
1. Zanim zaczniesz
Celem tych ćwiczeń w Codelabs jest wykorzystanie wyników poprzednich ćwiczeń z programowania z tej serii dotyczących wykrywania spamu w komentarzach za pomocą TensorFlow.js.
W ramach ostatnich ćwiczeń w Codelabs udało Ci się stworzyć w pełni działającą stronę fikcyjnego bloga wideo. Udało Ci się filtrować komentarze pod kątem spamu, zanim trafiły one na serwer w celu przechowywania lub do innych połączonych klientów, korzystając z wytrenowanego w przeglądarce modelu wykrywania spamu w komentarzach opartego na TensorFlow.js.
Końcowy wynik ćwiczenia z programowania znajdziesz poniżej:
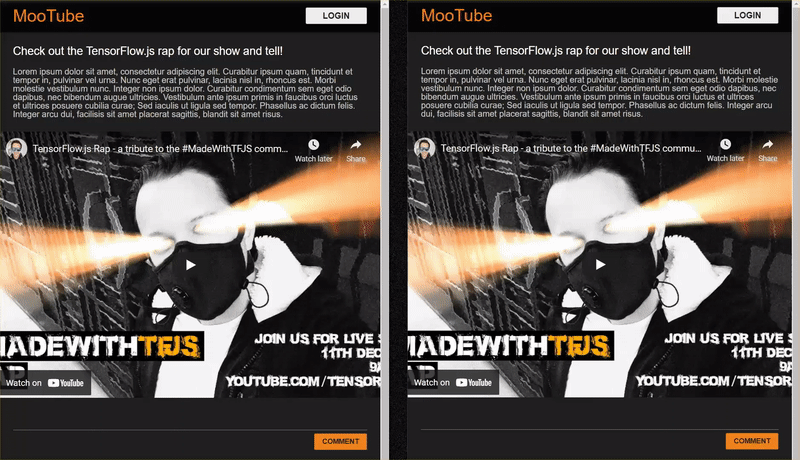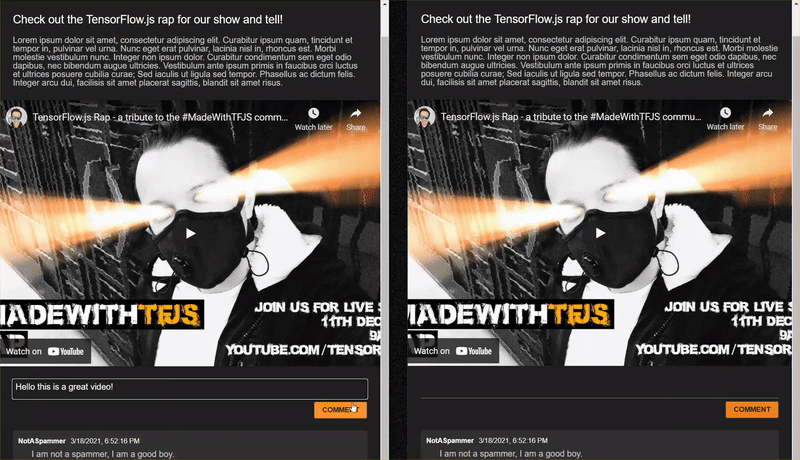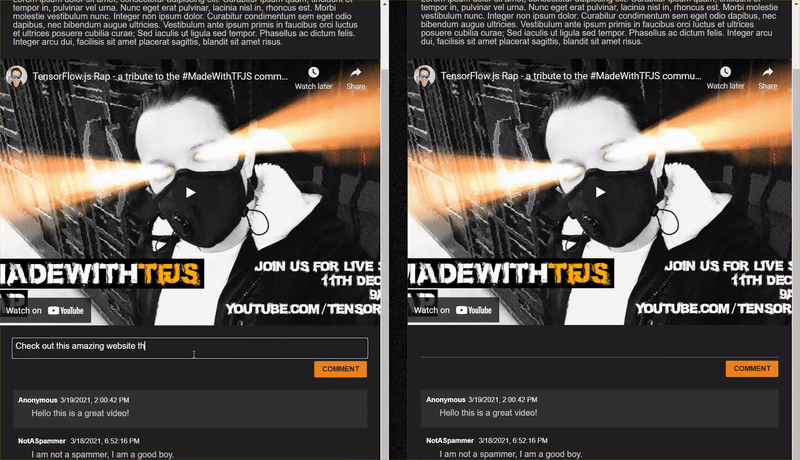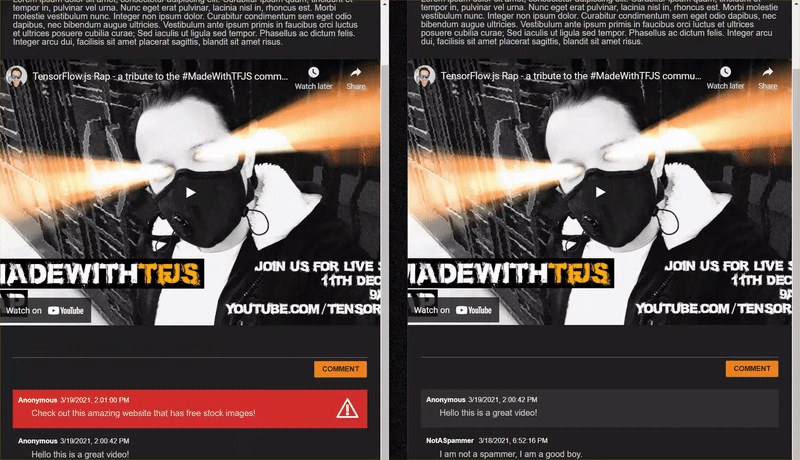
Rozwiązanie okazało się bardzo skuteczne, ale występują też skrajne przypadki, których nie udało się wykryć. Możesz ponownie wytrenować model, aby uwzględnić sytuacje, których nie był w stanie obsłużyć.
Skupia się on na przetwarzaniu języka naturalnego (sztuce poznawania ludzkiego języka na komputerze) i pokazuje, jak zmodyfikować utworzoną wcześniej aplikację internetową (zdecydowanie zalecamy ukończenie ćwiczeń z programowania w odpowiedniej kolejności), aby rozwiązać rzeczywisty problem spamu w komentarzach, z którym z pewnością dotyka wielu twórców stron internetowych podczas pracy nad jedną z coraz większej liczby popularnych aplikacji internetowych.
W ramach tego ćwiczenia w programie pójdziesz o krok dalej i przetrenujesz model ML tak, aby uwzględniał zmiany w treści wiadomości zawierających spam, które mogą się zmieniać w miarę upływu czasu na podstawie bieżących trendów lub popularnych tematów dyskusji. Pozwoli Ci to zadbać o aktualność modelu i uwzględnienie takich zmian.
Wymagania wstępne
- Udało Ci się ukończyć pierwsze ćwiczenia z programowania z tej serii.
- Podstawowa znajomość technologii internetowych, w tym HTML, CSS i JavaScript.
Co utworzysz
Ponownie wykorzystasz utworzoną wcześniej witrynę w fikcyjnym blogu wideo z sekcją komentarzy w czasie rzeczywistym i zaktualizujesz ją tak, aby wczytać niestandardowo wytrenowaną wersję modelu wykrywania spamu przy użyciu TensorFlow.js. Dzięki temu będzie ona działać lepiej w przypadkach skrajnych, w których wcześniej się to nie udało. Oczywiście jako programiści i inżynierowie stron internetowych możesz zmienić ten hipotetyczny interfejs użytkownika i użyć go ponownie w dowolnej witrynie, nad którą pracujesz na co dzień, i dostosować rozwiązanie do każdego zastosowania klienta – na przykład bloga, forum lub systemu CMS, takiego jak Drupal.
Czas na hakowanie...
Czego się nauczysz
W ramach ćwiczenia:
- Identyfikuj przypadki skrajne, w których występowały błędy wytrenowanego modelu
- Ponownie wytrenuj model klasyfikacji spamu utworzony w Kreatorze modeli.
- Wyeksportuj ten model oparty na Pythonie do formatu TensorFlow.js, aby móc go używać w przeglądarkach.
- Zaktualizuj hostowany model i jego słownik o nowo wytrenowany model i sprawdź wyniki
W tym module zakładamy, że znasz język HTML5, CSS i JavaScript. Będziesz też uruchamiać kod Pythona w „colab” musisz ponownie wytrenować model utworzony w Kreatorze modeli, ale do tego nie jest wymagana znajomość Pythona.
2. Skonfiguruj kod
Ponownie będziesz hostować i modyfikować aplikację internetową na Glitch.com. Jeśli nie udało Ci się jeszcze wykonać tych ćwiczeń w warunkach wstępnych, możesz sklonować wynik tutaj jako punkt wyjścia. Jeśli masz pytania dotyczące działania kodu, przed kontynuowaniem zdecydowanie zalecamy ukończenie poprzednich ćwiczeń z programowania.
W przypadku Glitcha kliknij przycisk Remiksuj ten fragment, aby utworzyć rozwidlenie i utworzyć nowy zestaw plików, które możesz edytować.
3. Odkryj przypadki skrajne w poprzednim rozwiązaniu
Po otwarciu utworzonej przed chwilą sklonowanej witryny i wpisaniu kilku komentarzy zauważysz, że większość czasu działa zgodnie z oczekiwaniami, blokujesz komentarze, które wyglądają jak spam, i pozwalasz na udzielanie prawidłowych odpowiedzi.
Jeśli jednak okaże się, że jesteś sprytny i postarasz się sformułować różne frazy, aby złamać model, prawdopodobnie w pewnym momencie uda Ci się osiągnąć sukces. Po pewnym czasie prób i błędów możesz ręcznie tworzyć przykłady takie jak te poniżej. Spróbuj wkleić te dane do istniejącej aplikacji internetowej, sprawdź konsolę i zapoznaj się z prawdopodobnymi prawdopodobieństwami, że dany komentarz nie zawiera spamu:
Wiarygodne komentarze opublikowane bez problemów (prawdziwie negatywne):
- „Uwielbiam ten film – dobra robota”. Spam związany z prawdopodobieństwem: 47,91854%
- „Te wersje demonstracyjne były super. Czy chce Pan/Pani dowiedzieć się więcej?” Spam związany z prawdopodobieństwem: 47,15898%
- „Na jakiej stronie mogę znaleźć więcej informacji?” Spam związany z prawdopodobieństwem: 15,32495%
To świetne, prawdopodobieństwo dla wszystkich tych zdarzeń jest bardzo niskie. Przed podjęciem działania wystarczy, że ukończysz domyślne SPAM_THRESHOLD, czyli 75% (zdefiniowane w kodzie script.js z poprzedniego ćwiczenia w Codelabs).
Teraz spróbujmy napisać więcej irytujących komentarzy, które zostaną oznaczone jako spam, mimo że nimi nie są...
Wiarygodne komentarze oznaczone jako spam (wyniki fałszywie pozytywne):
- „Czy ktoś może podać link do strony internetowej z maską, którą nosi?” Spam związany z prawdopodobieństwem: 98,46466%
- „Czy mogę kupić ten utwór w Spotify? Ktoś proszę o informację”. Spam związany z prawdopodobieństwem: 94,40953%
- „Czy ktoś może skontaktować się ze mną i przekazać mi szczegółowe instrukcje pobierania TensorFlow.js?” Spam związany z prawdopodobieństwem: 83,20084%
O nie! Wygląda na to, że te wiarygodne komentarze są oznaczane jako spam, mimo że powinny być dozwolone. Jak rozwiązać ten problem?
Prostym sposobem jest zwiększenie SPAM_THRESHOLD do ponad 98,5% pewności. W takim przypadku błędnie sklasyfikowane komentarze są publikowane. Mając to na uwadze, przejdźmy do innych możliwych rozwiązań poniżej...
Komentarze zawierające spam oznaczone jako spam (prawdziwie pozytywne):
- „To fajne, ale link do pobierania na mojej stronie jest lepszy”. Spam związany z prawdopodobieństwem: 99,77873%
- „Wiem, że niektórzy, którzy mogą zlecić Ci leki, tylko widzą mój plik pr0dla szczegółów” Spam związany z prawdopodobieństwem: 98,46955%
- „Otwórz mój profil, aby pobrać jeszcze lepsze filmy, które są jeszcze lepsze. http://example.com” – spam prawdopodobieństwa: 96,26383%
Wszystko działa zgodnie z oczekiwaniami przy pierwotnym progu 75%, ale biorąc pod uwagę, że w poprzednim kroku wartość SPAM_THRESHOLD wynosiła ponad 98,5%, oznaczałoby to, że zostaną przepuszczone 2 przykłady, więc być może próg jest za wysoki. Może 96% to lepsze? Jeśli jednak to zrobisz, jeden z komentarzy w poprzedniej sekcji (wynikiem fałszywie pozytywnym) zostanie oznaczony jako spam, jeśli był prawidłowy, bo jego ocena wynosi 98,46466%.
W takim przypadku najlepiej jest przechwycić wszystkie prawdziwe komentarze ze spamem i po prostu ponownie się nauczyć, jeśli chodzi o powyższe błędy. Po ustawieniu progu na 96% wszystkie wyniki prawdziwie pozytywne są nadal rejestrowane i eliminujesz 2 z powyższych wyników fałszywie pozytywnych. Nieźle, że zmieniłeś tylko 1 numer.
Kontynuujmy...
Komentarze zawierające spam, które mogły zostać opublikowane (wyniki fałszywie negatywne):
- „Otwórz profil, żeby pobrać jeszcze lepsze filmy, które są jeszcze lepsze!” Spam związany z prawdopodobieństwem: 7,54926%
- "Skorzystaj ze zniżki na zajęcia treningowe na siłowni! zobacz pr0file!" Spam związany z prawdopodobieństwem: 17,49849%
- „Oomor, akcja GOOG poszła na wyższy poziom! Nie zwlekaj! Spam związany z prawdopodobieństwem: 20,42894%
W przypadku takich komentarzy nie można nic zrobić, zmieniając wartość SPAM_THRESHOLD. Obniżenie progu spamu z 96% do 9% spowoduje oznaczenie prawdziwych komentarzy jako spamu. Jeden z nich ma ocenę 58%, mimo że jest wiarygodny. Jedynym sposobem radzenia sobie z takimi komentarzami jest ponowne wytrenowanie modelu z uwzględnieniem takich skrajnych przypadków uwzględnionych w danych treningowych, aby uczył się on dostosowywać swój widok świata na to, co jest spamem, a co nie.
Obecnie jedynym sposobem na wytrenowanie modelu jest ponowne wytrenowanie modelu. Przedstawiliśmy też sposób, w jaki można zawęzić próg, w którym można uznać coś za spam, aby zwiększyć wydajność. Jako człowiek 75% wydaje się całkiem pewnie, ale w tym modelu trzeba zwiększyć skuteczność do poziomu bliższego 81,5%, aby uzyskać większą skuteczność na przykładowych danych wejściowych.
Nie ma jednej magicznej wartości, która sprawdzałaby się w różnych modelach. Wartość progowa musi być ustawiona osobno dla każdego modelu po wypróbowaniu eksperymentów z rzeczywistymi danymi, by sprawdzić, co się sprawdza.
W niektórych sytuacjach wynik fałszywie pozytywny (lub negatywny) może mieć poważne konsekwencje (np. w branży medycznej), dlatego możesz ustawić bardzo wysoki próg i poprosić o większą liczbę ręcznych weryfikacji w przypadku tych, które nie spełniają tego progu. To Ty jako deweloper wybierasz tę opcję, więc musisz trochę poeksperymentować.
4. Ponownie naucz model wykrywania spamu w komentarzach
W poprzedniej sekcji zidentyfikowaliśmy skrajne przypadki, w których model nie działał prawidłowo. Jedyną opcją było ponowne wytrenowanie modelu, aby uwzględnić te sytuacje. W systemach produkcyjnych można zauważyć takie komentarze z czasem w sytuacji, gdy ktoś ręcznie oznacza komentarz jako spam, który został przez niego przepuszczony, lub moderatorzy sprawdzający oznaczone komentarze, zdają sobie sprawę, że niektóre w rzeczywistości nie są spamem i mogą oznaczać komentarze do ponownego szkolenia. Zakładając, że zgromadzisz sporo nowych danych na temat tych skrajnych przypadków (aby uzyskać najlepsze rezultaty, przygotuj kilka odmian nowych zdań), teraz pokażemy Ci, jak ponownie wytrenować model z uwzględnieniem tych skrajnych przypadków.
Gotowe podsumowanie modelu
Użyty gotowy model był modelem utworzonym przez inną firmę za pomocą Kreatora modeli, który korzysta z „osadzonego przeciętnego słowa” modelu do działania.
Ponieważ model został utworzony w Kreatorze modeli, musisz na chwilę przejść na Pythona, aby wytrenować go ponownie, a następnie wyeksportować go do formatu TensorFlow.js, aby można było używać go w przeglądarce. Na szczęście używanie ich modeli w Kreatorze modeli jest bardzo proste, więc instrukcje nie powinny sprawiać trudności. Przedstawimy Ci cały proces, więc nie martw się, jeśli nie znasz jeszcze Pythona.
Współpraca
W ramach tego ćwiczenia w programie chcesz skonfigurować serwer z systemem Linux i zainstalować wszystkie zainstalowane narzędzia Python, możesz więc po prostu wykonać kod w przeglądarce za pomocą „notatnika Colab”. Te notatniki mogą łączyć się z „backendem” czyli po prostu serwer z wstępnie zainstalowanymi elementami, z których można uruchomić dowolny kod w przeglądarce i zobaczyć wyniki. Jest to bardzo przydatne podczas szybkiego tworzenia prototypów lub użycia ich w samouczkach podobnych do tego.
Otwórz stronę colab.research.google.com, aby wyświetlić ekran powitalny, który wygląda tak:
Teraz kliknij przycisk Nowy notatnik w prawym dolnym rogu wyskakującego okienka. Powinien wyświetlić się pusty tekst Colab:
Świetnie. Następnym krokiem jest połączenie współpracy we frontendzie z serwerem backendu, aby można było wykonać napisany kod w Pythonie. Aby to zrobić, kliknij Połącz w prawym górnym rogu i wybierz Połącz z hostowanym środowiskiem wykonawczym.
Po nawiązaniu połączenia w miejscu powinny pojawić się ikony pamięci RAM i dysku, na przykład:
Dobra robota! Możesz teraz zacząć kodować w Pythonie, aby ponownie wytrenować model Kreatora modeli. Należy wykonać poniższe instrukcje.
Krok 1
Skopiuj poniższy kod z pierwszej, pustej komórki. Zainstaluje ona za Ciebie usługę TensorFlow Lite Model Maker za pomocą menedżera pakietów Pythona o nazwie „pip” Jest on podobny do npm, który większość czytelników tego modułu kodu może być lepiej znana z ekosystemu JS:
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Wklejenie kodu do komórki nie spowoduje jego wykonania. Następnie najedź kursorem na szarą komórkę, do której wklejono powyższy kod, pojawi się mały przycisk „play” w lewej części komórki zostanie wyświetlona ikona wyróżniona poniżej:
 Kliknij przycisk odtwarzania, aby uruchomić kod wpisany w komórce.
Kliknij przycisk odtwarzania, aby uruchomić kod wpisany w komórce.
Widoczny będzie proces instalowania aplikacji Kreator modeli:
Po zakończeniu wykonywania kodu w komórce (jak pokazano na ilustracji), przejdź do następnego kroku poniżej.
Krok 2
Następnie dodaj nową komórkę z kodem, jak pokazano na ilustracji, aby wkleić więcej kodu za pierwszą komórką i uruchomić go oddzielnie:
W następnej uruchomionej komórce będzie znajdować się pewna liczba importów, których będzie musiał użyć kod w pozostałej części notatnika. Skopiuj poniższy kod i wklej go w utworzonej nowej komórce:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
To dość standardowe, nawet jeśli nie znasz Pythona. Importujesz tylko niektóre narzędzia i funkcje Kreatora modeli potrzebne do klasyfikatora spamu. Spowoduje to również sprawdzenie, czy korzystasz z TensorFlow 2.x, co jest wymagane do korzystania z Kreatora modeli.
Na koniec, tak jak poprzednio, uruchom kod w komórce, naciskając klawisz odtwarzania po najechaniu kursorem na komórkę, a potem dodaj nową komórkę z kodem, aby wykonać następny krok.
Krok 3
Następnie pobierz dane z serwera zdalnego na swoje urządzenie i ustaw zmienną training_data jako ścieżkę do wynikowego pliku lokalnego:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
Kreator modeli umożliwia trenowanie modeli na podstawie prostych plików CSV, takich jak ten pobrany. Musisz tylko określić, które kolumny zawierają tekst, a które etykiety. W kroku 5 dowiesz się, jak to zrobić. Jeśli chcesz, możesz samodzielnie pobrać plik CSV, aby sprawdzić, co zawiera.
Z pewnością zauważysz, że ten plik nazywa się jm_blog_comments_extras.csv – jest to oryginalne dane treningowe użyte do wygenerowania pierwszego modelu spamu w komentarzach, połączone z nowymi danymi o przypadkach skrajnych, które zostały przez Ciebie wykryte, w taki sposób, że wszystko jest w jednym pliku. Oprócz nowych zdań, z których chcesz się uczyć, potrzebujesz też oryginalnych danych treningowych używanych do trenowania modelu.
Opcjonalnie: jeśli pobierzesz ten plik CSV i sprawdzisz kilka ostatnich wierszy, zobaczysz przykłady skrajnych przypadków, które wcześniej nie działały prawidłowo. Zostały właśnie dodane na końcu istniejących danych treningowych, które były używane przez gotowy model do trenowania.
Uruchom tę komórkę, a po jej zakończeniu dodaj nową komórkę i przejdź do kroku 4.
Krok 4
W Kreatorze modeli nie można tworzyć modeli od podstaw. Zwykle korzystasz z istniejących modeli, które możesz następnie dostosować do swoich potrzeb.
W Kreatorze modeli masz do dyspozycji kilka wektorów dystrybucyjnych modeli wyuczonych, ale najprostszym i najszybszym jest average_word_vec, którego użyto do utworzenia witryny we wcześniejszych ćwiczeniach z programowania. Oto kod:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Uruchom kod po wklejeniu go w nowej komórce.
Omówienie
num_words
parametr
Jest to liczba słów, których model ma używać. Może Ci się wydawać, że im więcej, tym lepiej, ale z drugiej strony istnieje jakiś pułap, który zależy od częstotliwości występowania poszczególnych słów. Jeśli użyjesz każdego słowa w całym korpusie, model może spróbować nauczyć się i równoważyć waga słów, które zostały użyte tylko raz – nie jest to zbyt przydatne. W każdym korpusie tekstowym zobaczysz, że wiele słów jest używanych tylko 1 lub 2 razy. Ogólnie nie warto ich używać w modelu, ponieważ mają one znikomy wpływ na ogólne nastawienie. Możesz więc dostroić model na dowolną liczbę słów za pomocą parametru num_words. Mniejsza liczba oznacza mniejszy i szybszy model, ale może być mniej dokładny, ponieważ rozpoznaje mniej słów. Większa liczba oznacza większy i potencjalnie wolniejszy model. Znalezienie optymalizatora jest kluczowe. To Ty jako inżynier systemów uczących się musisz określić, co sprawdzi się najlepiej w Twoim przypadku.
Omówienie
wordvec_dim
parametr
Parametr wordvec_dim to liczba wymiarów, których chcesz użyć jako wektora każdego słowa. Wymiary te to w zasadzie różne cechy (utworzone przez algorytm uczenia maszynowego podczas trenowania), na podstawie których można mierzyć dane słowo. Na tej podstawie program próbuje najlepiej powiązać słowa, które są podobne w danym sensie.
Jeśli na przykład chcesz użyć wymiaru „medycyna”, np. „pille”, może uzyskać tutaj wysoki wynik w tym wymiarze i być powiązana z innymi słowami o wysokiej punktacji, takimi jak „rentgen”, ale „kot” uzyska niski wynik w tym wymiarze. Może się okazać, że „wymiar medyczny” jest przydatny do określania spamu w połączeniu z innymi potencjalnymi wymiarami, które mogą być uznane za istotne.
W przypadku słów, które mają wysokie wyniki w „wymiarze medycznym” może okazać się, że drugi wymiar, który wiąże słowa z ciałem ludzkim, może być przydatny. Słowa takie jak „noga”, „ręka”, „szyja” może mieć tutaj wysoki wynik i dość wysoki w wymiarze medycznym.
Model może wykorzystać te wymiary, aby umożliwić mu wykrywanie słów, które z większym prawdopodobieństwem wiążą się ze spamem. Być może spamerskie e-maile z większym prawdopodobieństwem zawierają słowa będące zarówno medycznymi, jak i ludzkimi częściami ciała.
Zgodnie z ogólną zasadą ustaloną na podstawie badań, w przypadku tego parametru dobrze sprawdza się czwarty pierwiastek z liczby słów. Jeśli mam użyć 2000 słów, dobrym punktem wyjścia będzie 7 wymiarów. Możesz też zmienić liczbę użytych słów.
Omówienie
seq_len
parametr
Modele są zwykle bardzo sztywne, jeśli chodzi o wartości wejściowe. W przypadku modelu językowego oznacza to, że może on klasyfikować zdania o konkretnej, statycznej długości. Jest to określane przez parametr seq_len, który oznacza „długość sekwencji”. Gdy zamienisz słowa w liczby (lub tokeny), zdanie stanie się sekwencją tych tokenów. Twój model zostanie więc wytrenowany (w tym przypadku) do klasyfikowania i rozpoznawania zdań z 20 tokenami. Jeśli zdanie jest dłuższe, zostanie skrócone. Jeśli film będzie krótszy, zostanie dopełniony – tak jak w pierwszym ćwiczeniu z programowania z tej serii.
Krok 5. Wczytaj dane treningowe
Wcześniej pobrałeś(-aś) plik CSV. Teraz trzeba skorzystać z programu wczytującego dane, aby zamienić je w dane treningowe rozpoznawane przez model.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Po otwarciu pliku CSV w edytorze zobaczysz, że każdy wiersz ma tylko 2 wartości, które są opisane w pierwszym wierszu pliku. Zwykle każdy wpis jest następnie uznawany za „kolumnę”. Deskryptor pierwszej kolumny to commenttext, a pierwszy wpis w każdym wierszu to tekst komentarza.
Podobnie deskryptor dla drugiej kolumny to spam. Zobaczysz, że druga pozycja w każdym wierszu ma wartość TRUE lub FALSE, aby wskazać, czy dany tekst jest uznawany za spam. Inne właściwości ustawiają specyfikację modelu utworzoną w kroku 4, wraz ze znakiem separatora, czyli w tym przypadku przecinkiem, ponieważ plik jest rozdzielany przecinkami. Możesz też ustawić parametr tasowania, aby losowo zmieniać kolejność danych treningowych, tak aby elementy, które były podobne lub zebrane razem, były rozłożone w losowym zbiorze danych.
Następnie za pomocą funkcji data.split() podzielisz dane na dane treningowe i testowe. Wartość 0,9 oznacza, że 90% zbioru danych będzie używane do trenowania, a reszta do testowania.
Krok 6. Utwórz model
Dodaj kolejną komórkę, w której dodamy kod tworzący model:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
W ten sposób w Kreatorze modeli powstanie model klasyfikatora tekstu. Musisz wtedy określić dane treningowe, których chcesz użyć (które zostały zdefiniowane w kroku 4), specyfikację modelu (ustaloną również w kroku 4) oraz liczbę epok, w tym przypadku 50.
Podstawową zasadą uczenia maszynowego jest to, że jest to forma dopasowywania wzorców. Najpierw wczyta wytrenowane wagi dla słów i spróbuje je pogrupować za pomocą „prognozy”. a które nie, a które nie. Za pierwszym razem prawdopodobnie będzie to 50:50, ponieważ model dopiero się uruchamia, tak jak poniżej:

Następnie zmierzy te wyniki i zmieni wagi modelu, aby ulepszyć prognozę, a następnie będzie próbować ponownie. Oto epoka. Dlatego określenie epok=50 powoduje przejście przez tę „pętlę” 50 razy, jak pokazano poniżej:

Gdy osiągniesz 50. epokę, model odnotuje znacznie wyższy poziom dokładności. W tym przypadku wynik to 99,1%.
Krok 7. Wyeksportuj model
Po zakończeniu trenowania możesz wyeksportować model. TensorFlow trenuje model we własnym formacie, który trzeba przekonwertować na format TensorFlow.js, aby można było go użyć na stronie internetowej. Wystarczy wkleić ten kod w nowej komórce i wykonać zadanie:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
Po wykonaniu tego kodu kliknij małą ikonę folderu po lewej stronie Colab, aby przejść do folderu wyeksportowanego powyżej (w katalogu głównym – może być konieczne przejście na wyższy poziom) i odszukać pakiet ZIP zawierający wyeksportowane pliki w usłudze ModelFiles.zip.
Pobierz ten plik ZIP na komputer, ponieważ będziesz używać tych plików tak samo jak w pierwszym ćwiczeniu z programowania:
Świetnie. To już koniec Pythona. Teraz możesz wrócić do znanego i lubianego środowiska JavaScript. Uff...
5. Obsługa nowego modelu systemów uczących się
Teraz możesz już prawie załadować model. Zanim to zrobisz, musisz przesłać nowe pliki modelu pobrane wcześniej w ramach ćwiczeń z programowania, aby były hostowane i użyteczne w Twoim kodzie.
Najpierw rozpakuj pliki modelu pobranego właśnie z uruchomionego właśnie notatnika Colab Kreatora modeli. W poszczególnych folderach powinny wyświetlić się następujące pliki:
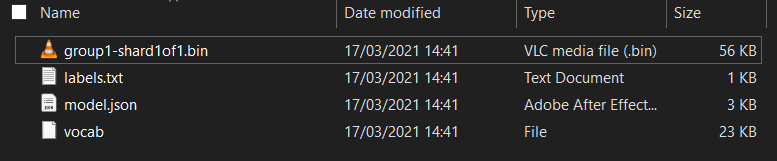
Co tu jest?
model.json– to jeden z plików tworzących wytrenowany model TensorFlow.js. Odwołasz się do tego konkretnego pliku w kodzie JS.group1-shard1of1.bin– jest to plik binarny zawierający znaczną część zapisanych danych dla wyeksportowanego modelu TensorFlow.js. Musi być hostowany gdzieś na serwerze, aby można go było pobrać do tego samego katalogu comodel.jsonpowyżej.vocab– ten dziwny plik bez rozszerzenia pochodzi z Kreatora modeli, który pokazuje, jak zakodować słowa w zdaniach, by model rozumieł, jak ich używać. W następnej sekcji znajdziesz więcej informacji na ten temat.labels.txt– zawiera tylko powstałe nazwy klas, które model będzie prognozował. W przypadku tego modelu, jeśli otworzysz go w edytorze tekstu, będzie on miał wartość „false” (fałsz). i „true” z informacją „nie jest spamem” lub „spam” jako dane wyjściowe prognozy.
Hostowanie plików modelu TensorFlow.js
Najpierw umieść wygenerowane na serwerze WWW pliki model.json i *.bin, aby można było uzyskiwać do nich dostęp na swojej stronie internetowej.
Usuwanie istniejących plików modelu
Pracujesz nad wynikami pierwszego ćwiczenia z programowania w tej serii, więc musisz najpierw usunąć przesłane istniejące pliki modelu. Jeśli korzystasz z Glitch.com, w panelu plików po lewej stronie znajdź model.json i group1-shard1of1.bin, kliknij menu z 3 kropkami przy każdym pliku i wybierz usuń, jak widać poniżej:
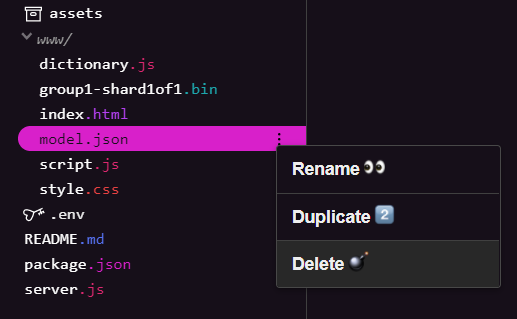
Przesyłanie nowych plików do Glitch
Świetnie. Teraz prześlij nowe:
- Otwórz folder assets w panelu po lewej stronie projektu Glitch i usuń wszystkie przesłane wcześniej zasoby, jeśli mają te same nazwy.
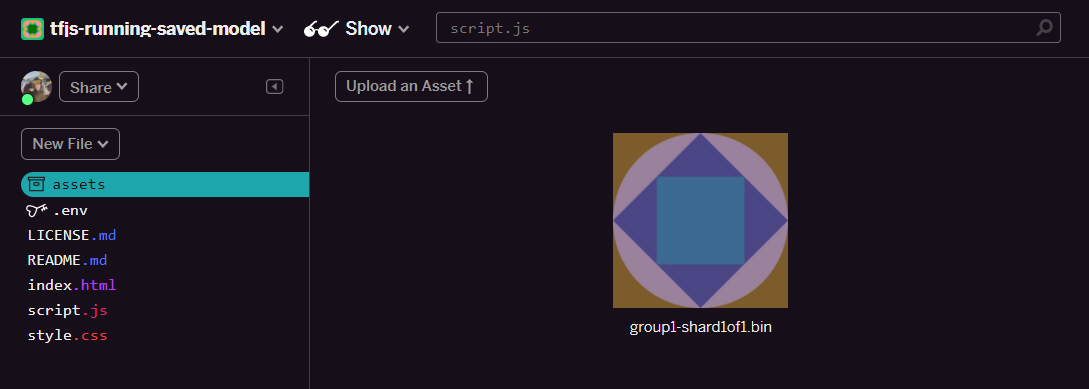
- Kliknij Prześlij zasób i wybierz
group1-shard1of1.bin, aby przesłać zasób do tego folderu. Po przesłaniu plik powinien wyglądać podobnie do tego:
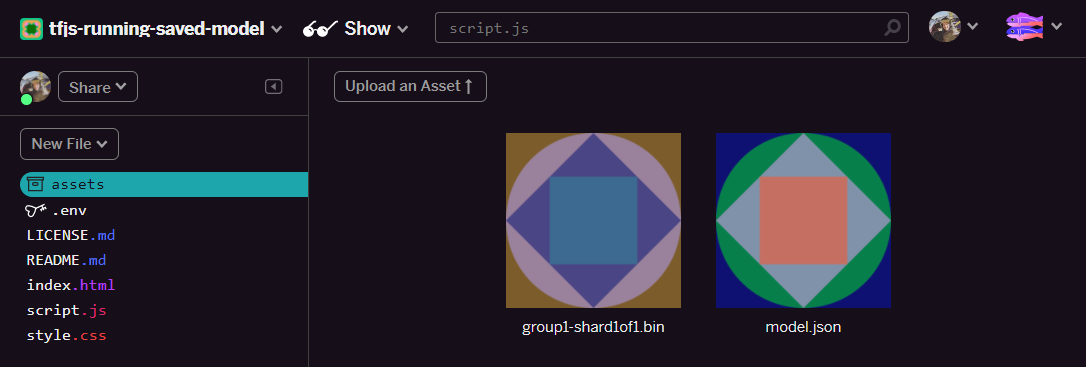
- Świetnie. Teraz zrób to samo z plikiem model.json, więc 2 pliki powinny znajdować się w folderze zasobów w ten sposób:
- Jeśli klikniesz przesłany przed chwilą plik
group1-shard1of1.bin, możesz skopiować adres URL do jego lokalizacji. Skopiuj teraz tę ścieżkę, jak pokazano poniżej:
- W lewym dolnym rogu ekranu kliknij Narzędzia > Terminal. Poczekaj na wczytanie okna terminala.
- Po załadowaniu wpisz poniższy kod i naciśnij Enter, aby zmienić katalog na folder
www:
terminal:
cd www
- Następnie za pomocą polecenia
wgetpobierz 2 przesłane pliki, zastępując poniższe adresy URL adresami wygenerowanymi dla plików w folderze zasobów w usłudze Glitch (sprawdź niestandardowy adres URL każdego pliku w folderze zasobów).
Zwróć uwagę na odstęp między tymi dwoma adresami URL i pamiętaj, że potrzebne adresy będą się różnić od przedstawionych, ale będą wyglądać podobnie:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Świetnie! Utworzyłeś kopię plików przesłanych do folderu www.
Jednak obecnie zostaną one pobrane pod dziwnymi nazwami. Gdy wpiszesz w terminalu ls i naciśniesz Enter, zobaczysz coś takiego:

- Użyj polecenia
mv, aby zmienić nazwy plików. Wpisz w konsoli następujące polecenie i po każdym wierszu naciśnij Enter:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Na koniec odśwież projekt Glitch, wpisując
refreshw terminalu i naciskając Enter:
terminal:
refresh
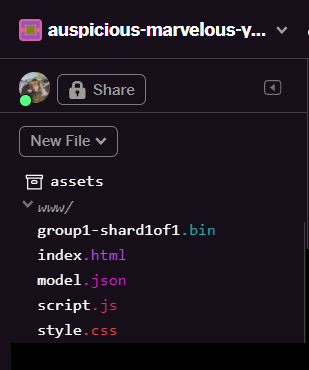
Po odświeżeniu strony w folderze www interfejsu powinny być widoczne model.json i group1-shard1of1.bin:
Świetnie. Ostatnim krokiem jest zaktualizowanie pliku dictionary.js.
- Przekonwertuj nowo pobrany plik słownictwa na prawidłowy format JS ręcznie za pomocą edytora tekstu lub za pomocą tego narzędzia i zapisz wynik w formacie
dictionary.jsw folderzewww. Jeśli masz już plikdictionary.js, możesz po prostu skopiować i wkleić nową zawartość, a następnie zapisać plik.
Super! Udało Ci się zaktualizować wszystkie zmienione pliki. Jeśli teraz spróbujesz użyć witryny, zorientujesz się, jak ponownie wytrenowany model powinien uwzględniać wykryte i wyciągnięte w ten sposób przypadki skrajne:
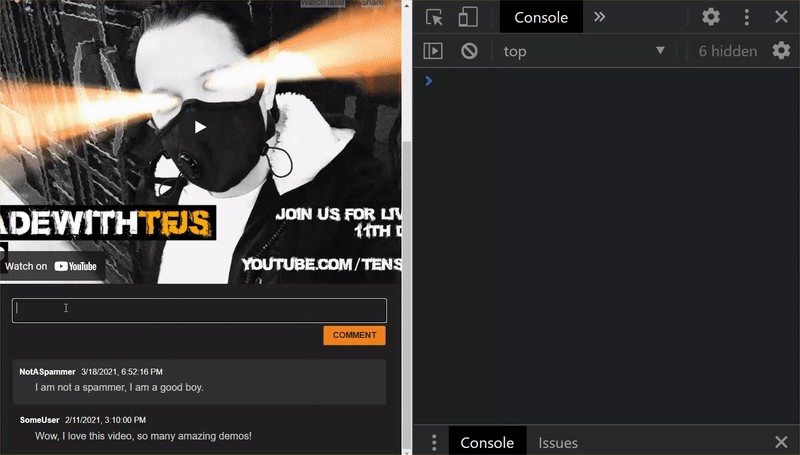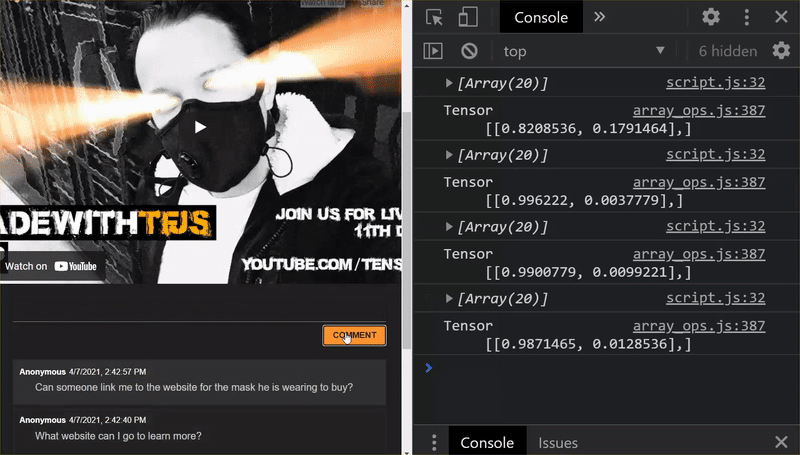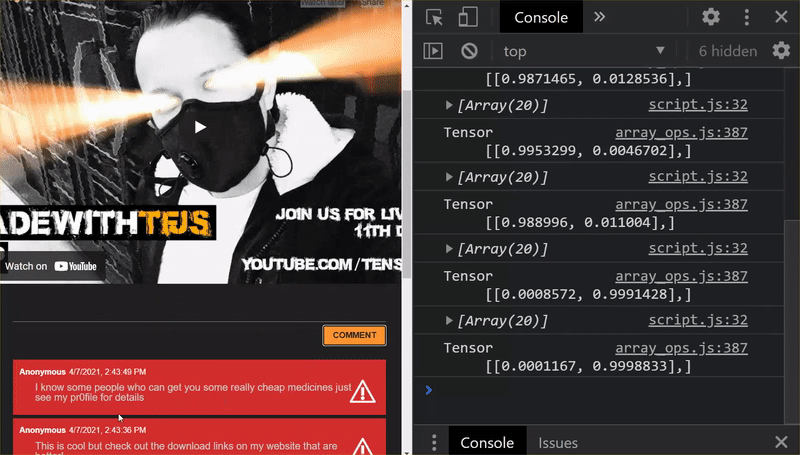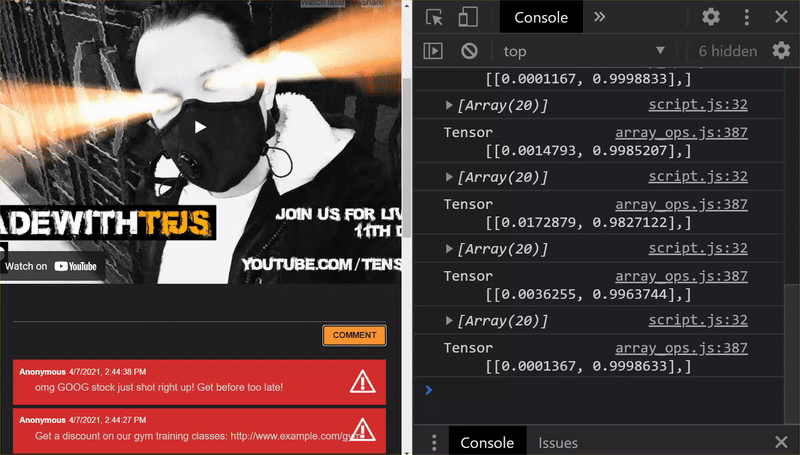
Jak widać, pierwsze 6 z nich zostało poprawnie sklasyfikowanych jako „Nie spam”, a druga grupa (6) została zidentyfikowana jako spam. Super!
Spróbujmy też kilku odmian, aby sprawdzić, czy dobrze uogólniono. Na początku było jedno zdanie z błędami, takie jak:
„O, akcja GOOG poszła na wyższy poziom! Nie zwlekaj!”
Ten komunikat został prawidłowo sklasyfikowany jako spam, ale co się stanie, jeśli zmienisz ten typ na:
„Zatem akcje XYZ właśnie wzrosły. Kup je, zanim będzie za późno!
Oto prognoza na 98% prawdopodobieństwa, że to spam, i jest poprawna, mimo że nieco zmieniono symbol giełdowy i treść wiadomości.
Oczywiście, jeśli naprawdę spróbujesz przełamać ten nowy model, będziesz w stanie to zrobić, ale sprowadza się to do zebrania jeszcze większej ilości danych szkoleniowych, aby maksymalnie zwiększyć szanse na uchwycenie większej liczby niepowtarzalnych odmian typowych sytuacji, z jakimi możesz się zetknąć w internecie. W przyszłym ćwiczeniu w Codelabs pokażemy, jak stale ulepszać model na podstawie bieżących danych.
6. Gratulacje!
Gratulacje! Udało Ci się ponownie wytrenować istniejący model systemów uczących się tak, aby aktualizował się tak, aby obsługiwał znalezione przypadki brzegowe, i wdrożył te zmiany w przeglądarce za pomocą TensorFlow.js na potrzeby rzeczywistej aplikacji.
Podsumowanie
W ramach tego ćwiczenia w Codelabs:
- Wykryliśmy skrajne przypadki, które nie działały, gdy użyto gotowego modelu spamu w komentarzach.
- Wytrenowano model Kreatora modeli ponownie, aby uwzględniał wykryte przypadki skrajne
- Nowy wytrenowany model został wyeksportowany do formatu TensorFlow.js
- Zaktualizowano aplikację internetową, aby korzystała z nowych plików
Co dalej?
Ta aktualizacja działa doskonale, ale, podobnie jak w przypadku każdej aplikacji internetowej, z czasem zachodzą zmiany. O wiele lepiej byłoby, gdyby aplikacja stale się rozwijała, zamiast robić to za każdym razem ręcznie. Czy zastanawiasz się, w jaki sposób możliwe było automatyczne ponowne wytrenowanie modelu po uzyskaniu np. 100 nowych komentarzy oznaczonych jako nieprawidłowo sklasyfikowane? Postaw na inżynierię sieciową, a zapewne uda Ci się wymyślić, jak stworzyć automatyczny potok. Jeśli nie, to bez obaw. Kolejne ćwiczenia z programowania z tej serii pokażą Ci, jak to zrobić.
Podziel się z nami tym, co udało Ci się stworzyć
Możesz z łatwością wykorzystać swoje dzisiejsze materiały również w innych kreatywnych celach, więc zachęcamy do kreatywnego myślenia i dalszego hakowania.
Pamiętaj, aby oznaczyć nas w mediach społecznościowych hashtagiem #MadeWithTFJS, aby mieć szansę na zaprezentowanie Twojego projektu na blogu TensorFlow lub nawet na przyszłych wydarzeniach. Chętnie zobaczymy, co stworzysz.
Dowiedz się więcej o programie TensorFlow.js w języku angielskim
- Użyj hostingu Firebase, aby wdrożyć i hostować model TensorFlow.js na dużą skalę.
- Tworzenie inteligentnej kamery internetowej z użyciem gotowego modelu wykrywania obiektów za pomocą TensorFlow.js
Strony, na których można płacić za zakupy
- Oficjalna strona internetowa TensorFlow.js
- Gotowe modele TensorFlow.js
- Interfejs API TensorFlow.js
- Programy TensorFlow.js & Opowiedz – zainspiruj się i zobacz, co zrobili inni.