
1. Prima di iniziare
Questo codelab è progettato per basarsi sul risultato finale del codelab precedente di questa serie per il rilevamento di spam nei commenti mediante TensorFlow.js.
Nell'ultimo codelab hai creato una pagina web completamente funzionante per un video blog fittizio. Hai potuto filtrare i commenti per rilevare lo spam prima che venissero inviati al server per l'archiviazione oppure ad altri client connessi, utilizzando un modello preaddestrato di rilevamento dello spam dei commenti basato su TensorFlow.js nel browser.
Il risultato finale del codelab è il seguente:
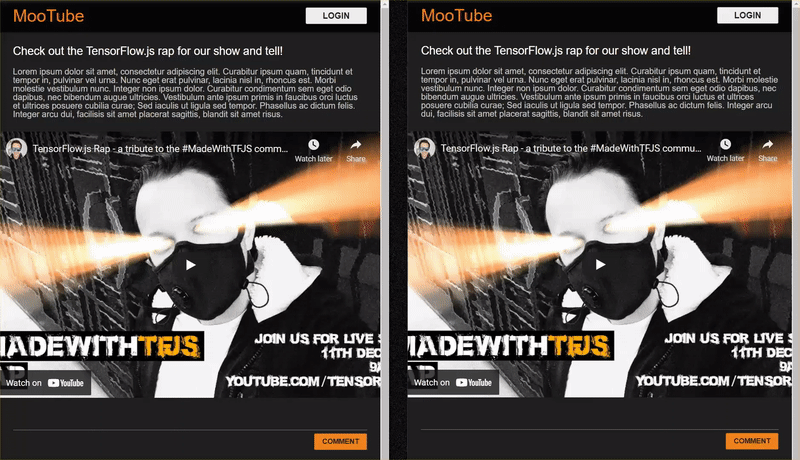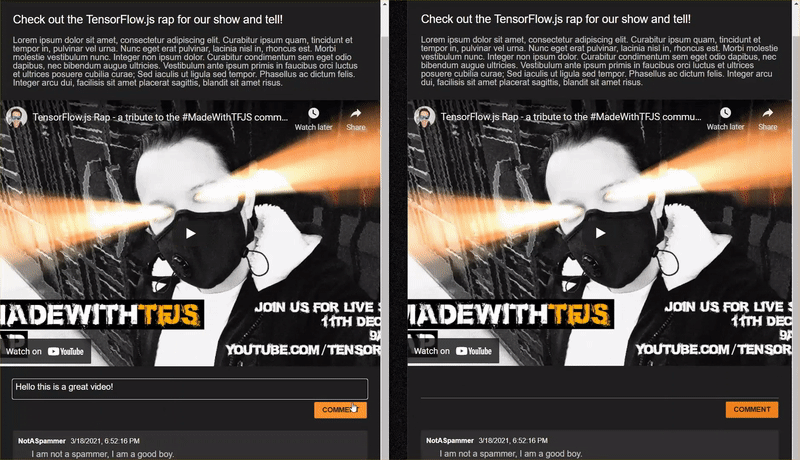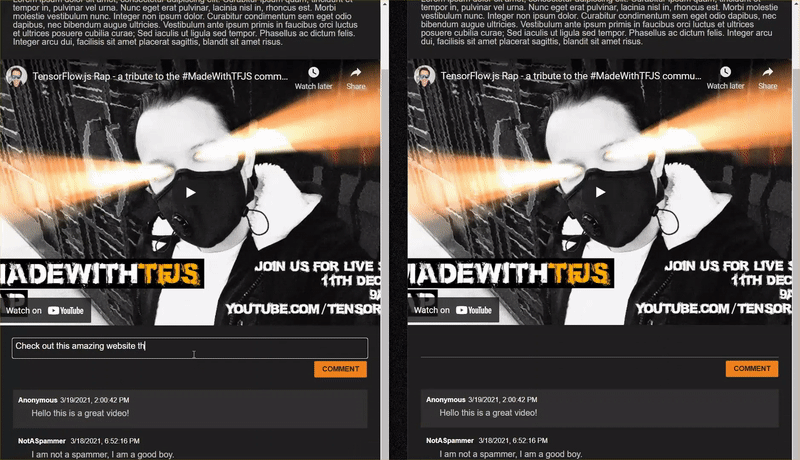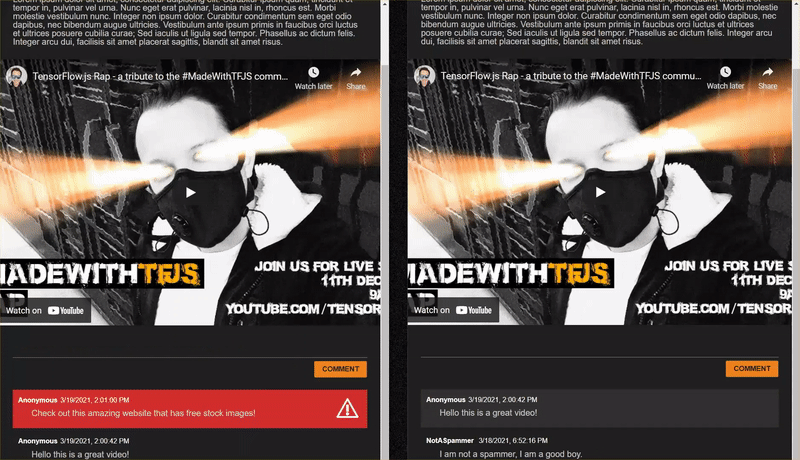
Sebbene abbia funzionato molto bene, ci sono casi limite da esplorare che non è stato in grado di rilevare. Puoi addestrare nuovamente il modello per tenere conto delle situazioni che non è stato in grado di gestire.
Questo codelab si concentra sull'utilizzo dell'elaborazione del linguaggio naturale (l'arte di comprendere il linguaggio umano con un computer) e mostra come modificare un'app web esistente che hai creato (ti consigliamo vivamente di seguire i codelab in ordine), per affrontare il vero problema dei commenti spam, che molti sviluppatori web incontreranno sicuramente quando lavorano su una delle app web più popolari di oggi.
In questo codelab farai un ulteriore passo avanti, readdestrando il tuo modello ML per tenere conto delle variazioni nei contenuti dei messaggi di spam che possono evolversi nel tempo, in base alle tendenze attuali o agli argomenti di discussione più frequenti, consentendoti di mantenere il modello aggiornato e tenere conto di questi cambiamenti.
Prerequisiti
- È stato completato il primo codelab di questa serie.
- Conoscenza di base delle tecnologie web, tra cui HTML, CSS e JavaScript.
Cosa creerai
Riutilizzerai il sito web creato in precedenza per un video blog fittizio con una sezione di commenti in tempo reale ed eseguirai l'upgrade per caricare una versione addestrata personalizzata del modello di rilevamento dello spam utilizzando TensorFlow.js, in modo che abbia prestazioni migliori sui casi limite per i quali in precedenza non avrebbe funzionato. Naturalmente, in qualità di ingegneri e sviluppatori web potresti modificare questa ipotetica UX per riutilizzarla su qualsiasi sito web su cui lavori nella tua quotidianità e adattare la soluzione per adattarla a qualsiasi caso d'uso dei clienti: magari si tratta di un blog, un forum o una qualche forma di CMS, come ad esempio Drupal.
Cominciamo con l'hack...
Cosa imparerai a fare
Imparerai a:
- Identifica i casi limite su cui il modello preaddestrato non funzionava
- Reimposta il modello di classificazione spam creato con Model Maker.
- Esporta questo modello basato su Python nel formato TensorFlow.js per utilizzarlo nei browser.
- Aggiorna il modello ospitato e il relativo dizionario con quello appena addestrato e controlla i risultati
Per questo lab è necessaria la familiarità con HTML5, CSS e JavaScript. Eseguirai anche del codice Python tramite un "co lab" per riaddestrare il modello creato con Model Maker, ma per farlo non è richiesta alcuna familiarità con Python.
2. Configura per programmare
Ancora una volta utilizzerai Glitch.com per ospitare e modificare l'applicazione web. Se non hai già completato il codelab prerequisito, puoi clonare il risultato finale qui come punto di partenza. Se hai domande sul funzionamento del codice, ti consigliamo vivamente di completare il codelab precedente che spiegava come rendere funzionante questa app web prima di continuare.
Su Glitch, ti basta fare clic sul pulsante Esegui il remix dei contenuti per creare un fork e creare un nuovo insieme di file che potrai modificare.
3. Scopri i casi limite nella soluzione precedente
Se apri il sito web completato che hai appena clonato e provi a digitare alcuni commenti, noterai che per la maggior parte del tempo funziona come previsto, bloccando i commenti che sembrano spam come previsto e consentendo attraverso risposte legittime.
Tuttavia, se si sviluppano l'abilità e si cercano di formulare frasi per rompere il modello, è probabile che prima o poi ci si riesca a trovare il modello. Con qualche tentativo puoi creare manualmente esempi come quelli mostrati di seguito. Prova a incollarli nell'app web esistente, controlla la console e controlla le probabilità che il commento sia spam:
Commenti legittimi pubblicati senza problemi (veri negativi):
- "Wow, adoro quel video, ottimo lavoro." Probabilità spam: 47,91854%
- "Sono state adorate queste demo. Hai altri dettagli?" Probabilità spam: 47,15898%
- "Quale sito web posso visitare per saperne di più?" Probabilità spam: 15,32495%
Questo è un ottimo risultato, le probabilità per tutti i casi precedenti sono piuttosto basse e riescono a superare il valore predefinito SPAM_THRESHOLD con una probabilità minima del 75% prima che venga intrapresa un'azione (definita nel codice script.js del codelab precedente).
Proviamo a scrivere commenti più audaci che vengono contrassegnati come spam anche se non lo sono...
Commenti legittimi contrassegnati come spam (falsi positivi):
- "Qualcuno può collegare il sito web per la mascherina che indossa?" Probabilità spam: 98,46466%
- "Posso acquistare questo brano su Spotify? Fammi sapere se qualcuno". Probabilità spam: 94,40953%
- "Qualcuno può contattarmi con i dettagli su come scaricare TensorFlow.js?" Probabilità spam: 83,20084%
Oh no! Sembra che questi commenti legittimi vengano contrassegnati come spam quando dovrebbero essere consentiti. Come puoi risolvere il problema?
Un'opzione semplice è aumentare il SPAM_THRESHOLD per un livello di sicurezza di oltre il 98,5%. In tal caso, i commenti classificati in modo erroneo verranno pubblicati. Tenendo conto di ciò, continuiamo con gli altri possibili risultati riportati di seguito...
Commenti spam contrassegnati come spam (veri positivi):
- "Fantastico, ma dai un'occhiata ai link per il download sul mio sito web che sono migliori!" Probabilità spam: 99,77873%
- "Conosco che alcune persone che possono ricevere dei farmaci, vedono il mio file pr0file per i dettagli." Probabilità di spam: 98,46955%
- "Vai sul mio profilo per scaricare altri video ancora più incredibili. http://example.com" Probabilità di spam: 96,26383%
Ok, l'operazione funziona come previsto con la nostra soglia originale del 75%, ma dato che nel passaggio precedente hai modificato SPAM_THRESHOLD in modo che abbia un livello di affidabilità superiore al 98,5%, significa che 2 esempi qui potrebbero essere lasciati passare, quindi forse la soglia è troppo alta. Forse il 96% è meglio? Se lo fai, uno dei commenti nella sezione precedente (falsi positivi) verrebbe contrassegnato come spam se è legittimo, in quanto valutato al 98,46466%.
In questo caso probabilmente è meglio acquisire tutti questi veri commenti spam e riaddestrarli per gli errori precedenti. Impostando la soglia al 96%, vengono comunque acquisiti tutti i veri positivi e vengono eliminati 2 dei falsi positivi precedenti. Non male per cambiare un solo numero.
Continuiamo...
Commenti spam che è stato possibile pubblicare (falsi negativi):
- "Vai sul mio profilo per scaricare video ancora più incredibili e ancora migliori." Probabilità spam: 7,54926%
- "Ottieni uno sconto sui nostri corsi di allenamento in palestra, vedi pr0file!" Probabilità spam: 17,49849%
- "Le azioni GOOG sono appena arrivate! Andate troppo tardi!" Probabilità spam: 20,42894%
Per questi commenti non è possibile fare nulla semplicemente modificando ulteriormente il valore SPAM_THRESHOLD. Se riduci la soglia di spam dal 96% al 9% circa, i commenti autentici vengono contrassegnati come spam: uno di questi ha una valutazione del 58% anche se è legittimo. L'unico modo per gestire commenti come questi sarebbe quello di riaddestrare il modello con i casi limite inclusi nei dati di addestramento, in modo che impari a modificare la sua visione del mondo in base a ciò che è spam o meno.
Anche se l'unica opzione che rimane al momento è quella di riaddestrare il modello, hai anche visto come perfezionare la soglia di quando decidi di chiamare qualcosa di spam per migliorare anche le prestazioni. Da un essere umano, il 75% sembra abbastanza sicuro, ma per questo modello è stato necessario un aumento più vicino all'81,5% per essere più efficace con input di esempio.
Non esiste un valore magico che funzioni bene su diversi modelli e questo valore di soglia deve essere impostato in base al modello dopo aver sperimentato dati reali per ciò che funziona bene.
Potrebbero verificarsi alcune situazioni in cui un falso positivo (o negativo) potrebbe avere gravi conseguenze (ad es.nel settore medico). Pertanto, puoi regolare la soglia in modo che sia molto alta e richiedere ulteriori revisioni manuali per coloro che non la soddisfano. Questa è una tua scelta come sviluppatore e richiede qualche esperimento.
4. Reimpostare il modello di rilevamento dei commenti spam
Nella sezione precedente hai identificato una serie di casi limite che non funzionavano per il modello, con l'unica possibilità di riaddestrarlo affinché tenga conto di queste situazioni. In un sistema di produzione, è possibile ritrovarli con il passare del tempo, man mano che le persone segnalano manualmente un commento come spam che è stato lasciato passare o i moderatori che esaminano i commenti segnalati si rendono conto che alcuni non sono effettivamente spam e potrebbero contrassegnare questi commenti per la riaddestramento. Supponendo che tu abbia raccolto una serie di nuovi dati per questi casi limite (per ottenere i migliori risultati, dovresti avere alcune varianti di queste nuove frasi, se possibile), ora vedremo come riaddestrare il modello tenendo presenti questi casi limite.
Riepilogo del modello predefinito
Il modello predefinito che hai utilizzato era un modello creato da una terza parte tramite Model Maker che si avvale di una "media incorporamento di parole" che il modello funzioni.
Poiché il modello è stato creato con Model Maker, dovrai passare brevemente a Python per riaddestrare il modello, quindi esportare il modello creato nel formato TensorFlow.js in modo da poterlo utilizzare nel browser. Per fortuna, Model Maker semplifica l'utilizzo dei propri modelli, quindi dovrebbe essere abbastanza facile da seguire e ti guideremo nella procedura, quindi non preoccuparti se non hai mai usato Python prima d'ora.
Colab
Dato che in questo codelab non ti preoccupa la configurazione di un server Linux con tutte le varie utilità Python installate, puoi semplicemente eseguire il codice tramite il browser web utilizzando un "blocco note Colab". Questi blocchi note possono connettersi a un "backend" - che è semplicemente un server con alcuni elementi preinstallati, da cui puoi eseguire codice arbitrario all'interno del browser web e vedere i risultati. Questa funzionalità è molto utile per la prototipazione rapida o per l'utilizzo in tutorial come questo.
Visita il sito colab.research.google.com e visualizzerai una schermata di benvenuto, come mostrato di seguito:
Ora fai clic sul pulsante Nuovo blocco note nella parte inferiore destra della finestra popup. Dovresti vedere un collegamento vuoto come questo:
Bene. Il passaggio successivo consiste nel connettere il frontend Colab a un server di backend in modo da poter eseguire il codice Python che scriverai. Per farlo, fai clic su Connetti in alto a destra e seleziona Connetti a runtime ospitato.
Dopo la connessione, al loro posto dovrebbero comparire le icone RAM e Disco, come questa:
Ottimo lavoro! Ora puoi iniziare a programmare in Python per riaddestrare il modello Model Maker. A tale scopo, procedi nel seguente modo.
Passaggio 1
Nella prima cella attualmente vuota, copia il codice riportato di seguito. Installerà automaticamente TensorFlow Lite Model Maker utilizzando il gestore di pacchetti di Python "pip" (È simile a npm, con cui la maggior parte dei lettori di questo codelab potrebbe avere più familiarità dall'ecosistema JavaScript):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Tuttavia, se incolli il codice nella cella, il codice non verrà eseguito. Quindi, passa il mouse sopra la cella grigia in cui hai incollato il codice riportato sopra e una piccola "riproduzione". verrà visualizzata a sinistra della cella, evidenziata sotto:
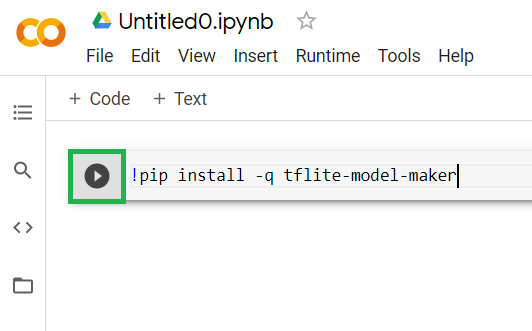 Fai clic sul pulsante di riproduzione per eseguire il codice appena digitato nella cella.
Fai clic sul pulsante di riproduzione per eseguire il codice appena digitato nella cella.
Ora puoi vedere l'installazione di Model maker:
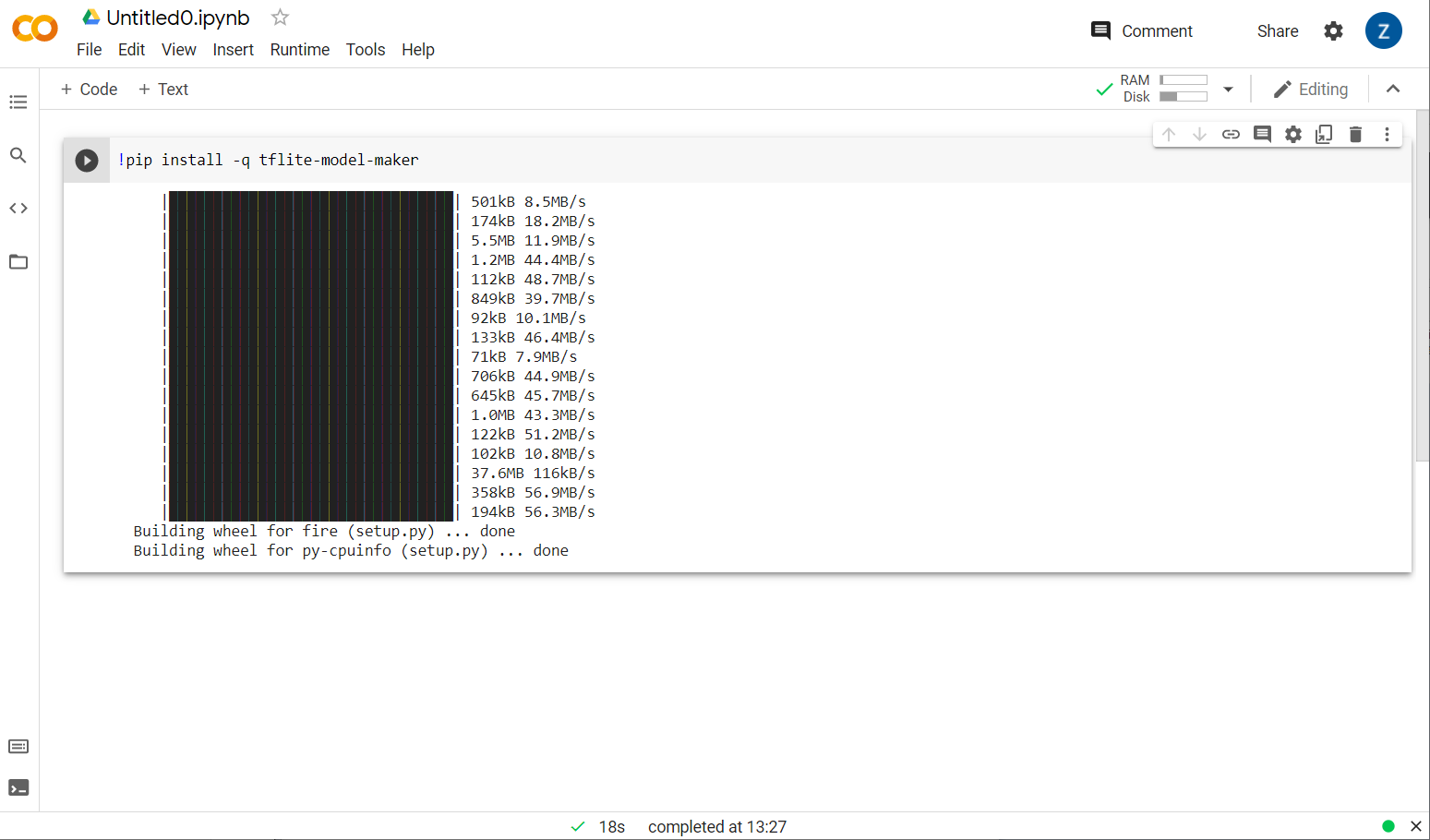
Una volta completata l'esecuzione di questa cella, come mostrato, vai al passaggio successivo qui sotto.
Passaggio 2
Quindi, aggiungi una nuova cella di codice come mostrato in modo da poter incollare altro codice dopo la prima cella ed eseguirlo separatamente:
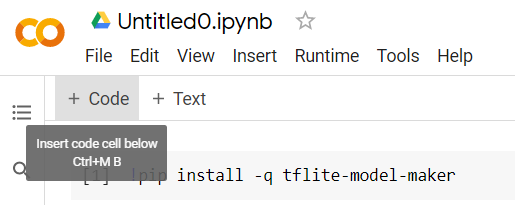
La cella successiva eseguita avrà una serie di importazioni che dovrà essere utilizzata dal codice nel resto del blocco note. Copia e incolla il codice riportato di seguito nella nuova cella creata:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Sono piuttosto standard, anche se non hai familiarità con Python. Stai importando solo alcune utilità e le funzioni di Model Maker necessarie per il classificatore di spam. Questa operazione verificherà anche se è in esecuzione TensorFlow 2.x, obbligatorio per l'utilizzo di Model Maker.
Infine, proprio come prima, esegui la cella premendo il tasto "play" quando passi il mouse sopra la cella e aggiungi una nuova cella di codice per il passaggio successivo.
Passaggio 3
Successivamente, scaricherai sul dispositivo i dati da un server remoto e imposterai la variabile training_data in modo che corrisponda al percorso del file locale scaricato:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Model Maker può addestrare modelli partendo da semplici file CSV come quello scaricato. Devi solo specificare quali colonne contengono il testo e quali contengono le etichette. Per farlo, segui il passaggio 5. Se vuoi, puoi scaricare direttamente il file CSV per vedere cosa contiene.
Più attentamente noterai che il nome di questo file è jm_blog_comments_extras.csv: questo file è semplicemente i dati di addestramento originali che abbiamo utilizzato per generare il primo modello di spam dei commenti combinato con i nuovi dati relativi ai casi limite che hai scoperto, quindi è tutto in un unico file. Hai bisogno dei dati di addestramento originali utilizzati anche per addestrare il modello, oltre alle nuove frasi da cui vuoi imparare.
Facoltativo:se scarichi questo file CSV e controlli le ultime righe, vedrai esempi di casi limite che in precedenza non funzionavano correttamente. Sono stati appena aggiunti alla fine dei dati di addestramento esistenti utilizzati dal modello predefinito per l'addestramento.
Esegui questa cella, quindi al termine dell'esecuzione aggiungi una nuova cella e vai al passaggio 4.
Passaggio 4
Quando utilizzi Model Maker, non crei modelli da zero, In genere utilizzi modelli esistenti che poi personalizzerai in base alle tue esigenze.
Model Maker fornisce diversi incorporamenti di modelli preaddestrati che puoi utilizzare, ma il modo più semplice e rapido per iniziare è average_word_vec, che è quello che hai utilizzato nel codelab precedente per creare il tuo sito web. Ecco il codice:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Eseguilo dopo averlo incollato nella nuova cella.
Informazioni sul
num_words
parametro
Questo è il numero di parole che vuoi che il modello utilizzi. Si potrebbe pensare che più sia meglio, ma in genere c'è un punto giusto basato sulla frequenza di utilizzo di ogni parola. Utilizzando ogni parola dell'intero corpus, il modello potrebbe cercare di imparare e bilanciare i pesi delle parole utilizzate una sola volta, il che non è molto utile. In ogni corpus di testo scoprirai che molte parole vengono utilizzate solo una o due volte e in genere non vale la pena utilizzarle nel modello, poiché hanno un impatto trascurabile sul sentiment complessivo. In questo modo puoi ottimizzare il modello in base al numero di parole che vuoi utilizzando il parametro num_words. Un numero più piccolo qui avrà un modello più piccolo e più veloce, ma potrebbe essere meno preciso, in quanto riconosce meno parole. Un numero maggiore qui avrà un modello più grande e potenzialmente più lento. Trovare il punto giusto è fondamentale e, in qualità di machine learning engineer, spetta a te capire cosa funziona meglio per il tuo caso d'uso.
Informazioni sul
wordvec_dim
parametro
Il parametro wordvec_dim è il numero di dimensioni che vuoi utilizzare per il vettore di ogni parola. Queste dimensioni sono essenzialmente le diverse caratteristiche (create dall'algoritmo di machine learning durante l'addestramento) che una determinata parola può essere misurata in base alle quali il programma utilizzerà per cercare di associare al meglio parole simili in qualche modo significativo.
Ad esempio, se avessi una dimensione che indica il livello di "medico" una parola era, una parola come "pillole" può avere un punteggio elevato qui in questa dimensione ed essere associato ad altre parole con il miglior punteggio, come "raggi x", ma "gatto" con un punteggio basso in questa dimensione. Potrebbe emergere che una "dimensione medica" è utile per determinare lo spam se combinato con altre potenziali dimensioni che potrebbero decidere di utilizzare.
Nel caso di parole con un punteggio elevato nella "dimensione medica" potrebbe immaginare che una seconda dimensione che mette in correlazione parole con il corpo umano possa essere utile. Parole come "gamba", "braccio", "collo" può avere un punteggio alto qui e anche abbastanza alto nel campo medico.
Il modello può utilizzare queste dimensioni per consentire di rilevare le parole che hanno maggiori probabilità di essere associate allo spam. Magari le email di spam hanno maggiori probabilità di contenere parole che appartengono sia alla medicina che alla parte del corpo umano.
La regola empirica determinata dalla ricerca è che la quarta radice del numero di parole funziona bene per questo parametro. Quindi, se utilizzo 2000 parole, un buon punto di partenza sono 7 dimensioni. Se modifichi il numero di parole utilizzate, puoi modificare anche questo valore.
Informazioni sul
seq_len
parametro
I modelli sono generalmente molto rigidi per quanto riguarda i valori di input. Per un modello linguistico, ciò significa che può classificare frasi di una lunghezza particolare statica. Ciò viene determinato dal parametro seq_len, dove è l'acronimo di "Sequence length". Quando converti le parole in numeri (o token), una frase diventa una sequenza di questi token. Di conseguenza, il tuo modello verrà addestrato (in questo caso) a classificare e riconoscere frasi con 20 token. Se la frase è più lunga di questa lunghezza, verrà troncata. Se è più breve, verrà riempito, proprio come nel primo codelab di questa serie.
Passaggio 5 - Carica i dati di addestramento
In precedenza hai scaricato il file CSV. Ora è il momento di utilizzare un caricatore di dati per trasformarli in dati di addestramento che il modello può riconoscere.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Se apri il file CSV in un editor, noterai che ogni riga contiene solo due valori, descritti con testo nella prima riga del file. Generalmente ciascuna voce viene considerata come una "colonna". Vedrai che il descrittore per la prima colonna è commenttext e che la prima voce su ogni riga è il testo del commento.
Allo stesso modo, il descrittore della seconda colonna è spam e vedrai che la seconda voce in ogni riga è TRUE o FALSE per indicare se quel testo è considerato spam nei commenti o meno. Le altre proprietà impostano le specifiche del modello che hai creato nel passaggio 4, insieme a un carattere di delimitatore, che in questo caso è una virgola, in quanto il file è separato da virgole. Puoi anche impostare un parametro di shuffle per riorganizzare in modo casuale i dati di addestramento, in modo che gli elementi che potrebbero essere stati simili o raccolti insieme vengano distribuiti in modo casuale nel set di dati.
Utilizzerai quindi data.split() per suddividere i dati in quelli di addestramento e di test. Il valore .9 indica che il 90% del set di dati verrà utilizzato per l'addestramento, il resto per i test.
Passaggio 6 - Crea il modello
Aggiungi un'altra cella in cui aggiungeremo il codice per creare il modello:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
In questo modo viene creato un modello di classificazione del testo con Model Maker. Devi specificare i dati di addestramento che vuoi utilizzare (definiti nel passaggio 4), la specifica del modello (che è stata configurata anche al passaggio 4) e un numero di epoche, in questo caso 50.
Il principio di base del machine learning è che si tratta di una forma di corrispondenza di pattern. Inizialmente, carica i pesi preaddestrati per le parole e tenta di raggrupparli insieme con una "previsione" di quali, una volta raggruppati, indicano spam e quali no. Per la prima volta, è probabile che si avvicini alle 50:50, poiché il modello è appena iniziato come mostrato di seguito:

Quindi misurerà i risultati di questa previsione, cambierà i pesi del modello per regolare la sua previsione e riproverà. Questa è un'epoca. Quindi, specificando epochs=50, seguirà quel "loop" 50 volte come mostrato:

Quando raggiungi la 50a epoca, il modello registrerà un livello di accuratezza molto più elevato. In questo caso, mostra il 99,1%.
Passaggio 7 - Esportare il modello
Al termine dell'addestramento, puoi esportare il modello. TensorFlow addestra un modello nel suo formato, che deve essere convertito nel formato TensorFlow.js per essere utilizzato su una pagina web. Incolla il codice seguente in una nuova cella ed eseguilo:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
Dopo aver eseguito questo codice, se fai clic sull'icona a forma di cartella piccola a sinistra di Colab, puoi accedere alla cartella in cui hai esportato il codice in alto (nella directory principale, potresti dover salire di livello) e trovare il pacchetto ZIP dei file esportati contenuti in ModelFiles.zip.
Scarica subito questo file ZIP sul tuo computer perché utilizzerai quei file proprio come nel primo codelab:
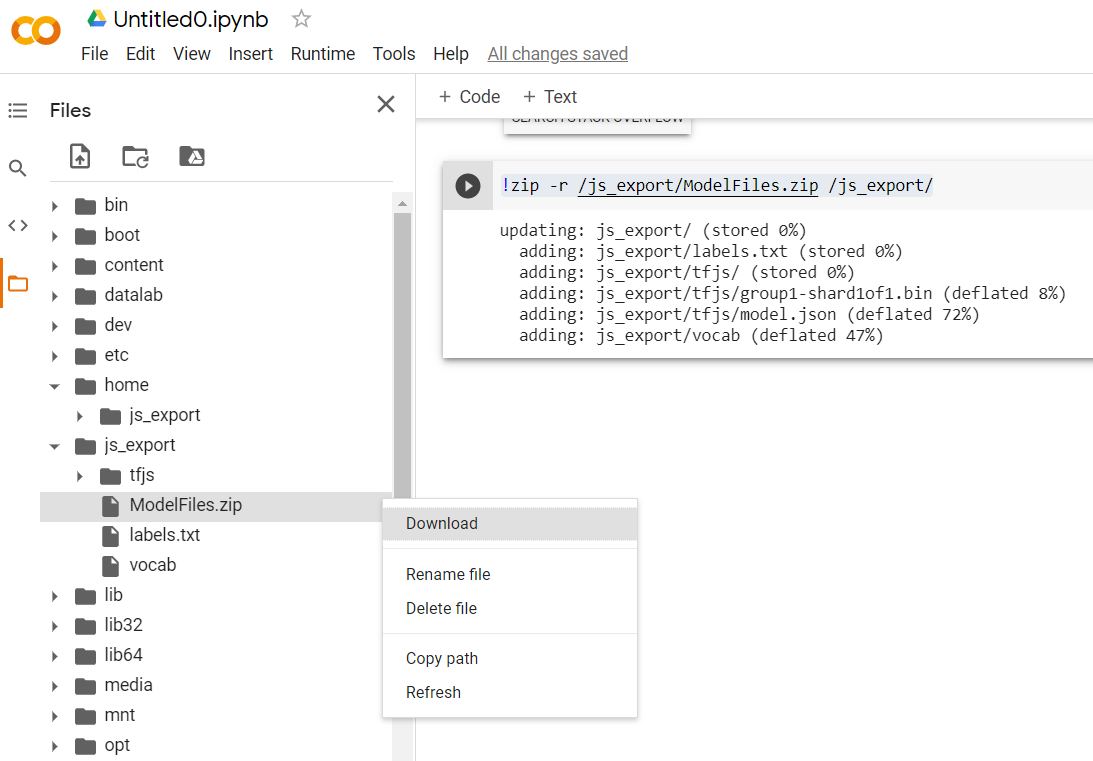
Bene. La parte Python è terminata. Ora puoi tornare al linguaggio JavaScript che conosci e apprezzi. Finalmente.
5. Gestione del nuovo modello di machine learning
Ora sei quasi pronto per caricare il modello. Prima di poterlo fare, devi caricare i nuovi file del modello scaricati in precedenza nel codelab, in modo che siano ospitati e utilizzabili all'interno del tuo codice.
Innanzitutto, se non l'hai ancora fatto, decomprimi i file del modello appena scaricato dal blocco note di Colab Model Maker che hai appena eseguito. Dovresti vedere i seguenti file contenuti all'interno delle varie cartelle:
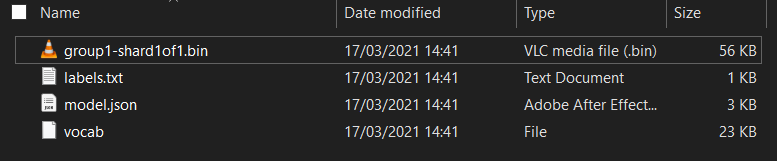
Cosa c'è qui?
model.json: uno dei file che compongono il modello TensorFlow.js addestrato. Farai riferimento a questo file specifico nel codice JS.group1-shard1of1.bin: si tratta di un file binario contenente gran parte dei dati salvati per il modello TensorFlow.js esportato e dovrà essere ospitato sul tuo server per il download nella stessa directory del filemodel.jsonsopra indicato.vocab- Questo strano file senza estensione è un file di Model Maker che ci mostra come codificare le parole nelle frasi in modo che il modello capisca come utilizzarle. Approfondiremo questo aspetto nella prossima sezione.labels.txt: contiene semplicemente i nomi di classe risultanti che il modello prevede. Se apri il file nell'editor di testo del modello, il valore sarà semplicemente "false" e "true" indicato che indica "non spam" o "spam" come output di previsione.
Ospita i file del modello TensorFlow.js
Per prima cosa posiziona i file model.json e *.bin generati su un server web in modo da potervi accedere tramite la tua pagina web.
Eliminare i file del modello esistenti
Poiché stai sviluppando il risultato finale del primo codelab di questa serie, devi prima eliminare i file del modello esistenti caricati. Se utilizzi Glitch.com, seleziona il riquadro dei file a sinistra per model.json e group1-shard1of1.bin, fai clic sul menu a discesa con tre puntini per ogni file e seleziona elimina come mostrato:
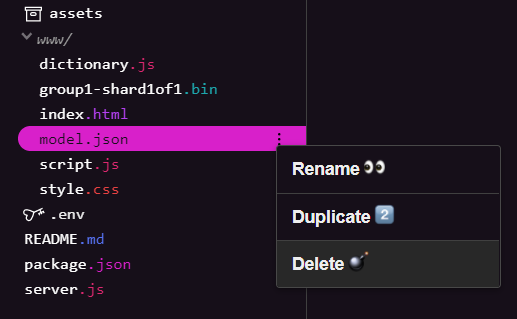
Caricamento di nuovi file su Glitch
Bene. Ora carica i nuovi file:
- Apri la cartella assets nel riquadro a sinistra del tuo progetto Glitch ed elimina tutti i vecchi asset caricati se hanno gli stessi nomi.
- Fai clic su Carica un asset e seleziona
group1-shard1of1.binda caricare in questa cartella. Una volta caricato, l'URL dovrebbe avere il seguente aspetto:
- Bene. Ora ripeti la stessa operazione anche per il file model.json, quindi nella cartella degli asset dovrebbero essere presenti due file in questo modo:
- Se fai clic sul file
group1-shard1of1.binche hai appena caricato, potrai copiare l'URL nella relativa posizione. Copia questo percorso ora come mostrato:
- Nella parte in basso a sinistra dello schermo, fai clic su Strumenti > Terminale. Attendi che venga caricata la finestra del terminale.
- Una volta caricato, digita quanto segue, quindi premi Invio per impostare la directory sulla cartella
www:
terminale:
cd www
- Successivamente, utilizza
wgetper scaricare i 2 file appena caricati sostituendo gli URL di seguito con quelli generati per i file nella cartella degli asset su Glitch (controlla la cartella degli asset per l'URL personalizzato di ciascun file).
Tieni presente che lo spazio tra i due URL e che gli URL che dovrai utilizzare saranno diversi da quelli mostrati, ma saranno simili:
terminale
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Eccellente. Hai creato una copia dei file caricati nella cartella www.
Tuttavia, adesso verranno scaricati con nomi strani. Se digiti ls nel terminale e premi Invio, verrà visualizzato un risultato simile a questo:

- Rinomina i file con il comando
mv. Digita quanto segue nella console e premi Invio dopo ogni riga:
terminale:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Infine, aggiorna il progetto Glitch digitando
refreshnel terminale e premi Invio:
terminale:
refresh
Dopo l'aggiornamento, dovresti ora vedere model.json e group1-shard1of1.bin nella cartella www dell'interfaccia utente:
Bene. L'ultimo passaggio consiste nell'aggiornare il file dictionary.js.
- Converti il nuovo file vocabolario scaricato nel formato JS corretto manualmente tramite l'editor di testo o utilizzando questo strumento e salva l'output risultante come
dictionary.jsnella cartellawww. Se hai già un filedictionary.js, puoi semplicemente copiare e incollare i nuovi contenuti al suo interno e salvare il file.
Bene! Hai aggiornato tutti i file modificati. Se ora provi a utilizzare il sito web, vedrai come il modello riaddestrato dovrebbe essere in grado di tenere conto dei casi limite rilevati e da cui apprendono, come mostrato di seguito:
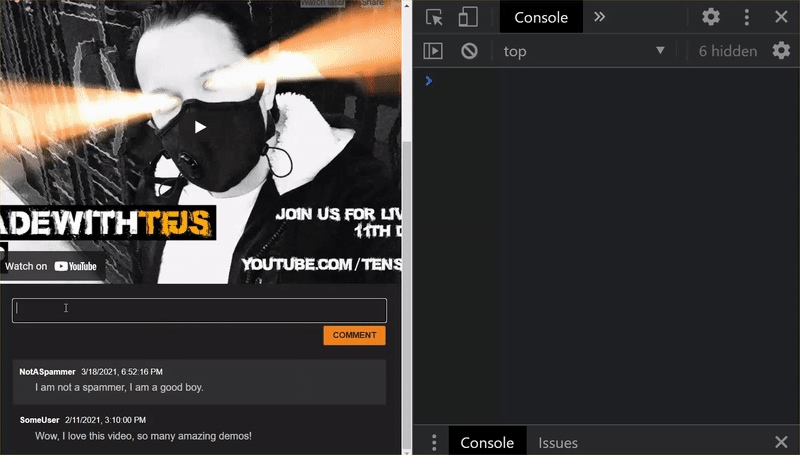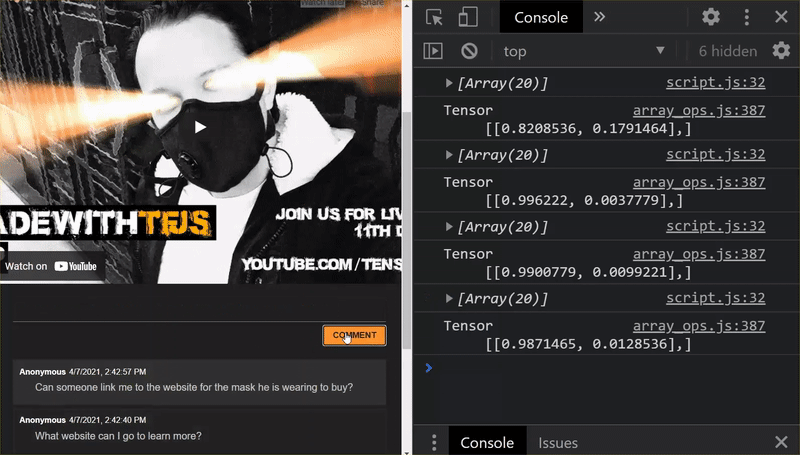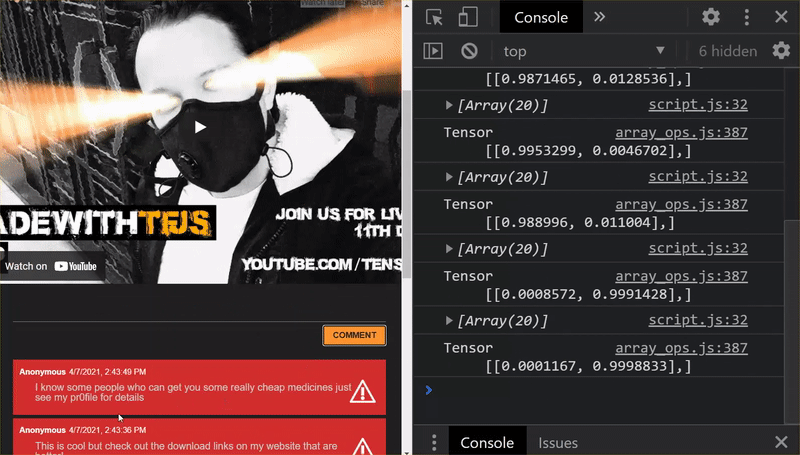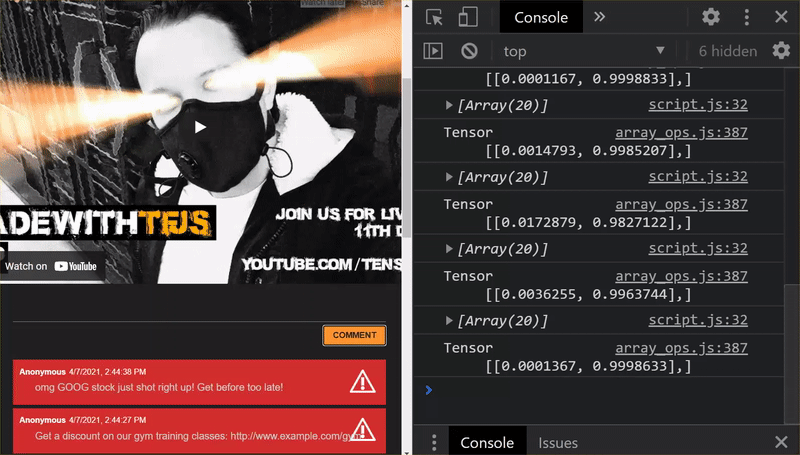
Come puoi vedere, i primi 6 ora sono classificati correttamente come non spam e il secondo gruppo di 6 viene tutti identificato come spam. Perfetto!
Proviamo anche alcune varianti per vedere se si è generalizzata. In origine, era presente una frase con errori come:
"Le azioni di GOOG hanno appena fatto! Arriva troppo tardi."
Questo indirizzo è classificato correttamente come spam, ma cosa succede se lo modifichi in:
"Quindi il valore delle azioni XYZ è aumentato! Acquista un po' prima che sia troppo tardi."
Questo valore indica una probabilità del 98% di essere spam, il che è corretto anche se hai cambiato leggermente il simbolo di borsa e il testo.
Ovviamente, se si cerca davvero di rompere questo nuovo modello, sarà possibile farlo, e si riserverà la raccolta di ancora più dati di addestramento per avere le migliori possibilità di acquisire varianti più uniche per le situazioni comuni che in genere si incontrano online. In un codelab futuro ti mostreremo come migliorare continuamente il tuo modello con dati in tempo reale non appena viene segnalato.
6. Complimenti!
Complimenti, hai addestrato di nuovo un modello di machine learning esistente ad aggiornarsi in modo che funzioni per i casi periferici che hai individuato e hai eseguito il deployment di queste modifiche nel browser con TensorFlow.js per un'applicazione reale.
Riepilogo
In questo codelab:
- Individuati casi limite che non funzionavano quando si utilizzava il modello di commenti spam predefinito
- Il modello Model Maker è stato addestrato nuovamente per tenere conto dei casi limite che hai individuato
- Nuovo modello addestrato esportato nel formato TensorFlow.js
- Aggiornamento dell'app web per l'utilizzo dei nuovi file
Passaggi successivi
Questo aggiornamento funziona molto bene, ma, come per qualsiasi applicazione web, i cambiamenti avvengono nel tempo. Sarebbe molto meglio se l'app migliorasse continuamente nel tempo, invece di doverla fare manualmente ogni volta. Riesci a pensare a come potresti aver automatizzato questi passaggi per riaddestrare automaticamente un modello dopo aver, ad esempio, 100 nuovi commenti contrassegnati come classificati in modo errato? Indossa il tuo normale cappello di web engineering e probabilmente riuscirai a capire come creare una pipeline per farlo automaticamente. In caso contrario, non preoccuparti, nel prossimo codelab della serie ti verrà spiegato come fare.
Condividi con noi ciò che crei
Puoi facilmente estendere ciò che hai realizzato oggi anche per altri casi d'uso creativi. Ti incoraggiamo a pensare fuori dagli schemi e continuare ad hackerare.
Ricordati di taggarci sui social media utilizzando l'hashtag #MadeWithTFJS per avere la possibilità che il tuo progetto venga pubblicato nel blog di TensorFlow o anche per eventi futuri. Ci piacerebbe vedere cosa realizzi.
Altri codelab TensorFlow.js per approfondire
- Utilizza Firebase Hosting per eseguire il deployment e ospitare un modello TensorFlow.js su larga scala.
- Crea una webcam smart utilizzando un modello di rilevamento degli oggetti predefinito con TensorFlow.js
Siti web da controllare
- Sito web ufficiale TensorFlow.js
- Modelli predefiniti TensorFlow.js
- API TensorFlow.js
- TensorFlow.js Show & Racconta: lasciati ispirare e scopri cosa hanno realizzato gli altri.