
1. Zanim zaczniesz
Uczenie maszynowe to dziś bardzo popularne hasło. Wydaje się, że aplikacje są dostępne bez ograniczeń, a w najbliższej przyszłości może stać się częścią niemal każdej branży. Jeśli pracujesz jako inżynier lub projektant, interfejs lub backend i znasz język JavaScript, te ćwiczenia z programowania pomogą Ci dodać uczenie maszynowe do Twoich umiejętności.
Wymagania wstępne
To ćwiczenie w Codelabs jest przeznaczone dla doświadczonych inżynierów, którzy znają język JavaScript.
Co utworzysz
W ramach tego ćwiczenia w Codelabs
- Utwórz stronę internetową, która korzysta z systemów uczących się bezpośrednio w przeglądarce przez TensorFlow.js i wykrywa typowe obiekty (tak, w tym więcej niż jeden naraz) z transmisji z kamery internetowej.
- Zwiększ wydajność swojej zwykłej kamery internetowej, aby identyfikować obiekty i uzyskiwać współrzędne ramki ograniczającej każdego znalezionego obiektu
- Zaznacz znaleziony obiekt w strumieniu wideo w ten sposób:
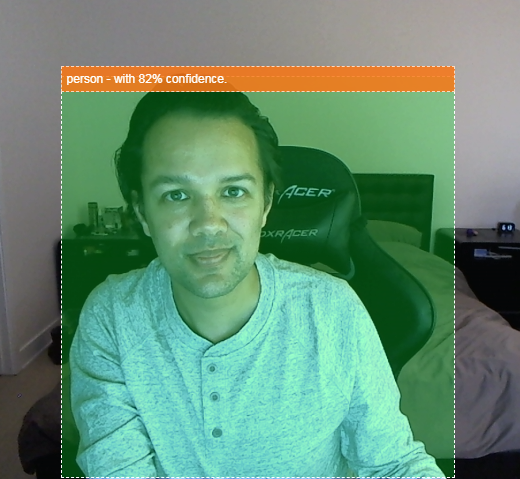
Wyobraź sobie, że możesz wykryć, czy ktoś jest na filmie, i liczyć liczbę osób w danym momencie, aby oszacować natężenie ruchu w danym obszarze w ciągu dnia. Możesz też wysłać sobie alert o wykryciu psa w pomieszczeniu w Twoim domu, kiedy Cię nie ma, a może wtedy nie powinno tak być. Gdyby udało Ci się to zrobić, na pewno będziesz na dobrej drodze do stworzenia własnej wersji kamery Google Nest, która będzie Cię powiadamiać, gdy zauważy intruz (dowolnego typu) za pomocą własnego niestandardowego sprzętu. Dobrze. Czy to trudne? Nie. Czas na hakowanie...
Czego się nauczysz
- Jak wczytać wytrenowany model TensorFlow.js.
- Jak skopiować dane z transmisji z kamery internetowej na żywo i narysować je na obszarze roboczym.
- Sposób klasyfikowania ramki obrazu w celu znalezienia ramek ograniczających dowolny obiekt, który został wytrenowany do rozpoznawania przez model.
- Jak używać danych zwracanych z modelu do wyróżniania znalezionych obiektów.
To ćwiczenie w Codelabs koncentruje się na tym, jak zacząć korzystać z już wytrenowanych modeli TensorFlow.js. Pojęcia i bloki kodu, które nie mają związku z TensorFlow.js i systemami uczącymi się, nie zostały wyjaśnione. Można je po prostu skopiować i wkleić.
2. Co to jest TensorFlow.js?

TensorFlow.js to biblioteka systemów uczących się typu open source, która umożliwia uruchamianie JavaScriptu wszędzie. Opiera się on na pierwotnej bibliotece TensorFlow napisanej w języku Python i ma na celu odtworzenie tego środowiska programistycznego oraz zestawu interfejsów API w ekosystemie JavaScriptu.
Gdzie można korzystać z tej funkcji?
JavaScript jest łatwy w obsłudze, dlatego możesz teraz z łatwością pisać w jednym języku i wykonywać uczenie maszynowe na wszystkich poniższych platformach:
- Po stronie klienta w przeglądarce używamy wbudowanego JavaScriptu
- Po stronie serwera, a nawet urządzenia IoT, takie jak Raspberry Pi, korzystające z Node.js
- Aplikacje komputerowe wykorzystujące technologię Electron
- natywne aplikacje mobilne wykorzystujące komponent React Native,
TensorFlow.js obsługuje też wiele backendów w każdym z tych środowisk (rzeczywistych środowisk sprzętowych, w których można go uruchamiać, np. CPU lub WebGL. „backend” w tym kontekście nie oznacza to środowiska po stronie serwera – backend do wykonywania może na przykład znajdować się po stronie klienta w WebGL), aby zapewnić zgodność i jednocześnie zapewnić szybkie działanie. Obecnie TensorFlow.js obsługuje:
- Wykonanie WebGL na karcie graficznej urządzenia (GPU) – to najszybszy sposób na uruchamianie większych modeli (o rozmiarach powyżej 3 MB) z akceleracją GPU.
- Wykonywanie narzędzi Web Assembly (WASM) na CPU – w celu poprawy wydajności procesora na różnych urządzeniach, na przykład na telefonach komórkowych starszej generacji. Sprawdza się to lepiej w mniejszych modelach (poniżej 3 MB), które w WASM działają szybciej na procesorach niż w WebGL ze względu na wymagania związane z przesyłaniem materiałów do procesora graficznego.
- Wykonanie procesora – środowisko zastępcze nie powinno być dostępne. To najwolniejszy z trzech, ale zawsze gotowy.
Uwaga: możesz wymusić stosowanie jednego z tych backendów, jeśli wiesz, na którym urządzeniu będzie wykonywane działanie. Jeśli nie określisz tego, możesz po prostu pozwolić TensorFlow.js zdecydować za Ciebie.
Supermocy po stronie klienta
Uruchomienie kodu TensorFlow.js w przeglądarce na komputerze klienckim może przynieść szereg korzyści, które warto rozważyć.
Prywatność
Możesz trenować i klasyfikować dane na komputerze klienckim bez konieczności wysyłania ich na serwer internetowy firmy zewnętrznej. W niektórych przypadkach może to być wymagane w celu zachowania zgodności z przepisami obowiązującymi w danym kraju, np. RODO, lub w przypadku przetwarzania danych, które użytkownik chce zachować na swoim komputerze, a nie wysyłać do innych firm.
Szybkość
Dzięki temu, że nie trzeba wysyłać danych na serwer zdalny, wnioskowanie (czynność klasyfikowania danych) może być szybsze. Co więcej, po przyznaniu dostępu przez użytkownika będziesz mieć bezpośredni dostęp do czujników urządzenia, takich jak aparat, mikrofon, GPS, akcelerometr i inne.
Zasięg i skala
Wystarczy jedno kliknięcie, aby każdy na całym świecie mógł kliknąć wysłany przez Ciebie link, otworzyć stronę internetową w przeglądarce i wykorzystać to, co udało Ci się osiągnąć. Użycie systemu uczącego się nie wymaga skomplikowanej konfiguracji systemu Linux po stronie serwera ze sterownikami CUDA i nie tylko.
Koszt
Brak serwerów oznacza, że jedyną rzeczą, za którą musisz zapłacić, jest sieć CDN do przechowywania plików HTML, CSS, JS i modeli. Koszt sieci CDN jest znacznie wyższy niż w przypadku serwera (potencjalnie z podłączoną kartą graficzną) działającym przez całą dobę.
Funkcje po stronie serwera
Poniższe funkcje są dostępne dzięki wdrożeniu TensorFlow.js w Node.js.
Pełna obsługa CUDA
Aby włączyć akcelerację karty graficznej, po stronie serwera musisz zainstalować sterowniki NVIDIA CUDA, aby umożliwić TensorFlow współpracę z kartą graficzną (inaczej niż w przeglądarce, która używa WebGL – nie trzeba instalować). Pełna obsługa technologii CUDA pozwala jednak w pełni wykorzystać możliwości karty graficznej niższego poziomu, co pozwala skrócić czas trenowania i wnioskowania. Wydajność jest porównywalna z implementacją TensorFlow w języku Python, ponieważ obie korzystają z tego samego backendu w C++.
Rozmiar modelu
Aby tworzyć najbardziej zaawansowane modele na podstawie badań, możesz pracować z bardzo dużymi modelami, nawet o wielkości gigabajtów. Tych modeli nie można obecnie uruchamiać w przeglądarce ze względu na ograniczenia wykorzystania pamięci przez poszczególne karty przeglądarki. Aby móc uruchamiać te większe modele, możesz użyć środowiska Node.js na własnym serwerze ze specyfikacjami sprzętowymi, które są wymagane do wydajnego działania takiego modelu.
IOT
Node.js jest obsługiwany na popularnych komputerach jednopłytkowych, takich jak Raspberry Pi, co z kolei oznacza, że na takich urządzeniach możesz uruchamiać modele TensorFlow.js.
Szybkość
Node.js jest napisany w języku JavaScript, co oznacza, że korzysta z kompilacji w odpowiednim momencie. Oznacza to, że gdy korzystasz z Node.js, możesz często zauważyć wzrost wydajności, ponieważ jest on optymalizowany w czasie działania, a zwłaszcza w przypadku wstępnego przetwarzania danych. Świetnym przykładem tego jest to studium przypadku, które pokazuje, jak firma Hugging Face wykorzystała środowisko Node.js, aby dwukrotnie zwiększyć wydajność modelu przetwarzania języka naturalnego.
Znasz już podstawy środowiska TensorFlow.js, wiesz, gdzie może być uruchamiany i jakie są jego zalety, więc możesz teraz zacząć robić z nim przydatne rzeczy.
3. Wytrenowane modele
TensorFlow.js udostępnia różne, wytrenowane modele systemów uczących się. Modele te zostały wytrenowane przez zespół TensorFlow.js i opakowane w łatwą w obsłudze klasę. To świetny sposób, by zrobić pierwsze kroki w korzystaniu z systemów uczących się. Zamiast tworzyć i trenować model, aby rozwiązać problem, jako punkt wyjścia możesz zaimportować już wytrenowany model.
stale powiększającą się listę łatwych w użyciu, już wytrenowanych modeli, na stronie Modele dla JavaScriptu Tensorflow.js. Przekonwertowane modele TensorFlow, które działają w TensorFlow.js, są też dostępne w innych miejscach, np. w TensorFlow Hub.
Dlaczego warto używać wytrenowanego modelu?
Rozpoczęcie od popularnego, wytrenowanego modelu, jeśli odpowiada Twoim potrzebom, ma wiele zalet:
- Nie musisz samodzielnie zbierać danych do trenowania. Przygotowywanie danych w prawidłowym formacie i oznaczanie ich etykietami tak, aby system uczący się mógł używać ich do uczenia się, może być bardzo czasochłonne i kosztowne.
- Umiejętność szybkiego prototypowania koncepcji w krótszym czasie i w krótszym czasie.
Nie ma sensu „wymyślać koła na nowo” gdy już wytrenowany model będzie wystarczający do realizacji Twoich zadań, pozwalając Ci skupić się na wykorzystaniu wiedzy uzyskanej od modelu podczas realizowania kreatywnych pomysłów. - Wykorzystanie najnowocześniejszych metod badań. Już wytrenowane modele są często oparte na popularnych badaniach, dzięki czemu masz dostęp do takich modeli, a także poznają ich skuteczność w świecie rzeczywistym.
- Łatwość użycia i bogata dokumentacja. Ze względu na popularność takich modeli.
- Przenoszenie zdolności do nauki. Niektóre wytrenowane modele oferują możliwości transferu wiedzy, czyli przenoszenia informacji uzyskanych z jednego zadania systemów uczących się do innego, podobnego przykładu. Na przykład model, który został pierwotnie wytrenowany do rozpoznawania kotów, można ponownie wytrenować do rozpoznawania psów, jeśli przekażesz mu nowe dane treningowe. To przyspieszy, ponieważ nie zaczniesz od pustego obszaru roboczego. Model może wykorzystać to, co już nauczył się rozpoznawać koty, a potem rozpoznać nową rzecz – psy też mają oczy i ucho, więc jeśli już wie, jak znaleźć te cechy, jesteśmy w połowie drogi. Znacznie szybciej wytrenuj model na własnych danych.
Co to jest COCO-SSD?
COCO-SSD to nazwa wytrenowanego modelu ML wykrywania obiektów, którego użyjesz podczas tego ćwiczenia w Codelabs, które ma na celu lokalizację i identyfikację wielu obiektów na jednym obrazie. Innymi słowy, może poinformować Cię o ramce ograniczającej obiektów, które została wytrenowana tak, aby znalazła lokalizację obiektu na każdym obrazie, który mu przedstawisz. Oto przykład:

Jeśli na powyższym obrazie jest więcej niż 1 pies, zostaną Ci podane współrzędne 2 ramek ograniczających, które opisują lokalizację każdej z nich. System COCO-SSD został wstępnie wytrenowany tak, aby rozpoznawał 90 typowych przedmiotów codziennego użytku, takich jak człowiek, samochód czy kot.
Skąd się wzięła ta nazwa?
Nazwa może brzmieć dziwnie, ale ma 2 akronimy:
- COCO: oznacza fakt, że model został wytrenowany na zbiorze danych COCO (Common Objects in Context), który każdy może pobrać i wykorzystać do trenowania własnych modeli. Zbiór danych zawiera ponad 200 tys. obrazów oznaczonych etykietami,które można wykorzystać do nauki.
- SSD (wykrywanie wielofunkcyjnego pojedynczego ujęcia): odnosi się do części architektury modelu, która została użyta w implementacji modelu. Nie musisz znać się w ćwiczeniach z programowania, ale jeśli chcesz dowiedzieć się więcej o SSD tutaj,
4. Konfiguracja
Czego potrzebujesz
- Nowoczesna przeglądarka.
- Podstawowa znajomość języka HTML, CSS i JavaScript oraz Narzędzi deweloperskich w Chrome (wyświetlanie danych wyjściowych konsoli).
Rozpocznij kodowanie
Dla Glitch.com lub Codepen.io utworzono standardowe szablony, od których można zacząć. Wystarczy jedno kliknięcie, aby skopiować dowolny szablon jako stan podstawowy w tym module kodu.
W przypadku błędu kliknij przycisk Remiksuj to, aby utworzyć rozwidlenie i utworzyć nowy zestaw plików, które możesz edytować.
W Codepen możesz też kliknąć rozwidlenie w prawym dolnym rogu ekranu.
Ten prosty szkielet zawiera następujące pliki:
- Strona HTML (index.html)
- Arkusz stylów (style.css)
- Plik do pisania kodu JavaScript (script.js)
Dla Twojej wygody do biblioteki TensorFlow.js dodaliśmy do pliku HTML importowany plik. Wygląda on następująco:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
Alternatywnie: użyj preferowanego edytora stron internetowych lub pracuj lokalnie
Jeśli chcesz pobrać kod i pracować lokalnie lub w innym edytorze online, po prostu utwórz 3 podane wyżej pliki w tym samym katalogu, a następnie skopiuj i wklej do każdego z nich kod z naszego błędu.
5. Wypełnij szkielet HTML
Wszystkie prototypy wymagają podstawowego rusztowania HTML. Użyjesz go później do renderowania danych wyjściowych modelu systemów uczących się. Skonfigurujmy to teraz:
- tytuł strony,
- Tekst opisu
- Przycisk do włączania kamery internetowej
- Tag wideo do renderowania strumienia z kamery internetowej
Aby skonfigurować te funkcje, otwórz index.html i wklej istniejący kod w następujący sposób:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>Multiple object detection using pre trained model in TensorFlow.js</title>
<meta charset="utf-8">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="style.css">
</head>
<body>
<h1>Multiple object detection using pre trained model in TensorFlow.js</h1>
<p>Wait for the model to load before clicking the button to enable the webcam - at which point it will become visible to use.</p>
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="camView">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay muted width="640" height="480"></video>
</div>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js" type="text/javascript"></script>
<!-- Load the coco-ssd model to use to recognize things in images -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script src="script.js" defer></script>
</body>
</html>
Zrozumienie kodu
Zwróć uwagę na kilka ważnych rzeczy, które zostały dodane:
- Dodałeś tag
<h1>, kilka tagów<p>w nagłówku oraz informacje o sposobie korzystania ze strony. Nic specjalnego.
Dodaliśmy też tag sekcji reprezentujący miejsce demonstracyjne:
index.html
<section id="demos" class="invisible">
<p>Hold some objects up close to your webcam to get a real-time classification! When ready click "enable webcam" below and accept access to the webcam when the browser asks (check the top left of your window)</p>
<div id="liveView" class="webcam">
<button id="webcamButton">Enable Webcam</button>
<video id="webcam" autoplay width="640" height="480"></video>
</div>
</section>
- Początkowo przypiszesz temu elementowi
sectionklasę „invisible”. Możesz w ten sposób pokazać użytkownikowi, że gotowy model jest gotowy. Możesz też kliknąć przycisk Włącz kamerę internetową. - Dodano przycisk Włącz kamerę internetową, którego styl określasz w CSS.
- Dodano również tag wideo, do którego będziesz przesyłać obraz z kamery internetowej. Wkrótce skonfigurujesz to w swoim kodzie JavaScript.
Jeśli wyświetlisz teraz podgląd danych wyjściowych, powinny one wyglądać mniej więcej tak:

6. Dodaj styl
Domyślne ustawienia elementu
Najpierw dodajmy style do właśnie dodanych elementów HTML, aby mieć pewność, że będą się renderować prawidłowo:
style.css
body {
font-family: helvetica, arial, sans-serif;
margin: 2em;
color: #3D3D3D;
}
h1 {
font-style: italic;
color: #FF6F00;
}
video {
display: block;
}
section {
opacity: 1;
transition: opacity 500ms ease-in-out;
}
Następnie dodaj kilka przydatnych klas CSS, które pomogą w różnych stanach interfejsu użytkownika, na przykład gdy chcemy ukryć przycisk lub sprawić, że obszar demonstracyjny będzie niedostępny, jeśli model nie jest jeszcze gotowy.
style.css
.removed {
display: none;
}
.invisible {
opacity: 0.2;
}
.camView {
position: relative;
float: left;
width: calc(100% - 20px);
margin: 10px;
cursor: pointer;
}
.camView p {
position: absolute;
padding: 5px;
background-color: rgba(255, 111, 0, 0.85);
color: #FFF;
border: 1px dashed rgba(255, 255, 255, 0.7);
z-index: 2;
font-size: 12px;
}
.highlighter {
background: rgba(0, 255, 0, 0.25);
border: 1px dashed #fff;
z-index: 1;
position: absolute;
}
Świetnie. To wszystko. Jeśli udało Ci się zastąpić style 2 fragmentami kodu powyżej, podgląd na żywo powinien wyglądać tak:

Zwróć uwagę, że tekst obszaru demonstracyjnego i przycisk są niedostępne, ponieważ kod HTML domyślnie ma klasę „invisible”. zastosowano. Gdy model będzie gotowy do użycia, do usunięcia tej klasy użyjesz JavaScriptu.
7. Utwórz szkielet JavaScript
Odwoływanie się do kluczowych elementów DOM
Najpierw upewnij się, że masz dostęp do kluczowych części strony, które trzeba będzie edytować lub uzyskać do nich później w kodzie:
script.js
const video = document.getElementById('webcam');
const liveView = document.getElementById('liveView');
const demosSection = document.getElementById('demos');
const enableWebcamButton = document.getElementById('webcamButton');
Sprawdź, czy masz pomoc dotyczącą kamery internetowej
Możesz teraz dodać funkcje wspomagające, które pomogą Ci sprawdzić, czy używana przeglądarka umożliwia dostęp do transmisji z kamery internetowej za pomocą getUserMedia:
script.js
// Check if webcam access is supported.
function getUserMediaSupported() {
return !!(navigator.mediaDevices &&
navigator.mediaDevices.getUserMedia);
}
// If webcam supported, add event listener to button for when user
// wants to activate it to call enableCam function which we will
// define in the next step.
if (getUserMediaSupported()) {
enableWebcamButton.addEventListener('click', enableCam);
} else {
console.warn('getUserMedia() is not supported by your browser');
}
// Placeholder function for next step. Paste over this in the next step.
function enableCam(event) {
}
Pobieram transmisję z kamery internetowej
Następnie skopiuj i wklej ten kod, by wypełnić zdefiniowaną powyżej funkcję enableCam, która wcześniej była pusta:
script.js
// Enable the live webcam view and start classification.
function enableCam(event) {
// Only continue if the COCO-SSD has finished loading.
if (!model) {
return;
}
// Hide the button once clicked.
event.target.classList.add('removed');
// getUsermedia parameters to force video but not audio.
const constraints = {
video: true
};
// Activate the webcam stream.
navigator.mediaDevices.getUserMedia(constraints).then(function(stream) {
video.srcObject = stream;
video.addEventListener('loadeddata', predictWebcam);
});
}
Na koniec dodaj tymczasowy kod, aby sprawdzić, czy kamera działa.
Poniższy kod będzie udawał, że Twój model został załadowany i włącza przycisk aparatu, aby można było go kliknąć. Cały kod zastąpisz w następnym kroku, więc za chwilę trzeba będzie go usunąć ponownie:
script.js
// Placeholder function for next step.
function predictWebcam() {
}
// Pretend model has loaded so we can try out the webcam code.
var model = true;
demosSection.classList.remove('invisible');
Świetnie. Po uruchomieniu kodu i kliknięciu przycisku w obecnej wersji powinno pojawić się coś takiego:

8. Wykorzystanie modelu systemów uczących się
Wczytywanie modelu
Możesz teraz wczytać model COCO-SSD.
Po zakończeniu inicjowania włącz na swojej stronie internetowej obszar demonstracyjny i przycisk (wklej ten kod na tymczasowy kod dodany pod koniec ostatniego kroku):
script.js
// Store the resulting model in the global scope of our app.
var model = undefined;
// Before we can use COCO-SSD class we must wait for it to finish
// loading. Machine Learning models can be large and take a moment
// to get everything needed to run.
// Note: cocoSsd is an external object loaded from our index.html
// script tag import so ignore any warning in Glitch.
cocoSsd.load().then(function (loadedModel) {
model = loadedModel;
// Show demo section now model is ready to use.
demosSection.classList.remove('invisible');
});
Po dodaniu powyższego kodu i odświeżeniu podglądu na żywo możesz zauważyć, że kilka sekund po wczytaniu strony (zależnie od szybkości sieci) przycisk Włącz kamerę internetową automatycznie wyświetla się, gdy model jest gotowy do użycia. Funkcja predictWebcam została jednak wklejona. Nadszedł czas, by to w pełni zdefiniować, ponieważ nasz kod nie będzie obecnie działał w żaden sposób.
Kolejny krok do następnego!
Klasyfikowanie klatki z kamery internetowej
Uruchom poniższy kod, aby umożliwić aplikacji ciągłe pobieranie klatki ze strumienia z kamery internetowej, gdy przeglądarka jest gotowa, i przekazanie jej do modelu w celu sklasyfikowania.
Model przeanalizuje wyniki i narysuje tag <p> we wskazanych współrzędnych, a następnie doda tekst do etykiety obiektu, jeśli mieści się w pewnym stopniu pewności.
script.js
var children = [];
function predictWebcam() {
// Now let's start classifying a frame in the stream.
model.detect(video).then(function (predictions) {
// Remove any highlighting we did previous frame.
for (let i = 0; i < children.length; i++) {
liveView.removeChild(children[i]);
}
children.splice(0);
// Now lets loop through predictions and draw them to the live view if
// they have a high confidence score.
for (let n = 0; n < predictions.length; n++) {
// If we are over 66% sure we are sure we classified it right, draw it!
if (predictions[n].score > 0.66) {
const p = document.createElement('p');
p.innerText = predictions[n].class + ' - with '
+ Math.round(parseFloat(predictions[n].score) * 100)
+ '% confidence.';
p.style = 'margin-left: ' + predictions[n].bbox[0] + 'px; margin-top: '
+ (predictions[n].bbox[1] - 10) + 'px; width: '
+ (predictions[n].bbox[2] - 10) + 'px; top: 0; left: 0;';
const highlighter = document.createElement('div');
highlighter.setAttribute('class', 'highlighter');
highlighter.style = 'left: ' + predictions[n].bbox[0] + 'px; top: '
+ predictions[n].bbox[1] + 'px; width: '
+ predictions[n].bbox[2] + 'px; height: '
+ predictions[n].bbox[3] + 'px;';
liveView.appendChild(highlighter);
liveView.appendChild(p);
children.push(highlighter);
children.push(p);
}
}
// Call this function again to keep predicting when the browser is ready.
window.requestAnimationFrame(predictWebcam);
});
}
Naprawdę ważne wywołanie w tym nowym kodzie to model.detect().
Wszystkie gotowe modele dla TensorFlow.js mają taką funkcję (jej nazwa może się zmieniać w zależności od modelu, więc sprawdź szczegóły w dokumentacji), która faktycznie przeprowadza wnioskowanie przez systemy uczące się.
Wnioskowanie to po prostu uwzględnienie danych wejściowych i przeprowadzenie ich przez model systemów uczących się (zasadniczo dużą liczbę operacji matematycznych), a następnie podanie określonych wyników. Dzięki gotowym modelom TensorFlow.js zwracamy nasze prognozy w postaci obiektów JSON, dzięki czemu są one łatwe w użyciu.
Szczegółowe informacje o tej funkcji prognozowania znajdziesz w dokumentacji w GitHubie dotyczącej modelu COCO-SSD. Ta funkcja wykonuje wiele pracy w tle i przyjmuje dowolne „podobne zdjęcia”. jako jego parametr, np. obraz, wideo, obiekt canvas itd. Korzystanie z gotowych modeli może zaoszczędzić dużo czasu i wysiłku, ponieważ nie musisz pisać kodu samodzielnie – możesz od razu go otworzyć.
Po uruchomieniu tego kodu powinien wyświetlić się obraz podobny do tego:
Na koniec zobacz przykład kodu wykrywającego wiele obiektów jednocześnie:

Super! Wyobraźcie sobie teraz, jak łatwo byłoby stworzyć urządzenie, takie jak Nest Cam za pomocą starego telefonu, które będzie powiadamiać Cię, gdy zauważy Twojego psa lub kota na kanapie. Jeśli masz problemy z kodem, sprawdź moją ostateczną roboczą wersję tutaj i sprawdź, czy coś nie zostało skopiowane prawidłowo.
9. Gratulacje
Gratulujemy wykonania pierwszych kroków przy użyciu TensorFlow.js i systemów uczących się w przeglądarce. Teraz musisz wykorzystać te skromne początki i zmienić je w coś kreatywne. Co zamierzasz stworzyć?
Podsumowanie
W ramach tego ćwiczenia w Codelabs:
- Poznaj zalety używania TensorFlow.js w porównaniu z innymi formami TensorFlow.
- Poznaj sytuacje, w których warto zacząć od wytrenowanego modelu systemów uczących się.
- Utworzenie w pełni działającej strony internetowej, która może w czasie rzeczywistym klasyfikować obiekty za pomocą Twojej kamery internetowej, takich jak:
- Tworzenie szkieletu HTML dla treści
- Definiowanie stylów elementów i klas HTML
- Skonfigurowanie rusztowania JavaScript w celu interakcji z kodem HTML i wykrywania obecności kamery internetowej
- Wczytuję wytrenowany model TensorFlow.js
- Użycie wczytanego modelu do ciągłej klasyfikacji strumienia z kamery internetowej i rysowanie ramki ograniczającej wokół obiektów na zdjęciu.
Dalsze kroki
Podziel się z nami tym, co udało Ci się osiągnąć! Utworzone na potrzeby tego ćwiczenia z programowania możesz łatwo rozszerzyć również na inne przypadki użycia kreacji. Zachęcamy do kreatywnego myślenia i dalszego hakowania po zakończeniu sesji.
- Obejrzyj wszystkie obiekty rozpoznawane przez ten model i zastanów się, jak możesz wykorzystać tę wiedzę, by wykonać określone działanie. Które pomysły kreatywne można teraz zrealizować, uzupełniając dotychczasowe działania?
(Możesz np. dodać prostą warstwę po stronie serwera, by za pomocą gniazda elektrycznego wysyłać powiadomienia do innego urządzenia, gdy zauważy ono określony przez Ciebie obiekt. Może to być świetny sposób na odbudowanie starego smartfona i nadanie mu nowego przeznaczenia. Możliwości są nieograniczone).
- Oznacz nas w mediach społecznościowych hashtagiem #MadeWithTFJS, aby mieć szansę na zaprezentowanie Twojego projektu na naszym blogu TensorFlow, a nawet na zaprezentowanie go podczas przyszłych wydarzeń TensorFlow.
Dowiedz się więcej o programie TensorFlow.js w języku angielskim
- Tworzenie sieci neuronowej od zera w TensorFlow.js
- Rozpoznawanie dźwięku z wykorzystaniem transferu uczenia się w TensorFlow.js
- Niestandardowa klasyfikacja obrazów za pomocą uczenia maszynowego w TensorFlow.js