
关于此 Codelab
1. 概览
在此 Codelab 中,您将结合使用 Neo4j、Google Vertex AI 和 Gemini 的强大功能,构建智能电影推荐聊天机器人。该系统的核心是 Neo4j 知识图谱,它通过丰富的相互关联的节点和关系网络对电影、演员、导演、类型等进行建模。
为了通过语义理解提升用户体验,您将使用 Vertex AI 的 text-embedding-004 模型(或更高版本)根据电影剧情概览生成向量嵌入。这些嵌入在 Neo4j 中编入索引,以便基于相似性快速检索。
最后,您将集成 Gemini 来支持对话式界面,让用户能够提出自然语言问题(例如“如果我喜欢《星际穿越》,应该看什么电影?”),并根据语义相似性和基于图的上下文接收个性化的电影建议。
在本 Codelab 中,您将采用分步方法,具体步骤如下:
- 构建包含电影相关实体和关系的 Neo4j 知识图谱
- 使用 Vertex AI 为电影简介生成/加载文本嵌入
- 实现一个由 Gemini 提供支持的 Gradio 聊天机器人界面,该界面将矢量搜索与基于图的 Cypher 执行相结合
- (可选)将应用作为独立 Web 应用部署到 Cloud Run
学习内容
- 如何使用 Cypher 和 Neo4j 创建和填充电影知识图谱
- 如何使用 Vertex AI 生成和处理语义文本嵌入
- 如何使用 GraphRAG 结合使用 LLM 和知识图谱进行智能检索
- 如何使用 Gradio 构建人性化的聊天界面
- 如何选择性地在 Google Cloud Run 上部署
所需条件
- Chrome 网络浏览器
- Gmail 账号
- 启用了结算功能的 Google Cloud 项目
- 一个免费的 Neo4j Aura 数据库账号
- 基本熟悉终端命令和 Python(有帮助,但不是必需的)
此 Codelab 面向各种级别的开发者(包括新手),其示例应用中使用了 Python 和 Neo4j。虽然对 Python 和图数据库有基本的了解会很有帮助,但无需任何相关经验即可理解相关概念或跟随本教程学习。

2. 设置 Neo4j AuraDB
Neo4j 是一款领先的原生图数据库,可将数据存储为节点(实体)和关系(实体之间的关联)网络,非常适合了解关联至关重要的用例,例如推荐、欺诈检测、知识图谱等。与依赖于刚性表或分层结构的关系型数据库或基于文档的数据库不同,Neo4j 的灵活图模型可直观、高效地表示复杂的相互关联的数据。
Neo4j 使用图模型,而不是像关系型数据库那样以行和表的形式组织数据,其中信息表示为节点(实体)和关系(这些实体之间的连接)。借助这种模型,您可以非常直观地处理具有内在关联的数据,例如人物、地点、产品,或者在我们的示例中,电影、演员和类型。
例如,在电影数据集中:
- 节点可以表示
Movie、Actor或Director - 关系可以是
ACTED_IN或DIRECTED
借助这种结构,您可以轻松提出以下问题:
- 这位演员出演过哪些电影?
- 哪些演员与 Christopher Nolan 合作过?
- 根据共同演员或类型的类似电影有哪些?
Neo4j 附带一种名为 Cypher 的强大查询语言,专为查询图表而设计。借助 Cypher,您可以以简洁且易于阅读的方式表达复杂的模式和关联。
Neo4j 提供多种部署选项,可根据您的需求进行选择:
- 自行管理:使用 Neo4j Desktop 或作为 Docker 映像(在本地或您自己的云端)在您自己的基础架构上运行 Neo4j。

- 云端管理:使用 Marketplace 产品在热门云服务提供商上部署 Neo4j。
- 全代管式:使用 Neo4j AuraDB,这是 Neo4j 的全代管式云数据库即服务,可为您处理预配、扩缩、备份和安全性。
在此 Codelab 中,我们将使用 Neo4j AuraDB Free,即 AuraDB 的免费层级。它提供了一个全托管式图数据库实例,具有足够的存储空间和功能,可用于构建原型、学习和构建小型应用,非常适合我们构建由 GenAI 驱动的电影推荐聊天机器人的目标。
您将创建一个免费的 AuraDB 实例,使用连接凭据将其连接到您的应用,并在本实验中使用该实例存储和查询电影知识图谱。
为什么使用图表?
在传统的关系型数据库中,若要回答诸如“哪些电影与《盗梦空间》相似,因为它们有共同的演员或属于同一类型?”之类的问题,就需要跨多个表执行复杂的 JOIN 操作。随着关系深度的增加,性能和可读性会降低。
不过,Neo4j 等图数据库旨在高效遍历关系,因此非常适合推荐系统、语义搜索和智能助理。它们有助于捕获使用传统数据模型难以表示的现实世界情境,例如协作网络、故事情节或观看者偏好。
通过将这些关联数据与 Gemini 等 LLM 和 Vertex AI 中的矢量嵌入相结合,我们可以强化聊天机器人的体验,让其能够以更个性化、更相关的方式推理、检索和回复。
免费创建 Neo4j AuraDB
- 访问 https://console.neo4j.io
- 使用您的 Google 账号或电子邮件地址登录。
- 点击“创建免费实例”。
- 在实例预配期间,系统会显示一个弹出式窗口,其中显示了数据库的连接凭据。
请务必从弹出式窗口中下载并安全地保存以下详细信息,这些信息对于将应用连接到 Neo4j 至关重要:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
您将在下一步中使用这些值配置项目中的 .env 文件,以便通过 Neo4j 进行身份验证。

Neo4j AuraDB Free 非常适合开发、实验以及此 Codelab 中所述的小规模应用。它提供宽松的使用限制,最多支持 20 万个节点和 40 万个关系。虽然它提供了构建和查询知识图谱所需的所有基本功能,但不支持自定义插件或增加存储空间等高级配置。对于生产工作负载或较大的数据集,您可以升级到更高层级的 AuraDB 方案,以获得更大的容量、更出色的性能和企业级功能。
至此,关于设置 Neo4j AuraDB 后端的部分已完成。在下一步中,我们将创建一个 Google Cloud 项目、克隆代码库并配置必要的环境变量,以便准备好开发环境,然后再开始我们的 Codelab。
3. 准备工作
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,这是一个在 Google Cloud 中运行的命令行环境,它预加载了 bq。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 通过以下命令启用所需的 API。此过程可能需要几分钟的时间,请耐心等待。
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
成功执行该命令后,您应该会看到以下消息:“Operation .... finished successfully”。
您可以通过控制台搜索各个产品或使用此链接,以替代 gcloud 命令。
如果缺少任何 API,您随时可以在实现过程中启用它。
如需了解 gcloud 命令和用法,请参阅文档。
克隆代码库并设置环境设置
下一步是克隆我们将在本 Codelab 的其余部分中引用的示例代码库。假设您在 Cloud Shell 中,请在主目录中输入以下命令:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
如需启动编辑器,请点击 Cloud Shell 窗口工具栏上的“打开编辑器”。点击左上角的菜单栏,然后依次选择“File”(文件)→“Open Folder”(打开文件夹),如下所示:
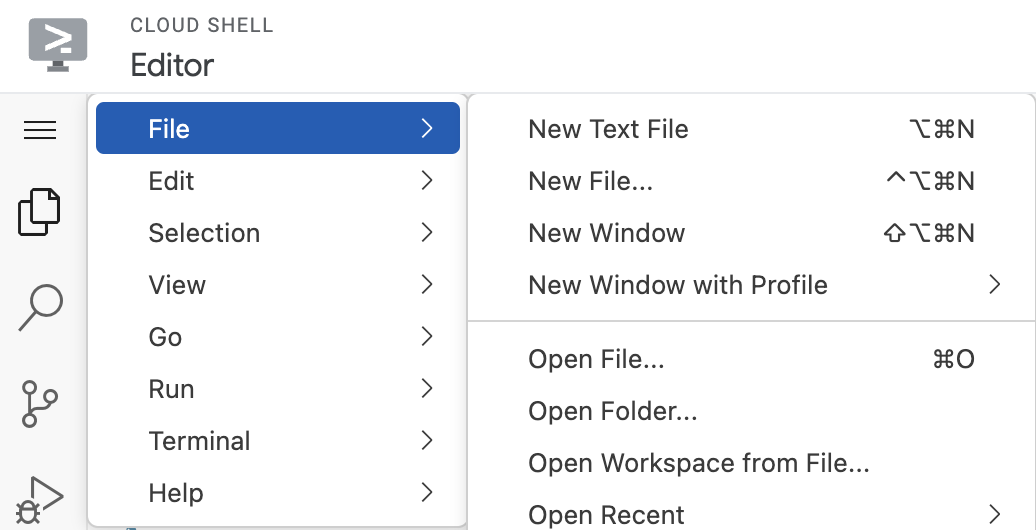
选择 neo4j-vertexai-codelab 文件夹,您应该会看到该文件夹打开,并且结构与下方显示的结构略有相似:

接下来,我们需要设置将在整个 Codelab 中使用的环境变量。点击 example.env 文件,您应该会看到如下所示的内容:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
现在,在 example.env 文件所在的文件夹中创建一个名为 .env 的新文件,并复制现有 example.env 文件的内容。现在,更新以下变量:
NEO4J_URI、NEO4J_USER、NEO4J_PASSWORD和NEO4J_DATABASE:- 使用在上一步中创建 Neo4j AuraDB 免费实例时提供的凭据填写这些值。
- 对于 AuraDB Free,
NEO4J_DATABASE通常设置为 neo4j。 PROJECT_ID和LOCATION:- 如果您是通过 Google Cloud Shell 运行此 Codelab,则可以将这些字段留空,因为系统会根据您当前的项目配置自动推断出这些字段。
- 如果您是在本地或 Cloud Shell 之外运行,请将
PROJECT_ID更新为您之前创建的 Google Cloud 项目的 ID,并将LOCATION设置为您为该项目选择的区域(例如 us-central1)。
填写完这些值后,保存 .env 文件。此配置将允许您的应用同时连接到 Neo4j 和 Vertex AI 服务。
设置开发环境的最后一步是创建 Python 虚拟环境并安装 requirements.txt 文件中列出的所有必需依赖项。这些依赖项包括与 Neo4j、Vertex AI、Gradio 等搭配使用所需的库。
首先,运行以下命令创建一个名为 .venv 的虚拟环境:
python -m venv .venv
创建环境后,我们需要使用以下命令激活所创建的环境
source .venv/bin/activate
现在,您应该会在终端提示开头看到 (.venv),表示环境处于活动状态。例如:(.venv) yourusername@cloudshell:
现在,运行以下命令安装所需的依赖项:
pip install -r requirements.txt
下面是该文件中列出的关键依赖项的快照:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
成功安装所有依赖项后,您的本地 Python 环境将会完全配置完毕,可以运行此 Codelab 中的脚本和聊天机器人。
太棒了!现在,我们可以继续执行下一步了:了解数据集并为创建图表和进行语义丰富准备。
4. 准备 Movies 数据集
我们的第一项任务是准备电影数据集,我们将使用该数据集构建知识图谱并为推荐聊天机器人提供支持。我们将使用现有的开放式数据集,而不是从头开始。
我们将使用 Rounak Banik 的 电影数据集,这是 Kaggle 上的一个知名公共数据集。该数据集包含 TMDB 中超过 45,000 部电影的元数据,包括演员、工作人员、关键字、评分等。

若要构建可靠且有效的电影推荐聊天机器人,首先必须使用干净、一致且结构化的数据。虽然 Kaggle 的电影数据集是一项丰富的资源,包含超过 45,000 条电影记录和详细的元数据(包括类型、演员、剧组等),但其中也包含噪声、不一致性和嵌套数据结构,不适合图模型或语义嵌入。
为解决此问题,我们预处理并归一化了数据集,以确保其非常适合构建 Neo4j 知识图谱并生成高质量的嵌入。此流程涉及以下步骤:
- 移除重复记录和不完整记录
- 标准化关键字段(例如,类型名称、人物名称)
- 将复杂的嵌套结构(例如演员和剧组)展平为结构化 CSV
- 选择约 12,000 部电影的代表性子集,以便不超出 Neo4j AuraDB 免费版的限制
高质量的归一化数据有助于确保:
- 数据质量:最大限度地减少错误和不一致性,以便提供更准确的建议
- 查询性能:简化后的结构可提高检索速度并减少冗余
- 嵌入准确性:干净的输入可生成更有意义且符合上下文的向量嵌入
您可以在此 GitHub 代码库的 normalized_data/ 文件夹中访问经过清理和标准化的数据集。此数据集也会镜像到 Google Cloud Storage 存储分区中,以便在后续的 Python 脚本中轻松访问。
数据已清理完毕,现在我们可以将其加载到 Neo4j 中,并开始构建电影知识图谱了。
5. 构建电影知识图谱
为了为支持 GenAI 的电影推荐聊天机器人提供支持,我们需要以一种方式构建电影数据集,以捕获电影、演员、导演、类型和其他元数据之间的丰富关联网络。在本部分中,我们将使用您之前准备的经过清理和标准化的数据集,在 Neo4j 中构建电影知识图谱。
我们将使用 Neo4j 的 LOAD CSV 功能来提取托管在公共 Google Cloud Storage (GCS) 存储分区中的 CSV 文件。这些文件代表电影数据集的不同组成部分,例如电影、类型、演员、工作人员、制片公司和用户评分。
第 1 步:创建约束条件和索引
在导入数据之前,最好先创建约束条件和索引,以强制执行数据完整性并优化查询性能。
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
第 2 步:导入电影元数据和关系
我们来看看如何使用 LOAD CSV 命令导入电影元数据。以下示例创建了具有标题、简介、语言和运行时等关键属性的电影节点:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
类似的 Cypher 命令可用于导入相关实体,例如类型、制作公司、语言、国家/地区、演员、剧组和评分。
通过 Python 加载完整图
我们建议您使用此 Codelab 中提供的自动化 Python 脚本,而不是手动运行多个 Cypher 查询。
脚本 graph_build.py 会使用 .env 文件中的凭据,将整个数据集从 GCS 加载到 Neo4j AuraDB 实例中。
python graph_build.py
该脚本将依次加载所有必要的 CSV 文件,创建节点和关系,并构建完整的电影知识图谱。
|
|


验证图表
加载完成后,您可以通过运行简单的 Cypher 查询来验证图,例如:
MATCH (m:Movie) RETURN m LIMIT 5;
MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, m.title LIMIT 5;
现在,您应该会看到图表中填充了电影、人物、类型等信息,接下来就可以在下一步中丰富其语义了!
6. 生成和加载嵌入以执行向量相似度搜索
为了在聊天机器人中启用语义搜索,我们需要为电影简介生成向量嵌入。这些嵌入会将文本数据转换为可比较相似度的数值向量,这样即使查询与影视内容的标题或说明不完全匹配,聊天机器人也能检索出相关影视内容。
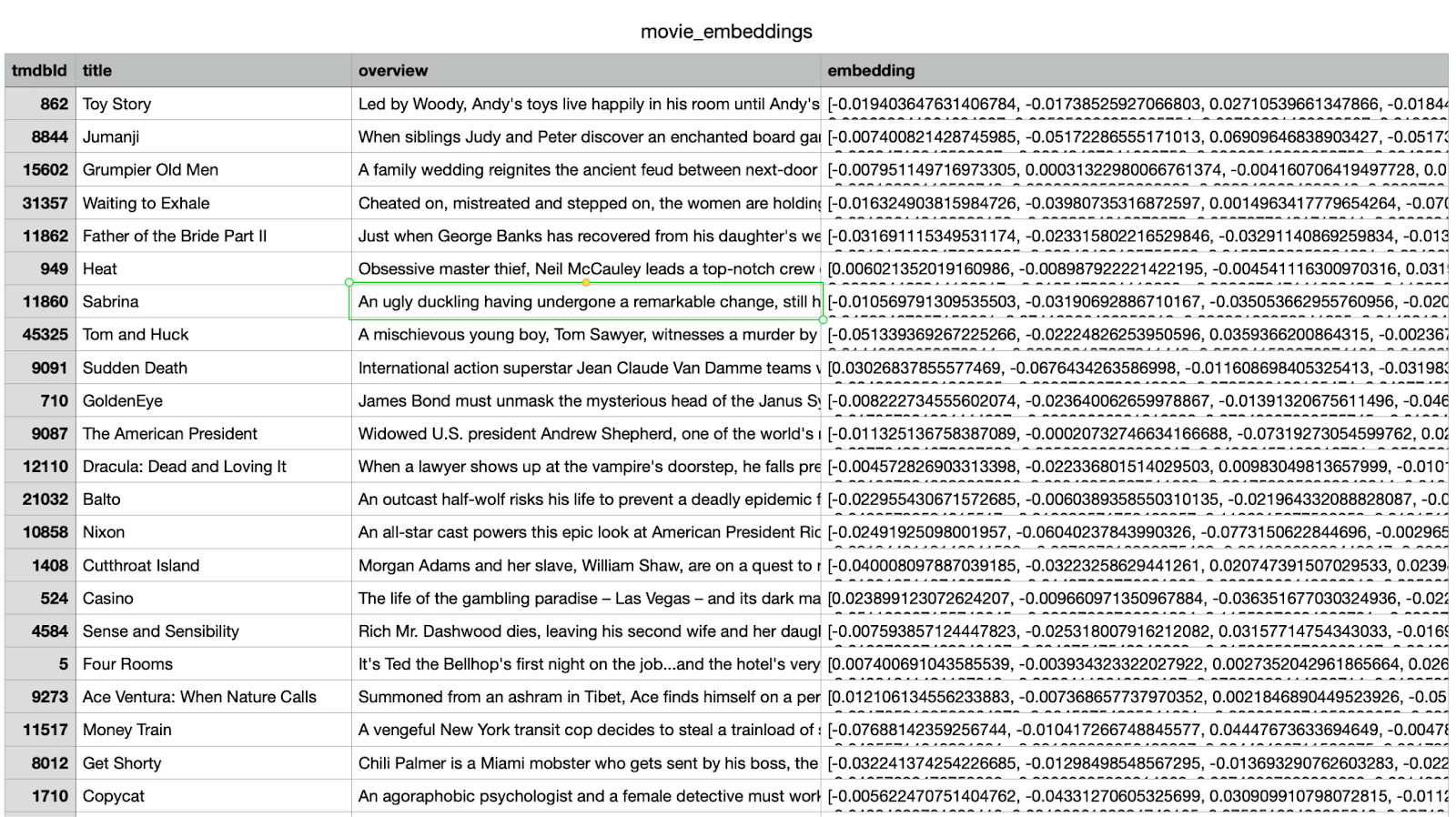
方案 1:通过 Cypher 加载预计算的嵌入
如需快速将嵌入附加到 Neo4j 中的相应 Movie 节点,请在 Neo4j 浏览器中运行以下 Cypher 命令:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
此命令会从 CSV 读取嵌入矢量,并将其作为属性 (m.embedding) 附加到每个 Movie 节点。
方案 2:使用 Python 加载嵌入
您还可以使用提供的 Python 脚本以编程方式加载嵌入。如果您在自己的环境中工作或想要自动执行此流程,此方法非常有用:
python load_embeddings.py
此脚本会从 GCS 读取相同的 CSV,并使用 Python Neo4j 驱动程序将嵌入写入 Neo4j。
[可选] 自行生成嵌入(用于探索)
如果您想了解嵌入的生成方式,可以探索 generate_embeddings.py 脚本本身中的逻辑。它使用 Vertex AI 通过 text-embedding-004 模型嵌入每个电影简介文本。
如需自行尝试,请打开并运行代码中的嵌入生成部分。如果您是在 Cloud Shell 中运行,则可以注释掉以下代码行,因为 Cloud Shell 已通过您的有效账号进行了身份验证:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
将嵌入加载到 Neo4j 后,您的电影知识图谱就会变得具有语义感知,从而支持使用向量相似性进行强大的自然语言搜索!
7. 电影推荐聊天机器人
知识图和矢量嵌入已到位,接下来,将所有内容整合到一个功能齐全的对话式界面中,即由 GenAI 赋能的电影推荐聊天机器人。
此聊天机器人是使用 Gradio 在 Python 中实现的,Gradio 是一个轻量级 Web 框架,用于构建直观的界面。核心逻辑位于 app.py 中,该模块会连接到您的 Neo4j AuraDB 实例,并使用 Google Vertex AI 和 Gemini 来处理自然语言查询并做出回复。
工作方式
- 用户输入自然语言查询,例如“推荐《星际穿越》等科幻惊悚片”
- 使用 Vertex AI 的
text-embedding-004模型为查询生成向量嵌入 - 在 Neo4j 中执行向量搜索,以检索语义相似的电影
- 使用 Gemini 可执行以下操作:
- 在上下文中解读查询
- 根据向量搜索结果和 Neo4j 架构生成自定义 Cypher 查询
- 执行查询以提取相关图数据(例如演员、导演、类型)
- 以对话方式为用户总结结果

这种混合方法称为 GraphRAG(图检索增强生成),它结合了语义检索和结构化推理,可生成更准确、更具上下文且更具解释性的建议。
在本地运行聊天机器人
激活您的虚拟环境(如果尚未激活),然后使用以下命令启动聊天机器人:
python app.py
您应该会看到类似于如下内容的输出:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡如需对外共享聊天机器人,请在 app.py 的 launch() 函数中设置 share=True。
与聊天机器人互动
打开终端中显示的本地网址(通常为 http://0.0.0.0:8080),以访问聊天机器人界面。
尝试这样提问:
- “如果我喜欢《星际穿越》,应该看什么电影?”
- “推荐诺拉·艾芙隆导演的爱情电影”
- “我想看汤姆·汉克斯主演的家庭电影”
- “查找涉及人工智能的惊悚片”
聊天机器人将:
✅ 了解查询
✅ 使用嵌入查找在语义上相似的电影情节
✅ 生成并运行 Cypher 查询以提取相关的图上下文
✅ 在几秒钟内返回友好且个性化的推荐
您现在拥有的功能
您刚刚构建了一个由 GraphRAG 驱动的电影聊天机器人,它结合了以下各项:
- 向量搜索,用于实现语义相关性
- 使用 Neo4j 进行知识图谱推理
- 通过 Gemini 实现 LLM 功能
- 使用 Gradio 的流畅聊天界面
此架构构成了可扩展到由 GenAI 支持的更高级搜索、推荐或推理系统的基础。
8. (可选)部署到 Google Cloud Run
如果您想公开使用电影推荐聊天机器人,可以将其部署到 Google Cloud Run,这是一个全代管式无服务器平台,可自动扩缩您的应用并抽象化所有基础架构问题。
此部署使用:
requirements.txt- 用于定义 Python 依赖项(Neo4j、Vertex AI、Gradio 等)Dockerfile- 用于打包应用.env.yaml- 用于在运行时安全地传递环境变量
第 1 步:准备 .env.yaml
在根目录中创建一个名为 .env.yaml 的文件,其中包含以下内容:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 此格式优于 --set-env-vars,因为它更具可伸缩性、可控版本且更易读。
第 2 步:设置环境变量
在终端中,设置以下环境变量(将占位符值替换为实际的项目设置):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
第 2 步:创建 Artifact Registry 并构建容器
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
此命令会使用 Dockerfile 打包您的应用,并将容器映像上传到 Google Cloud Artifact Registry。
第 3 步:部署到 Cloud Run
现在,使用 .env.yaml 文件部署您的应用以进行运行时配置:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
访问聊天机器人
部署完成后,Cloud Run 会提供一个公共网址,例如:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
在浏览器中打开此网址即可访问已部署的 Gradio 聊天机器人界面,准备使用 GraphRAG、Gemini 和 Neo4j 处理电影推荐!
备注和提示
- 确保您的
Dockerfile在构建期间运行pip install -r requirements.txt。 - 如果您不使用 Cloud Shell,则需要使用具有 Vertex AI 和 Artifact Registry 权限的服务账号对环境进行身份验证。
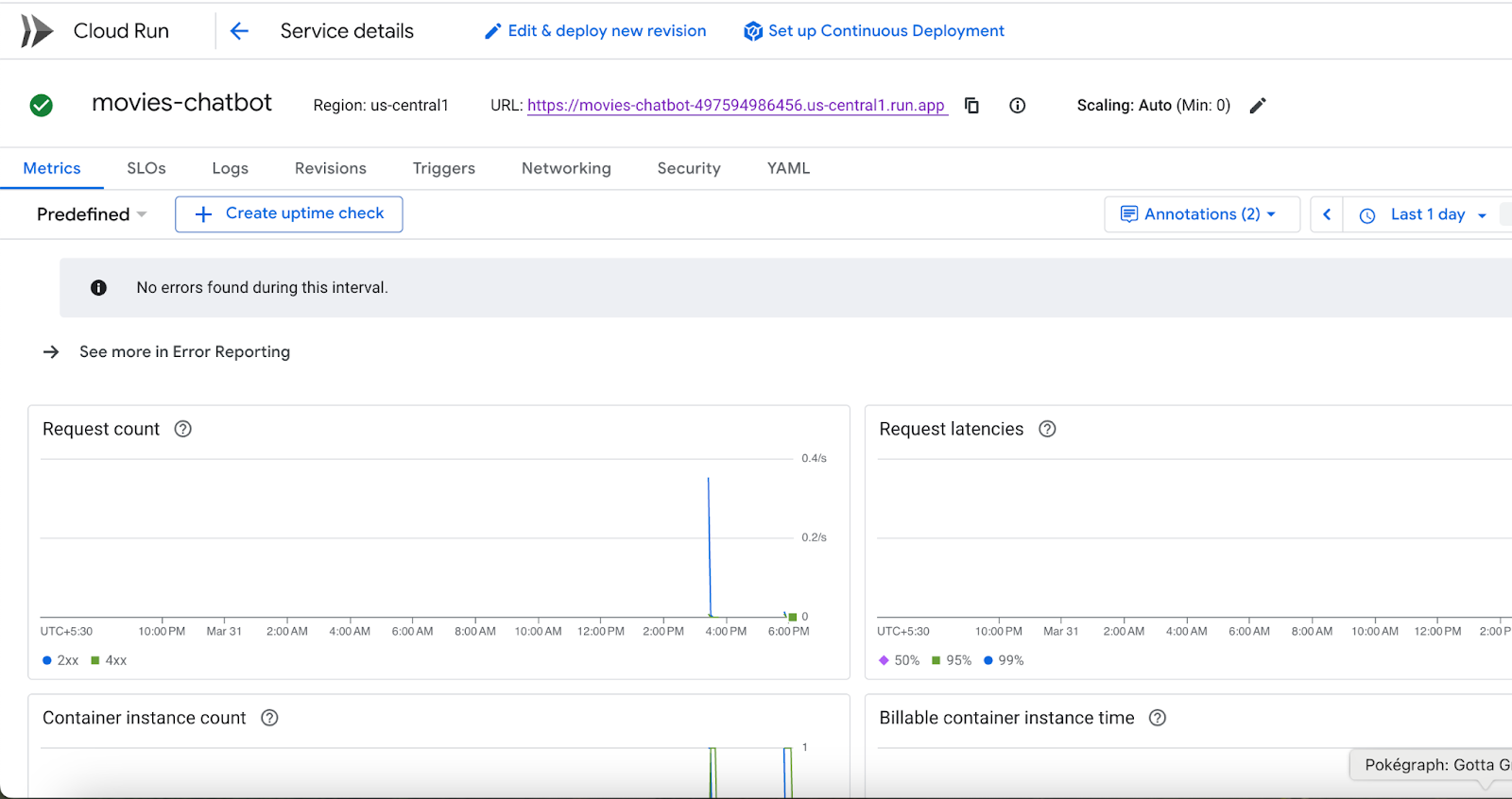
- 您可以通过 Google Cloud 控制台 > Cloud Run 监控部署日志和指标。
您还可以访问 Google Cloud 控制台中的 Cloud Run,在 Cloud Run 中查看服务列表。movies-chatbot 服务应是其中列出的服务之一(如果不是唯一的服务)。

您可以点击特定服务名称(在本例中为 movies-chatbot),查看服务的详细信息,例如网址、配置、日志等。
至此,您的电影推荐聊天机器人现已部署、可扩缩且可共享。🎉
10. 恭喜
您已成功使用 Neo4j、Vertex AI 和 Gemini 构建并部署了由 GraphRAG 提供支持、由 GenAI 增强的电影推荐聊天机器人。通过将 Neo4j 的图原生建模功能与 Vertex AI 的语义搜索功能以及 Gemini 的自然语言推理功能相结合,您可以打造出超越基本搜索的智能系统,该系统能够理解用户意图、对关联数据进行推理,以及以对话方式做出回答。
在此 Codelab 中,您完成了以下操作:
✅ 在 Neo4j 中构建了一个真实的电影知识图谱,以对电影、演员、类型和关系进行建模
✅ 使用 Vertex AI 的文本嵌入模型为电影剧情概览生成向量嵌入
✅实现了 GraphRAG,结合了矢量搜索和 LLM 生成的 Cypher 查询,以实现更深入的多跳推理
✅ 集成了 Gemini,以便以自然语言解读用户问题、生成 Cypher 查询并总结图表结果
✅ 使用 Gradio 创建了直观的聊天界面
✅ 可选择将聊天机器人部署到 Google Cloud Run,以实现可扩缩的无服务器托管
后续步骤
此架构不仅适用于电影推荐,还可扩展到:
- 图书和音乐发现平台
- 学术研究助理
- 商品推荐引擎
- 医疗保健、金融和法律知识助理
无论您在哪里拥有复杂的关系 + 丰富的文本数据,知识图谱 + LLM + 语义嵌入的组合都可以为新一代智能应用提供强大的支持。
随着 Gemini 等多模态 GenAI 模型的不断发展,您将能够纳入更丰富的上下文、图片、语音和个性化信息,从而构建真正以人为本的系统。
不断探索、不断构建,同时别忘了及时了解 Neo4j、Vertex AI 和 Google Cloud 的最新动态,以便将您的智能应用提升到新的水平!如需探索更多实用知识图谱教程,请访问 Neo4j GraphAcademy。