이 Codelab 정보
2. Vertex AI 소개
이 실습에서는 Google Cloud에서 제공되는 최신 AI 제품을 사용합니다. Vertex AI는 Google Cloud 전반의 ML 제품을 원활한 개발 환경으로 통합합니다. 예전에는 AutoML로 학습된 모델과 커스텀 모델은 별도의 서비스를 통해 액세스할 수 있었습니다. 새 서비스는 다른 새로운 제품과 함께 두 가지 모두를 단일 API로 결합합니다. 기존 프로젝트를 Vertex AI로 이전할 수도 있습니다.
Vertex AI에는 엔드 투 엔드 ML 워크플로를 지원하는 다양한 제품이 포함되어 있습니다. 이 실습에서는 아래에 강조 표시된 예측 및 Workbench 제품에 중점을 둡니다.

3. 사용 사례 개요
이 실습에서는 TensorFlow Hub에서 사전 학습된 모델을 가져와 Vertex AI에 배포하는 방법을 알아봅니다. TensorFlow Hub는 임베딩, 텍스트 생성, 음성 텍스트 변환, 이미지 세분화 등 다양한 문제 영역을 위해 학습된 모델의 저장소입니다.
이 실습에서 사용되는 예는 ImageNet 데이터 세트로 사전 학습된 MobileNet V1 이미지 분류 모델입니다. TensorFlow Hub 또는 기타 유사한 딥 러닝 저장소의 기성 모델을 활용하면 모델 학습에 대해 걱정할 필요 없이 다양한 예측 작업을 위한 고품질 ML 모델을 배포할 수 있습니다.
4. 환경 설정
이 Codelab을 실행하려면 결제가 사용 설정된 Google Cloud Platform 프로젝트가 필요합니다. 프로젝트를 만들려면 여기의 안내를 따르세요.
1단계: Compute Engine API 사용 설정
아직 사용 설정되지 않은 경우 Compute Engine으로 이동하고 사용 설정을 선택합니다.
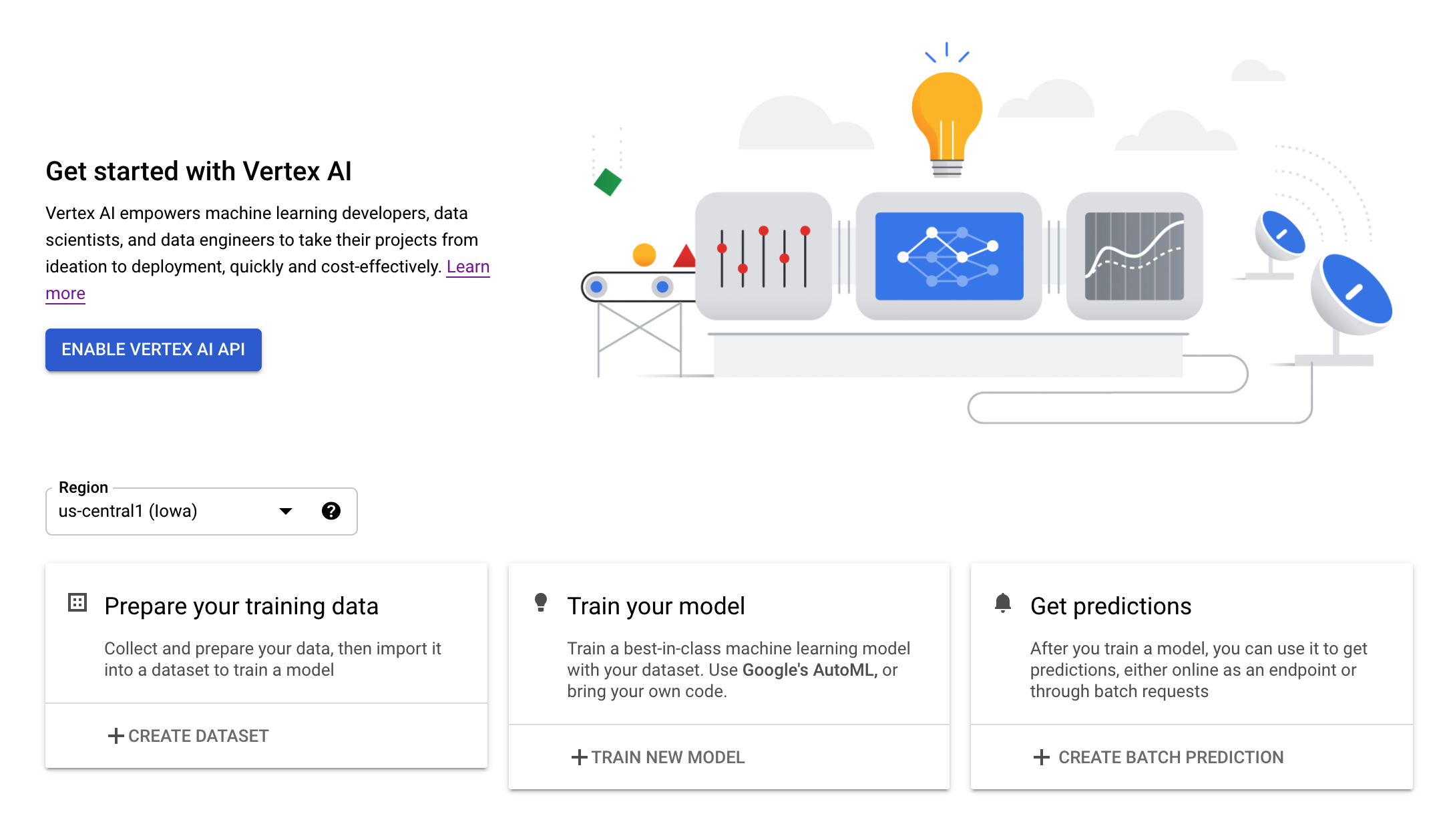
2단계: Vertex AI API 사용 설정
Cloud Console의 Vertex AI 섹션으로 이동하고 Vertex AI API 사용 설정을 클릭합니다.
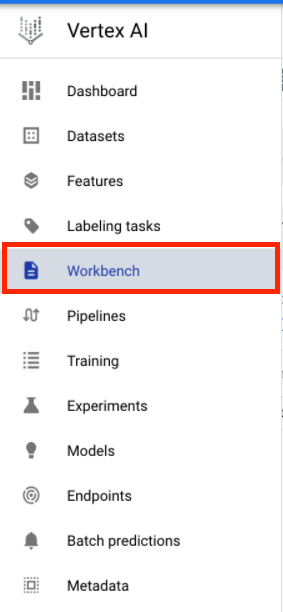
3단계: Vertex AI Workbench 인스턴스 만들기
Cloud 콘솔의 Vertex AI 섹션에서 'Workbench'를 클릭합니다.
Notebooks API를 아직 사용 설정하지 않은 경우 사용 설정합니다.

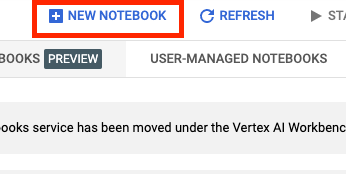
사용 설정했으면 관리형 노트북을 클릭합니다.

그런 다음 새 노트북을 선택합니다.
노트북 이름을 지정하고 권한에서 서비스 계정을 선택합니다.
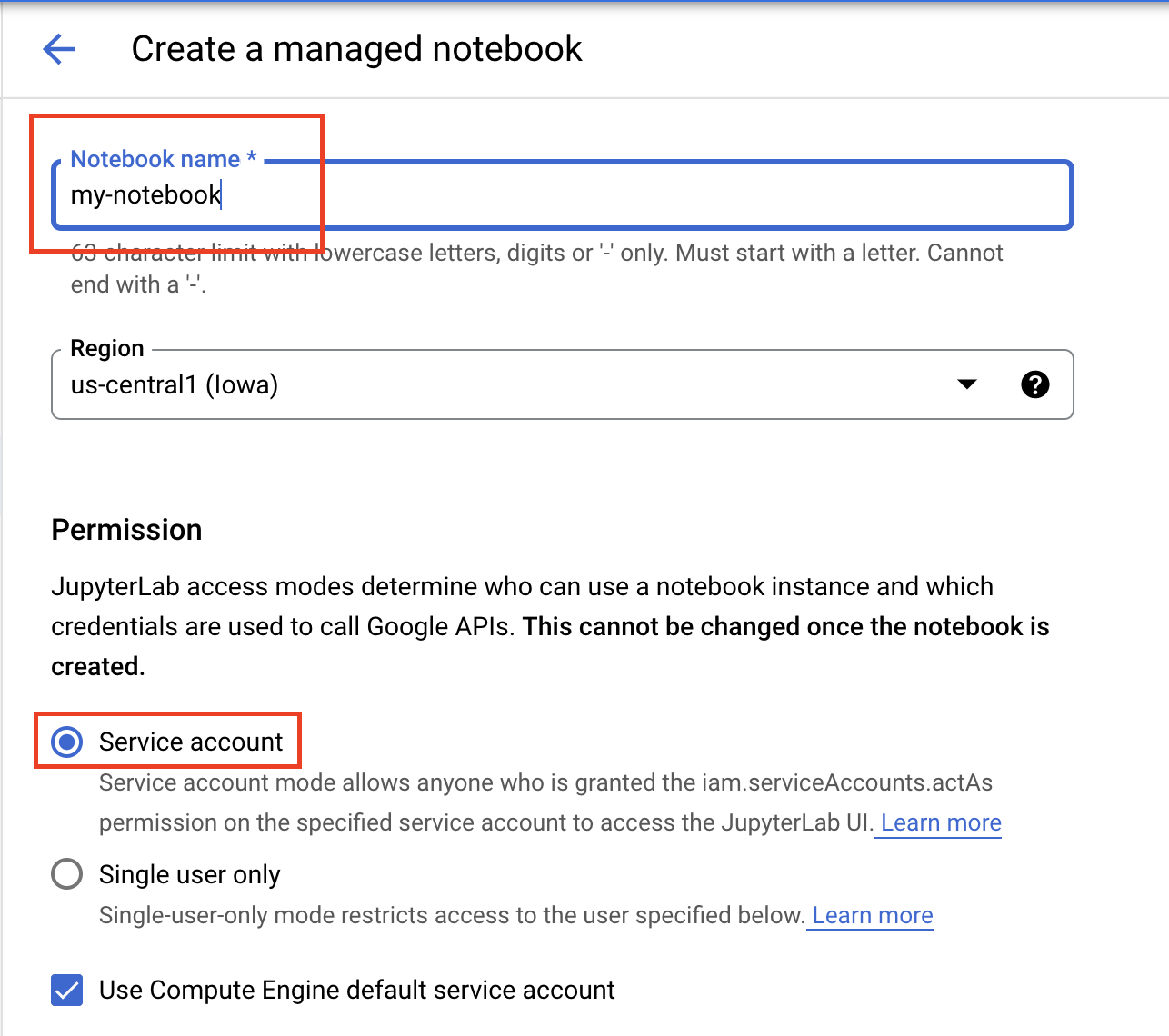
고급 설정을 선택합니다.
아직 사용 설정되지 않은 경우 보안에서 '터미널 사용 설정'을 선택합니다.
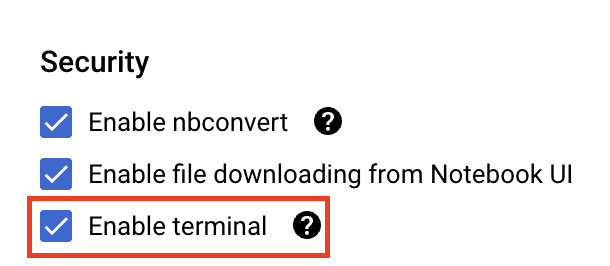
다른 고급 설정은 모두 그대로 두면 됩니다.
그런 다음 만들기를 클릭합니다. 인스턴스를 프로비저닝하는 데 몇 분 정도 걸립니다.
인스턴스가 생성되면 JupyterLab 열기를 선택합니다.

5. 모델 등록
1단계: Cloud Storage에 모델 업로드
이 링크를 클릭하여 ImageNet 데이터 세트에서 학습된 MobileNet V1 모델의 TensorFlow Hub 페이지로 이동합니다.
다운로드를 선택하여 저장된 모델 아티팩트를 다운로드합니다.

Google Cloud 콘솔의 Cloud Storage 섹션에서 만들기를 선택합니다.

버킷 이름을 지정하고 리전으로 us-central1을 선택합니다. 그런 다음 만들기를 클릭합니다.
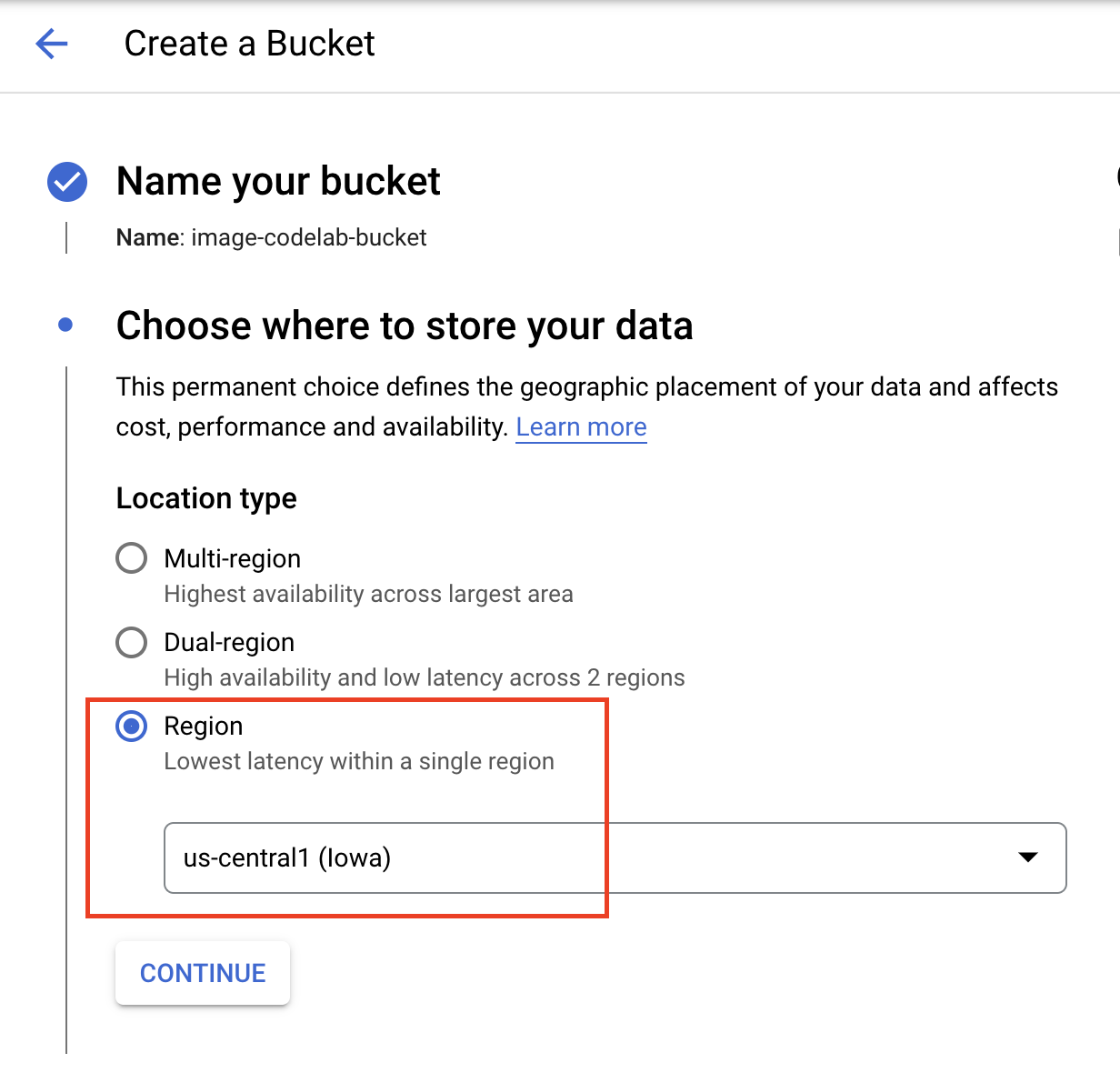
다운로드한 TensorFlow 허브 모델을 버킷에 업로드합니다. 먼저 파일의 압축을 풀어야 합니다.
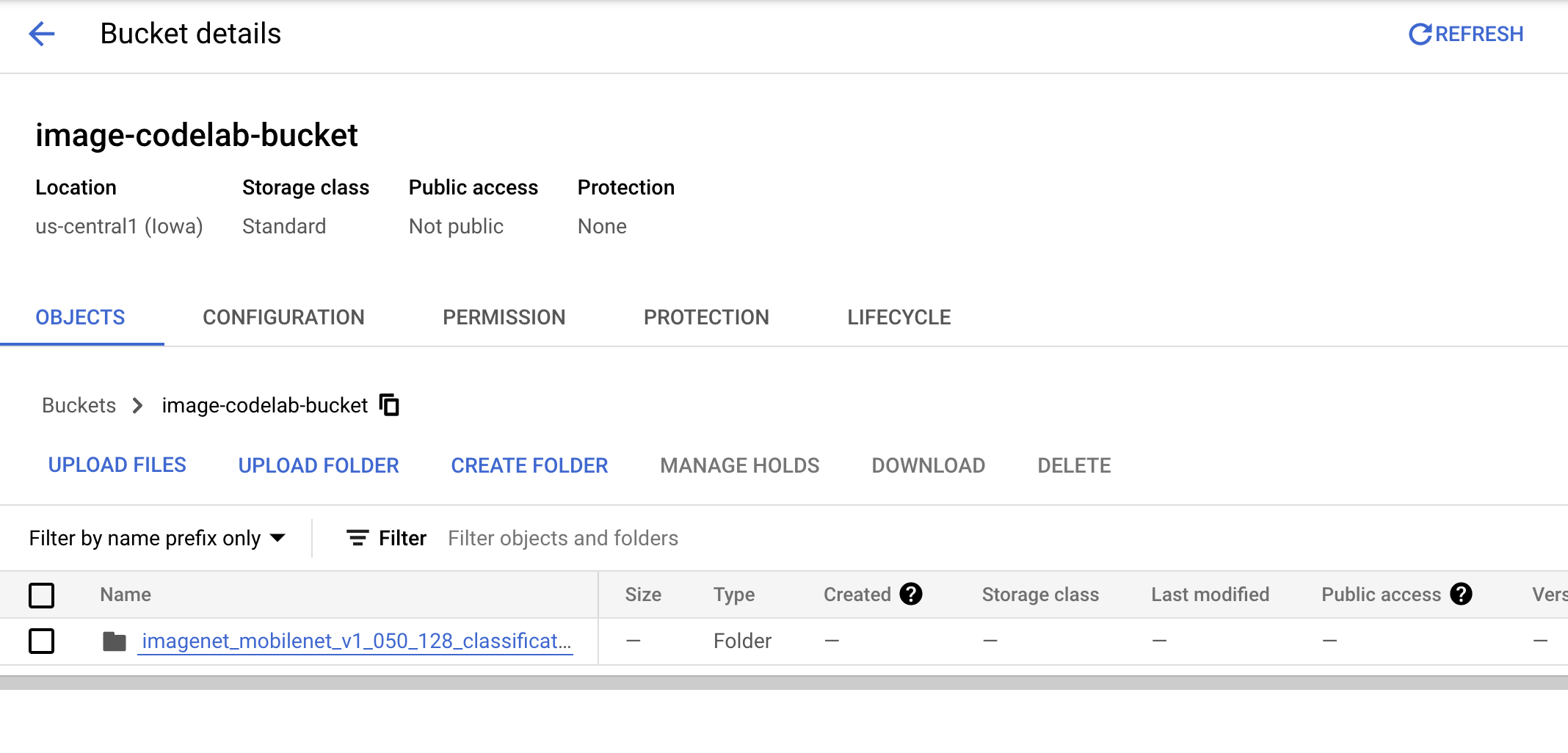
버킷이 다음과 같이 표시됩니다.
imagenet_mobilenet_v1_050_128_classification_5/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.index
2단계: 레지스트리로 모델 가져오기
Cloud 콘솔의 Vertex AI Model Registry 섹션으로 이동합니다.

가져오기 선택
새 모델로 가져오기를 선택한 후 모델 이름을 지정합니다.
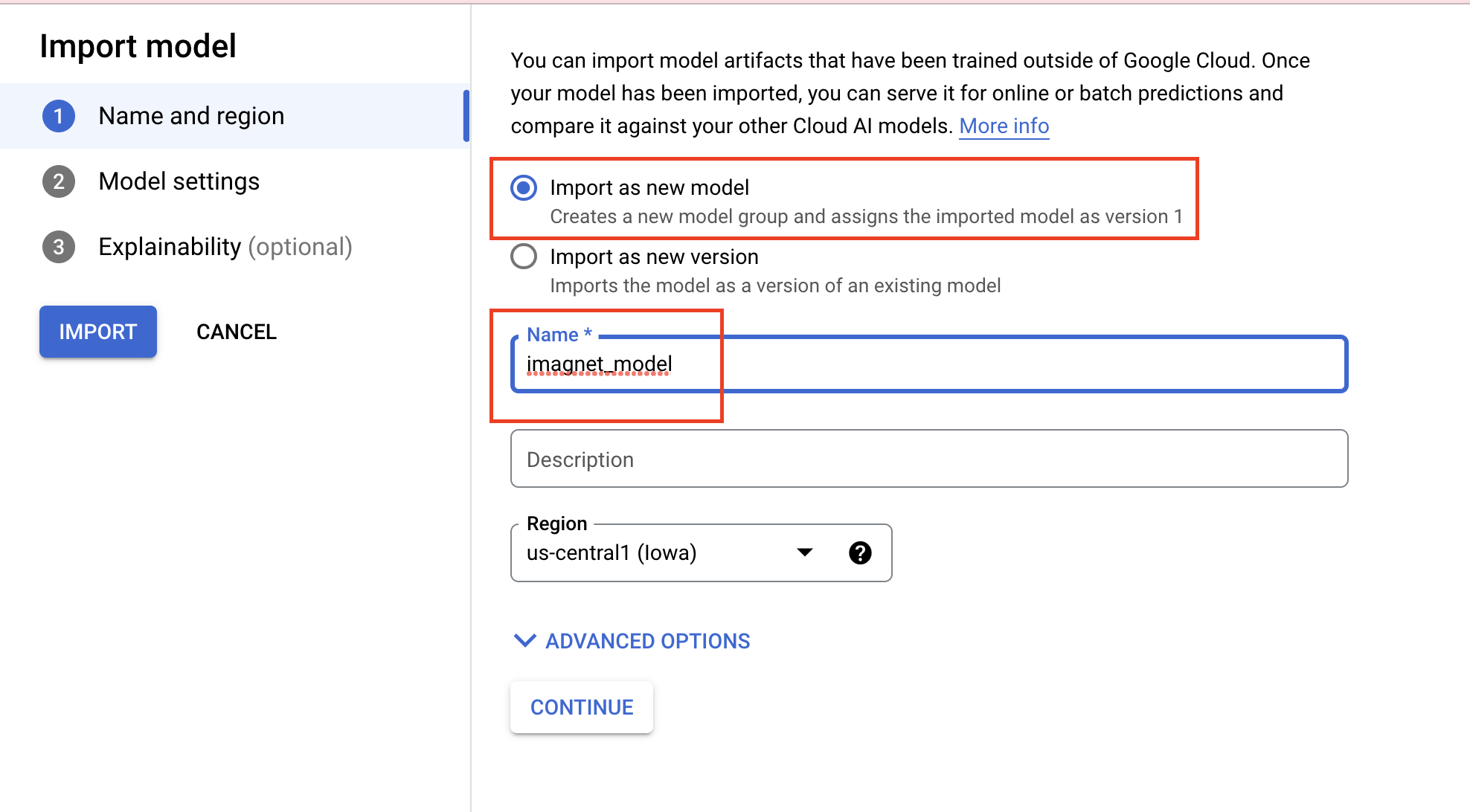
모델 설정에서 최신 사전 빌드된 TensorFlow 컨테이너를 지정합니다. 그런 다음 Cloud Storage에서 모델 아티팩트를 저장한 경로를 선택합니다.
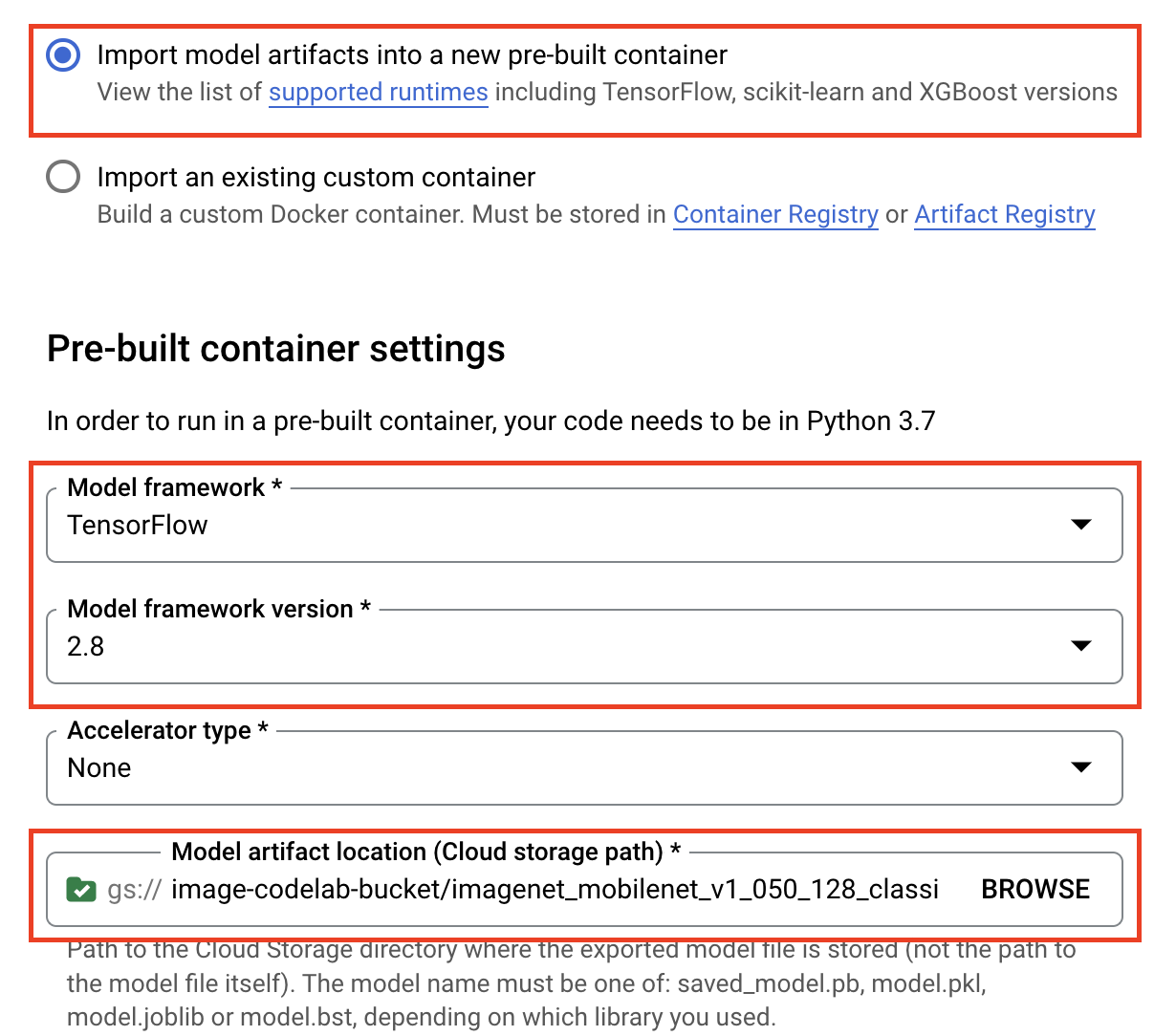
설명 가능성 섹션은 건너뛰어도 됩니다.
그런 다음 가져오기를 선택합니다.
가져온 후에는 모델 레지스트리에 모델이 표시됩니다.

6. 모델 배포
모델 레지스트리에서 모델 오른쪽에 있는 점 3개를 선택하고 엔드포인트에 배포를 클릭합니다.
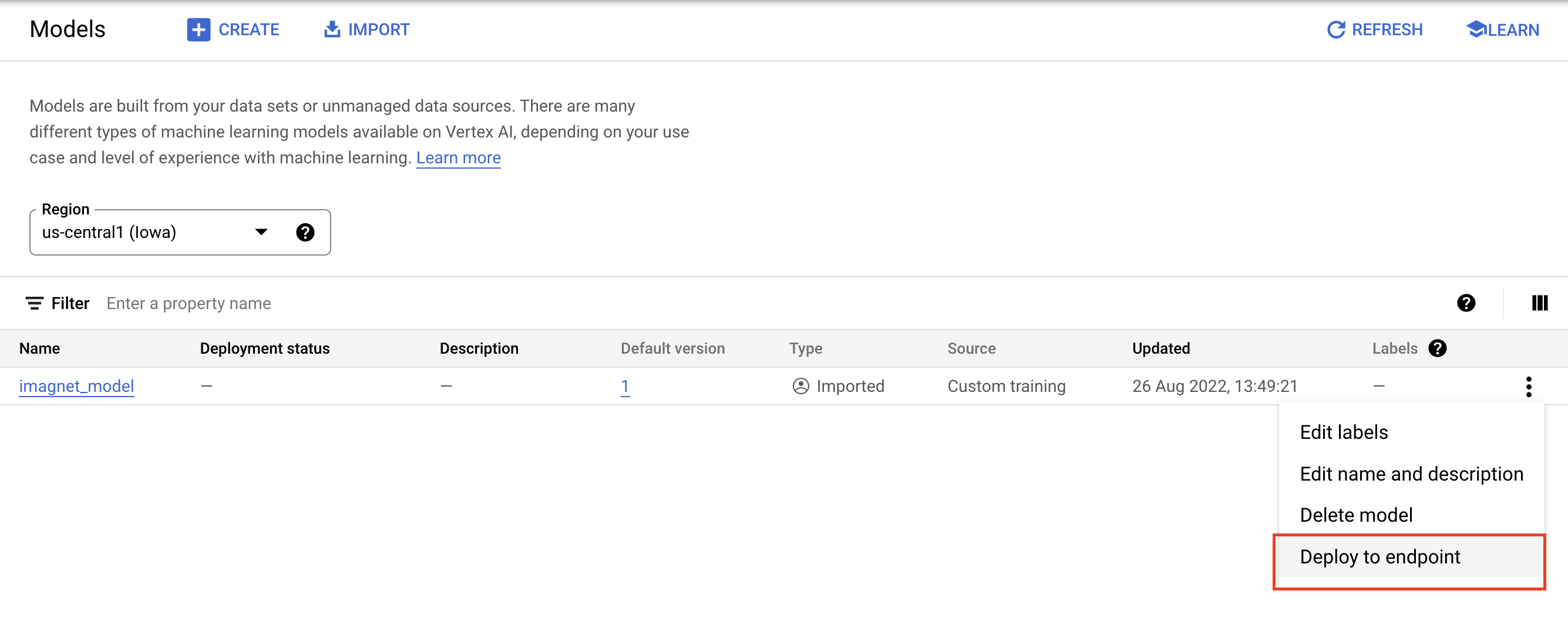
엔드포인트 정의에서 새 엔드포인트 만들기를 선택한 다음 엔드포인트 이름을 지정합니다.
모델 설정에서 최대 컴퓨팅 노드 수를 1로, 머신 유형을 n1-standard-2으로 설정하고 다른 모든 설정은 그대로 둡니다. 그런 다음 배포를 클릭합니다.

배포되면 배포 상태가 Vertex AI에 배포됨으로 변경됩니다.

7. 예측 가져오기
설정 단계에서 만든 Workbench 노트북을 엽니다. 런처에서 새 TensorFlow 2 노트북을 만듭니다.

다음 셀을 실행하여 필요한 라이브러리를 가져옵니다.
from google.cloud import aiplatform
import tensorflow as tf
import numpy as np
from PIL import Image
TensorFlow Hub에서 다운로드한 MobileNet 모델은 ImageNet 데이터 세트에서 학습되었습니다. MobileNet 모델의 출력은 ImageNet 데이터 세트의 클래스 라벨에 해당하는 숫자입니다. 이 숫자를 문자열 라벨로 변환하려면 이미지 라벨을 다운로드해야 합니다.
# Download image labels
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
엔드포인트에 연결하려면 엔드포인트 리소스를 정의해야 합니다. {PROJECT_NUMBER} 및 {ENDPOINT_ID}를 바꿔야 합니다.
PROJECT_NUMBER = "{PROJECT_NUMBER}"
ENDPOINT_ID = "{ENDPOINT_ID}"
endpoint = aiplatform.Endpoint(
endpoint_name=f"projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
콘솔의 홈페이지에서 프로젝트 번호를 찾을 수 있습니다.

Vertex AI 엔드포인트 섹션의 엔드포인트 ID입니다.
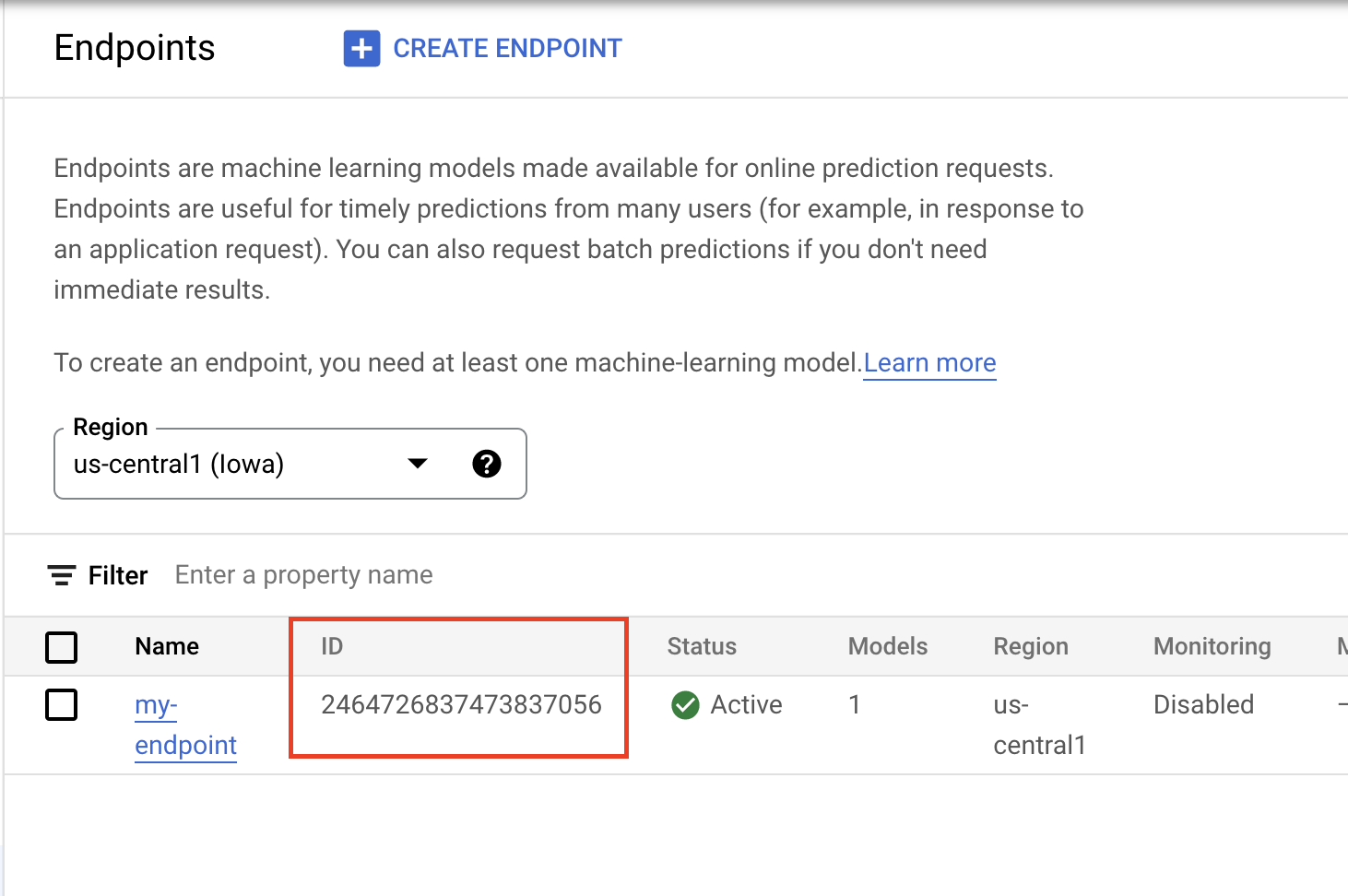
다음으로 엔드포인트를 테스트합니다.
먼저 다음 이미지를 다운로드하여 인스턴스에 업로드합니다.

PIL로 이미지를 엽니다. 그런 다음 크기를 255씩 조절합니다. 모델에서 예상하는 이미지 크기는 모델의 TensorFlow Hub 페이지에서 확인할 수 있습니다.
IMAGE_PATH = "test-image.jpg"
IMAGE_SIZE = (128, 128)
im = Image.open(IMAGE_PATH)
im = im.resize(IMAGE_SIZE
im = np.array(im)/255.0
다음으로, HTTP 요청의 본문에 전송할 수 있도록 NumPy 데이터를 목록으로 변환합니다.
x_test = im.astype(np.float32).tolist()
마지막으로 엔드포인트에 예측을 호출한 다음 해당하는 문자열 라벨을 조회합니다.
# make prediction request
result = endpoint.predict(instances=[x_test]).predictions
# post process result
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
8. [선택사항] TF Serving을 사용하여 예측 최적화
보다 현실적인 예를 들어, 이미지를 먼저 NumPy에 로드하는 대신 이미지 자체를 엔드포인트로 직접 전송하는 것이 좋습니다. 이 방법은 더 효율적이지만 TensorFlow 모델의 서빙 함수를 수정해야 합니다. 입력 데이터를 모델이 예상하는 형식으로 변환하려면 이 수정이 필요합니다.
1단계: 게재 함수 수정
새 TensorFlow 노트북을 열고 필요한 라이브러리를 가져옵니다.
from google.cloud import aiplatform
import tensorflow as tf
저장된 모델 아티팩트를 다운로드하는 대신 이번에는 TensorFlow SavedModel을 Keras 레이어로 래핑하는 hub.KerasLayer를 사용하여 모델을 TensorFlow에 로드합니다. 모델을 만들려면 다운로드한 TF Hub 모델을 레이어로 사용하여 Keras Sequential API를 사용하고 모델에 입력 도형을 지정하면 됩니다.
tfhub_model = tf.keras.Sequential(
[hub.KerasLayer("https://tfhub.dev/google/imagenet/mobilenet_v1_050_128/classification/5")]
)
tfhub_model.build([None, 128, 128, 3])
앞서 만든 버킷의 URI를 정의합니다.
BUCKET_URI = "gs://{YOUR_BUCKET}"
MODEL_DIR = BUCKET_URI + "/bytes_model"
온라인 예측 서버에 요청을 전송하면 HTTP 서버에서 요청을 수신합니다. HTTP 서버는 HTTP 요청 콘텐츠 본문에서 예측 요청을 추출합니다. 추출된 예측 요청은 서빙 함수로 전달됩니다. Vertex AI 사전 빌드된 예측 컨테이너의 경우 요청 콘텐츠가 tf.string로 제공 함수에 전달됩니다.
이미지를 예측 서비스에 전달하려면 압축된 이미지 바이트를 base64로 인코딩해야 네트워크를 통해 바이너리 데이터를 전송하는 동안 콘텐츠가 수정되지 않게 안전합니다.
배포된 모델은 입력 데이터를 원시 (비압축) 바이트로 예상하므로 base64 인코딩된 데이터를 원시 바이트 (예: JPEG)로 다시 변환한 후 모델 입력 요구사항과 일치하도록 사전 처리한 다음 배포된 모델에 입력으로 전달해야 합니다.
이 문제를 해결하려면 서빙 함수 (serving_fn)를 정의하고 사전 처리 단계로 모델에 연결합니다. @tf.function 데코레이터를 추가하여 제공 함수가 CPU의 업스트림이 아닌 기본 모델에 통합되도록 합니다.
CONCRETE_INPUT = "numpy_inputs"
def _preprocess(bytes_input):
decoded = tf.io.decode_jpeg(bytes_input, channels=3)
decoded = tf.image.convert_image_dtype(decoded, tf.float32)
resized = tf.image.resize(decoded, size=(128, 128))
return resized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(bytes_inputs):
decoded_images = tf.map_fn(
_preprocess, bytes_inputs, dtype=tf.float32, back_prop=False
)
return {
CONCRETE_INPUT: decoded_images
} # User needs to make sure the key matches model's input
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(bytes_inputs):
images = preprocess_fn(bytes_inputs)
prob = m_call(**images)
return prob
m_call = tf.function(tfhub_model.call).get_concrete_function(
[tf.TensorSpec(shape=[None, 128, 128, 3], dtype=tf.float32, name=CONCRETE_INPUT)]
)
tf.saved_model.save(tfhub_model, MODEL_DIR, signatures={"serving_default": serving_fn})
예측을 위한 데이터를 HTTP 요청 패킷으로 전송하면 이미지 데이터는 base64로 인코딩되지만 TensorFlow 모델은 numpy 입력을 사용합니다. 게재 함수는 base64에서 numpy 배열로 변환합니다.
예측 요청을 할 때는 모델 대신 서빙 함수로 요청을 라우팅해야 하므로 서빙 함수의 입력 레이어 이름을 알아야 합니다. 이 이름은 게재 함수 서명에서 가져올 수 있습니다.
loaded = tf.saved_model.load(MODEL_DIR)
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input name:", serving_input)
2단계: 레지스트리로 가져오고 배포
이전 섹션에서는 UI를 통해 Vertex AI Model Registry로 모델을 가져오는 방법을 알아봤습니다. 이 섹션에서는 SDK를 대신 사용하는 다른 방법을 살펴봅니다. 원하는 경우 여기에서 UI를 대신 사용할 수 있습니다.
model = aiplatform.Model.upload(
display_name="optimized-model",
artifact_uri=MODEL_DIR,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest",
)
print(model)
UI 대신 SDK를 사용하여 모델을 배포할 수도 있습니다.
endpoint = model.deploy(
deployed_model_display_name='my-bytes-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
3단계: 모델 테스트
이제 엔드포인트를 테스트할 수 있습니다. 제공 함수를 수정했으므로 이제 이미지를 먼저 NumPy에 로드하는 대신 요청에서 이미지를 직접 (base64로 인코딩) 전송할 수 있습니다. 이렇게 하면 Vertex AI 예측 크기 제한에 도달하지 않고도 더 큰 이미지를 전송할 수 있습니다.
이미지 라벨 다시 다운로드
import numpy as np
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
이미지를 Base64로 인코딩합니다.
import base64
with open("test-image.jpg", "rb") as f:
data = f.read()
b64str = base64.b64encode(data).decode("utf-8")
이전에 serving_input 변수에 정의한 제공 함수의 입력 레이어 이름을 지정하여 예측을 호출합니다.
instances = [{serving_input: {"b64": b64str}}]
# Make request
result = endpoint.predict(instances=instances).predictions
# Convert image class to string label
predicted_class = tf.math.argmax(result[0], axis=-1)
string_label = imagenet_labels[predicted_class]
print(f"label ID: {predicted_class}")
print(f"string label: {string_label}")
🎉 수고하셨습니다. 🎉
Vertex AI를 사용하여 다음을 수행하는 방법을 배웠습니다.
- 선행 학습된 모델 호스팅 및 배포
Vertex의 다른 부분에 대해 자세히 알아보려면 문서를 확인하세요.
9. 삭제
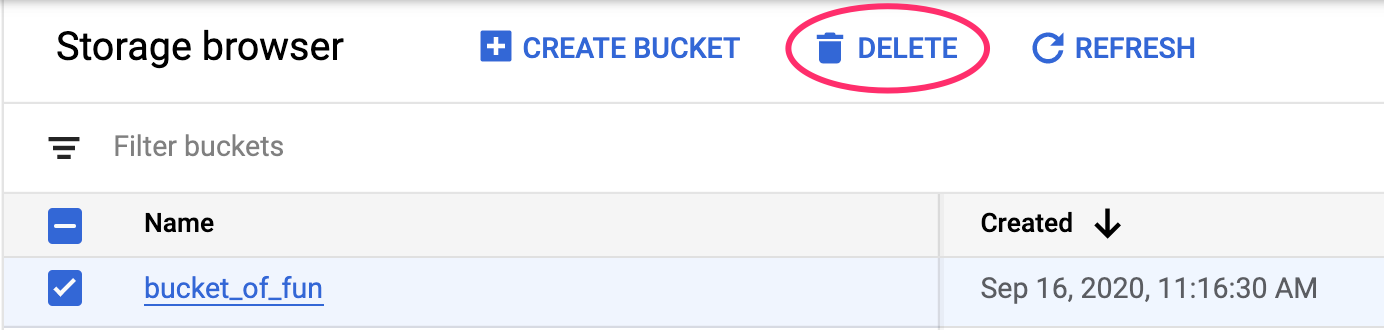
Vertex AI Workbench 관리 노트북에는 유휴 상태 종료 기능이 있으므로 인스턴스 종료에 대해 걱정할 필요가 없습니다. 인스턴스를 수동으로 종료하려면 콘솔의 Vertex AI Workbench 섹션에서 '중지' 버튼을 클릭합니다. 노트북을 완전히 삭제하려면 '삭제' 버튼을 클릭합니다.

스토리지 버킷을 삭제하려면 Cloud 콘솔의 탐색 메뉴를 사용하여 스토리지로 이동하고 버킷을 선택하고 '삭제'를 클릭합니다.