
Informazioni su questo codelab
1. Panoramica
Le TPU sono molto veloci. Il flusso di dati di addestramento deve stare al passo con la velocità di addestramento. In questo lab imparerai a caricare i dati da GCS con l'API tf.data.Dataset per alimentare la tua TPU.
Questo lab è la Parte 1 della sessione "Keras su TPU" Google Cloud. Puoi farlo nel seguente ordine o in modo indipendente.
- [THIS LAB] Pipeline di dati a velocità TPU: tf.data.Dataset e TFRecords
- Il tuo primo modello Keras, con Transfer Learning
- Reti neurali convoluzionali, con Keras e TPU
- Convnet moderne, Squeezenet, Xception, con Keras e TPU

Obiettivi didattici
- utilizzare l'API tf.data.Dataset per caricare i dati di addestramento.
- Utilizzare il formato TFRecord per caricare in modo efficiente i dati di addestramento da GCS
Feedback
Se noti qualcosa che non va in questo lab del codice, faccelo sapere. Il feedback può essere fornito tramite i problemi di GitHub [link per il feedback].
2. Guida rapida di Google Colaboratory
Questo lab utilizza Google Collaboratory e non richiede alcuna configurazione da parte tua. Colaboratory è una piattaforma di blocchi note online a scopo didattico. Offre l'addestramento senza costi di CPU, GPU e TPU.

Puoi aprire questo blocco note di esempio ed eseguire un paio di celle per acquisire familiarità con Colaboratory.
Seleziona un backend TPU

Nel menu Colab, seleziona Runtime > Modifica il tipo di runtime, quindi seleziona TPU. In questo codelab, utilizzerai una potente TPU (Tensor Processing Unit) supportata per l'addestramento con accelerazione hardware. La connessione al runtime avverrà automaticamente alla prima esecuzione oppure puoi utilizzare il pulsante nell'angolo in alto a destra.
Esecuzione di blocchi note

Esegui le celle una alla volta facendo clic su una cella e premendo Maiusc-Invio. Puoi anche eseguire l'intero blocco note con Runtime > Esegui tutto
Sommario

Tutti i blocchi note hanno un sommario. Puoi aprirlo utilizzando la freccia nera a sinistra.
Celle nascoste

Alcune celle mostreranno solo il titolo. Si tratta di una funzionalità del blocco note specifica per Colab. Puoi fare doppio clic sopra per vedere il codice al loro interno, ma di solito non è molto interessante. In genere supportano o le funzioni di visualizzazione. Devi comunque eseguire queste celle per definire le funzioni all'interno.
Autenticazione

Colab può accedere ai tuoi bucket Google Cloud Storage privati, a condizione che tu esegua l'autenticazione con un account autorizzato. Lo snippet di codice riportato sopra attiverà un processo di autenticazione.
3. [INFO] Che cosa sono le Tensor Processing Unit (TPU)?
In breve

Codice per l'addestramento di un modello sulla TPU in Keras (e utilizza GPU o CPU se non è disponibile una TPU):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Oggi useremo le TPU per creare e ottimizzare un classificatore di fiori a velocità interattive (minuti per addestramento).
Perché le TPU?
Le GPU moderne sono organizzate in base a "core" programmabili, un'architettura molto flessibile che consente loro di gestire una varietà di attività come rendering 3D, deep learning, simulazioni fisiche e così via. Le TPU, invece, abbinano un processore vettoriale classico a un'unità di moltiplicazione della matrice dedicata ed eccellono in qualsiasi attività in cui dominano le moltiplicazioni matriciali di grandi dimensioni, come le reti neurali.

Illustrazione: uno strato di rete neurale densa come una moltiplicazione della matrice, con un batch di otto immagini elaborate contemporaneamente attraverso la rete neurale. Esegui la moltiplicazione di una riga per colonna per verificare che venga effettivamente calcolata una somma ponderata di tutti i valori in pixel di un'immagine. Anche gli strati convoluzionali possono essere rappresentati come moltiplicazioni matriciali, anche se è un po' più complicato ( spiegazione qui, nella sezione 1).
L'hardware
MXU e VPU
Un core TPU v2 è composto da un'unità Matrix Multiply (MXU) che esegue moltiplicazioni matriciali e da una Vector Processing Unit (VPU) per tutte le altre attività, come attivazioni, softmax, ecc. La VPU gestisce i calcoli in float32 e int32. MXU, invece, funziona in un formato in virgola mobile a 16-32 bit a precisione mista.

Virgola mobile con precisione mista e bfloat16
MXU calcola le moltiplicazioni matriciali utilizzando gli input bfloat16 e gli output float32. Gli accumuli intermedi vengono eseguiti con precisione float32.

L'addestramento della rete neurale è in genere resistente al rumore introdotto da una precisione in virgola mobile ridotta. In alcuni casi il rumore aiuta persino l'ottimizzatore a convergere. La precisione in virgola mobile a 16 bit è stata tradizionalmente utilizzata per accelerare i calcoli, ma i formati float16 e float32 hanno intervalli molto diversi. La riduzione della precisione da float32 a float16 solitamente si verifica in overflow e underflow. Esistono delle soluzioni, ma in genere è necessario un lavoro aggiuntivo per far funzionare float16.
Ecco perché Google ha introdotto il formato bfloat16 nelle TPU. bfloat16 è un float32 troncato con esattamente gli stessi bit di esponente e lo stesso intervallo di float32. Ciò, aggiunto al fatto che le TPU calcolano le moltiplicazioni delle matrici in precisione mista con gli input bfloat16 ma con gli output float32, e ciò significa che, in genere, non sono necessarie modifiche al codice per trarre vantaggio dai guadagni in termini di prestazioni derivanti dalla precisione ridotta.
Array di sistolica
La MXU implementa le moltiplicazioni matriciali nell'hardware utilizzando un cosiddetto "array sistolica" un'architettura in cui gli elementi dei dati fluiscono attraverso un array di unità di calcolo hardware. In medicina, "sistolica" si riferisce alle contrazioni cardiache e al flusso sanguigno, qui al flusso di dati.
L'elemento base di una moltiplicazione matriciale è un prodotto scalare tra una linea di una matrice e una colonna dell'altra (vedi l'illustrazione nella parte superiore di questa sezione). Per una moltiplicazione matriciale Y=X*W, un elemento del risultato sarebbe:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Su una GPU, questo prodotto scalare viene programmato in un "core" GPU. e poi eseguirla su quanti più "core" disponibili in parallelo per provare a calcolare contemporaneamente ogni valore della matrice risultante. Se la matrice risultante è grande 128x128, ciò richiederebbe 128x128=16K "core" la disponibilità, cosa che in genere non è possibile. Le GPU più grandi hanno circa 4000 core. Una TPU, invece, utilizza il minimo indispensabile di hardware per le unità di calcolo nella MXU: solo bfloat16 x bfloat16 => float32 moltiplicatori, nient'altro. Queste sono così piccole che una TPU può implementarne 16K in un MXU di 128x128 ed elaborare questa moltiplicazione della matrice in una volta sola.
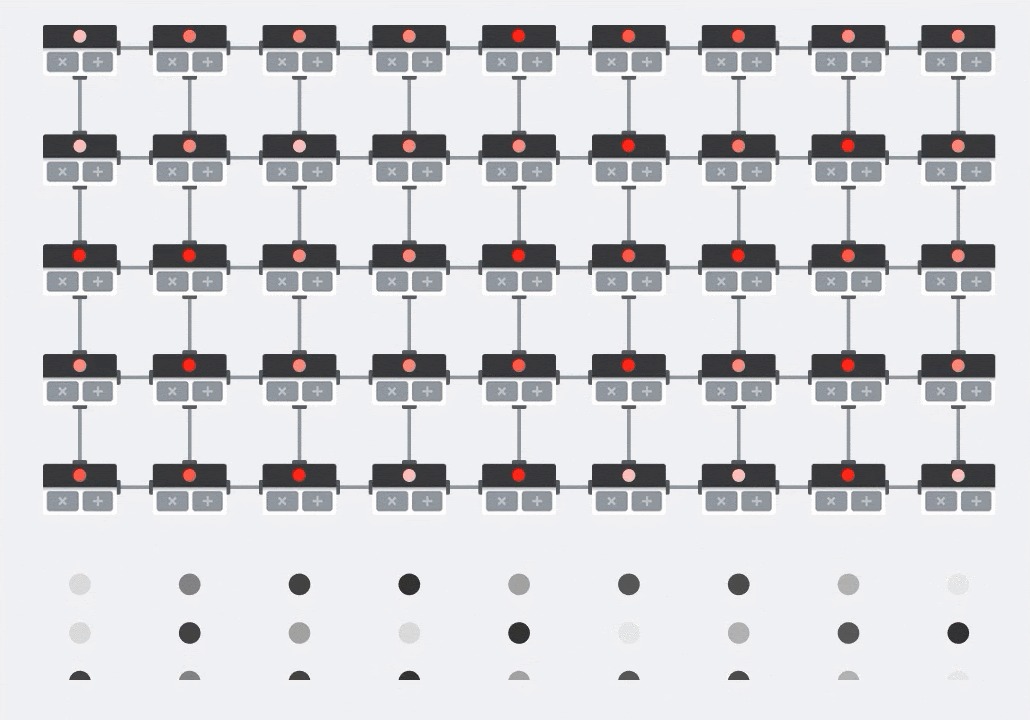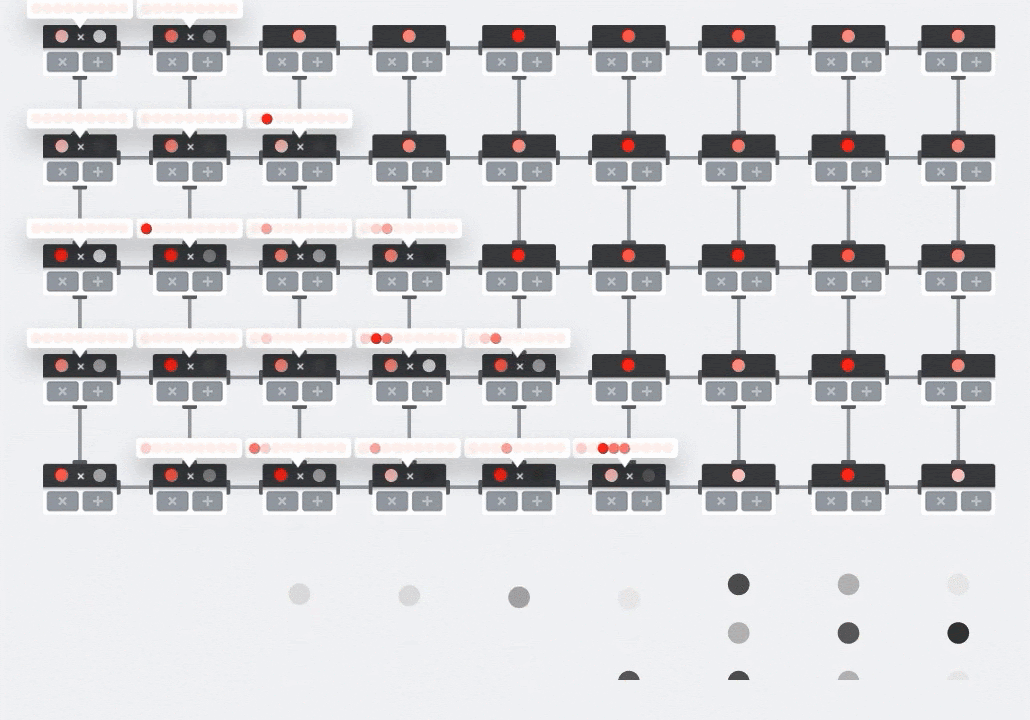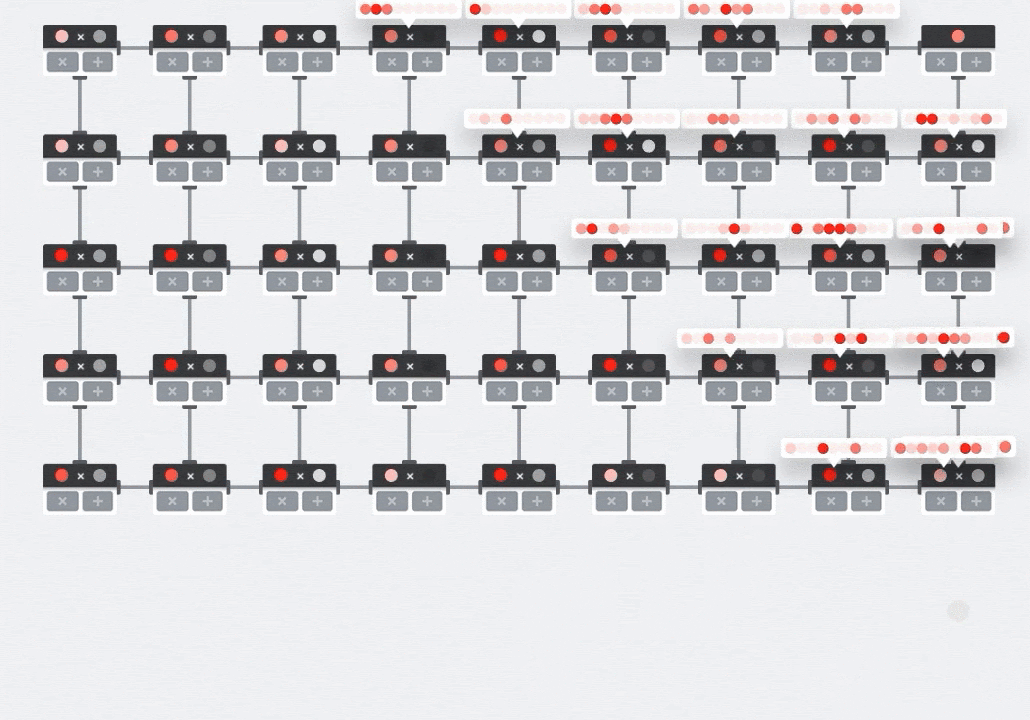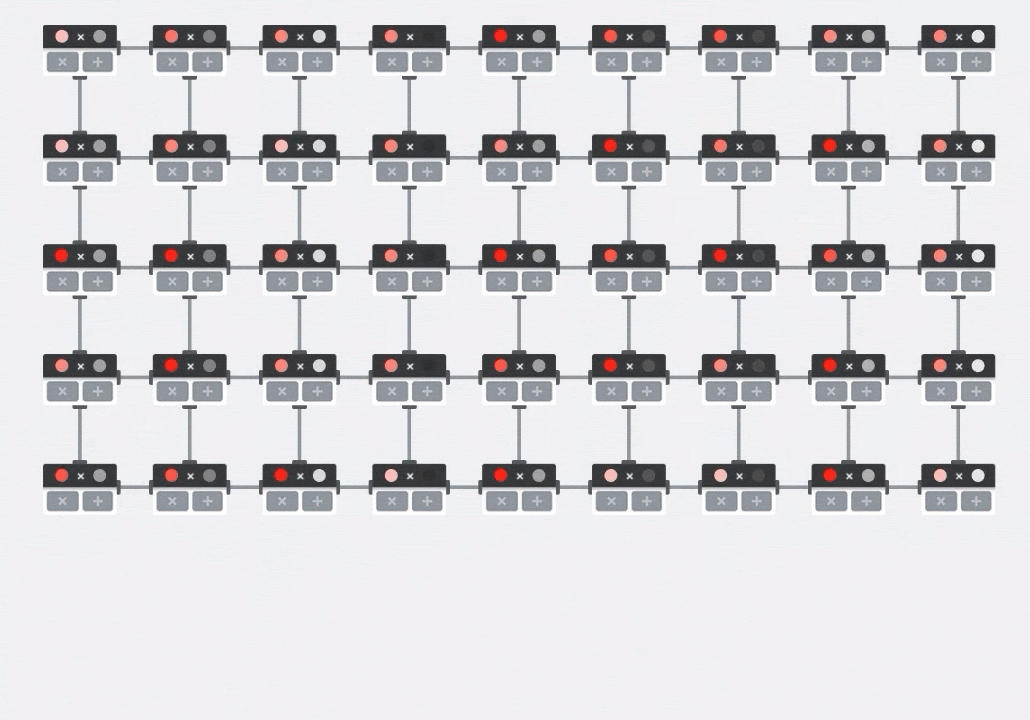
Illustrazione: l'array sistolica MXU. Gli elementi di calcolo sono accumulatori multipli. I valori di una matrice vengono caricati nell'array (punti rossi). I valori dell'altra matrice fluiscono attraverso l'array (punti grigi). Le linee verticali propagano i valori verso l'alto. Le linee orizzontali propagano somme parziali. Viene lasciato come esercizio all'utente per verificare che man mano che i dati fluiscono attraverso l'array, si ottiene il risultato della moltiplicazione matriciale che esce dal lato destro.
Inoltre, mentre i prodotti scalare vengono calcolati in un MXU, le somme intermedie si limitano a passare tra le unità di calcolo adiacenti. Non è necessario archiviarli e recuperarli nella/dalla memoria o persino in un file di registro. Il risultato finale è che l'architettura dell'array di sistolica TPU ha un significativo vantaggio in termini di densità e potenza, oltre a un vantaggio in termini di velocità non trascurabile rispetto a una GPU, quando si calcolano le moltiplicazioni delle matrici.
Cloud TPU
Quando richiedi un " Cloud TPU v2" su Google Cloud, hai una macchina virtuale (VM) con una scheda TPU collegata al PCI. La scheda TPU ha quattro chip TPU dual-core. Ogni core TPU è dotato di una VPU (Vector Processing Unit) e di una MXU (MatriX moltiplicazione) 128 x 128. Questa "Cloud TPU" è quindi generalmente connesso tramite la rete alla VM che lo ha richiesto. Il quadro completo sarà quindi simile a questo:

Illustrazione: la tua VM con una rete "Cloud TPU" collegata alla rete acceleratore. "Cloud TPU" è composta da una VM con una scheda TPU PCI collegata a quattro chip TPU dual-core.
Pod TPU
Nei data center di Google, le TPU sono collegate a un'interconnessione HPC (computing ad alte prestazioni) che può farle apparire come un unico acceleratore molto grande. Google li chiama pod e possono comprendere fino a 512 core TPU v2 o 2048 core TPU v3.

Illustrazione: un pod TPU v3. Rack e schede TPU collegate tramite interconnessione HPC.
Durante l'addestramento, i gradienti vengono scambiati tra i core TPU utilizzando l'algoritmo all-Reduce ( qui è una buona spiegazione di all-Reduce). Il modello in fase di addestramento può sfruttare l'hardware eseguendo l'addestramento su batch di grandi dimensioni.

Illustrazione: sincronizzazione dei gradienti durante l'addestramento utilizzando l'algoritmo All-Reduce sulla rete HPC mesh toroidale 2-D di Google TPU.
Il software
Addestramento di grandi dimensioni del batch
La dimensione del batch ideale per le TPU è di 128 elementi di dati per core TPU, ma l'hardware può già mostrare un buon utilizzo da 8 elementi di dati per core TPU. Ricorda che una Cloud TPU ha 8 core.
In questo codelab utilizzeremo l'API Keras. In Keras, il batch specificato è la dimensione globale del batch per l'intera TPU. I batch verranno automaticamente suddivisi in 8 core e eseguiti su 8 core della TPU.

Per ulteriori suggerimenti sulle prestazioni, consulta la Guida alle prestazioni TPU. Per dimensioni dei batch molto grandi, potrebbe essere necessaria un'attenzione particolare in alcuni modelli. Per ulteriori dettagli, consulta LARSOptimizer.
Dietro le quinte: XLA
I programmi TensorFlow definiscono i grafici di calcolo. La TPU non esegue direttamente il codice Python, ma esegue il grafico di calcolo definito dal tuo programma TensorFlow. Un compilatore chiamato XLA (Accelerated Linear Algebra compiler) trasforma il grafico TensorFlow dei nodi di calcolo in codice macchina TPU. Questo compilatore esegue anche molte ottimizzazioni avanzate sul codice e sul layout della memoria. La compilazione avviene automaticamente quando il lavoro viene inviato alla TPU. Non è necessario includere in modo esplicito XLA nella catena di build.

Illustrazione: per l'esecuzione su TPU, il grafico di calcolo definito dal programma Tensorflow viene prima tradotto in una rappresentazione XLA (Accelerated Linear Algebra compiler), quindi compilato da XLA nel codice macchina TPU.
Utilizzo delle TPU in Keras
Le TPU sono supportate tramite l'API Keras a partire da Tensorflow 2.1. Il supporto Keras funziona su TPU e pod di TPU. Ecco un esempio che funziona su TPU, GPU e CPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
In questo snippet di codice:
TPUClusterResolver().connect()trova la TPU sulla rete. Funziona senza parametri sulla maggior parte dei sistemi Google Cloud (job AI Platform, Colaboratory, Kubeflow, Deep Learning VM create tramite l'utilità "ctpu up"). Questi sistemi sanno dove si trova la loro TPU grazie a una variabile di ambiente TPU_NAME. Se crei una TPU manualmente, imposta l'ambiente TPU_NAME var. sulla VM da cui la utilizzi o chiamaTPUClusterResolvercon parametri espliciti:TPUClusterResolver(tp_uname, zone, project)TPUStrategyè la parte che implementa la distribuzione e "all-Reduce" di sincronizzazione dei gradienti.- La strategia viene applicata attraverso un ambito. Il modello deve essere definito all'interno della strategia scope().
- La funzione
tpu_model.fitprevede un oggetto tf.data.Dataset per l'input per l'addestramento delle TPU.
Attività comuni di portabilità delle TPU
- Sebbene esistano molti modi per caricare i dati in un modello TensorFlow, per le TPU è necessario l'uso dell'API
tf.data.Dataset. - Le TPU sono molto veloci e l'importazione dei dati spesso diventa un collo di bottiglia quando vengono eseguite. Nella Guida alle prestazioni TPU puoi trovare strumenti per individuare i colli di bottiglia dei dati e altri suggerimenti per le prestazioni.
- I numeri int8 o int16 vengono trattati come int32. La TPU non ha un hardware intero che opera su meno di 32 bit.
- Alcune operazioni di TensorFlow non sono supportate. L'elenco è disponibile qui. La buona notizia è che questo limite si applica solo al codice di addestramento, ovvero al passaggio in avanti e indietro attraverso il modello. Puoi comunque utilizzare tutte le operazioni TensorFlow nella pipeline di input dei dati perché verranno eseguite sulla CPU.
tf.py_funcnon è supportato sulla TPU.
4. Caricamento dati in corso…






Lavoreremo con un set di dati di immagini floreali. L'obiettivo è imparare a classificarli in 5 tipi di fiori. Il caricamento dei dati viene eseguito utilizzando l'API tf.data.Dataset. Per prima cosa, conosciamo l'API.
Pratico
Apri il blocco note seguente, esegui le celle (Maiusc-Invio) e segui le istruzioni ovunque vedi "LAVORO RICHIESTA" dell'etichetta.

Fun with tf.data.Dataset (playground).ipynb
Ulteriori informazioni
Informazioni sui "fiori" set di dati
Il set di dati è organizzato in cinque cartelle. Ogni cartella contiene fiori di un solo tipo. Le cartelle prendono il nome di girasoli, margherita, dente di leone, tulipani e rose. I dati sono ospitati in un bucket pubblico su Google Cloud Storage. Estratto:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Perché tf.data.Dataset?
Keras e Tensorflow accettano i set di dati in tutte le loro funzioni di addestramento e valutazione. Una volta caricati i dati in un set di dati, l'API offre tutte le funzionalità comuni utili per i dati di addestramento sulla rete neurale:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
In questo articolo puoi trovare suggerimenti per le prestazioni e best practice per i set di dati. La documentazione di riferimento è disponibile qui.
Nozioni di base su tf.data.Dataset
I dati di solito si trovano in più file, qui le immagini. Puoi creare un set di dati di nomi file chiamando:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Poi devi "mappare" a ogni nome file, che in genere carica e decodifica il file in dati effettivi in memoria:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
Per eseguire l'iterazione su un set di dati:
for data in my_dataset:
print(data)
Set di dati di tuple
Nell'apprendimento supervisionato, un set di dati di addestramento è generalmente composto da coppie di dati di addestramento e risposte corrette. Per consentire questa operazione, la funzione di decodifica può restituire tuple. Avrai quindi un set di dati di tuple e le tuple verranno restituite quando esegui l'iterazione. I valori restituiti sono tensori TensorFlow pronti per essere utilizzati dal modello. Puoi chiamare .numpy() per visualizzare i valori non elaborati:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Conclusione:caricare le immagini una alla volta è lento!
Man mano che esegui l'iterazione su questo set di dati, vedrai che puoi caricare qualcosa come 1-2 immagini al secondo. Troppo lento! Gli acceleratori hardware che utilizzeremo per l'addestramento sono in grado di sostenere molte volte questo ritmo. Vai alla prossima sezione per vedere come raggiungere questo obiettivo.
Soluzione
Ecco il blocco note della soluzione. Puoi utilizzarla se non riesci a proseguire.
Fun with tf.data.Dataset (solution).ipynb
Argomenti trattati
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Set di dati di tuple
- 😀 l'iterazione tramite i set di dati
Dedica qualche istante a leggere questo elenco di controllo.
5. Caricamento rapido dei dati
Gli acceleratori hardware TPU (Tensor Processing Unit) che utilizzeremo in questo lab sono molto veloci. Spesso la sfida consiste nell'fornire dati a questi dati abbastanza velocemente da non farli perdere tempo. Google Cloud Storage (GCS) è in grado di sostenere una velocità effettiva molto elevata, ma, come con tutti i sistemi di archiviazione sul cloud, l'avvio di una connessione comporta un certo costo in avanti e indietro. Pertanto, avere i nostri dati memorizzati in migliaia di singoli file non è l'ideale. Li raggruppaamo in un numero inferiore di file e utilizziamo la potenza di tf.data.Dataset per leggere da più file in parallelo.
Read-through
Il codice che carica i file immagine, li ridimensiona a una dimensione comune e li archivia in 16 file TFRecord si trova nel blocco note seguente. Leggilo rapidamente. Non è necessario eseguirla, poiché per il resto del codelab verranno forniti dati correttamente formattati in TFRecord.
Flower pictures to TFRecords.ipynb
Layout di dati ideale per una velocità effettiva ottimale di GCS
Formato file TFRecord
Il formato file preferito di Tensorflow per l'archiviazione dei dati è il formato TFRecord basato su protobuf. Possono funzionare anche altri formati di serializzazione, ma puoi caricare un set di dati direttamente dai file TFRecord scrivendo:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Per ottenere prestazioni ottimali, ti consigliamo di utilizzare il codice più complesso riportato di seguito per leggere da più file TFRecord contemporaneamente. Questo codice leggerà da N file in parallelo e ignorerà l'ordine dei dati a favore della velocità di lettura.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Scheda di riferimento di TFRecord
Nei TFRecord possono essere archiviati tre tipi di dati: stringhe di byte (elenco di byte), numeri interi a 64 bit e numeri in virgola mobile a 32 bit. Vengono sempre archiviati come elenchi, un singolo elemento di dati sarà un elenco di dimensione 1. Puoi utilizzare le seguenti funzioni helper per archiviare i dati in TFRecord.
scrittura di stringhe di byte
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
scrivere numeri interi
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
scrivere messaggi mobili
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
scrivendo un TFRecord, usando gli assistenti indicati sopra
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
Per leggere i dati dai TFRecord, devi prima dichiarare il layout dei record archiviati. Nella dichiarazione, puoi accedere a qualsiasi campo denominato come elenco di lunghezza fissa o elenco di lunghezza variabile:
leggi dai TFRecord
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Snippet di codice utili:
leggi i singoli elementi dei dati
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
leggere elenchi di elementi a dimensioni fisse
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
leggi un numero variabile di dati
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
Una funzione VarLenFeature restituisce un vettore sparso ed è necessario un passaggio aggiuntivo dopo la decodifica di TFRecord:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
È anche possibile avere campi facoltativi nei TFRecord. Se specifichi un valore predefinito durante la lettura di un campo, se il campo non è presente viene restituito il valore predefinito anziché un errore.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
Argomenti trattati
- 🤔 partizionamento orizzontale dei file di dati per un rapido accesso da GCS
- ⬤ come scrivere TFRecord. (Hai già dimenticato la sintassi? Non c'è problema, aggiungi questa pagina ai preferiti come scheda di riferimento)
- 🤔 Caricare un set di dati da TFRecords utilizzando TFRecordDataset
Dedica qualche istante a leggere questo elenco di controllo.
6. Complimenti!
Ora puoi fornire dati a una TPU. Continua con il lab successivo
- [THIS LAB] Pipeline di dati a velocità TPU: tf.data.Dataset e TFRecords
- Il tuo primo modello Keras, con Transfer Learning
- Reti neurali convoluzionali, con Keras e TPU
- Convnet moderne, Squeezenet, Xception, con Keras e TPU
TPU nella pratica
TPU e GPU sono disponibili su Cloud AI Platform:
- Nelle Deep Learning VM
- In AI Platform Notebooks
- Nei job di AI Platform Training
Infine, ci piacerebbe ricevere feedback. Facci sapere se noti qualcosa che non va in questo lab o se pensi che dovrebbe essere migliorato. Il feedback può essere fornito tramite i problemi di GitHub [link per il feedback].

|
|

