Informacje o tym ćwiczeniu (w Codelabs)
1. Omówienie
W tym module użyjesz Vertex AI, aby wytrenować i udostępnić model z danymi tabelarycznymi. Jest to najnowsza oferta związana z AI w Google Cloud, która jest obecnie w wersji testowej.
Czego się nauczysz
Poznasz takie zagadnienia jak:
- Przesyłanie zarządzanego zbioru danych do Vertex AI
- Trenowanie modelu przy użyciu AutoML
- Wdróż w punkcie końcowym wytrenowany model AutoML i użyj tego punktu końcowego do otrzymywania prognoz
Całkowity koszt uruchomienia tego modułu w Google Cloud wynosi około 22 USD.
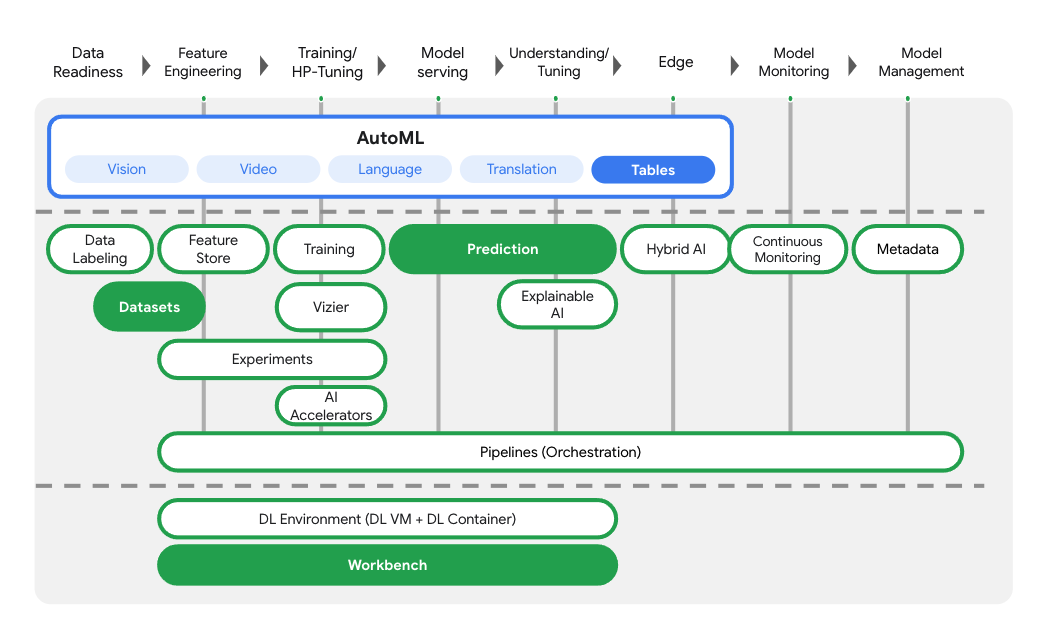
2. Wprowadzenie do Vertex AI
W tym module wykorzystano najnowszą ofertę usług AI dostępną w Google Cloud. Vertex AI integruje ofertę systemów uczących się z całego Google Cloud, tworząc bezproblemowe środowisko programistyczne. Wcześniej modele wytrenowane z użyciem AutoML i modele niestandardowe były dostępne w oddzielnych usługach. Nowa oferta jest łączona w 1 interfejs API wraz z innymi nowymi usługami. Możesz też przenieść istniejące projekty do Vertex AI. Jeśli masz jakieś uwagi, odwiedź stronę pomocy.
Vertex AI obejmuje wiele różnych usług, które obsługują kompleksowe przepływy pracy ML. W tym module skupimy się na wskazanych poniżej usługach: AutoML do analizy danych tabelarycznych, prognozowaniu i usłudze Workbench.
3. Skonfiguruj środowisko
Aby uruchomić to ćwiczenia z programowania, musisz mieć projekt Google Cloud Platform z włączonymi płatnościami. Aby utworzyć projekt, postępuj zgodnie z tymi instrukcjami.
Krok 1. Włącz Compute Engine API
Przejdź do Compute Engine i wybierz opcję Włącz, jeśli nie jest jeszcze włączona. Będzie Ci to potrzebne do utworzenia instancji notatnika.
Krok 2. Włącz interfejs Vertex AI API
Przejdź do sekcji Vertex AI w konsoli Cloud i kliknij Włącz interfejs Vertex AI API.
Krok 3. Utwórz instancję Vertex AI Workbench
W sekcji Vertex AI w konsoli Cloud kliknij Workbench:
W sekcji Notatniki zarządzane przez użytkownika kliknij Nowy notatnik:

Następnie wybierz najnowszą wersję typu instancji TensorFlow Enterprise (z LTS) bez GPU:

Użyj opcji domyślnych i kliknij Utwórz.
Krok 5. Otwórz notatnik
Po utworzeniu instancji wybierz Otwórz JupyterLab:

Dane, których użyjemy do trenowania naszego modelu, pochodzą ze zbioru danych wykrywania oszustw kart kredytowych. Użyjemy wersji tego zbioru danych udostępnionej publicznie w BigQuery.
4. Tworzenie zarządzanego zbioru danych
W Vertex AI możesz tworzyć zarządzane zbiory danych dla różnych typów danych. Możesz następnie generować statystyki dla tych zbiorów danych i używać ich do trenowania modeli za pomocą AutoML lub własnego kodu modelu.
Krok 1. Utwórz zbiór danych
W menu Vertex w konsoli wybierz Zbiory danych:
W tym module utworzymy model wykrywania oszustw, który pozwoli określić, czy dana transakcja dokonana przy użyciu karty kredytowej powinna zostać sklasyfikowana jako oszustwo.
Na stronie Zbiory danych nadaj nazwę zbiorowi danych, a potem kliknij kolejno Tabela i Regresja/klasyfikacja. Następnie utwórz zbiór danych:

Istnieje kilka opcji importowania danych do zarządzanych zbiorów danych w Vertex:
- Przesłanie pliku lokalnego z komputera
- Wybieranie plików z Cloud Storage
- Wybieranie danych z BigQuery
W tym miejscu będziemy przesyłać dane z publicznej tabeli BigQuery.
Krok 2. Zaimportuj dane z BigQuery
Kliknij „Wybierz tabelę lub widok z BigQuery”. jako metodę importu, a potem w polu tabeli BigQuery skopiuj ten kod: bigquery-public-data.ml_datasets.ulb_fraud_detection. Następnie kliknij Dalej:

Po zaimportowaniu zbioru danych zobaczysz coś takiego:

Jeśli chcesz, możesz kliknąć Wygeneruj statystyki, aby wyświetlić dodatkowe informacje o tym zbiorze danych. Nie jest to jednak wymagane przed przejściem do następnego kroku. Ten zbiór danych zawiera prawdziwe transakcje kartą kredytową. Większość nazw kolumn jest zasłonięta, dlatego nazywają się V1, V2 itd.
5. Trenowanie modelu przy użyciu AutoML
Po przesłaniu zarządzanego zbioru danych możemy zacząć trenować model z wykorzystaniem tych danych. Będziemy trenować model klasyfikacji do prognozowania, czy określona transakcja jest oszustwem. Vertex AI udostępnia 2 opcje dotyczące modeli trenowania:
- AutoML: trenuj wysokiej jakości modele przy minimalnym nakładzie pracy i bez specjalistycznej wiedzy z zakresu systemów uczących się.
- Trenowanie niestandardowe: uruchamiaj niestandardowe aplikacje treningowe w chmurze za pomocą jednego z gotowych kontenerów Google Cloud lub użyj własnego.
W tym module do trenowania użyjemy AutoML.
Krok 1. Rozpocznij zadanie szkoleniowe
Na stronie ze szczegółami zbioru danych, w którym została przerwana w poprzednim kroku, w prawym górnym rogu wybierz Wytrenuj nowy model. Wybierz Klasyfikacja jako cel, pozostaw opcję AutoML wybraną do trenowania modelu, a potem kliknij Dalej:

Nadaj swojemu modelowi nazwę lub użyj nazwy domyślnej. W sekcji Kolumna docelowa wybierz Klasa. Jest to liczba całkowita wskazująca, czy konkretna transakcja była oszustwem (0 – brak oszustwa, 1 – oszustwo).
Następnie kliknij Dalej:

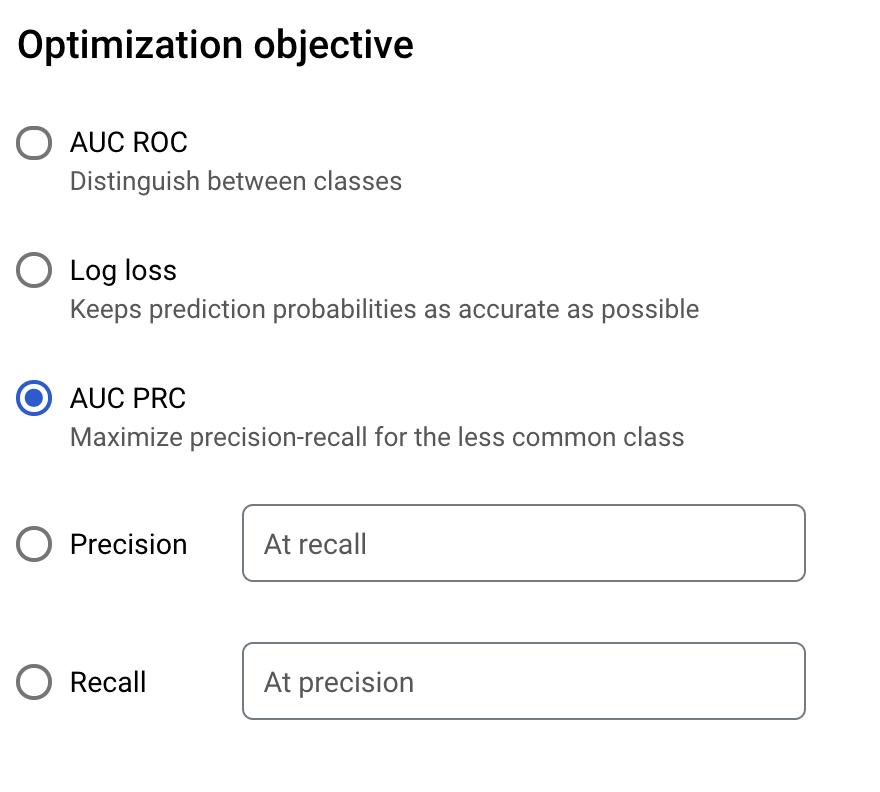
Na tym etapie przewiń w dół i kliknij, aby rozwinąć Opcje zaawansowane. Ponieważ ten zbiór danych jest mocno nierówny (mniej niż 1% danych zawiera fałszywe transakcje), wybierz opcję AUC PRC, która zmaksymalizuje precyzję i czułość w przypadku mniej powszechnej klasy:
Kliknij Dalej i przejdź do ostatniego kroku (obliczenia i ceny). Wpisz 1 jako liczbę godzin pracy węzłów w ramach budżetu i pozostaw włączone wczesne zatrzymywanie. Wytrenowanie modelu AutoML przez 1 godzinę obliczeniową to zwykle dobry początek do zrozumienia, czy istnieje związek między wybranymi cechami a etykietą. Następnie możesz zmodyfikować funkcje i trenować przez dłuższy czas, aby zwiększyć wydajność modelu. Następnie wybierz Rozpocznij trenowanie.
Po zakończeniu zadania trenowania otrzymasz e-maila. Szkolenie zajmie trochę dłużej niż godzinę, żeby uwzględnić czas na rozruch i rozbiórkę zasobów.
6. Poznaj wskaźniki oceny modelu
W tym kroku sprawdzimy skuteczność naszego modelu.
Po zakończeniu zadania trenowania modelu otwórz kartę Modele w Vertex. Kliknij wytrenowany model i otwórz kartę Ocena. Jest wiele wskaźników oceny, ale skupimy się na 2: Tablicy pomyłek i znaczeniu funkcji.
Krok 1. Przeanalizuj tablicę pomyłek
Tablica pomyłek podaje odsetek przykładów z każdej klasy w zbiorze testowym, które zostały prawidłowo prognozowane przez nasz model. W przypadku niezrównoważonego zbioru danych, takiego jak ten, który mamy do czynienia, jest to lepszy wskaźnik wydajności naszego modelu niż ogólna dokładność.
Pamiętaj, że mniej niż 1% przykładów w naszym zbiorze danych dotyczyło fałszywych transakcji, więc jeśli dokładność naszego modelu wynosi 99%, jest spore prawdopodobieństwo, że zgaduje on po prostu klasę nieoszustw w 99% przypadków. Dlatego sprawdzanie dokładności naszego modelu dla każdej klasy jest tutaj lepszym wskaźnikiem.
Gdy przewiniesz kartę Ocena w dół, zobaczysz tabelę pomyłek podobną do tej (dokładne wartości procentowe mogą być różne):
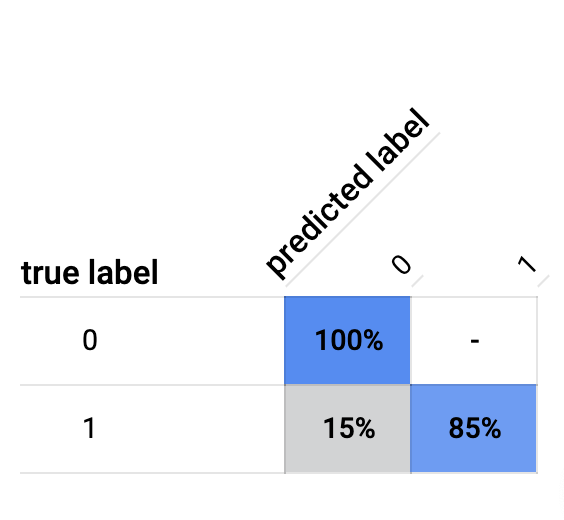
Tablica pomyłek wskazuje, że nasz początkowy model jest w stanie prawidłowo sklasyfikować 85% fałszywych przykładów w zestawie testowym. To całkiem nieźle, zwłaszcza biorąc pod uwagę znaczny brak równowagi między zbiorami danych. Następnie moglibyśmy spróbować trenować model przez więcej godzin obliczeniowych, aby sprawdzić, czy uda się nam poprawić jakość na poziomie 85%.
Krok 2. Sprawdź znaczenie cech
Pod tablicą pomyłek powinien znajdować się wykres ważności funkcji, który wygląda tak:

Pokazuje to funkcje, które były największym sygnałem dla naszego modelu podczas tworzenia prognoz. Znaczenie cech to jeden z typów Explainable AI – pola zawierającego różne metody pozwalające uzyskać lepszy wgląd w model ML. Widoczny tutaj wykres znaczenia cech jest obliczany jako dane zbiorcze na podstawie wszystkich prognoz naszego modelu w zbiorze testowym. Pokazuje on najważniejsze funkcje w grupie przykładów.
Ten wykres byłby ciekawszy, gdyby większość funkcji w naszym zbiorze danych nie była zasłonięta. Możemy się na przykład dowiedzieć, że największym wskaźnikiem oszustw jest rodzaj transakcji (przekazanie, wpłata itp.).
W scenariuszu w świecie rzeczywistym te wartości ważności cech mogą pomóc nam ulepszać model i zwiększyć wiarygodność prognoz. Możemy zdecydować się na usunięcie najmniej istotnych funkcji przy następnym trenowaniu modelu lub połączyć 2 bardziej istotne cechy w różnych cech, aby sprawdzić, czy poprawi to wydajność modelu.
Sprawdzamy tutaj ważność cech we wsadzie, ale możemy też uzyskać znaczenie poszczególnych funkcji w Vertex AI. Zobaczymy, jak to zrobić, gdy wdrożymy nasz model.
7. Wdrażanie modelu w punkcie końcowym
Mamy już wytrenowany model. Następnym krokiem jest utworzenie punktu końcowego w Vertex. Z zasobem modelu w Vertex może być powiązanych wiele punktów końcowych, a ruch można dzielić między punkty końcowe.
Krok 1. Utwórz punkt końcowy
Na stronie modelu otwórz kartę Wdróż i testuj, a następnie kliknij Wdróż w punkcie końcowym:
Nadaj punktowi końcowemu nazwę, na przykład fraud_v1, ustaw dostęp na Standardowy i kliknij Dalej.
Pozostaw domyślne ustawienia podziału ruchu i typu maszyny, a potem kliknij kolejno Gotowe i Dalej.
W tym punkcie końcowym nie będziemy używać monitorowania modelu, więc możesz pozostawić tę opcję niezaznaczoną i kliknąć Wdróż. Wdrożenie punktu końcowego może potrwać kilka minut. Po zakończeniu pojawi się obok niej zielony znacznik wyboru:

Jesteś blisko! Teraz możesz otrzymywać prognozy dotyczące wdrożonego modelu.
8. Uzyskiwanie prognoz dotyczących naszego wdrożonego modelu
Istnieje kilka opcji uzyskiwania prognoz modelu:
- Interfejs Vertex AI
- Interfejs Vertex AI API
Pokażemy jedne i drugie.
Krok 1. Pobierz prognozy modelu w interfejsie użytkownika
Na stronie modelu, na której widoczny jest punkt końcowy (w miejscu, w którym skończyliśmy w ostatnim kroku), przewiń w dół do sekcji Testowanie modelu:
W tym przypadku Vertex AI wybrał losowe wartości dla każdej cechy naszego modelu, których możemy użyć do wygenerowania prognozy testowej. Jeśli chcesz, możesz je zmienić. Przewiń w dół strony i kliknij Przeprowadź prognozę.
W sekcji Wynik prognozy powinna być widoczna prognozowana wartość procentowa modelu dla poszczególnych klas. Na przykład wskaźnik ufności 0.99 dla klasy 0 oznacza, że według modelu w tym przykładzie w 99% przypadków nie było oszustwa.
Krok 2. Pobierz prognozy modeli za pomocą interfejsu Vertex AI API
Interfejs to świetny sposób na sprawdzenie, czy wdrożony punkt końcowy działa zgodnie z oczekiwaniami. Możliwe jednak, że zechcesz dynamicznie otrzymywać prognozy za pomocą wywołania interfejsu API REST. Aby pokazać Ci, jak uzyskiwać w tym miejscu prognozy dotyczące modeli, użyjemy instancji Vertex Workbench utworzonej przez Ciebie na początku tego modułu.
Następnie otwórz utworzoną instancję notatnika i otwórz notatnik w języku Python 3 z Menu z aplikacjami:

Aby zainstalować pakiet Vertex SDK, w notatniku uruchom w komórce to polecenie:
!pip3 install google-cloud-aiplatform --upgrade --user
Następnie dodaj komórkę w notatniku, aby zaimportować pakiet SDK i utworzyć odwołanie do wdrożonego właśnie punktu końcowego:
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/us-central1/endpoints/YOUR-ENDPOINT-ID"
)
Dwie wartości w ciągu endpoint_name w powyższym ciągu znaków endpoint_name zastąp numerem projektu i punktem końcowym. Aby znaleźć numer projektu, otwórz panel projektu i pobierz wartość „Numer projektu”.
Identyfikator punktu końcowego znajdziesz w sekcji punktów końcowych w konsoli:

Na koniec utwórz prognozę dla punktu końcowego, kopiując i uruchamiając poniższy kod w nowej komórce:
test_instance={
'Time': 80422,
'Amount': 17.99,
'V1': -0.24,
'V2': -0.027,
'V3': 0.064,
'V4': -0.16,
'V5': -0.152,
'V6': -0.3,
'V7': -0.03,
'V8': -0.01,
'V9': -0.13,
'V10': -0.18,
'V11': -0.16,
'V12': 0.06,
'V13': -0.11,
'V14': 2.1,
'V15': -0.07,
'V16': -0.033,
'V17': -0.14,
'V18': -0.08,
'V19': -0.062,
'V20': -0.08,
'V21': -0.06,
'V22': -0.088,
'V23': -0.03,
'V24': 0.01,
'V25': -0.04,
'V26': -0.99,
'V27': -0.13,
'V28': 0.003
}
response = endpoint.predict([test_instance])
print('API response: ', response)
W przypadku klasy 0 powinna pojawić się prognoza około .67. Oznacza to, że według modelu istnieje 67% prawdopodobieństwa, że ta transakcja nie jest oszustwem.
🎉 Gratulacje! 🎉
Wiesz już, jak używać Vertex AI do:
- Przesyłanie zarządzanego zbioru danych
- Trenowanie i ocena modelu na danych tabelarycznych przy użyciu AutoML
- Wdrażanie modelu w punkcie końcowym
- Uzyskuj prognozy w punkcie końcowym modelu za pomocą pakietu SDK dla Vertex
Więcej informacji o różnych częściach Vertex AI znajdziesz w dokumentacji.
9. Czyszczenie
Jeśli chcesz nadal korzystać z notatnika utworzonego w tym module, zalecamy wyłączenie go, gdy nie jest używany. W interfejsie Workbench w konsoli Cloud wybierz notatnik, a następnie kliknij Zatrzymaj.
Aby całkowicie usunąć notatnik, po prostu kliknij przycisk Usuń znajdujący się w prawym górnym rogu.
Aby usunąć wdrożony punkt końcowy, przejdź do sekcji Punkty końcowe w konsoli Vertex AI i wycofaj wdrożenie modelu z punktu końcowego:

Aby usunąć zasobnik na dane, w menu nawigacyjnym w konsoli Cloud przejdź do Cloud Storage, wybierz swój zasobnik i kliknij Usuń: