
1. Genel Bakış
Bu laboratuvarda, Iowa eyaletindeki içki satışlarıyla ilgili herkese açık veri kümesini temizlemek ve analiz etmek için BigQuery Studio'daki bir Python not defterinden BigQuery DataFrames'i kullanacaksınız. Analizler keşfetmek için BigQuery ML ve uzak işlev özelliklerinden yararlanın.
Coğrafi bölgelerdeki satışları karşılaştırmak için bir Python not defteri oluşturacaksınız. Bu, herhangi bir yapılandırılmış veride çalışacak şekilde uyarlanabilir.
Hedefler
Bu laboratuvarda, aşağıdaki görevleri nasıl gerçekleştireceğinizi öğreneceksiniz:
- BigQuery Studio'da Python not defterlerini etkinleştirme ve kullanma
- BigQuery DataFrames paketini kullanarak BigQuery'ye bağlanma
- BigQuery ML kullanarak doğrusal regresyon oluşturma
- Tanıdık pandas benzeri bir sözdizimi kullanarak karmaşık toplama ve birleştirme işlemleri gerçekleştirme
2. Şartlar
Başlamadan önce
Bu codelab'deki talimatları uygulamak için BigQuery Studio'nun etkinleştirildiği bir Google Cloud projesine ve bağlı bir faturalandırma hesabına ihtiyacınız vardır.
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Google Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
- BigQuery Studio'yu öğe yönetimi için etkinleştirme talimatlarını uygulayın.
BigQuery Studio'yu hazırlama
Boş bir not defteri oluşturup bir çalışma zamanına bağlayın.
- Google Cloud Console'da BigQuery Studio'ya gidin.
- + düğmesinin yanındaki ▼ simgesini tıklayın.
- Python not defteri'ni seçin.
- Şablon seçiciyi kapatın.
- Yeni bir kod hücresi oluşturmak için + Kod'u seçin.
- Kod hücresinden BigQuery DataFrames paketinin en son sürümünü yükleyin.Aşağıdaki komutu yazın.
%pip install --upgrade bigframes --quiet
3. Herkese açık bir veri kümesini okuma
Yeni bir kod hücresinde aşağıdakileri çalıştırarak BigQuery DataFrames paketini başlatın:
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
Not: Bu eğitimde, pandas benzeri filtreleme ile kullanıldığında daha verimli sorgulara olanak tanıyan deneysel "kısmi sıralama modu" kullanılmaktadır. Sıkı bir sıralama veya dizin gerektiren bazı pandas özellikleri çalışmayabilir.
bigframes paketinizin sürümünü şu komutla kontrol edin:
bpd.__version__
Bu eğitim için 1.27.0 veya sonraki bir sürüm gereklidir.
Iowa'daki alkollü içecek perakende satışları
Iowa alkollü içecek perakende satışları veri kümesi, Google Cloud'un herkese açık veri kümesi programı aracılığıyla BigQuery'de sağlanır. Bu veri kümesi, 1 Ocak 2012'den beri Iowa eyaletinde perakendeciler tarafından bireylere satış için yapılan tüm toptan içki satın alma işlemlerini içerir. Veriler, Iowa Ticaret Bakanlığı'na bağlı Alkollü İçecekler Bölümü tarafından toplanır.
BigQuery'de, Iowa'daki perakende içki satışlarını analiz etmek için bigquery-public-data.iowa_liquor_sales.sales sorgusunu çalıştırın. Bir sorgu dizesinden veya tablo kimliğinden DataFrame oluşturmak için bigframes.pandas.read_gbq() yöntemini kullanın.
"df" adlı bir DataFrame oluşturmak için yeni bir kod hücresinde aşağıdakileri çalıştırın:
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
DataFrame hakkında temel bilgileri keşfetme
Verilerin küçük bir örneğini indirmek için DataFrame.peek() yöntemini kullanın.
Bu hücreyi çalıştırın:
df.peek()
Beklenen çıkış:
index invoice_and_item_number date store_number store_name ...
0 RINV-04620300080 2023-04-28 10197 SUNSHINE FOODS / HAWARDEN
1 RINV-04864800097 2023-09-25 2621 HY-VEE FOOD STORE #3 / SIOUX CITY
2 RINV-05057200028 2023-12-28 4255 FAREWAY STORES #058 / ORANGE CITY
3 ...
Not: head() sıralama gerektirir ve bir veri örneğini görselleştirmek istiyorsanız genellikle peek()'den daha az verimlidir.
Tıpkı pandas'ta olduğu gibi, kullanılabilir tüm sütunları ve bunlara karşılık gelen veri türlerini görmek için DataFrame.dtypes özelliğini kullanın. Bunlar, pandas ile uyumlu bir şekilde gösterilir.
Bu hücreyi çalıştırın:
df.dtypes
Beklenen çıkış:
invoice_and_item_number string[pyarrow]
date date32[day][pyarrow]
store_number string[pyarrow]
store_name string[pyarrow]
address string[pyarrow]
city string[pyarrow]
zip_code string[pyarrow]
store_location geometry
county_number string[pyarrow]
county string[pyarrow]
category string[pyarrow]
category_name string[pyarrow]
vendor_number string[pyarrow]
vendor_name string[pyarrow]
item_number string[pyarrow]
item_description string[pyarrow]
pack Int64
bottle_volume_ml Int64
state_bottle_cost Float64
state_bottle_retail Float64
bottles_sold Int64
sale_dollars Float64
volume_sold_liters Float64
volume_sold_gallons Float64
dtype: object
DataFrame.describe() yöntemi, DataFrame'deki bazı temel istatistikleri sorgular. Bu özet istatistiklerini Pandas DataFrame olarak indirmek için DataFrame.to_pandas() komutunu çalıştırın.
Bu hücreyi çalıştırın:
df.describe("all").to_pandas()
Beklenen çıkış:
invoice_and_item_number date store_number store_name ...
nunique 30305765 <NA> 3158 3353 ...
std <NA> <NA> <NA> <NA> ...
mean <NA> <NA> <NA> <NA> ...
75% <NA> <NA> <NA> <NA> ...
25% <NA> <NA> <NA> <NA> ...
count 30305765 <NA> 30305765 30305765 ...
min <NA> <NA> <NA> <NA> ...
50% <NA> <NA> <NA> <NA> ...
max <NA> <NA> <NA> <NA> ...
9 rows × 24 columns
4. Verileri görselleştirme ve temizleme
Iowa alkollü içecek perakende satışları veri kümesi, perakende mağazalarının bulunduğu yer de dahil olmak üzere ayrıntılı coğrafi bilgiler sağlar. Coğrafi bölgelerdeki trendleri ve farklılıkları belirlemek için bu verileri kullanın.
Posta koduna göre satışları görselleştirme
DataFrame.plot.hist() gibi çeşitli yerleşik görselleştirme yöntemleri vardır. Bu yöntemi, posta koduna göre içki satışlarını karşılaştırmak için kullanın.
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
volume_by_zip.plot.hist(bins=20)
Beklenen çıkış:
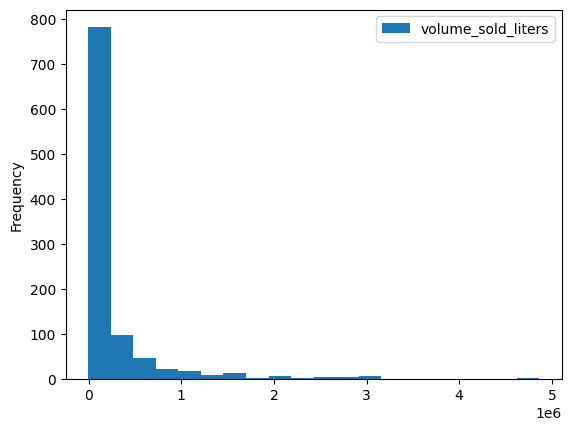
En çok alkolün hangi posta kodlarında satıldığını görmek için çubuk grafik kullanın.
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Beklenen çıkış:

Verileri temizleme
Bazı posta kodlarının sonunda .0 işareti bulunur. Veri toplama sürecinde bir yerde posta kodları yanlışlıkla kayan nokta değerlerine dönüştürülmüş olabilir. Posta kodlarını temizlemek için normal ifadeler kullanın ve analizi tekrarlayın.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
volume_by_zip = df.groupby("zip_code").agg({"volume_sold_liters": "sum"})
(
volume_by_zip
.sort_values("volume_sold_liters", ascending=False)
.head(25)
.to_pandas()
.plot.bar(rot=80)
)
Beklenen çıkış:

5. Satışlardaki korelasyonları keşfetme
Neden bazı posta kodlarında diğerlerinden daha fazla satış yapılıyor? Bir hipoteze göre bu durum, nüfus büyüklüğündeki farklılıklardan kaynaklanıyor. Nüfusu daha fazla olan bir posta kodunda daha fazla içki satılması muhtemeldir.
Nüfus ile içki satış hacmi arasındaki korelasyonu hesaplayarak bu hipotezi test edin.
Diğer veri kümeleriyle birleştirme
ABD Nüfus Sayımı Bürosu'nun Amerikan Topluluk Anketi posta kodu tablolama alanı anketi gibi bir nüfus veri kümesiyle birleştirin.
census_acs = bpd.read_gbq_table("bigquery-public-data.census_bureau_acs.zcta_2020_5yr")
American Community Survey, eyaletleri GEOID'ye göre tanımlar. Posta kodu tablolama alanlarında GEOID, posta koduna eşittir.
volume_by_pop = volume_by_zip.join(
census_acs.set_index("geo_id")
)
Posta kodu tablolama alanı nüfuslarını satılan alkol miktarıyla karşılaştırmak için bir dağılım grafiği oluşturun.
(
volume_by_pop[["volume_sold_liters", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="volume_sold_liters")
)
Beklenen çıkış:
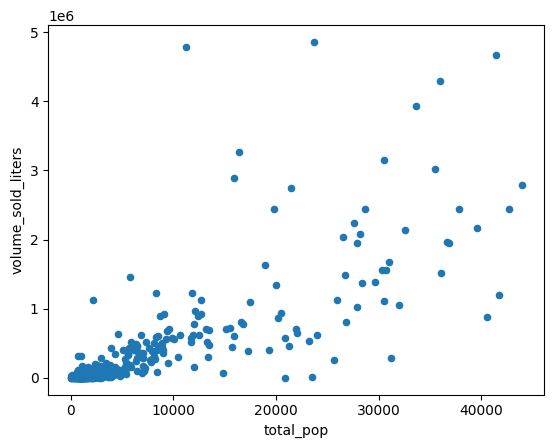
Korelasyonları hesaplama
Trend yaklaşık olarak doğrusal görünüyor. Nüfusun içki satışlarını ne kadar iyi tahmin edebildiğini kontrol etmek için bu verilere doğrusal regresyon modeli uygulayın.
from bigframes.ml.linear_model import LinearRegression
feature_columns = volume_by_pop[["total_pop"]]
label_columns = volume_by_pop[["volume_sold_liters"]]
# Create the linear model
model = LinearRegression()
model.fit(feature_columns, label_columns)
score yöntemini kullanarak eşleşmenin ne kadar iyi olduğunu kontrol edin.
model.score(feature_columns, label_columns).to_pandas()
Örnek çıkış:
mean_absolute_error mean_squared_error mean_squared_log_error median_absolute_error r2_score explained_variance
0 245065.664095 224398167097.364288 5.595021 178196.31289 0.380096 0.380096
Bir dizi popülasyon değerinde predict işlevini çağırarak en uygun çizgiyi çizin.
import matplotlib.pyplot as pyplot
import numpy as np
import pandas as pd
line = pd.Series(np.arange(0, 50_000), name="total_pop")
predictions = model.predict(line).to_pandas()
zips = volume_by_pop[["volume_sold_liters", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["volume_sold_liters"])
pyplot.plot(
line,
predictions.sort_values("total_pop")["predicted_volume_sold_liters"],
marker=None,
color="red",
)
Beklenen çıkış:

Değişen varyans sorununu ele alma
Önceki grafikteki veriler heteroskedastik görünüyor. En iyi uyum doğrusu etrafındaki varyans, popülasyonla birlikte büyür.
Belki de kişi başına satın alınan alkol miktarı nispeten sabittir.
volume_per_pop = (
volume_by_pop[volume_by_pop['total_pop'] > 0]
.assign(liters_per_pop=lambda df: df["volume_sold_liters"] / df["total_pop"])
)
(
volume_per_pop[["liters_per_pop", "total_pop"]]
.to_pandas()
.plot.scatter(x="total_pop", y="liters_per_pop")
)
Beklenen çıkış:
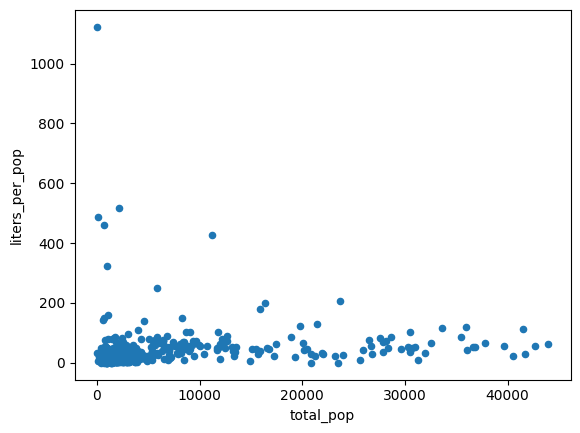
Satın alınan alkolün ortalama litresini iki farklı şekilde hesaplayın:
- Iowa'da kişi başına satın alınan ortalama alkol miktarı nedir?
- Kişi başına satın alınan alkol miktarının tüm posta kodlarındaki ortalaması nedir?
(1) numaralı grafikte, eyaletin tamamında ne kadar alkol satın alındığı gösterilmektedir. (2) numaralı alanda, ortalama posta kodu gösterilir. Farklı posta kodlarında farklı nüfuslar olduğundan bu değer, (1) numaralı alanla aynı olmayabilir.
df = (
bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
.assign(
zip_code=lambda _: _["zip_code"].str.replace(".0", "")
)
)
census_state = bpd.read_gbq(
"bigquery-public-data.census_bureau_acs.state_2020_5yr",
index_col="geo_id",
)
volume_per_pop_statewide = (
df['volume_sold_liters'].sum()
/ census_state["total_pop"].loc['19']
)
volume_per_pop_statewide
Beklenen çıktı: 87.997
average_per_zip = volume_per_pop["liters_per_pop"].mean()
average_per_zip
Beklenen çıktı: 67.139
Bu ortalamaları yukarıdakine benzer şekilde çizin.
import numpy as np
import pandas as pd
from matplotlib import pyplot
line = pd.Series(np.arange(0, 50_000), name="total_pop")
zips = volume_per_pop[["liters_per_pop", "total_pop"]].to_pandas()
pyplot.scatter(zips["total_pop"], zips["liters_per_pop"])
pyplot.plot(line, np.full(line.shape, volume_per_pop_statewide), marker=None, color="magenta")
pyplot.plot(line, np.full(line.shape, average_per_zip), marker=None, color="red")
Beklenen çıkış:
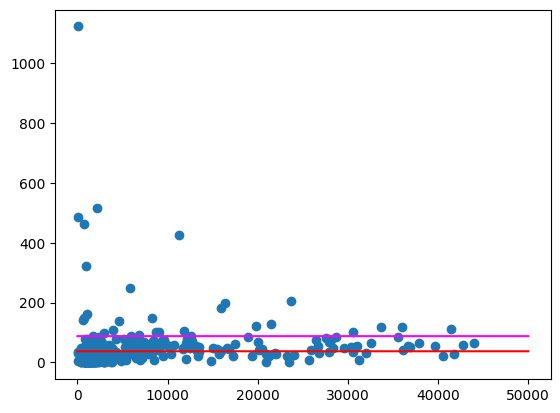
Özellikle nüfusun daha az olduğu bölgelerde, hâlâ oldukça büyük aykırı değerler içeren bazı posta kodları vardır. Bunun nedenini tahmin etmek alıştırma olarak bırakılmıştır. Örneğin, bazı posta kodları bölgedeki tek içki dükkanını içerdiğinden nüfusları düşük ancak tüketimleri yüksek olabilir. Bu durumda, çevredeki posta kodlarının nüfusuna göre hesaplama yapmak bu aykırı değerleri bile ortadan kaldırabilir.
6. Satılan içki türlerini karşılaştırma
Iowa eyaletindeki içki perakende satışları veritabanı, coğrafi verilere ek olarak satılan ürünle ilgili ayrıntılı bilgileri de içerir. Belki de bunları analiz ederek coğrafi bölgelerdeki zevk farklılıklarını ortaya çıkarabiliriz.
Kategorileri keşfedin
Öğeler veritabanında kategorilere ayrılır. Kaç kategori var?
import bigframes.pandas as bpd
bpd.options.bigquery.ordering_mode = "partial"
bpd.options.display.repr_mode = "deferred"
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
df.category_name.nunique()
Beklenen çıktı: 103
Hacme göre en popüler kategoriler hangileri?
counts = (
df.groupby("category_name")
.agg({"volume_sold_liters": "sum"})
.sort_values(["volume_sold_liters"], ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)

ARRAY veri türüyle çalışma
Viski, rom, votka ve daha birçok içeceğin farklı kategorileri vardır. Bunları bir şekilde gruplandırmak istiyorum.
Series.str.split() yöntemini kullanarak kategori adlarını ayrı kelimelere bölerek başlayın. explode() yöntemini kullanarak bu dizinin iç içe yerleştirilmiş yapısını kaldırın.
category_parts = df.category_name.str.split(" ").explode()
counts = (
category_parts
.groupby(category_parts)
.size()
.sort_values(ascending=False)
.to_pandas()
)
counts.head(25).plot.bar(rot=80)

category_parts.nunique()
Beklenen çıktı: 113
Yukarıdaki grafiğe baktığımızda, verilerde VODKA ve VODKAS'ın hâlâ ayrı olduğunu görüyoruz. Kategorileri daha küçük bir kümeye daraltmak için daha fazla gruplandırma yapılması gerekir.
7. BigQuery DataFrames ile NLTK'yı kullanma
Yalnızca 100 kadar kategori olduğundan, bazı bulgular yazmak veya hatta kategoriden daha geniş içki türüne manuel olarak eşleme oluşturmak mümkündür. Alternatif olarak, bu tür bir eşleme oluşturmak için Gemini gibi bir büyük dil modeli kullanılabilir. BigQuery DataFrames'i Gemini ile kullanmak için BigQuery DataFrames'i kullanarak yapılandırılmamış verilerden analiz elde etme adlı codelab'i deneyin.
Bunun yerine, bu verileri işlemek için daha geleneksel bir doğal dil işleme paketi olan NLTK'yı kullanın. Örneğin, "kök bulucu" adı verilen bir teknoloji, çoğul ve tekil isimleri aynı değerde birleştirebilir.
Kelimelerin gövdelerini çıkarmak için NLTK'yı kullanma
NLTK paketi, Python'dan erişilebilen doğal dil işleme yöntemleri sunar. Denemek için paketi yükleyin.
%pip install nltk
Ardından paketi içe aktarın. Sürümü inceleyin. Bu ad, eğitimin ilerleyen bölümlerinde kullanılacaktır.
import nltk
nltk.__version__
Kelimeleri standartlaştırmanın bir yolu, kelimenin "kökünü" almaktır. Bu işlem, çoğul için sondaki "s" gibi tüm ekleri kaldırır.
def stem(word: str) -> str:
# https://www.nltk.org/howto/stem.html
import nltk.stem.snowball
# Avoid failure if a NULL is passed in.
if not word:
return word
stemmer = nltk.stem.snowball.SnowballStemmer("english")
return stemmer.stem(word)
Birkaç kelime üzerinde deneyin.
stem("WHISKEY")
Beklenen çıktı: whiskey
stem("WHISKIES")
Beklenen çıktı: whiski
Maalesef bu, viskileri viskiyle aynı şekilde eşlemedi. Kelimelerin köklerini bulma araçları, düzensiz çoğullarla iyi çalışmaz. Temel kelimeyi ("lemma") belirlemek için daha gelişmiş teknikler kullanan bir lemmatizer'ı deneyin.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
return wnl.lemmatize(word.lower())
Birkaç kelime üzerinde deneyin.
lemmatize("WHISKIES")
Beklenen çıktı: whisky
lemmatize("WHISKY")
Beklenen çıktı: whisky
lemmatize("WHISKEY")
Beklenen çıktı: whiskey
Maalesef bu kök bulma aracı, "viski" kelimesini "viskiler" kelimesiyle aynı köke eşlemiyor. Bu kelime, Iowa perakende içki satışları veritabanı için özellikle önemli olduğundan sözlüğü kullanarak kelimeyi manuel olarak Amerikan yazımına eşleyin.
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Birkaç kelime üzerinde deneyin.
lemmatize("WHISKIES")
Beklenen çıktı: whiskey
lemmatize("WHISKEY")
Beklenen çıktı: whiskey
Tebrikler! Bu lemmatizer, kategorileri daraltmak için iyi sonuç verir. BigQuery ile kullanmak için buluta dağıtmanız gerekir.
Projenizi işlev dağıtımı için ayarlama
BigQuery'nin bu işleve erişebilmesi için bunu buluta dağıtmadan önce tek seferlik kurulum yapmanız gerekir.
Yeni bir kod hücresi oluşturun ve your-project-id kısmını bu eğitim için kullandığınız Google Cloud proje kimliğiyle değiştirin.
project_id = "your-project-id"
Bu işlevin herhangi bir bulut kaynağına erişmesi gerekmediğinden, izinsiz bir hizmet hesabı oluşturun.
from google.cloud import iam_admin_v1
from google.cloud.iam_admin_v1 import types
iam_admin_client = iam_admin_v1.IAMClient()
request = types.CreateServiceAccountRequest()
account_id = "bigframes-no-permissions"
request.account_id = account_id
request.name = f"projects/{project_id}"
display_name = "bigframes remote function (no permissions)"
service_account = types.ServiceAccount()
service_account.display_name = display_name
request.service_account = service_account
account = iam_admin_client.create_service_account(request=request)
print(account.email)
Beklenen çıktı: bigframes-no-permissions@your-project-id.iam.gserviceaccount.com
İşlevi barındıracak bir BigQuery veri kümesi oluşturun.
from google.cloud import bigquery
bqclient = bigquery.Client(project=project_id)
dataset = bigquery.Dataset(f"{project_id}.functions")
bqclient.create_dataset(dataset, exists_ok=True)
Uzak işlev dağıtma
Henüz etkinleştirilmemişse Cloud Functions API'yi etkinleştirin.
!gcloud services enable cloudfunctions.googleapis.com
Şimdi işlevinizi yeni oluşturduğunuz veri kümesine dağıtın. Önceki adımlarda oluşturduğunuz işleve bir @bpd.remote_function dekoratörü ekleyin.
@bpd.remote_function(
dataset=f"{project_id}.functions",
name="lemmatize",
# TODO: Replace this with your version of nltk.
packages=["nltk==3.9.1"],
cloud_function_service_account=f"bigframes-no-permissions@{project_id}.iam.gserviceaccount.com",
cloud_function_ingress_settings="internal-only",
)
def lemmatize(word: str) -> str:
# https://stackoverflow.com/a/18400977/101923
# https://www.nltk.org/api/nltk.stem.wordnet.html#module-nltk.stem.wordnet
import nltk
import nltk.stem.wordnet
# Avoid failure if a NULL is passed in.
if not word:
return word
nltk.download('wordnet')
wnl = nltk.stem.wordnet.WordNetLemmatizer()
lemma = wnl.lemmatize(word.lower())
table = {
"whisky": "whiskey", # Use the American spelling.
}
return table.get(lemma, lemma)
Dağıtım işlemi yaklaşık iki dakika sürer.
Uzaktan kumanda işlevlerini kullanma
Dağıtım tamamlandıktan sonra bu işlevi test edebilirsiniz.
lemmatize = bpd.read_gbq_function(f"{project_id}.functions.lemmatize")
words = bpd.Series(["whiskies", "whisky", "whiskey", "vodkas", "vodka"])
words.apply(lemmatize).to_pandas()
Beklenen çıkış:
0 whiskey
1 whiskey
2 whiskey
3 vodka
4 vodka
dtype: string
8. İllere göre alkol tüketimini karşılaştırma
lemmatize işlevi kullanıma sunulduğundan beri kategorileri birleştirmek için bu işlevi kullanabilirsiniz.
Kategoriyi en iyi şekilde özetleyen kelimeyi bulma
Öncelikle, veritabanındaki tüm kategorilerin DataFrame'ini oluşturun.
df = bpd.read_gbq_table("bigquery-public-data.iowa_liquor_sales.sales")
categories = (
df['category_name']
.groupby(df['category_name'])
.size()
.to_frame()
.rename(columns={"category_name": "total_orders"})
.reset_index(drop=False)
)
categories.to_pandas()
Beklenen çıkış:
category_name total_orders
0 100 PROOF VODKA 99124
1 100% AGAVE TEQUILA 724374
2 AGED DARK RUM 59433
3 AMARETTO - IMPORTED 102
4 AMERICAN ALCOHOL 24351
... ... ...
98 WATERMELON SCHNAPPS 17844
99 WHISKEY LIQUEUR 1442732
100 WHITE CREME DE CACAO 7213
101 WHITE CREME DE MENTHE 2459
102 WHITE RUM 436553
103 rows × 2 columns
Ardından, noktalama işaretleri ve "öğe" gibi birkaç dolgu kelimesi hariç olmak üzere kategorilerdeki tüm kelimelerin yer aldığı bir DataFrame oluşturun.
words = (
categories.assign(
words=categories['category_name']
.str.lower()
.str.split(" ")
)
.assign(num_words=lambda _: _['words'].str.len())
.explode("words")
.rename(columns={"words": "word"})
)
words = words[
# Remove punctuation and "item", unless it's the only word
(words['word'].str.isalnum() & ~(words['word'].str.startswith('item')))
| (words['num_words'] == 1)
]
words.to_pandas()
Beklenen çıkış:
category_name total_orders word num_words
0 100 PROOF VODKA 99124 100 3
1 100 PROOF VODKA 99124 proof 3
2 100 PROOF VODKA 99124 vodka 3
... ... ... ... ...
252 WHITE RUM 436553 white 2
253 WHITE RUM 436553 rum 2
254 rows × 4 columns
Gruplandırmadan sonra lemmatize etmenin Cloud Function'ınızdaki yükü azaltacağını unutmayın. Veritabanındaki birkaç milyon satırın her birine kökünü bulma işlevini uygulamak mümkündür ancak bu, gruplandırmadan sonra uygulamaktan daha maliyetli olur ve kota artışı gerektirebilir.
lemmas = words.assign(lemma=lambda _: _["word"].apply(lemmatize))
lemmas.to_pandas()
Beklenen çıkış:
category_name total_orders word num_words lemma
0 100 PROOF VODKA 99124 100 3 100
1 100 PROOF VODKA 99124 proof 3 proof
2 100 PROOF VODKA 99124 vodka 3 vodka
... ... ... ... ... ...
252 WHITE RUM 436553 white 2 white
253 WHITE RUM 436553 rum 2 rum
254 rows × 5 columns
Kelimeler köklerine ayrıldıktan sonra, kategoriyi en iyi özetleyen kökü seçmeniz gerekir. Kategorilerde çok fazla işlev kelimesi olmadığından, bir kelime birden fazla kategoride görünüyorsa özetleme kelimesi olarak daha uygun olma olasılığı yüksektir (ör. viski).
lemma_counts = (
lemmas
.groupby("lemma", as_index=False)
.agg({"total_orders": "sum"})
.rename(columns={"total_orders": "total_orders_with_lemma"})
)
categories_with_lemma_counts = lemmas.merge(lemma_counts, on="lemma")
max_lemma_count = (
categories_with_lemma_counts
.groupby("category_name", as_index=False)
.agg({"total_orders_with_lemma": "max"})
.rename(columns={"total_orders_with_lemma": "max_lemma_count"})
)
categories_with_max = categories_with_lemma_counts.merge(
max_lemma_count,
on="category_name"
)
categories_mapping = categories_with_max[
categories_with_max['total_orders_with_lemma'] == categories_with_max['max_lemma_count']
].groupby("category_name", as_index=False).max()
categories_mapping.to_pandas()
Beklenen çıkış:
category_name total_orders word num_words lemma total_orders_with_lemma max_lemma_count
0 100 PROOF VODKA 99124 vodka 3 vodka 7575769 7575769
1 100% AGAVE TEQUILA 724374 tequila 3 tequila 1601092 1601092
2 AGED DARK RUM 59433 rum 3 rum 3226633 3226633
... ... ... ... ... ... ... ...
100 WHITE CREME DE CACAO 7213 white 4 white 446225 446225
101 WHITE CREME DE MENTHE 2459 white 4 white 446225 446225
102 WHITE RUM 436553 rum 2 rum 3226633 3226633
103 rows × 7 columns
Artık her kategoriyi özetleyen tek bir lemma olduğuna göre bunu orijinal DataFrame ile birleştirin.
df_with_lemma = df.merge(
categories_mapping,
on="category_name",
how="left"
)
df_with_lemma[df_with_lemma['category_name'].notnull()].peek()
Beklenen çıkış:
invoice_and_item_number ... lemma total_orders_with_lemma max_lemma_count
0 S30989000030 ... vodka 7575769 7575769
1 S30538800106 ... vodka 7575769 7575769
2 S30601200013 ... vodka 7575769 7575769
3 S30527200047 ... vodka 7575769 7575769
4 S30833600058 ... vodka 7575769 7575769
5 rows × 30 columns
İlleri karşılaştırma
Her ilçedeki satışları karşılaştırarak farklılıkları görebilirsiniz.
county_lemma = (
df_with_lemma
.groupby(["county", "lemma"])
.agg({"volume_sold_liters": "sum"})
# Cast to an integer for more deterministic equality comparisons.
.assign(volume_sold_int64=lambda _: _['volume_sold_liters'].astype("Int64"))
)
Her ülkede en çok satılan ürünü (lemma) bulun.
county_max = (
county_lemma
.reset_index(drop=False)
.groupby("county")
.agg({"volume_sold_int64": "max"})
)
county_max_lemma = county_lemma[
county_lemma["volume_sold_int64"] == county_max["volume_sold_int64"]
]
county_max_lemma.to_pandas()
Beklenen çıkış:
volume_sold_liters volume_sold_int64
county lemma
SCOTT vodka 6044393.1 6044393
APPANOOSE whiskey 292490.44 292490
HAMILTON whiskey 329118.92 329118
... ... ... ...
WORTH whiskey 100542.85 100542
MITCHELL vodka 158791.94 158791
RINGGOLD whiskey 65107.8 65107
101 rows × 2 columns
İlçeler birbirinden ne kadar farklı?
county_max_lemma.groupby("lemma").size().to_pandas()
Beklenen çıkış:
lemma
american 1
liqueur 1
vodka 15
whiskey 83
dtype: Int64
Çoğu ülkede viski, hacim bakımından en popüler ürün olurken 15 ülkede votka en popüler üründür. Bunu eyalet genelindeki en popüler içki türleriyle karşılaştırın.
total_liters = (
df_with_lemma
.groupby("lemma")
.agg({"volume_sold_liters": "sum"})
.sort_values("volume_sold_liters", ascending=False)
)
total_liters.to_pandas()
Beklenen çıkış:
volume_sold_liters
lemma
vodka 85356422.950001
whiskey 85112339.980001
rum 33891011.72
american 19994259.64
imported 14985636.61
tequila 12357782.37
cocktails/rtd 7406769.87
...
Viski ve votkanın hacmi neredeyse aynıdır. Votka, eyalet genelinde viskiden biraz daha fazla satılmaktadır.
Oranları karşılaştırma
Her ilçedeki satışların benzersiz özellikleri nelerdir? İlçeyi eyaletin geri kalanından farklı kılan nedir?
Hangi içki satış hacimlerinin eyalet genelindeki satış oranına göre beklenenden en çok orantısal olarak farklılaştığını bulmak için Cohen's h ölçüsünü kullanın.
import numpy as np
total_proportions = total_liters / total_liters.sum()
total_phi = 2 * np.arcsin(np.sqrt(total_proportions))
county_liters = df_with_lemma.groupby(["county", "lemma"]).agg({"volume_sold_liters": "sum"})
county_totals = df_with_lemma.groupby(["county"]).agg({"volume_sold_liters": "sum"})
county_proportions = county_liters / county_totals
county_phi = 2 * np.arcsin(np.sqrt(county_proportions))
cohens_h = (
(county_phi - total_phi)
.rename(columns={"volume_sold_liters": "cohens_h"})
.assign(cohens_h_int=lambda _: (_['cohens_h'] * 1_000_000).astype("Int64"))
)
Cohen's h değeri her lemma için ölçüldüğüne göre, her ilçedeki eyalet genelindeki orandan en büyük farkı bulun.
# Note: one might want to use the absolute value here if interested in counties
# that drink _less_ of a particular liquor than expected.
largest_per_county = cohens_h.groupby("county").agg({"cohens_h_int": "max"})
counties = cohens_h[cohens_h['cohens_h_int'] == largest_per_county["cohens_h_int"]]
counties.sort_values('cohens_h', ascending=False).to_pandas()
Beklenen çıkış:
cohens_h cohens_h_int
county lemma
EL PASO liqueur 1.289667 1289667
ADAMS whiskey 0.373591 373590
IDA whiskey 0.306481 306481
OSCEOLA whiskey 0.295524 295523
PALO ALTO whiskey 0.293697 293696
... ... ... ...
MUSCATINE rum 0.053757 53757
MARION rum 0.053427 53427
MITCHELL vodka 0.048212 48212
WEBSTER rum 0.044896 44895
CERRO GORDO cocktails/rtd 0.027496 27495
100 rows × 2 columns
Cohen's h değeri ne kadar yüksek olursa o tür alkolün tüketim miktarında eyalet ortalamalarına kıyasla istatistiksel olarak anlamlı bir fark olma olasılığı o kadar artar. Daha küçük pozitif değerlerde, tüketimdeki fark eyalet genelindeki ortalamadan farklıdır ancak bu fark rastgele farklılıklardan kaynaklanabilir.
Bir not: EL PASO ilçesi, Iowa'daki bir ilçe gibi görünmüyor. Bu durum, bu sonuçlara tam olarak güvenmeden önce verilerin temizlenmesi gerektiğini gösterebilir.
İlçeleri görselleştirme
Her ilin coğrafi alanını almak için bigquery-public-data.geo_us_boundaries.counties tablosuyla birleştirin. ABD'deki ilçe adları benzersiz olmadığından yalnızca Iowa'daki ilçeleri içerecek şekilde filtreleyin. Iowa'nın FIPS kodu "19"dur.
counties_geo = (
bpd.read_gbq("bigquery-public-data.geo_us_boundaries.counties")
.assign(county=lambda _: _['county_name'].str.upper())
)
counties_plus = (
counties
.reset_index(drop=False)
.merge(counties_geo[counties_geo['state_fips_code'] == '19'], on="county", how="left")
.dropna(subset=["county_geom"])
.to_pandas()
)
counties_plus
Beklenen çıkış:
county lemma cohens_h cohens_h_int geo_id state_fips_code ...
0 ALLAMAKEE american 0.087931 87930 19005 19 ...
1 BLACK HAWK american 0.106256 106256 19013 19 ...
2 WINNESHIEK american 0.093101 93101 19191 19 ...
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
96 CLINTON tequila 0.075708 75707 19045 19 ...
97 POLK tequila 0.087438 87438 19153 19 ...
98 LEE schnapps 0.064663 64663 19111 19 ...
99 rows × 23 columns
Bu farklılıkları haritada görselleştirmek için GeoPandas'ı kullanın.
import geopandas
counties_plus = geopandas.GeoDataFrame(counties_plus, geometry="county_geom")
# https://stackoverflow.com/a/42214156/101923
ax = counties_plus.plot(figsize=(14, 14))
counties_plus.apply(
lambda row: ax.annotate(
text=row['lemma'],
xy=row['county_geom'].centroid.coords[0],
ha='center'
),
axis=1,
)

9. Temizleme
Bu eğitim için yeni bir Google Cloud projesi oluşturduysanız oluşturulan tablolar veya diğer kaynaklar için ek ücret alınmasını önlemek üzere bu projeyi silebilirsiniz.
Alternatif olarak, bu eğitim için oluşturulan Cloud Functions işlevlerini, hizmet hesaplarını ve veri kümelerini silebilirsiniz.
10. Tebrikler!
BigQuery DataFrames'i kullanarak yapılandırılmış verileri temizleyip analiz etmiş olmanız gerekir. Bu süreçte Google Cloud'un herkese açık veri kümelerini, BigQuery Studio'daki Python not defterlerini, BigQuery ML'yi, BigQuery uzak işlevlerini ve BigQuery DataFrame'lerin gücünü keşfettiniz. Tebrikler!
Sonraki adımlar
- Bu adımları ABD adları veritabanı gibi diğer verilere uygulayın.
- Not defterinizde Python kodu oluşturmayı deneyin. BigQuery Studio'daki Python not defterleri Colab Enterprise tarafından desteklenir. İpucu: Test verileri oluşturma konusunda yardım istemenin oldukça faydalı olduğunu düşünüyorum.
- GitHub'daki BigQuery DataFrames ile ilgili örnek not defterlerini inceleyin.
- BigQuery Studio'da not defteri çalıştırmak için bir program oluşturun.
- Üçüncü taraf Python paketlerini BigQuery ile entegre etmek için BigQuery DataFrames ile Uzak İşlev dağıtın.