
1. Antes de começar
Este codelab foi desenvolvido com base no resultado final do codelab anterior desta série para a detecção de spam de comentários usando o TensorFlow.js.
No último codelab, você criou uma página da Web totalmente funcional para um videoblog fictício. Com um modelo de detecção de spam de comentários pré-treinado com a tecnologia do TensorFlow.js no navegador, você conseguiu filtrar comentários para identificar spam antes de serem enviados ao servidor para armazenamento ou a outros clientes conectados.
O resultado final desse codelab é mostrado abaixo:
Embora isso tenha funcionado muito bem, há casos extremos que não foram detectados. É possível treinar novamente o modelo para considerar as situações com que ele não conseguiu lidar.
Este codelab se concentra no uso do processamento de linguagem natural (a arte de entender a linguagem humana em um computador) e mostra como modificar um app da Web que você criou (é altamente recomendável seguir os codelabs na ordem) para lidar com o problema real do spam de comentários, que muitos desenvolvedores Web certamente vão encontrar ao trabalhar em um dos cada vez mais apps da Web conhecidos.
Neste codelab, você vai retreinar seu modelo de ML para considerar mudanças no conteúdo de mensagens de spam que podem evoluir ao longo do tempo, com base em tendências atuais ou tópicos de discussão em alta, permitindo que você mantenha o modelo atualizado e considere essas mudanças.
Pré-requisitos
- O primeiro codelab desta série foi concluído.
- Conhecimento básico de tecnologias da Web, incluindo HTML, CSS e JavaScript.
O que você vai criar
Você vai reutilizar o site criado anteriormente para um videoblog fictício com uma seção de comentários em tempo real e fazer o upgrade dele para carregar uma versão treinada e personalizada do modelo de detecção de spam usando o TensorFlow.js. Assim, ele terá um desempenho melhor em casos extremos em que havia falhado antes. É claro que, como desenvolvedores e engenheiros da Web, é possível mudar essa UX hipotética para reutilização em qualquer site em que você esteja trabalhando em suas funções diárias e adaptar a solução para se adequar a qualquer caso de uso do cliente, como um blog, fórum ou alguma forma de CMS, como Drupal, por exemplo.
Vamos começar...
O que você vai aprender
Você vai:
- Identificar casos extremos em que o modelo pré-treinado estava falhando
- Treine novamente o modelo de classificação de spam que foi criado com o Model Maker.
- Exporte esse modelo baseado em Python para o formato TensorFlow.js e use-o em navegadores.
- Atualizar o modelo hospedado e o dicionário dele com o modelo recém-treinado e verificar os resultados
Para este laboratório, é necessário ter familiaridade com HTML5, CSS e JavaScript. Você também vai executar códigos Python em um "laboratório prático" para treinar novamente o modelo criado com o Model Maker, mas não é preciso ter familiaridade com Python para fazer isso.
2. Comece a programar
Mais uma vez, você usará o Glitch.com para hospedar e modificar o aplicativo da Web. Se você ainda não concluiu o codelab de pré-requisitos, clone o resultado final aqui como ponto de partida. Se você tiver dúvidas sobre como o código funciona, é altamente recomendável concluir o codelab anterior, que mostra como fazer esse app da Web funcional antes de continuar.
No Glitch, basta clicar no botão remixar este para bifurcar o conteúdo e criar um novo conjunto de arquivos que você pode editar.
3. Descobrir casos extremos na solução anterior
Se você abrir o site que acabou de clonar e tentar digitar alguns comentários, perceberá que na maior parte do tempo ele funciona conforme o esperado, bloqueando comentários que soam como spam como esperado e permitindo o envio de respostas legítimas.
No entanto, se você usar a criatividade e tentar formular coisas para quebrar o modelo, provavelmente terá sucesso em algum momento. Com um pouco de tentativa e erro, é possível criar manualmente exemplos como os mostrados abaixo. Tente colá-los no aplicativo da web existente, verifique o console e veja as probabilidades que retornam se o comentário for spam:
Comentários legítimos postados sem problemas (verdadeiros negativos):
- "Uau, eu amo esse vídeo, trabalho incrível." Probabilidade de spam: 47,91854%
- "Adorei essas demonstrações. Mais alguma informação?" Probabilidade de spam: 47,15898%
- "Qual site posso acessar para saber mais?" Probabilidade de spam: 15,32495%
Isso é ótimo. As probabilidades de todas as opções acima são muito baixas e passam pelo SPAM_THRESHOLD padrão com uma probabilidade mínima de 75% antes que a ação seja realizada (definida no código script.js do codelab anterior).
Agora vamos tentar escrever alguns comentários mais agressivos que serão marcados como spam mesmo que não sejam...
Comentários legítimos marcados como spam (falsos positivos):
- "Alguém pode vincular o site da máscara que está usando?" Probabilidade de spam: 98,46466%
- "Posso comprar esta música no Spotify? Por favor, me avise." Probabilidade de spam: 94,40953%
- "Alguém pode entrar em contato comigo para explicar como fazer o download do TensorFlow.js?" Probabilidade de spam: 83,20084%
Ah, não! Parece que esses comentários legítimos estão sendo marcados como spam quando deveriam ser permitidos. Como você pode corrigir isso?
Uma opção simples é aumentar o SPAM_THRESHOLD para ter mais de 98,5% de confiança. Nesse caso, esses comentários classificados incorretamente seriam postados. Com isso em mente, vamos continuar com os outros resultados possíveis abaixo...
Comentários de spam marcados como spam (verdadeiros positivos):
- "Isso é legal, mas dê uma olhada nos links de download no meu site que são melhores." Probabilidade de spam: 99,77873%
- "Conheço algumas pessoas que podem comprar remédios para você. Basta acessar meu pr0file para mais detalhes." Probabilidade de spam: 98,46955%
- "Acesse meu perfil para fazer o download de vídeos ainda melhores e ainda melhores. http://example.com" Probabilidade de spam: 96,26383%
Isso está funcionando conforme o esperado com nosso limite original de 75%, mas como na etapa anterior você mudou o SPAM_THRESHOLD para um nível de confiança acima de 98, 5%, isso significa que dois exemplos aqui seriam permitidos, então talvez o limite seja muito alto. Talvez 96% seja melhor? Mas se você fizer isso, um dos comentários da seção anterior (falsos positivos) seria marcado como spam quando fosse legítimo, com uma classificação de 98,46466%.
Nesse caso, provavelmente é melhor capturar todos esses comentários de spam reais e treinar novamente para as falhas acima. Ao definir o limite como 96%, todos os verdadeiros positivos ainda serão capturados, e você eliminará dois dos falsos positivos acima. Nada mal por mudar um único número.
Vamos continuar...
Comentários de spam que podiam ser postados (falsos negativos):
- "Acesse meu perfil para fazer o download de vídeos ainda melhores." Probabilidade de spam: 7,54926%
- "Ganhe desconto em nossas aulas de ginástica, veja pr0file!" Probabilidade de spam: 17,49849%
- "as ações da bolsa de valores acabaram de subir! Chegue antes! Probabilidade de spam: 20,42894%
Para esses comentários, não há nada que você possa fazer simplesmente mudando o valor SPAM_THRESHOLD. Reduzir o limite de spam de 96% para cerca de 9% vai fazer com que comentários genuínos sejam marcados como spam. Um deles tem uma classificação de 58%, mesmo que seja legítimo. A única maneira de lidar com comentários como esses seria treinar novamente o modelo com esses casos extremos incluídos nos dados de treinamento para que ele aprenda a ajustar a própria visão do mundo quanto ao que é spam ou não.
Embora a única opção disponível seja treinar o modelo novamente, você também viu como refinar o limite de quando você decide chamar algo de spam para melhorar o desempenho. Como ser humano, 75% parece bastante confiante, mas para esse modelo você precisava aumentar perto de 81,5% para ser mais eficaz com entradas de exemplo.
Não existe um valor mágico que funcione bem em diferentes modelos, e esse valor limite precisa ser definido em cada modelo após a realização de experimentos com dados reais para descobrir o que funciona bem.
Em algumas situações, um falso positivo (ou negativo) pode ter consequências sérias (por exemplo, no setor médico). Portanto, ajuste o limite para um valor muito alto e solicite mais análises manuais para quem não atende ao limite. Como desenvolvedor, essa é sua escolha e requer alguns testes.
4. Treinar novamente o modelo de detecção de spam de comentários
Na seção anterior, você identificou vários casos extremos que falharam no modelo. Nesse caso, a única opção era treiná-lo de novo para lidar com essas situações. Em um sistema de produção, você pode encontrá-los ao longo do tempo à medida que as pessoas sinalizam um comentário como spam manualmente ou os moderadores que revisam comentários sinalizados percebem que alguns não são spam e podem marcá-los para novo treinamento. Supondo que você reuniu um monte de novos dados para esses casos extremos (para melhores resultados, você deve ter algumas variações dessas novas frases, se puder), agora vamos continuar mostrando como treinar novamente o modelo com esses casos extremos em mente.
Resumo do modelo pré-criado
O modelo predefinido que você usou foi criado por um terceiro via Model Maker e usa uma "incorporação média de palavras". para funcionar.
Como o modelo foi criado com o Model Maker, você precisará alternar brevemente para Python para retreiná-lo e, em seguida, exportar o modelo criado para o formato TensorFlow.js para usá-lo no navegador. Felizmente, o Model Maker simplifica muito o uso dos modelos, o que facilita acompanhá-lo. Vamos orientar você ao longo do processo. Não se preocupe se nunca tiver usado o Python antes.
Colabs (em inglês)
Neste codelab, como não estamos muito preocupados em configurar um servidor Linux com todos os utilitários Python instalados, basta executar o código pelo navegador da Web usando um "Notebook do Colab". Eles podem se conectar a um back-end que é simplesmente um servidor com alguns recursos pré-instalados, dos quais você pode executar um código arbitrário dentro do navegador da Web e ver os resultados. Isso é muito útil para prototipagem rápida ou para uso em tutoriais como este.
Acesse colab.research.google.com e você verá uma tela de boas-vindas como esta:
Agora, clique no botão Novo notebook no canto inferior direito da janela pop-up. Você verá um Colab em branco como este:
Ótimo! A próxima etapa é conectar o Colab de front-end a um servidor de back-end para executar o código Python que você vai criar. Para isso, clique em Conectar no canto superior direito e selecione Conectar ao ambiente de execução hospedado.
Após a conexão, ícones de RAM e disco devem aparecer em seu lugar, da seguinte forma:
Bom trabalho! Agora é possível começar a programar em Python para treinar novamente o modelo do Model Maker. Basta seguir as etapas abaixo.
Etapa 1
Na primeira célula que estiver vazia, copie o código abaixo. Ele vai instalar o TensorFlow Lite Model Maker para você usando o gerenciador de pacotes do Python chamado "pip". Ele é semelhante ao npm, com que a maioria dos leitores deste codelab pode estar mais familiarizada no ecossistema do JS:
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
No entanto, colar o código na célula não o executará. Em seguida, passe o mouse sobre a célula cinza na qual colou o código acima e sobre uma pequena aparecerá à esquerda da célula, conforme destacado abaixo:
 Clique no botão de reprodução para executar o código que acabou de ser digitado na célula.
Clique no botão de reprodução para executar o código que acabou de ser digitado na célula.
Você verá o Model Maker sendo instalado:
Quando a execução dessa célula for concluída, conforme mostrado, avance para a próxima etapa abaixo.
Etapa 2
Em seguida, adicione uma nova célula de código, conforme mostrado, para que você possa colar um pouco mais de código após a primeira célula e executá-lo separadamente:
A próxima célula executada terá uma série de importações que o código no restante do notebook precisará usar. Copie e cole o seguinte na célula criada:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Isso é muito padrão, mesmo que você não esteja familiarizado com Python. Você está apenas importando alguns utilitários e as funções do Model Maker necessárias para o classificador de spam. Isso também verifica se você está executando o TensorFlow 2.x, que é um requisito para usar o Model Maker.
Por fim, como antes, execute a célula pressionando o botão "reproduzir" ícone ao passar o mouse sobre a célula, e, em seguida, adicionar uma nova célula de código para a próxima etapa.
Etapa 3
Em seguida, você fará o download dos dados de um servidor remoto para seu dispositivo e definirá a variável training_data como o caminho do arquivo local resultante baixado:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
O Model Maker pode treinar modelos a partir de arquivos CSV simples, como o transferido por download. Você só precisa especificar quais colunas contêm o texto e quais contêm os rótulos. Você verá como fazer isso na Etapa 5. Faça o download direto do arquivo CSV para conferir o conteúdo, se quiser.
Os leitores atentos notam que o nome desse arquivo é jm_blog_comments_extras.csv. Esse arquivo é simplesmente os dados de treinamento originais que usamos para gerar o primeiro modelo de spam de comentários combinado com os novos dados de caso extremo descobertos, por isso tudo fica em um só arquivo. Você também precisa dos dados de treinamento originais usados para treinar o modelo, além das novas frases que quer aprender.
Opcional:se você fizer o download deste arquivo CSV e verificar as últimas linhas, vão encontrar exemplos de casos extremos que não estavam funcionando corretamente antes. Eles foram adicionados ao final dos dados de treinamento atuais do modelo pré-criado usado para treinar a si mesmo.
Execute essa célula e, quando a execução terminar, adicione uma nova célula e prossiga para a etapa 4.
Etapa 4
Ao usar o Model Maker, você não cria modelos do zero. Geralmente, você usa modelos atuais que depois são personalizados de acordo com suas necessidades.
O Model Maker oferece vários embeddings de modelos pré-aprendidos que podem ser usados, mas o mais simples e rápido de começar é o average_word_vec, que você usou no codelab anterior para criar seu site. O código fica assim:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Execute esse código depois de colar na nova célula.
Noções básicas sobre
num_words
parâmetro
Esse é o número de palavras que você quer que o modelo use. Você pode achar que quanto mais, melhor, mas geralmente há um ponto ideal com base na frequência de uso de cada palavra. Se você usar todas as palavras no corpus, o modelo poderá tentar aprender e equilibrar os pesos das palavras que são usadas apenas uma vez, o que não é muito útil. Em qualquer corpus de texto, é possível observar que muitas palavras são usadas apenas uma ou duas vezes. Geralmente, não vale a pena usá-las no modelo, porque elas têm um impacto insignificante no sentimento geral. Assim, é possível ajustar seu modelo com base no número de palavras que você quiser usando o parâmetro num_words. Um número menor aqui terá um modelo menor e mais rápido, mas pode ser menos preciso, já que reconhece menos palavras. Um número maior aqui terá um modelo maior e potencialmente mais lento. Encontrar o ponto ideal é fundamental e cabe a você, como engenheiro de machine learning, descobrir o que funciona melhor para seu caso de uso.
Noções básicas sobre
wordvec_dim
parâmetro
O parâmetro wordvec_dim é o número de dimensões que você quer usar para o vetor de cada palavra. Essas dimensões são essencialmente as diferentes características (criadas pelo algoritmo de machine learning durante o treinamento) que podem ser medidas pelo programa para tentar associar melhor palavras semelhantes de alguma forma significativa.
Por exemplo, se você tiver uma dimensão de quão "médica" uma palavra era, uma palavra como "pílulas" podem ter uma pontuação alta nesta dimensão e estar associadas a outras palavras com pontuação alta, como "raio-x", mas "gato" teria uma pontuação baixa nessa dimensão. Pode ser que uma "dimensão médica" é útil para determinar o spam quando combinado com outras possíveis dimensões significativas que ele pode usar.
No caso de palavras com pontuação alta na "dimensão médica" ele pode descobrir que uma 2a dimensão que correlaciona palavras com o corpo humano pode ser útil. Palavras como "perna", "braço", "pescoço" podem ter uma pontuação alta aqui e também bem alta na dimensão médica.
O modelo pode usar essas dimensões para detectar palavras com maior probabilidade de associação a spam. Talvez os e-mails de spam tenham mais chances de conter palavras médicas e de corpo humano.
A regra prática determinada pela pesquisa é que a quarta raiz do número de palavras funciona bem para esse parâmetro. Portanto, se eu estiver usando 2.000 palavras, um bom ponto de partida são as sete dimensões. Se você mudar o número de palavras usadas, também poderá mudar essa configuração.
Noções básicas sobre
seq_len
parâmetro
Os modelos geralmente são muito rígidos quando se trata de valores de entrada. Para um modelo de linguagem, isso significa que ele pode classificar frases com um comprimento específico e estático. Isso é determinado pelo parâmetro seq_len, em que significa "duração da sequência". Quando você converte palavras em números (ou tokens), uma frase se torna uma sequência desses tokens. Assim, seu modelo será treinado (neste caso) para classificar e reconhecer frases com 20 tokens. Se a frase for maior do que isso, ela ficará truncada. Se ela for mais curta, terá padding, assim como no primeiro codelab desta série.
Etapa 5: carregar os dados de treinamento
Anteriormente, você fez o download do arquivo CSV. Agora é hora de usar um carregador de dados para transformá-los em dados de treinamento que o modelo possa reconhecer.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Se você abrir o arquivo CSV em um editor, verá que cada linha tem apenas dois valores, que são descritos com texto na primeira linha. Normalmente, cada entrada é considerada uma "coluna". Você verá que o descritor da primeira coluna é commenttext e que a primeira entrada em cada linha é o texto do comentário.
Da mesma forma, o descritor da segunda coluna é spam, e a segunda entrada em cada linha é TRUE ou FALSE para indicar se o texto é considerado spam de comentários ou não. As outras propriedades definem a especificação de modelo que você criou na etapa 4, junto com um caractere delimitador, que, neste caso, é uma vírgula, já que o arquivo é separado por vírgula. Você também define um parâmetro de embaralhamento para reorganizar aleatoriamente os dados de treinamento. Assim, itens que podem ter sido semelhantes ou coletados juntos são distribuídos de maneira aleatória pelo conjunto de dados.
Em seguida, você vai usar data.split() para dividir os dados em dados de treinamento e teste. O valor 0, 9 indica que 90% do conjunto de dados será usado para treinamento e o restante para teste.
Etapa 6: criar o modelo
Adicione outra célula onde adicionaremos código para criar o modelo:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
Isso cria um modelo de classificador de texto com o Model Maker. Você especifica os dados de treinamento que quer usar (o que foi definido na etapa 4), a especificação do modelo (que também foi definida na etapa 4) e um número de períodos, neste caso, 50.
O princípio básico do machine learning é que ele é uma forma de correspondência de padrões. Inicialmente, ele carrega os pesos pré-treinados das palavras e tenta agrupá-los com uma "previsão" quais quando agrupados indicam spam e quais não indicam. Na primeira vez, provavelmente será próximo a 50:50, já que o modelo está apenas começando, conforme mostrado abaixo:

Depois, ele mede os resultados e muda os pesos do modelo para ajustar a previsão e tenta de novo. Isso é um período. Portanto, ao especificar epochs=50, ele passará por esse "loop" 50 vezes, conforme mostrado:

Por isso, quando você chegar à época 50, o modelo informará um nível de acurácia muito maior. Neste caso, mostrar 99,1%!
Etapa 7: exportar o modelo
Quando o treinamento terminar, você poderá exportar o modelo. O TensorFlow treina um modelo no próprio formato, e isso precisa ser convertido para o formato TensorFlow.js para uso em uma página da Web. Basta colar o seguinte em uma nova célula e executá-la:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
!zip -r /js_export/ModelFiles.zip /js_export/
Depois de executar esse código, se você clicar no pequeno ícone de pasta à esquerda do Colab, poderá acessar a pasta para a qual exportou acima (no diretório raiz, talvez seja necessário subir um nível) e encontrar o pacote ZIP dos arquivos exportados contidos em ModelFiles.zip.
Faça o download deste arquivo ZIP no seu computador agora porque você os usará como no primeiro codelab:
Ótimo! A parte do Python acabou. Agora você pode voltar para a Terra do JavaScript, que você conhece e adora. Ufa.
5. Como disponibilizar o novo modelo de machine learning
Agora está quase tudo pronto para você carregar o modelo. Mas antes de fazer isso, você precisa fazer upload dos novos arquivos de modelo baixados anteriormente no codelab para que eles fiquem hospedados e possam ser usados no seu código.
Primeiro, se você ainda não fez isso, descompacte os arquivos do modelo que acabou de baixar do bloco do Colab do Model Maker que acabou de executar. Você verá os seguintes arquivos dentro de suas diversas pastas:
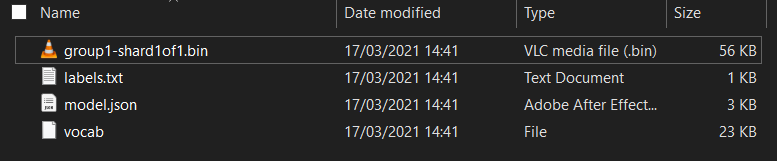
O que você tem aqui?
model.json: é um dos arquivos que compõem o modelo treinado do TensorFlow.js. Você fará referência a esse arquivo específico no código JS.group1-shard1of1.bin: é um arquivo binário que contém grande parte dos dados salvos para o modelo do TensorFlow.js exportado e precisa estar hospedado em algum lugar no seu servidor para download, no mesmo diretório quemodel.jsonacima.vocab: esse arquivo estranho sem extensão é do Model Maker e mostra como codificar palavras nas frases para que o modelo entenda como usá-las. Você vai saber mais sobre isso na próxima seção.labels.txt: contém simplesmente os nomes de classe resultantes que o modelo vai prever. Para este modelo, se você abrir o arquivo em seu editor de texto, ele simplesmente terá "false" e "true" listado indicando "não é spam" ou "spam" como saída da previsão.
Hospedar os arquivos de modelo do TensorFlow.js
Primeiro, coloque os arquivos model.json e *.bin que foram gerados em um servidor da Web para acessá-los na sua página da Web.
Excluir arquivos de modelo existentes
Como você está usando o resultado final do primeiro codelab desta série, primeiro exclua os arquivos de modelo já enviados. Se você estiver usando o Glitch.com, basta verificar o painel de arquivos à esquerda para model.json e group1-shard1of1.bin, clicar no menu suspenso de três pontos para cada arquivo e selecionar delete, conforme mostrado:
Como fazer upload de novos arquivos para o Glitch
Ótimo! Agora faça upload dos novos:
- Abra a pasta assets no painel esquerdo do projeto Glitch e exclua todos os recursos antigos enviados por upload se eles tiverem os mesmos nomes.
- Clique em Fazer upload de um recurso e selecione
group1-shard1of1.binpara enviar para essa pasta. Ele terá esta aparência após o upload:
- Ótimo! Agora faça o mesmo com o arquivo model.json para que dois arquivos estejam na pasta de recursos, desta forma:
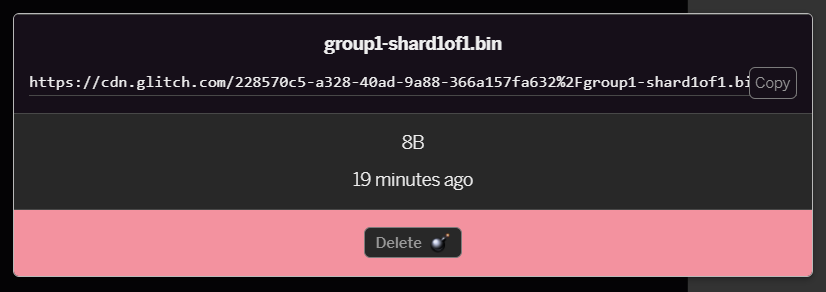
- Se você clicar no arquivo
group1-shard1of1.binque acabou de enviar, poderá copiar o URL para o local dele. Copie este caminho agora, conforme mostrado:
- No canto inferior esquerdo da tela, clique em Ferramentas > Terminal. Aguarde a janela do terminal carregar.
- Depois do carregamento, digite o código abaixo e pressione Enter para acessar a pasta
www:
terminal:
cd www
- Em seguida, use
wgetpara fazer o download dos dois arquivos que você acabou de enviar. Para isso, substitua os URLs abaixo pelos URLs que você gerou para os arquivos na pasta de recursos do Glitch. Verifique a pasta de recursos para o URL personalizado de cada arquivo.
Observe que o espaço entre os dois URLs e que os URLs que você vai precisar usar serão diferentes dos mostrados, mas serão parecidos:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Demais! Você fez uma cópia dos arquivos enviados para a pasta www.
No entanto, no momento o download será feito com nomes estranhos. Se você digitar ls no terminal e pressionar Enter, aparecerá algo parecido com isto:

- Use o comando
mvpara renomear os arquivos. Digite o seguinte comando no console e pressione Enter após cada linha:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Por fim, atualize o projeto Glitch digitando
refreshno terminal e pressionando Enter:
terminal:
refresh
Após a atualização, model.json e group1-shard1of1.bin vão aparecer na pasta www da interface do usuário:
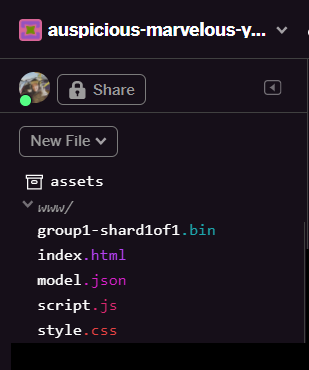
Ótimo! A última etapa é atualizar o arquivo dictionary.js.
- Converta o novo arquivo de vocabulário salvo para o formato JS correto manualmente pelo editor de texto ou usando esta ferramenta e salve o resultado como
dictionary.jsna pastawww. Se você já tiver um arquivodictionary.js, basta copiar e colar o novo conteúdo nele e salvar o arquivo.
Uhuuu! Você atualizou todos os arquivos alterados e, se tentar usar o site, vai perceber como o modelo treinado novamente deve ser capaz de considerar os casos extremos descobertos e aprendidos, conforme mostrado:
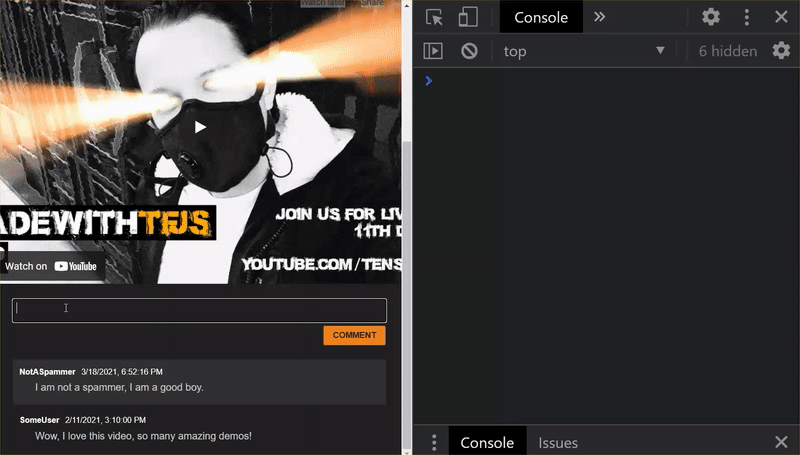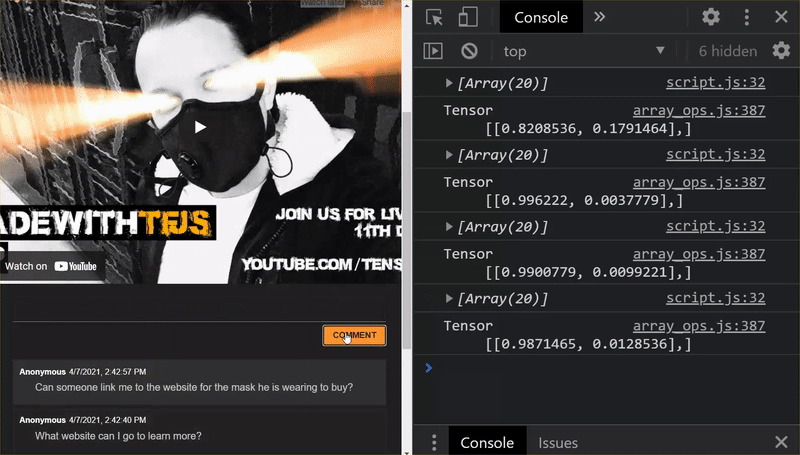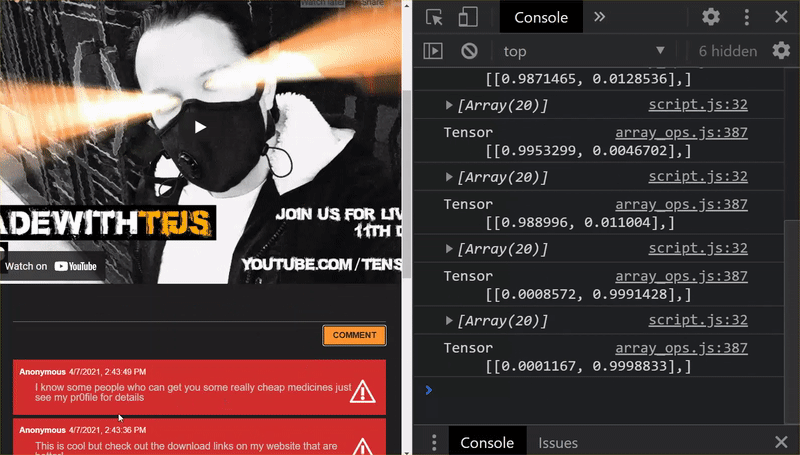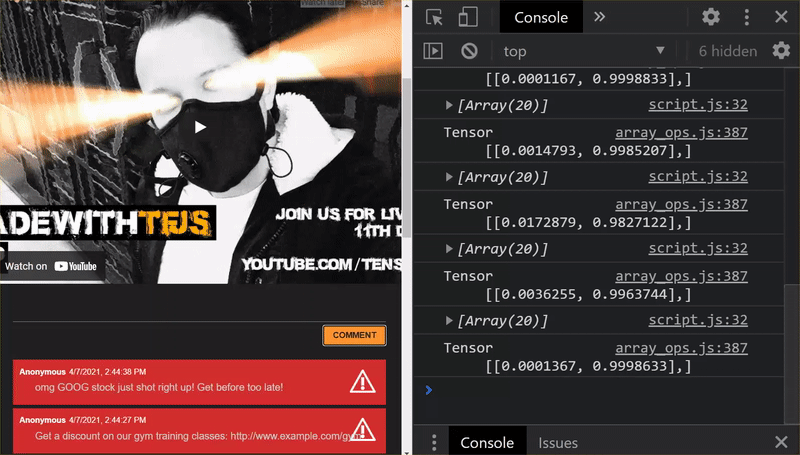
Como você pode ver, agora os seis primeiros são classificados corretamente como não sendo spam, e o segundo lote de seis são todos identificados como spam. Perfeito!
Vamos tentar também algumas variações para ver se ela generaliza bem. Originalmente, havia uma sentença falha como:
"as ações da bolsa de valores acabaram de subir! Chegue antes!"
Agora isso é classificado corretamente como spam, mas o que acontecerá se você mudar para:
"Portanto, o valor das ações da XYZ acabou de aumentar! Compre algumas logo antes que seja tarde demais."
Aqui você recebe uma previsão de 98% de probabilidade de ser spam, o que está correto, mesmo que você tenha alterado o símbolo da ação e o texto um pouco.
É claro que, se você realmente tentar quebrar esse novo modelo, isso se resumirá a coletar ainda mais dados de treinamento para ter a melhor chance de capturar mais variações exclusivas para as situações comuns que você provavelmente encontrará on-line. Em um próximo codelab, vamos mostrar como melhorar continuamente o modelo com dados em tempo real conforme eles são sinalizados.
6. Parabéns!
Parabéns! Você conseguiu treinar novamente um modelo de machine learning para atualizá-lo a fim de trabalhar com os casos extremos encontrados e implantou essas alterações no navegador com o TensorFlow.js para um aplicativo real.
Resumo
Neste codelab, você aprendeu a:
- Descobrimos casos extremos que não funcionam com o modelo predefinido de spam de comentários
- Treinou novamente o modelo do Model Maker para considerar os casos extremos que você descobriu
- Exportação do novo modelo treinado para o formato TensorFlow.js
- Atualizou seu app da Web para usar os novos arquivos
Qual é a próxima etapa?
Portanto, essa atualização funciona muito bem, mas como acontece com qualquer aplicativo da Web, mudanças acontecerão ao longo do tempo. Seria muito melhor se o app se melhorasse continuamente ao longo do tempo, em vez de ter que fazer isso manualmente a cada vez. Você consegue pensar em como automatizar essas etapas para treinar um modelo de novo depois de ter, por exemplo, cem novos comentários marcados como classificados incorretamente? Coloque seu chapéu de engenharia da Web e você provavelmente descobrirá como criar um pipeline para fazer isso automaticamente. Caso contrário, não se preocupe, confira o próximo codelab da série para saber como fazer isso.
Compartilhe o que você sabe conosco
É possível estender facilmente o que você criou hoje para outros casos de uso criativos também. Incentivamos você a pensar fora da caixa e continuar a inovar.
Não se esqueça de nos marcar nas redes sociais usando a hashtag #MadeWithTFJS para que seu projeto apareça no blog do TensorFlow ou em eventos futuros. Adoraríamos saber o que você faz.
Mais codelabs do TensorFlow.js para mais detalhes
- Usar o Firebase Hosting para implantar e hospedar um modelo do TensorFlow.js em grande escala.
- Criar uma webcam inteligente usando um modelo pronto de detecção de objetos com o TensorFlow.js
Sites para conferir
- Site oficial do TensorFlow.js
- Modelos prontos do TensorFlow.js
- API TensorFlow.js
- Apresentação do TensorFlow.js e Conte: inspire-se e veja o que outras pessoas criaram.