
1. مقدمة
تاريخ آخر تعديل: 2026-03-04
أصبحت قواعد بيانات المتّجهات من التكنولوجيات الأساسية لأنظمة الذكاء الاصطناعي الحديثة. من خلال تمثيل البيانات كعمليات تضمين عالية الأبعاد تستوعب المعنى الدلالي، يمكن الاستفادة من هذه التكنولوجيا في كل شيء، بدءًا من البحث الدلالي الذي يفهم نية المستخدم، ووصولاً إلى محرّكات الاقتراحات التي تعرض المحتوى ذي الصلة، والتوليد المعزّز بالاسترجاع، ووكلاء الذكاء الاصطناعي الذين يقدّمون ردودًا من النماذج اللغوية الكبيرة استنادًا إلى معلومات حقيقية وحديثة. تعتمد شركات التكنولوجيا الكبرى، بما في ذلك Google، على هذه التكنولوجيا على نطاق واسع لمعالجة مليارات من عمليات البحث والاقتراحات والمصادر يوميًا.
ومع ذلك، لا يزال إنشاء بحث متّجه جاهز للاستخدام في مرحلة الإنتاج أمرًا صعبًا. أطلقت Google مؤخرًا الإصدار 2.0 من خدمة Vertex AI Vector Search لتغيير ذلك، وهي خدمة مُدارة بالكامل مصمَّمة لإزالة التعقيد في التصميم والتشغيل الذي يبطئ أداء الفِرق.

لماذا يكون البحث عن المتّجهات أصعب ممّا يبدو؟
المفهوم بسيط. التنفيذ؟ وهنا تصبح الأمور معقّدة.

إنشاء التضمين: تتطلّب عملية البحث المتّجهي تحويل بياناتك إلى تمثيلات رقمية (تضمينات) تعكس المعنى الدلالي. وهذا يعني أنّه عليك طلب واجهة برمجة تطبيقات للتضمين، وتجميع طلباتك، والتعامل مع حدود المعدّل، وتخزين المتجهات. في كل مرة تتغير فيها بياناتك، عليك إعادة تشغيل خط الأنابيب. وهي البنية الأساسية التي يجب إنشاؤها قبل أن تتمكّن من بدء البحث.
متجر الميزات: تقدّم العديد من منتجات البحث المتّجه فهرسًا متّجهًا فقط يعرض قائمة بمعرّفات السلع لكل عملية بحث. لعرض نتائج البحث الكاملة للمستخدمين، تحتاج إلى متجر ميزات أو متجر قيم مفتاحية منفصلَين لاسترداد بيانات المنتج الفعلية، مثل الأسماء والأسعار والفئات وعناوين URL للصور بالملّي ثانية، وذلك من خلال تمرير أرقام التعريف هذه. في كثير من الحالات، عليك أيضًا تنفيذ فلترة معقّدة على ميزات السلع، مثل السعر أو الفئة أو مدى التوفّر. وهذا يعني إنشاء وصيانة خدمتين مختلفتين: إحداهما للبحث المتّجه، والأخرى لاسترداد البيانات وفلترتها. يتطلّب كل تحديث واستعلام الوصول إلى كلا النظامين ومزامنتهما.
تحسين الفهرس: لإنشاء فهارس البحث عن أقرب جار تقريبي (ANN) تحتوي على ملايين العناصر، عليك اتّخاذ قرارات الخبراء للحصول على أفضل أداء: كم عدد العناصر التي يجب أن تحتوي عليها كل عقدة فهرس؟ ما هي النسبة المئوية للفهرس التي يجب فحصها لكل طلب بحث لتحقيق التوازن بين الاسترجاع ووقت الاستجابة؟ ما هو حجم التقسيم الذي يتطابق مع مجموعة البيانات؟ هذه قرارات متعلقة بالبنية الأساسية لتعلُّم الآلة ولا صلة لها بمنتجك الفعلي.
البحث المختلط: تتفوق ميزة البحث الدلالي في فهم النية من البحث، إذ يمكنها العثور على "سراويل سباحة" عندما يبحث المستخدمون عن "ملابس رجالية مناسبة للشاطئ". لكنّها لا تعمل مع رموز المنتجات، مثل "SKU-12345" التي لا تحمل أي معنى دلالي، وتواجه صعوبة في التعامل مع المصطلحات أو أسماء العلامات التجارية الجديدة التي لم يرَها نموذج التضمين من قبل. تتعامل ميزة البحث عن الكلمات الرئيسية مع هذه الحالات، ولكنّها لا تفهم السياق الدلالي. يحتاج المستخدمون إلى كليهما، ولهذا السبب أصبح البحث المختلط ضروريًا. ومع ذلك، فإنّ إنشاءه ليس أمرًا بسيطًا. تحتاج إلى محرّك بحث عن النص الكامل يتضمّن تقسيمًا إلى رموز مميزة أو فهارس معكوسة أو تضمينات متفرقة، بالإضافة إلى محرّك البحث المستند إلى المتجهات. بعد ذلك، عليك تنفيذ طلبات بحث متوازية على كلتا الآلتين، وتوحيد أنظمة التسجيل المختلفة، ودمج النتائج باستخدام تقنيات مثل Reciprocal Rank Fusion.
كيف يحلّ الإصدار 2.0 من "البحث الدلالي" هذه المشاكل؟
يحلّ Vector Search 2.0 على Google Cloud كلّاً من هذه التحديات مباشرةً:


في ورشة العمل هذه، سننشئ عملية بحث مختلطة مُدارة بالكامل باستخدام 10,000 منتج أزياء من مجموعة بيانات TheLook للتجارة الإلكترونية.
ما هو الإصدار 2.0 من "البحث عن المتّجهات"؟
Vector Search 2.0 هي قاعدة بيانات متّجهة ذاتية الضبط ومُدارة بالكامل من Google Cloud، وهي تستند إلى خوارزمية ScaNN (الجيران الأقرب القابلين للتوسيع) من Google، وهي التكنولوجيا نفسها التي تعمل بها "بحث Google" وYouTube وGoogle Play.
عوامل التميّز الرئيسية
- الفهرسة بدون وقت استجابة إلى الفهرسة على نطاق المليارات: ابدأ التطوير على الفور بدون وقت استجابة للفهرسة باستخدام kNN (أقرب k من الجيران)، ثم وسِّع نطاق الفهرسة إلى مليارات المتجهات مع وقت استجابة بالملّي ثانية باستخدام فهارس ANN (أقرب جار تقريبي) على نطاق Google للإنتاج، وكل ذلك باستخدام واجهة برمجة التطبيقات ومجموعة البيانات نفسها.
- ميزة "تخزين البيانات الموحّد": يمكنك تخزين كل من التضمينات المتجهة والبيانات المقدَّمة من المستخدم معًا (بدون الحاجة إلى قاعدة بيانات أو متجر ميزات منفصلَين).
- عمليات التضمين التلقائية: يمكنك إنشاء عمليات تضمين دلالية تلقائيًا باستخدام نماذج التضمين في Vertex AI.
- البحث المضمّن عن النص الكامل: يوفّر بحثًا مضمّنًا عن النص الكامل بدون الحاجة إلى إنشاء تضمينات متفرقة بنفسك. يمكنك أيضًا اختيار استخدام عمليات التضمين المتفرّقة الخاصة بك (مثل BM25 وSPLADE) مع Vector Search لإجراء بحث مخصّص عن النص الكامل.
- البحث المختلط: يمكنك الجمع بين البحث الدلالي والبحث المستند إلى الكلمات الرئيسية/الرموز في طلب بحث واحد باستخدام ترتيب RRF الذكي.
- الضبط الذاتي: أداء محسَّن تلقائيًا بدون إعداد يدوي
- جاهز للمؤسسات: قابلية توسّع وأمان وامتثال مدمجة
البنية الأساسية
يتضمّن الإصدار 2.0 من "البحث المتّجه" ثلاثة مكوّنات رئيسية:
- المجموعات: حاويات تفرض المخطط على بياناتك
- عناصر البيانات: عناصر فردية تتضمّن بيانات وتضمينات متجهة
- الفهارس: يمكنك البحث الفوري عن أقرب جار لبياناتك باستخدام kNN. للبحث عن الجيران الأقربين بوقت استجابة منخفض، استخدِم فهرس شبكة عصبية اصطناعية.
- بدء سريع: يمكنك استخدام kNN على الفور بدون أي وقت إعداد، ما يجعله مثاليًا للتطوير ومجموعات البيانات الصغيرة.
- التوسّع إلى مرحلة الإنتاج: استخدِم فهارس الشبكات العصبية التقريبية الأقرب جارًا (ANN) لإجراء عمليات بحث على نطاق واسع (مليار مستند) مع وقت استجابة أقل من ثانية، وذلك باستخدام خوارزمية ScaNN.
لنستكشف كل مفهوم من خلال أمثلة عملية.
2. إنشاء ميزة "البحث عن أزياء" في TheLook
لنفترض أنّ أحد العملاء وصل إلى موقعك الإلكتروني للتجارة الإلكترونية وكتب "شيء لطيف لقضاء عطلة على الشاطئ". باستخدام البحث التقليدي عن الكلمات الرئيسية، لن يحصلوا على أي نتائج لأنّ ما من منتج في الكتالوج الخاص بك يحتوي على تلك الكلمات نفسها. ويغادرون المكان محبطين.
والآن، تخيَّل تجربة مختلفة. يؤدي طلب البحث نفسه إلى عرض فساتين صيفية وملابس سباحة قصيرة وسراويل قصيرة فضفاضة، أي المنتجات التي تتطابق تمامًا مع ما يريده العميل، على الرغم من أنّ أيًا منها لا يحتوي على كلمة "شاطئ" في عنوانه. هذه هي تجربة البحث المتّجه التي تتيحها.
لتوضيح كيف تتيح Vector Search 2.0 ذلك، سننشئ نظام بحث عن المنتجات باستخدام مجموعة بيانات TheLook، وهي مجموعة بيانات واقعية للتجارة الإلكترونية تضم 30,000 قطعة ملابس عصرية ضمن 26 فئة. يتضمّن كل منتج سمات يمكنك العثور عليها في أي كتالوج حقيقي:

التحديات التي سنواجهها في "بحث Google"
لا يبحث العملاء الحقيقيون بالطريقة التي تتوقّعها قواعد البيانات. يبحثون بالطريقة التي يفكّرون بها:

يحلّ Vector Search 2.0 جميع هذه التحديات الأربعة من خلال بنية موحّدة.
بنية بيانات الإصدار 2.0 من Vector Search
قبل الخوض في تفاصيل الرمز، دعنا نتعرّف على طريقة تنظيم Vector Search 2.0 لبياناتك. تستند البنية إلى ثلاثة مفاهيم رئيسية: المجموعات وعناصر البيانات والفهارس.

تحدّد المجموعة بنية بياناتك، أي الحقول التي تريد تخزينها والحقول التي يجب تضمينها. عناصر البيانات هي العناصر الفعلية (المنتجات أو المستندات أو الصور) المخزَّنة في مجموعة، ولكل عنصر بيانات ومتجهات من إنشاء تلقائي أو متجهات خاصة بك. يحسّن الفهرس طلبات البحث على نطاق واسع، ما يتيح وقت استجابة بالمللي ثانية على مستوى مليارات العناصر. يمكنك البدء بدون فهرس للتطوير بدون أي وقت إعداد، ثم إضافة فهرس عند الحاجة إلى أداء الإنتاج.
إنشاء ميزة "بحث TheLook": الخطوات التفصيلية
لننشئ الآن نظامًا عمليًا للبحث عن المنتجات. سنحمّل 10,000 منتج أزياء من TheLook، ونفعّل عمليات التضمين التلقائي، وننفّذ عمليات بحث دلالية وبحثًا عن كلمات رئيسية وبحثًا مختلطًا، وكل ذلك في حوالي 50 سطرًا من الرمز البرمجي.
افتح دفتر الملاحظات: مقدمة عن Vertex AI Vector Search 2.0
استخدام ميزة "البحث المختلط"
يتوافق الإصدار 2.0 من "البحث المتّجه" مع ثلاثة أوضاع بحث: البحث الدلالي (يفهم القصد من خلال التضمينات)، والبحث النصي (مطابقة الكلمات الرئيسية)، والبحث المختلط (يجمع بين الوضعين). تقدّم ميزة "البحث المختلط" أفضل النتائج لمعظم حالات الاستخدام، إذ يعثر "البحث الدلالي" على "سراويل سباحة" عندما يبحث المستخدمون عن "ملابس رجالية للشاطئ"، بينما يضمن "البحث النصي" عدم تفويت النتائج المطابقة تمامًا، مثل رموز المنتجات.

أهمية تضمين أنواع المهام
لاحظ مَعلمات task_type في الرمز أعلاه: RETRIEVAL_DOCUMENT عند فهرسة المنتجات، وQUESTION_ANSWERING عند البحث. هذا ليس إجراءً عشوائيًا، بل هو أسلوب أساسي لتحسين جودة البحث من خلال السماح لنموذج التضمين بالعمل كنموذج اقتراحات.
تعتمد معظم حالات استخدام البحث المتّجه على مطابقة التشابه البسيط، ولكنّ هذا غالبًا ما يفشل في توفير جودة بحث على مستوى الإنتاج لأنّ الأسئلة والأجوبة ليست متشابهة بطبيعتها في مساحة التضمين. "ما هي الأنشطة المناسبة لقضاء عطلة على الشاطئ؟" و"سراويل سباحة" لهما دلالات مختلفة، ولكن يجب أن يكونا متطابقَين. تحلّ تضمينات نوع المهمة هذه المشكلة من خلال تحسين نموذج التضمين للعلاقات غير المتماثلة: يتم تضمين المستندات بشكل مختلف عن طلبات البحث، ما يؤدي إلى إنشاء مساحة تضمين تتجمّع فيها التطابقات ذات الصلة، ما يضيف إمكانية تقديم الاقتراحات والعثور على العناصر ذات الصلة استنادًا إلى نية المستخدم.

يمكن أن يؤدي استخدام التضمينات الخاصة بالمهام إلى تحسين جودة البحث بنسبة تتراوح بين %30 و%40 مقارنةً بالتضمينات العامة. للحصول على نظرة متعمّقة حول طريقة عمل هذه الميزة، يُرجى الاطّلاع على دفتر ملاحظات حول تضمين أنواع المهام.
من صفر إلى مليار
لإنشاء تطبيقات على نطاق واسع، توفّر "البحث المتّجه 2.0" فهارس ANN (البحث التقريبي عن أقرب الجيران) المستندة إلى خوارزمية ScaNN (البحث القابل للتوسّع عن أقرب الجيران) من Google، وهي التكنولوجيا نفسها المستخدَمة في "بحث Google" وYouTube وGoogle Play. تضحّي الشبكة العصبونية التقريبية بكمية صغيرة من الدقة (حوالي %99) مقابل تحقيق مكاسب كبيرة في السرعة: وقت استجابة أقل من 10 ملي ثانية حتى مع توفّر مليارات المتجهات.
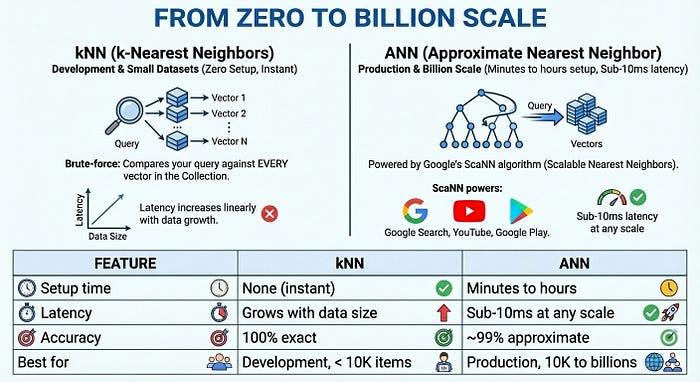
الصورة الكاملة
في خمس خطوات فقط، استغرقت الخطوات من 1 إلى 4 حوالي 5 دقائق فقط، أنشأنا نظام بحث عن المنتجات جاهزًا للاستخدام:
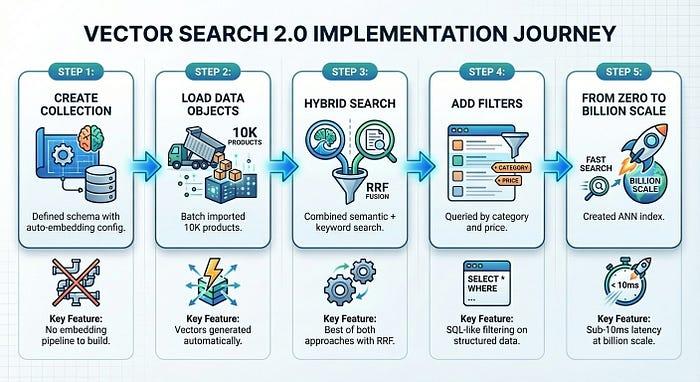
تزيل ميزة "البحث المستنِد إلى المتّجهات 2.0" تعقيد البنية الأساسية الذي يؤدي عادةً إلى إبطاء استخدام البحث المستنِد إلى المتّجهات. يمكنك التركيز على منتجك، بينما تتولّى المنصة عمليات التضمين والفهرسة والتوسيع.
3- تهانينا
تهانينا، لقد أنشأت بنجاح تطبيقك الأول باستخدام Vector Search 2.0.