
เกี่ยวกับ Codelab นี้
1 ภาพรวม
ในโค้ดแล็บนี้ คุณจะได้สร้างแชทบ็อตแนะนำภาพยนตร์ที่ชาญฉลาดด้วยการรวมความสามารถของ Neo4j, Google Vertex AI และ Gemini หัวใจสำคัญของระบบนี้คือกราฟความรู้ Neo4j ที่ใช้จำลองภาพยนตร์ นักแสดง ผู้กำกับ ประเภท และอื่นๆ ผ่านเครือข่ายโหนดและความสัมพันธ์ที่เชื่อมโยงกัน
คุณจะสร้างการฝังเวกเตอร์จากภาพรวมของพล็อตภาพยนตร์โดยใช้โมเดล text-embedding-004 (หรือใหม่กว่า) ของ Vertex AI เพื่อปรับปรุงประสบการณ์ของผู้ใช้ด้วยความเข้าใจเชิงความหมาย ระบบจะจัดทําดัชนีการฝังเหล่านี้ใน Neo4j เพื่อการดึงข้อมูลตามความคล้ายคลึงกันอย่างรวดเร็ว
สุดท้าย คุณผสานรวม Gemini เพื่อขับเคลื่อนอินเทอร์เฟซแบบสนทนาที่ผู้ใช้สามารถถามคำถามเป็นภาษาธรรมชาติได้ เช่น "ฉันควรดูภาพยนตร์เรื่องไหนหากชอบ Interstellar" และรับคำแนะนำภาพยนตร์ที่ปรับให้เหมาะกับคุณโดยอิงตามความคล้ายคลึงเชิงความหมายและบริบทที่อิงตามกราฟ
คุณจะทําตามขั้นตอนทีละขั้นตอนต่อไปนี้ผ่าน Codelab
- สร้างกราฟความรู้ Neo4j ด้วยเอนทิตีและความสัมพันธ์ที่เกี่ยวข้องกับภาพยนตร์
- สร้าง/โหลดการฝังข้อความสำหรับภาพรวมของภาพยนตร์โดยใช้ Vertex AI
- ใช้อินเทอร์เฟซแชทบ็อต Gradio ที่ทำงานด้วย Gemini ซึ่งรวมการค้นหาเวกเตอร์เข้ากับการดำเนินการ Cypher ตามกราฟ
- (ไม่บังคับ) ติดตั้งใช้งานแอปใน Cloud Run เป็นเว็บแอปพลิเคชันแบบสแตนด์อโลน
สิ่งที่จะได้เรียนรู้
- วิธีสร้างและป้อนข้อมูลกราฟความรู้เกี่ยวกับภาพยนตร์โดยใช้ Cypher และ Neo4j
- วิธีใช้ Vertex AI เพื่อสร้างและทํางานกับการฝังข้อความเชิงความหมาย
- วิธีรวม LLM กับกราฟความรู้เพื่อการดึงข้อมูลอัจฉริยะโดยใช้ GraphRAG
- วิธีสร้างอินเทอร์เฟซแชทที่ใช้งานง่ายโดยใช้ Gradio
- วิธีทำให้ใช้งานได้ใน Google Cloud Run (ไม่บังคับ)
สิ่งที่ต้องมี
- เว็บเบราว์เซอร์ Chrome
- บัญชี Gmail
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- บัญชี Neo4j Aura DB ฟรี
- มีความรู้พื้นฐานเกี่ยวกับคำสั่งในเทอร์มินัลและ Python (มีประโยชน์แต่ไม่จำเป็นต้องมี)
Codelab นี้ออกแบบมาสำหรับนักพัฒนาซอฟต์แวร์ทุกระดับ (รวมถึงผู้เริ่มต้น) โดยใช้ Python และ Neo4j ในแอปพลิเคชันตัวอย่าง แม้ว่าการมีความคุ้นเคยพื้นฐานกับ Python และฐานข้อมูลกราฟจะมีประโยชน์ แต่คุณก็ไม่จำเป็นต้องมีประสบการณ์มาก่อนเพื่อทำความเข้าใจแนวคิดหรือทำตาม

2 ตั้งค่า Neo4j AuraDB
Neo4j เป็นฐานข้อมูลกราฟเนทีฟชั้นนําที่เก็บข้อมูลเป็นเครือข่ายโหนด (เอนทิตี) และความสัมพันธ์ (การเชื่อมต่อระหว่างเอนทิตี) จึงเหมาะสําหรับกรณีการใช้งานที่การทําความเข้าใจการเชื่อมต่อเป็นกุญแจสําคัญ เช่น คําแนะนํา การตรวจจับการประพฤติมิชอบ กราฟความรู้ และอื่นๆ โมเดลกราฟที่ยืดหยุ่นของ Neo4j ช่วยให้แสดงข้อมูลที่ซับซ้อนและเชื่อมโยงกันได้อย่างมีประสิทธิภาพและใช้งานง่าย ซึ่งแตกต่างจากฐานข้อมูลที่สัมพันธ์กันหรือฐานข้อมูลที่อิงตามเอกสารซึ่งใช้ตารางแบบตายตัวหรือโครงสร้างตามลําดับชั้น
Neo4j ใช้โมเดลกราฟแทนการจัดระเบียบข้อมูลเป็นแถวและตารางเหมือนฐานข้อมูลเชิงสัมพันธ์ โดยข้อมูลจะแสดงเป็นโหนด (เอนทิตี) และความสัมพันธ์ (การเชื่อมต่อระหว่างเอนทิตีเหล่านั้น) รูปแบบนี้ช่วยให้ใช้งานข้อมูลที่มีการเชื่อมโยงกันโดยพื้นฐานได้อย่างง่ายดาย เช่น บุคคล สถานที่ ผลิตภัณฑ์ หรือในกรณีของเราคือภาพยนตร์ นักแสดง และประเภท
เช่น ในชุดข้อมูลภาพยนตร์
- โหนดอาจแสดงถึง
Movie,ActorหรือDirector - ความสัมพันธ์อาจเป็น
ACTED_INหรือDIRECTED
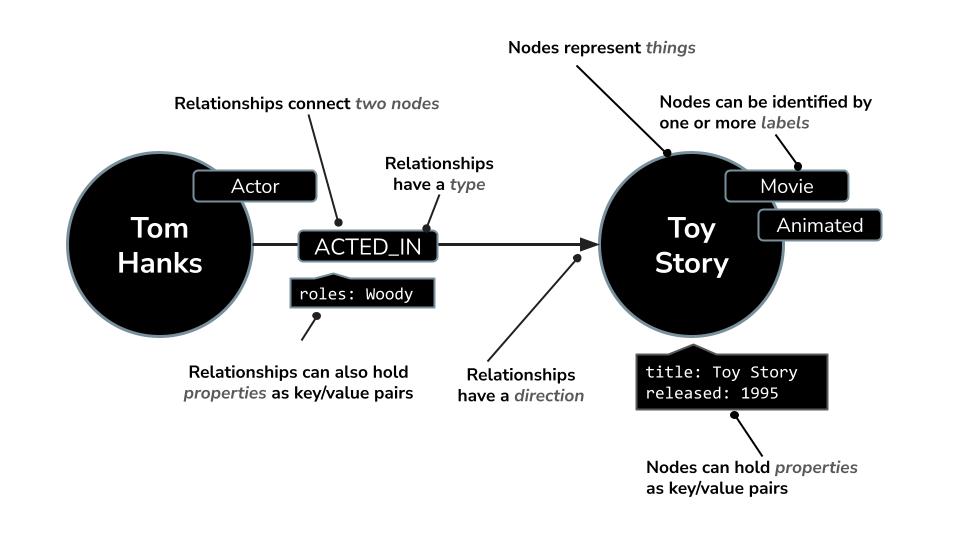
โครงสร้างนี้ช่วยให้คุณถามคําถามต่างๆ ได้อย่างง่ายดาย เช่น
- นักแสดงรายนี้แสดงในภาพยนตร์เรื่องใดบ้าง
- ใครเคยร่วมงานกับคริสโตเฟอร์ โนแลนบ้าง
- ภาพยนตร์ที่คล้ายกันตามนักแสดงหรือประเภทที่แชร์กันคืออะไร
Neo4j มาพร้อมกับภาษาการค้นหาที่มีประสิทธิภาพที่เรียกว่า Cypher ซึ่งออกแบบมาเพื่อการค้นหากราฟโดยเฉพาะ Cypher ช่วยให้คุณแสดงรูปแบบและการเชื่อมต่อที่ซับซ้อนในลักษณะที่กระชับและอ่านง่าย ตัวอย่างเช่น การค้นหา Cypher นี้ใช้ MERGE เพื่อให้แน่ใจว่าการสร้างนักแสดง ภาพยนตร์ และความสัมพันธ์ของนักแสดงกับรายละเอียดบทบาทจะไม่ซ้ำกัน
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j มีตัวเลือกต่างๆ ในการติดตั้งใช้งานตามความต้องการของคุณ ดังนี้
- จัดการด้วยตนเอง: เรียกใช้ Neo4j ในโครงสร้างพื้นฐานของคุณเองโดยใช้ Neo4j Desktop หรือเป็นอิมเมจ Docker (ในองค์กรหรือในระบบคลาวด์ของคุณเอง)
- ระบบคลาวด์ที่จัดการ: ติดตั้งใช้งาน Neo4j ในผู้ให้บริการระบบคลาวด์ยอดนิยมโดยใช้ข้อเสนอใน Marketplace
- มีการจัดการครบวงจร: ใช้ Neo4j AuraDB ซึ่งเป็นบริการฐานข้อมูลระบบคลาวด์แบบครบวงจรของ Neo4j ซึ่งจัดการการจัดสรร การปรับขนาด การสำรองข้อมูล และการรักษาความปลอดภัยให้คุณ
ใน Codelab นี้ เราจะใช้ Neo4j AuraDB Free ซึ่งเป็นรุ่นที่ไม่มีค่าใช้จ่ายของ AuraDB ซึ่งให้บริการอินสแตนซ์ฐานข้อมูลกราฟที่มีการจัดการอย่างเต็มรูปแบบพร้อมพื้นที่เก็บข้อมูลและฟีเจอร์เพียงพอสำหรับการสร้างต้นแบบ การเรียนรู้ และการสร้างแอปพลิเคชันขนาดเล็ก ซึ่งเหมาะอย่างยิ่งสำหรับเป้าหมายของเราในการสร้างแชทบ็อตแนะนำภาพยนตร์ที่ทำงานด้วย GenAI
คุณจะต้องสร้างอินสแตนซ์ AuraDB ฟรี เชื่อมต่อกับแอปพลิเคชันโดยใช้ข้อมูลเข้าสู่ระบบการเชื่อมต่อ และใช้เพื่อจัดเก็บและค้นหากราฟความรู้เกี่ยวกับภาพยนตร์ตลอดทั้งห้องทดลองนี้
เหตุผลที่ควรใช้กราฟ
ในฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม การตอบคําถามอย่าง"ภาพยนตร์เรื่องใดที่คล้ายกับ Inception โดยอิงตามนักแสดงหรือประเภทที่แชร์กัน" จะเกี่ยวข้องกับการดำเนินการ JOIN ที่ซับซ้อนในหลายตาราง ยิ่งความสัมพันธ์มีความซับซ้อนมากขึ้น ประสิทธิภาพและการอ่านก็ยิ่งแย่ลง
แต่ฐานข้อมูลกราฟอย่าง Neo4j สร้างขึ้นเพื่อสำรวจความสัมพันธ์อย่างมีประสิทธิภาพ จึงเหมาะสําหรับระบบการแนะนํา การค้นหาเชิงความหมาย และผู้ช่วยอัจฉริยะ ข้อมูลนี้ช่วยจับบริบทในชีวิตจริง เช่น เครือข่ายการทำงานร่วมกัน เรื่องราว หรือค่ากําหนดของผู้ชม ซึ่งอาจแสดงได้ยากโดยใช้โมเดลข้อมูลแบบดั้งเดิม
การรวมข้อมูลแบบเชื่อมต่อนี้เข้ากับ LLM เช่น Gemini และการฝังเวกเตอร์จาก Vertex AI จะช่วยเพิ่มประสิทธิภาพประสบการณ์การใช้งานแชทบ็อต ซึ่งช่วยให้แชทบ็อตสามารถหาเหตุผล ดึงข้อมูล และตอบกลับด้วยวิธีที่ตรงใจและมีความเกี่ยวข้องมากขึ้น
การสร้าง Neo4j AuraDB ฟรี
- ไปที่ https://console.neo4j.io
- ลงชื่อเข้าสู่ระบบด้วยบัญชี Google หรืออีเมล
- คลิก "สร้างอินสแตนซ์แบบไม่มีค่าใช้จ่าย"
- ขณะจัดสรรอินสแตนซ์ หน้าต่างป๊อปอัปจะปรากฏขึ้นเพื่อแสดงข้อมูลเข้าสู่ระบบสำหรับการเชื่อมต่อฐานข้อมูล
โปรดดาวน์โหลดและบันทึกรายละเอียดต่อไปนี้จากป๊อปอัปอย่างปลอดภัย เนื่องจากข้อมูลเหล่านี้จำเป็นต่อการเชื่อมต่อแอปพลิเคชันกับ Neo4j
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
คุณจะใช้ค่าเหล่านี้เพื่อกำหนดค่าไฟล์ .env ในโปรเจ็กต์เพื่อตรวจสอบสิทธิ์กับ Neo4j ในขั้นตอนถัดไป

Neo4j AuraDB Free เหมาะสําหรับการพัฒนา การทดสอบ และแอปพลิเคชันขนาดเล็ก เช่น Codelab นี้ แพ็กเกจนี้มีข้อจำกัดด้านการใช้งานที่กว้างขวาง โดยรองรับโหนด 200,000 รายการและความสัมพันธ์ 400,000 รายการ แม้ว่าจะมีฟีเจอร์ที่จำเป็นทั้งหมดในการสร้างและค้นหากราฟความรู้ แต่ก็ไม่รองรับการกำหนดค่าขั้นสูง เช่น ปลั๊กอินที่กำหนดเองหรือพื้นที่เก็บข้อมูลเพิ่มขึ้น สำหรับเวิร์กโหลดเวอร์ชันที่ใช้งานจริงหรือชุดข้อมูลขนาดใหญ่ คุณสามารถอัปเกรดเป็นแพ็กเกจ AuraDB ระดับที่สูงขึ้นซึ่งมีพื้นที่เก็บข้อมูล ประสิทธิภาพ และฟีเจอร์ระดับองค์กรที่มากขึ้น
ในส่วนการตั้งค่าแบ็กเอนด์ Neo4j AuraDB เสร็จสมบูรณ์แล้ว ในขั้นตอนถัดไป เราจะสร้างโปรเจ็กต์ Google Cloud, โคลนที่เก็บ และกำหนดค่าตัวแปรสภาพแวดล้อมที่จำเป็นเพื่อเตรียมสภาพแวดล้อมการพัฒนาให้พร้อมก่อนเริ่มใช้งาน Codelab
3 ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าเปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าเปิดใช้การเรียกเก็บเงินในโปรเจ็กต์หรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud และโหลด bq ไว้ล่วงหน้า คลิก "เปิดใช้งาน Cloud Shell" ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและโปรเจ็กต์ได้รับการตั้งค่าเป็นรหัสโปรเจ็กต์ของคุณโดยใช้คําสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากยังไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คําสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็นผ่านคำสั่งที่แสดงด้านล่าง การดำเนินการนี้อาจใช้เวลาสักครู่ โปรดอดทนรอ
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
เมื่อเรียกใช้คําสั่งสําเร็จ คุณควรเห็นข้อความว่า "การดำเนินการ .... เสร็จสมบูรณ์แล้ว"
อีกทางเลือกหนึ่งสำหรับคำสั่ง gcloud คือผ่านคอนโซลโดยค้นหาผลิตภัณฑ์แต่ละรายการหรือใช้ลิงก์นี้
หากมี API ใดขาดหายไป คุณสามารถเปิดใช้งานได้ทุกเมื่อในระหว่างการติดตั้งใช้งาน
โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
โคลนที่เก็บและตั้งค่าสภาพแวดล้อม
ขั้นตอนถัดไปคือการโคลนที่เก็บข้อมูลตัวอย่างที่เราจะใช้อ้างอิงในโค้ดแล็บที่เหลือ สมมติว่าคุณอยู่ใน Cloud Shell ให้ป้อนคำสั่งต่อไปนี้จากไดเรกทอรีหน้าแรก
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
หากต้องการเปิดเครื่องมือแก้ไข ให้คลิกเปิดเครื่องมือแก้ไขในแถบเครื่องมือของหน้าต่าง Cloud Shell คลิกแถบเมนูที่มุมซ้ายบน แล้วเลือก "ไฟล์" → "เปิดโฟลเดอร์" ดังที่แสดงด้านล่าง

เลือกโฟลเดอร์ neo4j-vertexai-codelab แล้วคุณควรเห็นโฟลเดอร์เปิดขึ้นโดยมีโครงสร้างคล้ายกับที่แสดงด้านล่าง

ถัดไป เราต้องตั้งค่าตัวแปรสภาพแวดล้อมที่จะใช้ในโค้ดแล็บ คลิกไฟล์ example.env แล้วคุณจะเห็นเนื้อหาดังที่แสดงด้านล่าง
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
ตอนนี้ให้สร้างไฟล์ใหม่ชื่อ .env ในโฟลเดอร์เดียวกับไฟล์ example.env แล้วคัดลอกเนื้อหาของไฟล์ example.env ที่มีอยู่ จากนั้นอัปเดตตัวแปรต่อไปนี้
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDและNEO4J_DATABASE- กรอกค่าเหล่านี้โดยใช้ข้อมูลเข้าสู่ระบบที่ระบุระหว่างการสร้างอินสแตนซ์ Neo4j AuraDB ฟรีในขั้นตอนก่อนหน้า
- โดยปกติแล้ว
NEO4J_DATABASEจะตั้งค่าเป็น neo4j สำหรับ AuraDB ฟรี PROJECT_IDและLOCATION- หากเรียกใช้ Codelab จาก Google Cloud Shell คุณสามารถเว้นช่องเหล่านี้ว่างไว้ได้ เนื่องจากระบบจะอนุมานค่าจากการกำหนดค่าโปรเจ็กต์ที่ใช้งานอยู่โดยอัตโนมัติ
- หากคุณเรียกใช้เครื่องในเครื่องหรือนอก Cloud Shell ให้อัปเดต
PROJECT_IDด้วยรหัสของโปรเจ็กต์ Google Cloud ที่คุณสร้างไว้ก่อนหน้านี้ และตั้งค่าLOCATIONเป็นภูมิภาคที่คุณเลือกสำหรับโปรเจ็กต์นั้น (เช่น us-central1)
เมื่อกรอกค่าเหล่านี้แล้ว ให้บันทึกไฟล์ .env การกําหนดค่านี้จะช่วยให้แอปพลิเคชันเชื่อมต่อกับทั้งบริการ Neo4j และ Vertex AI ได้
ขั้นตอนสุดท้ายในการตั้งค่าสภาพแวดล้อมการพัฒนาคือการสร้างสภาพแวดล้อมเสมือนของ Python และติดตั้งไลบรารีที่ต้องพึ่งพาทั้งหมดที่ระบุไว้ในไฟล์ requirements.txt ไลบรารีเหล่านี้รวมถึงไลบรารีที่จําเป็นสําหรับทํางานร่วมกับ Neo4j, Vertex AI, Gradio และอื่นๆ
ก่อนอื่น ให้สร้างสภาพแวดล้อมเสมือนชื่อ .venv โดยเรียกใช้คําสั่งต่อไปนี้
python -m venv .venv
เมื่อสร้างสภาพแวดล้อมแล้ว เราจะต้องเปิดใช้งานสภาพแวดล้อมที่สร้างขึ้นด้วยคําสั่งต่อไปนี้
source .venv/bin/activate
ตอนนี้คุณควรเห็น (.venv) ที่จุดเริ่มต้นของพรอมต์เทอร์มินัล ซึ่งบ่งบอกว่าสภาพแวดล้อมทำงานอยู่ เช่น (.venv) yourusername@cloudshell:
จากนั้นติดตั้งไลบรารีที่จำเป็นโดยเรียกใช้คำสั่งต่อไปนี้
pip install -r requirements.txt
ภาพรวมของข้อกําหนดเบื้องต้นที่สําคัญที่แสดงในไฟล์มีดังนี้
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
เมื่อติดตั้งข้อกําหนดทั้งหมดเรียบร้อยแล้ว ระบบจะกําหนดค่าสภาพแวดล้อม Python ในเครื่องให้พร้อมใช้งานสคริปต์และแชทบ็อตในโค้ดแล็บนี้อย่างสมบูรณ์
เยี่ยมมาก ตอนนี้เราพร้อมที่จะไปยังขั้นตอนถัดไป ซึ่งก็คือการทำความเข้าใจชุดข้อมูลและเตรียมชุดข้อมูลสําหรับการสร้างกราฟและการเพิ่มความสมบูรณ์เชิงความหมาย
4 เตรียมชุดข้อมูลภาพยนตร์
งานแรกของเราคือเตรียมชุดข้อมูลภาพยนตร์ที่จะใช้สร้างกราฟความรู้และขับเคลื่อนแชทบอทแนะนำ เราจะใช้ชุดข้อมูลแบบเปิดที่มีอยู่และต่อยอดจากชุดข้อมูลนั้นแทนที่จะเริ่มต้นจากศูนย์
เราใช้ The Movies Dataset โดย Rounak Banik ซึ่งเป็นชุดข้อมูลสาธารณะที่รู้จักกันดีซึ่งมีอยู่ใน Kaggle ซึ่งรวมถึงข้อมูลเมตาของภาพยนตร์กว่า 45,000 เรื่องจาก TMDB รวมถึงนักแสดง ทีมงาน คีย์เวิร์ด การจัดประเภท และอื่นๆ

หากต้องการสร้างแชทบ็อตแนะนำภาพยนตร์ที่เชื่อถือได้และมีประสิทธิภาพ คุณจะต้องเริ่มต้นด้วย Structured Data ที่สะอาด สม่ำเสมอ และถูกต้อง แม้ว่าชุดข้อมูลภาพยนตร์จาก Kaggle จะเป็นแหล่งข้อมูลที่อุดมสมบูรณ์ซึ่งมีระเบียนภาพยนตร์มากกว่า 45,000 รายการและข้อมูลเมตาโดยละเอียด ซึ่งรวมถึงประเภท นักแสดง ทีมงาน และอื่นๆ แต่ก็มีข้อมูลที่ไม่เกี่ยวข้อง ความไม่สอดคล้อง และโครงสร้างข้อมูลที่ซ้อนกันซึ่งไม่เหมาะสําหรับการสร้างโมเดลกราฟหรือการฝังข้อมูลเชิงความหมาย
ในการแก้ปัญหานี้ เราได้เตรียมข้อมูลและทำให้ชุดข้อมูลเป็นมาตรฐานเพื่อให้เหมาะกับการสร้างกราฟความรู้ Neo4j และสร้างการฝังคุณภาพสูง กระบวนการนี้เกี่ยวข้องกับสิ่งต่อไปนี้
- การนำระเบียนที่ซ้ำกันและไม่สมบูรณ์ออก
- การใช้ฟิลด์คีย์ที่เป็นมาตรฐาน (เช่น ชื่อประเภท ชื่อบุคคล)
- การแปลงโครงสร้างที่ซับซ้อนซึ่งซ้อนกัน (เช่น นักแสดงและทีมงาน) เป็น CSV ที่มีโครงสร้าง
- การเลือกชุดย่อยของภาพยนตร์ประมาณ 12,000 เรื่องเพื่อไม่ให้เกินขีดจำกัดของ Neo4j AuraDB แบบไม่มีค่าใช้จ่าย
ข้อมูลที่แปลงเป็นมาตรฐานและมีคุณภาพสูงจะช่วยให้มั่นใจได้ว่า
- คุณภาพของข้อมูล: ลดข้อผิดพลาดและความไม่สอดคล้องเพื่อให้คำแนะนำที่แม่นยำยิ่งขึ้น
- ประสิทธิภาพการค้นหา: โครงสร้างที่มีประสิทธิภาพยิ่งขึ้นช่วยเพิ่มความเร็วในการดึงข้อมูลและลดความซ้ำซ้อน
- ความแม่นยำของการฝัง: ข้อมูลที่สะอาดจะทำให้เวกเตอร์การฝังตามบริบทมีความหมายมากขึ้น
คุณสามารถเข้าถึงชุดข้อมูลที่ล้างและทำให้เป็นไปตามมาตรฐานได้ในโฟลเดอร์ normalized_data/ ของที่เก็บ GitHub นี้ ชุดข้อมูลนี้ยังได้รับการมิเรอร์ไว้ในที่เก็บข้อมูล Google Cloud Storage เพื่อให้เข้าถึงสคริปต์ Python ที่กำลังจะเผยแพร่ได้ง่ายๆ
เมื่อล้างข้อมูลและเตรียมข้อมูลเรียบร้อยแล้ว เราก็พร้อมที่จะโหลดข้อมูลไปยัง Neo4j และเริ่มสร้างกราฟความรู้เกี่ยวกับภาพยนตร์
5 สร้างกราฟความรู้ภาพยนตร์
ในการขับเคลื่อนแชทบ็อตแนะนำภาพยนตร์ที่เปิดใช้ GenAI เราต้องจัดโครงสร้างชุดข้อมูลภาพยนตร์ในลักษณะที่เก็บเครือข่ายการเชื่อมต่อที่สมบูรณ์ระหว่างภาพยนตร์ นักแสดง ผู้กำกับ ประเภท และข้อมูลเมตาอื่นๆ ในส่วนนี้ เราจะสร้าง Movies Knowledge Graph ใน Neo4j โดยใช้ชุดข้อมูลที่ล้างและทำให้ถูกต้องซึ่งคุณเตรียมไว้ก่อนหน้านี้
เราจะใช้ความสามารถ LOAD CSV ของ Neo4j เพื่อนำเข้าไฟล์ CSV ที่โฮสต์ในที่เก็บข้อมูล Google Cloud Storage (GCS) สาธารณะ ไฟล์เหล่านี้แสดงถึงองค์ประกอบต่างๆ ของชุดข้อมูลภาพยนตร์ เช่น ภาพยนตร์ ประเภท นักแสดง ทีมงาน บริษัทโปรดักชัน และคะแนนของผู้ใช้
ขั้นตอนที่ 1: สร้างข้อจำกัดและดัชนี
ก่อนนําเข้าข้อมูล คุณควรสร้างข้อจำกัดและดัชนีเพื่อบังคับใช้ความสมบูรณ์ของข้อมูลและเพิ่มประสิทธิภาพการค้นหา
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
ขั้นตอนที่ 2: นําเข้าข้อมูลเมตาและความสัมพันธ์ของภาพยนตร์
มาดูวิธีที่เรานําเข้าข้อมูลเมตาของภาพยนตร์โดยใช้คําสั่ง LOAD CSV ตัวอย่างนี้จะสร้างโหนดภาพยนตร์ที่มีแอตทริบิวต์หลัก เช่น ชื่อ ภาพรวม ภาษา และรันไทม์
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
ในทำนองเดียวกัน คุณสามารถนำเข้าและลิงก์เอนทิตีอื่นๆ เช่น ประเภท บริษัทสร้างภาพยนตร์ ภาษาที่ใช้ ประเทศ นักแสดง ทีมงาน และการให้คะแนนของผู้ใช้ได้โดยใช้ไฟล์ CSV และการค้นหา Cypher ที่เกี่ยวข้อง
โหลดกราฟแบบเต็มผ่าน Python
เราขอแนะนำให้ใช้สคริปต์ Python แบบอัตโนมัติที่มีให้ในโค้ดแล็บนี้แทนการเรียกใช้การค้นหา Cypher หลายรายการด้วยตนเอง
สคริปต์ graph_build.py จะโหลดชุดข้อมูลทั้งหมดจาก GCS ไปยังอินสแตนซ์ Neo4j AuraDB โดยใช้ข้อมูลเข้าสู่ระบบในไฟล์ .env
python graph_build.py
สคริปต์จะโหลดไฟล์ CSV ที่จำเป็นทั้งหมดตามลำดับ สร้างโหนดและความสัมพันธ์ ตลอดจนจัดโครงสร้างกราฟความรู้ที่สมบูรณ์เกี่ยวกับภาพยนตร์
|
|

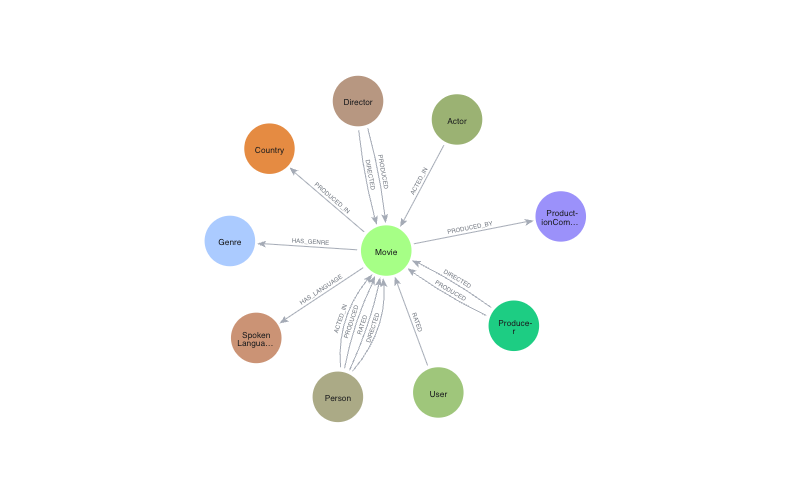
ตรวจสอบความถูกต้องของกราฟ
หลังจากโหลดแล้ว คุณสามารถตรวจสอบกราฟได้โดยเรียกใช้สคริปต์ต่อไปนี้
python validate_graph.py
ซึ่งจะแสดงข้อมูลสรุปคร่าวๆ เกี่ยวกับสิ่งที่อยู่ในกราฟ เช่น จำนวนภาพยนตร์ นักแสดง ประเภท และความสัมพันธ์ต่างๆ เช่น ACTED_IN, DIRECTED ฯลฯ เพื่อให้แน่ใจว่าการนําเข้าสําเร็จ
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
ตอนนี้คุณควรเห็นกราฟที่สร้างขึ้นด้วยภาพยนตร์ บุคคล ประเภท และอื่นๆ พร้อมที่จะเพิ่มความหมายในขั้นตอนถัดไป
6 สร้างและโหลดการฝังเพื่อทำการค้นหาความคล้ายคลึงของเวกเตอร์
หากต้องการเปิดใช้การค้นหาเชิงความหมายในแชทบ็อต เราต้องสร้างการฝังเวกเตอร์สำหรับข้อมูลภาพรวมของภาพยนตร์ ข้อมูลเชิงลึกเหล่านี้จะเปลี่ยนข้อมูลข้อความให้เป็นเวกเตอร์ตัวเลขที่เปรียบเทียบความคล้ายกันได้ ซึ่งช่วยให้แชทบ็อตดึงข้อมูลภาพยนตร์ที่เกี่ยวข้องได้แม้ว่าคำค้นหาจะไม่ตรงกับชื่อหรือคำอธิบายอย่างตรงทั้งหมด
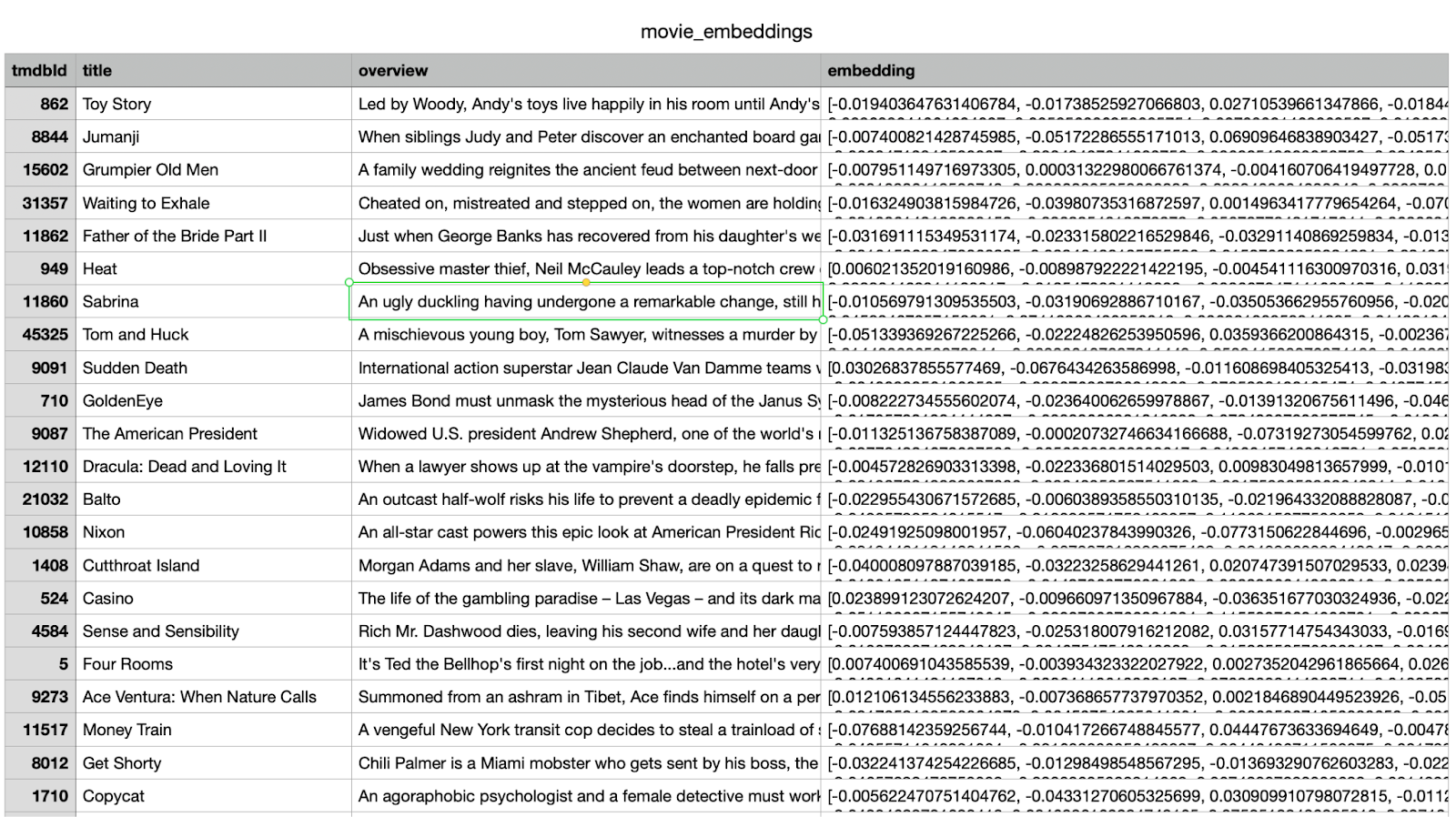
ตัวเลือกที่ 1: โหลดการฝังที่ประมวลผลไว้ล่วงหน้าผ่าน Cypher
หากต้องการแนบการฝังกับโหนด Movie ที่เกี่ยวข้องใน Neo4j อย่างรวดเร็ว ให้เรียกใช้คําสั่ง Cypher ต่อไปนี้ในเบราว์เซอร์ Neo4j
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
คำสั่งนี้จะอ่านเวกเตอร์การฝังจาก CSV และแนบเป็นพร็อพเพอร์ตี้ (m.embedding) ในโหนด Movie แต่ละโหนด
ตัวเลือกที่ 2: โหลดการฝังโดยใช้ Python
นอกจากนี้ คุณยังโหลดการฝังแบบเป็นโปรแกรมได้โดยใช้สคริปต์ Python ที่ให้มา แนวทางนี้มีประโยชน์ในกรณีที่คุณทํางานในสภาพแวดล้อมของคุณเองหรือต้องการทําให้กระบวนการทํางานอัตโนมัติ
python load_embeddings.py
สคริปต์นี้จะอ่าน CSV เดียวกันจาก GCS และเขียนการฝังลงใน Neo4j โดยใช้ไดรเวอร์ Python Neo4j
[ไม่บังคับ] สร้างการฝังด้วยตนเอง (สําหรับการสํารวจ)
หากต้องการทําความเข้าใจวิธีสร้างการฝัง คุณสามารถดูตรรกะในสคริปต์ generate_embeddings.py เอง โดยใช้ Vertex AI เพื่อฝังข้อความภาพรวมของภาพยนตร์แต่ละเรื่องโดยใช้โมเดล text-embedding-004
หากต้องการลองใช้ด้วยตนเอง ให้เปิดและเรียกใช้ส่วนการสร้างการฝังของโค้ด หากคุณเรียกใช้ใน Cloud Shell คุณสามารถใส่ความคิดเห็นในบรรทัดต่อไปนี้ได้ เนื่องจาก Cloud Shell ได้รับการตรวจสอบสิทธิ์ผ่านบัญชีที่ใช้งานอยู่ของคุณแล้ว
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
เมื่อโหลดการฝังลงใน Neo4j แล้ว กราฟความรู้ของภาพยนตร์จะคำนึงถึงความหมาย พร้อมรองรับการค้นหาด้วยภาษาที่เป็นธรรมชาติที่มีประสิทธิภาพโดยใช้ความคล้ายคลึงของเวกเตอร์
7 แชทบ็อตแนะนำภาพยนตร์
เมื่อสร้างกราฟความรู้และการฝังเวกเตอร์แล้ว ก็ถึงเวลารวมทุกอย่างเข้าด้วยกันเป็นอินเทอร์เฟซแบบสนทนาที่ใช้งานได้อย่างเต็มรูปแบบ ซึ่งก็คือแชทบ็อตแนะนำภาพยนตร์ที่ทำงานด้วย GenAI
แชทบ็อตนี้ติดตั้งใช้งานใน Python โดยใช้ Gradio ซึ่งเป็นเฟรมเวิร์กเว็บที่มีน้ำหนักเบาสําหรับการสร้างอินเทอร์เฟซผู้ใช้ที่ใช้งานง่าย ตรรกะหลักอยู่ใน app.py ซึ่งเชื่อมต่อกับอินสแตนซ์ Neo4j AuraDB และใช้ Google Vertex AI และ Gemini เพื่อประมวลผลและตอบกลับการค้นหาที่เป็นภาษาธรรมชาติ
วิธีการทำงาน
- ผู้ใช้พิมพ์คําค้นหาที่เป็นภาษาธรรมชาติเช่น "แนะนำภาพยนตร์ไซไฟระทึกขวัญให้ฉันหน่อย เช่น Interstellar"
- สร้างการฝังเวกเตอร์สําหรับคําค้นหาโดยใช้โมเดล
text-embedding-004ของ Vertex AI - ทำการค้นหาเวกเตอร์ใน Neo4j เพื่อดึงข้อมูลภาพยนตร์ที่คล้ายกันตามความหมาย
- ใช้ Gemini เพื่อทำสิ่งต่อไปนี้
- ตีความคําค้นหาในบริบท
- สร้างการค้นหา Cypher ที่กำหนดเองตามผลการค้นหาเวกเตอร์และสคีมา Neo4j
- ดำเนินการค้นหาเพื่อดึงข้อมูลกราฟที่เกี่ยวข้อง (เช่น นักแสดง ผู้กำกับ ประเภท)
- สรุปผลลัพธ์เป็นบทสนทนาสำหรับผู้ใช้
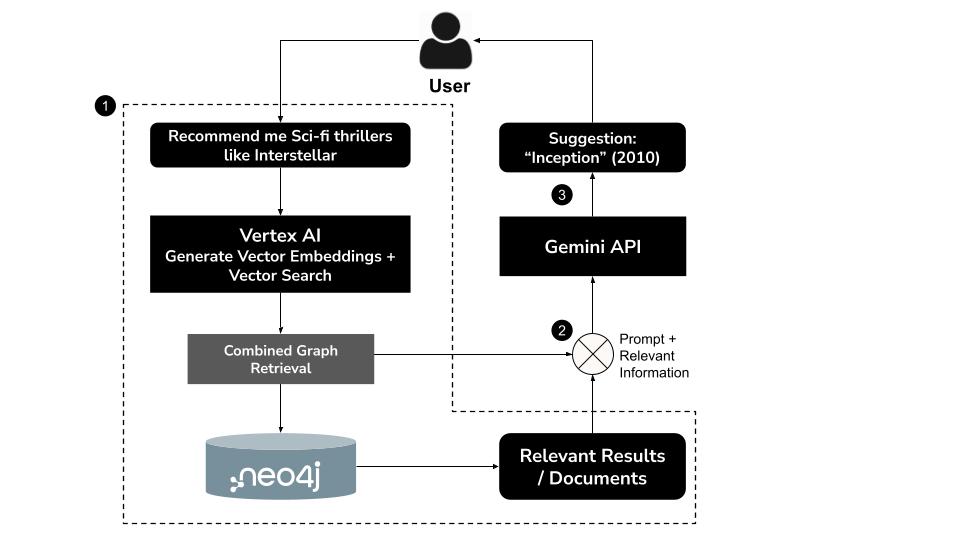
แนวทางแบบผสมผสานนี้เรียกว่า GraphRAG (Graph Retrieval-Augmented Generation) ซึ่งรวมการดึงข้อมูลเชิงความหมายและการให้เหตุผลแบบมีโครงสร้างเข้าด้วยกันเพื่อสร้างคําแนะนําที่แม่นยํามากขึ้น อิงตามบริบท และอธิบายได้
เรียกใช้แชทบ็อตในเครื่อง
เปิดใช้งานสภาพแวดล้อมเสมือน (หากยังไม่ได้เปิดใช้งาน) จากนั้นเปิดใช้แชทบ็อตด้วยคำสั่งต่อไปนี้
python app.py
คุณควรเห็นเอาต์พุตที่คล้ายกับตัวอย่างต่อไปนี้
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 หากต้องการแชร์แชทบ็อตกับภายนอก ให้ตั้งค่า share=True ในฟังก์ชัน launch() ใน app.py
โต้ตอบกับแชทบ็อต
เปิด URL ในพื้นที่ที่แสดงในเทอร์มินัล (โดยปกติคือ 👉 http://0.0.0.0:8080) เพื่อเข้าถึงอินเทอร์เฟซแชทบ็อต
ลองถามคำถามอย่างเช่น
- "ฉันควรดูอะไรหากชอบ Interstellar"
- "แนะนำภาพยนตร์โรแมนติกที่กำกับโดย Nora Ephron"
- "ฉันอยากดูภาพยนตร์สำหรับครอบครัวที่มีทอม แฮงส์"
- "ค้นหาภาพยนตร์ระทึกขวัญที่เกี่ยวข้องกับปัญญาประดิษฐ์"
แชทบ็อตจะทำสิ่งต่อไปนี้
✅ ทําความเข้าใจคําค้นหา
✅ ค้นหาพล็อตภาพยนตร์ที่คล้ายกันตามความหมายโดยใช้การฝัง
✅ สร้างและเรียกใช้การค้นหา Cypher เพื่อดึงข้อมูลบริบทกราฟที่เกี่ยวข้อง
✅ แสดงคําแนะนําที่ปรับเปลี่ยนในแบบของคุณและเข้าใจง่ายภายในไม่กี่วินาที
สิ่งที่คุณมีตอนนี้
คุณเพิ่งสร้างแชทบ็อตแนะนำภาพยนตร์ที่ทำงานด้วย GraphRAG ซึ่งรวมข้อมูลต่อไปนี้
- การค้นหาเวกเตอร์เพื่อดูความเกี่ยวข้องเชิงความหมาย
- การอนุมานกราฟความรู้ด้วย Neo4j
- ความสามารถของ LLM ผ่าน Gemini
- อินเทอร์เฟซการแชทที่ราบรื่นด้วย Gradio
สถาปัตยกรรมนี้จะเป็นรากฐานที่คุณสามารถขยายไปสู่ระบบการค้นหา คำแนะนำ หรือการหาเหตุผลขั้นสูงขึ้นที่ทำงานด้วย GenAI
8 (ไม่บังคับ) การปรับใช้ใน Google Cloud Run
หากต้องการให้แชทบ็อตแนะนำภาพยนตร์เข้าถึงได้แบบสาธารณะ คุณสามารถทำให้แชทบ็อตใช้งานได้ใน Google Cloud Run ซึ่งเป็นแพลตฟอร์มแบบ Serverless ที่มีการจัดการครบวงจรซึ่งจะปรับขนาดแอปโดยอัตโนมัติและนำข้อกังวลเกี่ยวกับโครงสร้างพื้นฐานทั้งหมดออก
การติดตั้งใช้งานนี้ใช้สิ่งต่อไปนี้
requirements.txt— เพื่อกำหนดการอ้างอิง Python (Neo4j, Vertex AI, Gradio ฯลฯ)Dockerfile- เพื่อแพ็กเกจแอปพลิเคชัน.env.yaml— เพื่อส่งตัวแปรสภาพแวดล้อมอย่างปลอดภัยเมื่อรันไทม์
ขั้นตอนที่ 1: เตรียม .env.yaml
สร้างไฟล์ชื่อ .env.yaml ในไดเรกทอรีรูทที่มีเนื้อหาดังต่อไปนี้
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 เราขอแนะนำให้ใช้รูปแบบนี้แทน --set-env-vars เนื่องจากปรับขนาดได้ ควบคุมเวอร์ชันได้ และอ่านง่ายกว่า
ขั้นตอนที่ 2: ตั้งค่าตัวแปรสภาพแวดล้อม
ในเทอร์มินัล ให้ตั้งค่าตัวแปรสภาพแวดล้อมต่อไปนี้ (แทนที่ค่าตัวยึดตําแหน่งด้วยการตั้งค่าโปรเจ็กต์จริง)
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
ขั้นตอนที่ 2: สร้างที่เก็บอาร์ติแฟกต์และสร้างคอนเทนเนอร์
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
คำสั่งนี้จะแพ็กเกจแอปของคุณโดยใช้ Dockerfile และอัปโหลดอิมเมจคอนเทนเนอร์ไปยัง Google Cloud Artifact Registry
ขั้นตอนที่ 3: ติดตั้งใช้งานใน Cloud Run
ตอนนี้ให้ทําให้การเผยแพร่แอปโดยใช้ไฟล์ .env.yaml สําหรับการกําหนดค่ารันไทม์
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
เข้าถึงแชทบ็อต
เมื่อทำให้ใช้งานได้แล้ว Cloud Run จะแสดง URL สาธารณะ เช่น
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
เปิด URL นี้ในเบราว์เซอร์เพื่อเข้าถึงอินเทอร์เฟซแชทบ็อต Gradio ที่ติดตั้งใช้งาน ซึ่งพร้อมจัดการคำแนะนำภาพยนตร์โดยใช้ GraphRAG, Gemini และ Neo4j
หมายเหตุและเคล็ดลับ
- ตรวจสอบว่า
Dockerfileเรียกใช้pip install -r requirements.txtในระหว่างการสร้าง - หากไม่ได้ใช้ Cloud Shell คุณจะต้องตรวจสอบสิทธิ์สภาพแวดล้อมโดยใช้บัญชีบริการที่มีสิทธิ์ Vertex AI และ Artifact Registry
- คุณสามารถตรวจสอบบันทึกและเมตริกการทำให้ใช้งานได้จาก Google Cloud Console > Cloud Run
นอกจากนี้ คุณยังไปที่ Cloud Run จากคอนโซล Google Cloud ได้ด้วย และจะเห็นรายการบริการใน Cloud Run บริการ movies-chatbot ควรเป็นหนึ่งในบริการ (หากไม่ใช่บริการเดียว) ที่แสดงอยู่ในนั้น

คุณสามารถดูรายละเอียดของบริการ เช่น URL, การกําหนดค่า, บันทึก และอื่นๆ ได้โดยคลิกที่ชื่อบริการที่ต้องการ (ในกรณีนี้คือ movies-chatbot)

การดำเนินการนี้ทำให้แชทบ็อตแนะนำภาพยนตร์ใช้งานได้ ปรับขนาดได้ และแชร์ได้ 🎉
9 ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าจัดการทรัพยากร
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
10 ขอแสดงความยินดี
คุณสร้างและติดตั้งใช้งานแชทบอทแนะนำภาพยนตร์ที่ทำงานด้วย GraphRAG และเพิ่มประสิทธิภาพด้วย GenAI โดยใช้ Neo4j, Vertex AI และ Gemini เรียบร้อยแล้ว การรวมความสามารถในการโมเดลแบบกราฟเนทีฟของ Neo4j กับการค้นหาเชิงความหมายผ่าน Vertex AI และการหาเหตุผลจากภาษาที่เป็นธรรมชาติผ่าน Gemini จะทำให้คุณสร้างระบบอัจฉริยะที่เหนือกว่าการค้นหาพื้นฐาน ซึ่งจะเข้าใจความตั้งใจของผู้ใช้ หาเหตุผลจากข้อมูลที่เชื่อมต่อกัน และโต้ตอบแบบการสนทนา
ในโค้ดแล็บนี้ คุณได้ทําสิ่งต่อไปนี้
✅ สร้างกราฟความรู้เกี่ยวกับภาพยนตร์ในชีวิตจริงใน Neo4j เพื่อจำลองภาพยนตร์ นักแสดง ประเภท และความสัมพันธ์
✅ เวกเตอร์เชิงลึกที่สร้างขึ้นสำหรับภาพรวมของพล็อตภาพยนตร์โดยใช้โมเดลการฝังข้อความของ Vertex AI
✅ ติดตั้งใช้งาน GraphRAG ซึ่งรวมการค้นหาเวกเตอร์และการค้นหา Cypher ที่ LLM สร้างขึ้นเข้าด้วยกันเพื่อการอนุมานแบบหลาย Hop ที่ลึกยิ่งขึ้น
✅ ผสานรวม Gemini เพื่อตีความคําถามของผู้ใช้ สร้างการค้นหา Cypher และสรุปผลลัพธ์ของกราฟเป็นภาษาที่เป็นธรรมชาติ
✅ สร้างอินเทอร์เฟซแชทที่ใช้งานง่ายโดยใช้ Gradio
✅ ทำให้แชทบ็อตใช้งานได้ใน Google Cloud Run (ไม่บังคับ) เพื่อการโฮสติ้งแบบปรับขนาดได้และไม่มีเซิร์ฟเวอร์
ขั้นตอนต่อไปคือ
สถาปัตยกรรมนี้ไม่ได้จำกัดอยู่แค่การแนะนำภาพยนตร์เท่านั้น แต่ยังขยายไปถึงสิ่งต่อไปนี้
- แพลตฟอร์มการค้นพบหนังสือและเพลง
- ผู้ช่วยวิจัยทางวิชาการ
- เครื่องมือแนะนำผลิตภัณฑ์
- ผู้ช่วยด้านความรู้ด้านการดูแลสุขอนามัย การเงิน และกฎหมาย
ไม่ว่าคุณจะอยู่ที่ใดก็ตามที่มีความสัมพันธ์ที่ซับซ้อน + ข้อมูลข้อความที่สมบูรณ์ การใช้ Knowledge Graph + LLM + การฝังเชิงความหมายร่วมกันนี้จะช่วยขับเคลื่อนแอปพลิเคชันอัจฉริยะรุ่นถัดไป
เมื่อโมเดล GenAI แบบหลายรูปแบบอย่าง Gemini พัฒนาขึ้น คุณจะรวมบริบท รูปภาพ เสียงพูด และการปรับเปลี่ยนในแบบของคุณให้สมบูรณ์ยิ่งขึ้นเพื่อสร้างระบบที่มุ่งเน้นมนุษย์อย่างแท้จริงได้
สำรวจและสร้างต่อไป และอย่าลืมติดตามข่าวสารล่าสุดจาก Neo4j, Vertex AI และ Google Cloud เพื่อยกระดับแอปพลิเคชันอัจฉริยะของคุณไปอีกขั้น ดูบทแนะนำกราฟความรู้แบบลงมือปฏิบัติเพิ่มเติมที่ Neo4j GraphAcademy