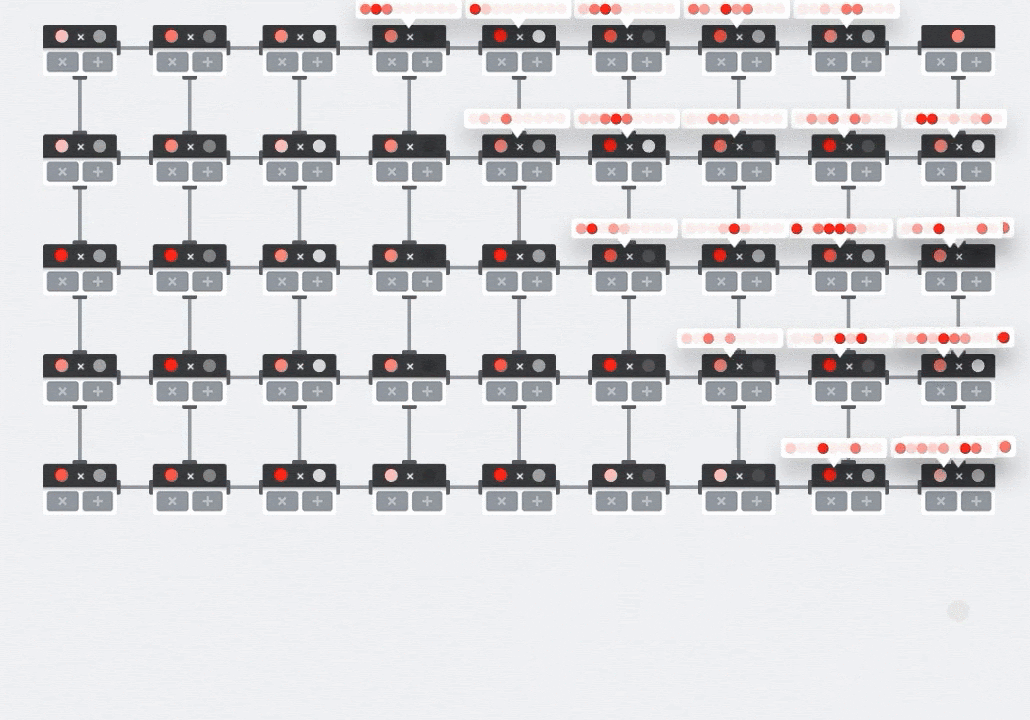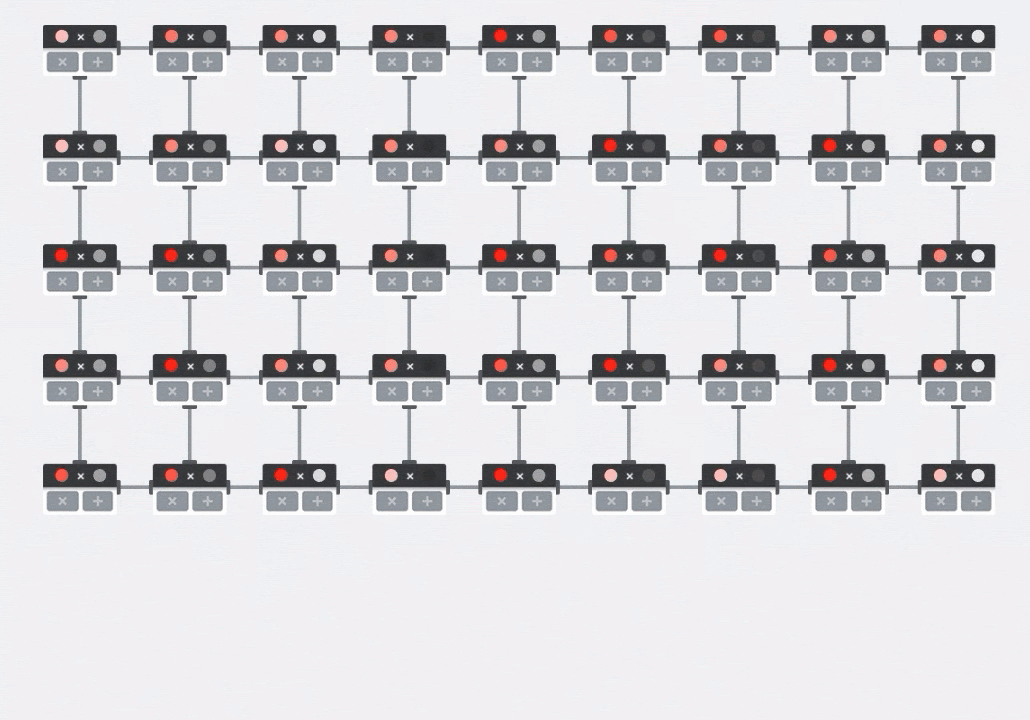
ภาพประกอบ: อาร์เรย์ซิสโตลิก MXU องค์ประกอบการคำนวณคือตัวคูณสะสม ระบบจะโหลดค่าของเมทริกซ์หนึ่งลงในอาร์เรย์ (จุดสีแดง) ค่าของเมทริกซ์อื่นๆ จะไหลผ่านอาร์เรย์ (จุดสีเทา) เส้นแนวตั้งจะส่งต่อค่าขึ้นไป เส้นแนวนอนจะส่งต่อผลรวมบางส่วน ผู้ใช้ต้องตรวจสอบว่าเมื่อข้อมูลไหลผ่านอาร์เรย์ คุณจะได้รับผลลัพธ์ของการคูณเมทริกซ์ที่ออกมาจากด้านขวา
นอกจากนี้ ขณะที่ MXU กำลังคำนวณผลคูณแบบดอท ผลรวมขั้นกลางจะไหลเวียนระหว่างหน่วยประมวลผลที่อยู่ติดกัน ไม่จำเป็นต้องจัดเก็บและดึงข้อมูลจากหน่วยความจำหรือแม้แต่ไฟล์รีจิสเตอร์ ผลลัพธ์ที่ได้คือสถาปัตยกรรมอาร์เรย์ซิสโตลิกของ TPU มีข้อได้เปรียบด้านความหนาแน่นและกำลังอย่างมาก รวมถึงข้อได้เปรียบด้านความเร็วที่สำคัญเมื่อเทียบกับ GPU ในการคำนวณการคูณเมทริกซ์
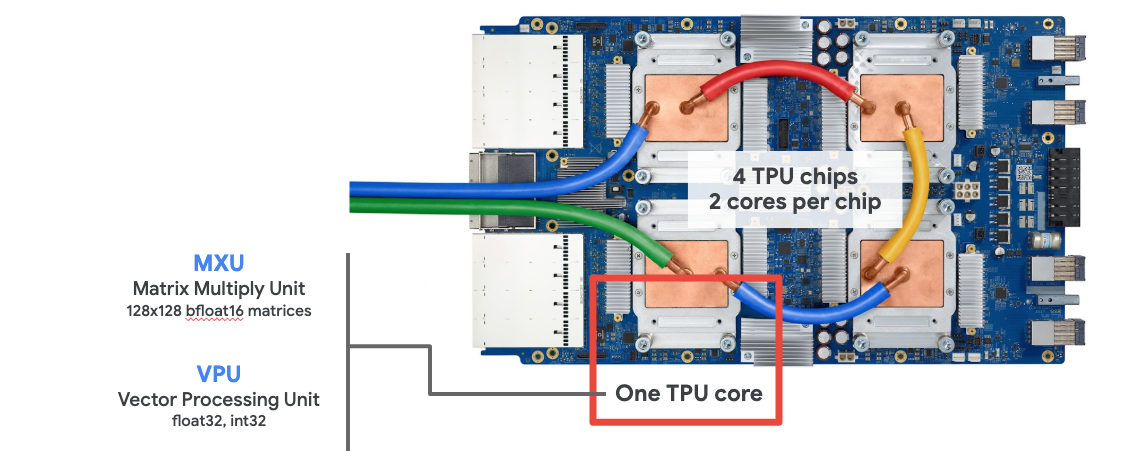
Cloud TPU
เมื่อขอ "Cloud TPU v2" ใน Google Cloud Platform คุณจะได้รับเครื่องเสมือน (VM) ที่มีบอร์ด TPU ที่เชื่อมต่อกับ PCI บอร์ด TPU มีชิป TPU แบบดูอัลคอร์ 4 ตัว แต่ละคอร์ TPU มี VPU (หน่วยประมวลผลเวกเตอร์) และ MXU (หน่วยคูณเมทริกซ์) ขนาด 128x128 จากนั้นโดยปกติแล้ว "Cloud TPU" นี้จะเชื่อมต่อผ่านเครือข่ายกับ VM ที่ขอ ดังนั้นภาพรวมทั้งหมดจึงมีลักษณะดังนี้
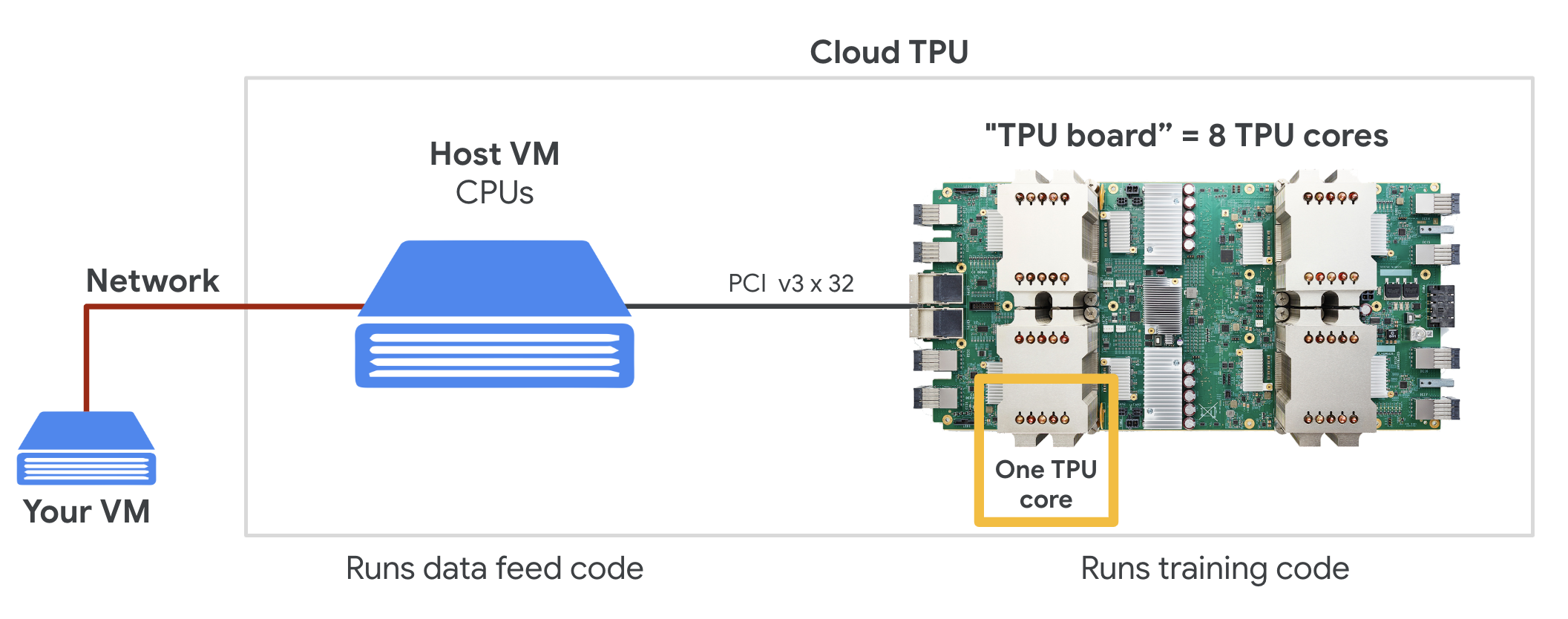
ภาพประกอบ: VM ของคุณที่มีตัวเร่ง Cloud TPU ที่เชื่อมต่อกับเครือข่าย "Cloud TPU" เองประกอบด้วย VM ที่มีบอร์ด TPU ที่เชื่อมต่อ PCI ซึ่งมีชิป TPU แบบดูอัลคอร์ 4 ตัว
พ็อด TPU
ในศูนย์ข้อมูลของ Google นั้น TPU จะเชื่อมต่อกับอินเทอร์คอนเน็กต์การประมวลผลประสิทธิภาพสูง (HPC) ซึ่งทำให้ TPU ปรากฏเป็นตัวเร่งขนาดใหญ่มากตัวเดียว Google เรียกหน่วยประมวลผลเหล่านี้ว่าพ็อด ซึ่งมีแกน TPU v2 ได้สูงสุด 512 แกน หรือแกน TPU v3 ได้สูงสุด 2048 แกน

ภาพ: พ็อด TPU v3 บอร์ดและแร็ค TPU ที่เชื่อมต่อผ่านการเชื่อมต่อถึงกันของ HPC
ในระหว่างการฝึก อัลกอริทึม All-Reduce จะใช้เพื่อแลกเปลี่ยนการไล่ระดับระหว่างคอร์ TPU ( คำอธิบายที่ดีเกี่ยวกับ All-Reduce อยู่ที่นี่) โมเดลที่กำลังฝึกสามารถใช้ประโยชน์จากฮาร์ดแวร์ได้โดยการฝึกในขนาดกลุ่มใหญ่

ภาพ: การซิงโครไนซ์การไล่ระดับสีระหว่างการฝึกโดยใช้อัลกอริทึม All-Reduce ในเครือข่าย HPC แบบเมชโทโรดัล 2 มิติของ TPU ของ Google
ซอฟต์แวร์
การฝึกที่มีขนาดกลุ่มใหญ่
ขนาดกลุ่มที่เหมาะสมสำหรับ TPU คือ 128 รายการข้อมูลต่อแกน TPU แต่ฮาร์ดแวร์สามารถแสดงการใช้งานที่ดีได้ตั้งแต่ 8 รายการข้อมูลต่อแกน TPU โปรดทราบว่า Cloud TPU 1 เครื่องมี 8 คอร์
ในโค้ดแล็บนี้ เราจะใช้ Keras API ใน Keras กลุ่มที่คุณระบุคือขนาดกลุ่มส่วนกลางสำหรับ TPU ทั้งหมด ระบบจะแยกกลุ่มของคุณออกเป็น 8 กลุ่มโดยอัตโนมัติและเรียกใช้ใน 8 คอร์ของ TPU

ดูเคล็ดลับเพิ่มเติมเกี่ยวกับประสิทธิภาพได้ที่คู่มือประสิทธิภาพ TPU สำหรับขนาดกลุ่มที่ใหญ่มาก โมเดลบางรุ่นอาจต้องมีการดูแลเป็นพิเศษ โปรดดูรายละเอียดเพิ่มเติมที่ LARSOptimizer
กลไกภายใน: XLA
โปรแกรม TensorFlow จะกำหนดกราฟการคำนวณ TPU ไม่ได้รันโค้ด Python โดยตรง แต่จะรันกราฟการคำนวณที่กำหนดโดยโปรแกรม TensorFlow เบื้องหลังแล้ว คอมไพเลอร์ที่ชื่อว่า XLA (คอมไพล์พีชคณิตเชิงเส้นแบบเร่งความเร็ว) จะแปลงกราฟ TensorFlow ของโหนดการคำนวณเป็นรหัสเครื่อง TPU นอกจากนี้ คอมไพเลอร์นี้ยังทำการเพิ่มประสิทธิภาพขั้นสูงหลายอย่างในโค้ดและเลย์เอาต์หน่วยความจำ การคอมไพล์จะเกิดขึ้นโดยอัตโนมัติเมื่อส่งงานไปยัง TPU คุณไม่จำเป็นต้องรวม XLA ไว้ในห่วงโซ่การสร้างอย่างชัดเจน
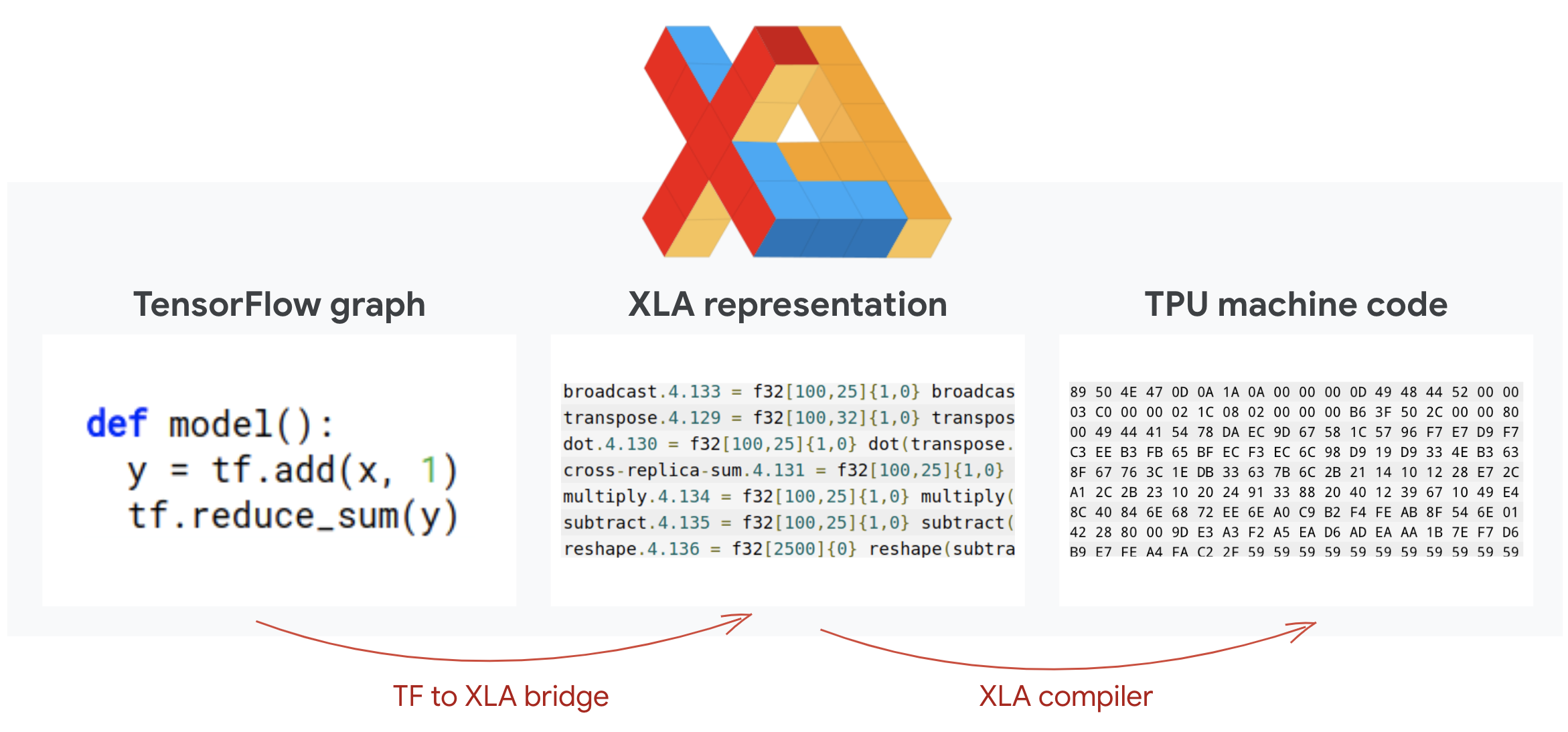
ภาพประกอบ: หากต้องการเรียกใช้ใน TPU ระบบจะแปลกราฟการคำนวณที่กำหนดโดยโปรแกรม TensorFlow เป็นการแสดง XLA (คอมไพเลอร์พีชคณิตเชิงเส้นแบบเร่ง) ก่อน จากนั้น XLA จะคอมไพล์เป็นรหัสเครื่อง TPU
การใช้ TPU ใน Keras
Tensorflow 2.1 เป็นต้นไปรองรับ TPU ผ่าน Keras API การรองรับ Keras จะทำงานบน TPU และ TPU Pod ต่อไปนี้คือตัวอย่างที่ใช้ได้กับ TPU, GPU และ CPU
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
ในข้อมูลโค้ดนี้
TPUClusterResolver().connect()ค้นหา TPU ในเครือข่าย โดยจะทำงานได้โดยไม่ต้องใช้พารามิเตอร์ในระบบ Google Cloud ส่วนใหญ่ (งาน AI Platform, Colaboratory, Kubeflow, VM สำหรับ Deep Learning ที่สร้างผ่านยูทิลิตี "ctpu up") ระบบเหล่านี้ทราบว่า TPU อยู่ที่ใดเนื่องจากตัวแปรสภาพแวดล้อม TPU_NAME หากสร้าง TPU ด้วยตนเอง ให้ตั้งค่าตัวแปรสภาพแวดล้อม TPU_NAME ใน VM ที่คุณใช้ หรือเรียกใช้TPUClusterResolverโดยใช้พารามิเตอร์ที่ชัดเจน:TPUClusterResolver(tp_uname, zone, project)TPUStrategyเป็นส่วนที่ใช้การกระจายและอัลกอริทึมการซิงค์การไล่ระดับสี "all-reduce"- กลยุทธ์นี้ใช้ผ่านขอบเขต ต้องกำหนดโมเดลภายในขอบเขตกลยุทธ์()
- ฟังก์ชัน
tpu_model.fitต้องการออบเจ็กต์ tf.data.Dataset เป็นอินพุตสำหรับการฝึก TPU
งานทั่วไปในการพอร์ต TPU
- แม้ว่าจะมีหลายวิธีในการโหลดข้อมูลในโมเดล TensorFlow แต่สำหรับ TPU คุณต้องใช้
tf.data.DatasetAPI - TPU ทำงานได้รวดเร็วมาก และการนำเข้าข้อมูลมักกลายเป็นคอขวดเมื่อเรียกใช้บน TPU คุณใช้เครื่องมือเพื่อตรวจหาจุดคอขวดของข้อมูลและเคล็ดลับอื่นๆ เกี่ยวกับประสิทธิภาพได้ในคู่มือประสิทธิภาพของ TPU
- ระบบจะถือว่าตัวเลข int8 หรือ int16 เป็น int32 TPU ไม่มีฮาร์ดแวร์จำนวนเต็มที่ทำงานน้อยกว่า 32 บิต
- ไม่รองรับการดำเนินการบางอย่างของ TensorFlow ดูรายการได้ที่นี่ ข่าวดีคือข้อจำกัดนี้มีผลกับโค้ดการฝึกเท่านั้น ซึ่งหมายถึงการส่งต่อและส่งย้อนกลับผ่านโมเดล คุณยังคงใช้การดำเนินการ Tensorflow ทั้งหมดในไปป์ไลน์อินพุตข้อมูลได้เนื่องจากระบบจะดำเนินการบน CPU
- TPU ไม่รองรับ
tf.py_func
4. กำลังโหลดข้อมูล






เราจะทำงานกับชุดข้อมูลรูปภาพดอกไม้ โดยมีเป้าหมายเพื่อเรียนรู้การจัดหมวดหมู่ดอกไม้เป็น 5 ประเภท การโหลดข้อมูลจะดำเนินการโดยใช้ tf.data.Dataset API ก่อนอื่น มาทำความรู้จักกับ API กัน
ลงมือปฏิบัติ
โปรดเปิด Notebook ต่อไปนี้ เรียกใช้เซลล์ (Shift-ENTER) และทำตามวิธีการทุกครั้งที่เห็นป้ายกำกับ "ต้องดำเนินการ"

Fun with tf.data.Dataset (playground).ipynb
ข้อมูลเพิ่มเติม
เกี่ยวกับชุดข้อมูล "ดอกไม้"
ชุดข้อมูลจัดระเบียบไว้ใน 5 โฟลเดอร์ แต่ละโฟลเดอร์จะมีดอกไม้ 1 ชนิด โฟลเดอร์มีชื่อว่า sunflowers, daisy, dandelion, tulips และ roses โดยข้อมูลจะโฮสต์อยู่ใน Bucket สาธารณะใน Google Cloud Storage ข้อความที่ตัดตอนมา
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
ทำไมต้อง tf.data.Dataset
Keras และ TensorFlow ยอมรับชุดข้อมูลในฟังก์ชันการฝึกและประเมินทั้งหมด เมื่อโหลดข้อมูลในชุดข้อมูลแล้ว API จะมีฟังก์ชันการทำงานทั่วไปทั้งหมดที่เป็นประโยชน์สำหรับข้อมูลฝึกฝนโครงข่ายระบบประสาทเทียม ดังนี้
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
ดูเคล็ดลับด้านประสิทธิภาพและแนวทางปฏิบัติแนะนำเกี่ยวกับชุดข้อมูลได้ในบทความนี้ ดูเอกสารอ้างอิงได้ที่นี่
พื้นฐานของ tf.data.Dataset
โดยปกติแล้วข้อมูลจะอยู่ในไฟล์หลายไฟล์ ซึ่งในที่นี้คือรูปภาพ คุณสร้างชุดข้อมูลของชื่อไฟล์ได้โดยการเรียกใช้
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
จากนั้นคุณจะ "แมป" ฟังก์ชันกับชื่อไฟล์แต่ละชื่อ ซึ่งโดยปกติจะโหลดและถอดรหัสไฟล์เป็นข้อมูลจริงในหน่วยความจำ
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
วิธีทำซ้ำในชุดข้อมูล
for data in my_dataset:
print(data)
ชุดข้อมูลของทูเพิล
ในการเรียนรู้แบบมีผู้ดูแล ชุดข้อมูลการฝึกมักประกอบด้วยคู่ของข้อมูลการฝึกและคำตอบที่ถูกต้อง หากต้องการอนุญาตให้ทำเช่นนี้ ฟังก์ชันการถอดรหัสจะแสดงผลเป็นทูเพิลได้ จากนั้นคุณจะมีชุดข้อมูลของ Tuple และระบบจะแสดง Tuple เมื่อคุณทำซ้ำในชุดข้อมูล ค่าที่ส่งคืนคือเทนเซอร์ TensorFlow ที่พร้อมให้โมเดลของคุณใช้ คุณเรียกใช้ .numpy() กับอาร์กิวเมนต์เพื่อดูค่าดิบได้ดังนี้
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
สรุป:การโหลดรูปภาพทีละรูปจะช้า
เมื่อทำซ้ำชุดข้อมูลนี้ คุณจะเห็นว่าสามารถโหลดรูปภาพได้ประมาณ 1-2 รูปต่อวินาที ช้าเกินไป ตัวเร่งฮาร์ดแวร์ที่เราจะใช้ในการฝึกสามารถรองรับอัตรานี้ได้หลายเท่า ไปที่ส่วนถัดไปเพื่อดูวิธีที่เราจะทำสิ่งนี้ให้สำเร็จ
Solution
สมุดบันทึกวิธีแก้ปัญหา คุณสามารถใช้ฟีเจอร์นี้ได้หากติดขัด
Fun with tf.data.Dataset (solution).ipynb
สิ่งที่เราได้พูดถึง
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 ชุดข้อมูลของทูเพิล
- 😀 การวนซ้ำผ่านชุดข้อมูล
โปรดสละเวลาสักครู่เพื่อพิจารณารายการตรวจสอบนี้ในใจ
5. โหลดข้อมูลอย่างรวดเร็ว
ตัวเร่งฮาร์ดแวร์ Tensor Processing Unit (TPU) ที่เราจะใช้ในแล็บนี้ทำงานได้รวดเร็วมาก ความท้าทายมักอยู่ที่การป้อนข้อมูลให้โมเดลอย่างรวดเร็วพอที่จะทำให้โมเดลทำงานอยู่เสมอ Google Cloud Storage (GCS) สามารถรักษาปริมาณงานที่สูงมากได้ แต่เช่นเดียวกับระบบพื้นที่เก็บข้อมูลบนคลาวด์ทั้งหมด การเริ่มการเชื่อมต่อจะทำให้เกิดการรับส่งข้อมูลในเครือข่าย ดังนั้นการจัดเก็บข้อมูลเป็นไฟล์แต่ละไฟล์หลายพันไฟล์จึงไม่ใช่แนวทางที่ดี เราจะจัดกลุ่มไฟล์เป็นจำนวนน้อยลงและใช้ความสามารถของ tf.data.Dataset เพื่ออ่านจากหลายไฟล์แบบขนาน
การอ่านบท
โค้ดที่โหลดไฟล์รูปภาพ ปรับขนาดให้เป็นขนาดทั่วไป แล้วจัดเก็บไว้ในไฟล์ TFRecord 16 ไฟล์อยู่ใน Notebook ต่อไปนี้ โปรดอ่านอย่างรวดเร็ว คุณไม่จำเป็นต้องดำเนินการนี้ เนื่องจากเราจะให้ข้อมูลที่จัดรูปแบบ TFRecord อย่างถูกต้องสำหรับส่วนที่เหลือของ Codelab
Flower pictures to TFRecords.ipynb
เลย์เอาต์ข้อมูลที่เหมาะสมเพื่อให้ได้อัตราการรับส่งข้อมูล GCS ที่ดีที่สุด
รูปแบบไฟล์ TFRecord
รูปแบบไฟล์ที่ TensorFlow ต้องการใช้ในการจัดเก็บข้อมูลคือรูปแบบ TFRecord ที่อิงตาม protobuf รูปแบบการซีเรียลไลซ์อื่นๆ ก็ใช้ได้เช่นกัน แต่คุณสามารถโหลดชุดข้อมูลจากไฟล์ TFRecord ได้โดยตรงโดยเขียนดังนี้
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
ขอแนะนำให้ใช้โค้ดที่ซับซ้อนกว่านี้ต่อไปนี้เพื่ออ่านจากไฟล์ TFRecord หลายไฟล์พร้อมกันเพื่อให้ได้ประสิทธิภาพสูงสุด โค้ดนี้จะอ่านจากไฟล์ N แบบขนานและไม่สนใจลำดับข้อมูลเพื่อเพิ่มความเร็วในการอ่าน
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
ข้อมูลสรุปของ TFRecord
TFRecords จัดเก็บข้อมูลได้ 3 ประเภท ได้แก่ สตริงไบต์ (รายการไบต์) จำนวนเต็ม 64 บิต และจำนวนเต็ม 32 บิต โดยจะจัดเก็บเป็นรายการเสมอ และองค์ประกอบข้อมูลเดียวจะเป็นรายการที่มีขนาด 1 คุณใช้ฟังก์ชันช่วยต่อไปนี้เพื่อจัดเก็บข้อมูลลงใน TFRecord ได้
การเขียนสตริงไบต์
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
การเขียนจำนวนเต็ม
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
การเขียนลอย
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
การเขียน TFRecord โดยใช้ตัวช่วยด้านบน
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
หากต้องการอ่านข้อมูลจาก TFRecord คุณต้องประกาศเลย์เอาต์ของบันทึกที่คุณจัดเก็บไว้ก่อน ในการประกาศ คุณสามารถเข้าถึงฟิลด์ที่มีชื่อเป็นรายการแบบคงที่หรือรายการแบบความยาวตัวแปรได้
การอ่านจาก TFRecord
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
ข้อมูลโค้ดที่มีประโยชน์
การอ่านองค์ประกอบข้อมูลเดียว
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
การอ่านรายการองค์ประกอบที่มีขนาดคงที่
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
อ่านรายการข้อมูลจํานวนตัวแปร
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
VarLenFeature จะแสดงผลเวกเตอร์แบบกระจัดกระจาย และต้องมีขั้นตอนเพิ่มเติมหลังจากถอดรหัส TFRecord
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
นอกจากนี้ คุณยังมีช่องที่ไม่บังคับใน TFRecords ได้ด้วย หากคุณระบุค่าเริ่มต้นเมื่ออ่านฟิลด์ ระบบจะแสดงค่าเริ่มต้นแทนที่จะแสดงข้อผิดพลาดหากไม่มีฟิลด์
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
สิ่งที่เราได้พูดถึง
- 🤔 การแบ่งไฟล์ข้อมูลเพื่อให้เข้าถึงจาก GCS ได้อย่างรวดเร็ว
- 😓 วิธีเขียน TFRecord (คุณลืมไวยากรณ์ไปแล้วใช่ไหม ไม่เป็นไร ให้บุ๊กมาร์กหน้านี้เป็นชีตโกง)
- 🤔 โหลด Dataset จาก TFRecords โดยใช้ TFRecordDataset
โปรดสละเวลาสักครู่เพื่อพิจารณารายการตรวจสอบนี้ในใจ
6. [INFO] ตัวแยกประเภทโครงข่ายระบบประสาทเทียมเบื้องต้น
โดยสรุป
หากคุณทราบคำศัพท์ทั้งหมดที่ตัวหนาในย่อหน้าถัดไปแล้ว ให้ไปที่แบบฝึกหัดถัดไป หากคุณเพิ่งเริ่มต้นเรียนรู้เชิงลึก เราขอต้อนรับและโปรดอ่านต่อ
สำหรับโมเดลที่สร้างเป็นลำดับของเลเยอร์ Keras มี Sequential API ตัวอย่างเช่น คุณเขียนตัวแยกประเภทรูปภาพที่ใช้เลเยอร์แบบหนาแน่น 3 เลเยอร์ใน Keras ได้ดังนี้
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
โครงข่ายระบบประสาทเทียมแบบหนาแน่น
ซึ่งเป็นโครงข่ายระบบประสาทเทียมที่ง่ายที่สุดสำหรับการจัดหมวดหมู่รูปภาพ ซึ่งประกอบด้วย "นิวรอน" ที่จัดเรียงเป็นชั้นๆ เลเยอร์แรกจะประมวลผลข้อมูลอินพุตและส่งเอาต์พุตไปยังเลเยอร์อื่นๆ เรียกว่า "หนาแน่น" เนื่องจากแต่ละนิวรอนเชื่อมต่อกับนิวรอนทั้งหมดในเลเยอร์ก่อนหน้า
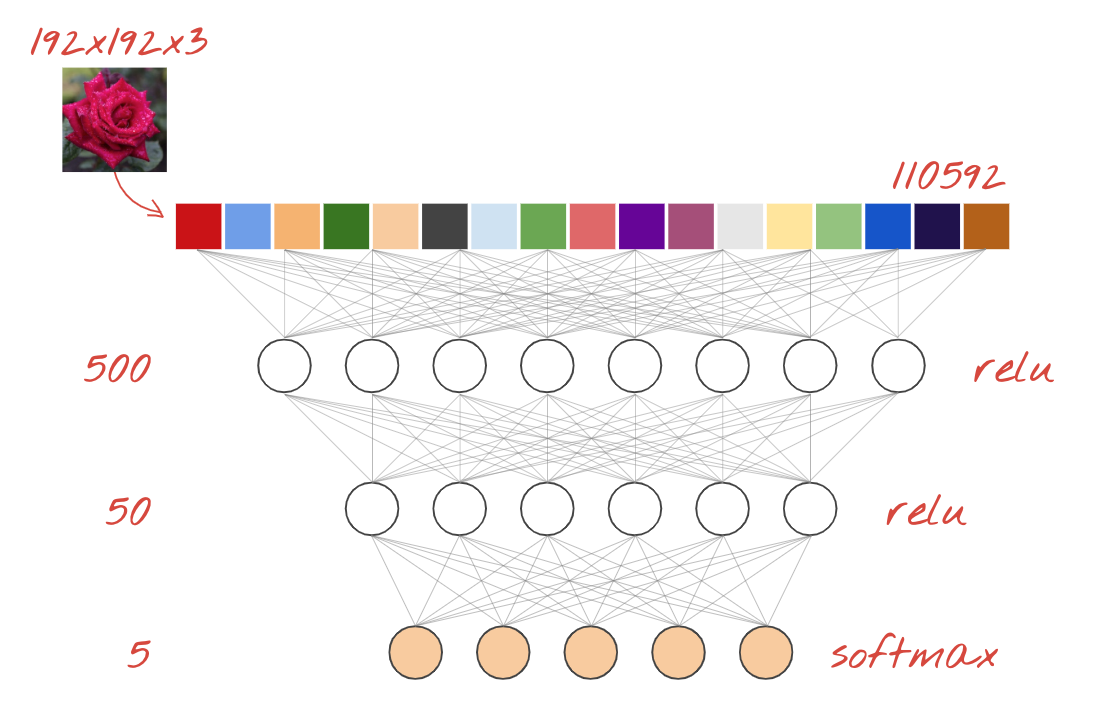
คุณสามารถป้อนรูปภาพลงในเครือข่ายดังกล่าวได้โดยการแปลงค่า RGB ของพิกเซลทั้งหมดให้เป็นเวกเตอร์ยาวและใช้เป็นอินพุต แม้จะไม่ใช่เทคนิคที่ดีที่สุดสำหรับการจดจำรูปภาพ แต่เราจะปรับปรุงเทคนิคนี้ในภายหลัง
เซลล์ประสาท การเปิดใช้งาน RELU
"นิวรอน" จะคำนวณผลรวมแบบถ่วงน้ำหนักของอินพุตทั้งหมด เพิ่มค่าที่เรียกว่า "อคติ" และป้อนผลลัพธ์ผ่านสิ่งที่เรียกว่า "ฟังก์ชันกระตุ้น" โดยตอนแรกเราจะไม่ทราบค่าถ่วงน้ำหนักและค่าอคติ โดยจะเริ่มต้นแบบสุ่มและ "เรียนรู้" ด้วยการฝึกโครงข่ายระบบประสาทเทียมกับข้อมูลที่ทราบจำนวนมาก
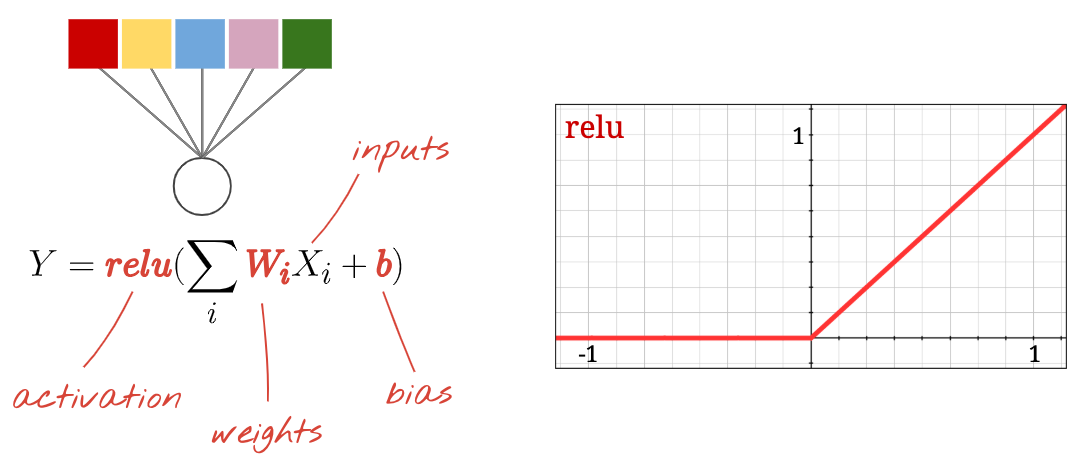
ฟังก์ชันการเปิดใช้งานที่ได้รับความนิยมมากที่สุดเรียกว่า RELU สำหรับ Rectified Linear Unit ฟังก์ชันนี้ใช้งานง่ายมาก ดังที่เห็นในกราฟด้านบน
ฟังก์ชันกระตุ้น Softmax
เครือข่ายด้านบนลงท้ายด้วยเลเยอร์ 5 นิวรอนเนื่องจากเราจัดประเภทดอกไม้เป็น 5 หมวดหมู่ (กุหลาบ ทิวลิป แดนดิไลออน เดซี่ และทานตะวัน) ระบบจะเปิดใช้งานนิวรอนในเลเยอร์กลางโดยใช้ฟังก์ชันการเปิดใช้งาน RELU แบบคลาสสิก แต่ในเลเยอร์สุดท้าย เราต้องการคำนวณตัวเลขระหว่าง 0 ถึง 1 ซึ่งแสดงถึงความน่าจะเป็นที่ดอกไม้นี้จะเป็นดอกกุหลาบ ดอกทิวลิป และอื่นๆ สำหรับกรณีนี้ เราจะใช้ฟังก์ชันการเปิดใช้งานที่เรียกว่า "softmax"
การใช้ Softmax กับเวกเตอร์ทำได้โดยการหาเลขชี้กำลังของแต่ละองค์ประกอบ แล้วทำให้เวกเตอร์เป็นปกติ โดยปกติจะใช้ L1 Norm (ผลรวมของค่าสัมบูรณ์) เพื่อให้ค่ารวมกันเป็น 1 และสามารถตีความเป็นความน่าจะเป็นได้
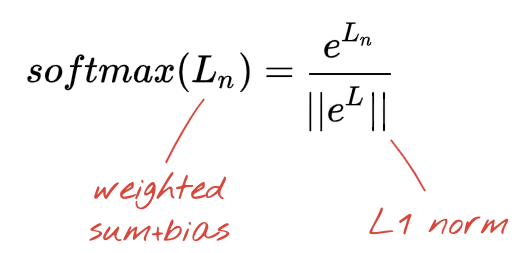
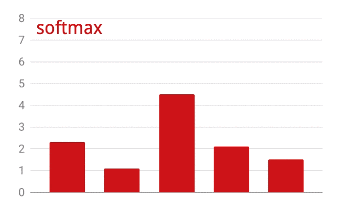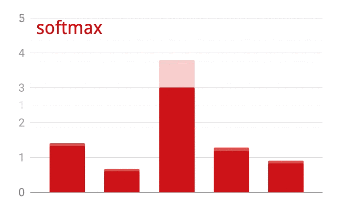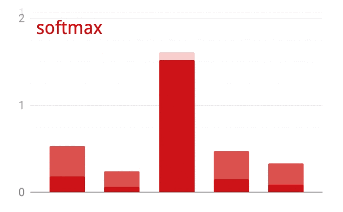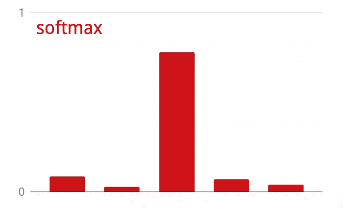
การสูญเสียแบบ Cross-Entropy
เมื่อโครงข่ายระบบประสาทเทียมสร้างการคาดการณ์จากรูปภาพอินพุตแล้ว เราต้องวัดว่าการคาดการณ์นั้นดีเพียงใด กล่าวคือ ระยะห่างระหว่างสิ่งที่โครงข่ายระบบประสาทเทียมบอกเรากับคำตอบที่ถูกต้อง ซึ่งมักเรียกว่า "ป้ายกำกับ" โปรดทราบว่าเรามีป้ายกำกับที่ถูกต้องสำหรับรูปภาพทั้งหมดในชุดข้อมูล
ระยะทางใดก็ได้ แต่สำหรับปัญหาการจัดประเภท "ระยะทางครอสเอนโทรปี" ที่เรียกว่ามีประสิทธิภาพมากที่สุด เราจะเรียกฟังก์ชันนี้ว่าฟังก์ชันข้อผิดพลาดหรือ "การสูญเสีย"
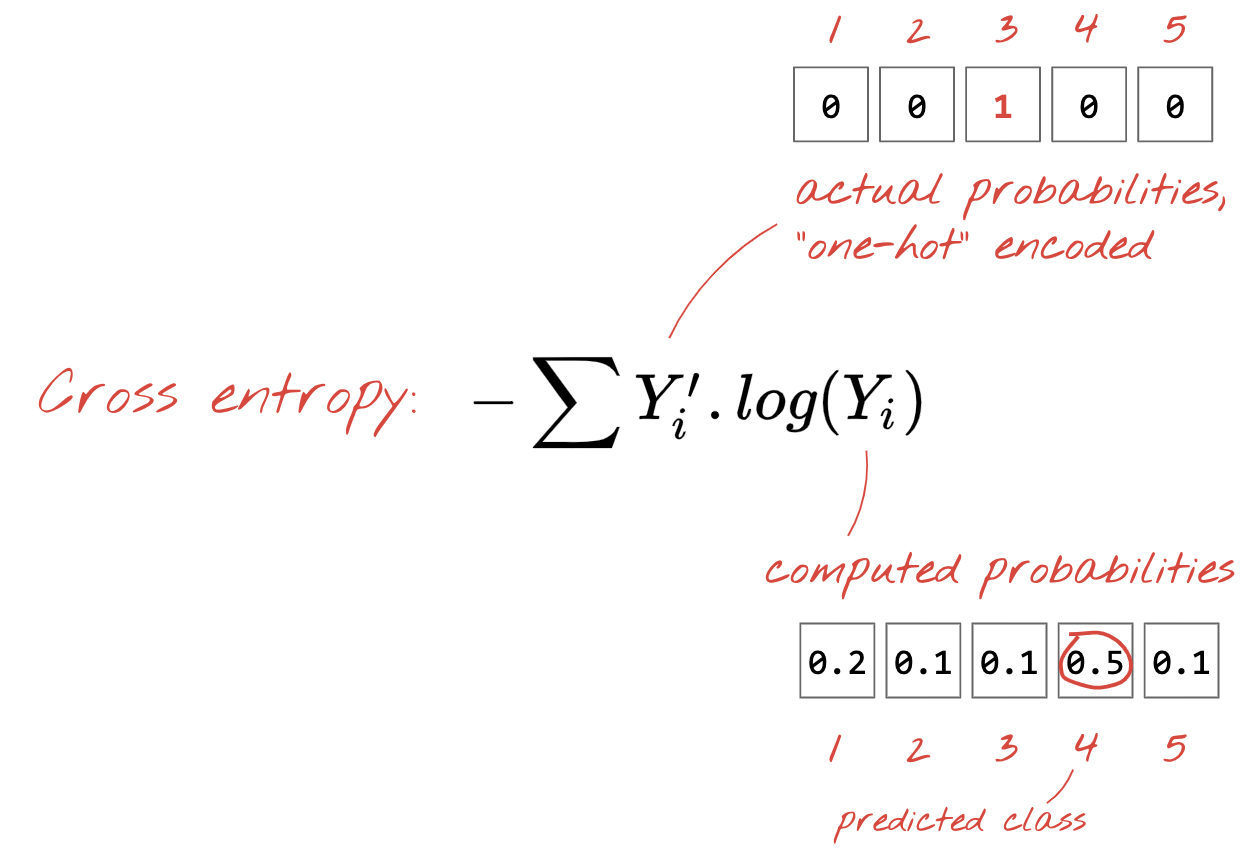
การไล่ระดับสี
"การฝึก" โครงข่ายระบบประสาทเทียมหมายถึงการใช้รูปภาพและป้ายกำกับการฝึกเพื่อปรับน้ำหนักและอคติเพื่อลดฟังก์ชันการสูญเสียเอนโทรปีแบบครอสให้เหลือน้อยที่สุด วิธีการทำงานมีดังนี้
Cross-Entropy เป็นฟังก์ชันของน้ำหนัก อคติ พิกเซลของรูปภาพการฝึก และคลาสที่ทราบ
หากเราคำนวณอนุพันธ์ย่อยของครอสเอนโทรปีเทียบกับน้ำหนักทั้งหมดและอคติทั้งหมด เราจะได้ "การไล่ระดับ" ซึ่งคำนวณสำหรับรูปภาพ ป้ายกำกับ และค่าปัจจุบันของน้ำหนักและอคติที่กำหนด โปรดทราบว่าเรามีค่าถ่วงน้ำหนักและไบแอสได้หลายล้านรายการ ดังนั้นการคำนวณการไล่ระดับจึงดูเหมือนเป็นงานที่ต้องทำมาก โชคดีที่ TensorFlow จัดการเรื่องนี้ให้เรา คุณสมบัติทางคณิตศาสตร์ของเกรเดียนต์คือจะชี้ "ขึ้น" เนื่องจากเราต้องการไปในทิศทางที่ครอสเอนโทรปีต่ำ เราจึงไปในทิศทางตรงกันข้าม เราอัปเดตน้ำหนักและอคติด้วยเศษส่วนของค่าการไล่ระดับ จากนั้นเราจะทำซ้ำไปเรื่อยๆ โดยใช้รูปภาพและป้ายกำกับการฝึกชุดถัดไปในลูปการฝึก หวังว่าวิธีนี้จะช่วยให้ค่าเอนโทรปีแบบครอสลดลงเหลือน้อยที่สุด แม้ว่าจะไม่มีอะไรรับประกันว่าค่าต่ำสุดนี้จะเป็นค่าเดียวก็ตาม
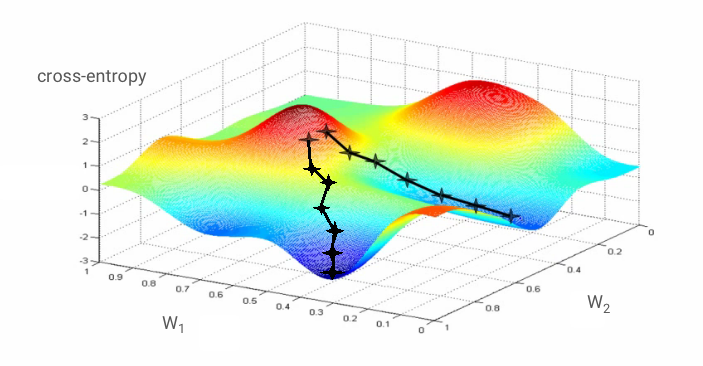
การประมวลผลแบบมินิแบตช์และโมเมนตัม
คุณสามารถคำนวณการไล่ระดับสีในรูปภาพตัวอย่างเพียงรูปเดียวและอัปเดตน้ำหนักและอคติได้ทันที แต่การทำเช่นนั้นในกลุ่มรูปภาพ เช่น 128 รูป จะทำให้ได้การไล่ระดับสีที่แสดงถึงข้อจำกัดที่กำหนดโดยรูปภาพตัวอย่างต่างๆ ได้ดีกว่า และจึงมีแนวโน้มที่จะบรรลุโซลูชันได้เร็วขึ้น ขนาดของมินิแบตช์เป็นพารามิเตอร์ที่ปรับได้
เทคนิคนี้ซึ่งบางครั้งเรียกว่า "การไล่ระดับความชันแบบสุ่ม" มีประโยชน์อีกอย่างที่ใช้งานได้จริงมากกว่า นั่นคือการทำงานกับกลุ่มยังหมายถึงการทำงานกับเมทริกซ์ขนาดใหญ่ขึ้น และโดยปกติแล้วการเพิ่มประสิทธิภาพเมทริกซ์เหล่านี้ใน GPU และ TPU จะทำได้ง่ายกว่า
อย่างไรก็ตาม การบรรจบกันอาจยังคงวุ่นวายเล็กน้อยและอาจหยุดลงได้หากเวกเตอร์การไล่ระดับเป็น 0 ทั้งหมด ซึ่งหมายความว่าเราพบค่าต่ำสุดแล้วใช่ไหม ไม่เสมอไป คอมโพเนนต์การไล่ระดับสีอาจเป็น 0 ในค่าต่ำสุดหรือค่าสูงสุด เมื่อมีเวกเตอร์การไล่ระดับที่มีองค์ประกอบหลายล้านรายการ หากองค์ประกอบทั้งหมดเป็น 0 ความน่าจะเป็นที่ 0 ทุกตัวจะสอดคล้องกับจุดต่ำสุดและไม่มีตัวใดสอดคล้องกับจุดสูงสุดจะค่อนข้างน้อย ในพื้นที่ที่มีหลายมิติ จุดอานม้าเป็นเรื่องปกติ และเราไม่ต้องการหยุดที่จุดดังกล่าว
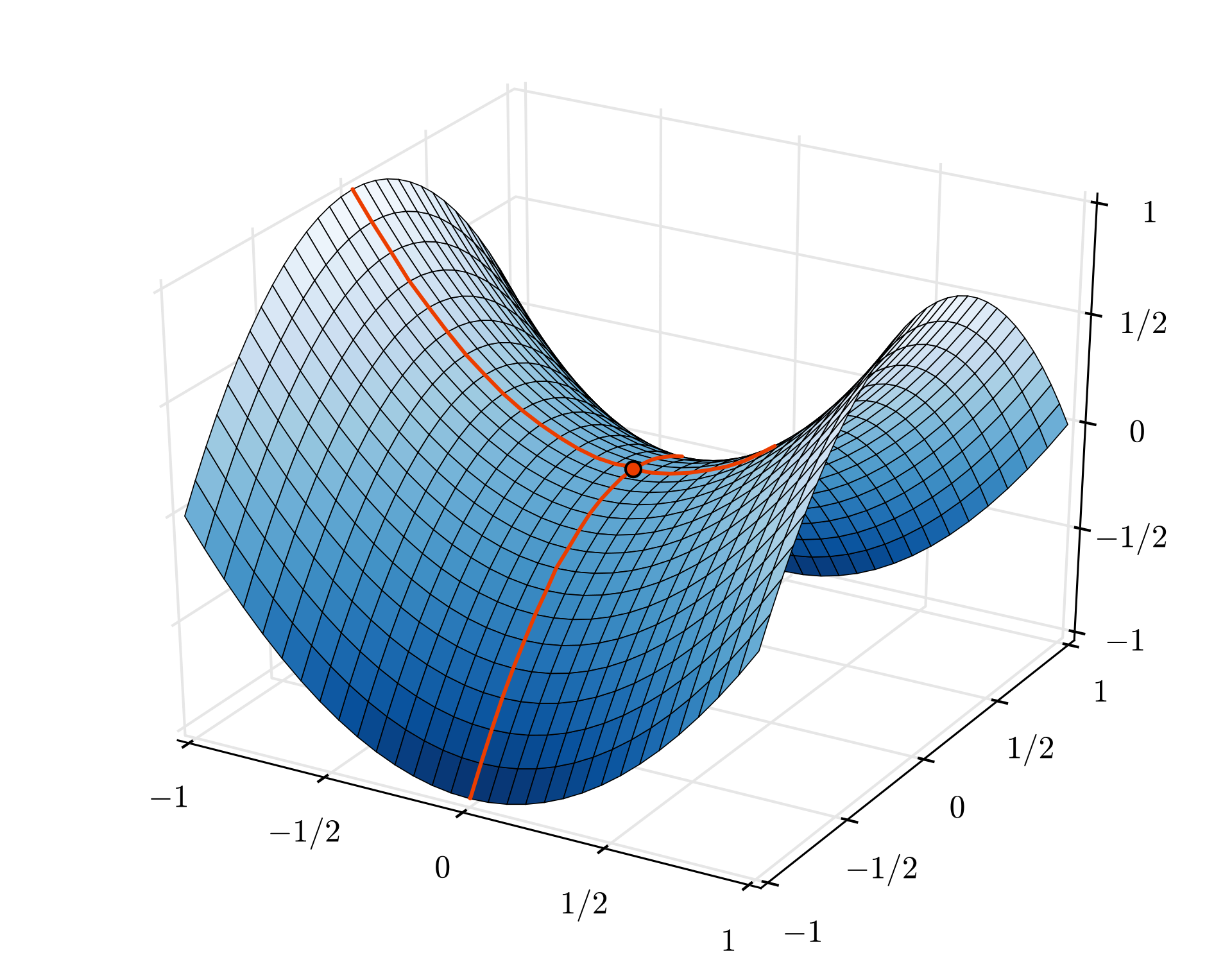
ภาพประกอบ: จุดอานม้า ค่าการไล่ระดับเป็น 0 แต่ไม่ใช่ค่าต่ำสุดในทุกทิศทาง (การระบุแหล่งที่มาของรูปภาพ Wikimedia: By Nicoguaro - Own work, CC BY 3.0)
วิธีแก้คือการเพิ่มโมเมนตัมให้กับอัลกอริทึมการเพิ่มประสิทธิภาพเพื่อให้ผ่านจุดอานม้าไปได้โดยไม่ต้องหยุด
อภิธานศัพท์
กลุ่มหรือกลุ่มย่อย: การฝึกจะดำเนินการกับกลุ่มข้อมูลฝึกฝนและป้ายกำกับเสมอ ซึ่งจะช่วยให้อัลกอริทึมทำงานได้ มิติข้อมูล "กลุ่ม" มักจะเป็นมิติข้อมูลแรกของเทนเซอร์ข้อมูล ตัวอย่างเช่น Tensor ที่มีรูปร่าง [100, 192, 192, 3] มีรูปภาพ 100 รูปขนาด 192x192 พิกเซล โดยมีค่า 3 ค่าต่อพิกเซล (RGB)
การสูญเสียแบบครอสเอนโทรปี: ฟังก์ชันการสูญเสียพิเศษที่มักใช้ในตัวแยกประเภท
เลเยอร์ Dense: เลเยอร์ของนิวรอนที่นิวรอนแต่ละตัวเชื่อมต่อกับนิวรอนทั้งหมดในเลเยอร์ก่อนหน้า
ฟีเจอร์: บางครั้งอินพุตของโครงข่ายระบบประสาทเทียมเรียกว่า "ฟีเจอร์" ศิลปะในการพิจารณาว่าควรป้อนส่วนใดของชุดข้อมูล (หรือการรวมกันของส่วนต่างๆ) ลงในโครงข่ายระบบประสาทเทียมเพื่อให้ได้การคาดการณ์ที่ดีเรียกว่า "Feature Engineering"
ป้ายกำกับ: ชื่ออื่นของ "คลาส" หรือคำตอบที่ถูกต้องในปัญหาการแยกประเภทภายใต้การดูแล
อัตราการเรียนรู้: เศษส่วนของค่าการไล่ระดับที่ใช้ในการอัปเดตน้ำหนักและอคติในแต่ละการวนซ้ำของลูปการฝึก
ลอจิท: เอาต์พุตของเลเยอร์ของนิวรอนก่อนที่จะใช้ฟังก์ชันการกระตุ้นเรียกว่า "ลอจิท" คำนี้มาจาก "ฟังก์ชันโลจิสติก" หรือที่เรียกว่า "ฟังก์ชันซิกมอยด์" ซึ่งเคยเป็นฟังก์ชันกระตุ้นที่ได้รับความนิยมมากที่สุด "เอาต์พุตของนิวรอนก่อนฟังก์ชันลอจิสติก" เปลี่ยนชื่อเป็น "ลอจิท"
loss: ฟังก์ชันข้อผิดพลาดที่เปรียบเทียบเอาต์พุตของโครงข่ายระบบประสาทเทียมกับคำตอบที่ถูกต้อง
นิวรอน: คำนวณผลรวมแบบถ่วงน้ำหนักของอินพุต เพิ่มอคติ และป้อนผลลัพธ์ผ่านฟังก์ชันการเปิดใช้งาน
การเข้ารหัสแบบ One-hot: ระบบจะเข้ารหัสคลาส 3 จาก 5 เป็นเวกเตอร์ที่มีองค์ประกอบ 5 รายการ ซึ่งเป็น 0 ทั้งหมด ยกเว้นรายการที่ 3 ซึ่งเป็น 1
relu: หน่วยเชิงเส้นที่แก้ไขแล้ว ฟังก์ชันการเปิดใช้งานยอดนิยมสำหรับนิวรอน
sigmoid: ฟังก์ชันกระตุ้นอีกฟังก์ชันหนึ่งที่เคยได้รับความนิยมและยังคงมีประโยชน์ในกรณีพิเศษ
softmax: ฟังก์ชันการกระตุ้นพิเศษที่ทำงานกับเวกเตอร์ เพิ่มความแตกต่างระหว่างคอมโพเนนต์ที่ใหญ่ที่สุดกับคอมโพเนนต์อื่นๆ ทั้งหมด และยังทำให้เวกเตอร์เป็นปกติเพื่อให้มีผลรวมเป็น 1 เพื่อให้สามารถตีความเป็นเวกเตอร์ของความน่าจะเป็นได้ ใช้เป็นขั้นตอนสุดท้ายในตัวแยกประเภท
เทนเซอร์: "เทนเซอร์" คล้ายกับเมทริกซ์ แต่มีจำนวนมิติข้อมูลเท่าใดก็ได้ Tensor 1 มิติคือเวกเตอร์ Tensor 2 มิติคือเมทริกซ์ จากนั้นคุณก็จะมีเทนเซอร์ที่มี 3, 4, 5 หรือมากกว่านั้น
7. การเรียนรู้แบบถ่ายโอน
สำหรับปัญหาการแยกประเภทรูปภาพ เลเยอร์แบบหนาแน่นอาจไม่เพียงพอ เราต้องเรียนรู้เกี่ยวกับเลเยอร์ Convolutional และวิธีต่างๆ ในการจัดเรียงเลเยอร์
แต่เราก็ใช้ทางลัดได้เช่นกัน มีโครงข่ายประสาทเทียมแบบ Convolution ที่ได้รับการฝึกอย่างเต็มรูปแบบให้ดาวน์โหลด คุณสามารถตัดเลเยอร์สุดท้ายของโมเดล ซึ่งก็คือส่วนหัวของการจัดประเภท Softmax ออก แล้วแทนที่ด้วยเลเยอร์ของคุณเอง น้ำหนักและความเอนเอียงที่ฝึกแล้วทั้งหมดจะยังคงอยู่ตามเดิม คุณจะฝึกเลเยอร์ Softmax ที่เพิ่มเข้าไปใหม่เท่านั้น เทคนิคนี้เรียกว่าการเรียนรู้แบบถ่ายโอน และที่น่าทึ่งคือเทคนิคนี้จะใช้ได้ตราบใดที่ชุดข้อมูลที่ใช้ฝึกโครงข่ายประสาทเทียมล่วงหน้า "ใกล้เคียง" กับชุดข้อมูลของคุณมากพอ
ลงมือปฏิบัติ
โปรดเปิด Notebook ต่อไปนี้ เรียกใช้เซลล์ (Shift-ENTER) และทำตามวิธีการทุกครั้งที่เห็นป้ายกำกับ "ต้องดำเนินการ"
Keras Flowers transfer learning (playground).ipynb
ข้อมูลเพิ่มเติม
การเรียนรู้แบบถ่ายโอนช่วยให้คุณได้รับประโยชน์จากทั้งสถาปัตยกรรมโครงข่ายระบบประสาทเทียมแบบคอนโวลูชันขั้นสูงที่พัฒนาโดยนักวิจัยชั้นนำ และการฝึกแบบล่วงหน้าในชุดข้อมูลรูปภาพขนาดใหญ่ ในกรณีของเรา เราจะใช้การเรียนรู้แบบถ่ายโอนจากเครือข่ายที่ฝึกใน ImageNet ซึ่งเป็นฐานข้อมูลรูปภาพที่มีพืชและฉากกลางแจ้งจำนวนมาก ซึ่งใกล้เคียงกับดอกไม้
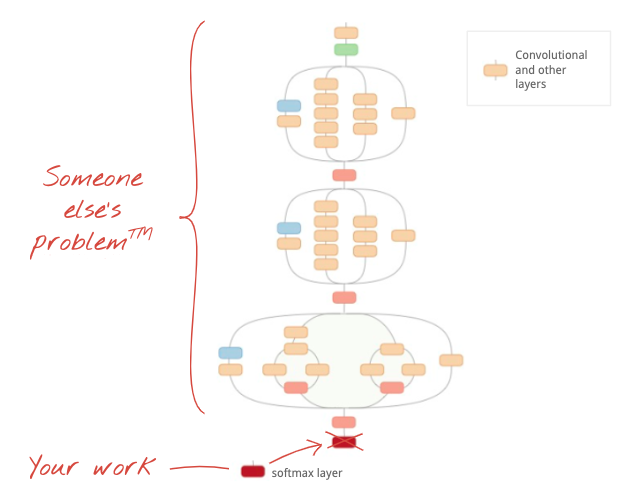
ภาพประกอบ: ใช้โครงข่ายประสาทแบบคอนโวลูชันที่ซับซ้อนซึ่งได้รับการฝึกแล้วเป็นกล่องดำ โดยฝึกเฉพาะส่วนหัวของการแยกประเภทใหม่ ซึ่งเรียกว่าการเรียนรู้แบบถ่ายโอน เราจะมาดูว่าการจัดเรียงเลเยอร์ Convolutional ที่ซับซ้อนเหล่านี้ทำงานอย่างไรในภายหลัง แต่ตอนนี้เป็นปัญหาของคนอื่น
การเรียนรู้แบบถ่ายโอนใน Keras
ใน Keras คุณสามารถสร้างอินสแตนซ์ของโมเดลที่ฝึกไว้ล่วงหน้าจากtf.keras.applications.*คอลเล็กชัน ตัวอย่างเช่น MobileNet V2 เป็นสถาปัตยกรรมแบบ Convolutional ที่ดีมากซึ่งมีขนาดที่เหมาะสม การเลือก include_top=False จะทำให้คุณได้รับโมเดลที่ผ่านการฝึกมาก่อนโดยไม่มีเลเยอร์ Softmax สุดท้าย เพื่อให้คุณเพิ่มเลเยอร์ของคุณเองได้
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
นอกจากนี้ ให้สังเกตการตั้งค่า pretrained_model.trainable = False ด้วย ซึ่งจะตรึงน้ำหนักและอคติของโมเดลที่ผ่านการฝึกมาก่อนเพื่อให้คุณฝึกเลเยอร์ Softmax เท่านั้น โดยปกติแล้วจะเกี่ยวข้องกับน้ำหนักเพียงไม่กี่รายการ และสามารถทำได้อย่างรวดเร็วโดยไม่ต้องใช้ชุดข้อมูลขนาดใหญ่มาก อย่างไรก็ตาม หากคุณมีข้อมูลจำนวนมาก การเรียนรู้แบบโอนจะทำงานได้ดียิ่งขึ้นด้วย pretrained_model.trainable = True จากนั้นน้ำหนักที่ฝึกไว้ล่วงหน้าจะให้ค่าเริ่มต้นที่ยอดเยี่ยม และยังคงปรับได้โดยการฝึกเพื่อแก้ปัญหาให้ดียิ่งขึ้น
สุดท้าย ให้สังเกตเลเยอร์ Flatten() ที่แทรกก่อนเลเยอร์ Dense Softmax เลเยอร์แบบหนาแน่นจะทำงานกับเวกเตอร์ข้อมูลแบบแบน แต่เราไม่ทราบว่าโมเดลที่ผ่านการฝึกมาก่อนจะส่งคืนอะไร เราจึงต้องลดความชันของกราฟ ในบทถัดไป เมื่อเราเจาะลึกสถาปัตยกรรมแบบ Convolutional เราจะอธิบายรูปแบบข้อมูลที่เลเยอร์ Convolutional ส่งคืน
คุณควรมีความแม่นยำเกือบ 75% ด้วยวิธีนี้
Solution
สมุดบันทึกวิธีแก้ปัญหา คุณสามารถใช้ฟีเจอร์นี้ได้หากติดขัด
Keras Flowers transfer learning (solution).ipynb
สิ่งที่เราได้พูดถึง
- 🤔 วิธีเขียนตัวแยกประเภทใน Keras
- 🤓 กำหนดค่าด้วยเลเยอร์สุดท้ายของ Softmax และการสูญเสียแบบ Cross-Entropy
- 😈 การเรียนรู้แบบถ่ายโอน
- 🤔 การฝึกโมเดลแรก
- 🧐 ติดตามการสูญเสียและความแม่นยำระหว่างการฝึก
โปรดสละเวลาสักครู่เพื่อพิจารณารายการตรวจสอบนี้ในใจ
8. [INFO] โครงข่ายระบบประสาทเทียมแบบ Convolution
โดยสรุป
หากคุณทราบคำศัพท์ทั้งหมดที่ตัวหนาในย่อหน้าถัดไปแล้ว ให้ไปที่แบบฝึกหัดถัดไป หากคุณเพิ่งเริ่มต้นใช้งาน Convolutional Neural Network โปรดอ่านต่อ
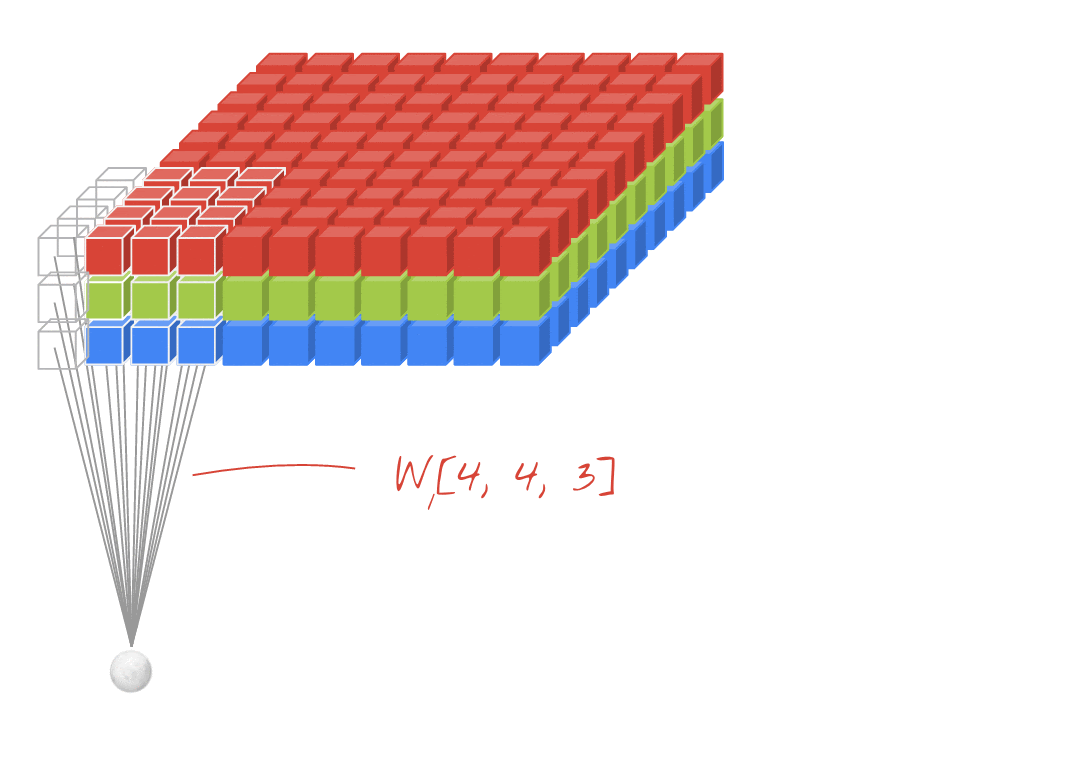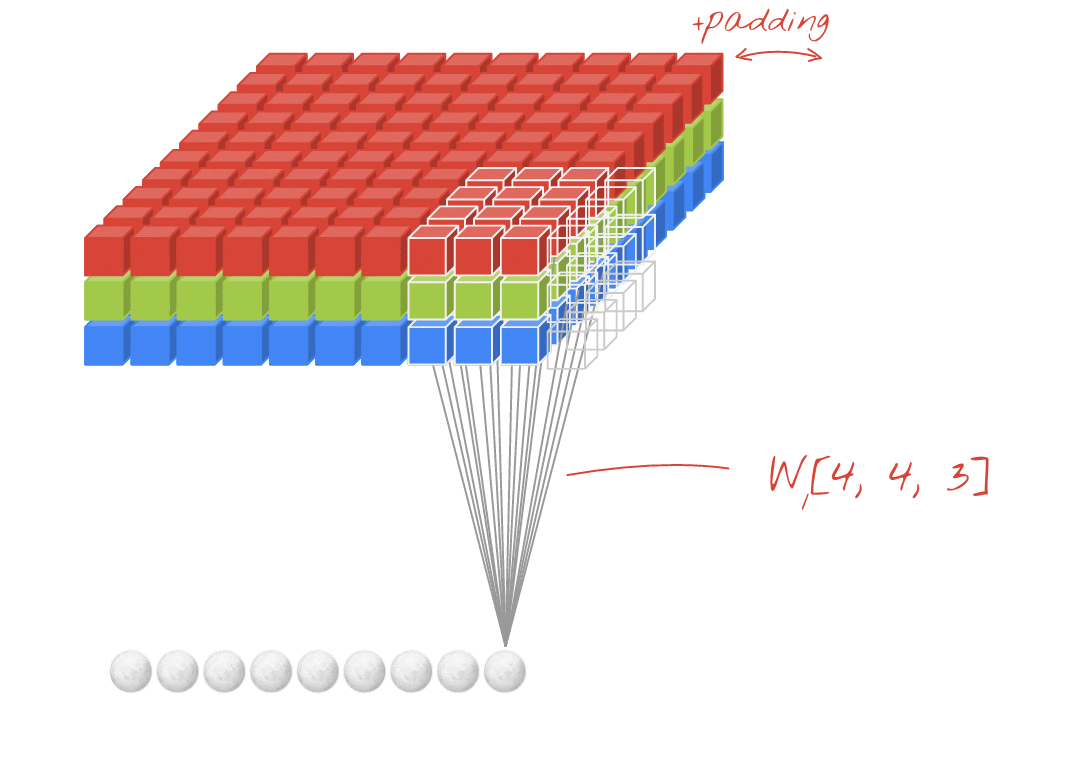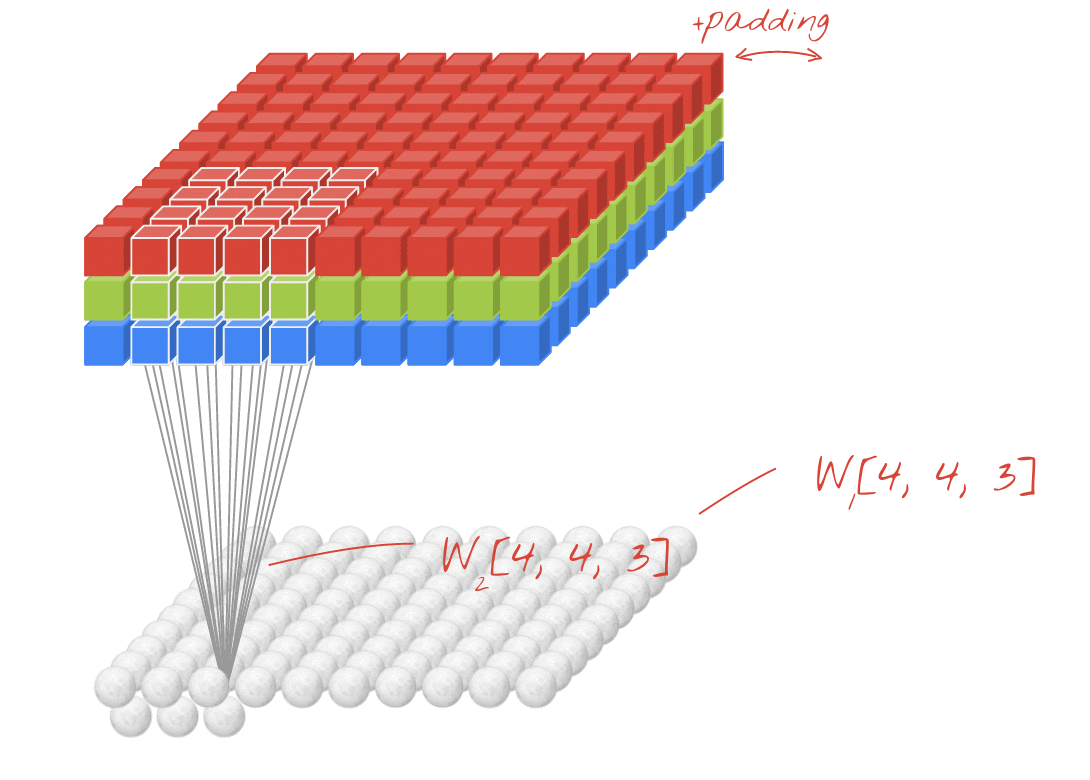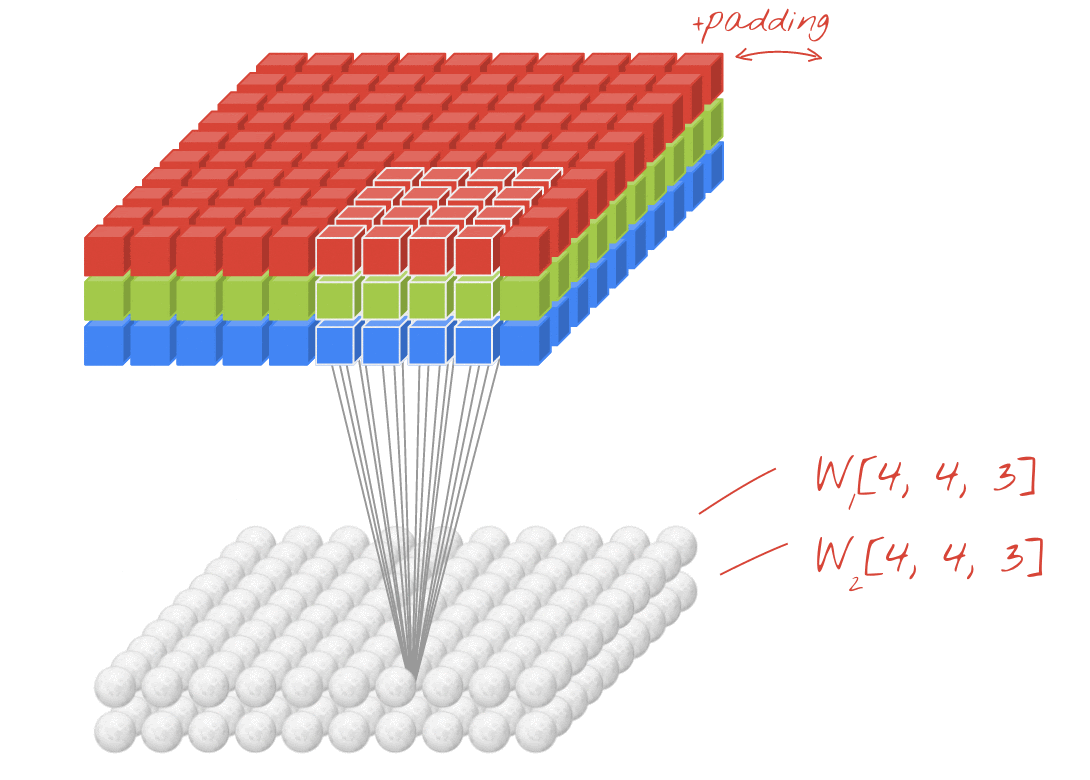
ภาพประกอบ: การกรองรูปภาพด้วยฟิลเตอร์ 2 ตัวที่ต่อเนื่องกันซึ่งประกอบด้วยน้ำหนักที่เรียนรู้ได้ 4x4x3=48 รายการ
โครงข่ายระบบประสาทเทียมแบบ Convolution อย่างง่ายใน Keras มีลักษณะดังนี้
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=3, filters=24, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=6, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
โครงข่ายประสาทเทียมแบบคอนโวลูชัน 101
ในเลเยอร์ของเครือข่าย Convolutional "นิวรอน" จะทำการหาผลรวมแบบถ่วงน้ำหนักของพิกเซลที่อยู่เหนือขึ้นไปในบริเวณเล็กๆ ของรูปภาพเท่านั้น โดยจะเพิ่มอคติและป้อนผลรวมผ่านฟังก์ชันการเปิดใช้งาน เช่นเดียวกับที่นิวรอนในเลเยอร์ Dense ปกติจะทำ จากนั้นจะดำเนินการนี้ซ้ำทั่วทั้งรูปภาพโดยใช้น้ำหนักเดียวกัน โปรดทราบว่าในเลเยอร์แบบหนาแน่น นิวรอนแต่ละตัวจะมีน้ำหนักของตัวเอง ในที่นี้ "แพตช์" เดียวของน้ำหนักจะเลื่อนไปทั่วรูปภาพในทั้ง 2 ทิศทาง ("การสังวัตนาการ") เอาต์พุตมีค่ามากเท่ากับจำนวนพิกเซลในรูปภาพ (แม้ว่าอาจต้องมีการเว้นขอบบ้าง) ซึ่งเป็นการดำเนินการกรองโดยใช้น้ำหนัก 4x4x3=48
อย่างไรก็ตาม น้ำหนัก 48 รายการจะไม่เพียงพอ หากต้องการเพิ่มระดับอิสระ เราจะทำซ้ำการดำเนินการเดียวกันกับชุดน้ำหนักใหม่ ซึ่งจะสร้างเอาต์พุตตัวกรองชุดใหม่ เราจะเรียกช่องเอาต์พุตนี้ว่า "แชแนล" โดยเปรียบเทียบกับแชแนล R,G,B ในรูปภาพอินพุต
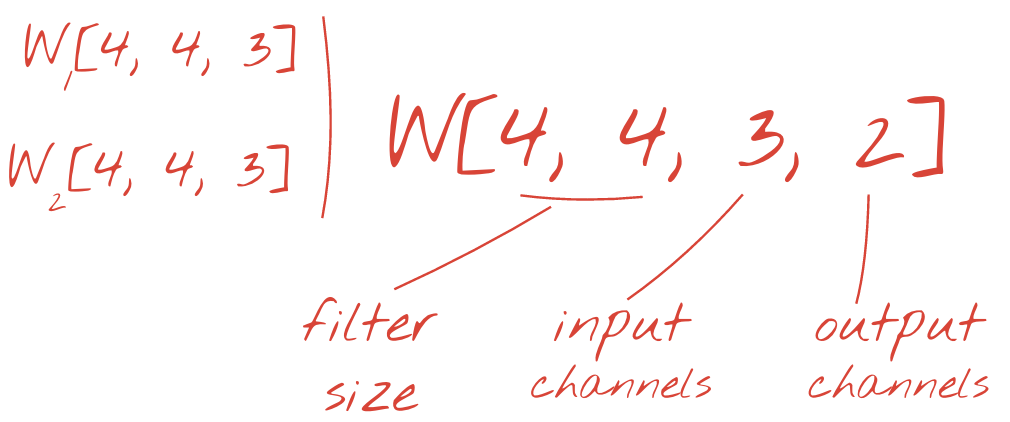
คุณสามารถรวมชุดน้ำหนัก 2 ชุด (หรือมากกว่า) เป็น Tensor เดียวได้โดยการเพิ่มมิติข้อมูลใหม่ ซึ่งจะทำให้เราได้รูปร่างทั่วไปของเทนเซอร์น้ำหนักสำหรับเลเยอร์ Convolutional เนื่องจากจำนวนช่องอินพุตและเอาต์พุตเป็นพารามิเตอร์ เราจึงเริ่มซ้อนและเชื่อมต่อเลเยอร์ Convolutional ได้
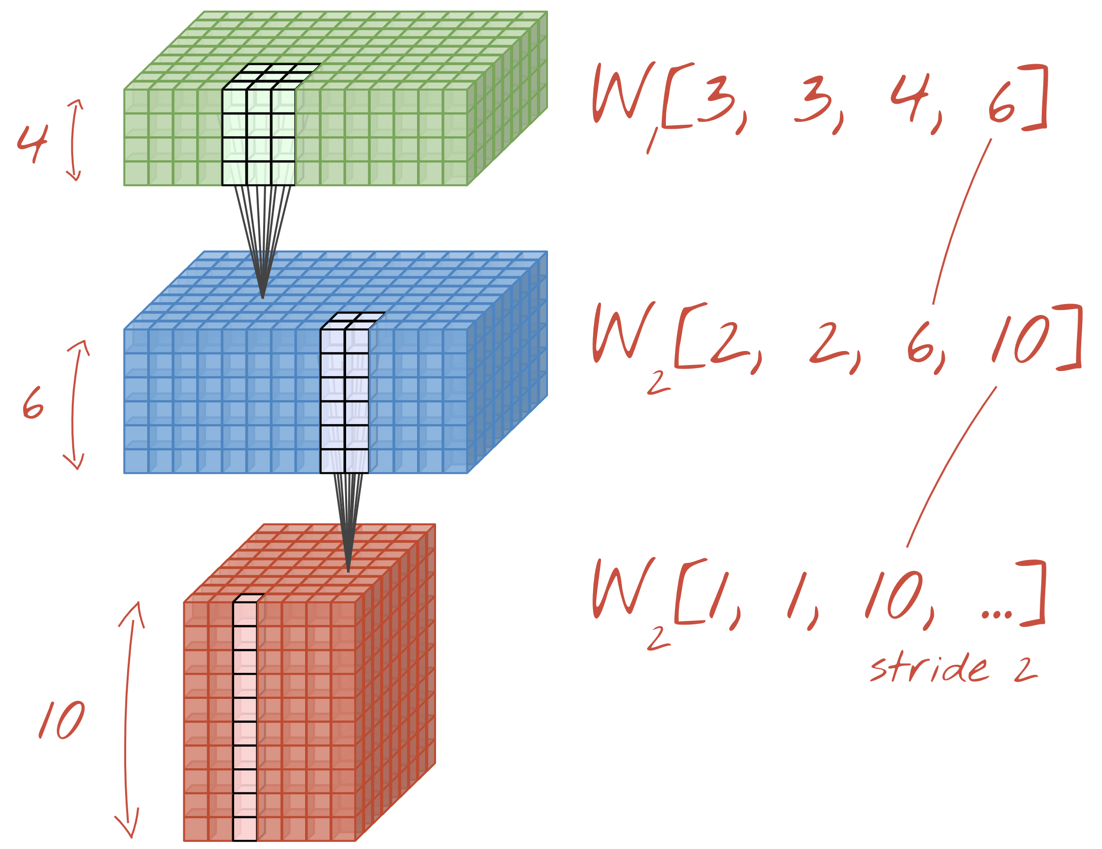
ภาพประกอบ: โครงข่ายประสาทแบบคอนโวลูชันจะเปลี่ยน "ก้อน" ข้อมูลให้เป็น "ก้อน" ข้อมูลอื่นๆ
การสังวัตน์แบบก้าวกระโดด การรวมสูงสุด
การดำเนินการ Convolution ด้วย Stride 2 หรือ 3 จะช่วยให้เราลดขนาด Data Cube ที่ได้ในมิติแนวนอนได้ด้วย ซึ่งทำได้ 2 วิธีที่นิยมใช้กัน ดังนี้
- การสังวัตน์แบบมีระยะก้าวกระโดด: ตัวกรองแบบเลื่อนตามที่อธิบายไว้ข้างต้น แต่มีระยะก้าวกระโดด > 1
- Max Pooling: หน้าต่างเลื่อนที่ใช้การดำเนินการ MAX (โดยปกติจะใช้กับแพตช์ 2x2 ซึ่งทำซ้ำทุกๆ 2 พิกเซล)

ภาพประกอบ: การเลื่อนหน้าต่างการคำนวณ 3 พิกเซลจะทำให้ค่าเอาต์พุตน้อยลง การสังวัตน์แบบมีระยะก้าวย่างหรือการพูลสูงสุด (สูงสุดในหน้าต่าง 2x2 ที่เลื่อนตามระยะก้าวย่าง 2) เป็นวิธีลดขนาดก้อนข้อมูลในมิติข้อมูลแนวนอน
ตัวแยกประเภทแบบ Convolutions
สุดท้าย เราจะแนบส่วนหัวของการจัดประเภทโดยการทำให้คิวบ์ข้อมูลสุดท้ายแบนราบและป้อนผ่านเลเยอร์ที่หนาแน่นซึ่งเปิดใช้งาน Softmax โดยทั่วไปแล้ว ตัวแยกประเภทแบบ Convolutional จะมีลักษณะดังนี้
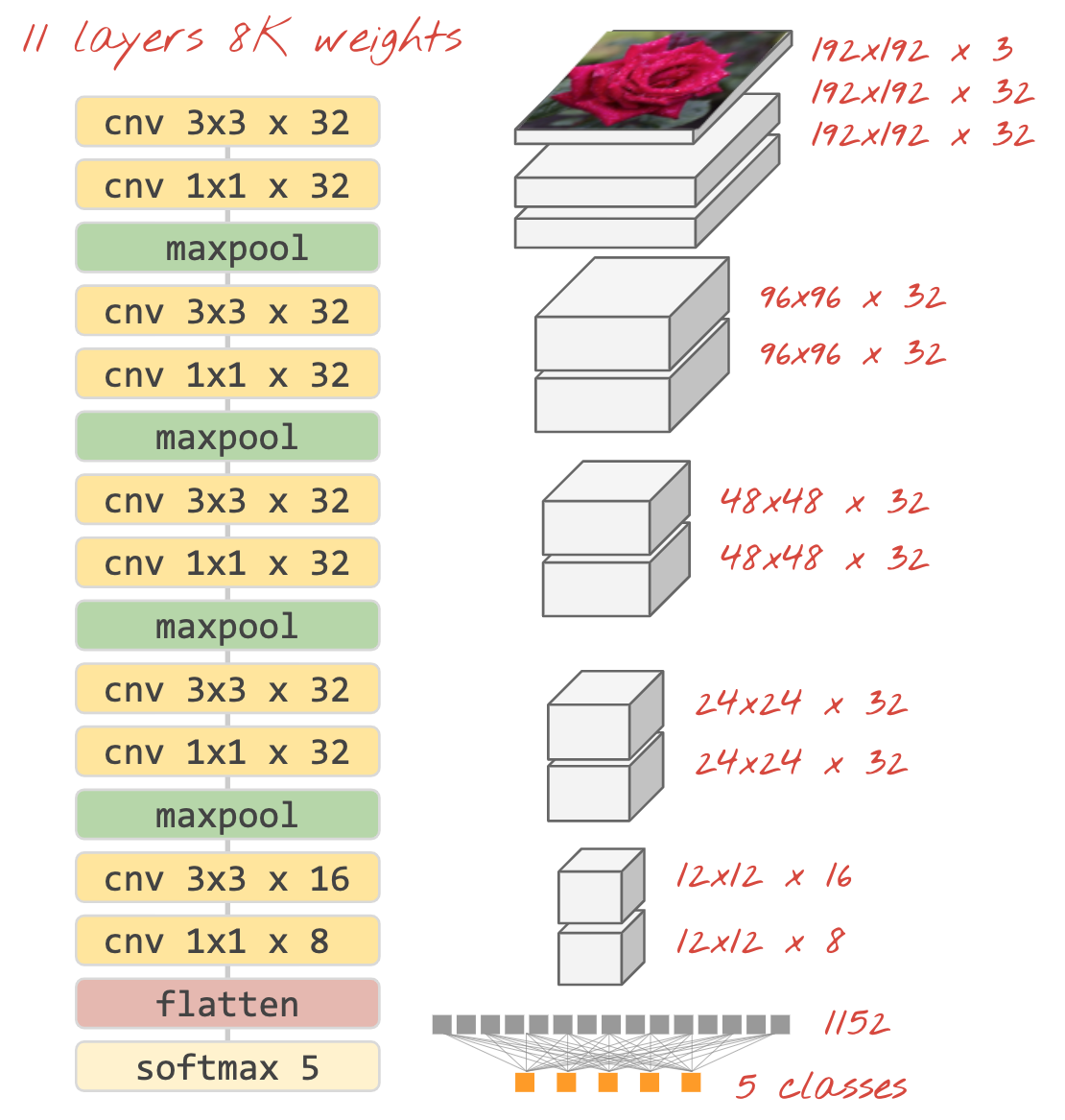
ภาพประกอบ: ตัวแยกประเภทรูปภาพที่ใช้เลเยอร์ Convolutional และ Softmax โดยใช้ฟิลเตอร์ 3x3 และ 1x1 เลเยอร์ MaxPool จะใช้ค่าสูงสุดของกลุ่มจุดข้อมูล 2x2 ส่วนหัวการแยกประเภทจะใช้เลเยอร์แบบหนาแน่นที่มีการเปิดใช้งาน Softmax
ใน Keras
สแต็ก Convolutional ที่แสดงด้านบนสามารถเขียนใน Keras ได้ดังนี้
model = tf.keras.Sequential([
# input: images of size 192x192x3 pixels (the three stands for RGB channels)
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu', input_shape=[192, 192, 3]),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=32, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Conv2D(kernel_size=3, filters=16, padding='same', activation='relu'),
tf.keras.layers.Conv2D(kernel_size=1, filters=8, padding='same', activation='relu'),
tf.keras.layers.Flatten(),
# classifying into 5 categories
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy'])
9. Convnet ที่กำหนดเอง
ลงมือปฏิบัติ
มาสร้างและฝึกโครงข่ายระบบประสาทเทียมแบบคอนโวลูชันตั้งแต่ต้นกัน การใช้ TPU จะช่วยให้เราทำซ้ำได้อย่างรวดเร็ว โปรดเปิด Notebook ต่อไปนี้ เรียกใช้เซลล์ (Shift-ENTER) และทำตามวิธีการทุกครั้งที่เห็นป้ายกำกับ "ต้องดำเนินการ"
Keras_Flowers_TPU (playground).ipynb
เป้าหมายคือการเอาชนะความแม่นยำ 75% ของโมเดลการเรียนรู้แบบถ่ายโอน โมเดลนั้นมีความได้เปรียบเนื่องจากได้รับการฝึกมาก่อนในชุดข้อมูลที่มีรูปภาพนับล้าน ในขณะที่เรามีรูปภาพเพียง 3, 670 รูปที่นี่ คุณลดราคาให้เท่ากับราคาของร้านอื่นได้ไหม
ข้อมูลเพิ่มเติม
มีกี่เลเยอร์และมีขนาดเท่าใด
การเลือกขนาดเลเยอร์เป็นศิลปะมากกว่าวิทยาศาสตร์ คุณต้องหาสมดุลที่เหมาะสมระหว่างการมีพารามิเตอร์ (น้ำหนักและอคติ) น้อยเกินไปกับมากเกินไป หากมีน้ำหนักน้อยเกินไป โครงข่ายระบบประสาทเทียมจะไม่สามารถแสดงความซับซ้อนของรูปร่างดอกไม้ได้ หากมีมากเกินไป โมเดลอาจ "Overfitting" กล่าวคือ เชี่ยวชาญในรูปภาพการฝึกและไม่สามารถสรุปได้ หากมีพารามิเตอร์จำนวนมาก โมเดลก็จะฝึกได้ช้าเช่นกัน ใน Keras ฟังก์ชัน model.summary() จะแสดงโครงสร้างและจำนวนพารามิเตอร์ของโมเดล
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 192, 192, 16) 448
_________________________________________________________________
conv2d_1 (Conv2D) (None, 192, 192, 30) 4350
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 96, 96, 30) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 96, 96, 60) 16260
_________________________________________________________________
...
_________________________________________________________________
global_average_pooling2d (Gl (None, 130) 0
_________________________________________________________________
dense (Dense) (None, 90) 11790
_________________________________________________________________
dense_1 (Dense) (None, 5) 455
=================================================================
Total params: 300,033
Trainable params: 300,033
Non-trainable params: 0
_________________________________________________________________
เคล็ดลับบางประการมีดังนี้
- การมีหลายเลเยอร์คือสิ่งที่ทำให้โครงข่ายประสาทแบบ "ลึก" มีประสิทธิภาพ สำหรับปัญหาการจดจำดอกไม้ที่เรียบง่ายนี้ การใช้ 5-10 เลเยอร์ก็เพียงพอแล้ว
- ใช้ตัวกรองขนาดเล็ก โดยทั่วไปแล้วฟิลเตอร์ 3x3 จะใช้ได้ดีทุกที่
- นอกจากนี้ยังใช้ฟิลเตอร์ขนาด 1x1 ได้ด้วยและมีราคาถูก โดยไม่ได้ "กรอง" อะไรจริงๆ แต่จะคำนวณการรวมเชิงเส้นของช่อง สลับกับตัวกรองจริง (ดูข้อมูลเพิ่มเติมเกี่ยวกับ "การบิด 1x1" ได้ในส่วนถัดไป)
- สำหรับปัญหาการจัดประเภทเช่นนี้ ให้ดาวน์แซมเปิลบ่อยๆ ด้วยเลเยอร์ Max Pooling (หรือการสังวัตน์ที่มีระยะก้าวยาวกว่า 1) คุณไม่สนใจว่าดอกไม้อยู่ที่ไหน สนใจเพียงแค่ว่าเป็นดอกกุหลาบหรือดอกแดนดิไลออน ดังนั้นการสูญเสียข้อมูล x และ y จึงไม่สำคัญ และการกรองพื้นที่ขนาดเล็กจึงมีราคาถูกกว่า
- โดยปกติแล้ว จำนวนฟิลเตอร์จะคล้ายกับจำนวนคลาสที่ส่วนท้ายของเครือข่าย (เหตุใดจึงเป็นเช่นนั้น ดูเคล็ดลับ "Global Average Pooling" ด้านล่าง) หากคุณจัดประเภทเป็นหลายร้อยประเภท ให้เพิ่มจำนวนตัวกรองทีละน้อยในเลเยอร์ที่ต่อเนื่องกัน สําหรับชุดข้อมูลดอกไม้ที่มี 5 คลาส การกรองด้วยตัวกรองเพียง 5 ตัวจะไม่เพียงพอ คุณใช้จำนวนตัวกรองเดียวกันในเลเยอร์ส่วนใหญ่ได้ เช่น 32 และลดจำนวนตัวกรองลงเมื่อใกล้ถึงเลเยอร์สุดท้าย
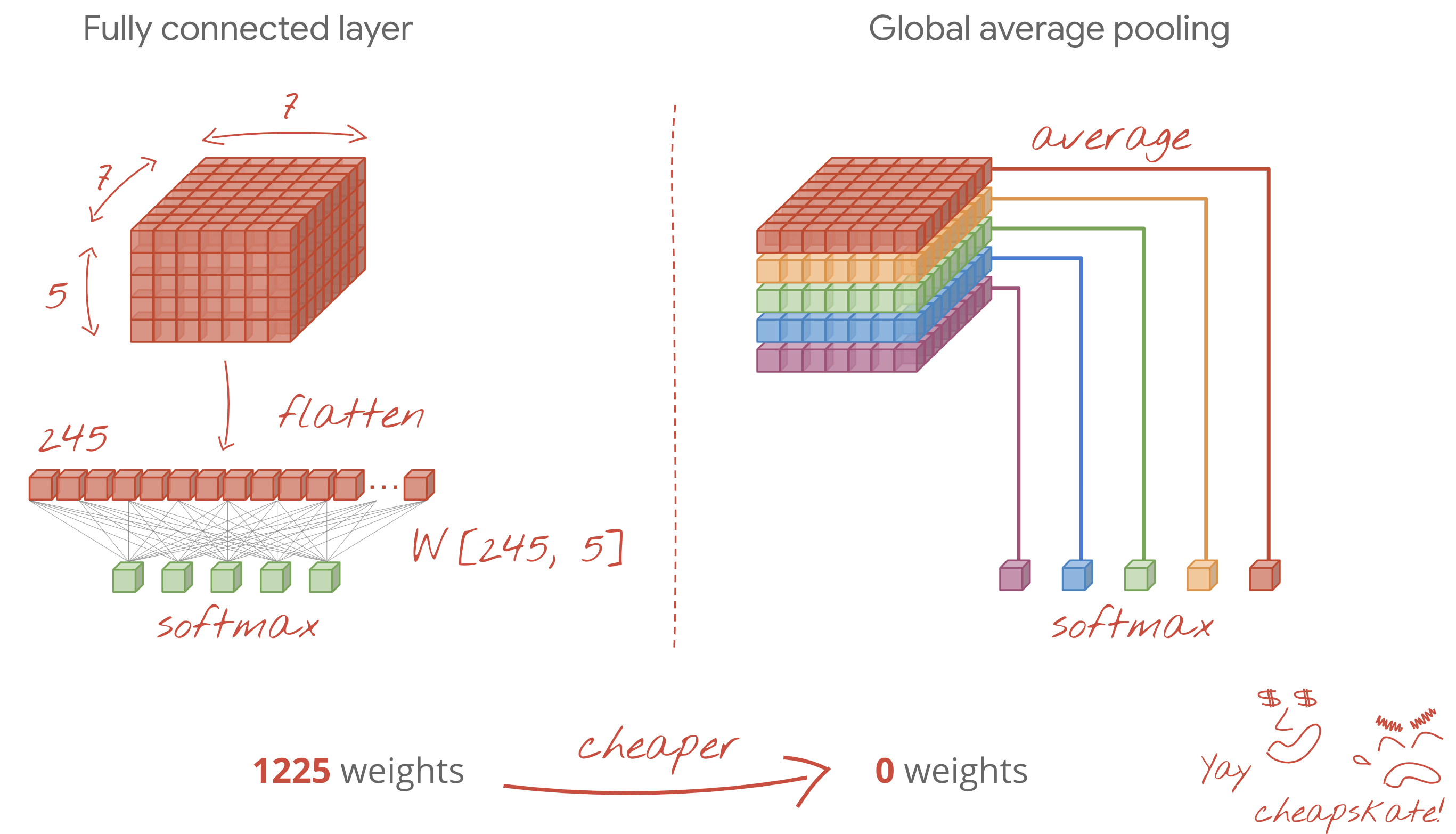
- เลเยอร์ Dense สุดท้ายมีค่าใช้จ่ายสูง โดยอาจมีน้ำหนักมากกว่าเลเยอร์ Convolutional ทั้งหมดรวมกัน ตัวอย่างเช่น แม้ว่าเอาต์พุตจาก Data Cube สุดท้ายที่มีจุดข้อมูล 24x24x10 จะสมเหตุสมผลมาก แต่เลเยอร์แบบหนาแน่นที่มีนิวรอน 100 ตัวก็จะมีน้ำหนัก 24x24x10x100=576,000 !!! พยายามคิดให้รอบคอบ หรือลองใช้ Global Average Pooling (ดูด้านล่าง)
การรวบรวมข้อมูลเฉลี่ยทั่วโลก
แทนที่จะใช้เลเยอร์หนาแน่นที่มีราคาแพงที่ส่วนท้ายของ Convolutional Neural Network คุณสามารถแยก "ก้อน" ข้อมูลขาเข้าออกเป็นหลายส่วนตามจำนวนคลาส เฉลี่ยค่า และป้อนค่าเหล่านี้ผ่านฟังก์ชันการเปิดใช้งาน Softmax การสร้างส่วนหัวการแยกประเภทด้วยวิธีนี้จะไม่มีค่าใช้จ่าย ใน Keras ไวยากรณ์คือ tf.keras.layers.GlobalAveragePooling2D().
Solution
สมุดบันทึกวิธีแก้ปัญหา คุณสามารถใช้ฟีเจอร์นี้ได้หากติดขัด
Keras_Flowers_TPU (solution).ipynb
สิ่งที่เราได้พูดถึง
- 🤔 เล่นกับเลเยอร์ Convolutional
- 🤓 ทดลองใช้ Max Pooling, Strides, Global Average Pooling ฯลฯ
- 😀 ทำซ้ำโมเดลในโลกแห่งความเป็นจริงได้อย่างรวดเร็วบน TPU
โปรดสละเวลาสักครู่เพื่อพิจารณารายการตรวจสอบนี้ในใจ
10. [INFO] สถาปัตยกรรม Convolutional สมัยใหม่
โดยสรุป
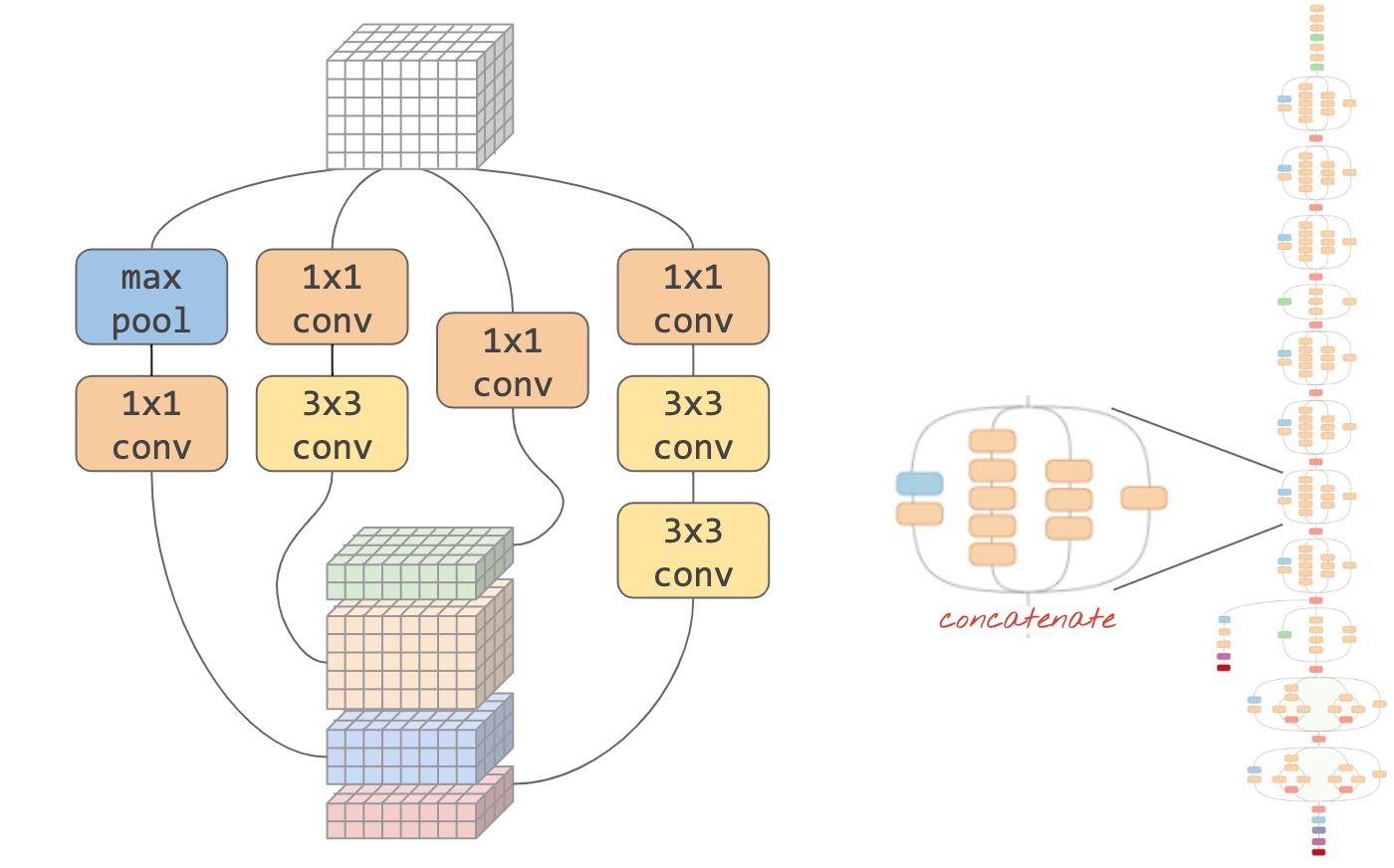
ภาพ: "โมดูล" แบบ Convolutional ตอนนี้ควรทำอย่างไร เลเยอร์ Max-Pool ตามด้วยเลเยอร์ Convolutional 1x1 หรือการรวมเลเยอร์แบบอื่น ลองใช้ทั้งหมดนี้ ต่อผลลัพธ์ และปล่อยให้เครือข่ายตัดสิน ทางด้านขวา: สถาปัตยกรรมแบบ Convolutional " Inception" ที่ใช้โมดูลดังกล่าว
ใน Keras หากต้องการสร้างโมเดลที่โฟลว์ข้อมูลสามารถแยกสาขาเข้าและออกได้ คุณต้องใช้รูปแบบโมเดล "ฟังก์ชัน" มีตัวอย่างดังต่อไปนี้
l = tf.keras.layers # syntax shortcut
y = l.Conv2D(filters=32, kernel_size=3, padding='same',
activation='relu', input_shape=[192, 192, 3])(x) # x=input image
# module start: branch out
y1 = l.Conv2D(filters=32, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(y)
y = l.concatenate([y1, y3]) # output now has 64 channels
# module end: concatenation
# many more layers ...
# Create the model by specifying the input and output tensors.
# Keras layers track their connections automatically so that's all that's needed.
z = l.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, z)
เคล็ดลับอื่นๆ
ฟิลเตอร์ขนาดเล็ก 3x3
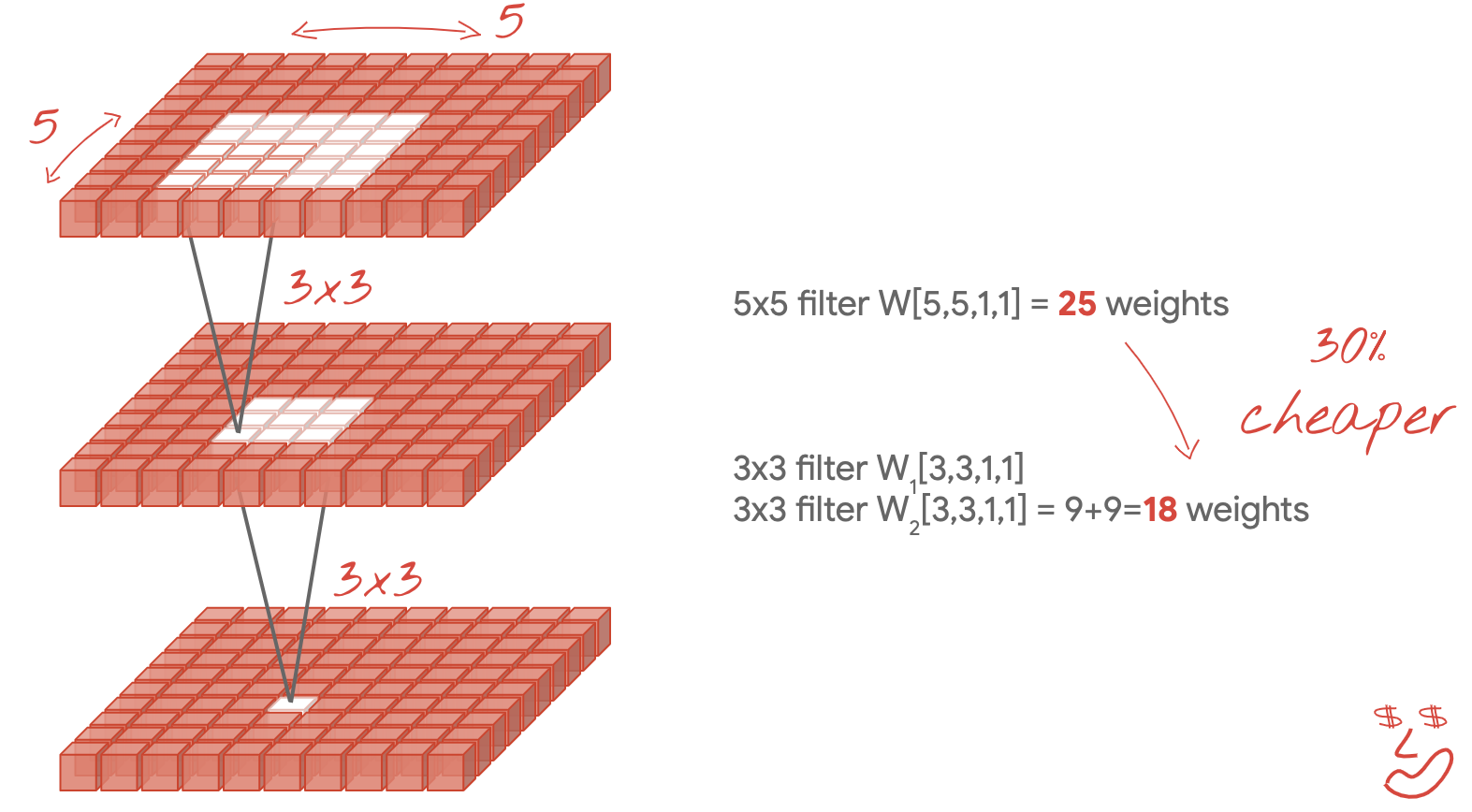
ในภาพนี้ คุณจะเห็นผลลัพธ์ของฟิลเตอร์ 3x3 2 รายการติดต่อกัน ลองย้อนรอยว่าจุดข้อมูลใดที่ทำให้เกิดผลลัพธ์นี้ โดยตัวกรอง 3x3 2 ตัวที่ต่อเนื่องกันจะคำนวณการรวมกันของภูมิภาค 5x5 ซึ่งไม่ใช่การรวมกันแบบเดียวกับที่ฟิลเตอร์ 5x5 จะคำนวณ แต่ก็ควรลองใช้เนื่องจากฟิลเตอร์ 3x3 2 ตัวที่ต่อเนื่องกันมีราคาถูกกว่าฟิลเตอร์ 5x5 ตัวเดียว
การสังวัตนาการ 1x1 ?
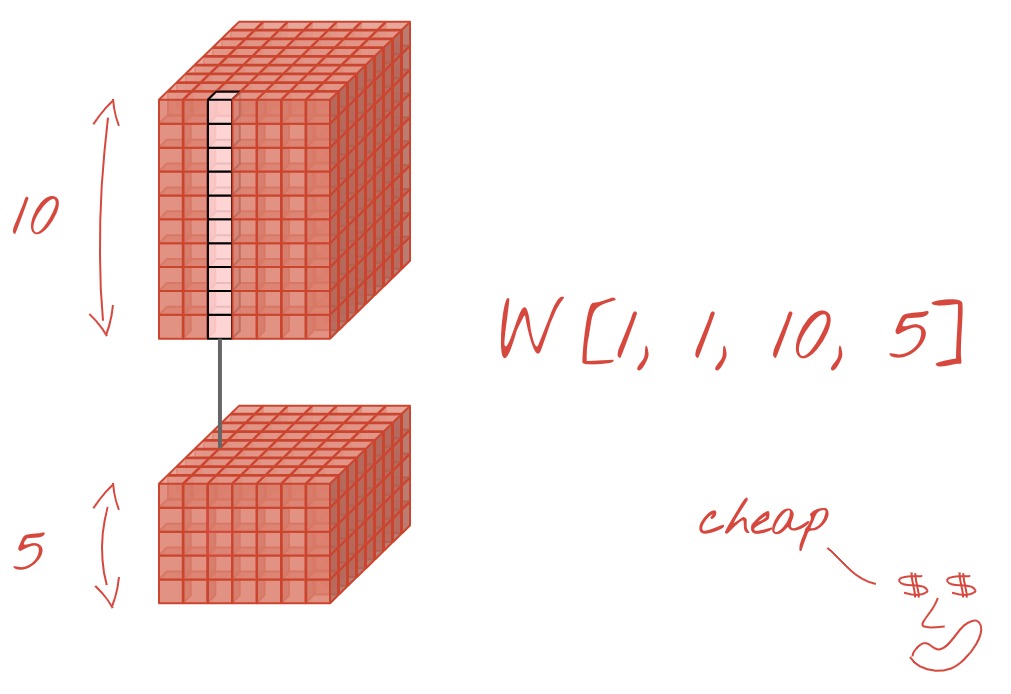
ในทางคณิตศาสตร์ การคูณแบบ "1x1" คือการคูณด้วยค่าคงที่ ซึ่งไม่ใช่แนวคิดที่มีประโยชน์มากนัก อย่างไรก็ตาม ในเครือข่ายประสาทแบบคอนโวลูชัน โปรดทราบว่าตัวกรองจะใช้กับคิวบ์ข้อมูล ไม่ใช่แค่รูปภาพ 2 มิติ ดังนั้น ฟิลเตอร์ "1x1" จะคำนวณผลรวมแบบถ่วงน้ำหนักของคอลัมน์ข้อมูล 1x1 (ดูภาพประกอบ) และเมื่อเลื่อนฟิลเตอร์ไปตามข้อมูล คุณจะได้รับการรวมเชิงเส้นของแชแนลของอินพุต ซึ่งมีประโยชน์จริงๆ หากคุณคิดว่าช่องเป็นผลลัพธ์ของการดำเนินการกรองแต่ละรายการ เช่น ตัวกรองสำหรับ "หูแหลม" ตัวกรองอีกรายการสำหรับ "หนวด" และตัวกรองที่ 3 สำหรับ "ตาเรียว" เลเยอร์ Convolutional "1x1" จะคำนวณการรวมเชิงเส้นที่เป็นไปได้หลายรายการของฟีเจอร์เหล่านี้ ซึ่งอาจมีประโยชน์เมื่อมองหา "แมว" นอกจากนี้ เลเยอร์ 1x1 ยังใช้น้ำหนักน้อยกว่าด้วย
11. Squeezenet
เอกสาร"Squeezenet" ได้แสดงวิธีง่ายๆ ในการรวมแนวคิดเหล่านี้เข้าด้วยกัน ผู้เขียนแนะนำการออกแบบโมดูล Convolutional ที่เรียบง่ายมาก โดยใช้เฉพาะเลเยอร์ Convolutional ขนาด 1x1 และ 3x3
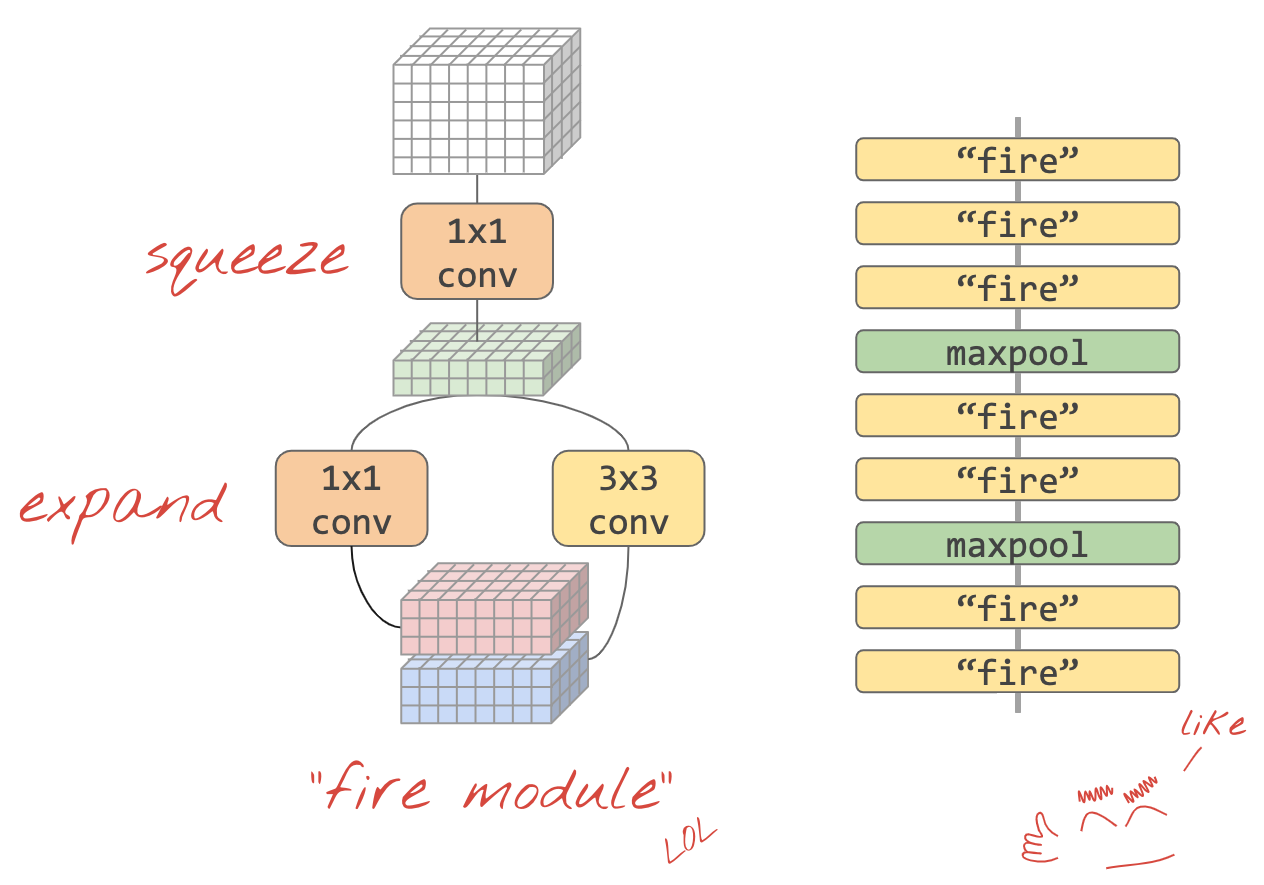
ภาพ: สถาปัตยกรรม SqueezeNet ที่อิงตาม "โมดูล Fire" โดยจะสลับเลเยอร์ 1x1 ที่ "บีบ" ข้อมูลขาเข้าในมิติแนวตั้ง ตามด้วยเลเยอร์ Convolutional แบบ 1x1 และ 3x3 แบบขนาน 2 เลเยอร์ที่ "ขยาย" ความลึกของข้อมูลอีกครั้ง
ลงมือปฏิบัติ
ทำต่อในสมุดบันทึกก่อนหน้าและสร้างโครงข่ายระบบประสาทเทียมแบบ Convolutional ที่ได้แรงบันดาลใจจาก SqueezeNet คุณจะต้องเปลี่ยนโค้ดโมเดลเป็น "รูปแบบฟังก์ชัน" ของ Keras
Keras_Flowers_TPU (playground).ipynb
ข้อมูลเพิ่มเติม
การกำหนดฟังก์ชันตัวช่วยสำหรับโมดูล SqueezeNet จะมีประโยชน์สำหรับการฝึกนี้
def fire(x, squeeze, expand):
y = l.Conv2D(filters=squeeze, kernel_size=1, padding='same', activation='relu')(x)
y1 = l.Conv2D(filters=expand//2, kernel_size=1, padding='same', activation='relu')(y)
y3 = l.Conv2D(filters=expand//2, kernel_size=3, padding='same', activation='relu')(y)
return tf.keras.layers.concatenate([y1, y3])
# this is to make it behave similarly to other Keras layers
def fire_module(squeeze, expand):
return lambda x: fire(x, squeeze, expand)
# usage:
x = l.Input(shape=[192, 192, 3])
y = fire_module(squeeze=24, expand=48)(x) # typically, squeeze is less than expand
y = fire_module(squeeze=32, expand=64)(y)
...
model = tf.keras.Model(x, y)
เป้าหมายในครั้งนี้คือการบรรลุความแม่นยำ 80%
สิ่งที่ควรลอง
เริ่มด้วยเลเยอร์ Convolutional เดียว แล้วตามด้วย "fire_modules" สลับกับเลเยอร์ MaxPooling2D(pool_size=2) คุณสามารถทดลองใช้เลเยอร์การจัดกลุ่มสูงสุด 2-4 เลเยอร์ในเครือข่าย รวมถึงใช้โมดูล Fire ต่อเนื่อง 1, 2 หรือ 3 โมดูลระหว่างเลเยอร์การจัดกลุ่มสูงสุด
ในโมดูลไฟ พารามิเตอร์ "บีบ" ควรมีขนาดเล็กกว่าพารามิเตอร์ "ขยาย" พารามิเตอร์เหล่านี้เป็นจำนวนตัวกรอง โดยปกติแล้วจะมีค่าตั้งแต่ 8 ถึง 196 คุณสามารถทดลองใช้สถาปัตยกรรมที่จำนวนฟิลเตอร์จะเพิ่มขึ้นเรื่อยๆ ผ่านเครือข่าย หรือสถาปัตยกรรมที่ตรงไปตรงมาซึ่งโมดูล Fire ทั้งหมดมีจำนวนฟิลเตอร์เท่ากัน
มีตัวอย่างดังต่อไปนี้
x = tf.keras.layers.Input(shape=[*IMAGE_SIZE, 3]) # input is 192x192 pixels RGB
y = tf.keras.layers.Conv2D(kernel_size=3, filters=32, padding='same', activation='relu')(x)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.MaxPooling2D(pool_size=2)(y)
y = fire_module(24, 48)(y)
y = tf.keras.layers.GlobalAveragePooling2D()(y)
y = tf.keras.layers.Dense(5, activation='softmax')(y)
model = tf.keras.Model(x, y)
ในตอนนี้ คุณอาจสังเกตเห็นว่าการทดสอบไม่เป็นไปตามที่คาดหวัง และเป้าหมายความแม่นยำ 80% ดูเหมือนจะอยู่ไกลเกินเอื้อม ได้เวลาสำหรับเคล็ดลับราคาถูกอีก 2-3 อย่าง
การทำให้เป็นมาตรฐานแบบกลุ่ม
Batch Norm จะช่วยแก้ปัญหาการบรรจบกันที่คุณพบ เราจะอธิบายรายละเอียดเกี่ยวกับเทคนิคนี้ในเวิร์กช็อปครั้งถัดไป สำหรับตอนนี้ โปรดใช้เป็นตัวช่วย "มหัศจรรย์" ที่ไม่จำเป็นต้องรู้รายละเอียดภายในโดยการเพิ่มบรรทัดนี้หลังเลเยอร์ Convolutional ทุกเลเยอร์ในเครือข่าย รวมถึงเลเยอร์ภายในฟังก์ชัน fire_module
y = tf.keras.layers.BatchNormalization(momentum=0.9)(y)
# please adapt the input and output "y"s to whatever is appropriate in your context
เราต้องลดพารามิเตอร์โมเมนตัมจากค่าเริ่มต้นที่ 0.99 เป็น 0.9 เนื่องจากชุดข้อมูลมีขนาดเล็ก ไม่ต้องสนใจรายละเอียดนี้ในตอนนี้
การเพิ่มข้อมูล
คุณจะได้รับเปอร์เซ็นต์เพิ่มขึ้นอีก 2-3 เปอร์เซ็นต์โดยการเพิ่มข้อมูลด้วยการเปลี่ยนรูปแบบง่ายๆ เช่น การพลิกซ้ายขวาของการเปลี่ยนแปลงความอิ่มตัว


ซึ่งทำได้ง่ายมากใน TensorFlow ด้วย tf.data.Dataset API กำหนดฟังก์ชันการเปลี่ยนรูปแบบใหม่สำหรับข้อมูลของคุณ
def data_augment(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_saturation(image, lower=0, upper=2)
return image, label
จากนั้นใช้ในการเปลี่ยนรูปแบบข้อมูลขั้นสุดท้าย (เซลล์ "ชุดข้อมูลการฝึกและชุดข้อมูลการตรวจสอบ" ฟังก์ชัน "get_batched_dataset")
dataset = dataset.repeat() # existing line
# insert this
if augment_data:
dataset = dataset.map(data_augment, num_parallel_calls=AUTO)
dataset = dataset.shuffle(2048) # existing line
อย่าลืมทําให้การเพิ่มข้อมูลเป็นแบบไม่บังคับ และเพิ่มโค้ดที่จําเป็นเพื่อให้แน่ใจว่าเฉพาะชุดข้อมูลการฝึกเท่านั้นที่จะได้รับการเพิ่ม การเพิ่มชุดข้อมูลการตรวจสอบจึงไม่มีประโยชน์
ตอนนี้คุณควรมีความแม่นยำ 80% ใน 35 ยุค
Solution
สมุดบันทึกวิธีแก้ปัญหา คุณสามารถใช้ฟีเจอร์นี้ได้หากติดขัด
Keras_Flowers_TPU_squeezenet.ipynb
สิ่งที่เราได้พูดถึง
- 🤔 โมเดล "รูปแบบฟังก์ชัน" ของ Keras
- 🤓 สถาปัตยกรรม Squeezenet
- 🤓 การเพิ่มข้อมูลด้วย tf.data.datset
โปรดสละเวลาสักครู่เพื่อพิจารณารายการตรวจสอบนี้ในใจ
12. Xception ที่ปรับแต่งแล้ว
การสังวัตน์แบบแยกได้
เมื่อเร็วๆ นี้ วิธีการใช้เลเยอร์ Convolutional แบบอื่นได้รับความนิยมมากขึ้น นั่นคือ Convolution แบบแยกความลึก เราทราบว่าชื่อนี้ค่อนข้างยาว แต่แนวคิดนั้นเรียบง่ายมาก โดยจะใช้งานใน TensorFlow และ Keras เป็น tf.keras.layers.SeparableConv2D
การ Convolution แบบแยกกันได้จะเรียกใช้ตัวกรองในรูปภาพเช่นกัน แต่จะใช้ชุดน้ำหนักที่แตกต่างกันสำหรับแต่ละแชแนลของรูปภาพอินพุต จากนั้นจะตามด้วย "การสังวัตนาการแบบ 1x1" ซึ่งเป็นชุดของผลคูณแบบดอทที่ให้ผลรวมแบบถ่วงน้ำหนักของแชแนลที่กรองแล้ว โดยจะมีการคำนวณการรวมช่องสัญญาณแบบถ่วงน้ำหนักตามความจำเป็นด้วยน้ำหนักใหม่ทุกครั้ง
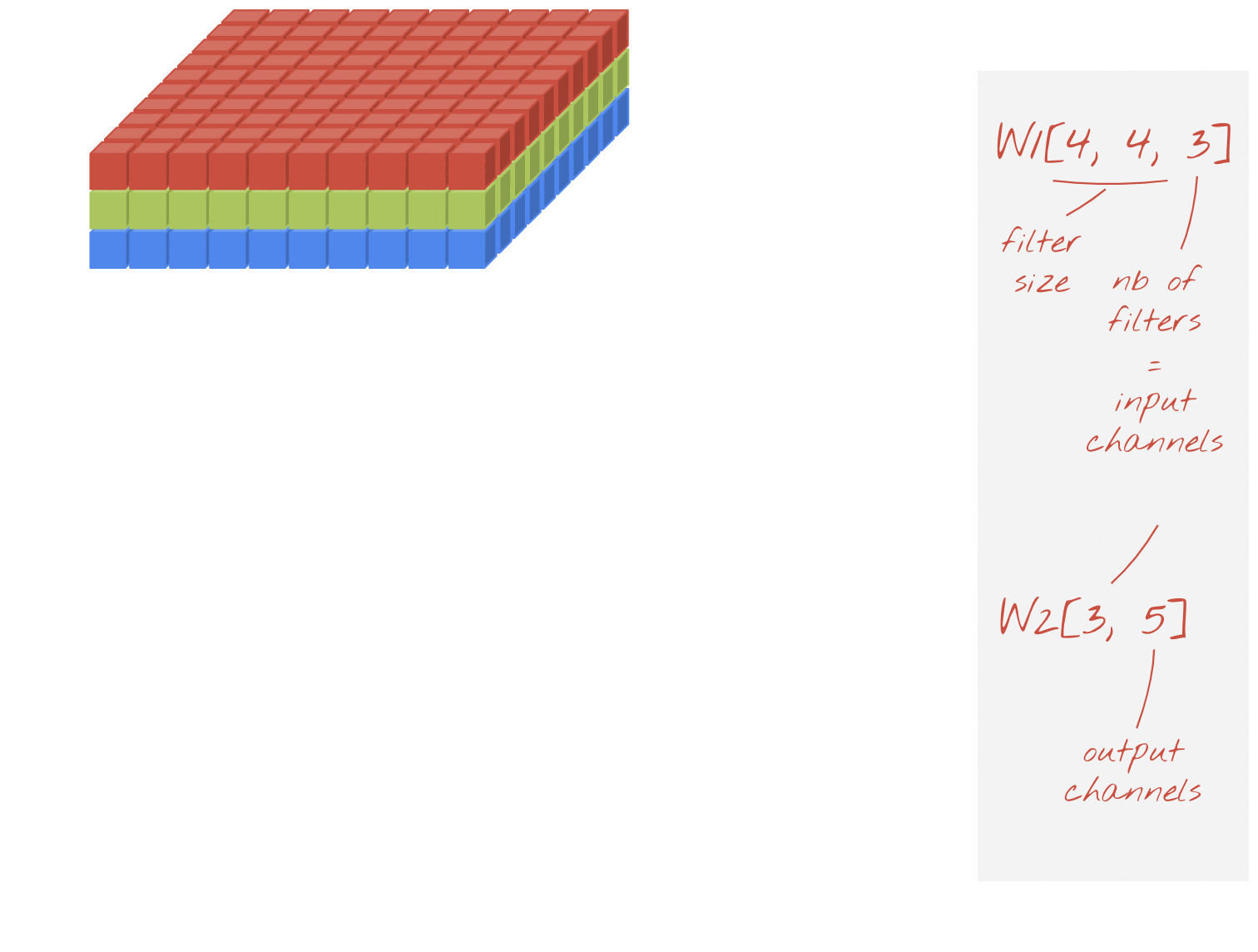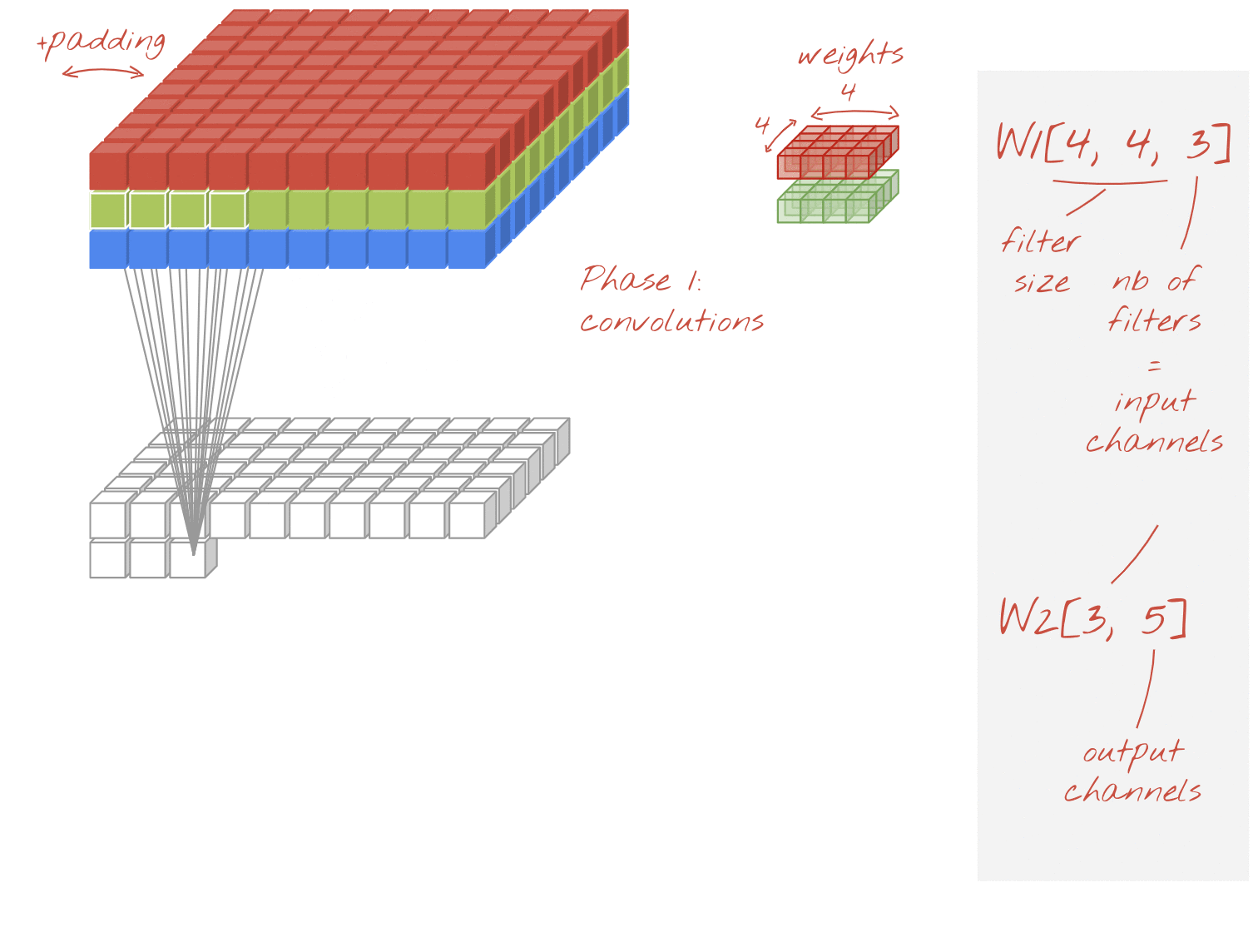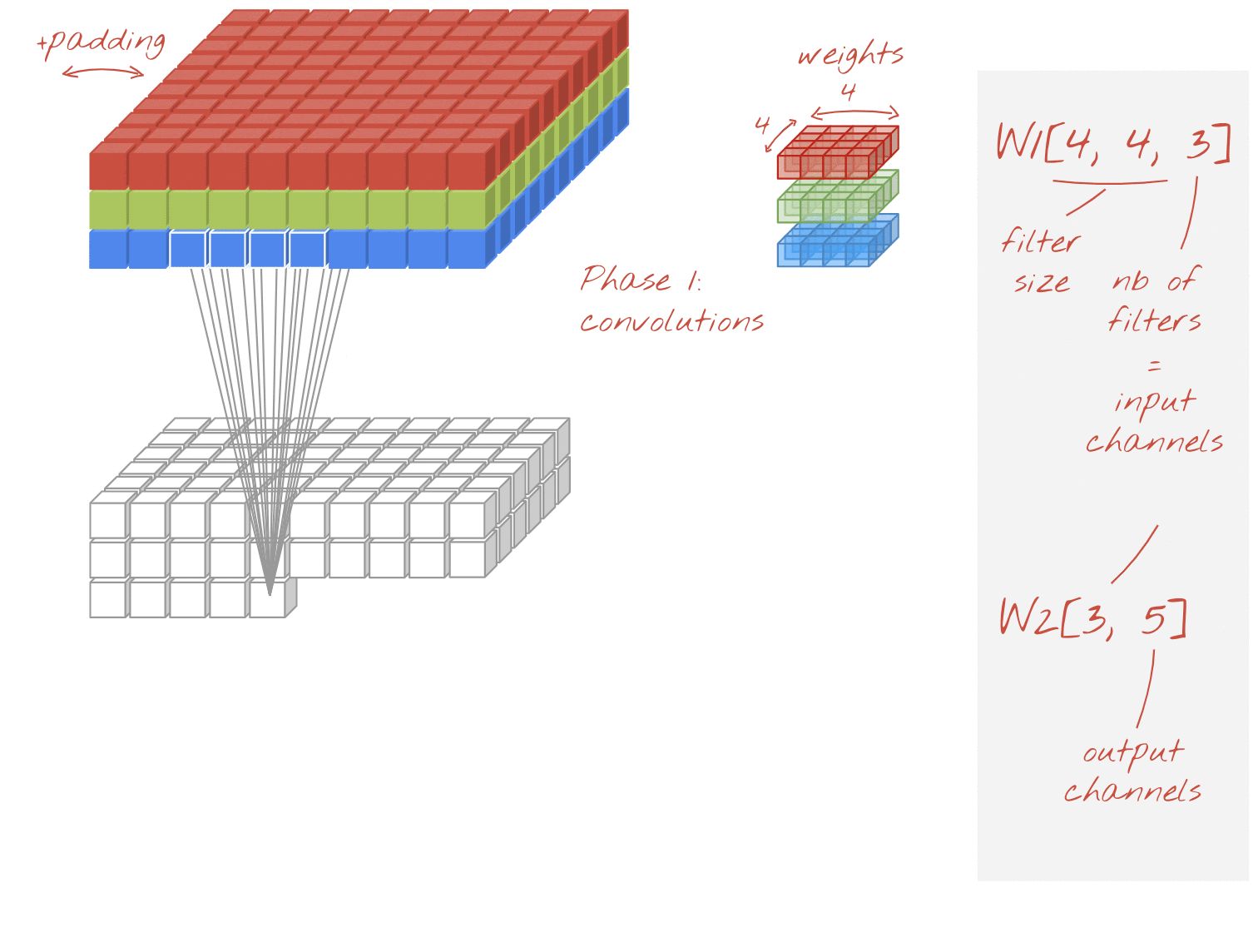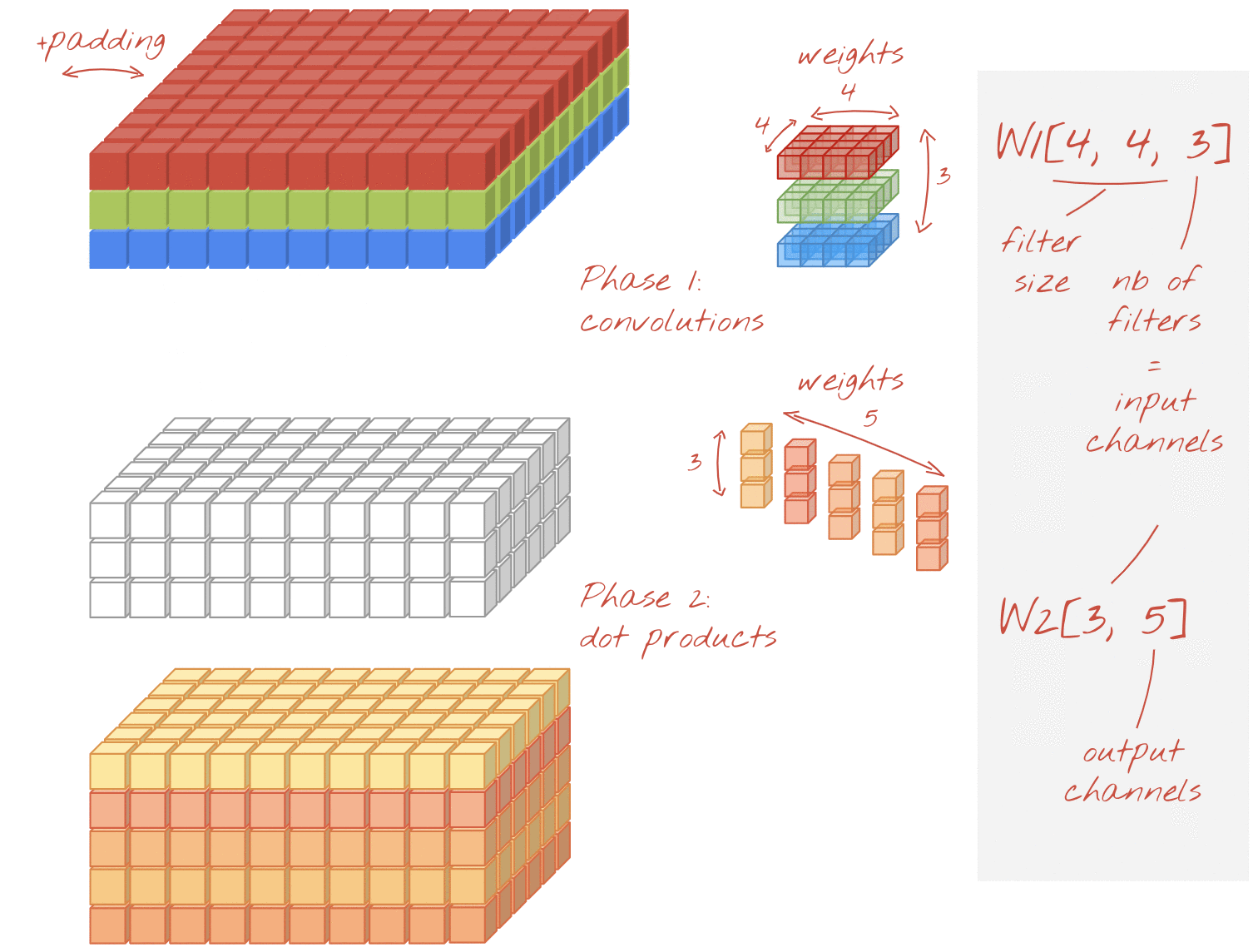
ภาพ: การคูณแบบแยกกัน เฟสที่ 1: การบิดเบือนที่มีตัวกรองแยกต่างหากสำหรับแต่ละช่อง ระยะที่ 2: การรวมช่องเชิงเส้น ทำซ้ำโดยใช้ชุดน้ำหนักใหม่จนกว่าจะได้จำนวนช่องเอาต์พุตที่ต้องการ คุณทำเฟส 1 ซ้ำได้เช่นกัน โดยใช้ค่าถ่วงน้ำหนักใหม่ในแต่ละครั้ง แต่ในทางปฏิบัติแล้วมักไม่ค่อยมีการทำซ้ำ
การแยก Convolution ออกจากกันใช้ในสถาปัตยกรรมเครือข่าย Convolutional ล่าสุดส่วนใหญ่ ได้แก่ MobileNetV2, Xception และ EfficientNet อย่างไรก็ตาม MobileNetV2 คือสิ่งที่คุณใช้สำหรับการเรียนรู้แบบถ่ายโอนก่อนหน้านี้
โดยมีราคาถูกกว่าการ Convolution ปกติ และพบว่ามีประสิทธิภาพในทางปฏิบัติเช่นเดียวกัน น้ำหนักของตัวอย่างที่แสดงด้านบนมีดังนี้
เลเยอร์ Convolutional: 4 x 4 x 3 x 5 = 240
เลเยอร์ Convolution ที่แยกได้: 4 x 4 x 3 + 3 x 5 = 48 + 15 = 63
ผู้อ่านสามารถลองคำนวณจำนวนการคูณที่จำเป็นในการใช้เลเยอร์ Convolutional แต่ละสไตล์ในลักษณะเดียวกัน การคูณแบบแยกส่วนมีขนาดเล็กกว่าและมีประสิทธิภาพในการคำนวณมากกว่า
ลงมือปฏิบัติ
เริ่มใหม่จาก Notebook ของ Playground "การถ่ายโอนการเรียนรู้" แต่คราวนี้ให้เลือก Xception เป็นโมเดลที่ฝึกไว้ล่วงหน้า Xception ใช้เฉพาะการผสานรวมที่แยกออกได้ ปล่อยให้น้ำหนักทั้งหมดฝึกได้ เราจะปรับแต่งน้ำหนักที่ฝึกไว้ล่วงหน้าในข้อมูลของเราแทนที่จะใช้เลเยอร์ที่ฝึกไว้ล่วงหน้าตามนั้น
Keras Flowers transfer learning (playground).ipynb
เป้าหมาย: ความแม่นยำ > 95% (ไม่เชื่อก็ต้องเชื่อว่าทำได้จริงๆ)
เนื่องจากเป็นแบบฝึกหัดสุดท้าย จึงต้องใช้โค้ดและงานด้านวิทยาศาสตร์ข้อมูลเพิ่มเติมเล็กน้อย
ข้อมูลเพิ่มเติมเกี่ยวกับการปรับแต่ง
Xception พร้อมใช้งานในโมเดลที่ฝึกไว้ล่วงหน้ามาตรฐานใน tf.keras.application.* อย่าลืมปล่อยให้น้ำหนักทั้งหมดฝึกได้ในครั้งนี้
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3],
include_top=False)
pretrained_model.trainable = True
หากต้องการให้ได้ผลลัพธ์ที่ดีเมื่อปรับแต่งโมเดล คุณจะต้องให้ความสำคัญกับอัตราการเรียนรู้และใช้กำหนดการอัตราการเรียนรู้ที่มีช่วงเพิ่มประสิทธิภาพหลังการเรียนรู้ ดังนี้
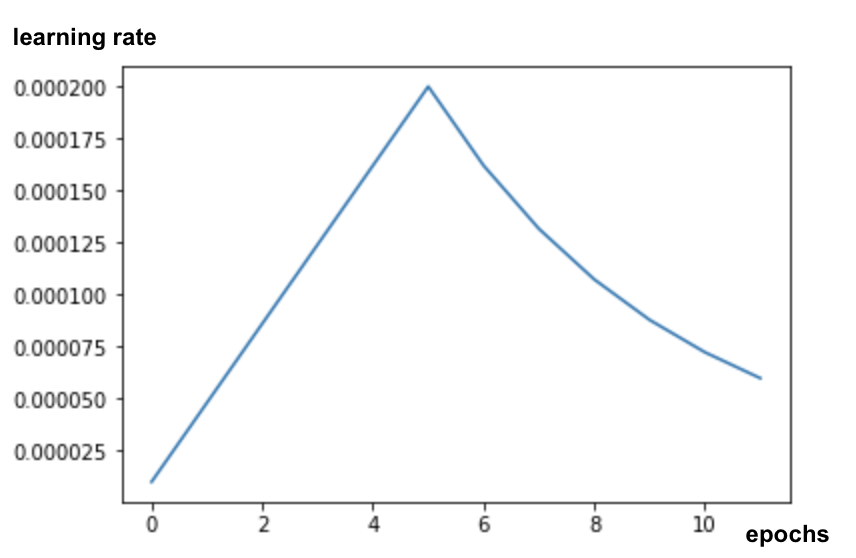
การเริ่มต้นด้วยอัตราการเรียนรู้มาตรฐานจะรบกวนน้ำหนักที่ฝึกไว้ล่วงหน้าของโมเดล การเริ่มต้นอย่างค่อยเป็นค่อยไปจะช่วยรักษาไว้จนกว่าโมเดลจะยึดตามข้อมูลของคุณและสามารถแก้ไขได้อย่างสมเหตุสมผล หลังจากเพิ่มขึ้นแล้ว คุณจะใช้ Learning Rate แบบคงที่หรือแบบลดลงแบบเอ็กซ์โปเนนเชียลต่อไปก็ได้
ใน Keras คุณจะระบุอัตราการเรียนรู้ผ่าน Callback ซึ่งคุณสามารถคำนวณอัตราการเรียนรู้ที่เหมาะสมสำหรับแต่ละ Epoch ได้ Keras จะส่งอัตราการเรียนรู้ที่ถูกต้องไปยังตัวเพิ่มประสิทธิภาพสำหรับแต่ละ Epoch
def lr_fn(epoch):
lr = ...
return lr
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_fn, verbose=True)
model.fit(..., callbacks=[lr_callback])
Solution
สมุดบันทึกวิธีแก้ปัญหา คุณสามารถใช้ฟีเจอร์นี้ได้หากติดขัด
07_Keras_Flowers_TPU_xception_fine_tuned_best.ipynb
สิ่งที่เราได้พูดถึง
- 🤔 การผสานรวมที่แยกความลึกได้
- 🤓 กำหนดการอัตราการเรียนรู้
- 😈 การปรับแต่งโมเดลที่ฝึกไว้ล่วงหน้า
โปรดสละเวลาสักครู่เพื่อพิจารณารายการตรวจสอบนี้ในใจ
13. ยินดีด้วย
คุณได้สร้างโครงข่ายระบบประสาทเทียมแบบ Convolution ที่ทันสมัยเป็นครั้งแรกและฝึกให้มีความแม่นยำมากกว่า 90% โดยทำการฝึกซ้ำๆ ในเวลาเพียงไม่กี่นาทีด้วย TPU
TPU ในทางปฏิบัติ
TPU และ GPU พร้อมให้บริการใน Vertex AI ของ Google Cloud
สุดท้ายนี้ เรายินดีรับฟังความคิดเห็น โปรดแจ้งให้เราทราบหากพบสิ่งผิดปกติในห้องทดลองนี้หรือหากคุณคิดว่าควรมีการปรับปรุง คุณแสดงความคิดเห็นได้ผ่านปัญหาใน GitHub [feedback link]

|
|

