
1. Descripción general
En este codelab, compilarás un chatbot inteligente de recomendación de películas combinando el poder de Neo4j, Google Vertex AI y Gemini. En el centro de este sistema, se encuentra un Gráfico de conocimiento de Neo4j que modela películas, actores, directores, géneros y mucho más a través de una red rica de nodos y relaciones interconectados.
Para mejorar la experiencia del usuario con la comprensión semántica, generarás incorporaciones vectoriales a partir de resúmenes de argumentos de películas con el modelo text-embedding-004 de Vertex AI (o una versión posterior). Estas incorporaciones se indexan en Neo4j para una recuperación rápida basada en la similitud.
Por último, integrarás Gemini para potenciar una interfaz de conversación en la que los usuarios puedan hacer preguntas en lenguaje natural, como "¿Qué debería mirar si me gustó Interstellar?", y recibir sugerencias de películas personalizadas en función de la similitud semántica y el contexto basado en gráficos.
En el codelab, seguirás un enfoque paso a paso de la siguiente manera:
- Crea un gráfico de conocimiento de Neo4j con entidades y relaciones relacionadas con películas
- Genera o carga incorporaciones de texto para sinopsis de películas con Vertex AI
- Implementa una interfaz de chatbot de Gradio potenciada por Gemini que combine la búsqueda de vectores con la ejecución de Cypher basada en gráficos
- (Opcional) Implementa la app en Cloud Run como una aplicación web independiente
Qué aprenderás
- Cómo crear y propagar un gráfico de conocimiento de películas con Cypher y Neo4j
- Cómo usar Vertex AI para generar incorporaciones de texto semánticas y trabajar con ellas
- Cómo combinar LLM y Gráficos de conocimiento para la recuperación inteligente con GraphRAG
- Cómo compilar una interfaz de chat fácil de usar con Gradio
- Cómo implementar de forma opcional en Google Cloud Run
Requisitos
- Navegador web Chrome
- Una cuenta de Gmail
- Un proyecto de Google Cloud con la facturación habilitada
- Una cuenta gratuita de la base de datos de Neo4j Aura
- Conocimientos básicos sobre los comandos de la terminal y Python (son útiles, pero no obligatorios)
Este codelab, diseñado para desarrolladores de todos los niveles (incluidos los principiantes), usa Python y Neo4j en su aplicación de ejemplo. Si bien puede ser útil tener conocimientos básicos de Python y bases de datos de gráficos, no se requiere experiencia previa para comprender los conceptos o seguir el curso.
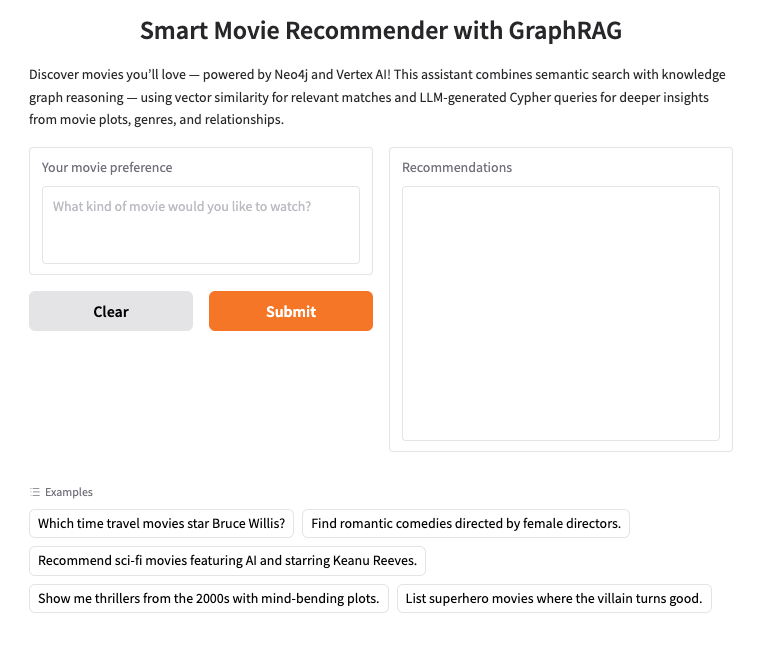
2. Configura Neo4j AuraDB
Neo4j es una base de datos de gráficos nativa líder que almacena datos como una red de nodos (entidades) y relaciones (conexiones entre entidades), lo que la hace ideal para casos de uso en los que comprender las conexiones es clave, como recomendaciones, detección de fraudes, gráficos de conocimiento y mucho más. A diferencia de las bases de datos relacionales o basadas en documentos que dependen de tablas rígidas o estructuras jerárquicas, el modelo de grafo flexible de Neo4j permite una representación intuitiva y eficiente de datos complejos y interconectados.
En lugar de organizar los datos en filas y tablas como las bases de datos relacionales, Neo4j usa un modelo de grafo, en el que la información se representa como nodos (entidades) y relaciones (conexiones entre esas entidades). Este modelo es excepcionalmente intuitivo para trabajar con datos que están vinculados de forma inherente, como personas, lugares, productos o, en nuestro caso, películas, actores y géneros.
Por ejemplo, en un conjunto de datos de películas:
- Un nodo puede representar un
Movie,ActoroDirector. - Una relación puede ser
ACTED_INoDIRECTED.
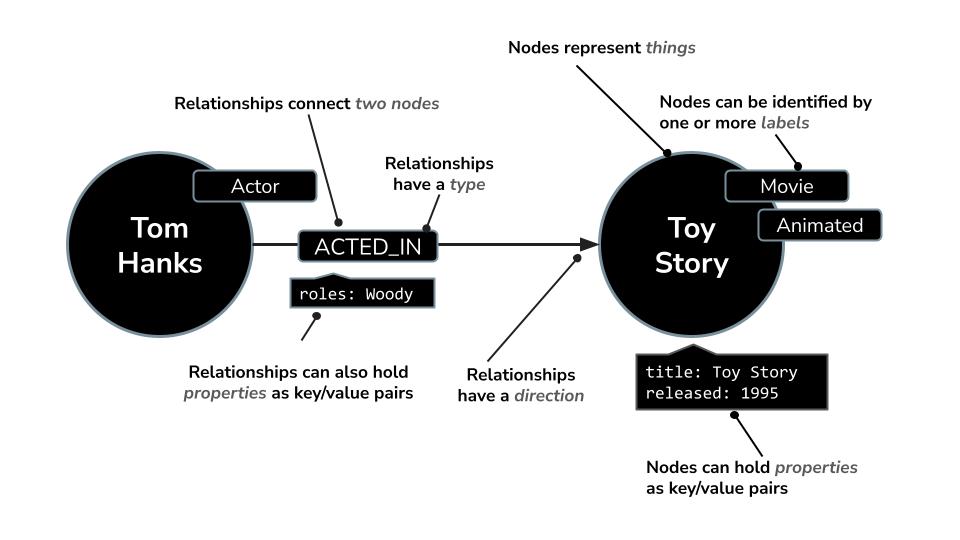
Esta estructura te permite hacer preguntas fácilmente, como las siguientes:
- ¿En qué películas apareció este actor?
- ¿Quién trabajó con Christopher Nolan?
- ¿Qué son las películas similares basadas en actores o géneros compartidos?
Neo4j incluye un potente lenguaje de consulta llamado Cypher, diseñado específicamente para consultar gráficos. Cypher te permite expresar patrones y conexiones complejos de una manera concisa y legible. Por ejemplo, esta consulta de Cypher usa MERGE para garantizar la creación única del actor, la película y su relación con los detalles del rol, lo que evita duplicados.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j ofrece varias opciones de implementación según tus necesidades:
- Autoadministrado: Ejecuta Neo4j en tu propia infraestructura con Neo4j Desktop o como una imagen de Docker (local o en tu propia nube).
- Administrado en la nube: Implementa Neo4j en proveedores de servicios en la nube populares con las ofertas del mercado.
- Completamente administrado: Usa Neo4j AuraDB, la base de datos como servicio en la nube completamente administrada de Neo4j, que controla el aprovisionamiento, el escalamiento, las copias de seguridad y la seguridad por ti.
En este codelab, usaremos Neo4j AuraDB Free, el nivel sin costo de AuraDB. Proporciona una instancia de base de datos de grafos completamente administrada con suficiente almacenamiento y funciones para crear prototipos, aprender y compilar aplicaciones pequeñas, lo que es perfecto para nuestro objetivo de crear un chatbot de recomendación de películas potenciado por IA generativa.
En este lab, crearás una instancia gratuita de AuraDB, la conectarás a tu aplicación con credenciales de conexión y la usarás para almacenar y consultar tu gráfico de conocimiento de películas.
¿Por qué usar gráficos?
En las bases de datos relacionales tradicionales, responder preguntas como "¿Qué películas son similares a Inception en función del elenco o el género compartidos?" implicaría operaciones JOIN complejas en varias tablas. A medida que aumenta la profundidad de las relaciones, el rendimiento y la legibilidad se degradan.
Sin embargo, las bases de datos de gráficos como Neo4j se compilan para navegar de manera eficiente por las relaciones, lo que las convierte en una opción natural para los sistemas de recomendación, la búsqueda semántica y los asistentes inteligentes. Ayudan a capturar el contexto del mundo real, como redes de colaboración, historias o preferencias de los usuarios, que pueden ser difíciles de representar con modelos de datos tradicionales.
Si combinamos estos datos conectados con LLM como Gemini y incorporaciones de vectores de Vertex AI, podemos potenciar la experiencia del chatbot, lo que le permite razonar, recuperar y responder de una manera más personalizada y relevante.
Creación gratuita de Neo4j AuraDB
- Visita https://console.neo4j.io.
- Accede con tu Cuenta de Google o correo electrónico.
- Haz clic en "Crear instancia gratuita".
- Mientras se aprovisiona la instancia, aparecerá una ventana emergente que mostrará las credenciales de conexión de tu base de datos.
Asegúrate de descargar y guardar de forma segura los siguientes detalles de la ventana emergente, ya que son esenciales para conectar tu aplicación a Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Usarás estos valores para configurar el archivo .env en tu proyecto y autenticarte con Neo4j en el siguiente paso.

Neo4j AuraDB Free es adecuado para el desarrollo, la experimentación y las aplicaciones a pequeña escala, como este codelab. Ofrece límites de uso generosos, admite hasta 200,000 nodos y 400,000 relaciones. Si bien proporciona todas las funciones esenciales necesarias para compilar y consultar un gráfico de conocimiento, no admite configuraciones avanzadas, como complementos personalizados o almacenamiento adicional. Para las cargas de trabajo de producción o los conjuntos de datos más grandes, puedes actualizar a un plan de AuraDB de nivel superior que ofrezca mayor capacidad, rendimiento y funciones de nivel empresarial.
De esta manera, se completa la sección para configurar tu backend de Neo4j AuraDB. En el siguiente paso, crearemos un proyecto de Google Cloud, clonaremos el repositorio y configuraremos las variables de entorno necesarias para preparar tu entorno de desarrollo antes de comenzar con nuestro codelab.
3. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto .
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con bq. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te hayas autenticado y que el proyecto esté configurado con tu ID con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs requeridas con el siguiente comando. Este proceso puede tardar unos minutos, así que ten paciencia.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Si la ejecución del comando se realiza correctamente, deberías ver el mensaje "Operation .... finished successfully".
La alternativa al comando gcloud es buscar cada producto en la consola o usar este vínculo.
Si falta alguna API, puedes habilitarla durante el transcurso de la implementación.
Consulta la documentación para ver los comandos y el uso de gcloud.
Clona el repositorio y configura el entorno
El siguiente paso es clonar el repositorio de muestra al que haremos referencia en el resto del codelab. Si estás en Cloud Shell, ingresa el siguiente comando desde tu directorio principal:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Para iniciar el editor, haz clic en Abrir editor en la barra de herramientas de la ventana de Cloud Shell. Haz clic en la barra de menú en la esquina superior izquierda y selecciona File → Open Folder, como se muestra a continuación:

Selecciona la carpeta neo4j-vertexai-codelab y deberías ver que se abre con una estructura similar a la que se muestra a continuación:

A continuación, debemos configurar las variables de entorno que se usarán en todo el codelab. Haz clic en el archivo example.env y deberías ver el contenido como se muestra a continuación:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Ahora crea un archivo nuevo llamado .env en la misma carpeta que el archivo example.env y copia el contenido del archivo example.env existente. Ahora, actualiza las siguientes variables:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDyNEO4J_DATABASE:- Completa estos valores con las credenciales que se proporcionaron durante la creación de la instancia gratuita de Neo4j AuraDB en el paso anterior.
- Por lo general,
NEO4J_DATABASEse establece en neo4j para AuraDB Free. PROJECT_IDyLOCATION:- Si ejecutas el codelab desde Google Cloud Shell, puedes dejar estos campos en blanco, ya que se inferirán automáticamente de la configuración de tu proyecto activo.
- Si ejecutas la acción de forma local o fuera de Cloud Shell, actualiza
PROJECT_IDcon el ID del proyecto de Google Cloud que creaste antes y estableceLOCATIONen la región que seleccionaste para ese proyecto (p.ej., us-central1).
Una vez que hayas completado estos valores, guarda el archivo .env. Esta configuración permitirá que tu aplicación se conecte a los servicios de Neo4j y Vertex AI.
El último paso para configurar tu entorno de desarrollo es crear un entorno virtual de Python y, luego, instalar todas las dependencias necesarias que se indican en el archivo requirements.txt. Estas dependencias incluyen bibliotecas necesarias para trabajar con Neo4j, Vertex AI, Gradio y mucho más.
Primero, ejecuta el siguiente comando para crear un entorno virtual llamado .venv:
python -m venv .venv
Una vez creado el entorno, deberemos activarlo con el siguiente comando:
source .venv/bin/activate
Ahora deberías ver (.venv) al comienzo de la instrucción de la terminal, lo que indica que el entorno está activo. Por ejemplo: (.venv) yourusername@cloudshell:
Ahora, ejecuta el siguiente comando para instalar las dependencias requeridas:
pip install -r requirements.txt
A continuación, se muestra un resumen de las dependencias clave que se enumeran en el archivo:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Una vez que se instalen correctamente todas las dependencias, tu entorno local de Python estará completamente configurado para ejecutar las secuencias de comandos y el chatbot de este codelab.
¡Genial! Ya está todo listo para pasar al siguiente paso: comprender el conjunto de datos y prepararlo para la creación de gráficos y el enriquecimiento semántico.
4. Prepara el conjunto de datos de Movies
Nuestra primera tarea es preparar el conjunto de datos de películas que usaremos para crear el gráfico de conocimiento y potenciar nuestro chatbot de recomendación. En lugar de empezar desde cero, usaremos un conjunto de datos abiertos existente y lo desarrollaremos.
Usamos The Movies Dataset de Rounak Banik, un conjunto de datos públicos conocido disponible en Kaggle. Incluye metadatos de más de 45,000 películas de TMDB, como el elenco, el equipo técnico, las palabras clave, las calificaciones y mucho más.
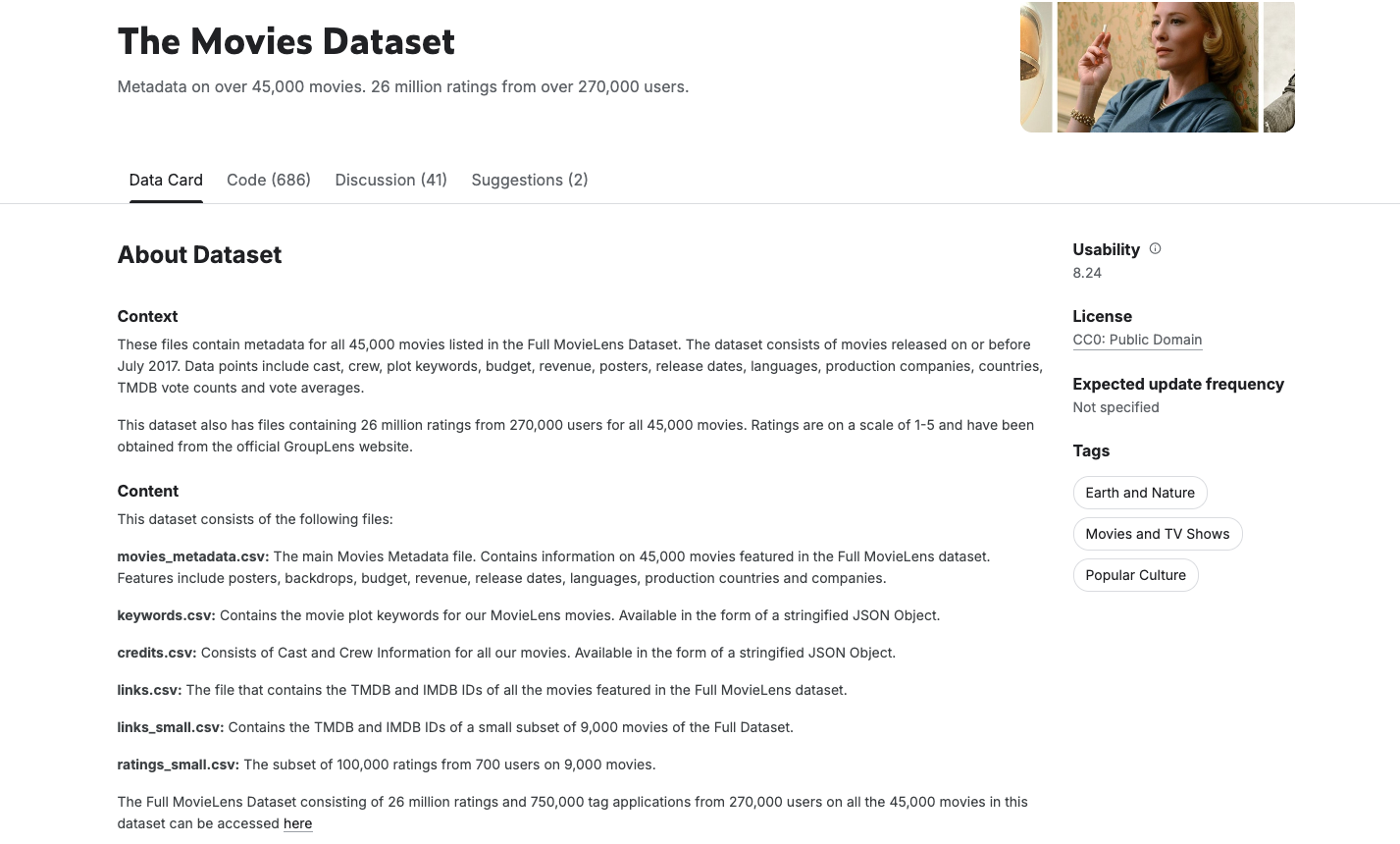
Para crear un chatbot de recomendación de películas confiable y eficaz, es esencial comenzar con datos limpios, coherentes y estructurados. Si bien el conjunto de datos de películas de Kaggle es un recurso rico con más de 45,000 registros de películas y metadatos detallados, incluidos géneros, elenco, equipo técnico y mucho más, también contiene ruido, inconsistencias y estructuras de datos anidadas que no son ideales para el modelado de grafos o la incorporación semántica.
Para abordar este problema, procesamos y normalizamos el conjunto de datos para garantizar que sea adecuado para crear un gráfico de conocimiento de Neo4j y generar incorporaciones de alta calidad. Este proceso incluyó lo siguiente:
- Cómo quitar duplicados y registros incompletos
- Estandarizar los campos clave (p.ej., nombres de géneros y nombres de personas)
- Aplanar estructuras anidadas complejas (p.ej., elenco y equipo) en archivos CSV estructurados
- Selecciona un subconjunto representativo de alrededor de 12,000 películas para mantenerte dentro de los límites de Neo4j AuraDB Free.
Los datos normalizados y de alta calidad ayudan a garantizar lo siguiente:
- Calidad de los datos: Minimiza los errores y las inconsistencias para obtener recomendaciones más precisas.
- Rendimiento de las consultas: La estructura optimizada mejora la velocidad de recuperación y reduce la redundancia.
- Precisión de la incorporación: Las entradas limpias generan incorporaciones vectoriales más significativas y contextuales.
Puedes acceder al conjunto de datos limpio y normalizado en la carpeta normalized_data/ de este repositorio de GitHub. Este conjunto de datos también se replica en un bucket de Google Cloud Storage para facilitar el acceso en las próximas secuencias de comandos de Python.
Con los datos limpios y listos, ya podemos cargarlos en Neo4j y comenzar a construir nuestro gráfico de conocimiento de películas.
5. Cómo crear un Gráfico de conocimiento de películas
Para potenciar nuestro chatbot de recomendación de películas habilitado por IA generativa, debemos estructurar nuestro conjunto de datos de películas de una manera que capture la rica red de conexiones entre películas, actores, directores, géneros y otros metadatos. En esta sección, crearemos un grafo de conocimiento de películas en Neo4j con el conjunto de datos limpio y normalizado que preparaste antes.
Usaremos la función LOAD CSV de Neo4j para transferir archivos CSV alojados en un bucket público de Google Cloud Storage (GCS). Estos archivos representan diferentes componentes del conjunto de datos de películas, como películas, géneros, elenco, equipo técnico, productoras y calificaciones de usuarios.
Paso 1: Crea restricciones e índices
Antes de importar datos, se recomienda crear índices y restricciones para aplicar la integridad de los datos y optimizar el rendimiento de las consultas.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Paso 2: Importa metadatos y relaciones de películas
Veamos cómo importamos los metadatos de las películas con el comando LOAD CSV. En este ejemplo, se crean nodos de película con atributos clave, como título, sinopsis, idioma y duración:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Del mismo modo, puedes importar y vincular otras entidades, como géneros, compañías de producción, idiomas hablados, países, elenco, equipo de producción y calificaciones de los usuarios, con sus respectivos archivos CSV y consultas de Cypher.
Carga el grafo completo a través de Python
En lugar de ejecutar varias consultas de Cypher de forma manual, te recomendamos que uses la secuencia de comandos de Python automatizada que se proporciona en este codelab.
La secuencia de comandos graph_build.py carga todo el conjunto de datos de GCS en tu instancia de Neo4j AuraDB con las credenciales de tu archivo .env.
python graph_build.py
La secuencia de comandos cargará de forma secuencial todos los archivos CSV necesarios, creará nodos y relaciones, y estructurará tu gráfico de conocimiento de películas completo.
|
|

.png")
Valida tu gráfico
Después de cargarlo, puedes validar tu gráfico ejecutando la siguiente secuencia de comandos:
python validate_graph.py
Esto te brindará un resumen rápido de lo que contiene tu gráfico: cuántas películas, actores, géneros y relaciones como ACTED_IN, DIRECTED, etc., están presentes, lo que garantiza que la importación se realizó correctamente.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Ahora deberías ver que tu gráfico se propagó con películas, personas, géneros y mucho más, listo para enriquecerse semánticamente en el siguiente paso.
6. Genera y carga incorporaciones para realizar una búsqueda de similitud de vectores
Para habilitar la búsqueda semántica en nuestro chatbot, debemos generar incorporaciones de vectores para los resúmenes de películas. Estas incorporaciones transforman los datos textuales en vectores numéricos que se pueden comparar en función de la similitud, lo que permite que el chatbot recupere películas relevantes, incluso si la consulta no coincide exactamente con el título o la descripción.

Opción 1: Carga incorporaciones calculadas previamente a través de Cypher
Para adjuntar rápidamente las incorporaciones a los nodos Movie correspondientes en Neo4j, ejecuta el siguiente comando Cypher en el navegador de Neo4j:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Este comando lee los vectores de incorporación del archivo CSV y los adjunta como una propiedad (m.embedding) en cada nodo Movie.
Opción 2: Carga incorporaciones con Python
También puedes cargar las incorporaciones de forma programática con la secuencia de comandos de Python proporcionada. Este enfoque es útil si trabajas en tu propio entorno o quieres automatizar el proceso:
python load_embeddings.py
Esta secuencia de comandos lee el mismo CSV de GCS y escribe las incorporaciones en Neo4j con el controlador Neo4j de Python.
[Opcional] Genera tus propias incorporaciones (para la exploración)
Si te interesa comprender cómo se generan las incorporaciones, puedes explorar la lógica en la propia secuencia de comandos de generate_embeddings.py. Usa Vertex AI para incorporar cada texto de descripción general de la película con el modelo text-embedding-004.
Para probarlo por tu cuenta, abre y ejecuta la sección de generación de incorporación del código. Si ejecutas la prueba en Cloud Shell, puedes comentar la siguiente línea, ya que Cloud Shell ya está autenticado a través de tu cuenta activa:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Una vez que se cargan las incorporaciones en Neo4j, tu gráfico de conocimiento de películas se vuelve consciente de la semántica y está listo para admitir una búsqueda potente en lenguaje natural con similitud de vectores.
7. El chatbot de recomendación de películas
Con tu gráfico de conocimiento y las incorporaciones de vectores en su lugar, es hora de unir todo en una interfaz de conversación completamente funcional: tu chatbot de recomendación de películas potenciado por IA generativa.
Este chatbot se implementa en Python con Gradio, un framework web ligero para compilar interfaces de usuario intuitivas. La lógica principal se encuentra en app.py, que se conecta a tu instancia de Neo4j AuraDB y usa Google Vertex AI y Gemini para procesar y responder consultas de lenguaje natural.
Cómo funciona
- El usuario escribe una consulta en lenguaje natural, p.ej., "Recomiéndame thrillers de ciencia ficción como Interstellar"
- Genera una incorporación de vector para la consulta con el modelo
text-embedding-004de Vertex AI. - Realiza una búsqueda vectorial en Neo4j para recuperar películas semánticamente similares
- Usa Gemini para lo siguiente:
- Interpreta la consulta en contexto
- Genera una consulta Cypher personalizada en función de los resultados de la búsqueda vectorial y el esquema de Neo4j.
- Ejecuta la consulta para extraer datos de gráficos relacionados (p. ej., actores, directores y géneros).
- Resume los resultados de forma conversacional para el usuario.
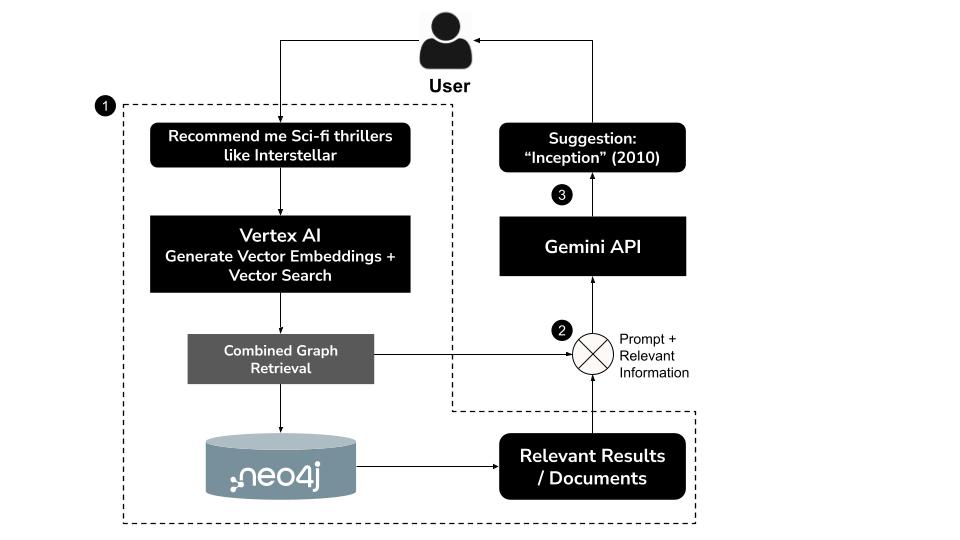
Este enfoque híbrido, conocido como GraphRAG (generación mejorada por recuperación de gráficos), combina la recuperación semántica y el razonamiento estructurado para producir recomendaciones más precisas, contextuales y explicables.
Ejecuta el chatbot de forma local
Activa tu entorno virtual (si aún no lo has hecho) y, luego, inicia el chatbot con el siguiente comando:
python app.py
Deberías ver un resultado similar al siguiente:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Para compartir el chatbot de forma externa, configura share=True en la función launch() en app.py.
Interactúa con el chatbot
Abre la URL local que se muestra en la terminal (por lo general, 👉 http://0.0.0.0:8080) para acceder a la interfaz del chatbot.
Haz preguntas como las siguientes:
- "¿Qué debería mirar si me gustó Interstellar?"
- "Sugerir una película romántica dirigida por Nora Ephron"
- "Quiero mirar una película familiar con Tom Hanks"
- "Encuentra películas de suspenso que incluyan inteligencia artificial"
El chatbot hará lo siguiente:
✅ Comprende la consulta
✅ Encuentra tramas de películas semánticamente similares con incorporaciones
✅ Genera y ejecuta una consulta de Cypher para recuperar el contexto del gráfico relacionado
✅ Muestra una recomendación personalizada y amigable en cuestión de segundos.
Qué tienes ahora
Acabas de crear un chatbot de películas con GraphRAG que combina lo siguiente:
- Búsqueda de vectores para la relevancia semántica
- Razonamiento de gráficos de conocimiento con Neo4j
- Funciones de LLM a través de Gemini
- Una interfaz de chat fluida con Gradio
Esta arquitectura forma una base que puedes extender a sistemas de búsqueda, recomendación o razonamiento más avanzados potenciados por la IA generativa.
8. Implementación en Google Cloud Run (opcional)
Si deseas que el público pueda acceder a tu chatbot de recomendación de películas, puedes implementarlo en Google Cloud Run, una plataforma sin servidores y completamente administrada que escala automáticamente tu app y quita la complejidad de toda la infraestructura.
En esta implementación, se usa lo siguiente:
requirements.txt: Para definir dependencias de Python (Neo4j, Vertex AI, Gradio, etcétera)Dockerfile: Para empaquetar la aplicación.env.yaml: Para pasar variables de entorno de forma segura en el entorno de ejecución
Paso 1: Prepara .env.yaml
Crea un archivo llamado .env.yaml en el directorio raíz con el siguiente contenido:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Este formato es preferible a --set-env-vars, ya que es más escalable, controlable por versión y legible.
Paso 2: Configura las variables de entorno
En la terminal, configura las siguientes variables de entorno (reemplaza los valores de los marcadores de posición por la configuración real de tu proyecto):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Paso 2: Crea Artifact Registry y compila el contenedor
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Este comando empaqueta tu app con Dockerfile y sube la imagen del contenedor a Google Cloud Artifact Registry.
Paso 3: Implementa en Cloud Run
Ahora, implementa tu app con el archivo .env.yaml para la configuración del entorno de ejecución:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Accede al chatbot
Una vez que se implemente, Cloud Run proporcionará una URL pública como la siguiente:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Abre esta URL en tu navegador para acceder a la interfaz del chatbot de Gradio que se implementó, lista para manejar recomendaciones de películas con GraphRAG, Gemini y Neo4j.
Notas y sugerencias
- Asegúrate de que tu
Dockerfileejecutepip install -r requirements.txtdurante la compilación. - Si no usas Cloud Shell, deberás autenticar tu entorno con una cuenta de servicio que tenga permisos de Vertex AI y Artifact Registry.
- Puedes supervisar los registros y las métricas de la implementación desde consola de Google Cloud > Cloud Run.
También puedes visitar Cloud Run desde la consola de Google Cloud y verás la lista de servicios en Cloud Run. El servicio movies-chatbot debe ser uno de los servicios (si no es el único) que aparece allí.

Para ver los detalles del servicio, como la URL, las configuraciones, los registros y mucho más, haz clic en el nombre específico del servicio (movies-chatbot en nuestro caso).
Con esto, tu chatbot de recomendación de películas ahora está implementado, escalable y se puede compartir. 🎉
9. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
10. Felicitaciones
Compilaste y, luego, implementaste correctamente un chatbot de recomendación de películas potenciado por GraphRAG y mejorado por GenAI con Neo4j, Vertex AI y Gemini. Cuando combinas las capacidades de modelado nativo de gráficos de Neo4j con la búsqueda semántica a través de Vertex AI y el razonamiento de lenguaje natural a través de Gemini, creas un sistema inteligente que va más allá de la búsqueda básica: comprende la intención del usuario, razona sobre los datos conectados y responde de forma conversacional.
En este codelab, lograste lo siguiente:
✅ Compilaste un Gráfico de conocimiento de películas del mundo real en Neo4j para modelar películas, actores, géneros y relaciones.
✅ Se generaron incorporaciones de vectores para las sinopsis de películas con los modelos de incorporación de texto de Vertex AI.
✅ Se implementó GraphRAG, que combina la búsqueda de vectores y las consultas de Cypher generadas por LLM para un razonamiento más profundo y de varios saltos.
✅ Se integró Gemini para interpretar las preguntas de los usuarios, generar consultas de Cypher y resumir los resultados de los gráficos en lenguaje natural.
✅ Creaste una interfaz de chat intuitiva con Gradio
✅ Implementaste tu chatbot de forma opcional en Google Cloud Run para obtener un hosting sin servidores y escalable
¿Qué sigue?
Esta arquitectura no se limita a las recomendaciones de películas, sino que se puede extender a lo siguiente:
- Plataformas de descubrimiento de libros y música
- Asistentes de investigación académica
- Motores de recomendación de productos
- Asistentes de conocimiento legal, financiero y de atención médica
En cualquier lugar donde tengas relaciones complejas y datos textuales enriquecidos, esta combinación de gráficos de conocimiento, LLM y incorporaciones semánticas puede potenciar la nueva generación de aplicaciones inteligentes.
A medida que evolucionen los modelos de IA generativa multimodal como Gemini, podrás incorporar aún más contexto, imágenes, voz y personalización para crear sistemas verdaderamente centrados en las personas.
Continúa explorando y creando, y no olvides mantenerte al tanto de las novedades de Neo4j, Vertex AI y Google Cloud para llevar tus aplicaciones inteligentes al siguiente nivel. Explora más instructivos prácticos sobre gráficos de conocimiento en Neo4j GraphAcademy.