
1. Prima di iniziare
Machine learning è una parola molto in voga al giorno d'oggi. Le sue applicazioni sembrano essere illimitate e sembra destinata a toccare quasi ogni settore nel prossimo futuro. Se lavori come ingegnere o designer, front-end o backend e conosci JavaScript, questo codelab è stato scritto per aiutarti a iniziare ad aggiungere il machine learning alle tue competenze.
Prerequisiti
Questo codelab è stato scritto per ingegneri esperti che hanno già familiarità con JavaScript.
Cosa creerai
In questo codelab,
- Crea una pagina web che utilizzi il machine learning direttamente nel browser web tramite TensorFlow.js per classificare e rilevare oggetti comuni, (sì, anche più di uno alla volta), dallo stream da webcam live.
- Ricarica la normale webcam per identificare gli oggetti e ottenere le coordinate del riquadro di delimitazione di ciascun oggetto trovato
- Metti in evidenza l'oggetto trovato nel video stream, come mostrato di seguito:
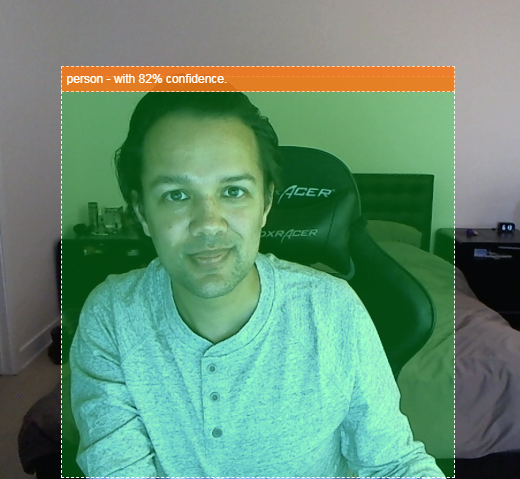
Immagina di essere in grado di rilevare se una persona è presente in un video, in modo da poter contare quante persone erano presenti in un dato momento per stimare il livello di affollamento di una determinata zona durante la giornata o di inviarti un avviso quando il tuo cane è stato rilevato in una stanza di casa tua mentre sei fuori casa e che forse non dovrebbe essere dentro. Se potessi farlo, saresti sulla strada giusta per creare la tua versione personalizzata di videocamere Google Nest in grado di avvisarti se rileva un intruso (di qualsiasi tipo) usando il tuo hardware personalizzato. Piuttosto comodo. È difficile? No. Cominciamo con l'hack...
Cosa imparerai a fare
- Come caricare un modello TensorFlow.js preaddestrato.
- Come acquisire dati dallo stream di una webcam in diretta e disegnarli sulla tela.
- Come classificare un frame immagine per trovare i riquadri di delimitazione degli oggetti che il modello è stato addestrato a riconoscere.
- Come utilizzare i dati restituiti dal modello per evidenziare gli oggetti trovati.
Questo codelab è incentrato su come iniziare a utilizzare i modelli preaddestrati TensorFlow.js. I concetti e i blocchi di codice non pertinenti per TensorFlow.js e il machine learning non sono spiegati, ma ti vengono forniti semplicemente di copia e incolla.
2. Che cos'è TensorFlow.js?

TensorFlow.js è una libreria open source di machine learning che può essere eseguita ovunque JavaScript possa essere eseguito. Si basa sulla libreria TensorFlow originale scritta in Python e mira a ricreare questa esperienza di sviluppo e un insieme di API per l'ecosistema JavaScript.
Dove può essere utilizzato?
Data la portabilità di JavaScript, ora puoi scrivere in un solo linguaggio ed eseguire facilmente il machine learning su tutte le seguenti piattaforme:
- Lato client nel browser web con JavaScript Vanilla
- Lato server e persino dispositivi IoT come Raspberry Pi che utilizzano Node.js
- App desktop che utilizzano Electron
- App native per dispositivi mobili che utilizzano React Native
TensorFlow.js supporta anche più backend all'interno di ciascuno di questi ambienti (ad esempio gli ambienti basati su hardware effettivi che può eseguire all'interno, come CPU o WebGL. Un "backend" in questo contesto non significa un ambiente lato server: il backend per l'esecuzione potrebbe essere sul lato client, ad esempio, in WebGL) per garantire la compatibilità e garantire anche la velocità. Attualmente TensorFlow.js supporta:
- Esecuzione WebGL sulla scheda grafica del dispositivo (GPU): è il modo più veloce per eseguire modelli più grandi (superiori a 3 MB) con accelerazione GPU.
- Esecuzione di Web Assembly (WASM) sulla CPU: per migliorare le prestazioni della CPU su tutti i dispositivi, inclusi, ad esempio, telefoni cellulari meno recenti. È più adatto a modelli più piccoli (di dimensioni inferiori a 3 MB) che possono essere eseguiti più velocemente sulla CPU con WASM rispetto a WebGL a causa dell'overhead associato al caricamento dei contenuti su un processore grafico.
- Esecuzione CPU: il fallback non dovrebbe essere disponibile in nessuno degli altri ambienti. È il più lento dei tre, ma è sempre disponibile.
Nota: puoi scegliere di forzare uno di questi backend se sai su quale dispositivo eseguirai l'esecuzione oppure puoi lasciare che sia TensorFlow.js a decidere per te, se non lo specifichi.
Superpoteri lato client
L'esecuzione di TensorFlow.js nel browser web sul computer client può portare a numerosi vantaggi che vale la pena prendere in considerazione.
Privacy
È possibile addestrare e classificare i dati sul computer client senza mai inviarli a un server web di terze parti. In alcuni casi potrebbe essere necessario rispettare le leggi locali, come ad esempio il GDPR, o durante l'elaborazione di dati che l'utente potrebbe voler conservare sul proprio computer e non essere inviati a terze parti.
Velocità
Poiché non devi inviare i dati a un server remoto, l'inferenza (l'atto di classificare i dati) può essere più veloce. Inoltre, avrai accesso diretto ai sensori del dispositivo, come fotocamera, microfono, GPS, accelerometro e altri, se l'utente ti concede l'accesso.
Copertura e scalabilità
Con un solo clic chiunque nel mondo può fare clic su un link che hai inviato, aprire la pagina web nel proprio browser e utilizzare ciò che hai creato. Non è necessaria una configurazione Linux lato server complessa con driver CUDA e molto altro solo per utilizzare il sistema di machine learning.
Costo
Nessun server significa che l'unica cosa che devi pagare è una CDN per ospitare i tuoi file HTML, CSS, JS e modello. Il costo di una CDN è molto più economico che tenere un server (potenzialmente con una scheda grafica collegata) in esecuzione 24/7.
Funzionalità lato server
L'implementazione di Node.js di TensorFlow.js attiva le seguenti funzionalità.
Supporto CUDA completo
Sul lato server, per l'accelerazione della scheda grafica, devi installare i driver NVIDIA CUDA per consentire a TensorFlow di funzionare con la scheda grafica (a differenza del browser che utilizza WebGL - nessuna installazione necessaria). Tuttavia, con il supporto CUDA completo è possibile sfruttare appieno le capacità di livello inferiore della scheda grafica, con tempi di addestramento e inferenza più rapidi. Le prestazioni sono uguali a quelle dell'implementazione di TensorFlow Python, in quanto entrambi condividono lo stesso backend C++.
Dimensioni modello
Nel caso di modelli all'avanguardia provenienti dalla ricerca, potresti lavorare con modelli molto grandi, ad esempio di gigabyte. Questi modelli al momento non possono essere eseguiti nel browser web a causa delle limitazioni di utilizzo della memoria per scheda del browser. Per eseguire questi modelli di dimensioni maggiori puoi utilizzare Node.js sul tuo server con le specifiche hardware necessarie per eseguire questo modello in modo efficiente.
IoT
Node.js è supportato su computer a scheda singola popolari come Raspberry Pi, il che a sua volta significa che puoi eseguire i modelli TensorFlow.js anche su questi dispositivi.
Velocità
Node.js è scritto in JavaScript, il che significa che trae vantaggio dalla compilazione just-in-time. Ciò significa che spesso potresti notare un miglioramento delle prestazioni quando utilizzi Node.js, in quanto verrà ottimizzato in fase di runtime, in particolare per qualsiasi pre-elaborazione. Un ottimo esempio di ciò può essere visto in questo case study, che mostra come Hugging Face ha utilizzato Node.js per ottenere un aumento delle prestazioni di 2 volte per il proprio modello di elaborazione del linguaggio naturale.
Ora che conosci le nozioni di base di TensorFlow.js, dove può essere eseguito e alcuni dei vantaggi, iniziamo a utilizzarlo.
3. Modelli preaddestrati
TensorFlow.js fornisce una varietà di modelli di machine learning (ML) preaddestrati. Questi modelli sono stati addestrati dal team TensorFlow.js e racchiusi in un corso facile da usare e sono un ottimo modo per muovere i primi passi con il machine learning. Anziché creare e addestrare un modello per risolvere il problema, puoi importare un modello preaddestrato come punto di partenza.
Puoi trovare un elenco crescente di modelli preaddestrati facili da usare nella pagina Modelli per JavaScript di Tensorflow.js. Esistono anche altri posti in cui è possibile ottenere modelli TensorFlow convertiti che funzionano in TensorFlow.js, tra cui TensorFlow Hub.
Perché dovrei utilizzare un modello preaddestrato?
Inizia con un modello preaddestrato molto popolare, se si adatta al caso d'uso desiderato, ad esempio:
- Non è necessario raccogliere personalmente i dati di addestramento. Preparare i dati nel formato corretto e etichettarli in modo che un sistema di machine learning possa utilizzarli per apprendere può essere molto costoso in termini di tempo e denaro.
- La capacità di prototipare rapidamente un'idea con costi e tempi ridotti.
Non ha senso "reinventare la ruota" i casi in cui un modello preaddestrato può essere sufficientemente buono per fare ciò di cui hai bisogno, consentendoti di concentrarti sull'utilizzo delle conoscenze fornite dal modello per realizzare le tue idee creative. - Utilizzo di ricerche all'avanguardia. I modelli preaddestrati si basano spesso su ricerche popolari e ti consentono di acquisire familiarità con tali modelli e di comprenderne le prestazioni nel mondo reale.
- Facilità di utilizzo e documentazione completa. A causa della popolarità di questi modelli.
- Capacità di transfer learning. Alcuni modelli preaddestrati offrono funzionalità di transfer learning, che sono essenzialmente la pratica di trasferire le informazioni apprese da un'attività di machine learning a un altro esempio simile. Ad esempio, un modello originariamente addestrato a riconoscere i gatti potrebbe essere riaddestrato a riconoscere i cani, se gli fornisci nuovi dati di addestramento. Sarà più veloce perché non inizierai con una tela vuota. Il modello può utilizzare ciò che ha già imparato a riconoscere i gatti per riconoscere poi la nuova cosa: i cani, dopotutto, hanno anche occhi e orecchie, quindi se sa già come individuare queste caratteristiche, siamo a metà strada. Riaddestra il modello con i tuoi dati in modo molto più veloce.
Che cos'è il COCO-SSD?
COCO-SSD è il nome di un modello ML preaddestrato per il rilevamento di oggetti che utilizzerai durante questo codelab, che mira a localizzare e identificare più oggetti in una singola immagine. In altre parole, può farti sapere il riquadro di delimitazione degli oggetti che è stato addestrato a trovare per darti la posizione di quell'oggetto in qualsiasi immagine che gli presenti. Un esempio è riportato nell'immagine seguente:

Se nell'immagine sopra fosse presente più di un cane, verranno fornite le coordinate di 2 riquadri di delimitazione, che descrivono la posizione di ciascuno. Il COCO-SSD è stato preaddestrato per riconoscere 90 oggetti comuni di uso quotidiano, come persone, auto, gatti e così via.
Da dove proviene il nome?
Il nome potrebbe sembrare strano, ma deriva da due acronimi:
- COCO: si riferisce al fatto che è stato addestrato sul set di dati COCO (Common Objects in Context), liberamente disponibile per il download e l'utilizzo da parte di chiunque durante l'addestramento dei propri modelli. Il set di dati contiene oltre 200.000 immagini etichettate che è possibile utilizzare per apprendere.
- SSD (Single Shot MultiBox Detection): fa riferimento a parte dell'architettura del modello utilizzata nell'implementazione del modello. Non è necessario comprenderlo per il codelab, ma se ti interessa puoi scoprire di più su SSD qui.
4. Configurazione
Che cosa ti serve
- Un browser web moderno.
- Conoscenza di base di HTML, CSS, JavaScript e Chrome DevTools (visualizzazione dell'output della console).
Iniziamo a programmare
Sono stati creati modelli boilerplate da cui iniziare per Glitch.com o Codepen.io. Puoi semplicemente clonare uno dei modelli come stato base per questo lab di codice con un solo clic.
Su Glitch, fai clic sul pulsante Esegui il remix dei contenuti per creare un fork e creare un nuovo set di file che potrai modificare.
In alternativa, su Codepen, fai clic su fork nella parte inferiore destra dello schermo.
Questo scheletro molto semplice fornisce i seguenti file:
- Pagina HTML (index.html)
- Foglio di stile (style.css)
- File per scrivere il nostro codice JavaScript (script.js)
Per comodità, è disponibile un'importazione aggiunta nel file HTML per la libreria TensorFlow.js. Ha questo aspetto:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Alternativa: utilizza il tuo editor web preferito o lavora localmente
Se vuoi scaricare il codice e lavorare in locale o su un altro editor online, crea semplicemente i 3 file denominati sopra nella stessa directory e copia e incolla in ciascuno di essi il codice dal nostro boilerplate Glitch.
5. Compila lo scheletro HTML
Tutti i prototipi richiedono uno scaffolding HTML di base. Lo utilizzerai per eseguire il rendering dell'output del modello di machine learning in un secondo momento. Configuriamolo ora:
- Un titolo per la pagina
- Testo descrittivo
- Un pulsante per attivare la webcam
- Un tag video su cui eseguire il rendering dello stream con la webcam
Per impostare queste funzioni, apri index.html e incolla il codice esistente con il seguente codice:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
Comprendere il codice
Nota alcuni elementi chiave che hai aggiunto:
- Hai aggiunto un tag
<h1>e alcuni tag<p>per l'intestazione, nonché alcune informazioni su come utilizzare la pagina. Niente di speciale qui.
Hai anche aggiunto un tag di sezione che rappresenta il tuo spazio dimostrativo:
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- Inizialmente, assegna a
sectionla classe "invisibile". In questo modo puoi illustrare visivamente all'utente quando il modello è pronto e puoi fare clic sul pulsante attiva webcam. - Hai aggiunto il pulsante Attiva webcam, che potrai applicare al tuo CSS.
- Hai anche aggiunto un tag video a cui trasmetterai in streaming l'input della webcam. La configurerai a breve nel tuo codice JavaScript.
Se adesso visualizzi l'anteprima dell'output, dovrebbe avere un aspetto simile al seguente:

6. Aggiungi stile
Valori predefiniti elemento
Innanzitutto, aggiungiamo gli stili per gli elementi HTML appena aggiunti per assicurarci che vengano visualizzati correttamente:
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
Successivamente, aggiungi alcune classi CSS utili per agevolare i vari stati dell'interfaccia utente, ad esempio quando vogliamo nascondere il pulsante o rendere l'area demo non disponibile se il modello non è ancora pronto.
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
Bene. Non serve altro. Se hai sovrascritto gli stili con le due parti di codice precedenti, l'anteprima live ora dovrebbe essere simile alla seguente:

Nota come il testo dell'area demo e il pulsante non sono disponibili, poiché l'HTML per impostazione predefinita ha la classe "invisible" applicati. Utilizzerai JavaScript per rimuovere questa classe quando il modello sarà pronto per essere utilizzato.
7. Crea scheletro JavaScript
Riferimento agli elementi chiave del DOM
Innanzitutto, assicurati di poter accedere alle parti principali della pagina che dovrai manipolare o a cui potrai accedere in seguito nel nostro codice:
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
Verificare il supporto della webcam
Ora puoi aggiungere alcune funzioni assistive per verificare se il browser che stai utilizzando supporta l'accesso allo stream con webcam tramite getUserMedia:
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
Recupero dello stream della webcam
Successivamente, compila il codice per la funzione enableCam vuota in precedenza definita sopra copiando e incollando il codice riportato di seguito:
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
Infine, aggiungi del codice temporaneo per verificare se la webcam funziona.
Il codice seguente simula il modello caricato e attiva il pulsante della fotocamera, in modo che tu possa fare clic su di esso. Sostituisci tutto questo codice nel prossimo passaggio, quindi preparati a eliminarlo di nuovo tra poco:
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
Bene. Se hai eseguito il codice e hai fatto clic sul pulsante così com'è, dovresti vedere qualcosa di simile a questo:

8. Utilizzo del modello di machine learning
Caricamento del modello
Ora puoi caricare il modello COCO-SSD.
Al termine dell'inizializzazione, abilita l'area e il pulsante demo sulla tua pagina web (incolla questo codice sul codice temporaneo che hai aggiunto alla fine dell'ultimo passaggio):
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
Una volta aggiunto il codice riportato sopra e aggiornato la visione in diretta, noterai che alcuni secondi dopo il caricamento della pagina (a seconda della velocità della rete) il pulsante attiva webcam viene visualizzato automaticamente quando il modello è pronto per l'uso. Tuttavia, hai incollato anche la funzione predictWebcam. Ora è il momento di definirli completamente, dato che al momento il nostro codice non fa nulla.
Andiamo al prossimo passaggio.
Classificare un frame dalla webcam
Esegui il codice riportato di seguito per consentire all'app di recuperare continuamente un frame dallo stream della webcam quando il browser è pronto e di passarlo al modello per la classificazione.
Il modello analizzerà quindi i risultati, disegna un tag <p> in corrispondenza delle coordinate restituite e imposta il testo sull'etichetta dell'oggetto, se è superiore a un determinato livello di confidenza.
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
La chiamata molto importante in questo nuovo codice è model.detect().
Tutti i modelli predefiniti per TensorFlow.js hanno una funzione come questa (il cui nome può cambiare da modello a modello, quindi consulta la documentazione per maggiori dettagli) che esegue effettivamente l'inferenza di machine learning.
L'inferenza è semplicemente l'atto di prendere degli input e farli funzionare attraverso il modello di machine learning (in pratica molte operazioni matematiche) per poi fornire dei risultati. Con i modelli predefiniti TensorFlow.js, le previsioni vengono restituite sotto forma di oggetti JSON, il che semplifica l'uso.
Puoi trovare tutti i dettagli di questa funzione di previsione nella nostra documentazione GitHub per il modello COCO-SSD qui. Questa funzione svolge molte operazioni "dietro le quinte": può accettare qualsiasi tipo di immagine come parametro, ad esempio un'immagine, un video, un canvas e così via. L'utilizzo di modelli predefiniti può farti risparmiare molto tempo e fatica, perché non dovrai scrivere questo codice personalmente e potrai usarlo subito.
L'esecuzione di questo codice ora dovrebbe restituire un'immagine simile alla seguente:
Infine, ecco un esempio di codice che rileva più oggetti contemporaneamente:

Bene! Potreste immaginare quanto sarebbe semplice prendere qualcosa di simile per creare un dispositivo come una Nest Cam usando un vecchio smartphone che vi avvisi quando vede il vostro cane sul divano o il vostro gatto sul divano. Se riscontri problemi con il codice, controlla la mia versione finale funzionante qui per vedere se hai copiato qualcosa di errato.
9. Complimenti
Complimenti, hai fatto i primi passi nell'utilizzo di TensorFlow.js e del machine learning nel browser web. Ora sta a te prendere queste umili origini e trasformarle in qualcosa di creativo. Cosa farai?
Riepilogo
In questo codelab:
- Scopri i vantaggi di utilizzare TensorFlow.js rispetto ad altre forme di TensorFlow.
- Scopri le situazioni in cui potresti voler iniziare con un modello di machine learning preaddestrato.
- È stata creata una pagina web completamente funzionante in grado di classificare oggetti in tempo reale utilizzando la webcam, tra cui:
- Creazione di uno scheletro HTML per i contenuti
- Definizione degli stili per gli elementi e le classi HTML
- Configurare lo scaffolding JavaScript per interagire con il codice HTML e rilevare la presenza di una webcam
- Caricamento di un modello TensorFlow.js preaddestrato
- Utilizzo del modello caricato per effettuare classificazioni continue dello streaming con la webcam e tracciare un riquadro di delimitazione intorno agli oggetti nell'immagine.
Passaggi successivi
Condividi con noi ciò che crei. Puoi facilmente estendere ciò che hai creato per questo codelab anche ad altri casi d'uso relativi alle creatività. Ti invitiamo a pensare fuori dagli schemi e continuare ad attaccare quando hai finito.
- Controlla tutti gli oggetti che questo modello è in grado di riconoscere e pensa a come potresti utilizzare queste conoscenze per eseguire un'azione. Quali idee creative potrebbero essere implementate integrando ciò che hai realizzato oggi?
Potresti aggiungere un semplice livello lato server per inviare una notifica a un altro dispositivo quando rileva un determinato oggetto di tua scelta utilizzando websocket. Sarebbe un ottimo modo per riciclare un vecchio smartphone e dargli un nuovo scopo. Le possibilità sono illimitate.)
- Taggaci sui social media utilizzando l'hashtag #MadeWithTFJS per avere la possibilità che il tuo progetto venga mostrato nel nostro blog di TensorFlow o anche in occasione di eventi TensorFlow futuri.
Altri codelab TensorFlow.js per approfondire
- Crea una rete neurale da zero in TensorFlow.js
- Riconoscimento audio mediante Transfer Learning in TensorFlow.js
- Classificazione personalizzata di immagini mediante Transfer Learning in TensorFlow.js