
1. Giới thiệu
Lần cập nhật gần đây nhất: ngày 4 tháng 3 năm 2026
Tìm kiếm vectơ hoặc Cơ sở dữ liệu vectơ đã trở thành một công nghệ nền tảng cho các hệ thống AI hiện đại. Bằng cách biểu thị dữ liệu dưới dạng các mục nhúng có nhiều chiều nắm bắt ý nghĩa ngữ nghĩa, mô hình này hỗ trợ mọi thứ, từ tính năng tìm kiếm ngữ nghĩa hiểu ý định của người dùng, đến các công cụ đề xuất hiển thị nội dung có liên quan, đến tính năng Tạo nội dung tăng cường khả năng truy xuất (RAG) và các AI Agent cung cấp thông tin thực tế, mới nhất cho các câu trả lời của LLM. Các công ty công nghệ lớn, bao gồm cả Google, dựa vào công nghệ này ở quy mô lớn để xử lý hàng tỷ lượt tìm kiếm, đề xuất và thông tin cơ bản mỗi ngày.
Tuy nhiên, việc xây dựng tính năng tìm kiếm vectơ sẵn sàng cho hoạt động sản xuất vẫn là một thách thức. Gần đây, Google đã phát hành Vertex AI Vector Search 2.0 để thay đổi điều đó. Đây là một dịch vụ được quản lý hoàn toàn, được thiết kế để loại bỏ sự phức tạp về thiết kế và hoạt động khiến các nhóm làm việc chậm hơn.

Tại sao Tìm kiếm vectơ khó hơn bạn nghĩ
Khái niệm này rất đơn giản. Việc triển khai? Đó là lúc mọi thứ trở nên phức tạp.

Quá trình tạo vectơ nhúng. Tính năng tìm kiếm vectơ yêu cầu bạn chuyển đổi dữ liệu thành các biểu diễn bằng số (dữ liệu nhúng) để nắm bắt ý nghĩa ngữ nghĩa. Điều này có nghĩa là bạn cần gọi một API nhúng, tạo yêu cầu hàng loạt, xử lý giới hạn về tốc độ và lưu trữ các vectơ. Mỗi khi dữ liệu thay đổi, bạn sẽ chạy lại quy trình. Đó là cơ sở hạ tầng mà bạn phải xây dựng trước khi có thể bắt đầu tìm kiếm.
Cửa hàng tính năng. Nhiều sản phẩm tìm kiếm vectơ chỉ cung cấp một chỉ mục vectơ trả về danh sách mã mặt hàng cho mỗi lượt tìm kiếm. Để phân phát kết quả tìm kiếm đầy đủ cho người dùng, bạn cần có một cửa hàng tính năng hoặc cửa hàng khoá-giá trị riêng biệt để truy xuất dữ liệu mặt hàng thực tế (tên, giá, danh mục, URL hình ảnh tính bằng mili giây) bằng cách truyền các mã nhận dạng đó. Trong nhiều trường hợp, bạn cũng cần triển khai bộ lọc phức tạp trên các đặc điểm của mặt hàng, chẳng hạn như giá, danh mục hoặc tình trạng còn hàng. Điều này có nghĩa là bạn phải xây dựng và duy trì hai dịch vụ riêng biệt: một dịch vụ để tìm kiếm vectơ, một dịch vụ để truy xuất và lọc dữ liệu. Mỗi lần cập nhật và truy vấn đều yêu cầu bạn phải truy cập và đồng bộ hoá cả hai hệ thống.
Điều chỉnh chỉ mục. Để tạo chỉ mục hàng xóm gần nhất (ANN) gần đúng với hàng triệu mặt hàng, bạn cần đưa ra quyết định của chuyên gia để đạt được hiệu suất tốt nhất: Mỗi nút chỉ mục nên chứa bao nhiêu mặt hàng? Cần quét bao nhiêu phần trăm chỉ mục cho mỗi truy vấn để cân bằng khả năng thu hồi với độ trễ? Kích thước phân đoạn nào phù hợp với tập dữ liệu của bạn? Đây là những quyết định về cơ sở hạ tầng học máy không liên quan gì đến sản phẩm thực tế của bạn.
Tìm kiếm kết hợp. Tìm kiếm ngữ nghĩa có khả năng hiểu rõ ý định – tìm thấy "Quần bơi" khi người dùng tìm kiếm "trang phục nam đi biển". Nhưng mô hình này không hoạt động hiệu quả đối với các mã sản phẩm như "SKU-12345" không có ý nghĩa ngữ nghĩa và gặp khó khăn với các thuật ngữ mới hoặc tên thương hiệu mà mô hình nhúng chưa từng thấy. Tính năng tìm kiếm từ khoá xử lý những trường hợp này nhưng bỏ lỡ ngữ cảnh ngữ nghĩa. Người dùng cần cả hai, đó là lý do khiến tìm kiếm kết hợp trở nên cần thiết. Tuy nhiên, việc xây dựng một hệ thống như vậy không hề đơn giản. Bạn cần một công cụ tìm kiếm toàn văn bản có tính năng mã hoá, chỉ mục đảo ngược hoặc các mục nhúng thưa thớt – ngoài công cụ tìm kiếm vectơ. Sau đó, bạn phải chạy các truy vấn song song trên cả hai công cụ, chuẩn hoá các hệ thống tính điểm khác nhau và hợp nhất kết quả bằng các kỹ thuật như Hợp nhất thứ hạng tương hỗ.
Cách Vector Search 2.0 giải quyết những vấn đề này
Vector Search 2.0 trên Google Cloud giải quyết trực tiếp từng thách thức này:


Trong hội thảo này, chúng ta sẽ xây dựng một tính năng tìm kiếm kết hợp được quản lý hoàn toàn bằng cách sử dụng 10.000 sản phẩm thời trang từ tập dữ liệu thương mại điện tử TheLook.
Tìm kiếm vectơ 2.0 là gì?
Vector Search 2.0 là cơ sở dữ liệu vectơ tự điều chỉnh, được quản lý toàn diện của Google Cloud, được xây dựng dựa trên thuật toán ScaNN (Tìm kiếm lân cận có thể mở rộng) của Google – công nghệ tương tự như công nghệ hỗ trợ Google Tìm kiếm, YouTube và Google Play.
Điểm khác biệt chính
- Lập chỉ mục từ 0 đến hàng tỷ: Bắt đầu phát triển ngay lập tức mà không cần thời gian lập chỉ mục bằng kNN (k-Lân cận gần nhất), sau đó mở rộng quy mô lên hàng tỷ vectơ với độ trễ mili giây bằng chỉ mục ANN (Lân cận gần nhất gần đúng) quy mô Google cho hoạt động sản xuất – tất cả đều có cùng một API và cùng một tập dữ liệu
- Lưu trữ dữ liệu hợp nhất: Lưu trữ cả các vectơ nhúng và dữ liệu do người dùng cung cấp cùng nhau (không cần cơ sở dữ liệu hoặc kho lưu trữ tính năng riêng biệt)
- Auto-Embeddings: Tự động tạo các mục nhúng ngữ nghĩa bằng các mô hình nhúng Vertex AI
- Tính năng Tìm kiếm toàn văn tích hợp sẵn: Cung cấp tính năng tìm kiếm toàn văn tích hợp sẵn mà bạn không cần tự tạo các vectơ nhúng thưa. Bạn cũng có thể chọn sử dụng các vectơ thưa của riêng mình (ví dụ: BM25, SPLADE) với tính năng Tìm kiếm vectơ để tìm kiếm toàn văn theo cách tuỳ chỉnh.
- Tìm kiếm kết hợp: Kết hợp tìm kiếm dựa trên ngữ nghĩa và từ khoá/mã thông báo trong một cụm từ tìm kiếm duy nhất với tính năng xếp hạng RRF thông minh
- Tự điều chỉnh: Tự động tối ưu hoá hiệu suất mà không cần định cấu hình thủ công
- Dành cho doanh nghiệp: Khả năng mở rộng, bảo mật và tuân thủ được tích hợp sẵn
Cấu trúc cốt lõi
Vector Search 2.0 có 3 thành phần chính:
- Tập hợp: Vùng chứa được thực thi giản đồ cho dữ liệu của bạn
- Đối tượng dữ liệu: Các mục riêng lẻ có dữ liệu và vectơ nhúng
- Chỉ mục: Tìm kiếm tức thì dữ liệu lân cận nhất bằng kNN. Để tìm kiếm hàng xóm gần nhất có độ trễ thấp, hãy sử dụng chỉ mục ANN.
- Bắt đầu nhanh chóng: Sử dụng kNN ngay lập tức mà không cần thiết lập – phù hợp cho quá trình phát triển và tập dữ liệu nhỏ
- Mở rộng quy mô sản xuất: Sử dụng chỉ mục ANN để tìm kiếm quy mô hàng tỷ với độ trễ dưới một giây nhờ thuật toán ScaNN
Hãy cùng khám phá từng khái niệm thông qua các ví dụ thực tế!
2. Xây dựng công cụ tìm kiếm thời trang TheLook
Hãy tưởng tượng có một khách hàng truy cập vào trang web thương mại điện tử của bạn và nhập cụm từ "đồ gì đó dễ thương để đi nghỉ ở bãi biển". Với tính năng tìm kiếm bằng từ khoá truyền thống, họ sẽ không nhận được kết quả nào vì không có sản phẩm nào trong danh mục của bạn chứa chính xác những từ đó. Họ chán nản và rời đi.
Bây giờ, hãy tưởng tượng một trải nghiệm khác. Cùng một cụm từ tìm kiếm sẽ trả về váy hai dây, áo che đồ bơi và quần soóc ống rộng – những sản phẩm hoàn toàn phù hợp với ý định của khách hàng, mặc dù không có sản phẩm nào chứa từ "bãi biển" trong tiêu đề. Đó là trải nghiệm mà tính năng tìm kiếm bằng vectơ mang lại.
Để minh hoạ cách Vector Search 2.0 giúp bạn thực hiện việc này, chúng ta sẽ xây dựng một hệ thống tìm kiếm sản phẩm bằng cách sử dụng TheLook, một tập dữ liệu thương mại điện tử thực tế với 30.000 mặt hàng thời trang thuộc 26 danh mục. Mỗi sản phẩm đều có các thuộc tính mà bạn sẽ thấy trong mọi danh mục thực:

Những thách thức về tìm kiếm mà chúng tôi sẽ giải quyết
Khách hàng thực tế không tìm kiếm theo cách mà cơ sở dữ liệu mong đợi. Họ tìm kiếm theo cách họ nghĩ:

Vector Search 2.0 giải quyết cả 4 thách thức này bằng một cấu trúc hợp nhất.
Cấu trúc dữ liệu của tính năng Tìm kiếm vectơ 2.0
Trước khi đi sâu vào mã, hãy tìm hiểu cách Vector Search 2.0 sắp xếp dữ liệu của bạn. Cấu trúc này tập trung vào 3 khái niệm chính: Tập hợp, Đối tượng dữ liệu và Chỉ mục.
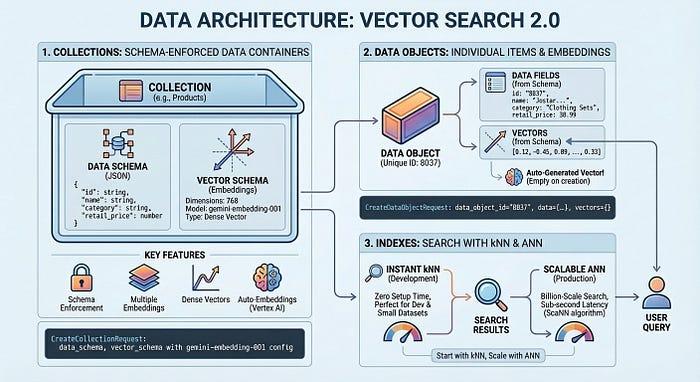
Tập hợp xác định cấu trúc dữ liệu của bạn – các trường bạn muốn lưu trữ và những trường nào cần được nhúng. Đối tượng dữ liệu là các mục thực tế (sản phẩm, tài liệu, hình ảnh) được lưu trữ trong một Bộ sưu tập, mỗi mục có dữ liệu và vectơ được tạo tự động hoặc vectơ của riêng bạn. Chỉ mục tối ưu hoá các truy vấn ở quy mô lớn, cho phép độ trễ mili giây trên hàng tỷ mục. Bạn có thể bắt đầu mà không cần chỉ mục để phát triển mà không mất thời gian thiết lập, sau đó thêm chỉ mục khi cần hiệu suất sản xuất.
Xây dựng tính năng tìm kiếm của TheLook: Từng bước
Bây giờ, hãy xây dựng một hệ thống tìm kiếm sản phẩm hoạt động. Chúng ta sẽ tải 10.000 mặt hàng thời trang từ TheLook, bật tính năng nhúng tự động và chạy các cụm từ tìm kiếm ngữ nghĩa, từ khoá và kết hợp – tất cả chỉ trong khoảng 50 dòng mã.
Mở sổ tay: Giới thiệu về Vertex AI Vector Search 2.0
Tìm kiếm kết hợp trong thực tế
Vector Search 2.0 hỗ trợ 3 chế độ tìm kiếm: tìm kiếm ngữ nghĩa (hiểu ý định thông qua các embeddings), tìm kiếm văn bản (so khớp từ khoá) và tìm kiếm kết hợp (kết hợp cả hai). Tìm kiếm kết hợp mang lại kết quả tốt nhất cho hầu hết các trường hợp sử dụng – tìm kiếm ngữ nghĩa tìm thấy "Quần bơi" khi người dùng tìm kiếm "trang phục nam đi biển", trong khi Tìm kiếm văn bản đảm bảo không bỏ lỡ các kết quả khớp chính xác như mã sản phẩm.

Vì sao việc nhúng loại tác vụ lại quan trọng
Lưu ý các tham số task_type trong đoạn mã ở trên: RETRIEVAL_DOCUMENT khi lập chỉ mục sản phẩm và QUESTION_ANSWERING khi tìm kiếm. Đây không phải là một con số tuỳ ý mà là một kỹ thuật quan trọng để cải thiện chất lượng tìm kiếm bằng cách cho phép mô hình nhúng hoạt động như một mô hình đề xuất.
Hầu hết các trường hợp sử dụng tính năng tìm kiếm vectơ đều dựa vào tính năng so khớp mức độ tương tự đơn giản, nhưng điều này thường không mang lại chất lượng tìm kiếm ở cấp độ sản xuất vì câu hỏi và câu trả lời vốn không tương tự nhau trong không gian nhúng. "What's good for a beach vacation?" (Tôi nên mang theo những gì cho một kỳ nghỉ ở bãi biển?) và "Board Shorts" (Quần bơi) có ngữ nghĩa khác nhau, nhưng chúng phải khớp với nhau. Các mục nhúng loại nhiệm vụ giải quyết vấn đề này bằng cách tối ưu hoá mô hình nhúng cho các mối quan hệ bất đối xứng: tài liệu được nhúng khác với các cụm từ tìm kiếm, tạo ra một không gian nhúng nơi các kết quả phù hợp được nhóm lại với nhau – bổ sung khả năng đề xuất, tìm các mục có liên quan dựa trên ý định của người dùng.

Việc sử dụng các vectơ nhúng dành riêng cho từng tác vụ có thể cải thiện chất lượng tìm kiếm từ 30% đến 40% so với các vectơ nhúng chung. Để nghiên cứu chuyên sâu về cách hoạt động của tính năng này, hãy xem sổ tay Nhúng loại tác vụ.
Từ con số không đến quy mô hàng tỷ
Để sản xuất ở quy mô lớn, Vector Search 2.0 cung cấp các chỉ mục ANN (Tìm kiếm lân cận gần đúng) dựa trên thuật toán ScaNN (Tìm kiếm lân cận có khả năng mở rộng) của Google – công nghệ tương tự được dùng cho Google Tìm kiếm, YouTube và Google Play. ANN đánh đổi một lượng nhỏ độ chính xác (~99%) để đạt được tốc độ tăng đáng kể: độ trễ dưới 10 mili giây ngay cả với hàng tỷ vectơ.

The Complete Picture
Chỉ trong 5 bước (trong đó các bước từ 1 đến 4 chỉ mất khoảng 5 phút), chúng tôi đã xây dựng một hệ thống tìm kiếm sản phẩm sẵn sàng cho hoạt động sản xuất:

Vector Search 2.0 loại bỏ sự phức tạp về cơ sở hạ tầng, vốn thường làm chậm quá trình áp dụng tính năng tìm kiếm vectơ. Bạn tập trung vào sản phẩm của mình; nền tảng này sẽ xử lý việc nhúng, lập chỉ mục và mở rộng quy mô.
3. Xin chúc mừng
Xin chúc mừng! Bạn đã tạo thành công ứng dụng đầu tiên của mình bằng tính năng Tìm kiếm vectơ 2.0!