
1. 简介
在此 Codelab 中,您将学习如何在 GKE 上部署 AlloyDB Omni,并将其与部署在同一 Kubernetes 集群中的开放嵌入模型搭配使用。在同一 GKE 集群中将模型部署在数据库实例旁边,可缩短延迟时间并减少对第三方服务的依赖。此外,如果数据不得离开组织且不允许使用第三方服务,安全要求可能也会要求这样做。
前提条件
- 对 Google Cloud 控制台有基本的了解
- 具备命令行界面和 Cloud Shell 方面的基本技能
学习内容
- 如何在 Google Kubernetes 集群上部署 AlloyDB Omni
- 如何连接到 AlloyDB Omni
- 如何将数据加载到 AlloyDB Omni
- 如何将开放嵌入模型部署到 GKE
- 如何在 AlloyDB Omni 中注册嵌入模型
- 如何为语义搜索生成嵌入
- 如何在 AlloyDB Omni 中使用生成的嵌入进行语义搜索
- 如何在 AlloyDB 中创建和使用向量索引
所需条件
- Google Cloud 账号和 Google Cloud 项目
- 支持 Google Cloud 控制台和 Cloud Shell 的网络浏览器,例如 Chrome
2. 设置和要求
自定进度的环境设置
- 登录 Google Cloud 控制台,然后创建一个新项目或重复使用现有项目。如果您还没有 Gmail 或 Google Workspace 账号,则必须创建一个。

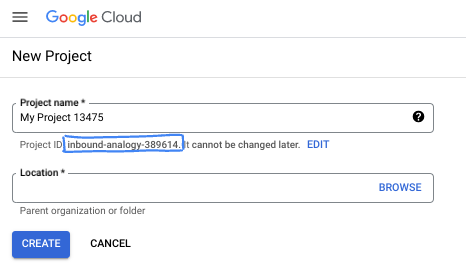
- 项目名称是此项目参与者的显示名称。它是 Google API 尚未使用的字符串。您可以随时对其进行更新。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Cloud 控制台会自动生成一个唯一字符串;通常情况下,您无需关注该字符串。在大多数 Codelab 中,您都需要引用项目 ID(通常用
PROJECT_ID标识)。如果您不喜欢生成的 ID,可以再随机生成一个 ID。或者,您也可以尝试自己的项目 ID,看看是否可用。完成此步骤后便无法更改该 ID,并且此 ID 在项目期间会一直保留。 - 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
- 接下来,您需要在 Cloud 控制台中启用结算功能,以便使用 Cloud 资源/API。运行此 Codelab 应该不会产生太多的费用(如果有的话)。若要关闭资源以避免产生超出本教程范围的结算费用,您可以删除自己创建的资源或删除项目。Google Cloud 新用户符合参与 300 美元免费试用计划的条件。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:

预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
3. 准备工作
启用 API
输出如下:
在 Cloud Shell 中,确保项目 ID 已设置:
PROJECT_ID=$(gcloud config get-value project)
echo $PROJECT_ID
如果 Cloud Shell 配置中未定义此变量,请使用以下命令进行设置
export PROJECT_ID=<your project>
gcloud config set project $PROJECT_ID
启用所有必要的服务:
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
预期输出
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=test-project-001-402417 student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417 Updated property [core/project]. student@cloudshell:~ (test-project-001-402417)$ gcloud services enable compute.googleapis.com gcloud services enable container.googleapis.com Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. 在 GKE 上部署 AlloyDB Omni
如需在 GKE 上部署 AlloyDB Omni,我们需要按照 AlloyDB Omni operator 要求中列出的要求准备 Kubernetes 集群。
创建 GKE 集群
我们需要部署一个标准 GKE 集群,其池配置足以部署包含 AlloyDB Omni 实例的 Pod。Omni 需要至少 2 个 CPU 和 8 GB RAM,并留出一些空间来运行运营商和监控服务。
为您的部署设置环境变量。
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=e2-standard-4
然后,我们使用 gcloud 创建 GKE 标准集群。
gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
预期的控制台输出:
student@cloudshell:~ (gleb-test-short-001-415614)$ export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
export MACHINE_TYPE=n2-highmem-2
Your active configuration is: [gleb-test-short-001-415614]
student@cloudshell:~ (gleb-test-short-001-415614)$ gcloud container clusters create ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION} \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--release-channel=rapid \
--machine-type=${MACHINE_TYPE} \
--num-nodes=1
Note: The Kubelet readonly port (10255) is now deprecated. Please update your workloads to use the recommended alternatives. See https://cloud.google.com/kubernetes-engine/docs/how-to/disable-kubelet-readonly-port for ways to check usage and for migration instructions.
Note: Your Pod address range (`--cluster-ipv4-cidr`) can accommodate at most 1008 node(s).
Creating cluster alloydb-ai-gke in us-central1..
NAME: omni01
ZONE: us-central1-a
MACHINE_TYPE: e2-standard-4
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.3
EXTERNAL_IP: 35.232.157.123
STATUS: RUNNING
student@cloudshell:~ (gleb-test-short-001-415614)$
准备集群
我们需要安装 cert-manager 服务等所需组件。我们可以按照文档中的步骤安装 cert-manager
我们将使用 Kubernetes 命令行工具 kubectl,该工具已安装在 Cloud Shell 中。在使用该实用程序之前,我们需要获取集群的凭据。
gcloud container clusters get-credentials ${CLUSTER_NAME} --region=${LOCATION}
现在,我们可以使用 kubectl 安装 cert-manager:
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml
预期的控制台输出(已隐去部分信息):
student@cloudshell:~$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.2/cert-manager.yaml namespace/cert-manager created customresourcedefinition.apiextensions.k8s.io/certificaterequests.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/certificates.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/challenges.acme.cert-manager.io created customresourcedefinition.apiextensions.k8s.io/clusterissuers.cert-manager.io created ... validatingwebhookconfiguration.admissionregistration.k8s.io/cert-manager-webhook created
安装 AlloyDB Omni
您可以使用 helm 实用程序安装 AlloyDB Omni 操作符。
运行以下命令以安装 AlloyDB Omni Operator:
export GCS_BUCKET=alloydb-omni-operator
export HELM_PATH=$(gcloud storage cat gs://$GCS_BUCKET/latest)
export OPERATOR_VERSION="${HELM_PATH%%/*}"
gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
--create-namespace \
--namespace alloydb-omni-system \
--atomic \
--timeout 5m
预期的控制台输出(已隐去部分信息):
student@cloudshell:~$ gcloud storage cp gs://$GCS_BUCKET/$HELM_PATH ./ --recursive
Copying gs://alloydb-omni-operator/1.2.0/alloydbomni-operator-1.2.0.tgz to file://./alloydbomni-operator-1.2.0.tgz
Completed files 1/1 | 126.5kiB/126.5kiB
student@cloudshell:~$ helm install alloydbomni-operator alloydbomni-operator-${OPERATOR_VERSION}.tgz \
> --create-namespace \
> --namespace alloydb-omni-system \
> --atomic \
> --timeout 5m
NAME: alloydbomni-operator
LAST DEPLOYED: Mon Jan 20 13:13:20 2025
NAMESPACE: alloydb-omni-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
student@cloudshell:~$
安装 AlloyDB Omni 操作符后,我们可以继续部署数据库集群。
以下是启用了 googleMLExtension 参数和内部(专用)负载平衡器的部署清单示例:
apiVersion: v1
kind: Secret
metadata:
name: db-pw-my-omni
type: Opaque
data:
my-omni: "VmVyeVN0cm9uZ1Bhc3N3b3Jk"
---
apiVersion: alloydbomni.dbadmin.goog/v1
kind: DBCluster
metadata:
name: my-omni
spec:
databaseVersion: "15.7.0"
primarySpec:
adminUser:
passwordRef:
name: db-pw-my-omni
features:
googleMLExtension:
enabled: true
resources:
cpu: 1
memory: 8Gi
disks:
- name: DataDisk
size: 20Gi
storageClass: standard
dbLoadBalancerOptions:
annotations:
networking.gke.io/load-balancer-type: "internal"
allowExternalIncomingTraffic: true
密码的 Secret 值是“VeryStrongPassword”密码字词的 Base64 表示法。更可靠的方法是使用 Google Secret Manager 存储密码值。您可以在文档中详细了解。
将清单保存为 my-omni.yaml,以便在下一步中应用。如果您在 Cloud Shell 中,可以按终端右上角的“打开编辑器”按钮,使用编辑器执行此操作。
将文件保存为名为 my-omni.yaml 的文件后,按“打开终端”按钮返回终端。
使用 kubectl 实用程序将 my-omni.yaml 清单应用于集群:
kubectl apply -f my-omni.yaml
预期的控制台输出:
secret/db-pw-my-omni created dbcluster.alloydbomni.dbadmin.goog/my-omni created
使用 kubectl 实用程序检查 my-omni 集群的状态:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
在部署期间,集群会经历不同的阶段,最终应以 DBClusterReady 状态结束。
预期的控制台输出:
$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady
连接到 AlloyDB Omni
使用 Kubernetes Pod 连接
集群准备就绪后,我们就可以在 AlloyDB Omni 实例 pod 上使用 PostgreSQL 客户端二进制文件。我们找到 pod ID,然后使用 kubectl 直接连接到 pod 并运行客户端软件。密码是通过 my-omni.yaml 中的哈希设置的 VeryStrongPassword:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
控制台输出示例:
DB_CLUSTER_NAME=my-omni
DB_CLUSTER_NAMESPACE=default
DBPOD=`kubectl get pod --selector=alloydbomni.internal.dbadmin.goog/dbcluster=$DB_CLUSTER_NAME,alloydbomni.internal.dbadmin.goog/task-type=database -n $DB_CLUSTER_NAMESPACE -o jsonpath='{.items[0].metadata.name}'`
kubectl exec -ti $DBPOD -n $DB_CLUSTER_NAMESPACE -c database -- psql -h localhost -U postgres
Password for user postgres:
psql (15.7)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_128_GCM_SHA256, compression: off)
Type "help" for help.
postgres=#
5. 在 GKE 上部署 AI 模型
如需测试 AlloyDB Omni AI 与本地模型的集成,我们需要将模型部署到集群。
为模型创建节点池
如需运行模型,我们需要准备一个节点池来运行推理。从性能角度来看,最佳方法是使用图形加速器的池,采用节点配置(例如 g2-standard-8 搭配 L4 Nvidia 加速器)。
使用 L4 加速器创建节点池:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container node-pools create gpupool \
--accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
--project=${PROJECT_ID} \
--location=${LOCATION} \
--node-locations=${LOCATION}-a \
--cluster=${CLUSTER_NAME} \
--machine-type=g2-standard-8 \
--num-nodes=1
预期输出
student@cloudshell$ export PROJECT_ID=$(gcloud config get project)
Your active configuration is: [pant]
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
student@cloudshell$ gcloud container node-pools create gpupool \
> --accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
> --project=${PROJECT_ID} \
> --location=${LOCATION} \
> --node-locations=${LOCATION}-a \
> --cluster=${CLUSTER_NAME} \
> --machine-type=g2-standard-8 \
> --num-nodes=1
Note: Machines with GPUs have certain limitations which may affect your workflow. Learn more at https://cloud.google.com/kubernetes-engine/docs/how-to/gpus
Note: Starting in GKE 1.30.1-gke.115600, if you don't specify a driver version, GKE installs the default GPU driver for your node's GKE version.
Creating node pool gpupool...done.
Created [https://container.googleapis.com/v1/projects/student-test-001/zones/us-central1/clusters/alloydb-ai-gke/nodePools/gpupool].
NAME MACHINE_TYPE DISK_SIZE_GB NODE_VERSION
gpupool g2-standard-8 100 1.31.4-gke.1183000
准备部署清单
如需部署模型,我们需要准备部署清单。
我们使用的是 Hugging Face 中的 BGE Base v1.5 嵌入模型。您可以点击此处阅读模型卡片。如需部署模型,我们可以使用 Hugging Face 中已准备好的说明和 GitHub 中的部署软件包。
克隆软件包
git clone https://github.com/huggingface/Google-Cloud-Containers
编辑清单,将 cloud.google.com/gke-accelerator 值替换为 nvidia-l4,并为资源添加限制。
vi Google-Cloud-Containers/examples/gke/tei-deployment/gpu-config/deployment.yaml
下面是更正后的清单。
apiVersion: apps/v1
kind: Deployment
metadata:
name: tei-deployment
spec:
replicas: 1
selector:
matchLabels:
app: tei-server
template:
metadata:
labels:
app: tei-server
hf.co/model: Snowflake--snowflake-arctic-embed-m
hf.co/task: text-embeddings
spec:
containers:
- name: tei-container
image: us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-embeddings-inference-cu122.1-4.ubuntu2204:latest
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
env:
- name: MODEL_ID
value: Snowflake/snowflake-arctic-embed-m
- name: NUM_SHARD
value: "1"
- name: PORT
value: "8080"
volumeMounts:
- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: data
volumes:
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 1Gi
- name: data
emptyDir: {}
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-l4
部署模型
我们需要为部署准备一个服务账号和一个命名空间。
创建一个 Kubernetes 命名空间 hf-gke-namespace。
export NAMESPACE=hf-gke-namespace
kubectl create namespace $NAMESPACE
创建 Kubernetes 服务账号
export SERVICE_ACCOUNT=hf-gke-service-account
kubectl create serviceaccount $SERVICE_ACCOUNT --namespace $NAMESPACE
部署模型
kubectl apply -f Google-Cloud-Containers/examples/gke/tei-deployment/gpu-config
验证部署
kubectl get pods
验证模型服务
kubectl get service tei-service
它应显示正在运行的服务类型 ClusterIP
示例输出:
student@cloudshell$ kubectl get service tei-service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE tei-service ClusterIP 34.118.233.48 <none> 8080/TCP 10m
我们将使用该服务的 CLUSTER-IP 作为端点地址。模型嵌入可以通过 URI http://34.118.233.48:8080/embed 进行响应。您稍后在 AlloyDB Omni 中注册模型时会用到它。
我们可以使用 kubectl port-forward 命令公开该服务来对其进行测试。
kubectl port-forward service/tei-service 8080:8080
端口转发将在一个 Cloud Shell 会话中运行,我们需要另一个会话来对其进行测试。
使用顶部的“+”号打开另一个 Cloud Shell 标签页。
然后,在新 shell 会话中运行 curl 命令。
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs":"Test"}' \
-H 'Content-Type: application/json'
它应返回一个矢量数组,如以下示例输出(已隐去)所示:
curl http://localhost:8080/embed \
> -X POST \
> -d '{"inputs":"Test"}' \
> -H 'Content-Type: application/json'
[[-0.018975832,0.0071419072,0.06347208,0.022992613,0.014205903
...
-0.03677433,0.01636146,0.06731572]]
6. 在 AlloyDB Omni 中注册模型
如需测试 AlloyDB Omni 如何与部署的模型搭配使用,我们需要创建一个数据库并注册该模型。
创建数据库
创建一个 GCE 虚拟机作为跳转盒,从客户端虚拟机连接到 AlloyDB Omni,然后创建数据库。
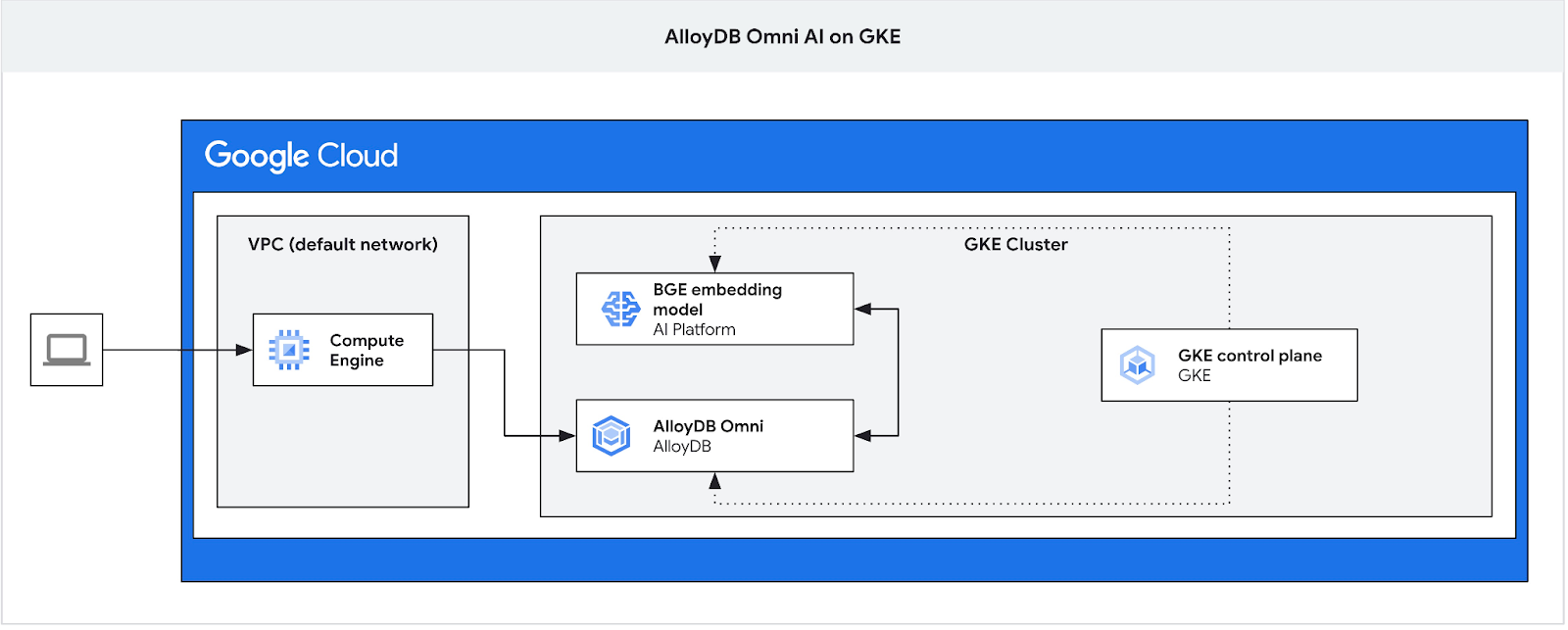
我们需要跳转盒,因为 Omni 的 GKE 外部负载平衡器可让您使用专用 IP 地址从 VPC 访问,但不允许您从 VPC 外部连接。这种方式通常更安全,并且不会将您的数据库实例公开到互联网。请查看下方示意图,以便了解详情。
如需在 Cloud Shell 会话中创建虚拟机,请执行以下命令:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE
在 Cloud Shell 中使用 kubectl 查找 AlloyDB Omni 端点 IP:
kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default
记下 PRIMARYENDPOINT。这里给出了一个示例,
所得结果:
student@cloudshell:~$ kubectl get dbclusters.alloydbomni.dbadmin.goog my-omni -n default NAME PRIMARYENDPOINT PRIMARYPHASE DBCLUSTERPHASE HAREADYSTATUS HAREADYREASON my-omni 10.131.0.33 Ready DBClusterReady student@cloudshell:~$
10.131.0.33 是我们在示例中用于连接到 AlloyDB Omni 实例的 IP。
使用 gcloud 连接到虚拟机:
gcloud compute ssh instance-1 --zone=$ZONE
如果系统提示生成 SSH 密钥,请按照说明操作。如需详细了解 SSH 连接,请参阅文档。
在与虚拟机的 SSH 会话中,安装 PostgreSQL 客户端:
sudo apt-get update
sudo apt-get install --yes postgresql-client
导出 AlloyDB Omni 负载平衡器 IP,如以下示例所示(将 IP 替换为您的负载平衡器 IP):
export INSTANCE_IP=10.131.0.33
连接到 AlloyDB Omni,密码为 VeryStrongPassword,通过 my-omni.yaml 中的哈希设置:
psql "host=$INSTANCE_IP user=postgres sslmode=require"
在建立的 psql 会话中,执行以下命令:
create database demo;
退出会话并连接到数据库演示(或者您也可以在同一会话中运行“\c demo”)
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
创建转换函数
对于第三方嵌入模型,我们需要创建转换函数,以将输入和输出格式转换为模型和内部函数所需的格式。
以下是用于处理输入的转换函数:
-- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
在连接到演示数据库时,执行提供的代码,如示例输出所示:
demo=# -- Input Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_input_transform(model_id VARCHAR(100), input_text TEXT)
RETURNS JSON
LANGUAGE plpgsql
AS $$
DECLARE
transformed_input JSON;
model_qualified_name TEXT;
BEGIN
SELECT json_build_object('inputs', input_text, 'truncate', true)::JSON INTO transformed_input;
RETURN transformed_input;
END;
$$;
CREATE FUNCTION
demo=#
下面是将模型响应转换为实数数组的输出函数:
-- Output Transform Function corresponding to the custom model endpoint
CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON)
RETURNS REAL[]
LANGUAGE plpgsql
AS $$
DECLARE
transformed_output REAL[];
BEGIN
SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output;
RETURN transformed_output;
END;
$$;
在同一会话中执行它:
demo=# -- Output Transform Function corresponding to the custom model endpoint CREATE OR REPLACE FUNCTION tei_text_output_transform(model_id VARCHAR(100), response_json JSON) RETURNS REAL[] LANGUAGE plpgsql AS $$ DECLARE transformed_output REAL[]; BEGIN SELECT ARRAY(SELECT json_array_elements_text(response_json->0)) INTO transformed_output; RETURN transformed_output; END; $$; CREATE FUNCTION demo=#
注册模型
现在,我们可以在数据库中注册模型了。
以下是用于注册名称为 bge-base-1.5 的模型的程序调用,请将 IP 地址 34.118.233.48 替换为您的模型服务 IP 地址(kubectl get service tei-service 的输出):
CALL
google_ml.create_model(
model_id => 'bge-base-1.5',
model_request_url => 'http://34.118.233.48:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
在连接到演示数据库的情况下,执行所提供的代码:
demo=# CALL
google_ml.create_model(
model_id => 'bge-base-1.5',
model_request_url => 'http://34.118.233.48:8080/embed',
model_provider => 'custom',
model_type => 'text_embedding',
model_in_transform_fn => 'tei_text_input_transform',
model_out_transform_fn => 'tei_text_output_transform');
CALL
demo=#
我们可以使用以下测试查询来测试寄存器模型,该查询应返回一个实数数组。
select google_ml.embedding('bge-base-1.5','What is AlloyDB Omni?');
7. 在 AlloyDB Omni 中测试模型
加载数据
为了测试 AlloyDB Omni 如何与部署的模型搭配使用,我们需要加载一些数据。我使用了与 AlloyDB 中某个其他 Codelab 中相同的数据来进行向量搜索。
加载数据的方法之一是使用 Google Cloud SDK 和 PostgreSQL 客户端软件。我们可以使用创建演示数据库时所用的客户端虚拟机。如果您使用的是虚拟机映像的默认设置,Google Cloud SDK 应该已安装在此处。不过,如果您使用的是没有 Google SDK 的自定义映像,则可以按照文档中的说明进行添加。
导出 AlloyDB Omni 负载平衡器 IP,如以下示例所示(将 IP 替换为您的负载平衡器 IP):
export INSTANCE_IP=10.131.0.33
连接到数据库并启用 pgvector 扩展程序。
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
在 psql 会话中:
CREATE EXTENSION IF NOT EXISTS vector;
退出 psql 会话,然后在命令行会话中执行命令以将数据加载到演示数据库。
创建表:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo"
预期的控制台输出:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=demo" Password for user postgres: SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@cloudshell:~$
以下是创建的表的列表:
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
输出:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\dt+"
Password for user postgres:
List of relations
Schema | Name | Type | Owner | Persistence | Access method | Size | Description
--------+------------------+-------+----------+-------------+---------------+------------+-------------
public | cymbal_embedding | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_inventory | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_products | table | postgres | permanent | heap | 8192 bytes |
public | cymbal_stores | table | postgres | permanent | heap | 8192 bytes |
(4 rows)
student@cloudshell:~$
将数据加载到 cymbal_products 表中:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header"
预期的控制台输出:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_products from stdin csv header" COPY 941 student@cloudshell:~$
以下是 cymbal_products 表中的几行示例。
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
输出:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT uniq_id,left(product_name,30),left(product_description,50),sale_price FROM cymbal_products limit 3"
Password for user postgres:
uniq_id | left | left | sale_price
----------------------------------+--------------------------------+----------------------------------------------------+------------
a73d5f754f225ecb9fdc64232a57bc37 | Laundry Tub Strainer Cup | Laundry tub strainer cup Chrome For 1-.50, drain | 11.74
41b8993891aa7d39352f092ace8f3a86 | LED Starry Star Night Light La | LED Starry Star Night Light Laser Projector 3D Oc | 46.97
ed4a5c1b02990a1bebec908d416fe801 | Surya Horizon HRZ-1060 Area Ru | The 100% polypropylene construction of the Surya | 77.4
(3 rows)
student@cloudshell:~$
将数据加载到 cymbal_inventory 表中:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header"
预期的控制台输出:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_inventory from stdin csv header" Password for user postgres: COPY 263861 student@cloudshell:~$
以下是 cymbal_inventory 表中的几行示例。
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
输出:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT * FROM cymbal_inventory LIMIT 3"
Password for user postgres:
store_id | uniq_id | inventory
----------+----------------------------------+-----------
1583 | adc4964a6138d1148b1d98c557546695 | 5
1490 | adc4964a6138d1148b1d98c557546695 | 4
1492 | adc4964a6138d1148b1d98c557546695 | 3
(3 rows)
student@cloudshell:~$
将数据加载到 cymbal_stores 表中:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header"
预期的控制台输出:
student@cloudshell:~$ gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "\copy cymbal_stores from stdin csv header" Password for user postgres: COPY 4654 student@cloudshell:~$
以下是 cymbal_stores 表中的几行示例。
psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
输出:
student@cloudshell:~$ psql "host=$INSTANCE_IP user=postgres dbname=demo" -c "SELECT store_id, name, zip_code FROM cymbal_stores limit 3"
Password for user postgres:
store_id | name | zip_code
----------+-------------------+----------
1990 | Mayaguez Store | 680
2267 | Ware Supercenter | 1082
4359 | Ponce Supercenter | 780
(3 rows)
student@cloudshell:~$
构建嵌入
使用 psql 连接到演示数据库,并根据 cymbal_products 表中所述的商品名称和说明为商品构建嵌入。
连接到演示数据库:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
我们使用带有列嵌入的 cymbal_embedding 表来存储嵌入,并将商品说明用作函数的文本输入。
为查询启用时间记录,以便稍后与远程模型进行比较:
\timing
运行查询以构建嵌入:
INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('bge-base-1.5',product_description)::vector FROM cymbal_products;
预期的控制台输出:
demo=# INSERT INTO cymbal_embedding(uniq_id,embedding) SELECT uniq_id, google_ml.embedding('bge-base-1.5',product_description)::vector FROM cymbal_products;
INSERT 0 941
Time: 11069.762 ms (00:11.070)
demo=#
在此示例中,为 941 条记录构建嵌入大约需要 11 秒。
运行测试查询
使用 psql 连接到演示数据库,并启用计时功能来衡量查询的执行时间,就像我们在构建嵌入时所做的那样。
我们将余弦距离用作向量搜索算法,查找与“这里适合种植什么样的果树?”等请求匹配的前 5 个商品。
在 psql 会话中,执行以下命令:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
预期的控制台输出:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.22753925487632942
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.23497374266229387
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.24215884459965364
California Redwood | This is a beautiful redwood tree that can grow to be over 300 feet tall. It is a | 1000.00 | 93230 | 0.24564130578287147
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.24846117929767153
(5 rows)
Time: 28.724 ms
demo=#
查询运行了 28 毫秒,并从 cymbal_products 表返回了与请求匹配且在商店 1583 中拥有可用商品目录的树列表。
构建 ANN 索引
当数据集较小时,可以轻松使用完全搜索来扫描所有嵌入,但当数据量增加时,加载时间和响应时间也会增加。为了提升性能,您可以对嵌入数据构建索引。下面的示例展示了如何针对向量数据使用 Google ScaNN 索引实现此目的。
如果连接断开,请重新连接到演示数据库:
psql "host=$INSTANCE_IP user=postgres sslmode=require dbname=demo"
启用 alloydb_scann 扩展程序:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
构建索引:
CREATE INDEX cymbal_embedding_scann ON cymbal_embedding USING scann (embedding cosine);
尝试使用之前的查询,并比较结果:
demo=# SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(ce.embedding <=> google_ml.embedding('bge-base-1.5','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_embedding ce on
ce.uniq_id=cp.uniq_id
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
product_name | description | sale_price | zip_code | distance
-----------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.22753925487632942
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.23497374266229387
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.24215884459965364
California Redwood | This is a beautiful redwood tree that can grow to be over 300 feet tall. It is a | 1000.00 | 93230 | 0.24564130578287147
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.2533482837690365
(5 rows)
Time: 14.665 ms
demo=#
查询执行时间略有缩短,对于更大的数据集,这种改进会更加明显。结果非常相似,只有 Cherry 被 Fremont Cottonwood 替换了。
请尝试其他查询,并参阅文档,详细了解如何选择矢量索引。
别忘了,AlloyDB Omni 还有更多功能和实验室。
8. 清理环境
现在,我们可以使用 AlloyDB Omni 和 AI 模型删除 GKE 集群
删除 GKE 集群
在 Cloud Shell 中,执行以下命令:
export PROJECT_ID=$(gcloud config get project)
export LOCATION=us-central1
export CLUSTER_NAME=alloydb-ai-gke
gcloud container clusters delete ${CLUSTER_NAME} \
--project=${PROJECT_ID} \
--region=${LOCATION}
预期的控制台输出:
student@cloudshell:~$ gcloud container clusters delete ${CLUSTER_NAME} \
> --project=${PROJECT_ID} \
> --region=${LOCATION}
The following clusters will be deleted.
- [alloydb-ai-gke] in [us-central1]
Do you want to continue (Y/n)? Y
Deleting cluster alloydb-ai-gke...done.
Deleted
删除虚拟机
在 Cloud Shell 中,执行以下命令:
export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
预期的控制台输出:
student@cloudshell:~$ export PROJECT_ID=$(gcloud config get project)
export ZONE=us-central1-a
gcloud compute instances delete instance-1 \
--project=${PROJECT_ID} \
--zone=${ZONE}
Your active configuration is: [cloudshell-5399]
The following instances will be deleted. Any attached disks configured to be auto-deleted will be deleted unless they are attached to any other instances or the `--keep-disks` flag is given and specifies them for keeping. Deleting a disk
is irreversible and any data on the disk will be lost.
- [instance-1] in [us-central1-a]
Do you want to continue (Y/n)? Y
Deleted
如果您为此 Codelab 创建了新项目,则可以改为删除整个项目:https://console.cloud.google.com/cloud-resource-manager
9. 恭喜
恭喜您完成此 Codelab。
所学内容
- 如何在 Google Kubernetes 集群上部署 AlloyDB Omni
- 如何连接到 AlloyDB Omni
- 如何将数据加载到 AlloyDB Omni
- 如何将开放嵌入模型部署到 GKE
- 如何在 AlloyDB Omni 中注册嵌入模型
- 如何为语义搜索生成嵌入
- 如何在 AlloyDB Omni 中使用生成的嵌入进行语义搜索
- 如何在 AlloyDB 中创建和使用向量索引
如需详细了解如何在 AlloyDB Omni 中使用 AI,请参阅文档。
10. 调查问卷
输出如下: