
关于此 Codelab
1. 概览
在各个行业中,专利研究都是了解竞争格局、发现潜在许可或收购机会以及避免侵犯现有专利的关键工具。
专利研究涉及的范围非常广,而且非常复杂。从无数技术摘要中过滤出相关创新是一项艰巨的任务。传统的基于关键字的搜索通常不准确且耗时。摘要冗长且技术性强,很难快速掌握核心思想。这可能会导致研究人员错过关键专利,或在不相关的结果上浪费时间。
这场革命背后的秘诀在于向量搜索。向量搜索不会依赖简单的关键字匹配,而是将文本转换为数值表示法(嵌入)。这样一来,我们就可以根据查询的含义(而不仅仅是所用的具体字词)进行搜索。在文献搜索领域,这项功能是一项革命性的突破。想象一下,即使文档中没有使用“可穿戴心率监测器”这个确切词组,您也能找到相关专利。
目标
在此 Codelab 中,我们将利用 AlloyDB、pgvector 扩展程序、原地 Gemini 1.5 Pro、嵌入和向量搜索,努力使专利搜索过程更快、更直观且极其精确。
构建内容
在本实验中,您将:
- 创建 AlloyDB 实例并加载“专利公开数据集”数据
- 在 AlloyDB 中启用 pgvector 和生成式 AI 模型扩展程序
- 根据数据分析生成嵌入
- 针对用户搜索文本执行实时余弦相似度搜索
- 在无服务器 Cloud Functions 中部署解决方案
下图展示了实现过程中涉及的数据流和步骤。
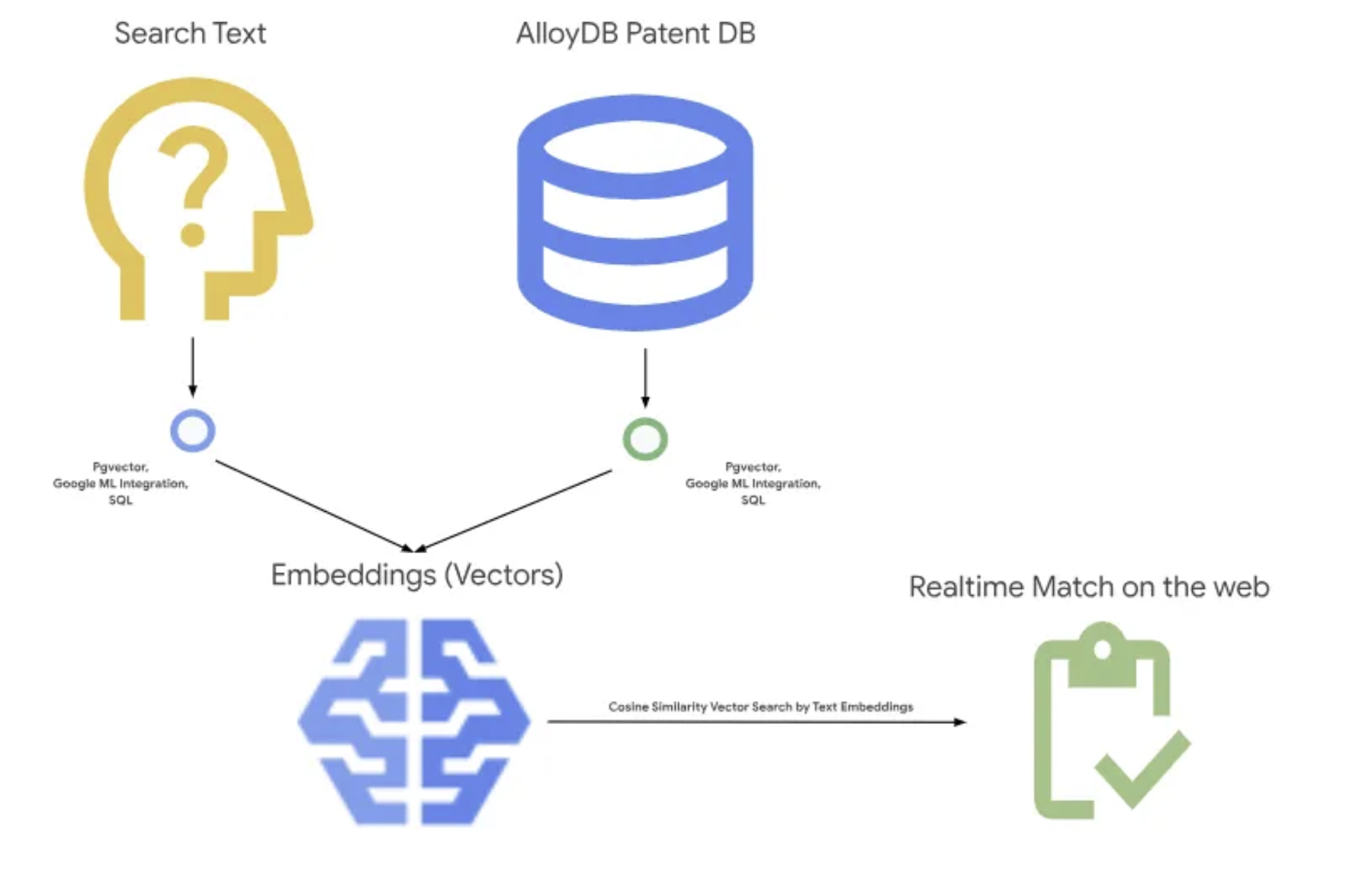
High level diagram representing the flow of the Patent Search Application with AlloyDB
要求
2. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,这是一个在 Google Cloud 中运行的命令行环境,它预加载了 bq。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 启用所需的 API。 您可以在 Cloud Shell 终端中使用 gcloud 命令:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
除了使用 gcloud 命令,您还可以通过控制台搜索每个产品或使用此链接。
如需了解 gcloud 命令和用法,请参阅文档。
3. 准备 AlloyDB 数据库
接下来,我们来创建 AlloyDB 集群、实例和表,以便加载专利数据集。
创建 AlloyDB 对象
创建集群 ID 为“patent-cluster”、密码为“alloydb”、与 PostgreSQL 15 兼容且区域为“us-central1”、网络设置为“default”的集群和实例。将实例 ID 设置为“patent-instance”。点击“创建集群”。如需了解如何创建集群的详细信息,请访问以下链接:https://cloud.google.com/alloydb/docs/cluster-create。
创建表
您可以在 AlloyDB Studio 中使用以下 DDL 语句创建表:
CREATE TABLE patents_data ( id VARCHAR(25), type VARCHAR(25), number VARCHAR(20), country VARCHAR(2), date VARCHAR(20), abstract VARCHAR(300000), title VARCHAR(100000), kind VARCHAR(5), num_claims BIGINT, filename VARCHAR(100), withdrawn BIGINT) ;
启用扩展程序
为了构建专利搜索应用,我们将使用扩展程序 pgvector 和 google_ml_integration。借助 pgvector 扩展程序,您可以存储和搜索向量嵌入。google_ml_integration 扩展程序提供用于访问 Vertex AI 预测端点以在 SQL 中获取预测结果的函数。运行以下 DDL 以启用这些扩展程序:
CREATE EXTENSION vector;
CREATE EXTENSION google_ml_integration;
授予权限
运行以下语句,以授予对“embedding”函数的执行权限:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
为 AlloyDB 服务账号授予 Vertex AI User 角色
在 Google Cloud IAM 控制台中,向 AlloyDB 服务账号(类似于:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)授予“Vertex AI 用户”角色访问权限。PROJECT_NUMBER 将包含您的项目编号。
或者,您也可以使用 gcloud 命令授予访问权限:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
更改表以添加用于存储嵌入的向量列
运行以下 DDL,将 abstract_embeddings 字段添加到我们刚刚创建的表中。此列将允许存储文本的向量值:
ALTER TABLE patents_data ADD column abstract_embeddings vector(3072);
4. 将专利数据加载到数据库中
我们将使用 BigQuery 上的 Google 专利公共数据集作为我们的数据集。我们将使用 AlloyDB Studio 运行查询。alloydb-pgvector 代码库包含我们将运行以加载专利数据的 insert_into_patents_data.sql 脚本。
- 在 Google Cloud 控制台中,打开 AlloyDB 页面。
- 选择新创建的集群,然后点击相应实例。
- 在 AlloyDB 导航菜单中,点击 AlloyDB Studio。使用凭据登录。
- 点击右侧的新建标签页图标,打开新标签页。
- 将上述
insert_into_patents_data.sql脚本中的insert查询语句复制到编辑器中。您可以复制 50-100 条 insert 语句,以便快速演示此使用情形。 - 点击运行。查询结果会显示在结果表中。
5. 为专利数据创建嵌入
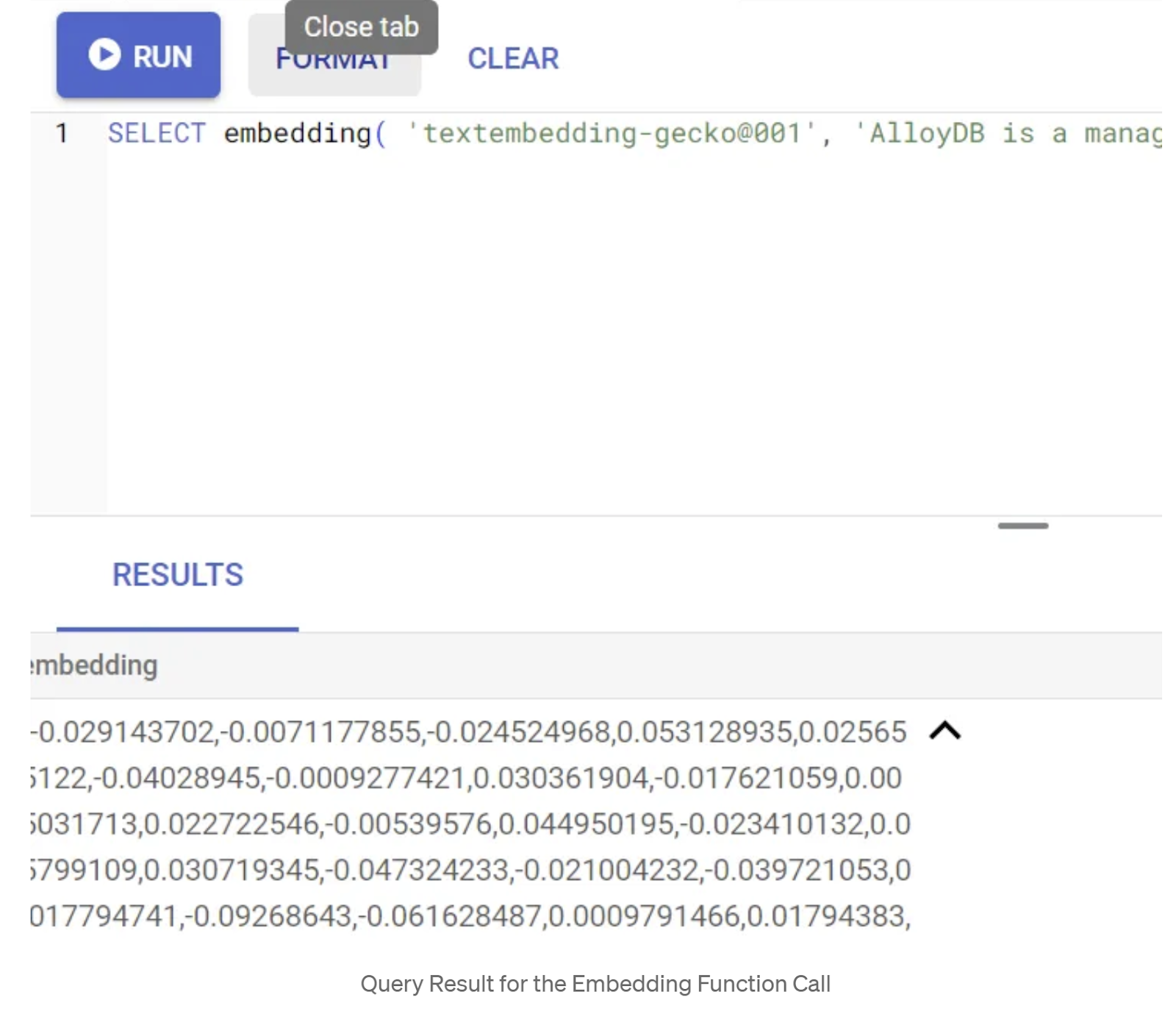
首先,我们运行以下示例查询来测试嵌入函数:
SELECT embedding( 'gemini-embedding-001', 'AlloyDB is a managed, cloud-hosted SQL database service.');
这应该会返回查询中示例文本的嵌入向量,该向量看起来像一个浮点数数组。如下所示:
更新 abstract_embeddings 向量字段
运行以下 DML 以使用相应的嵌入内容更新表中的专利摘要:
UPDATE patents_data set abstract_embeddings = embedding( 'gemini-embedding-001', abstract);
6. 执行 Vector Search
现在,表、数据和嵌入都已准备就绪,接下来我们来针对用户搜索文本执行实时向量搜索。您可以通过运行以下查询来测试这一点:
SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('gemini-embedding-001', 'A new Natural Language Processing related Machine Learning Model')::vector LIMIT 10;
在此查询中,
- 用户搜索文本为:“A new Natural Language Processing related Machine Learning Model”。
- 我们正在使用模型 gemini-embedding-001 在 embedding() 方法中将其转换为嵌入。
- “<=>”表示使用余弦相似度距离方法。
- 我们将嵌入方法的结果转换为向量类型,以使其与存储在数据库中的向量兼容。
- LIMIT 10 表示我们选择的是与搜索文本最接近的 10 个匹配项。
结果如下:
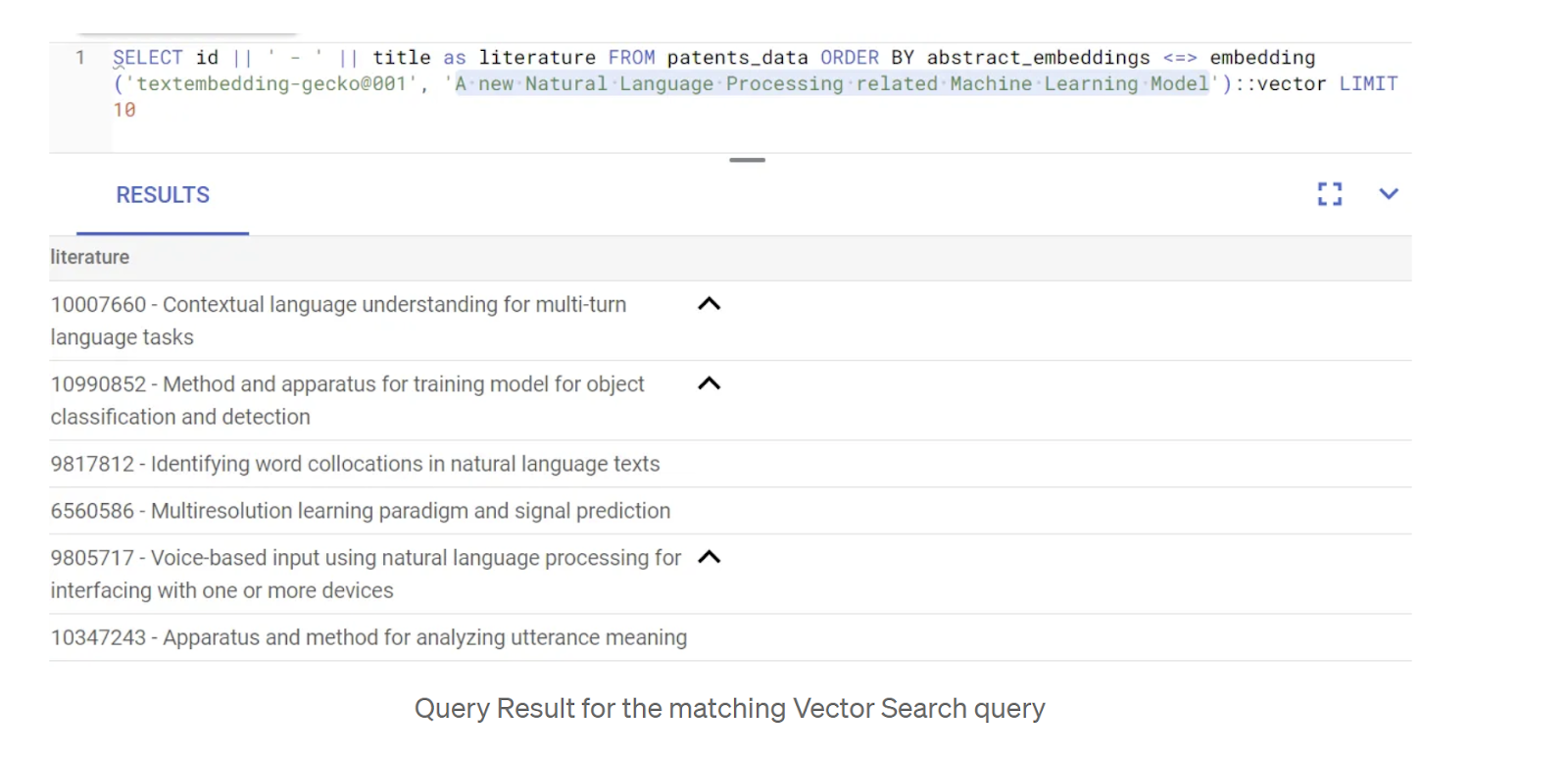
从搜索结果中可以看出,匹配项与搜索文本非常接近。
7. 将应用迁移到 Web
准备好将此应用迁移到 Web 上了吗?请按以下步骤操作:
- 前往 Cloud Shell Editor,然后点击编辑器左下角(状态栏)的“Cloud Code - 登录”图标。选择已启用结算功能的当前 Google Cloud 项目,并确保您也已通过 Gemini 登录同一项目(在状态栏的右下角)。
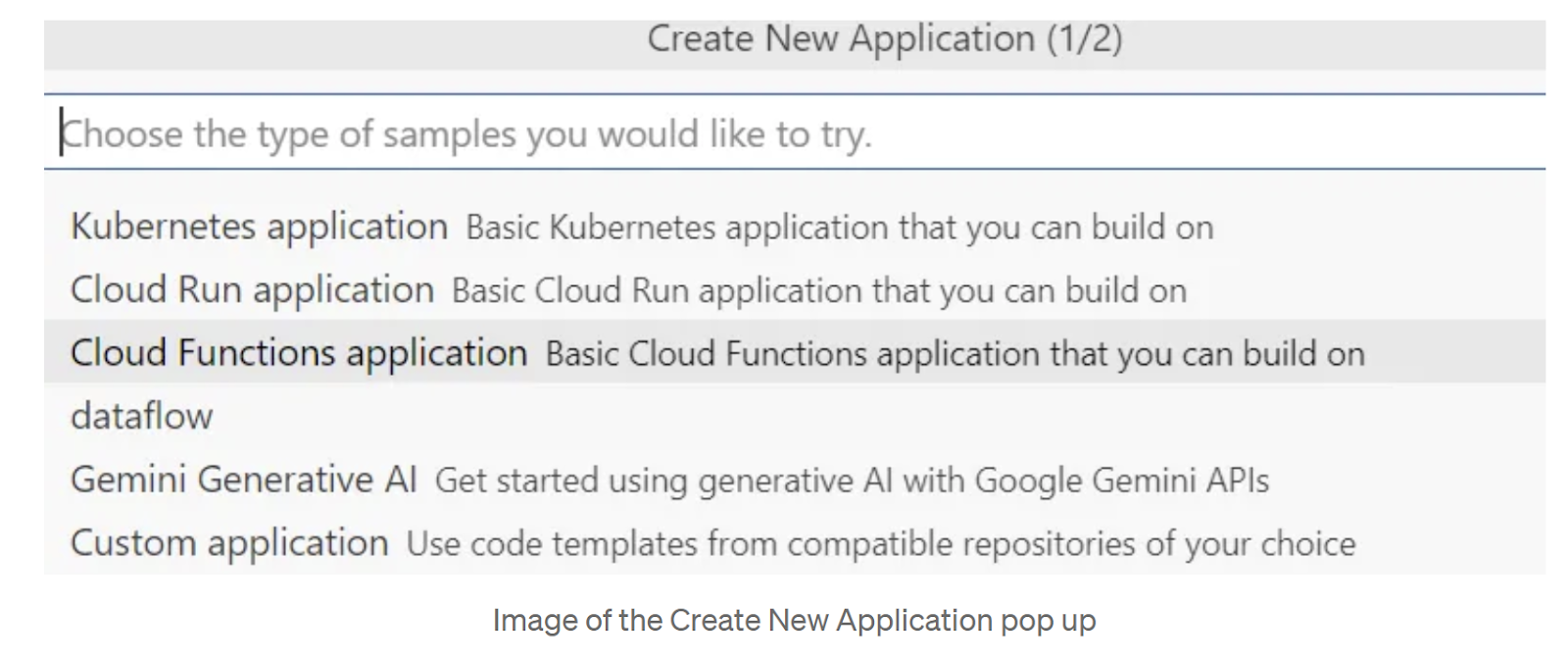
- 点击 Cloud Code 图标,然后等待 Cloud Code 对话框弹出。选择“新建应用”,然后在“创建新应用”弹出式窗口中选择“Cloud Functions 应用”:
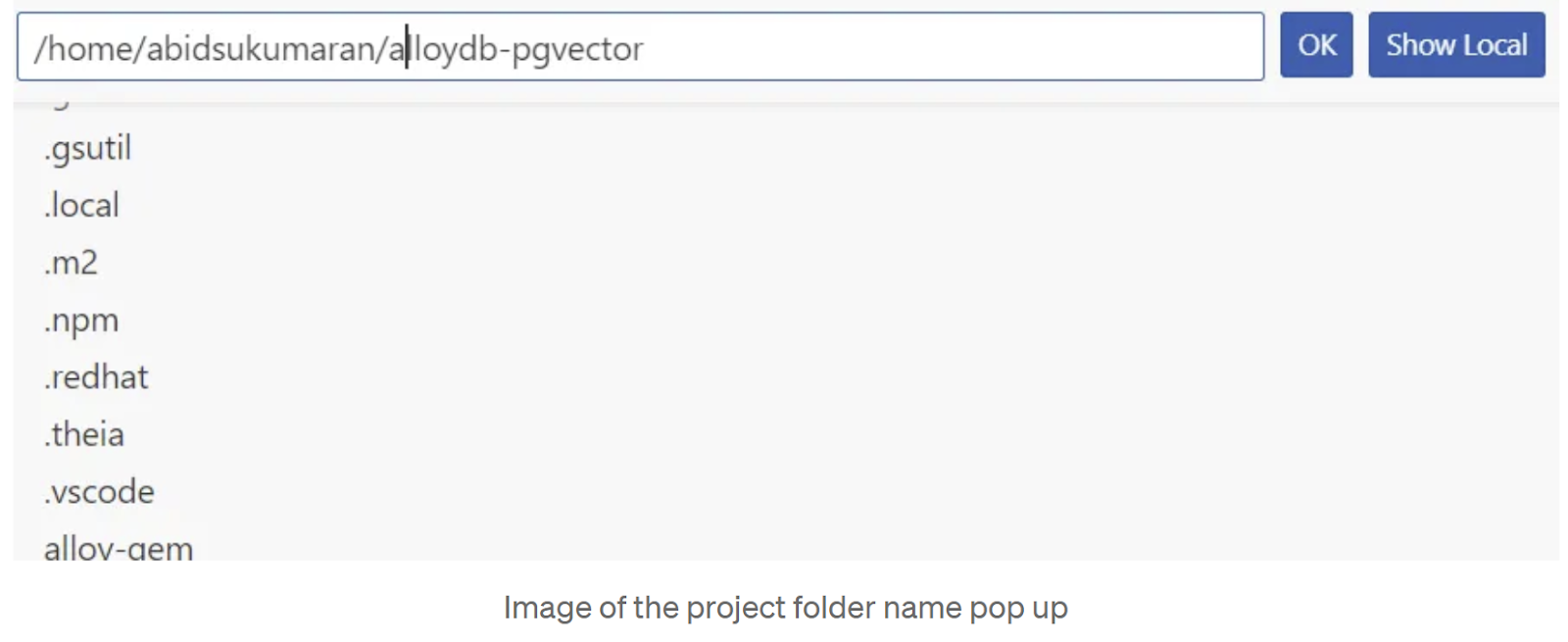
在“创建新应用”弹出窗口的第 2/2 页中,选择“Java:Hello World”,然后在首选位置输入项目名称“alloydb-pgvector”,然后点击“确定”:
- 在生成的项目结构中,搜索 pom.xml 并将其替换为代码库文件中的内容。除了以下依赖项之外,它还应具有其他几个依赖项:

- 将 HelloWorld.java 文件替换为 repo 文件中的内容。
请注意,您必须将以下值替换为实际值:
String ALLOYDB_DB = "postgres";
String ALLOYDB_USER = "postgres";
String ALLOYDB_PASS = "*****";
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
//Replace YOUR_PROJECT_ID, YOUR_CLUSTER, YOUR_INSTANCE with your actual values
请注意,该函数需要将搜索文本作为输入参数(键为“search”),并且在此实现中,我们仅返回数据库中最接近的一个匹配项:
// Get the request body as a JSON object.
JsonObject requestJson = new Gson().fromJson(request.getReader(), JsonObject.class);
String searchText = requestJson.get("search").getAsString();
//Sample searchText: "A new Natural Language Processing related Machine Learning Model";
BufferedWriter writer = response.getWriter();
String result = "";
HikariDataSource dataSource = AlloyDbJdbcConnector();
try (Connection connection = dataSource.getConnection()) {
//Retrieve Vector Search by text (converted to embeddings) using "Cosine Similarity" method
try (PreparedStatement statement = connection.prepareStatement("SELECT id || ' - ' || title as literature FROM patents_data ORDER BY abstract_embeddings <=> embedding('tgemini-embedding-001', '" + searchText + "' )::vector LIMIT 1")) {
ResultSet resultSet = statement.executeQuery();
resultSet.next();
String lit = resultSet.getString("literature");
result = result + lit + "\n";
System.out.println("Matching Literature: " + lit);
}
writer.write("Here is the closest match: " + result);
}
- 如需部署您刚刚创建的 Cloud Functions 函数,请从 Cloud Shell 终端运行以下命令。请务必先使用以下命令导航到相应的项目文件夹:
cd alloydb-pgvector
然后运行以下命令:
gcloud functions deploy patent-search --gen2 --region=us-central1 --runtime=java11 --source=. --entry-point=cloudcode.helloworld.HelloWorld --trigger-http
重要步骤:
开始部署后,您应该能够在 Google Cloud Run Functions 控制台中看到这些函数。搜索新创建的函数并将其打开,修改配置并更改以下内容:
- 前往“运行时、构建、连接和安全设置”
- 将超时时间增加到 180 秒
- 前往“连接”标签页:
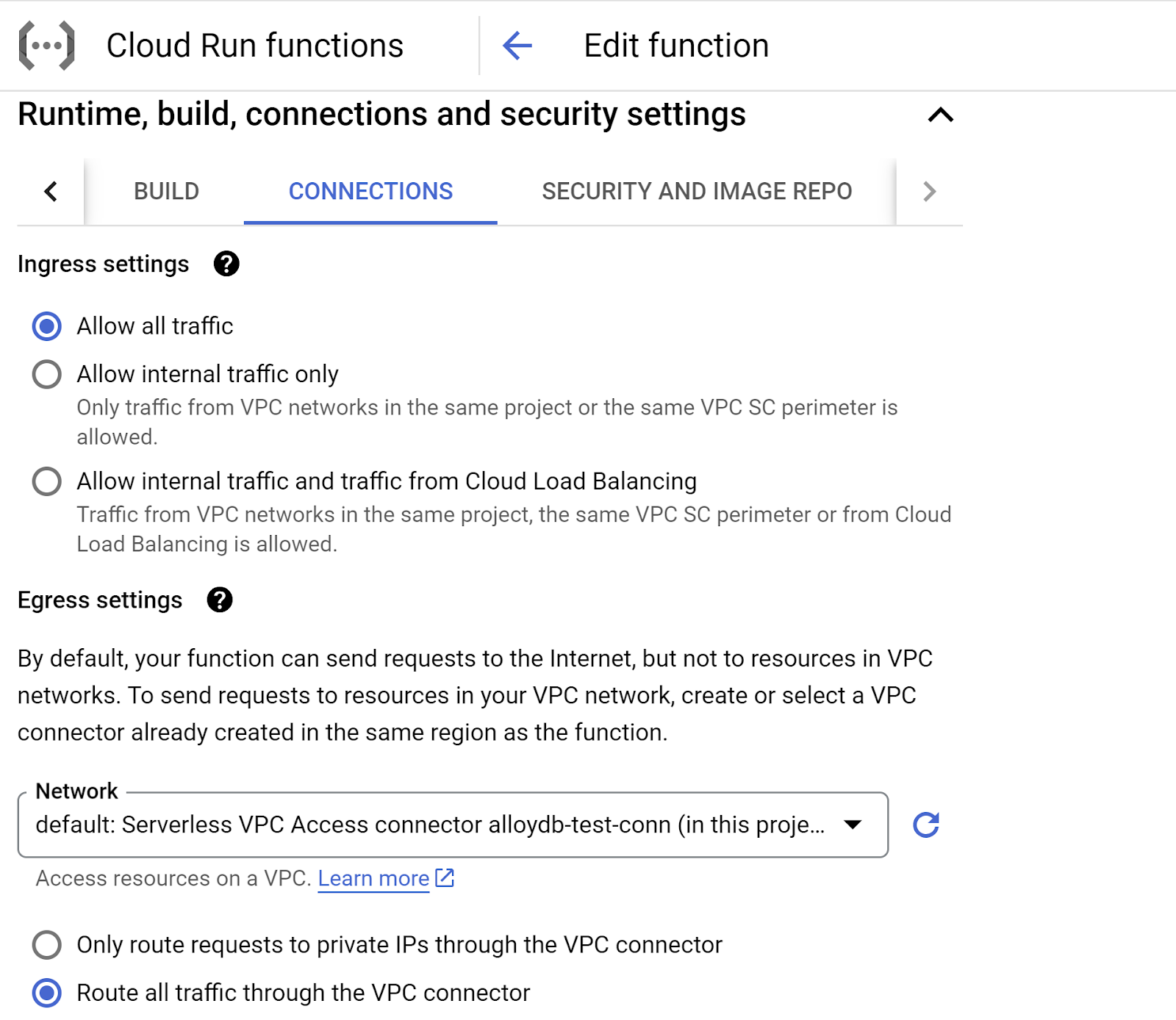
- 在“入站流量设置”下,确保已选择“允许所有流量”。
- 在“出站流量设置”下,点击“网络”下拉菜单,然后选择“添加新的 VPC 连接器”选项,并按照随即显示的对话框中的说明操作:
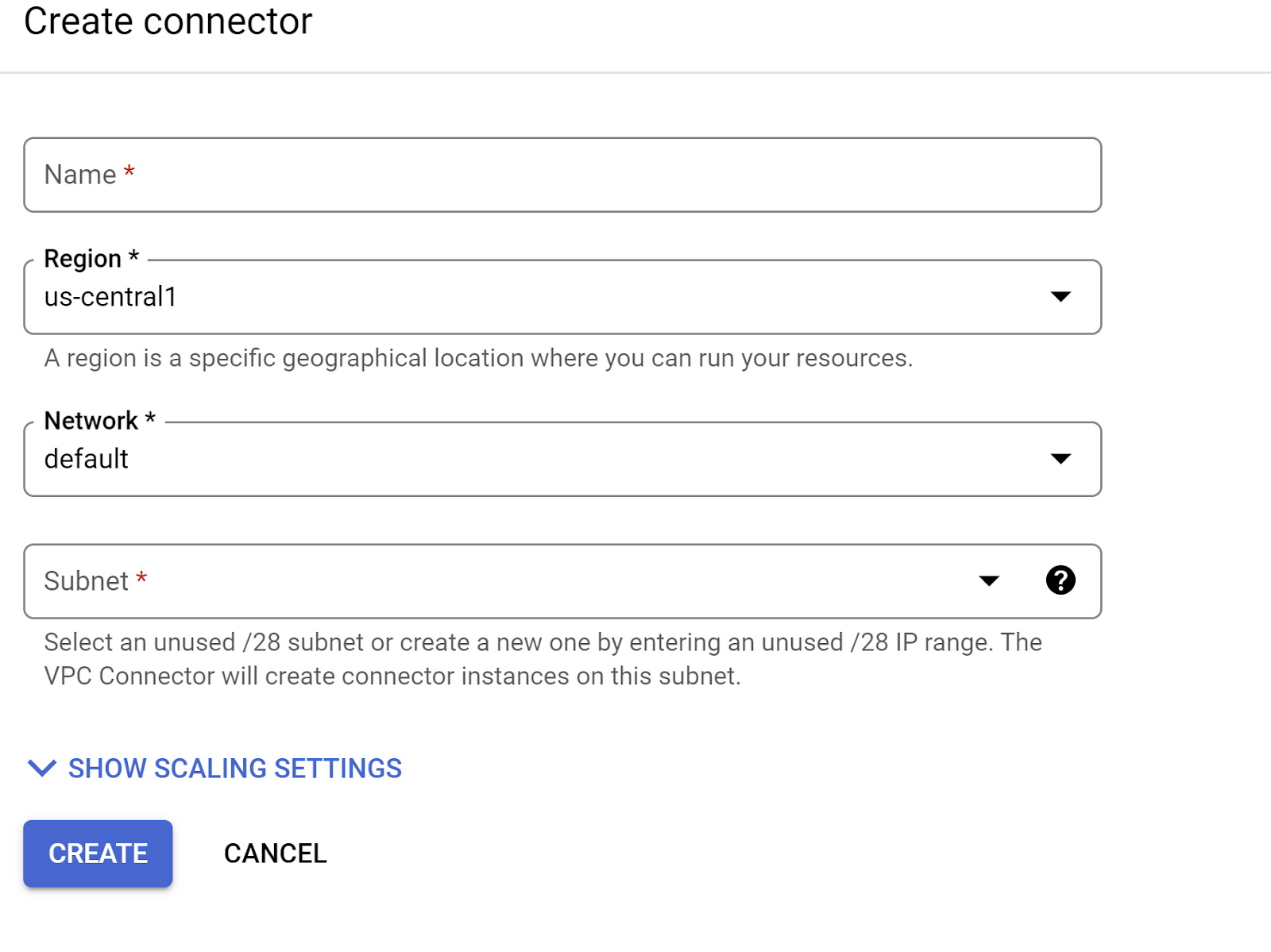
- 为 VPC 连接器提供一个名称,并确保该区域与您的实例相同。将“网络”值保留为默认值,并将“子网”设置为“自定义 IP 范围”,IP 范围为 10.8.0.0 或类似的可用范围。
- 展开“显示缩放设置”,并确保您的配置完全符合以下要求:
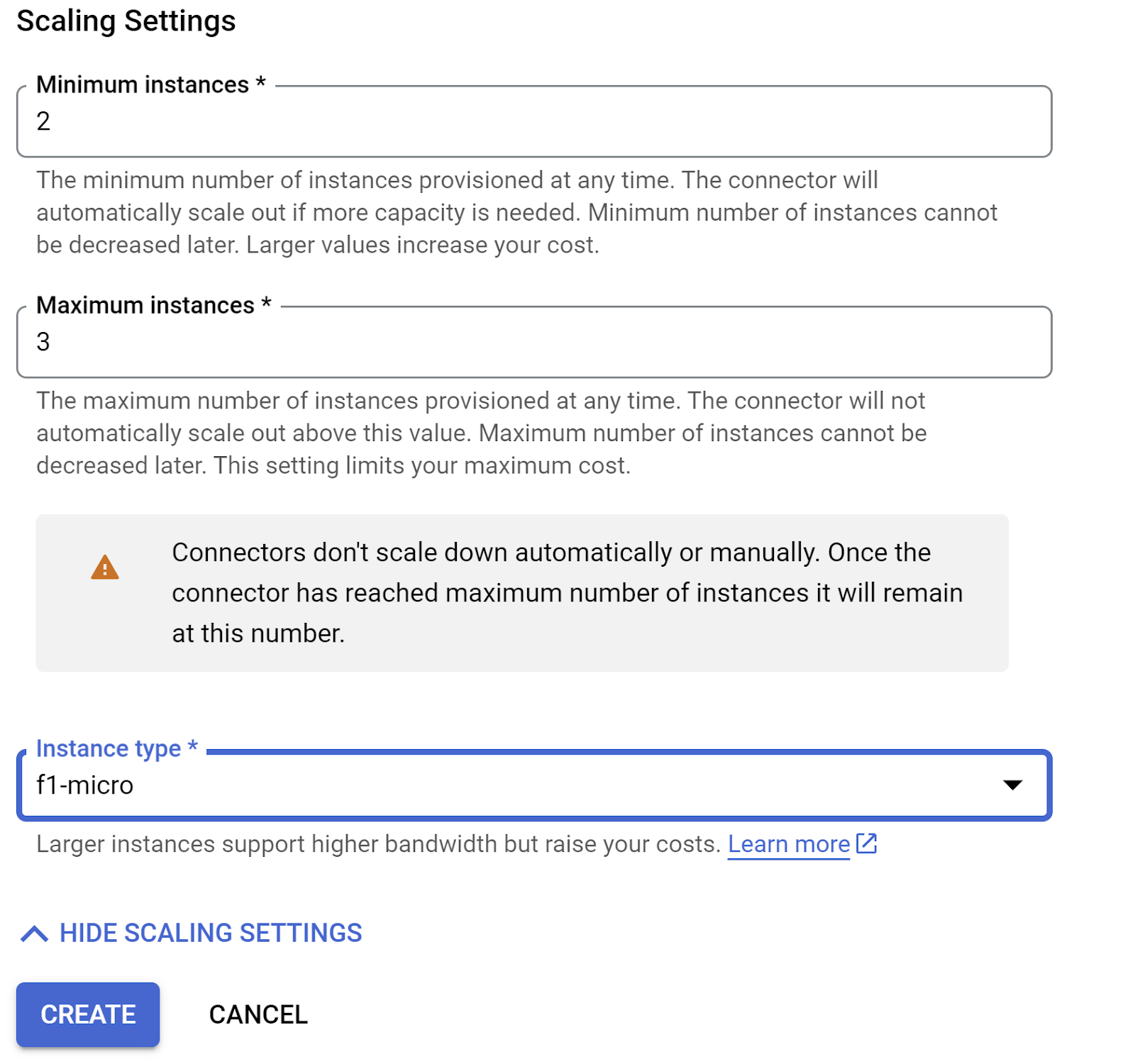
- 点击“创建”,此连接器现在应会列在出站流量设置中。
- 选择新创建的连接器
- 选择通过此 VPC 连接器路由所有流量。
8. 测试应用
部署完成后,您应该会看到以下格式的端点:
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/patent-search
您可以在 Cloud Shell 终端中运行以下命令来对其进行测试:
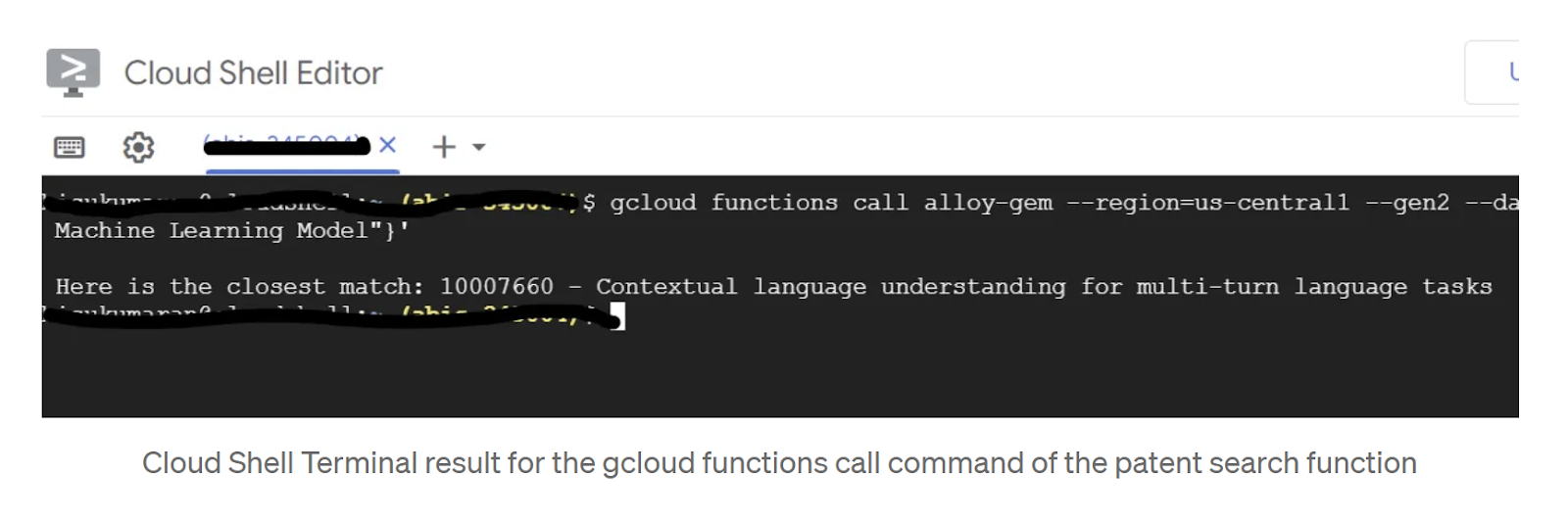
gcloud functions call patent-search --region=us-central1 --gen2 --data '{"search": "A new Natural Language Processing related Machine Learning Model"}'
结果:
您还可以通过 Cloud Functions 列表进行测试。选择已部署的函数,然后前往“测试”标签页。在“配置触发事件”部分中,针对请求 JSON 的文本框中输入以下内容:
{"search": "A new Natural Language Processing related Machine Learning Model"}
点击“测试函数”按钮,您可以在页面右侧看到结果:
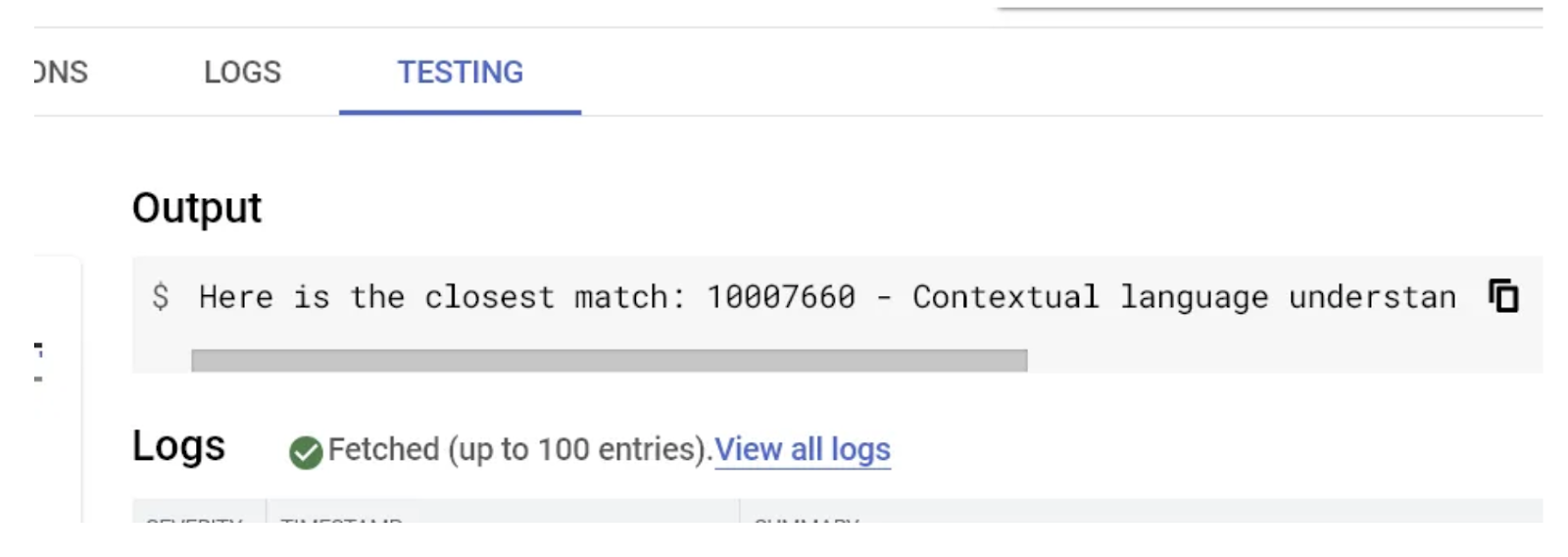
大功告成!在 AlloyDB 数据上使用嵌入模型执行相似性向量搜索就是这么简单。
10. 恭喜
恭喜!您已成功使用 AlloyDB、pgvector 和矢量搜索执行相似度搜索。通过结合 AlloyDB、Vertex AI 和 Vector Search 的功能,我们在使文献搜索变得易于访问、高效且真正以含义为导向方面取得了巨大进步。