
程式碼研究室簡介
1. 簡介

什麼是 WebGPU?
WebGPU 是全新的現代化 API,可在網頁應用程式中存取 GPU 功能。
Modern API
在 WebGPU 推出之前,WebGL 提供 WebGPU 的部分功能。這項技術可支援新類型的豐富網頁內容,開發人員也已利用這項技術打造出令人驚豔的內容。不過,此 API 是以 2007 年發布的 OpenGL ES 2.0 API 為基礎,而該 API 又是以更早期的 OpenGL API 為基礎。這段期間,GPU 已大幅進化,用於與 GPU 介接的本機 API 也隨著 Direct3D 12、Metal 和 Vulkan 而進化。
WebGPU 將這些新型 API 的進步功能帶入網頁平台。這個 API 著重於以跨平台方式啟用 GPU 功能,同時提供在網路上使用起來很自然的 API,且比其所建構的某些原生 API 更精簡。
轉譯
GPU 通常與快速轉譯精細圖形有關,WebGPU 也不例外。這項工具具備所需功能,可支援目前在電腦和行動裝置 GPU 上最常見的多種轉譯技術,並提供可在未來隨著硬體功能持續進化而新增的新功能。
運算
除了轉譯之外,WebGPU 還能發揮 GPU 的潛力,執行一般用途的高度平行工作負載。這些運算著色器可獨立使用,無需任何算繪元件,也可以做為算繪管線中緊密整合的部分。
在今天的程式碼研究室中,您將瞭解如何善用 WebGPU 的算繪和運算功能,以便建立簡單的入門專案!
建構項目
在本程式碼研究室中,您將使用 WebGPU 建構 Conway's Game of Life。您的應用程式將會:
- 使用 WebGPU 的算繪功能繪製簡單的 2D 圖形。
- 使用 WebGPU 的運算功能執行模擬作業。

生命遊戲是一種稱為細胞自動機的系統,其中的單元格會根據一組規則隨時間變換狀態。在生命遊戲中,每個格子的啟用或停用狀態,取決於相鄰格子有多少個處於啟用狀態,因此會產生有趣的圖案,讓您在觀看時看到變化。
課程內容
- 如何設定 WebGPU 和畫布。
- 如何繪製簡單的 2D 幾何圖形。
- 如何使用頂點和片段著色器來修改繪製內容。
- 如何使用運算著色器執行簡單模擬。
本程式碼研究室著重於介紹 WebGPU 背後的基本概念。這並非 API 的完整檢閱,也不涵蓋 (或要求) 3D 矩陣數學等常見相關主題。
軟硬體需求
- ChromeOS、macOS 或 Windows 上的最新版 Chrome (113 以上版本)。WebGPU 是跨瀏覽器、跨平台的 API,但尚未在所有地方推出。
- 具備 HTML、JavaScript 和 Chrome 開發人員工具的相關知識。
您不必熟悉其他圖形 API (例如 WebGL、Metal、Vulkan 或 Direct3D),但如果您有相關經驗,就會發現 WebGPU 與這些 API 有很多相似之處,因此有助於您快速上手!
2. 做好準備
取得程式碼
本程式碼研究室沒有任何依附元件,而且會逐步引導您完成建立 WebGPU 應用程式所需的每個步驟,因此您不需要任何程式碼即可開始。不過,您可以在 https://glitch.com/edit/#!/your-first-webgpu-app 找到一些可做為檢查點的有效範例。如果您遇到問題,可以查看這些範例,並在進行時參考。
使用開發人員控制台!
WebGPU 是相當複雜的 API,包含許多規則,可確保正確使用。更糟的是,由於 API 的運作方式,它無法針對許多錯誤產生典型的 JavaScript 例外狀況,因此更難找出問題的確切來源。
使用 WebGPU 進行開發時,您一定會遇到問題,尤其是初學者,但這沒關係!API 背後的開發人員瞭解使用 GPU 開發時會遇到的挑戰,因此他們努力確保 WebGPU 程式碼發生錯誤時,開發人員工作室會顯示非常詳細且實用的訊息,協助您找出並修正問題。
在處理任何網路應用程式時,保持控制台開啟狀態總是很有幫助,但在本例中尤其如此!
3. 初始化 WebGPU
從 <canvas> 開始
如果您只想使用 WebGPU 進行運算,可以不顯示任何內容。不過,如果您想算繪任何內容 (如本程式碼研究室中要做的事),就需要使用畫布。因此,這是個不錯的起點!
請建立新的 HTML 文件,其中包含單一 <canvas> 元素,以及用於查詢畫布元素的 <script> 標記。(或使用 Glitch 中的 00-starter-page.html)。
- 使用以下程式碼建立
index.html檔案:
index.html
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>WebGPU Life</title>
</head>
<body>
<canvas width="512" height="512"></canvas>
<script type="module">
const canvas = document.querySelector("canvas");
// Your WebGPU code will begin here!
</script>
</body>
</html>
申請轉接器和裝置
您現在可以開始使用 WebGPU 了!首先,您應考量到 WebGPU 等 API 可能需要一段時間才能在整個網路生態系統中傳播。因此,第一個預防措施就是檢查使用者的瀏覽器是否可以使用 WebGPU。
- 如要檢查是否存在
navigator.gpu物件 (做為 WebGPU 的進入點),請新增下列程式碼:
index.html
if (!navigator.gpu) {
throw new Error("WebGPU not supported on this browser.");
}
理想情況下,您應該讓網頁改用不使用 WebGPU 的模式,以便在無法使用 WebGPU 時通知使用者。(或許可以改用 WebGL?)不過,在本程式碼研究室中,您只需擲回錯誤,即可停止程式碼的進一步執行。
確認瀏覽器支援 WebGPU 後,您可以開始為應用程式初始化 WebGPU,第一步是要求 GPUAdapter。您可以將轉接器視為 WebGPU 對裝置中特定 GPU 硬體的呈現方式。
- 如要取得轉接器,請使用
navigator.gpu.requestAdapter()方法。它會傳回承諾,因此最方便的方法是使用await呼叫它。
index.html
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) {
throw new Error("No appropriate GPUAdapter found.");
}
如果找不到適當的轉接器,傳回的 adapter 值可能會是 null,因此您需要處理這種情況。使用者的瀏覽器支援 WebGPU,但 GPU 硬體沒有使用 WebGPU 所需的所有功能,就可能發生這種情況。
大多數情況下,只要讓瀏覽器挑選預設轉接器即可 (如同您在這裡所做的),但如果有更進階的需求,您可以將引數傳遞至 requestAdapter(),指定您要在裝置 (例如某些筆記型電腦) 上使用低耗電或高效能硬體。
取得轉接器後,您必須先要求 GPUDevice,才能開始使用 GPU。裝置是主要介面,透過此介面可與 GPU 進行大部分互動。
- 呼叫
adapter.requestDevice()即可取得裝置,這也會傳回承諾。
index.html
const device = await adapter.requestDevice();
與 requestAdapter() 一樣,您也可以傳遞選項,以便進行更進階的用途,例如啟用特定硬體功能或要求更高的限制,但對於您的用途來說,預設值就足以運作。
設定 Canvas
有了裝置後,如果想在頁面上顯示任何內容,請再完成一項設定:將畫布設定為與剛才建立的裝置搭配使用。
- 如要執行這項操作,請先呼叫
canvas.getContext("webgpu"),從畫布要求GPUCanvasContext。(這個呼叫與您使用2d和webgl分別使用 2D 畫布或 WebGL 上下文類型初始化時的呼叫相同)。接著,傳回的context必須使用configure()方法與裝置建立關聯,如下所示:
index.html
const context = canvas.getContext("webgpu");
const canvasFormat = navigator.gpu.getPreferredCanvasFormat();
context.configure({
device: device,
format: canvasFormat,
});
您可以傳遞幾個選項,但最重要的是您要使用的 device 和 format,也就是情境應使用的紋理格式。
紋理是 WebGPU 用來儲存圖片資料的物件,每個紋理都有一種格式,可讓 GPU 瞭解資料如何在記憶體中排列。紋理記憶體的運作方式不在本程式碼研究室的範圍內。請務必瞭解的是,畫布內容會為程式碼提供紋理,讓程式碼繪製紋理,而您使用的格式可能會影響畫布顯示這些圖片的效率。不同類型的裝置在使用不同紋理格式時,效能表現最佳。如果您未使用裝置偏好的格式,在圖片顯示於網頁之前,系統可能會在幕後執行額外的記憶體複製作業。
幸好,您不必擔心這些問題,因為 WebGPU 會告訴您要使用哪種格式繪製畫布!在大多數情況下,您都會想傳遞呼叫 navigator.gpu.getPreferredCanvasFormat() 所傳回的值,如上所示。
清除畫布
您現在已擁有裝置,且已設定好畫布,因此可以開始使用裝置變更畫布的內容。首先,請使用單色填滿畫布。
如要執行這項操作 (或執行 WebGPU 中的其他操作),您必須向 GPU 提供一些指令,告知它要執行什麼操作。
- 為此,請讓裝置建立
GPUCommandEncoder,提供用於記錄 GPU 指令的介面。
index.html
const encoder = device.createCommandEncoder();
您要傳送至 GPU 的指令與算繪相關 (在本例中為清除畫布),因此下一步是使用 encoder 開始算繪通道。
算繪階段是指 WebGPU 中的所有繪圖作業。每個方法都會以 beginRenderPass() 呼叫開始,該呼叫會定義接收執行任何繪圖指令的輸出內容的紋理。更進階的用途可提供多個紋理,稱為附件,用途各異,例如儲存算繪幾何圖形的深度或提供反鋸齒效果。不過,這個應用程式只需要一個。
- 呼叫
context.getCurrentTexture()即可從先前建立的畫布內容取得紋理,此時會傳回像素寬度和高度的紋理,這些值會與畫布的width和height屬性,以及呼叫context.configure()時指定的format相符。
index.html
const pass = encoder.beginRenderPass({
colorAttachments: [{
view: context.getCurrentTexture().createView(),
loadOp: "clear",
storeOp: "store",
}]
});
紋理會以 colorAttachment 的 view 屬性提供。轉譯階段需要提供 GPUTextureView,而非 GPUTexture,這會告知轉譯作業要轉譯材質的哪些部分。這只對較進階的用途才重要,因此您在這裡呼叫 createView() 時,在紋理上不使用任何引數,表示您希望算繪通道使用整個紋理。
您也必須指定您希望算繪通道在開始和結束時,如何處理紋理:
- 如果
loadOp值為"clear",表示您希望在算繪通道開始時清除紋理。 storeOp值為"store"表示在轉譯作業完成後,您希望將轉譯作業期間完成的任何繪圖結果儲存至紋理。
算繪通道開始後,您就什麼都不用做!至少目前是如此。使用 loadOp: "clear" 啟動轉譯通道,即可清除紋理檢視畫面和畫布。
- 在
beginRenderPass()後立即新增下列呼叫,即可結束轉譯通道:
index.html
pass.end();
請務必瞭解,單純發出這些呼叫並不會讓 GPU 實際執行任何操作。它們只是記錄 GPU 稍後要執行的指令。
- 如要建立
GPUCommandBuffer,請在指令編碼器上呼叫finish()。指令緩衝區是已記錄指令的半透明句柄。
index.html
const commandBuffer = encoder.finish();
- 使用
GPUDevice的queue將指令緩衝區提交至 GPU。佇列會執行所有 GPU 指令,確保執行順序正確且同步處理正確。佇列的submit()方法會接收指令緩衝區陣列,但在本例中,您只有一個。
index.html
device.queue.submit([commandBuffer]);
提交指令緩衝區後,就無法再使用,因此不必保留。如要提交更多指令,您必須建構其他指令緩衝區。因此,這兩個步驟通常會合併為一個步驟,就像本程式碼研究室的範例頁面一樣:
index.html
// Finish the command buffer and immediately submit it.
device.queue.submit([encoder.finish()]);
將指令提交至 GPU 後,請讓 JavaScript 將控制權交還給瀏覽器。此時,瀏覽器會發現您已變更目前的內容紋理,並更新畫布,以便以圖片形式顯示該紋理。如果您之後想再次更新畫布內容,就必須記錄並提交新的指令緩衝區,再次呼叫 context.getCurrentTexture() 以取得算繪通道的新紋理。
- 重新載入頁面。請注意,畫布已填入黑色。恭喜!這表示您已成功建立第一個 WebGPU 應用程式。

挑選顏色!
不過老實說,黑色方塊實在很無聊。因此,請先花點時間進行個人化設定,再繼續閱讀下一節。
- 在
encoder.beginRenderPass()呼叫中,將含有clearValue的新行加入colorAttachment,如下所示:
index.html
const pass = encoder.beginRenderPass({
colorAttachments: [{
view: context.getCurrentTexture().createView(),
loadOp: "clear",
clearValue: { r: 0, g: 0, b: 0.4, a: 1 }, // New line
storeOp: "store",
}],
});
clearValue 會指示轉譯子序列在執行轉譯子序列開頭的 clear 作業時,應使用哪種顏色。傳入其中的字典包含四個值:r 代表紅色、g 代表綠色、b 代表藍色,而 a 代表alpha (透明度)。每個值的範圍為 0 到 1,這些值會共同描述該色彩通道的值。例如:
{ r: 1, g: 0, b: 0, a: 1 }是亮紅色。{ r: 1, g: 0, b: 1, a: 1 }是亮紫色。{ r: 0, g: 0.3, b: 0, a: 1 }是深綠色。{ r: 0.5, g: 0.5, b: 0.5, a: 1 }是灰色。{ r: 0, g: 0, b: 0, a: 0 }是預設的透明黑色。
本程式碼研究室中的範例程式碼和螢幕截圖使用深藍色,但您可以自由選擇所需顏色!
- 選擇顏色後,請重新載入頁面。畫布中應該會顯示您選擇的顏色。

4. 繪製幾何圖形
完成本節後,您的應用程式將在畫布上繪製一些簡單的幾何圖形:彩色正方形。請注意,這麼簡單的輸出內容似乎需要花費大量心力,但這是因為 WebGPU 的設計目的是能非常有效率地算繪大量幾何圖形。這種效率的副作用是,執行相對簡單的作業可能會顯得異常困難,但如果您要使用 WebGPU 這類 API 執行較複雜的作業,就會出現這種情況。
瞭解 GPU 的繪圖方式
在進行更多程式碼變更之前,建議您先快速瞭解 GPU 如何建立您在螢幕上看到的形狀。(如果您已熟悉 GPU 算繪的運作方式,請直接跳到「定義頂點」一節)。
與 Canvas 2D 等 API 不同,GPU 實際上只處理幾種不同的形狀 (或 WebGPU 稱之為基本形狀):點、線和三角形。在本程式碼研究室中,您只會使用三角形。
GPU 幾乎只處理三角形,因為三角形具有許多優異的數學特性,可讓 GPU 以可預測且有效率的方式輕鬆處理。幾乎所有您使用 GPU 繪製的內容都必須分割成三角形,GPU 才能繪製這些內容,且這些三角形必須由其角點定義。
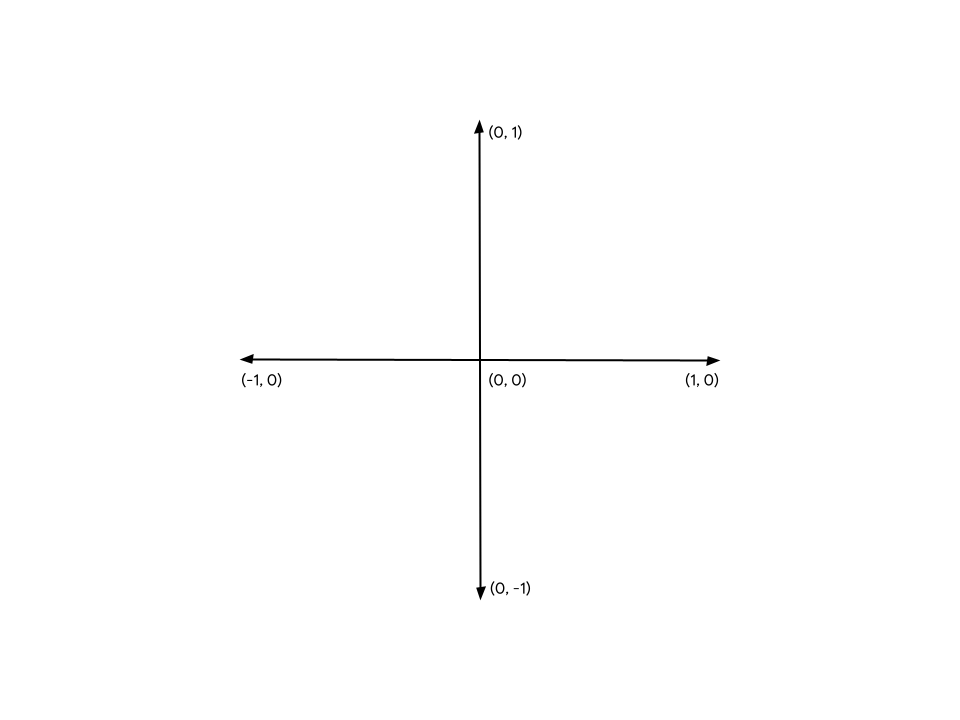
這些點 (或稱頂點) 會以 X、Y 和 (3D 內容的) Z 值提供,這些值會定義 WebGPU 或類似 API 定義的笛卡兒座標系統上的點。要思考座標系統的結構,最簡單的方法就是思考它與網頁上畫布的關係。無論畫布的寬度或高度為何,左邊緣一律會位於 X 軸的 -1 處,右邊緣一律會位於 X 軸的 +1 處。同樣地,底部邊緣在 Y 軸上總是 -1,頂部邊緣在 Y 軸上則是 +1。也就是說,(0, 0) 一律是畫布的中心,(-1, -1) 一律是左下角,(1, 1) 一律是右上角。這就是所謂的「剪輯區域」。
頂點很少在這個座標系統中定義,因此 GPU 會使用稱為「頂點著色器」的小型程式,執行將頂點轉換為剪輯空間所需的任何數學運算,以及繪製頂點所需的任何其他運算。舉例來說,著色器可能會套用某些動畫,或計算從頂點到光源的方向。這些著色器是由 WebGPU 開發人員 (也就是您) 編寫,可讓您以驚人的程度控管 GPU 的運作方式。
接著,GPU 會取用這些經過轉換的頂點所構成的所有三角形,並判斷畫面上哪些像素需要繪製這些三角形。接著,它會執行您撰寫的另一個小程式,也就是稱為「片段著色器」的程式,用來計算每個像素應有的顏色。這項計算可以簡單到傳回綠色,也可以複雜到計算表面相對於陽光反射的角度,並根據附近其他表面、經過霧氣過濾,以及表面金屬程度的影響而變化。這項計算完全由您控制,既能發揮效用,也可能令人不知所措。
這些像素顏色的結果會累積至紋理,然後顯示在螢幕上。
定義頂點
如先前所述,生命遊戲模擬功能會以格狀單元格顯示。您的應用程式需要一種方法來呈現格線,區分活動儲存格和非活動儲存格。本程式碼研究室採用的方法是在有效儲存格中繪製彩色方塊,並讓無效儲存格保持空白。
也就是說,您必須為 GPU 提供四個不同的點,每個正方形的四個角落各一個。舉例來說,在畫布中央繪製的正方形,從邊緣拉進的座標如下所示:

為了將這些座標提供給 GPU,您必須將這些值放入 TypedArray 中。如果您不熟悉 TypedArray,請先瞭解一下。TypedArray 是一組 JavaScript 物件,可讓您配置相鄰的記憶體區塊,並將系列中的每個元素解讀為特定資料類型。舉例來說,在 Uint8Array 中,陣列中的每個元素都是單一未簽署的位元組。TypedArrays 非常適合與對記憶體配置敏感的 API 傳送資料,例如 WebAssembly、WebAudio 和 (當然) WebGPU。
以方塊範例來說,由於值為小數,因此適合使用 Float32Array。
- 在程式碼中放入下列陣列宣告,建立可容納圖表中所有頂點位置的陣列。建議將其放在頂端,也就是
context.configure()呼叫的下方。
index.html
const vertices = new Float32Array([
// X, Y,
-0.8, -0.8,
0.8, -0.8,
0.8, 0.8,
-0.8, 0.8,
]);
請注意,間距和註解不會影響值,只是為了方便您閱讀。這有助您瞭解每個值組合如何組成一個頂點的 X 和 Y 座標。
但有個問題!GPU 是以三角形運作,還記得嗎?也就是說,您必須以三個一組的方式提供頂點。您有一個四人群組,解決方法是重複兩個頂點,藉此建立兩個三角形,並在正方形中間共用一條邊。
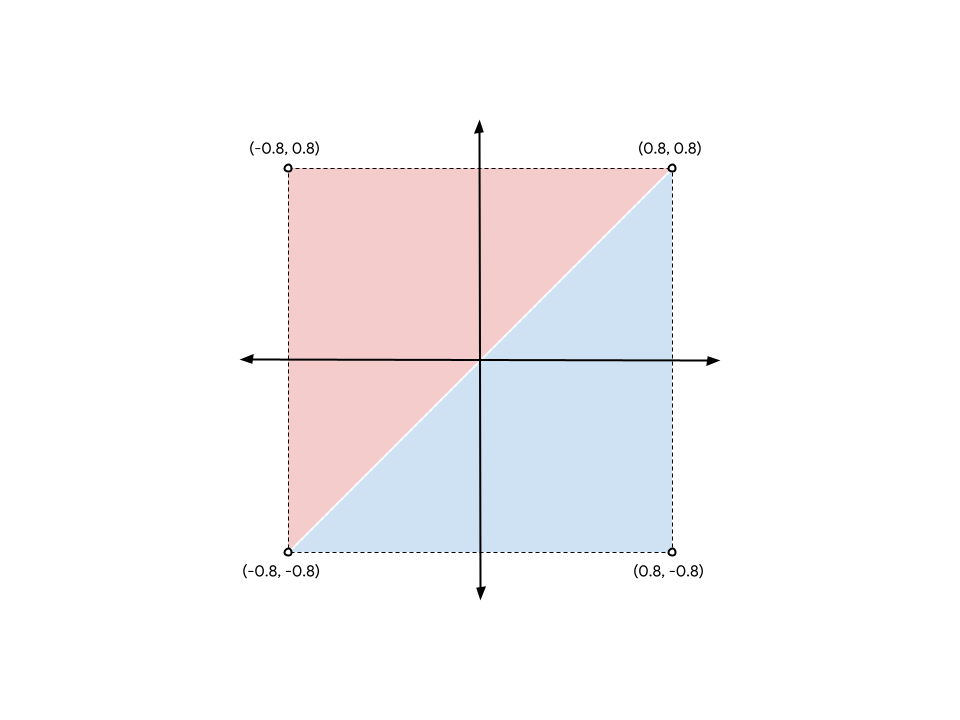
如要從圖表中形成正方形,您必須列出 (-0.8, -0.8) 和 (0.8, 0.8) 頂點兩次,一次用於藍色三角形,一次用於紅色三角形。(您也可以選擇以其他兩個角落分割正方形,這兩種方法沒有差異)。
- 更新先前的
vertices陣列,讓其看起來像這樣:
index.html
const vertices = new Float32Array([
// X, Y,
-0.8, -0.8, // Triangle 1 (Blue)
0.8, -0.8,
0.8, 0.8,
-0.8, -0.8, // Triangle 2 (Red)
0.8, 0.8,
-0.8, 0.8,
]);
雖然為了清楚起見,圖表中顯示兩個三角形之間有間隔,但頂點位置完全相同,且 GPU 會無縫渲染這兩個三角形。會顯示為單一實心正方形。
建立頂點緩衝區
GPU 無法使用 JavaScript 陣列中的資料繪製頂點。GPU 通常會擁有專屬記憶體,經過高度最佳化,可用於轉譯,因此您希望 GPU 在繪製時使用的任何資料,都必須放置在該記憶體中。
對於許多值 (包括頂點資料),GPU 端記憶體會透過 GPUBuffer 物件進行管理。緩衝區是 GPU 可輕鬆存取的記憶體區塊,並標記為特定用途。您可以將其視為類似於 GPU 可見的 TypedArray。
- 如要建立緩衝區來保留頂點,請在
vertices陣列定義後,將下列呼叫加入device.createBuffer()。
index.html
const vertexBuffer = device.createBuffer({
label: "Cell vertices",
size: vertices.byteLength,
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
});
首先,您必須為緩衝區指定標籤。您建立的每個 WebGPU 物件都可以附加選用標籤,而且我們強烈建議您這麼做!標籤可以是任何字串,只要能協助您識別物件即可。如果您遇到任何問題,這些標籤會用於 WebGPU 產生的錯誤訊息中,協助您瞭解發生錯誤的原因。
接著,請為緩衝區指定大小,單位為位元組。您需要 48 個位元組的緩衝區,計算方式為將 32 位元浮點大小 ( 4 個位元組) 乘以 vertices 陣列中的浮點數量 (12)。所幸,TypedArrays 已為您計算byteLength,因此您可以在建立緩衝區時使用這個值。
最後,您需要指定緩衝區的用途。這會是 GPUBufferUsage 標記的其中一個或多個,多個標記會與 | ( 位元或運算子) 運算子結合。在這種情況下,您可以指定要將緩衝區用於頂點資料 (GPUBufferUsage.VERTEX),並且要能夠將資料複製到其中 (GPUBufferUsage.COPY_DST)。
傳回給您的緩衝區物件是不可見的,您無法 (輕鬆) 檢查其所儲存的資料。此外,其大部分屬性都是不可變動的,也就是說,您無法在 GPUBuffer 建立後變更其大小,也無法變更用法旗標。您可以變更記憶體的內容。
緩衝區在最初建立時,其中所含的記憶體會初始化為零。您可以透過多種方式變更內容,但最簡單的方法是使用要複製的 TypedArray 呼叫 device.queue.writeBuffer()。
- 如要將頂點資料複製到緩衝區的記憶體中,請加入以下程式碼:
index.html
device.queue.writeBuffer(vertexBuffer, /*bufferOffset=*/0, vertices);
定義頂點版面配置
您現在有一個包含頂點資料的緩衝區,但就 GPU 而言,它只是一串位元組。如要使用這項功能繪製任何內容,您需要提供更多資訊。您必須能夠向 WebGPU 進一步說明頂點資料的結構。
- 使用
GPUVertexBufferLayout字典定義頂點資料結構:
index.html
const vertexBufferLayout = {
arrayStride: 8,
attributes: [{
format: "float32x2",
offset: 0,
shaderLocation: 0, // Position, see vertex shader
}],
};
乍看之下可能會有些混淆,但其實很容易分辨。
首先提供 arrayStride。這是 GPU 在尋找下一個頂點時,需要在緩衝區中向前跳過的位元組數量。正方形的每個頂點都由兩個 32 位元浮點數組成。如前所述,32 位元浮點值為 4 個位元組,因此兩個浮點值為 8 個位元組。
接著是 attributes 屬性,這是陣列。屬性是編碼至每個頂點的個別資訊片段。頂點只包含一個屬性 (頂點位置),但較進階的用途通常會使用包含多個屬性的頂點,例如頂點的顏色或幾何圖形表面指向的方向。不過,這不在本程式碼研究室的範圍內。
在單一屬性中,您必須先定義資料的 format。這項資訊來自 GPUVertexFormat 類型清單,其中說明 GPU 可理解的每種頂點資料類型。頂點各有兩個 32 位元浮點值,因此您使用 float32x2 格式。舉例來說,如果頂點資料是由四個 16 位元未簽署整數組成,則應改用 uint16x4。你發現了嗎?
接著,offset 會說明這個特定屬性在頂點中開始的位元組數。只有在緩衝區包含多個屬性時,您才需要擔心這個問題,但本程式碼研究室不會出現這種情況。
最後,您有 shaderLocation。這個值是介於 0 到 15 之間的任意數字,且每個定義的屬性都必須是專屬值。它會將此屬性連結至頂點著色器中的特定輸入內容,您將在下一節中瞭解這項作業。
請注意,雖然您現在已定義這些值,但實際上並未將這些值傳遞至任何 WebGPU API。我們會在後續說明,但在定義頂點時,最容易思考這些值,因此現在設定這些值,以利日後使用。
從著色器開始
您現在擁有要算繪的資料,但仍需要明確告知 GPU 如何處理這些資料。這類問題大多是著色器造成的。
著色器是您編寫並在 GPU 上執行的小型程式。每個著色器都會在資料的不同階段上運作:頂點處理、片段處理或一般運算。因為這些程式碼位於 GPU 上,因此結構比一般 JavaScript 更嚴謹。但這種結構可讓它們快速執行,而且更重要的是,可同時執行!
WebGPU 中的著色器是以 WGSL (WebGPU 著色語言) 編寫。從語法角度來看,WGSL 有點類似 Rust,其功能旨在讓常見類型的 GPU 工作 (例如向量和矩陣運算) 更容易、更快速地完成。完整介紹著色語言超出本程式碼研究室的範圍,但希望您在逐步操作簡單範例時,能掌握一些基本概念。
著色器本身會以字串形式傳遞至 WebGPU。
- 複製下列程式碼到
vertexBufferLayout下方,建立輸入著色器程式碼的位置:
index.html
const cellShaderModule = device.createShaderModule({
label: "Cell shader",
code: `
// Your shader code will go here
`
});
如要建立著色器,請呼叫 device.createShaderModule(),並提供選用的 label 和 WGSL code 做為字串。(請注意,您必須使用反引號才能允許多行字串!)新增有效的 WGSL 程式碼後,函式會傳回含有編譯結果的 GPUShaderModule 物件。
定義頂點著色器
請從頂點著色器開始,因為 GPU 也是從這裡開始!
頂點著色器會定義為函式,而 GPU 會針對 vertexBuffer 中的每個頂點呼叫該函式一次。由於 vertexBuffer 包含六個位置 (頂點),因此您定義的函式會呼叫六次。每次呼叫時,系統會將 vertexBuffer 的不同位置做為引數傳遞至函式,而頂點著色器函式的工作就是在剪輯空間中傳回對應的位置。
請注意,這些方法不一定會依序呼叫。相反地,GPU 擅長並行執行這類著色器,可能同時處理數百 (甚至數千) 個頂點!這正是 GPU 驚人速度的一大原因,但也有一些限制。為了確保極端並行處理,頂點著色器無法彼此通訊。每個著色器叫用只能查看單一頂點的資料,也只能輸出單一頂點的值。
在 WGSL 中,您可以將頂點著色器函式命名為任何名稱,但必須在前面加上 @vertex 屬性,才能指出代表哪個著色器階段。WGSL 會使用 fn 關鍵字表示函式,使用括號宣告任何引數,並使用大括號定義範圍。
- 建立空白的
@vertex函式,如下所示:
index.html (createShaderModule 程式碼)
@vertex
fn vertexMain() {
}
不過,這並非有效做法,因為頂點著色器必須「至少」傳回在剪輯空間中處理的頂點最終位置。這一律會以 4 維向量提供。向量在著色器中是常見的用法,因此會在該語言中視為第一類原始元素,並使用自己的類型,例如 vec4f 是 4 維向量。2D 向量 (vec2f) 和 3D 向量 (vec3f) 也有類似的類型!
- 如要指出傳回的值是必要位置,請使用
@builtin(position)屬性標記該值。->符號用來表示這是函式傳回的值。
index.html (createShaderModule 程式碼)
@vertex
fn vertexMain() -> @builtin(position) vec4f {
}
當然,如果函式有傳回類型,您必須在函式主體中實際傳回值。您可以使用 vec4f(x, y, z, w) 語法建立新的 vec4f 以供傳回。x、y 和 z 值都是浮點數,在傳回值中表示頂點在剪輯空間中的位置。
- 傳回
(0, 0, 0, 1)的靜態值,在技術上您擁有有效的頂點著色器,但這個頂點著色器永遠不會顯示任何內容,因為 GPU 會將產生的三角形視為單一點,然後捨棄。
index.html (createShaderModule 程式碼)
@vertex
fn vertexMain() -> @builtin(position) vec4f {
return vec4f(0, 0, 0, 1); // (X, Y, Z, W)
}
您應該要使用您建立的緩衝區資料,方法是為函式宣告引數,並使用 @location() 屬性和類型,以符合您在 vertexBufferLayout 中所述的內容。您指定了 0 的 shaderLocation,因此請在 WGSL 程式碼中使用 @location(0) 標示引數。您也將格式定義為 float32x2,這是 2D 向量,因此在 WGSL 中,您的引數為 vec2f。您可以自行命名,但由於這些屬性代表的是頂點位置,因此使用「pos」等名稱會比較自然。
- 將著色器函式變更為下列程式碼:
index.html (createShaderModule 程式碼)
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
return vec4f(0, 0, 0, 1);
}
而現在您需要傳回該位置。由於位置是 2D 向量,而傳回類型是 4D 向量,因此您必須稍微變更。您要做的是從位置引數中取得兩個元件,並將其放入傳回向量的前兩個元件,讓最後兩個元件分別為 0 和 1。
- 明確指出要使用的定位元件,即可傳回正確的位置:
index.html (createShaderModule 程式碼)
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
return vec4f(pos.x, pos.y, 0, 1);
}
不過,由於這類對應方式在著色器中相當常見,您也可以在方便的簡寫中將位置向量做為第一個引數傳遞,這兩種做法意義相同。
- 使用下列程式碼重新編寫
return陳述式:
index.html (createShaderModule 程式碼)
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
return vec4f(pos, 0, 1);
}
這就是初始頂點著色器!做法很簡單,只要將位置有效傳遞即可,但這麼做就足以開始。
定義片段著色器
接下來是片段著色器。片段著色器的運作方式與頂點著色器非常相似,但不是針對每個頂點叫用,而是針對每個繪製的像素叫用。
片段著色器一律會在頂點著色器之後呼叫。GPU 會擷取頂點著色器的輸出內容,並將其三角化,從三個點的集合中建立三角形。然後透過找出輸出色彩附件中哪些像素包含在三角形中,將每個三角形轉為點陣,然後為每個像素呼叫片段著色器一次。片段著色器會傳回顏色,通常是根據頂點著色器和紋理等資產傳送至該著色器的值計算而得,而 GPU 會將這些值寫入顏色附件。
和頂點著色器一樣,片段著色器也是以大量並行的方式執行。就輸入和輸出而言,它們比頂點著色器更具彈性,但您可以將其視為只為每個三角形的每個像素傳回一個顏色。
WGSL 片段著色器函式會以 @fragment 屬性表示,並傳回 vec4f。不過,在本例中,向量代表的是顏色,而非位置。傳回值必須具有 @location 屬性,才能指出要將傳回的顏色寫入 beginRenderPass 呼叫的哪個 colorAttachment。由於你只有一個附件,位置為 0。
- 建立空白的
@fragment函式,如下所示:
index.html (createShaderModule 程式碼)
@fragment
fn fragmentMain() -> @location(0) vec4f {
}
傳回向量的四個元件分別是紅色、綠色、藍色和 alpha 顏色值,這些值的解讀方式與先前在 beginRenderPass 中設定的 clearValue 完全相同。vec4f(1, 0, 0, 1) 是亮紅色,似乎是方塊的適當顏色。不過,您可以自由設定任何顏色!
- 設定傳回的顏色向量,如下所示:
index.html (createShaderModule 程式碼)
@fragment
fn fragmentMain() -> @location(0) vec4f {
return vec4f(1, 0, 0, 1); // (Red, Green, Blue, Alpha)
}
這就是完整的片段著色器!這並不是很有趣的程式碼,它只是將每個三角形的每個像素設為紅色,但目前這就足夠了。
提醒一下,新增上述著色器程式碼後,您的 createShaderModule 呼叫現在會如下所示:
index.html
const cellShaderModule = device.createShaderModule({
label: 'Cell shader',
code: `
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
return vec4f(pos, 0, 1);
}
@fragment
fn fragmentMain() -> @location(0) vec4f {
return vec4f(1, 0, 0, 1);
}
`
});
建立轉譯管道
著色器模組無法單獨用於算繪。相反地,您必須將其用於 GPURenderPipeline 的一部分,並透過呼叫 device.createRenderPipeline() 建立。算繪管道會控制如何繪製幾何圖形,包括要使用的著色器、如何解讀頂點緩衝區中的資料、應算繪哪種幾何圖形 (線條、點、三角形...) 等等。
算繪管道是整個 API 中最複雜的物件,但請放心!您可以傳遞的大部分值都是選用的,您只需提供幾個值即可開始。
- 建立轉譯管道,如下所示:
index.html
const cellPipeline = device.createRenderPipeline({
label: "Cell pipeline",
layout: "auto",
vertex: {
module: cellShaderModule,
entryPoint: "vertexMain",
buffers: [vertexBufferLayout]
},
fragment: {
module: cellShaderModule,
entryPoint: "fragmentMain",
targets: [{
format: canvasFormat
}]
}
});
每個管道都需要 layout,用來說明管道需要哪些輸入類型 (除了頂點緩衝區),但您實際上並沒有任何輸入。幸運的是,您現在可以傳遞 "auto",管道會從著色器建構自己的版面配置。
接下來,您必須提供 vertex 階段的詳細資料。module 是包含頂點著色器的 GPUShaderModule,而 entryPoint 則提供著色器程式碼中函式的名稱,該函式會在每次頂點叫用時呼叫。(您可以在單一著色器模組中使用多個 @vertex 和 @fragment 函式!)緩衝區是 GPUVertexBufferLayout 物件的陣列,可說明在使用此管道的頂點緩衝區中,資料的封裝方式。幸運的是,您先前已在 vertexBufferLayout 中定義過這個值!請在以下位置傳入該值。
最後,您可以查看 fragment 階段的詳細資料。這也包括著色器模組和entryPoint,例如頂點階段。最後一點是定義此管道使用的 targets。這是一個字典陣列,提供管道輸出至的顏色附件詳細資料,例如紋理 format。這些細節必須與此管道所用任何算繪通道的 colorAttachments 中提供的紋理相符。算繪通道會使用畫布內容中的紋理,並使用您在 canvasFormat 中儲存的值做為格式,因此您會在此傳遞相同的格式。
這還不是您在建立轉譯管道時可以指定的所有選項,但已足以滿足本程式碼研究室的需求!
繪製正方形
這樣一來,您現在就擁有繪製正方形所需的一切!
- 如要繪製正方形,請返回
encoder.beginRenderPass()和pass.end()的呼叫組合,然後在兩者之間新增下列新指令:
index.html
// After encoder.beginRenderPass()
pass.setPipeline(cellPipeline);
pass.setVertexBuffer(0, vertexBuffer);
pass.draw(vertices.length / 2); // 6 vertices
// before pass.end()
這會為 WebGPU 提供繪製方塊所需的所有資訊。首先,您會使用 setPipeline() 指明應使用哪個管道進行繪圖。包括使用的著色器、頂點資料的版面配置,以及其他相關的狀態資料。
接下來,您會使用包含正方形頂點的緩衝區呼叫 setVertexBuffer()。您會使用 0 呼叫它,因為此緩衝區對應至目前管線 vertex.buffers 定義中的第 0 個元素。
最後,您可以呼叫 draw(),在完成所有前置設定後,這個呼叫看起來似乎非常簡單。您只需要傳入應算繪的頂點數量,系統會從目前設定的頂點緩衝區擷取,並透過目前設定的管道進行解讀。您可以將其硬式編碼為 6,但如果從頂點陣列 (每個頂點 12 個浮點數 / 2 個座標 == 6 個頂點) 計算,表示如果您決定用圓形取代方塊,手動更新的項目就會比較少。
- 重新整理畫面,終於看到您努力的成果:一個大大的彩色正方形。

5. 繪製格線
首先,請花點時間祝賀自己!在螢幕上取得幾何圖形的第一個位元通常是大多數 GPU API 最困難的步驟之一。您可以透過這裡執行的所有操作,以較小的步驟完成,方便您隨時驗證進度。
本節將說明以下內容:
- 如何從 JavaScript 將變數 (稱為「統一」) 傳遞至著色器。
- 如何使用統一變數來變更算繪行為。
- 如何使用實例繪製相同幾何圖形的多種不同變化版本。
定義格線
如要算繪格線,您必須瞭解格線的基礎資訊。寬度和高度各包含多少個儲存格?這取決於開發人員,但為了簡化操作,請將格線視為正方形 (相同的寬度和高度),並使用 2 的冪次方大小。(這樣之後的運算會比較簡單)。您最終會希望將其設為更大,但在本節的其餘部分中,請將格線大小設為 4x4,因為這樣比較容易說明本節中使用的部分數學概念。之後再擴大!
- 在 JavaScript 程式碼頂端加入常數,即可定義格線大小。
index.html
const GRID_SIZE = 4;
接下來,您需要更新方塊的算繪方式,以便在畫布上放入 GRID_SIZE 個方塊。GRID_SIZE也就是說,方塊必須縮小許多,而且需要很多個方塊。
因此,您可以透過讓頂點緩衝區大幅增加,並在其中定義 GRID_SIZE 倍 GRID_SIZE 的正方形,以正確的大小和位置來處理這個問題。實際上,這類程式碼也不會太糟!只需要幾個 for 迴圈和一些數學運算。但這也無法充分利用 GPU,且會使用比必要更多的記憶體來產生效果。本節將探討更適合 GPU 的做法。
建立統一緩衝區
首先,您需要將所選的格線大小傳達至著色器,因為著色器會使用該大小變更顯示方式。您可以將大小硬式編碼至著色器,但這表示您每次想要變更格線大小時,都必須重新建立著色器和算繪管道,這會耗費大量資源。更好的方法是將格狀大小以統一的方式提供給著色器。
您先前已瞭解,每個頂點著色器的每個調用都會傳遞來自頂點緩衝區的不同值。均勻值是緩衝區的值,每次叫用時都相同。這些值可用於傳達幾何圖形 (例如位置)、動畫的整個影格 (例如目前時間),甚至是應用程式的整個生命週期 (例如使用者偏好設定) 的常見值。
- 新增下列程式碼,建立統一緩衝區:
index.html
// Create a uniform buffer that describes the grid.
const uniformArray = new Float32Array([GRID_SIZE, GRID_SIZE]);
const uniformBuffer = device.createBuffer({
label: "Grid Uniforms",
size: uniformArray.byteLength,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST,
});
device.queue.writeBuffer(uniformBuffer, 0, uniformArray);
這段程式碼應該很熟悉,因為它幾乎與先前用於建立頂點緩衝區的程式碼完全相同!這是因為統一變數會透過與頂點相同的 GPUBuffer 物件,與 WebGPU API 進行通訊,主要差異在於這次的 usage 包含 GPUBufferUsage.UNIFORM,而非 GPUBufferUsage.VERTEX。
在著色器中存取統一值
- 新增下列程式碼,定義均一化函式:
index.html (createShaderModule 呼叫)
// At the top of the `code` string in the createShaderModule() call
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
return vec4f(pos / grid, 0, 1);
}
// ...fragmentMain is unchanged
這會在著色器中定義名為 grid 的統一變數,這是一個 2D 浮點向量,與您剛剛複製至統一緩衝區的陣列相符。並指定該均一化函式會繫結至 @group(0) 和 @binding(0)。稍後會說明這些值的含義。
接著,您可以在著色器程式碼的其他位置,視需要使用格線向量。在這個程式碼中,您會將頂點位置除以格線向量。由於 pos 是 2D 向量,而 grid 是 2D 向量,WGSL 會執行元件式除法。也就是說,結果與 vec2f(pos.x / grid.x, pos.y / grid.y) 相同。
這類向量運算在 GPU 著色器中非常常見,因為許多轉譯和運算技巧都需要這些運算。
在您這個案例中,這表示 (如果您使用的是 4 格格的大小),您算繪的正方形會是原始大小的四分之一。如果你想在一個資料列或資料欄中放入四個圖片,這就很適合!
建立繫結群組
不過,在著色器中宣告統一變數,並不會將其連結至您建立的緩衝區。如要這麼做,您必須建立並設定繫結群組。
繫結群組是一組資源,您可以同時讓著色器存取這些資源。它可以包含多種緩衝區類型,例如您的統一緩衝區,以及紋理和取樣器等其他資源,這些資源並未在此處提及,但 WebGPU 算繪技術中常見。
- 建立統一緩衝區和轉譯管道後,請新增下列程式碼,使用統一緩衝區建立繫結群組:
index.html
const bindGroup = device.createBindGroup({
label: "Cell renderer bind group",
layout: cellPipeline.getBindGroupLayout(0),
entries: [{
binding: 0,
resource: { buffer: uniformBuffer }
}],
});
除了現行的標準 label 外,您還需要 layout,說明這個繫結群組包含哪些類型的資源。您會在後續步驟中進一步探討這個問題,但目前您可以放心地向管道要求繫結群組版面配置,因為您是使用 layout: "auto" 建立管道。這會導致管道自動根據您在著色器程式碼中宣告的繫結,建立繫結群組版面配置。在這種情況下,您會要求它 getBindGroupLayout(0),其中 0 對應您在著色器中輸入的 @group(0)。
指定版面配置後,您會提供 entries 的陣列。每個項目都是字典,至少包含下列值:
binding,對應您在著色器中輸入的@binding()值。在這種情況下:0。resource:這是您要在指定繫結索引的變數中公開的實際資源。在本例中,就是統一緩衝區。
這個函式會傳回 GPUBindGroup,這是一個不透明且不可變動的處理常式。您無法變更繫結群組指向的資源,但可以變更這些資源的內容。舉例來說,如果您變更統一緩衝區,以便包含新的格線大小,日後使用此繫結群組的繪圖呼叫就會反映此變更。
繫結繫結群組
建立繫結群組後,您仍需要在繪製時告知 WebGPU 使用該群組。幸好這項操作相當簡單。
- 回到轉譯通道,並在
draw()方法前方新增這一行:
index.html
pass.setPipeline(cellPipeline);
pass.setVertexBuffer(0, vertexBuffer);
pass.setBindGroup(0, bindGroup); // New line!
pass.draw(vertices.length / 2);
傳遞做為第一個引數的 0 會對應到著色器程式碼中的 @group(0)。您表示 @group(0) 中的每個 @binding 都會使用這個繫結群組中的資源。
而現在,您可以將統一緩衝區公開給著色器!
- 重新整理頁面,畫面應如下所示:

太棒了!你的方塊現在只有原來的四分之一大小!這並沒有什麼特別之處,但這表示您確實已套用均勻變數,且著色器現在可以存取格線的大小。
在著色器中操控幾何圖形
您現在可以在著色器中參照格線大小,並開始操控要算繪的幾何圖形,以符合所需的格線模式。請先考量您想達成的目標。
您必須從概念上將畫布分割成個別的儲存格。為了維持 X 軸向右移動時會增加,Y 軸向上移動時也會增加的慣例,請將第一個單元格放在畫布左下角。這樣一來,您就會得到如下所示的版面配置,其中包含目前的正方形幾何圖形:
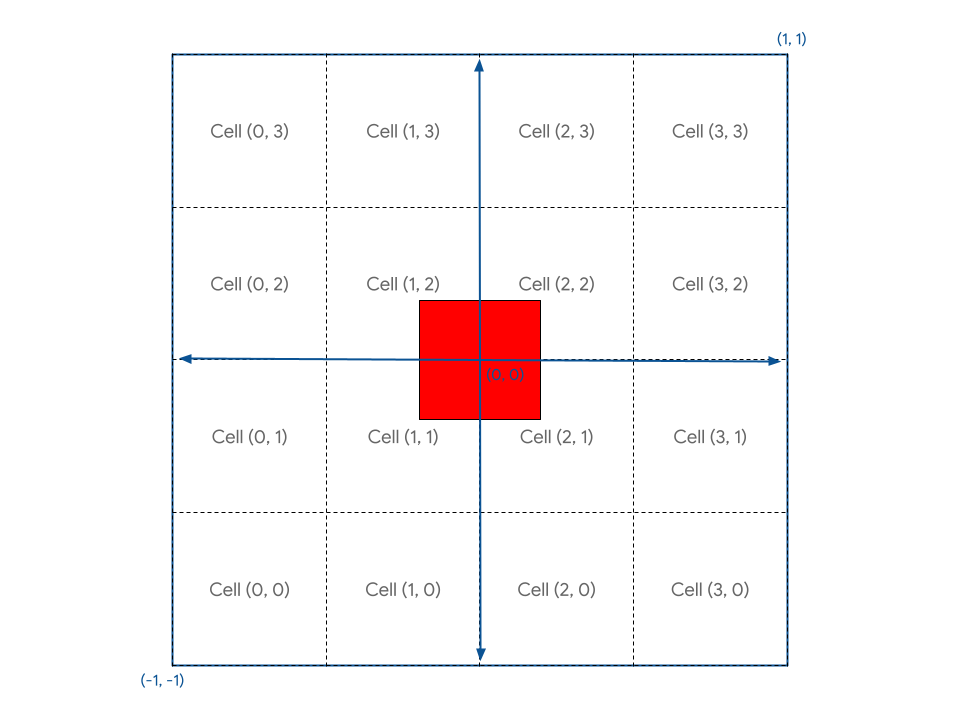
您需要在著色器中找出方法,讓您在任何單元格中,根據單元格座標放置正方形幾何圖形。
首先,您可以看到方塊並未與任何單元格對齊,因為它是定義為環繞畫布中心。您需要將方塊向下移動半個儲存格,這樣方塊才能在儲存格內排列整齊。
修正這個問題的方法之一,是更新方塊的頂點緩衝區。您可以移動頂點,讓左下角位於 (0.1, 0.1) 而非 (-0.8, -0.8),這樣就能讓這個正方形更貼近儲存格邊界。不過,由於您可以完全控制頂點在著色器中處理的方式,因此只要使用著色器程式碼,就能輕鬆將頂點推到適當位置!
- 使用下列程式碼變更頂點著色器模組:
index.html (createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
// Add 1 to the position before dividing by the grid size.
let gridPos = (pos + 1) / grid;
return vec4f(gridPos, 0, 1);
}
這會將每個頂點向上和向右移動一個單位 (請注意,這是剪輯空間的一半),然後再除以格線大小。結果是與格線對齊的正方形,位於原點附近。
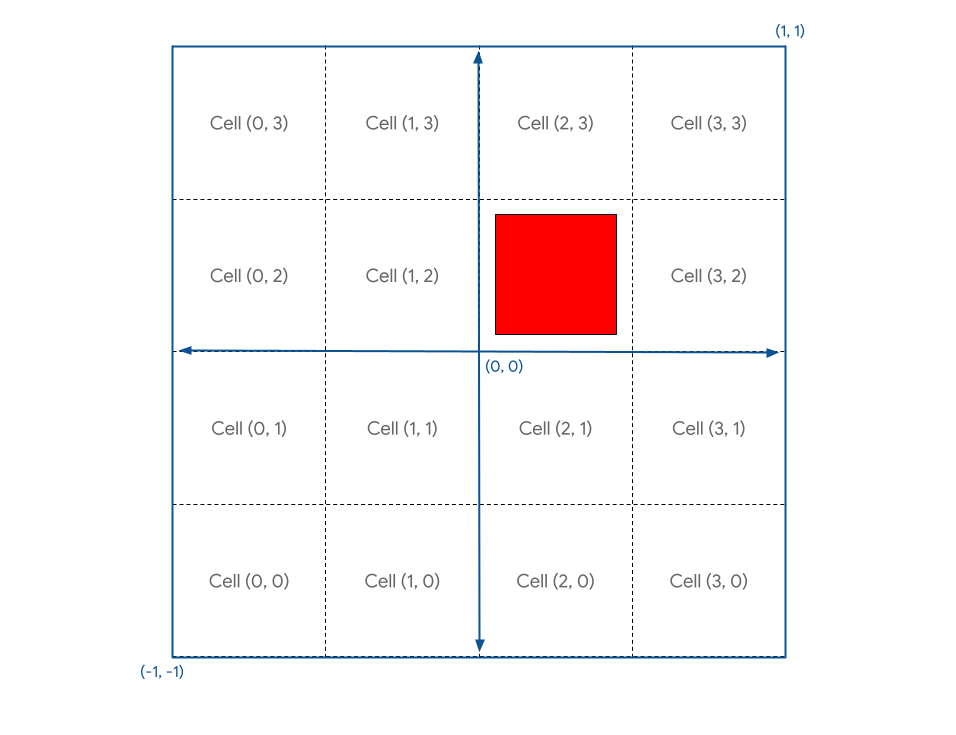
接著,由於畫布的座標系統會將 (0, 0) 放在中央,而 (-1, -1) 則位於左下方,而您希望 (0, 0) 位於左下方,因此您需要將幾何圖形的位置乘以 (-1, -1),然後除以網格大小,才能將幾何圖形移至該角落。
- 轉譯幾何圖形的位置,如下所示:
index.html (createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
// Subtract 1 after dividing by the grid size.
let gridPos = (pos + 1) / grid - 1;
return vec4f(gridPos, 0, 1);
}
這樣一來,正方形就會完美地置於 (0, 0) 格中!
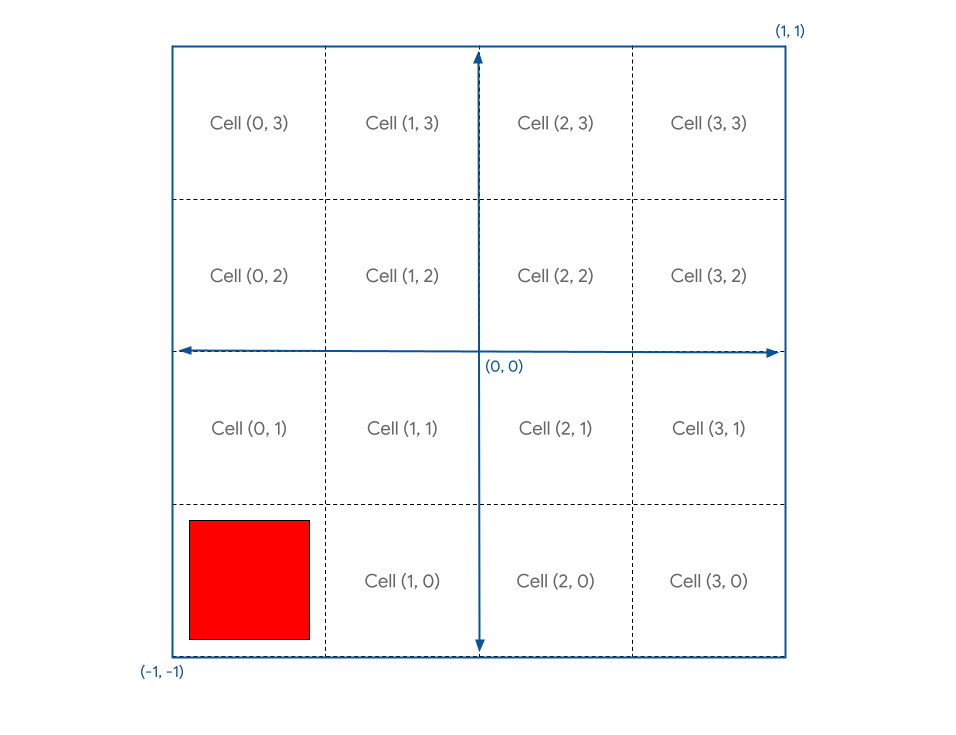
如果想將圖表放入其他儲存格,如要找出該值,請在著色器中宣告 cell 向量,並使用 let cell = vec2f(1, 1) 等靜態值填入該向量。
如果將該值新增至 gridPos,則會撤銷演算法中的 - 1,這不是您想要的結果。您只想將方塊在每個儲存格中移動一個格線單位 (畫布四分之一)。看來你需要再將 grid 除以 grid!
- 變更格線位置,例如:
index.html (createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
let cell = vec2f(1, 1); // Cell(1,1) in the image above
let cellOffset = cell / grid; // Compute the offset to cell
let gridPos = (pos + 1) / grid - 1 + cellOffset; // Add it here!
return vec4f(gridPos, 0, 1);
}
重新整理後,您會看到以下畫面:
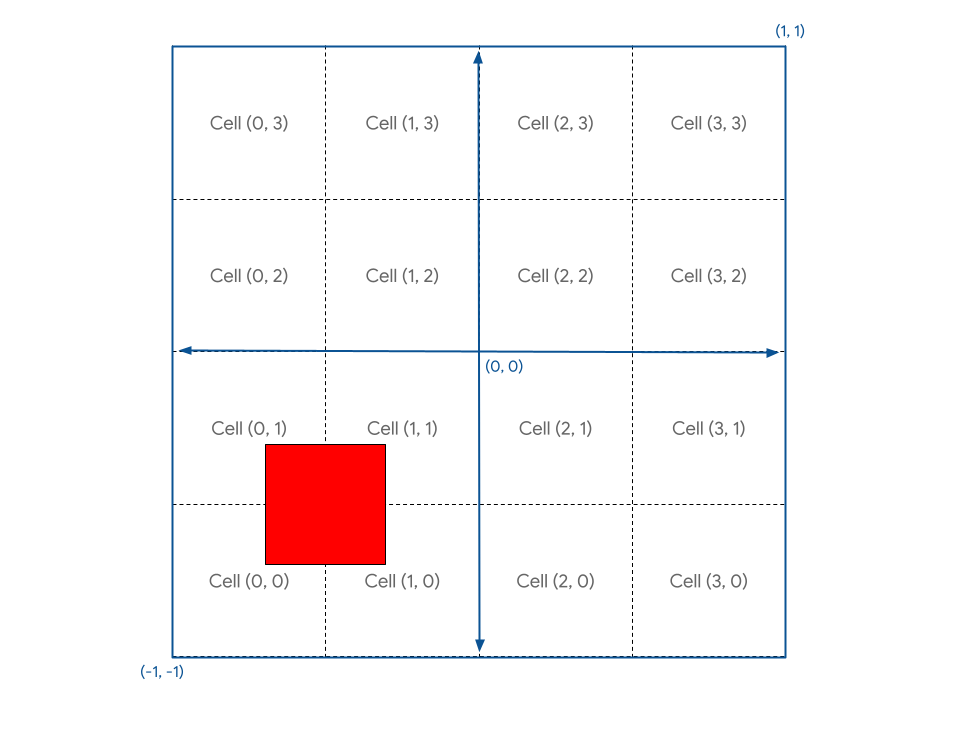
嗯…不太符合你的要求。
這是因為畫布座標從 -1 到 +1,因此實際上是 2 個單位。也就是說,如果您想將頂點移動到畫布四分之一的距離,就必須移動 0.5 個單位。這項錯誤很容易發生,因為 GPU 座標的推理方式很容易出錯!所幸,修正方式也同樣簡單。
- 將偏移量乘以 2,如下所示:
index.html (createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f) ->
@builtin(position) vec4f {
let cell = vec2f(1, 1);
let cellOffset = cell / grid * 2; // Updated
let gridPos = (pos + 1) / grid - 1 + cellOffset;
return vec4f(gridPos, 0, 1);
}
這樣一來,您就能獲得想要的結果。
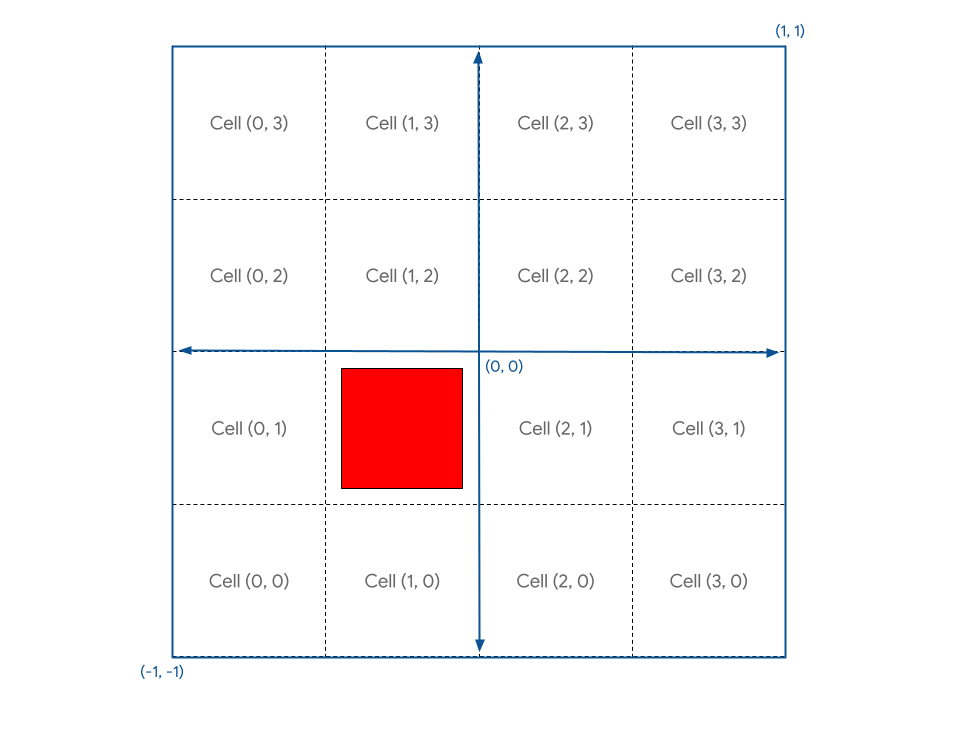
螢幕截圖如下所示:

此外,您現在可以將 cell 設為格線邊界範圍內的任何值,然後重新整理,即可在所需位置看到正方形的算繪結果。
繪製執行個體
您現在可以透過一些數學運算,將正方形放在所需位置,下一步則是在格線的每個單元格中算繪一個正方形。
您可以透過以下方式處理這個問題:將儲存格座標寫入統一緩衝區,然後針對每個格線中的正方形分別呼叫 draw 一次,每次都更新統一值。不過,由於 GPU 每次都必須等待 JavaScript 寫入新的座標,因此速度會非常慢。要讓 GPU 發揮良好效能,其中一個關鍵就是盡可能減少 GPU 等待系統其他部分的時間!
您可以改用稱為「例項化」的技術。實例化是一種方法,可讓 GPU 透過單一 draw 呼叫繪製相同幾何圖形的多個副本,這比為每個副本呼叫 draw 一次還要快上許多。每個幾何圖形副本都稱為「例項」。
- 如要告知 GPU,您需要足夠的方塊例項來填滿格線,請在現有的繪圖呼叫中新增一個引數:
index.html
pass.draw(vertices.length / 2, GRID_SIZE * GRID_SIZE);
這會告訴系統,您要讓系統繪製正方形的六個 (vertices.length / 2) 頂點 16 (GRID_SIZE * GRID_SIZE) 次。但重新整理頁面後,您仍會看到以下畫面:
這是因為這是因為您在同一個位置繪製所有 16 個方塊。您需要在著色器中加入一些額外邏輯,以便根據個別例項重新定位幾何圖形。
在著色器中,除了來自頂點緩衝區的頂點屬性 (例如 pos) 之外,您還可以存取 WGSL 的內建值。這些是 WebGPU 計算的值,其中一個值是 instance_index。instance_index 是從 0 到 number of instances - 1 的無符號 32 位元數字,可用於著色器邏輯。對於每個處理的頂點,其值都相同,且是同個例項的一部分。也就是說,頂點著色器會以 0 的 instance_index 呼叫六次,每個頂點緩衝區的位置各一次。然後再重複六次,使用 instance_index 的 1,然後再重複六次,使用 instance_index 的 2,依此類推。
如要查看實際運作情形,您必須在著色器輸入內容中加入內建的 instance_index。請按照與位置相同的方式執行這項操作,但請使用 @builtin(instance_index) 而非 @location 屬性標記,然後將任何名稱指派給引數。(您可以將其命名為 instance,以便與程式碼範例相符)。然後將其用於著色器邏輯!
- 使用
instance取代儲存格座標:
index.html
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f,
@builtin(instance_index) instance: u32) ->
@builtin(position) vec4f {
let i = f32(instance); // Save the instance_index as a float
let cell = vec2f(i, i); // Updated
let cellOffset = cell / grid * 2;
let gridPos = (pos + 1) / grid - 1 + cellOffset;
return vec4f(gridPos, 0, 1);
}
如果你現在重新整理畫面,就會發現確實有超過一個方塊!但你無法看到全部 16 個。

這是因為您產生的儲存格座標是 (0, 0)、(1, 1)、(2, 2)... 一直到 (15, 15),但只有前四個座標可放入畫布。如要建立所需的格線,您必須轉換 instance_index,讓每個索引對應至格線中不重複的單元格,如下所示:

計算方式相當簡單。針對每個儲存格 X 值,您需要 instance_index 和格線寬度的模值,您可以在 WGSL 中使用 % 運算子執行此操作。而對於每個儲存格 Y 值,您希望 instance_index 除以格線寬度,並捨去任何小數餘數。您可以使用 WGSL 的 floor() 函式執行這項操作。
- 變更計算方式,如下所示:
index.html
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f,
@builtin(instance_index) instance: u32) ->
@builtin(position) vec4f {
let i = f32(instance);
// Compute the cell coordinate from the instance_index
let cell = vec2f(i % grid.x, floor(i / grid.x));
let cellOffset = cell / grid * 2;
let gridPos = (pos + 1) / grid - 1 + cellOffset;
return vec4f(gridPos, 0, 1);
}
更新程式碼後,您終於可以看到期待已久的方格格線了!

- 現在已能正常運作,請返回並調高格線大小!
index.html
const GRID_SIZE = 32;

完成!您現在可以將這個格線做得非常大,一般 GPU 也能順利處理。您會在遇到任何 GPU 效能瓶頸之前,就停止看到個別方塊。
6. 額外學分:讓圖片更鮮豔!
您已為程式碼研究室的其餘部分奠定基礎,因此現在可以輕鬆跳到下一節。雖然方格網格使用相同顏色也能達到效果,但看起來並不特別吸引人,對吧?幸好,您可以透過一些數學和著色器程式碼,讓畫面亮度提升一些!
在著色器中使用結構
到目前為止,您已從頂點著色器傳出一個資料:轉換後的位置。但您其實可以從端點著色器傳回更多資料,然後在片段著色器中使用這些資料!
傳回資料的唯一方法,就是從頂點著色器傳出資料。頂點著色器一律必須傳回位置,因此如果您想一併傳回任何其他資料,就必須將該資料放入結構體中。WGSL 中的結構體是具名物件類型,包含一或多個具名屬性。屬性也可以使用 @builtin 和 @location 等屬性標示。您可以在任何函式外宣告這些類別,然後視需要將其例項傳遞至函式內或從函式中傳出。舉例來說,請考慮目前的頂點著色器:
index.html (createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(@location(0) pos: vec2f,
@builtin(instance_index) instance: u32) ->
@builtin(position) vec4f {
let i = f32(instance);
let cell = vec2f(i % grid.x, floor(i / grid.x));
let cellOffset = cell / grid * 2;
let gridPos = (pos + 1) / grid - 1 + cellOffset;
return vec4f(gridPos, 0, 1);
}
- 使用結構描述來表示函式輸入和輸出內容:
index.html (createShaderModule 呼叫)
struct VertexInput {
@location(0) pos: vec2f,
@builtin(instance_index) instance: u32,
};
struct VertexOutput {
@builtin(position) pos: vec4f,
};
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(input: VertexInput) -> VertexOutput {
let i = f32(input.instance);
let cell = vec2f(i % grid.x, floor(i / grid.x));
let cellOffset = cell / grid * 2;
let gridPos = (input.pos + 1) / grid - 1 + cellOffset;
var output: VertexOutput;
output.pos = vec4f(gridPos, 0, 1);
return output;
}
請注意,這項操作需要使用 input 參照輸入位置和例項索引,且您一開始傳回的結構體必須先宣告為變數,並設定其個別屬性。在這種情況下,這不會造成太大差異,實際上會讓著色器函式變得更長,但隨著著色器變得越來越複雜,使用結構體可說是整理資料的絕佳方法。
在頂點和片段函式之間傳遞資料
提醒您,您的 @fragment 函式應盡可能簡單:
index.html (createShaderModule 呼叫)
@fragment
fn fragmentMain() -> @location(0) vec4f {
return vec4f(1, 0, 0, 1);
}
您沒有接收任何輸入內容,而是將單色 (紅色) 做為輸出內容。不過,如果著色器能進一步瞭解所著色的幾何圖形,您就能利用這些額外資料讓畫面更有趣。舉例來說,如果您想根據單元格座標變更每個方塊的顏色,該怎麼做呢?@vertex 階段會知道要轉譯哪個單元格,您只需將該單元格傳遞至 @fragment 階段即可。
如要在頂點和片段階段之間傳遞任何資料,您必須在輸出結構體中加入資料,並使用我們選擇的 @location。由於您要傳遞單元格座標,請將該座標新增至先前的 VertexOutput 結構體,然後在傳回前於 @vertex 函式中設定該座標。
- 變更頂點著色器的傳回值,如下所示:
index.html (createShaderModule 呼叫)
struct VertexInput {
@location(0) pos: vec2f,
@builtin(instance_index) instance: u32,
};
struct VertexOutput {
@builtin(position) pos: vec4f,
@location(0) cell: vec2f, // New line!
};
@group(0) @binding(0) var<uniform> grid: vec2f;
@vertex
fn vertexMain(input: VertexInput) -> VertexOutput {
let i = f32(input.instance);
let cell = vec2f(i % grid.x, floor(i / grid.x));
let cellOffset = cell / grid * 2;
let gridPos = (input.pos + 1) / grid - 1 + cellOffset;
var output: VertexOutput;
output.pos = vec4f(gridPos, 0, 1);
output.cell = cell; // New line!
return output;
}
- 在
@fragment函式中,新增具備相同@location的引數,即可接收值。(名稱不必相同,但這樣比較容易追蹤)。
index.html (createShaderModule 呼叫)
@fragment
fn fragmentMain(@location(0) cell: vec2f) -> @location(0) vec4f {
// Remember, fragment return values are (Red, Green, Blue, Alpha)
// and since cell is a 2D vector, this is equivalent to:
// (Red = cell.x, Green = cell.y, Blue = 0, Alpha = 1)
return vec4f(cell, 0, 1);
}
- 或者,您也可以改用結構體:
index.html (createShaderModule 呼叫)
struct FragInput {
@location(0) cell: vec2f,
};
@fragment
fn fragmentMain(input: FragInput) -> @location(0) vec4f {
return vec4f(input.cell, 0, 1);
}
- 由於程式碼中這兩個函式都是在同一個著色器模組中定義,因此另一個替代做法是重複使用
@vertex階段的輸出結構體!這樣一來,您就能輕鬆傳遞值,因為名稱和位置自然一致。
index.html (createShaderModule 呼叫)
@fragment
fn fragmentMain(input: VertexOutput) -> @location(0) vec4f {
return vec4f(input.cell, 0, 1);
}
無論您選擇哪種模式,結果都是您可以存取 @fragment 函式中的儲存格編號,並且可以使用該編號來影響顏色。使用上述任何程式碼時,輸出結果如下所示:

色彩確實變多了,但看起來不太好看。您可能會好奇,為何只有左側和底部的資料列不同。這是因為您從 @fragment 函式傳回的顏色值會預期每個通道介於 0 到 1 之間,而任何超出該範圍的值都會被截斷。另一方面,儲存格值的範圍則是沿著每個軸線從 0 到 32。您會看到,第一列和第一欄在紅色或綠色色版中立即達到完整 1 值,而後續每個儲存格都會固定為相同的值。
如果您希望顏色之間的轉換更為流暢,就需要為每個色彩通道傳回小數值,理想情況下,每個軸都應從零開始,並以一結束,也就是說,您還需要將 grid 除以另一個值!
- 變更片段著色器,如下所示:
index.html (createShaderModule 呼叫)
@fragment
fn fragmentMain(input: VertexOutput) -> @location(0) vec4f {
return vec4f(input.cell/grid, 0, 1);
}
重新整理頁面後,您會發現新的程式碼「確實」會在整個格狀區塊中產生更漂亮的漸層色彩。
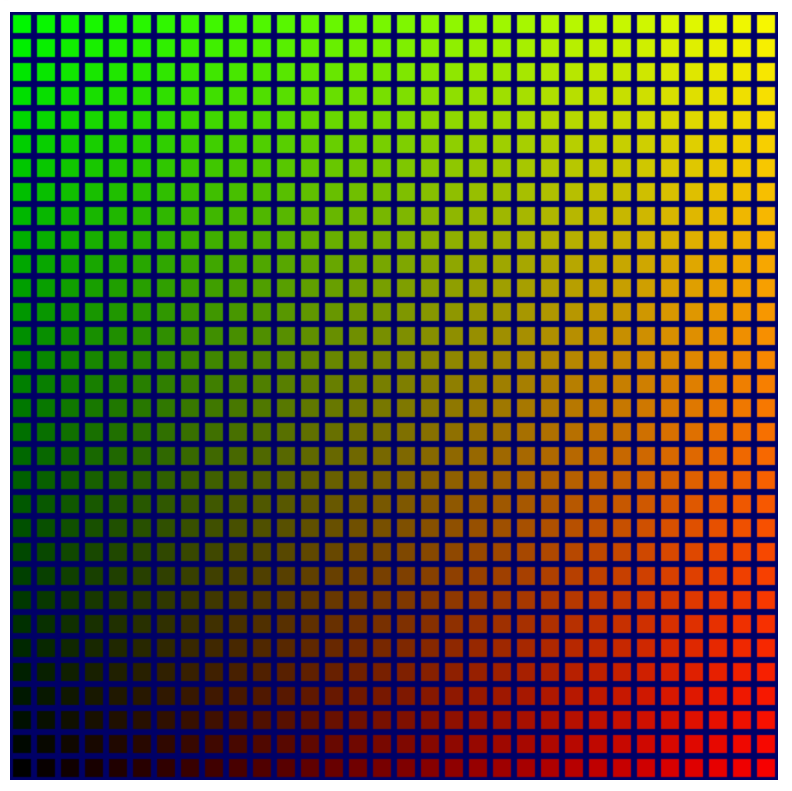
雖然這確實是項改善,但現在左下方有一個不幸的黑暗角落,其中的格線會變成黑色。開始進行生命遊戲模擬時,格狀畫面中難以辨識的部分會遮住實際情況。希望能改善這個問題。
幸運的是,您還有一個未使用的色彩通道 (藍色) 可用。理想的效果是讓藍色最亮,其他顏色最暗,然後隨著其他顏色亮度增加而淡出。最簡單的方法是讓管道開始於 1,並減去其中一個儲存格值。可以是 c.x 或 c.y。試試看這兩種方法,然後選擇你偏好的做法!
- 在片段著色器中加入較亮的顏色,如下所示:
createShaderModule 呼叫
@fragment
fn fragmentMain(input: VertexOutput) -> @location(0) vec4f {
let c = input.cell / grid;
return vec4f(c, 1-c.x, 1);
}
結果看起來相當不錯!
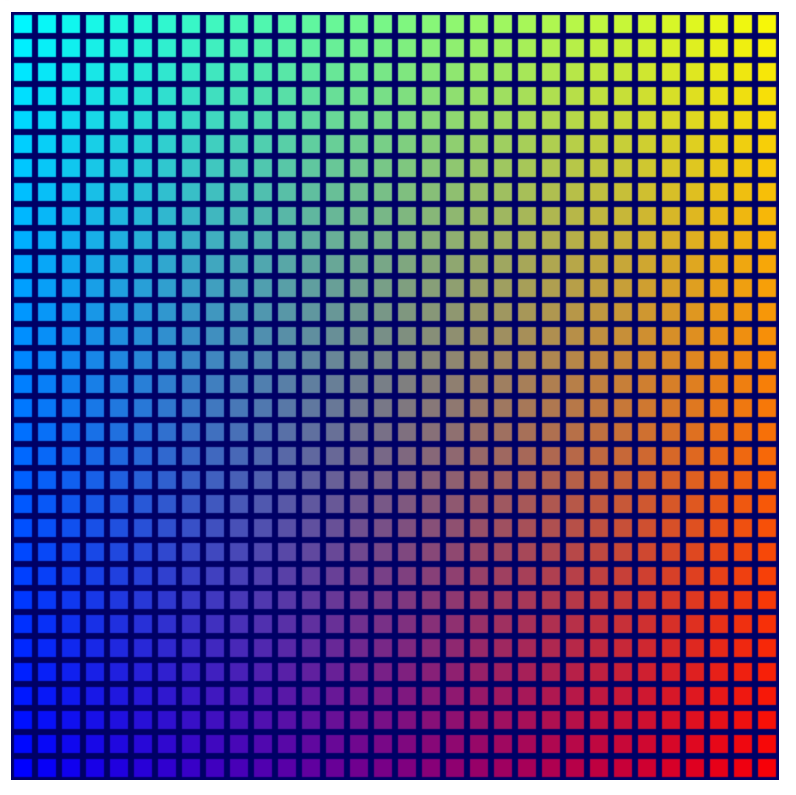
這不是必要步驟!不過,由於這張圖片看起來比較好看,因此已納入對應的檢查點來源檔案,本程式碼研究室的其他螢幕截圖也都採用這個更鮮豔的格線。
7. 管理儲存格狀態
接下來,您需要根據儲存在 GPU 上的某些狀態,控制格狀顯示的哪些儲存格。這對於最終模擬結果至關重要!
您只需要每個儲存格的開關信號,因此任何可讓您儲存幾乎所有值類型的大型陣列選項都適用。您可能會認為這是統一緩衝區的另一個用途!雖然可以讓這項功能運作,但難度較高,因為統一緩衝區的大小有限,無法支援動態大小的陣列 (您必須在著色器中指定陣列大小),也無法由運算著色器寫入。最後一個項目最有問題,因為您想在運算著色器的 GPU 上執行 Game of Life 模擬。
幸運的是,還有另一種緩衝選項可避免所有這些限制。
建立儲存空間緩衝區
儲存緩衝區是一般用途的緩衝區,可在運算著色器中讀取及寫入,並在頂點著色器中讀取。它們可以非常大,而且不需要在著色器中宣告特定大小,因此更像是一般記憶體。您可以使用這個值來儲存儲存格狀態。
- 如要為儲存格狀態建立儲存緩衝區,請使用目前可能開始變得熟悉的緩衝區建立程式碼片段:
index.html
// Create an array representing the active state of each cell.
const cellStateArray = new Uint32Array(GRID_SIZE * GRID_SIZE);
// Create a storage buffer to hold the cell state.
const cellStateStorage = device.createBuffer({
label: "Cell State",
size: cellStateArray.byteLength,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST,
});
就像頂點和統一緩衝區一樣,請使用適當大小呼叫 device.createBuffer(),然後務必指定 GPUBufferUsage.STORAGE 的用法。
您可以使用與先前相同的方式填入緩衝區,方法是將值填入相同大小的 TypedArray,然後呼叫 device.queue.writeBuffer()。因為您想查看緩衝區對格線的影響,因此請先填入可預測的內容。
- 使用下列程式碼啟用每隔一個儲存格:
index.html
// Mark every third cell of the grid as active.
for (let i = 0; i < cellStateArray.length; i += 3) {
cellStateArray[i] = 1;
}
device.queue.writeBuffer(cellStateStorage, 0, cellStateArray);
在著色器中讀取儲存緩衝區
接著,請更新著色器,在轉譯格線之前查看儲存緩衝區的內容。這與先前新增制服的方式非常類似。
- 使用下列程式碼更新著色器:
index.html
@group(0) @binding(0) var<uniform> grid: vec2f;
@group(0) @binding(1) var<storage> cellState: array<u32>; // New!
首先,您需要新增繫結點,該點會位於格線均勻器下方。您希望 @group 與 grid 保持一致,但 @binding 數字必須不同。var 類型為 storage,可反映不同的緩衝區類型。您為 cellState 提供的類型不是單一向量,而是 u32 值的陣列,以便與 JavaScript 中的 Uint32Array 相符。
接著,在 @vertex 函式的主體中,查詢儲存格狀態。由於狀態會儲存在儲存空間緩衝區的平面陣列中,因此您可以使用 instance_index 來查詢目前儲存格中的值!
如果狀態指出該儲存格處於停用狀態,您該如何關閉該儲存格?由於從陣列取得的有效和無效狀態分別為 1 和 0,因此您可以根據有效狀態縮放幾何圖形!縮放比例為 1 時,幾何圖形會保持不變;縮放比例為 0 時,幾何圖形會縮減為單一點,然後 GPU 會捨棄該點。
- 請更新著色器程式碼,根據單元格的活動狀態縮放位置。狀態值必須轉換為
f32,才能符合 WGSL 的型別安全性規定:
index.html
@vertex
fn vertexMain(@location(0) pos: vec2f,
@builtin(instance_index) instance: u32) -> VertexOutput {
let i = f32(instance);
let cell = vec2f(i % grid.x, floor(i / grid.x));
let state = f32(cellState[instance]); // New line!
let cellOffset = cell / grid * 2;
// New: Scale the position by the cell's active state.
let gridPos = (pos*state+1) / grid - 1 + cellOffset;
var output: VertexOutput;
output.pos = vec4f(gridPos, 0, 1);
output.cell = cell;
return output;
}
將儲存空間緩衝區新增至繫結群組
在您看到儲存格狀態生效之前,請先將儲存格緩衝區新增至繫結群組。由於它是與統一緩衝區相同的 @group 的一部分,因此請將其加進 JavaScript 程式碼中的相同繫結群組。
- 新增儲存空間緩衝區,如下所示:
index.html
const bindGroup = device.createBindGroup({
label: "Cell renderer bind group",
layout: cellPipeline.getBindGroupLayout(0),
entries: [{
binding: 0,
resource: { buffer: uniformBuffer }
},
// New entry!
{
binding: 1,
resource: { buffer: cellStateStorage }
}],
});
請確認新項目的 binding 與著色器中對應值的 @binding() 相符!
完成後,您應該可以重新整理,並在格狀檢視畫面中看到圖案。
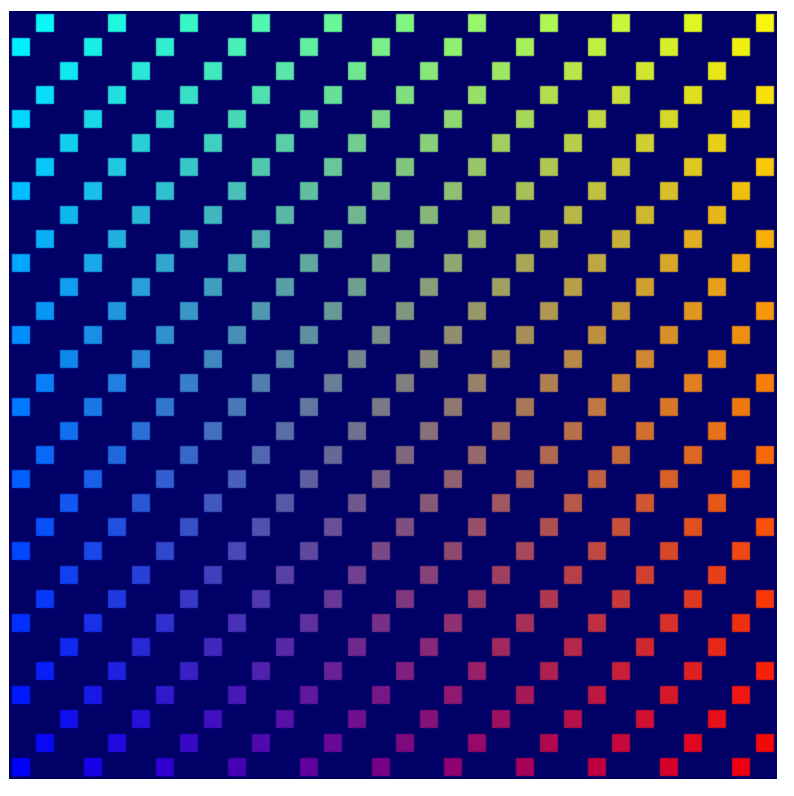
使用 ping-pong 緩衝區模式
您正在建構的模擬作業通常會使用至少兩份狀態副本。在模擬的每個步驟中,它們會從一個狀態副本讀取資料,並寫入另一個副本。接著,在下一個步驟中,將其翻轉,並從先前寫入的狀態讀取。這通常稱為「ping pong」模式,因為狀態的最新版本會在每個步驟的狀態副本之間來回彈跳。
為什麼需要這樣做?請參考簡化的範例:假設您正在編寫非常簡單的模擬程式,其中每個步驟都會將任何有效區塊向右移動一個儲存格。為方便理解,您可以在 JavaScript 中定義資料和模擬資料:
// Example simulation. Don't copy into the project!
const state = [1, 0, 0, 0, 0, 0, 0, 0];
function simulate() {
for (let i = 0; i < state.length-1; ++i) {
if (state[i] == 1) {
state[i] = 0;
state[i+1] = 1;
}
}
}
simulate(); // Run the simulation for one step.
但如果您執行該程式碼,活動儲存格會在一步驟中移動到陣列的結尾!這是因為因為您會持續更新狀態,因此您將活動儲存格移至右側,然後查看下一個儲存格,然後...已啟用!最好再將它移到右側。您在觀察資料時同時變更資料,這會導致結果遭到破壞。
使用 Ping Pong 模式,您就能確保一律只使用上一個步驟的結果執行模擬的下一個步驟。
// Example simulation. Don't copy into the project!
const stateA = [1, 0, 0, 0, 0, 0, 0, 0];
const stateB = [0, 0, 0, 0, 0, 0, 0, 0];
function simulate(inArray, outArray) {
outArray[0] = 0;
for (let i = 1; i < inArray.length; ++i) {
outArray[i] = inArray[i-1];
}
}
// Run the simulation for two step.
simulate(stateA, stateB);
simulate(stateB, stateA);
- 在您自己的程式碼中使用這個模式,更新儲存空間緩衝區配置,以便建立兩個相同的緩衝區:
index.html
// Create two storage buffers to hold the cell state.
const cellStateStorage = [
device.createBuffer({
label: "Cell State A",
size: cellStateArray.byteLength,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST,
}),
device.createBuffer({
label: "Cell State B",
size: cellStateArray.byteLength,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST,
})
];
- 為了方便您查看兩個緩衝區之間的差異,請為兩個緩衝區填入不同的資料:
index.html
// Mark every third cell of the first grid as active.
for (let i = 0; i < cellStateArray.length; i+=3) {
cellStateArray[i] = 1;
}
device.queue.writeBuffer(cellStateStorage[0], 0, cellStateArray);
// Mark every other cell of the second grid as active.
for (let i = 0; i < cellStateArray.length; i++) {
cellStateArray[i] = i % 2;
}
device.queue.writeBuffer(cellStateStorage[1], 0, cellStateArray);
- 如要在算繪中顯示不同的儲存空間緩衝區,請更新繫結群組,讓其擁有兩種不同的變化版本:
index.html
const bindGroups = [
device.createBindGroup({
label: "Cell renderer bind group A",
layout: cellPipeline.getBindGroupLayout(0),
entries: [{
binding: 0,
resource: { buffer: uniformBuffer }
}, {
binding: 1,
resource: { buffer: cellStateStorage[0] }
}],
}),
device.createBindGroup({
label: "Cell renderer bind group B",
layout: cellPipeline.getBindGroupLayout(0),
entries: [{
binding: 0,
resource: { buffer: uniformBuffer }
}, {
binding: 1,
resource: { buffer: cellStateStorage[1] }
}],
})
];
設定轉譯迴圈
到目前為止,您每次重新整理頁面都只會執行一次繪圖作業,但現在您想顯示隨時間更新的資料。為此,您需要一個簡單的轉譯迴圈。
算繪迴圈是無限重複的迴圈,會在特定間隔內將內容繪製至畫布。許多遊戲和其他想以流暢動畫呈現的內容,都會使用 requestAnimationFrame() 函式,以螢幕刷新的速度 (每秒 60 次) 安排回呼。
這個應用程式也可以使用這項功能,但在這種情況下,您可能會希望更新步驟較長,以便更輕鬆地追蹤模擬作業的執行情形。請改為自行管理迴圈,以便控制模擬更新的速率。
- 首先,請選擇模擬更新的速度 (200 毫秒即可,但您可以視需要加快或放慢速度),然後追蹤已完成的模擬步驟數。
index.html
const UPDATE_INTERVAL = 200; // Update every 200ms (5 times/sec)
let step = 0; // Track how many simulation steps have been run
- 接著,將目前用於轉譯的所有程式碼移至新函式。使用
setInterval()安排該函式以所需間隔重複執行。請確認函式也會更新步數,並使用該函式選取要繫結的兩個繫結群組。
index.html
// Move all of our rendering code into a function
function updateGrid() {
step++; // Increment the step count
// Start a render pass
const encoder = device.createCommandEncoder();
const pass = encoder.beginRenderPass({
colorAttachments: [{
view: context.getCurrentTexture().createView(),
loadOp: "clear",
clearValue: { r: 0, g: 0, b: 0.4, a: 1.0 },
storeOp: "store",
}]
});
// Draw the grid.
pass.setPipeline(cellPipeline);
pass.setBindGroup(0, bindGroups[step % 2]); // Updated!
pass.setVertexBuffer(0, vertexBuffer);
pass.draw(vertices.length / 2, GRID_SIZE * GRID_SIZE);
// End the render pass and submit the command buffer
pass.end();
device.queue.submit([encoder.finish()]);
}
// Schedule updateGrid() to run repeatedly
setInterval(updateGrid, UPDATE_INTERVAL);
現在,當您執行應用程式時,您會看到畫布會在您建立的兩個狀態緩衝區之間來回切換。
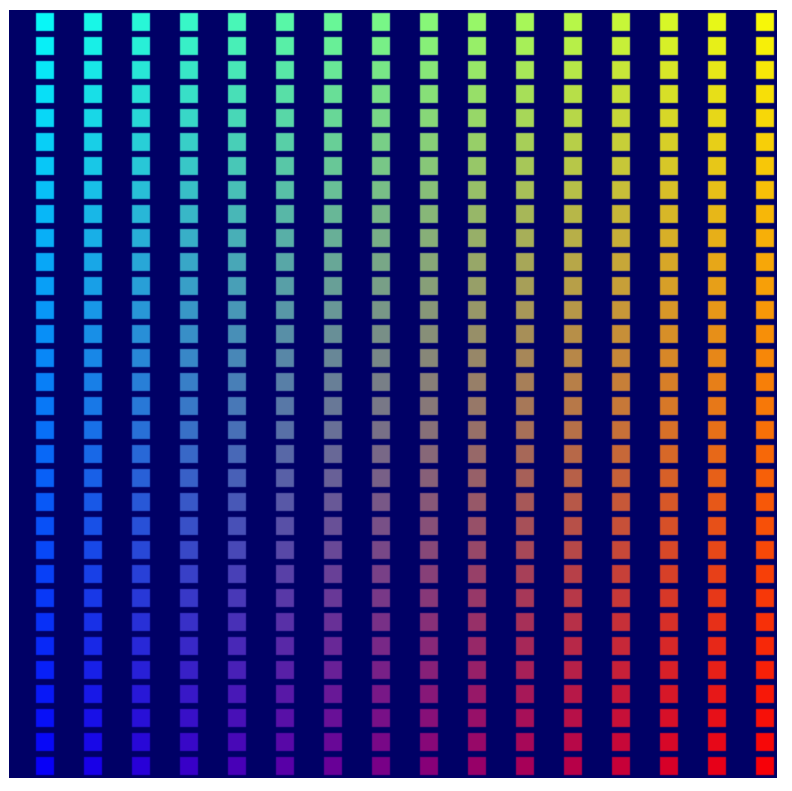
這樣一來,您幾乎完成了轉譯作業!您已準備就緒,可在下一個步驟中顯示建立的 Game of Life 模擬輸出內容,並開始使用運算著色器。
顯然,WebGPU 的算繪功能遠不止於您在這裡探索的內容,但其餘部分超出本程式碼研究室的範圍。希望這能讓您充分體驗 WebGPU 的算繪運作方式,進而更容易掌握 3D 算繪等進階技術。
8. 執行模擬
接下來,我們要完成最後一個主要部分:在運算著色器中執行 Game of Life 模擬!
終於可以使用運算著色器了!
在本程式碼研究室中,您已抽象地瞭解運算著色器,但它們究竟是什麼呢?
計算著色器與頂點著色器和片段著色器相似,都是為了在 GPU 上以極度平行的方式執行而設計,但與其他兩個著色器階段不同的是,它們沒有特定的輸入和輸出組合。您只會從所選來源 (例如儲存空間緩衝區) 讀取及寫入資料。也就是說,您必須告知系統要叫用多少次著色器函式,而非為每個頂點、例項或像素執行一次。接著,當您執行著色器時,系統會告知您正在處理哪個叫用作業,您可以決定要存取哪些資料,以及要執行哪些作業。
運算著色器必須在著色器模組中建立,就像頂點和片段著色器一樣,因此請將運算著色器加入程式碼,開始使用。如您所知,考量到您已實作的其他著色器結構,計算著色器的主函式需要標示 @compute 屬性。
- 使用以下程式碼建立運算著色器:
index.html
// Create the compute shader that will process the simulation.
const simulationShaderModule = device.createShaderModule({
label: "Game of Life simulation shader",
code: `
@compute
fn computeMain() {
}`
});
由於 GPU 經常用於 3D 圖形,因此運算著色器的結構可讓您要求沿著 X、Y 和 Z 軸叫用著色器的次數。這樣一來,您就能輕鬆調度符合 2D 或 3D 格狀的運算工作,非常適合您的用途!您需要為此著色器呼叫 GRID_SIZE 次 GRID_SIZE 次,每個模擬資料單元各一次。
由於 GPU 硬體架構的特性,這個格線會分成工作群組。工作群組有 X、Y 和 Z 大小,雖然每個大小都可以設為 1,但通常將工作群組設為稍大一點,有助於提升效能。針對著色器,請選擇 8 x 8 的任意工作群組大小。這項功能可用於追蹤 JavaScript 程式碼。
- 定義工作群組大小的常數,如下所示:
index.html
const WORKGROUP_SIZE = 8;
您還需要使用 JavaScript 的範本字面值,將工作群組大小新增至著色器函式,以便輕鬆使用剛剛定義的常數。
- 將工作群組大小新增至著色器函式,如下所示:
index.html (Compute createShaderModule 呼叫)
@compute
@workgroup_size(${WORKGROUP_SIZE}, ${WORKGROUP_SIZE}) // New line
fn computeMain() {
}
這會告訴著色器,使用此函式完成的工作是在 (8 x 8 x 1) 群組中完成。(未指定的軸預設值為 1,但您至少必須指定 X 軸)。
與其他著色器階段一樣,您可以接受各種 @builtin 值,做為輸入至運算著色器函式的值,以便告知您正在執行哪個叫用作業,並決定要執行哪些工作。
- 新增
@builtin值,如下所示:
index.html (Compute createShaderModule 呼叫)
@compute @workgroup_size(${WORKGROUP_SIZE}, ${WORKGROUP_SIZE})
fn computeMain(@builtin(global_invocation_id) cell: vec3u) {
}
您會傳入 global_invocation_id 內建項目,這是一個無符號整數的三維向量,可指出您在著色器叫用格線中的位置。您會為每個格中的單元格執行此著色器一次。您會看到 (0, 0, 0)、(1, 0, 0)、(1, 1, 0)... 一直到 (31, 31, 0) 等數字,這表示您可以將其視為要操作的儲存格索引!
運算著色器也可以使用統一變數,使用方式與頂點和片段著色器相同。
- 使用與運算著色器搭配的統一值,以便告知您格線大小,如下所示:
index.html (Compute createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f; // New line
@compute @workgroup_size(${WORKGROUP_SIZE}, ${WORKGROUP_SIZE})
fn computeMain(@builtin(global_invocation_id) cell: vec3u) {
}
就像在頂點著色器中一樣,您也可以將單元格狀態公開為儲存緩衝區。但在本例中,您需要兩個!由於運算著色器沒有必要的輸出內容 (例如頂點位置或片段顏色),因此將值寫入儲存空間緩衝區或紋理,是取得運算著色器結果的唯一方法。使用先前學到的 ping-pong 方法,您有一個儲存緩衝區可用於提供目前的網格狀態,以及一個用於寫入網格新狀態的緩衝區。
- 將儲存格輸入和輸出狀態公開為儲存緩衝區,如下所示:
index.html (Compute createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
// New lines
@group(0) @binding(1) var<storage> cellStateIn: array<u32>;
@group(0) @binding(2) var<storage, read_write> cellStateOut: array<u32>;
@compute @workgroup_size(${WORKGROUP_SIZE}, ${WORKGROUP_SIZE})
fn computeMain(@builtin(global_invocation_id) cell: vec3u) {
}
請注意,第一個儲存空間緩衝區是使用 var<storage> 宣告,因此為唯讀,但第二個儲存空間緩衝區則是使用 var<storage, read_write> 宣告。這樣一來,您就能讀取及寫入緩衝區,並將該緩衝區用於運算著色器的輸出內容。(WebGPU 中沒有唯寫儲存模式)。
接下來,您需要有一種方法,將儲存格索引對應至線性儲存陣列。這基本上與您在頂點著色器中所做的相反,在頂點著色器中,您將線性 instance_index 對應至 2D 格線單元格。(提醒你,當時的演算法為 vec2f(i % grid.x, floor(i / grid.x)))。
- 編寫函式以便往另一個方向移動。它會取用儲存格 Y 值,並將其乘以格線寬度,然後加上儲存格 X 值。
index.html (Compute createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
@group(0) @binding(1) var<storage> cellStateIn: array<u32>;
@group(0) @binding(2) var<storage, read_write> cellStateOut: array<u32>;
// New function
fn cellIndex(cell: vec2u) -> u32 {
return cell.y * u32(grid.x) + cell.x;
}
@compute @workgroup_size(${WORKGROUP_SIZE}, ${WORKGROUP_SIZE})
fn computeMain(@builtin(global_invocation_id) cell: vec3u) {
}
最後,為了確認這項功能是否正常運作,請實作一個非常簡單的演算法:如果目前有一個單元格處於開啟狀態,則會關閉,反之亦然。雖然這還不是 Game of Life,但足以證明運算著色器運作正常。
- 新增簡單的演算法,如下所示:
index.html (Compute createShaderModule 呼叫)
@group(0) @binding(0) var<uniform> grid: vec2f;
@group(0) @binding(1) var<storage> cellStateIn: array<u32>;
@group(0) @binding(2) var<storage, read_write> cellStateOut: array<u32>;
fn cellIndex(cell: vec2u) -> u32 {
return cell.y * u32(grid.x) + cell.x;
}
@compute @workgroup_size(${WORKGROUP_SIZE}, ${WORKGROUP_SIZE})
fn computeMain(@builtin(global_invocation_id) cell: vec3u) {
// New lines. Flip the cell state every step.
if (cellStateIn[cellIndex(cell.xy)] == 1) {
cellStateOut[cellIndex(cell.xy)] = 0;
} else {
cellStateOut[cellIndex(cell.xy)] = 1;
}
}
以上就是 Compute Shader 的內容,至少目前是如此!不過,您必須先進行其他幾項變更,才能看到結果。
使用 Bind Group 和管道版面配置
您可能會注意到,上述著色器主要使用與轉譯管道相同的輸入內容 (統一緩衝區和儲存空間緩衝區)。您可能會認為只要使用相同的繫結群組即可,對吧?好消息是,您可以!但需要進行更多手動設定。
每次建立繫結群組時,都必須提供 GPUBindGroupLayout。先前您是在轉譯管道上呼叫 getBindGroupLayout() 來取得版面配置,而您在建立時提供 layout: "auto",因此系統會自動建立版面配置。這種做法在您只使用單一管道時非常實用,但如果有多個管道想要共用資源,您就必須明確建立版面配置,然後將其提供給繫結群組和管道。
為協助您瞭解原因,請考慮以下情況:在轉譯管道中,您使用單一統一緩衝區和單一儲存緩衝區,但在剛剛編寫的運算著色器中,您需要第二個儲存緩衝區。由於兩個著色器都使用相同的 @binding 值來處理統一和第一個儲存區緩衝區,因此您可以在管道之間共用這些值,且轉譯管道會忽略未使用的第二個儲存區緩衝區。您需要建立配置,描述繫結群組中「所有」資源,而非僅描述特定管道使用的資源。
- 如要建立該版面配置,請呼叫
device.createBindGroupLayout():
index.html
// Create the bind group layout and pipeline layout.
const bindGroupLayout = device.createBindGroupLayout({
label: "Cell Bind Group Layout",
entries: [{
binding: 0,
// Add GPUShaderStage.FRAGMENT here if you are using the `grid` uniform in the fragment shader.
visibility: GPUShaderStage.VERTEX | GPUShaderStage.COMPUTE,
buffer: {} // Grid uniform buffer
}, {
binding: 1,
visibility: GPUShaderStage.VERTEX | GPUShaderStage.COMPUTE,
buffer: { type: "read-only-storage"} // Cell state input buffer
}, {
binding: 2,
visibility: GPUShaderStage.COMPUTE,
buffer: { type: "storage"} // Cell state output buffer
}]
});
這個結構與建立繫結群組本身的結構類似,因為您會描述 entries 的清單。差別在於您必須說明項目必須是哪種資源類型,以及該資源的使用方式,而非提供資源本身。
在每個項目中,您都會提供資源的 binding 編號,這會與著色器中的 @binding 值相符 (如您在建立繫結群組時所學到的)。您也必須提供 visibility,這是 GPUShaderStage 標記,用於指出哪些著色器階段可使用該資源。您希望在頂點和運算著色器中,都能存取統一和第一個儲存區緩衝區,但第二個儲存區緩衝區只需要在運算著色器中存取。
最後,請指出所使用的資源類型。這會是不同的字典鍵,取決於您需要公開的內容。在這裡,所有三個資源都是緩衝區,因此您可以使用 buffer 鍵來定義每個資源的選項。其他選項包括 texture 或 sampler,但您不需要使用這些選項。
在緩衝區字典中,您可以設定所使用的緩衝區 type 等選項。預設值為 "uniform",因此您可以將字典留空,以便繫結 0。(不過,您至少必須設定 buffer: {},才能將項目識別為緩衝區)。繫結 1 的類型為 "read-only-storage",因為您不會在著色器中使用 read_write 存取權,而繫結 2 的類型為 "storage",因為您會使用 read_write 存取權!
建立 bindGroupLayout 後,您可以在建立繫結群組時傳入該值,而非從管道中查詢繫結群組。這表示您需要在每個繫結群組中新增儲存空間緩衝區項目,以符合您剛剛定義的版面配置。
- 更新繫結群組建立作業,如下所示:
index.html
// Create a bind group to pass the grid uniforms into the pipeline
const bindGroups = [
device.createBindGroup({
label: "Cell renderer bind group A",
layout: bindGroupLayout, // Updated Line
entries: [{
binding: 0,
resource: { buffer: uniformBuffer }
}, {
binding: 1,
resource: { buffer: cellStateStorage[0] }
}, {
binding: 2, // New Entry
resource: { buffer: cellStateStorage[1] }
}],
}),
device.createBindGroup({
label: "Cell renderer bind group B",
layout: bindGroupLayout, // Updated Line
entries: [{
binding: 0,
resource: { buffer: uniformBuffer }
}, {
binding: 1,
resource: { buffer: cellStateStorage[1] }
}, {
binding: 2, // New Entry
resource: { buffer: cellStateStorage[0] }
}],
}),
];
由於繫結群組已更新為使用這個明確的繫結群組版面配置,您需要更新轉譯管道,以便使用相同的版面配置。
index.html
const pipelineLayout = device.createPipelineLayout({
label: "Cell Pipeline Layout",
bindGroupLayouts: [ bindGroupLayout ],
});
管道版面配置是指一或多個管道使用的繫結群組版面配置清單 (在本例中,您有一個)。陣列中繫結群組版面的順序必須與著色器中的 @group 屬性相符。(這表示 bindGroupLayout 與 @group(0) 相關聯)。
- 管道版面配置完成後,請更新算繪管道,以便使用該版面配置,而非
"auto"。
index.html
const cellPipeline = device.createRenderPipeline({
label: "Cell pipeline",
layout: pipelineLayout, // Updated!
vertex: {
module: cellShaderModule,
entryPoint: "vertexMain",
buffers: [vertexBufferLayout]
},
fragment: {
module: cellShaderModule,
entryPoint: "fragmentMain",
targets: [{
format: canvasFormat
}]
}
});
建立運算管道
就像您需要運算管道才能使用頂點和片段著色器一樣,您也需要運算管道才能使用運算著色器。幸運的是,運算管道遠比轉譯管道簡單,因為它們沒有任何要設定的狀態,只有著色器和版面配置。
- 使用以下程式碼建立運算管道:
index.html
// Create a compute pipeline that updates the game state.
const simulationPipeline = device.createComputePipeline({
label: "Simulation pipeline",
layout: pipelineLayout,
compute: {
module: simulationShaderModule,
entryPoint: "computeMain",
}
});
請注意,您傳入的是新的 pipelineLayout,而非 "auto",就像在更新後的轉譯管道中一樣,這樣可確保轉譯管道和運算管道都能使用相同的繫結群組。
運算通行證
這就是實際使用運算管道的方式!由於您是在轉譯階段執行轉譯作業,因此您可能會猜到需要在運算階段執行運算作業。運算和轉譯工作可在同一個指令編碼器中執行,因此您需要稍微重新排序 updateGrid 函式。
- 將編碼器建立作業移至函式的頂端,然後開始使用該作業執行運算傳遞 (在
step++之前)。
index.html
// In updateGrid()
// Move the encoder creation to the top of the function.
const encoder = device.createCommandEncoder();
const computePass = encoder.beginComputePass();
// Compute work will go here...
computePass.end();
// Existing lines
step++; // Increment the step count
// Start a render pass...
和運算管道一樣,運算階段的啟動程序比算繪階段簡單許多,因為您不必擔心任何附件。
您應該在算繪階段前執行運算階段,因為這樣一來,算繪階段就能立即使用運算階段的最新結果。這也是您在各次掃描之間遞增 step 計數的原因,這樣運算管線的輸出緩衝區就會成為轉譯管線的輸入緩衝區。
- 接下來,請在運算階段內設定管道和繫結群組,並使用與轉譯階段相同的模式在繫結群組之間切換。
index.html
const computePass = encoder.beginComputePass();
// New lines
computePass.setPipeline(simulationPipeline);
computePass.setBindGroup(0, bindGroups[step % 2]);
computePass.end();
- 最後,您可以將工作調度至運算著色器,而不是像在轉譯通道中一樣繪製,並告知運算著色器要在每個軸上執行的工作群組數量。
index.html
const computePass = encoder.beginComputePass();
computePass.setPipeline(simulationPipeline);
computePass.setBindGroup(0, bindGroups[step % 2]);
// New lines
const workgroupCount = Math.ceil(GRID_SIZE / WORKGROUP_SIZE);
computePass.dispatchWorkgroups(workgroupCount, workgroupCount);
computePass.end();
請注意,非常重要的是,您傳遞至 dispatchWorkgroups() 的數字不是叫用次數!而是由著色器中的 @workgroup_size 定義的執行工作群組數量。
如果您希望著色器執行 32x32 次,以涵蓋整個格線,且工作群組大小為 8x8,則需要調度 4x4 個工作群組 (4 * 8 = 32)。因此,您必須將格線大小除以工作群組大小,然後將該值傳遞至 dispatchWorkgroups()。
現在,您可以再次重新整理頁面,您應該會看到每個更新都會將格線反轉。
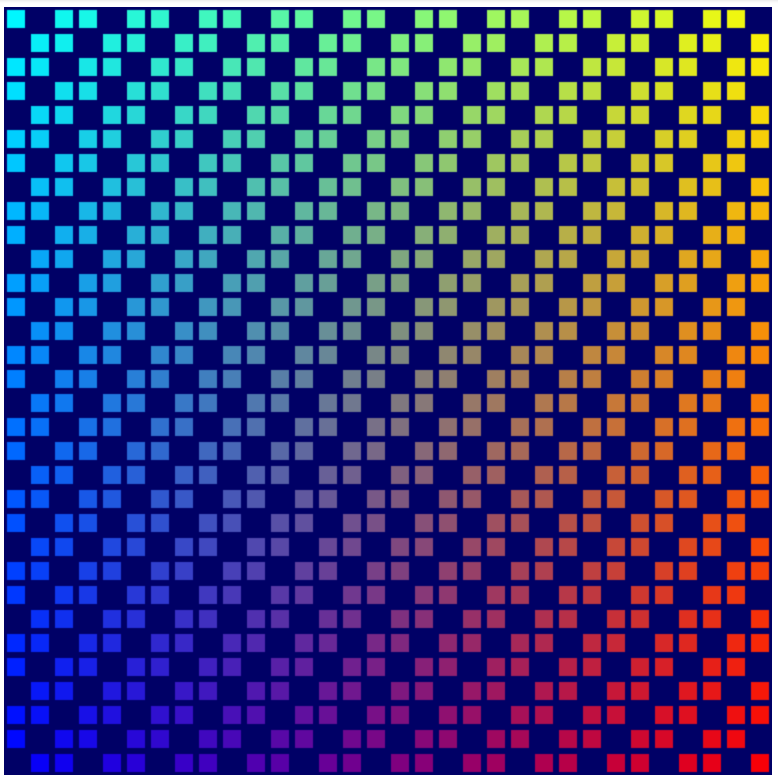
實作生命遊戲的演算法
在更新運算著色器以實作最終演算法之前,您需要返回用於初始化儲存緩衝區內容的程式碼,並更新該程式碼,以便在每次載入網頁時產生隨機緩衝區。(規則圖案並不是很有趣的生命遊戲起始點)。您可以隨意隨機化值,但有個簡單的方法可以讓您快速取得合理的結果。
- 如要讓每個儲存格以隨機狀態啟動,請將
cellStateArray初始化更新為以下程式碼:
index.html
// Set each cell to a random state, then copy the JavaScript array
// into the storage buffer.
for (let i = 0; i < cellStateArray.length; ++i) {
cellStateArray[i] = Math.random() > 0.6 ? 1 : 0;
}
device.queue.writeBuffer(cellStateStorage[0], 0, cellStateArray);
您現在終於可以實作 Game of Life 模擬遊戲的邏輯了。經過這麼多步驟才完成的著色器程式碼,可能會讓您大失所望,因為它可能非常簡單!
首先,您必須瞭解任何儲存格有多少相鄰儲存格是活動的。您不需要知道哪些是有效的,只需要知道數量即可。
- 如要更輕鬆地取得相鄰儲存格資料,請新增
cellActive函式,以便傳回指定座標的cellStateIn值。
index.html (Compute createShaderModule 呼叫)
fn cellActive(x: u32, y: u32) -> u32 {
return cellStateIn[cellIndex(vec2(x, y))];
}
如果儲存格處於活動狀態,cellActive 函式會傳回 1,因此如果您將所有八個相鄰儲存格呼叫 cellActive 的傳回值加總起來,就能得知有多少相鄰儲存格處於活動狀態。
- 找出有效鄰點的數量,如下所示:
index.html (Compute createShaderModule 呼叫)
fn computeMain(@builtin(global_invocation_id) cell: vec3u) {
// New lines:
// Determine how many active neighbors this cell has.
let activeNeighbors = cellActive(cell.x+1, cell.y+1) +
cellActive(cell.x+1, cell.y) +
cellActive(cell.x+1, cell.y-1) +
cellActive(cell.x, cell.y-1) +
cellActive(cell.x-1, cell.y-1) +
cellActive(cell.x-1, cell.y) +
cellActive(cell.x-1, cell.y+1) +
cellActive(cell.x, cell.y+1);
不過,這會導致一個小問題:如果您要檢查的單元格位於版面配置邊緣之外,會發生什麼情況?根據您目前的 cellIndex() 邏輯,它會溢出到下一個或上一個資料列,或是超出緩衝區!
針對生命遊戲,常見且簡單的解決方法是讓格線邊緣的單元格將格線另一側的單元格視為相鄰單元格,藉此產生一種迴繞效果。
- 透過對
cellIndex()函式進行小幅變更,支援格線迴轉。
index.html (Compute createShaderModule 呼叫)
fn cellIndex(cell: vec2u) -> u32 {
return (cell.y % u32(grid.y)) * u32(grid.x) +
(cell.x % u32(grid.x));
}
使用 % 運算子將 X 和 Y 單元格包裝在格狀區域之外,可確保您不會存取儲存緩衝區外圍。這樣一來,您就能放心,因為 activeNeighbors 的數量是可預測的。
然後套用下列四種規則之一:
- 任何鄰居數少於兩個的單元格都會失效。
- 任何有兩個或三個相鄰格的有效單元都會保持有效。
- 任何有三個相鄰格子的非活動格子都會變成活動格子。
- 任何擁有超過三個相鄰格子的單元格都會變成無效。
您可以使用一系列的 if 陳述式執行此操作,但 WGSL 也支援 switch 陳述式,這類陳述式非常適合用於此邏輯。
- 實作 Game of Life 邏輯,如下所示:
index.html (Compute createShaderModule 呼叫)
let i = cellIndex(cell.xy);
// Conway's game of life rules:
switch activeNeighbors {
case 2: { // Active cells with 2 neighbors stay active.
cellStateOut[i] = cellStateIn[i];
}
case 3: { // Cells with 3 neighbors become or stay active.
cellStateOut[i] = 1;
}
default: { // Cells with < 2 or > 3 neighbors become inactive.
cellStateOut[i] = 0;
}
}
以下是最終運算著色器模組呼叫的參考範例:
index.html
const simulationShaderModule = device.createShaderModule({
label: "Life simulation shader",
code: `
@group(0) @binding(0) var<uniform> grid: vec2f;
@group(0) @binding(1) var<storage> cellStateIn: array<u32>;
@group(0) @binding(2) var<storage, read_write> cellStateOut: array<u32>;
fn cellIndex(cell: vec2u) -> u32 {
return (cell.y % u32(grid.y)) * u32(grid.x) +
(cell.x % u32(grid.x));
}
fn cellActive(x: u32, y: u32) -> u32 {
return cellStateIn[cellIndex(vec2(x, y))];
}
@compute @workgroup_size(${WORKGROUP_SIZE}, ${WORKGROUP_SIZE})
fn computeMain(@builtin(global_invocation_id) cell: vec3u) {
// Determine how many active neighbors this cell has.
let activeNeighbors = cellActive(cell.x+1, cell.y+1) +
cellActive(cell.x+1, cell.y) +
cellActive(cell.x+1, cell.y-1) +
cellActive(cell.x, cell.y-1) +
cellActive(cell.x-1, cell.y-1) +
cellActive(cell.x-1, cell.y) +
cellActive(cell.x-1, cell.y+1) +
cellActive(cell.x, cell.y+1);
let i = cellIndex(cell.xy);
// Conway's game of life rules:
switch activeNeighbors {
case 2: {
cellStateOut[i] = cellStateIn[i];
}
case 3: {
cellStateOut[i] = 1;
}
default: {
cellStateOut[i] = 0;
}
}
}
`
});
這樣就完成了!大功告成!重新整理頁面,看看新建的細胞自動機器如何成長!