
1. 事前準備
從推薦電影或餐廳,到主打娛樂影片,推薦引擎 (也稱為推薦工具) 都是機器學習的重要應用。推薦工具可協助您從大量候選對象顯示吸睛內容。舉例來說,Google Play 商店提供數百萬個可安裝的應用程式,而 YouTube 則有數十億部影片可供觀看。此外,每天還會新增更多應用程式和影片。
在本程式碼研究室中,您將瞭解如何使用以下程式碼建構完整堆疊建議工具:
- TensorFlow Recommenders 用於訓練擷取資訊和排名模型,以便提供電影推薦內容
- 使用 TensorFlow Serving 提供模型
- Flutter 建立跨平台應用程式來顯示推薦電影
必要條件
- 使用 Dart 進行 Flutter 開發的基本知識
- 使用 TensorFlow 進行機器學習的基本知識,例如訓練和部署
- 熟悉推薦系統的基本知識
- 對 Python、終端機和 Docker 有基本瞭解
課程內容
- 如何使用 TensorFlow 建議工具訓練擷取和排名模型
- 如何使用 TensorFlow Serving 提供訓練過的推薦模型
- 如何建構跨平台 Flutter 應用程式以顯示推薦項目
軟硬體需求
- Flutter SDK
- Flutter 適用的 Android 和 iOS 設定
- Flutter 的電腦設定
- Flutter 的網路設定
- 適用於 Flutter 和 Dart 的 Visual Studio Code (VS Code) 設定
- Docker
- Bash
- Python 3.7 以上版本
- 存取 Colab
2. 設定 Flutter 開發環境
進行 Flutter 開發作業時,需要有兩件軟體才能完成這個程式碼研究室:Flutter SDK 和編輯器。
您可以使用下列任一裝置執行程式碼研究室的前端:
- iOS 模擬器 (需要安裝 Xcode 工具)。
- Android Emulator (需要在 Android Studio 中設定)。
- 瀏覽器 (必須使用 Chrome 進行偵錯)。
- 下載 Windows、Linux 或 macOS 桌面應用程式。您必須在要部署的平台上進行開發。因此,如果您想要開發 Windows 電腦版應用程式,就必須在 Windows 上進行開發,以便存取適當的建構鏈結。如要進一步瞭解作業系統的特定需求,請參閱 docs.flutter.dev/desktop。
如果是後端,您需要:
- Linux 電腦或採用 Intel 技術的 Mac。
3. 做好準備
如要下載本程式碼研究室的程式碼:
- 前往本程式碼研究室的 GitHub 存放區。
- 按一下「程式碼」>下載 ZIP 檔案即可下載這個程式碼研究室的所有程式碼。
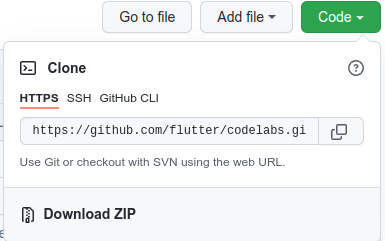
- 解壓縮下載的 ZIP 檔案,將包含所需所有資源的
codelabs-main根資料夾解壓縮。
在本程式碼研究室中,您只需要位於存放區內 tfrs-flutter/ 子目錄中的檔案,該檔案包含多個資料夾:
step0到step5資料夾內含您可以依本程式碼研究室中每個步驟建構的範例程式碼。finished資料夾包含已完成的範例應用程式的程式碼。- 每個資料夾都包含一個
backend子資料夾,當中包含推薦引擎後端程式碼,以及一個包含 Flutter 前端程式碼的frontend子資料夾
4. 下載專案的依附元件
後端
我們要使用 Flask 建立後端。開啟終端機並執行下列指令:
pip install Flask flask-cors requests numpy
前端
- 在 VS Code 中,按一下「File」(檔案) > 開啟資料夾,然後從您先前下載的原始碼中選取
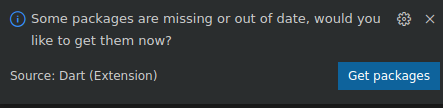
step0資料夾。 - 開啟
step0/frontend/lib/main.dart檔案如果系統顯示 VS Code 對話方塊,提示您下載範例應用程式所需的套件,請按一下「Get package」(取得套件)。 - 如果沒有看到這個對話方塊,請開啟終端機,然後在
step0/frontend資料夾中執行flutter pub get指令。
5. 步驟 0:執行範例應用程式
- 在 VS Code 中開啟
step0/frontend/lib/main.dart檔案,確認 Android Emulator 或 iOS 模擬器已正確設定,且會顯示在狀態列中。
舉例來說,搭配 Android Emulator 使用 Pixel 5 時,畫面上顯示的內容如下:

搭載 iOS 模擬器的 iPhone 13 會出現以下內容:

- 按一下「開始偵錯」圖示
 。
。
執行並探索應用程式
應用程式應該會在 Android Emulator 或 iOS 模擬器上啟動。使用者介面非常簡單,有一個文字欄位可讓使用者輸入文字做為 User ID。Flutter 應用程式會將查詢要求傳送至後端,後端執行 2 個建議模型,並傳回電影推薦項目排名清單。前端會在收到回應後在 UI 中顯示結果。
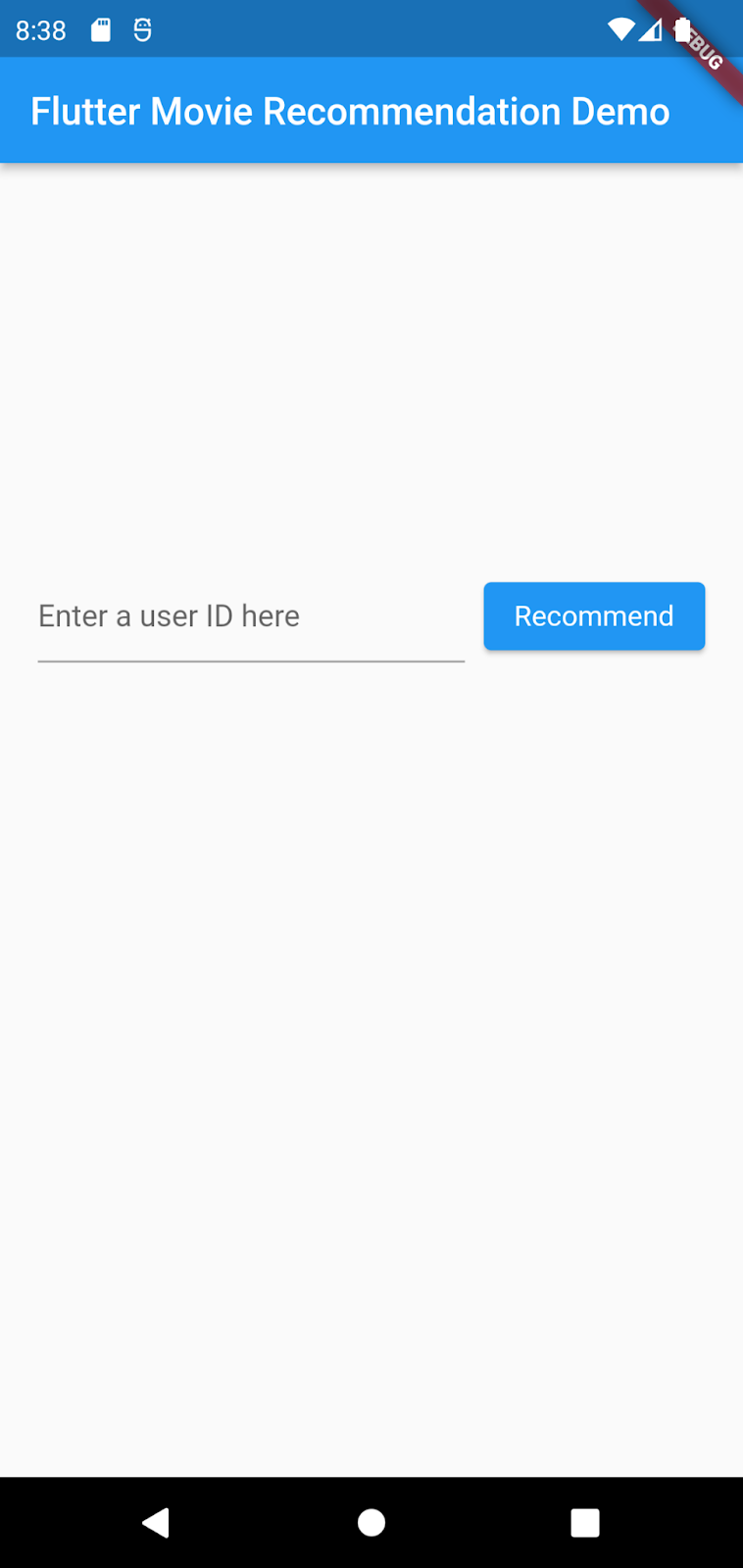
如果您現在點選「Recommendation」(建議),系統目前不會與後端通訊,因此不會有任何反應。
6. 步驟 1:建立推薦引擎的擷取和排名模型
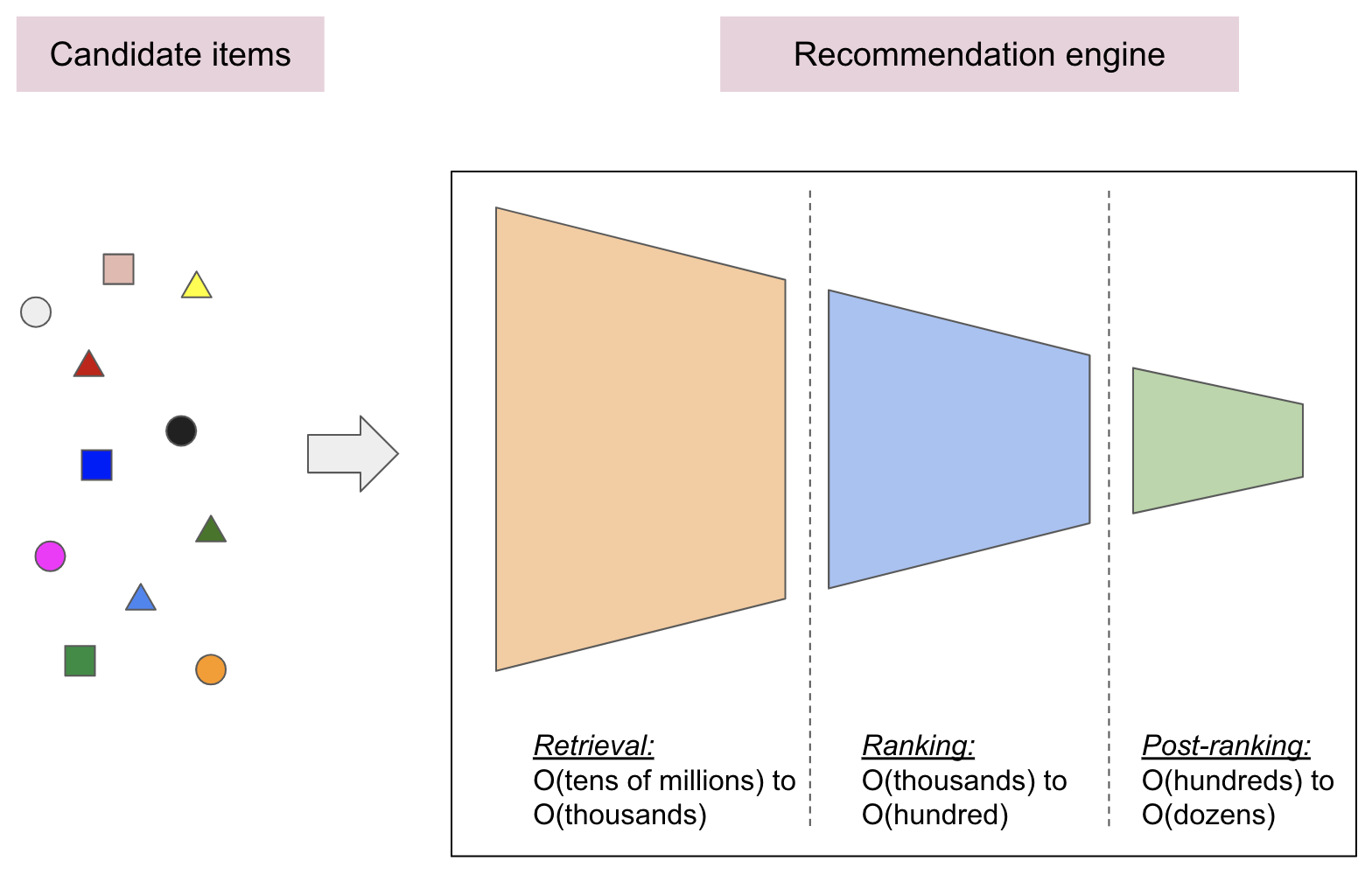
實際的推薦引擎通常包含多個階段:
- 在擷取階段,負責從所有可能候選對像中選出一組初始的候選人。這個模型的主要目標在於有效率地擴散所有使用者不感興趣的候選人。由於擷取模型可能處理數百萬個候選項目,因此必須具有高效率的運算能力。
- 排名階段會擷取擷取模型的輸出內容並進行微調,藉此選取最佳建議。這項工作的任務是,將使用者可能感興趣的項目組合縮小到可能候選清單的清單中 (按照數百個順序排列)。
- 排名後階段有助於確保多元性、新鮮度和公平性,並將候選項目重整為一組有用的推薦內容。
在本程式碼研究室中,您將使用熱門的 MovieLens 資料集訓練擷取模型和排名模型。你可以在 Colab 中開啟下方的訓練程式碼,然後按照指示操作:
7. 步驟 2:建立推薦引擎後端
現在您已將擷取和排名模型訓練完成,接下來就可以部署模型並建立後端。
啟動 TensorFlow Serving
由於您必須同時使用擷取和排名模型來產生建議電影清單,因此必須使用 TensorFlow Serving 同時部署兩者。
- 在終端機中,前往電腦上的
step2/backend資料夾,然後使用 Docker 啟動 TensorFlow Serving:
docker run -t --rm -p 8501:8501 -p 8500:8500 -v "$(pwd)/:/models/" tensorflow/serving --model_config_file=/models/models.config
Docker 會先自動下載 TensorFlow Serving 映像檔,然後需要一分鐘的時間。之後,TensorFlow Serving 應該開始執行。記錄應如以下程式碼片段所示:
2022-04-24 09:32:06.461702: I tensorflow_serving/model_servers/server_core.cc:465] Adding/updating models.
2022-04-24 09:32:06.461843: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: retrieval
2022-04-24 09:32:06.461907: I tensorflow_serving/model_servers/server_core.cc:591] (Re-)adding model: ranking
2022-04-24 09:32:06.576920: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: retrieval version: 123}
2022-04-24 09:32:06.576993: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: retrieval version: 123}
2022-04-24 09:32:06.577011: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: retrieval version: 123}
2022-04-24 09:32:06.577848: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/retrieval/exported-retrieval/123
2022-04-24 09:32:06.583809: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-04-24 09:32:06.583879: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/retrieval/exported-retrieval/123
2022-04-24 09:32:06.584970: I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-04-24 09:32:06.629900: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-04-24 09:32:06.634662: I external/org_tensorflow/tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 2800000000 Hz
2022-04-24 09:32:06.672534: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/retrieval/exported-retrieval/123
2022-04-24 09:32:06.673629: I tensorflow_serving/core/basic_manager.cc:740] Successfully reserved resources to load servable {name: ranking version: 123}
2022-04-24 09:32:06.673765: I tensorflow_serving/core/loader_harness.cc:66] Approving load for servable version {name: ranking version: 123}
2022-04-24 09:32:06.673786: I tensorflow_serving/core/loader_harness.cc:74] Loading servable version {name: ranking version: 123}
2022-04-24 09:32:06.674731: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:38] Reading SavedModel from: /models/ranking/exported-ranking/123
2022-04-24 09:32:06.683557: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:90] Reading meta graph with tags { serve }
2022-04-24 09:32:06.683601: I external/org_tensorflow/tensorflow/cc/saved_model/reader.cc:132] Reading SavedModel debug info (if present) from: /models/ranking/exported-ranking/123
2022-04-24 09:32:06.688665: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 110815 microseconds.
2022-04-24 09:32:06.690019: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/retrieval/exported-retrieval/123/assets.extra/tf_serving_warmup_requests
2022-04-24 09:32:06.693025: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: retrieval version: 123}
2022-04-24 09:32:06.702594: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:206] Restoring SavedModel bundle.
2022-04-24 09:32:06.745361: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:190] Running initialization op on SavedModel bundle at path: /models/ranking/exported-ranking/123
2022-04-24 09:32:06.772363: I external/org_tensorflow/tensorflow/cc/saved_model/loader.cc:277] SavedModel load for tags { serve }; Status: success: OK. Took 97633 microseconds.
2022-04-24 09:32:06.774853: I tensorflow_serving/servables/tensorflow/saved_model_warmup_util.cc:59] No warmup data file found at /models/ranking/exported-ranking/123/assets.extra/tf_serving_warmup_requests
2022-04-24 09:32:06.777706: I tensorflow_serving/core/loader_harness.cc:87] Successfully loaded servable version {name: ranking version: 123}
2022-04-24 09:32:06.778969: I tensorflow_serving/model_servers/server_core.cc:486] Finished adding/updating models
2022-04-24 09:32:06.779030: I tensorflow_serving/model_servers/server.cc:367] Profiler service is enabled
2022-04-24 09:32:06.784217: I tensorflow_serving/model_servers/server.cc:393] Running gRPC ModelServer at 0.0.0.0:8500 ...
[warn] getaddrinfo: address family for nodename not supported
2022-04-24 09:32:06.785748: I tensorflow_serving/model_servers/server.cc:414] Exporting HTTP/REST API at:localhost:8501 ...
[evhttp_server.cc : 245] NET_LOG: Entering the event loop ...
建立新端點
由於 TensorFlow Serving 不支援「鏈結」多個依序模型,您需要建立能連結擷取和排名模型的新服務。
- 請將以下程式碼新增至
step2/backend/recommendations.py檔案的get_recommendations()函式中:
user_id = request.get_json()["user_id"]
retrieval_request = json.dumps({"instances": [user_id]})
retrieval_response = requests.post(RETRIEVAL_URL, data=retrieval_request)
movie_candidates = retrieval_response.json()["predictions"][0]["output_2"]
ranking_queries = [
{"user_id": u, "movie_title": m}
for (u, m) in zip([user_id] * NUM_OF_CANDIDATES, movie_candidates)
]
ranking_request = json.dumps({"instances": ranking_queries})
ranking_response = requests.post(RANKING_URL, data=ranking_request)
movies_scores = list(np.squeeze(ranking_response.json()["predictions"]))
ranked_movies = [
m[1] for m in sorted(list(zip(movies_scores, movie_candidates)), reverse=True)
]
return make_response(jsonify({"movies": ranked_movies}), 200)
啟動 Flask 服務
您現在可以啟動 Flask 服務。
- 前往終端機中的
step2/backend/資料夾,然後執行下列指令:
FLASK_APP=recommender.py FLASK_ENV=development flask run
Flask 會在 http://localhost:5000/recommend 站上新端點。記錄應如下所示:
* Serving Flask app 'recommender.py' (lazy loading) * Environment: development * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat * Debugger is active! * Debugger PIN: 705-382-264 127.0.0.1 - - [25/Apr/2022 19:44:47] "POST /recommend HTTP/1.1" 200 -
您可以傳送範例要求至端點,確保它如預期運作:
curl -X POST -H "Content-Type: application/json" -d '{"user_id":"42"}' http://localhost:5000/recommend
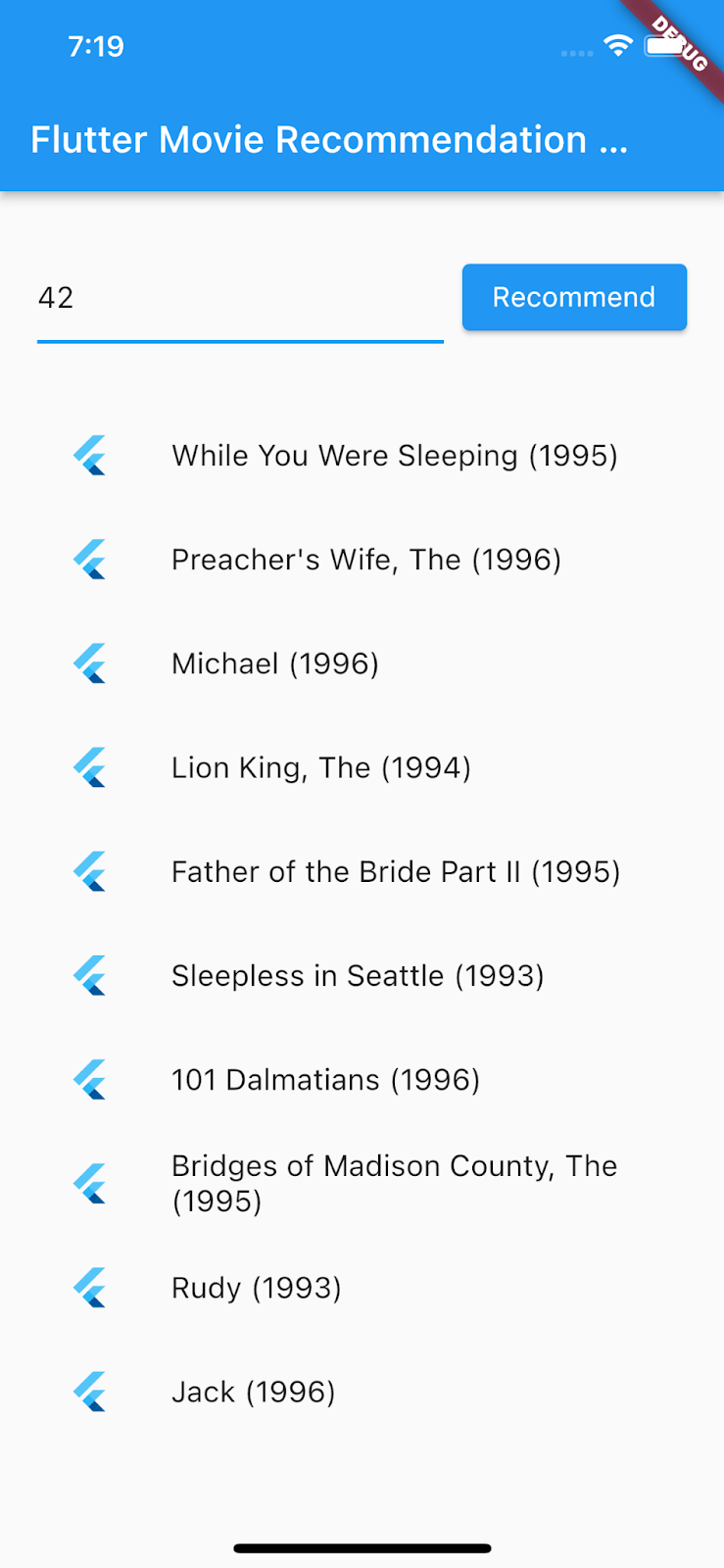
端點會傳回使用者 42 推薦的電影清單:
{
"movies": [
"While You Were Sleeping (1995)",
"Preacher's Wife, The (1996)",
"Michael (1996)",
"Lion King, The (1994)",
"Father of the Bride Part II (1995)",
"Sleepless in Seattle (1993)",
"101 Dalmatians (1996)",
"Bridges of Madison County, The (1995)",
"Rudy (1993)",
"Jack (1996)"
]
}
大功告成!您已成功建立後端,以便依據使用者 ID 推薦電影。
8. 步驟 3:建立 Android 和 iOS 版的 Flutter 應用程式
後端已準備就緒。您可以開始傳送要求,透過 Flutter 應用程式查詢電影推薦項目。
前端應用程式相當簡單。它只有 TextField 會擷取使用者 ID,並將要求 (在 recommend() 函式中) 傳送至您剛剛建構的後端。收到回應後,應用程式 UI 會在 ListView 中顯示建議的電影。
- 請將以下程式碼新增至
step3/frontend/lib/main.dart檔案的recommend()函式中:
final response = await http.post(
Uri.parse('http://' + _server + ':5000/recommend'),
headers: <String, String>{
'Content-Type': 'application/json',
},
body: jsonEncode(<String, String>{
'user_id': _userIDController.text,
}),
);
應用程式收到來自後端的回應後,請更新使用者介面,以顯示指定使用者的推薦影片清單。
- 請在上述程式碼的正下方加入此程式碼:
if (response.statusCode == 200) {
return List<String>.from(jsonDecode(response.body)['movies']);
} else {
throw Exception('Error response');
}
開始執行
- 按一下「Start debugging」圖示 ,然後等待應用程式載入。
- 輸入使用者 ID (例如42),然後選取「推薦」。

9. 步驟 4:在電腦平台上執行 Flutter 應用程式
除了 Android 和 iOS 之外,Flutter 也支援電腦平台,包括 Linux、Mac 和 Windows。
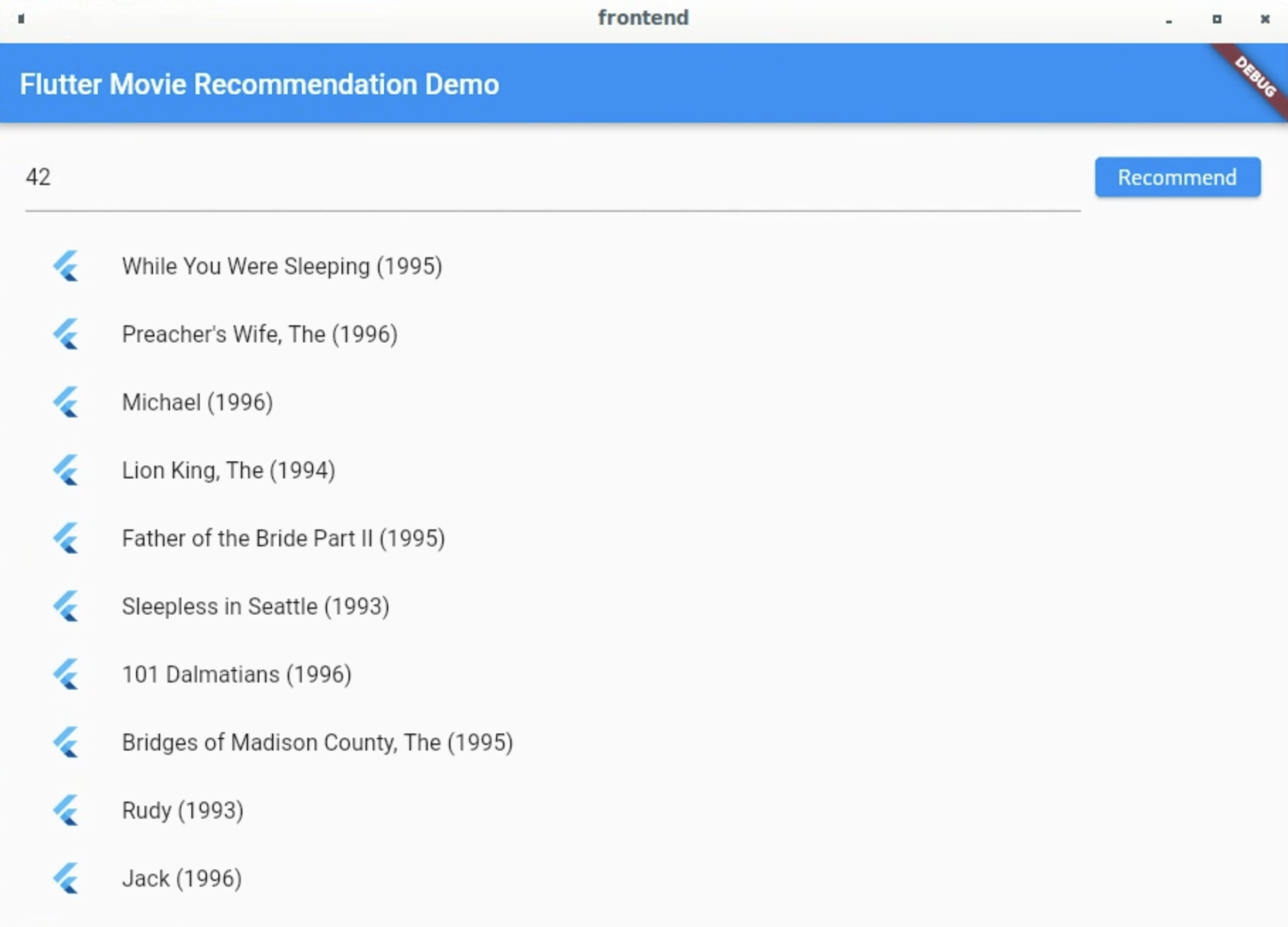
Linux
- 確認 VSCode 狀態列中的目標裝置已設為
 。
。 - 按一下「Start debugging」圖示 ,然後等待應用程式載入。
- 輸入使用者 ID (例如42),然後選取「推薦」。
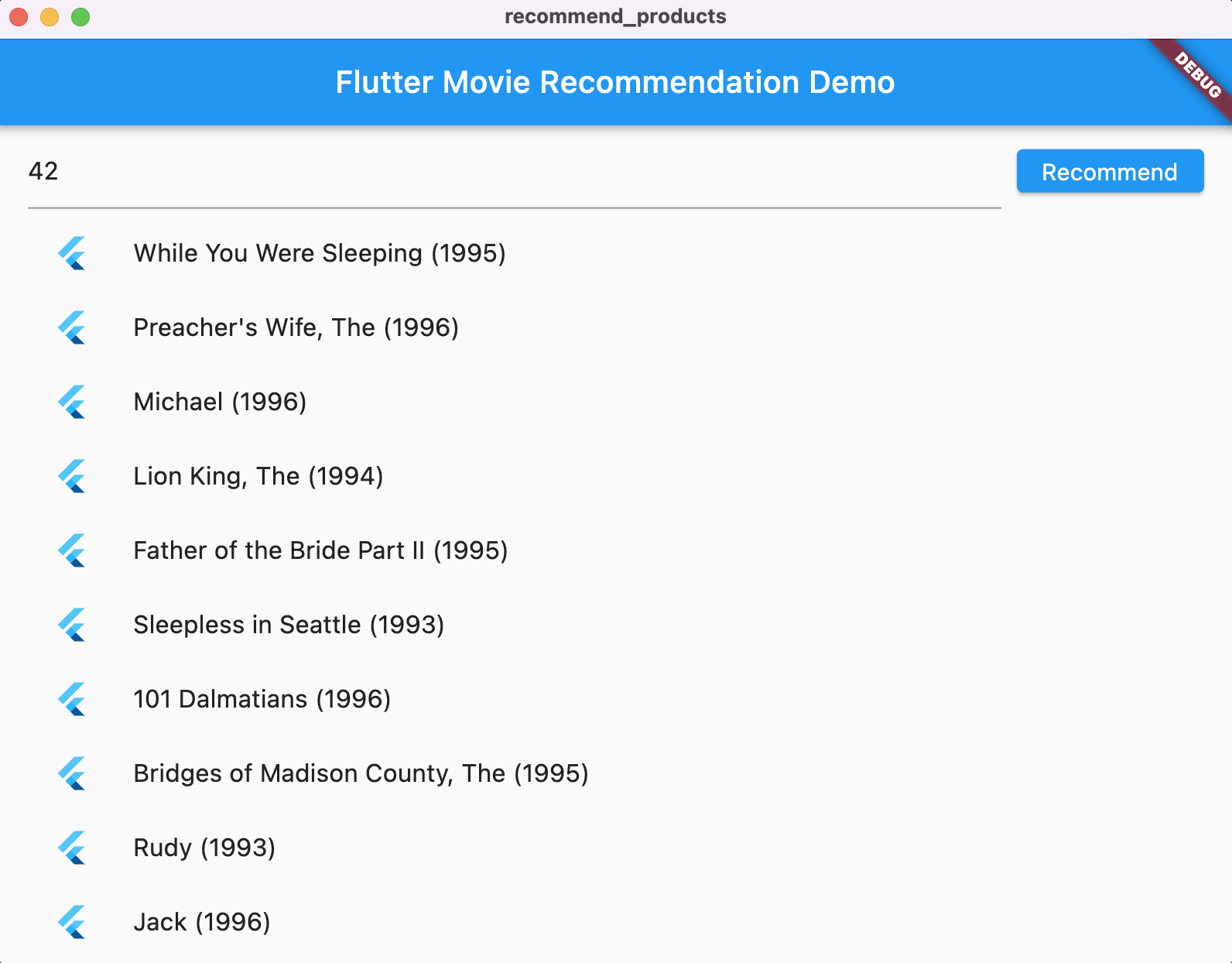
Mac
- 在 Mac 中,由於應用程式會將 HTTP 要求傳送至後端,因此您必須設定適當的授權。詳情請參閱「授權與應用程式沙箱」。
請分別將此程式碼新增至 step4/frontend/macOS/Runner/DebugProfile.entitlements 和 step4/frontend/macOS/Runner/Release.entitlements:
<key>com.apple.security.network.client</key>
<true/>
- 確認 VSCode 狀態列中的目標裝置已設為
 。
。 - 按一下「Start debugging」圖示 ,然後等待應用程式載入。
- 輸入使用者 ID (例如42),然後選取「推薦」。
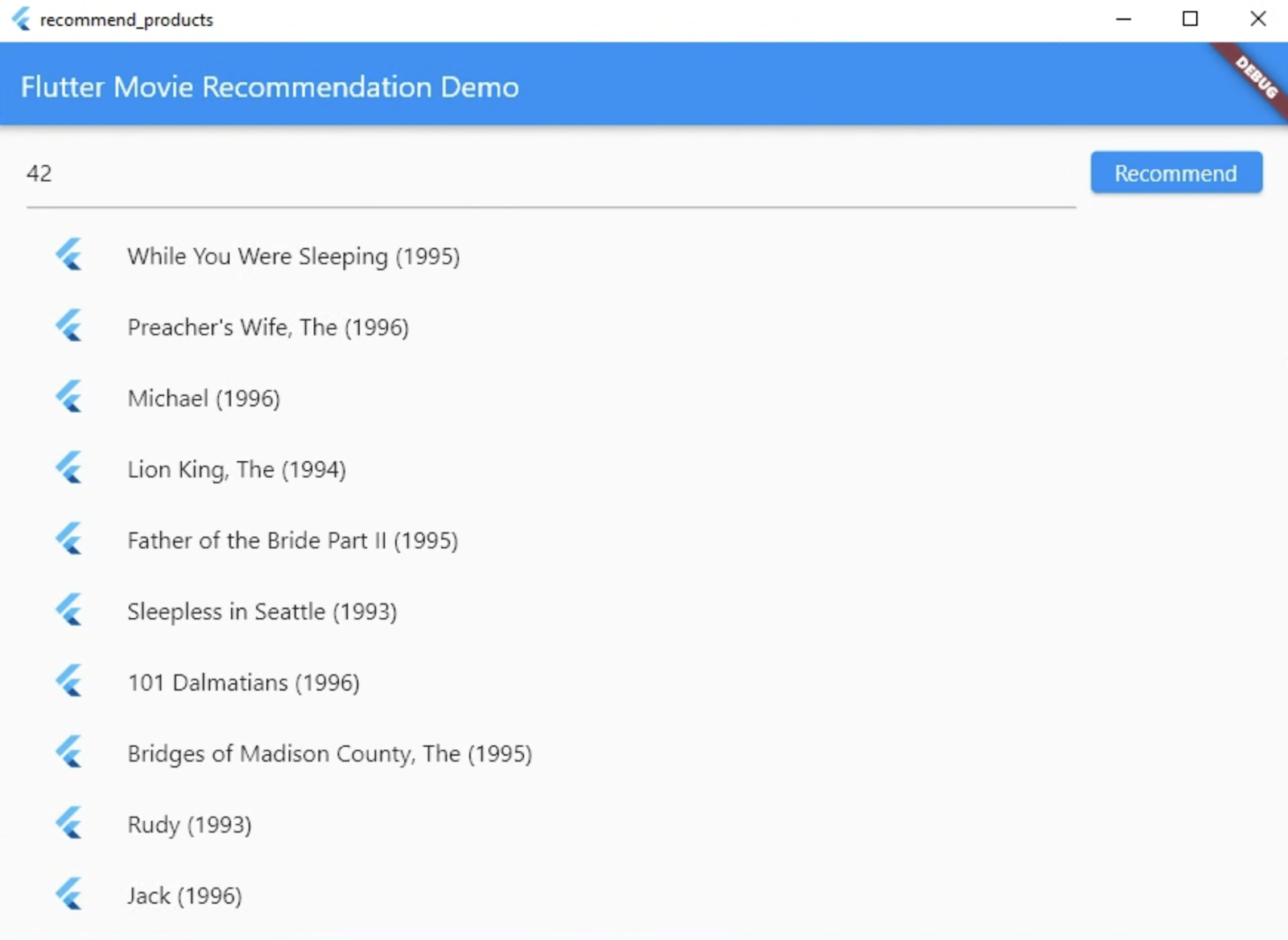
Windows
- 確認 VSCode 狀態列中的目標裝置已設為
 。
。 - 按一下「Start debugging」圖示 ,然後等待應用程式載入。
- 輸入使用者 ID (例如42),然後選取「推薦」。
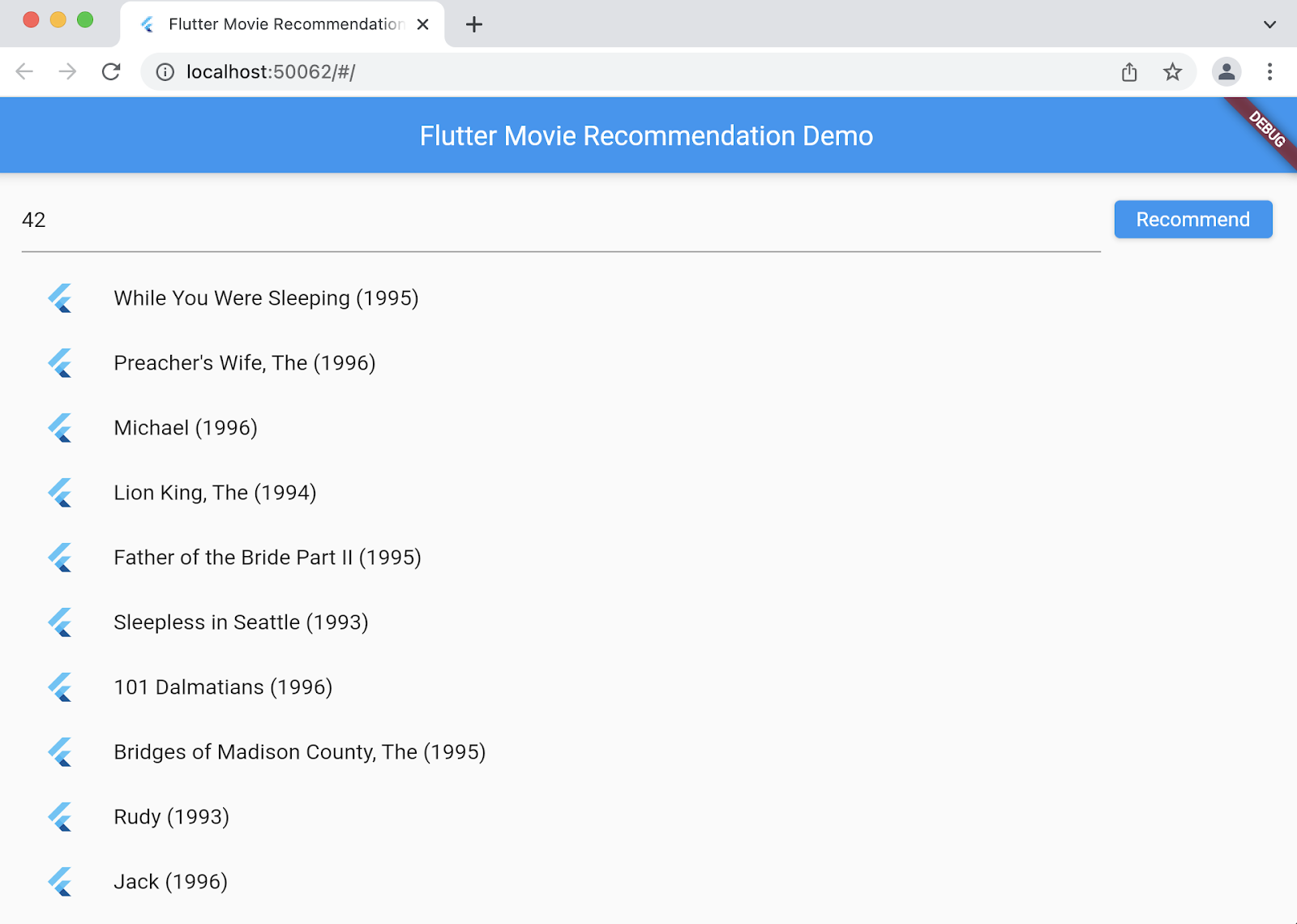
10. 步驟 5:在網路平台上執行 Flutter 應用程式
您還可以在 Flutter 應用程式中新增網頁支援。根據預設,Flutter 應用程式會自動啟用網路平台,你只需啟動這個平台即可。
- 確認 VSCode 狀態列中的目標裝置已設為
 。
。 - 按一下「開始偵錯」圖示 ,然後等待 Chrome 瀏覽器載入應用程式。
- 輸入使用者 ID (例如42),然後選取「推薦」。
11. 恭喜
您建構了完整堆疊應用程式,向使用者推薦電影!
雖然這款應用程式只會推薦電影,但您已瞭解建構強大推薦引擎的整體工作流程,也掌握了使用 Flutter 應用程式推薦內容的能力。您可以輕鬆將所學應用在其他情境中,例如電子商務、美食和短片。