
1. Ringkasan
Di berbagai industri, penelusuran kontekstual adalah fungsi penting yang menjadi inti dan pusat aplikasi mereka. Retrieval Augmented Generation telah menjadi pendorong utama evolusi teknologi penting ini sejak beberapa waktu lalu dengan mekanisme pengambilan yang didukung AI Generatif. Model generatif, dengan jendela konteks yang besar dan kualitas output yang mengesankan, mengubah AI. RAG menyediakan cara sistematis untuk memasukkan konteks ke dalam aplikasi dan agen AI, dengan mendasarkannya pada database terstruktur atau informasi dari berbagai media. Data kontekstual ini sangat penting untuk kejelasan kebenaran dan akurasi output, tetapi seberapa akurat hasil tersebut? Apakah bisnis Anda sangat bergantung pada akurasi kecocokan dan relevansi kontekstual ini? Jika demikian, project ini akan menarik bagi Anda.
Rahasia kotor penelusuran vektor bukan hanya membuatnya, tetapi mengetahui apakah kecocokan vektor Anda benar-benar bagus. Kita semua pernah mengalaminya, menatap kosong daftar hasil, bertanya-tanya, 'Apakah alat ini berfungsi?' Mari kita pelajari cara mengevaluasi kualitas kecocokan vektor Anda. "Jadi, apa yang berubah di RAG?", tanya Anda. Segala-galanya! Selama bertahun-tahun, Retrieval Augmented Generation (RAG) terasa seperti sasaran yang menjanjikan, tetapi sulit dicapai. Sekarang, akhirnya, kita memiliki alat untuk mem-build aplikasi RAG dengan performa dan keandalan yang diperlukan untuk tugas penting.
Sekarang kita sudah memiliki pemahaman dasar tentang 3 hal:
- Arti penelusuran kontekstual bagi agen Anda dan cara melakukannya menggunakan Vector Search.
- Kami juga membahas secara mendalam cara mendapatkan Penelusuran Vektor dalam cakupan data Anda, yaitu dalam database Anda sendiri (semua Database Google Cloud mendukungnya, jika Anda belum mengetahuinya).
- Kami melangkah lebih jauh dari yang lain dalam memberi tahu Anda cara mencapai kemampuan RAG Penelusuran Vektor yang ringan dengan performa dan kualitas tinggi dengan kemampuan Penelusuran Vektor AlloyDB yang didukung oleh indeks ScaNN.
Jika Anda belum membaca 3 eksperimen RAG dasar, menengah, dan sedikit lanjutan tersebut, sebaiknya baca 3 eksperimen tersebut di sini, di sini, dan di sini dalam urutan yang tercantum.
Penelusuran Paten membantu pengguna menemukan paten yang relevan secara kontekstual dengan teks penelusuran mereka dan kami telah membuat versinya sebelumnya. Sekarang kita akan membuatnya dengan fitur RAG baru dan lanjutan yang memungkinkan penelusuran kontekstual yang dikontrol kualitas untuk aplikasi tersebut. Mari kita mulai.
Gambar di bawah menunjukkan alur keseluruhan tentang apa yang terjadi dalam aplikasi ini.~ 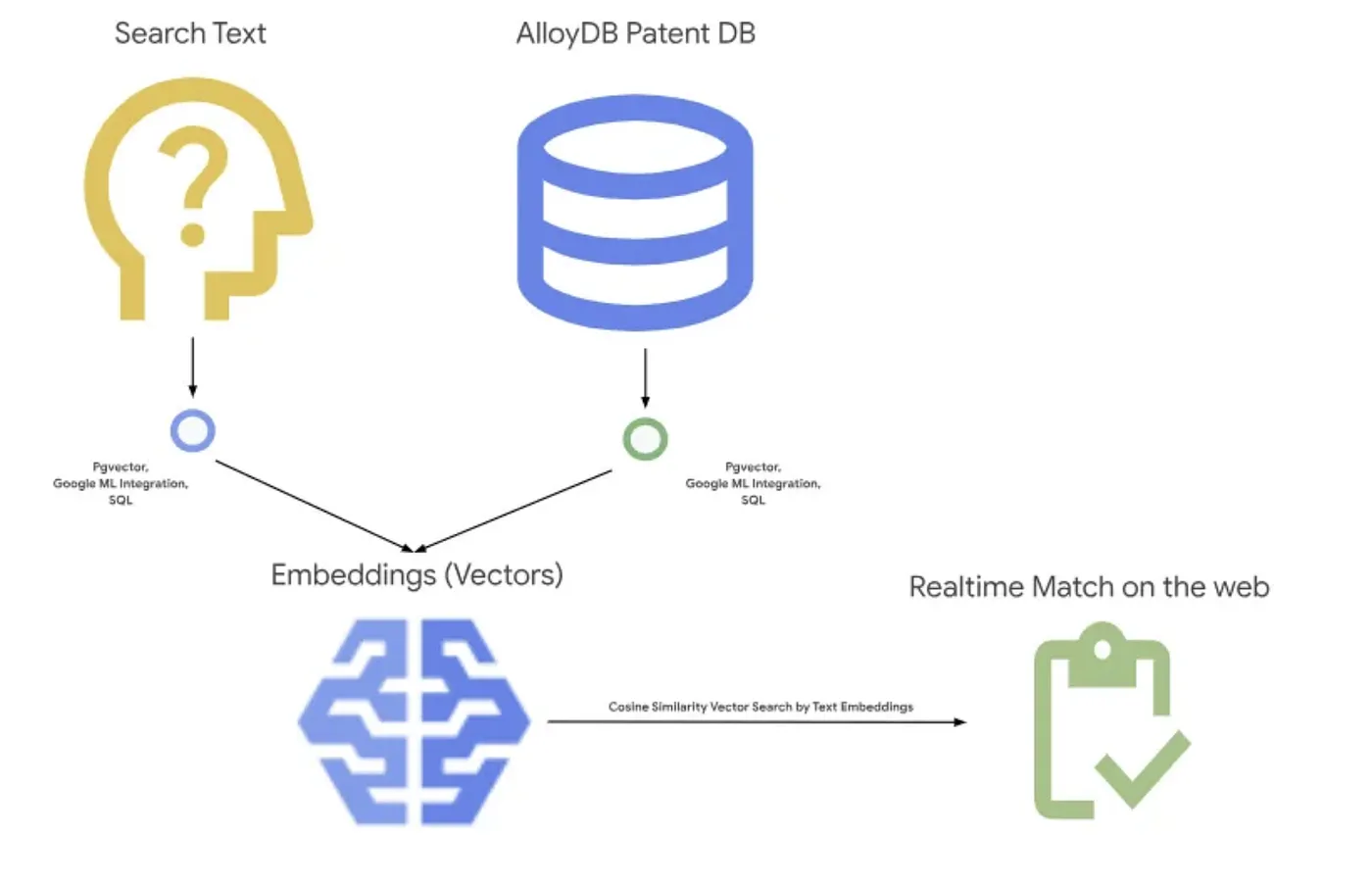
Tujuan
Izinkan pengguna menelusuri paten berdasarkan deskripsi tekstual dengan performa yang lebih baik dan kualitas yang lebih tinggi sekaligus dapat menilai kualitas kecocokan yang dihasilkan menggunakan fitur RAG terbaru AlloyDB.
Yang akan Anda build
Sebagai bagian dari lab ini, Anda akan:
- Membuat instance AlloyDB & memuat Set Data Publik Paten
- Membuat indeks metadata dan indeks ScaNN
- Mengimplementasikan Penelusuran Vektor lanjutan di AlloyDB menggunakan metode pemfilteran inline ScaNN
- Mengimplementasikan fitur Recall eval
- Mengevaluasi respons kueri
Persyaratan
2. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project .
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud. Klik Aktifkan Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda akan memeriksa apakah Anda sudah diautentikasi dan project ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Mengaktifkan API yang diperlukan. Anda dapat menggunakan perintah gcloud di terminal Cloud Shell:
gcloud services enable alloydb.googleapis.com compute.googleapis.com cloudresourcemanager.googleapis.com servicenetworking.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudfunctions.googleapis.com aiplatform.googleapis.com
Alternatif untuk perintah gcloud adalah melalui konsol dengan menelusuri setiap produk atau menggunakan link ini.
Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
3. Penyiapan database
Di lab ini, kita akan menggunakan AlloyDB sebagai database untuk data paten. Layanan ini menggunakan cluster untuk menyimpan semua resource, seperti database dan log. Setiap cluster memiliki instance utama yang menyediakan titik akses ke data. Tabel akan menyimpan data sebenarnya.
Mari kita buat cluster, instance, dan tabel AlloyDB tempat set data paten akan dimuat.
Membuat cluster dan instance
- Buka halaman AlloyDB di Cloud Console. Cara mudah untuk menemukan sebagian besar halaman di Konsol Cloud adalah dengan menelusurinya menggunakan kotak penelusuran konsol.
- Pilih BUAT CLUSTER dari halaman tersebut:

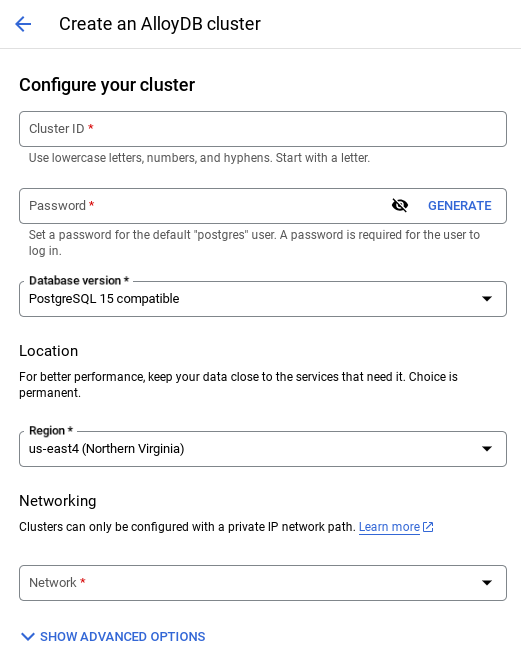
- Anda akan melihat layar seperti di bawah. Buat cluster dan instance dengan nilai berikut (Pastikan nilainya cocok jika Anda meng-clone kode aplikasi dari repo):
- cluster id: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / terbaru direkomendasikan
- Region: "
us-central1" - Networking: "
default"
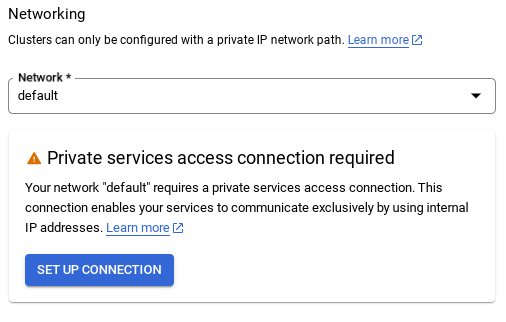
- Saat memilih jaringan default, Anda akan melihat layar seperti di bawah ini.
Pilih SIAPAKAN KONEKSI.
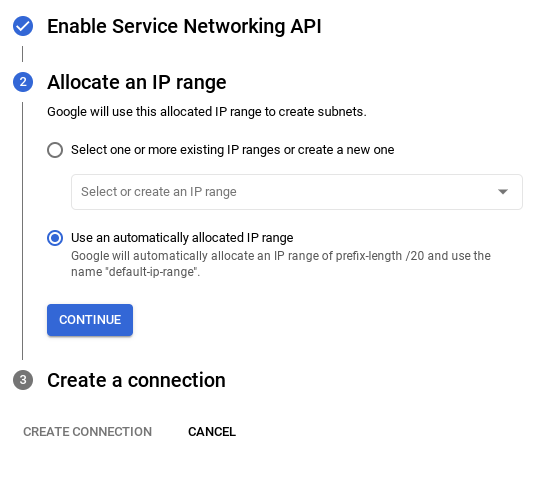
- Dari sana, pilih "Gunakan rentang IP yang dialokasikan secara otomatis", lalu Lanjutkan. Setelah meninjau informasi, pilih BUAT KONEKSI.
- Setelah jaringan disiapkan, Anda dapat terus membuat cluster. Klik CREATE CLUSTER untuk menyelesaikan penyiapan cluster seperti yang ditunjukkan di bawah ini:
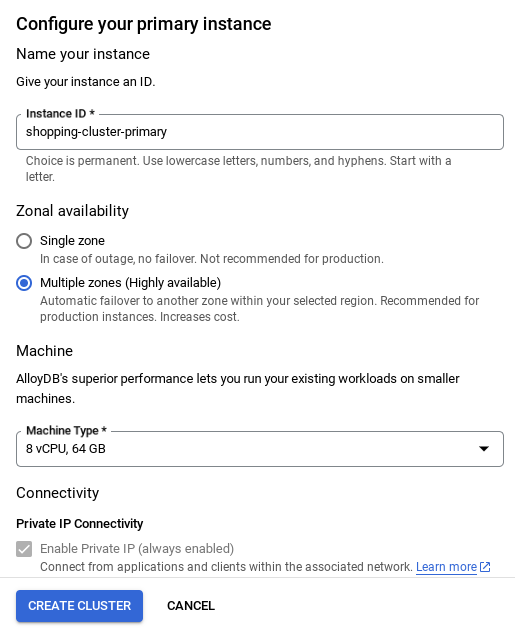
Pastikan untuk mengubah ID instance (yang dapat Anda temukan pada saat konfigurasi cluster / instance) menjadi
vector-instance. Jika Anda tidak dapat mengubahnya, jangan lupa untuk menggunakan ID instance Anda di semua referensi mendatang.
Perhatikan bahwa pembuatan Cluster akan memerlukan waktu sekitar 10 menit. Setelah berhasil, Anda akan melihat layar yang menampilkan ringkasan cluster yang baru saja Anda buat.
4. Penyerapan data
Sekarang saatnya menambahkan tabel dengan data tentang toko. Buka AlloyDB, pilih cluster utama, lalu AlloyDB Studio:
Anda mungkin perlu menunggu instance selesai dibuat. Setelah selesai, login ke AlloyDB menggunakan kredensial yang Anda buat saat membuat cluster. Gunakan data berikut untuk mengautentikasi ke PostgreSQL:
- Nama pengguna : "
postgres" - Database : "
postgres" - Sandi : "
alloydb"
Setelah Anda berhasil melakukan autentikasi ke AlloyDB Studio, perintah SQL akan dimasukkan di Editor. Anda dapat menambahkan beberapa jendela Editor menggunakan tanda plus di sebelah kanan jendela terakhir.
Anda akan memasukkan perintah untuk AlloyDB di jendela editor, menggunakan opsi Run, Format, dan Clear sesuai kebutuhan.
Mengaktifkan Ekstensi
Untuk mem-build aplikasi ini, kita akan menggunakan ekstensi pgvector dan google_ml_integration. Ekstensi pgvector memungkinkan Anda menyimpan dan menelusuri embedding vektor. Ekstensi google_ml_integration menyediakan fungsi yang Anda gunakan untuk mengakses endpoint prediksi Vertex AI guna mendapatkan prediksi di SQL. Aktifkan ekstensi ini dengan menjalankan DDL berikut:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jika Anda ingin memeriksa ekstensi yang telah diaktifkan di database, jalankan perintah SQL ini:
select extname, extversion from pg_extension;
Membuat tabel
Anda dapat membuat tabel menggunakan pernyataan DDL di bawah di AlloyDB Studio:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT, abstract_embeddings vector(768)) ;
Kolom abstract_embeddings akan memungkinkan penyimpanan untuk nilai vektor teks.
Berikan Izin
Jalankan pernyataan di bawah untuk memberikan eksekusi pada fungsi "penyematan":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Memberikan PERAN Pengguna Vertex AI ke akun layanan AlloyDB
Dari konsol Google Cloud IAM, berikan akses ke peran "Vertex AI User" ke akun layanan AlloyDB (yang terlihat seperti ini: service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com). PROJECT_NUMBER akan memiliki nomor project Anda.
Atau, Anda dapat menjalankan perintah di bawah dari Terminal Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Memuat data paten ke dalam database
Set Data Publik Paten Google di BigQuery akan digunakan sebagai set data kami. Kita akan menggunakan AlloyDB Studio untuk menjalankan kueri. Data diambil dari file insert_scripts.sql ini dan kita akan menjalankannya untuk memuat data paten.
- Di konsol Google Cloud, buka halaman AlloyDB.
- Pilih cluster yang baru dibuat, lalu klik instance.
- Di menu Navigasi AlloyDB, klik AlloyDB Studio. Login dengan kredensial Anda.
- Buka tab baru dengan mengklik ikon Tab baru di sebelah kanan.
- Salin pernyataan kueri
insertdari skripinsert_scripts.sqlyang disebutkan di atas ke editor. Anda dapat menyalin 10-50 pernyataan penyisipan untuk demo singkat kasus penggunaan ini. - Klik Run. Hasil kueri Anda akan muncul di tabel Results.
Catatan: Anda mungkin melihat bahwa skrip penyisipan memiliki banyak data di dalamnya. Hal ini karena kita telah menyertakan penyematan dalam skrip penyisipan. Klik "Lihat Raw" jika Anda mengalami masalah saat memuat file di GitHub. Hal ini dilakukan untuk menghemat waktu Anda (pada langkah-langkah mendatang) dalam membuat lebih dari beberapa penyematan (misalnya maksimal 20-25) jika Anda menggunakan akun penagihan kredit uji coba untuk Google Cloud.
5. Membuat Embedding untuk data paten
Pertama, mari kita uji fungsi penyematan, dengan menjalankan contoh kueri berikut:
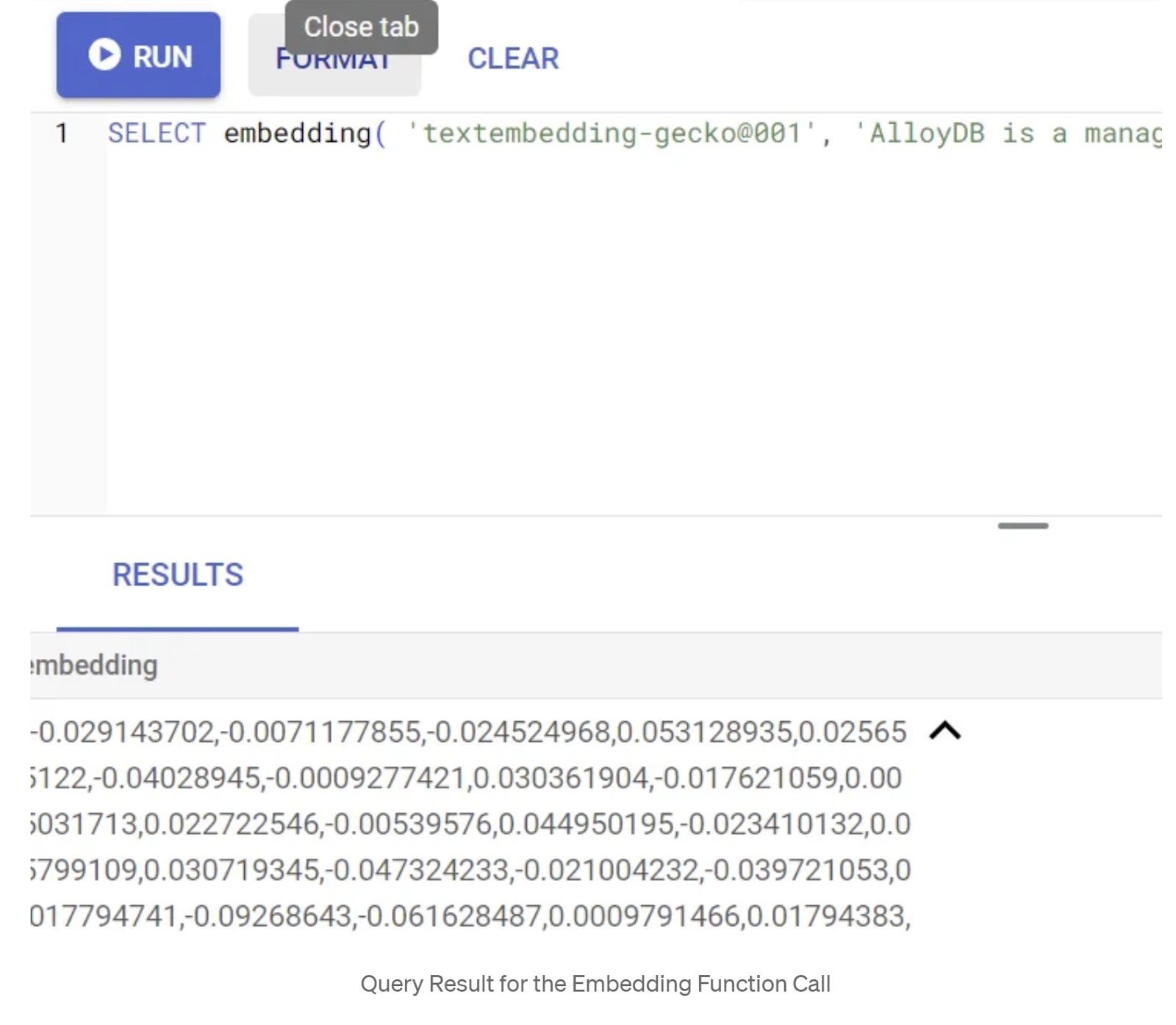
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Tindakan ini akan menampilkan vektor penyematan, yang terlihat seperti array float, untuk teks contoh dalam kueri. Tampilannya seperti ini:
Memperbarui kolom Vektor abstract_embeddings
Jalankan DML di bawah untuk memperbarui abstrak paten dalam tabel dengan penyematan yang sesuai hanya jika Anda belum menyisipkan data abstract_embeddings sebagai bagian dari skrip penyisipan:
UPDATE patents_data set abstract_embeddings = embedding( 'text-embedding-005', abstract);
Anda mungkin mengalami masalah saat membuat lebih dari beberapa penyematan (misalnya maksimal 20-25) jika menggunakan akun penagihan kredit uji coba untuk Google Cloud. Jadi, karena alasan itu, saya telah menyertakan penyematan dalam skrip penyisipan dan Anda akan memilikinya di tabel yang dimuat jika telah menyelesaikan langkah "memuat data paten ke dalam database".
6. Melakukan RAG Lanjutan dengan Fitur baru AlloyDB
Setelah tabel, data, dan penyematan siap, mari kita lakukan Penelusuran Vektor real-time untuk teks penelusuran pengguna. Anda dapat mengujinya dengan menjalankan kueri di bawah:
SELECT id || ' - ' || title as title FROM patents_data ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Dalam kueri ini,
- Teks yang ditelusuri pengguna adalah: "Sentiment Analysis".
- Kita mengonversinya menjadi embedding dalam metode embedding() menggunakan model: text-embedding-005.
- "<=>" mewakili penggunaan metode jarak COSINE SIMILARITY.
- Kita mengonversi hasil metode penyematan ke jenis vektor agar kompatibel dengan vektor yang disimpan dalam database.
- LIMIT 10 menunjukkan bahwa kita memilih 10 kecocokan terdekat dari teks penelusuran.
AlloyDB membawa RAG Penelusuran Vektor ke tingkat berikutnya:
Ada banyak hal yang diperkenalkan. Dua dari fitur yang berfokus pada developer adalah:
- Pemfilteran Inline
- Evaluator Recall
Pemfilteran Inline
Sebelumnya, sebagai developer, Anda harus melakukan kueri Penelusuran Vektor dan harus menangani pemfilteran dan recall. Pengoptimal Kueri AlloyDB membuat pilihan tentang cara menjalankan kueri dengan filter. Pemfilteran inline adalah teknik pengoptimalan kueri baru yang memungkinkan pengoptimal kueri AlloyDB mengevaluasi kondisi pemfilteran metadata dan penelusuran vektor secara bersamaan, dengan memanfaatkan indeks vektor dan indeks pada kolom metadata. Hal ini telah meningkatkan performa recall, sehingga developer dapat memanfaatkan apa yang ditawarkan AlloyDB secara langsung.
Pemfilteran inline paling cocok untuk kasus dengan selektifitas sedang. Saat menelusuri indeks vektor, AlloyDB hanya menghitung jarak untuk vektor yang cocok dengan kondisi pemfilteran metadata (filter fungsional Anda dalam kueri biasanya ditangani dalam klausa WHERE). Hal ini sangat meningkatkan performa untuk kueri ini yang melengkapi keunggulan pasca-filter atau pra-filter.
- Menginstal atau mengupdate ekstensi pgvector
CREATE EXTENSION IF NOT EXISTS vector WITH VERSION '0.8.0.google-3';
Jika ekstensi pgvector sudah diinstal, upgrade ekstensi vektor ke versi 0.8.0.google-3 atau yang lebih baru untuk mendapatkan kemampuan evaluator recall.
ALTER EXTENSION vector UPDATE TO '0.8.0.google-3';
Langkah ini hanya perlu dijalankan jika ekstensi vektor Anda adalah <0.8.0.google-3>.
Catatan penting: Jika jumlah baris kurang dari 100, Anda tidak perlu membuat indeks ScaNN karena indeks ini tidak akan berlaku untuk baris yang lebih sedikit. Dalam hal ini, lewati langkah-langkah berikut.
- Untuk membuat indeks ScaNN, instal ekstensi alloydb_scann.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
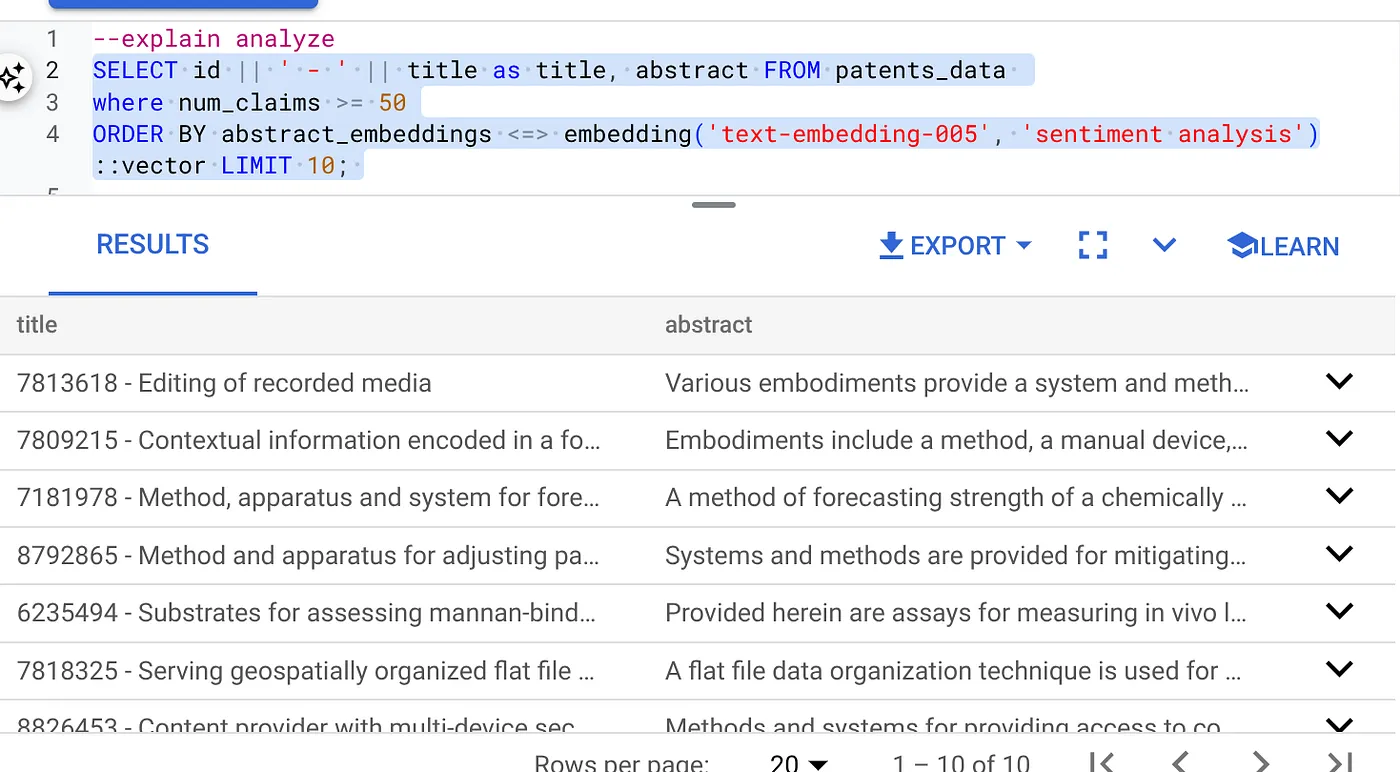
- Pertama, jalankan Kueri Penelusuran Vektor tanpa indeks dan tanpa mengaktifkan Filter Inline:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
Hasilnya akan terlihat seperti:
- Jalankan Explain Analyze di dalamnya: (tanpa indeks atau Pemfilteran Inline)
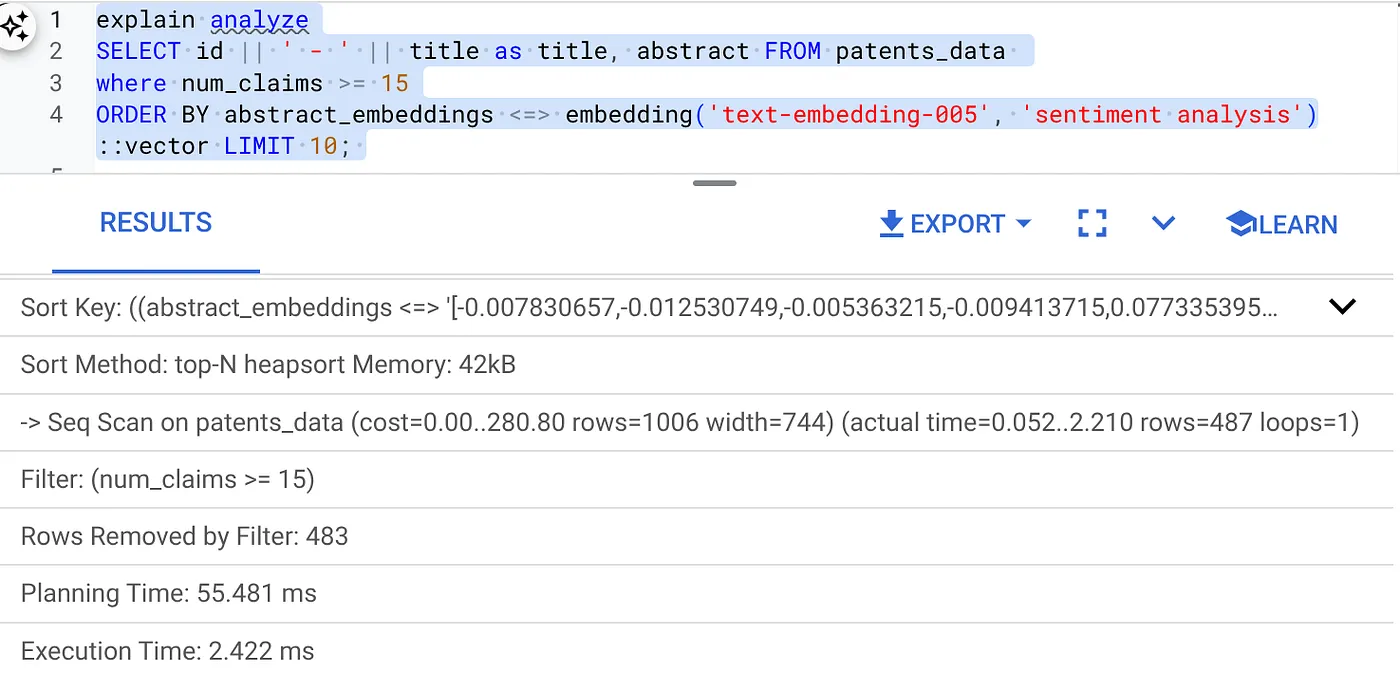
Waktu eksekusi adalah 2,4 md
- Mari kita buat indeks reguler pada kolom num_claims agar kita dapat memfilter berdasarkan kolom tersebut:
CREATE INDEX idx_patents_data_num_claims ON patents_data (num_claims);
- Mari kita buat indeks ScaNN untuk aplikasi Penelusuran Paten. Jalankan kode berikut dari AlloyDB Studio:
CREATE INDEX patent_index ON patents_data
USING scann (abstract_embeddings cosine)
WITH (num_leaves=32);
Catatan penting: (num_leaves=32) berlaku untuk total set data kami dengan lebih dari 1.000 baris. Jika jumlah baris kurang dari 100, Anda tidak perlu membuat indeks karena indeks tidak akan berlaku untuk baris yang lebih sedikit.
- Tetapkan Pemfilteran Inline yang diaktifkan di Indeks ScaNN:
SET scann.enable_inline_filtering = on
- Sekarang, mari kita jalankan kueri yang sama dengan filter dan Penelusuran Vektor di dalamnya:
SELECT id || ' - ' || title as title FROM patents_data
WHERE num_claims >= 15
ORDER BY abstract_embeddings <=> embedding('text-embedding-005', 'Sentiment Analysis')::vector LIMIT 10;
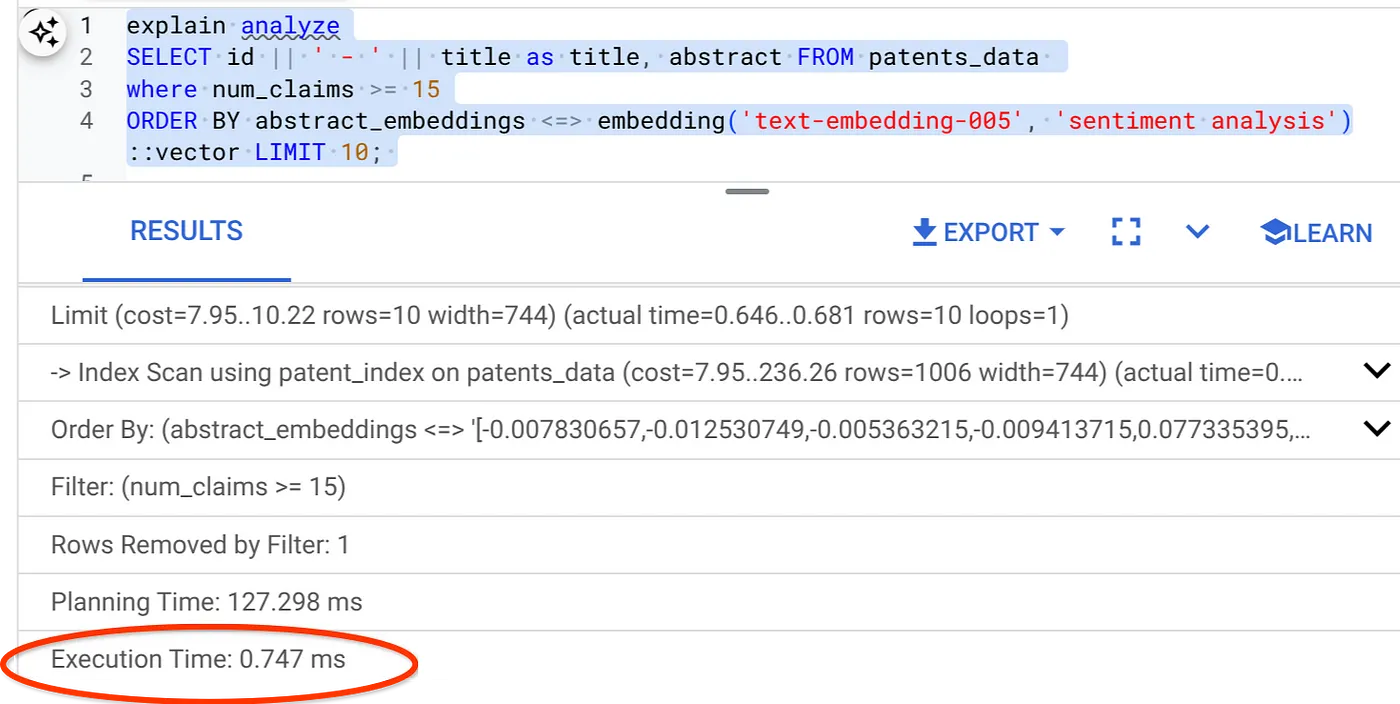
Seperti yang dapat Anda lihat, waktu eksekusi berkurang secara signifikan untuk Penelusuran Vektor yang sama. Pemfilteran Inline yang diinfusi dengan indeks ScaNN di Penelusuran Vektor telah memungkinkan hal ini.
Selanjutnya, mari kita evaluasi recall untuk Vector Search yang diaktifkan ScaNN ini.
Evaluator Recall
Perolehan dalam penelusuran kemiripan adalah persentase instance relevan yang diambil dari penelusuran, yaitu jumlah positif benar. Ini adalah metrik yang paling umum digunakan untuk mengukur kualitas penelusuran. Salah satu sumber penurunan recall berasal dari perbedaan antara penelusuran perkiraan tetangga terdekat, atau aNN, dan penelusuran tetangga terdekat k (persis), atau kNN. Indeks vektor seperti ScaNN AlloyDB menerapkan algoritma aNN, sehingga Anda dapat mempercepat penelusuran vektor pada set data besar dengan mengorbankan sedikit recall. Sekarang, AlloyDB memberi Anda kemampuan untuk mengukur kompromi ini langsung di database untuk setiap kueri dan memastikannya stabil dari waktu ke waktu. Anda dapat memperbarui parameter kueri dan indeks sebagai respons terhadap informasi ini untuk mendapatkan hasil dan performa yang lebih baik.
Apa logika di balik recall hasil penelusuran?
Dalam konteks penelusuran vektor, recall mengacu pada persentase vektor yang ditampilkan indeks yang merupakan tetangga terdekat sebenarnya. Misalnya, jika kueri tetangga terdekat untuk 20 tetangga terdekat menampilkan 19 tetangga terdekat dari kebenaran nyata, maka perolehannya adalah 19/20x100 = 95%. Perolehan adalah metrik yang digunakan untuk kualitas penelusuran, dan didefinisikan sebagai persentase hasil yang ditampilkan yang secara objektif paling dekat dengan vektor kueri.
Anda dapat menemukan recall untuk kueri vektor pada indeks vektor untuk konfigurasi tertentu menggunakan fungsi evaluate_query_recall. Fungsi ini memungkinkan Anda menyesuaikan parameter untuk mencapai hasil recall kueri vektor yang Anda inginkan.
Catatan Penting:
Jika Anda mengalami error izin ditolak pada indeks HNSW dalam langkah-langkah berikut, lewati seluruh bagian evaluasi recall ini untuk saat ini. Hal ini mungkin terkait dengan batasan akses pada saat ini karena baru dirilis pada saat codelab ini didokumentasikan.
- Tetapkan flag Enable Index Scan di indeks ScaNN & indeks HNSW:
SET scann.enable_indexscan = on
SET hnsw.enable_index_scan = on
- Jalankan kueri berikut di AlloyDB Studio:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 25 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Fungsi evaluate_query_recall mengambil kueri sebagai parameter dan menampilkan recall-nya. Saya menggunakan kueri yang sama dengan yang digunakan untuk memeriksa performa sebagai kueri input fungsi. Saya telah menambahkan SCaNN sebagai metode indeks. Untuk opsi parameter lainnya, lihat dokumentasi.
Recall untuk kueri Penelusuran Vektor ini yang telah kita gunakan:
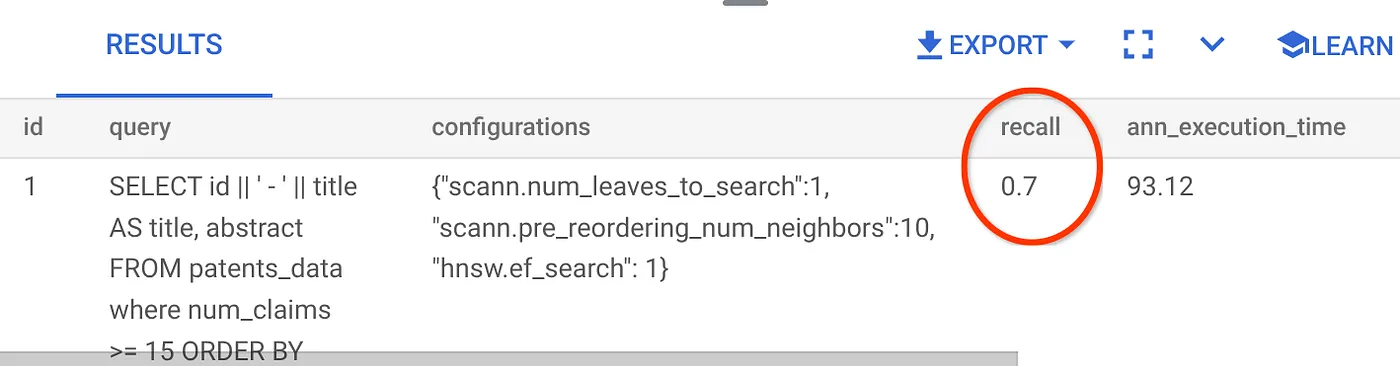
Saya melihat bahwa RECALL adalah 70%. Sekarang saya dapat menggunakan informasi ini untuk mengubah parameter indeks, metode, dan parameter kueri serta meningkatkan recall untuk Penelusuran Vektor ini.
7. Mengujinya dengan parameter kueri & indeks yang diubah
Sekarang, mari kita uji kueri dengan mengubah parameter kueri berdasarkan recall yang diterima.
- Saya telah mengubah jumlah baris dalam set hasil menjadi 7 (dari 25 sebelumnya) dan saya melihat peningkatan RECALL, yaitu 86%.

Artinya, secara real time, saya dapat memvariasikan jumlah kecocokan yang dapat dilihat pengguna untuk meningkatkan relevansi kecocokan sesuai dengan konteks penelusuran pengguna.
- Mari kita coba lagi dengan mengubah parameter indeks:
Untuk pengujian ini, saya akan menggunakan "Jarak L2", bukan fungsi jarak kemiripan "Kosinus". Saya juga akan mengubah batas kueri menjadi 10 untuk menunjukkan apakah ada peningkatan kualitas hasil penelusuran meskipun jumlah kumpulan hasil penelusuran meningkat.
[SEBELUMNYA] Kueri yang menggunakan fungsi jarak Kesamaan Kosinus:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <=> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Catatan Sangat Penting: Anda mungkin bertanya, "Bagaimana kita tahu kueri ini menggunakan kemiripan COSINE?" Anda dapat mengidentifikasi fungsi jarak dengan menggunakan "<=>" untuk merepresentasikan jarak Cosine.
Link dokumen untuk fungsi jarak Vector Search.
Hasil kueri di atas adalah:
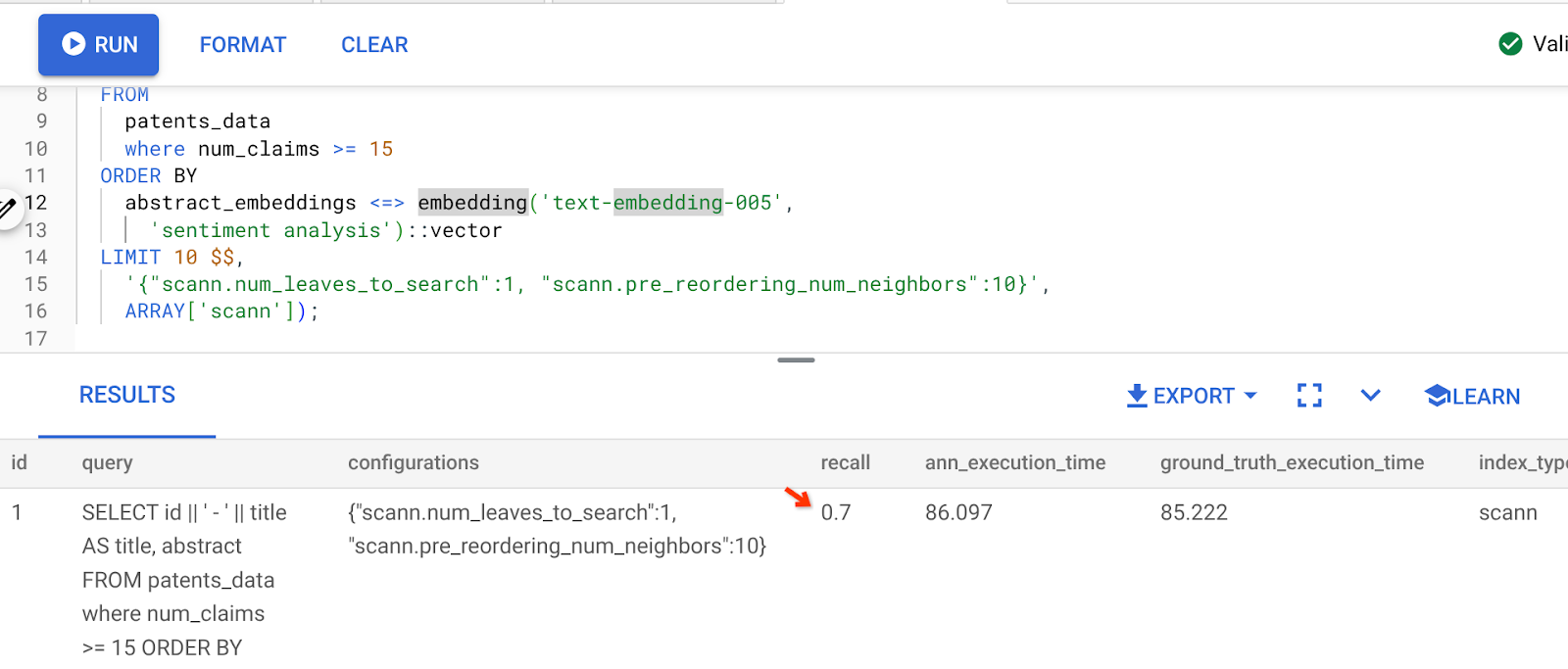
Seperti yang dapat Anda lihat, RECALL adalah 70% tanpa perubahan pada logika indeks kami. Ingat indeks ScaNN yang kita buat di langkah 6 bagian Pemfilteran Inline, "patent_index "? Indeks yang sama masih efektif saat kita menjalankan kueri di atas.
Sekarang, mari kita buat indeks dengan kueri fungsi jarak yang berbeda: Jarak L2: <->
drop index patent_index;
CREATE INDEX patent_index_L2 ON patents_data
USING scann (abstract_embeddings L2)
WITH (num_leaves=32);
Pernyataan drop index hanya untuk memastikan tidak ada indeks yang tidak perlu di tabel.
Sekarang, saya dapat menjalankan kueri berikut untuk mengevaluasi RECALL setelah mengubah fungsi jarak fungsi Penelusuran Vektor saya.
[AFTER] Kueri yang menggunakan fungsi jarak Kesamaan Kosinus:
SELECT
*
FROM
evaluate_query_recall($$
SELECT
id || ' - ' || title AS title,
abstract
FROM
patents_data
where num_claims >= 15
ORDER BY
abstract_embeddings <-> embedding('text-embedding-005',
'sentiment analysis')::vector
LIMIT 10 $$,
'{"scann.num_leaves_to_search":1, "scann.pre_reordering_num_neighbors":10}',
ARRAY['scann']);
Hasil kueri di atas adalah:
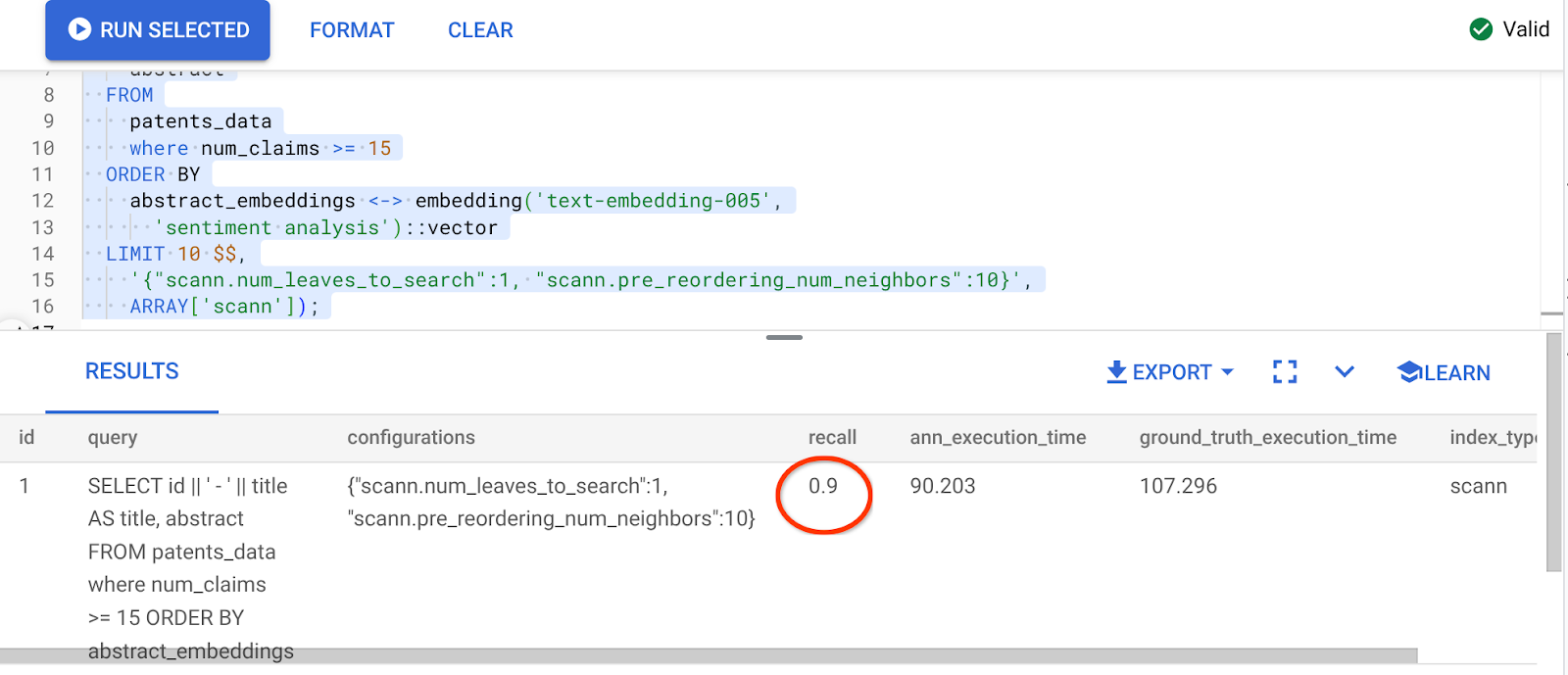
Transformasi nilai recall yang luar biasa, 90%!!!
Ada parameter lain yang dapat Anda ubah dalam indeks, seperti num_leaves, dll., berdasarkan nilai recall yang diinginkan dan set data yang digunakan aplikasi Anda.
8. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam postingan ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman resource manager.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
- Atau, Anda cukup menghapus cluster AlloyDB (ubah lokasi di hyperlink ini jika Anda tidak memilih us-central1 untuk cluster pada saat konfigurasi) yang baru saja kita buat untuk project ini dengan mengklik tombol HAPUS CLUSTER.
9. Selamat
Selamat! Anda telah berhasil membuat kueri Penelusuran Paten kontekstual dengan penelusuran Vektor lanjutan AlloyDB untuk performa tinggi dan membuatnya benar-benar berbasis makna. Saya telah menyusun aplikasi agen multi-alat yang dikontrol kualitas yang menggunakan ADK dan semua hal AlloyDB yang telah kita bahas di sini untuk membuat Agen Penelusuran & Penganalisis Vektor Paten yang berperforma tinggi dan berkualitas yang dapat Anda lihat di sini: https://youtu.be/Y9fvVY0yZTY
Jika Anda ingin mempelajari cara mem-build agen tersebut, lihat codelab ini.