
1. Introdução
Imagine poder preparar seus dados para análise de forma mais rápida e eficiente sem precisar ser um especialista em programação. Com o Preparação de dados do BigQuery, isso é possível. Esse recurso poderoso simplifica a ingestão, a transformação e a limpeza de dados, colocando a preparação de dados nas mãos de todos os profissionais de dados da sua organização.
Tudo pronto para descobrir os segredos ocultos nos dados do seu produto?
Pré-requisitos
- Conhecimento básico do console do Google Cloud
- Noções básicas de SQL
O que você vai aprender
- Como o preparo de dados do BigQuery pode limpar e transformar seus dados brutos em informações úteis de business intelligence usando um exemplo realista do setor de moda e beleza.
- Como executar e programar a preparação de dados limpos
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome
2. Configuração básica e requisitos
Configuração de ambiente autoguiada
- Faça login no console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma se ainda não tiver uma conta do Gmail ou do Google Workspace.



- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$300 de avaliação sem custos.
3. Antes de começar
Ativar API
Para usar o Gemini no BigQuery, você precisa ativar a API Gemini para Google Cloud. Geralmente, essa etapa é realizada por um administrador de serviço ou proprietário do projeto com a permissão IAM serviceusage.services.enable.
- Para ativar a API Gemini para Google Cloud, acesse a página Gemini para Google Cloud no Google Cloud Marketplace. Acesse o Gemini para Google Cloud
- No seletor de projetos, escolha um projeto.
- Clique em Ativar. A página é atualizada e mostra o status Ativado. O Gemini no BigQuery agora está disponível no projeto selecionado do Google Cloud para todos os usuários que têm as permissões necessárias do IAM.
Configurar funções e permissões para desenvolver preparações de dados
- Em "IAM e administrador", selecione "IAM".

- Selecione seu usuário e clique no ícone de lápis para "Editar principal".

Para usar o BigQuery Data Preparation, você precisa dos seguintes papéis e permissões:
- Editor de dados do BigQuery (roles/bigquery.dataEditor)
- Consumidor do Service Usage (roles/serviceusage.serviceUsageConsumer)
4. Como encontrar e assinar a listagem "demonstração de preparo de dados do bq" no BigQuery Analytics Hub
Usaremos o conjunto de dados bq data preparation demo neste tutorial. É um conjunto de dados vinculado no BigQuery Analytics Hub que vamos ler.
A preparação de dados nunca grava na origem, e vamos pedir que você defina uma tabela de destino para gravar. A tabela com que vamos trabalhar neste exercício tem apenas 1.000 linhas para manter os custos mínimos,mas o preparo de dados é executado no BigQuery e vai ser dimensionado.
Siga estas etapas para encontrar e assinar o conjunto de dados vinculado:
- Acesse o Analytics Hub: no console do Google Cloud, navegue até o BigQuery.
- No menu de navegação do BigQuery, em "Governance", selecione "Analytics Hub".
- Pesquise a listagem: na interface do Analytics Hub, clique em Pesquisar listagens.
- Digite
bq data preparation demona barra de pesquisa e pressione Enter.
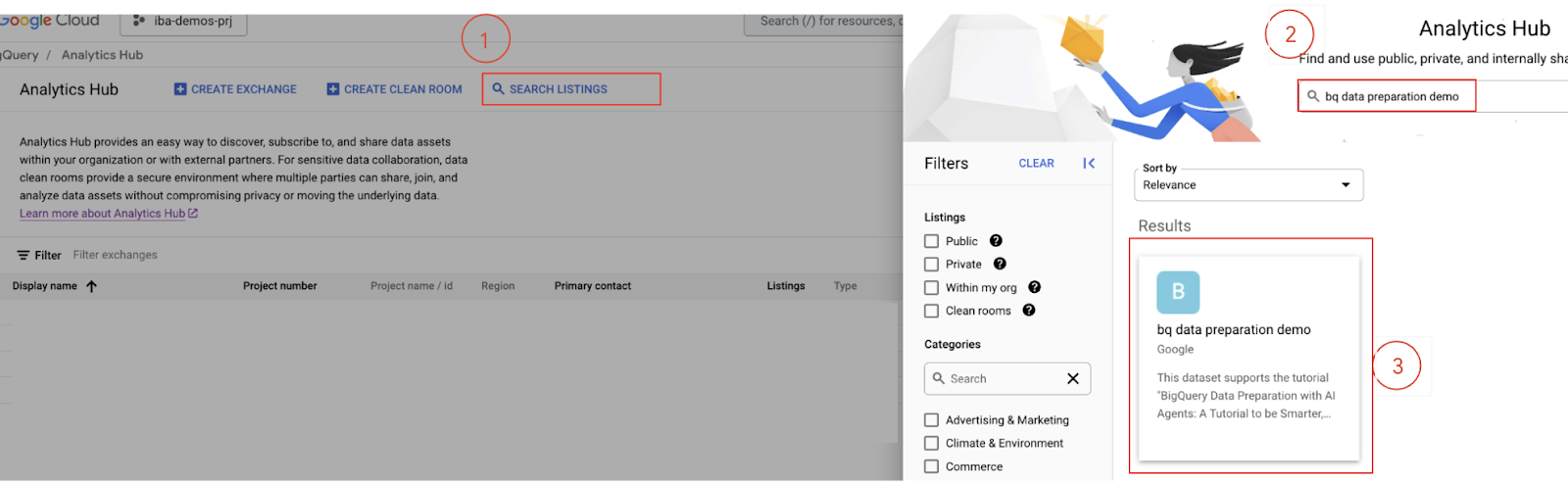
- Inscreva-se na listagem: selecione a listagem
bq data preparation demonos resultados da pesquisa. - Na página de detalhes da listagem, clique no botão Assinar.
- Revise as caixas de diálogo de confirmação e atualize o projeto/conjunto de dados, se necessário. Os padrões devem estar corretos.
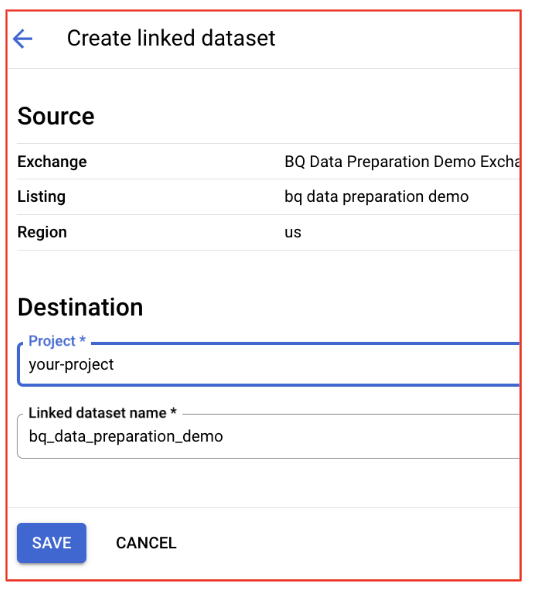
- Acessar o conjunto de dados no BigQuery: depois que você se inscrever, os conjuntos de dados na lista serão vinculados ao seu projeto do BigQuery.
Volte ao BigQuery Studio.
5. Analisar os dados e iniciar a preparação de dados
- Localize o conjunto de dados e a tabela: no painel "Explorador", selecione seu projeto e encontre o conjunto de dados incluído na lista
bq data preparation demo. Selecione a tabelastg_product. - Abrir no Preparo de dados: clique nos três pontos verticais ao lado do nome da tabela e selecione
Open in Data Preparation.
Isso vai abrir a tabela na interface de preparação de dados, pronta para você começar a transformar seus dados.

Como você pode ver na visualização de dados abaixo, temos alguns desafios de dados que vamos enfrentar, incluindo:
- A coluna de preço contém o valor e a moeda, o que dificulta a análise.
- A coluna "Produto" mistura o nome e a categoria do produto (separados por um símbolo de barra vertical |).

O Gemini analisa seus dados imediatamente e sugere várias transformações. Neste exemplo, há várias recomendações. Nas próximas etapas, vamos aplicar as que precisamos.

6. Como processar a coluna de preço
Vamos abordar a coluna Preço. Como vimos, ele contém a moeda e o valor. Nosso objetivo é separar esses dados em duas colunas distintas: "Currency" e "Amount".
O Gemini identificou várias recomendações para a coluna "Preço".
- Encontre uma recomendação que diga algo como:
Descrição: "Esta expressão remove o "USD " inicial do campo especificado"
REGEXP_REPLACE(Price,` `r'^USD\s',` `r'')
- Selecionar visualização

- Selecione "Aplicar".
Na coluna Preço, converta o tipo de dados de STRING para NUMERIC.
- Encontre uma recomendação que diga algo como:
Descrição: "Converte a coluna "Preço" de string de tipo para float64"
SAFE_CAST(Price AS float64)
- Selecione "Aplicar".
Agora você vai ver três etapas aplicadas na lista.

7. Como lidar com a coluna de produtos
A coluna do produto contém o nome e a categoria do produto, separados por um pipe (|).
Podemos usar a linguagem natural novamente, mas vamos explorar outro recurso poderoso do Gemini.
Limpar o nome do produto
- Selecione a parte da categoria de uma entrada de produto que inclui o caractere
|e exclua.

O Gemini reconhece esse padrão de forma inteligente e sugere uma transformação para aplicar a toda a coluna.
- Selecione "Editar".

A recomendação do Gemini é perfeita: ela remove tudo depois do caractere "|", isolando o nome do produto.
Mas desta vez não queremos substituir os dados originais.
- No menu suspenso da coluna de destino, selecione "Criar nova coluna".
- Defina o nome como ProductName.

- Visualize as mudanças para garantir que tudo esteja certo.
- Aplique a transformação.
Extrair a categoria do produto
Usando a linguagem natural, vamos instruir o Gemini a extrair a palavra após a barra vertical (>) na coluna "Produto". Esse valor extraído será substituído na coluna "Produto".
- Clique em
Add Steppara adicionar uma nova etapa de transformação.

- Selecione
Transformationno menu suspenso. - No campo de comando de linguagem natural, insira "extrair a palavra após o pipe (|) na coluna "Produto"." Em seguida, pressione Return para gerar o SQL.

- Deixe a coluna de destino como "Produto".
- Clique em Aplicar.
A transformação vai gerar os seguintes resultados.

8. Como mesclar para enriquecer os dados
Muitas vezes, você vai querer enriquecer seus dados com informações de outras fontes. No nosso exemplo, vamos mesclar os dados do produto com os atributos estendidos do produto, stg_extended_product, de uma tabela de terceiros. Essa tabela inclui detalhes como marca e data de lançamento.
- Clique em
Add Step. - Selecionar
Join - Navegue até a tabela
stg_extended_product.

O Gemini no BigQuery escolheu automaticamente a chave de mesclagem de ID do produto e qualificou os lados esquerdo e direito, já que o nome da chave é idêntico.
Observação: confira se o campo de descrição mostra "Join by productid". Se ele incluir outras chaves de mesclagem, substitua o campo de descrição por "Mesclar por productid" e selecione o botão "Gerar" no campo de descrição para gerar novamente a expressão de mesclagem com a seguinte condição L.
productid
= R.
productid. 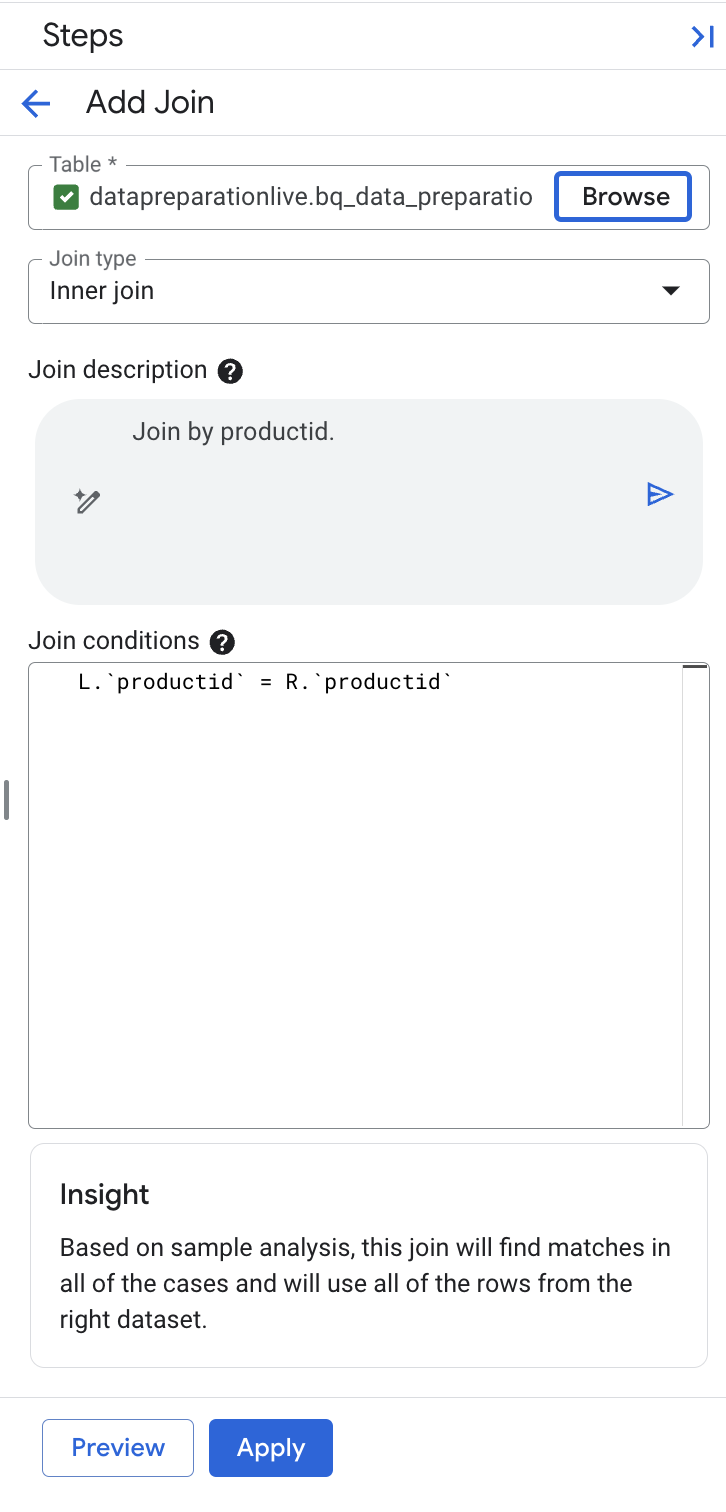
- Se quiser, selecione "Visualizar" para conferir os resultados.
- Clique em
Apply.
Como limpar os atributos estendidos
Embora a mesclagem tenha sido bem-sucedida, os dados de atributos estendidos precisam de limpeza. A coluna LaunchDate tem formatos de data inconsistentes, e a coluna Brand contém alguns valores ausentes.
Vamos começar pela coluna LaunchDate.

Antes de criar transformações, confira as recomendações do Gemini.
- Clique no nome da coluna
LaunchDate. Você vai ver algumas recomendações geradas semelhantes às da imagem abaixo.

- Se você encontrar uma recomendação com o SQL abaixo, aplique a recomendação e pule as próximas etapas.
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Se não houver uma recomendação correspondente ao SQL acima, clique em
Add Step. - Selecione
Transformation. - No campo SQL, insira o seguinte:
COALESCE(SAFE.PARSE_DATE('%Y-%m-%d',
LaunchDate),SAFE.PARSE_DATE('%Y/%m/%d', LaunchDate))
- Defina
Target ColumnscomoLaunchDate. - Clique em
Apply.
A coluna "LaunchDate" agora tem um formato de data consistente.

9. Como adicionar uma tabela de destino
Nosso conjunto de dados está limpo e pronto para ser carregado em uma tabela de dimensão no data warehouse.
- Clique em
ADD STEP. - Selecione
Destination. - Preencha os parâmetros necessários: Conjunto de dados:
bq_data_preparation_demoTabela:DimProduct - Clique em
Save.

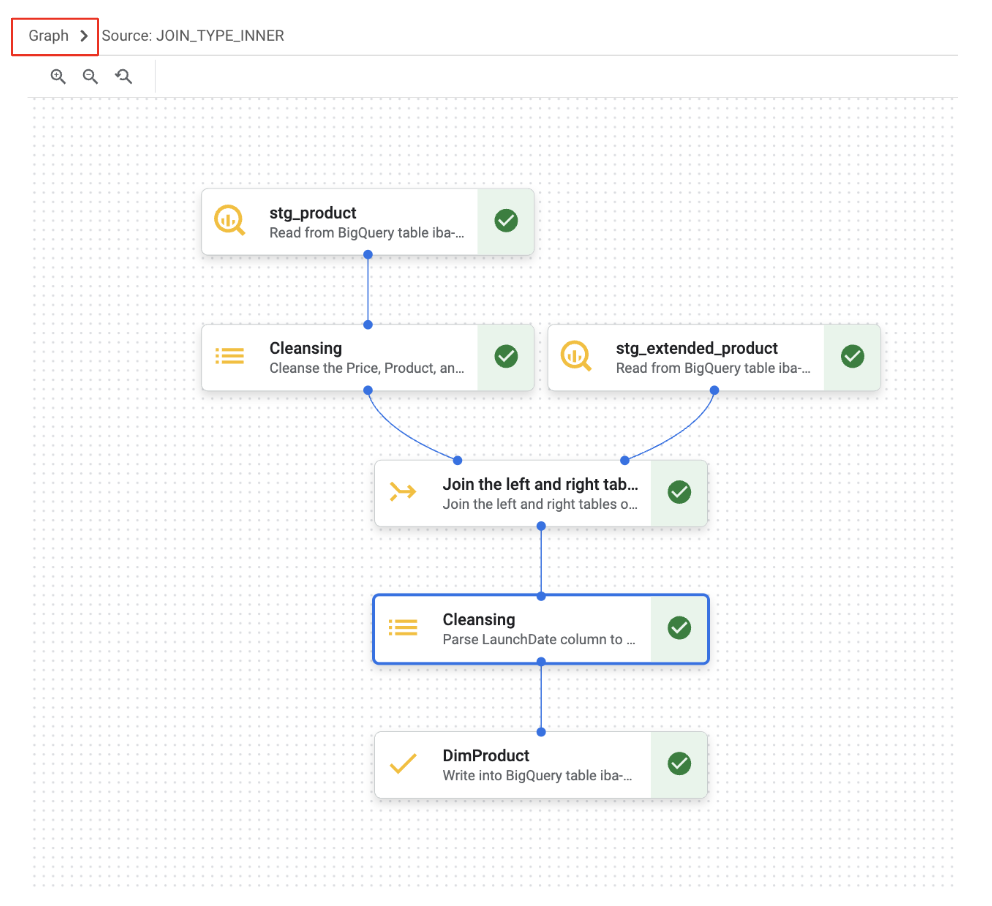
Agora trabalhamos com as guias "Dados" e "Esquema". Além disso, o BigQuery Data Preparation oferece uma visualização em gráfico que mostra a sequência de etapas de transformação no pipeline.
10. Bônus A: Como processar a coluna "Manufacturer" e criar uma tabela de erros
Também identificamos valores vazios na coluna Manufacturer. Para esses registros, queremos implementar uma verificação de qualidade de dados e movê-los para uma tabela de erros para análise posterior.
Criar uma tabela de erros
- Clique no botão
Moreao lado do títulostg_product data preparation. - Na seção
Setting, selecioneError Table. - Marque a caixa
Enable error tablee configure as configurações da seguinte maneira:
- Conjunto de dados: selecione
bq_data_preparation_demo - Tabela: insira
err_dataprep - Em
Define duration for keeping errors, selecione30 days (default).
- Clique em
Save.

Configurar a validação na coluna "Fabricante"
- Selecione a coluna "Fabricante".
- O Gemini provavelmente identificou uma transformação relevante. Encontre a recomendação que está mantendo apenas linhas em que o campo "Manufacturer" não está vazio. Ele terá um SQL semelhante a este:
Manufacturer IS NOT NULL
2.Clique no botão "Editar" na recomendação para analisá-la.

- Marque a opção "As linhas de validação com falhas vão para a tabela de erros", se ela não estiver marcada.
- Clique em
Apply.
A qualquer momento, você pode revisar, modificar ou excluir as transformações aplicadas clicando no botão "Etapas aplicadas".

Limpar a coluna ProductID_1 redundante
A coluna ProductID_1, que duplica o ProductID da nossa tabela combinada, agora pode ser excluída.
- Acesse a guia
Schema. - Clique nos três pontos ao lado da coluna
ProductID_1. - Clique em
Drop.
Agora já podemos executar o job de preparação de dados e validar todo o pipeline. Quando estivermos satisfeitos com os resultados, poderemos programar o job para execução automática.
- Antes de sair da visualização de preparação de dados, salve suas preparações. Ao lado do título
stg_product data preparation, você verá um botãoSave. Clique no botão para salvar.
11. Limpar o ambiente
- Exclua o
stg_product data preparation. - Excluir o conjunto de dados
bq data preparation demo
12. Parabéns
Parabéns por concluir o codelab.
O que vimos
- Como configurar a preparação de dados
- Como abrir tabelas e navegar pela preparação de dados
- Como dividir colunas com dados numéricos e de descrição de unidade
- Padronizar formatos de data
- Como executar preparações de dados