1. סקירה כללית
בשיעור ה-Lab הזה תלמדו איך להגדיר ולהשיק הפעלות notebook באמצעות Vertex AI Workbench.
מה לומדים
נסביר לכם איך:
- שימוש בפרמטרים ב-notebook
- הגדרה והפעלה של הפעלות notebook דרך ממשק המשתמש של Vertex AI Workbench
העלות הכוללת להרצת שיעור ה-Lab הזה ב-Google Cloud היא כ-2$.
2. מבוא ל-Vertex AI
בשיעור ה-Lab הזה נעשה שימוש במוצר ה-AI החדש ביותר שזמין ב-Google Cloud. Vertex AI משלב את הצעות למידת המכונה ב-Google Cloud ליצירת חוויית פיתוח חלקה. בעבר, היה אפשר לגשת למודלים שהותאמו אישית ולמודלים שהותאמו באמצעות AutoML דרך שירותים נפרדים. המוצר החדש משלב את כל ממשקי ה-API האלה בממשק API אחד, לצד מוצרים חדשים אחרים. תוכלו גם להעביר פרויקטים קיימים ל-Vertex AI. יש לך משוב? אפשר למצוא אותו בדף התמיכה.
Vertex AI כולל מוצרים רבים ושונים לתמיכה בתהליכי עבודה של למידת מכונה מקצה לקצה. שיעור ה-Lab הזה יתמקד ב-Vertex AI Workbench.
בעזרת Vertex AI Workbench משתמשים יכולים לפתח במהירות תהליכי עבודה מבוססי notebook מקצה לקצה באמצעות אינטגרציה עמוקה עם שירותי נתונים (כמו Dataproc , Dataflow , BigQuery ו-Dataplex) ו-Vertex AI. בעזרת ה-API הזה, מדעני הנתונים יכולים להתחבר לשירותי הנתונים של GCP, לנתח מערכי נתונים, להתנסות בשיטות שונות ליצירת מודלים, לפרוס מודלים מאומנים בסביבת הייצור ולנהל את MLOps במהלך מחזור החיים של המודל.
3. סקירה כללית של התרחיש לדוגמה
בשיעור ה-Lab הזה תשתמשו בלמידת העברה כדי לאמן מודל לסיווג תמונות במערך הנתונים של DeepWeeds מ-TensorFlow Datasets. תשתמשו ב-TensorFlow Hub כדי להתנסות בווקטורים של פיצ'רים שנשלפו מארכיטקטורות של מודלים שונות, כמו ResNet50, Inception ו-MobileNet. אם כולם עברו אימון מראש על בסיס מערך הנתונים בנצ'מרק של ImageNet. השימוש במנהל ה-notebook דרך ממשק המשתמש של Vertex AI Workbench תפעיל משימות ב-Vertex AI Training שמשתמשות במודלים האלה שעברו אימון מראש, ויאמנו מחדש את השכבה האחרונה לזהות את המחלקות ממערך הנתונים של DeepWeeds.
4. הגדרת הסביבה
כדי להריץ את ה-Codelab הזה צריך פרויקט ב-Google Cloud Platform שהחיוב מופעל בו. כדי ליצור פרויקט, יש לפעול לפי ההוראות האלה.
שלב 1: מפעילים את ממשק ה-API של Compute Engine
עוברים אל Compute Engine ובוחרים באפשרות Enable (הפעלה) אם היא לא מופעלת עדיין.
שלב 2: מפעילים את Vertex AI API
עוברים לקטע Vertex AI במסוף Cloud ולוחצים על Enable Vertex AI API.
שלב 3: יצירת מכונה של Vertex AI Workbench
בקטע Vertex AI במסוף Cloud, לוחצים על Workbench:
מפעילים את Notebooks API, אם עדיין לא פועלים.
לאחר ההפעלה, לוחצים על פנקסי רשימות מנוהלים:
לאחר מכן בוחרים באפשרות מחברות חדשה.
נותנים שם ל-notebook ולוחצים על הגדרות מתקדמות.
בקטע 'הגדרות מתקדמות', מפעילים כיבוי ללא פעילות ומגדירים את מספר הדקות ל-60. כלומר, המחשב יכבה באופן אוטומטי כשהוא לא בשימוש כדי שלא תצברו עלויות מיותרות.

אפשר להשאיר את כל שאר ההגדרות המתקדמות כפי שהן.
לאחר מכן, לוחצים על יצירה.
אחרי יצירת המכונה, בוחרים באפשרות Open JupyterLab.

בפעם הראשונה שתשתמשו במכונה חדשה, תתבקשו לבצע אימות.
ל-Vertex AI Workbench יש שכבת תאימות למחשוב שמאפשרת להפעיל ליבות של TensorFlow, PySpark, R ועוד, והכול ממכונת notebook אחת. לאחר האימות, תוכלו לבחור את סוג ה-notebook שבו אתם רוצים להשתמש ממרכז האפליקציות.
בשיעור ה-Lab הזה, בוחרים את הליבה 2 של TensorFlow.

5. כתיבת קוד אימון
מערך הנתונים של DeepWeeds כולל 17,509 תמונות שמצלמים שמונה מינים שונים של עשבים שמקורם באוסטרליה. בקטע הזה תכתבו את הקוד שיעבד מראש את מערך הנתונים של DeepWeeds, ותצרו ולאמן מודל לסיווג תמונות באמצעות וקטורים של פיצ'רים שהורדתם מ-TensorFlow Hub.
צריך להעתיק את קטעי הקוד הבאים לתאים של ה-notebook. לא חובה להריץ את התאים.
שלב 1: מורידים מערך הנתונים ומעבדים אותו מראש
קודם כול, מתקינים את הגרסה הלילית של מערכי הנתונים של TensorFlow כדי לוודא שאנחנו משתמשים בגרסה האחרונה של מערך הנתונים של DeepWeeds.
!pip install tfds-nightly
לאחר מכן, מייבאים את הספריות הנדרשות:
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_hub as hub
מורידים את הנתונים ממערכי נתונים של TensorFlow ומחלצים את מספר המחלקות ואת גודל מערך הנתונים.
data, info = tfds.load(name='deep_weeds', as_supervised=True, with_info=True)
NUM_CLASSES = info.features['label'].num_classes
DATASET_SIZE = info.splits['train'].num_examples
מגדירים פונקציית עיבוד מראש כדי להגדיל את נתוני התמונה ב-255.
def preprocess_data(image, label):
image = tf.image.resize(image, (300,300))
return tf.cast(image, tf.float32) / 255., label
מערך הנתונים של DeepWeeds לא כולל פיצולים של רכבת/אימות. הוא מגיע רק עם מערך נתונים לאימון. בקוד שבהמשך משתמשים ב-80% מהנתונים האלה לאימון, וב-20% הנותרים לאימות.
# Create train/validation splits
# Shuffle dataset
dataset = data['train'].shuffle(1000)
train_split = 0.8
val_split = 0.2
train_size = int(train_split * DATASET_SIZE)
val_size = int(val_split * DATASET_SIZE)
train_data = dataset.take(train_size)
train_data = train_data.map(preprocess_data)
train_data = train_data.batch(64)
validation_data = dataset.skip(train_size)
validation_data = validation_data.map(preprocess_data)
validation_data = validation_data.batch(64)
שלב 2: יצירת מודל
אחרי שיצרתם מערכי נתונים של אימון ואימות, אתם מוכנים לבנות את המודל שלכם. ב-TensorFlow Hub יש וקטורים של תכונות, שהם מודלים שעברו אימון מקדים, ללא שכבת הסיווג העליונה. כדי ליצור כלי לחילוץ תכונות, עטיפה את המודל שעבר אימון מראש ב-hub.KerasLayer, שעוטף את TensorFlow savedModel כשכבת Keras. אחר כך תצטרכו להוסיף שכבת סיווג וליצור מודל באמצעות Keras Sequential API.
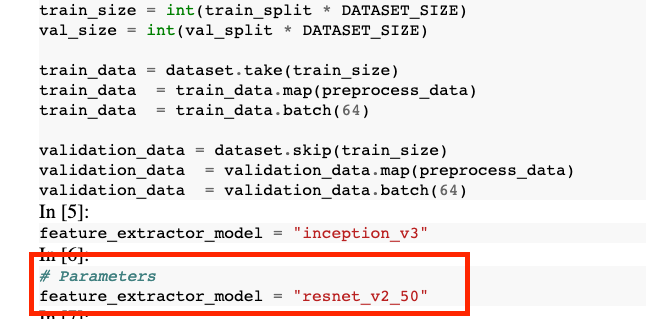
קודם כול, מגדירים את הפרמטר feature_extractor_model, שהוא השם של וקטור המאפיינים של TensorFlow Hub שבו תשתמשו כבסיס למודל.
feature_extractor_model = "inception_v3"
בשלב הבא צריך להפוך את התא הזה לתא פרמטר, שיאפשר לך להעביר ערך של feature_extractor_model בזמן הריצה.
קודם כול בוחרים את התא ולוחצים על הכלי לבדיקת נכסים בחלונית השמאלית.

תגים הם דרך פשוטה להוסיף מטא-נתונים לפנקס. מקלידים 'Parameters' (פרמטרים) בתיבה 'הוספת תג' ולהקיש על Enter. מאוחר יותר, כשתקבעו את הביצוע, תעבירו את הערכים השונים, במקרה הזה, את מודל TensorFlow Hub שתרצו לבדוק. שימו לב: צריך להקליד את המילה 'פרמטרים' (ולא אף מילה אחרת), כך מנהל ה-notebook יודע אילו תאים צריך להזין בפרמטרים.

כדי לסגור את הכלי לבדיקת נכסים, לוחצים שוב על סמל גלגל השיניים הכפול.
יוצרים תא חדש ומגדירים את tf_hub_uri, שבו משתמשים בהוספת מחרוזות (string interpolation) כדי להחליף את השם של המודל המאומן מראש שרוצים להשתמש בו כמודל הבסיס להרצה ספציפית של המחברות. כברירת מחדל, הגדרת את feature_extractor_model כ-"inception_v3", אבל ערכים חוקיים אחרים הם "resnet_v2_50" או "mobilenet_v1_100_224". אתם יכולים למצוא אפשרויות נוספות בקטלוג של TensorFlow Hub.
tf_hub_uri = f"https://tfhub.dev/google/imagenet/{feature_extractor_model}/feature_vector/5"
בשלב הבא, יוצרים את הכלי לחילוץ תכונות באמצעות hub.KerasLayer ומעבירים את הערך tf_hub_uri שהגדרתם למעלה. מגדירים את הארגומנט trainable=False כדי להקפיא את המשתנים, כך שהאימון ישנה רק את שכבת הסיווג החדשה שתוסיפו למעלה.
feature_extractor_layer = hub.KerasLayer(
tf_hub_uri,
trainable=False)
כדי להשלים את המודל, עוטפים את השכבה של מחלץ המאפיינים במודל tf.keras.Sequential ומוסיפים שכבה מקושרת באופן מלא לצורך סיווג. מספר היחידות בראש הסיווג הזה צריך להיות שווה למספר המחלקות במערך הנתונים:
model = tf.keras.Sequential([
feature_extractor_layer,
tf.keras.layers.Dense(units=NUM_CLASSES)
])
לבסוף, הידור וההתאמה של המודל.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['acc'])
model.fit(train_data, validation_data=validation_data, epochs=3)
6. הפעלת notebook
לוחצים על סמל ביצוע בחלק העליון של ה-notebook.
שלב 1: הגדרה של משימת האימון
נותנים להפעלה שם ומספקים קטגוריית אחסון בפרויקט.
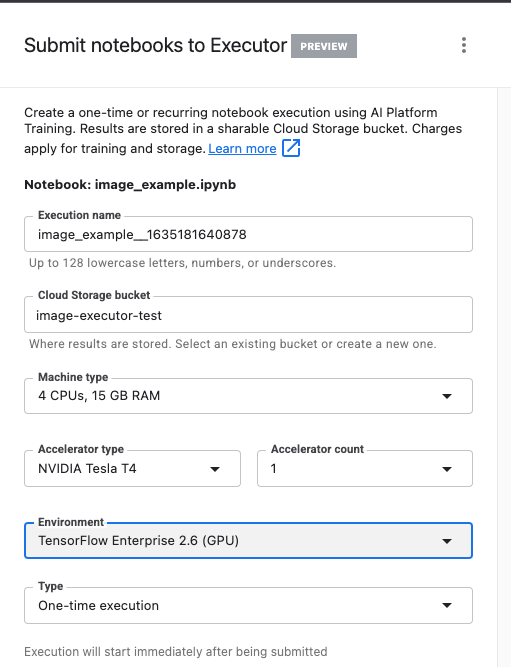
מגדירים את סוג המכונה בתור 4 מעבדים, RAM בנפח 15GB.
ולהוסיף 1 NVIDIA GPU.
מגדירים את הסביבה כ-TensorFlow Enterprise 2.6 (GPU).
בוחרים באפשרות 'ביצוע חד-פעמי'.
שלב 2: מגדירים פרמטרים
לוחצים על התפריט הנפתח אפשרויות מתקדמות כדי להגדיר את הפרמטר. כותבים feature_extractor_model=resnet_v2_50 בתיבה. הפעולה הזו תבטל את inception_v3, ערך ברירת המחדל שהגדרתם לפרמטר הזה ביומן, ותחליף אותו ב-resnet_v2_50.

אפשר להשאיר את התיבה use default service account מסומנת.
לאחר מכן לוחצים על שליחה.
שלב 3: בחינת התוצאות
בכרטיסייה 'פעולות' בממשק המשתמש של המסוף אפשר לראות את הסטטוס של הפעלת ה-notebook.

אם תלחצו על שם הביצוע, תועברו למשימת האימון של Vertex AI שבה ה-notebook פועל.
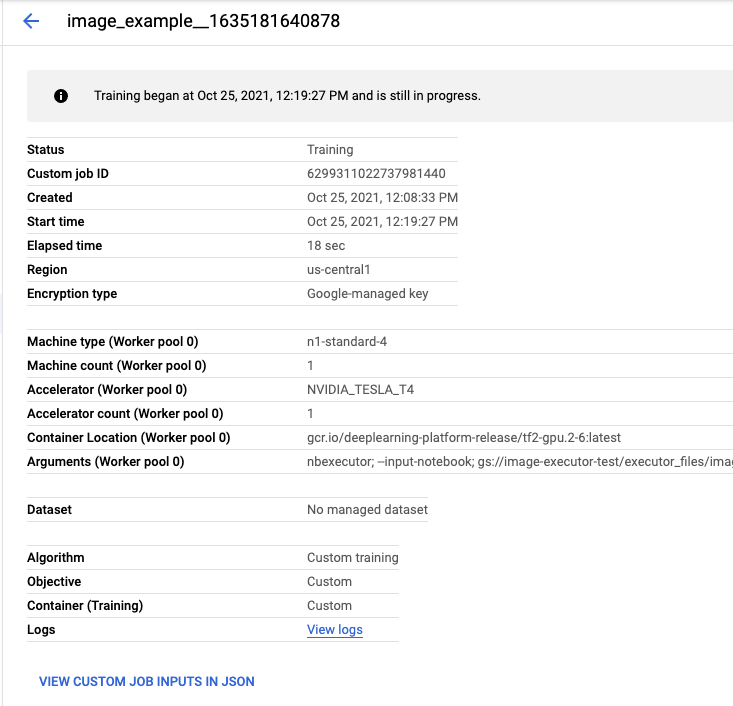
בסיום המשימה, תוכלו ללחוץ על הצגת התוצאה כדי לראות את ה-notebook של הפלט.

ב-notebook של הפלט, הערך של feature_extractor_model הוחלף בערך שהעברת בזמן הריצה.
🎉 כל הכבוד! 🎉
למדתם איך להשתמש ב-Vertex AI Workbench כדי:
- שימוש בפרמטרים ב-notebook
- הגדרה והפעלה של הפעלות notebook דרך ממשק המשתמש של Vertex AI Workbench
כדי לקבל מידע נוסף על החלקים השונים ב-Vertex AI, אתם יכולים לעיין במסמכי העזרה.
7. הסרת המשאבים
כברירת מחדל, קובצי notebook מנוהלים מושבתים אוטומטית אחרי 180 דקות של חוסר פעילות. כדי לכבות את המכונה באופן ידני, לוחצים על הלחצן Stop (עצירה) בקטע Vertex AI Workbench במסוף. כדי למחוק את המחברות כולה, לוחצים על הלחצן 'מחיקה'.

כדי למחוק את הקטגוריה של Storage, עוברים לתפריט הניווט במסוף Cloud, לוחצים על Storage, בוחרים את הקטגוריה ולוחצים על Delete: