
Atelier de programmation : Créer un chatbot de recommandation de films à l'aide de Neo4j et de Vertex AI
À propos de cet atelier de programmation
1. Présentation
Dans cet atelier de programmation, vous allez créer un chatbot de recommandation de films intelligent en combinant les fonctionnalités de Neo4j, de Google Vertex AI et de Gemini. Au cœur de ce système se trouve un Knowledge Graph Neo4j qui modélise les films, les acteurs, les réalisateurs, les genres, etc. via un réseau riche de nœuds et de relations interconnectés.
Pour améliorer l'expérience utilisateur grâce à la compréhension sémantique, vous allez générer des représentations vectorielles continues à partir des résumés des intrigues de films à l'aide du modèle text-embedding-004 (ou version ultérieure) de Vertex AI. Ces représentations vectorielles continues sont indexées dans Neo4j pour une récupération rapide basée sur la similarité.
Enfin, vous allez intégrer Gemini pour alimenter une interface conversationnelle dans laquelle les utilisateurs peuvent poser des questions en langage naturel, comme "Que puis-je regarder si j'ai aimé Interstellar ?", et recevoir des suggestions de films personnalisées en fonction de la similarité sémantique et du contexte basé sur des graphiques.
Au cours de l'atelier de programmation, vous allez suivre une approche par étapes, comme suit:
- Créer un Knowledge Graph Neo4j avec des entités et des relations liées aux films
- Générer/charger des représentations vectorielles continues de texte pour les résumés de films à l'aide de Vertex AI
- Implémenter une interface de chatbot Gradio basée sur Gemini qui combine la recherche vectorielle et l'exécution Cypher basée sur des graphes
- (Facultatif) Déployer l'application sur Cloud Run en tant qu'application Web autonome
Points abordés
- Créer et renseigner un Knowledge Graph de films à l'aide de Cypher et de Neo4j
- Générer et utiliser des représentations vectorielles continues sémantiques de texte avec Vertex AI
- Combiner des LLM et des Knowledge Graphs pour une récupération intelligente à l'aide de GraphRAG
- Créer une interface de chat conviviale à l'aide de Gradio
- Déployer facultativement sur Google Cloud Run
Prérequis
- Navigateur Web Chrome
- Un compte Gmail
- Un projet Google Cloud avec facturation activée
- Un compte de base de données Neo4j Aura sans frais
- Connaître les bases de Python et des commandes de terminal (recommandé, mais non obligatoire)
Cet atelier de programmation, conçu pour les développeurs de tous niveaux (y compris les débutants), utilise Python et Neo4j dans son application exemple. Bien que vous deviez connaître les bases de Python et des bases de données graphiques, aucune expérience préalable n'est requise pour comprendre les concepts ou suivre le cours.

2. Configurer Neo4j AuraDB
Neo4j est une base de données de graphes native de premier plan qui stocke les données sous forme de réseau de nœuds (entités) et de relations (connexions entre les entités). Elle est donc idéale pour les cas d'utilisation où la compréhension des connexions est essentielle, comme les recommandations, la détection de fraude, les graphes de connaissances, etc. Contrairement aux bases de données relationnelles ou basées sur des documents qui reposent sur des tables rigides ou des structures hiérarchiques, le modèle de graphique flexible de Neo4j permet de représenter de manière intuitive et efficace des données complexes et interconnectées.
Au lieu d'organiser les données en lignes et en tables comme les bases de données relationnelles, Neo4j utilise un modèle de graphique, dans lequel les informations sont représentées sous forme de nœuds (entités) et de relations (connexions entre ces entités). Ce modèle permet de travailler de manière exceptionnellement intuitive avec des données intrinsèquement liées, comme des personnes, des lieux, des produits ou, dans notre cas, des films, des acteurs et des genres.
Par exemple, dans un ensemble de données de films:
- Un nœud peut représenter un
Movie, unActorou unDirector. - Une relation peut être
ACTED_INouDIRECTED.

Cette structure vous permet de poser facilement des questions telles que:
- Dans quels films cet acteur est-il apparu ?
- Qui a travaillé avec Christopher Nolan ?
- Quels sont les films similaires en fonction des acteurs ou des genres qu'ils partagent ?
Neo4j est fourni avec un langage de requête puissant appelé Cypher, conçu spécifiquement pour interroger des graphes. Cypher vous permet d'exprimer des schémas et des connexions complexes de manière concise et lisible. Par exemple, cette requête Cypher utilise MERGE pour créer de manière unique l'acteur, le film et leur relation avec les détails du rôle, ce qui évite les doublons.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j propose plusieurs options de déploiement en fonction de vos besoins:
- Autogéré: exécutez Neo4j sur votre propre infrastructure à l'aide de Neo4j Desktop ou en tant qu'image Docker (sur site ou dans votre propre cloud).
- Gestion cloud: déployez Neo4j sur des fournisseurs cloud populaires à l'aide d'offres de place de marché.
- Entièrement géré: utilisez Neo4j AuraDB, la base de données cloud entièrement gérée de Neo4j, qui gère le provisionnement, la mise à l'échelle, les sauvegardes et la sécurité à votre place.
Dans cet atelier de programmation, nous utiliserons Neo4j AuraDB Free, l'offre sans frais d'AuraDB. Il fournit une instance de base de données de graphes entièrement gérée avec suffisamment d'espace de stockage et de fonctionnalités pour le prototypage, l'apprentissage et la création de petites applications. Il est donc idéal pour notre objectif de créer un chatbot de recommandation de films optimisé par l'IA générative.
Vous allez créer une instance AuraDB sans frais, la connecter à votre application à l'aide d'identifiants de connexion et l'utiliser pour stocker et interroger votre graphique de connaissances sur les films tout au long de cet atelier.
Pourquoi utiliser des graphiques ?
Dans les bases de données relationnelles traditionnelles, répondre à des questions telles que "Quels films sont similaires à Inception en fonction de la distribution ou du genre partagés ?" implique des opérations JOIN complexes sur plusieurs tables. À mesure que la profondeur des relations augmente, les performances et la lisibilité diminuent.
Toutefois, les bases de données de graphes comme Neo4j sont conçues pour parcourir efficacement les relations. Elles sont donc idéales pour les systèmes de recommandation, la recherche sémantique et les assistants intelligents. Ils permettent de capturer le contexte réel (comme les réseaux de collaboration, les intrigues ou les préférences des spectateurs), qui peut être difficile à représenter à l'aide de modèles de données traditionnels.
En combinant ces données connectées à des LLM comme Gemini et des embeddings vectoriels de Vertex AI, nous pouvons optimiser l'expérience du chatbot, ce qui lui permet de raisonner, de récupérer des informations et de répondre de manière plus personnalisée et pertinente.
Création sans frais de Neo4j AuraDB
- Accédez à https://console.neo4j.io.
- Connectez-vous avec votre compte Google ou votre adresse e-mail.
- Cliquez sur "Créer une instance sans frais".
- Pendant le provisionnement de l'instance, une fenêtre pop-up s'affiche, indiquant les identifiants de connexion de votre base de données.
Veillez à télécharger et à enregistrer de manière sécurisée les informations suivantes dans la fenêtre pop-up. Elles sont essentielles pour connecter votre application à Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Vous utiliserez ces valeurs pour configurer le fichier .env de votre projet afin de vous authentifier avec Neo4j à l'étape suivante.
Neo4j AuraDB Free est adapté au développement, aux tests et aux applications à petite échelle, comme cet atelier de programmation. Il offre des limites d'utilisation généreuses, avec jusqu'à 200 000 nœuds et 400 000 relations. Bien qu'il fournisse toutes les fonctionnalités essentielles pour créer et interroger un graphique de connaissances, il n'est pas compatible avec les configurations avancées telles que les plug-ins personnalisés ou l'augmentation de l'espace de stockage. Pour les charges de travail de production ou les ensembles de données plus volumineux, vous pouvez passer à un forfait AuraDB de niveau supérieur qui offre une capacité, des performances et des fonctionnalités d'entreprise supérieures.
Vous avez terminé la section sur la configuration du backend Neo4j AuraDB. À l'étape suivante, nous allons créer un projet Google Cloud, cloner le dépôt et configurer les variables d'environnement nécessaires pour préparer votre environnement de développement avant de commencer notre atelier de programmation.
3. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud et fourni avec bq. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini avec votre ID de projet à l'aide de la commande suivante:
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises à l'aide de la commande ci-dessous. Cette opération peut prendre quelques minutes. Veuillez patienter.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Une fois la commande exécutée, le message Operation .... finished successfully (Opération terminée) s'affiche.
Vous pouvez également rechercher chaque produit dans la console ou utiliser ce lien.
Si une API est manquante, vous pouvez toujours l'activer au cours de l'implémentation.
Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Cloner le dépôt et configurer les paramètres de l'environnement
L'étape suivante consiste à cloner l'exemple de dépôt que nous allons référencer dans le reste de l'atelier de programmation. Si vous êtes dans Cloud Shell, exécutez la commande suivante à partir de votre répertoire d'accueil:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Pour lancer l'éditeur, cliquez sur Ouvrir l'éditeur dans la barre d'outils de la fenêtre Cloud Shell. Cliquez sur la barre de menu en haut à gauche, puis sélectionnez "File" (Fichier) → "Open Folder" (Ouvrir un dossier), comme illustré ci-dessous:

Sélectionnez le dossier neo4j-vertexai-codelab. Il devrait s'ouvrir avec une structure quelque peu similaire, comme illustré ci-dessous:

Nous devons ensuite configurer les variables d'environnement qui seront utilisées tout au long de l'atelier de programmation. Cliquez sur le fichier example.env. Le contenu devrait s'afficher comme indiqué ci-dessous:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Créez maintenant un fichier nommé .env dans le même dossier que le fichier example.env, puis copiez le contenu du fichier example.env existant. Mettez à jour les variables suivantes:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDetNEO4J_DATABASE:- Renseignez ces valeurs à l'aide des identifiants fournis lors de la création de l'instance Neo4j AuraDB Free à l'étape précédente.
NEO4J_DATABASEest généralement défini sur neo4j pour AuraDB Free.PROJECT_IDetLOCATION:- Si vous exécutez l'atelier de programmation à partir de Google Cloud Shell, vous pouvez laisser ces champs vides, car ils seront automatiquement inférés à partir de la configuration de votre projet actif.
- Si vous exécutez l'application localement ou en dehors de Cloud Shell, remplacez
PROJECT_IDpar l'ID du projet Google Cloud que vous avez créé précédemment et définissezLOCATIONsur la région que vous avez sélectionnée pour ce projet (par exemple, us-central1).
Une fois que vous avez rempli ces valeurs, enregistrez le fichier .env. Cette configuration permettra à votre application de se connecter aux services Neo4j et Vertex AI.
La dernière étape de la configuration de votre environnement de développement consiste à créer un environnement virtuel Python et à installer toutes les dépendances requises listées dans le fichier requirements.txt. Ces dépendances incluent les bibliothèques nécessaires pour travailler avec Neo4j, Vertex AI, Gradio, etc.
Commencez par créer un environnement virtuel nommé .venv en exécutant la commande suivante:
python -m venv .venv
Une fois l'environnement créé, nous devons l'activer à l'aide de la commande suivante :
source .venv/bin/activate
(.venv) devrait maintenant s'afficher au début de l'invite du terminal, ce qui indique que l'environnement est actif. Par exemple : (.venv) yourusername@cloudshell:
Installez maintenant les dépendances requises en exécutant la commande suivante:
pip install -r requirements.txt
Voici un aperçu des principales dépendances listées dans le fichier:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Une fois toutes les dépendances installées, votre environnement Python local sera entièrement configuré pour exécuter les scripts et le chatbot de cet atelier de programmation.
Parfait ! Vous pouvez maintenant passer à l'étape suivante : comprendre l'ensemble de données et le préparer à la création de graphiques et à l'enrichissement sémantique.
4. Préparer l'ensemble de données "Films"
Notre première tâche consiste à préparer l'ensemble de données "Films" que nous utiliserons pour créer le graphique de connaissances et alimenter notre chatbot de recommandation. Plutôt que de repartir de zéro, nous allons utiliser un jeu de données ouvert existant et nous appuyer dessus.
Nous utilisons l' ensemble de données Movies de Rounak Banik, un ensemble de données public bien connu disponible sur Kaggle. Il comprend les métadonnées de plus de 45 000 films de TMDB, y compris les acteurs, l'équipe, les mots clés, les notes, etc.

Pour créer un chatbot de recommandation de films fiable et efficace, il est essentiel de commencer par des données propres, cohérentes et structurées. Bien que l'ensemble de données Movies de Kaggle soit une ressource riche avec plus de 45 000 enregistrements de films et des métadonnées détaillées (y compris les genres, les acteurs, l'équipe, etc.), il contient également du bruit, des incohérences et des structures de données imbriquées qui ne sont pas idéales pour la modélisation de graphes ni l'encapsulation sémantique.
Pour y remédier, nous avons prétraité et normalisé l'ensemble de données afin de nous assurer qu'il est adapté à la création d'un Knowledge Graph Neo4j et à la génération d'embeddings de haute qualité. Ce processus a impliqué les étapes suivantes:
- Supprimer les doublons et les enregistrements incomplets
- Standardisation des champs clés (par exemple, noms de genres, noms de personnes)
- Aplatir des structures imbriquées complexes (par exemple, la distribution et l'équipe) dans des fichiers CSV structurés
- Sélection d'un sous-ensemble représentatif d'environ 12 000 films pour respecter les limites de Neo4j AuraDB Free
Les données normalisées de haute qualité permettent de garantir:
- Qualité des données: minimise les erreurs et les incohérences pour des recommandations plus précises
- Performances des requêtes: la structure simplifiée améliore la vitesse de récupération et réduit la redondance.
- Précision des embeddings: les entrées propres génèrent des embeddings vectoriels plus pertinents et contextuels.
Vous pouvez accéder à l'ensemble de données nettoyé et normalisé dans le dossier normalized_data/ de ce dépôt GitHub. Cet ensemble de données est également mis en miroir dans un bucket Google Cloud Storage pour un accès facile dans les futurs scripts Python.
Maintenant que les données sont nettoyées et prêtes, nous pouvons les charger dans Neo4j et commencer à construire notre Knowledge Graph de films.
5. Créer un Knowledge Graph sur les films
Pour alimenter notre chatbot de recommandation de films compatible avec l'IA générative, nous devons structurer notre ensemble de données de films de manière à capturer le riche réseau de connexions entre les films, les acteurs, les réalisateurs, les genres et d'autres métadonnées. Dans cette section, nous allons créer un Graphe de connaissances sur les films dans Neo4j à l'aide de l'ensemble de données nettoyé et normalisé que vous avez préparé précédemment.
Nous allons utiliser la fonctionnalité LOAD CSV de Neo4j pour ingérer des fichiers CSV hébergés dans un bucket public Google Cloud Storage (GCS). Ces fichiers représentent différents composants de l'ensemble de données sur les films, tels que les films, les genres, les acteurs, l'équipe, les sociétés de production et les notes des utilisateurs.
Étape 1: Créer des contraintes et des index
Avant d'importer des données, il est recommandé de créer des contraintes et des index pour appliquer l'intégrité des données et optimiser les performances des requêtes.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Étape 2: Importer les métadonnées et les relations des films
Voyons comment importer les métadonnées de films à l'aide de la commande LOAD CSV. Cet exemple crée des nœuds "Movie" avec des attributs clés tels que le titre, le résumé, la langue et la durée:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
De même, vous pouvez importer et associer d'autres entités telles que les genres, les sociétés de production, les langues parlées, les pays, la distribution, l'équipe technique et les notes des utilisateurs à l'aide de leurs fichiers CSV et requêtes Cypher respectifs.
Charger le graphique complet via Python
Plutôt que d'exécuter manuellement plusieurs requêtes Cypher, nous vous recommandons d'utiliser le script Python automatisé fourni dans cet atelier de programmation.
Le script graph_build.py charge l'ensemble de données complet à partir de GCS dans votre instance Neo4j AuraDB à l'aide des identifiants de votre fichier .env.
python graph_build.py
Le script charge séquentiellement tous les fichiers CSV nécessaires, crée des nœuds et des relations, et structure votre graphique de connaissances complet sur les films.
|
|


Valider votre graphique
Une fois le chargement effectué, vous pouvez valider votre graphique en exécutant le script suivant:
python validate_graph.py
Vous obtiendrez ainsi un résumé rapide de votre graphique: le nombre de films, d'acteurs, de genres et de relations (comme ACTED_IN, DIRECTED, etc.) présents, ce qui vous permettra de vérifier que votre importation a bien été effectuée.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Votre graphique devrait maintenant être rempli de films, de personnes, de genres, etc., et prêt à être enrichi sémantiquement à l'étape suivante.
6. Générer et charger des embeddings pour effectuer une recherche de similarité vectorielle
Pour activer la recherche sémantique dans notre chatbot, nous devons générer des représentations vectorielles continues pour les résumés de films. Ces embeddings transforment les données textuelles en vecteurs numériques que l'on peut comparer pour déterminer leur similarité. Le chatbot peut ainsi récupérer des films pertinents même si la requête ne correspond pas exactement au titre ou à la description.

Option 1: Charger des représentations vectorielles continues précalculées via Cypher
Pour associer rapidement les représentations vectorielles continues aux nœuds Movie correspondants dans Neo4j, exécutez la commande Cypher suivante dans le navigateur Neo4j:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Cette commande lit les vecteurs d'encapsulation du fichier CSV et les associe en tant que propriété (m.embedding) à chaque nœud Movie.
Option 2: Charger des représentations vectorielles continues à l'aide de Python
Vous pouvez également charger les représentations vectorielles continues de manière programmatique à l'aide du script Python fourni. Cette approche est utile si vous travaillez dans votre propre environnement ou si vous souhaitez automatiser le processus:
python load_embeddings.py
Ce script lit le même fichier CSV à partir de GCS et écrit les représentations vectorielles continues dans Neo4j à l'aide du pilote Neo4j Python.
[Facultatif] Générer vous-même des représentations vectorielles continues (pour l'exploration)
Si vous souhaitez comprendre comment les embeddings sont générés, vous pouvez explorer la logique du script generate_embeddings.py lui-même. Il utilise Vertex AI pour intégrer le texte de chaque synopsis de film à l'aide du modèle text-embedding-004.
Pour essayer par vous-même, ouvrez et exécutez la section de génération d'embeddings du code. Si vous exécutez le script dans Cloud Shell, vous pouvez commenter la ligne suivante, car Cloud Shell est déjà authentifié via votre compte actif:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Une fois les embeddings chargés dans Neo4j, votre knowledge graph de films devient sensible à la sémantique et est prêt à prendre en charge une recherche en langage naturel puissante à l'aide de la similarité vectorielle.
7. Le chatbot de recommandation de films
Maintenant que votre graphique de connaissances et vos représentations vectorielles continues sont en place, il est temps de les rassembler dans une interface conversationnelle entièrement fonctionnelle : votre chatbot de recommandation de films optimisé par l'IA générative.
Ce chatbot est implémenté en Python à l'aide de Gradio, un framework Web léger permettant de créer des interfaces utilisateur intuitives. La logique de base se trouve dans app.py, qui se connecte à votre instance Neo4j AuraDB et utilise Google Vertex AI et Gemini pour traiter et répondre aux requêtes en langage naturel.
Fonctionnement
- L'utilisateur saisit une requête en langage naturel, par exemple : "Recommande-moi des thrillers de science-fiction comme "Interstellar".
- Générer un embedding vectoriel pour la requête à l'aide du modèle
text-embedding-004de Vertex AI - Effectuer une recherche vectorielle dans Neo4j pour récupérer des films sémantiquement similaires
- Utilisez Gemini pour:
- Interpréter la requête dans son contexte
- Générer une requête Cypher personnalisée basée sur les résultats de la recherche vectorielle et le schéma Neo4j
- Exécuter la requête pour extraire les données de graphique associées (acteurs, réalisateurs, genres, par exemple)
- Récapituler les résultats de manière conversationnelle pour l'utilisateur
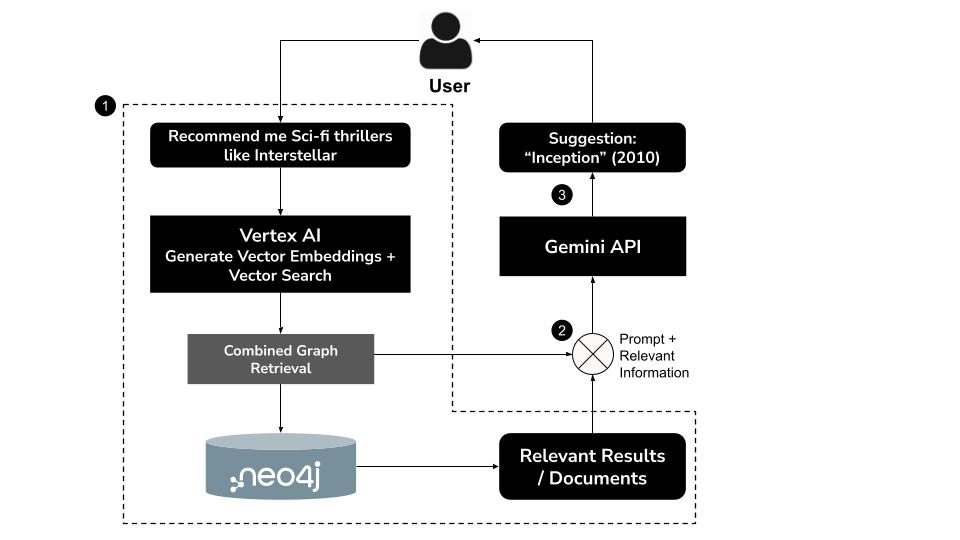
Cette approche hybride, appelée GraphRAG (Graph Retrieval-Augmented Generation), combine la récupération sémantique et le raisonnement structuré pour produire des recommandations plus précises, contextuelles et explicables.
Exécuter le chatbot en local
Activez votre environnement virtuel (s'il n'est pas déjà actif), puis lancez le chatbot avec:
python app.py
Un résultat semblable aux lignes suivantes doit s'afficher :
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Pour partager le chatbot en externe, définissez share=True dans la fonction launch() de app.py.
Interagir avec le chatbot
Ouvrez l'URL locale affichée dans votre terminal (généralement 👉 http://0.0.0.0:8080) pour accéder à l'interface du chatbot.
Posez-vous des questions comme:
- "Que dois-je regarder si j'ai aimé "Interstellar" ?"
- "Suggérez-moi un film romantique réalisé par Nora Ephron"
- "Je veux regarder un film familial avec Tom Hanks"
- "Recherche des thrillers impliquant l'intelligence artificielle"
Le chatbot:
✅ Comprendre la requête
✅ Trouver des intrigues de films sémantiquement similaires à l'aide d'embeddings
✅ Générer et exécuter une requête Cypher pour extraire le contexte de graphique associé
✅ Renvoyer une recommandation personnalisée et conviviale en quelques secondes
Ce que vous avez actuellement
Vous venez de créer un chatbot de films basé sur GraphRAG qui combine:
- Recherche vectorielle pour la pertinence sémantique
- Raisonnement de Knowledge Graph avec Neo4j
- Fonctionnalités LLM via Gemini
- Une interface de chat fluide avec Gradio
Cette architecture constitue une base que vous pouvez étendre à des systèmes de recherche, de recommandation ou de raisonnement plus avancés, alimentés par l'IA générative.
8. (Facultatif) Déployer sur Google Cloud Run
Si vous souhaitez rendre votre chatbot de recommandations de films accessible au public, vous pouvez le déployer sur Google Cloud Run, une plate-forme sans serveur entièrement gérée qui fait évoluer automatiquement votre application et élimine toutes les contraintes liées à l'infrastructure.
Ce déploiement utilise:
requirements.txt: pour définir des dépendances Python (Neo4j, Vertex AI, Gradio, etc.)Dockerfile: pour empaqueter l'application.env.yaml: pour transmettre des variables d'environnement de manière sécurisée au moment de l'exécution
Étape 1: Préparation de .env.yaml
Créez un fichier nommé .env.yaml dans votre répertoire racine avec le contenu suivant:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Ce format est préférable à --set-env-vars, car il est plus évolutif, plus lisible et plus facile à contrôler en termes de version.
Étape 2: Configurer les variables d'environnement
Dans votre terminal, définissez les variables d'environnement suivantes (remplacez les valeurs d'espace réservé par les paramètres de votre projet réel):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Étape 2: Créez Artifact Registry et créez le conteneur
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Cette commande empaquette votre application à l'aide de Dockerfile et importe l'image du conteneur dans Google Cloud Artifact Registry.
Étape 3: Déployer dans Cloud Run
Déployez maintenant votre application à l'aide du fichier .env.yaml pour la configuration d'exécution:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Accéder au chatbot
Une fois déployé, Cloud Run fournit une URL publique, par exemple:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Ouvrez cette URL dans votre navigateur pour accéder à l'interface de votre chatbot Gradio déployée, prête à gérer les recommandations de films à l'aide de GraphRAG, Gemini et Neo4j.
Remarques et conseils
- Assurez-vous que votre
Dockerfileexécutepip install -r requirements.txtlors de la compilation. - Si vous n'utilisez pas Cloud Shell, vous devez authentifier votre environnement à l'aide d'un compte de service disposant d'autorisations Vertex AI et Artifact Registry.
- Vous pouvez surveiller les journaux et les métriques de déploiement à partir de Google Cloud Console > Cloud Run.
Vous pouvez également accéder à Cloud Run dans la console Google Cloud pour afficher la liste des services dans Cloud Run. Le service movies-chatbot doit figurer parmi les services (sinon le seul) listés.

Vous pouvez afficher les détails du service, tels que l'URL, les configurations, les journaux, etc., en cliquant sur le nom du service spécifique (movies-chatbot dans notre cas).

Votre chatbot de recommandation de films est désormais déployé, évolutif et partageable. 🎉
9. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit:
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
10. Félicitations
Vous avez réussi à créer et à déployer un chatbot de recommandation de films optimisé par l'IA générative et GraphRAG à l'aide de Neo4j, de Vertex AI et de Gemini. En combinant les capacités de modélisation natives de graphes de Neo4j avec la recherche sémantique via Vertex AI et le raisonnement en langage naturel via Gemini, vous avez créé un système intelligent qui va au-delà de la recherche de base. Il comprend l'intention de l'utilisateur, raisonne sur les données connectées et répond de manière conversationnelle.
Dans cet atelier de programmation, vous avez effectué les opérations suivantes:
✅ Création d'un Knowledge Graph de films réels dans Neo4j pour modéliser les films, les acteurs, les genres et les relations
✅ Généré des représentations vectorielles continues pour les résumés de l'intrigue de films à l'aide des modèles d'embedding textuel de Vertex AI
✅ Implémentation de GraphRAG, qui combine la recherche vectorielle et les requêtes Cypher générées par un LLM pour un raisonnement plus approfondi et multi-hop
✅ Intégration de Gemini pour interpréter les questions des utilisateurs, générer des requêtes Cypher et résumer les résultats des graphiques en langage naturel
✅ Vous avez créé une interface de chat intuitive à l'aide de Gradio.
✅ Vous avez éventuellement déployé votre chatbot sur Google Cloud Run pour un hébergement évolutif et sans serveur.
Et maintenant ?
Cette architecture n'est pas limitée aux recommandations de films. Elle peut être étendue aux éléments suivants:
- Plates-formes de découverte de livres et de musique
- Assistants de recherche universitaires
- Moteurs de recommandation de produits
- Assistants de connaissances dans le domaine de la santé, de la finance et du droit
Partout où vous avez des relations complexes et des données textuelles riches, cette combinaison de Graphes de connaissances, de LLM et d'embeddings sémantiques peut alimenter la prochaine génération d'applications intelligentes.
À mesure que les modèles d'IA générative multimodale comme Gemini évolueront, vous pourrez intégrer des éléments de contexte, d'images, de langage et de personnalisation encore plus riches pour créer des systèmes véritablement axés sur l'humain.
Continuez à explorer et à créer, et n'oubliez pas de vous tenir informé des dernières actualités sur Neo4j, Vertex AI et Google Cloud pour faire passer vos applications intelligentes au niveau supérieur. Découvrez d'autres tutoriels pratiques sur les Knowledge Graphs sur la GraphAcademy de Neo4j.