
۱. مقدمه
آخرین بهروزرسانی: 2026-03-04
جستجوی برداری یا پایگاه داده برداری، به یک فناوری بنیادی برای سیستمهای هوش مصنوعی مدرن تبدیل شده است. این فناوری با نمایش دادهها به صورت جاسازیهای با ابعاد بالا که معنای معنایی را در بر میگیرند، همه چیز را از جستجوی معنایی که قصد کاربر را درک میکند، گرفته تا موتورهای توصیهگر که محتوای مرتبط را نمایش میدهند، و تولید افزوده بازیابی (RAG) و عاملهای هوش مصنوعی که پاسخهای LLM را در اطلاعات واقعی و بهروز قرار میدهند، تقویت میکند. شرکتهای بزرگ فناوری از جمله گوگل، در مقیاس وسیع برای پردازش میلیاردها جستجو، توصیه و زمینهسازی روزانه به این فناوری متکی هستند.
با این حال، ساخت جستجوی برداری آماده برای تولید همچنان چالش برانگیز است. گوگل اخیراً Vertex AI Vector Search 2.0 را برای تغییر این وضعیت منتشر کرده است - یک سرویس کاملاً مدیریت شده که برای از بین بردن پیچیدگیهای طراحی و عملیاتی که تیمها را کند میکند، طراحی شده است.

چرا جستجوی برداری سختتر از آن چیزی است که به نظر میرسد
مفهوم ساده است. پیادهسازی؟ اینجاست که مسائل پیچیده میشوند.

تولید جاسازی. جستجوی برداری نیاز به تبدیل دادههای شما به نمایشهای عددی (جاسازیها) دارد که معنای معنایی را در بر میگیرند. این بدان معناست که شما باید یک API جاسازی را فراخوانی کنید، درخواستهای خود را دستهبندی کنید، محدودیتهای سرعت را مدیریت کنید و بردارها را ذخیره کنید. هر بار که دادههای شما تغییر میکند، خط لوله را دوباره اجرا میکنید. این زیرساختی است که باید قبل از شروع جستجو، آن را بسازید.
فروشگاه ویژگی. بسیاری از محصولات جستجوی برداری فقط یک فهرست برداری ارائه میدهند که لیستی از شناسههای اقلام را برای هر جستجو برمیگرداند. برای ارائه نتایج جستجوی کامل به کاربران، به یک فروشگاه ویژگی یا فروشگاه کلید-مقدار جداگانه نیاز دارید تا دادههای واقعی اقلام - نامها، قیمتها، دستهها، URLهای تصویر در میلیثانیه - را با ارسال آن شناسهها بازیابی کنید. در بسیاری از موارد، شما همچنین نیاز به پیادهسازی فیلترهای پیچیده روی ویژگیهای اقلام مانند قیمت، دسته یا در دسترس بودن دارید. این به معنای ساخت و نگهداری دو سرویس مختلف است: یکی برای جستجوی برداری، یکی برای بازیابی دادهها و فیلتر کردن. هر بهروزرسانی و پرسوجو نیاز به دسترسی و همگامسازی هر دو سیستم دارد.
تنظیم شاخص. برای ساخت شاخصهای تقریبی نزدیکترین همسایه (ANN) با میلیونها آیتم، باید تصمیمات کارشناسی بگیرید تا بهترین عملکرد را داشته باشید: هر گره شاخص باید چند آیتم را در خود جای دهد؟ چه درصدی از شاخص باید در هر پرسوجو اسکن شود تا تعادل بین فراخوانی و تأخیر برقرار شود؟ چه اندازه شاردی با مجموعه داده شما مطابقت دارد؟ اینها تصمیمات زیرساخت یادگیری ماشین هستند که هیچ ارتباطی با محصول واقعی شما ندارند.
جستجوی ترکیبی. جستجوی معنایی در درک هدف عالی عمل میکند - پیدا کردن "شورتهای تختهای" وقتی کاربران "لباس مردانه برای ساحل" را جستجو میکنند. اما در کدهای محصولی مانند "SKU-12345" که هیچ معنای معنایی ندارند، شکست میخورد و با اصطلاحات یا نامهای تجاری تازه ابداع شده که مدل جاسازی هرگز ندیده است، مشکل دارد. جستجوی کلمات کلیدی این موارد را مدیریت میکند اما زمینه معنایی را از دست میدهد. کاربران به هر دو نیاز دارند، به همین دلیل جستجوی ترکیبی ضروری شده است. با این حال، ساخت آن به هیچ وجه کار سادهای نیست. شما به یک موتور جستجوی متن کامل با توکنسازی، فهرستهای معکوس یا جاسازیهای پراکنده - علاوه بر موتور جستجوی برداری خود - نیاز دارید. سپس باید پرسوجوهای موازی را در هر دو موتور اجرا کنید، سیستمهای امتیازدهی مختلف آنها را عادیسازی کنید و نتایج را با تکنیکهایی مانند Reciprocal Rank Fusion ادغام کنید.
چگونه جستجوی برداری ۲.۰ این مشکلات را حل میکند
جستجوی برداری ۲.۰ در گوگل کلود مستقیماً به هر یک از این چالشها میپردازد:


در این کارگاه، ما یک جستجوی ترکیبی کاملاً مدیریتشده با استفاده از ۱۰،۰۰۰ محصول مد از مجموعه دادههای تجارت الکترونیک TheLook خواهیم ساخت.
جستجوی برداری ۲.۰ چیست؟
Vector Search 2.0 پایگاه داده برداری کاملاً مدیریتشده و خودتنظیم گوگل کلود است که بر اساس الگوریتم ScaNN (Scalable Nearest Neighbors) گوگل ساخته شده است - همان فناوری که موتور جستجوی گوگل، یوتیوب و گوگل پلی را قدرتمند میکند.
تمایزات کلیدی
- شاخصگذاری صفر تا شاخصگذاری میلیاردی : بلافاصله با زمان شاخصگذاری صفر با استفاده از kNN (k-Nearest Neighbors) شروع به توسعه کنید، سپس با شاخصگذاریهای ANN (Approximate Nearest Neighbor) در مقیاس گوگل، برای تولید، به میلیاردها بردار با تأخیر میلیثانیه مقیاس دهید - همه با API و مجموعه داده یکسان
- ذخیرهسازی یکپارچه دادهها : هم دادههای جاسازیشده برداری و هم دادههای ارائه شده توسط کاربر را با هم ذخیره کنید (به پایگاه داده یا فروشگاه ویژگی جداگانهای نیاز نیست)
- جاسازیهای خودکار : با استفاده از مدلهای جاسازی هوش مصنوعی Vertex، جاسازیهای معنایی را به طور خودکار ایجاد میکند.
- جستجوی متن کامل داخلی : جستجوی متن کامل داخلی را بدون نیاز به ایجاد جاسازیهای پراکنده توسط خودتان فراهم میکند. همچنین میتوانید از جاسازیهای پراکنده خود (مثلاً BM25، SPLADE) با جستجوی برداری برای جستجوی متن کامل سفارشی استفاده کنید.
- جستجوی ترکیبی : جستجوی معنایی و جستجوی مبتنی بر کلمه کلیدی/توکن را در یک پرسوجوی واحد با رتبهبندی هوشمند RRF ترکیب کنید.
- خودتنظیمی : عملکرد بهینه خودکار بدون پیکربندی دستی
- آماده برای سازمانها : مقیاسپذیری، امنیت و انطباقپذیری داخلی
معماری هسته
جستجوی برداری ۲.۰ سه جزء اصلی دارد:
- مجموعهها : کانتینرهای مبتنی بر طرحواره برای دادههای شما
- اشیاء داده : اقلام منفرد با جاسازیهای داده و برداری
- شاخصها : جستجوی فوری نزدیکترین همسایه با kNN در دادهها. برای جستجوی نزدیکترین همسایه با تأخیر کم، از شاخص ANN استفاده کنید.
- شروع سریع : بلافاصله و بدون نیاز به زمان راهاندازی از kNN استفاده کنید - مناسب برای توسعه و مجموعه دادههای کوچک
- مقیاسپذیری برای تولید : استفاده از شاخصهای ANN برای جستجوی در مقیاس میلیاردی با تأخیر زیر ثانیه که توسط الگوریتم ScaNN پشتیبانی میشود
بیایید هر مفهوم را با مثالهای عملی بررسی کنیم!
۲. ساخت جستجوی مد TheLook
تصور کنید یک مشتری وارد سایت تجارت الکترونیک شما میشود و عبارت «چیزی بامزه برای تعطیلات ساحلی» را تایپ میکند. با جستجوی سنتی کلمات کلیدی، آنها هیچ نتیجهای دریافت نمیکنند - هیچ محصولی در کاتالوگ شما دقیقاً شامل آن کلمات نیست. آنها ناامید میشوند و سایت را ترک میکنند.
حالا یک تجربه متفاوت را تصور کنید. همان عبارت جستجو، لباسهای تابستانی، لباسهای شنای پوشیده و شلوارکهای گشاد را برمیگرداند - محصولاتی که کاملاً با آنچه مشتری در ذهن داشته مطابقت دارند، حتی اگر هیچکدام کلمه "ساحل" را در عنوان خود نداشته باشند. این همان تجربهای است که جستجوی برداری ارائه میدهد.
برای نشان دادن اینکه چگونه Vector Search 2.0 این امر را ممکن میسازد، ما یک سیستم جستجوی محصول با استفاده از TheLook ، یک مجموعه داده تجارت الکترونیک واقعگرایانه با 30،000 کالای مد در 26 دسته، خواهیم ساخت. هر محصول دارای ویژگیهایی است که در هر کاتالوگ واقعی پیدا میکنید:

چالشهای جستجویی که ما حل خواهیم کرد
مشتریان واقعی آنطور که پایگاههای داده انتظار دارند جستجو نمیکنند، بلکه آنطور که فکر میکنند جستجو میکنند:

Vector Search 2.0 هر چهار چالش را با یک معماری یکپارچه حل میکند.
معماری داده جستجوی برداری ۲.۰
قبل از پرداختن به کد، بیایید بفهمیم که Vector Search 2.0 چگونه دادههای شما را سازماندهی میکند. معماری آن بر سه مفهوم کلیدی متمرکز است: مجموعهها (Collections)، اشیاء داده (Data Objects) و شاخصها (Indexes).

یک مجموعه، ساختار داده شما را تعریف میکند - فیلدهایی که میخواهید ذخیره کنید و اینکه کدام یک باید جاسازی شوند. اشیاء داده، اقلام واقعی (محصولات، اسناد، تصاویر) ذخیره شده در یک مجموعه هستند که هر کدام دادهها و بردارهای تولید شده خودکار یا بردارهای خودتان را دارند. یک فهرست، پرسوجوها را در مقیاس بهینه میکند و تأخیر میلیثانیهای را در میلیاردها مورد امکانپذیر میسازد. میتوانید بدون یک فهرست برای توسعه با زمان راهاندازی صفر شروع کنید، سپس وقتی به عملکرد تولید نیاز دارید، یکی اضافه کنید.
ساخت جستجوی TheLook: گام به گام
حالا بیایید یک سیستم جستجوی محصول کاربردی بسازیم. ما ۱۰،۰۰۰ آیتم مد را از TheLook بارگذاری خواهیم کرد، جاسازیهای خودکار را فعال میکنیم و جستجوهای معنایی، کلمات کلیدی و ترکیبی را اجرا خواهیم کرد - همه اینها در حدود ۵۰ خط کد انجام میشود.
دفترچه یادداشت را باز کنید: مقدمهای بر جستجوی برداری هوش مصنوعی ورتکس ۲.۰
جستجوی ترکیبی در عمل
جستجوی برداری ۲.۰ از سه حالت جستجو پشتیبانی میکند: جستجوی معنایی (هدف را از طریق جاسازیها درک میکند)، جستجوی متنی (تطبیق کلمات کلیدی) و جستجوی ترکیبی (هر دو را ترکیب میکند). جستجوی ترکیبی بهترین نتایج را برای اکثر موارد استفاده ارائه میدهد - جستجوی معنایی وقتی کاربران "لباس مردانه برای ساحل" را جستجو میکنند، "شورتهای تختهای" را پیدا میکند، در حالی که جستجوی متنی تضمین میکند که تطابقهای دقیقی مانند کدهای محصول از دست نرفته باشند.

چرا جاسازیهای نوع وظیفه اهمیت دارند؟
به پارامترهای task_type در کد بالا توجه کنید: RETRIEVAL_DOCUMENT هنگام فهرستبندی محصولات و QUESTION_ANSWERING هنگام جستجو. این یک امر دلخواه نیست - این یک تکنیک کلیدی برای بهبود کیفیت جستجو با اجازه دادن به مدل جاسازی است که مانند یک مدل توصیه عمل کند.
بیشتر موارد استفاده از جستجوی برداری به تطبیق ساده شباهت متکی هستند، اما این روش اغلب نمیتواند کیفیت جستجوی سطح تولید را ارائه دهد زیرا سوالات و پاسخها ذاتاً در فضای جاسازی مشابه نیستند. "چه چیزی برای تعطیلات ساحلی خوب است؟" و "Board Shorts" معانی متفاوتی دارند، اما باید با هم مطابقت داشته باشند. جاسازیهای نوع وظیفه این مشکل را با بهینهسازی مدل جاسازی برای روابط نامتقارن حل میکنند: اسناد به طور متفاوتی از پرسوجوها جاسازی میشوند و یک فضای جاسازی ایجاد میکنند که در آن تطابقهای مرتبط در کنار هم قرار میگیرند - قابلیت توصیه را اضافه میکند و موارد مرتبط را بر اساس قصد کاربر پیدا میکند.
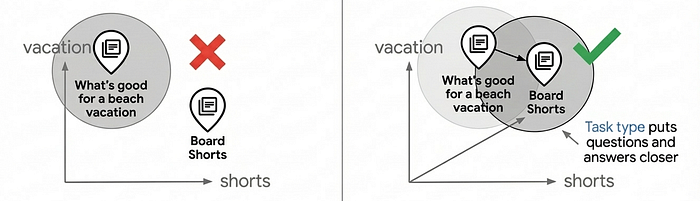
استفاده از جاسازیهای وظیفهمحور میتواند کیفیت جستجو را در مقایسه با جاسازیهای عمومی، 30 تا 40 درصد بهبود بخشد. برای آشنایی بیشتر با نحوهی عملکرد این روش، به دفترچهی جاسازی نوع وظیفه مراجعه کنید.
از مقیاس صفر تا میلیارد
برای تولید در مقیاس بزرگ، Vector Search 2.0 شاخصهای ANN (تقریبی نزدیکترین همسایه) را ارائه میدهد که توسط الگوریتم ScaNN (مقیاسپذیر نزدیکترین همسایهها) گوگل پشتیبانی میشوند - همان فناوری پشت جستجوی گوگل، یوتیوب و گوگل پلی. ANN مقدار کمی از دقت (~99٪) را برای افزایش سرعت عظیم فدا میکند: تأخیر زیر 10 میلیثانیه حتی با میلیاردها بردار.

تصویر کامل
تنها در پنج مرحله - که مراحل ۱ تا ۴ فقط حدود ۵ دقیقه طول کشید - ما یک سیستم جستجوی محصول آماده برای تولید ساختیم:

جستجوی برداری ۲.۰ پیچیدگی زیرساختی را که معمولاً پذیرش جستجوی برداری را کند میکند، از بین میبرد. شما روی محصول خود تمرکز میکنید؛ پلتفرم، جاسازیها، نمایهسازی و مقیاسبندی را مدیریت میکند.
۳. تبریک میگویم
تبریک میگویم، شما با موفقیت اولین برنامه خود را با Vector Search 2.0 ساختید!