
Pipelines de dados com velocidade de TPU: tf.data.Dataset e TFRecords
Sobre este codelab
1. Visão geral
As TPUs são muito rápidas. O fluxo de dados de treinamento precisa acompanhar a velocidade delas. Neste laboratório, você vai aprender a carregar dados do GCS com a API tf.data.Dataset para alimentar a TPU.
Este laboratório é parte 1 do curso "Keras na TPU" Google Workspace. Você pode fazer isso na ordem a seguir ou de forma independente.
- [ESTE LABORATÓRIO] Pipelines de dados de velocidade da TPU: tf.data.Dataset e TFRecords
- Seu primeiro modelo do Keras com aprendizado por transferência
- Redes neurais convolucionais, com Keras e TPUs
- Convnets modernas, squeezenet, xception, com Keras e TPUs

O que você vai aprender
- Usar a API tf.data.Dataset para carregar dados de treinamento
- Usar o formato TFRecord para carregar dados de treinamento do GCS de modo eficiente
Feedback
Se você encontrar algo de errado nesse codelab, informe-nos. O feedback pode ser enviado pela página de problemas do GitHub [link do feedback].
2. Guia de início rápido do Google Colaboratory
Este laboratório usa o Google Collaboratory, e você não precisa configurar nada. O Colaboratory é uma plataforma de notebooks on-line para fins educacionais. Ele oferece treinamento sem custo financeiro de CPU, GPU e TPU.

Abra este notebook de exemplo e analise algumas células para se familiarizar com o Colaboratory.
Selecionar um back-end de TPU

No menu do Colab, selecione Ambiente de execução > Mude o tipo de ambiente de execução e selecione a TPU. Neste codelab, você usará uma TPU (Unidade de Processamento de Tensor) poderosa com suporte para treinamento acelerado por hardware. A conexão com o ambiente de execução vai ocorrer automaticamente na primeira execução ou você pode usar o botão "Conectar" no canto superior direito.
Execução do notebook

Execute uma célula de cada vez clicando em uma célula e usando Shift-ENTER. Também é possível executar todo o notebook em Ambiente de execução > Executar tudo
Índice

Todos os notebooks têm um índice. Para abri-lo, use a seta preta à esquerda.
Células ocultas

Algumas células mostrarão apenas o título. Este é um recurso de notebook específico para o Colab. É possível clicar duas vezes neles para ver o código deles, mas normalmente não é muito interessante. Normalmente, são funções de suporte ou visualização. Você ainda precisa executar essas células para que as funções internas sejam definidas.
Authentication

O Colab pode acessar seus buckets particulares do Google Cloud Storage desde que você faça a autenticação com uma conta autorizada. O snippet de código acima acionará um processo de autenticação.
3. [INFO] O que são Unidades de Processamento de Tensor (TPUs)?
Resumindo

O código para treinar um modelo em TPU no Keras (e usar a GPU ou a CPU se uma TPU não estiver disponível):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Hoje, vamos usar TPUs para criar e otimizar um classificador de flores em velocidades interativas (minutos por execução de treinamento).
Por que usar TPUs?
As GPUs modernas são organizadas em torno de "núcleos programáveis", uma arquitetura muito flexível que permite lidar com diversas tarefas, como renderização 3D, aprendizado profundo, simulações físicas etc. Por outro lado, as TPUs combinam um processador vetorial clássico com uma unidade de multiplicação de matriz dedicada e se destacam em qualquer tarefa em que as multiplicações de matrizes grandes dominam, como redes neurais.

Ilustração: uma camada de rede neural densa como uma multiplicação de matrizes, com um lote de oito imagens processadas pela rede neural de uma só vez. Execute a multiplicação de uma linha x coluna para verificar se ela está de fato fazendo uma soma ponderada de todos os valores de pixels de uma imagem. As camadas convolucionais também podem ser representadas como multiplicações de matrizes, embora isso seja um pouco mais complicado ( explicação aqui, na seção 1).
O hardware
MXU e VPU
O núcleo da TPU v2 é composto de uma unidade de multiplicação de matriz (MXU) que executa multiplicações de matriz e uma Unidade de processamento vetorial (VPU) para todas as outras tarefas, como ativações, softmax etc. A VPU lida com cálculos de float32 e int32. O MXU, por outro lado, opera em um formato de ponto flutuante de precisão mista de 16 a 32 bits.

Ponto flutuante de precisão mista e bfloat16
O MXU calcula multiplicações de matrizes usando entradas bfloat16 e saídas float32. Acumulações intermediárias são realizadas com precisão de float32.

O treinamento de rede neural costuma ser resistente ao ruído introduzido por uma precisão de ponto flutuante reduzida. Há casos em que o ruído até ajuda a convergir o otimizador. A precisão de ponto flutuante de 16 bits tem sido usada tradicionalmente para acelerar cálculos, mas os formatos float16 e float32 têm intervalos muito diferentes. Reduzir a precisão de float32 para float16 geralmente resulta em overflows e underflows. Existem soluções, mas é necessário um trabalho adicional para que o float16 funcione.
Foi por isso que o Google introduziu o formato bfloat16 nas TPUs. bfloat16 é um float32 truncado com exatamente os mesmos bits e intervalo expoentes que float32. Isso, somado ao fato de que as TPUs computam multiplicações de matrizes em precisão mista com entradas bfloat16 e saídas float32, significa que, normalmente, nenhuma mudança no código é necessária para se beneficiar dos ganhos de desempenho com precisão reduzida.
Matriz sistólica
O MXU implementa multiplicações de matrizes no hardware usando a chamada "matriz sistólica" arquitetura em que os elementos de dados fluem por uma matriz de unidades de computação de hardware. (Em medicina, “sistólico” se refere às contrações cardíacas e ao fluxo sanguíneo; aqui, ao fluxo de dados.)
O elemento básico de uma multiplicação de matrizes é um produto escalar entre uma linha de uma matriz e uma coluna de outra matriz (veja a ilustração no início desta seção). No caso da multiplicação de matrizes Y=X*W, um elemento do resultado seria:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
Em uma GPU, é possível programar esse produto escalar em um "núcleo" da GPU e executá-lo em quantos núcleos em paralelo para tentar calcular todos os valores da matriz resultante de uma só vez. Se a matriz resultante fosse 128 x 128 grande, isso exigiria 128 x 128=16 mil "núcleos" estejam disponíveis, o que normalmente não é possível. As maiores GPUs têm cerca de 4.000 núcleos. Por outro lado, as TPUs usam o mínimo de hardware possível para as unidades de computação na MXU: apenas bfloat16 x bfloat16 => float32 de acumuladores de multiplicação, nada mais. Eles são tão pequenos que uma TPU pode implementar 16 K deles em um MXU de 128 x 128 e processar essa multiplicação de matrizes de uma vez.
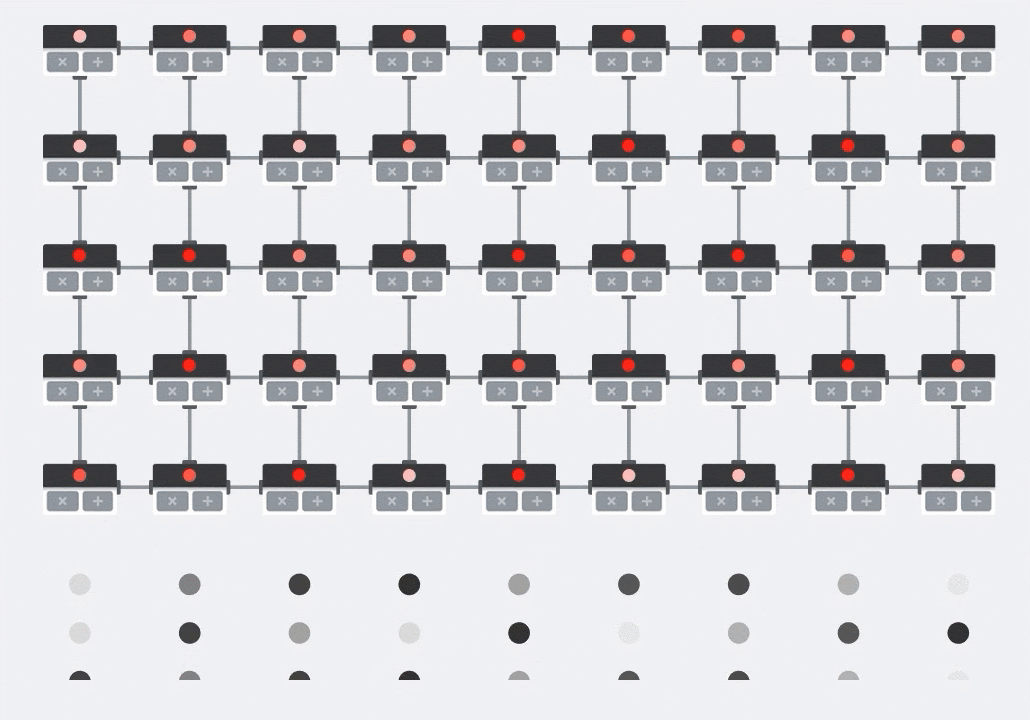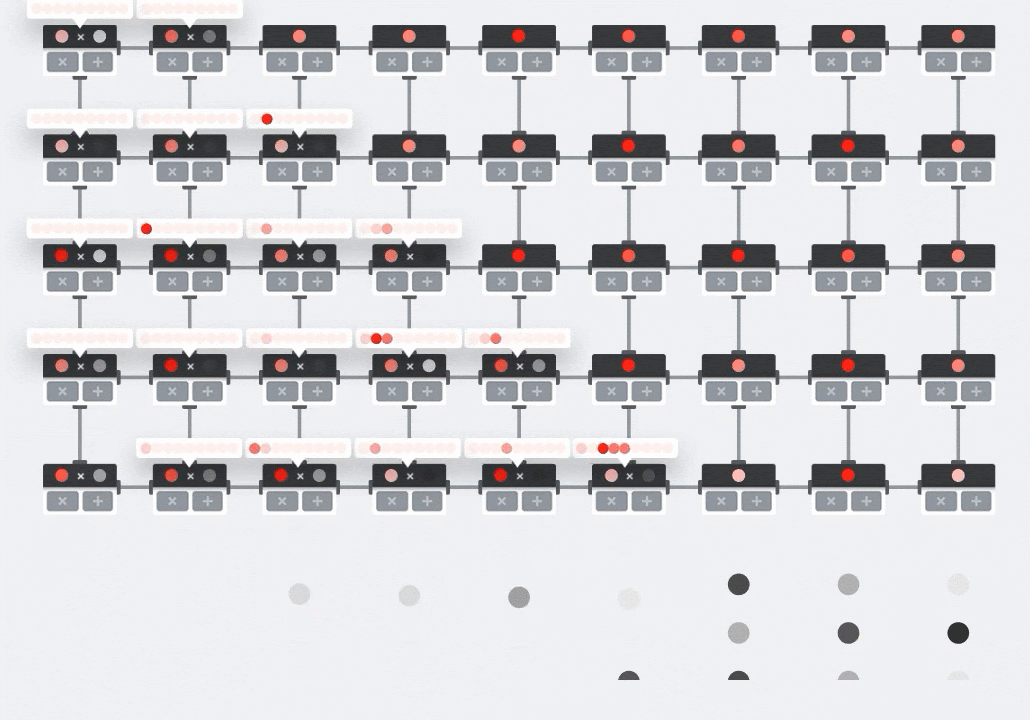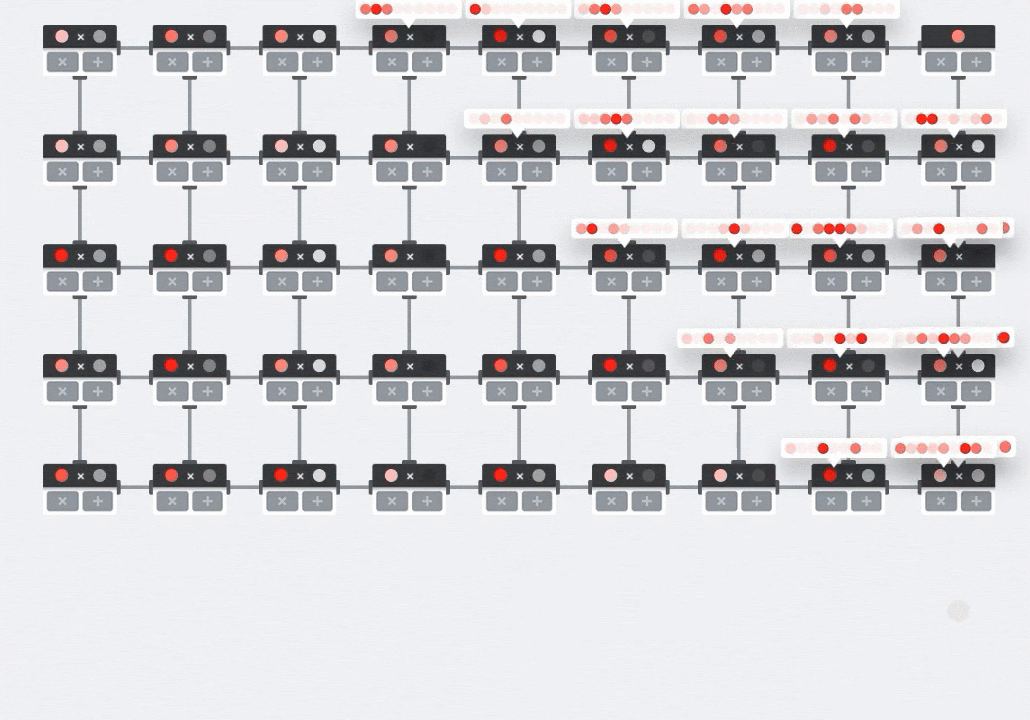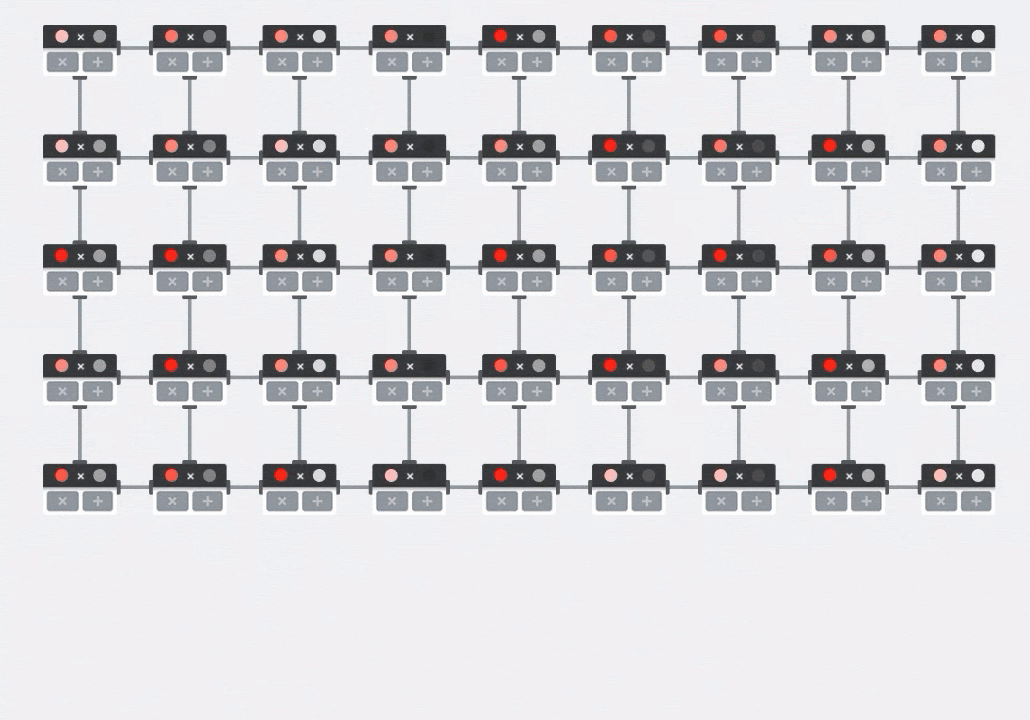
Ilustração: a matriz sistólica da MXU. Os elementos de computação são acumuladores de multiplicação. Os valores de uma matriz são carregados nela (pontos vermelhos). Os valores da outra matriz fluem pela matriz (pontos cinza). As linhas verticais propagam os valores para cima. Linhas horizontais propagam somas parciais. Como exercício, o usuário precisa verificar se, à medida que os dados fluem pela matriz, o resultado da multiplicação de matrizes é gerado do lado direito.
Além disso, enquanto os produtos pontuais são calculados em um MXU, as somas intermediárias simplesmente fluem entre as unidades de computação adjacentes. Eles não precisam ser armazenados e recuperados da/da memória ou mesmo de um arquivo de registro. O resultado final é que a arquitetura de matriz sistólica de TPU tem uma vantagem significativa de densidade e potência, além de uma vantagem de velocidade insignificante em relação a uma GPU, ao computar multiplicações de matrizes.
Cloud TPU
Quando você solicita uma " Cloud TPU v2" no Google Cloud Platform, você recebe uma máquina virtual (VM) com uma placa de TPU conectada a PCI. A placa de TPU tem quatro chips de TPU de dois núcleos. Cada núcleo de TPU possui uma unidade de processamento vetorial (VPU, na sigla em inglês) e uma unidade de multiplicação de matriz (MXU, na sigla em inglês) de 128 x 128. Essa "Cloud TPU" geralmente está conectada pela rede à VM que a solicitou. O quadro completo fica assim:
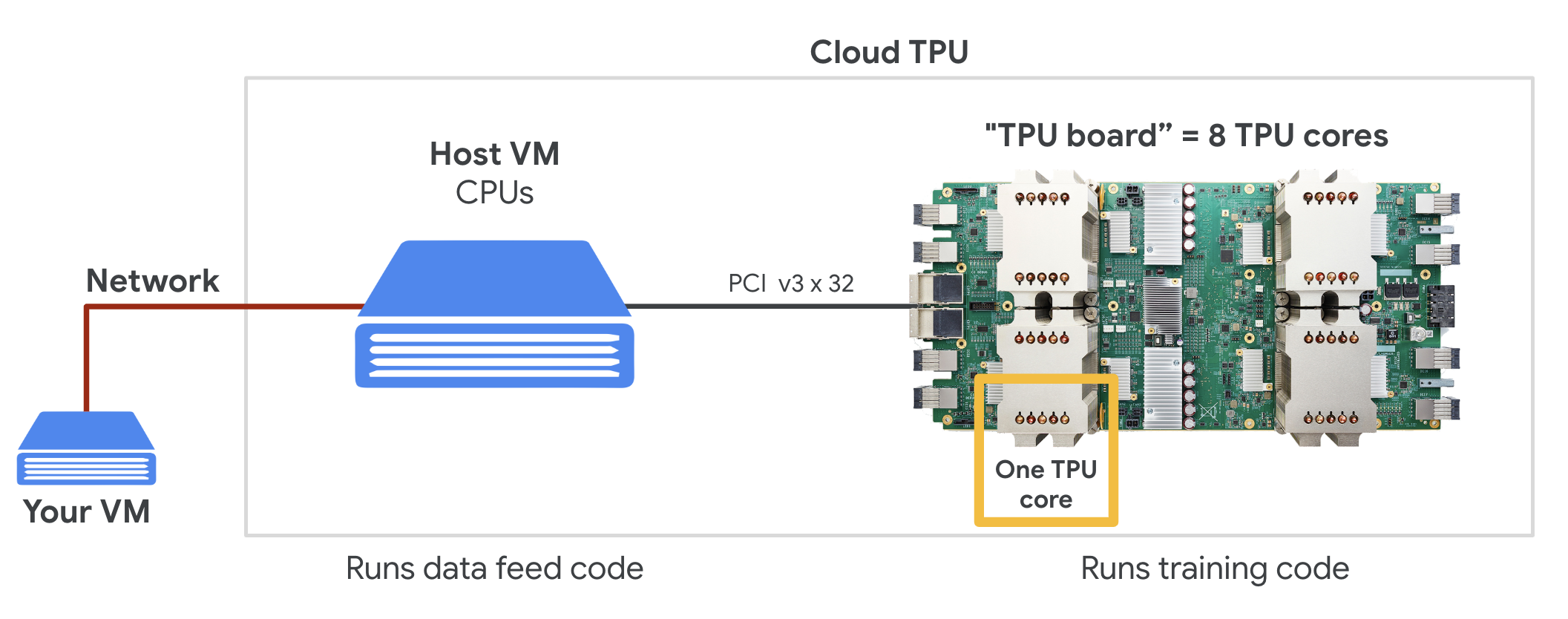
Ilustração: sua VM com um "Cloud TPU" conectado à rede acelerador. "O Cloud TPU" Ela é composta de uma VM com uma placa de TPU conectada a PCI e com quatro chips de TPU dual-core.
Pods de TPU
Nos data centers do Google, as TPUs são conectadas a uma interconexão de computação de alto desempenho (HPC), que pode fazê-las parecer um acelerador muito grande. O Google os chama de pods, e eles podem abranger até 512 núcleos de TPU v2 ou 2.048 núcleos de TPU v3.

Ilustração: um pod da TPU v3. Placas e racks de TPU conectados por interconexão HPC.
Durante o treinamento, os gradientes são trocados entre núcleos de TPU usando o algoritmo de redução total. Confira uma boa explicação sobre a redução total. O modelo que está sendo treinado pode aproveitar o hardware ao treinar em grandes tamanhos de lote.

Ilustração: sincronização de gradientes durante o treinamento usando o algoritmo de redução total na rede HPC de malha toroidal 2D do Google TPU.
O software
Treinamento de tamanho de lote grande
O tamanho de lote ideal para TPUs é de 128 itens de dados por núcleo de TPU, mas o hardware já mostra uma boa utilização de 8 itens de dados por núcleo de TPU. Lembre-se de que uma Cloud TPU tem 8 núcleos.
Neste codelab, vamos usar a API Keras. No Keras, o lote especificado é o tamanho global do lote de toda a TPU. Seus lotes serão divididos automaticamente em oito e executados nos oito núcleos da TPU.

Para mais dicas sobre desempenho, consulte o Guia de desempenho da TPU. Para tamanhos de lote muito grandes, pode ser necessário cuidado especial em alguns modelos. Consulte LARSOptimizer para mais detalhes.
Em segundo plano: XLA
Os programas do TensorFlow definem gráficos de computação. Ela não executa o código Python diretamente, e sim o gráfico de computação definido pelo programa do TensorFlow. Nos bastidores, um compilador chamado XLA (Acelerador de álgebra linear) transforma o gráfico de nós de computação do Tensorflow em código de máquina da TPU. Esse compilador também executa muitas otimizações avançadas no código e no layout da memória. A compilação acontece automaticamente conforme o trabalho é enviado para a TPU. Você não precisa incluir o XLA explicitamente na sua cadeia de compilação.
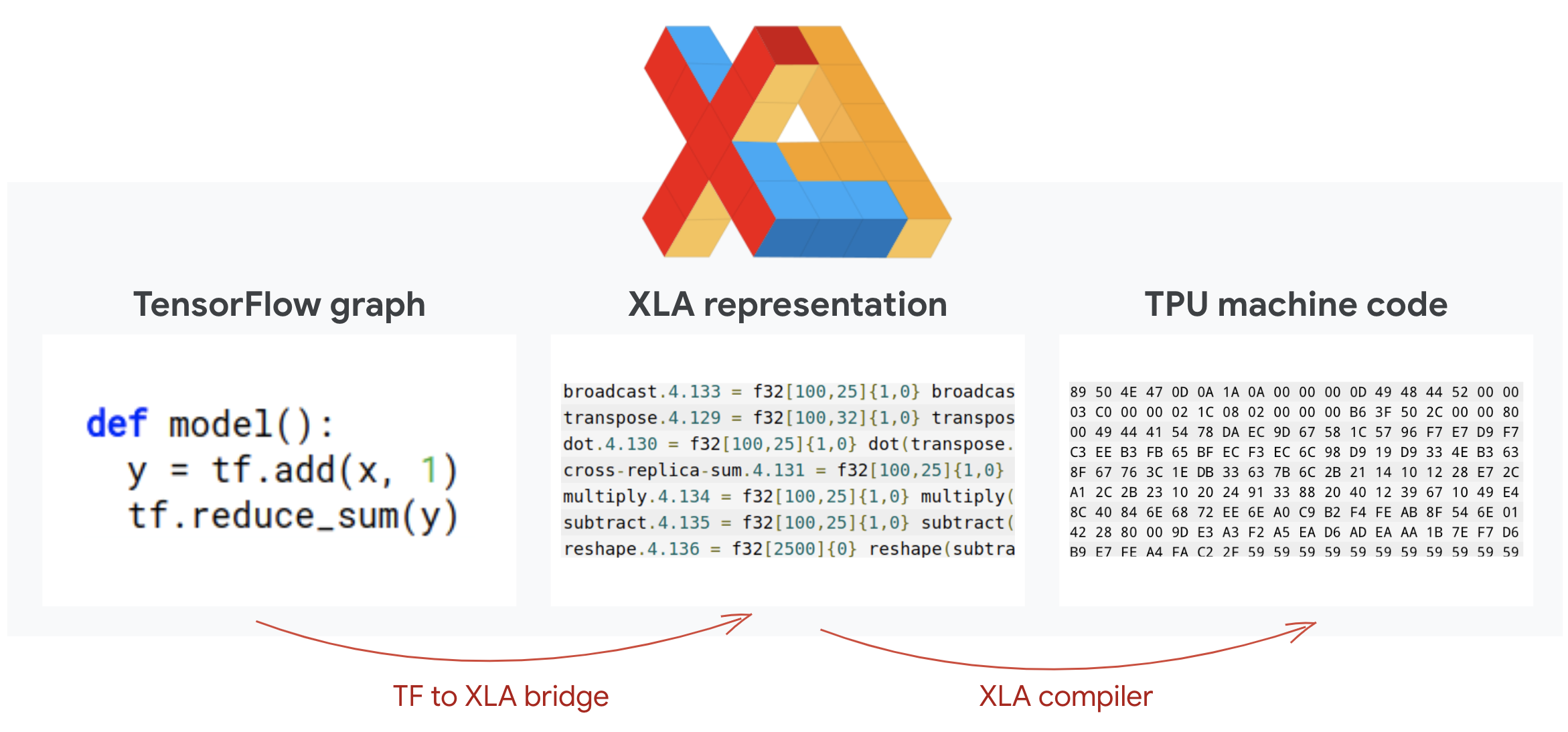
Ilustração: para ser executado em TPU, o gráfico de computação definido pelo programa Tensorflow é primeiro convertido em uma representação do XLA (acelerador de álgebra linear) e depois compilado pelo XLA no código de máquina da TPU.
Como usar TPUs no Keras
As TPUs são compatíveis com a API Keras a partir do Tensorflow 2.1. O suporte ao Keras funciona em TPUs e pods de TPU. Veja um exemplo que funciona em TPU, GPU(s) e CPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
Neste snippet de código:
TPUClusterResolver().connect()encontra a TPU na rede. Ele funciona sem parâmetros na maioria dos sistemas do Google Cloud (jobs do AI Platform, Colaboratory, Kubeflow, VMs de aprendizado profundo criados com o utilitário "vpc up"). Esses sistemas sabem onde a TPU está graças a uma variável de ambiente TPU_NAME. Se você criar uma TPU manualmente, defina o ambiente TPU_NAME. var. na VM da qual ele está sendo usado ou chameTPUClusterResolvercom parâmetros explícitos:TPUClusterResolver(tp_uname, zone, project)TPUStrategyé a parte que implementa a distribuição e a "redução total" algoritmo de sincronização de gradiente.- A estratégia é aplicada por meio de um escopo. O modelo precisa ser definido dentro do scope() da estratégia.
- A função
tpu_model.fitespera um objeto tf.data.Dataset para entrada no treinamento da TPU.
Tarefas comuns de portabilidade de TPU
- Embora existam muitas maneiras de carregar dados em um modelo do Tensorflow, para as TPUs, o uso da API
tf.data.Dataseté obrigatório. - TPUs são muito rápidas, e a ingestão de dados geralmente se torna um gargalo durante a execução nelas. Existem ferramentas que podem ser usadas para detectar gargalos de dados e outras dicas de desempenho no Guia de desempenho da TPU.
- os números int8 ou int16 são tratados como int32. A TPU não tem hardware inteiro que opera em menos de 32 bits.
- Algumas operações do Tensorflow não são compatíveis. Confira esta lista. A boa notícia é que essa limitação se aplica apenas ao código de treinamento, ou seja, à passagem para frente e para trás pelo seu modelo. Ainda é possível usar todas as operações do TensorFlow no pipeline de entrada de dados, já que elas serão executadas na CPU.
tf.py_funcnão é compatível com a TPU.
4. Como carregar dados






Vamos trabalhar com um conjunto de dados de fotos de flores. O objetivo é aprender a classificá-las em cinco tipos de flores. O carregamento de dados é realizado usando a API tf.data.Dataset. Primeiro, vamos conhecer a API.
Na prática
Abra o notebook a seguir, execute as células (Shift-ENTER) e siga as instruções sempre que aparecer a mensagem "WORK REQUIRED" rótulo.

Fun with tf.data.Dataset (playground).ipynb
Informações adicionais
Sobre "flores" conjunto de dados
O conjunto de dados é organizado em cinco pastas. Cada pasta contém flores de um tipo. As pastas são chamadas de girassóis, margaridas, dentes-de-leão, tulipas e rosas. Os dados são hospedados em um bucket público no Google Cloud Storage. Trecho:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Por que usar o tf.data.Dataset?
O Keras e o Tensorflow aceitam conjuntos de dados em todas as funções de treinamento e avaliação. Depois de carregar dados em um conjunto de dados, a API oferece todas as funcionalidades comuns úteis para dados de treinamento de redes neurais:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
Confira dicas de desempenho e práticas recomendadas de conjuntos de dados neste artigo. A documentação de referência está aqui.
Noções básicas sobre tf.data.Dataset
Os dados geralmente vêm em vários arquivos, aqui, imagens. É possível criar um conjunto de dados de nomes de arquivos chamando:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
Depois, você "mapeia" uma função para cada nome de arquivo que normalmente vai carregar e decodificar o arquivo em dados reais na memória:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
Para iterar em um conjunto de dados:
for data in my_dataset:
print(data)
Conjuntos de dados de tuplas
No aprendizado supervisionado, um conjunto de dados de treinamento normalmente é composto por pares de dados de treinamento e respostas corretas. Para permitir isso, a função de decodificação pode retornar tuplas. Em seguida, você terá um conjunto de dados de tuplas e tuplas que será retornado quando você iterar nele. Os valores retornados são tensores do TensorFlow prontos para serem consumidos pelo modelo. Chame .numpy() neles para ver valores brutos:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Conclusão:o carregamento de uma imagem por vez é lento.
Ao iterar nesse conjunto de dados, você verá que é possível carregar algo como 1 ou 2 imagens por segundo. Muito lento! Os aceleradores de hardware que vamos usar no treinamento podem manter essa taxa muitas vezes. Vá para a próxima seção para ver como conseguiremos isso.
Solução
Este é o notebook da solução. Você pode usá-la se tiver dificuldades.
Fun with tf.data.Dataset (solution).ipynb
O que vimos
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Conjuntos de dados de tuplas
- 😀 iterando com conjuntos de dados
Reserve um momento para rever esta lista de verificação em sua cabeça.
5. Carregamento rápido de dados
Os aceleradores de hardware da Unidade de Processamento de Tensor (TPU) que vamos usar neste laboratório são muito rápidos. O desafio muitas vezes é alimentá-los com dados rápido o suficiente para mantê-los ocupados. O Google Cloud Storage (GCS) é capaz de sustentar uma alta capacidade de processamento, mas, assim como todos os sistemas de armazenamento em nuvem, iniciar uma conexão custa certa rede para frente e para trás. Portanto, ter nossos dados armazenados como milhares de arquivos individuais não é o ideal. Vamos agrupá-los em um número menor de arquivos e usar a capacidade de tf.data.Dataset para ler vários arquivos em paralelo.
Leitura
O código que carrega arquivos de imagem, os redimensiona para um tamanho comum e os armazena em 16 arquivos TFRecord está no notebook a seguir. Por favor, leia-o rapidamente. Não é necessário executá-la porque os dados formatados em TFRecord serão fornecidos corretamente para o restante do codelab.
Flower pictures to TFRecords.ipynb
Layout de dados ideal para a capacidade ideal do GCS
Formato de arquivo TFRecord
O formato de arquivo preferencial do Tensorflow para armazenar dados é o TFRecord baseado em protobuf. Outros formatos de serialização também funcionam, mas é possível carregar um conjunto de dados de arquivos TFRecord diretamente escrevendo:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Para um desempenho ideal, recomendamos usar o código mais complexo abaixo para ler vários arquivos TFRecord de uma só vez. Esse código lerá os arquivos N em paralelo e desconsiderará a ordem dos dados para favorecer a velocidade de leitura.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
Folha de referência do TFRecord
É possível armazenar três tipos de dados em TFRecords: strings de bytes (lista de bytes), números inteiros de 64 bits e flutuantes de 32 bits. Eles são sempre armazenados como listas, um único elemento de dados será uma lista de tamanho 1. É possível usar as funções auxiliares a seguir para armazenar dados em TFRecords.
como gravar strings de bytes
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
gravar números inteiros
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
gravar flutuações
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
criar um TFRecord usando os auxiliares acima
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
Para ler dados do TFRecords, primeiro é preciso declarar o layout dos registros armazenados. Na declaração, você pode acessar qualquer campo nomeado como uma lista de tamanho fixo ou variável:
lendo no TFRecords
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Snippets de código úteis:
Como ler elementos de dados únicos
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
ler listas de elementos de tamanho fixo
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
Como ler um número variável de itens de dados
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
Um VarLenFeature retorna um vetor esparso. Depois de decodificar o TFRecord, é necessário realizar uma etapa adicional:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
Também é possível ter campos opcionais no TFRecords. Se você especificar um valor padrão ao ler um campo, ele será retornado em vez de um erro se o campo estiver ausente.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
O que vimos
- 🤔 Fragmentação de arquivos de dados para acesso rápido pelo GCS
- 😝 como escrever TFRecords. (Você já esqueceu a sintaxe? Tudo bem. Adicione esta página aos favoritos como uma folha de referência.
- 🤔 Como carregar um conjunto de dados do TFRecords usando o TFRecordDataset
Reserve um momento para rever esta lista de verificação em sua cabeça.
6. Parabéns!
Agora é possível alimentar uma TPU com dados. Prossiga para o próximo laboratório
- [ESTE LABORATÓRIO] Pipelines de dados com velocidade de TPU: tf.data.Dataset e TFRecords
- Seu primeiro modelo do Keras com aprendizado por transferência
- Redes neurais convolucionais, com Keras e TPUs
- Convnets modernas, squeezenet, xception, com Keras e TPUs
TPUs na prática
TPUs e GPUs estão disponíveis na AI Platform do Cloud:
- em VMs de aprendizado profundo
- nos Notebooks do AI Platform
- Nos jobs do AI Platform Training
Finalmente, adoramos feedback. Avise nossa equipe se você encontrar algo errado no laboratório ou achar que ele precisa ser melhorado. O feedback pode ser enviado pela página de problemas do GitHub [link do feedback].

|
|

