
1. Hinweis
Dieses Codelab baut auf dem Endergebnis des vorherigen Codelabs dieser Reihe zur Erkennung von Spamkommentaren mit TensorFlow.js auf.
Im letzten Codelab haben Sie eine voll funktionsfähige Webseite für einen fiktiven Videoblog erstellt. Mit einem vortrainierten Modell zur Spamerkennung von Kommentaren, unterstützt von TensorFlow.js im Browser, konnten Sie Kommentare nach Spam filtern, bevor sie zum Speichern an den Server oder an andere verbundene Clients gesendet wurden.
Hier sehen Sie das Endergebnis dieses Codelabs:
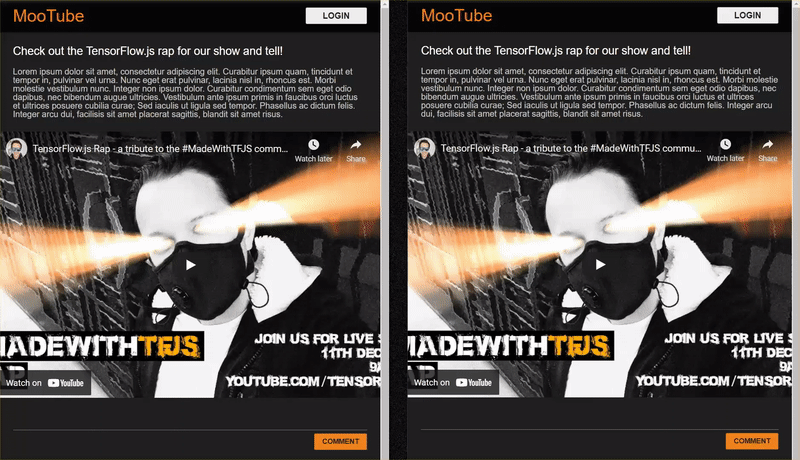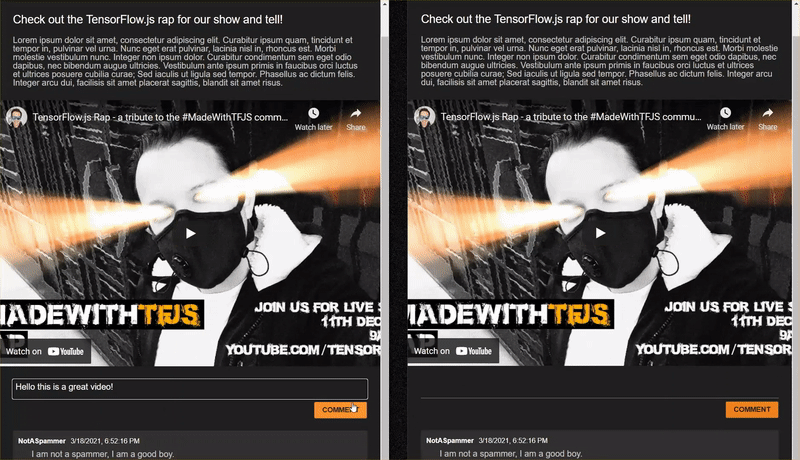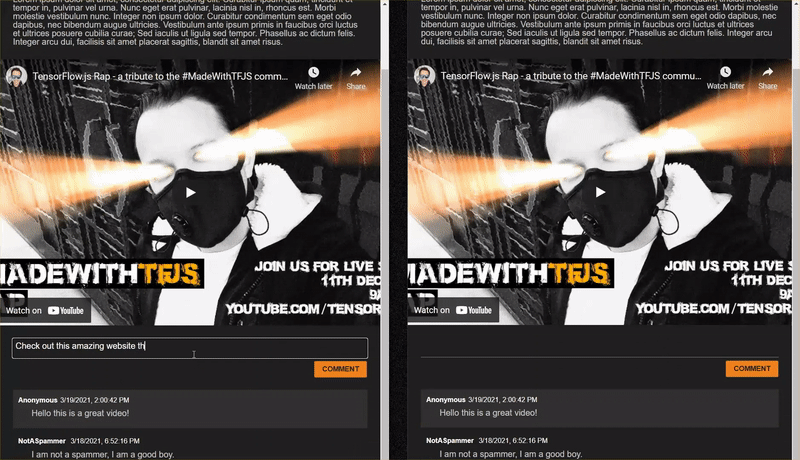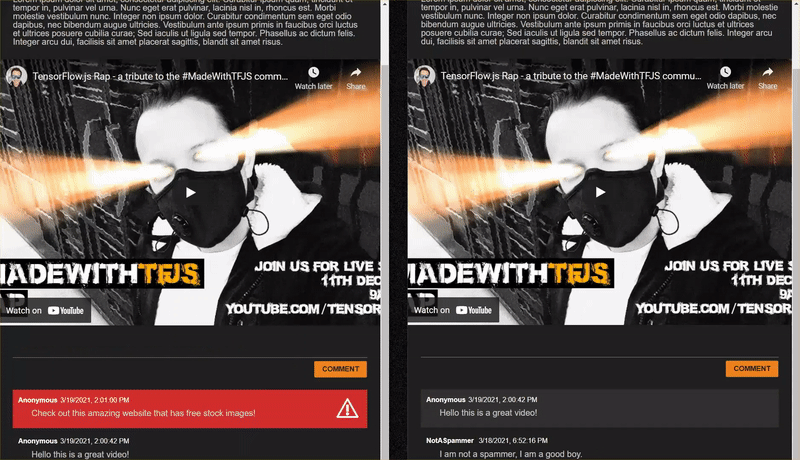
Das hat zwar sehr gut funktioniert, es gibt aber auch Grenzfälle, die nicht erkannt wurden. Sie können das Modell neu trainieren, um die Situationen zu berücksichtigen, die es nicht bewältigen konnte.
Dieses Codelab konzentriert sich auf Natural Language Processing (die Kunst, menschliche Sprache auf einem Computer zu verstehen) und zeigt Ihnen, wie Sie eine von Ihnen erstellte Webanwendung modifizieren können. Wir empfehlen Ihnen dringend, die Codelabs in der richtigen Reihenfolge durchzuarbeiten, um das sehr reale Problem des Kommentar-Spams anzugehen, auf den viele Webentwickler sicherlich stoßen werden, wenn sie an einer der ständig wachsenden beliebten Web-Apps arbeiten.
In diesem Codelab trainieren Sie Ihr ML-Modell noch einen Schritt weiter, um Änderungen beim Inhalt von Spamnachrichten zu berücksichtigen, die sich im Laufe der Zeit aufgrund aktueller Trends oder beliebter Diskussionsthemen ändern können. So können Sie das Modell auf dem neuesten Stand halten und solche Änderungen berücksichtigen.
Vorbereitung
- Du hast das erste Codelab dieser Reihe abgeschlossen.
- Grundkenntnisse in Webtechnologien wie HTML, CSS und JavaScript
Inhalt
Sie verwenden die zuvor erstellte Website für einen fiktiven Videoblog mit einem Kommentarbereich in Echtzeit und aktualisieren sie, um eine angepasste, trainierte Version des Spamerkennungsmodells mithilfe von TensorFlow.js zu laden. So schneidet sie in Grenzfällen besser ab. Natürlich können Sie als Webentwickler und -ingenieur diese hypothetische UX für die Wiederverwendung auf jeder Website ändern, an der Sie in Ihrer täglichen Arbeit arbeiten, und die Lösung an den Anwendungsfall eines Kunden anpassen, z. B. ein Blog, ein Forum oder eine Form von CMS wie zum Beispiel Drupal.
Lass uns hacken...
Aufgaben in diesem Lab
Sie werden Folgendes tun:
- Grenzfälle identifizieren, in denen das vortrainierte Modell fehlgeschlagen ist
- Trainieren Sie das mit Model Maker erstellte Spam-Klassifizierungsmodell noch einmal.
- Exportieren Sie dieses auf Python basierende Modell zur Verwendung in Browsern in das TensorFlow.js-Format.
- Aktualisieren Sie das gehostete Modell und sein Wörterbuch mit dem neu trainierten Modell und prüfen Sie die Ergebnisse
Für dieses Lab wird vorausgesetzt, dass Sie mit HTML5, CSS und JavaScript vertraut sind. Außerdem führen Sie über ein Co-Lab Python-Code aus. Notebook, um das mit Model Maker erstellte Modell neu zu trainieren. Dazu sind jedoch keine Kenntnisse von Python erforderlich.
2. Code einrichten
Auch hier nutzen Sie Glitch.com, um die Webanwendung zu hosten und zu modifizieren. Wenn Sie das erforderliche Codelab noch nicht abgeschlossen haben, können Sie das Endergebnis hier als Ausgangspunkt klonen. Wenn Sie Fragen zur Funktionsweise des Codes haben, sollten Sie das vorherige Codelab abschließen, in dem die Erstellung dieser funktionierenden Webanwendung erläutert wurde, bevor Sie fortfahren.
In Glitch klicken Sie einfach auf die Schaltfläche Remix this (Remix erstellen), um ihn zu verzweigen und einen neuen Satz Dateien zu erstellen, die Sie bearbeiten können.
3. Grenzfälle in der vorherigen Lösung erkennen
Wenn Sie die fertige Website öffnen, die Sie gerade geklont haben, und versuchen, einige Kommentare einzugeben, werden Sie feststellen, dass die meisten Kommentare wie erwartet blockiert werden und legitime Antworten zugelassen werden.
Wenn Sie jedoch geschickt vorgehen und versuchen, Dinge zu formulieren, die das Modell zerbrechen, werden Sie wahrscheinlich irgendwann erfolgreich sein. Mit etwas Ausprobieren können Sie Beispiele wie die unten gezeigten manuell erstellen. Versuchen Sie, diese in die vorhandene Webanwendung einzufügen, sehen Sie in der Konsole nach, wie wahrscheinlich es ist, dass es sich bei dem Kommentar um Spam handelt:
Seriöse Kommentare, die ohne Problem gepostet wurden (echt negative Elemente):
- „Wow, ich liebe dieses Video, super Arbeit.“ Wahrscheinlichkeits-Spam: 47,91854%
- „Diese Demos gefallen mir sehr gut! Haben Sie weitere Informationen?“ Wahrscheinlichkeits-Spam: 47,15898%
- „Auf welcher Website finde ich weitere Informationen?“ Wahrscheinlichkeits-Spam: 15,32495%
Das ist großartig, die Wahrscheinlichkeit für alle oben genannten Optionen ist ziemlich niedrig und erreicht erfolgreich die Standardwahrscheinlichkeit SPAM_THRESHOLD einer minimalen Wahrscheinlichkeit von 75 %, bevor Maßnahmen ergriffen werden (definiert im Code script.js aus dem vorherigen Codelab).
Schreiben wir jetzt ein paar ausgefallenere Kommentare, die als Spam markiert werden, obwohl sie es nicht sind...
Seriöse Kommentare, die als Spam markiert wurden (falsch positive Ergebnisse):
- „Kann jemand die Website mit der Maske verlinken, die er trägt?“ Wahrscheinlichkeits-Spam: 98,46466%
- „Kann ich diesen Song auf Spotify kaufen? Bitte sagen Sie mir Bescheid.“ Wahrscheinlichkeits-Spam: 94,40953%
- „Kann mich jemand kontaktieren, der Ihnen genau erklärt, wie man TensorFlow.js herunterlädt?“ Wahrscheinlichkeits-Spam: 83,20084%
Oh nein! Diese seriösen Kommentare werden anscheinend als Spam markiert, obwohl sie erlaubt werden sollten. Wie können Sie das ändern?
Eine einfache Möglichkeit besteht darin, den SPAM_THRESHOLD auf über 98,5% zu erhöhen. In diesem Fall werden die falsch klassifizierten Kommentare gepostet. Vor diesem Hintergrund fahren wir mit den anderen möglichen Ergebnissen unten fort...
Spamkommentare, die als Spam markiert wurden (echt positive Nachrichten):
- „Das ist cool, aber sieh dir die Downloadlinks auf meiner Website an, die besser sind.“ Wahrscheinlichkeits-Spam: 99,77873%
- „Einige Leute, die dir Medikamente besorgen, findest du in meiner PR0Datei.“ Wahrscheinlichkeitsspam: 98,46955%
- „Sieh dir mein Profil an, um noch mehr tolle Videos herunterzuladen, die noch besser sind! http://beispiel.de" Wahrscheinlichkeits-Spam: 96,26383%
Bei unserem ursprünglichen Grenzwert von 75% funktioniert das wie erwartet.Da Sie jedoch im vorherigen Schritt SPAM_THRESHOLD auf einen Konfidenzwert von über 98,5% geändert haben, würden 2 Beispiele hier durchgelassen werden, sodass der Grenzwert möglicherweise zu hoch ist. Vielleicht sind 96% besser? Wenn Sie dies jedoch tun, wird einer der Kommentare im vorherigen Abschnitt (falsch positive Ergebnisse) als Spam markiert, obwohl er legitim ist, da er mit 98,46466 % bewertet wurde.
In diesem Fall ist es wahrscheinlich am besten, all diese Spamkommentare zu erfassen und das Training einfach für die oben genannten Fehler zu wiederholen. Wenn Sie den Grenzwert auf 96% festlegen, werden alle richtig positiven Ergebnisse trotzdem erfasst und Sie entfernen zwei der oben falsch positiven Ergebnisse. Das ist gar nicht so schlimm, wenn man einfach nur eine Zahl ändert.
Weiter...
Spamkommentare, die gepostet werden dürfen (falsch negative Ergebnisse):
- „Sieh dir mein Profil an, um noch mehr tolle Videos herunterzuladen, die noch besser sind.“ Wahrscheinlichkeits-Spam: 7,54926%
- "Erhalten Sie einen Rabatt auf unsere Fitnessstudiotrainings siehe pr0file!" Wahrscheinlichkeits-Spam: 17,49849%
- „Wow, GOOG-Aktie ist soeben geflogen! Komm vorher zu spät!“ Wahrscheinlichkeits-Spam: 20,42894%
Bei diesen Kommentaren können Sie nicht einfach den SPAM_THRESHOLD-Wert weiter ändern. Wenn der Grenzwert für Spam von 96% auf ~9% gesenkt wird, werden echte Kommentare als Spam markiert. Einer davon hat eine Bewertung von 58 %, obwohl er seriös ist. Die einzige Möglichkeit, mit solchen Kommentaren umzugehen, besteht darin, das Modell mit solchen Grenzfällen neu zu trainieren, die in den Trainingsdaten enthalten sind, damit es lernt, seine Sicht der Welt auf Spam anzupassen.
Die einzige Option, die derzeit links ist, besteht darin, das Modell neu zu trainieren. Sie haben aber auch gesehen, wie Sie den Schwellenwert für die Spam-Bezeichnung eingrenzen können, um die Leistung zu verbessern. Als Mensch scheinen 75% ziemlich sicher zu sein, aber für dieses Modell mussten Sie eine Steigerung auf 81,5% erreichen, um mit Beispieleingaben effektiver zu sein.
Es gibt keinen magischen Wert, der in verschiedenen Modellen gut funktioniert. Dieser Grenzwert muss für jedes Modell festgelegt werden, nachdem mit realen Daten experimentiert wurde, was gut funktioniert.
In einigen Situationen kann ein falsch positives (oder negatives) Ergebnis schwerwiegende Folgen haben (z. B. in der Medizinbranche). In diesem Fall können Sie Ihren Grenzwert sehr hoch ansetzen und weitere manuelle Überprüfungen anfordern, wenn der Grenzwert nicht erreicht wird. Dies ist Ihre Entscheidung als Entwickler und erfordert einiges an Experimentieren.
4. Modell zur Spamerkennung von Kommentaren neu trainieren
Im vorherigen Abschnitt haben Sie eine Reihe von Grenzfällen identifiziert, die für das Modell fehlschlagen, bei denen die einzige Option darin bestand, das Modell neu zu trainieren, um diese Situationen zu berücksichtigen. In Produktionssystemen kann es im Laufe der Zeit passieren, dass Kommentare manuell als Spam gemeldet werden oder Moderatoren, die gemeldete Kommentare prüfen, feststellen, dass es sich bei einigen nicht wirklich um Spam handelt, und diese Kommentare zur erneuten Schulung markieren. Angenommen, Sie haben eine Reihe neuer Daten für diese Grenzfälle gesammelt (für optimale Ergebnisse sollten Sie, wenn möglich, einige Variationen der neuen Sätze haben), werden wir Ihnen nun zeigen, wie Sie das Modell unter Berücksichtigung dieser Grenzfälle neu trainieren.
Zusammenfassung des vorgefertigten Modells
Sie haben ein vorgefertigtes Modell verwendet, das von einem Drittanbieter über Model Maker erstellt wurde und eine „durchschnittliche Worteinbettung“ verwendet. damit das Modell funktioniert.
Da das Modell mit Model Maker erstellt wurde, müssen Sie kurz zu Python wechseln, um es neu zu trainieren, und dann das erstellte Modell in das TensorFlow.js-Format exportieren, damit Sie es im Browser verwenden können. Glücklicherweise ist die Verwendung der Modelle in Model Maker sehr einfach, sodass das leicht nachvollziehbar sein sollte. Wir führen Sie durch den Prozess. Machen Sie sich also keine Sorgen, wenn Sie noch nie mit Python gearbeitet haben.
Colabs
Da Sie in diesem Codelab nicht allzu sehr besorgt sind und einen Linux-Server mit allen installierten Python-Dienstprogrammen einrichten möchten, können Sie Code einfach mithilfe eines „Colab-Notebooks“ über den Webbrowser ausführen. Diese Notebooks können eine Verbindung zu einem „Back-End“ herstellen Hierbei handelt es sich einfach um einen Server, auf dem einiges vorinstalliert ist. Von diesem aus können Sie dann beliebigen Code im Webbrowser ausführen und die Ergebnisse sehen. Dies ist sehr nützlich für schnelles Prototyping oder für die Verwendung in Tutorials wie dieser.
Rufen Sie einfach colab.research.google.com auf. Es wird ein Begrüßungsbildschirm wie hier dargestellt angezeigt:
Klicken Sie jetzt rechts unten im Pop-up-Fenster auf die Schaltfläche New Notebook (Neues Notebook). Sie sollten ein leeres Colab wie das folgende sehen:
Sehr gut! Der nächste Schritt besteht darin, das Frontend-Colab mit einem Backend-Server zu verbinden, damit Sie den zu schreibenden Python-Code ausführen können. Klicken Sie dazu rechts oben auf Verbinden und wählen Sie Mit gehosteter Laufzeit verbinden aus.
Sobald die Verbindung hergestellt ist, sollten die Symbole für RAM und Laufwerk wie folgt angezeigt werden:
Klasse! Sie können jetzt mit dem Programmieren in Python beginnen, um das Model Maker-Modell neu zu trainieren. Führen Sie stattdessen einfach die unten aufgeführten Schritte aus.
Schritt 1
Kopieren Sie den folgenden Code in die erste Zelle, die derzeit leer ist. TensorFlow Lite Model Maker wird mit dem Python-Paketmanager namens „pip“ installiert. (ähnlich wie npm, das die meisten Leser dieses Code-Labs aus dem JS-Ökosystem vielleicht besser kennen):
!apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
!pip install -q tflite-model-maker
Wird Code in die Zelle eingefügt, wird er nicht ausgeführt. Bewegen Sie den Mauszeiger auf die graue Zelle, in die Sie den obigen Code eingefügt haben, und klicken Sie auf wird links von der Zelle angezeigt (siehe unten):
 Klicken Sie auf die Wiedergabeschaltfläche, um den gerade in die Zelle eingegebenen Code auszuführen.
Klicken Sie auf die Wiedergabeschaltfläche, um den gerade in die Zelle eingegebenen Code auszuführen.
Der Modellhersteller wird nun installiert:
Wenn die Ausführung dieser Zelle wie gezeigt abgeschlossen ist, fahren Sie mit dem nächsten Schritt unten fort.
Schritt 2
Fügen Sie als Nächstes wie gezeigt eine neue Codezelle hinzu, damit Sie nach der ersten Zelle weiteren Code einfügen und separat ausführen können:
Die nächste ausgeführte Zelle enthält eine Reihe von Importen, die der Code im Rest des Notebooks verwenden muss. Kopieren Sie den folgenden Text und fügen Sie ihn in die neu erstellte Zelle ein:
import numpy as np
import os
from tflite_model_maker import configs
from tflite_model_maker import ExportFormat
from tflite_model_maker import model_spec
from tflite_model_maker import text_classifier
from tflite_model_maker.text_classifier import DataLoader
import tensorflow as tf
assert tf.__version__.startswith('2')
tf.get_logger().setLevel('ERROR')
Ziemlich einfach, auch wenn Sie mit Python nicht vertraut sind. Sie importieren nur einige Dienstprogramme und die Model Maker-Funktionen, die für den Spamklassifikator benötigt werden. Dadurch wird auch geprüft, ob Sie TensorFlow 2.x verwenden. Dies ist eine Voraussetzung für die Verwendung von Model Maker.
Führen Sie abschließend wie zuvor die Zelle aus, indem Sie auf die , wenn Sie den Mauszeiger auf die Zelle bewegen, und dann eine neue Codezelle für den nächsten Schritt hinzufügen.
Schritt 3
Als Nächstes laden Sie die Daten von einem Remote-Server auf Ihr Gerät herunter und legen die Variable training_data auf den Pfad der resultierenden, heruntergeladenen lokalen Datei fest:
data_file = tf.keras.utils.get_file(fname='comment-spam-extras.csv', origin='https://storage.googleapis.com/jmstore/TensorFlowJS/EdX/code/6.5/jm_blog_comments_extras.csv', extract=False)
In Model Maker können Modelle mit einfachen CSV-Dateien wie der heruntergeladenen trainiert werden. Sie müssen nur angeben, welche Spalten den Text und welche die Beschriftungen enthalten. Wie Sie dazu vorgehen, erfahren Sie in Schritt 5. Sie können die CSV-Datei auch direkt herunterladen und sich den Inhalt ansehen.
Sie werden sehr aufmerksam sehen, dass diese Datei jm_blog_comments_extras.csv heißt. Diese Datei ist einfach die ursprünglichen Trainingsdaten, die wir zum Generieren des ersten Spammodells für Kommentare verwendet haben, kombiniert mit den neuen Grenzfalldaten, die Sie gefunden haben, sodass sich alles in einer Datei befindet. Zusätzlich zu den neuen Sätzen, die Sie lernen möchten, benötigen Sie die ursprünglichen Trainingsdaten, die zum Trainieren des Modells verwendet werden.
Optional:Wenn Sie diese CSV-Datei herunterladen und sich die letzten Zeilen ansehen, finden Sie Beispiele für Grenzfälle, die zuvor nicht richtig funktioniert haben. Sie wurden gerade am Ende der bestehenden Trainingsdaten hinzugefügt, die das vorgefertigte Modell zum Trainieren verwendet hat.
Führen Sie diese Zelle aus, fügen Sie nach Abschluss der Ausführung eine neue Zelle hinzu und fahren Sie mit Schritt 4 fort.
Schritt 4
Wenn Sie Model Maker verwenden, werden keine neuen Modelle erstellt. Im Allgemeinen verwenden Sie vorhandene Modelle, die Sie dann an Ihre Anforderungen anpassen.
Model Maker bietet mehrere vorlernbare Modelleinbettungen, die Sie verwenden können. Die einfachste und schnellste Methode ist average_word_vec, das Sie im vorherigen Codelab zum Erstellen Ihrer Website verwendet haben. Hier ist der Code:
spec = model_spec.get('average_word_vec')
spec.num_words = 2000
spec.seq_len = 20
spec.wordvec_dim = 7
Fahren Sie fort und führen Sie die Abfrage aus, nachdem Sie sie in die neue Zelle eingefügt haben.
Die
num_words
Parameter
Dies ist die Anzahl der Wörter, die das Modell verwenden soll. Sie denken vielleicht, dass je mehr, desto besser, aber im Allgemeinen gibt es einen optimalen Punkt basierend auf der Häufigkeit, mit der die einzelnen Wörter verwendet werden. Wenn Sie jedes Wort im gesamten Korpus verwenden, könnte das Modell versuchen, die Gewichtung von Wörtern, die nur einmal verwendet werden, zu lernen und auszugleichen. Das ist nicht sehr nützlich. Sie werden in jedem Textkorpus feststellen, dass viele Wörter nur ein- oder zweimal verwendet werden und es im Allgemeinen nicht sinnvoll ist, sie in Ihrem Modell zu verwenden, da sie einen geringen Einfluss auf die allgemeine Stimmung haben. So können Sie Ihr Modell mit dem Parameter num_words auf die gewünschte Anzahl von Wörtern abstimmen. Eine kleinere Zahl hier hat ein kleineres und schnelleres Modell, aber es könnte weniger genau sein, da es weniger Wörter erkennt. Eine größere Zahl hier hat ein größeres und möglicherweise langsameres Modell. Es ist wichtig, die ideale Lösung zu finden. Als Machine Learning Engineer liegt es an Ihnen, herauszufinden, was für Ihren Anwendungsfall am besten funktioniert.
Die
wordvec_dim
Parameter
Der Parameter wordvec_dim ist die Anzahl der Dimensionen, die Sie für den Vektor jedes Worts verwenden möchten. Diese Dimensionen sind im Wesentlichen die unterschiedlichen Eigenschaften, die beim Training durch den Algorithmus für maschinelles Lernen erzeugt werden und anhand derer das Programm gemessen werden kann, um Wörter, die sich ähnlich sind, bestmöglich zuzuordnen.
Wenn Sie z. B. die Dimension „Medizin“ ein Wort wie „Pillen“ kann hier in dieser Dimension eine hohe Bewertung erzielen und mit anderen Wörtern mit hoher Bewertung wie „Röntgen“, aber „Katze“ in Verbindung gebracht werden für diese Dimension niedrig. Es kann sich herausstellen, dass eine "medizinische Dimension" ist nützlich, um Spam in Kombination mit anderen potenziellen Dimensionen zu erkennen, die möglicherweise wichtig sind.
Bei Wörtern mit hoher Bewertung in der „medizinischen Dimension“ könnte eine zweite Dimension, die Wörter mit dem menschlichen Körper in Beziehung setzt, nützlich sein. Wörter wie „Bein“, „Arm“, „Hals“ kann hier hoch und auch in der medizinischen Dimension recht hoch gewertet werden.
Anhand dieser Dimensionen kann das Modell dann Wörter erkennen, die mit höherer Wahrscheinlichkeit mit Spam in Verbindung gebracht werden. Möglicherweise enthalten Spam-E-Mails eher Wörter, die sowohl medizinische als auch menschliche Körperteile enthalten.
Die Faustregel, die sich aus der Forschung ergeben hat, besagt, dass die vierte Wurzel der Anzahl von Wörtern für diesen Parameter gut funktioniert. Wenn ich also 2.000 Wörter verwende, sind 7 Dimensionen ein guter Ausgangspunkt dafür. Wenn du die Anzahl der verwendeten Wörter änderst, kannst du das auch ändern.
Die
seq_len
Parameter
Modelle sind in der Regel sehr starr, wenn es um Eingabewerte geht. Bei einem Language Model bedeutet dies, dass das Language Model Sätze mit einer bestimmten statischen Länge klassifizieren kann. Dies wird durch den Parameter seq_len bestimmt, bei dem dies für „Sequenzlänge“ steht. Wenn Sie Wörter in Zahlen (oder Tokens) umwandeln, wird ein Satz zu einer Folge dieser Tokens. Ihr Modell wird also (in diesem Fall) darauf trainiert, Sätze mit 20 Tokens zu klassifizieren und zu erkennen. Sollte der Satz länger sein, wird er gekürzt. Wenn sie kürzer ist, werden sie aufgefüllt – genau wie im ersten Codelab dieser Reihe.
Schritt 5: Trainingsdaten laden
Zuvor haben Sie die CSV-Datei heruntergeladen. Jetzt ist es an der Zeit, ein Datenladeprogramm zu verwenden, um dies in Trainingsdaten umzuwandeln, die das Modell erkennen kann.
data = DataLoader.from_csv(
filename=data_file,
text_column='commenttext',
label_column='spam',
model_spec=spec,
delimiter=',',
shuffle=True,
is_training=True)
train_data, test_data = data.split(0.9)
Wenn Sie die CSV-Datei in einem Editor öffnen, sehen Sie, dass jede Zeile nur zwei Werte enthält, die mit Text in der ersten Zeile der Datei beschrieben werden. In der Regel wird jeder Eintrag als „Spalte“ betrachtet. Sie sehen, dass der Deskriptor für die erste Spalte commenttext lautet und dass der erste Eintrag in jeder Zeile der Text des Kommentars ist.
In ähnlicher Weise lautet der Deskriptor für die zweite Spalte spam. Sie sehen, dass der zweite Eintrag in jeder Zeile TRUE oder FALSE ist, um anzugeben, ob dieser Text als Kommentar-Spam gilt. Die anderen Eigenschaften legen die in Schritt 4 erstellte Modellspezifikation zusammen mit einem Trennzeichen fest, das in diesem Fall ein Komma ist, da die Datei durch Kommas getrennt ist. Sie legen auch einen Shuffle-Parameter fest, um die Trainingsdaten nach dem Zufallsprinzip neu anzuordnen, sodass Dinge, die möglicherweise ähnlich waren oder zusammen gesammelt wurden, nach dem Zufallsprinzip über das Dataset verteilt werden.
Anschließend verwenden Sie data.split(), um die Daten in Trainings- und Testdaten aufzuteilen. „0,9“ gibt an, dass 90% des Datasets für das Training und der Rest für Tests verwendet werden.
Schritt 6 – Modell erstellen
Fügen Sie eine weitere Zelle hinzu, in der wir Code zum Erstellen des Modells hinzufügen:
model = text_classifier.create(train_data, model_spec=spec, epochs=50)
Dadurch wird ein Textklassifikatormodell mit Model Maker erstellt. Sie geben die zu verwendenden Trainingsdaten (die in Schritt 4 definiert wurden), die Modellspezifikation (die ebenfalls in Schritt 4 eingerichtet wurde) und eine Reihe von Epochen an, in diesem Fall 50.
Das Grundprinzip des maschinellen Lernens ist, dass es eine Form des Musterabgleichs ist. Zunächst werden die vortrainierten Gewichtungen für die Wörter geladen und es wird versucht, sie mit einer "Vorhersage" zu gruppieren welche bei der Gruppierung auf Spam hinweisen und welche nicht. Beim ersten Mal ist es wahrscheinlich bei 50:50 Uhr, da das Modell erst am Anfang steht, wie unten gezeigt:

Anschließend werden die Ergebnisse gemessen und die Gewichtungen des Modells geändert, um die Vorhersage zu optimieren. Anschließend wird ein neuer Versuch unternommen. Dies ist eine Epoche. Wenn Sie also „epochs=50“ angeben, durchläuft er diese „Schleife“, 50 Mal wie gezeigt:

Wenn Sie also die 50. Epoche erreichen, meldet das Modell ein viel höheres Genauigkeitsniveau. In diesem Fall wird 99,1 % angezeigt!
Schritt 7 – Modell exportieren
Sobald das Training abgeschlossen ist, können Sie das Modell exportieren. TensorFlow trainiert ein Modell in seinem eigenen Format, das zur Verwendung auf einer Webseite in das TensorFlow.js-Format konvertiert werden muss. Fügen Sie einfach Folgendes in eine neue Zelle ein und führen Sie sie aus:
model.export(export_dir="/js_export/", export_format=[ExportFormat.TFJS, ExportFormat.LABEL, ExportFormat.VOCAB])
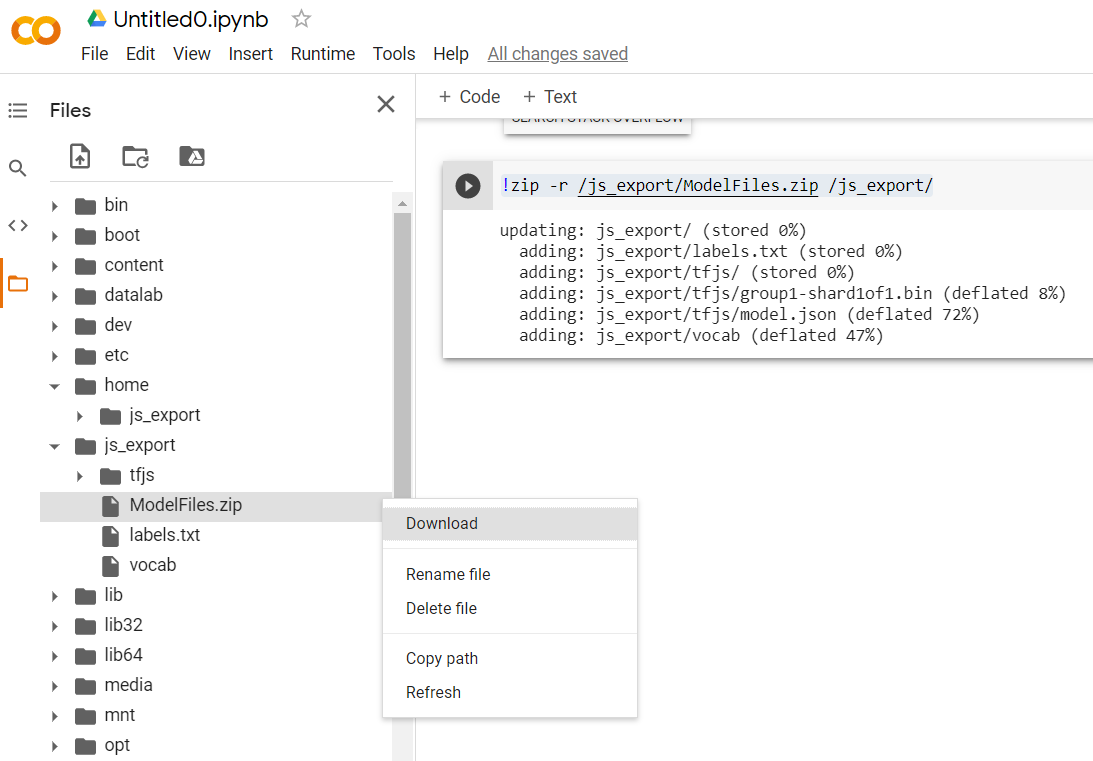
!zip -r /js_export/ModelFiles.zip /js_export/
Wenn Sie nach dem Ausführen dieses Codes auf das kleine Ordnersymbol links in Colab klicken, können Sie zu dem Ordner gehen, in den Sie oben exportiert haben (im Stammverzeichnis – Sie müssen möglicherweise eine Ebene nach oben gehen) und die ZIP-Datei mit den in ModelFiles.zip exportierten Dateien suchen.
Laden Sie diese ZIP-Datei jetzt auf Ihren Computer herunter, da Sie sie wie im ersten Codelab verwenden werden:
Sehr gut! Der Python-Teil ist nun vorbei, Sie können jetzt zum bekannten JavaScript-Land zurückkehren. Geschafft!
5. Bereitstellung des neuen Modells für maschinelles Lernen
Sie sind jetzt fast bereit, das Modell zu laden. Zuvor müssen Sie jedoch die neuen Modelldateien hochladen, die Sie zuvor im Codelab heruntergeladen haben, damit sie in Ihrem Code gehostet und verwendet werden können.
Falls noch nicht geschehen, entpacken Sie zuerst die Dateien für das Modell, das Sie aus dem gerade ausgeführten Colab-Notebook für Model Maker heruntergeladen haben. Die folgenden Dateien sollten in den verschiedenen Ordnern zu sehen sein:
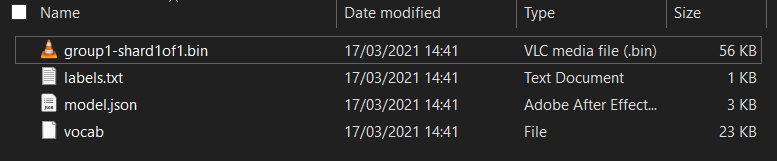
Was haben Sie hier?
model.json: Dies ist eine der Dateien, aus denen das trainierte TensorFlow.js-Modell besteht. Sie werden im JS-Code auf diese Datei verweisen.group1-shard1of1.bin: Dies ist eine Binärdatei, die einen Großteil der gespeicherten Daten für das exportierte TensorFlow.js-Modell enthält. Sie muss irgendwo auf Ihrem Server gehostet werden, damit sie im selben Verzeichnis wiemodel.jsonheruntergeladen werden kann.vocab: Diese seltsame Datei ohne Erweiterung ist etwas von Model Maker, das uns zeigt, wie Wörter in Sätzen codiert werden können, damit das Modell versteht, wie sie verwendet werden. Darauf gehen wir im nächsten Abschnitt näher ein.labels.txt: Enthält einfach die resultierenden Klassennamen, die das Modell vorhersagt. Wenn Sie die Datei in Ihrem Texteditor öffnen, steht für dieses Modell einfach "false". und „true“ mit der Kennzeichnung „Kein Spam“ oder „Spam“ als Vorhersageausgabe verwendet.
TensorFlow.js-Modelldateien hosten
Platzieren Sie die generierten model.json- und *.bin-Dateien auf einem Webserver, damit Sie über Ihre Webseite darauf zugreifen können.
Vorhandene Modelldateien löschen
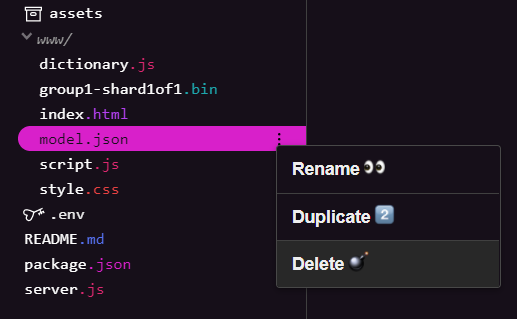
Da Sie auf dem Endergebnis des ersten Codelabs dieser Reihe aufbauen, müssen Sie zuerst die hochgeladenen Modelldateien löschen. Wenn du Glitch.com verwendest, klicke einfach auf der linken Seite im Bereich „Dateien“ auf model.json und group1-shard1of1.bin, klicke bei jeder Datei auf das Dreipunkt-Menü und wähle Löschen aus:
Neue Dateien in Glitch hochladen
Sehr gut! Laden Sie jetzt die neuen hoch:
- Öffnen Sie im linken Bereich Ihres Glitch-Projekts den Ordner assets und löschen Sie alle hochgeladenen Assets, die denselben Namen haben.
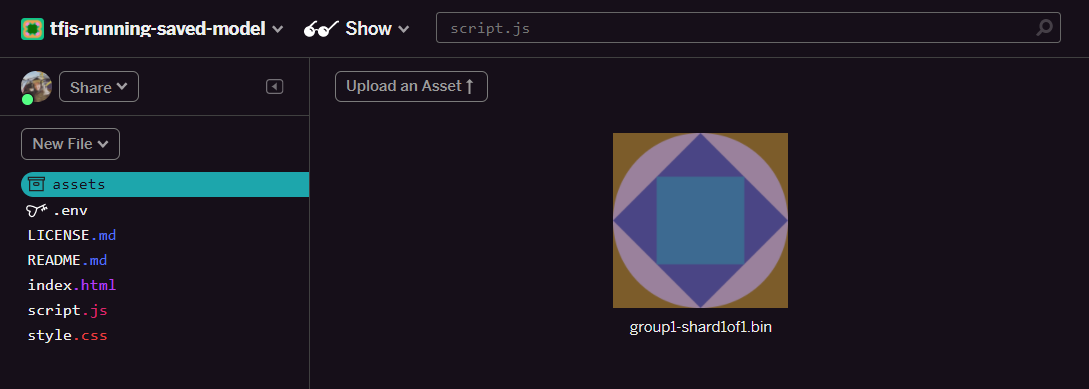
- Klicken Sie auf Asset hochladen und wählen Sie
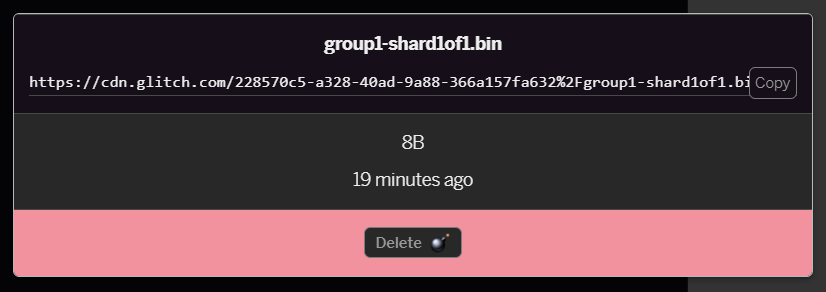
group1-shard1of1.binaus, das in diesen Ordner hochgeladen werden soll. Nach dem Hochladen sollte sie so aussehen:
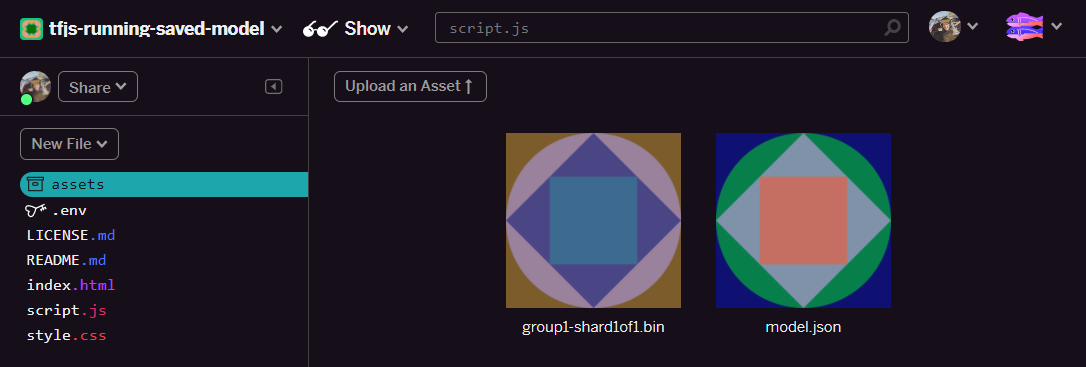
- Sehr gut! Wiederholen Sie diesen Schritt nun für die Datei model.json, sodass sich zwei Dateien in Ihrem Asset-Ordner befinden sollten:
- Wenn Sie auf die Datei
group1-shard1of1.binklicken, die Sie gerade hochgeladen haben, können Sie die URL an den Speicherort kopieren. Kopieren Sie diesen Pfad jetzt wie gezeigt:
- Klicken Sie unten links auf dem Bildschirm auf Tools > Terminal: Warten Sie, bis das Terminalfenster geladen ist.
- Geben Sie nach dem Laden Folgendes ein und drücken Sie dann die Eingabetaste, um das Verzeichnis in den Ordner
wwwzu wechseln:
Terminal:
cd www
- Verwende als Nächstes
wget, um die beiden soeben hochgeladenen Dateien herunterzuladen. Ersetzen Sie dazu die URLs unten durch die URLs, die Sie für die Dateien im Asset-Ordner in Glitch generiert haben. Im Asset-Ordner finden Sie die benutzerdefinierte URL jeder Datei.
Beachten Sie das Leerzeichen zwischen den beiden URLs. Die verwendeten URLs unterscheiden sich von den angezeigten URLs, sehen aber ähnlich aus:
Terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Super! Sie haben jetzt eine Kopie der Dateien erstellt, die in den Ordner „www“ hochgeladen wurden.
Derzeit werden sie jedoch mit merkwürdigen Namen heruntergeladen. Wenn Sie ls in das Terminal eingeben und die Eingabetaste drücken, erhalten Sie eine Ausgabe wie diese:

- Benennen Sie die Dateien mit dem Befehl
mvum. Geben Sie Folgendes in die Konsole ein und drücken Sie nach jeder Zeile die Eingabetaste:
Terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Aktualisieren Sie schließlich das Glitch-Projekt. Geben Sie dazu
refreshim Terminal ein und drücken Sie die Eingabetaste:
Terminal:
refresh
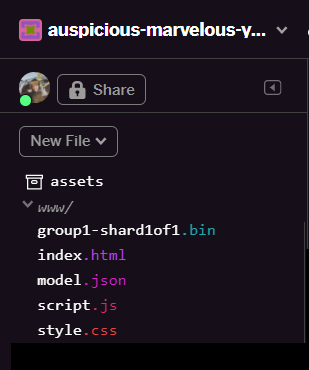
Nach der Aktualisierung sollten im Ordner www der Benutzeroberfläche jetzt model.json und group1-shard1of1.bin angezeigt werden:
Sehr gut! Im letzten Schritt aktualisieren Sie die Datei dictionary.js.
- Konvertieren Sie die neue heruntergeladene Vokabeldatei entweder manuell mithilfe Ihres Texteditors oder mithilfe dieses Tools in das richtige JS-Format und speichern Sie die resultierende Ausgabe als
dictionary.jsim Ordnerwww. Wenn Sie bereits einedictionary.js-Datei haben, können Sie den neuen Inhalt einfach kopieren und einfügen und die Datei speichern.
Endlich! Sie haben alle geänderten Dateien erfolgreich aktualisiert. Wenn Sie jetzt versuchen, die Website zu verwenden, werden Sie feststellen, wie das neu trainierte Modell die erkannten und daraus gelernten Grenzfälle berücksichtigen sollte:
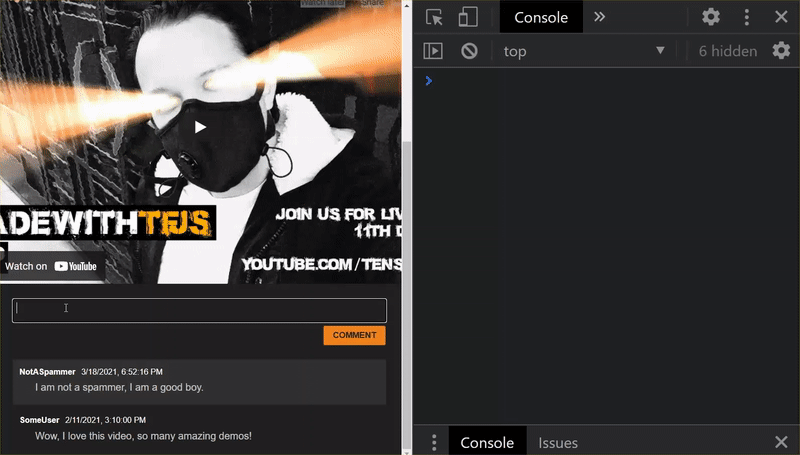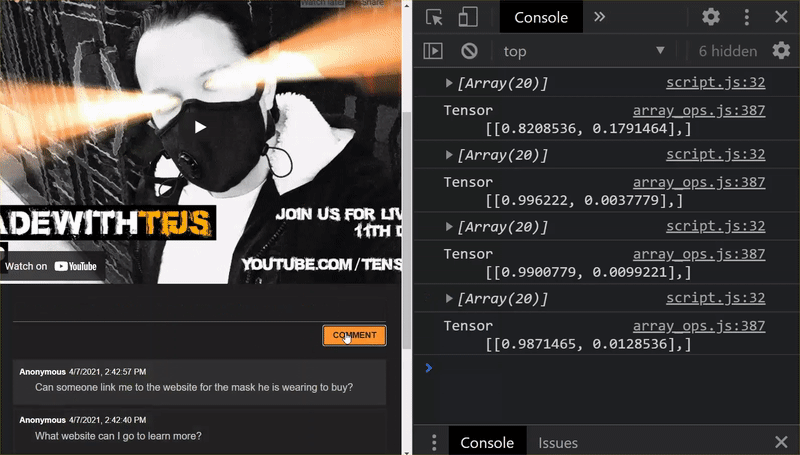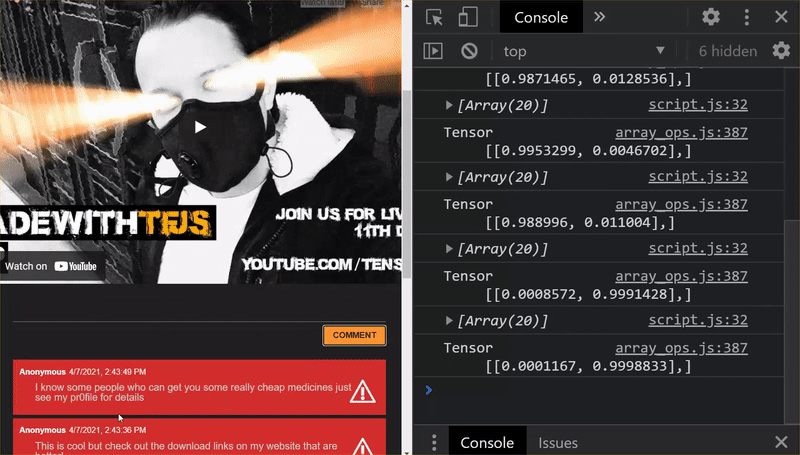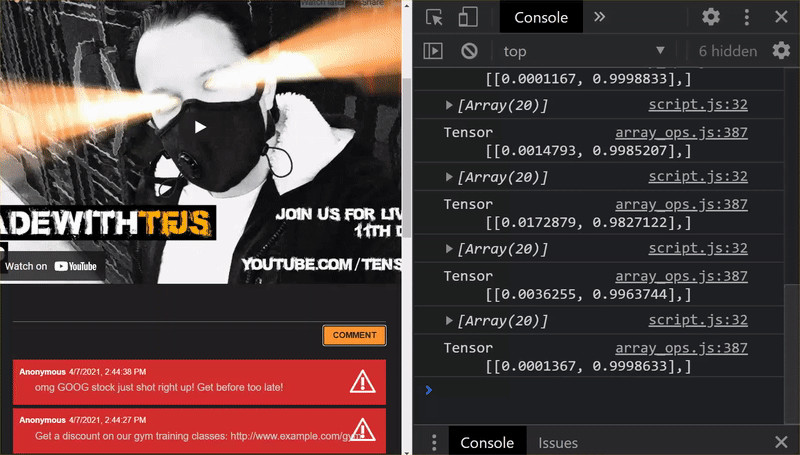
Wie Sie sehen, werden jetzt die ersten sechs korrekt als „Kein Spam“ klassifiziert und der zweite von sechs Batches wird alle als Spam eingestuft. Super!
Probieren wir auch einige Varianten aus, um festzustellen, ob sie gut verallgemeinert wurde. Ursprünglich gab es einen fehlgeschlagenen Satz wie:
„Die GOOG-Aktie ist gerade geflogen! Komm vorher zu spät!“
Diese Nachricht wurde nun korrekt als Spam klassifiziert. Was passiert jedoch, wenn Sie sie ändern in:
„Der Wert der Aktie XYZ ist gerade gestiegen! Kaufen Sie etwas, bevor es zu spät ist!"
Hier erhalten Sie eine Wahrscheinlichkeit von 98 %, dass es sich um Spam handelt. Das ist richtig, obwohl Sie das Aktiensymbol und den Wortlaut leicht geändert haben.
Natürlich können Sie dieses neue Modell wirklich durchbrechen. Es werden noch mehr Trainingsdaten gesammelt, um die besten Chancen zu haben, mehr einzigartige Varianten für häufig auftretende Online-Situationen zu erfassen. In einem zukünftigen Codelab zeigen wir Ihnen, wie Sie Ihr Modell mit Live-Daten, die gemeldet werden, kontinuierlich verbessern.
6. Glückwunsch!
Glückwunsch! Sie haben ein vorhandenes Modell für maschinelles Lernen neu trainiert, damit es für die von Ihnen gefundenen Grenzfälle angepasst wird. Diese Änderungen haben Sie dann mit TensorFlow.js im Browser für eine reale Anwendung implementiert.
Zusammenfassung
In diesem Codelab können Sie:
- Grenzfälle identifiziert, die mit dem vorgefertigten Modell für Spamkommentare nicht funktioniert haben
- Das Model Maker-Modell neu trainiert, um die von Ihnen entdeckten Grenzfälle zu berücksichtigen
- Das neue trainierte Modell wurde in das TensorFlow.js-Format exportiert.
- Die Webanwendung wurde für die Verwendung der neuen Dateien aktualisiert
Was liegt als Nächstes an?
Dieses Update funktioniert also hervorragend, aber wie bei jeder Webanwendung werden im Laufe der Zeit Änderungen vorgenommen. Es wäre viel besser, wenn die App im Laufe der Zeit kontinuierlich verbessert würde, anstatt dies jedes Mal manuell tun zu müssen. Haben Sie diese Schritte automatisiert, um ein Modell automatisch neu zu trainieren, nachdem Sie beispielsweise 100 neue Kommentare als falsch klassifiziert gekennzeichnet haben? Setzen Sie Ihre reguläre Webentwicklung auf und Sie werden wahrscheinlich herausfinden, wie Sie eine Pipeline erstellen können, um dies automatisch zu tun. Falls nicht, keine Sorge, im nächsten Codelab der Reihe erfahren Sie, wie das geht.
Deine Arbeit mit uns teilen
Ihr könnt das, was ihr heute gemacht habt, ganz einfach für andere kreative Anwendungsfälle erweitern. Wir ermutigen euch, unkonventionell zu denken und weiter Hacking zu betreiben.
Vergessen Sie nicht, uns in den sozialen Medien mit dem Hashtag #MadeWithTFJS zu taggen, damit Ihr Projekt im TensorFlow-Blog oder auf zukünftigen Veranstaltungen vorgestellt wird. Wir freuen uns auf Ihr Feedback.
Weitere TensorFlow.js-Codelabs, um tiefer in das Thema einzutauchen
- Mit Firebase Hosting ein TensorFlow.js-Modell in großem Maßstab bereitstellen und hosten
- Intelligente Webcam mit einem vorgefertigten Objekterkennungsmodell und TensorFlow.js erstellen
Interessante Websites
- Offizielle TensorFlow.js-Website
- Vordefinierte TensorFlow.js-Modelle
- TensorFlow.js-API
- TensorFlow.js-Anzeige und Erzählen: Lassen Sie sich inspirieren und sehen Sie sich an, was andere erstellt haben.