1. ภาพรวม
ในห้องทดลองนี้ คุณจะได้ดูวิธีกำหนดค่าและเปิดการดำเนินการกับสมุดบันทึกด้วย Vertex AI Workbench
สิ่งที่คุณเรียนรู้
โดยคุณจะได้เรียนรู้วิธีต่อไปนี้
- ใช้พารามิเตอร์ในสมุดบันทึก
- กำหนดค่าและเปิดการดำเนินการสมุดบันทึกจาก UI ของ Vertex AI Workbench
ค่าใช้จ่ายรวมในการเรียกใช้ห้องทดลองนี้บน Google Cloud อยู่ที่ประมาณ $2
2. ข้อมูลเบื้องต้นเกี่ยวกับ Vertex AI
ห้องทดลองนี้ใช้ข้อเสนอผลิตภัณฑ์ AI ใหม่ล่าสุดที่มีให้บริการใน Google Cloud Vertex AI ผสานรวมข้อเสนอ ML ใน Google Cloud เข้าด้วยกันเพื่อมอบประสบการณ์การพัฒนาที่ราบรื่น ก่อนหน้านี้โมเดลที่ฝึกด้วย AutoML และโมเดลที่กำหนดเองจะเข้าถึงได้ผ่านบริการแยกต่างหาก ข้อเสนอใหม่จะรวมทั้ง 2 อย่างไว้ใน API เดียว รวมทั้งผลิตภัณฑ์ใหม่อื่นๆ นอกจากนี้ คุณยังย้ายข้อมูลโปรเจ็กต์ที่มีอยู่ไปยัง Vertex AI ได้ด้วย หากมีความคิดเห็น โปรดดูหน้าการสนับสนุน
Vertex AI มีผลิตภัณฑ์ต่างๆ มากมายเพื่อรองรับเวิร์กโฟลว์ ML แบบครบวงจร ห้องทดลองนี้จะมุ่งเน้นที่ Vertex AI Workbench
Vertex AI Workbench ช่วยให้ผู้ใช้สร้างเวิร์กโฟลว์แบบสมุดบันทึกจากต้นทางถึงปลายทางได้อย่างรวดเร็วผ่านการผสานรวมเชิงลึกกับบริการข้อมูล (เช่น Dataproc, Dataflow, BigQuery และ Dataplex) และ Vertex AI ซึ่งช่วยให้นักวิทยาศาสตร์ข้อมูลเชื่อมต่อกับบริการข้อมูล GCP, วิเคราะห์ชุดข้อมูล, ทดสอบเทคนิคการสร้างรูปแบบต่างๆ, ติดตั้งใช้งานโมเดลที่ผ่านการฝึกอบรมในเวอร์ชันที่ใช้งานจริง และจัดการ MLOps ตลอดวงจรโมเดล
3. ภาพรวมกรณีการใช้งาน
ในห้องทดลองนี้ คุณจะได้ใช้การเรียนรู้การโอนเพื่อฝึกโมเดลการจัดประเภทอิมเมจในชุดข้อมูล DeepWeeds จากชุดข้อมูล TensorFlow คุณจะใช้ TensorFlow Hub เพื่อทดสอบเวกเตอร์ฟีเจอร์ที่ดึงมาจากสถาปัตยกรรมโมเดลต่างๆ เช่น ResNet50, Inception และ MobileNet ซึ่งทั้งหมดได้รับการฝึกล่วงหน้าในชุดข้อมูลการเปรียบเทียบ ImageNet การใช้ประโยชน์จากโอเปอเรเตอร์สมุดบันทึกผ่าน UI ของ Vertex AI Workbench จะช่วยเปิดงานในการฝึก Vertex AI ที่ใช้โมเดลก่อนการฝึกเหล่านี้และฝึกเลเยอร์สุดท้ายอีกครั้งให้จดจำคลาสจากชุดข้อมูล DeepWeeds
4. ตั้งค่าสภาพแวดล้อมของคุณ
คุณจะต้องมีโปรเจ็กต์ Google Cloud Platform ที่เปิดใช้การเรียกเก็บเงินเพื่อเรียกใช้ Codelab นี้ หากต้องการสร้างโปรเจ็กต์ ให้ทำตามวิธีการที่นี่
ขั้นตอนที่ 1: เปิดใช้ Compute Engine API
ไปที่ Compute Engine แล้วเลือกเปิดใช้ หากยังไม่ได้เปิดใช้
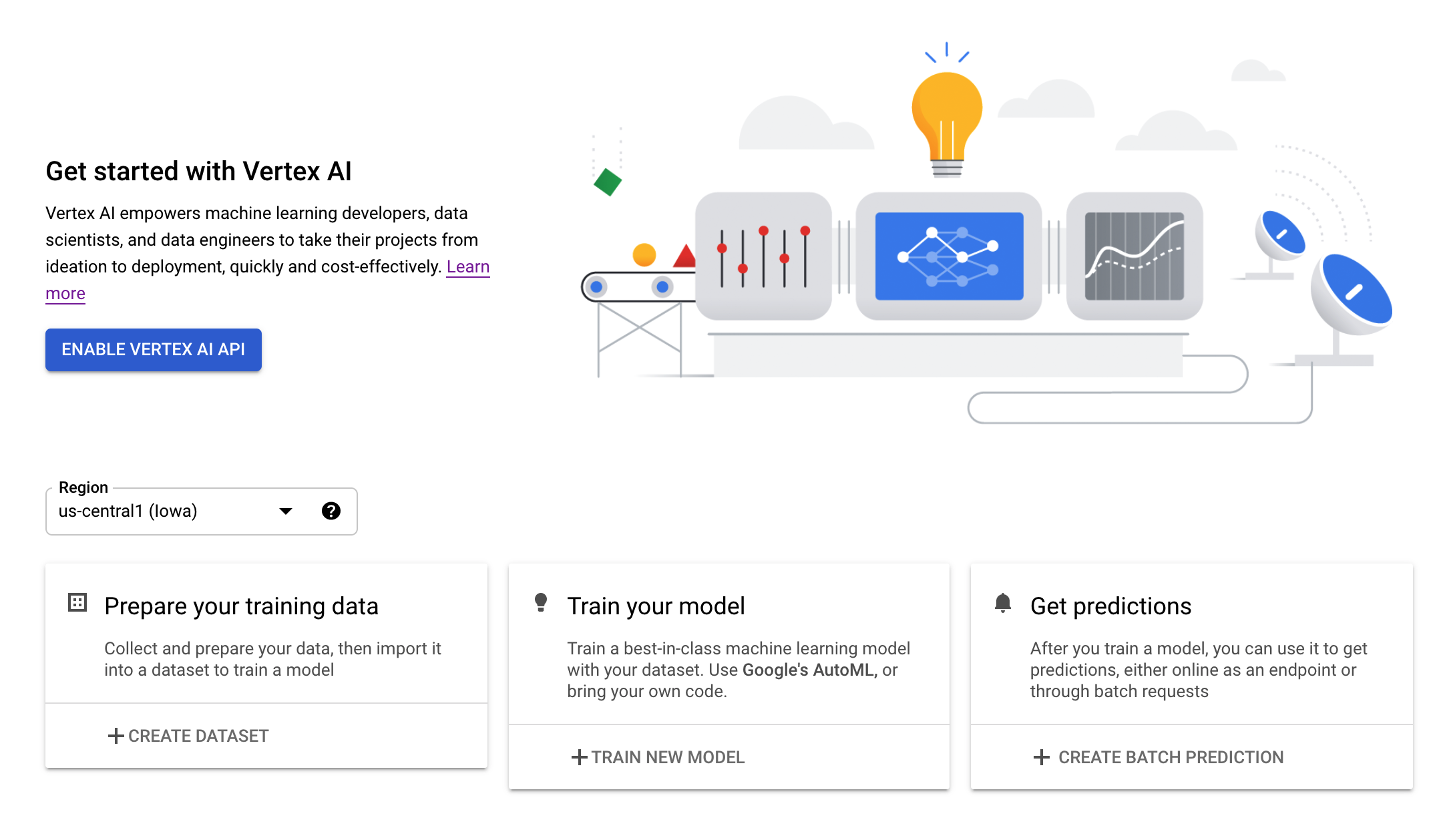
ขั้นตอนที่ 2: เปิดใช้ Vertex AI API
ไปที่ส่วน Vertex AI ของ Cloud Console แล้วคลิกเปิดใช้ Vertex AI API
ขั้นตอนที่ 3: สร้างอินสแตนซ์ Vertex AI Workbench
จากส่วน Vertex AI ของ Cloud Console ให้คลิก Workbench ดังนี้
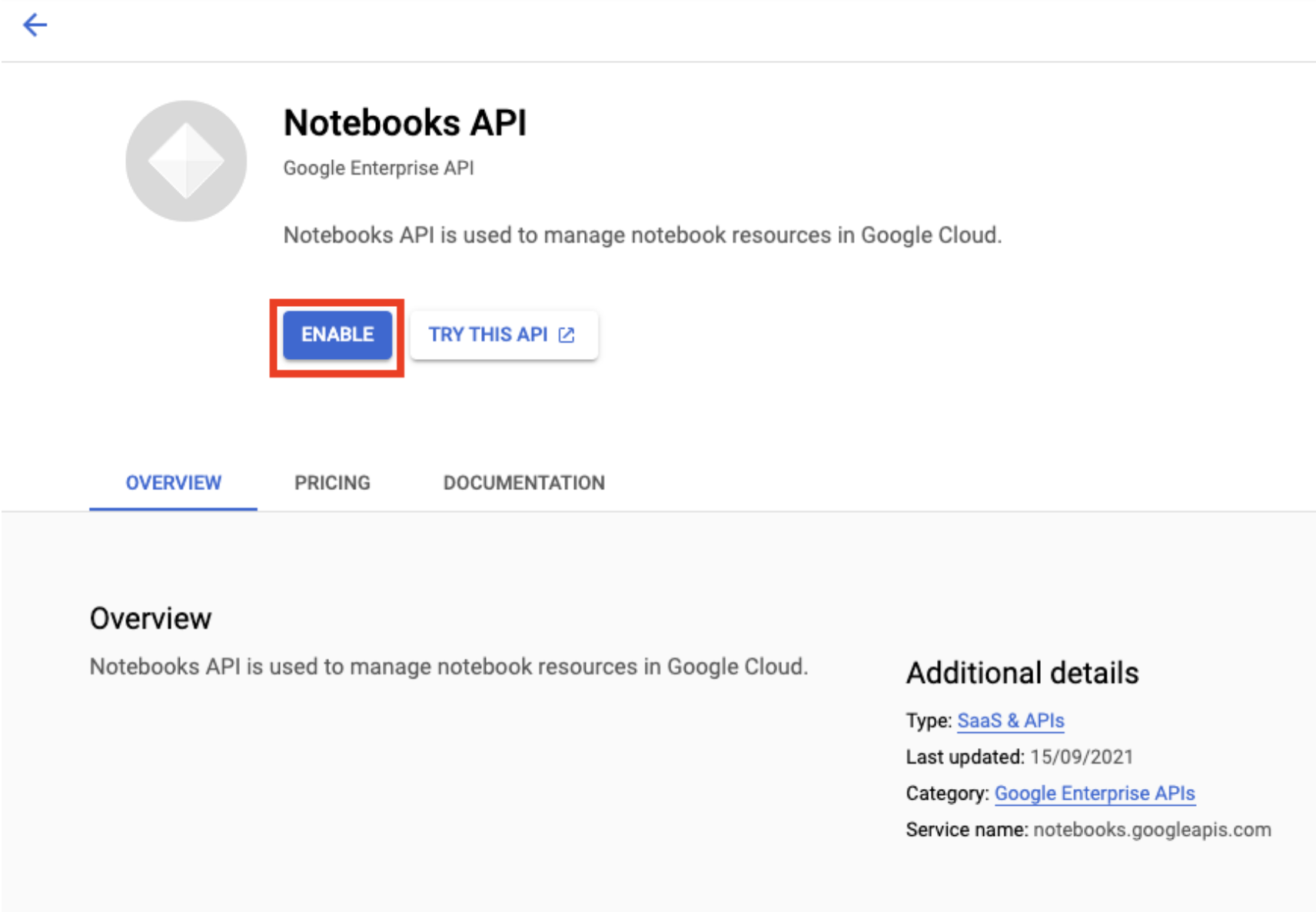
เปิดใช้ Notebooks API หากยังไม่ได้เปิดใช้
เมื่อเปิดใช้แล้ว ให้คลิกสมุดบันทึกที่มีการจัดการ
จากนั้นเลือกสมุดบันทึกใหม่
ตั้งชื่อสมุดบันทึก แล้วคลิกการตั้งค่าขั้นสูง
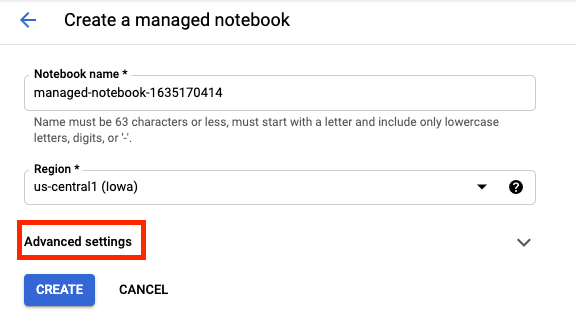
ภายใต้การตั้งค่าขั้นสูง ให้เปิดใช้การปิดเมื่อไม่มีการใช้งาน และตั้งค่าจำนวนนาทีเป็น 60 ซึ่งหมายความว่าโน้ตบุ๊คจะปิดโดยอัตโนมัติเมื่อไม่ได้ใช้งาน เพื่อไม่ให้คุณเสียค่าใช้จ่ายที่ไม่จำเป็น

คุณปล่อยการตั้งค่าขั้นสูงอื่นๆ ทั้งหมดไว้ตามเดิมได้
จากนั้นคลิกสร้าง
เมื่อสร้างอินสแตนซ์แล้ว ให้เลือก Open JupyterLab

ครั้งแรกที่คุณใช้อินสแตนซ์ใหม่ ระบบจะขอให้คุณตรวจสอบสิทธิ์
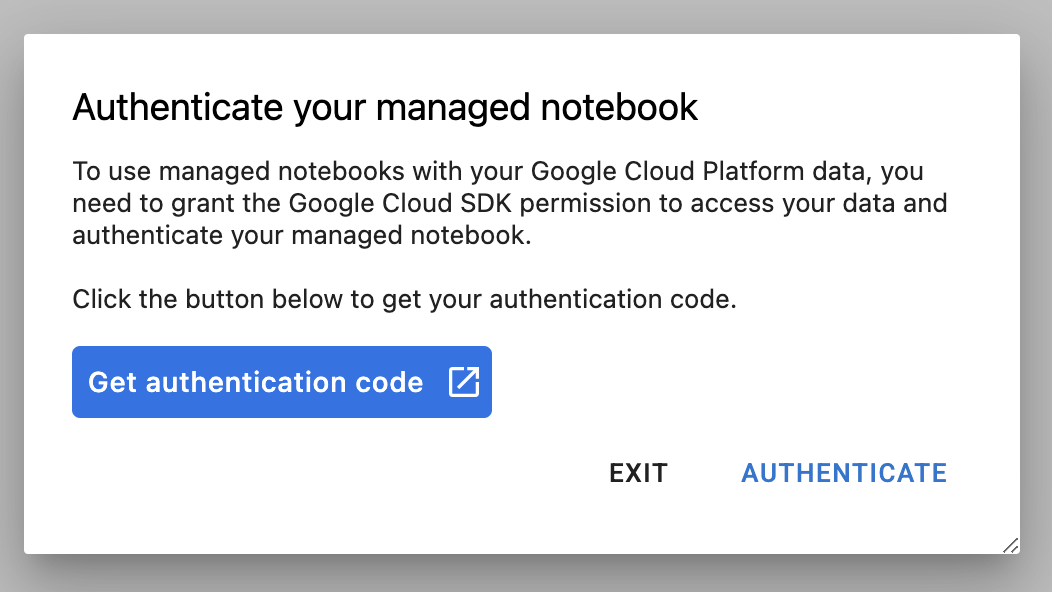
Vertex AI Workbench มีเลเยอร์ความเข้ากันได้ของการคำนวณที่ช่วยให้คุณเปิดใช้งานเคอร์เนลสําหรับ TensorFlow, PySpark, R และอื่นๆ ได้จากอินสแตนซ์โน้ตบุ๊กเดียว หลังจากตรวจสอบสิทธิ์แล้ว คุณจะเลือกประเภทของสมุดบันทึกที่ต้องการใช้จาก Launcher ได้
สำหรับห้องทดลองนี้ ให้เลือกเคอร์เนล TensorFlow 2

5. เขียนโค้ดการฝึก
ชุดข้อมูล DeepWeeds ประกอบด้วยภาพ 17,509 ภาพที่บันทึกวัชพืช 8 สายพันธุ์จากออสเตรเลีย ในส่วนนี้ คุณจะได้เขียนโค้ดเพื่อประมวลผลชุดข้อมูล DeepWeeds ล่วงหน้า รวมถึงสร้างและฝึกโมเดลการจัดประเภทรูปภาพโดยใช้เวกเตอร์ฟีเจอร์ที่ดาวน์โหลดจาก TensorFlow Hub
คุณจะต้องคัดลอกข้อมูลโค้ดต่อไปนี้ลงในเซลล์ของโน้ตบุ๊ก คุณจะเรียกใช้เซลล์หรือไม่ก็ได้
ขั้นตอนที่ 1: ดาวน์โหลดและประมวลผลชุดข้อมูลล่วงหน้า
ก่อนอื่น ให้ติดตั้งชุดข้อมูล TensorFlow เวอร์ชันกลางคืนเพื่อให้แน่ใจว่าเรากำลังเก็บชุดข้อมูล DeepWeeds เวอร์ชันล่าสุด
!pip install tfds-nightly
จากนั้นนำเข้าไลบรารีที่จำเป็นต่อไปนี้
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
ดาวน์โหลดข้อมูลจากชุดข้อมูล TensorFlow และแยกจำนวนคลาสและขนาดชุดข้อมูล
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
กำหนดฟังก์ชันการประมวลผลล่วงหน้าเพื่อปรับขนาดข้อมูลรูปภาพเป็น 255
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
ชุดข้อมูล DeepWeeds ไม่ได้มาพร้อมการแยกการฝึก/การตรวจสอบความถูกต้อง มาพร้อมกับชุดข้อมูลการฝึกเท่านั้น ในโค้ดด้านล่าง คุณจะใช้ข้อมูล 80% นั้นสำหรับการฝึก และ 20% ที่เหลือสำหรับการตรวจสอบ
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
ขั้นตอนที่ 2: สร้างโมเดล
เมื่อสร้างชุดข้อมูลการฝึกและชุดข้อมูลที่ใช้ตรวจสอบแล้ว คุณก็พร้อมที่จะสร้างโมเดล TensorFlow Hub มีเวกเตอร์ฟีเจอร์ ซึ่งเป็นโมเดลก่อนการฝึกที่ไม่มีเลเยอร์การแยกประเภทระดับบนสุด คุณจะสร้างเครื่องมือแยกฟีเจอร์ได้โดยการรวมโมเดลก่อนการฝึกด้วย hub.KerasLayer ซึ่งจะรวม TensorFlow savedModel เป็นเลเยอร์ Keras จากนั้นเพิ่มเลเยอร์การแยกประเภทและสร้างโมเดลด้วย Keras Slimit API
ก่อนอื่น ให้กำหนดพารามิเตอร์ feature_extractor_model ซึ่งเป็นชื่อของเวกเตอร์ฟีเจอร์ TensorFlow Hub ที่จะใช้เป็นพื้นฐานสำหรับโมเดลของคุณ
feature_extractor_model = "inception_v3"
ถัดไป คุณต้องทำให้เซลล์นี้เป็นเซลล์พารามิเตอร์ซึ่งจะช่วยให้คุณส่งค่าสำหรับ feature_extractor_model ขณะรันไทม์ได้
ก่อนอื่นให้เลือกเซลล์แล้วคลิกเครื่องมือตรวจสอบคุณสมบัติในแผงด้านขวา

แท็กเป็นวิธีง่ายๆ ในการเพิ่มข้อมูลเมตาลงในสมุดบันทึก พิมพ์ "parameters" ลงในช่อง "เพิ่มแท็ก" แล้วกด Enter เมื่อกำหนดค่าการดำเนินการในภายหลัง คุณจะต้องส่งค่าที่แตกต่างกัน ซึ่งในกรณีนี้คือโมเดล TensorFlow Hub ที่คุณต้องการทดสอบ โปรดทราบว่าคุณต้องพิมพ์คำว่า "parameters" (ไม่ใช่คำอื่น) เนื่องจากวิธีนี้ทำให้ตัวดำเนินการสมุดบันทึกรู้ว่าจะพารามิเตอร์เซลล์ใด

คุณปิดเครื่องมือตรวจสอบคุณสมบัติได้โดยคลิกไอคอนรูปเฟืองคู่อีกครั้ง
สร้างเซลล์ใหม่และกำหนด tf_hub_uri ซึ่งคุณจะใช้การประมาณค่าสตริงเพื่อแทนที่ชื่อของโมเดลที่ฝึกล่วงหน้าซึ่งคุณต้องการใช้เป็นโมเดลฐานสำหรับการทำงานที่เฉพาะเจาะจงของสมุดบันทึก ค่าเริ่มต้นเป็นคุณตั้งค่า feature_extractor_model เป็น "inception_v3" แต่ค่าที่ถูกต้องอื่นๆ คือ "resnet_v2_50" หรือ "mobilenet_v1_100_224" คุณดูตัวเลือกเพิ่มเติมได้ในแคตตาล็อก TensorFlow Hub
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
ถัดไป ให้สร้างเครื่องมือแยกองค์ประกอบโดยใช้ hub.KerasLayer และส่ง tf_hub_uri ที่คุณกำหนดไว้ด้านบน ตั้งค่าอาร์กิวเมนต์ trainable=False ให้ตรึงตัวแปรเพื่อให้การฝึกแก้ไขเฉพาะเลเยอร์ตัวแยกประเภทใหม่ที่คุณจะเพิ่มด้านบนเท่านั้น
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
หากต้องการสร้างโมเดลให้เสร็จสมบูรณ์ ให้รวมเลเยอร์เครื่องมือแยกฟีเจอร์ในโมเดล tf.keras.Sequential และเพิ่มเลเยอร์ที่เชื่อมต่อโดยสมบูรณ์สำหรับการจัดประเภท จำนวนหน่วยในส่วนหัวการจัดประเภทนี้ควรเท่ากับจำนวนคลาสในชุดข้อมูล
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
สุดท้าย คอมไพล์และทำให้โมเดลพอดี
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. ดำเนินการสมุดบันทึก
คลิกไอคอนผู้ดำเนินการที่ด้านบนของสมุดบันทึก

ขั้นตอนที่ 1: กำหนดค่างานการฝึก
ตั้งชื่อการเรียกใช้และระบุที่เก็บข้อมูลในโปรเจ็กต์
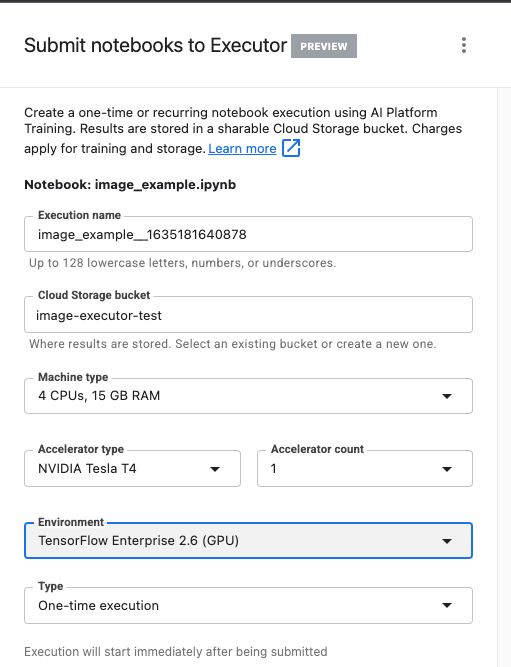
ตั้งค่าประเภทเครื่องเป็น CPU 4 เครื่อง, RAM ขนาด 15 GB
และเพิ่ม NVIDIA GPU 1 รายการ
ตั้งค่าสภาพแวดล้อมเป็น TensorFlow Enterprise 2.6 (GPU)
เลือกการดำเนินการแบบครั้งเดียว
ขั้นตอนที่ 2: กำหนดค่าพารามิเตอร์
คลิกเมนูแบบเลื่อนลงตัวเลือกขั้นสูงเพื่อตั้งค่าพารามิเตอร์ ในช่อง ให้พิมพ์ feature_extractor_model=resnet_v2_50 การดําเนินการนี้จะลบล้าง inception_v3 ซึ่งเป็นค่าเริ่มต้นที่คุณตั้งค่าไว้สําหรับพารามิเตอร์นี้ในสมุดบันทึกด้วย resnet_v2_50

คุณเลือกช่องใช้บัญชีบริการเริ่มต้นไว้ได้
จากนั้นคลิกส่ง
ขั้นตอนที่ 3: ตรวจสอบผลลัพธ์
ในแท็บ "การดำเนินการ" ใน UI ของคอนโซล คุณจะดูสถานะการดำเนินการของสมุดบันทึกได้
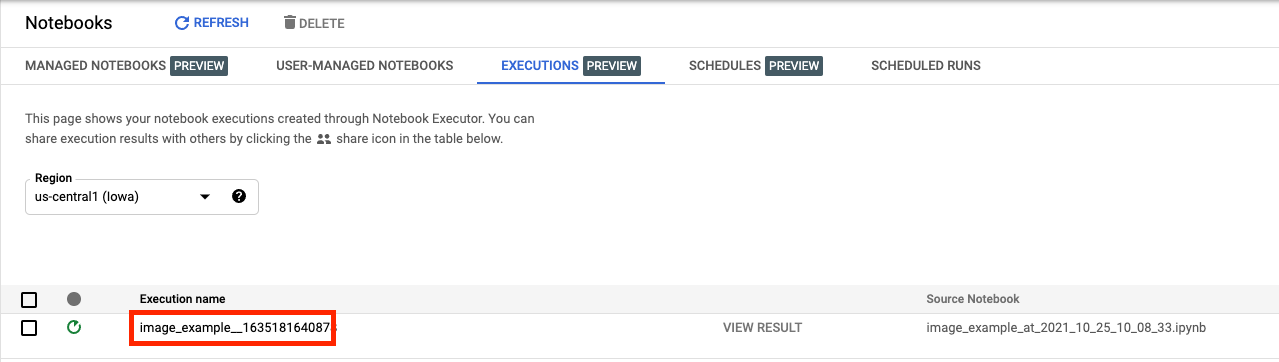
หากคลิกที่ชื่อการดำเนินการ ระบบจะนำคุณไปยังงานการฝึก Vertex AI ที่สมุดบันทึกทำงานอยู่

เมื่องานเสร็จสมบูรณ์แล้ว คุณสามารถดูสมุดบันทึกเอาต์พุตได้โดยคลิกดูผลลัพธ์

ในสมุดบันทึกเอาต์พุต คุณจะเห็นว่าค่าสำหรับ feature_extractor_model ถูกเขียนทับด้วยค่าที่คุณส่งขณะรันไทม์

🎉 ยินดีด้วย 🎉
คุณได้เรียนรู้วิธีใช้ Vertex AI Workbench เพื่อทำสิ่งต่อไปนี้แล้ว
- ใช้พารามิเตอร์ในสมุดบันทึก
- กำหนดค่าและเปิดการดำเนินการสมุดบันทึกจาก UI ของ Vertex AI Workbench
ดูข้อมูลเพิ่มเติมเกี่ยวกับส่วนต่างๆ ของ Vertex AI ได้ในเอกสารประกอบ
7. ล้างข้อมูล
โดยค่าเริ่มต้น สมุดบันทึกที่มีการจัดการจะปิดลงโดยอัตโนมัติหลังจากไม่มีการใช้งานเป็นเวลา 180 นาที หากต้องการปิดอินสแตนซ์ด้วยตนเอง ให้คลิกปุ่มหยุดในส่วน Vertex AI Workbench ของคอนโซล หากคุณต้องการลบสมุดบันทึกทั้งหมด ให้คลิกปุ่ม ลบ

หากต้องการลบที่เก็บข้อมูลของพื้นที่เก็บข้อมูล โดยใช้เมนูการนำทางใน Cloud Console จากนั้นเรียกดูพื้นที่เก็บข้อมูล เลือกที่เก็บข้อมูล แล้วคลิกลบ: