
เกี่ยวกับ Codelab นี้
1 ภาพรวม
การวิจัยสิทธิบัตรเป็นเครื่องมือสำคัญในอุตสาหกรรมต่างๆ ในการทำความเข้าใจสภาพแวดล้อมทางการแข่งขัน ระบุโอกาสในการออกใบอนุญาตหรือการเข้าซื้อกิจการที่อาจเกิดขึ้น และหลีกเลี่ยงการละเมิดสิทธิบัตรที่มีอยู่
การค้นคว้าเรื่องสิทธิบัตรนั้นกว้างขวางและซับซ้อน การกลั่นกรองบทคัดย่อทางเทคนิคจำนวนนับไม่ถ้วนเพื่อค้นหานวัตกรรมที่เกี่ยวข้องเป็นงานที่น่ากังวล การค้นหาแบบเดิมที่อิงตามคีย์เวิร์ดมักไม่แม่นยำและใช้เวลานาน บทคัดย่อมีความยาวและเป็นเชิงเทคนิค ทำให้เข้าใจแนวคิดหลักได้ยาก ซึ่งอาจทำให้ผู้วิจัยพลาดสิทธิบัตรสำคัญหรือเสียเวลาไปกับผลการค้นหาที่ไม่เกี่ยวข้อง
เคล็ดลับเบื้องหลังการปฏิวัติครั้งนี้คือการค้นหาเวกเตอร์ การค้นหาเวกเตอร์จะเปลี่ยนข้อความเป็นตัวแทนเชิงตัวเลข (การฝัง) แทนที่จะอาศัยการจับคู่คีย์เวิร์ดแบบง่าย ซึ่งช่วยให้เราค้นหาตามความหมายของคำค้นหาได้ ไม่ใช่แค่คำที่ใช้เท่านั้น ในโลกของการค้นหางานวรรณกรรม นี่คือการเปลี่ยนแปลงครั้งสำคัญ ลองนึกถึงการค้นหาสิทธิบัตรสำหรับ "เครื่องวัดอัตราการเต้นของหัวใจแบบสวมใส่" แม้ว่าจะไม่มีการใช้วลีที่ตรงกันในเอกสารก็ตาม
วัตถุประสงค์
ในโค้ดแล็บนี้ เราจะพยายามทำให้กระบวนการค้นหาสิทธิบัตรเร็วขึ้น ใช้งานง่ายขึ้น และแม่นยำอย่างยิ่งด้วยการใช้ประโยชน์จาก AlloyDB, ส่วนขยาย pgvector รวมถึง Gemini 1.5 Pro, Embeddings และ Vector Search ในตัว
สิ่งที่คุณจะสร้าง
ในห้องทดลองนี้ คุณจะทำสิ่งต่อไปนี้
- สร้างอินสแตนซ์ AlloyDB และโหลดข้อมูลชุดข้อมูลสาธารณะเกี่ยวกับสิทธิบัตร
- เปิดใช้ส่วนขยาย pgvector และโมเดล Generative AI ใน AlloyDB
- สร้างการฝังจากข้อมูลเชิงลึก
- ทำการค้นหาความคล้ายกันของโคไซน์แบบเรียลไทม์สำหรับข้อความค้นหาของผู้ใช้
- ติดตั้งใช้งานโซลูชันในฟังก์ชันระบบคลาวด์แบบ Serverless
แผนภาพต่อไปนี้แสดงโฟลว์ของข้อมูลและขั้นตอนที่เกี่ยวข้องในการติดตั้งใช้งาน
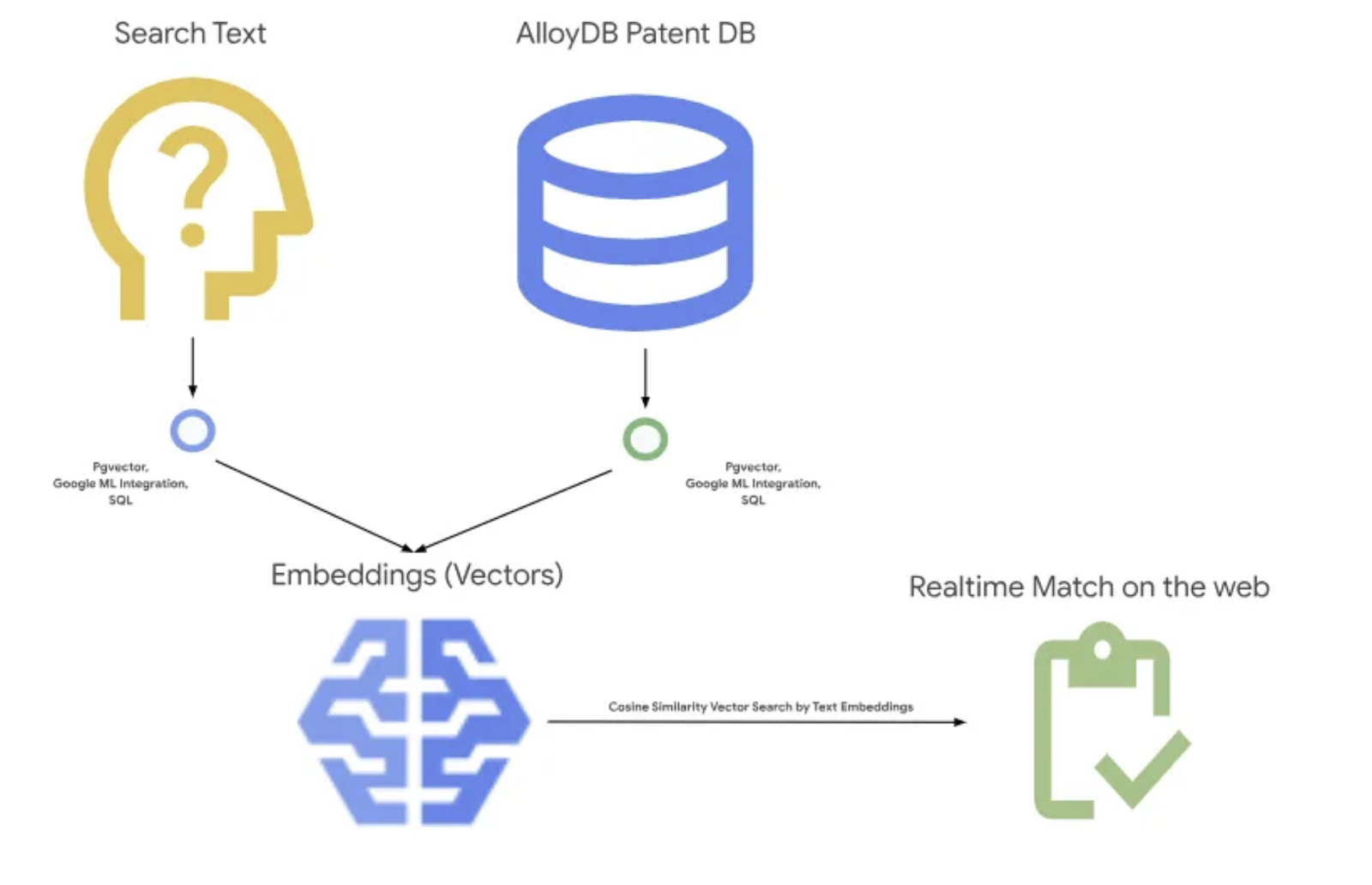
High level diagram representing the flow of the Patent Search Application with AlloyDB
ข้อกำหนด
2 ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud และโหลด bq ไว้ล่วงหน้า คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์ของคุณโดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น คุณใช้คำสั่ง gcloud ในเทอร์มินัล Cloud Shell ได้โดยทำดังนี้
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
คุณสามารถใช้คอนโซลแทนคำสั่ง gcloud ได้โดยค้นหาแต่ละผลิตภัณฑ์หรือใช้ลิงก์นี้
โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3 เตรียมฐานข้อมูล AlloyDB
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่จะโหลดชุดข้อมูลสิทธิบัตรกัน
สร้างออบเจ็กต์ AlloyDB
สร้างคลัสเตอร์และอินสแตนซ์ที่มีรหัสคลัสเตอร์ "patent-cluster" รหัสผ่าน "alloydb" เข้ากันได้กับ PostgreSQL 15 และภูมิภาคเป็น "us-central1" ตั้งค่าเครือข่ายเป็น "default" ตั้งรหัสอินสแตนซ์เป็น "patent-instance" คลิกสร้างคลัสเตอร์ ดูรายละเอียดการสร้างคลัสเตอร์ได้ที่ลิงก์ https://cloud.google.com/alloydb/docs/cluster-create
สร้างตาราง
คุณสร้างตารางได้โดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT) ;
เปิดใช้ส่วนขยาย
สำหรับการสร้างแอปค้นหาสิทธิบัตร เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เพื่อเข้าถึงปลายทางการคาดการณ์ของ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION vector;
CREATE EXTENSION google_ml_integration;
ให้สิทธิ์
เรียกใช้คำสั่งด้านล่างเพื่อให้สิทธิ์ดำเนินการในฟังก์ชัน "embedding"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล Google Cloud IAM ให้สิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" แก่บัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือจะให้สิทธิ์เข้าถึงโดยใช้คำสั่ง gcloud ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
แก้ไขตารางเพื่อเพิ่มคอลัมน์เวกเตอร์สำหรับจัดเก็บการฝัง
เรียกใช้ DDL ด้านล่างเพื่อเพิ่มฟิลด์ abstract_embeddings ลงในตารางที่เราเพิ่งสร้าง คอลัมน์นี้จะอนุญาตให้จัดเก็บค่าเวกเตอร์ของข้อความ
ALTER TABLE patents_data ADD column abstract_embeddings vector(3072);
4 โหลดข้อมูลสิทธิบัตรลงในฐานข้อมูล
เราจะใช้ชุดข้อมูลสาธารณะของ Google Patents ใน BigQuery เป็นชุดข้อมูล เราจะใช้ AlloyDB Studio เพื่อเรียกใช้การค้นหา ที่เก็บ alloydb-pgvector มีสคริปต์ insert_into_patents_data.sql ที่เราจะเรียกใช้เพื่อโหลดข้อมูลสิทธิบัตร
- เปิดหน้า AlloyDB ใน Google Cloud Console
- เลือกคลัสเตอร์ที่สร้างขึ้นใหม่ แล้วคลิกอินสแตนซ์
- ในเมนูการนำทางของ AlloyDB ให้คลิก AlloyDB Studio ลงชื่อเข้าใช้ด้วยข้อมูลเข้าสู่ระบบ
- เปิดแท็บใหม่โดยคลิกไอคอนแท็บใหม่ทางด้านขวา
- คัดลอก
insertคำสั่งค้นหาจากสคริปต์insert_into_patents_data.sqlที่กล่าวถึงข้างต้นไปยังเครื่องมือแก้ไข คุณสามารถคัดลอกคำสั่ง INSERT 50-100 รายการเพื่อสาธิตกรณีการใช้งานนี้อย่างรวดเร็ว - คลิกเรียกใช้ ผลลัพธ์ของคำค้นหาจะปรากฏในตารางผลลัพธ์
5 สร้างการฝังสำหรับข้อมูลสิทธิบัตร
ก่อนอื่น มาทดสอบฟังก์ชันการฝังโดยเรียกใช้การสืบค้นตัวอย่างต่อไปนี้
SELECT embedding( 'gemini-embedding-001', 'AlloyDB is a managed, cloud-hosted SQL database service.');
ซึ่งควรแสดงผลเวกเตอร์การฝังที่มีลักษณะคล้ายอาร์เรย์ของจำนวนทศนิยมสำหรับข้อความตัวอย่างในการค้นหา มีลักษณะดังนี้
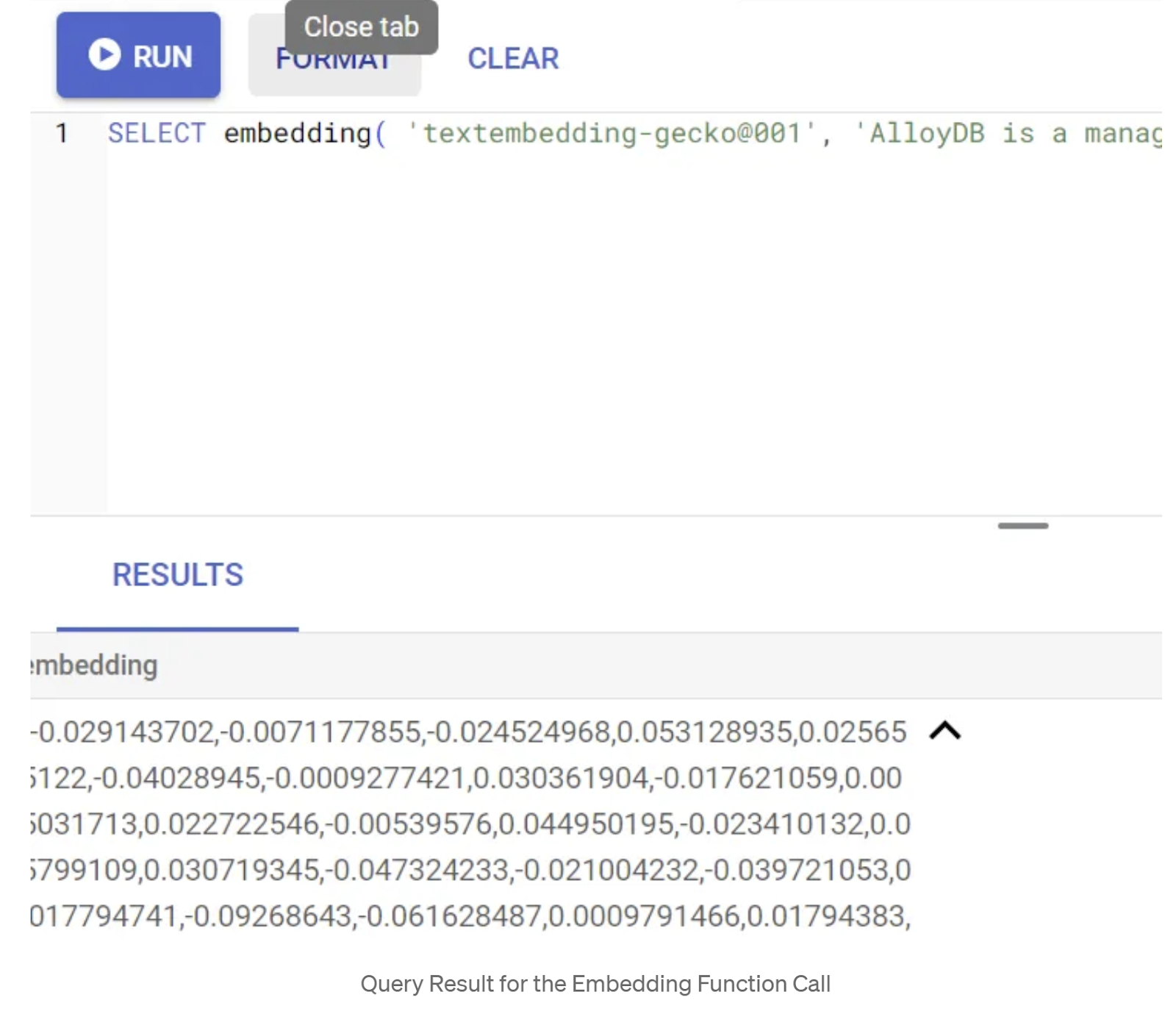
อัปเดตฟิลด์เวกเตอร์ abstract_embeddings
เรียกใช้ DML ด้านล่างเพื่ออัปเดตข้อมูลย่อของสิทธิบัตรในตารางด้วยการฝังที่เกี่ยวข้อง
UPDATE patents_data set abstract_embeddings = embedding( 'gemini-embedding-001', abstract);
6 ทำการค้นหาเวกเตอร์
ตอนนี้ตาราง ข้อมูล และการฝังพร้อมแล้ว เรามาทำการค้นหาเวกเตอร์แบบเรียลไทม์สำหรับข้อความค้นหาของผู้ใช้กัน คุณทดสอบได้โดยเรียกใช้คำค้นหาด้านล่าง
SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('gemini-embedding-001', 'A new Natural Language Processing related Machine Learning Model')::vector LIMIT 10;
ในคำค้นหานี้
- ข้อความค้นหาของผู้ใช้คือ "โมเดลแมชชีนเลิร์นนิงใหม่ที่เกี่ยวข้องกับการประมวลผลภาษาธรรมชาติ"
- เราจะแปลงเป็น Embedding ในเมธอด embedding() โดยใช้โมเดล gemini-embedding-001
- "<=>" แสดงถึงการใช้วิธีการวัดระยะทาง COSINE SIMILARITY
- เราจะแปลงผลลัพธ์ของวิธีการฝังเป็นประเภทเวกเตอร์เพื่อให้เข้ากันได้กับเวกเตอร์ที่จัดเก็บไว้ในฐานข้อมูล
- LIMIT 10 หมายความว่าเราจะเลือกผลการค้นหาที่ตรงกับข้อความค้นหามากที่สุด 10 รายการ
ผลลัพธ์ที่ได้มีดังนี้
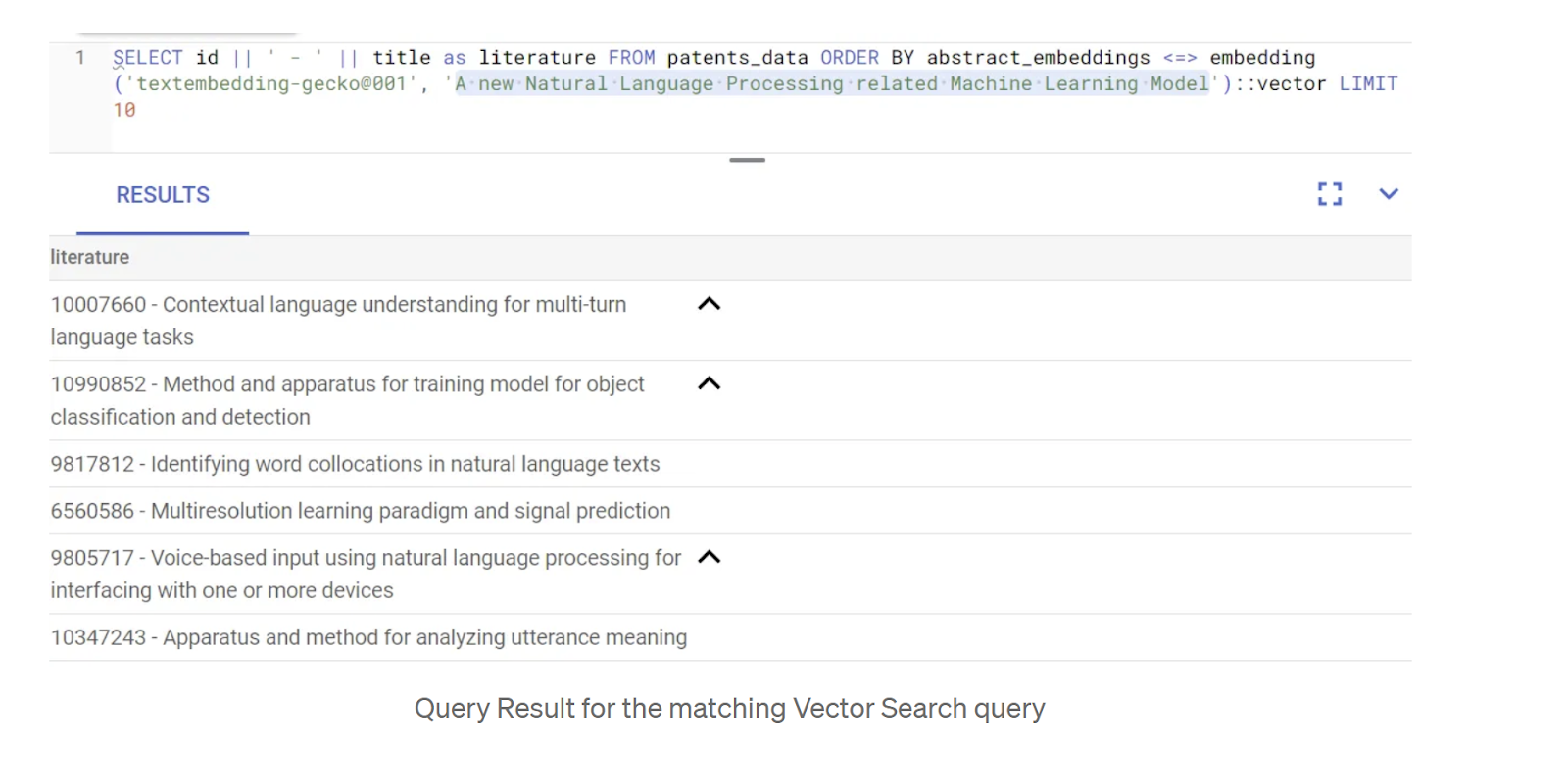
ดังที่คุณเห็นในผลการค้นหา ข้อความที่ตรงกันจะค่อนข้างใกล้เคียงกับข้อความค้นหา
7 นำแอปพลิเคชันไปใช้บนเว็บ
พร้อมที่จะนำแอปนี้ไปใช้บนเว็บแล้วใช่ไหม โดยทำตามขั้นตอนต่อไปนี้
- ไปที่ Cloud Shell Editor แล้วคลิกไอคอน "Cloud Code - ลงชื่อเข้าใช้" ที่มุมซ้ายล่าง (แถบสถานะ) ของโปรแกรมแก้ไข เลือกโปรเจ็กต์ Google Cloud ปัจจุบันที่เปิดใช้การเรียกเก็บเงินแล้ว และตรวจสอบว่าคุณได้ลงชื่อเข้าใช้โปรเจ็กต์เดียวกันจาก Gemini ด้วย (ที่มุมขวาของแถบสถานะ)
- คลิกไอคอน Cloud Code แล้วรอจนกว่ากล่องโต้ตอบ Cloud Code จะปรากฏขึ้น เลือกแอปพลิเคชันใหม่ แล้วเลือกแอปพลิเคชัน Cloud Functions ในป๊อปอัปสร้างแอปพลิเคชันใหม่
ในหน้า 2/2 ของป๊อปอัปสร้างแอปพลิเคชันใหม่ ให้เลือก Java: Hello World แล้วป้อนชื่อโปรเจ็กต์เป็น "alloydb-pgvector" ในตำแหน่งที่ต้องการ แล้วคลิกตกลง
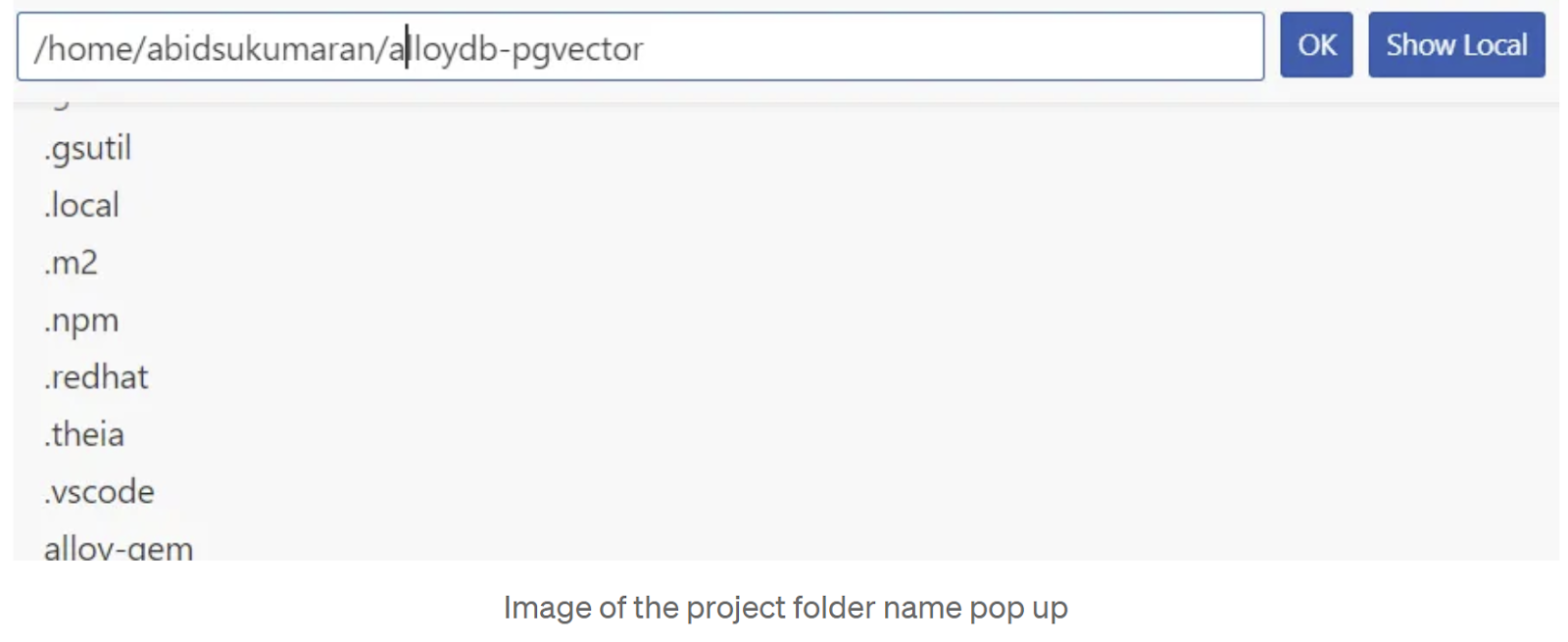
- ในโครงสร้างโปรเจ็กต์ที่ได้ ให้ค้นหา pom.xml แล้วแทนที่ด้วยเนื้อหาจากไฟล์ repo โดยควรมีทรัพยากร Dependency เหล่านี้เพิ่มเติมจากทรัพยากรอื่นๆ

- แทนที่ไฟล์ HelloWorld.java ด้วยเนื้อหาจากไฟล์ repo
โปรดทราบว่าคุณต้องแทนที่ค่าด้านล่างด้วยค่าจริง
String ALLOYDB_DB = "postgres";
String ALLOYDB_USER = "postgres";
String ALLOYDB_PASS = "*****";
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
//Replace YOUR_PROJECT_ID, YOUR_CLUSTER, YOUR_INSTANCE with your actual values
โปรดทราบว่าฟังก์ชันนี้คาดหวังให้ข้อความค้นหาเป็นพารามิเตอร์อินพุตที่มีคีย์ "search" และในการติดตั้งใช้งานนี้ เราจะแสดงผลเฉพาะรายการที่ตรงกันมากที่สุด 1 รายการจากฐานข้อมูล
// Get the request body as a JSON object.
JsonObject requestJson = new Gson().fromJson(request.getReader(), JsonObject.class);
String searchText = requestJson.get("search").getAsString();
//Sample searchText: "A new Natural Language Processing related Machine Learning Model";
BufferedWriter writer = response.getWriter();
String result = "";
HikariDataSource dataSource = AlloyDbJdbcConnector();
try (Connection connection = dataSource.getConnection()) {
//Retrieve Vector Search by text (converted to embeddings) using "Cosine Similarity" method
try (PreparedStatement statement = connection.prepareStatement("SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('tgemini-embedding-001', '" + searchText + "' )::vector LIMIT 1")) {
ResultSet resultSet = statement.executeQuery();
resultSet.next();
String lit = resultSet.getString("literature");
result = result + lit + "\n";
System.out.println("Matching Literature: " + lit);
}
writer.write("Here is the closest match: " + result);
}
- หากต้องการทําให้ Cloud Function ที่เพิ่งสร้างใช้งานได้ ให้เรียกใช้คําสั่งต่อไปนี้จากเทอร์มินัล Cloud Shell อย่าลืมไปที่โฟลเดอร์โปรเจ็กต์ที่เกี่ยวข้องก่อนโดยใช้คำสั่งต่อไปนี้
cd alloydb-pgvector
จากนั้นเรียกใช้คำสั่งต่อไปนี้
gcloud functions deploy patent-search --gen2 --region=us-central1 --runtime=java11 --source=. --entry-point=cloudcode.helloworld.HelloWorld --trigger-http
ขั้นตอนสำคัญ:
เมื่อตั้งค่าสำหรับการติดตั้งใช้งานแล้ว คุณควรจะเห็นฟังก์ชันในคอนโซลฟังก์ชัน Cloud Run ของ Google ค้นหาฟังก์ชันที่สร้างขึ้นใหม่แล้วเปิด แก้ไขการกำหนดค่า และเปลี่ยนค่าต่อไปนี้
- ไปที่การตั้งค่ารันไทม์ การสร้าง การเชื่อมต่อ และความปลอดภัย
- เพิ่มการหมดเวลาเป็น 180 วินาที
- ไปที่แท็บการเชื่อมต่อโดยทำดังนี้
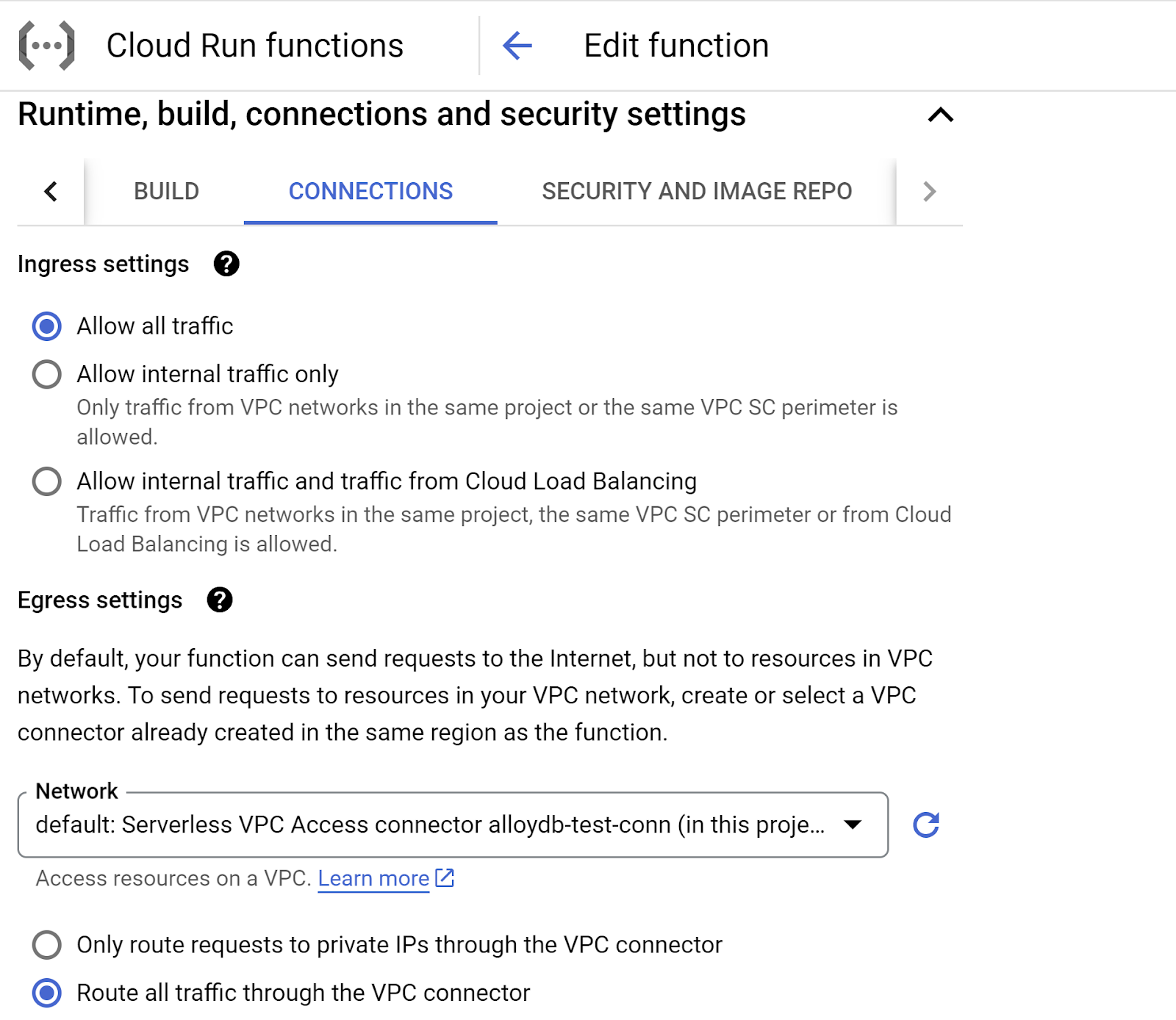
- ตรวจสอบว่าได้เลือก "อนุญาตการรับส่งข้อมูลทั้งหมด" ในการตั้งค่าขาเข้า
- ในส่วนการตั้งค่าขาออก ให้คลิกเมนูแบบเลื่อนลงของเครือข่าย แล้วเลือกตัวเลือก "เพิ่มตัวเชื่อมต่อ VPC ใหม่" จากนั้นทำตามวิธีการที่เห็นในกล่องโต้ตอบที่ปรากฏขึ้น
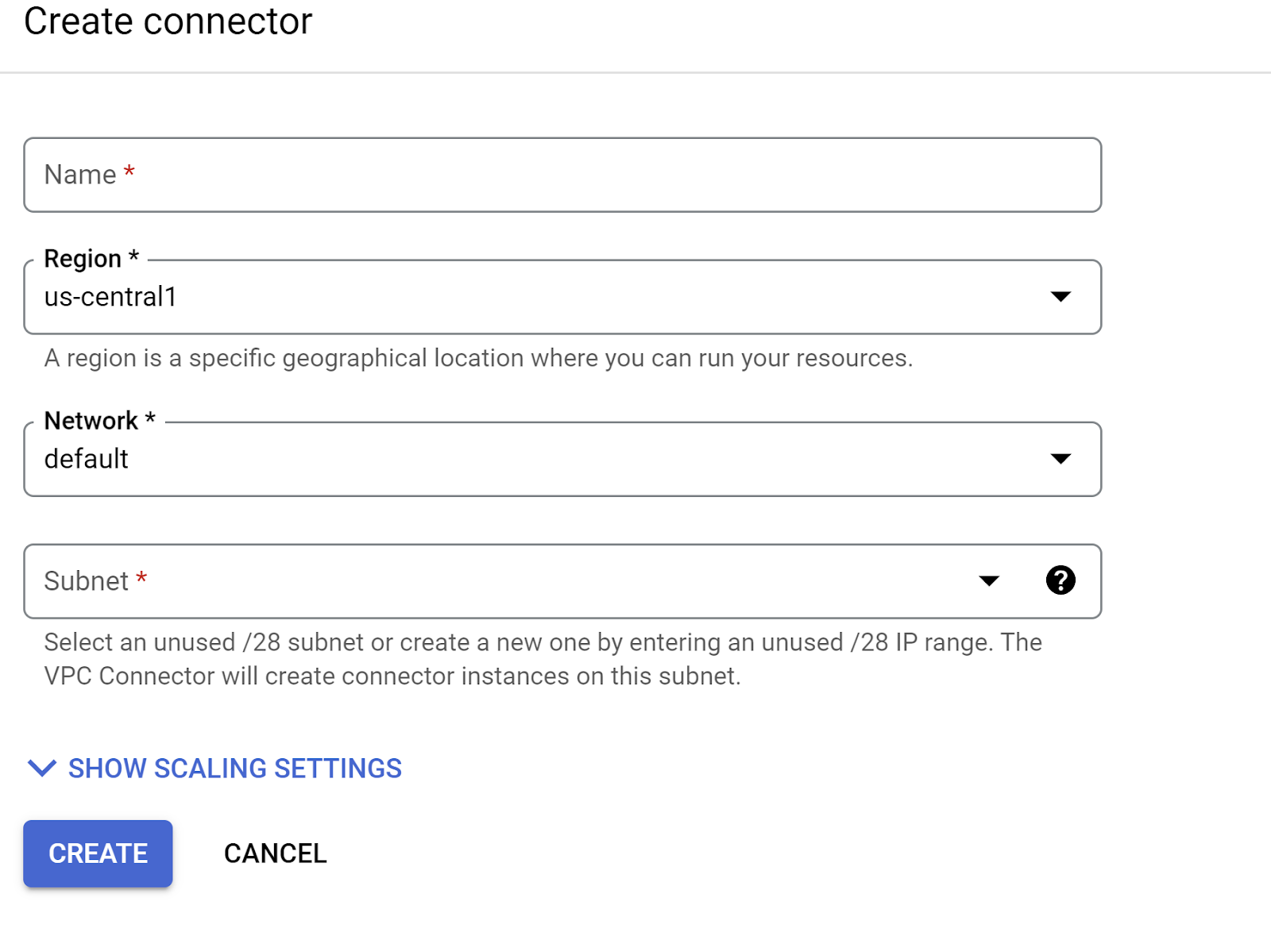
- ตั้งชื่อเครื่องมือเชื่อมต่อ VPC และตรวจสอบว่าภูมิภาคตรงกับอินสแตนซ์ ปล่อยให้ค่าเครือข่ายเป็นค่าเริ่มต้น และตั้งค่าเครือข่ายย่อยเป็นช่วง IP ที่กำหนดเองโดยมีช่วง IP เป็น 10.8.0.0 หรือค่าที่คล้ายกันที่ใช้ได้
- ขยาย "แสดงการตั้งค่าการปรับขนาด" และตรวจสอบว่าคุณได้ตั้งค่าการกำหนดค่าเป็นดังนี้
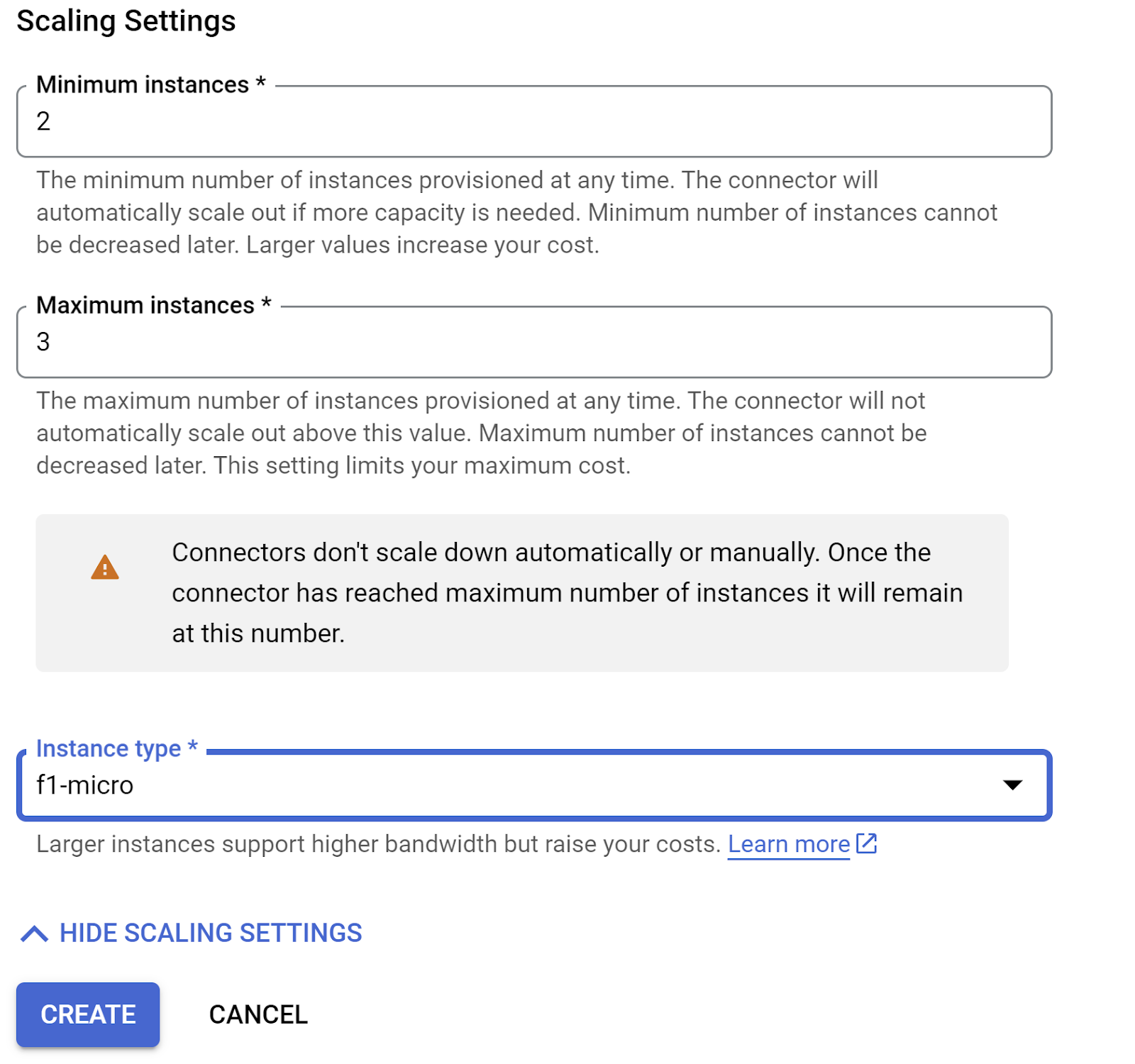
- คลิกสร้าง แล้วเครื่องมือเชื่อมต่อนี้ควรแสดงในการตั้งค่าขาออกในตอนนี้
- เลือกตัวเชื่อมต่อที่สร้างขึ้นใหม่
- เลือกให้กำหนดเส้นทางการรับส่งข้อมูลทั้งหมดผ่านเครื่องมือเชื่อมต่อ VPC นี้
8 ทดสอบแอปพลิเคชัน
เมื่อติดตั้งใช้งานแล้ว คุณจะเห็นปลายทางในรูปแบบต่อไปนี้
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/patent-search
คุณสามารถทดสอบได้จากเทอร์มินัล Cloud Shell โดยเรียกใช้คำสั่งต่อไปนี้
gcloud functions call patent-search --region=us-central1 --gen2 --data '{"search": "A new Natural Language Processing related Machine Learning Model"}'
ผลลัพธ์:
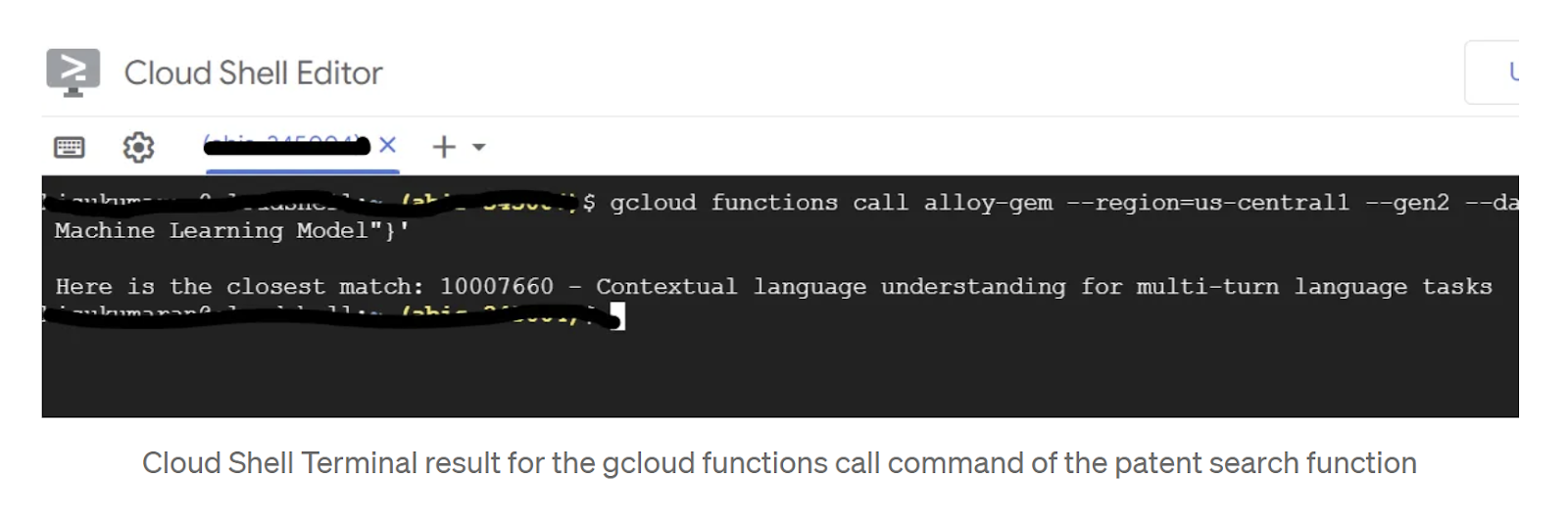
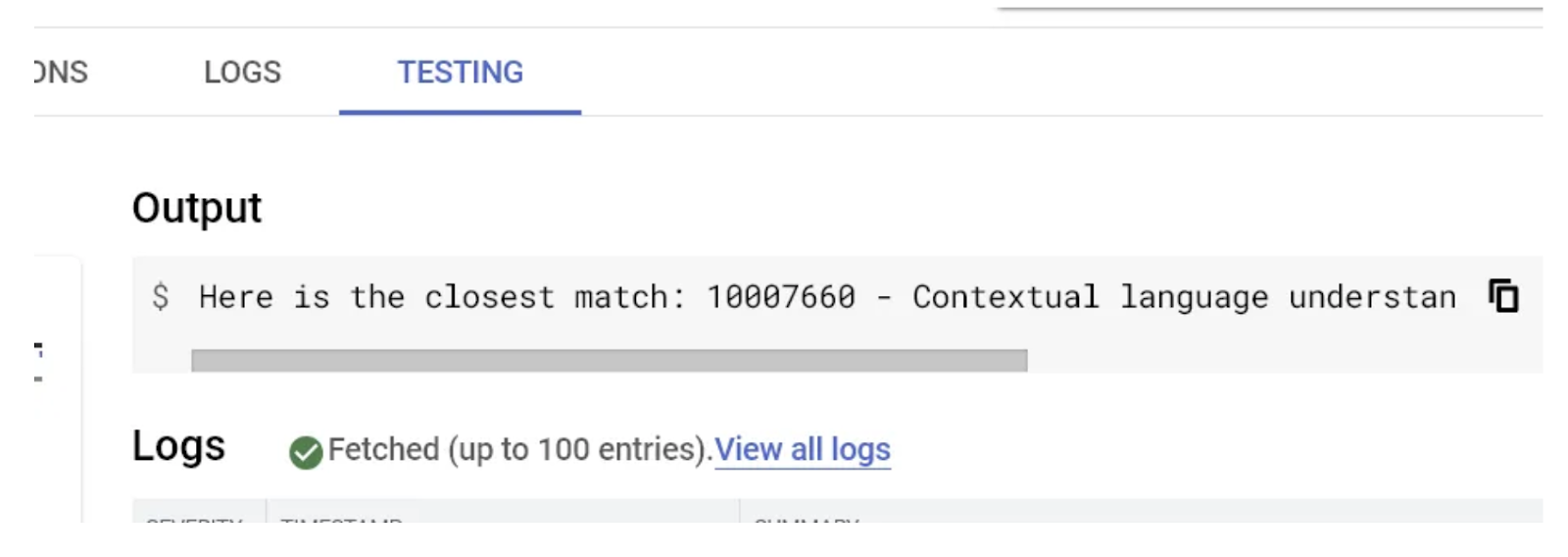
นอกจากนี้ คุณยังทดสอบจากรายการ Cloud Functions ได้ด้วย เลือกฟังก์ชันที่ติดตั้งใช้งานแล้วไปที่แท็บ "การทดสอบ" ในกล่องข้อความส่วนกำหนดค่าเหตุการณ์ทริกเกอร์สำหรับ JSON ของคำขอ ให้ป้อนข้อมูลต่อไปนี้
{"search": "A new Natural Language Processing related Machine Learning Model"}
คลิกปุ่มทดสอบฟังก์ชัน แล้วคุณจะเห็นผลลัพธ์ทางด้านขวาของหน้า
เท่านี้ก็เรียบร้อย การค้นหาเวกเตอร์ความคล้ายคลึงโดยใช้โมเดลการฝังในข้อมูล AlloyDB นั้นง่ายดายเพียงเท่านี้
9 ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่จัดการ
- แหล่งข้อมูล
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
10 ขอแสดงความยินดี
ยินดีด้วย คุณทำการค้นหาความคล้ายคลึงโดยใช้ AlloyDB, pgvector และการค้นหาเวกเตอร์เรียบร้อยแล้ว การผสานความสามารถของ AlloyDB, Vertex AI และ Vector Search ทำให้เราก้าวกระโดดไปข้างหน้าในการทำให้การค้นหางานเขียนเข้าถึงได้ มีประสิทธิภาพ และขับเคลื่อนด้วยความหมายอย่างแท้จริง